
Clustering Heterogeneous Data with k-Means by Mutual Information-Based Unsupervised Feature Transformation

Abstract
:1. Introduction
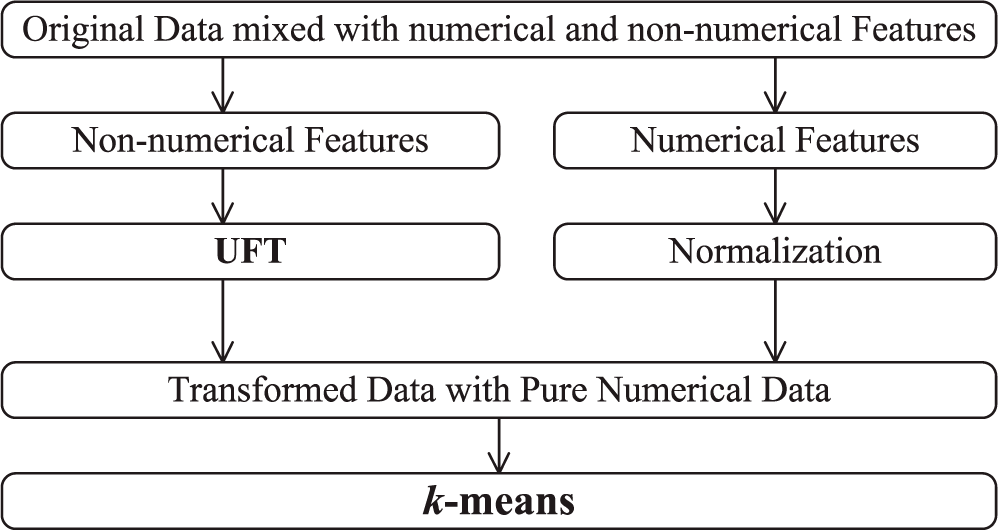
2. Unsupervised Feature Transformation (UFT) and UFT-k-means
3. Experiments and Analysis
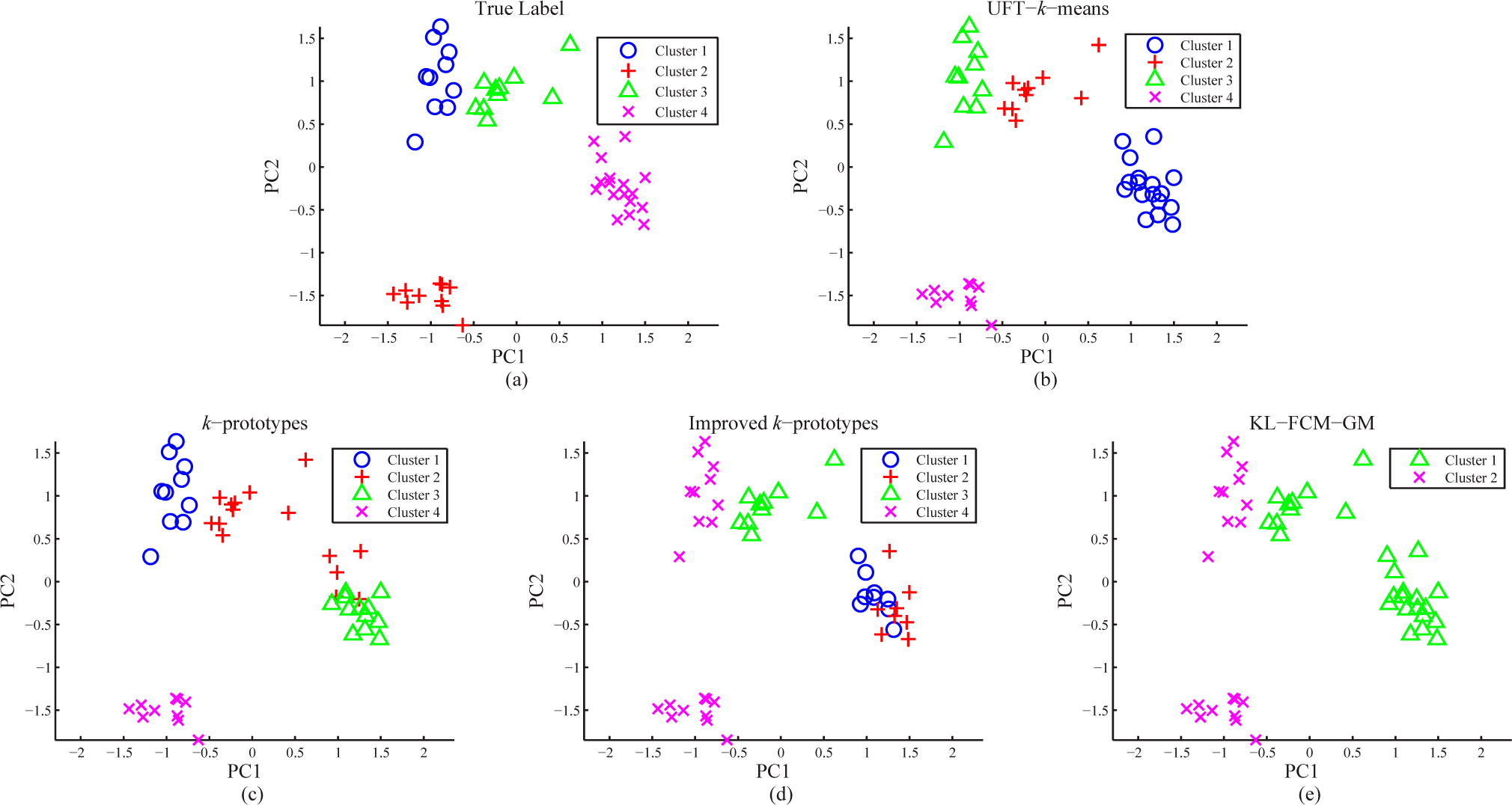
3.1. A Modified Real-World Dataset for Validation
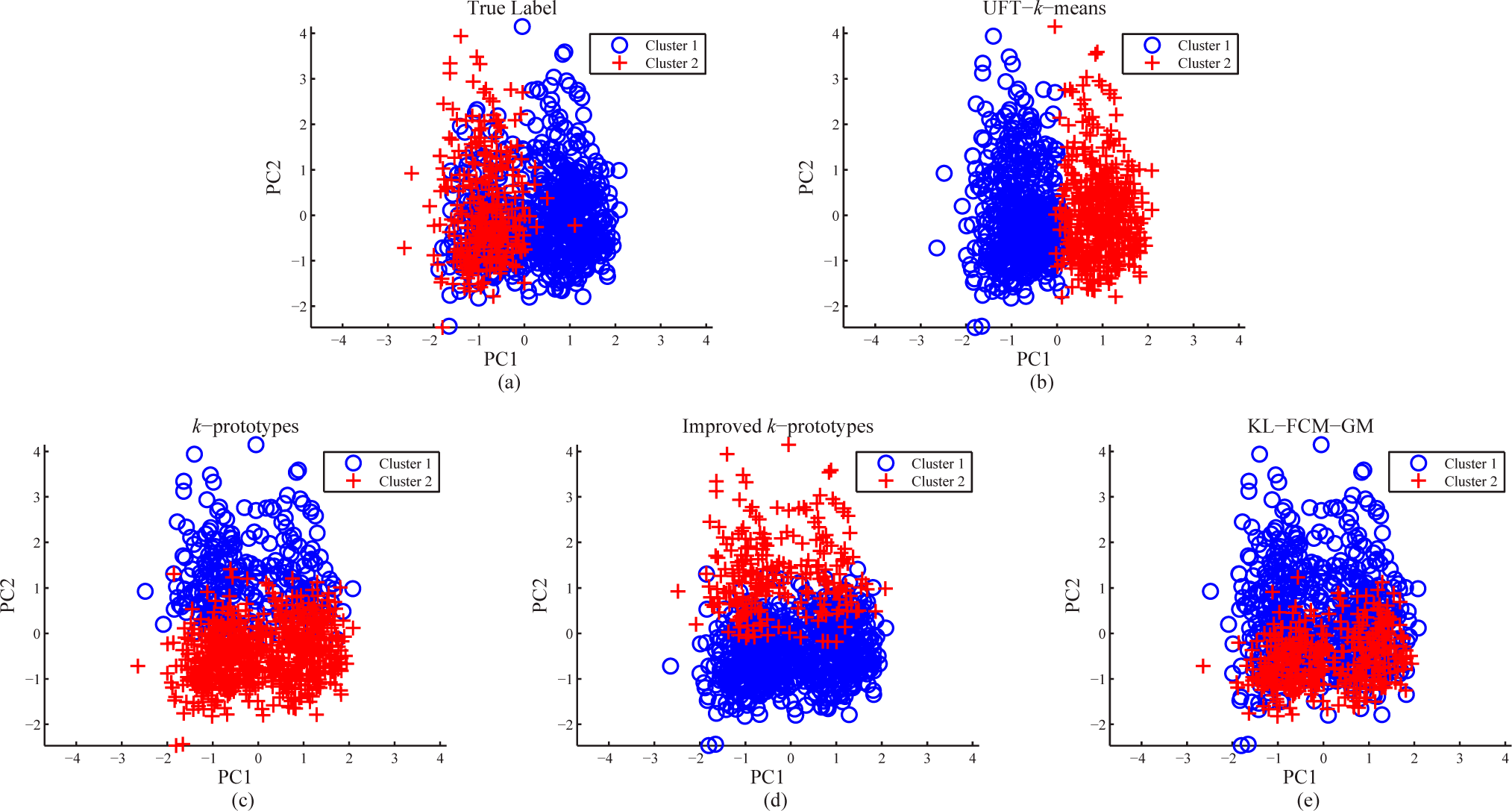
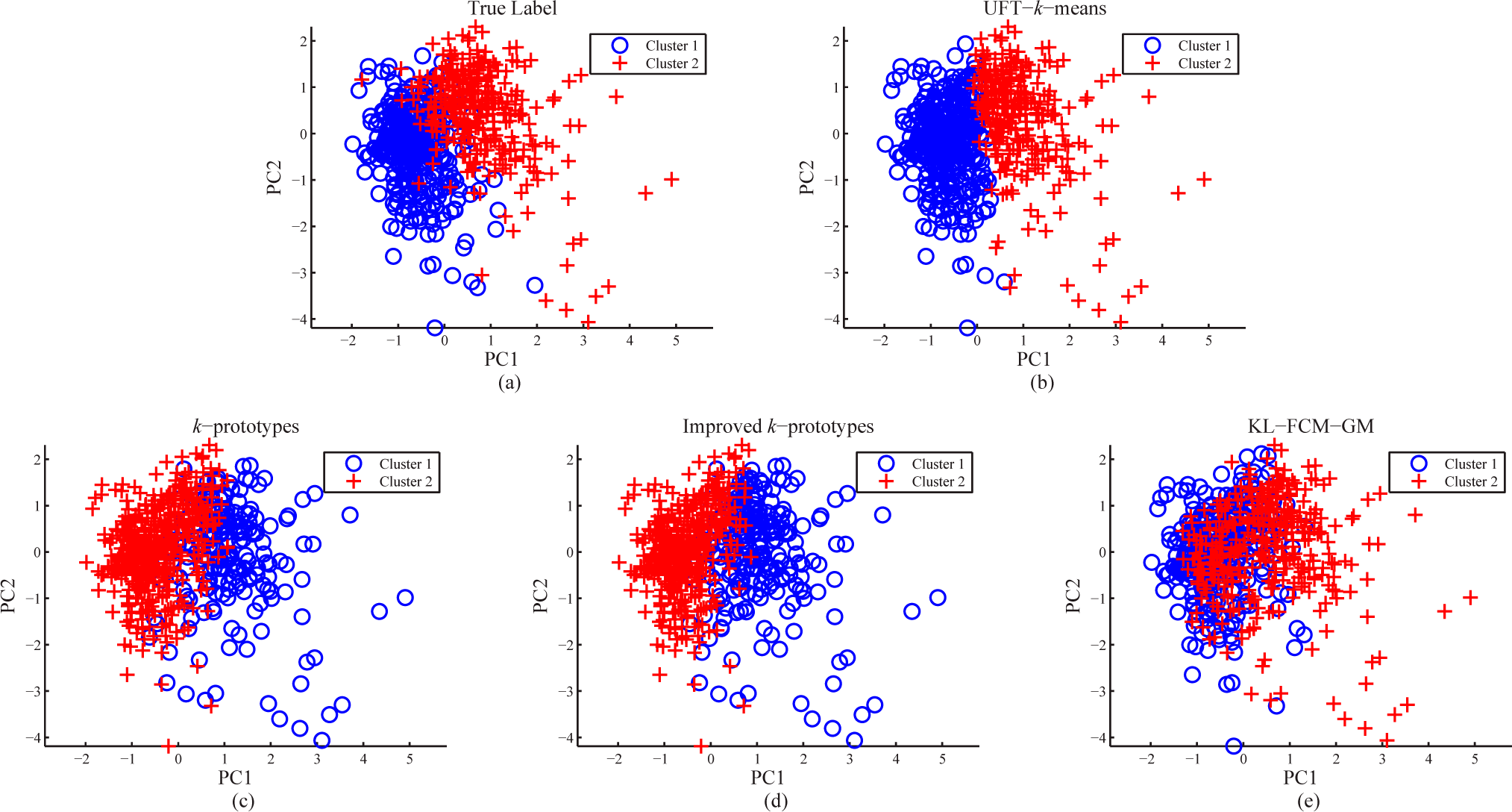
3.2. Real-World Datasets
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proc. of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Oakland, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Huang, Z.X. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar]
- Huang, Z.X.; Ng, M.K. A fuzzy k-modes algorithm for clustering categorical data. IEEE Trans. Fuzzy Syst. 1999, 7, 446–452. [Google Scholar] [Green Version]
- Arthur, D.; Vassilvitskii, S. k-means ++: The advantages of careful seeding. Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035.
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, PQ, Cananda, 4–6 June 1996; pp. 103–114.
- Guha, S.; Rastogi, R.; Shim, K. CURE: An efficient clustering algorithm for large databases. Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, Seattle, WA, USA, 1–4 June 1998; pp. 73–84.
- Barbará, D.; Li, Y.; Couto, J. COOLCAT: an entropy-based algorithm for categorical clustering. Proceedings of the Eleventh International Conference on Information and Knowledge Management, McLean, VA, USA, 4–9 Novermber 2002; pp. 582–589.
- He, H.; Tan, Y. A two-stage genetic algorithm for automatic clustering. Neurocomputing 2012, 81, 49–59. [Google Scholar]
- Nielsen, F.; Nock, R.; Amari, S. On clustering histograms with k-means by using mixed α-divergences. Entropy 2014, 16, 3273–3301. [Google Scholar]
- De Domenico, M.; Insolia, A. Entropic approach to multiscale clustering analysis. Entropy 2012, 14, 865–879. [Google Scholar]
- Li, C.; Biswas, G. Unsupervised learning with mixed numeric and nominal data. IEEE Trans. Knowl. Data Eng. 2002, 14, 673–690. [Google Scholar]
- Hsu, C.-C.; Lin, S.-H.; Tai, W.-S. Apply extended self-organizing map to cluster and classify mixed-type data. Neurocomputing 2011, 74, 3832–3842. [Google Scholar]
- Hsu, C.-C.; Chen, Y.C. Mining of mixed data with application to catalog marketing. Expert Syst. Appl. 2007, 32, 12–23. [Google Scholar]
- Goodall, D.W. A new similarity index based on probability. Biometrics 1966, 22, 882–907. [Google Scholar]
- Huang, Z. Clustering large data sets with mixed numeric and categorical values. Proceedings of the 1st Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, Singapore, 23–24 February 1997; pp. 21–34.
- Chatzis, S.P. A fuzzy c-means-type algorithm for clustering of data with mixed numeric and categorical attributes employing a probabilistic dissimilarity functional. Expert Syst. Appl. 2011, 38, 8684–8689. [Google Scholar]
- Ji, J.; Bai, T.; Zhou, C.; Ma, C.; Wang, Z. An improved k-prototypes clustering algorithm for mixed numeric and categorical data. Neurocomputing 2013, 120, 590–596. [Google Scholar]
- Ji, J.; Pang, W.; Zhou, C.; Han, X.; Wang, Z. A fuzzy k-prototype clustering algorithm for mixed numeric and categorical data. Knowl.-Based Syst 2012, 30, 129–135. [Google Scholar]
- David, G.; Averbuch, A. SpectralCAT: Categorical spectral clustering of numerical and nominal data. Pattern Recognit. 2012, 45, 416–433. [Google Scholar]
- Flach, P. Machine Learning: The Art and Science of Algorithms that Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- McLachlan, G.J.; Basford, K.E. Mixture Models. Inference and Applications to Clustering; CRC Press: Boca Raton, FL, USA, 1988. [Google Scholar]
- Blundell, R.; Bond, S. Initial conditions and moment restrictions in dynamic panel data models. J. Econ. 1998, 87, 115–143. [Google Scholar]
- Bache, K.; Lichman, M. UCI machine learning repository. Available online: http://archive.ics.uci.edu/ml accessed on 20 March 2015.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Algorithms | Accuracy |
|---|---|
| UFT-k-means | 89.05% |
| k-prototypes | 86.67% (γ = 2) |
| Improved k-prototypes | 84.76% (λ = 2.5) |
| KL-FCM-GM | 57.62% (λ = 1.1) |
| Datasets | Samples | Classes | Numerical Features | Non-numerical Features | Features |
|---|---|---|---|---|---|
| Soybean | 47 | 4 | 0 | 35 | 35 |
| Heart Statlog | 270 | 2 | 6 | 7 | 13 |
| Heart Cleveland | 297 | 5 | 6 | 7 | 13 |
| German | 1,000 | 2 | 3 | 17 | 20 |
| Australia | 690 | 2 | 6 | 8 | 14 |
| Zoo | 101 | 7 | 1 | 15 | 16 |
| Dermatology | 366 | 6 | 1 | 33 | 34 |
| Clustering Algorithms | Accuracy (%, Mean ± SD) | ||||||
|---|---|---|---|---|---|---|---|
| Soybean | Heart Statlog | Heart Cleveland | German | Australian | Zoo | Dermatology | |
| UFT-k-means | 96.17 ± 2.57 | 89.64 ± 0.26 | 65.32 ± 0.33 | 75.14 ± 0.46 | 91.19 ± 0.51 | 84.85 ± 2.05 | 63.02 ± 1.90 |
| UFT-GMM | 78.51 ± 9.07 | 83.80 ± 8.90 | 61.13 ± 2.18 | 70.07 ± 0.10 | 72.04 ± 3.28 | 74.80 ± 6.41 | 52.69 ± 5.54 |
| k-prototypes | 87.45 ± 3.82 | 78.89 ± 2.69 | 59.23 ± 1.03 | 70.00 ± 0.00 | 74.67 ± 0.06 | 77.95 ± 2.80 | 52.47 ± 3.74 |
| Improved k-prototypes | 90.85 ± 4.05 | 82.70 ± 4.07 | 59.26 ± 1.04 | 70.00 ± 0.00 | 78.72 ± 0.23 | 81.98 ± 4.62 | 52.40 ± 3.02 |
| KL-FCM-GM | 57.45 ± 4.37 | 74.96 ± 4.87 | 56.16 ± 1.06 | 70.00 ± 0.00 | 68.71 ± 1.19 | 40.59 ± 0.03 | 33.99 ± 8.02 |
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, M.; Chow, T.W.S.; Chan, R.H.M. Clustering Heterogeneous Data with k-Means by Mutual Information-Based Unsupervised Feature Transformation. Entropy 2015, 17, 1535-1548. https://0-doi-org.brum.beds.ac.uk/10.3390/e17031535
Wei M, Chow TWS, Chan RHM. Clustering Heterogeneous Data with k-Means by Mutual Information-Based Unsupervised Feature Transformation. Entropy. 2015; 17(3):1535-1548. https://0-doi-org.brum.beds.ac.uk/10.3390/e17031535
Chicago/Turabian StyleWei, Min, Tommy W. S. Chow, and Rosa H. M. Chan. 2015. "Clustering Heterogeneous Data with k-Means by Mutual Information-Based Unsupervised Feature Transformation" Entropy 17, no. 3: 1535-1548. https://0-doi-org.brum.beds.ac.uk/10.3390/e17031535