2. Systems: The View of Synergetics
We consider the
ideal case in which we have full knowledge about the parts of a system and their interactions. We distinguish the parts by an index,
,
where
is the total number of parts. Each part
is characterized by a set of time-dependent (real) variables
In order not to overload our presentation and to capture the essentials, we treat
and drop the index
l (Actually, by a relabeling of variables our treatment covers also the general case). The variables
are assumed to obey differential equations (where
).
represents a set of fixed control parameters.
fixes the deterministic evolution of
, whereas the “fluctuating forces”
represent the impact of chance events on
. While the study of Equation (3) with
is the subject of the discipline of dynamic systems theory (e.g., [
35]) with its subdisciplines such as bifurcation theory and chaos theory, these forces
must be taken into account close to instability points. In all cases we are concerned with functions
of which at least one is nonlinear with respect to
(Nevertheless, we call (3) Langevin equations because of their decomposition into
and
). Now, we study situations where the system’s behaviour changes qualitatively. To get an insight into what happens at such a “critical” point we first ignore
and assume that Equation (3) for a fixed value of
possesses a solution
. In our paper we assume that
is time-independent (though time-dependent cases have also been treated (e.g., [
7]). We check the stability of
by (in general) linear stability analysis by putting
small. This yields equations of the form
For their solution we write
as linear combination
where the coefficients
the eigenvectors of the Jacobean are chosen such that the matrix
becomes diagonal with eigenvalues
so that eventually
(Here we don’t discuss the case in which
is of the general Jordan’s normal form, also, note that the eigenvalues
are a special case of Lyapunov exponents.) When
is changed to
the real part of some eigenvalues
may become positive which indicates an instability and the corresponding
grow exponentially.
These variables define the OPs. As is witnessed by large classes of physical and chemical systems undergoing “nonequilibrium phase-transitions” higher order terms of
lead to a stabilization connected with a set of new states
which may be time-independent or time-dependent (e.g., a Hopf-bifurcation or deterministic chaos). Again an important insight gained by synergetics research is the fact that in large classes of practical interest, the number of OPs is much smaller than the number of parts. Now we come to the first central result: close to instability points, the behavior of the parts is determined by the OPs or as formula
For their derivation, including fluctuations we refer the reader to the literature [
7], where the explicit form of
is presented. Note that the explicit time-dependence of
stems
solely from the fluctuating forces. While the impact of fluctuations
is small and can be—at least in general—neglected away from the instability, there they become decisive. To deal with them properly we have to transform the Langevin-type Equation (3) into a Fokker–Planck equation for the time-dependent distribution function
:
where
and
For the derivation of Equation (5) it is assumed that the statistical average over the random process yields
and
: Dirac’s
-function: Though the details become involved, the central result that holds close to instability points can be formulated as
where
Pop is the distribution function of the OPs and
Ps the conditional probability for
given
.
represents the OP dynamics. A typical example concerning a nonequilibrium phase transition is the stationary distribution function [
36] of laser light amplitude
acting as OP.
close to laser threshold (instability point) (
: normalization as everywhere in our paper.
and
correspond to kinetic rate constants, where
is the control parameter). Below threshold,
, above it
.
This leads to a non-vanishing, stable amplitude .
Phase transitions of physical systems are well known (freezing of water to ice, ferromagnetism, superconductivity) and occur in
situations of (or close to) thermal equilibrium. Though the laser is a system far away from equilibrium, a remarkable formal analogy exists between Equation (11) and results of the Landau theory of phase transitions [
37,
38]. There the same expression appears with
where, e.g.,
is the
free energy,
Boltzmann’s constant and
absolute temperature. Landau introduced the notation order parameter phenomenologically. The essential difference between Equation (11) and (12) rests on the fact, that
depends on thermodynamic quantities whereas Equation (11) contains constants
depending on rates (time-dependent processes). In our approach the definition of OPs and their equations derives from a microscopic theory. While in the laser and some other physical systems (e.g., fluid dynamics, plasmas, nonequilibrium semiconductors) the fundamental Equations (3) are explicitely known, this is definitely not the case with respect to truly complex systems, in particular the human brain. It is here where our “second foundation of synergetics” comes into play.
3. MEP (Maximum Entropy Principle) in Thermodynamics and Beyond
As noted in
Section 1.3 above, since in the case of
complex systems only a limited amount of data is known, there is a need to make
unbiased guesses, consistent with the known data, on the state or function of the total system. To make such unbiased guesses, following Jaynes [
33,
34], we maximize (1) under constraints representing these data. The constraints under which entropy is maximized are fundamental in shaping the behavior and information theoretic properties of a system. As we will see later, one constraint could be a conservation of energy that can be expressed as an expectation given the probabilistic description (see below). We will denote constraints in an abstract and general way using
. For simplicity we put
c = 1. We distinguish the data representing “events” by an index
j. is the probability (or relative frequency) of the occurrence of event
j.
normalization
constraints
By use of Lagrange multipliers
,
the solution to this problem reads
Inserting Equation (16) in Equation (14), Equation (15) leads us to equations for
Jaynes [
33,
34] applied MEP to derive the general relations of thermodynamics by using
thermodynamic constraints. A simple example may illustrate the situation. Consider a system of non-interacting particles with energy levels
, of which the mean energy
is known.
This relation is the famous Boltzmann distribution function of statistical mechanics, where
serves for normalization Equation (14), and
,
: Boltzmann constant,
absolute temperature. This relation becomes particularly clear, when we treat a gas of particles moving with different velocities
and (kinetic) energy
so that instead of
we have to write
This simple example may provide the reader with a feeling how efficiently MEP works. However, there is a price to pay. It concerns the proper choice of the constraints. While in the case of thermodynamics their choice is largely agreed upon by the “community” (leaving aside few delicate details already discussed by Jaynes) the study of numerous nonequilibrium phase transitions has led us to the insight that in physical systems out of equilibrium and in nonphysical systems close to instability points quite other constraints apply.
To formulate them we assume that the system can be described by a set of variables
, which we represent by the vector
. Accordingly, we replace the index
in Equation (13) by
and
by
(assuming an appropriate discretization of
). Thus Equation (13) becomes
where
and
stands for
.
For the treatment of (second order) nonequilibrium phase transitions leading to
pattern formation, e.g., in fluids as well as to pattern
recognition it has turned out that the following constraints (in addition to Equation (21)) apply
Furthermore, it is assumed that
Maximizing Equation (20) under the constraints Equations (21)–(23) and using Lagrange multipliers
leads us to
where
stands for Equation (24). To be able to establish a connection with the microscopic theory (
cf. Section 2), we put
and find by replacing
in Equation (25) by
w,
We may choose
so that the matrixs
becomes symmetric. For its diagonalization we put
Thus Equation (26) is transformed into
where
We distinguish between positive and negative eigenvalues
,
By a comparison with the result of the microscopic theory we may adopt the parlance of nonequilibrium phase transitions. Thus the index means unstable and we denote as OPs. The index refers to the enslaved mode amplitude .
Accordingly, we decompose
where
and sums over
The integral
defines a function of
. We put
and introduce a new function
via
This definition guarantees that
is normalized over the space of
for any
. In order that Equation (39) remains unchanged by the introduction of
h we introduce the new function
via
In conclusion we may rewrite Equation (34) in the form
This allows us to write
and
defined by Equation (40).
Clearly, is a conditional probability whereas is the distribution function of the order parameter alone.
4. The Meaning of the Order Parameter Potential
In the preceding section “we” have made unbiased guesses on the behaviour of a complex system based on correlation functions as constraints. Inspired by the slaving principle of synergetics we have shown that the resulting probability distribution function is crucially determined by the order parameter potential (cf. Equations (41) and (43)). (We drop the index of the set so that .)
In the following we conceive our approach as the first step of a model of the function of a human brain (which, at this level of approach can be realized by a computer, e.g., the synergetic computer). Here the brain collects sensory inputs, which lead to neuronal activities
of neurons labeled by
. Measuring sensory inputs time and again the “brain” can identify prominent activity patterns governed by a set of OPs
. Each
can be interpreted as representing a specific percept—an “idea” such as an explanation for sensory data. The key notion here is that percepts are necessarily distributed representations—this is because the macroscopic OPs are distributed over the parts (neurons). On the other hand,
S as Shannon information leads to specific activity patterns
in the
physical system brain/computer. In this process, the network architecture of these systems serves as “filter” using the correlations. At any rate the brain/computer has learned a set of prototype patterns—based on the frequency of their occurrence. (As a side-remark: this approach lies at the bottom of some “big data algorithms”). Both
and
can be visualized as representing landscapes where the size of
V represents the height of surface at position
q or, more concisely, at position
. Note, however, that the set of OP spans a high-dimensional space so that our “picture” holds only in 1 and 2 dimensions
. However, it may help our intuition in the general case. Such a potential landscape possesses maxima and minima where because of
the valleys lie at those positions
where
is max.,
i.e., these percepts are most probable.
The establishment of
or
characterizes the learning period (including purification to be discussed below). The other period concerns recognition. In this case a pattern
q is offered which is distorted or incomplete as compared with one of the prototype patterns
(
Section 5). This means that the offered
q (or corresponding
) lies close to the bottom of the valley associated with that specific prototype pattern
. Pattern recognition is now realized by the “system brain” by pulling
(where
is a multidimensional vector) into
which requires a
dynamics. How can we derive such a dynamics from
? The answer is suggested by an analogy with mechanics: a “ball” sliding down the slope of a grassy hill. If there is only one OP
, this overdamped motion is described by
where
is a constant. In the general case of several order parameters we have
i.e., a gradient dynamics. Calling
error, the solution of Equation (47), means ”error correction“. (
cf., e.g., Friston’s [
39] comprehensive work). The formulation of Equation (47) is based on “hand waving” arguments. Can we derive it more systematically? The answer comes from a comparison between Equation (45) and the steady state solution of a Fokker–Planck equation with its drift and diffusion terms,
We have written instead of in Equation (5) to indicate that is now a different function.
Let us discuss the diffusion terms (
cf. Equations (5) and (7))
first, where
stems from the correlation function Equation (9). In view of our ignorance and in the spirit of making an unbiased guess we assume that the fluctuations are uncorrelated,
i.e., (Kronecker symbol). The next assumption is made that no
is favoured against another
what fluctuations are concerned. This requires
. Thus we guess a Fokker–Planck equation of the form Equation (5). To make contact with Equation (45) we consider the time-independent case
and try the guessed
Equation (45) as solution to Equation (50). We readily obtain
which is fulfilled by choosing the (vector) force
K as a gradient of a potential function,
Note that this choice is made by a simplistic argument,
i.e., by putting
. Thus we miss a whole class of processes for which
and
When G does not equal zero, the solution in Equation (55) requires that the flow associated with G is divergent-free (i.e., non-dissipative). This can be thought of as flow that does not change the potential and circulates on iso-potential contours. Indeed, it is often referred to as solenoidal flow. The decomposition of the flow into dissipative and non-dissipative (divergence-free) parts in Equation (54) is also known as the Helmholtz decomposition. To make the splitting of into and G unique we require that the flow caused by G is perpendicular to that of .
The positions of the valleys characterize objects which are most probable, or in other words salient and may represent in the spirit of Gibson’s [
40]
affordances. We will return to the latter issue when discussing perception-action. In this way
meaning is attributed to the valleys.
The Fokker–Planck equation is attached to a Langevin equation for the time-dependent variables . Provided the force derives from a potential Equation (52), then our above postulated Equation (47) follows directly from the Langevin Equation without noise and determines the overdamped motion of a particle in that potential. In the presence of noise the most probable path (when G = 0) is determined by Equation (47).
4.1. Sparse Potential Network for the OP “Purification”
For our discussion it suffices to put
and
. Using
W Equation (41), the equations of motion of our fictitious particle with coordinates
reads
where the coefficients
A,
D,
C are linear combinations of
in Equation (41). The primes’ at
indicate
and
, respectively. The extrema of
W (or
V),
i.e., maxima, minima, saddles are given by
As an inspection of Equations (56) and (57) reveals, extrema lie at
where
, and provided
(
cf. Equation (32)), we obtain
If an extremum lies at some , then also at .
From the mathematical point of view the appearance of the numerous coefficients
A and
D makes a discussion of the kind of extrema clumsy. Here it helps to look at neuroscience by interpreting the coefficients as synaptic strengths connecting neurons with activities
. Then we may invoke the principle that nature prefers sparse networks,
i.e., the “brain” will cut down superfluous connections. This is achieved by putting all
and all
We study the properties of so that stable minima of V (or maxima of W) result.
Consider the neighbourhood of , , .
If
increases,
W must decrease,
i.e.,
Because the sole “task” of
is to stabilize the maximum of
W (minimum of
V), its detailed dependence on the indices
u, u’ is irrelevant so that we may put quite generally
On the other hand, the position of the extremum is determined by both and according to Equation (59). As we will see below, enters into the corresponding prototype pattern vector .
Furthermore, the relative depths of the local minima of
V may serve as measure of the relative frequency of the respective
. The depths are given by
The relative frequencies will play an important role in
Section 6. As a consequence, at least what pattern
learning is concerned we must retain these pairs (
,
).
Contact can be made to the model of the synergetic computer [
5] if we put
for all
u, where
.
In this way, the
Synergetic Computer (
SC) model is derived here for the first time from first principles and elucidates an underlying assumption on the SC, namely all prototype patterns are (on average) equally often offered and their OPs are of equal size. (For more details of the learning procedure
cf. [
5]). An open question remains: are OPs mental constructs or are they material (“grand mother cells”?).
4.2 The OP in Relation to Semantic and Pragmatic Information
So far, our approach has been based on Shannon information. However, as shown in our previous studies [
1,
6] meaning enters in disguise into the definition of SHI. But where in our present formulation of SHI information with meaning, semantic or pragmatic, comes in? In a first step, the system (computer or neural net) has learned an attractor landscape. In a second step, an offered, incomplete pattern is pulled into a specific attractor.
PI and SI result because this attractor itself requires meaning by initiating now, or (in the case of memory alone) later, a chain of associations leading to actions and memory. Note that this is quite in line with contemporary consciousness research that we discuss below in
Section 10 (though we must not ignore the role of unconscious effects where no associative chain is “ignited”). This requires, of course, that, related to each person/object, previous experiences have been laid down internally in the observer or externally in the world—as modeled, for instance, by our notion of SIRN (synergetic inter-representation network). Commencing from the synergetic computer, SIRN describes the dynamics of such a chain of associations as a sequential interaction between internal representations constructed in the mind/brain and external representations constructed in the world (
cf. [
41,
42] and Chapter 7 in [
31]). Since internal as well as external representations can in fact be represented by order parameters, the corresponding associative chains can be formalized by a set of “feed forward” order parameter equations whose explicit discussion would go considerably beyond the scope of our contribution.
Both SI and PI refer to the meaning of information, as noted. On the face of it, the distinction between the two and between them and SHI, is clear: Given a message, SHI measures the quantity of information conveyed by this message, SI deals with the meaning conveyed by that message, while PI with the action it conveys; very much in line with the relations between syntax, semantics and pragmatics in semiotics—the study of signs [
43]. Applied to synergetics, the pattern recognition paradigm generally corresponds to SI, while that of the finger movement paradigm to PI. Thus, in the case of the approaching lady (above “Forms of Information” in
Section 1.2.2,
Figure 7) we have a play between SHI and SI, while in the case of the dog chasing the cat (above
Section 1.2.3,
Figure 8), a play between SHI and PI.
While in a first approximation this distinction between SI and PI seems to be rather obvious, an in-depth analysis reveals that PI and SI are intimately connected, and our interpretation is context-sensitive [
43]. Two examples may elucidate this: First, pattern recognition (associated with SI) is associated with the external action of saccadic eye movement
i.e., PI (see
Section 10 below) and second, action (PI) requires pre knowledge (SI) of possible choices beyond pure reflexes.
An important question is whether PI and/or SI can be
quantified. Based on the explicit example of the multi-mode laser, Atmanspacher and Scheingraber [
44] equate pragmatic information to efficiency (of the laser output as defined by Haken [
7]) as the change of an order parameter versus change of a control parameter. These authors interpret also pragmatic information in terms of nonequilibrium thermodynamics (entropy production) and consider pragmatic information as a measure of meaning. For a detailed discussion including recent results by Atmanspacher and coworkers we refer the reader to the forthcoming contributions by him to this special
Entropy issue on “Information and Selforganization”. As indicated above, we relate, at least in cognitive science, PI/SI to an associative process. In fact, based on an index
Hc that Atmanspacher and Scheingraber labeled “pragmatic information”, Walter Freeman [
45] was able in his EEG experiments on perception, to identify specific epochs of neural activity. In our interpretation, each epoch is related to an order parameter that governs a specific spatio-temporal activity patterns with high coherence, stability and intensity (reminiscent of laser light!). Dealing with such microscopic processes is, however, beyond our article (
cf. [
46]).
One prominent example of human cognition is the capability of categorization and abstraction. Take a simple example of a specific sea—say, the Mediterranean: from a SI point of view it is the abstract entity—sea or more specifically the Mediterranean, to be distinguish from the Atlantic ocean or the Black sea, etc.—all SI abstract entities. From the perspective of PI, the Med is an object that affords/or not (in the Gibsonian sense) the actions swimming, diving, sailing, fishing and so on. Humans’ usage of SI or PI is context and task dependent. In some cases we use SI (i.e., the approaching lady), in others PI (e.g., finger movements) and this usage affects the derived SHI and as a consequence the process of IA. As it seems, algorithms capturing categorization and in particular abstraction are still in their infancy.
4.3. Another Probability—Based Approach
Our approach offers an alternative to other probability-based approaches in theoretical biology including neuroscience, where the predominant method exploits Bayes’ Theorem (“Bayesian Inference”) which connects prior beliefs (hypotheses) with posterior beliefs.A prominent example is Karl Friston’s [
39] comprehensive work with his general free energy principle.
The application of both concepts to concrete processes requires specific “generative” (mathematical) models. Our starting point is Jaynes’ maximum entropy principle [
33] with our specific constraints which capture directly the data acquisition process and allow their interpretation. A detailed comparison between these approaches must be left to a later publication. As long as we use time-independent correlation functions (Equations (22) and (23)), we arrive at a time independent probability distribution defining a potential landscape. Up to here, there is a formal analogy with Friston’s free energy (leaving aside the question of generative models).
As we will demonstrate below, a number of important processes cannot be dealt with by these approaches alone. Examples we will treat below are saturation of attention, saccades of eye movements, scene analysis and rhythmic motions. Our approaches use the concept of quasi-attractors (see below,
Section 7 and
Section 8) as well as time-dependent correlation functions as constraints [
1]. The quasi-attractor concept deals with an escape process from an attractor state. For another recent approach
cf. [
47].
5. Determination of “Prototype” Patterns
We determine the pattern vector
belonging to the OP
According to Equations (29), (32) and (33)
and
First step (in general sufficient):
We choose that that maximizes Equation (70) for given . For an explicit example cf. Equation (80).
We insert Equations (68) and (71) in Equation (69) and identify the resulting
with
.
which provides us with the required learned prototype pattern
.
We show that are nearly orthogonal.
We put
where
is a normalization factor,
and form
Because of the smallness of the enslaved modes,
, the normalization constant becomes
for all
u, and
are nearly orthogonal,
i.e.,
To get an insight into the accuracy of Equation (72) we perform a second step as follows:
Second step:
Because of the conditional probability even for fixed
, we expect a distribution of prototype patterns around Equation (72). We determine the corresponding distribution function
which we may define by
where the average is taken over Equation (70),
fixed.
We use the Fourier representation of Dirac’s
δ function so that
where first we calculate
Provided we use the slaving principle in leading approximation, we may evaluate Equations (79) and (78) exactly and explicitly. Specialized to
, Equation (70) reads
where
In what follows, only integrals over Gaussians are involved. We first perform the integration over
to calculate
F where we obtain Gaussians with respect to
. When we integrate over
we arrive at the final result
where
can be regarded as a precision or inverse variance,
normalization.
Thus we obtain for the prototype pattern (up to a factor ) a Gaussian centred around Equation (72). If β large, Equation (82) reduces to a function so that Equation (72) becomes exact. Note that while we choose always , the eigenvectors may acquire positive and negative values.
This is a consequence of our choice of constraints Equation (23). To make contact with patterns presented by images with their non-negative grey value distribution we may add a uniform positive background b so that everywhere.
Pattern Recognition: A First Step
We consider an unbiased observer who has learned the prototype patterns but has no preferred expectations what to see. His/her task is to project the offered pattern vector
q onto the order parameter space by means of the prototype pattern vectors
. Two properties of the prototype vectors Equation (72) are important (
cf. [
5])
As can be shown, Equation (83) is a consequence of Equation (23). This relation takes care of the effect of on/off center cells of the eye (
cf. [
20,
21,
22]). Equation (23) and thus Equation (83) are achieved by substracting the average gray value of an image from each pixel gray value.
To exclude a bias, we normalize
In the following we will drop ^ so that it will be understood that Equation (72) is processed accordingly. Then we form
which defines the initial values of the OP dynamics according to the OP-potential and described by the Equations (62) and (65). Where again in the absence of a bias we must put
.
In the “generic“ case the
lie in the basin of attraction of a definite
so that the recognition task is solved. (For a discussion of this landscape
cf. [
5]). If the OP
s lie on an edge between two attractors, several procedures may be applied. More data (features) are required that might be collected by further glances (
cf. Section 8 on Saccades below), or by manipulating data (
cf. Section 7.2 dealing with information inflation/deflation below). A further possibility to escape this “dead lock” is the occurrence of an external or internal chance event (a fluctuation well known in physical systems). As we see below (
Section 8), the approach to an attractor state in visual recognition is the final result of multi-step and interlaced processes each of which can be represented by an algorithm, that we will describe later on.
6. The Invariance Problem
The concepts of symmetry and invariance play a fundamental role in physics. Here we meet them in a new context: (A) The identity problem (in psychology)—do some patterns belong to the same object? (B) The invariance problem—do some order parameters refer to the same object irrespective of its: Position in space (1)? Orientation in plane of observer (2)? Orientation out of plane (3)? Scale (4)? Deformations (5)? Mirror image (6)?
Leaving aside our specific use of the “order parameter” concept, the invariance problem is fundamental to machine vision as well as to neurocomputational models of brains. We refer the reader to an excellent overview over this vast field from a unifying point of view [
48] which summarizes also a more recent approach by these authors (
cf. a brief description of their important method in
Section 6.4 below). Our own approach is related to theirs though we add some further aspects and ignore other important ones. See below.
Our suggested strategy is based on the hypothesis (learning by a baby/child):
- (a)
most frequently observed patterns might be related.
- (b)
or supervised machine learning: the instructor presents the same object with different views time and again.
Problem (a) is more complicated than (b). We mainly address (a). We proceed in three steps.
6.1. Step 1
We determine the
most frequent by
or because of
In the “regular” case:
all
. In this case (
cf. Equation (66))
Because of Equation (87), this allows a strong discrimination between .
Clearly we must know for all u. We call the corresponding set of and their attached patterns: the ”salient set“.
6.2. Step 2
We consider the salient set. Are there transformations that can connect some or all members of the salient set?
Assume
normalized for all
considered. We require
where
means scalar product. The elements of
form a group (in the mathematical sense) of transformations related to 1–6 (see below).
There may be some limitations to these transformations:
(1) displacements may be small for humans (due to saccades), vertical orientation/upside/down is preferred—most frequently observed;
(2) and (3) there may be interpolations possible;
(4) only small deformations will be allowed (“morphing”).
6.3. Step 3: Construction of Transformations
To this end we replace and approximate the indices of
or
by a continuous two-dimensional spatial variable
x,
y, abbreviated by
x. Then
and
v are replaced by
and
, respectively.
is defined by
where
acts as follows,
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
The explicit representations of in the cases 1–4 show how can be parametrized.
Case (5) can be realized in a variety of ways by suitable choice of
or differently by a superposition of typical prototypes. Note that for small enough parameters,
can be considered as generators of a (non Abelian) group. However, we may equally well define any desired total transformation
as a product of
with finite parameters and denote it by
. Since several of the transformations
don’t commute, in practical applications their appropriate sequence of applications to an image may be important and must be discussed in detail. To fix the parameters we require
There are numerous optimization procedures for the solution of Equation (97) available. Again in the context of neurocomputing we may apply the method of steepest descent.
Just a side remark:
Algorithms that perform pattern transformation by translation, rotation and magnification are used even in smart phones and need not be discussed here. The same holds for deformations used for “morphing” by computers.
6.4. The Transformation Parameter Space
Each set
defines a specific transformation
in a space spanned by these parameters. A continuous change of
defines a trajectory in this space. Can we define a dynamics for such trajectories? Can it be based on some potential landscape or/and on some probabilistic approach? In view of what we have suggested above, this potential will be defined by
the starting point chosen at
.
The structure of Equation (98) was determined numerically in the case of translation and that of a somewhat generalized potential in the case of deformations [
5]. In both cases no trapping in unwanted minima occurs if the
parameters are not too large. What happens at the order parameter level after we could identify those
whose
are connected by transformations. These
define an object (a category) described by a new order parameter
. Different objects are described by different order parameters
. We denote Equation (98) by
and consider the matrix
for
(or, in practice, over a sufficiently long time interval). Then a number close to 1 will appear at those positions where
connects one
with another
:
The dots mark positions where
. By a simple linear transformation we may reshuffle the indices so that
acquires the form
where each box contains only 1 at each position and indicates a specific category. In a next step denotations can be attributed to each box by associative learning. However, we will not dwell on this issue. In each box a single element will be sufficient to represent the whole category. In the case of faces a single prototype pattern as member of the salient set may not be sufficient. Here we need (at least) two prototypes: front view and side view(s). Rotation out of the plane implies a suitable linear combination of both views. The same remark may apply to other objects.
Clearly, taking the relative probabilities of the occurrence of OPs might be too stringent. In such a case more
s may be taken into account. Once the representative
s are determined and stored by the system, the recognition process may run the same way as the categorization process described above. There are some invariance properties of the OP dynamics that are noteworthy. Because of the formulation of the recognition process as an initial value problem, this process is invariant under the joint transformation
of any image vector
and prototype vectors
,
i.e.,
provided
possesses an inverse
and the Jacobean is a constant (see
Appendix B.1).
On the other hand, we may subject either
or to some transformation
as deformation
[
49]. In psychology we speak of
assimilation in case of
and of adaptation in case of
. Both cases are equivalent if
and the Jacobean is a constant (for a proof see
Appendix B.2).
6.5. Information Deflation by Transformations [6]
We may distinguish different patterns by the label
g , where
may stand for a set of features,
i.e., the grey values of the pixels into which the pattern is decomposed. We decompose
into
(essential) and
(unessential) features, e.g.,
may characterize a face at a specific position in space with a specific orientation, a specific size and in a standard form,
i.e., without deformations, e.g., showing no facial expressions. A typical example is the photo in our passport!
then may represent transformations such as translation in space, rotations, scaling or deformations. Shannon information is given as usual by
where
is the probability to observe a pattern characterized by the label
.
We want to show that by means of the decomposition of
into
and
, which is achieved by the recognizing system,
i.e., our brain or an advanced computer, Shannon information Equation (101) can be deflated. To this end we write
as
so that Equation (101) reads
(we have dropped the factor
c that appears in Equation (101)).
According to general rules of probability theory we may decompose the joint probability
according to
where the first factor represents the conditional probability and the second factor the probability to observe the object at a specific location,
etc. before the transformation
has been made. The usual normalization conditions
and
must be observed. Inserting Equation (104) into Equation (103) and using Equation (105) allows us to cast
i into the form
where the first term is a sum over the different transformations
of the conditional information
averaged over the distribution
. The second term in Equation (107) represents the information of the transformation
T alone. When
T is irrelevant for the recognition, we may drop this term and thus deflate information to the first term in Equation (107). In a final step we may simplify the first sum in Equation (107) by estimating Equation (108) taking the most probable
for a
.
Taking into account the normalization condition (105) we then obtain an estimate for the deflated information according to
Equation (102) may serve as starting point to make contact with work byT. Poggio and his coworkers [
48]. To this end we identify
J (their
I) with a prototype pattern
subject to the conditions Equations (83) and (84),
d: number of pixels. These authors consider Equation (111) as vector in a Hilbert space
. Applications of some
T transforms
into another vector of
H. Applications of all elements
T of the considered group
on
generate a set of endpoints of the vectors that is invariant against all
and can be represented by a distribution function
. According to Anselmi
et al. [
48], two vectors
,
are equivalent if
These authors develop an efficient way to check Equation (112) based on a finite set of templates (ideally only one). They study very carefully the impact of accuracy (
i.e., resolution) on recognition. The important role of accuracy is clearly witnessed by hybrid images (
cf. Section 7.2 below). Their
can be generated also directly from our (102)
The effect of
can be visualized by forming an average image
where
A nice example is provided by faces of some population where the transformations
are “deformations” with respect to the average face represented by Equation (114) (
Figure 11).
For sake of completeness we quote a further method to construct invariant images. Image vectors such as Equation (114) are Fourier-transformed, their absolute value subjected to a logarithmic map in the complex plane, and the result again Fourier-transformed. The example of
Figure 12 and
Figure 13 suffices to demonstrate how an image that is invariant against translation, scale, and rotation is achieved.
6.6. Invariance and Good Gestalts
There is a close relation between the concept of “good Gestalts” [
52,
53,
54] and invariance: The circle as “good Gestalt” is invariant against rotations and a line as “good Gestalt” invariant against translation. As is witnessed by the Kaniza triangle illusion (
Figure 14,
left) our visual system tries to make interrupted lines “translation invariant” or, in the case of Olympic rings (
Figure 14,
right), the patterns locally rotation invariant. This “continuation principle” holds more generally in cases of partially hidden Gestalts. Other hints that the human brain performs “mental” rotations come from rather old psychological experiments (
Section 6.7).
6.7. Mental Imagery versus Computation
It seems worthwhile to relate the approach by Poggio and his coworkers [
48] and our approach in its more explicit computational form to the rather old debate on
mental imagery between the main representatives, Shephard [
55,
56] and Kosslyn [
57], on the one hand and Pylyshyn [
58], on the other. Here we quote
merely the experimental findings of the former. Subjects were asked whether two geometrical forms are the same when one of them has been
rotated [
55]. According to Shepard and Metzler [
56], the reaction times preceding decisions grew
linearly with the size of rotation angle. From further experiments by Kosslyn
et al. [
59] it can be concluded that such a linear dependence holds also between reaction time and
distance over which objects had to be displaced mentally. Pylyshyn [
58] asserts that the mind computes in a literal fashion. We agree to this statement at least insofar as the computational resolution of the invariance problem we have discussed is concerned. In fact the experimental result lend support to our approach.
8. Saccadic Eye Movements
As noted in
Section 1.2.3, IA is implemented by a sequence of actions that involve interplay between SHI and SI/PI. Our empirical basis was the process of vision as described in
Section 1.2.3 and
Figure 6. This process of vision is implemented by various activities that take place in the brain, but also by saccadic eye movements, to which we refer in this section. For a review on human saccadic eye movements
cf. Findlay & Walker [
64].
Our starting point is the concept of quasi-attractors developed in the previous section. As we’ll show now, this concept plays a fundamental role also in our model of saccades. Here we can literally observe how the direction of our glance is attracted to a salient area in an image, but then leaves it to be attracted by another area and so on.
A recent approach to treat saccades has been published by Friston
et al. [
47] where also references to earlier work can be found. Friston
et al. [
47] describe the process generative (sampling) sensory information based on a specific generative model in the frame of active inference equipped with suitable priors (hypotheses) maximizing salience. In this variational treatment, the potential (V) is associated with the surprise or the negative log probability of sensory samples under the generative model. Their form of information adaptation rests upon minimizing surprise (implicit in the flow down potential gradients described above). In particular, they simulate the active sampling of a visual scene given three hypotheses about its causes (namely an upright face, a rotated face and an inverted face). The ensuring eye movements are driven by a prior belief that surprise or uncertainty will be resolved by sampling each new part of the visual scene. Friston
et al. discussed also possible anatomical substrates. Our focus differs from Friston’s by stressing the aspects of information and selforganization in particular dealing with the enigma of crucial cues and the appropriate choice of prototypes (hypotheses).
8.1. Some Basic Facts
An image is projected through the eye’s pupil on the retina. If the eyeball is immobilized, the image is no more perceived after 1–3 s. This “blindness” effect is counteracted by small rapid motions of the eye ball (“microsaccades”). Here we are concerned with “macrosaccades”, however. The local resolution of the projected image is largest in the fovea and decreases (“blurring”) towards the periphery of the retina. The glance is consecutively directed to salient parts of the image so that their projections come into the fovea by a sequence of
macrosaccades. Basically they may serve two different purposes: learning or recognition. In both cases we distinguish between three phases of a macrosaccade:
- (1)
Even in spite of blurring the brain draws a rough map of the salient parts.
- (2)
In the following premotor covert phase attention is directed to one of the salient parts.
- (3)
An overt phase in which the eye ball makes a rotation so that an attention preselected spot is projected on the fovea.
After some saturation of attention, a new saccade is made to some other salient spot,
etc. The interplay between bottom-up and top-down processes is summarized, e.g., by van der Stighel and Nigboer [
65] as follows:
The activity in the saccade map is determined by the interaction between bottom-up (or stimulus-driven) and top-down (or task-driven) information (Ludwig & Gilchrist, 2002, Ludwig & Gilchrist 2003, van Zoest, Donk & Theeuwes, 2004). Bottom-up information reflects the influence from the outside world, every image that falls on our retina. Top-down information reflects all intentions and goals that one might have at a certain moment. As visual attention and eye movement are strongly related (Rizzolatti, Riggio & Sheliga, 1994, Van der Stighel & Theeuwes, 2007), both types of information reflect the same constructs as used in the attention literature (for a review, see Van der Stigchel, Belopolsky, Peters, Wijnen, Meeter & Theeuwes, 2009). The continuous competition between these two types of information has to be resolved in order to execute an eye movement. Behavioral studies have shown that bottom-up information is dominant early in the selection process, whereas top-down information can influence the selection process with increasing latency (Ludwig & Gilchrist, 2002, Ludwig & Gilchrist 2003, van Zoest et al., 2004).
—Van der Stighel and Nigboer [
65]
In our paper we want to deal with these processes from the point of view of information processing, in particular:
- (1)
how can we formalize the saccadic map?
- (2)
how can we formalize the competition between bottom-up and top-down influences?
- (3)
what happens when a salient spot falls onto the fovea?
- (4)
what determines when to start a new saccade?
In our approach we ignore a number of important effects, e.g., the “global effect” in which the “eye lands” in between two salient spots (
cf., e.g., [
65,
66]). We ignore the detailed eye ball dynamics (
cf., e.g., Hepp and coworkers: [
67,
68]).
8.2. Why Saccades?
Before we start an attempt at a modeling it is useful to deal with the questions why the human eyes perform saccades. Quite evidently the reason for saccades rests on the local differences of the spatial resolution of the retina. Thus the eyeball must be directed consecutively to the individual parts of the image to be recognized (or learned). Apparently, the eye does it in a most economic way by “visiting” only the most salient parts. As witnessed by Yarbus’ [
69] pioneering experiments, each such spot is visited only for some short time, then another one, then in case of several salient parts after visiting them, the first part is visited again. Why these
short individual visits instead of detailed ones? We believe that the reason lies in human evolution. As we will discuss, the saccades do not only serve data collection, but are used also for decision-making. In the following we will try to model both processes.
8.3. The Problem of Saliency
According to Yarbus [
69]: “… the elements attracting attention may contain, in the observer’s opinion, information useful and essential for perception”. How can we characterize such
salient elements when aiming at a mathematical model? First of all we expect an interplay of bottom-up processes (kind of stimuli) and top-down processes (e.g., expectations, hypotheses).
To get a preliminary insight, we again refer to Yarbus. According to his statements there is a decisive top-down influence, but it seems difficult (if not impossible) to draw
general conclusions on the kind of raw data offered by an image that may serve as cues. Many of them that could come to mind are ruled out by Yarbus, e.g., brightness, outlines, edges,
etc., so eventually no one seems to be left. Our attempt at a resolution of this dilemma rests on a basic principle ruling self-organization:
i.e., circular causality between order parameters and (enslaved) parts. We assume that each class (e.g., “faces”, “animal”,
etc.) is characterized by an order parameter and that the parts are the most important characteristic features of that class. We assume that the capability of extracting such salient feature is partly inherited, partly learned. The latter is an important topic in unsupervised learning by computers, e.g., by feed-forward networks with hidden variables. In the following we deal with an explicit example. Once the map of salient spots (attractors) is established, the situation the eyes (brain) are confronted with is typically the same as more generally a human (or animal) is confronted with in an affordance landscape we discuss in
Section 1.2.3 in more detail.
If there is only one attractor, the eyeball will be moved towards it. Here, we are not concerned with a modeling of equations of motion. The eyeball motion has been determined experimentally by Yarbus.
Here we are concerned with the brain’s reaction(s) in case of several attractors (spots) which may be spontaneous or by “decision” making based on hypotheses on the meaning of the image. From an evolutionary point of view, for the survival of an individual, the fast distinction between friend or foe is decisive. What are the most salient and typical features for both? Clearly, a pair of eyes. In fact, e.g., monkeys possess neurons (or assemblies of them) that are specialized for face recognition. Our point of view is supported by recent computer experiments by Hinton [
70] on machine vision, who used a multi-layer network (more than 20 layers network) to “destill” the most probable pattern occurring in many photographs of humans in different positions or groups of them. He found as pattern an egg-shaped figure with two dark circles at the eyes positions and that of the mouth. (The second most frequent pattern was a cat’s shape). Thus, in the case of two spots (or perhaps three; nose/mouth), the hypothesis that these spots represent eyes will be dominant and start a process to scrutinize these spots. If the answer is positive at one spot, this quasi-attractor will be closed (the criteria to be discussed below) and the next saccade will start to eventually scrutinize the other spot(s) (and so on, e.g., nose/mouth). As is witnessed by Yarbus’ experiments, the saccades are repeated leading to the recognition of a face. What happens if the “face-hypotheses” is not verified? We may assume that a process called “heuristics” starts, where hypotheses are tested consecutively depending on their relative probabilities. It is here, where our approach of
Section 6.1 comes in, where we determined the probabilities of learned order parameters
. (Which can be still more elaborated taking into account the invariance properties, if needed). What happens when the glance is directed such that the salient spot falls on the fovea. We may expect a process of pattern recognition such as we dealt with in
Section 5.1. However, why is this process repeated as shown by the experiments? A possible answer may be as follows: As dictated by evolution (as mentioned above), the decision “eye” or “not eye” must be made quickly. Thus in a first step it will be sufficient to compare the salient spot with a prototypical eye. This may be obtained by, e.g., a mere superposition of several different eyes, or by an eye whose OP had been learned most frequently. Since the distance
cannot be zero, it will be sufficient to close this present attractor provided
, where
is a predetermined critical distance. In the following saccades, sets of more detailed prototypes with smaller (or even zero)
may be tested.
8.4. Construction of the Salience Map
In the following we cast our approach into a mathematical form.
8.4.1. The Map: Image→Retina
The image in projected through the eye’s lens onto the retina. Using geometrical optics, there is a one—to one correspondence between the pixels of the image and those of the retina. To avoid too many technicalities we directly deal with the image projected on the retina. Idealizing the eyeball by a sphere, we use angular coordinates in the horizontal, , and the vertical .
The pixel position is thus characterized by and the projected gray value distribution by . Because of the eye movement, we must use two different coordinate systems:
(a) in resting position of eye,
. Because of the weaker resolution away from the fovea the projected image
is blurred (at the blind spot it even vanishes which we will ignore in the following). We model this effect by the convolution of
with a blurring function
,
We will define below.
(b) We turn to the rotated eyeball, where the coordinates
become
in rotated position, and we have to introduce a new coordinate system
relative to the gaze direction so that
and
An explicit example of
is a Gaussian of width
Note that because of decreasing resolution
. In the resting state
and in rotated state
8.4.2. Characterization of Saliences
At least in a number of cases, e.g., faces as witnessed by Yarbus’ results, saliences can be characterized by regions with high spatial frequencies. In other cases, other (e.g., hypothesis and/or instruction based) cues must be used. To construct an attractor landscape we apply a high band pass filter which can be realized by the convolution of with , where is a Gaussian with small width .
Any function is sent to .
Eventually, the potential landscape is formed by
where an average is taken over a small neighbourhood of
(or, equivalently, over
(microsaccades!), and
is a constant.
8.5. Dynamics of Saccades
8.5.1. Eyeball Fixed,
Two quantities have been determined before: (a) ; (b) .
(a) allows a preliminary check against fundamental prototype patterns, in particular faces (zero hypotheses)(needed in case of recognition, optional in case of learning).
We form
only in case of
recognition:
If large enough, we retain hypothesis; if not: heuristics (
cf. above
Section 8.2).
(b)
defines an attention parameter field
with maxima at
,
We attach an OP
to each maximum, where
is a measure of the amount with which that position is “occupied“ and correspondingly a local attention parameter
. We determine the trajectory
so that (after saccade)
The details of this process are not considered here.
8.5.2. Eye Ball Rotated to First (Presumably Closest to )
We invoke Equations (124) and (125)
where
.
The fixation of the initial values depends on learning/recognition. In case of learning we choose
and, in view of our previous computer experiments [
61],
In case of
recognition, the initial conditions are
with
chosen according to basic hypotheses: face (eyes, mouth).
We first consider learning.
We ignore the explicit dynamics of the saccades. At each saccade
some data on pattern
are selected
where the part (with indices
) falling on the fovea is sharper than its blurred surround.
(Note that
is an upper index and not a power). We may also think of suppression of the surround instead of blurring. Furthermore and still more important, because of the limited time, even in the fovea, the data acquisition will be incomplete. We assume that the finally recognized (“learned”) pattern is a superposition of
,
i.e.,
There is a subtlety to be taken into account. At each step the patterns
must be shifted by a coordinate transformation of
α, β to compensate the displacements of the projected images on the rotated retina so that in the relevant layer of the visual cortex a
stable input image results. We may assume that due to brain processes
To define the information of
, we require (with help of a normalization factor)
and put
Since the normalized superposition Equation (144) diminishes blurring of the total image, we may expect that
Equation (147) is decreased with an increasing number
of saccades. Furthermore, to have a measure for the data acquisition process we form the Kullback–Leibler information gain (
cf. [
71])
of the distribution
and require
or, in practice
because the learning capacity is limited. For a related use of information gain for learning
cf. Appendix D. There is an interesting analogy with the study (analysis) of rat’s behavior (See below), where eye movements seem to correspond to those of whiskers. These considerations conclude the learning procedure mediated by Equations (140) and (141). We now turn to
recognition.
8.6. Recognition
The basic steps concerning the updating of (cf. Equation (144)) are the same as before. However, the resulting intermediate serve time and again as offered test patterns to the recognition process modelled by the synergetic computer (SC) where a whole set of prototype patterns (“hypotheses”) is offered simultaneously. If the data contained in an (updated) are insufficient, the SC process does not lead to a unique attractor (prototype pattern) and must be repeated after some more saccades. We suppose that in the brain the SC is stopped after a given time, perhaps as a consequence of the attention saturation dynamics. All in all, the updating process is chopped at times where some so to allow the SC recognition process come in which may explain the various glance durations. Our model may shed light on the interplay between bottom-up and top-down process, i.e., data collection and prototype (hypotheses) checking. We assume that gaze duration is directly correlated with the SC-process.
In our approach we have dealt with the initial phase of saccades leading to the recognition of a face or even of that of a specific person, based on primitive cues. In our opinion, only then the observer may scrutinize an image based on his/her personal experience. At this point we may refer to Yarbus [
69]:
The human eyes and lips (and the eyes and mouth of an animal) are the most mobile and expressive elements of the face. The eyes and lips can tell an observer the mood of a person and his attitude towards the observer, the steps he may take next moment, and so on. It is therefore absolutely natural and understandable that the eyes and lips attract the attention more than any other part of the human face.
We can model this phenomenon by an adaption of the relative weights of the attention parameters in the course of the process.
8.7. Saccades of Instructed Observers
In the foregoing we have presented a model on saccades and information processing of an uninstructed and unbiased observer. We mention two more groups of experiments:
- (1)
Study of saccades (eye glances) of an observer who is questioned about the picture.
- (2)
As already noted by Yarbus [
69]:
Eye movements reflect the human thought processes; so the observer’s thought may be followed to some extent from records of eye movements (the thought accompanying the examination of the particular object). It is easy to determine from these records which elements attract the observer’s eye (and, consequently, his thought), in what order, and how often.
Such studies can be continued with investigations of language production. Here, for instance, saliency maps (attentional landscapes (e.g., [
72,
73]) can be established and their (information) entropy measured. This might open a way to connect our type of modelling with experimental findings by Coco and Keller [
74] to mention but one recent example.
8.8. Exploratory Behavior
In their above noted study, Friston
et al. [
47] (p. 151) refer to saccades eye movements as “exploratory behaviour and visual search strategies… an emergent property of minimizing surprise about sensations and their causes.” It is interesting to note that the notion of “exploratory behaviour” is central also to variety of domains in which the exploration is implemented by a moving (“behaving”) animal or human introduced to a novel environment.
Experimental studies exhibit remarkable analogies between exploratory behavior of human saccadic eye movements and whole body exploratory behaviour. Three main similarities are relevant here:
- (1)
As in eye movement so in whole body exploratory behaviour, the process is highly structured, consisting of distinct forms of body movement and action in the environment. For example ([
75,
76]), when a rat in normal conditions is being put into a circular arena (
Figure 23), it first moves forward relatively slowly, making frequent (5–14) stops until it reaches a certain threshold stop from which it begins a backward movement that is fast and with no stops. In the next excursion it moves fast through the previously explored “familiar” area, all the way to its final stop, from which it starts the exploratory forward movement, as before, and then the backward movement. This time, however, on its fast movement to the home base, it “takes a rest” in some of the previously determined stops. This exploratory behavior continues until the whole area is explored.
- (2)
As in saccadic eye movements, in whole body exploratory behaviour, salient features in the environment play an important role in determining the animal’s movement [
77,
78]: This is so with respect to the form of the explored area as a whole (
Figure 24), and this is so with respect to salient features within the area. Here it was found that not only those salient features attract the animal’s movement, but also that different spatial configurations of salient environmental objects, entail different forms of exploratory spatial movements. This is illustrated in
Figure 25 that maps the paths of progression of four rats in grid
versus irregular layouts during the 20 min of testing. In the grid layout, the rats’ movement was dispersed throughout the arena, spanning the objects and the perimeter. In the irregular layout, the rats’ movement was in relation to the start point and the nearby arena wall, covering only a portion of the arena area.
- (3)
As in saccadic eye movements, whole body exploratory behaviour of rats and mice, implemented as it is by whisking and locomotion, was found experimentally to be managed by alternate switching between forward and backward movement as described in point (1) above. Gordon
et al. [
79] have suggested a generic, information-theoretic model that accounts for the underlying principles of exploration behavior. Based on experimental exploratory behavioral studies of whisking and locomotion in rats and mice, their model indicates that these rodents maximized novelty signal-to-noise ratio during each
exploration episode, when novelty is defined as the accumulated information gain. In particular Gordon
et al. [
79] modelled approach-avoidence behavior where novelty is managed by alternate switching between efficient novelty seeking and reflexive-like novelty aversive motor primitives. Their quantitative model findings further suggest a process which is in line with our notion of IA, namely, “that curious animals do not attempt to maximize or minimize novelty, but rather maintain a constant flow of novelty by switching between behaviors that increase or reduce it.”
In terms of embodied cognition we have thus discussed above action-perception at three levels of scales: neurological level implemented by brain activities only; saccadic eye movement level implemented by both eye movement and neurological activity, and exploration by body movement that in the case of humans is implemented by all three.
9. From Finger Movement to Walking Speed
9.1. Finger Movement
In
Section 1.2.3 above we have suggested a rough approximation of the finger movement case study; in what follows we suggest a refined formal approximation. To this end consider
Figure 26 in which
ξ is the value of the OP phase
φ =
ξ.We define probability
,
(normalization) and SHI
i for value
ξ:
(also called “surprise”) realized are states (
cf. Figure 26) where
thus “information criterion” for
realizable states
The voluntary behavior may choose between 1 and 2 if the situation permits, but the state with higher i(ξ) (or higher V(ξ)) requires more effort in FM (finger movements).
Note, firstly, that in
Figure 26 the states at
φ = −π and
φ = π are identical. Secondly, that the transition from
Figure 26 left to
Figure 26 right is caused by change of a
control parameter. As noted above, in the case of FM it is the PI task that
prescribes the speed of finger movement.
A similar experiment, but in a situation of collective behavior, was conducted by Schmidt, Carello and Turvey [
80]: Two seated persons were asked to move their lower legs in parallel and watch each other while doing so (
Figure 27). As the speed of the legs’ movement increased, an involuntary transition to the antiparallel movement suddenly occurred, in line with the Haken–Kelso–Bunz [
32] phase transition model [
42] (pp. 87–90). This experiment is of special significance as it implies collective behaviour—a phenomenon that plays an important role in urban dynamics.
9.2. When in Rome Do as the Romans Do: Pedestrians’ Behavior in Cities
Pedestrian movement is probably the most salient aspect of humans’ behavior in cities. In 1976 Marc and Helen Bornstein [
81] have published a paper showing correlation between population size of cities and walking speed of pedestrians in these cities (
Figure 28); this, as part of their attempt to study the impact of urbanization on the pace of life.
Subsequent studies have supported and elaborated these findings [
82,
83]. More recently the issue appeared once again, this time, however, in the context of complexity theories of cities as part of an attempt to show that “many properties of cities from patent production and personal income to electrical cable length” as well as pedestrians walking speed, “are shown to be power law functions of population size with scaling exponents,
β, that fall into distinct universality classes”. [
84]. In this section we suggest to interpret behavior in general and behavior in cities in particular as a form of information adaptation.
Compared to the above IA interpretation of the FM paradigm, we can say the following about the correlation between city size and pedestrians’ speed of movement: First, unlike FM, here there is no explicit, externally determined, PI task. Rather the task is a property that emerges out of the interplay between SHI and SI. For example, when a newcomer settles in a city, s/he observes the other citizens and makes (hopefully unbiased) guesses on their behavior. In other words, s/he uses Shannon information, maximizes it under the observed constraints (e.g., average velocity, etc.). This allows her/him to determine the attractors, i.e., the PI that instructs him/her on how to behave in accordance with the general behavior.
9.3. A Mathematical Algorithmic Model
We start with the following definitions (see
Figure 29):
The relevant variables/parameters are:
Order parameter: mean velocity of pedestrians’ movement, ξ
Control parameter: city size, population density
City: A suggestion on V(ξ) (qualitative!)
Velocity ξ has all the properties of an
order parameter:
it describes a property of the total system: here velocity distribution and its most probable velocity;
it is brought about by the internal system dynamics;
it enslaves the behavior of the individual parts: the velocity ξ determines, how many people N(ξ) move at this velocity (on the average);
it is influenced by control parameter(s); here, city size;
a change of control parameter induces a qualitative macroscopic change: here change of velocity.
Our approach in terms of information adaptation runs as follows:
Shannon information
maximized under constraints! In the present case, constraints are not explicitly known, though most probably <
ξ> and <
ξ2> or similarly. In this case
, where
,
constitute “village” (or small town) if:
,
, “City”:
,
.
This is a typical “phase transition”! At any rate, we know how the outcome must look like (see above):
and the form of
V(ξ) can be deduced from experiments. Or, alternatively, by a “model” on V(
ξ) as described above. In particular, in the spirit of IA, the points of the minima of
V(ξ),
… represent the
semantic information PI (here, how fast to walk,
i.e., instruction).
9.4. The Synchronization Urge
Clearly, our new citizen does not use algorithms, but when we try to translate her/his
intuitive action into the language of information processing, we may arrive at our IA interpretation. Or, put differently, when we were to devise a “citizen” robot, we would equip its brain with our IA algorithm (There is presently an interesting debate on the relations (or virtue) of intuition versus algorithm (as e.g., applied to medical treatment in stroke units) by Gigerenzer [
85]. He thinks that in important cases intuition (or heuristics) is better than algorithms).
But what is the psychological-cognitive origin of this synchronization urge? Why would/should our newcomer synchronize behavior with the other inhabitants and why do they synchronize their walking speed in the first place? The answer comes from synchronization/coordination dynamics as in the above FM and Schmidt et al. (ibid.) experiments and HKB interpretation. As is well experienced and recorded, people walking together (who know each other) tend to synchronize pace, etc. (and also their speed). Intuitively, probably the same might happen when many anonymous people in high density are walking to the same direction—they will give rise to an order parameter that will enslave their walking speed, etc.
But why the walking speed in large cities is faster? There have been here several suggestions or rather speculations, ranging from the assumption that pedestrians try to avoid “social interference” [
81] and “sensory overload” [
86] that rises with the size of cities, to suggestions that people try to save time whose economic value is higher the larger the city is [
83].
To the latter we might add the following: behavioral movement in cities might be divided into productive (in workplace one produces and earns money) and non-productive (movement to workplace, i.e., commuting), which is often considered as a “waste of time”. With few exceptions (siesta), the larger the city the longer is the non-productive time (journey to work). In small cities where everything is nearby, there is no waste of time, but in large cities it is a problem. In the latter, as part of their attempt to minimize the waste of time associated with the movement to work, people move faster.
10. A Glance at Consciousness Research
While considered by neuroscientists for some time as a doubtful enterprise, more recently the field of consciousness research has become a serious and vivid domain of neuroscience. (
cf. e.g., Tononi [
87], Dehaene [
88] and others). In what follows we refer to Dehaene [
88] and show how our present elaboration fits into consciousness research. Dehaene’s [
88] hypotheses reads as follows: “Consciousness is global information processing in the cortex serving a massive distribution of relevant information over the whole brain. Consciousness selects, enhances and transmits relevant thoughts.”
In the 1990s, Francis Crick and Christoph Koch [
89,
90] recognized that
visual illusions provide science with means to follow up the fate of conscious or unconscious stimuli in the brain. A relevant phenomenon is “binocular rivalry” discovered by the English scientist Charles Wheatstone in 1838 [
91]. In his experiments, the two eyes are shown completely different images, e.g., a face and a house. Wheatstone found that the images do not merge, rather their perception oscillates. The same image is perceived for some time, while it disappears from our
conscious perception for some other time, and so on. Though in our paper in general we do not enter a discussion of the neurophysiological processes, we mention the results by David Leopold and Nikos Logothetis [
92]. They observed for the first time by experiments on the reactions of individual neurons of monkeys, which were trained to react to a visual illusion, that in the early stages (areas V1 and V2) the illusion was not present. However, in particular in the inferotemporal cortex and superior temporal sulcus, most neurons correlated with the subjective conscious perception.
Let us return to the “phenomenological” level. It is here where the Ditzinger-Haken [
61] approach (
cf. Section 7.1) comes in because the corresponding equations can be directly applied to model the switching phenomena the same way as they applied to the Borsellino
et al. experiments [
93]. In this model, attention parameters played a decisive role. Actually, the exploration of attention plays a fundamental role in consciousness research, e.g.,
blinking of attention. In analogy to the competition in binocular rivalry, during that blinking a competition occurs between two subsequently shown images at the same place but along the temporal axis. It will be tempting to apply the Ditzinger-Haken model also to this phenomenon. It is interesting to see, how the human brain deals with the “information bottle-neck”. It
avoids destroying information entities (in our approach governed and described by corresponding order parameters!) rather by merging their parts, be it in space, be it in time. The same phenomenon, where the whole wins over the parts can be observed in specific ambivalent images, e.g., Archimboldo’s painting. In terms of IA (information adaptation) the brain, time and again,
deflates SHI. Another effect, “inattention blindness” may become accessible to modelling by use of the same attention parameter concept as dealt with by the Fuchs-Haken [
51] procedure as outlined in
Section 7.3. In the experiment, subjects are asked to remember a letter shown in the upper corner of a screen (two trials). Then, in a third trial, in addition to that letter, a further object (e.g., even a word) appears in the middle for nearly a second. However, up to two thirds of the participants did not note it.
In particular by the psycho-physical technique of “masking” stimuli (e.g., optical,
cf. below) it has become possible to manipulate conscious
vs. unconscious responses of the brain (for a review
cf. [
88]). As these studies reveal, most parts of mental activity are unconscious and, in specific cases, “prepare” (in our words) a conscious percept. In the context of our approach the transition from unconscious to conscious is of particular interest. Indeed the experimental results by Del Cul
et al. [
94] lend strong support to our thesis [
42] that the human brain can be conceived as a
synergetic system. This implies that the brain is a self-organizing system that acquires specific macroscopic states in analogy to pattern formation of physical systems via non-equilibrium phase transitions (
cf. Figure 3b,c) [
94]. We used this analogy [
95,
96] to devise the synergetic computer as a model for pattern recognition [
5] (see also
Section 4.1 of our present paper).
In particular, we dealt with these transitions by means of order parameter concept. As remarked by Dehaene and Naccache [
97] the concept of phase transitions captures many properties of
conscious perception. As we know [
12], phase-transition both in equilibrium and
non-equilibrium systems are characterized by a
specific threshold of, in our terms, a
control parameter. Dehaene and Naccache [
97] invoked this fact to state “that a short stimulus remains subthreshold, whereas a slightly longer stimulus becomes completely visible”. In their decisive experiment Del Cul
et al. [
94] continuously changed a single physical parameter (“control parameter”) on the monitor. A number was shown for 16 ms, then a gap and finally a mask composed of a random sequence of letters. The duration of the gap was varied in small steps of 16 ms. While at short gaps the observers could see only the letters, at longer delays they could see the number. The reported perception of the number was “nothing or all” corresponding to “below or above threshold”. These results were supplemented by EEG measurements showing an “activation avalanche” of the so called P3 wave. For a detailed further discussion and references, also to other authors,
cf. [
88]. Our brief remarks may suffice here to indicate that we believe that our approach is a viable “mesoscopic” view at brain function and may serve as a frame for more detailed modelling at the level of groups of neurons, their synchronization,
etc. (see, e.g., [
98]). It is remarkable, that, as treated by synergetics (and in contrast to bifurcation theory) fluctuations of neuronal activity play an essential role in an explanation of the experimental results.


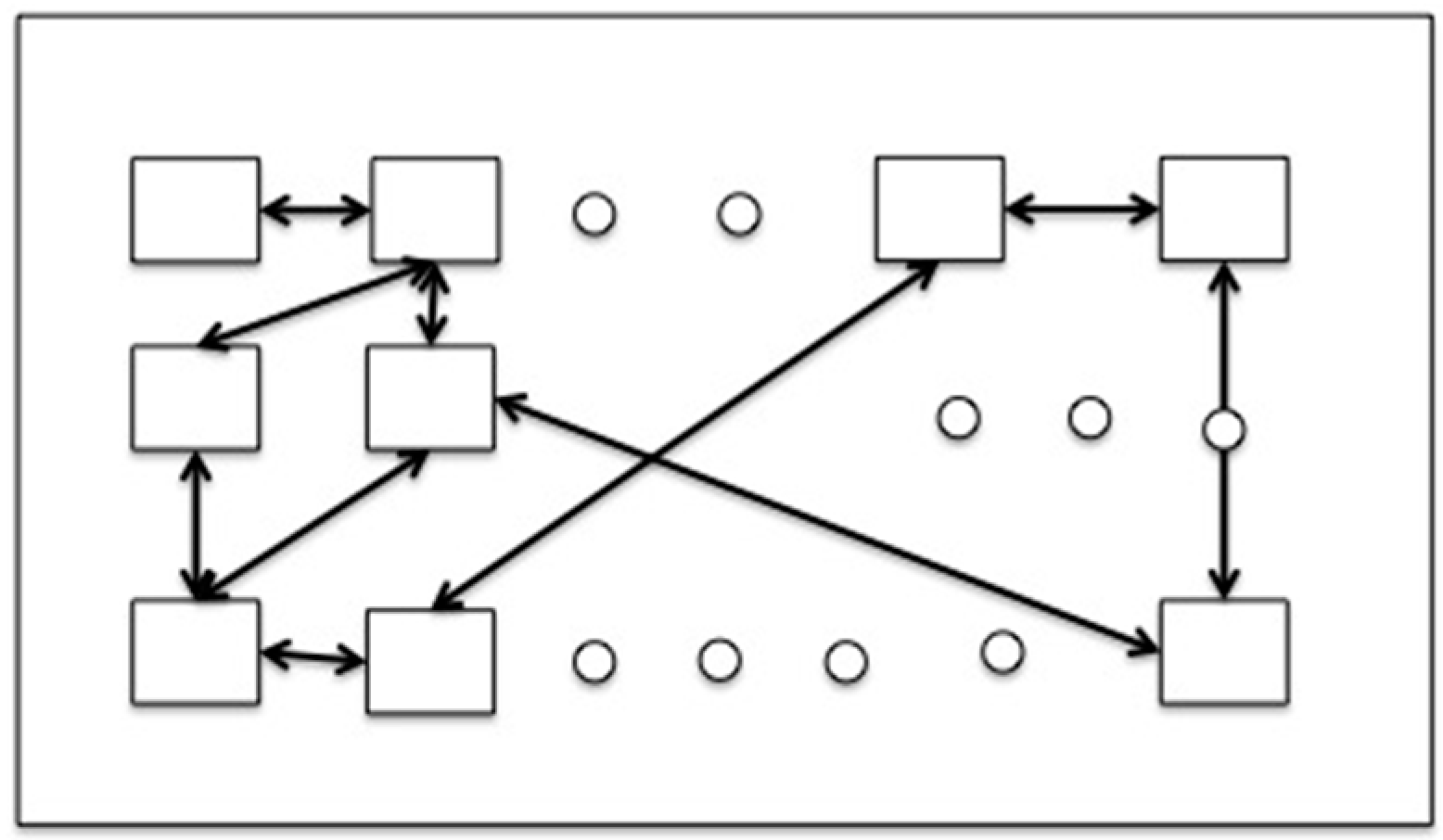{kind=link}
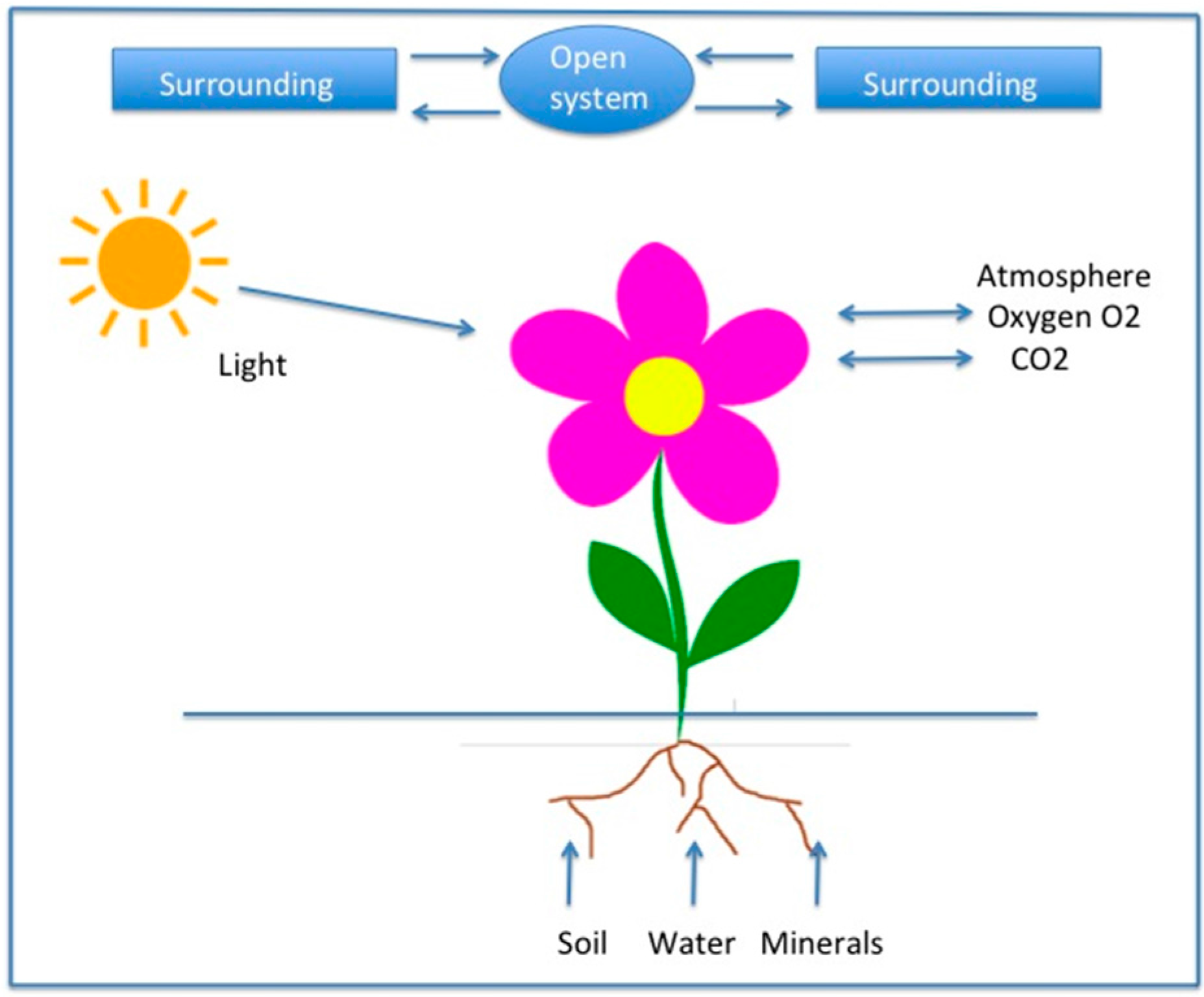{kind=link}
{kind=link}
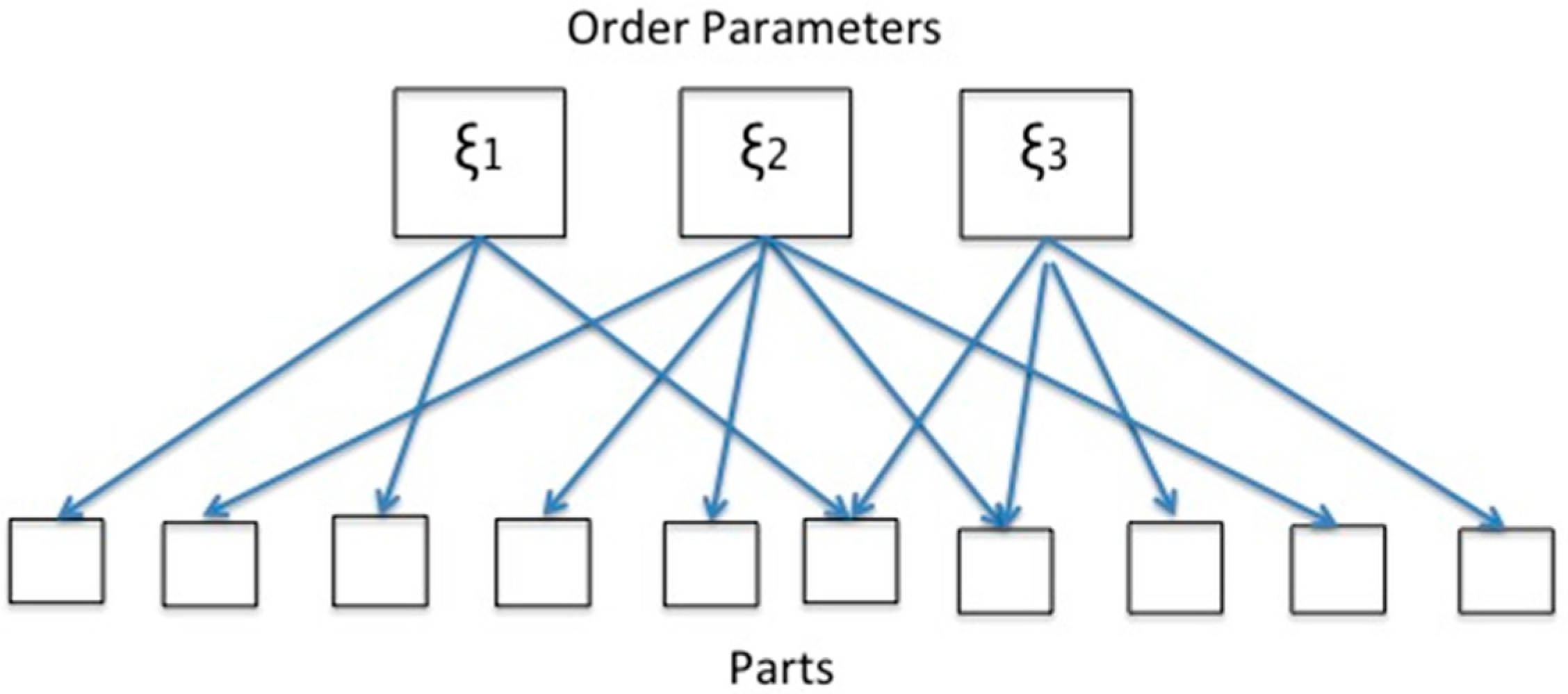{kind=link}
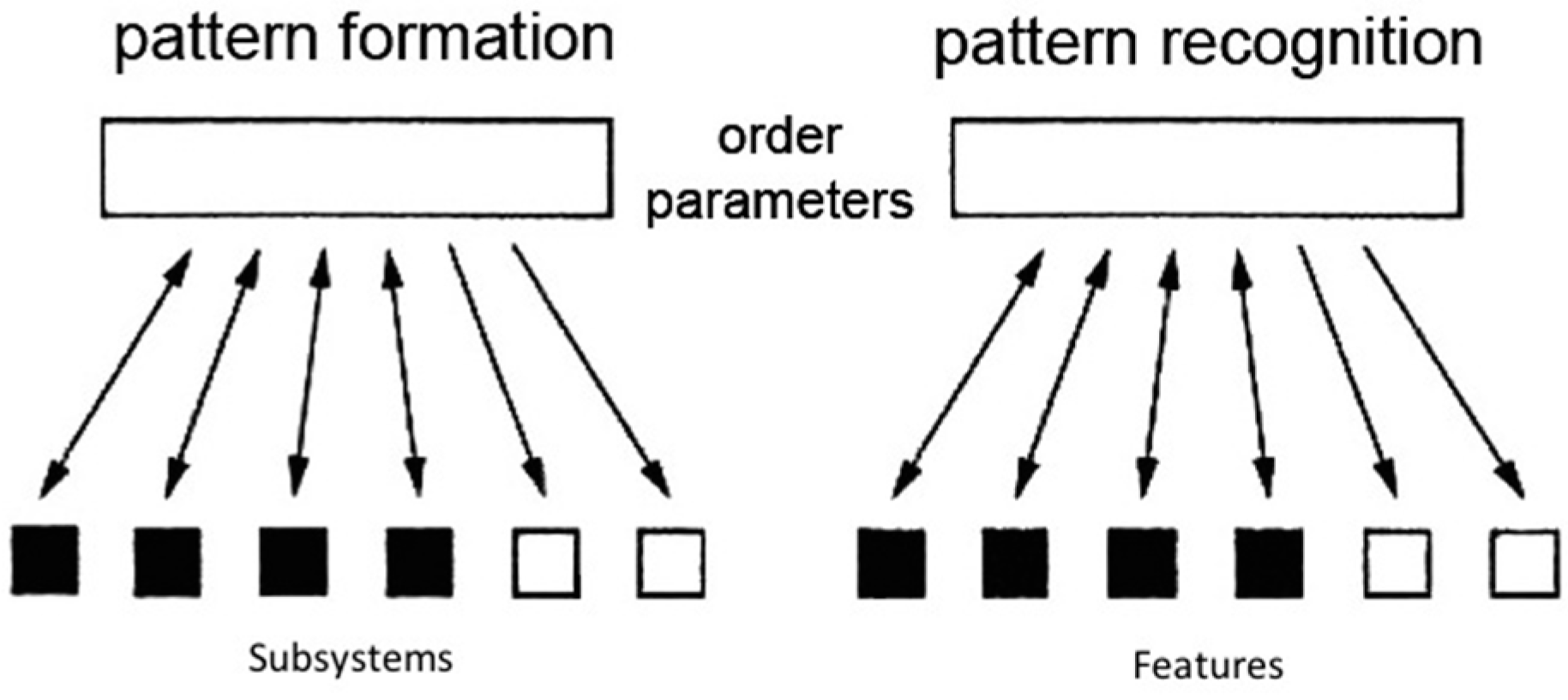{kind=link}
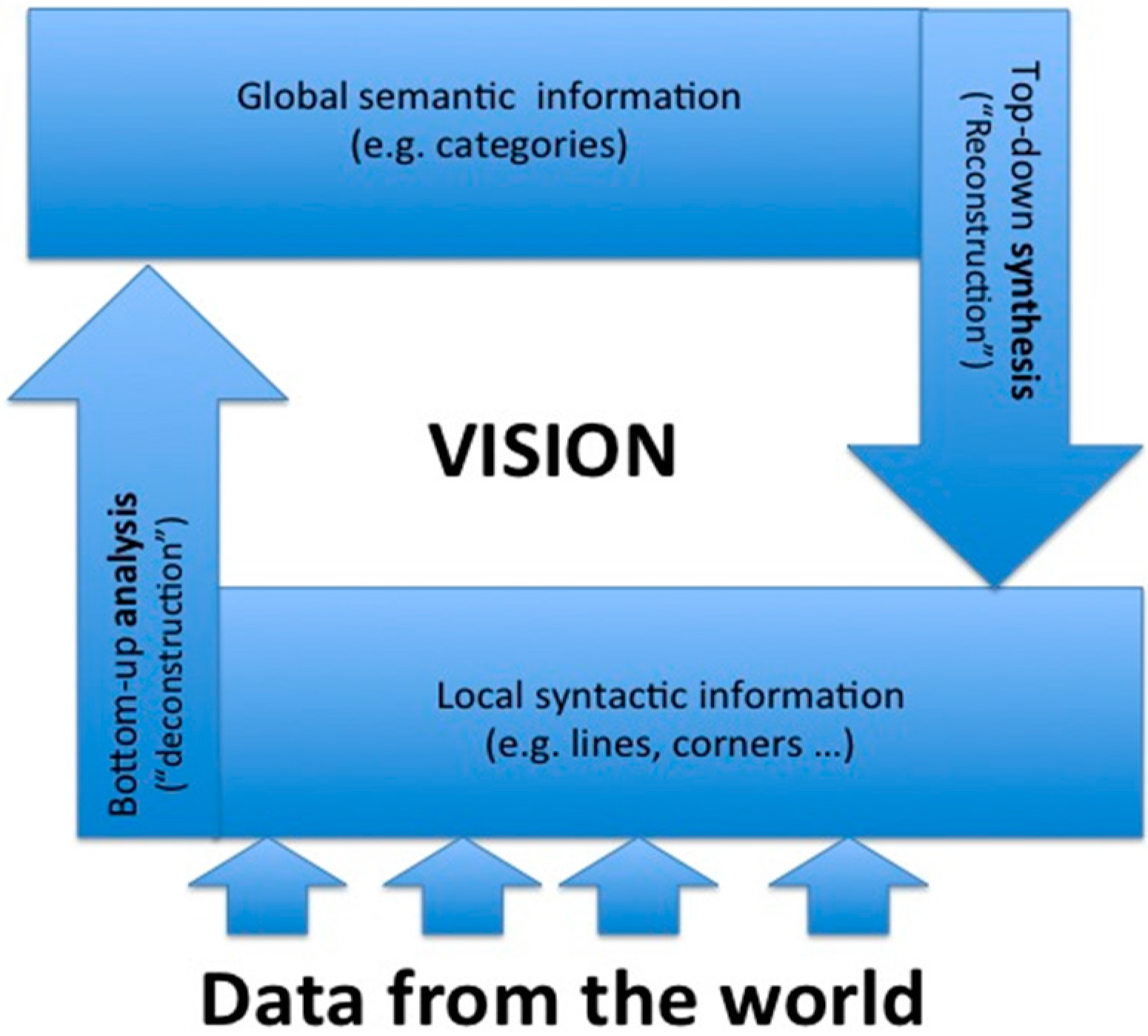{kind=link}
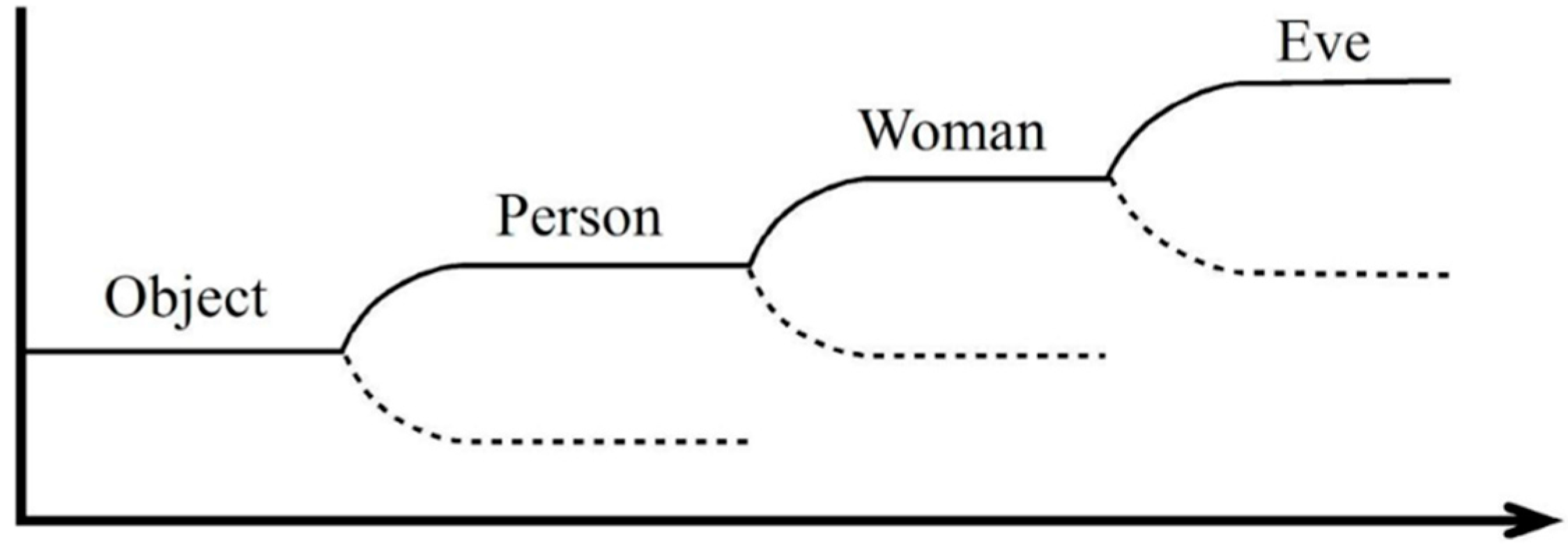{kind=link}
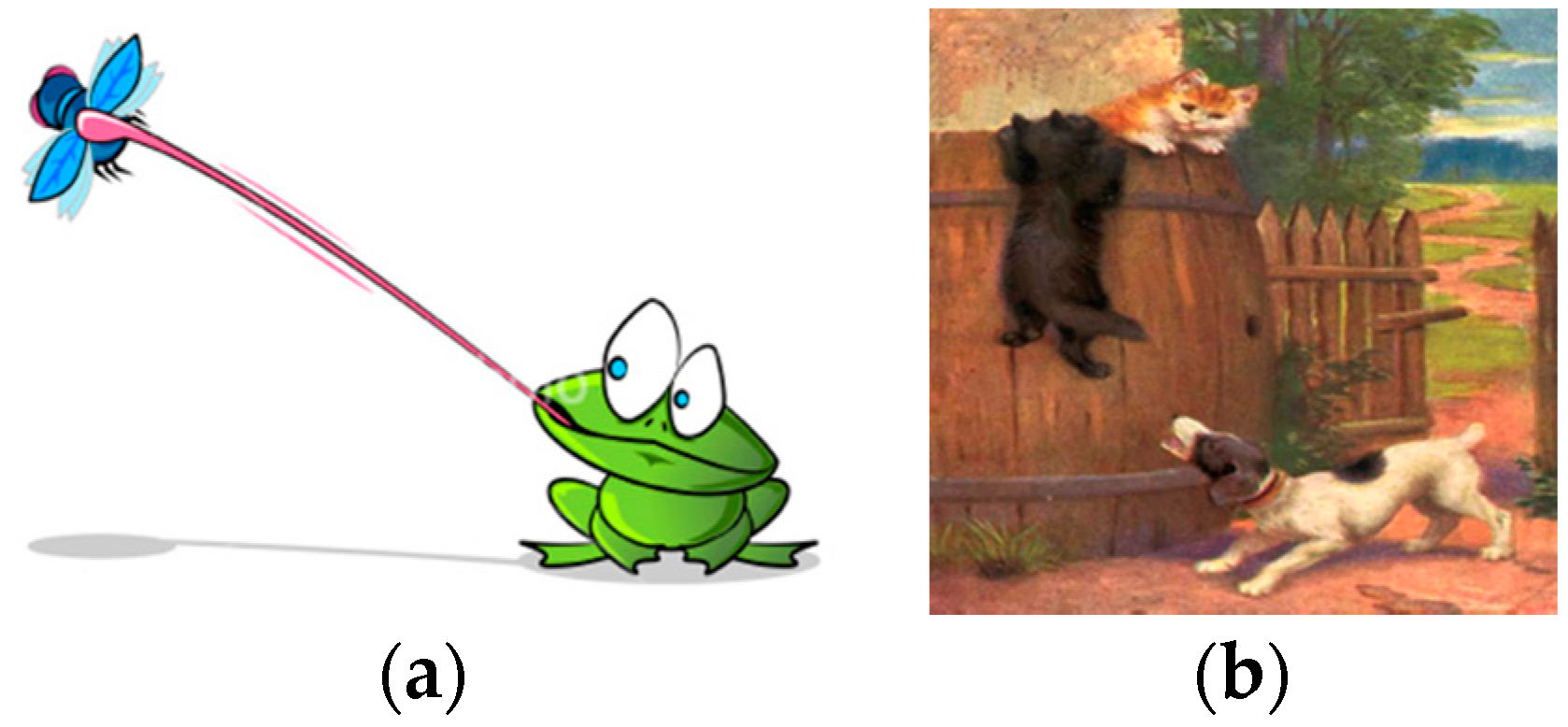{kind=link}
{kind=link}
{kind=link}
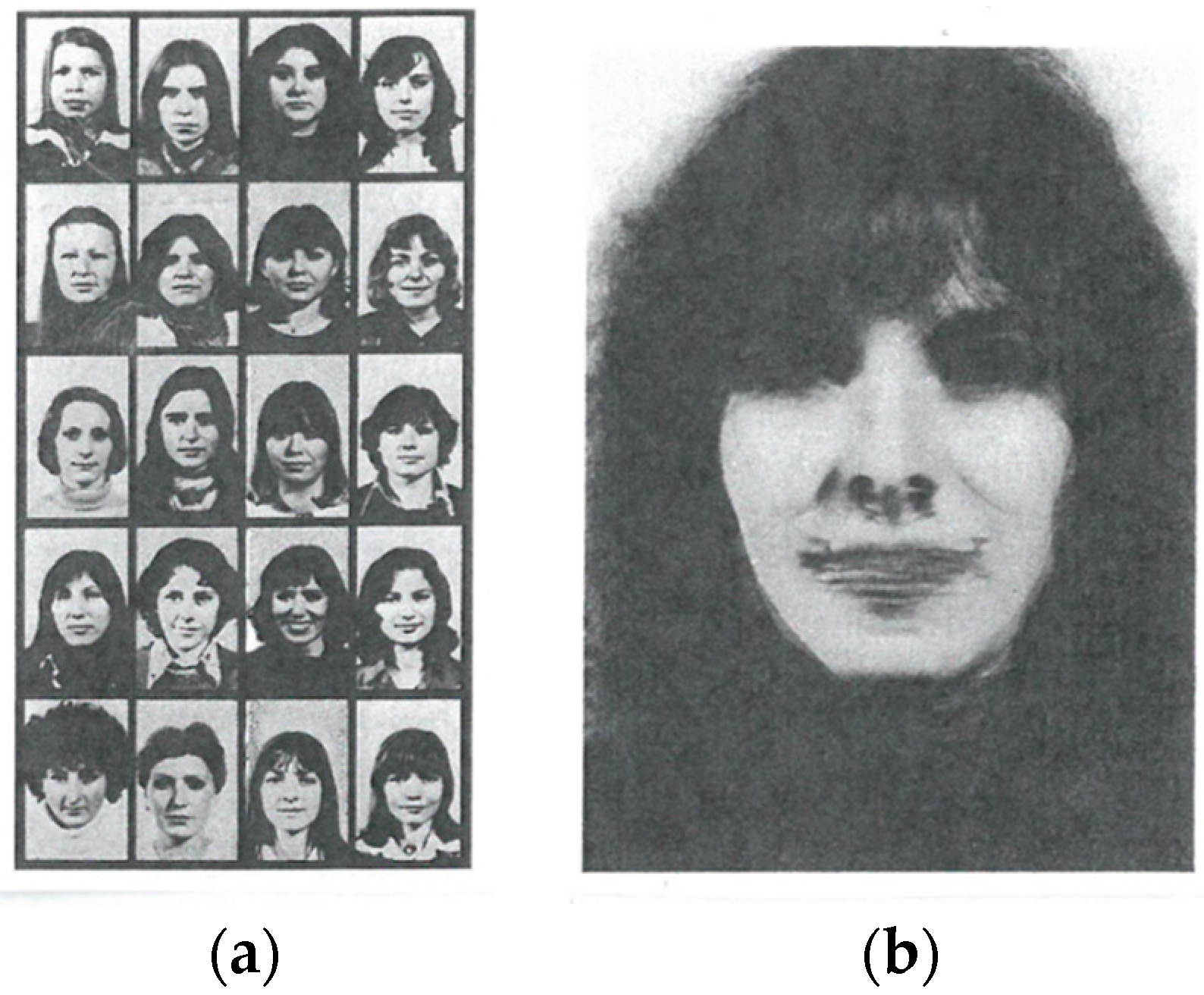{kind=link}
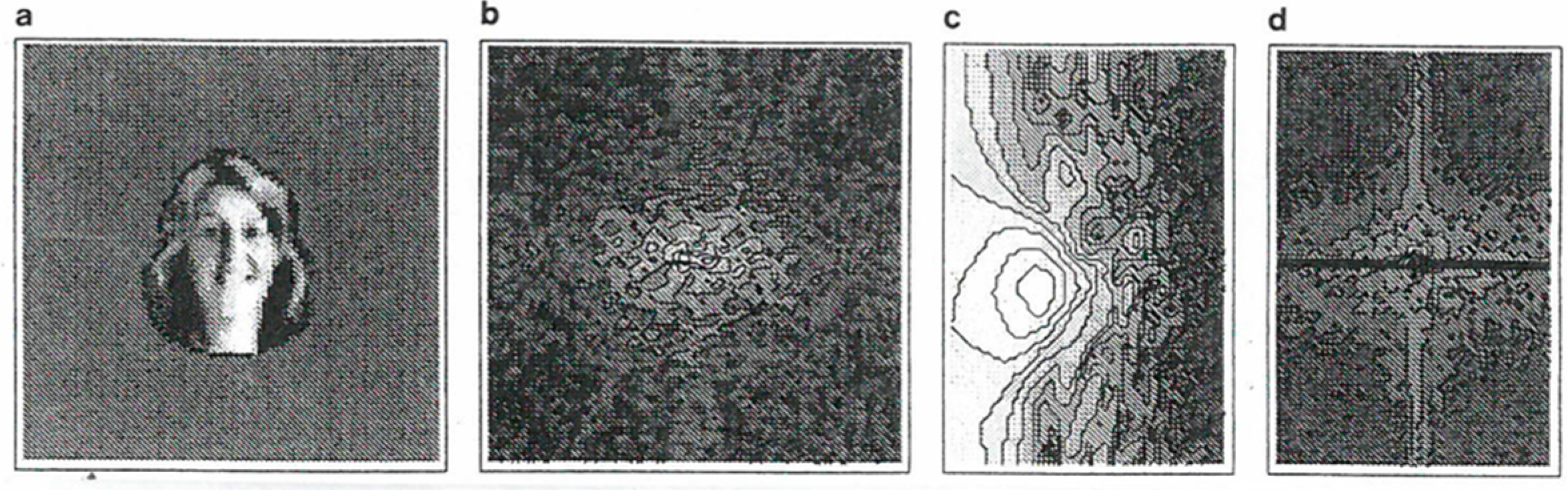{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
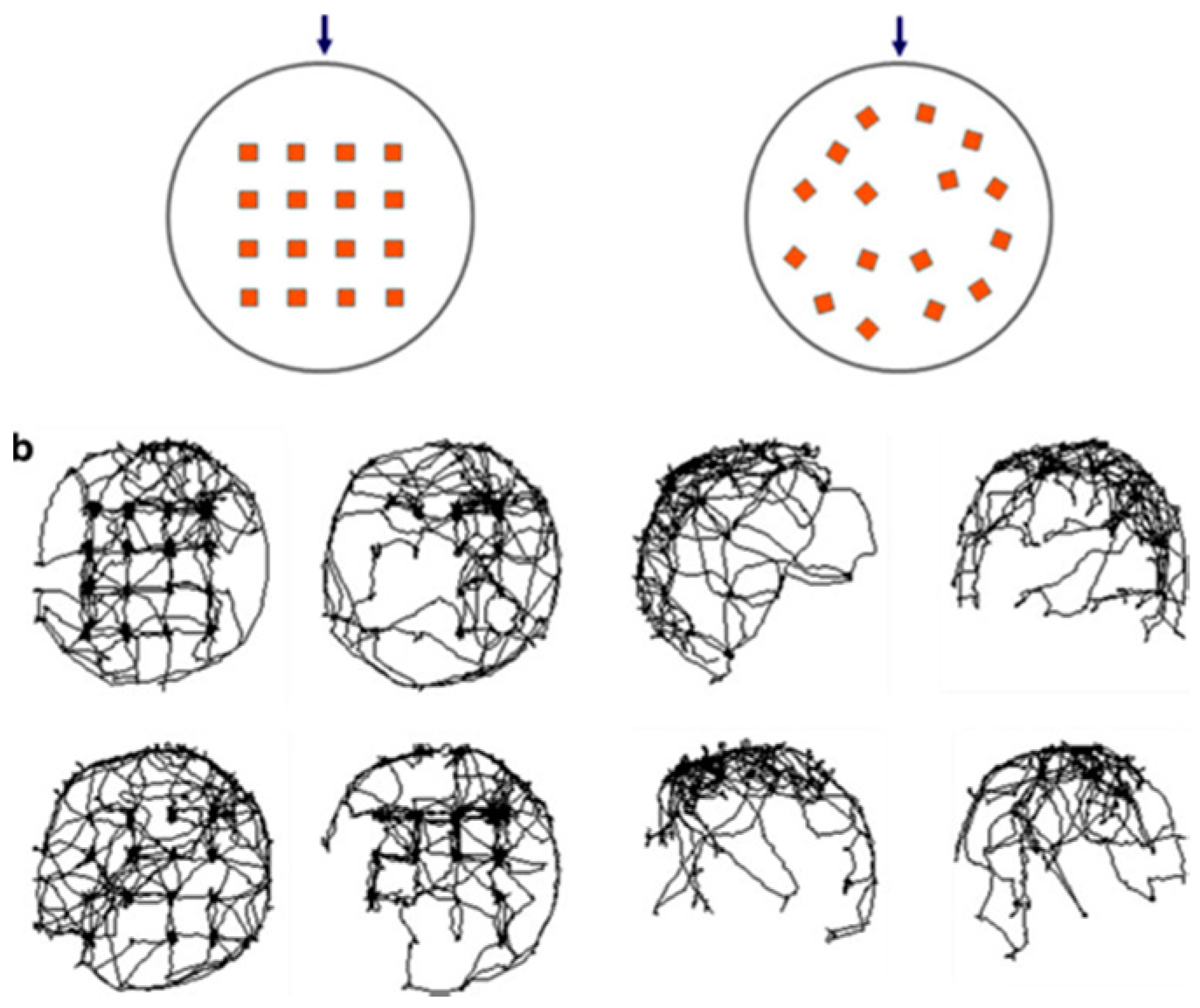{kind=link}
{kind=link}
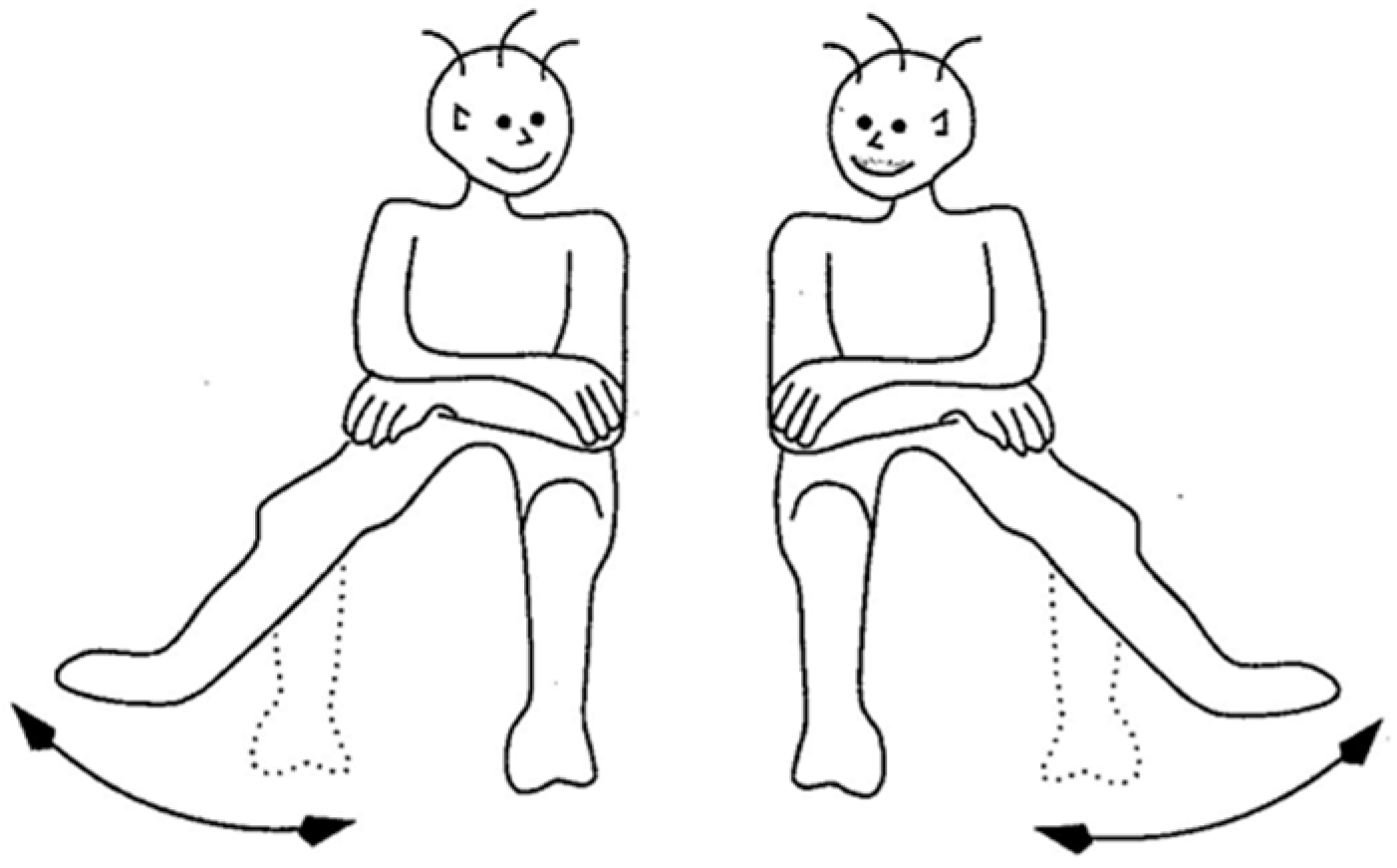{kind=link}
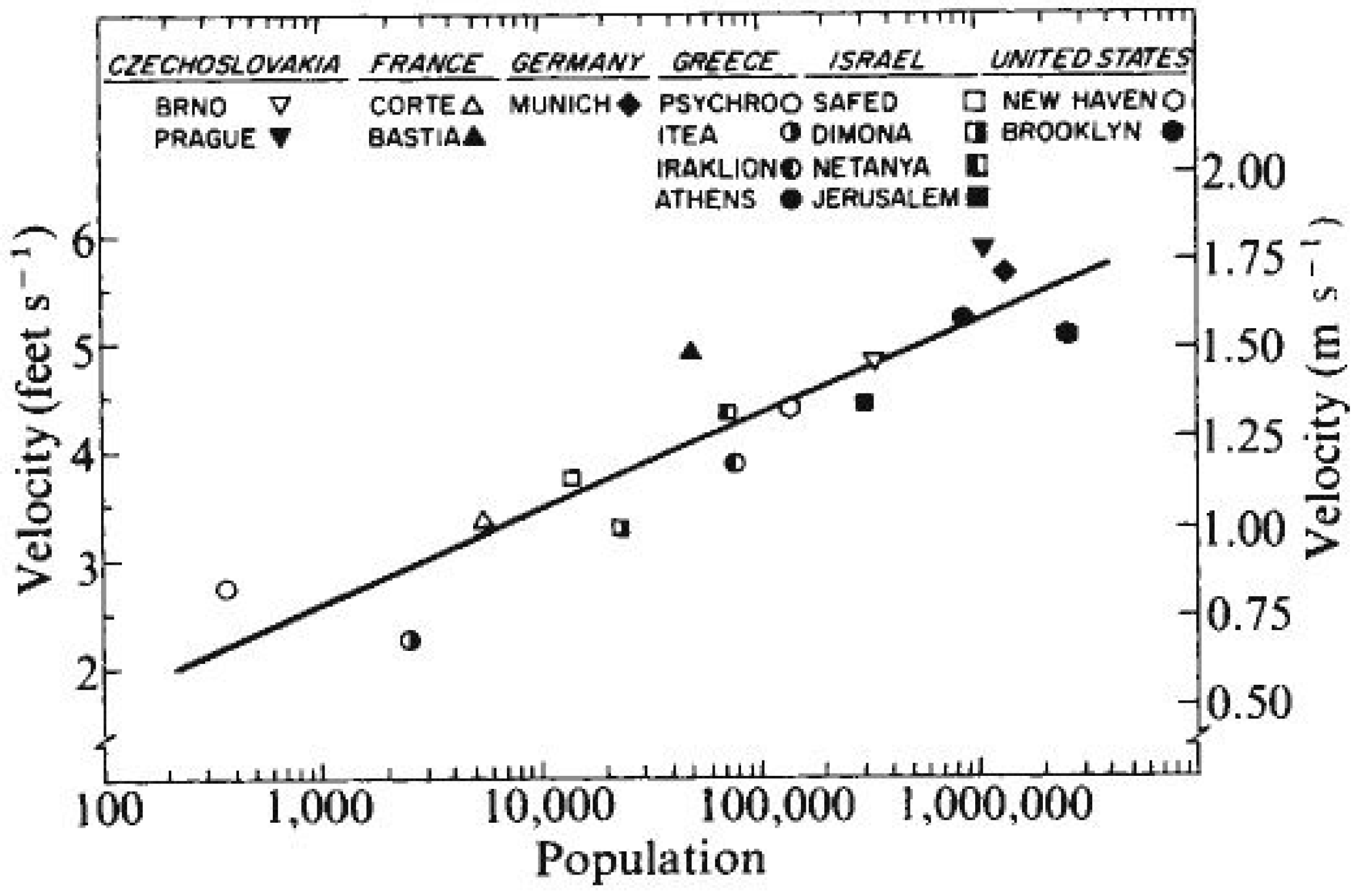{kind=link}
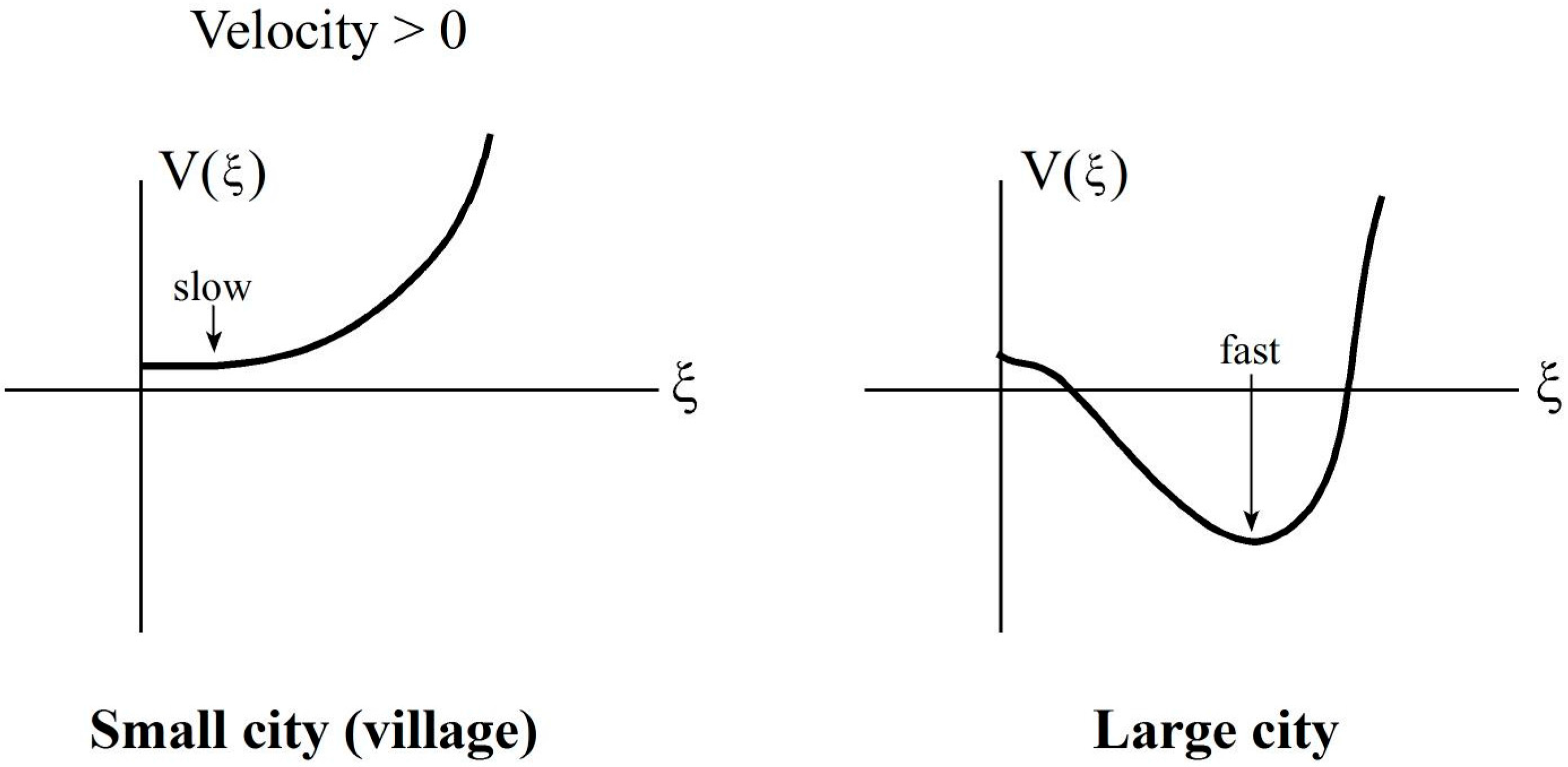{kind=link}
{kind=link}
{kind=link}






























