
A Two-Stage Maximum Entropy Prior of Location Parameter with a Stochastic Multivariate Interval Constraint and Its Properties

Abstract
:1. Introduction
2. Two-Stage Maximum Entropy Prior
2.1. Maximum Entropy Prior
2.2. Two-Stage Maximum Entropy Prior
2.3. Entropy of a Maximum Entropy Prior
2.3.1. Case 1: Two-stage Maximum Entropy Prior
2.3.2. Case 2: Constrained Maximum Entropy Prior
2.3.3. Case 3: Maximum Entropy Prior
3. Properties
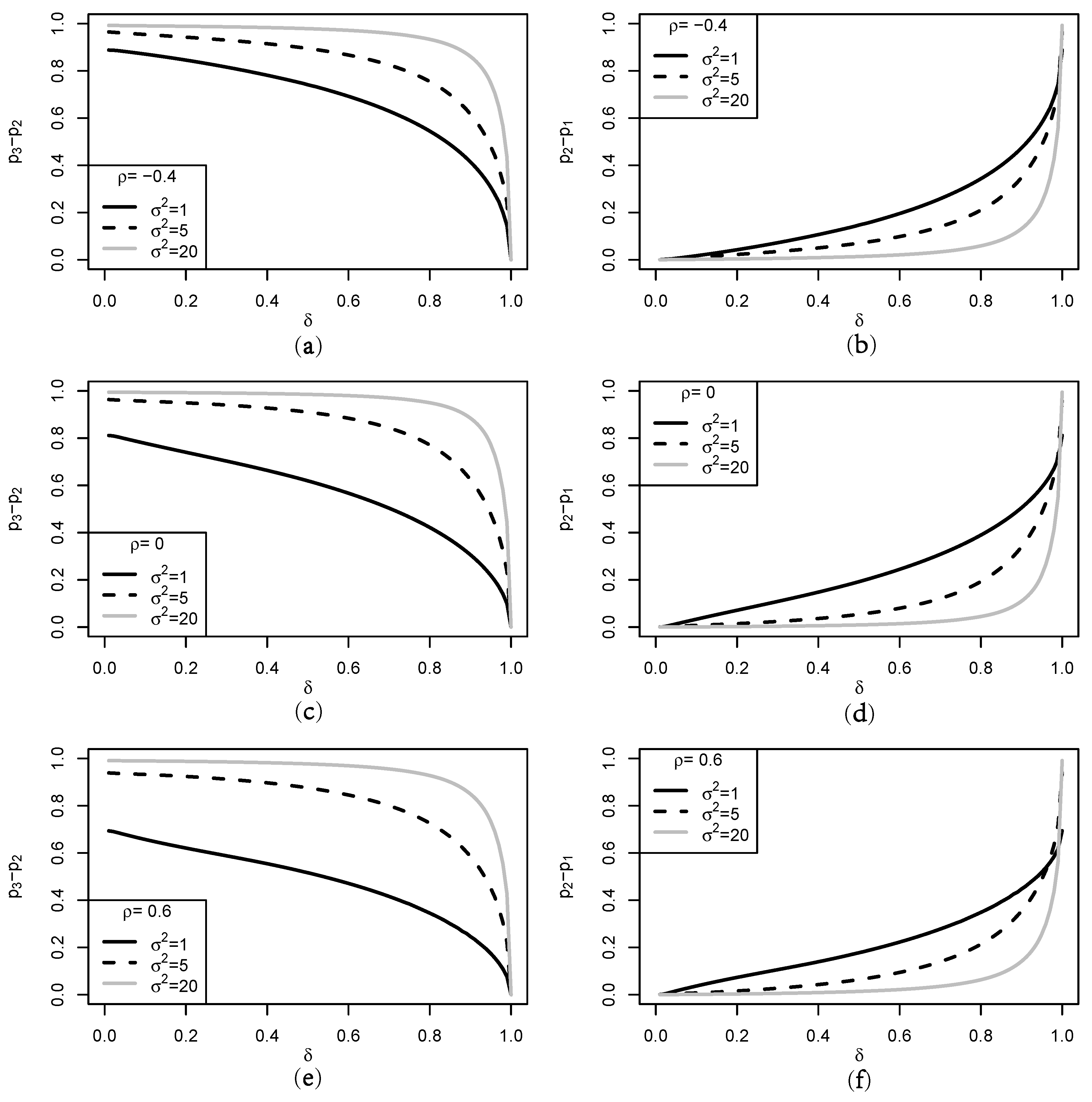
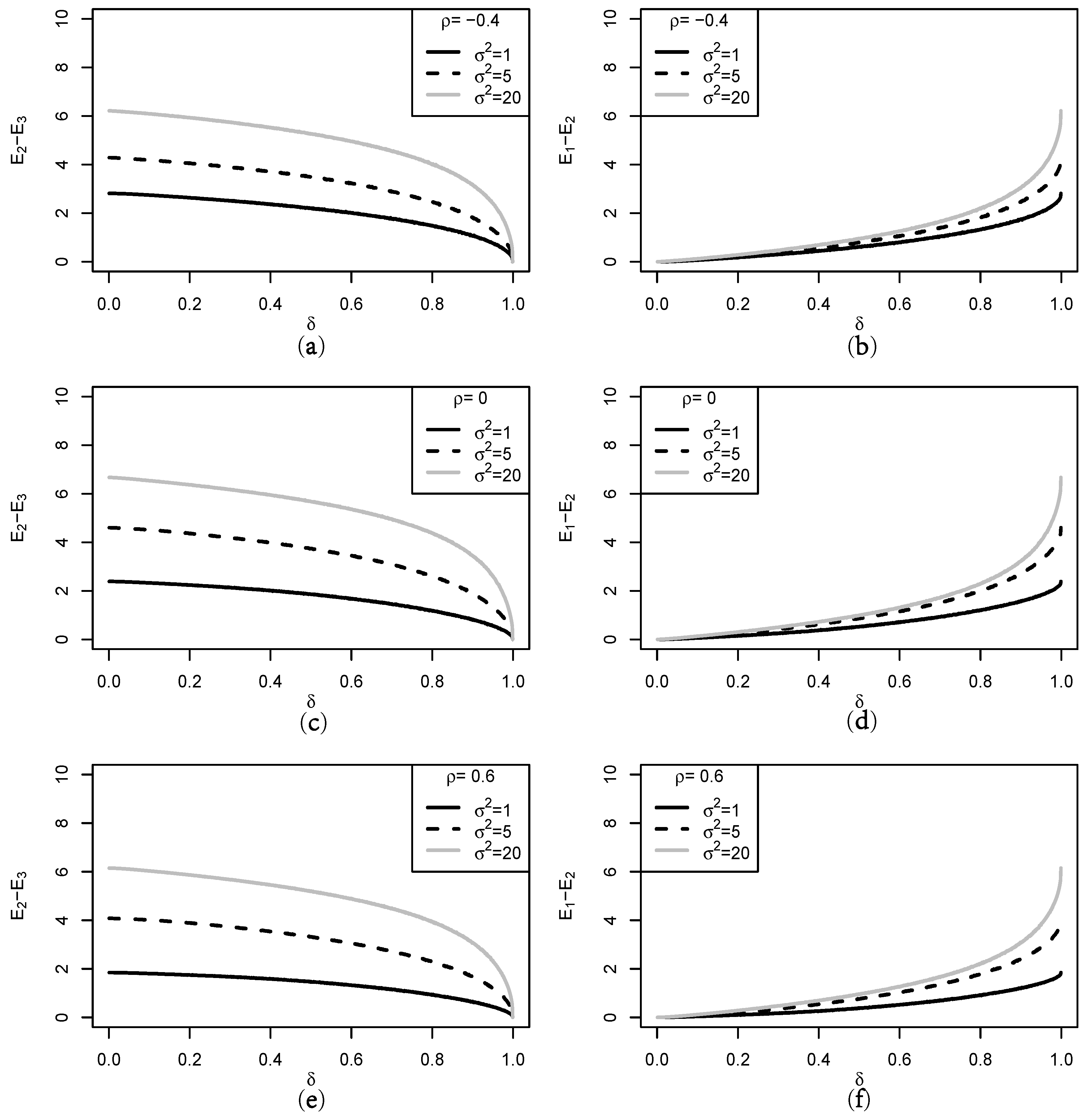
3.1. Objective Measure of Uncertainty
3.2. Properties of the Entropy
3.3. Posterior Distribution
4. Hierarchical Constrained Scale Mixture of Normal Model
4.1. The Hierarchical Model
4.2. The Gibbs Sampler
- (i)
- The full conditional posterior densities of ’s are given by:
- (ii)
- The full conditional distribution of is obtained by using the way analogous to the proof of Corollary 7. It is:where:and
- (iii)
- The full conditional posterior distribution of Λ is an inverse-Wishart distribution:where and
4.3. Markov Chain Monte Carlo Sampling Scheme
- note 1: Variable at i.e., the HCN (hierarchical constrained normal) model with the Gibbs sampler consists of two conditional distributions and To sample from the first full conditional posterior distribution, we can utilize the stochastic representations of the distribution in Corollary 8. The R package tmvtnorm and the R package mvtnorm can be used to sample from the distribution in Equation (22).
- note 2: According to choice of the distribution and the mixing function the HCSMN model may produce a different model other than the HCN model, such as hierarchical constrained multivariate (HC), hierarchical constrained multivariate , hierarchical constrained multivariate and hierarchical constrained multivariate models. See, e.g., [31,32], for various distributions of and corresponding function , which can be used to construct the HCSMN model.
- note 3: When the hierarchical constrained multivariate (HC) model is considered, the hierarchy of the model in Equation (19) consists of with and Thus, the Gibbs sampler comprises the conditional posterior Equations (21)–(23). Under the HC model, the distribution of Equation (21) reduces to:where and To limit model complexity, we consider only fixed ν, so that we can investigate different HC models. As suggested by [32], a uniform prior on () can be considered. However, this will bring additional computational burden.
- note 4: Except for the HCN and HC models, the Metropolis–Hastings algorithm within the Gibbs sampler is used for estimating the HCSMN models, because the conditional posterior densities Equation (20) do not have explicit forms of known distributions as in Equations (21) and (22). See, e.g., [22], for the algorithm for sampling from various mixing distributions, A general procedure for the algorithm is as follows: Given the current values , we independently generate a candidate from a proposal density as suggested by [33], which is used for a Metropolis–Hastings algorithm. Then, accept the candidate value with the acceptance rate:Because the target density is proportional to and is uniformly bounded for
- note 5: As noted from Equations (8) and (9), the second and third stage priors of the HCSMN model in Equation (19) reduce to the two-stage prior eliciting the stochastic multivariate interval constraint with degree of uncertainty Instead, if the maximum entropy prior and the constrained maximum entropy prior are used for the HCSMN, then the respective full conditional distributions of of the Gibbs sampler change from Equation (22) to:where and are the same as given in Equation (22).
4.4. Bayes Estimation
5. Numerical Illustrations
5.1. Simulation Study
5.2. Car Body Assembly Data Example
6. Conclusions
Acknowledgments
Conflicts of Interest
References
- O’Hagan, A. Bayes estimation of a convex quadratic. Biometrika 1973, 60, 565–572. [Google Scholar] [CrossRef]
- Steiger, J. When constraints interact: A caution about reference variables, identification constraints, and scale dependencies in structural equation modeling. Psychol. Methods 2002, 7, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Lopes, H.F.; West, M. Bayesian model assessment in factor analysis. Stat. Sin. 2004, 14, 41–67. [Google Scholar]
- Loken, E. Identification constraints and inference in factor models. Struct. Equ. Model. 2005, 12, 232–244. [Google Scholar] [CrossRef]
- O’Hagan, A.; Leonard, T. Bayes estimation subject to uncertainty about parameter constraints. Biometrika 1976, 63, 201–203. [Google Scholar] [CrossRef]
- Liseo, B.; Loperfido, N. A Bayesian interpretation of the multivariate skew-normal distribution. Stat. Probab. Lett. 2003, 49, 395–401. [Google Scholar] [CrossRef]
- Kim, H.J. On a class of multivariate normal selection priors and its applications in Bayesian inference. J. Korean Stat. Soc. 2011, 40, 63–73. [Google Scholar] [CrossRef]
- Kim, H.J. A measure of uncertainty regarding the interval constraint of normal mean elicited by two stages of a prior hierarchy. Sic. World J. 2014, 2014, 676545. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.J.; Choi, T. On Bayesian estimation of regression models subject to uncertainty about functional constraints. J. Korean Stat. Soc. 2015, 43, 133–147. [Google Scholar] [CrossRef]
- Kim, H.J.; Choi, T.; Lee, S. A hierarchical Bayesian regression model for the uncertain functional constraint using screened scale mixture of Gaussian distributions. Statistics 2016, 50, 350–376. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Branco, M.D.; Genton, M.G. A unified view on skewed distributions arising from selection. Can. J. Stat. 2006, 34, 581–601. [Google Scholar] [CrossRef]
- Kim, H.J. A class of weighted multivariate normal distributions and its properties. J. Multivar. Anal. 2008, 99, 1758–1771. [Google Scholar] [CrossRef]
- Jaynes, E.T. Prior probabilities. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 227–241. [Google Scholar] [CrossRef]
- Jaynes, E.T. Papers on Probability, Statistics, and Statistical Physics; Rosenkrantz, R.D., Ed.; Reidel: Boston, MA, USA, 1983. [Google Scholar]
- Smith, S.R.; Grandy, W. Maximum-Entropy and Bayesian Methods in Inverse Problems; Reidel: Boston, MA, USA, 2013. [Google Scholar]
- Ishwar, P.; Moulin, P. On the existence of characterization of the Maxent distribution under general moment inequality constraints. IEEE Trans. Inf. Theory 2005, 51, 3322–3333. [Google Scholar] [CrossRef]
- Rosenkrantz, R.D. Inference, Method, and Decision: Towards a Bayesian Philosophy and Science; Reidel: Boston, MA, USA, 1977. [Google Scholar]
- Rosenkrantz, R.D. (Ed.) E.T. Jaynes: Papers on Probability, Statistics, and Statistical Physics; Kluwer Academic: Dordrecht, The Netherlands, 1989.
- Yuen, K.V. Bayesian Methods for Structural Dynamics and Civil Engineering; John Wiley & Sons: Singapore, Singapore, 2010. [Google Scholar]
- Wu, N. The Maximum Entropy Method; Springer: New York, NY, USA, 2012. [Google Scholar]
- Cercignani, C. The Boltzman Equation and Its Applications; Springer: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Leonard, T.; Hsu, J.S.J. Bayesian Methods: An Analysis for Statisticians and Interdisciplinary Researchers; Cambridge University Press: New York, NY, USA, 1999. [Google Scholar]
- Kim, H.J.; Kim, H.-M. A Class of Rectangle-Screened Multivariate Normal Distributions and Its Applications. Statisitcs 2015, 49, 878–899. [Google Scholar] [CrossRef]
- Press, S.J. Applied Multivariate Analysis, 2nd ed.; Dover Publications, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Wilhelm, S.; Manjunath, B.G. Tmvtnorm: Truncated Multivariate Normal Distribution and Student t Distribution. Available online: http://CRAN.R-project.org/package=tmvtnorm (accessed on 17 May 2016).
- Genz, A.; Bretz, F. Computation of Multivariate Normal and t Probabilities; Springer: New York, NY, USA, 2009. [Google Scholar]
- Gupta, S.D. A note on some inequalities for multivariate normal distribution. Bull. Calcutta Stat. Assoc. 1969, 18, 179–180. [Google Scholar]
- Lindly, D.V. Bayesian Statistics: A Review; SIAM: Philadelphia, PA, USA, 1970. [Google Scholar]
- Khuri, A.I. Advanced Calculus with Applications in Statistics; John Wiley & Son: New York, NY, USA, 2003. [Google Scholar]
- Gamerman, D.; Lopes, H.F. Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference, 2nd ed.; Chapman and Hall: New York, NY, USA, 2006. [Google Scholar]
- Branco, M.D. A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef]
- Chen, M.-H.; Dey, D.K. Bayesian modeling of correlated binary response via scale mixture of multivariate normal link functions. Sankhyã 1998, 60, 322–343. [Google Scholar]
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Distribution in Statistics: Continuous Univariate Distributions, 2nd ed.; John Wiley & Son: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Prentice Hall: London, UK, 2007. [Google Scholar]
- Mardia, K.V.; Kent, J.T.; Bibby, J.M. Multivariate Analysis; Academic Press: London, UK, 1979. [Google Scholar]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; John Wiley & Son: New York, NY, USA, 2009. [Google Scholar]
- Heidelberger, P.; Welch, P. Simulation run length control in the presence of an initial transient. Oper. Res. 1992, 31, 1109–1144. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Dataset I | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| true | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| mean | 0.853 | 0.862 | 0.869 | 0.857 | 0.525 | 0.530 | 0.542 | 0.549 | 0.141 | 0.112 | 0.139 | 0.121 |
| s.d. | 0.203 | 0.212 | 0.196 | 0.194 | 0.189 | 0.187 | 0.176 | 0.167 | 0.099 | 0.111 | 0.096 | 0.055 |
| true | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| mean | 0.978 | 0.979 | 0.981 | 0.977 | 0.912 | 0.914 | 0.916 | 0.912 | 0.342 | 0.291 | 0.294 | 0.299 |
| s.d. | 0.073 | 0.072 | 0.074 | 0.068 | 0.060 | 0.067 | 0.069 | 0.064 | 0.037 | 0.058 | 0.077 | 0.064 |
| true | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 |
| mean | 1.837 | 1.846 | −1.853 | −1.842 | 1.306 | 1.314 | −1.331 | −1.349 | 0.599 | 0.501 | −0.483 | −0.493 |
| s.d. | 0.215 | 0.223 | 0.208 | 0.205 | 0.295 | 0.271 | 0.262 | 0.238 | 0.232 | 0.263 | 0.291 | 0.141 |
| true | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 |
| mean | 1.977 | 1.979 | −1.980 | −1.977 | 1.782 | 1.784 | −1.785 | −1.782 | 0.884 | 0.856 | −0.795 | −0.733 |
| s.d. | 0.074 | 0.072 | 0.074 | 0.068 | 0.068 | 0.065 | 0.068 | 0.062 | 0.029 | 0.051 | 0.068 | 0.062 |
| Dataset II | ||||||||||||
| true | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| mean | 0.681 | 0.691 | 0.688 | 0.774 | 0.332 | 0.368 | 0.403 | 0.361 | 0.155 | 0.157 | 0.158 | 0.161 |
| s.d. | 0.172 | 0.182 | 0.201 | 0.205 | 0.198 | 0.190 | 0.218 | 0.186 | 0.108 | 0.112 | 0.120 | 0.099 |
| true | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| mean | 1.003 | 0.974 | 1.033 | 1.006 | 0.802 | 0.818 | 0.814 | 0.806 | 0.362 | 0.411 | 0.341 | 0.351 |
| s.d. | 0.175 | 0.178 | 0.172 | 0.199 | 0.061 | 0.065 | 0.070 | 0.081 | 0.048 | 0.052 | 0.039 | 0.047 |
| true | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 |
| mean | 1.724 | 1.763 | −1.764 | −1.675 | 0.886 | 0.874 | −0.857 | −0.924 | 0.415 | 0.428 | −0.496 | −0.489 |
| s.d. | 0.239 | 0.230 | 0.245 | 0.231 | 0.324 | 0.319 | 0.343 | 0.313 | 0.201 | 0.196 | 0.193 | 0.204 |
| true | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 | 2.000 | 2.000 | −2.000 | −2.000 |
| mean | 2.018 | 1.943 | −1.991 | −2.103 | 1.702 | 1.699 | −1.715 | −1.689 | 0.967 | 0.986 | −0.965 | −0.959 |
| s.d. | 0.079 | 0.082 | 0.081 | 0.073 | 0.096 | 0.099 | 0.091 | 0.089 | 0.053 | 0.049 | 0.047 | 0.045 |
| Variable | Mean | s.d. | S-W | p-Value |
|---|---|---|---|---|
| −1.996 | 2.781 | 0.959 | 0.083 | |
| 7.426 | 5.347 | 0.989 | 0.926 |
| δ | Parameter | HCN | HCN | HCN | s.d. | MC Error | p-Value | |
|---|---|---|---|---|---|---|---|---|
| −1.874 | −1.321 | −1.665 | 0.581 | 0.005 | 0.483 | |||
| 7.045 | 4.814 | 6.332 | 1.089 | 0.008 | 0.354 | |||
| 0.8 | 0.423 | 7.549 | 7.863 | 7.682 | 1.231 | 0.007 | 0.551 | |
| −4.632 | −4.905 | −4.819 | 1.631 | 0.005 | 0.671 | |||
| 26.872 | 25.021 | 27.351 | 4.926 | 0.013 | 0.352 | |||
| −1.874 | −1.321 | −1.557 | 0.496 | 0.004 | 0.434 | |||
| 7.045 | 4.814 | 5.905 | 1.112 | 0.006 | 0.298 | |||
| 0.9 | 0.567 | 7.526 | 7.781 | 7.959 | 1.317 | 0.008 | 0.635 | |
| −4.726 | −5.347 | −4.989 | 1.546 | 0.006 | 0.712 | |||
| 27.587 | 25.347 | 28.012 | 4.836 | 0.012 | 0.384 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-J. A Two-Stage Maximum Entropy Prior of Location Parameter with a Stochastic Multivariate Interval Constraint and Its Properties. Entropy 2016, 18, 188. https://0-doi-org.brum.beds.ac.uk/10.3390/e18050188
Kim H-J. A Two-Stage Maximum Entropy Prior of Location Parameter with a Stochastic Multivariate Interval Constraint and Its Properties. Entropy. 2016; 18(5):188. https://0-doi-org.brum.beds.ac.uk/10.3390/e18050188
Chicago/Turabian StyleKim, Hea-Jung. 2016. "A Two-Stage Maximum Entropy Prior of Location Parameter with a Stochastic Multivariate Interval Constraint and Its Properties" Entropy 18, no. 5: 188. https://0-doi-org.brum.beds.ac.uk/10.3390/e18050188