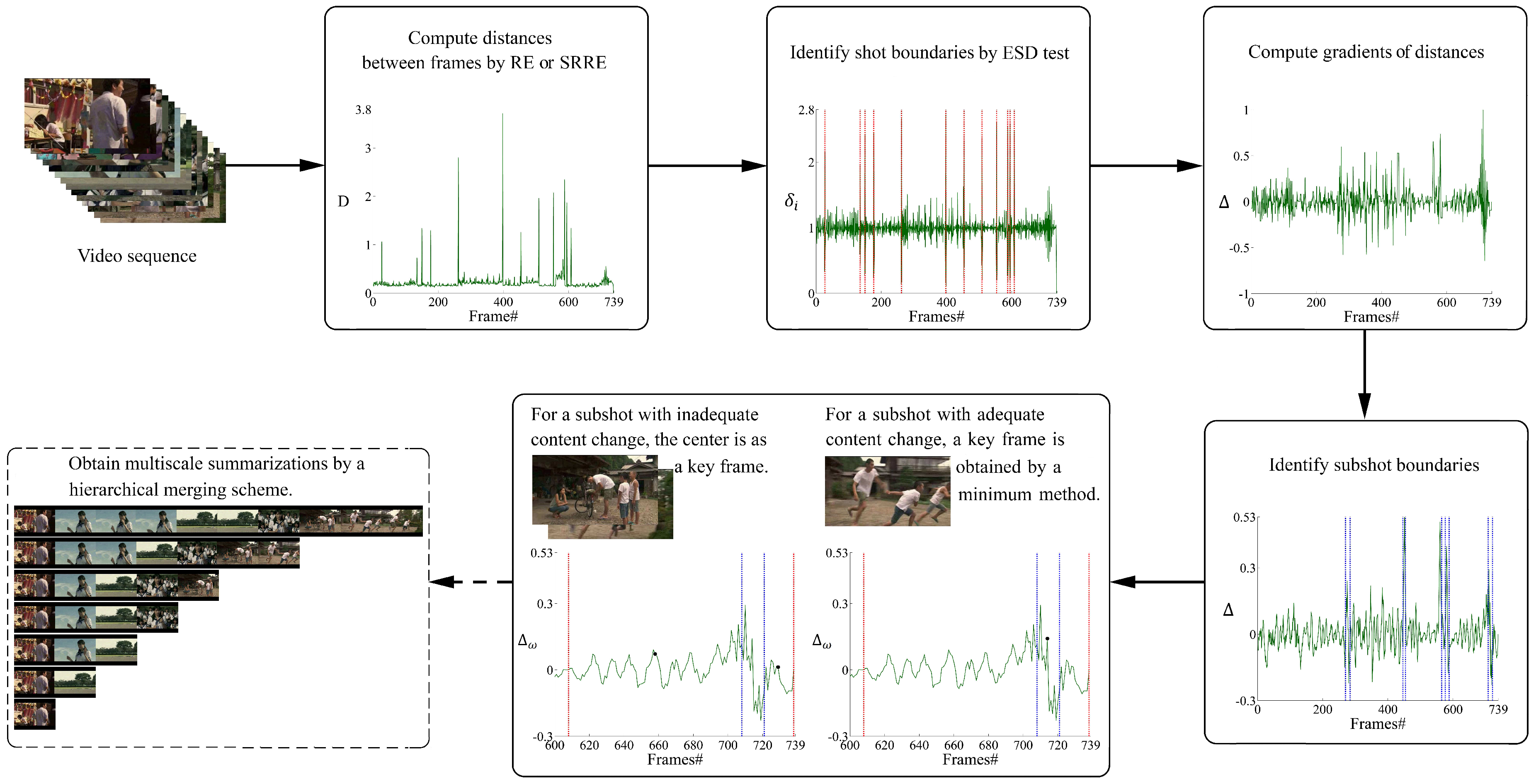
In this section, we present extensive tests on different characteristics of videos for the purpose of evaluating the performance of our proposed algorithm for key frame selection. All of the experiments are conducted on a Windows PC with Intel Core i3 CPU at 2.10 GHz and with 8 GB RAM. Notice that, in order to reduce the possible perturbations and noise, all of the key frame and runtime results are the average of five independent experiments.
5.1. A Performance Comparison Based on Common Test Videos
For the sake of a fair benchmark, we consider the methods using information theoretic distance measures in the shot-based computing mechanism. The RE- and SRRE-driven methods are firstly compared to the proposed algorithm using JSD, the approaches based on GGD [
13] and MI [
12], on the common video sequences. In addition, the algorithm applying the most classical Shannon entropy, namely the so-called ED [
11], is introduced for this kind of comparison. All of the parameters associated with the comparing approaches are carefully determined by the trial and error method [
35] based on extensive experiments to achieve the best possible performances, and simultaneously, the numbers of key frames issued by different methods are controlled to be as equal as possible. That is, the procedure of parameter tuning here can be considered as being split into training and testing steps, and all of the video sequences used are taken both as training and testing sets.
In tests, the video clips are composed of various contents. Namely, the videos may contain significant object and camera motions or not; they may have the camera moving, such as zooming, tilting and panning; also, they may have a fade in or out, a wipe and a dissolve as gradual transitions. These test videos are provided by “The Open Video Project database” [
36].
Table 1 lists the main information on the 46 test video sequences; for convenient use, we rename all of these videos as 1–46.
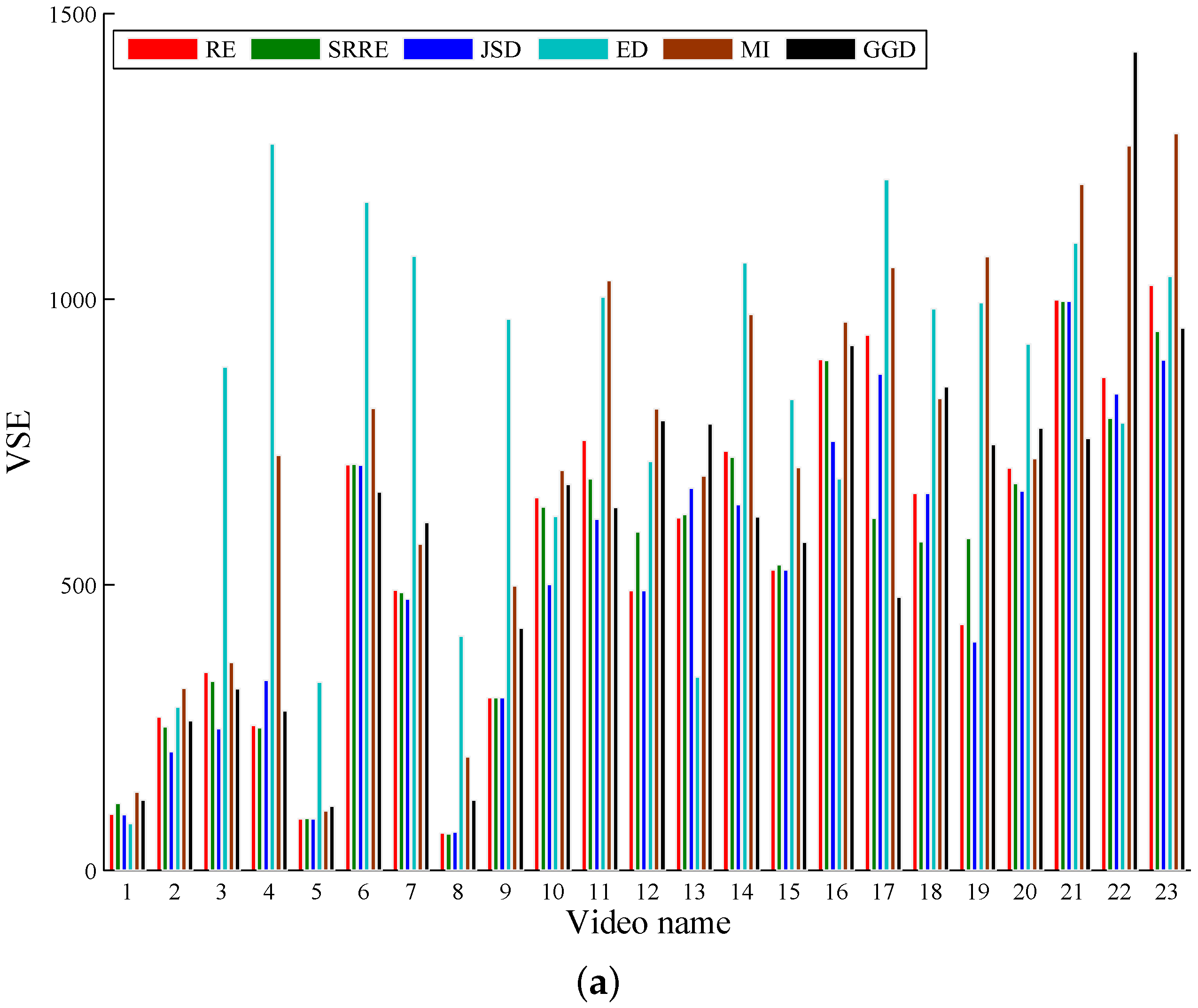
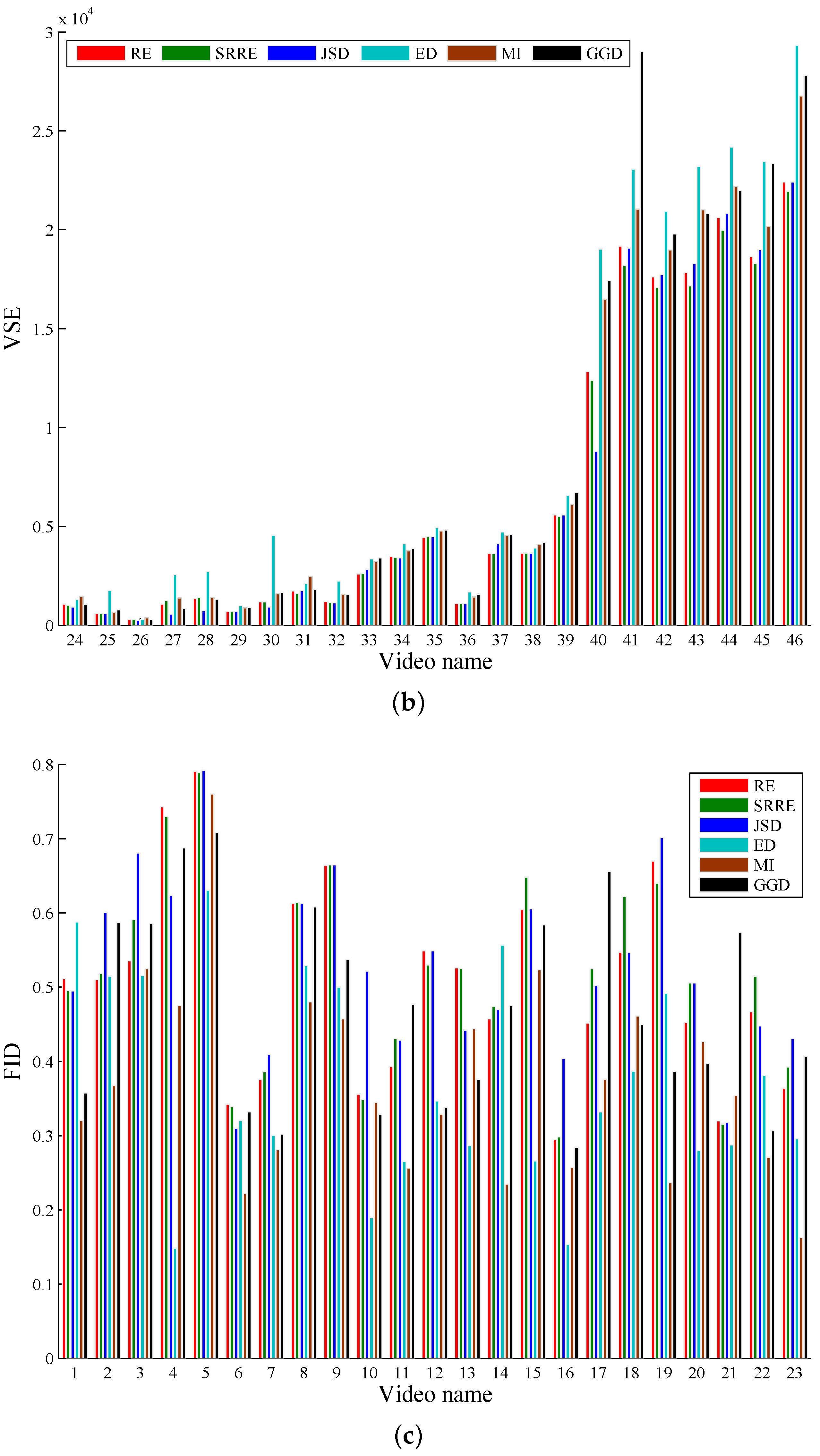
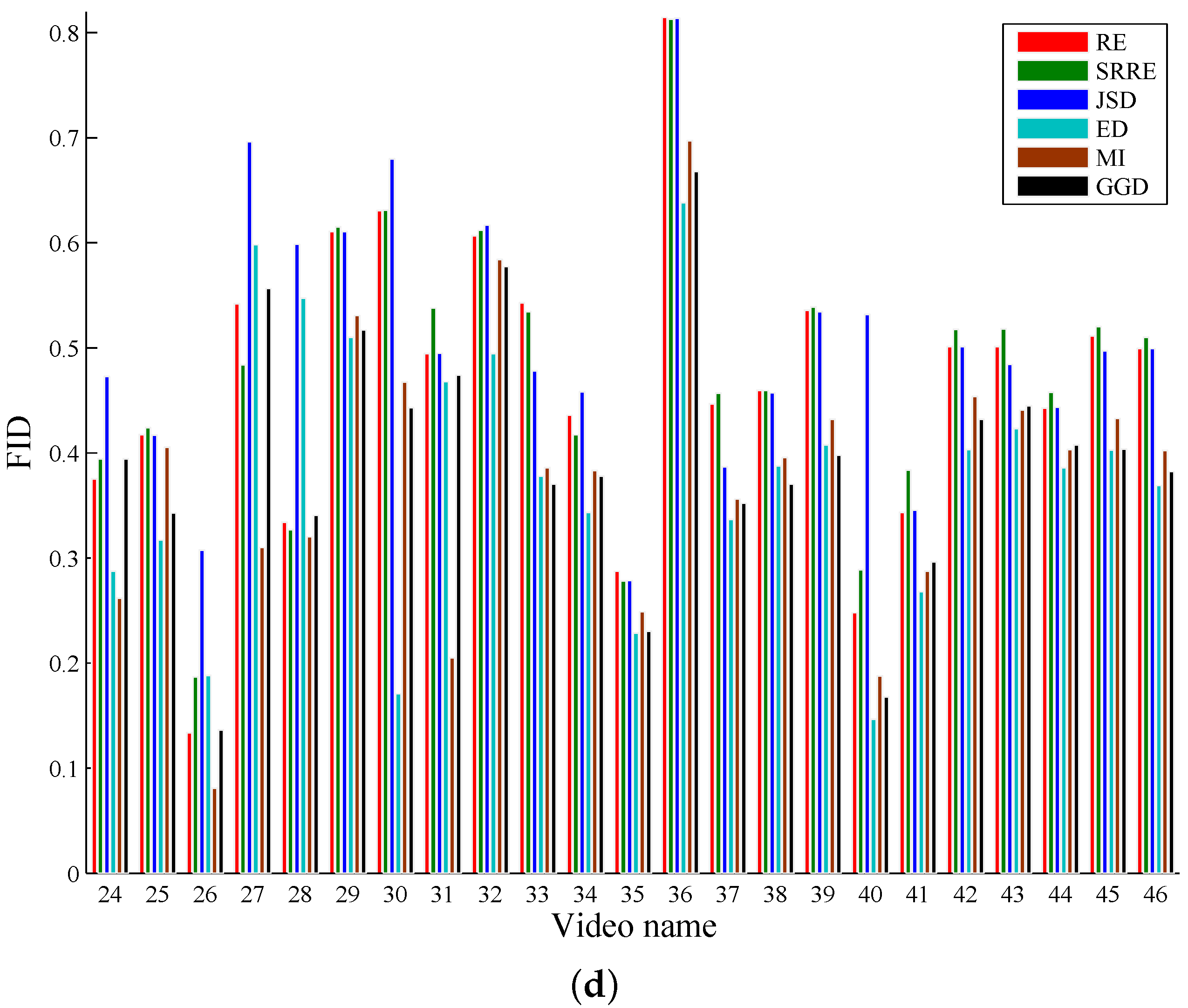
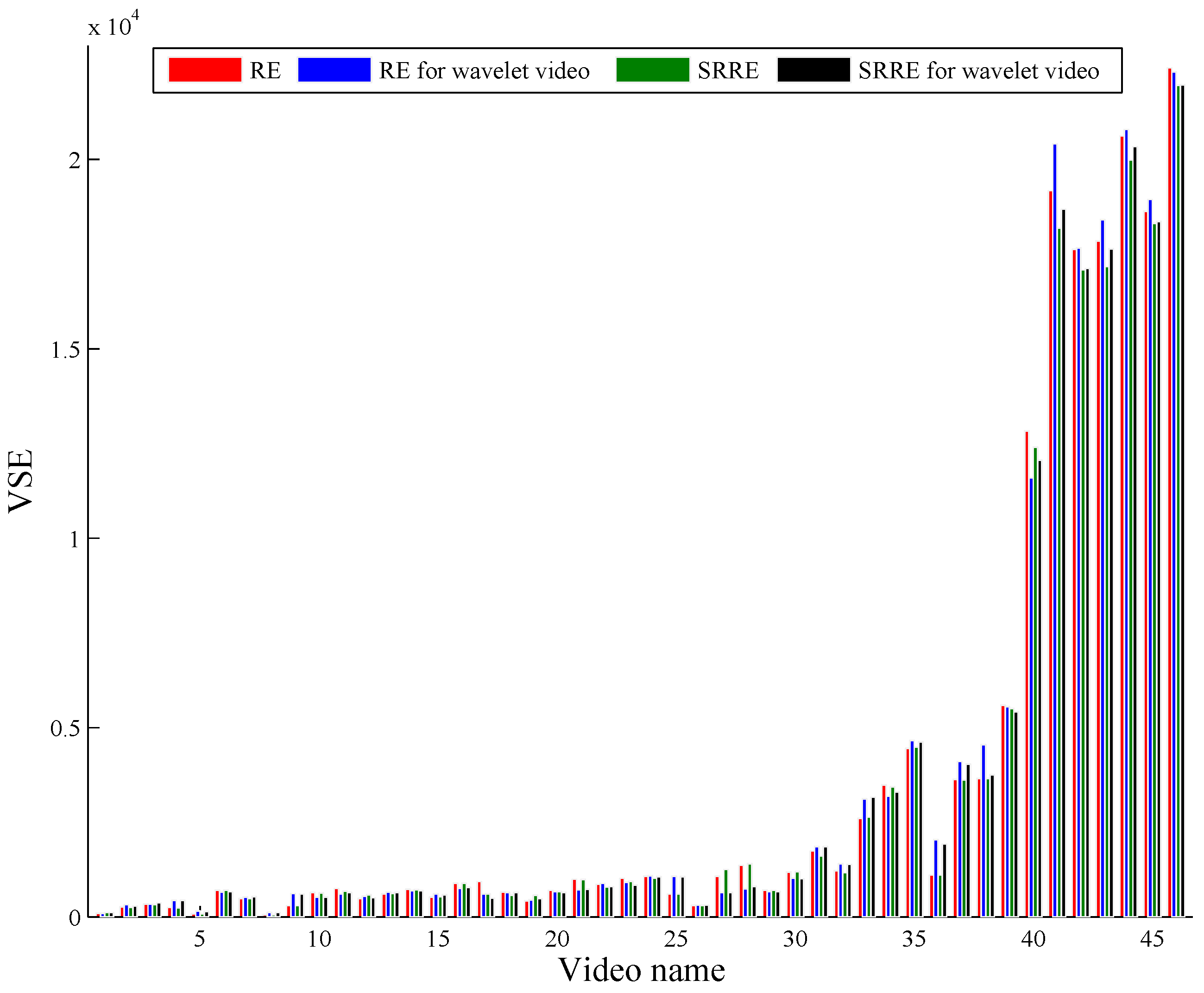
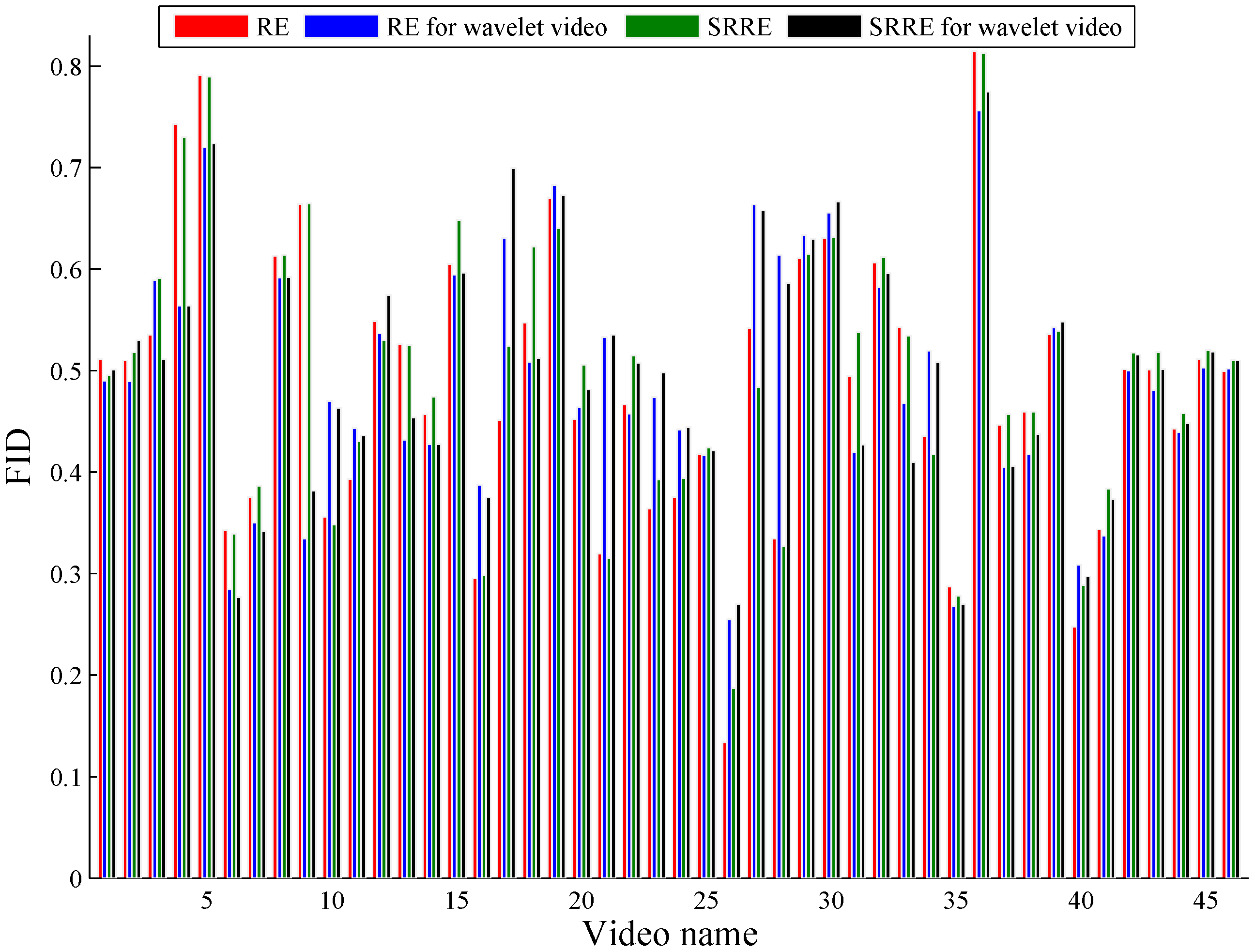
Two commonly-adopted criteria, video sampling error (VSE) [
37] and fidelity (FID) [
38,
39], are applied to evaluate the quality of key frames for representing the original video by different key frame extraction approaches. Notice that we obtain the similarity between two images for calculating VSE and FID according to the second model explained in [
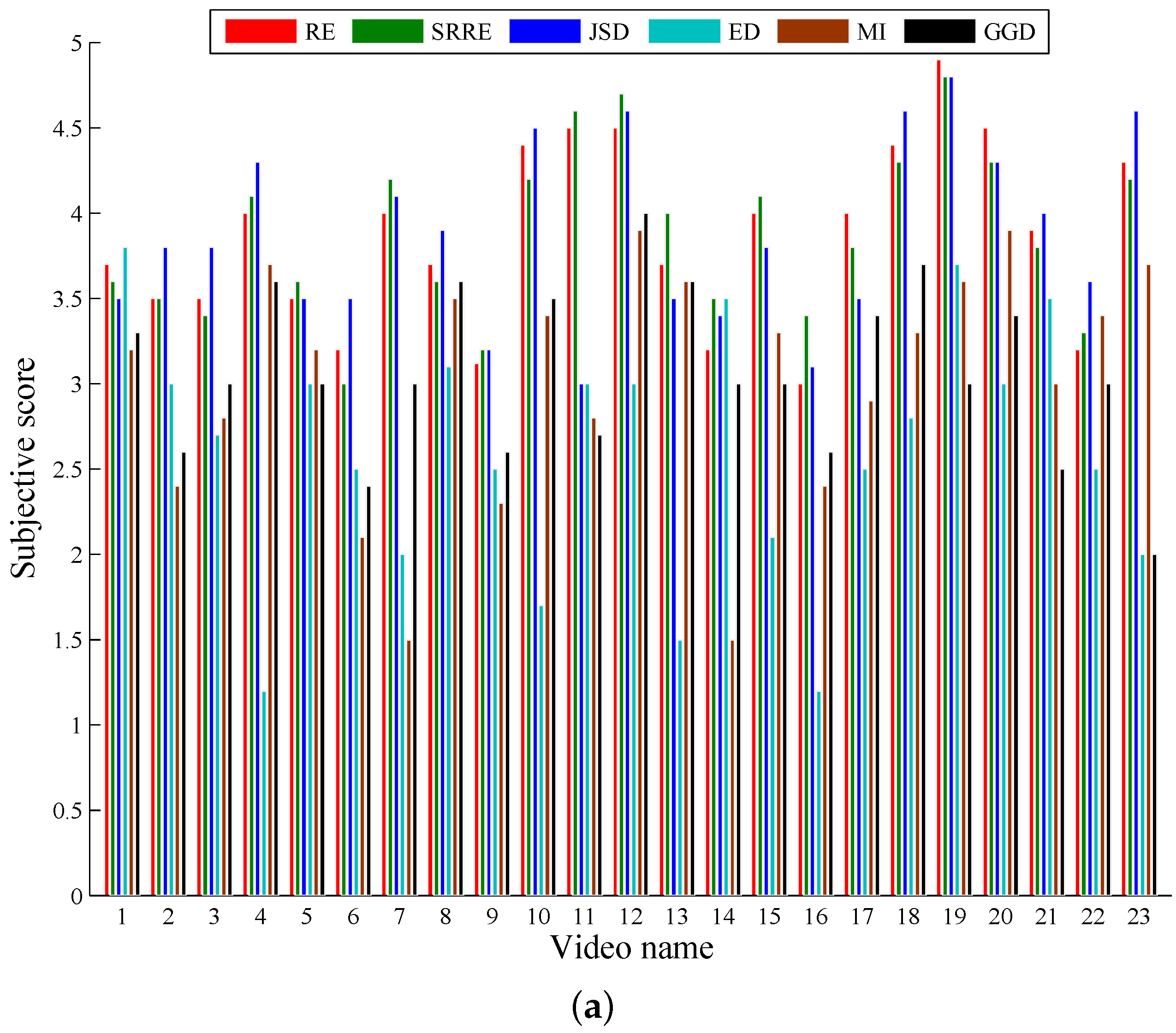
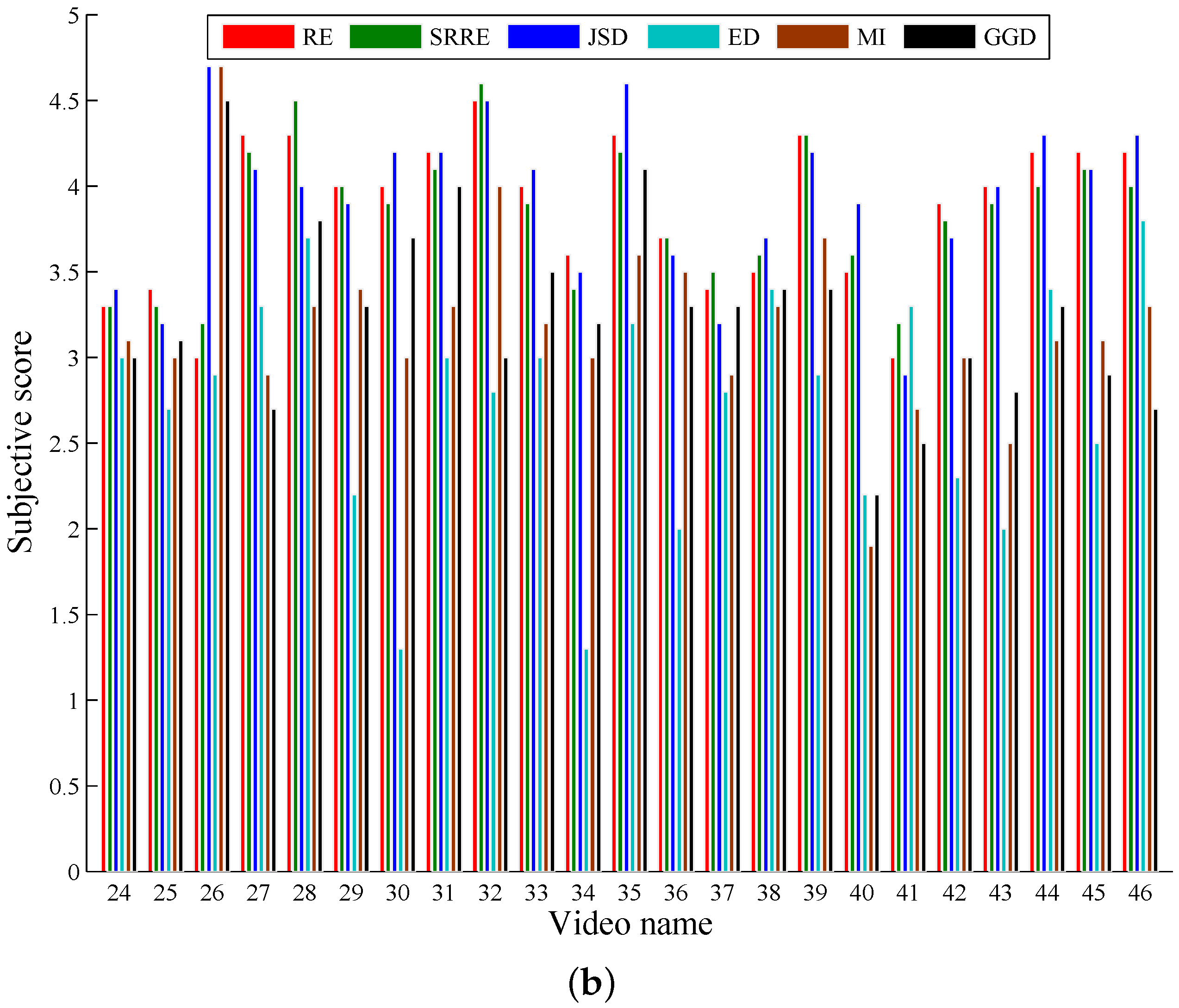
40]. This model defines an image as the combination of the average, the standard deviation and the third root of the skewness of the pixel values. In addition, we carry out formal subjective experiments to evaluate the performances by all of the key frame selection algorithms. In this paper, we invite ten totally irrelevant students as referees to conduct a user study by giving ratings on different approaches. The referees are independent during the procedure and are asked to give performance evaluations of all of the methods with the score between one and five. Two major criteria provided for these referees to rank the quality of the key frames are: (1) good coverage of the whole video contents; (2) little redundancy between key frames. The final result is the average on all of the scores of ten referees.
As illustrated by the objective and subjective evaluations respectively shown in
Figure 6 and
Figure 7 and the average (Avg) and standard error (SE) on the objective and subjective results separately presented in
Table 2 and
Table 3, RE- and SRRE-based methods perform very close to the JSD-driven scheme, and furthermore, RE and SRRE behave better than JSD on some test videos. In addition, our method using RE and SRRE behaves largely better than the algorithms using ED, GGD and MI, and we analyze the reasons as follows. The coverage of the video content by the ED-based method is not satisfactory due to its computational logic. This method uses the accumulation of the differences of the adjacent video frames. If the video content changes are not evenly distributed over the whole sequence, the key frames by this method cannot cover the content well. The GGD-based technique just considers the finer scale coefficients to measure the distance between adjacent video frames, leading to the inaccuracy of shot detection, especially when the video includes rich content changes. As for the MI-based algorithm, the joint probability distribution needed by MI is sparse if large video content changes occur; then in this case, the distance between video images cannot be estimated satisfactorily.
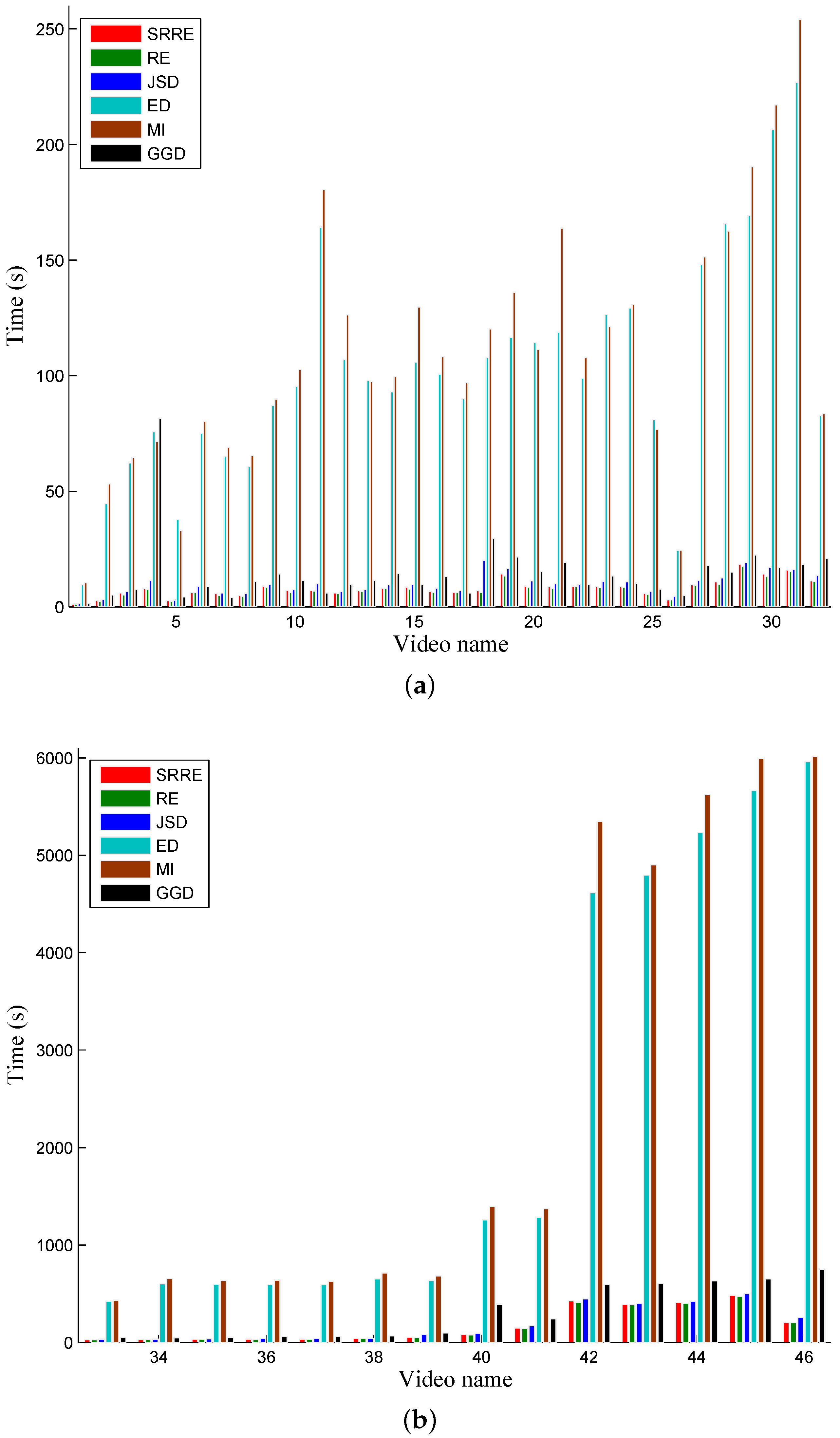
Especially, the proposed approaches using RE and SRRE run faster than the JSD-based technique. Notably, for example, on average, both RE- and SRRE-based methods use six seconds for extracting one key frame from 250 video images, while in this case, the JSD-driven scheme costs eight seconds, and we think this is because JSD needs more time to compute twice the KLD distance when measuring the distance between two frames. Surely, parallelism can be used for the computation of JSD, but unfortunately, the implementation complexity and some additional computational costs for parallelization limit its practical use, particularly considering that the purpose of the proposed technique is to do key frame selection on consumer computing platforms. The execution of other approaches for comparison is several times lower than the proposed technique. Runtime consumptions (in seconds) by different techniques are shown in
Figure 8, and the average (Avg) and standard error (SE) on these runtime results are detailed in
Table 4.
Figure 9 presents the memory usage (in KB) by different methods, and
Table 4 also lists the corresponding average (Avg) and standard error (SE) results. The memory cost by the JSD-based scheme is larger than those by the new algorithms using RE and SRRE, and the memory usage resulting from the approaches using ED, MI and GGD is much higher than that by the proposed technique.
Visual results are compatible with the objective evaluations mentioned above, and
Figure 10 gives such an example. It is obviously observable that the key frames obtained by the RE-, SRRE- and JSD-based methods can all represent and cover the original video very well. The visual appearance of the key frames by SRRE is better than that of the RE and JSD outputs, since both RE and JSD produce little repetition of similar key frames. This is exactly because the square root function can better handle the small distance between video images with small content changes. Apparently, the first frame, #19, and the last frame, #535, by the ED-based method cannot be the representatives of the video content. The GGD-based scheme performs unsatisfactorily; for example, the last key frame, #535, does not give the correct representation of the video content. The key frames selected by the algorithm based on MI include unnecessary redundancies, missing some information of the original video.
It should be pointed out that both the proposed RE-/SRRE-driven technique and our JSD-based previous work make use of the same computational logic, namely the shot/sub-shot division, for key frame extraction, because this is for dealing with video sequences of any kind in a simple, but effective way to make our underlying operational mechanism general enough. Please notice that, at first sight, RE/SRRE and JSD act as the distance measure of video frames in the same framework, but in spirit, our approaches respectively based on RE/SRRE and JSD do have significant distinctions from the point of view of algorithmic robustness. In reality, besides the reduced execution complexity by the utilization of RE and SRRE, the proposed key frame selection technique, compared to our previous method using JSD, largely improves its algorithm robustness and, thus, its practical usability for common users. To sum up, the proposed method achieves several important improvements, including the utilization of the extreme Studentized deviate (ESD) test and a corresponding adaptive correction for shot detection, smart ways for identifying sub-shots for both common and wavelet videos and multiscale video summarization for better presenting the video contents. These improvements have been detailed in
Section 1.
5.3. A Discussion on Dealing with Wavelet Video by RE and SRRE
Figure 11 and
Table 5 demonstrate that our method using RE and SRRE obtains reasonable key frames for common videos. Furthermore, as for the gradual transitions, both the RE- and SRRE-based algorithms perform better on wavelet video sequences than on common videos. For example, the last three frames in
Figure 14b obtained from the common video exhibit an unsatisfactory redundancy for the gradual transition; whereas, for the wavelet video, the gradual transition is demonstrated by Frame #2275 (
Figure 14c) only, without any redundancy. Frame #2190 in
Figure 14c extracted from the wavelet video presents less scene overlapping compared to #2242 in
Figure 14b selected from the common video. Additionally, an apparent content change presented by Frame #594 in
Figure 15c from the wavelet video is missed in
Figure 15b, indicating that the key frame selection by SRRE operated on the wavelet video is of better content coverage than on the common video. Notably, within a shot, gradual transitions usually make the partition of this shot rather complex. As a matter of fact, gradual transitions can be mainly reflected by the finest scale coefficients. Fortunately, our partitioning of a shot for the wavelet video is based on the pure use of finest scale coefficients. Thus, the proposed technique driven by RE and SRRE achieves more desirable performance for wavelet videos than for common videos. It is additionally worth pointing out that, for shot and sub-shot detections, the respective employments of coarsest and finest scale coefficients lead to a better efficiency than the use of both types of wavelet coefficients. Lastly, but also importantly, because wavelet-based compressed video data can be easily obtained and used in many application scenarios, our effort in using RE and SRRE for wavelet video sequences is obviously beneficial to the wide deployment of the proposed key frame selection approach.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}