A Load Balancing Algorithm Based on Maximum Entropy Methods in Homogeneous Clusters

Abstract
:
1. Introduction
2. Related Studies
3. Basic Concept
3.1 Entropy
3.2. Maximum Entropy Methods
3.3. Load Balancing
4. Model of the Algorithm and Its Properties
4.1. The Define of the Model
4.2. The Properties
5. Implementation of the Algorithm
- The collection and processing of load information on server nodes
- The selection of the scheduling policy
- The selection of the migration strategy
- The implementation of migration
5.1. Collection and Processing of Load Information
5.2. Selection of the Scheduling Policy
5.3. Selection of the Migration Strategy
5.4. Implementation of the Migration
- The tasks are always migrated from high-load nodes to low-load nodes, but not vice versa. It means that the migration is always toward the increasing trend of system entropy value.
- The tasks with too small an amount of calculation are beyond the selection scope of the migration because the migration needs to use system resources and execution time Maybe the time taken to do the migration is far beyond the execution time of tasks. This will cause a waste of system resources and time.
5.5 Description of the Algorithm
- Step 1. According to the information collected, we can calculate the load Lk and relative load factor pi of each server node as well as the average relative load factor, so as to obtain the system’s current entropy value. Then, we turn to Step 2;
- Step 2. To compare the system’s current entropy value H(t) with the threshold value H° we do the following:
- If the H(t) is less than H°, it means that the system load is unbalanced and needs migration. For the server nodes whose relative load factor pi of each server node is greater than or equal to the average relative load factor p°, the relative load factor pi should be sorted in descending order to form a server queue Qs. That is the server queue which needs to do the load migration; for the other server nodes whose relative load factor pi of each server node is less than the average relative load factor p°, the relative load factor pi should be sorted in ascending order to form a server queue Qt. That is the server queue which can accept the load. Then we turn to Step 3 to do the migration;
- If the H(t) is greater than or equals to H°, it shows that the system load is comparatively balanced and it is unnecessary to do the migration. We see if there is any new load to be scheduled and if there is, then we turn to Step 4 and do the scheduling operation; otherwise, return to Step 1 and calculate the next moment;
- Step 3. To traverse the queue Qs and Qt, and take out the nodes S and T to migrate the task on node S to node T, ensuring that the entropy of the system will increase after the migration. For the node S, the operation will be continued until the relative load factor pi of each server node is less than the average relative load factor p°, then we remove the node S from the queue Qs; for the node T, the operation will be finished when the relative load factor pi of each server node is greater than or equal to the average relative load factor p°, then we remove the node T from the queue Qt. The migration won’t be finished until any queue is empty, and then we go back to Step 1;
- Step 4. To schedule the new tasks, and form a server queue Q sorted by the relative load factor pi in ascending order, scanning this queue and finding out the node S whose entropy increased and is the maximum after the scheduling. If it exists, then the task is scheduled to the node S to finish the task scheduling, and then we return to Step 1.
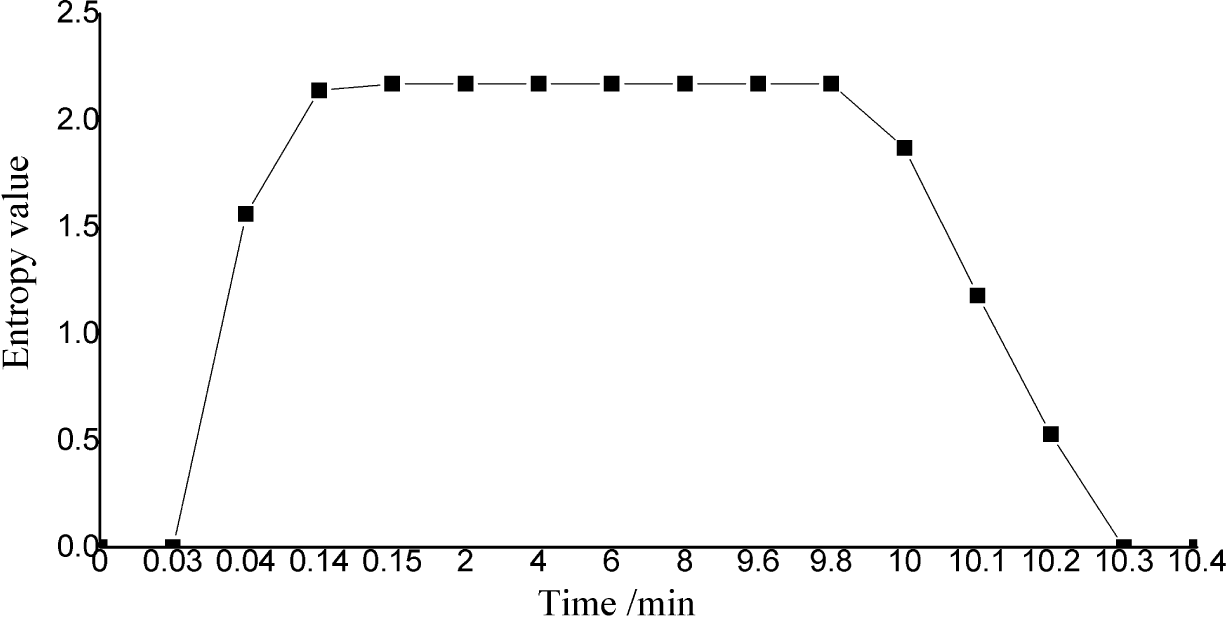
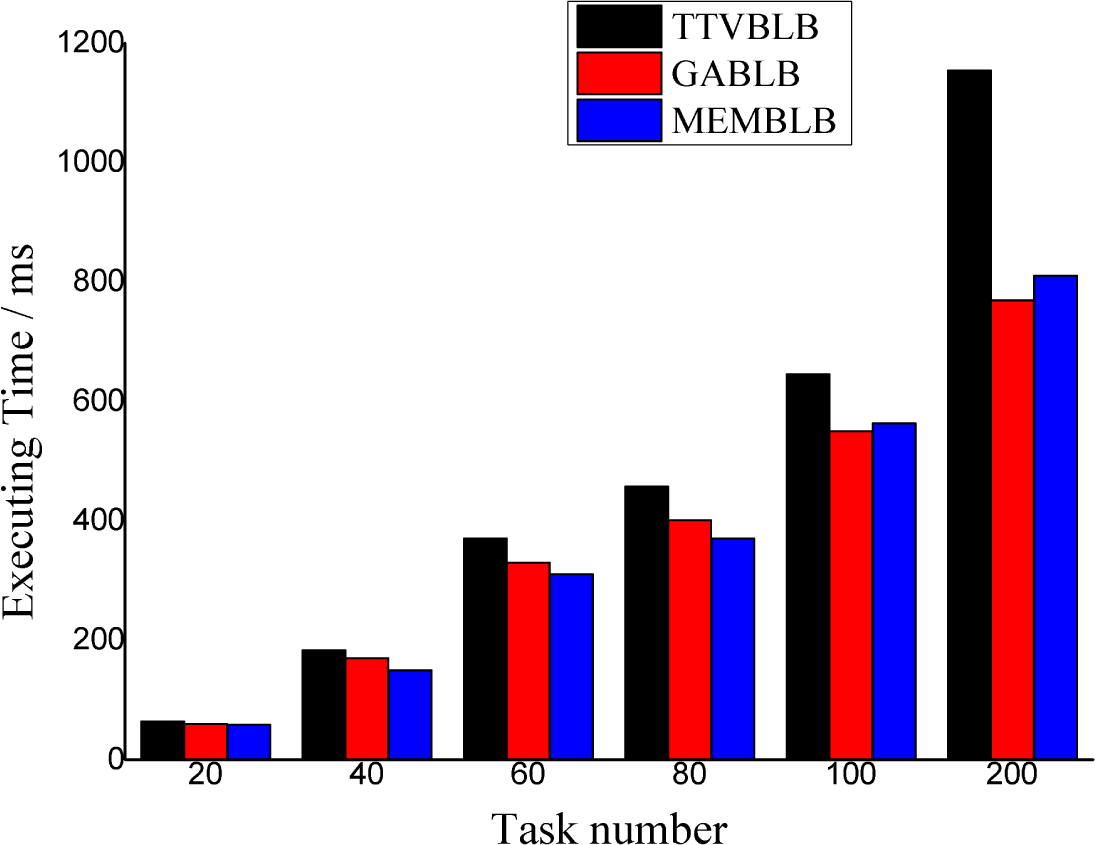
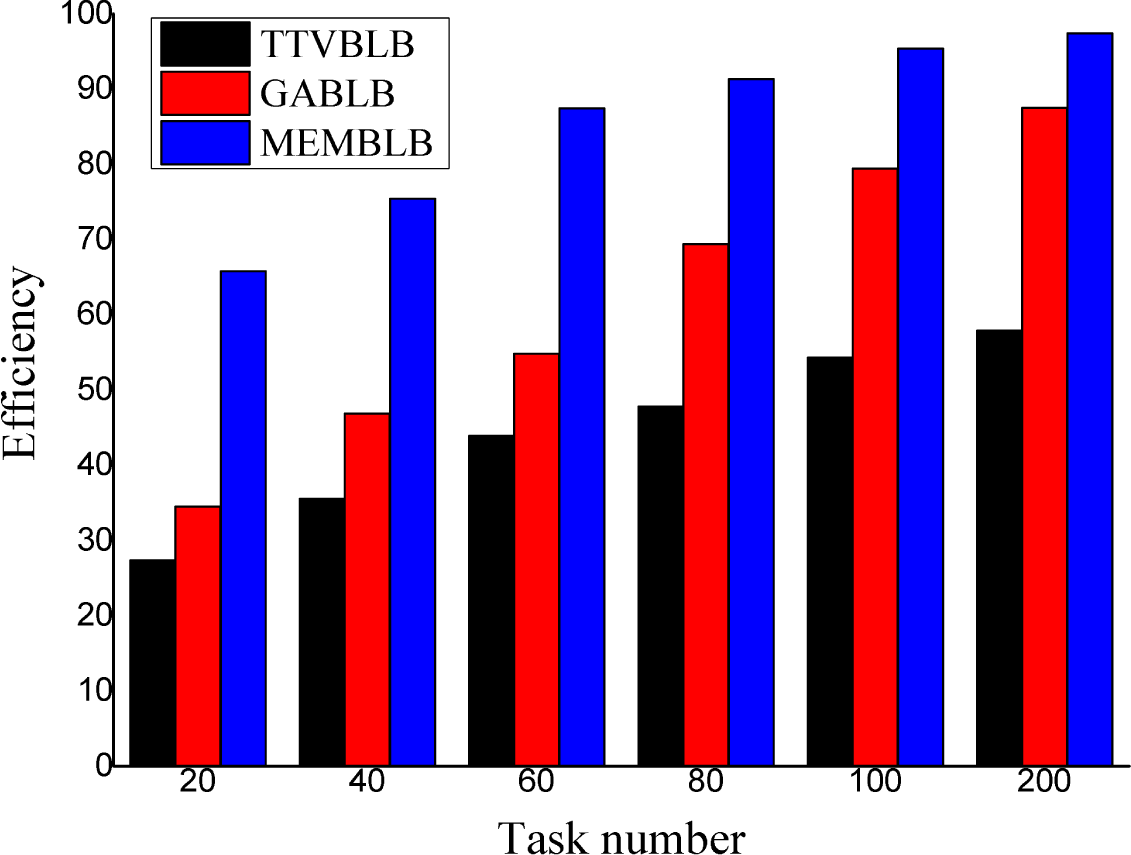
6. Experiments and Results
6.1. Environment of the Experiments
- OpenStack: OpenStack is an open source cloud management platform, which provides an easy way to create, manage, and release virtual machines. As is known to all, no two leaves are identical in the world, so it is difficult to create a completely homogeneous cluster. We solved this problem by using OpenStack to create some near-identical virtual machines with the same image. There are three servers with the same configuration of 2.4GHz CPU, 8G RAM and Ubuntu 12.04.
- Haproxy: Haproxy is an open source traditional load balancing procedure. We have changed the procedure to use the above two load balancing algorithms and compare them in the experiments.
- KVM: KVM is a virtualization platform, which provides some programmatic APIs to create, migrate and destroy virtual machines. In this experiment, OpenStack used KVM to create the virtual machines.
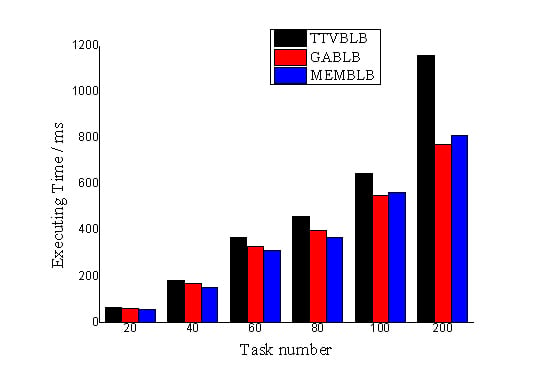
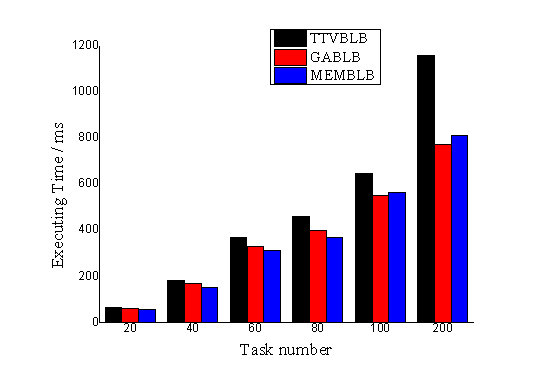
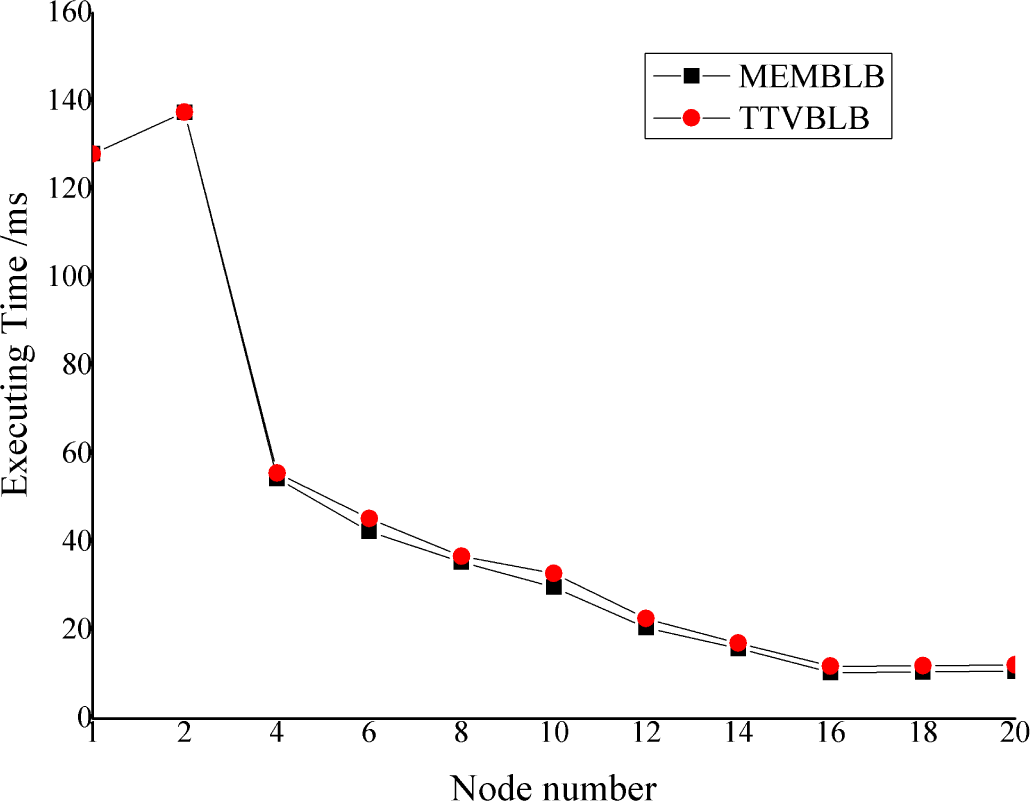
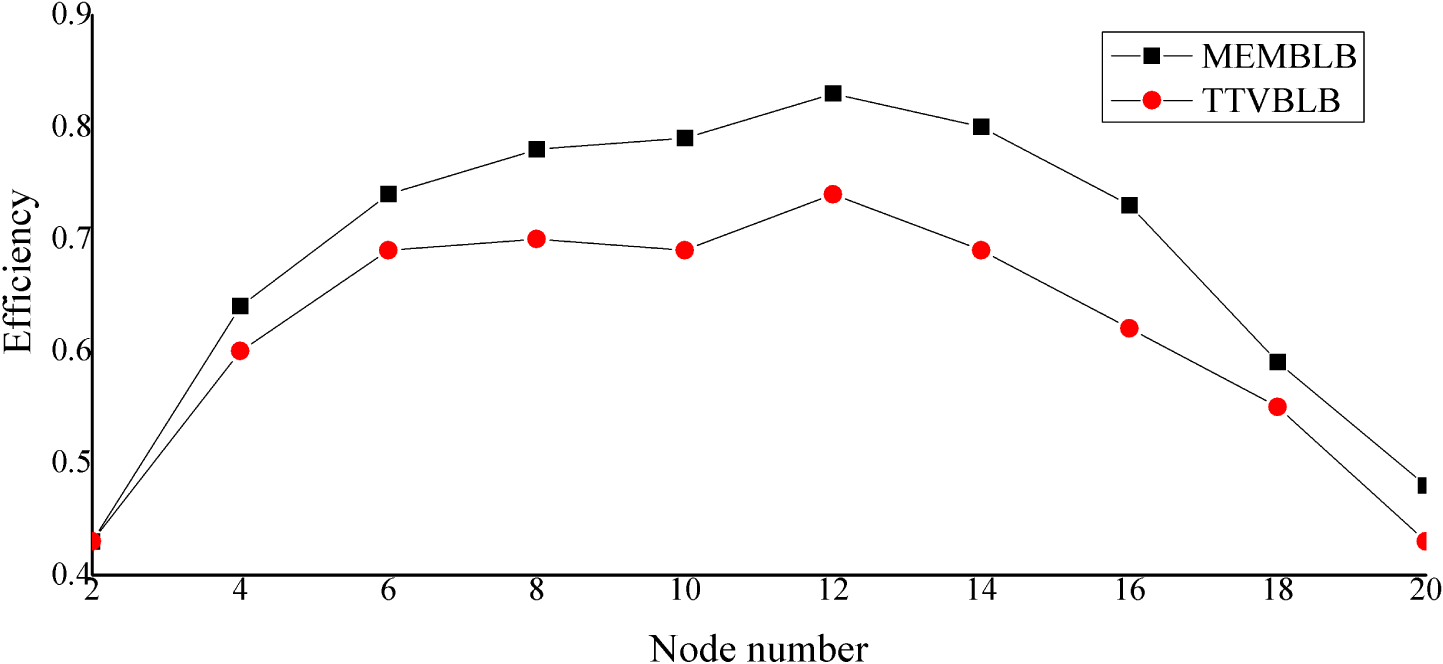
6.2. Results of the Experiments
6.3. Analysis of the Results
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dong, J.Y.; Wang, P.; Chen, L. The entropy value of load blance algorithm about cloud computer cluster. J. Chengdu Univ. Inf. Tech. 2010, 65, 581–583. [Google Scholar]
- Lu, K.Z.; Sun, H.Y. Parallel computing entropy in homogeneous cluster. J. Shenzhen Univ. Sci. Eng. 2009, 1, 26, In Chinese. [Google Scholar]
- LV, S. Load Balancing. Available online: http://kh.linuxvirtualserver.org/wiki/Load_balancing#Computing_Loa-d_Balancing accessed on 23 October 2014.
- Ibrahim, M.A.M.; Lu, X. In Performance of dynamic load balancing algorithm on cluster of workstations and PCs, In Proceedings of Fifth International Conference on Algorithms and Architectures for Parallel Processing, Los Alamitos, CA, USA, 23–25, October 2002; IEEE Comput. Society: Los Alamitos, CA, USA, 2002; pp. 44–47.
- Liu, Z.H.; Wang, X. Load balancing algorithm with genetic algorithm in virtual machines of cloud computing. J. Fuzhou Univ. (Nat. Sci. Ed.) 2012, 4, 9, In Chinese. [Google Scholar]
- Chau, S.C.; Fu, A.W. Load balancing between computing clusters, In Proceedings of the Fourth International Conference on Parallel and Distributed Computing, Applications and Technologies, 2003 (PDCAT’2003), Chengdu, China, 27#x02013;29, August 2003; pp. 548–551.
- Balasubramaniam, M.; Barker, K.; Banicescu, I.; Chrisochoides, N.; Pabico, J.P.; Carino, R.L. A novel dynamic load balancing library for cluster computing, In Third International Symposium on/Algorithms, Models and Tools for Parallel Computing on Heterogeneous Networks, Cork, Ireland, 5–7, July 2004; pp. 346–353.
- Sit, H.Y.; Ho, K.S.; Leong, H.V.; Luk, R.W.; Ho, L.K. An adaptive clustering approach to dynamic load balancing, In Proceedings of the 7th International Symposium on Parallel Architectures, Algorithms and Networks, Hong Kong, China, 10–12, May 2004; pp. 415–420.
- Dai, Y.; Cao, J. Fuzzy control-based heuristic algorithm for load balancing in workflow engine. J. Commun. 2006, 27, 84–89. [Google Scholar]
- Kim, Y.J.; Kim, B.K. Load balancing algorithm of parallel vision processing system for real-time navigation, In Proceedings of 2000 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2000), Takamatsu, Japan, 31 October–5 November 2000; pp. 1860–1865.
- Nair, C.; Prabhakar, B.; Shah, D. The randomness in randomized load balancing, In Proceedings of the Annual Allerton Conference on Communication Control and Computing, Monticello, IL, USA, October 2001; pp. 912–921.
- Zuo, L.Y.; Cao, Z.B.; Dong, S.B. Virtual resource evaluation model based on entropy optimized and dynamic weighted in cloud computing. J. Softw. 2013, 24, 1937–1946, In Chinese. [Google Scholar]
- Leibnitz, K.; Shimokawa, T.; Peper, F.; Murata, M. Maximum entropy based randomized routing in data-centric networks, In Proceedings of the 15th Asia-Pacific Network Operations and Management Symposium (APNOMS 2013), Hiroshima, Japan, 25#x02013;27, September 2013; pp. 1–6.
- Xie, W.X; Bedrosian, S. An information measure for fuzzy sets. IEEE Trans. Syst. Man Cybern 1984, 1, 151–156. [Google Scholar]
- Hu, C.; Wang, B. Distribution model based on maximum entropy principle. J. Shandong Univ. Tech.(Nat. Sci. Ed. 2008, 21, 87–90, In Chinese. [Google Scholar]
- Yang, J.; Hu, D.X.; Wu, Z.R. Bayesian uncertainty inverse analysis method based on pome. J. Zhejiang Univ.(Eng. Sci.) 2006, 40, 810–815, In Chinese. [Google Scholar]
- Lv, W. The applications of Maximum Entropy Method (MEM) and Bayes in data processing. Univ. Electron. Sci. Tech. China. 2006. volume, firstpage–lastpage. (In Chinese) [Google Scholar]
- Zou, H.; Luo, S.X. The computer cluster and the parrllel computer environment based on the networks. Comput. Tech. Geophys. Geochem. Explor. 2001, 23, 375–379, In Chinese. [Google Scholar]
- Luo, Y.J.; Li, X.L.; Sun, R.X. Summarization of the load-balancing algorithm. Sci-Tech Inf. Dev. Econ. 2008, 18, 134–136, In Chinese. [Google Scholar]
- Sun, H.Y.; Xie, W.X.; Yang, X. A. Load balancing algorithm based on Parallel computing entropy in HPC. J. Shenzhen Univ. Sci. Eng. 2007, 1, 24, In Chinese. [Google Scholar]
- Heirich, A. Analysis of Scalable Algorithms for Dynamic Load Balancing and Mapping with Application to Photo-Realistic Rendering. Ph.D. Thesis, California Institute of Technology, Pasadena, CA, USA, 1997. [Google Scholar]
- Sharma, R.; Kanungo, P. Dynamic load balancing algorithm for heterogeneous multi-core processors cluster, In Proceedings of the Fourth International Conference on Communication Systems and Network Technologies (CSNT 2014), Bhopal, India, 7–9, April 2014; pp. 288–292.
- Yun, S.Y.; Proutiere, A. Distributed load balancing in heterogenous systems, In Proceedings of the 48th Annual Conference on Information Sciences and Systems (CISS 2014), Princeton, NJ, USA, 19–21, March 2014; pp. 1–6.
- Li, H.-Y.; Du, J.-C.; Peng, J.; Wang, J.-Y. A load-balancing scheduling scheme based on heterogeneous workloads in cloud data centers. J. Sichuan Univ. (Eng. Sci. Ed.) 2013, 45, 112–117, In Chinese. [Google Scholar]
- Overman, R.E.; Prins, J.F.; Miller, L.A.; Minion, M.L. Dynamic load balancing of the adaptive fast multipole method in heterogeneous systems, In Proceedings of IEEE 27th International Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW 2013), Cambridge, MA, USA, 20–24, May 2013; pp. 1126–1135.
- Sheng, J.; Qi, B.; Dong, X.; Tang, L. Entropy weight and grey relation analysis based load balancing algorithm in heterogeneous wireless networks, In Proceedings of the 8th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM 2012), Shanghai, China, 21–23, September 2012; pp. 1–4.
- Chi, K.-H.; Yen, L.-H. Load distribution in non-homogeneous wireless local area networks. Wirel. Pers. Commun. 2014, 75, 2569–2587. [Google Scholar]
- Moreno, A.; Cesar, E.; Guevara, A.; Sorribes, J.; Margalef, T. Load balancing in homogeneous pipeline based applications. Parallel Comput 2012, 38, 125–139. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nodes | The load after scheduling
| |
|---|---|---|
| TTVBLB | MEMBLB | |
| Node A | 11 | 10 |
| Node B | 11 | 13 |
| Node C | 16 | 12 |
| Node D | 15 | 15 |
| Node E | 10 | 13 |
| Entropy | 1.5914 | 1.6010 |
| Nodes | the load after migration
| |
|---|---|---|
| TTVBLB | MEMBLB | |
| Node A | 13 | 12 |
| Node B | 11 | 13 |
| Node C | 13 | 12 |
| Node D | 13 | 13 |
| Node E | 13 | 13 |
| Entropy | 1.6074 | 1.6087 |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Wu, K.; Li, Y. A Load Balancing Algorithm Based on Maximum Entropy Methods in Homogeneous Clusters. Entropy 2014, 16, 5677-5697. https://0-doi-org.brum.beds.ac.uk/10.3390/e16115677
Chen L, Wu K, Li Y. A Load Balancing Algorithm Based on Maximum Entropy Methods in Homogeneous Clusters. Entropy. 2014; 16(11):5677-5697. https://0-doi-org.brum.beds.ac.uk/10.3390/e16115677
Chicago/Turabian StyleChen, Long, Kehe Wu, and Yi Li. 2014. "A Load Balancing Algorithm Based on Maximum Entropy Methods in Homogeneous Clusters" Entropy 16, no. 11: 5677-5697. https://0-doi-org.brum.beds.ac.uk/10.3390/e16115677