Decimative Multiplication of Entropy Arrays, with Application to Influenza

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results and Discussion
2.1. Results
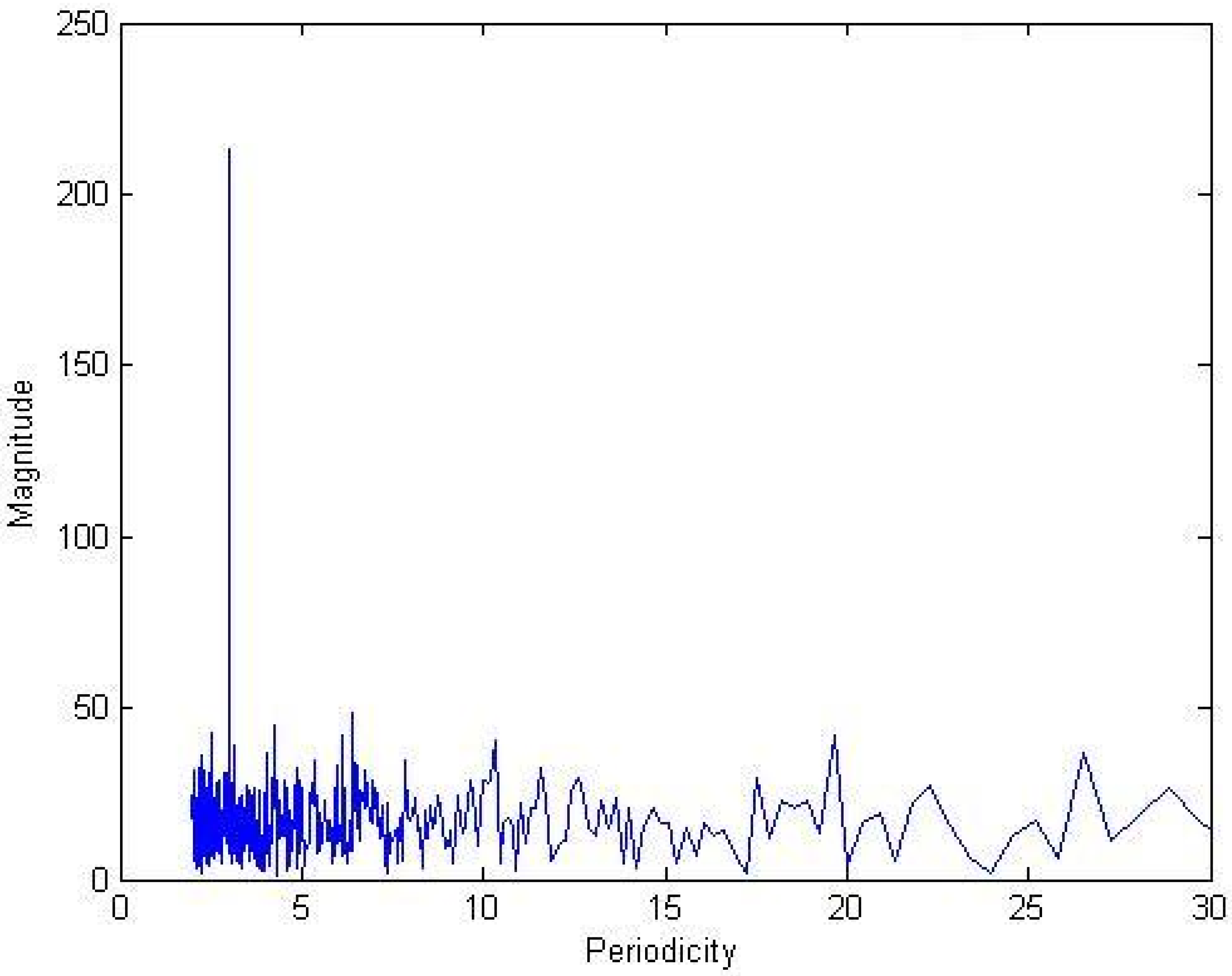
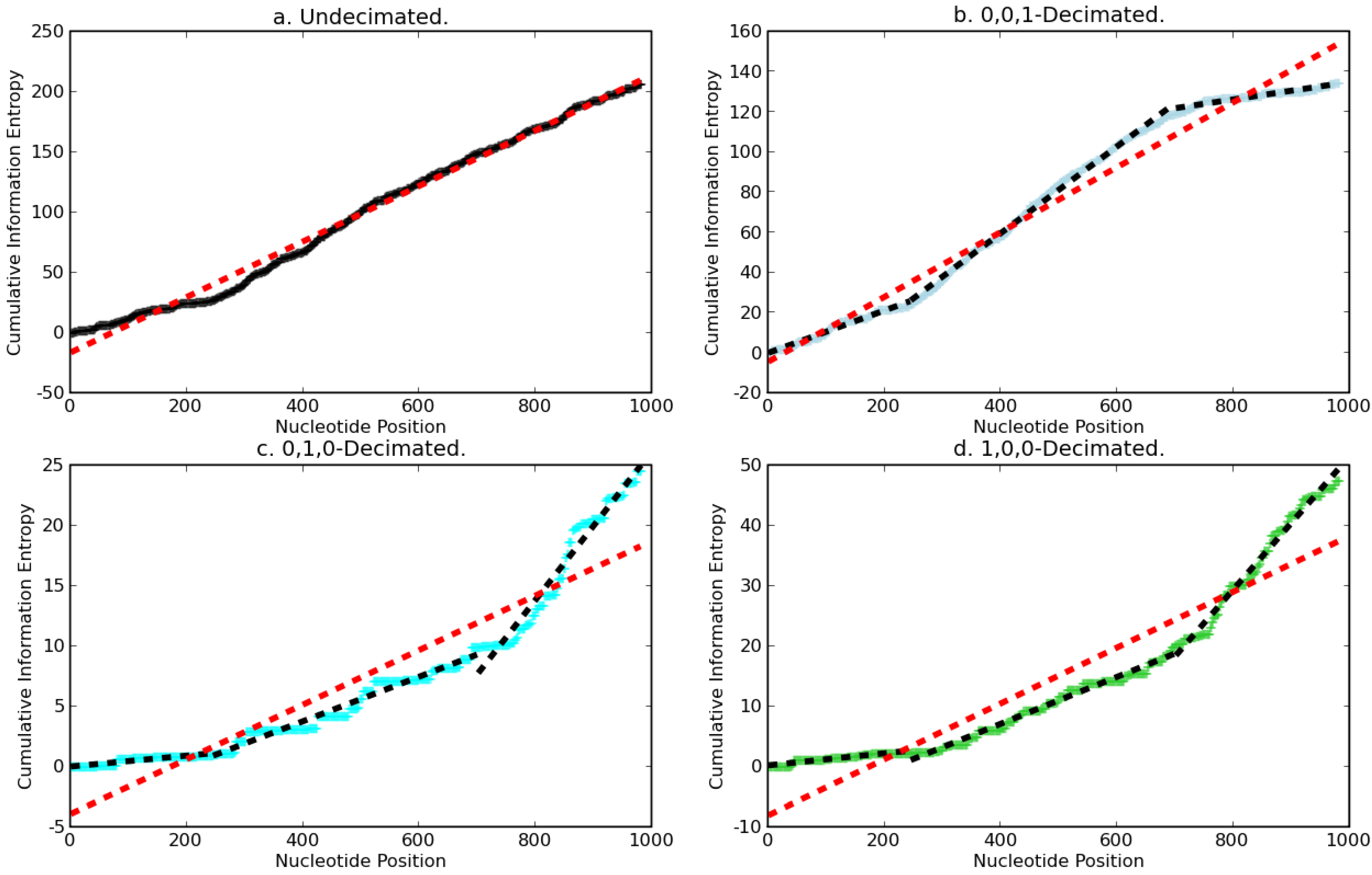
2.1.1. Decimation by a factor of three (3)
2.1.2. Decimation of combined subtype entropy

2.1.3. Individual subtype sequences
2.1.4. Spring 2009 swine flu pandemic

2.2. Discussion
3. Experimental Section
3.1. Information Entropy
3.2. Decimative Array Multiplication
array010 = [0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, … 0]
array100 = [1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, … 1]
3.3. Linear Regression
3.4. The Influenza Sequences
4. Conclusions
Acknowledgements
References
- Smith, S.W. Analog-to-Digital Conversion and Digital-to-Analog Conversion. In The Scientist and Engineer’s Guide to Digital Signal Processing; California Technical Publishing: San Diego, CA, USA, 1997; Chapter 3; Available online: http://www.dspguide.com/pdfbook.htm (accessed July 31, 2009).
- Murray, P.R.; Rosenthal, K.S.; Pfaller, M.A. Orthomyxoviruses. In Medical Microbiology, 6th ed.; Mosby: Maryland Heights, MO, 2008; pp. 583–592. [Google Scholar]
- Garbarine, E.; Rosen, G. The Effects of CG Content and Mutations on the Fourier Transform Method for Periodicity. In Proceedings of IEEE Genomic Signal Processing and Statistics Workshop (GENSIPS), Phoenix, AZ, June 2008.
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Techn J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Crick, F.H.C. Codon-Anticodon Pairing: The Wobble Hypothesis. J. Mol. Biol. 1966, 19, 548–555. [Google Scholar] [CrossRef]
- Lamb, R.A.; Lai, C.J.; Choppin, P.W. Sequences of mRNAs Derived from Genome RNA Segment 7 of Influenza Virus: Colinear and Interrupted mRNAs Code for Overlapping Proteins. Proc. Natl. Acad. Sci. USA 1981, 78, 4170–4174. [Google Scholar] [CrossRef] [PubMed]
- Thompson, W.A.; Fan, S.; Weltman, J.K. Information Entropy of Influenza A Segment 7. Entropy 2008, 10, 736–744. [Google Scholar] [CrossRef]
- Harris, A.; Forouhar, F.; Qiu, S.; Sha, B.; Luo, M. The Crystal Structure of the Influenza Matrix Protein M1 at Neutral pH: M1-M1 Protein Interfaces Can Rotate in the Oligomeric Structures of M1. Virology 2001, 289, 34–44. [Google Scholar] [CrossRef] [PubMed]
- Gog, J.R.; Santos Afonso, E.D.; Dalton, R.M.; Leclercq, I.; Tiley, L.; Elton, D.; von Kirchbach, J.C.; Naffakh, N.; Escriou, N.; Digard, P. Codon Conservation in the Influenza A Virus Genome Defines RNA Packaging Signals. Nucleic Acids Res. 2007, 35, 1897–1907. [Google Scholar] [CrossRef] [PubMed]
- Kudla, G.; Murray, A.W.; Tollervey, D.; Plotkin, J.B. Coding-sequence Determinants of Gene Expression in Escherichia Coli. Science 2009, 324, 255–258. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Barr, I.; Guo, F.; Lee, C. Evidence of a Novel RNA Secondary Structure in the Coding Region of HIV-1 Pol Gene. RNA 2008, 14, 2478–2488. [Google Scholar] [CrossRef] [PubMed]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source Scientific Tools for Python. 2001. Available online: http://www.scipy.org (accessed July 31, 2009).
- Bao, Y.; Bolotov, P.; Dernovoy, D.; Kiryutin, B.; Zaslavsky, L.; Tatusova, T.; Ostell, J.; Lipman, D. The Influenza Virus Resource at the National Center for Biotechnology Information. J. Virol. 2008, 82, 596–601. [Google Scholar] [CrossRef] [PubMed]
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Thompson, W.A.; Martwick, A.; Weltman, J.K. Decimative Multiplication of Entropy Arrays, with Application to Influenza. Entropy 2009, 11, 351-359. https://0-doi-org.brum.beds.ac.uk/10.3390/e11030351
Thompson WA, Martwick A, Weltman JK. Decimative Multiplication of Entropy Arrays, with Application to Influenza. Entropy. 2009; 11(3):351-359. https://0-doi-org.brum.beds.ac.uk/10.3390/e11030351
Chicago/Turabian StyleThompson, William A., Andy Martwick, and Joel K. Weltman. 2009. "Decimative Multiplication of Entropy Arrays, with Application to Influenza" Entropy 11, no. 3: 351-359. https://0-doi-org.brum.beds.ac.uk/10.3390/e11030351