
Empirical Laws and Foreseeing the Future of Technological Progress




Abstract
:1. Introduction
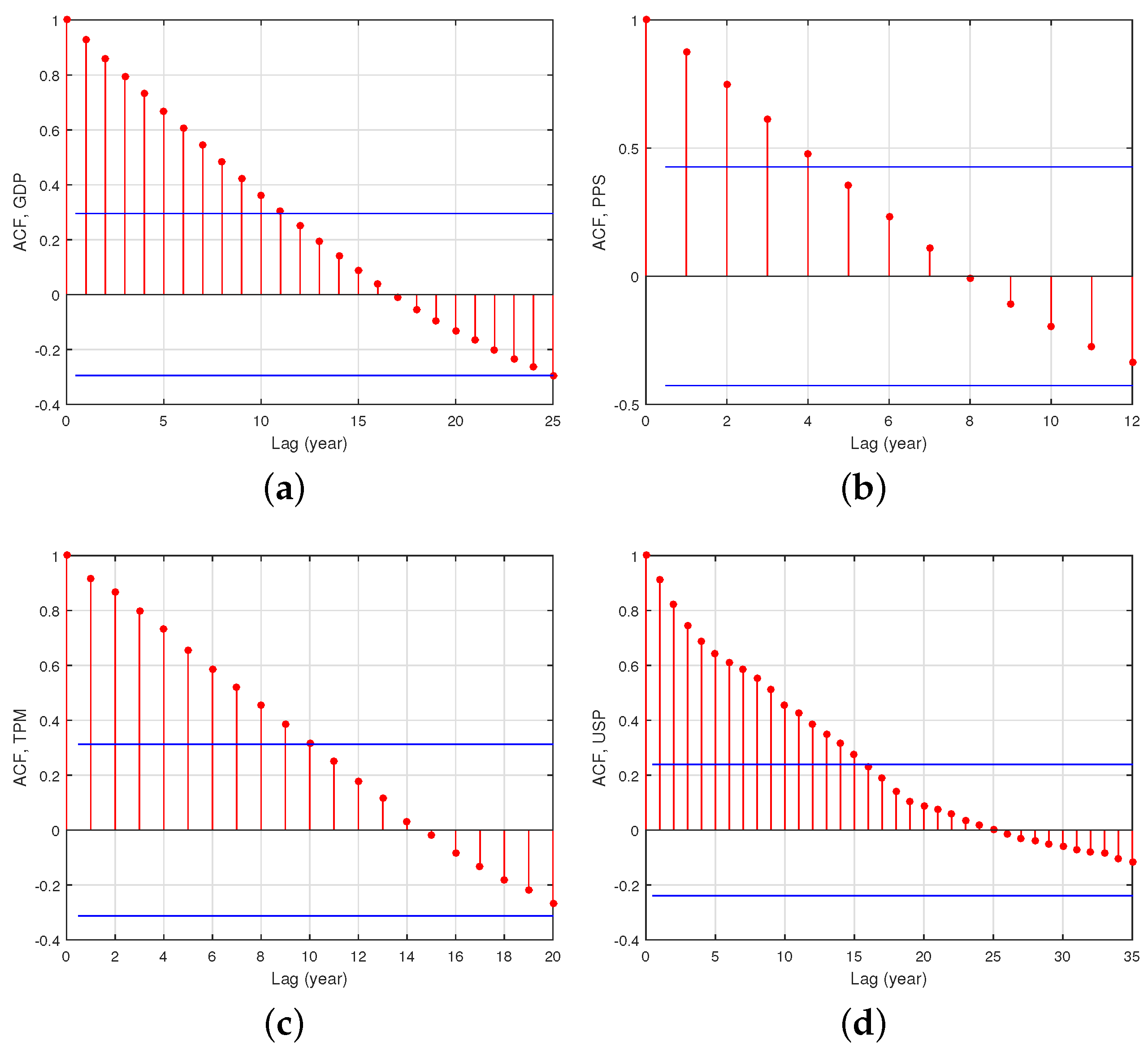
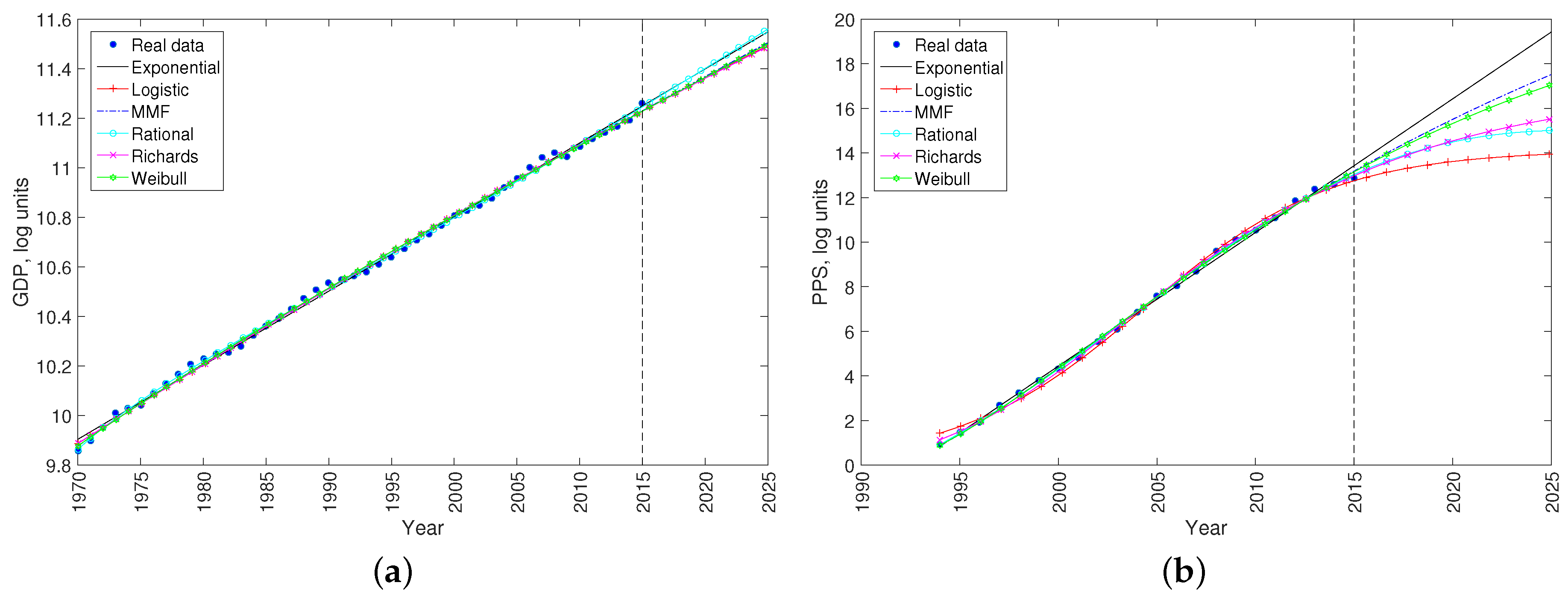
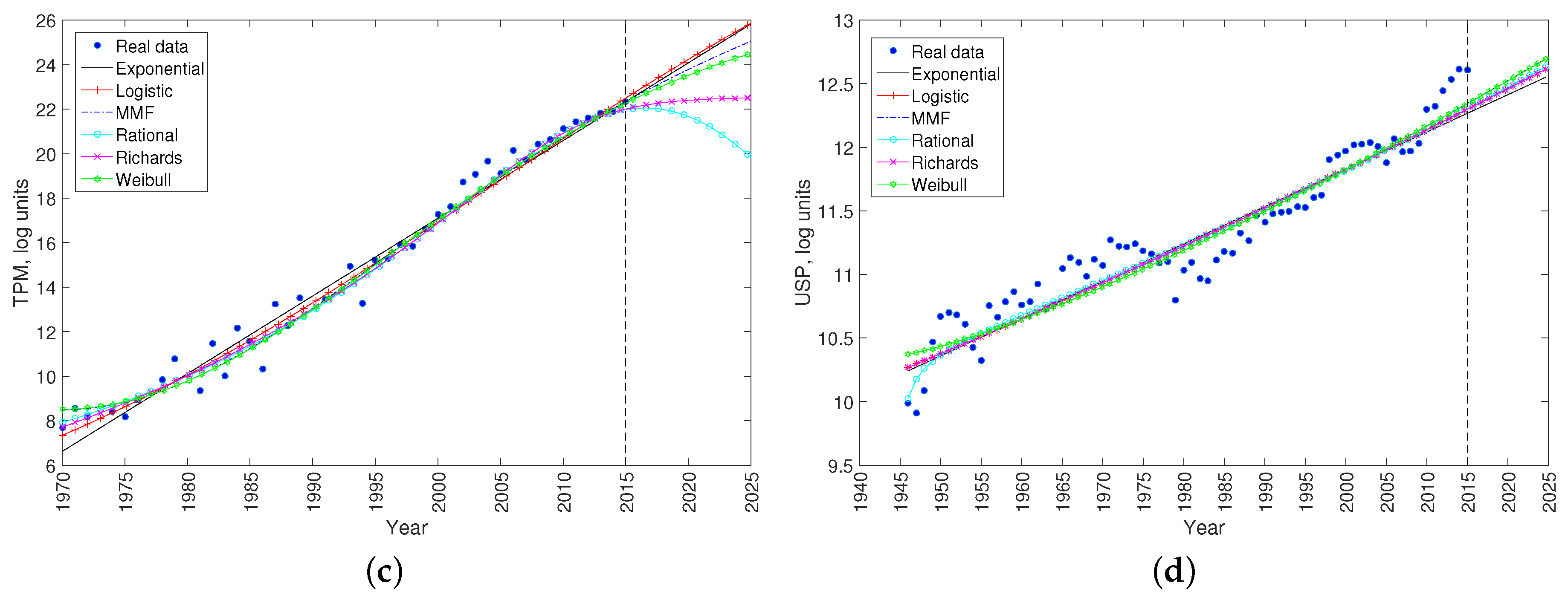
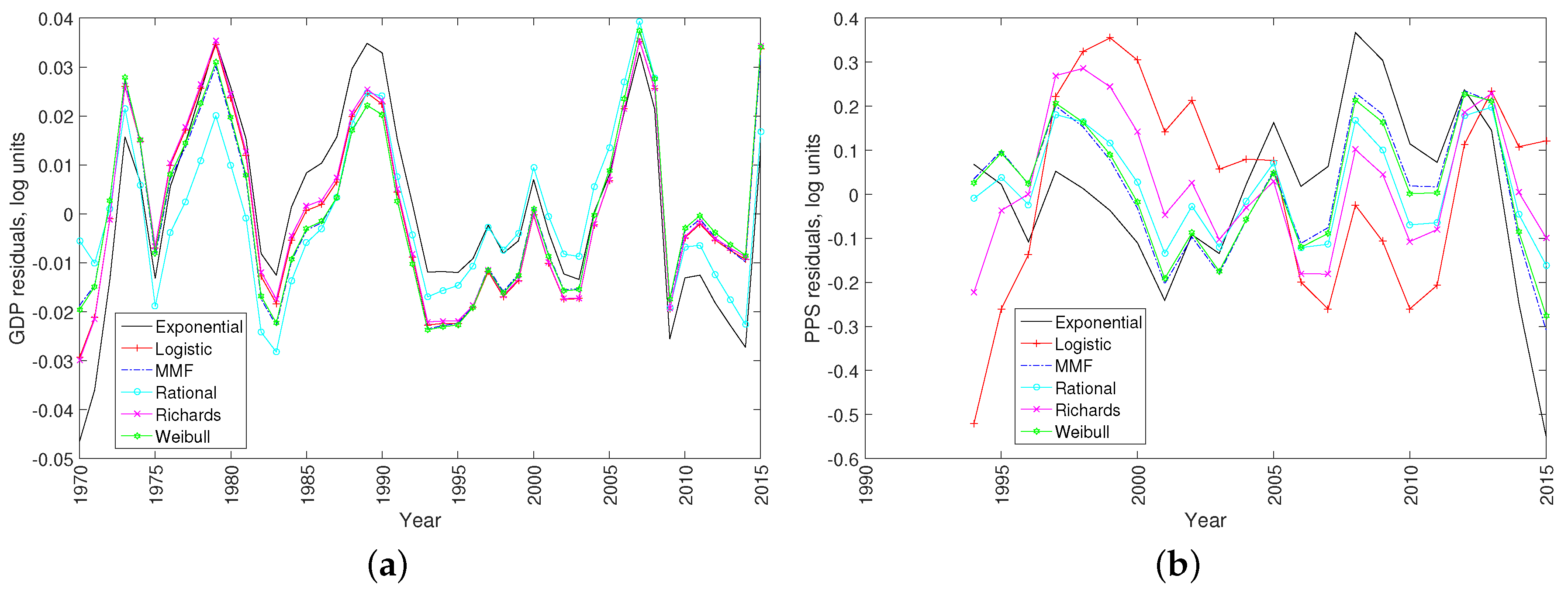
2. Data Analysis and Results
2.1. Nonlinear Least-Squares
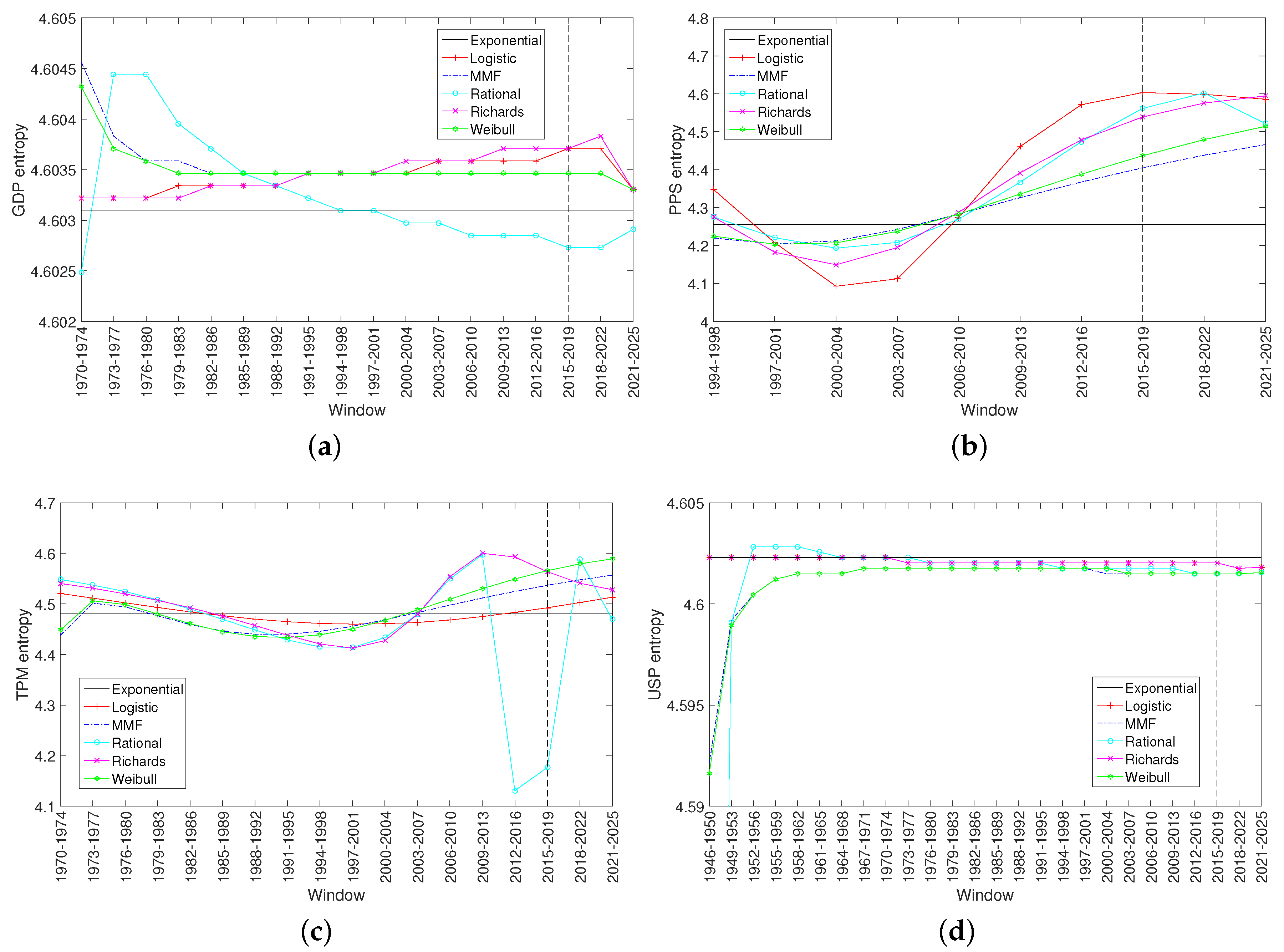
2.2. Entropy Analysis
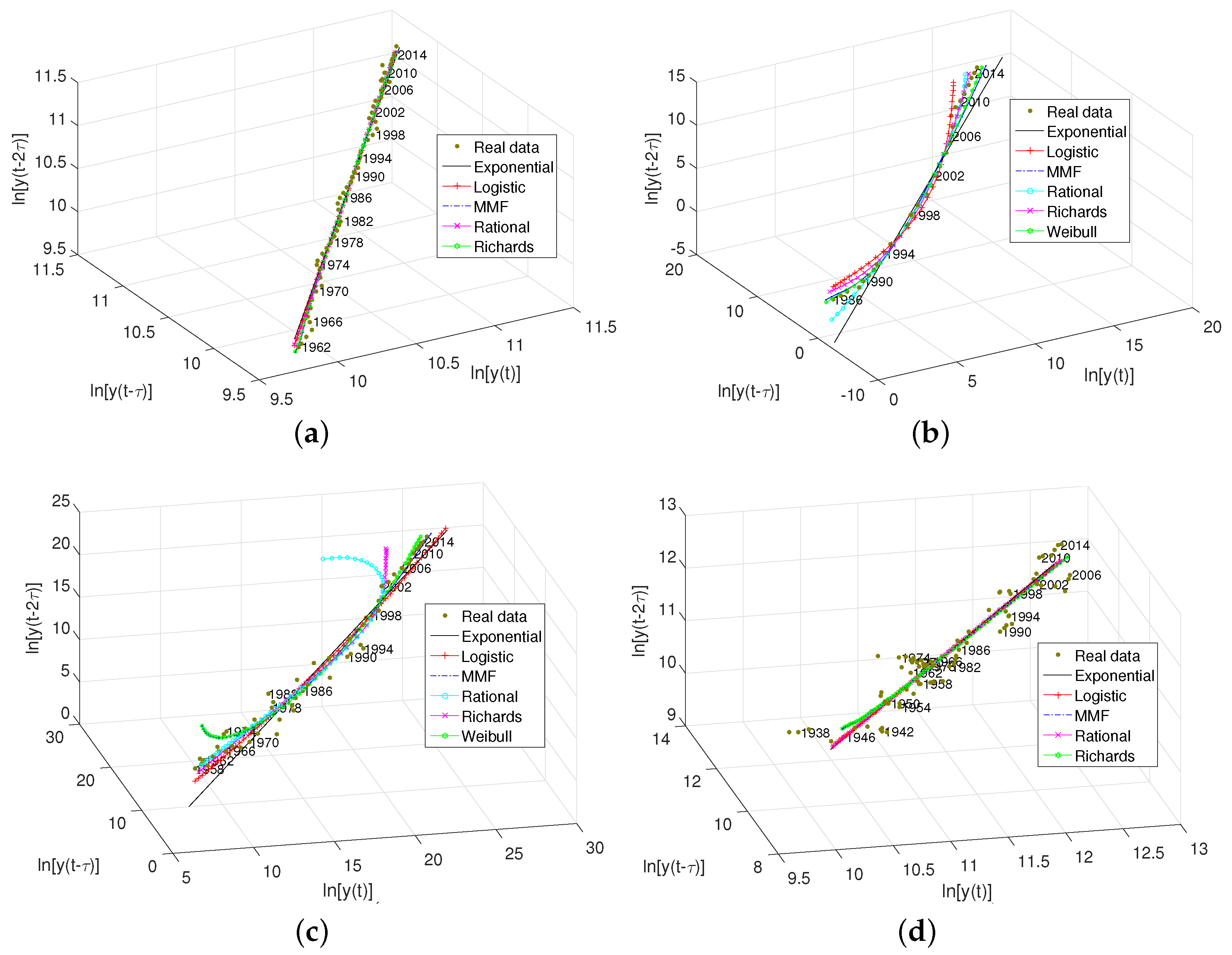
2.3. Pseudo-State Space
3. Discussion of the Results and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Moore, G. Cramming More Components Onto Integrated Circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Tuomi, I. The lives and death of Moore’s Law. First Monday 2002, 7, 11. [Google Scholar] [CrossRef]
- Mollick, E. Establishing Moore’s law. Ann. Histor. Comput. IEEE 2006, 28, 62–75. [Google Scholar] [CrossRef]
- Bondyopadhyay, P.K. Moore’s law governs the silicon revolution. Proc. IEEE 1998, 86, 78–81. [Google Scholar] [CrossRef]
- Schaller, R.R. Moore’s law: Past, present and future. Spectr. IEEE 1997, 34, 52–59. [Google Scholar] [CrossRef]
- Moore, G. Progress in digital integrated electronics. In Proceedings of the International Electron Devices Meeting, Washington, DC, USA, 1–3 December 1975; Volume 21, pp. 11–13.
- Sanders, T. The Moore’s Law of Moore’s Laws. MRS Bull. 2015, 40, 991–992. [Google Scholar] [CrossRef]
- Zhang, L.; Powell, J.J.; Baker, D.P. Exponential Growth and the Shifting Global Center of Gravity of Science Production, 1900–2011. Chang. Mag. High. Learn. 2015, 47, 46–49. [Google Scholar] [CrossRef]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- Korotayev, A. A compact macromodel of world system evolution. J. World Syst. Res. 2015, 11, 79–93. [Google Scholar] [CrossRef]
- Lambert, D.R.; Joyce, M.L.; Krentler, K.A. The Multiplying Literature: Moore’s Law at Work in Marketing. In Assessing the Different Roles of Marketing Theory and Practice in the Jaws of Economic Uncertainty; Springer: Heidelberg/Berlin, Germany, 2015; pp. 114–120. [Google Scholar]
- Chien, A.A.; Karamcheti, V. Moore’s Law: The first ending and a new beginning. Computer 2013, 48–53. [Google Scholar] [CrossRef]
- Iyer-Biswas, S.; Crooks, G.E.; Scherer, N.F.; Dinner, A.R. Universality in stochastic exponential growth. Phys. Rev. Lett. 2014, 113, 028101. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Amaral, L.A.N.; Canning, D.; Meyer, M.; Stanley, H.E. Universal features in the growth dynamics of complex organizations. Phys. Rev. Lett. 1998, 81, 3275. [Google Scholar] [CrossRef]
- Kurzweil, R. The Law of Accelerating Returns; Springer: Heidelberg/Berlin, Germany, 2004. [Google Scholar]
- Kim, N.S.; Austin, T.; Baauw, D.; Mudge, T.; Flautner, K.; Hu, J.S.; Irwin, M.J.; Kandemir, M.; Narayanan, V. Leakage current: Moore’s law meets static power. Computer 2003, 36, 68–75. [Google Scholar]
- Kurzweil, R. The Singularity Is Near: When Humans Transcend Biology; Viking: New York, NY, USA, 2005. [Google Scholar]
- Troyer, M. Beyond Moore’s law: Towards competitive quantum devices. In Proceedings of the 46th Annual Meeting of the APS Division of Atomic, Molecular and Optical Physics, Columbus, OH, USA, 8–12 June 2015; Volume 1, p. 2003.
- Toumey, C. Less is Moore. Nat. Nanotechnol. 2016, 11, 2–3. [Google Scholar] [CrossRef] [PubMed]
- Cavin, R.K.; Lugli, P., III; Zhirnov, V.V. Science and engineering beyond Moore’s law. Proc. IEEE 2012, 100, 1720–1749. [Google Scholar] [CrossRef]
- Sheu, B.; Wilcox, K.; Keshavarzi, A.; Antoniadis, D. EP1: Moore’s law challenges below 10 nm: Technology, design and economic implications. In Proceedings of the 2015 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 22–26 February 2015.
- Varghese, S.; Elemans, J.A.; Rowan, A.E.; Nolte, R.J. Molecular computing: Paths to chemical Turing machines. Chem. Sci. 2015, 6, 6050–6058. [Google Scholar] [CrossRef] [Green Version]
- Kendon, V.; Sebald, A.; Stepney, S. Heterotic computing: Exploiting hybrid computational devices. Phil. Trans. R. Soc. A 2015, 373, 20150091. [Google Scholar] [CrossRef] [PubMed]
- Nagy, B.; Farmer, J.D.; Bui, Q.M.; Trancik, J.E. Statistical basis for predicting technological progress. PLoS ONE 2013, 8, e52669. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koh, H.; Magee, C.L. A functional approach for studying technological progress: Application to information technology. Technol. Forecast. Soc. Chang. 2006, 73, 1061–1083. [Google Scholar] [CrossRef]
- Koh, H.; Magee, C.L. A functional approach for studying technological progress: Extension to energy technology. Technol. Forecast. Soc. Chang. 2008, 75, 735–758. [Google Scholar] [CrossRef]
- Machado, J.A.T. Complex dynamics of financial indices. Nonlinear Dyn. 2013, 74, 287–296. [Google Scholar] [CrossRef]
- Machado, J.A.T.; Mata, M.E. Pseudo phase plane and fractional calculus modeling of western global economic downturn. Commun. Nonlinear Sci. Numer. Simul. 2015, 22, 396–406. [Google Scholar] [CrossRef]
- The World Bank. Available online: www.worldbank.org (accessed on 1 June 2016).
- TOP500 Supercomputing Sites. Available online: http://www.top500.org/ (accessed on 1 June 2016).
- Transistor Count. Available online: https://en.wikipedia.org/wiki/Transistor_count (accessed on 1 June 2016).
- United States Patent and Trademark Office. Available online: http://www.uspto.gov/ (accessed on 1 June 2016).
- Coelho, M.C.; Mendes, E.M.; Aguirre, L.A. Testing for intracycle determinism in pseudoperiodic time series. Chaos Interdiscip. J. Nonlinear Sci. 2008, 18, 023125. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, D.T.; Glass, L. Direct test for determinism in a time series. Phys. Rev. Lett. 1992, 68. [Google Scholar] [CrossRef] [PubMed]
- Theiler, J.; Eubank, S.; Longtin, A.; Galdrikian, B.; Farmer, J.D. Testing for nonlinearity in time series: the method of surrogate data. Phys. D Nonlinear Phenom. 1992, 58, 77–94. [Google Scholar] [CrossRef]
- Lütkepohl, H.; Xu, F. The role of the log transformation in forecasting economic variables. Empir. Econ. 2012, 42, 619–638. [Google Scholar] [CrossRef] [Green Version]
- Fuller, S.H.; Millett, L.I. Computing performance: Game over or next level? Computer 2011, 44, 31–38. [Google Scholar] [CrossRef]
- Hubbert, M.K. Exponential growth as a transient phenomenon in human history. In Valuing the Earth: Economics, Ecology Ethics, 2nd ed.; Daly, H.E., Townsend, K.N., Eds.; MIT Press: Cambridge, MA, USA, 1993; pp. 113–126. [Google Scholar]
- Lopes, A.M.; Machado, J.A.T.; Pinto, C.M.; Galhano, A.M. Fractional dynamics and MDS visualization of earthquake phenomena. Comput. Math. Appl. 2013, 66, 647–658. [Google Scholar] [CrossRef]
- Carrillo, M.; González, J.M. A new approach to modelling sigmoidal curves. Technol. Forecas. Soc. Chang. 2002, 69, 233–241. [Google Scholar] [CrossRef]
- Tsoularis, A.; Wallace, J. Analysis of logistic growth models. Math. Biosci. 2002, 179, 21–55. [Google Scholar] [CrossRef]
- Lawson, C.L.; Hanson, R.J. Solving Least Squares Problems; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1974; Volume 161. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis; Wiley: New York, NY, USA, 1998; Volume 3. [Google Scholar]
- Mood, A.M.; Graybill, F.; Boes, D.C. Introduction to the Theory of Statistics; Mcgraw-Hill College: New York, NY, USA, 1974. [Google Scholar]
- Balasis, G.; Daglis, I.A.; Papadimitriou, C.; Anastasiadis, A.; Sandberg, I.; Eftaxias, K. Quantifying dynamical complexity of magnetic storms and solar flares via nonextensive Tsallis entropy. Entropy 2011, 13, 1865–1881. [Google Scholar] [CrossRef]
- Seely, A.J.; Newman, K.D.; Herry, C.L. Fractal Structure and Entropy Production within the Central Nervous System. Entropy 2014, 16, 4497–4520. [Google Scholar] [CrossRef]
- Machado, J.A.T.; Lopes, A.M. Analysis and visualization of seismic data using mutual information. Entropy 2013, 15, 3892–3909. [Google Scholar] [CrossRef]
- Machado, J.A.T.; Lopes, A.M. The persistence of memory. Nonlinear Dyn. 2014, 79, 63–82. [Google Scholar] [CrossRef]
- Machado, J.A.T. Accessing complexity from genome information. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 2237–2243. [Google Scholar] [CrossRef]
- Lopes, A.M.; Machado, J.A.T. Dynamic analysis of earthquake phenomena by means of pseudo phase plane. Nonlinear Dyn. 2013, 74, 1191–1202. [Google Scholar] [CrossRef]
- Takens, F. Detecting Strange Attractors in Turbulence; Springer: Heidelberg/Berlin, Germany, 1981. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Louhichi, S.; Ycart, B. Exponential growth of bifurcating processes with ancestral dependence. Adv. Appl. Probab. 2015, 47, 545–564. [Google Scholar] [CrossRef]
- Hunt, A.G. Exponential growth in Ebola outbreak since May 14, 2014. Complexity 2014, 20, 8–11. [Google Scholar] [CrossRef]
- Serbyn, M.; Papić, Z.; Abanin, D.A. Universal slow growth of entanglement in interacting strongly disordered systems. Phys. Rev. Lett. 2013, 110, 260601. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Brenes, I.A.; Komarova, N.L.; Wodarz, D. Tumor growth dynamics: Insights into evolutionary processes. Trends Ecol. Evol. 2013, 28, 597–604. [Google Scholar] [CrossRef] [PubMed]
- Pinto, C.; Mendes Lopes, A.M.; Machado, J.A.T. A review of power laws in real life phenomena. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 3558–3578. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Quine, M.; Robinson, J. A linear random growth model. J. Appl. Probab. 1990, 27, 499–509. [Google Scholar] [CrossRef]
- Brynjolfsson, E.; McAfee, A. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies; W. W. Norton & Company: New York, NY, USA, 2014. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| i | Performance Index | Time Range | Number of Points | Units |
|---|---|---|---|---|
| 1 | GDP | 1970–2015 | 46 | 2010 US$ |
| 2 | PPS | 1994–2015 | 42 | FLOPS |
| 3 | TPM | 1970–2015 | 102 | Transistors |
| 4 | USP | 1946–2015 | 70 | Patents |
| Exponential | Logistic | MMF | Rational | Richards | Weibull | |
|---|---|---|---|---|---|---|
| NRMSD, | NRMSD, | NRMSD, | NRMSD, | NRMSD, | NRMSD, | |
| GDP | 0.0138, 0.9976 | 0.0130, 0.9980 | 0.0124, 0.9982 | 0.0111, 0.9985 | 0.0131, 0.9979 | 0.0156, 0.9981 |
| PPS | 0.0186, 0.9962 | 0.0219, 0.9953 | 0.0159, 0.9973 | 0.0142, 0.9979 | 0.0163, 0.9973 | 0.0173, 0.9974 |
| TPM | 0.0713, 0.9521 | 0.0672, 0.9565 | 0.0669, 0.9578 | 0.0672, 0.9595 | 0.0672, 0.9594 | 0.0670, 0.9581 |
| USP | 0.0826, 0.8998 | 0.0796, 0.9040 | 0.0777, 0.9049 | 0.0760, 0.9124 | 0.0796, 0.9040 | 0.0779, 0.9047 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopes, A.M.; Tenreiro Machado, J.A.; Galhano, A.M. Empirical Laws and Foreseeing the Future of Technological Progress. Entropy 2016, 18, 217. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060217
Lopes AM, Tenreiro Machado JA, Galhano AM. Empirical Laws and Foreseeing the Future of Technological Progress. Entropy. 2016; 18(6):217. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060217
Chicago/Turabian StyleLopes, António M., José A. Tenreiro Machado, and Alexandra M. Galhano. 2016. "Empirical Laws and Foreseeing the Future of Technological Progress" Entropy 18, no. 6: 217. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060217