
Grey Coupled Prediction Model for Traffic Flow with Panel Data Characteristics


Abstract
:1. Introduction
2. Fundamental Theories
2.1. DGM(1,1) Model
2.2. The CTAGO Operator and Its Properties
2.3. The DGM(1,1) Model of the CTAGO Operation
- (1)
- The solution of the DGM(1,1) model (Equation (9)) is given by
- (2)
- The time response function of the CTAGO sequence is given by
- (3)
- After the inverse operation, the solution of the corresponding seasonal original sequence is given by
- (1)
- According to Equation (3), the following is clearly available:
- (2)
- , .
- (3)
- Based on property 1 and Equation (11), we have
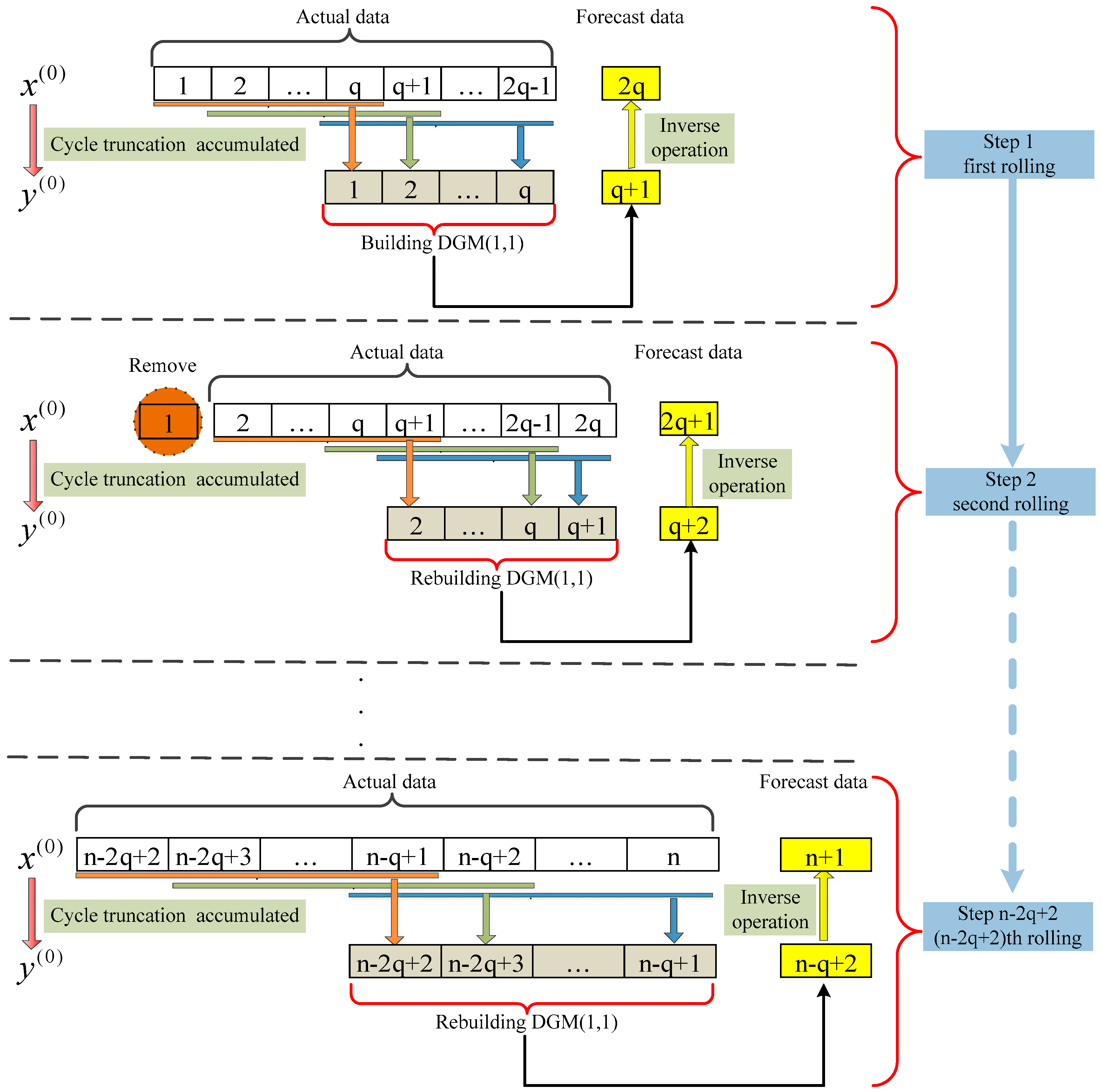
2.4. Rolling Grey Prediction Model: RDGM(1,1)
- Step 1
- The sequence is first used for DGM(1,1) modeling, and is predicted;
- Step 2
- The information is updated in real time, new observations are introduced, and the old information is removed. The rolling sequence is used for DGM(1,1) modeling, and is predicted;
- Step 3
- Step 2 is repeated until all the data points that need to be predicted have been obtained.
2.5. Rolling Seasonal Grey Model of CTAGO Sequences: RSDGM(1,1)
- (i)
- If is regarded as a disturbance of , from Theorem 1,Therefore, ,Thus,
- (ii)
- If is regarded as a disturbance of ,Similarly,
- (iii)
- If is regarded as a disturbance of , and also change. Then,When ,
- (iv)
- If is regarded as a disturbance of , and also change; then,thus,
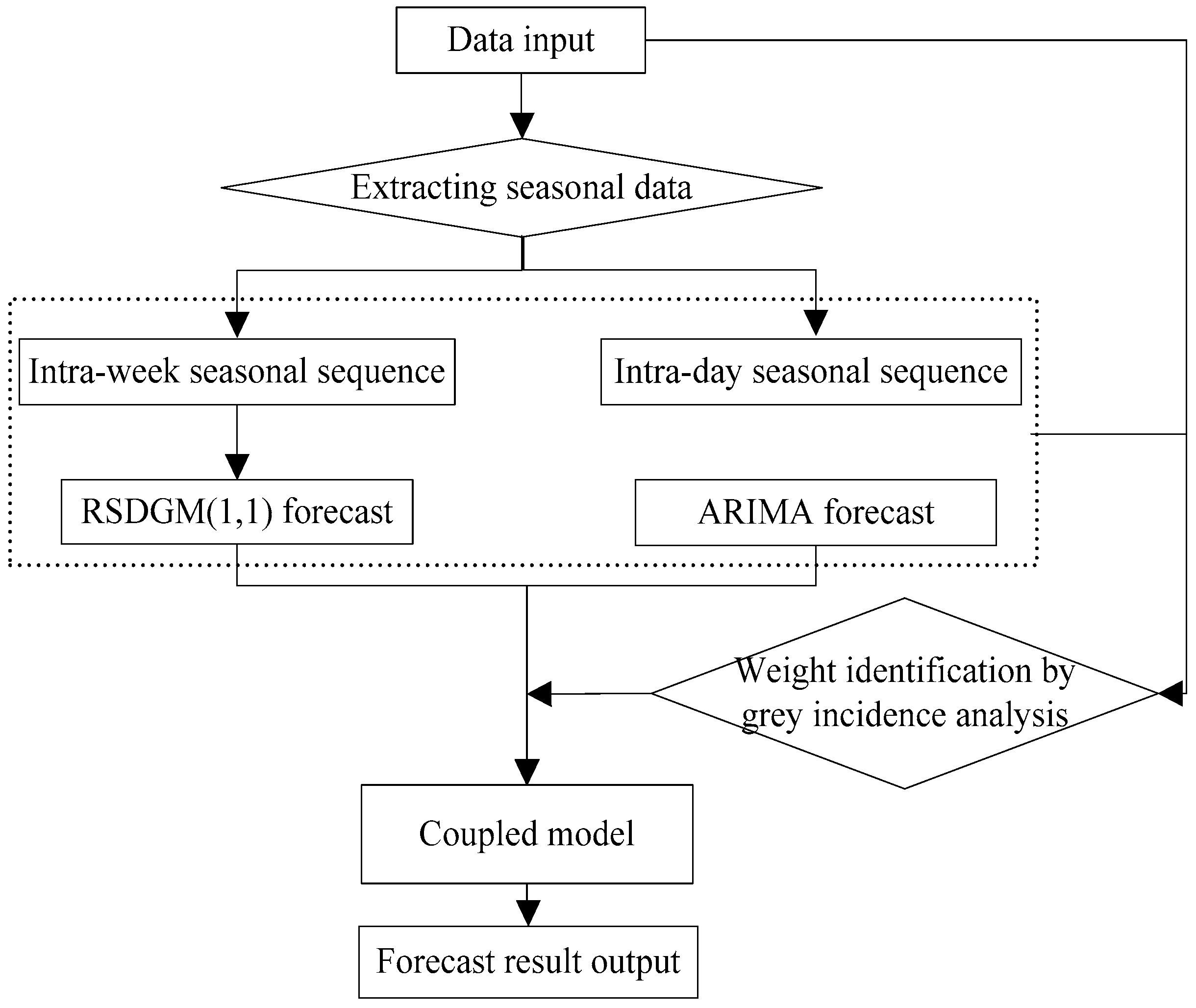
3. RSDGM(1,1)-ARIMA Coupled Model
3.1. ARIMA Model
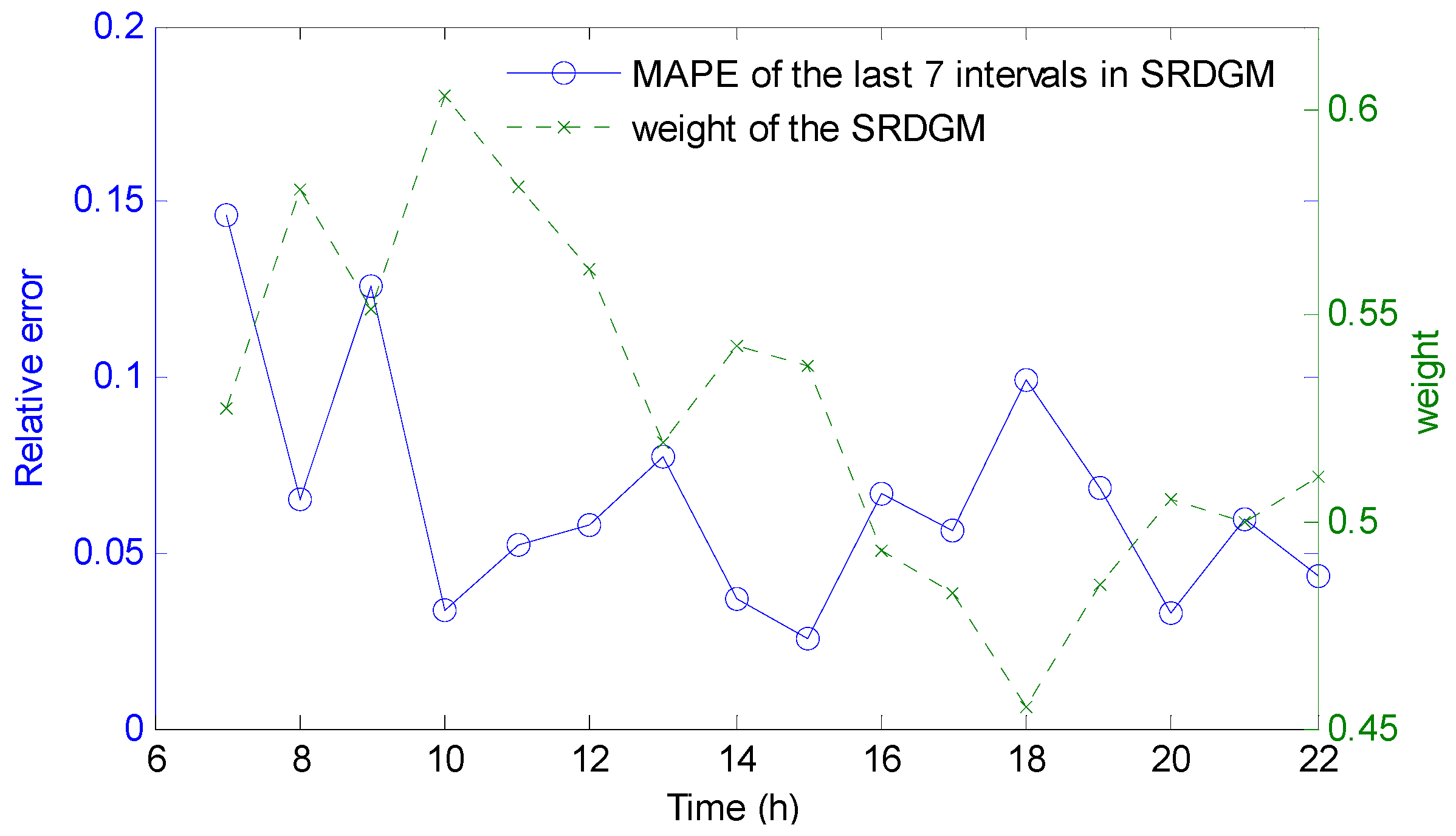
3.2. RSDGM(1,1)-ARIMA Coupled Model
- (1)
- The fitting value and real value sequence of the 7 time intervals before are extracted from the RSDGM and ARIMA model prediction periods, respectively:
- (2)
- According to Equation (19), the corresponding nearness grey relational degree and are obtained:
- (3)
- The corresponding weighted coefficients in the coupled model are determined by the nearness grey relational degree:
- (4)
- Equation (18) is used to solve the time-series and cross-sectional data coupled prediction:
4. Numerical Examples and Experimental Results
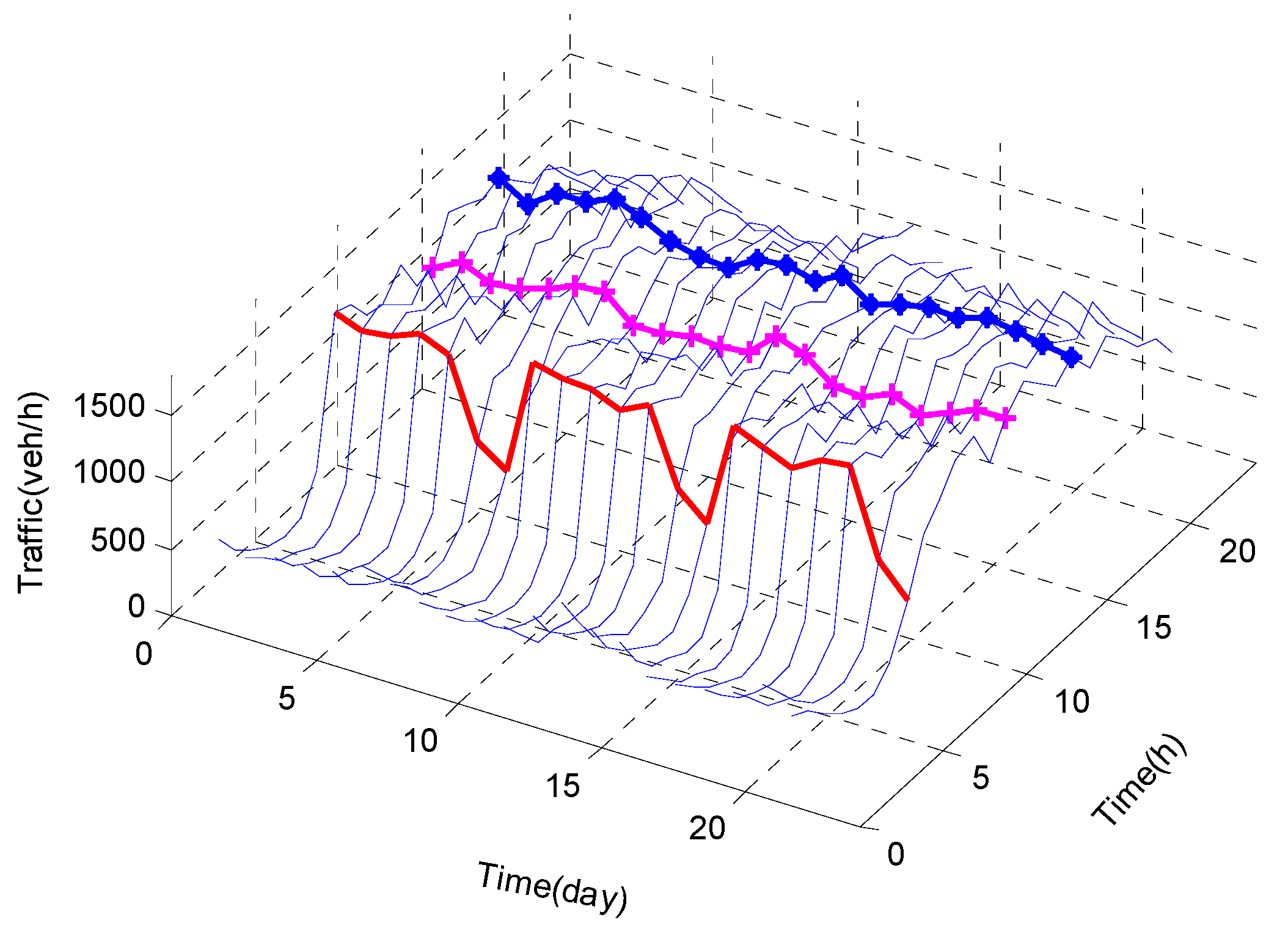
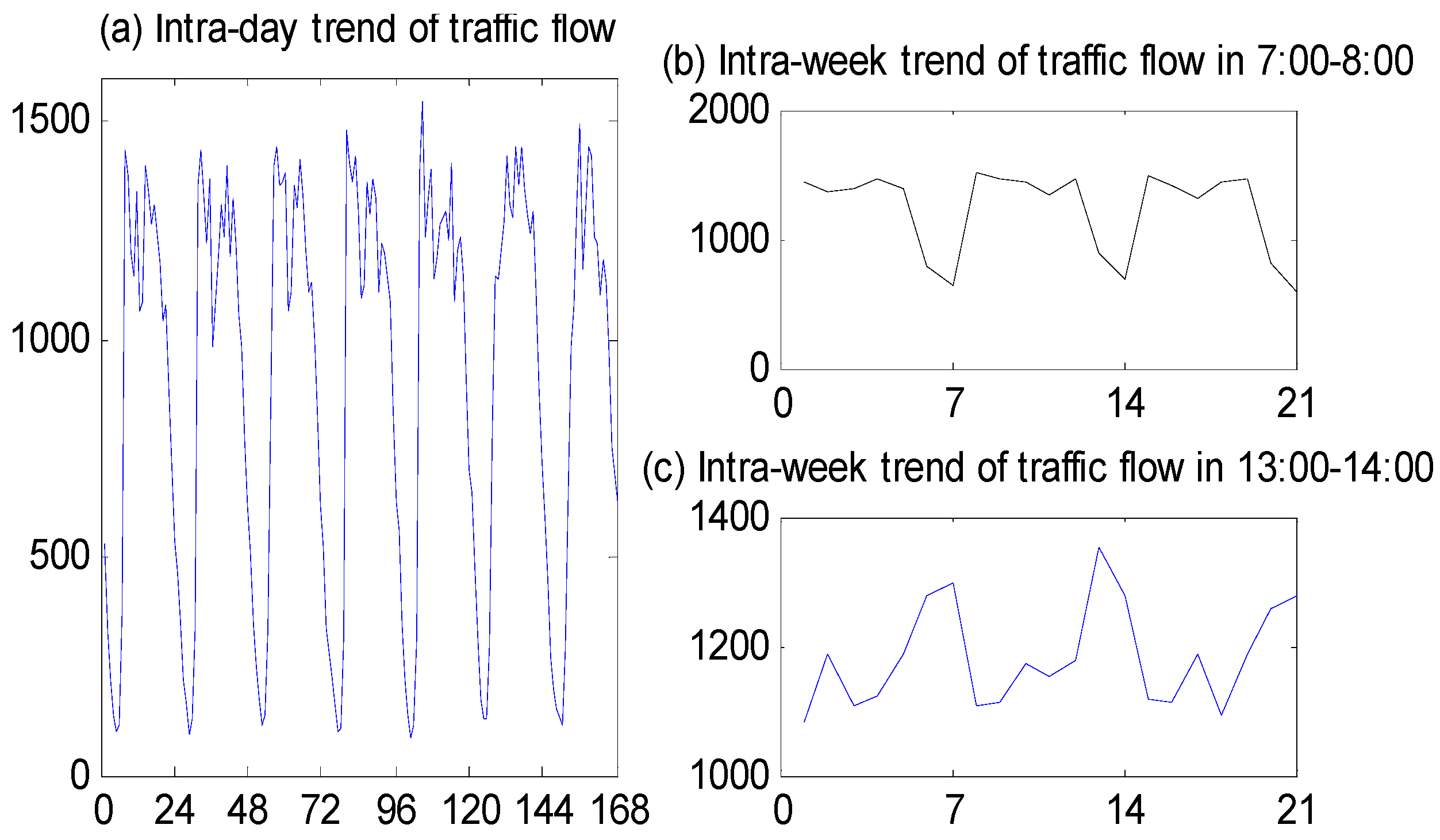
4.1. Data Description
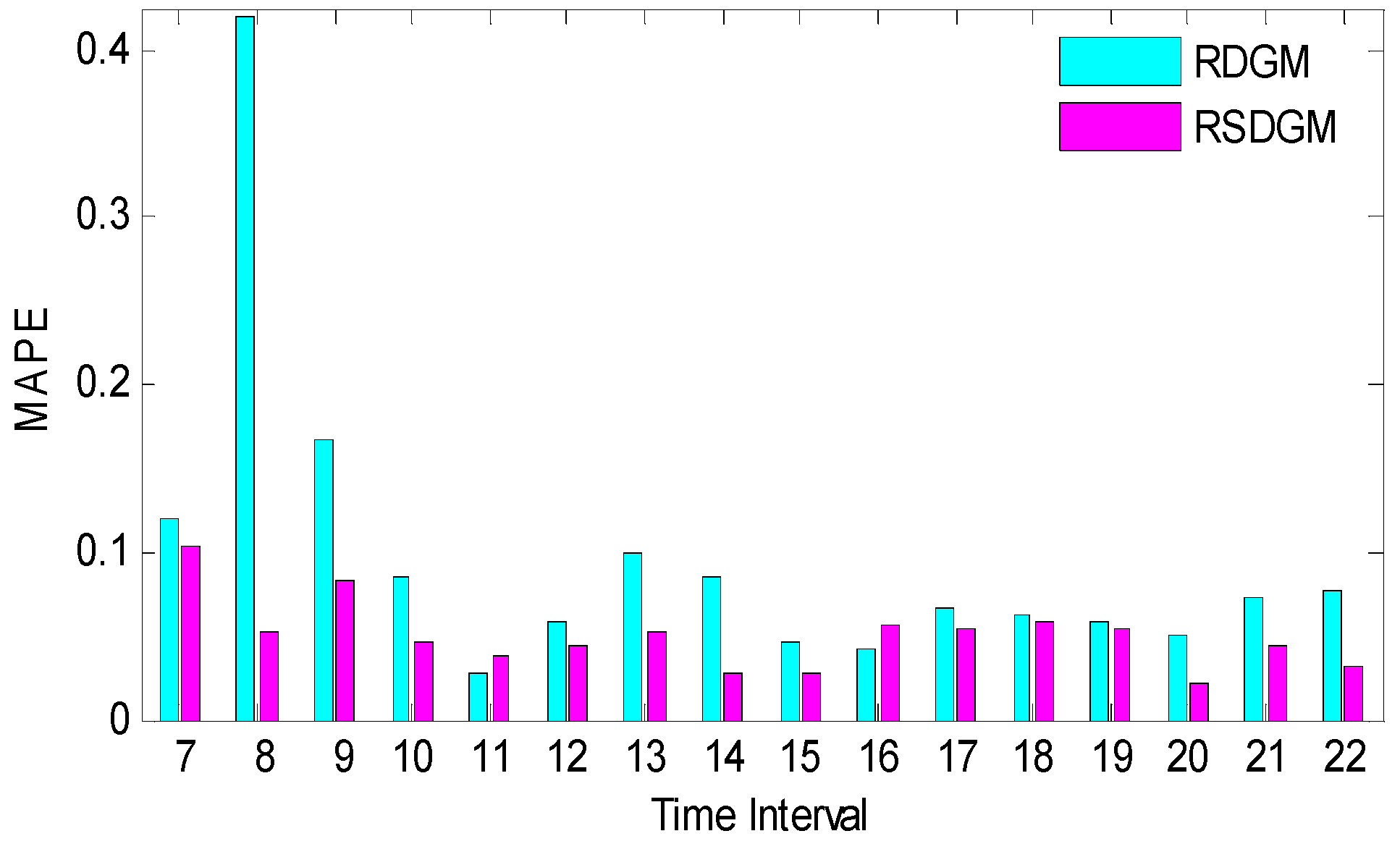
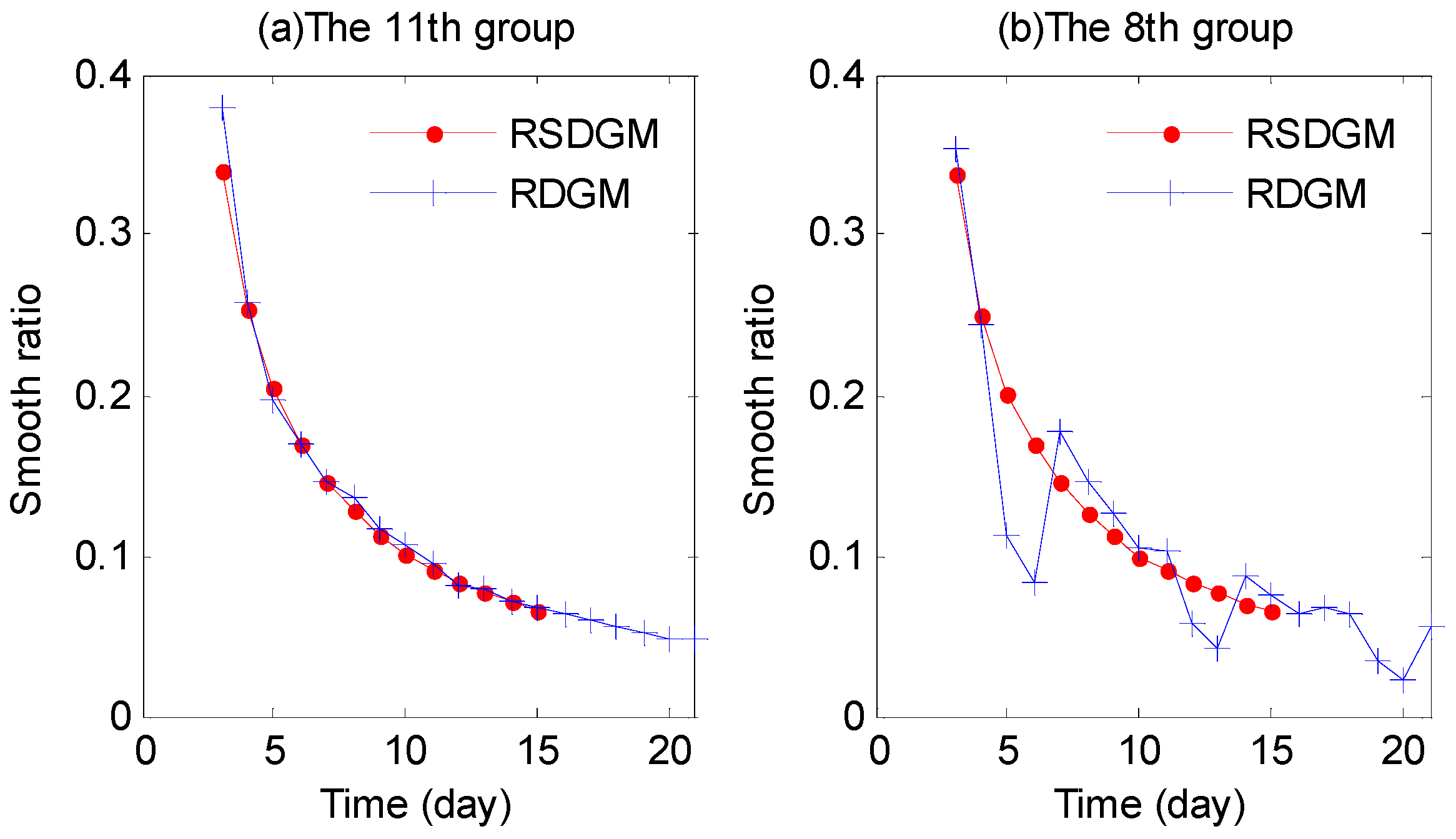
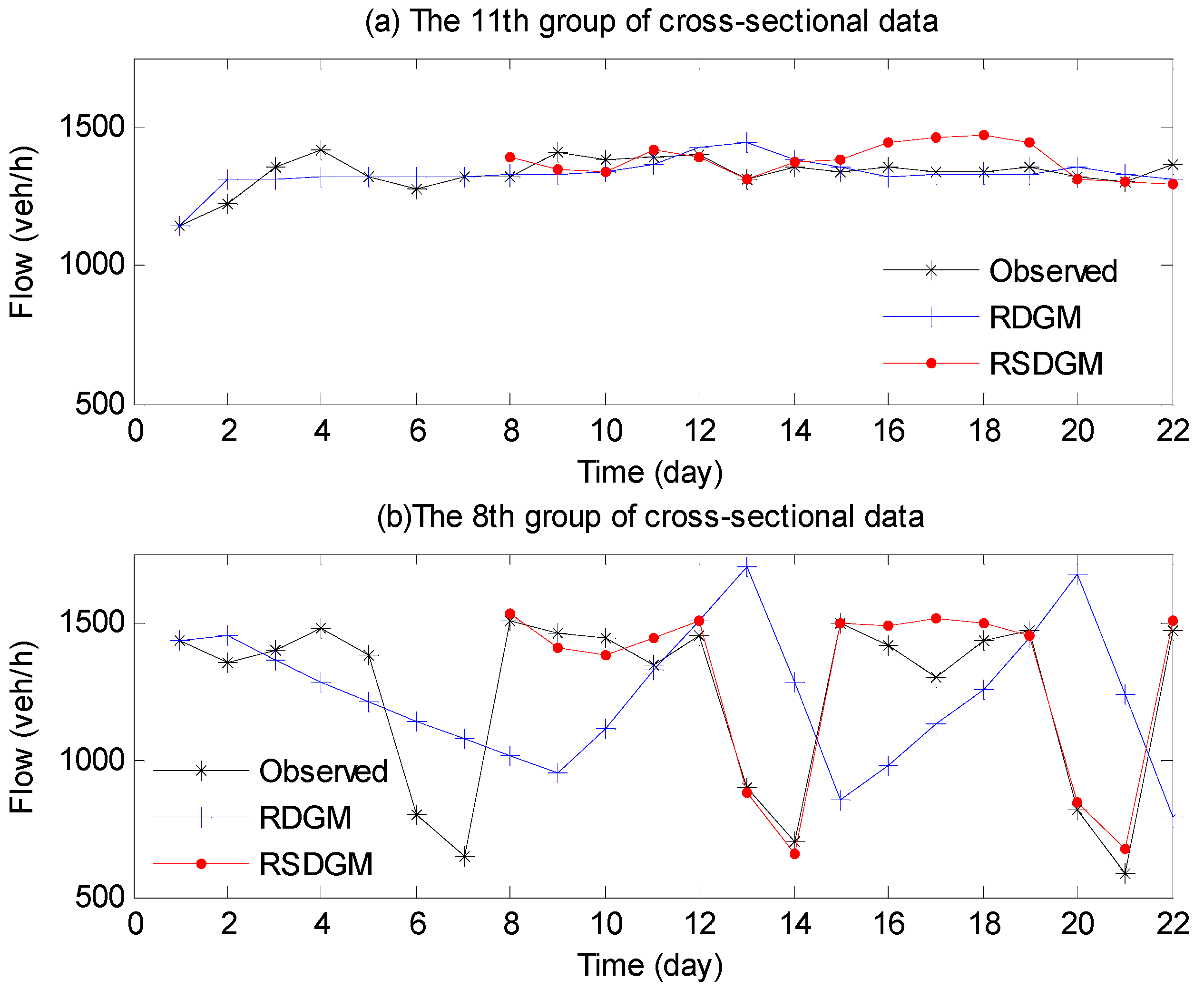
4.2. Analysis of RSDGM(1,1) Model Prediction Results
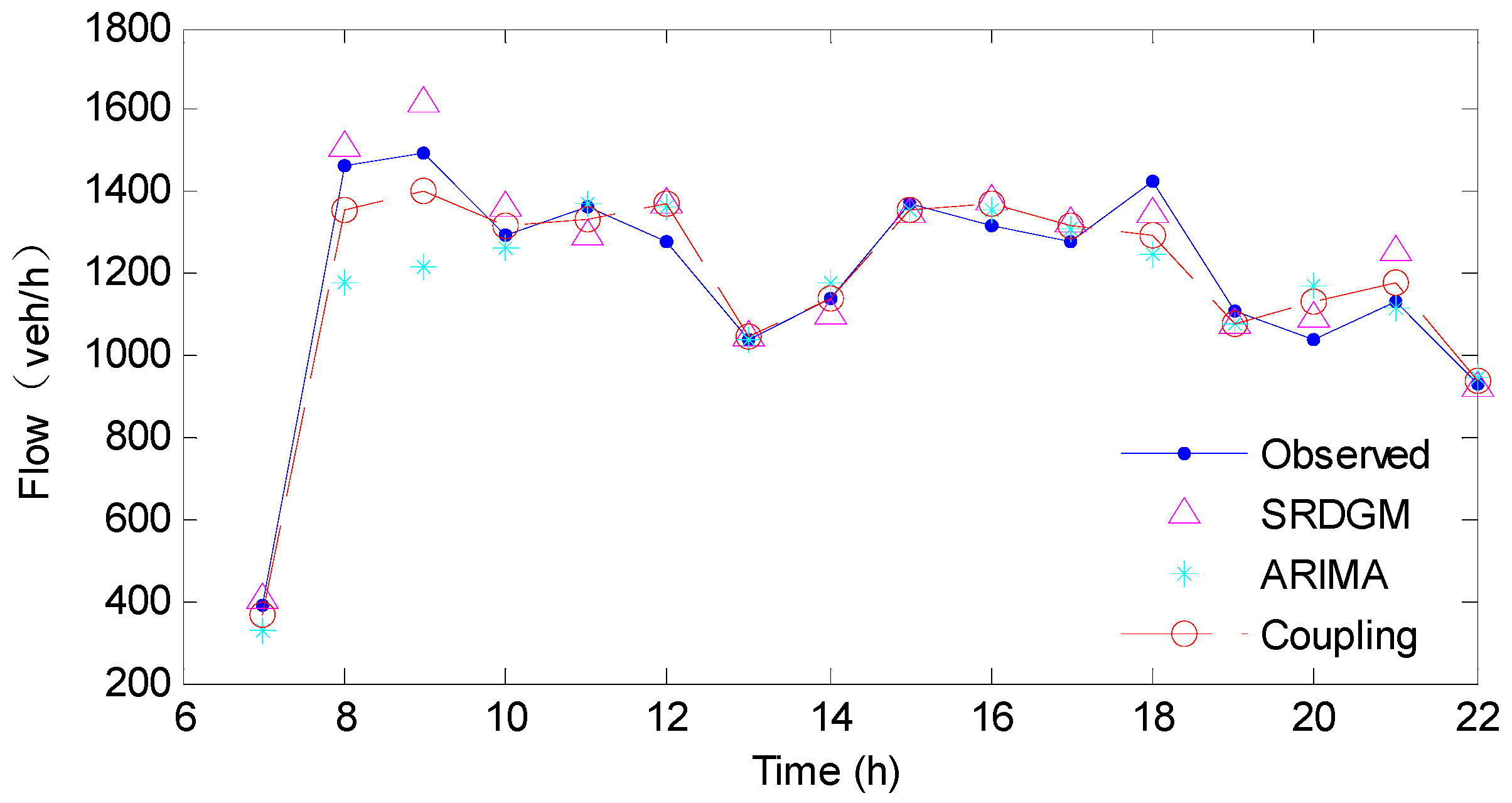
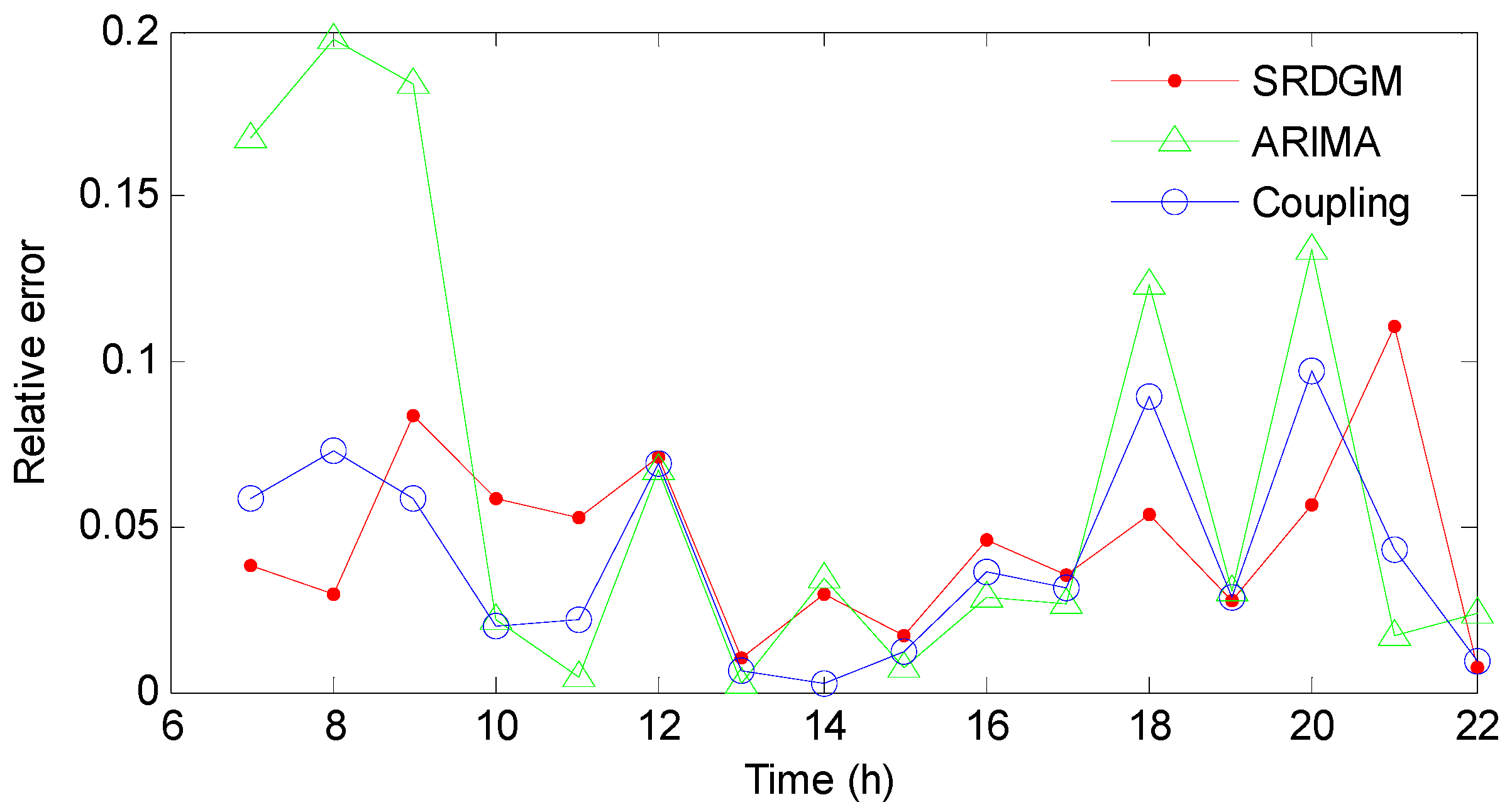
4.3. Analysis of the Coupled Model Prediction Results
5. Conclusions
- (1)
- For the weekly seasonality of the cross-sectional traffic flow data, the smooth ratio condition of the DGM(1,1) model is optimized using the CTAGO operator. The experimental results show that the CTAGO sequence can satisfy the quasi-smooth condition when the original seasonal cross-sectional traffic flow data does not. This improvement extends the application scope of the DGM(1,1) model and improves its prediction accuracy.
- (2)
- A new RSDGM(1,1) based on the CTAGO is established. The CTAGO operator can transform the seasonal fluctuation sequence of the traffic flow into a flat sequence, which can be used to achieve a high precision DGM(1,1) rolling model. Based on matrix perturbation analysis, the length of the sequence in the rolling model is determined, which not only achieves prediction with limited cross-sectional data but also reflects the weight priority of the previous data cycle in the weekly seasonal cross-sectional data.
- (3)
- A coupled model is established in which the weights are determined by the nearness grey relational degree. By using the nearness grey relational degree to identify the weights, the role of the benchmark model is reflected; moreover, extreme weights do not appear in the intelligent algorithm. The proposed coupled model not only obtains high precision prediction but also considers the performance of the RSDGM(1,1) and ARIMA models in the coupled process.
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| GM(1,1) | Grey model with a first-order differential equation and one variable |
| DGM(1,1) | Discrete grey model with a first-order differential equation and one variable |
| RDGM(1,1) | Rolling DGM(1,1) model |
| RSDGM(1,1) | Rolling seasonal DGM(1,1) model |
| The original non-negative observed sequence | |
| Cycle truncation accumulated generating operator sequence | |
| 1-AGO | First-order accumulated generating operation |
| CTAGO | Cycle truncation accumulated generating operation |
| APE | Absolute percentage error |
| MAPE | Mean absolute percentage error |
| EC | Equal coefficient |
| ARIMA | Autoregressive integrated moving average model |
References
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Ran, B.; Jin, P.J.; Boyce, D.; Qiu, T.Z.; Cheng, Y. Perspectives on Future Transportation Research: Impact of Intelligent Transportation System Technologies on Next Generation Transportation Modeling. J. Intell. Transp. Syst. 2012, 16, 226–242. [Google Scholar] [CrossRef]
- Kamarianakis, Y.; Gao, H.O.; Prastacos, P. Characterizing regimes in daily cycles of urban traffic using smooth-transition regressions. Transp. Res. Part C Emerg. Technol. 2010, 18, 821–840. [Google Scholar] [CrossRef]
- Sun, H.; Liu, H.; Xiao, H.; He, R.; Ran, B. Use of Local Linear Regression Model for Short-Term Traffic Forecasting. Transp. Res. Rec. J. Transp. Res. Board 2003, 1836, 143–150. [Google Scholar] [CrossRef]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 1–9. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. Part C Emerg. Technol. 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Guo, H.; Xiao, X.; Forrest, J. Urban road short- term traffic flow forecasting based on the delay and nonlinear grey model. J. Transp. Syst. Eng. Inf. Technol. 2013, 13, 60–66. [Google Scholar] [CrossRef]
- Mao, S.; Chen, Y.; Xiao, X. City Traffic Flow Prediction Based on Improved GM(1,1) Model. J. Grey Syst. 2012, 24, 337–346. [Google Scholar]
- Zhang, Y.; Zhang, Y.; Haghani, A. A hybrid short-term traffic flow forecasting method based on spectral analysis and statistical volatility model. Transp. Res. Part C Emerg. Technol. 2014, 43, 65–78. [Google Scholar] [CrossRef]
- Tchrakian, T.T.; Basu, B.; O’Mahony, M. Real-Time Traffic Flow Forecasting Using Spectral Analysis. IEEE Trans. Intell. Transp. 2012, 13, 519–526. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, J. Predicting Traffic Flow in Local Area Networks by the Largest Lyapunov Exponent. Entropy 2016, 18, 32. [Google Scholar] [CrossRef]
- Ko, E.; Ahn, J.; Kim, E. 3D Markov Process for Traffic Flow Prediction in Real-Time. Sensors 2016, 16, 147. [Google Scholar] [CrossRef] [PubMed]
- Tan, H.; Wu, Y.; Shen, B.; Jin, P.J.; Ran, B. Short-Term Traffic Prediction Based on Dynamic Tensor Completion. Trans. Intell. Transp. 2016, 17, 2123–2133. [Google Scholar] [CrossRef]
- Moretti, F.; Pizzuti, S.; Panzieri, S.; Annunziato, M. Urban traffic flow forecasting through statistical and neural network bagging ensemble hybrid modeling. Neurocomputing 2015, 167, 3–7. [Google Scholar] [CrossRef]
- Huang, M. Intersection traffic flow forecasting based on v-GSVR with a new hybrid evolutionary algorithm. Neurocomputing 2015, 147, 343–349. [Google Scholar] [CrossRef]
- Hong, W.; Dong, Y.; Zheng, F.; Lai, C. Forecasting urban traffic flow by SVR with continuous ACO. Appl. Math. Model. 2011, 35, 1282–1291. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, G.; Wang, Y.; Wang, H.; Liu, F.; Tang, J.; Zhang, G.; Wang, Y.; Wang, H.; Liu, F. A hybrid approach to integrate fuzzy C-means based imputation method with genetic algorithm for missing traffic volume data estimation. Transp. Res. Part C Emerg. Technol. 2014, 51, 29–40. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Li, L.; Hu, J.; Zhang, Z. The retrieval of intra-day trend and its influence on traffic prediction. Transp. Res. Part C Emerg. Technol. 2012, 22, 103–118. [Google Scholar] [CrossRef]
- Tang, J.; Wang, H.; Wang, Y.; Liu, X.; Liu, F. Hybrid Prediction Approach Based on Weekly Similarities of Traffic Flow for Different Temporal Scales. Transp. Res. Rec. J. Transp. Res. Board 2014, 2443, 21–31. [Google Scholar] [CrossRef]
- Zou, Y.; Hua, X.; Zhang, Y. Hybrid short-term freeway speed prediction methods based on periodic analysis. Can. J. Civ. Eng. 2015, 42, 570–582. [Google Scholar] [CrossRef]
- Barmpadimos, I.; Nufer, M.; Oderbolz, D.C.; Keller, J.; Aksoyoglu, S.; Hueglin, C.; Baltensperger, U.; Prévôt, A.S.H. The weekly cycle of ambient concentrations and traffic emissions of coarse (PM10–PM2.5) atmospheric particles. Atmos. Environ. 2011, 45, 4580–4590. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, Y.; Lu, H. Seasonal Autoregressive Integrated Moving Average and Support Vector Machine Models: Prediction of Short-Term Traffic Flow on Freeways. Transp. Res. Rec. J. Transp. Res. Board 2011, 2215, 85–92. [Google Scholar] [CrossRef]
- Wang, J.; Deng, W.; Guo, Y. New Bayesian combination method for short-term traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2014, 43, 79–94. [Google Scholar] [CrossRef]
- Wang, H.; Liu, L.; Qian, Z.; Wei, H.; Dong, S. Empirical Mode Decomposition-Autoregressive Integrated Moving Average. Transp. Res. Rec. J. Transp. Res. Board 2014, 2460, 66–76. [Google Scholar] [CrossRef]
- Tan, M.; Wong, S.C.; Xu, J.; Guan, Z.; Zhang, P. An Aggregation Approach to Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. 2009, 10, 60–69. [Google Scholar]
- Qiu, D.G.; Yang, H.Y. A short-term traffic flow forecast algorithm based on double seasonal time series. J. Sichuan Univ. 2013, 45, 64–68. [Google Scholar]
- Lu, J.; Xie, W.; Zhou, H.; Zhang, A. An optimized nonlinear grey Bernoulli model and its applications. Neurocomputing 2016, 177, 206–214. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, S.; John, R. Uncertainty Representation of Grey Numbers and Grey Sets. IEEE Trans. Cybern. 2014, 44, 1508–1517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bezuglov, A.; Comert, G. Short-term freeway traffic parameter prediction: Application of grey system theory models. Expert Syst. Appl. 2016, 62, 284–292. [Google Scholar] [CrossRef]
- Hosse, R.S.; Becker, U.; Manz, H. Grey Systems Theory Time Series Prediction applied to Road Traffic Safety in Germany. IFAC PapersOnLine 2016, 49, 231–236. [Google Scholar]
- Xia, M.; Wong, W.K. A seasonal discrete grey forecasting model for fashion retailing. Knowl. Based Syst. 2014, 57, 119–126. [Google Scholar] [CrossRef]
- Sifeng, L.; Yingjie, Y.; Naiming, X.; Jeffrey, F. New progress of Grey System Theory in the new millennium. Grey Syst. Theory Appl. 2016, 6, 2–31. [Google Scholar]
- Yuan, C.; Yang, Y.; Chen, D. Proximity and Similitude of Sequences Based on Grey Relational Analysis. J. Grey Syst. 2014, 26, 57–74. [Google Scholar]
- Zhang, Y.; Ye, N.; Wang, R.; Malekian, R. A Method for Traffic Congestion Clustering Judgment Based on Grey Relational Analysis. ISPRS Int. J. Geo-Inf. 2016, 5, 71. [Google Scholar] [CrossRef]
- Deng, J.L. Control problems of grey systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar]
- Liu, S.; Lin, Y. Grey Systems: Theory and Applications; Springer: London, UK, 2010; pp. 195–205. [Google Scholar]
- Xie, N.; Liu, S. Discrete grey forecasting model and its optimization. Appl. Math. Model. 2009, 33, 1173–1186. [Google Scholar] [CrossRef]
- Ma, X.; Liu, Z. Research on the novel recursive discrete multivariate grey prediction model and its applications. Appl. Math. Model. 2016, 40, 4876–4890. [Google Scholar] [CrossRef]
- Mao, S.; Gao, M.; Xiao, X.; Zhu, M. A novel fractional grey system model and its application. Appl. Math. Model. 2016, 40, 5063–5076. [Google Scholar] [CrossRef]
- Shen, Y.; He, B.; Qin, P. Fractional-Order Grey Prediction Method for Non-Equidistant Sequences. Entropy 2016, 18, 227. [Google Scholar] [CrossRef]
- Akay, D.; Atak, M. Grey prediction with rolling mechanism for electricity demand forecasting of Turkey. Energy 2007, 32, 1670–1675. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S. An optimized grey model for annual power load forecasting. Energy 2016, 107, 272–286. [Google Scholar] [CrossRef]
- Wu, L. Using fractional GM(1,1) model to predict the life of complex equipment. Grey Syst. Theory Appl. 2016, 6, 32–40. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Fang, Z.; Xu, H. Properties of the GM(1,1) with fractional order accumulation. Appl. Math. Comput. 2015, 252, 287–293. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Yao, L.; Yan, S. The effect of sample size on the grey system model. Appl. Math. Model. 2013, 37, 6577–6583. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, R. Application of metabolic GM(1,1) model in financial repression approach to the financing difficulty of the small and medium-sized enterprises. Grey Syst. Theory Appl. 2014, 4, 311–320. [Google Scholar] [CrossRef]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: New Jersey, NJ, USA, 1994; pp. 68–70. [Google Scholar]
- Li, M. Central South University Open ITS Data. Available online: http://www.openits.cn/openPaper/567.jhtml (accessed on 12 July 2016).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cross-Sectional Data Series | Time Interval | RDGM(1,1) | RSDGM(1,1) | ||
|---|---|---|---|---|---|
| Steps 1–8 Forecast MAPE (%) | 4 November Forecast APE (%) | Steps 1–8 Forecast MAPE (%) | 4 November Forecast APE (%) | ||
| 1 | 6:00–7:00 | 0.1207 | 0.3515 | 0.1028 | 0.0379 |
| 2 | 7:00–8:00 | 0.4204 | 0.4584 | 0.0519 | 0.0292 |
| 3 | 8:00–9:00 | 0.1682 | 0.2598 | 0.0839 | 0.0829 |
| 4 | 9:00–10:00 | 0.0842 | 0.1055 | 0.0453 | 0.0581 |
| 5 | 10:00–11:00 | 0.0271 | 0.0372 | 0.0383 | 0.0526 |
| 6 | 11:00–12:00 | 0.0576 | 0.0764 | 0.0434 | 0.0714 |
| 7 | 12:00–13:00 | 0.0992 | 0.0722 | 0.0525 | 0.0101 |
| 8 | 13:00–14:00 | 0.0848 | 0.1361 | 0.0286 | 0.0294 |
| 9 | 14:00–15:00 | 0.0453 | 0.0885 | 0.0278 | 0.0165 |
| 10 | 15:00–16:00 | 0.0411 | 0.0258 | 0.0560 | 0.0458 |
| 11 | 16:00–17:00 | 0.0671 | 0.0436 | 0.0541 | 0.0357 |
| 12 | 17:00–18:00 | 0.0629 | 0.0777 | 0.0580 | 0.0537 |
| 13 | 18:00–19:00 | 0.0591 | 0.0195 | 0.0545 | 0.0275 |
| 14 | 19:00–20:00 | 0.0500 | 0.1564 | 0.0224 | 0.0568 |
| 15 | 20:00–21:00 | 0.0723 | 0.0577 | 0.0435 | 0.1108 |
| 16 | 21:00–22:00 | 0.0779 | 0.0736 | 0.0326 | 0.0074 |
| MAPE | (0%, 3%) | (3%, 6%) | (6%, 10%) | (10%, 50%) |
|---|---|---|---|---|
| RDGM(1,1) | 1 | 5 | 7 | 3 |
| RSDGM(1,1) | 3 | 11 | 1 | 1 |
| Model | RSDGM(1,1) | ARIMA | Coupled Model with Equal Weight | Bayesian Combination Model | The Proposed Coupled Model |
|---|---|---|---|---|---|
| MAPE | 4.54% | 6.68% | 4.17% | 4.44% | 4.02% |
| EC | 0.9732 | 0.9503 | 0.9738 | 0.9722 | 0.9743 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Xiao, X.; Mao, S.; Rao, C.; Wen, J. Grey Coupled Prediction Model for Traffic Flow with Panel Data Characteristics. Entropy 2016, 18, 454. https://0-doi-org.brum.beds.ac.uk/10.3390/e18120454
Yang J, Xiao X, Mao S, Rao C, Wen J. Grey Coupled Prediction Model for Traffic Flow with Panel Data Characteristics. Entropy. 2016; 18(12):454. https://0-doi-org.brum.beds.ac.uk/10.3390/e18120454
Chicago/Turabian StyleYang, Jinwei, Xinping Xiao, Shuhua Mao, Congjun Rao, and Jianghui Wen. 2016. "Grey Coupled Prediction Model for Traffic Flow with Panel Data Characteristics" Entropy 18, no. 12: 454. https://0-doi-org.brum.beds.ac.uk/10.3390/e18120454