Entropy-Based Characterization of Internet Background Radiation


Abstract
:
1. Introduction
- Proposing entropy-based models for the IBR traffic analysis as a basis for a fast and lightweight recognition of new malicious events in wide area networks.
- Discovering correlations between anomalous traffic types detected with deep inspection techniques and traffic feature entropy variations.
- Providing a traffic-type dissection (in-depth and entropy based) of a representative portion of the IBR for three weeks of April, 2012, with a 10-minute time scope.
- Providing an entropy-based detection method to discover anomalies in the IBR for early warning purposes.
2. Related Work
3. Deep Packet Inspection
3.1. Dataset
3.2. Obtaining Traffic Types

3.3. Smee Types
- One or two packets (1or2pkts): a source that only sends one or two packets during the selected time interval (10 min), regardless of the protocol, destination IP or destination port. That means sources of all other classes send at least three packets.
- Unclassified traffic (unclass): packets and sources that do not match any of the following classes.
- TCP probe (tcpProb): a source that sends TCP packets to one destination IP and one destination port.
- TCP vertical scan (tcpVscan): a source that sends TCP packets to multiple destination ports of the same destination IP.
- TCP horizontal scan (tcpHscan): a source that sends TCP packets to the same port of multiple destination IPs (except to port 445).
- TCP unknown (tcpUnk): a source that sends TCP packets to multiple ports of multiple destination IPs.
- UDP probe (udpProb): a source that sends UDP packets to one destination IP and one destination port.
- UDP vertical scan (udpVscan): a source that sends UDP packets to multiple destination ports of the same destination IP.
- UDP horizontal scan (udpHscan): a source that sends UDP packets to the same port of multiple destination IPs.
- UDP unknown (udpUnk): a source that sends UDP packets to multiple ports of multiple destination IPs.
- ICMP only (icmpOnly): a source that only sends ICMP messages.
- TCP and UDP (tcp&udp): a source that sends both TCP and UDP packets during the checked time interval.
- μTorrent (uTorrent): a source that sends packets that fit the μTorrent packet profile. The μTorrent packets are identified in smee by analyzing the UDP packet payload.
- Conficker.C (confickC): a source that sends packets that fit a specific P2P packet format, which is used by the Conficker.C worm for spreading to other victims. For identifying Conficker.C P2P packets, smee uses the algorithm presented in [27].
- TCP backscatter (tcpBacks): a source that sends TCP packets with ACK or RST flags.
- DNS backscatter (dnsBacks): a source that sends TCP or UDP packets from the source port 53.
- TCP horizontal scan to port 445 (tcp445scan): a source that sends TCP packets to port 445 of multiple destination IPs.
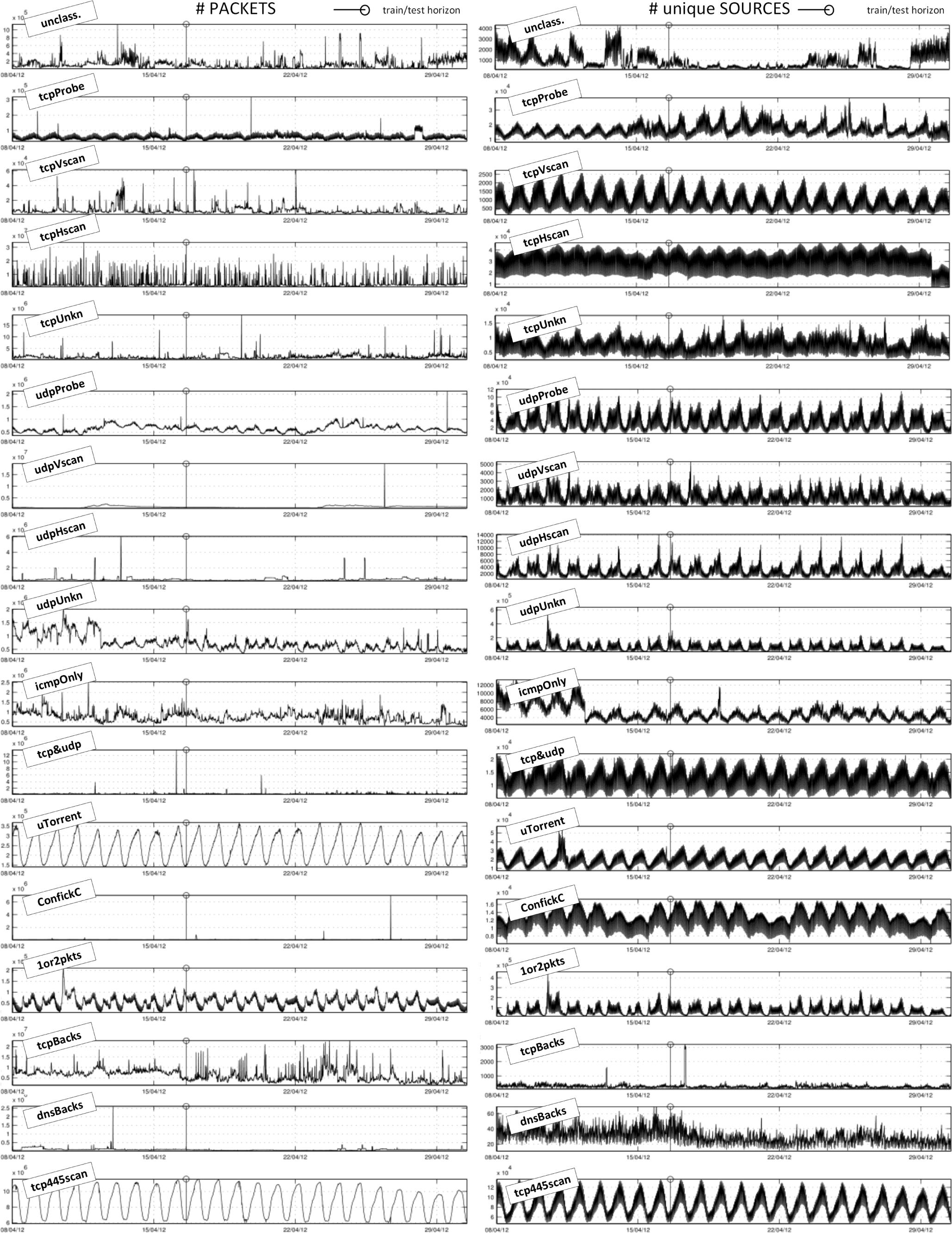
3.4. Analysis of Smee Time Series
- Strong periodicity in sources: As a general rule, the amount of sources exhibits strong oscillations with an hourly rate. Furthermore, daily patterns are clearly visible in almost all cases, but for the dnsBacks, tcpBacks and unclass traffic sources.
- Dominant traffic in the IBR: Most of the packets observed in the darkspace belong to TCP horizontal scan activities; 35.2% are scans to port 445 (tcp445scan) and 14.2% are other TCP scan packets (tcpHscan). The huge amount of scan packets to port 445 is in line with observations made by others in different darkspaces (e.g., [9,28]). The scans correspond to vulnerabilities exploited by different worms and dramatically increased with the outbreak of the conficker worm in November, 2008 [12]. 28.6% of the traffic in the darkspace originates from responses to TCP scans with spoofed addresses (tcpBacks). As for the source types, sources scanning port 445 (tcp445scan), sources sending only one or two packets (1or2pkts) and sources sending UDP unknown traffic (udpUnk) stand for 57.5% of the active sources (within a 10-minute time scope).
- Rare correlation between packets and sources: With a few exceptions (see the next paragraph), the shapes of unique sources’ time series do not correlate with their respective packets time series, which show a much more irregular behavior. From a global perspective, we are observing an underlying periodic traffic that belongs to the majority of the active sources. Peaks in packets do not usually affect the shape of unique sources because such irregularities are caused by a few very active sources, i.e., strong packet peaks are caused by a few sources. Table 2, row “pkts/src”, shows the values of standard deviations very similar to or even higher than the mean values. Therefore, considering one traffic type, it denotes either frequent strong peaks in the packet time series or very different levels of activity in the sources over time.The few traffic types that show a correlation between packets and sources are 1or2pkts, uTorrent, and tcp445scan. For the 1or2pkts traffic class, the relationship between packets and sources is established by definition, because one source in this class sends either one or two packets. For the tcp445scan, it can be assumed that scan tools also send a more or less fixed number of packets per time interval. For the uTorrent traffic, the origin of the relation remains unclear. The traffic may originate from misconfiguration at a few senders, which probably send a fixed number of packets.
- The Patch Tuesday effect: The early peak in 1or2pkts packets and sources (April 11, 2012, 01:00 UCT) corresponds to Microsoft’s Patch Tuesday release. The Patch Tuesday effect in darkspace data has been described in [15]. The increment of suspicious activity for this date is also clearly noticeable in the amount of udpUnkn sources. It also generates noticeable peaks in tcpVscan, tcpUnk, udpUnkn, udpProbe, icmpOnly and unclass packets.
- Independence among packets, correlation among sources: The generalized strong hourly and daily cyclic behavior for the sources makes source types show a high correlation among each other, but for the dnsBacks, tcpBacks and unclass cases. As for the packet types, only uTorrent and tcp445scan (and tcpProbe to a minor degree) show correlated signals. Correlations among the remaining packet time series hardly overcome random relationships.
- Independent peaks: Peaks among packet types are usually not coincident, except for the Patch Tuesday case. The same is valid for source types if we consider peaks that are not expected as part of the daily cycles.
4. Entropy Analysis of Network Traffic
4.1. Obtaining Entropy Signals

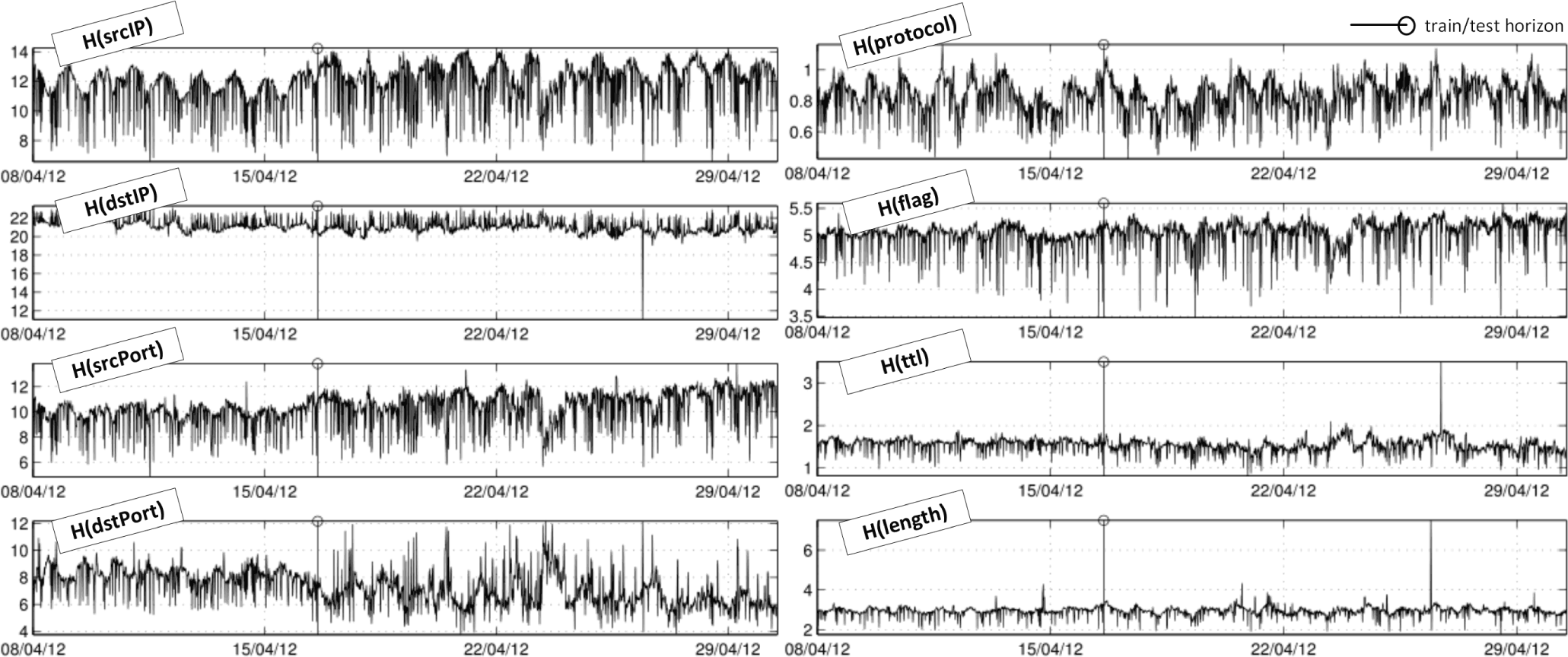
4.2. Univariate Analysis of Entropy Signals
- Daily and weekly trends in traffic: Variations in the distribution of the studied signals follow daily and weekly trends for all features, except for the flag feature. In other words, there are network phenomena submitted to daily and weekly recurrence patterns whose activity does not involve a characteristic effect on the flag values of their packets, but actually affects the rest of analyzed features. The distribution of IP sources, protocols and packet lengths exhibit a daily pattern. IP destination, source port and destination port distributions additionally show weekly repetitions.
- Nature of entropy distributions, skewed or disrupted by strong peaks: We also looked at the distribution of the entropy values (each value calculated from a 10-minute time interval) for the different features in order to see how the entropy values taken at different time intervals vary. Distributions of H(srcIP), H(TTL) and H(len) are far from being normal and skewed to more concentrated performances (source IPs) or dispersed states (TTLs and lengths). The intrinsic characteristics of every feature must be taken into account, i.e., IP sources are categorical values and their variability is much higher than possible values taken by TTLs and packet lengths. Furthermore, a few strong sources that suddenly become active can lead to a concentration of the srcIP feature distribution and can cause a sudden decrease in the entropy. In contrast, the entropy of destIP is always quite high, because sources target many different destinations if they scan the address space or answer to spoofed addresses. Protocols, source and destination port entropy distributions are closer to normal, but also skewed. The distribution of destination IP entropy is quite close to normal, but it is seriously disrupted by an isolated negative peak (outlier) that happens on April 26 at 22:30 UTC (corresponding to a udpVscan peak). The peak is clearly visible in Figure 4, H(dstIP) plot.
- Strong common peaks: Destination IP, TTL and packet length entropies exhibit strong peaks compared to their normal values. The most significant peak on April 26, 2012, at 22:30 UTC is noticeable in all entropy signals within a 30-minute scope, but for the TTL case (the closest strong peak of H(TTL) happens five hours later, and it is related to a different event: ConfickC peak). This peak around April 26 is especially significant in the following entropy signals: IP sources, IP destinations, source ports, destination ports and packet lengths. The coincidences of peaks among entropy signals happen frequently.
- Entropies are directly correlated, but for the IP destination entropy, which shows an inverse correlation: All signals under test show some positive correlations among them, but for the case of the IP destination entropy, which presents an inverse correlation to the other time series (except of the destination port entropy). Especially high are the positive correlations between IP source and source port entropies, also between flags and protocols, as well as the inverse correlation between IP destinations and protocols (some of theses correlation have been previously documented in [8]). The strong correlation between IP source and the source port is probably caused by the fact that sources select a random source port when sending an unsolicited packet. Therefore, if new sources become active, also new source ports are used. On the other hand, the negative correlation between the IP destination entropy and other feature entropies manifests that the increase of different target destinations mainly corresponds to automated algorithms sending clonal packets (e.g., scans); hence, the variability of other features decreases, since only the IP destination (sometimes also the destination port) are different. Finally, the destination port entropy shows quite random relationships with most of the other distributions, but for the TTL case.
5. Entropy-Based Modeling of the IP Darkspace
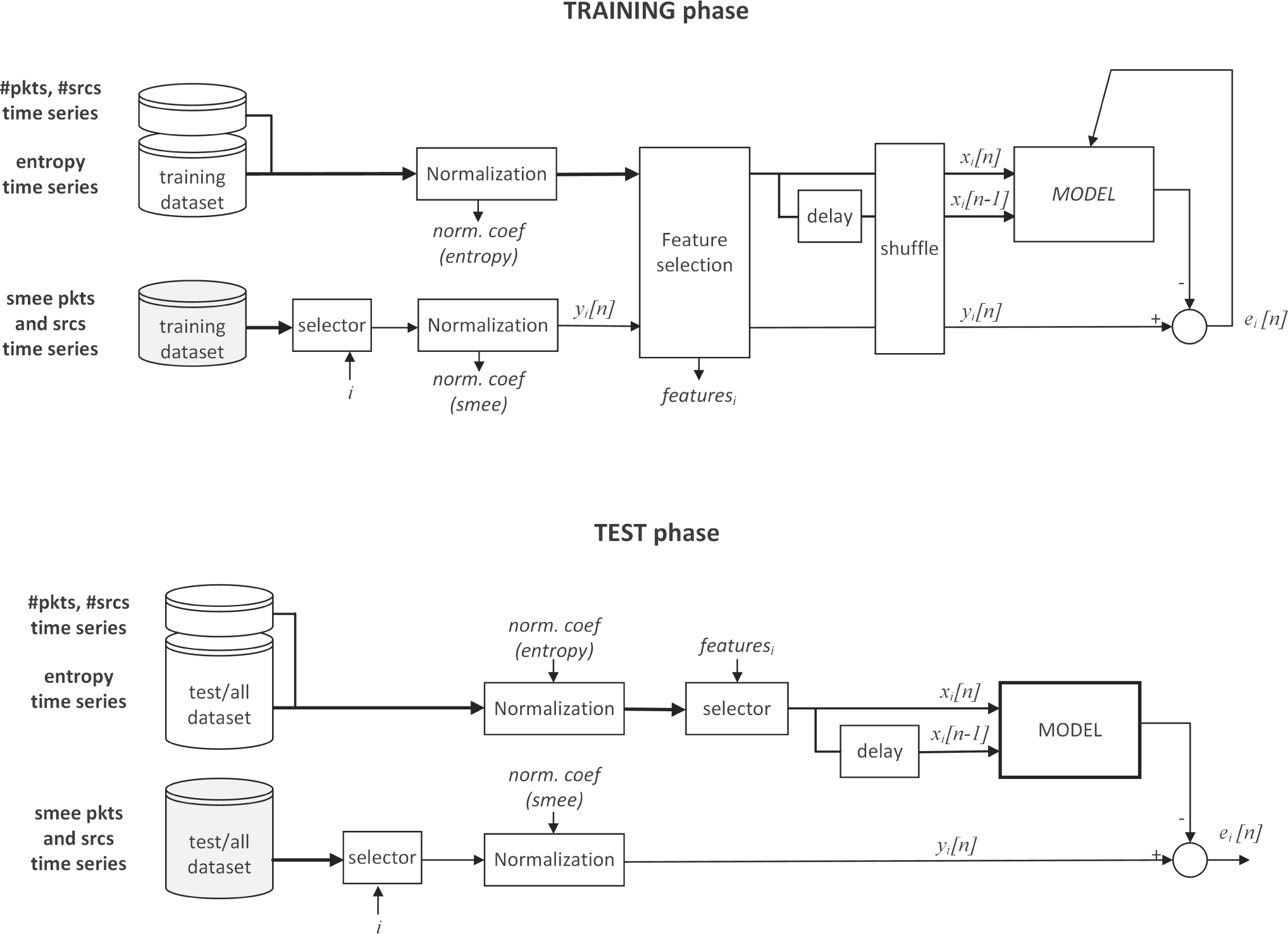
5.1. Modeling Scheme
- Datasets.
- Entropy time series, i.e., signals corresponding to distribution measures of flow-traffic features. We introduced them in Section 4, and they are displayed in Figure 4.
- Smee time series of sources and packets, introduced in Section 3 and shown in Figure 1.
- Total amount of packets (#pkts) and total amount of sources (#srcs), considering the whole darkspace and collected every 10 min. These two signals are easy to obtain and do not require any in-depth analysis.
The introduced datasets were split according to the deployment for the training and test phases. Training: 2000 samples, from April 8, 2012, 12:00 UTS, to April 17, 2012, 2:40 UTC); test: 1240 samples, from April 17, 2012, 2:50 UTC, to May 1, 2012, 00:00 UTC. - Selectors, applied in two different contexts:
- To filter the specific smee type time series to the model. i ∈ [1, …, 34] identifies every one of the time series displayed in Figure 1.
- To filter the set of entropy features required to feed the model. The specific group of features for every modeled smee (i.e., featuresi) depends on the feature selection process carried out during the training phase.
- Normalization was performed for all signals by using z-score transformations (statistical normalization); therefore, every time series got and σ2 = 1. Since, in a real case, test data would be captured on-line and therefore unknown during the model tuning phase, normalization coefficients found during the training phase were also utilized later to normalize test data.We additionally performed an ad hoc normalization (s-normalization) for displaying some results and figures in Section 6. This s-normalization is a linear manipulation of the x̄ and σ2 in order to fit more friendly rates for the implementation of a monitoring system prototype. Here, values “5” and “15” respectively stand for the signal under the test minimum and maximum during training data.
- Feature selection was carried out during the training phase by using least angle regression (LARS) with the least absolute selection and shrinkage operator (LASSO). This method is described in the next subsection, Section 5.2.
- The shuffle block jumbled input samples before presenting the vectors to the models during the training phase in order to avoid overfitting. The new set of samples is reordered by a pseudorandom number generator given a prefixed random seed.
- A delay step was applied to the inputs, doubling the number of predictors. Hence, models were also optionally provided with memory capabilities (entropy derivatives) to fit traffic types, i.e., the model additionally deployed x[n − 1] and not only x[n] as part of the input vector.
- Model. This block contains the regression algorithm deployed for modeling smee type time series. The different modeling methodologies tested in this work are described in the next subsection, Section 5.2. During the training phase, model outputs were compared to real values of the signal to abstract in order to tune the model with the obtained error. In the test phase, the error is stored to evaluate model performances.
5.2. Regression Techniques
- Is there any direct dependence between traffic types and flow-traffic feature entropies? If so, can we describe the relationships between them for specific traffic types?
- Is it possible to create entropy-based models for the indirect prediction of the traffic types amount?
- Least angle regression with LASSO:The LAR/LASSO solution performs linear regression, as well as evaluates the contribution of every input feature by providing a coefficient vector β, which expresses feature relevancy. In this work, we mainly used this method for feature selection, yet its linear regression performances were also considered in comparison with the rest of the models. The undertaken implementation is based on the algorithm proposed by Efron et al. in [29].For every studied smee type, the LASSO threshold was fixed after a combination of linear and logarithmic parameter optimization. All of the subsequent models were run twice: fed with all features and only with the feature set recommended by the LASSO.
- Artificial neural network (ANN):ANNs have been widely applied to solve classification and regression problems submitted to strong non-linearities and chaotic behaviors. An ANN emulates biological neural networks by presenting a highly parallel architecture to process input vectors. Here, we developed a classic feed-forward multi-layer perceptron, which was trained with a back propagation algorithm [30]. The network hidden layer size was (#features + #classes)/2 + 1; the training cycles were 1000, the learning rate 0.25 and the momentum 0.05, and the optimization was stopped when the error rate dropped below 1.0 × 10−5.
- k-nearest neighbor classifier (kNN)A kNN regression model consists of a simple nonparametric algorithm, which elaborates a problem map with the training samples and predicts the numerical target of a test sample by weighting the responses of the most similar training cases (neighbors) [31]. For the experiments, the distance metric was Euclidean-based, k was set to five neighbors and the contribution of every neighbor was proportionally weighted according to the distance to the test sample.
- Gaussian process (GP):A Gaussian process is quite a generally valid non-parametric technique for regression and prediction. In Gaussian processes, it is assumed that input data can be represented as a sample from a multivariate Gaussian distribution. Gaussian processes are more subtle than other fitting techniques, as they parameterize the data covariance structure instead of any regression function [32]. For the experiments, the used kernel type was a radial basis function (rbf), the kernel length-scale was set to 3.0, the maximum number of basis vectors to be used was 100 and the epsilon and geometrical tolerances were both set to 1.0 × 10−7.
- Polynomial regression:In a polynomial regression, data are forced to fit an n order polynomial function. Given a signal to model (yr), for the case with one independent variable (x) and one dependent variable or predicted outcome (yp), yp can be expressed as follows:where a0, …, an are the coefficients of the polynomial. Function coefficients are adjusted by using the least squares method: e = yr − yp(x); e stands for error.Polynomial regression is one of the simplest linear regression models; we utilized it to find linear correlations whenever possible, as they are the simplest and most understandable expressions of causal relationships. For the experiments, the maximum number of iterations was set to 5000, and the maximum degree of the polynomial was five.
6. Results
7. Discussion
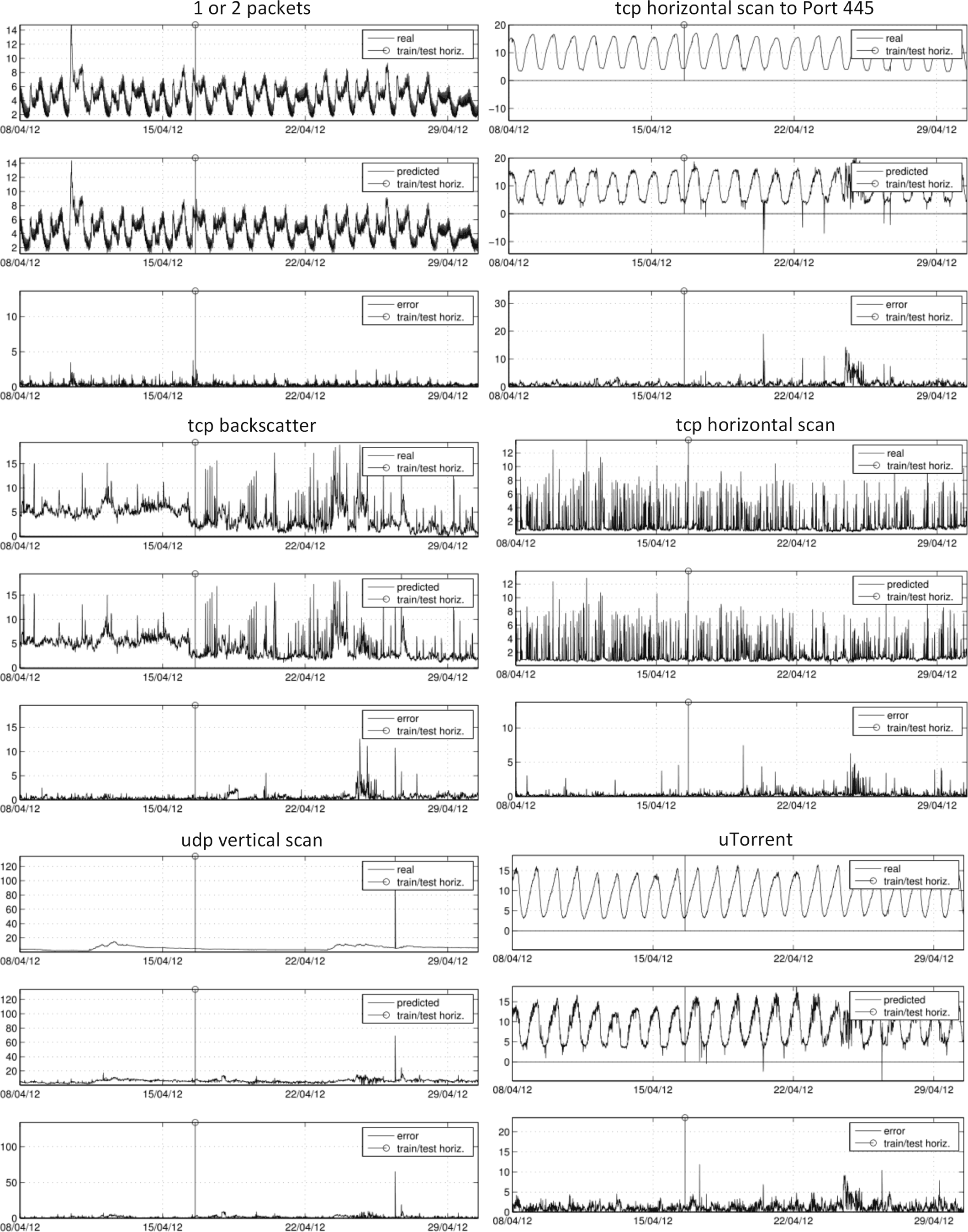
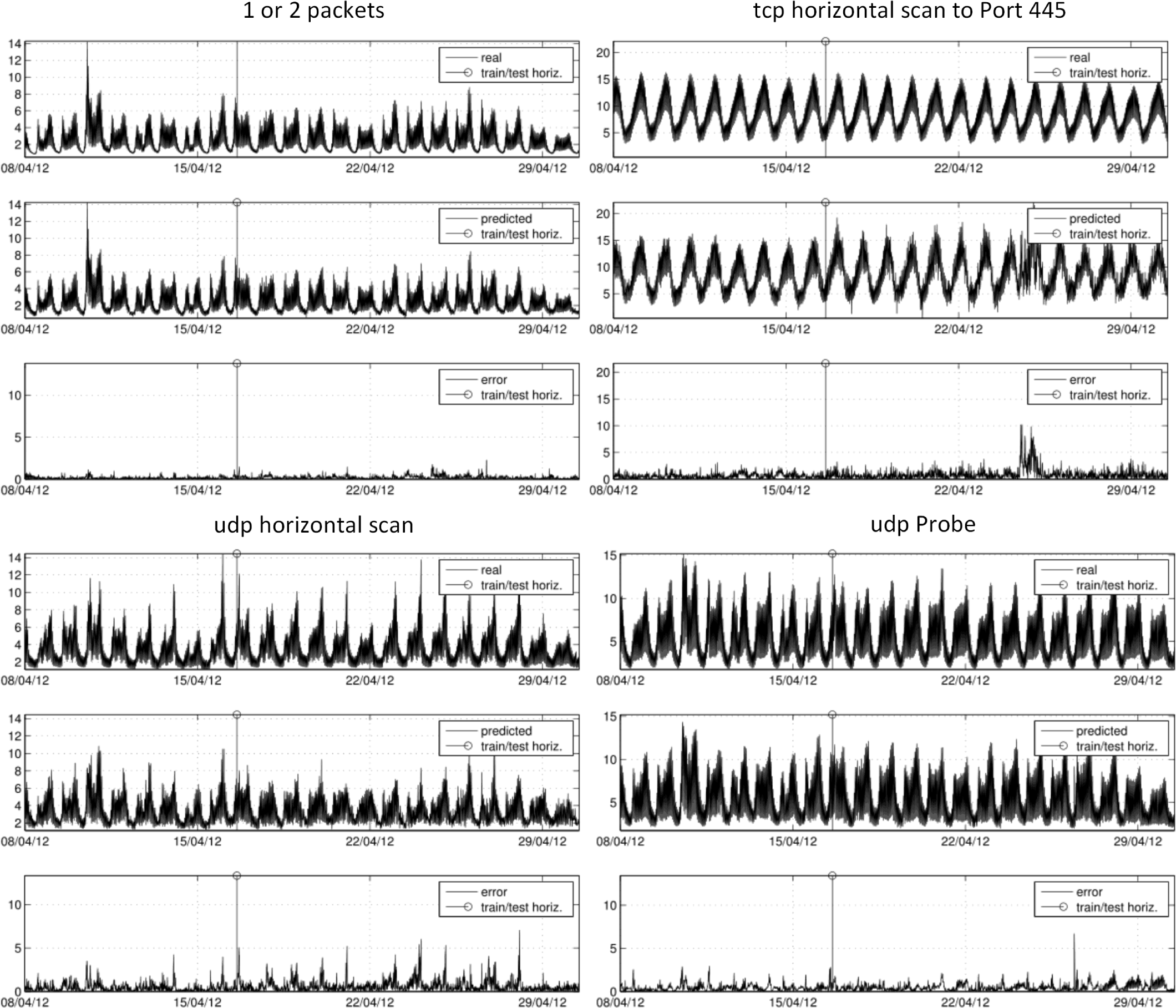
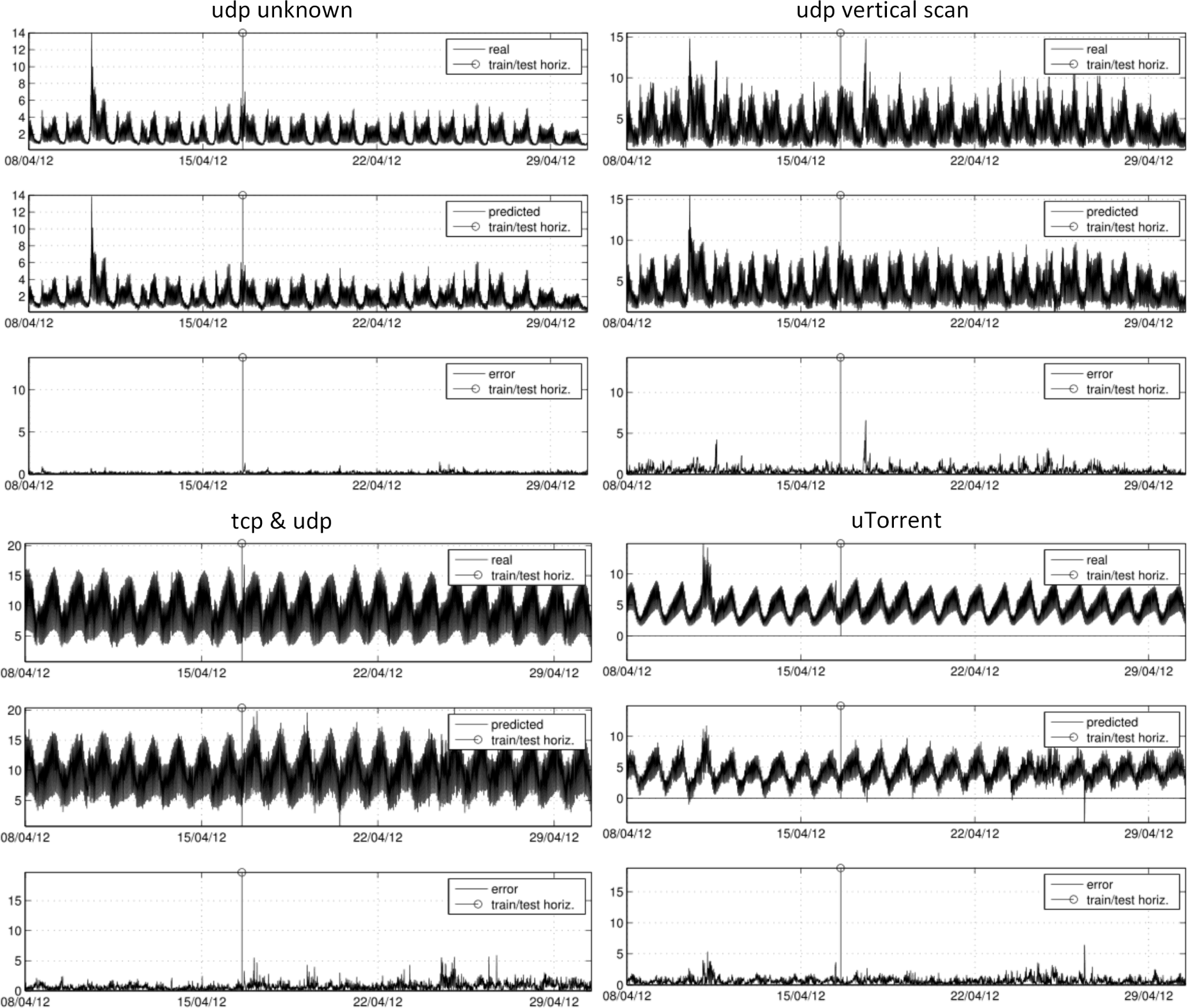
- Predictable packet types: Six out of 17 packet types can be satisfactorily modeled with an acceptable error rate. Predictable types coincide with the types that cover the highest percentage of the total traffic, e.g., tcpBacks (25.3%), tcp445scan (35.2%) tcpHscan (14.2%) and udpVscan (4.7%), which shares the fourth rank with a more irregular and unpredictable tcpUnk traffic. Such results are expected, as they significantly contribute to shape entropy signals. The contribution of other types with a lower presence can hardly be detected, partially because they are masked by noisy traffic and the more dominate traffic types or because they do not leave a significant imprint in the distribution of traffic-flow features. Exceptions are 1or2 (0.2%) and uTorrent (%1.0), whose particular and stable profiles make them traceable, even in spite of their low presence.
- Peak of udpVscan (packets): The peak on April 26 at 22:30 UTC, which relates to a sudden vertical scan on a specific machine, can be directly tracked in most of the entropy signals, most significantly for H(dstIP), H(dstPort) and H(length).
- Peak of ConfickC (packets): The peak on April 27 at 05:40 UTC, which relates to an increase of Conficker.C traffic, can be directly tracked in H(TTL). Regression models were not able to capture this evident correlation, because there was not any ConfickC peak in the training data.
- Predictable source types: To expect that the most common source types also contribute the most to the entropy signals could be misleading, as entropy signals are calculated from traffic packets as samples and not source types. In any case, there is an obvious correlation, and the four most common sources are traceable in our experiments (percentage values correspond to means obtained with a 10-minute time scope): tcp445scan (26.1%), 1or2 (16.6%), udpUnk (14.8%) and udpProb (9.6%). Although they have a lesser contribution, udpVscan, udpHscan, tcp&udp and uTorrent can be also satisfactorily modeled. The strong periodical (hourly, half-day and daily) behavior of source types is an advantage for regression methods in order to fit the general tendencies, but at the same time, it is a drawback that leads to overfitting and makes models unable to adequately match spontaneous peaks or events that break normal trends. This is noticeable in the difficulties in achieving some peaks in some cases, e.g., udpHscan or udpVscan.
- Unstable period of predictions: There is a disruption in some of the predicted signals from Samples 2370 to 2520 (approximately, from Tuesday, April 24, 2012, 23:00:00, to Thursday April 26, 2012, 00:00:00; 25 h). There is nothing significant, neither in entropy signals nor in smee types, that justifies this disrupted span. Means and standard deviations of packets and sources during this time period do not significantly differ from the statistics for the whole time series. Therefore, some phenomena may remain undetected, even with deep packet inspection analysis.
- Interpretation of dependencies and correlations: Bringing together all of the conducted analyses, we can roughly conclude that we found a correlation among entropy signals, a correlation among types of traffic sources and a lack of correlation among types of traffic packets. In a similar way, we found coincident peaks in entropies and sources, and non-coincident peaks in packets. Such behaviors indicate a stable, easily predictable traffic mass with strong hourly and daily periodicities that accounts for the majority of sources and a considerable rate of packets. Anomalies of this normality in the darkspace are not due to the massive arrangement of sources, but to a few sources with a sudden high activity. As we have seen in the predicted signals, this sudden high activity (peaks in packet types) can be detected by indirect measures of entropy over traffic flow features, at least in those traffic types that define a significant part of the traffic when considering the whole time scope.
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Floyd, S.; Paxson, V. Difficulties in Simulating the Internet. IEEE/ACM Trans. Netw. 2001, 9, 392–403. [Google Scholar]
- Dainotti, A.; Pescape, A.; Claffy, K. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar]
- Paxson, V. Bro intrusion detection system 2009. Available online: http://www.bro-ids.org accessed on 15 December 2014.
- PACE 2.0, Protocol and Application Classification with Metadata Extraction 2014. Available online: http://www.ipoque.com/en/products/pace accessed on 15 December 2014.
- CISCO. Network-Based Application Recognition, 2007, Classifying Network Traffic Using NBAR. Available online: http://www.cisco.com/c/en/us/td/docs/ios/12_4t/qos/configuration/guide/qsnbar1.html accessed on 15 December 2014.
- Lakhina, A.; Crovella, M.; Diot, C. Mining anomalies using traffic feature distributions. SIGCOMM Comput. Commun. Rev. 2005, 35, 217–228. [Google Scholar]
- Tellenbach, B.; Burkhart, M.; Sornette, D.; Maillart, T. Beyond Shannon: Characterizing Internet Traffic with Generalized Entropy Metrics. In Passive and Active Network Measurement, Proceedings of the 10th International Conference, PAM 2009, Seoul, Korea, 1–3 April 2009; Moon, S.B., Teixeira, R., Uhlig, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 239–248. [Google Scholar]
- Zseby, T.; Brownlee, N.; King, A.; Claffy, K. Nightlights: Entropy-based Metrics for Classifying Darkspace Traffic Patterns. In Passive and Active Measurement, Proceedings of the 15th International Conference, PAM 2014, Los Angeles, CA, USA, 10–11 March 2014; Faloutsos, M., Kuzmanovic, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 275–277. [Google Scholar]
- Wustrow, E.; Karir, M.; Bailey, M.; Jahanian, F.; Huston, G. Internet Background Radiation revisited, Proceedings of The 2010 ACM Internet Measurement Conference, Melbourne, Australia, 1–30 November 2010; pp. 62–74.
- Moore, D.; Paxson, V.; Savage, S.; Shannon, C.; Staniford, S.; Weaver, N. Inside the Slammer Worm. IEEE Secur. Priv. 2003, 1, 33–39. [Google Scholar]
- Moore, D.; Shannon, C.; Brown, D.; Voelker, G.; Savage, S. Inferring Internet Denial-of-Service Activity. ACM Trans. Comput. Syst. 2006, 24, 115–139. [Google Scholar]
- Aben, E. Conficker/Conflicker/Downadup as seen from the UCSD Network Telescope. Available online: http://www.caida.org/research/security/ms08-067/conficker.xml accessed on 15 December 2014.
- Brownlee, N. One-way Traffic Monitoring with Iatmon. In Passive and Active Measurement, Proceedings of The 13th International Conference on Passive and Active Measurement (PAM 2012), Vienna, Austria, 12–14 March 2012; Taft, N., Ricciato, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 179–188. [Google Scholar]
- Dainotti, A.; King, A.; Claffy, K.; Papale, F.; Pescape, A. Analysis of a “/0” Stealth Scan from a Botnet, Proceedings of the 2012 ACM Conference on Internet Measurement Conference, Boston, MA, USA, 14–16 November 2012; pp. 1–14.
- Zseby, T.; King, A.; Brownlee, N.; Claffy, K. The Day After Patch Tuesday: Effects Observable in IP Darkspace Traffic, Proceedings of Passive and Active Network Measurement Workshop (PAM’13), Hong Kong, China, 18–19 March 2013; pp. 273–275.
- Dainotti, A.; Squarcella, C.; Aben, E.; Claffy, K.C.; Chiesa, M.; Russo, M.; Pescapé, A. Analysis of Country-wide Internet Outages Caused by Censorship, Proceedings of The 2011 ACM Internet Measurement Conference, Berlin, Germany, 2–4 November 2011; pp. 1–18.
- Zseby, T.; Claffy, K. Workshop Report: Darkspace and Unsolicited Traffic Analysis (DUST). SIGCOMM Comput. Commun. Rev. 2012, 42, 49–53. [Google Scholar]
- CAIDA. The CAIDA UCSD Network Telescope “Patch Tuesday” Dataset. Available online: http://www.caida.org/data/passive/telescope-patch-tuesday_dataset.xml accessed on 22 December 2014.
- Corsaro, version 2.1.0; software suite for performing large-scale analysis of trace data; CAIDA: La Jolla, CA, USA, 2014.
- Treurniet, J. A Network Activity Classification Schema and Its Application to Scan Detection. IEEE/ACM Trans. Netw. 2011, 19, 1396–1404. [Google Scholar]
- Kim, M.S.; Kong, H.J.; Hong, S.C.; Chung, S.H.; Hong, J. A flow-based method for abnormal network traffic detection, Proceedings of The 10th IEEE/IFIP Network Operations and Management Symposium (NOMS 2004), Seoul, Korea, 19–23 April 2004; 1, pp. 599–612.
- Ziviani, A.; Gomes, A.T.A.; Monsores, M.; Rodrigues, P. Network anomaly detection using nonextensive entropy. IEEE Commun. Lett. 2007, 11, 1034–1036. [Google Scholar]
- Gu, Y.; McCallum, A.; Towsley, D. Detecting Anomalies in Network Traffic Using Maximum Entropy Estimation, Proceedings of The 2005 ACM Internet Measurement Conference, New Orleans, LA, USA, 19–21 October 2005; pp. 32–32.
- Pang, R.; Yegneswaran, V.; Barford, P.; Paxson, V.; Peterson, L. Characteristics of Internet Background Radiation, Proceedings of The 2004 ACM Internet Measurement Conference, Taormina, Italy, 25–27 October 2004; pp. 27–40.
- Ahmed, E.; Clark, A.; Mohay, G. Effective Change Detection in Large Repositories of Unsolicited Traffic, Proceedings of The Fourth International Conference on Internet Monitoring and Protection (ICIMP’09), Venice, Italy, 24–28 May 2009; pp. 1–6.
- Iglesias, F.; Zseby, T. Modelling IP darkspace traffic by means of clustering techniques, Proceedings of 2014 IEEE Conference on Communications and Network Security (CNS), San Francisco, CA, USA, 29–31 October 2014; pp. 166–174.
- Porras, P.; Saidi, H.; Yegneswaran, V. Conficker C P2P Protocol and Implementation. Available online: http://mtc.sri.com/Conficker/P2P/ accessed on 22 December 2014.
- Bailey, M.; Cooke, E.; Jahanian, F.; Nazario, J.; Watson, D. The Internet Motion Sensor: A Distributed Blackhole Monitoring System, Proceedings of The 2005 Network and Distributed System Security Symposium (NDSS’05), San Diego, CA, USA, 2–4 February 2005; pp. 167–179.
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Riedmiller, M. Advanced supervised learning in multi-layer perceptrons: From backpropagation to adaptive learning algorithms. Comput. Stand. Interfaces 1994, 16, 265–278. [Google Scholar]
- Samworth, R.J. Optimal weighted nearest neighbour classifiers. Ann. Stat. 2012, 40, 2733–2763. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of PACKETS | mean* | SD* | hourly per. | half-day per. | daily per. | weekly per. | Significant peaks** |
|---|---|---|---|---|---|---|---|
| unclass | 1.3 M | 1.2 M | — | — | — | — | 750, some |
| tcpProb | 0.6 M | 0.2 M | x | — | x | — | 1702 |
| tcpVscan | 0.1 M | 0.1 M | x | — | x | — | 1295, 2021, 1294, some |
| tcpHscanP | 34.6 M | 38.2 M | — | x | — | — | 509, 269, several |
| tcpUnk | 14.4 M | 10.8 M | — | — | x | — | 1634 |
| udpProb | 6.3 M | 1.3 M | — | — | — | x | 3100 |
| udpVscanP | 11.4 M | 5.1 M | — | — | — | x | 2654 |
| udpHscan | 4.8 M | 2.9 M | — | — | x | — | 774 |
| udpUnk | 7.5 M | 2.9 M | — | — | — | x | — |
| icmpOnlyP | 7.5 M | 2.5 M | — | x | — | x | 542, 355 |
| tcp&udp | 3.8 M | 3.1 M | x | x | x | — | 1169 |
| uTorrentP | 2.4 M | 0.7 M | — | — | x | — | — |
| confickC | 0.6 M | 1.4 M | — | — | x | — | 2698 |
| 1or2pktsP | 0.5 M | 0.3 M | — | x | x | — | 364 |
| tcpBacksP | 61.9 M | 28.4 M | — | — | — | x | several |
| dnsBacks | 0.9 M | 0.7 M | — | — | — | — | 717 |
| tcp445scanP | 86.0 M | 17.9 M | — | — | x | — | — |
| # unique SOURCES | mean* | SD* | hourly per. | half-day per. | daily per. | weekly per. | significant peaks** |
| unclass | 1.0 K | 0.8 K | x | — | — | — | unequal periods |
| tcpProb | 17.0 K | 4.2 K | x | — | x | — | 2526, 1758 |
| tcpVscan | 1.0 K | 0.5 K | x | — | x | — | — |
| tcpHscan | 30.3 K | 8.4 K | x | — | x | — | unequal last period |
| tcpUnk | 7.6 K | 2.7 K | x | — | x | — | — |
| udpProbS | 37.3 K | 22.2 K | x | x | x | — | — |
| udpVscanS | 1.2 K | 0.8 K | x | x | x | — | — |
| udpHscanS | 2.9 K | 1.9 K | x | x | x | — | — |
| udpUnkS | 61.1 K | 54.4 K | x | x | x | — | 366 |
| icmpOnly | 5.3 K | 2.1 K | — | — | x | x | 1590, unequal periods |
| tcp&udpS | 12.9 K | 4.0 K | x | — | x | — | — |
| uTorrentS | 19.5 K | 6.8 K | x | — | x | — | 444 |
| confickC | 12.8 K | 2.3 K | x | — | x | — | — |
| 1or2pktsS | 69.9 K | 48.1K | x | x | x | — | 366 |
| tcpBacks | 0.3 K | 0.2 K | x | — | x | — | 1344, 786 |
| dnsBacks | 31.2 | 9.7 | x | — | — | — | — |
| tcp445scanS | 86.0 K | 21.3 K | x | — | x | — | — |
| Smee class | packets (total) | packets (per 10 min) | sources (per 10 min) | pkts/src |
|---|---|---|---|---|
| unclass | 0.5% | 0.5% ± 0.46% | 0.3% ± 0.24% | 0.8 K±0.8 K |
| tcpProb | 0.2% | 0.2% ± 0.08% | 5.0% ± 1.60% | 3.7±1.9 |
| tcpVscan | 0.0% | 0.0% ± 0.02% | 0.3% ± 0.16% | 13.9 ± 13.6 |
| tcpHscanP | 14.2% | 12.1% ± 10.07% | 8.8% ± 2.06% | 29.4 ± 21.0 |
| tcpUnk | 5.9% | 4.9% ± 3.84% | 2.1% ± 0.56% | 272.3 ± 237.4 |
| udpProbS | 2.6% | 2.5% ± 0.61% | 9.6% ± 2.58% | 29.4 ± 21.0 |
| udpVscanPS | 4.7% | 4.4% ± 1.56% | 0.3% ± 0.12% | 2.2 K ± 1.9 K |
| udpHscanS | 2.0% | 1.9% ± 1.03% | 0.7% ± 0.24% | 425.2 ± 386.1 |
| udpUnkS | 3.1% | 3.7% ± 1.39% | 14.8% ± 7.14% | 79.1 ± 75.2 |
| icmpOnlyP | 3.1% | 3.6% ± 1.35% | 2.0% ± 0.85% | 190.3 ± 121.9 |
| tcp&udpS | 1.5% | 1.5% ± 1.12% | 3.7% ± 0.85% | 40.7 ± 36.5 |
| uTorrentPS | 1.0% | 0.9% ± 0.26% | 5.6% ± 1.87% | 15.4 ± 8.8 |
| confickC | 0.2% | 0.2% ± 0.19% | 3.9% ± 1.01% | 6.6 ± 11.9 |
| 1or2pktsPS | 0.2% | 0.2% ± 0.11% | 16.6% ± 5.50% | 1.8 ± 1.6 |
| tcpBacksP | 25.3% | 28.6% ± 8.44% | 0.1% ± 0.08% | 62.9 K ± 55.7 K |
| dnsBacks | 0.4% | 0.3% ± 0.25% | 0.0% ± 0.00% | 3.9 K ± 3.4 K |
| tcp445scanPS | 35.2% | 34.4% ± 7.39% | 26.1% ± 7.46% | 112.0 ± 48.5 |
| H(srcIP) | H(dstIP) | H(srcPort) | H(dstPort) | H(prot) | H(flag) | H(TTL) | H(len) | |
|---|---|---|---|---|---|---|---|---|
| Mean | 11.82 | 21.14 | 10.26 | 7.28 | 0.83 | 5.03 | 1.54 | 2.94 |
| SD | 1.37 | 0.67 | 1.25 | 1.26 | 0.11 | 0.25 | 0.16 | 0.24 |
| daily per. | first | second | second | second | first | — | second | first |
| weekly per. | — | first | first | first | — | — | first | — |
| Distribution | ||||||||
| negatively skewed | close to normal, strong neg. outliers | Close to normal, positively skewed | close to normal, short tails, slightly neg. skewed | Close to normal, positively skewed | positively skewed | strong pos. outliers | strong pos. outliers | |
| Peaks* | weak | strong | weak | weak | weak | weak | strong | strong |
| main | 2658 (−) | 2654 (−) | 509 (−) | 2231 (+) | 1344 (−) | 1218 (−) | 2698 (+) | 2654 (+) |
| Second | 2956 (−) | 2655 (−) | 2658 (−) | 2654 (+) | 509 (−) | 1634 (−) | 2697 (+) | 2655 (+) |
| Third | 509 (−) | — | 2219 (−) | 2261 (+) | 542 (+) | 2956 (−) | 2221 (+) | 1837 (+) |
| H(srcIP) | H(dstIP) | H(srcPort) | H(dstPort) | H(prot) | H(flag) | H(TTL) | H(len) | |
|---|---|---|---|---|---|---|---|---|
| H(srcIP) | 1 | −0.61 | 0.91 | −0.21 | 0.57 | 0.64 | 0.20 | 0.38 |
| H(dstIP) | −0.61 | 1 | −0.66 | 0.05 | −0.71 | −0.64 | −0.38 | −0.65 |
| H(srcPort) | 0.91 | −0.66 | 1 | −0.35 | 0.56 | 0.67 | 0.10 | 0.39 |
| H(dstPort) | −0.21 | 0.05 | −0.35 | 1 | 0.09 | 0.07 | 0.67 | 0.26 |
| H(prot) | 0.57 | −0.71 | 0.56 | 0.09 | 1 | 0.61 | 0.44 | 0.73 |
| H(flag) | 0.64 | −0.64 | 0.67 | 0.07 | 0.61 | 1 | 0.40 | 0.57 |
| H(TTL) | 0.20 | −0.38 | 0.10 | 0.67 | 0.44 | 0.40 | 1 | 0.49 |
| H(len) | 0.38 | −0.65 | 0.39 | 0.26 | 0.73 | 0.57 | 0.49 | 1 |
| Smee case | pkts/srcs | entropy - H(…) | other | best model | yt = … | RMSE* |
|---|---|---|---|---|---|---|
| 1or2pkts | pkts | prot | #srcs | ANN | f(xt, xt−1) | 0.26 (test) 0.20 (all) |
| tcp445scan | pkts | srcIP, dstPort, prot | #pkts, | ANN | f(xt, xt−1) | 0.44 (test) 0.36 (all) |
| tcpBacks | pkts | dstIP, srcPort, dstPort, prot, flags, | #pkts, | ANN | f(xt) | 0.77 (test) 0.63 (all) |
| tcpHscan | pkts | srcIP, dstIP, dstPort, TTL | #pkts | GP | f(xt) | 0.35 (test) 0.30 (all) |
| udpVscan | pkts | srcIP, dstIP len | #pkts #srcs | LARS/LASSO | f(xt) | 0.92 (test) 0.79 (all) |
| uTorrent | pkts | srcIP, dstIP, dstPort, prot, flag | #pkts #srcs | ANN | f(xt) | 0.45 (test) 0.40 (all) |
| 1or2pkts | srcs | srcIP, dstIP, prot, TTL | #pkts #srcs | ANN | f(xt, xt−1) | 0.21 (test) 0.19 (all) |
| tcp445scan | srcs | srcIP, dstPort, prot | #pkts, #srcs | ANN | f(xt, xt−1) | 0.43 (test) 0.37 (all) |
| udpHscan | srcs | prot, TTL | #srcs | LARS/LASSO | f(xt) | 0.48 (test) 0.48 (all) |
| udpVscan | srcs | srcIP, prot | #pkts #srcs | LARS/LASSO | f(xt) | 0.31 (test) 0.32 (all) |
| udpProbe | srcs | srcIP, dstIP, dstPort, prot, TTL | #srcs | ANN | f(xt) | 0.26 (test) 0.25 (all) |
| udpUnk | srcs | srcIP, srcPort, dstPort, prot, | #pkts #srcs | ANN | f(xt, xt−1) | 0.17 (test) 0.15 (all) |
| tcp&udp | srcs | srcIP, srcPort, dstPort, prot, TTL | #pkts #srcs | ANN | f(xt, xt−1) | 0.34 (test) 0.23 (all) |
| uTorrent | srcs | srcIP, dstIP, dstPort, prot | #pkts #srcs | ANN | f(xt, xt−1) | 0.43 (test) 0.44 (all) |
| unclass. | tcpProb | tcpVscan | tcpHscan | tcpUnk | udpProb | udpVscan | udpHscan | udpUnk | |
|---|---|---|---|---|---|---|---|---|---|
| PACKETS | — | — | — | good | — | — | good | — | — |
| SOURCES | — | — | — | — | — | good | poor | acceptable | excellent |
| icmpOnly | tcp&udp | uTorrent | concfickC | 1 or 2 | tcpBacks | dnsBacks | tcp445scan | ||
| PACKETS | poor | — | acceptable | — | excellent | good | — | good | — |
| SOURCES | — | good | acceptable | — | excellent | — | — | good | — |
| Smee case | linear terms | quadratic terms | cubic terms |
|---|---|---|---|
| tcpHoritz (pkts) | −a1H(srcIP), +b1H(dstIP), −d1H(dstPort), −f1H(TTL), +m1#pkts | ||
| udpVscan (pkts) | −a1H(srcIP), +b1H(dstIP), −h1H(len), +m1#pkts, −n1#srcs | ||
| tcpBacks (pkts) | −b1H(dstIP), +c1H(srcPort), +d1H(dstPort), −e1H(prot), −g1H(flags), +m1#pkts | ||
| udpProbe (srcs) | −a1H(srcIP), −b1H(dstIP), +d1H(dstPort) −f1H(TTL), +n1#srcs | +e3H(prot)3 | |
| *udpVscan (srcs) | −a1H(srcIP), −g1H(flags), −m1#pkts, +n1#srcs | +e2H(prot)2 | |
| *udpHscan (srcs) | +e1H(prot), +n1#srcs | +f2H(TTL)2 | |
| udpUnk (srcs) | −a1H(srcIP), −c1H(srcPort), +d1H(dstPort), +e1H(prot), −m1#pkts, +n1#srcs | ||
| 1or2pkts (srcs) | −a1H(srcIP), +e1H(prot), −f1H(TTL), −m1#pkts, +n1#srcs | +b2H(dstIP)2 | |
| tcp445Hscan (srcs) | a1H(srcIP), −d1H(dstPort), −e1H(prot), +m1#pkts, +n1#srcs |
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iglesias, F.; Zseby, T. Entropy-Based Characterization of Internet Background Radiation. Entropy 2015, 17, 74-101. https://0-doi-org.brum.beds.ac.uk/10.3390/e17010074
Iglesias F, Zseby T. Entropy-Based Characterization of Internet Background Radiation. Entropy. 2015; 17(1):74-101. https://0-doi-org.brum.beds.ac.uk/10.3390/e17010074
Chicago/Turabian StyleIglesias, Félix, and Tanja Zseby. 2015. "Entropy-Based Characterization of Internet Background Radiation" Entropy 17, no. 1: 74-101. https://0-doi-org.brum.beds.ac.uk/10.3390/e17010074