5.1. Rules for Comparing Different Performance Measures
Different from the comparison of classification models, it is difficult to compare performance measures, for no meta-measure can be employed to determine whether or not a performance measure is superior to others. In [
55], Wanderlooy
et al. proposed an experimental way to compare different measures. Suppose two measures,
and
, are under comparison. The rationale of the win-loss-equal statistics is as follows.
First of all, a dataset is randomly partitioned into three parts, 50% as the training set, 10% as the validation set and 40% as the test set. Subsequently, a certain number (such as ten) of new training sets are generated by randomly removing three features from the training set. From the ten training sets, ten different classifiers can be induced with a learning algorithm. From the ten induced classifiers, the two best classifiers are selected respectively by
and
using the validation set. Then, the two selected classifiers are evaluated by a measure (AUC in [
55]), which is called here the arbiter measure, on the test dataset. Finally, the true best classifier, which is chosen formerly by one (such as
) of the two measures, is obtained.
is called the winner and
the loser. If
and
give the same result,
and
are taken to be equal. The procedure is repeated a certain number of times, such as 2,000. Finally the win-loss-equal statistics of
vs. can be obtained and shown as a bar ranging from −1 to 1. The length from 0 to 1 of the bar represents the fraction of wins (
wins
). The length from −1 to 0 represents the fraction of losses. The length of equals is given by one minus the total length of the bar. The win-loss-equal statistics can be conducted on different datasets. One measure is taken to be superior if it wins in most of the win-loss-equal statistics.
It can be seen, by win-loss-equal statistics, the compared measures are verified if they could choose the correct classifiers. If one measure chooses in the training stage the classifier that appears to be the best in the testing stage, this measure is then taken to be superior to the compared ones. Hence, win-loss-equal statistics is a relatively fair way to compare different measures. However, by investigating the comparison process, one can find that the win-loss-equal statistics may be affected by the arbiter measure that is used to choose the true best classifiers. In other words, if one of the compared measures is used as the arbiter measure, this measure tends to win in the win-loss-equal statistics. Hence, for fairly comparing measures, we conducted experiments in the same way, but selected the true best classifiers with both the proposed measure pCEN and each of the compared measures as arbiter measures.
5.2. Experimental Comparison Between pCEN and MAE, MSE and the Variants of AUC
Though it was shown that confusion entropy is capable of measuring if samples of different classes are well separated from each other, it is necessary to investigate if the improved confusion entropy still possesses such a capability. The four variants of AUC are AUNU, AUNP, AU1U and AU1P. The first two variants are 1-
vs.-others version of AUC. Their original definitions can be found in [
24,
30]. The last two variants are the 1-
vs.-1 version of AUC. Their original definitions can be found in [
5,
31]. AU1P and AUNP also exploit the probabilities with which samples are classified into all classes. The definitions of the four variants are as follows.
The AUC of class
j over class
k is defined as:
where
if sample
s indeed belongs to class
j, otherwise
.
if
and
if
, otherwise
.
is the probability with which sample
s is classified into class
j. AUNU is defined as:
where
is the class formed by all classes, but class
j. AUNP is defined as:
AU1U is defined as:
AU1P is defined as:
Mean absolute error (MAE) and mean squared error (MSE), which was first introduced by Brier [
56], are two well-known performance measures for probabilistic models. The definitions of the two measures are as follows:
The 19 datasets are all from the UCI machine learning data repository [
57]. For conducting the experiment effectively and efficiently, we chose the datasets with sufficient attributes and not many samples. The description of the datasets is listed in
Table 9. In line with the comparing method reported in [
55], we conducted the experiment as follows. First of all, each dataset was randomly partitioned into three parts, 50% as the training set, 10% as the validation set and 40% as the test set. Subsequently, ten new training sets were formed by randomly removing three features from the training set. Ten different classifiers were trained with the same learning algorithm,
i.e., J48 unpruned and with Laplace correction implemented in Weka [
54], where J48 is the java version of C4.5 [
58]. The best classifiers were then selected according to rpCEN, pCEN and the four AUC variants using the validation set. Next, the six selected classifiers were evaluated by rpCEN as the arbiter measure on the test dataset. We finally obtained the true best classifier. For each measure, we calculated the regret of rpCEN,
i.e., the difference between the rpCEN of the true best classifier and that of the best classifier the measure selected. For each two compared measures, if the regret value of the first measure is smaller than that of the second measure, the first measure is taken to be the winner. The procedure was repeated 2,000 times. For each round, we compared rpCEN and pCEN with the four variants of AUC in pairs and determined which measure was the winner. The win-loss-equal statistics with regard to each pair of measures can be obtained for each of the datasets. For fairly comparing the measures, we also conducted experiments in the same way, but selected the true best classifiers by pCEN and each of the four variants of AUC as arbiter measures.
Table 9.
The nineteen datasets.
Table 9.
The nineteen datasets.
| Datasets | Samples | Attributes | Classes |
|---|
| allbp | 2,800 | 29 | 3 |
| allhypo | 2,800 | 29 | 5 |
| allrep | 2,800 | 29 | 4 |
| anneal | 798 | 38 | 6 |
| ann | 3,772 | 21 | 3 |
| calendarDOW | 200 | 32 | 6 |
| DNA -nominal | 2,000 | 60 | 3 |
| nursery | 11,947 | 8 | 5 |
| landsat | 4,435 | 36 | 6 |
| soybean | 307 | 35 | 19 |
| vehicle | 564 | 18 | 4 |
| horse | 299 | 21 | 3 |
| pendigits | 7,494 | 16 | 10 |
| segment | 1,500 | 20 | 7 |
| audiology | 199 | 71 | 24 |
| flag | 194 | 30 | 8 |
| Agaricus | 8,123 | 23 | 7 |
| connect-4 | 5,960 | 42 | 3 |
| car | 1,717 | 7 | 4 |
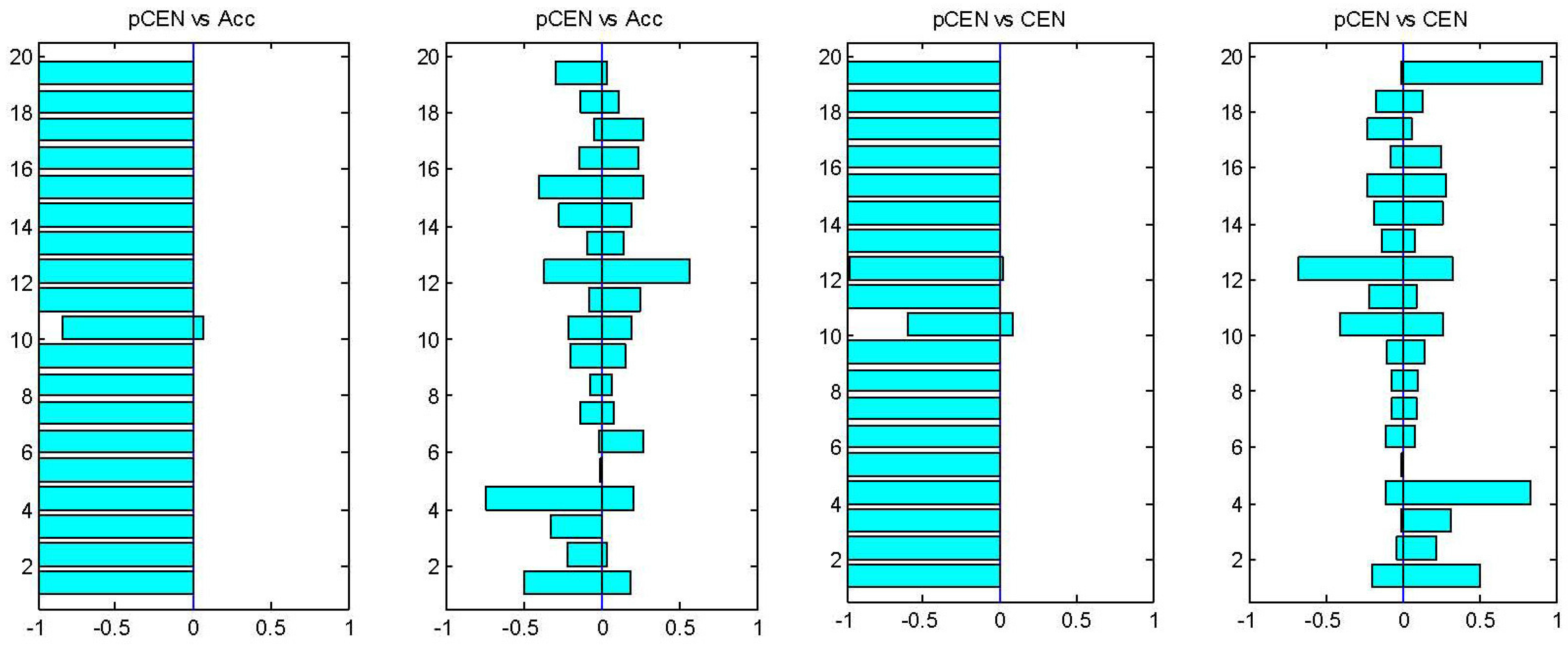
First of all, for simply showing the effectiveness of pCEN in comparison with the measures based on a threshold and a qualitative understanding of error, we simply present in
Figure 1 the win-loss-equal statistics of pCEN
vs. ACC and pCEN
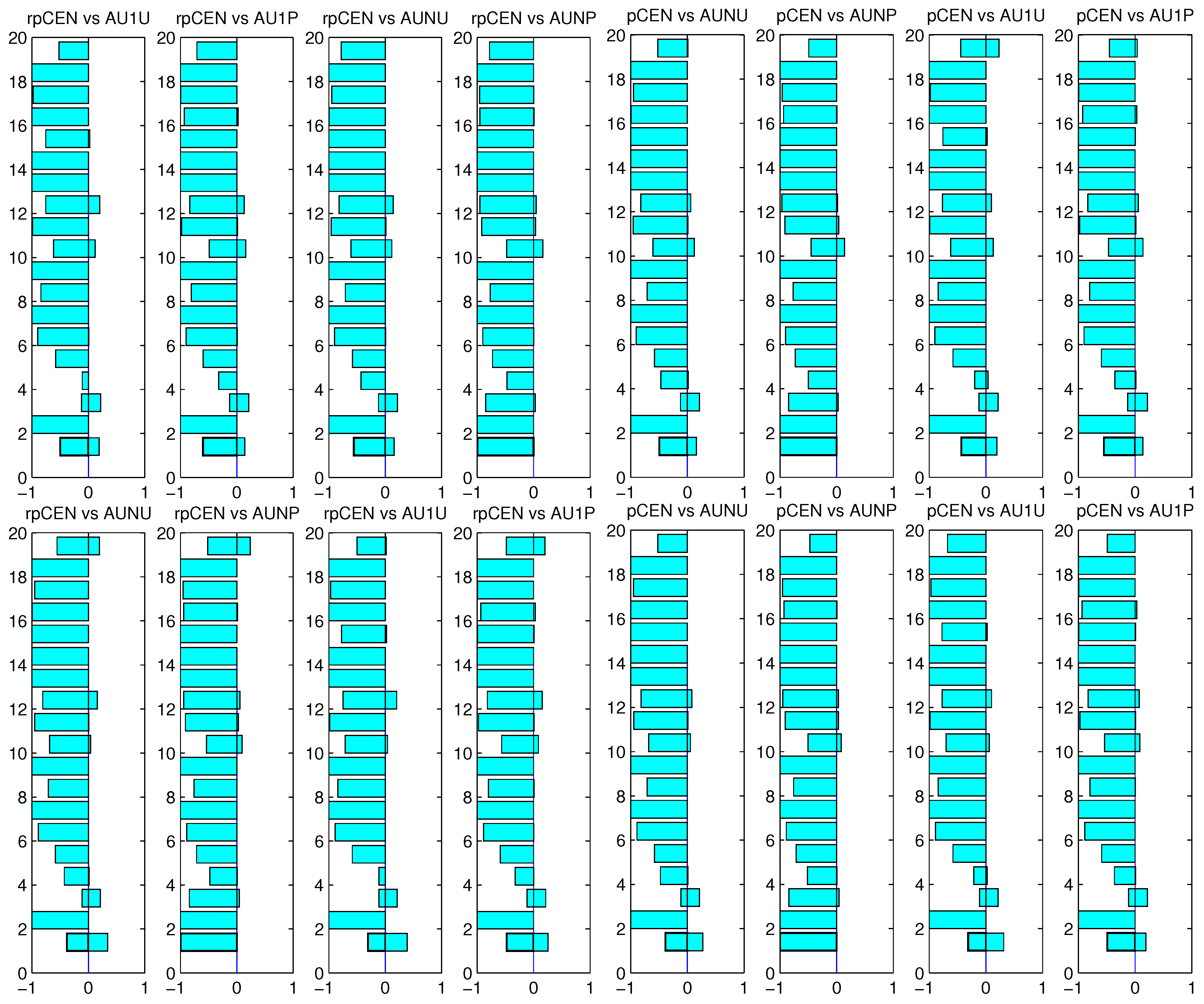
vs. CEN using pCEN, ACC and pCEN and CEN to choose the best classifiers. For comparing rpCEN and pCEN with the four variants of AUC, we present the win-loss-equal statistics using rpCEN and pCEN to choose the true best classifiers in
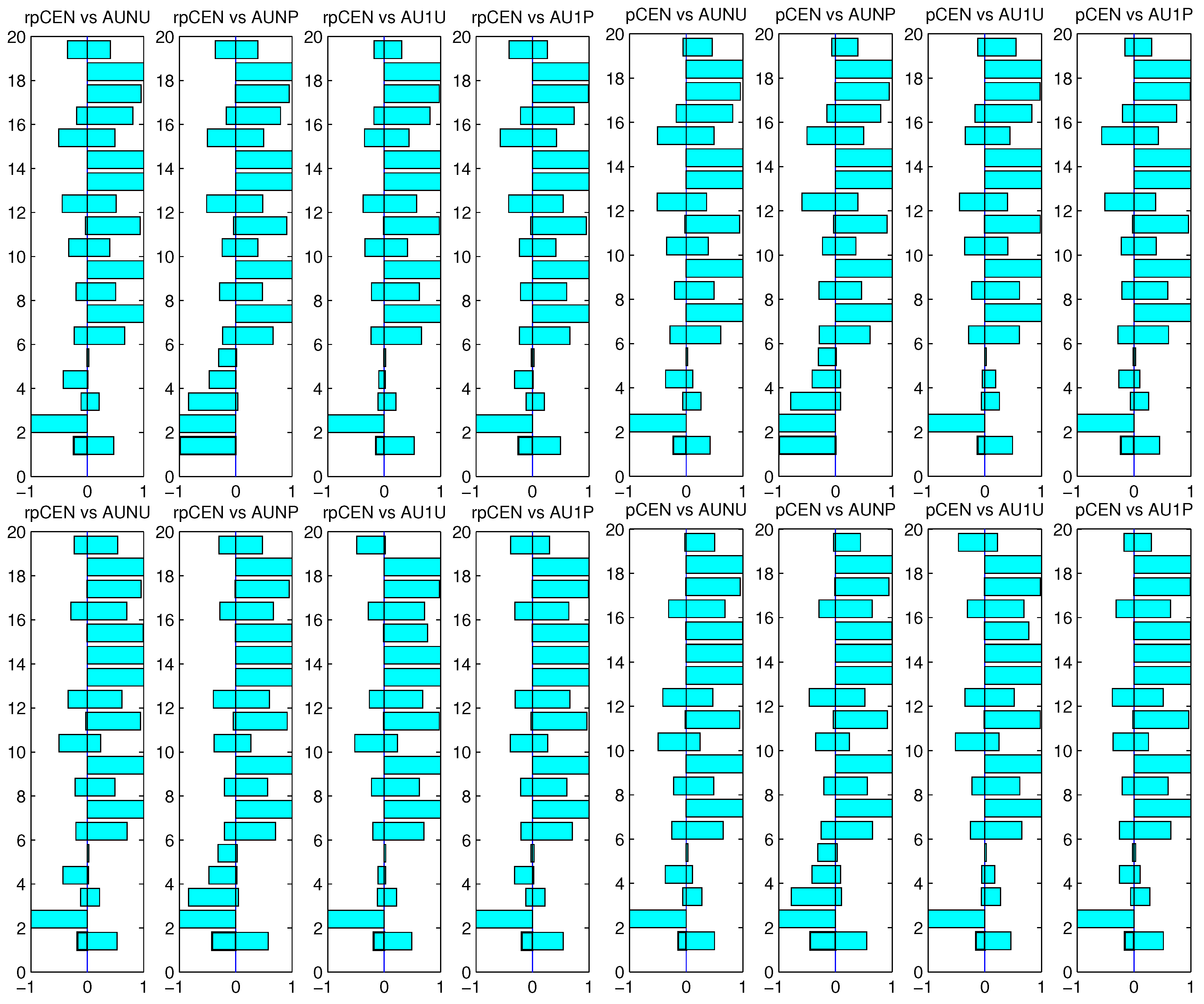
Figure 2. From
Figure 1, we can find that the probabilistic confusion entropy expectedly outperformed the accuracy and the confusion entropy on almost all of the datasets, which confirms the above discussion. From
Figure 2, we can see that the relative probabilistic confusion entropy and probabilistic confusion entropy outperformed the four variants of AUC on almost all the datasets except for the third one. From
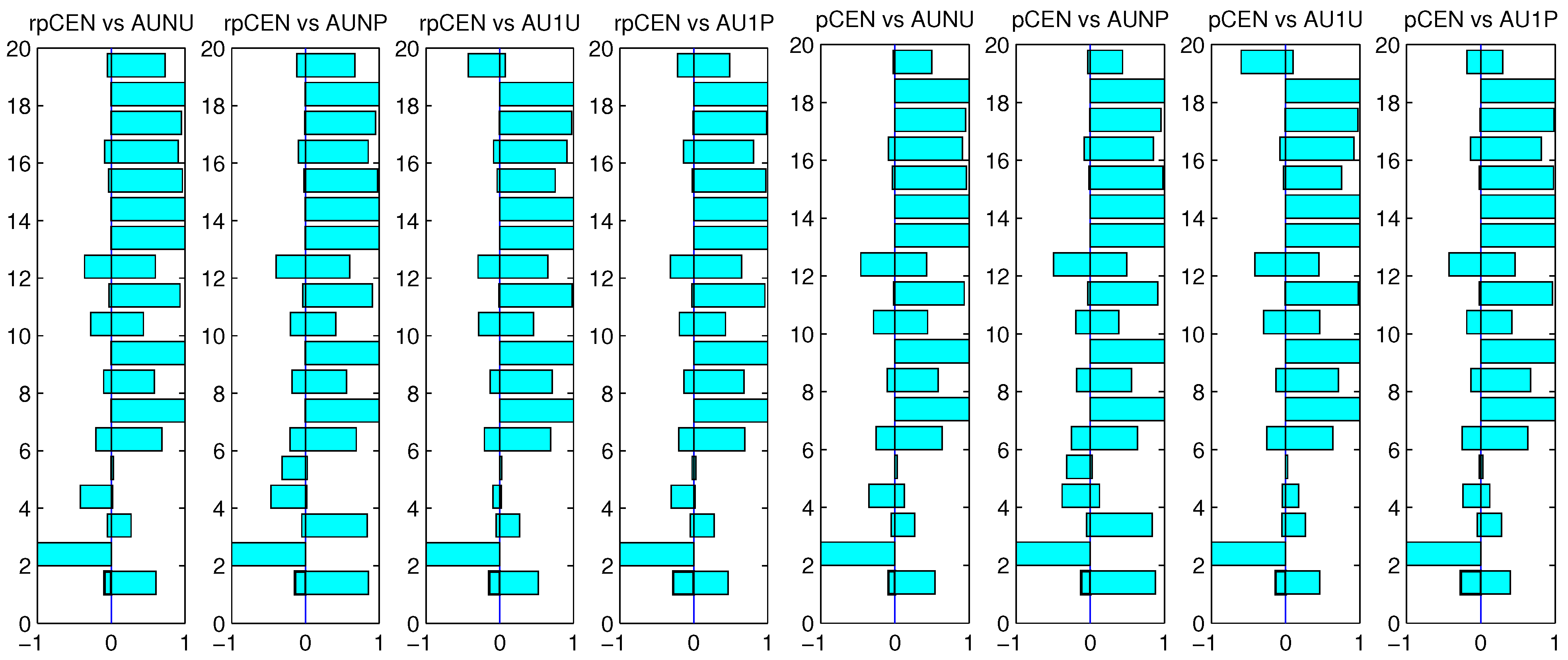
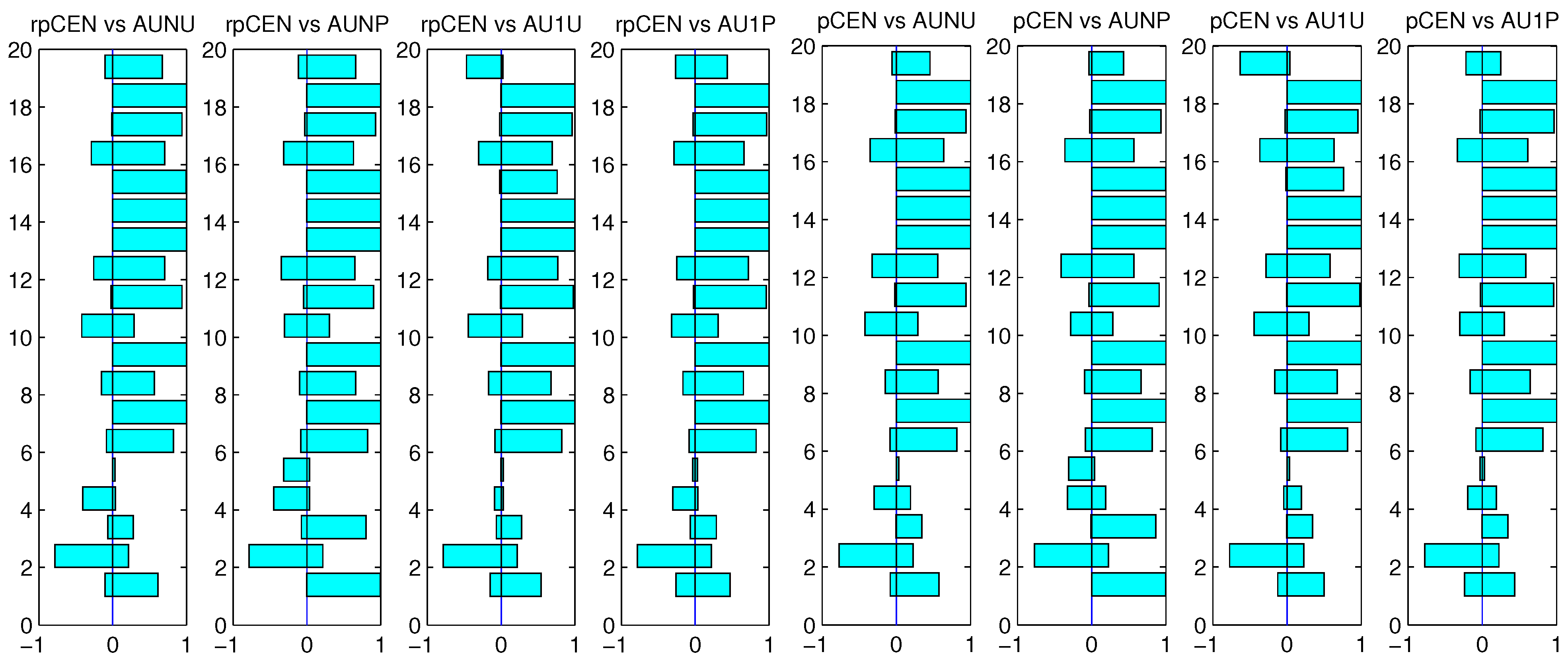
Figure 3 and
Figure 4, we can find that the four variants of AUC outperformed the two probabilistic confusion entropies on most of the datasets. The results shown in
Figure 2,
Figure 3 and
Figure 4 obviously indicate that choosing the true best classifiers by a measure tends to rank the measure higher than the other measures. Nevertheless, as one may notice on some of the datasets, the four variants, when they were employed to choose the true best classifiers, did not appear to be as good as the two probabilistic confusion entropies, when the two measures were used to choose the true best classifiers. Hence, we can still determine that the two probabilistic confusion entropies are more effective than the four variants of AUC from the results shown in
Figure 2,
Figure 3 and
Figure 4.
The win-loss-equal statistics using AUNU and AUNP to choose the true best classifiers are pictured in
Figure 3. The win-loss-equal statistics using AU1U and AU1P to choose the true best classifiers are pictured in
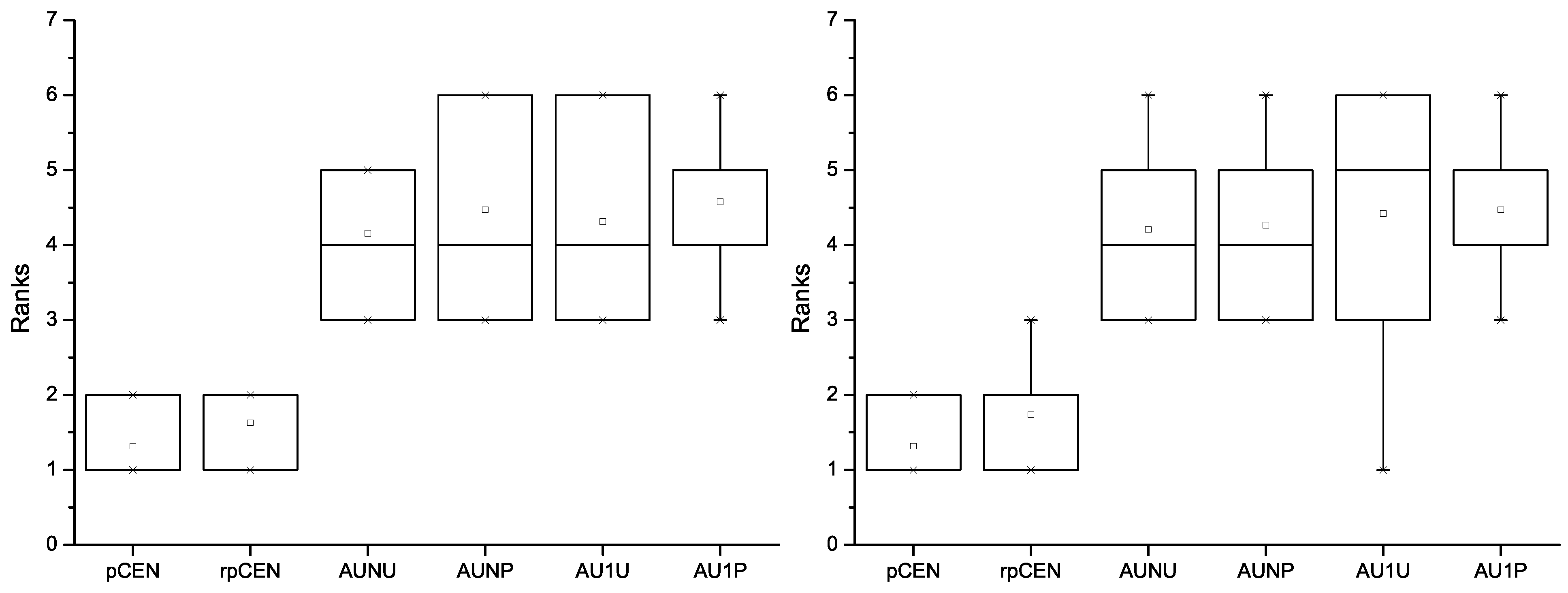
Figure 4For further revealing how the compared measures performed, we calculated the average regrets of the 2,000 rounds for all the datasets. For each dataset, we ranked the six compared measures. The best was ranked the first and the worst the sixth. The rank results using rpCEN and pCEN to choose the true best classifiers are pictured in
Figure 5. The rank results with respect to AUNU, AUNP, AU1U and AU1P are pictured in
Figure 6.
Figure 1.
Win-loss-equal statistics of pCEN vs. ACC (the left two) and pCEN vs. CEN (the right two). For each pair, the left figure corresponds to the results obtained using pCEN to choose the true best classifiers, the right corresponds to that using the compared measure.
Figure 1.
Win-loss-equal statistics of pCEN vs. ACC (the left two) and pCEN vs. CEN (the right two). For each pair, the left figure corresponds to the results obtained using pCEN to choose the true best classifiers, the right corresponds to that using the compared measure.
Figure 2.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using rpCEN (the upper two) and pCEN (the lower two) to choose the true best classifiers.
Figure 2.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using rpCEN (the upper two) and pCEN (the lower two) to choose the true best classifiers.
Figure 3.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using AUNU (the upper two) and AUNP (the lower two) to choose the true best classifiers.
Figure 3.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using AUNU (the upper two) and AUNP (the lower two) to choose the true best classifiers.
Figure 4.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using AU1U (the upper two) and AU1P (the lower two) to choose the true best classifiers.
Figure 4.
Win-loss-equal statistics of rpCEN, pCEN vs. AUNU, AUNP, AU1U and AU1P using AU1U (the upper two) and AU1P (the lower two) to choose the true best classifiers.
Figure 5.
The ranks of rpCEN, pCEN, AUNU, AUNP, AU1U and AU1P using rpCEN (the left) and pCEN (the right) to choose the true best classifiers.
Figure 5.
The ranks of rpCEN, pCEN, AUNU, AUNP, AU1U and AU1P using rpCEN (the left) and pCEN (the right) to choose the true best classifiers.
Figure 6.
The ranks of rpCEN, pCEN, AUNU, AUNP, AU1U and AU1P using AUNU (the upper left), AUNP (the upper right), AU1U (the lower left) and AU1P (the lower right) to choose the true best classifiers.
Figure 6.
The ranks of rpCEN, pCEN, AUNU, AUNP, AU1U and AU1P using AUNU (the upper left), AUNP (the upper right), AU1U (the lower left) and AU1P (the lower right) to choose the true best classifiers.
From
Figure 5 and
Figure 6, we can also find that the measures tended to be ranked higher when they were employed to choose the true best classifiers. Nevertheless, it is easy to find that the relative probabilistic confusion entropy and the probabilistic confusion entropy obviously outperformed the four variants of AUC. When rpCEN was used to choose the true best classifiers, no variant of AUC was ranked ahead of the two probabilistic confusion entropies on all datasets. Their average ranks turned out to be larger than 1 but smaller than 2. In comparison, though each variant of AUC was ranked higher on average than the other three variants and the two probabilistic confusion entropies when it was employed to choose the true best classifiers, all the other measures were ranked higher on some of the datasets. Besides, the average rank of each variant turned out to be larger than 2, even when it was employed to choose the true best classifiers.
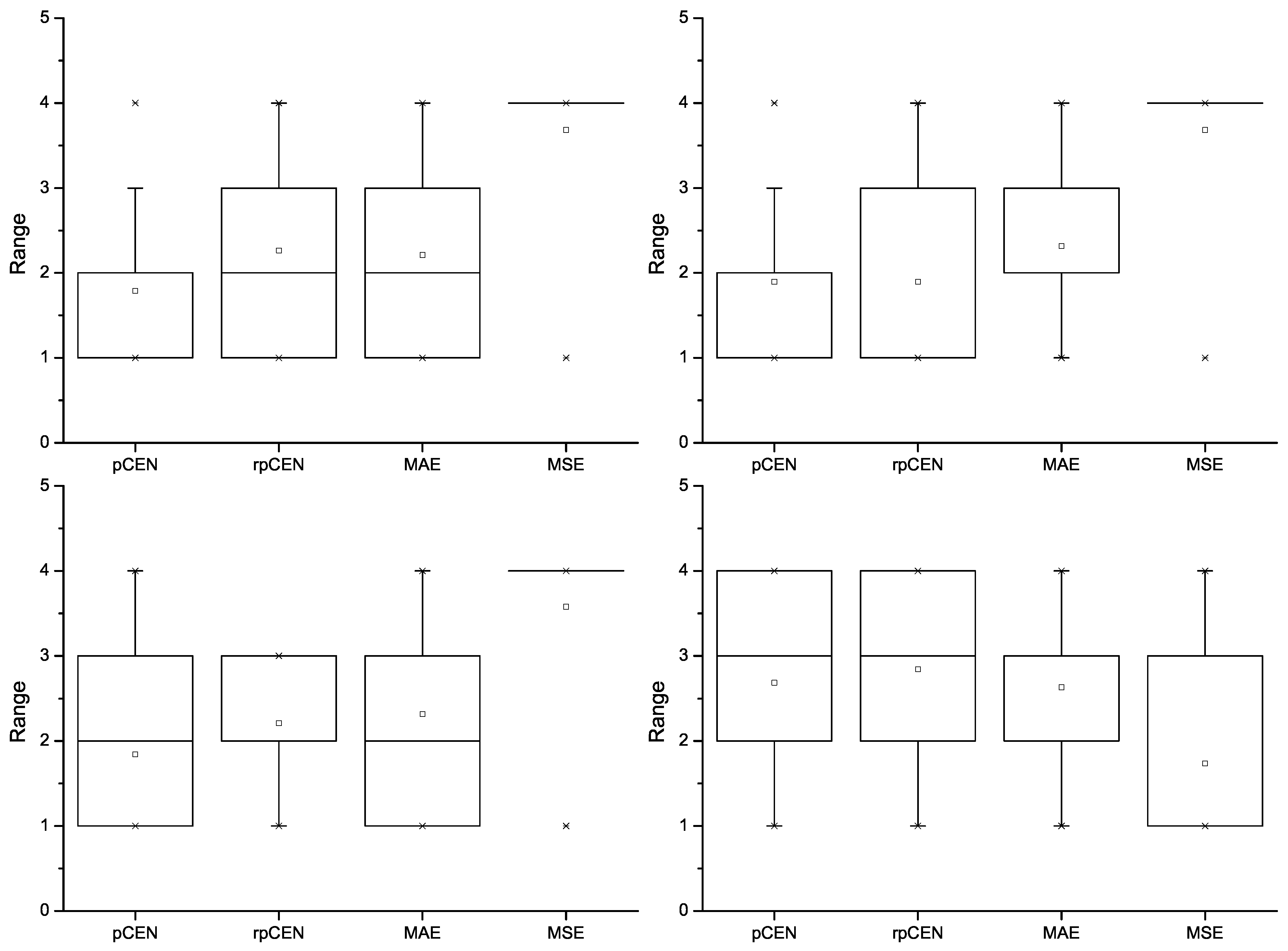
Figure 7.
Win-loss-equal statistics of rpCEN and pCEN vs. MAE and MSE using pCEN (the upper left), rpCEN (the upper right), MAE (the lower left) and MSE (the lower right) to choose the true best classifiers.
Figure 7.
Win-loss-equal statistics of rpCEN and pCEN vs. MAE and MSE using pCEN (the upper left), rpCEN (the upper right), MAE (the lower left) and MSE (the lower right) to choose the true best classifiers.
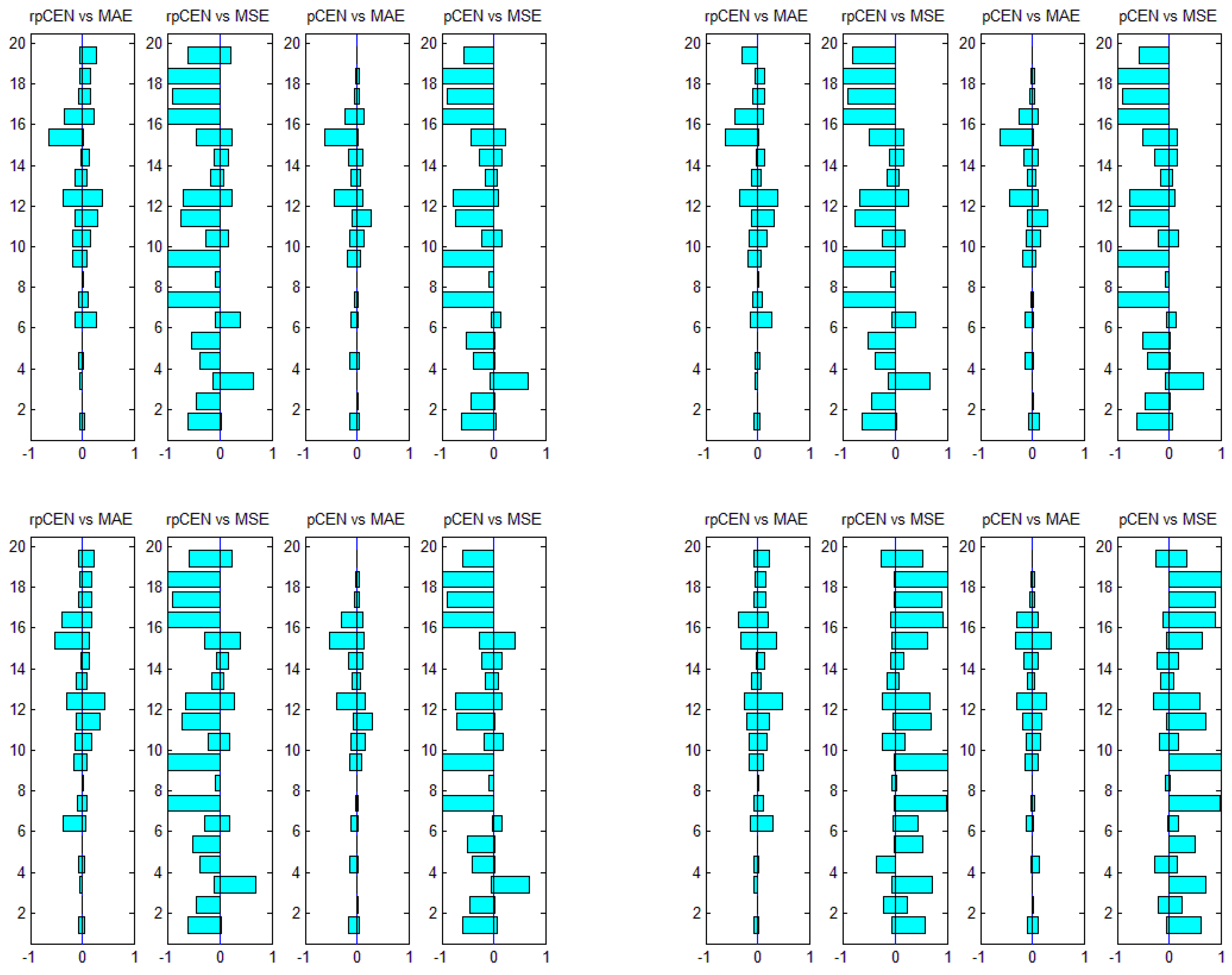
Experiments were similarly conducted to compare probabilistic confusion entropy with MAE and MSE. The win-loss-equal statistics of rpCEN, pCEN
vs. MAE and MSE are shown in
Figure 7. First of all, it can be noticed in
Figure 7 that pCEN, rpCEN and MSE appear to be superior respectively when they were used to choose the true best classifiers, though pCEN and rpCEN appear to be a little bit more superior to MSE. In contrast to this result, pCEN and rpCEN appear to be similar to MAE when each of the four measures, including MSE, was used to choose the true best classifiers. Besides, pCEN and rpCEN appear to be superior to MSE when MAE is used to choose the true best classifiers. For further investigating the relation between pCEN and rpCEN and MSE and MAE, the rank results with respect to the four measures are pictured in
Figure 8. From the figure, it also can be seen that pCEN, rpCEN and MSE appear to be superior respectively when they were used to choose the best classifiers. Additionally, in comparison, pCEN and rpCEN appear to be superior to MSE, for they were not ranked higher than 3, even when MSE or MAE was used to choose the true best classifiers. MAE ranks pCEN and rpCEN higher than MSE. It is obvious to see that pCEN and rpCEN is superior to MAE, even when MAE was used to choose the true best classifiers.
Figure 8.
The ranks of rpCEN, pCEN, MAE and MSE using pCEN (the upper left), rpCEN (the upper right), MAE (the lower left) and MSE (the lower right) to choose the true best classifiers.
Figure 8.
The ranks of rpCEN, pCEN, MAE and MSE using pCEN (the upper left), rpCEN (the upper right), MAE (the lower left) and MSE (the lower right) to choose the true best classifiers.
The results shown in
Figure 5,
Figure 6 and
Figure 8 indicate that the improved confusion entropy was capable of evaluating classifiers consistently for different datasets. It is more stable than the compared measure. Hence, the improved probabilistic confusion entropy is more reliable for classifier evaluation. All the results show that the two probabilistic confusion entropies are effective for evaluating classifiers.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
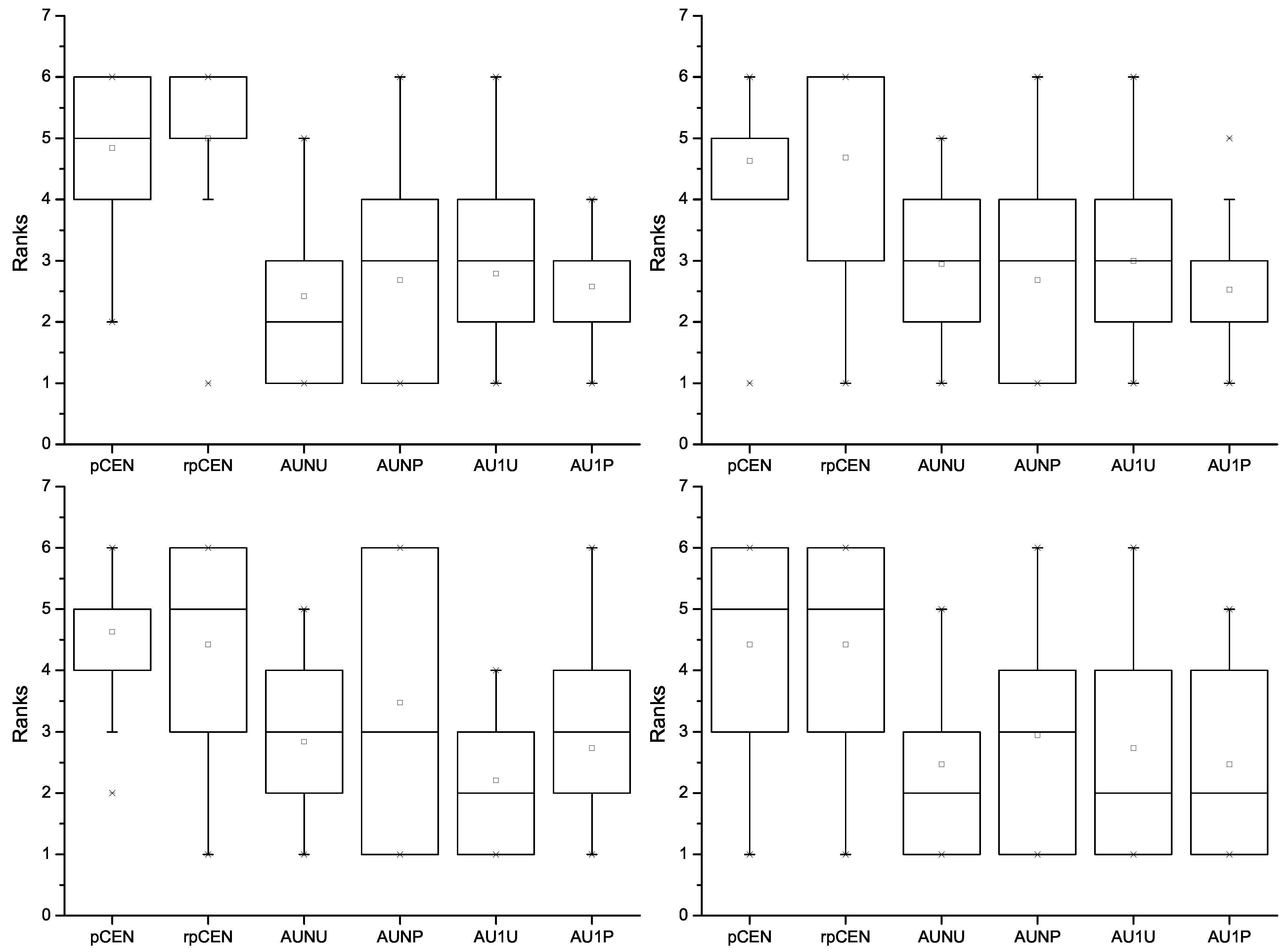{kind=link}
{kind=link}
{kind=link}








