4.2. Experiment 2
In next two experiments, a feature vector distance based algorithm is used for AAR for comparing with the results of the HCRF-based the algorithms. The algorithm is essentially a simple clustering based abnormal activity recognition method [
10,
11] and they both find abnormalities by comparing the testing activity with the normal activity. The feature vector distance-based algorithm uses the activity feature vector distance to measure the activity similarity. The activity feature vector is expressed by the change sensors and is a vector with dimensions equal to the sensor number. When one activity is carrying out, if the
i-th sensor state is changed, the
i-th value of the activity feature vector is denoted as 1, otherwise, the
i-th value of the activity feature vector is denoted as 0. For two activity feature vectors
and
, the distance between them is computed using the corresponding Euclidean distance:
where
N is the sensor number.
We use a method similar to the HCRF-based AAR algorithm to decide if the testing activity is abnormal. Given an activity feature vector
At of testing activity observation sequence
t and activity feature vector
ANi of the most similar normal activity
i, we assess testing activity by:
Also, there is
Fnormal ∈[0,100] for any testing activity. This experiment focuses on the recognition of “forgetting” abnormal activities and
Table 2 lists seven abnormal activities generated based on the five normal activities, where the first abnormal activity is generated by the first normal activity, the second abnormal activity is generated by the second normal activity, the third and the six abnormal activities are generated by the third normal activity, the four and the seven abnormal activities are generated by the fourth normal activity, the fifth abnormal activity is generated by the fifth normal activity. To validate
Algorithm 1, we recognize abnormal activities based on
Algorithm 1 and the feature vector distance, respectively.
According to
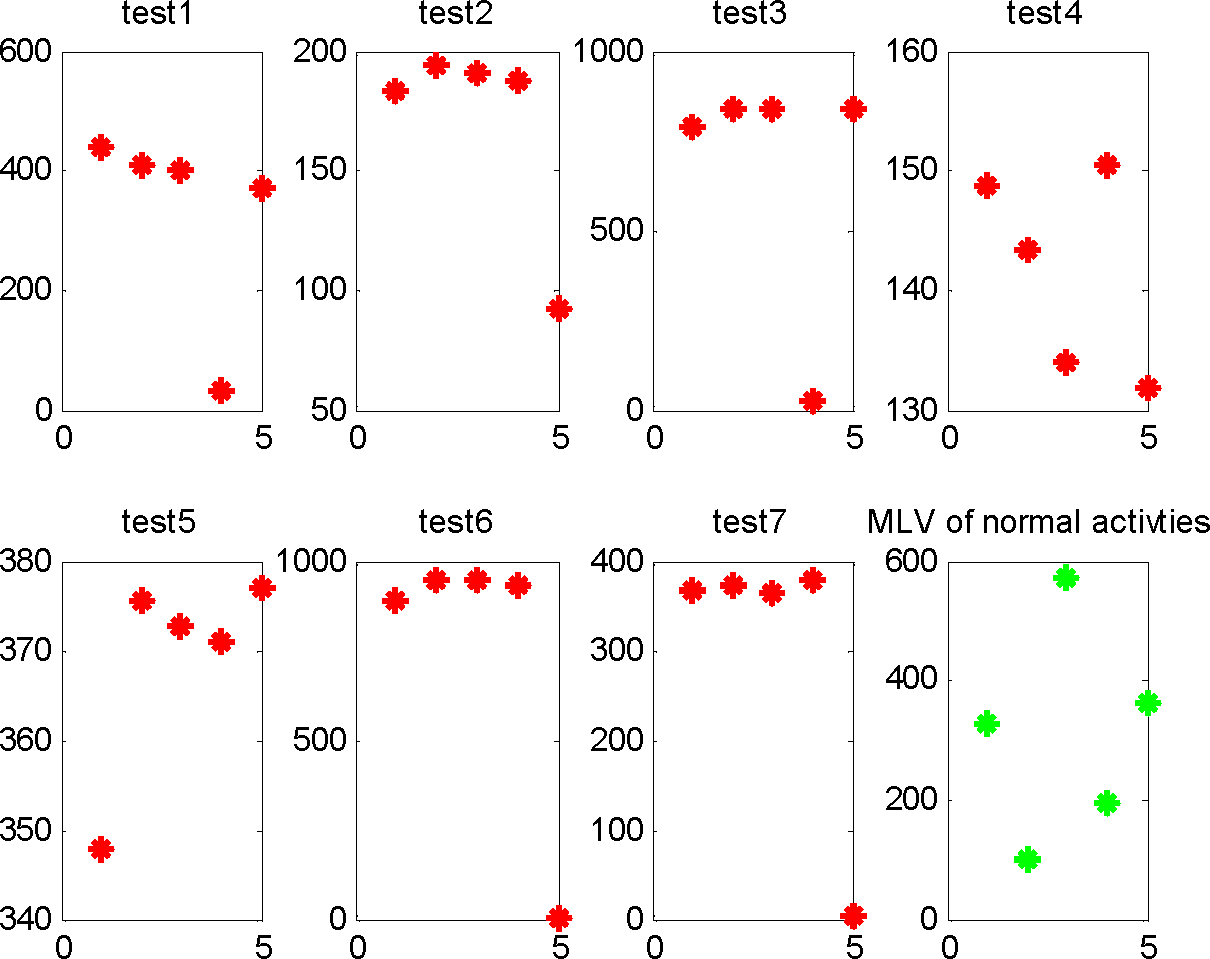
Algorithm 1, we first train HCRF using normal activities 1–5 and then compute their likelihood vectors based on the trained HCRF. The MLV and MLV index of normal activities 1–5 are (1, 326), (2, 100), (3, 573), (4, 195) and (5, 364), where the first value in brackets are the MLV indexes, and the second value in brackets are the MLVs.
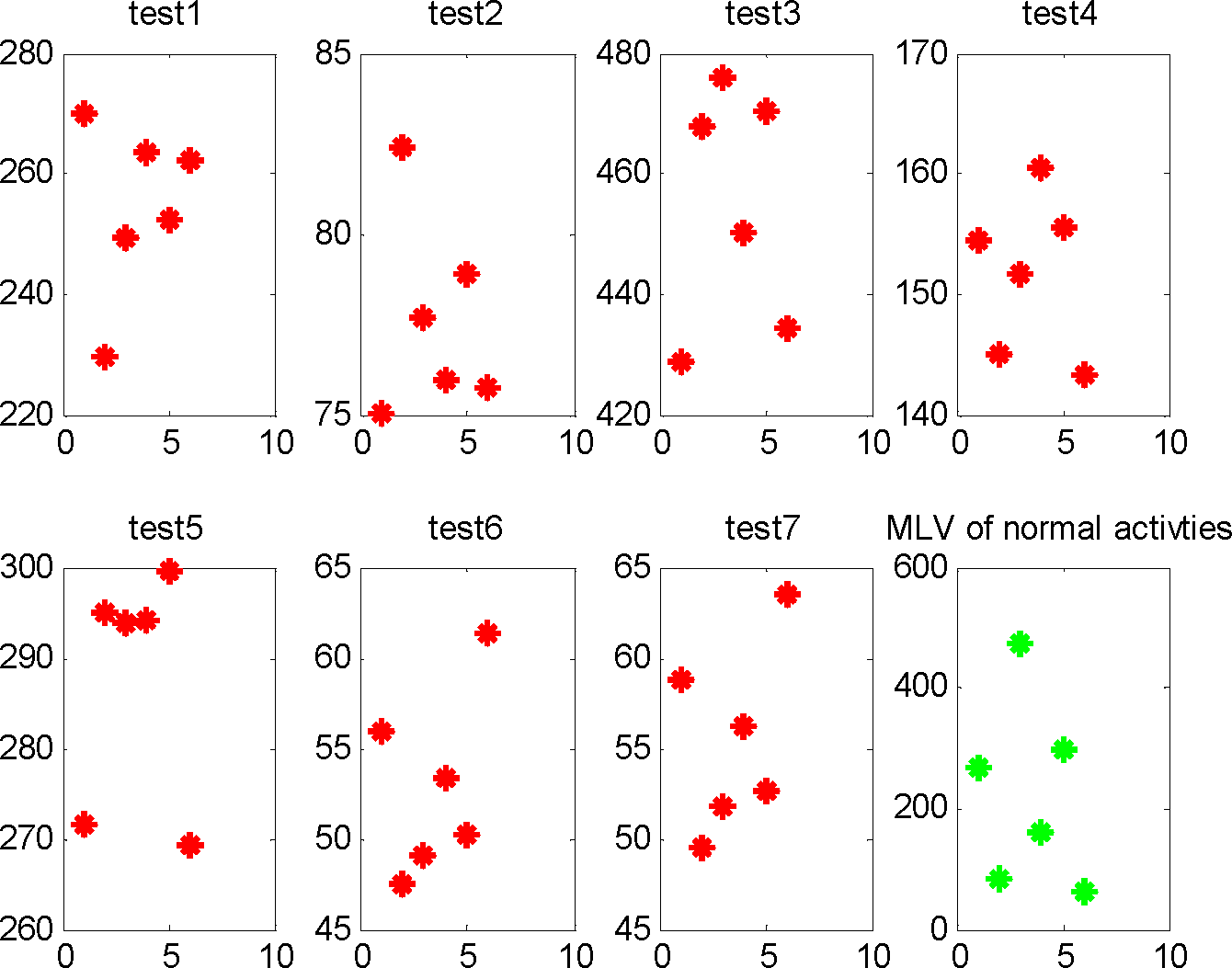
For each testing activity, we compute the likelihood vector of the observation sequence based on the trained HCRF, and find out the MLV and MLV index. The likelihood vectors of testing activities 1–7 are shown in
Table 3, where the first column represents the testing activities, and the second column represents the likelihood vectors. The likelihood vectors in this table represent the similarity between testing activities 1–7 and normal activities 1–5.
Figure 5 is the visualization of the likelihood vectors of seven testing sequences and the MLV of five normal activities from which we can find out the MLV index of testing activities. Then, we determine whether the testing activity is abnormal using
Equation (11). For instance, since the MLV index of testing activity 1 is 1, we consider testing activity 1 is most similar with normal activity 1. Computing
Fnormal using the MLV 438.6745 of testing activity 1 and the MLV 326 of the saved normal activity 1, we get
Fnormal = 65.43 < 98. Thus, we judge the testing activity 1 is an abnormal activity generated by the activity “Make a phone call”.
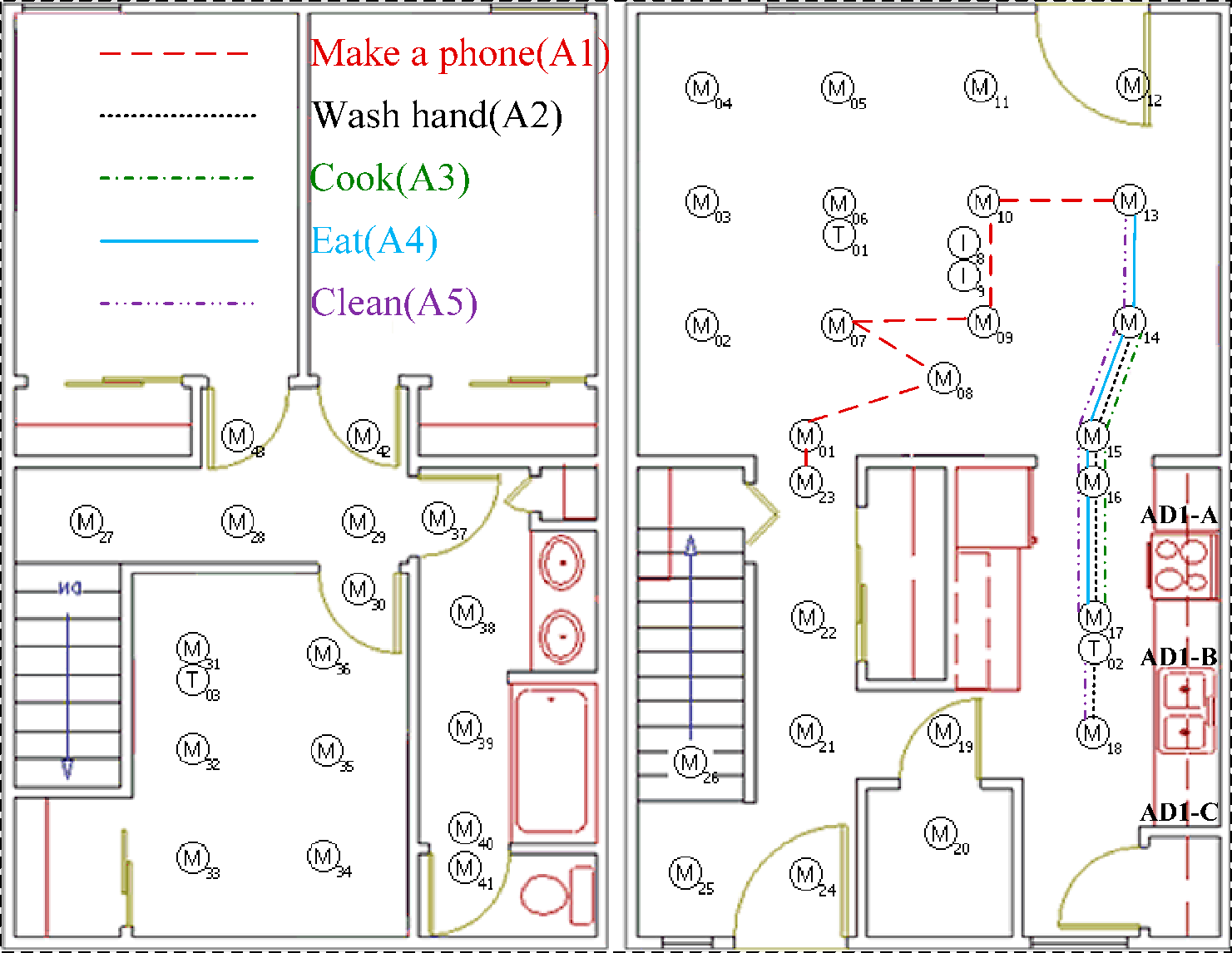
Finally, we find out the abnormal type by analyzing the observation sequence of testing activity. For instance, since the MLV index of testing activities 3, 6 are 3, they are both abnormal activities generated by the activity “Cook”. Comparing the observation sequences of testing activity 3 and activity “Cook”, we find I01, I02, I03, I05 do not give “PRESENT” states in the observation sequence of testing activity 3, and deduce it is the first abnormal type of the activity “Cook” that is “Forgets to replace spices”. Comparing the observation sequences of testing activity 6 and the normal activity “Cook”, we find AD1-A still senses water flow when M14 gives state ON and M17 gives state “OFF” in the observation sequence of testing activity 3, and deduce it is the second abnormal type of the activity “Cook” that is “Forgets to turn off microwave”. Also, since the MLV index of testing activity 4 and testing activity 7 is 4, we consider they are abnormal activities generated by the activity “eat”. By comparing the observation sequences of testing activity 4 and the activity “Eat”, we find there are no states change for I06 in the observation of the third testing activity, and deduce it is the first type abnormal of the activity “Eat” that is “Forgets to take medicine”. By comparing the observation sequences of the seven testing activities with the normal activity “Eat”, we find I06 gives two “ABSENT” and “PRESENT” states in the observation of testing activity 3, and deduce it is the second abnormal type of the activity “Eat” that is “Takes the medicine twice”.
The feature vector distance-based AAR algorithm first extracts the feature vectors of all normal activities and the testing activity, then computes the feature vector distance between the normal and testing activity.
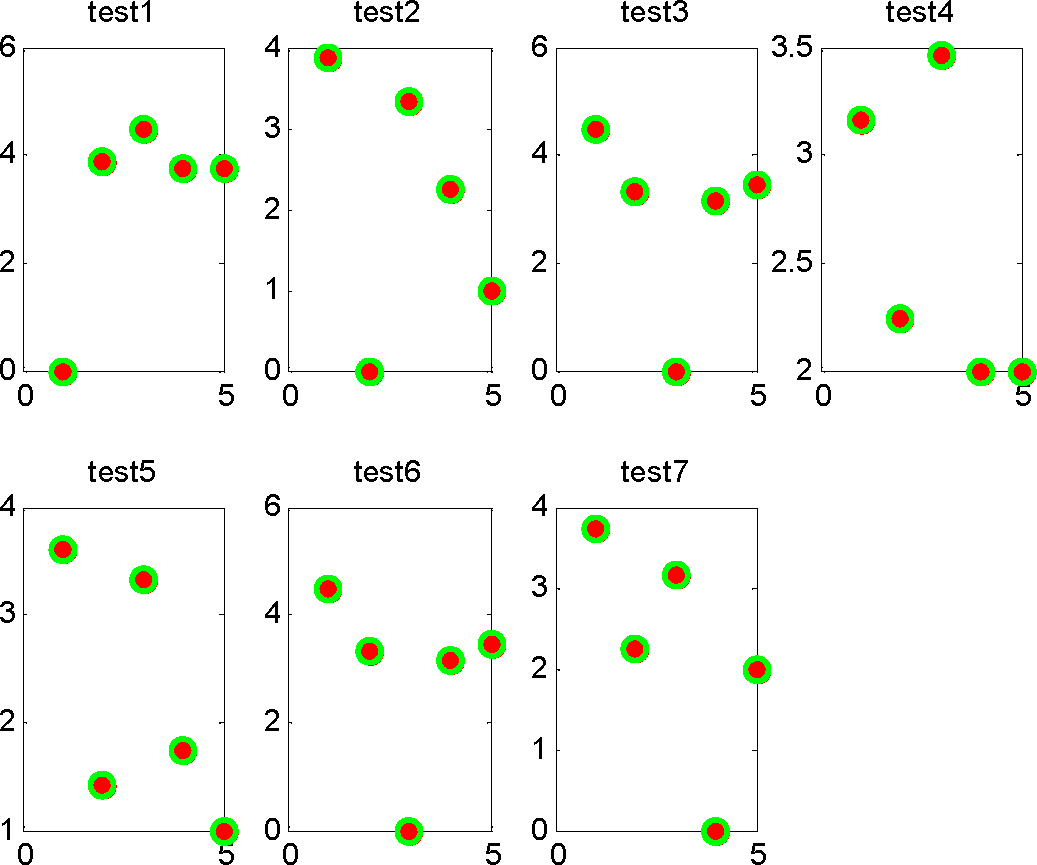
Table 4 lists the feature vector distances between the seven testing activities and five normal activities, where the first column represents testing activities, columns 2–5 represent the feature vector distances between the testing activity and the five normal activities.
Figure 6 is the visualization of the feature vector distances between test sequences 1–7 and normal sequences 1–5. As they show, the distance between testing activities 1–3, 6, 7 and normal activities 1–3, 3, 4 are all equal to zero. Thus, we cannot find the difference between them and judge them as normal activities, despite the fact testing activities 1–3, 6, 7 are abnormal activities. From the table we can see that both normal activities 4 and 5 have minimum distances with testing activity 4, thus we cannot find the most similar normal activity and cannot decide which activity has generated it. For testing activity 5, since there is minimum distance with normal activity 4, we consider normal activity 5 is the most similar to testing activity 5. We compute
Fnormal = with
Equation (13) and get
Fnormal < 98, thus we consider testing activity 5 is an abnormal activity that was generated by the activity “Clean”.
Obviously,
Algorithm 1 not only can recognize abnormal sub-activities of those seven activities quickly, but also can find the type of abnormality, while the feature vector distance-based AAR algorithm can recognize only one of these seven abnormal activities. This is because sequence AAR based on HCRF can capture the sub-structure and context relationships, and thus can distinguish the activities detected by the same sensor with different sensor order and frequency
4.3. Experiment 3
This experiment focuses on the recognition of “new activity” and is also based on the dataset “WSU Apartment Test bed, ADL adlnormal”. In this experiment, we generate another two activities and denote them as activity 6: “From the hall back to the bedroom”, and activity 7: “From the bedroom to the hall”. The two activities have same route, sensor type and sensor number, but have opposite directions, and different order and frequency.
To validate
Algorithm 2, we first consider activities 1–5 as training activities and activities 1–7 as testing activities to recognize abnormal activities based on
Algorithm 2 and feature vector distance respectively.
For abnormal activities based on
Algorithm 2, we first train HCRF with activities 1–5 and compute the likelihood vectors of training activities based on trained HCRF. The MLV and MLV index of activities 1–5 are denoted as (1, 326), (2, 100), (3, 573), (4, 195) and (5, 364). Then, we compute the likelihood vectors of the observation sequences of testing activities 1–7 based on the trained HCRF, respectively. The likelihood vectors of testing activities 1–7 are shown in
Table 5 and the visualization of likelihood vectors is shown in
Figure 7.
From the table we can see that the MLV of activities 1–5 are 326.2816, 100.1750, 573.7141, 195.1255, 364.3324 and the MLV indexes of activities 1–5 are 1–5. Because their MLV are very close to the MLV of the saved training activities 1–5 and for testing activities 1–5, Fnormal < 98, we consider testing activities 1–5 are normal activities. Since the MLV indexes of activities 6, 7 are 1, we compare the MLV 67.7235 and 70.7103 with the MLV of training activity 1 and get Fnormal < 98. Thus, we judge activities 6, 7 are rare abnormal activities. In addition to finding abnormalities, our algorithm can also distinguish them as the activities 6, 7 have unequal MLVs.
The feature vector distance-based AAR algorithm first extracts the feature vectors of training activities 1–5 and testing activities 1–7. Then the algorithm computes the feature vector distance between the corresponding training activity and testing activity.
Table 6 shows the feature vector distances between the testing activities 1–7 and training activities 1–5 and
Figure 8 is their visualization.
Because the minimum feature vector distances between testing activities 1–5 and training activities 1–5 are all zero, we consider them as normal activities. Because the testing activities 6, 7 and training activity 1 both have the minimum feature vector distances 1.7321 and
Fnormal < 98, we consider them as abnormal activities, but because the two testing activities have equivalent minimum feature vector distances with training activity 1, we cannot distinguish them. To further validate
Algorithm 2, we also take activities 1–6 as training activities and activities 1–7 as testing activities, and compare the result with the feature vector distance AAR algorithm. After training HCRF with activities 1–6, we compute the likelihood vectors of training activities based on the trained HCRF.
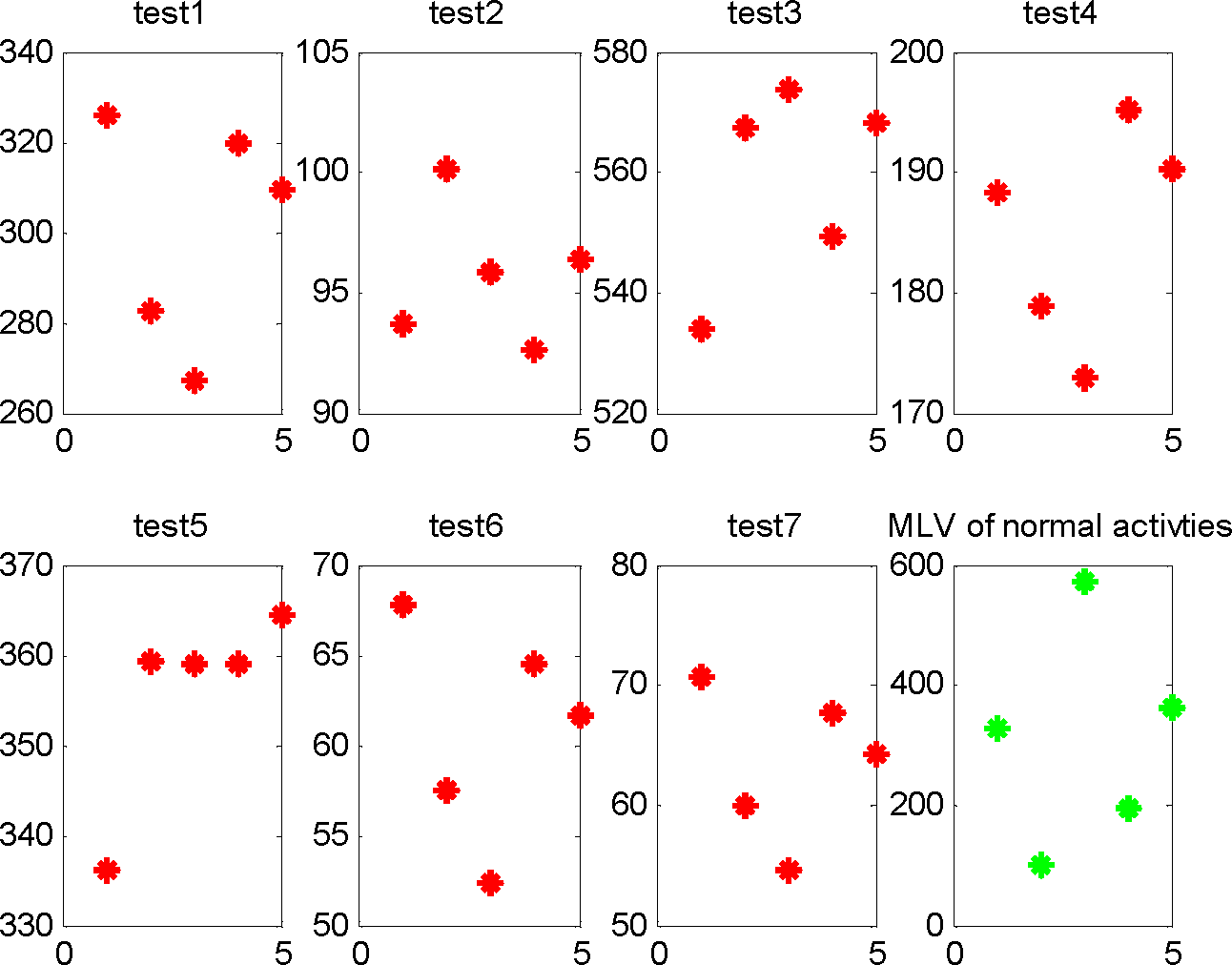
The MLV and MLV index of training activities 1–6 are denoted as (1, 269), (2, 82), (3, 475), (4, 160), (5, 299) and (6, 61). For testing activities 1–7, we compute the likelihood vectors of the observation sequences based on the trained HCRF, respectively, and the likelihood vectors of testing activities 1–7 are shown in
Table 7 and the visualization of likelihood vectors is shown in
Figure 9. As the table shows, the MLV of activities 1–7 are 269.8225, 82.358, 475.9057, 160.3794, 299.6182, 61.2882, 63.5533 and the MLV indexes of activities 1–7 are 1–6, 6. For testing activities 1–6, there are
Fnormal < 98. Thus we consider testing activities 1–6 are normal activities. Since the MLV indexes of activity 7 are 6, we compare the MLV 63.5533 with the MLV 61 of training activity 6 and get
Fnormal < 98. Thus, we judge activity 7 as a rare abnormal activity.
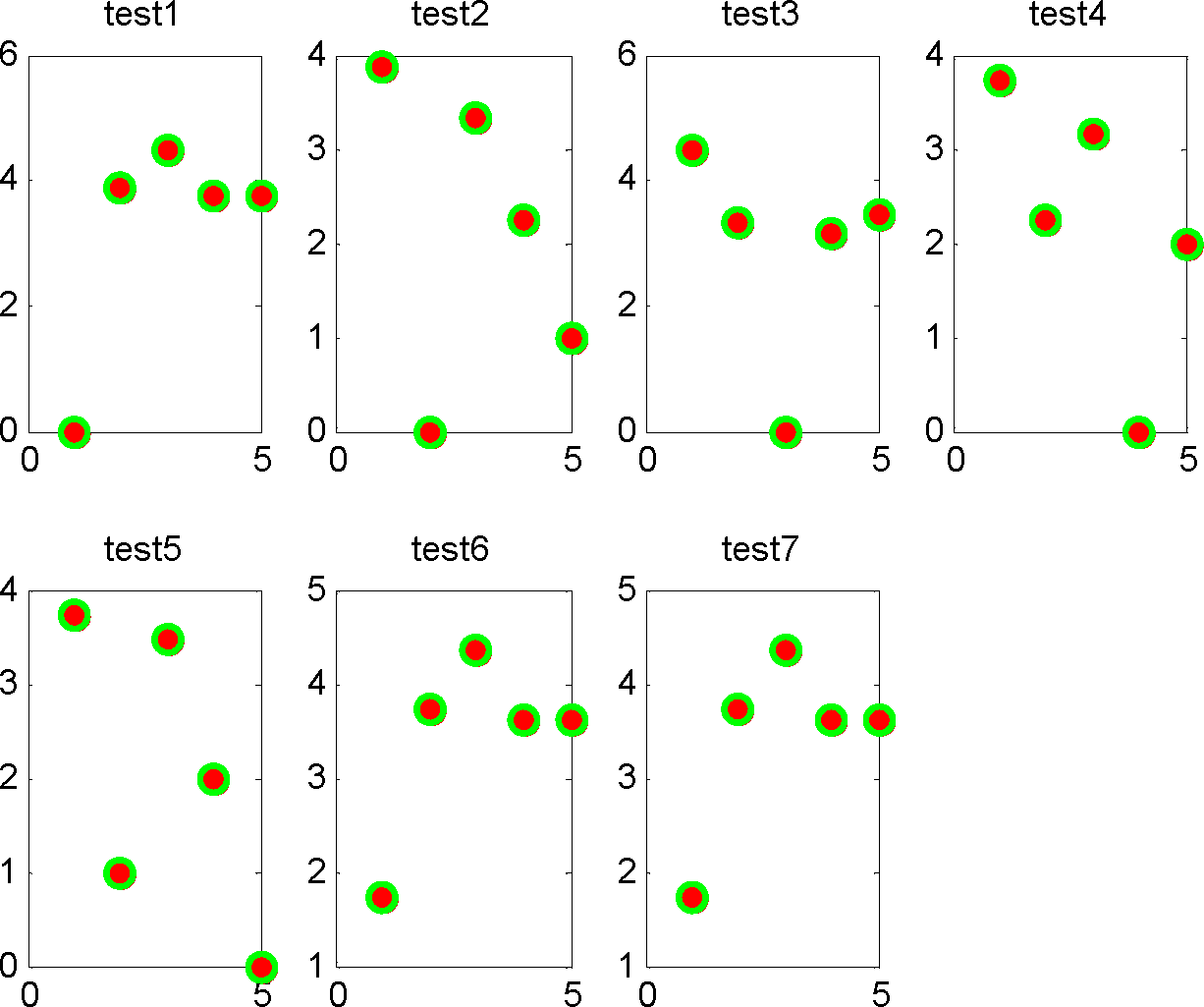
Similarly, the feature vector distance-based AAR algorithm first extracts the feature vector of training activities 1–6 and testing activities 1–7, and computes the feature vector distance between training activity and testing activity.
Table 8 is the feature vector distances between testing activities 1–7 and training activities 1–6. We also give the visualization of the feature vector distances between test sequences and normal sequences in
Figure 10. As we know, the activity 7 has not appeared before and is abnormal activity in fact. However, since the minimum feature vector distances between testing activities 1–7 and training activities 1–6 are all zero, we consider them as normal activities. From the assessing of testing activity 7 we can see that feature vector distance based AAR algorithm cannot distinguish activities with same sensor type and sensor number but difference order and frequency.
This experiment shows HCRF can recognize “new activity” and
Algorithm 2 not only can distinguish abnormal activities of different sensor types and sensor number well (activities 6 and 7), but also can distinguish abnormal activities with the same sensor type and sensor number but different sensor order and frequency (activity 7).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









