
Constant Slope Maps and the Vere-Jones Classification

1
Faculty of Civil Engineering, Czech Technical University in Prague, Thákurova 7, 16629 Praha 6, Czech Republic
2
Faculty of Mathematics, University of Vienna, Oskar Morgensternplatz 1, 1090 Wien, Austria
*
Author to whom correspondence should be addressed.
Entropy 2016, 18(6), 234; https://0-doi-org.brum.beds.ac.uk/10.3390/e18060234
Submission received: 22 April 2016
/
Revised: 6 June 2016
/
Accepted: 16 June 2016
/
Published: 22 June 2016
(This article belongs to the Special Issue Entropic Properties of Dynamical Systems)
Abstract
:We study continuous countably-piecewise monotone interval maps and formulate conditions under which these are conjugate to maps of constant slope, particularly when this slope is given by the topological entropy of the map. We confine our investigation to the Markov case and phrase our conditions in the terminology of the Vere-Jones classification of infinite matrices.
MSC:
37E05; 37B40; 46B25
1. Introduction
For , , a continuous map is said to be piecewise monotone if there are and points , such that T is monotone on each , . A piecewise monotone map T has constant slopes if for all .
The following results are well known for piecewise monotone interval maps:
Theorem 1
Theorem 2
([3]). If T has a constant slope s, then .
For continuous interval maps with a countably-infinite number of pieces of monotonicity, neither theorem is true; for examples, see [4] and [5]. One of the few facts that remains true in the countably-piecewise monotone setting is:
Proposition 1
([6]). If T is s-Lipschitz, then .
A continuous interval map T has constant slope s if for all but countably many points.
The question we want to address is when a continuous countably-piecewise monotone interval map T is conjugate to a map of constant slope λ. Particular attention will be given to the case when a slope is given by the topological entropy of T, which we call linearizability:
Definition 1.
A continuous map is said to be linearizable if it is conjugate to an interval map of constant slope .
We will confine ourselves to the Markov case and explore what can be said if only the transition matrix of a countably-piecewise monotone map is known in terms of the Vere-Jones classification [7], refined by [8].
The structure of our paper is as follows.
In Section 2 (: the class of countably-piecewise monotone Markov maps), we make precise the conditions on continuous interval maps under which we conduct our investigation; the set of all such maps will be denoted by (for countably-piecewise monotone Markov). In particular, we introduce a slack countable Markov partition of a map and distinguish between the operator and non-operator type respectively.
In Section 3 (conjugacy of a map from to a map of constant slope), we rephrase the key equivalence from [9] (Theorem 2.5): for the sake of completeness, we formulate Theorem 3, which relates the existence of a conjugacy to an “eigenvalue equation” (5), using both classical and slack countable Markov partitions; see Definition 2.
Section 4 (the Vere-Jones classification) is devoted to the Vere-Jones classification [7] that we use as a crucial tool in most of our proofs in later sections.
In Section 5 (entropy and the Vere-Jones classification in ), we show in Proposition 8 that the topological entropy of a map in question and (the logarithm of) the Perron value of its transition matrix coincide. Using this fact, we are able to verify in Proposition 9 that all of the transition matrices of a map corresponding to all of the possible Markov partitions of that map belong to the same class in the Vere-Jones classification; so we can speak about the Vere-Jones classification of a map from .
In Section 6 (linearizability), we present the main results of this text. We start with Proposition 10 showing two basic properties of a λ-solution of Equation (5) and Theorem 7 on locally eventually onto (leo) maps; see Definition 4. Afterwards, we describe conditions under which a local window perturbation—Theorems 8 and 9, resp. a global window perturbation—Theorems 10 and 11 results in a linearizable map.
In Section 7 (examples), various examples illustrating linearizability/conjugacy to a map of constant slope in the Vere-Jones classes are presented.
2. : The Class of Countably Piecewise Monotone Markov Maps
Definition 2.
A countable Markov partition for a continuous map consists of closed intervals with the following properties:
- Two elements of have pairwise disjoint interiors, and is at most countable.
- The partition is finite or countably-infinite;
- is monotone for each (classical Markov partition) or piecewise monotone for each ; in the latter case, we will speak of a slack Markov partition.
- For every and every maximal interval of monotonicity of T, if , then .
Remark 1.
The notion of a slack Markov partition will be useful in later sections of this paper, where we will work with window perturbations. If , then the ordinal type of need not be or .
Definition 3.
The class is the set of continuous interval maps satisfying:
- T is topologically mixing, i.e., for every open sets , there is an n, such that for all .
- T admits a countably-infinite Markov partition.
- .
Remark 2.
Since is topologically mixing by definition, it cannot be constant on any subinterval of .
Definition 4.
A map is called leo (locally eventually onto) if for every nonempty open set U, there is an , such that .
Remark 3.
Let be a piecewise monotone Markov map, i.e., such that orbits of turning points and endpoints are finite. Those orbits naturally determine a finite Markov partition for T. This partition can be easily be refined, in infinite ways, to countably-infinite Markov partitions. If T is topologically mixing and continuous, then we will consider T as an element of .
Proposition 2.
Let with a Markov partition . For every pair satisfying , there exist a maximal and intervals with pairwise disjoint interiors, such that is monotone and for each .
Proof.
Since is topologically mixing, it is not constant on any subinterval of . Fix a pair with . Since T is continuous, there has to be at least one, but at most a finite number of pairwise disjoint subintervals of i satisfying the conclusion. ☐
For a given with a Markov partition , applying Proposition 2, we associate with the transition matrix defined by:
If is a classical Markov partition of some , then each .
Remark 4.
For the sake of clarity, we will write when a map , a concrete Markov partition for T and its transition matrix with respect to are assumed.
For an infinite matrix M indexed by a countable index set , we can consider the powers of M:
Proposition 3.
Let .
- (i)
- For each and , the entry of is finite.
- (ii)
- The entry if and only if there are exactly m subintervals , …, of i with pairwise disjoint interiors, such that , .
Proof.
A matrix M indexed by the elements of represents a bounded linear operator on the Banach space of summable sequences indexed by , provided that the supremum of the columnar sums is finite. Then, is realized through left multiplication:
The matrix represents the n-th power of and by Gelfand’s formula, the spectral radius .
Remark 5.
If , the supremum in (3) is finite if and only if:
Since this condition does not depend on a concrete choice of , we will say the map T is of an operator type when the condition (4) is fulfilled and of a non-operator type otherwise.
3. Conjugacy of a Map from to a Map of Constant Slope
This section is devoted to the fundamental observation regarding a possible conjugacy of an element of to a map of constant slope. It is presented in Theorem 3.
Let . We are interested in positive real numbers λ and nonzero nonnegative sequences satisfying , or equivalently:
Definition 5.
A nonzero nonnegative sequence satisfying (5) will be called a λ-solution (for M). If in addition , it will be called a summable λ-solution (for M).
Remark 6.
Since every is topologically mixing, any nonzero nonnegative λ-solution is in fact positive: if solves Equation (5), and , then by Proposition 3(ii) for some sufficiently large n, .
Let denote the class of all maps from of constant slope λ, i.e., if for all, but countably many points.
The core of the following theorem has been proven in [9] (Theorem 2.5). Since we will work with maps from that are topologically mixing, we use topological conjugacies only; see [10] (Proposition 4.6.9). The theorem will enable us to change freely between classical/slack Markov partitions of the map in question.
Theorem 3.
Let . The following conditions are equivalent.
- (i)
- For some , the map T is conjugate via a continuous increasing onto map to some map .
- (ii)
- For some classical Markov partition for T, there is a positive summable λ-solution of Equation (5).
- (iii)
- For every classical Markov partition for T, there is a positive summable λ-solution of Equation (5).
- (iv)
- For every slack Markov partition for T, there is a positive summable λ-solution of Equation (5).
- (v)
- For some slack Markov partition for T, there is a positive summable λ-solution of Equation (5).
Remark 7.
Remark 8.
Proof of Theorem 3.
The equivalence of (i), (ii) and (iii) has been proven in [9]. Since (iv) implies (iii) and (v), it suffices to show that (iii) implies (iv) and (v) implies (ii).
(iii)(iv). Let us assume that is a slack Markov partition for T. Obviously, there is a classical partition for T which is finer than , i.e., every element of is contained in some element of . Using (iii), we can consider a positive summable λ-solution of Equation (5). Let be defined as:
Clearly, the positive sequence is from . Denoting and the transition matrices corresponding to the partitions , , we can write:
where the equality follows from the Markov property of T on and :
Therefore, by Equation (6), for a given slack Markov partition (for T), we find a positive summable λ-solution of Equation (5).
(v)(ii). Assume that for some slack Markov partition for T, there is a positive summable λ-solution of Equation (5). As in the previous part, we can consider a classical Markov partition finer than . Using again the property (7), let us put:
Then, is positive, and we will show that it is a summable λ-solution of Equation (5). Fix an , and use the property (7) for for which . Then:
Hence, summing Equation (9) through all j’s from that are T-covered by , we obtain with the help of Equation (8),
Maps are continuous, topologically mixing with positive topological entropy. Thus, all possible semi-conjugacies described in [9] (Theorem 2.5) will be in fact conjugacies; see [10] (Proposition 4.6.9). Many properties hold under the assumption of positive entropy or for countably-piecewise continuous maps. One interesting example of a countably-piecewise continuous and countably-piecewise monotone (still topologically mixing) map will be presented in Section 7. However, since the technical details are much more involved and would obscure the ideas, we confine the proofs to .
4. The Vere-Jones Classification
Let us consider a matrix , where the index set is finite or countably infinite. The matrix M will be called:
- irreducible, if for each pair of indices , there exists a positive integer n, such that , and
- aperiodic, if for each index , the value .
Remark 9.
Since is topologically mixing, its transition matrix M is irreducible and aperiodic.
In the sequel, we follow the approach suggested by Vere-Jones [7].
Proposition 4.
- (i)
- Let be a nonnegative irreducible aperiodic matrix indexed by a countable index set . There exists a common value , such that for each :
- (ii)
- For any value and all :
- the series are either all convergent or all divergent;
- as , either all or none of the sequences tend to zero.
Remark 10.
The number defined by Equation (10) is often called the Perron value of M. In the whole text, we will assume that for a given nonnegative irreducible aperiodic matrix , its Perron value is finite.
4.1. Entropy, Generating Functions and the Vere-Jones Classes
To a given irreducible aperiodic matrix with entries from corresponds a strongly-connected directed graph containing edges from i to j.
The Gurevich entropy of M (or of ) is defined as:
where is the large eigenvalue of the finite transition matrix . Gurevich proved that:
Proposition 5
([13]). .
Since by Proposition 4, the value is a common radius of convergence of the power series , we immediately obtain for each pair ,
It is well known that in :
- equals the number of paths of length n connecting i to j.
Following [7], for each , we will consider the following coefficients:
- The first entrance to j: equals the number of paths of length n connecting i to j, without the appearance of j in between.
- The last exit of i: equals the number of paths of length n connecting i to j, without the appearance of i in between.
Clearly, for each . Furthermore, it will be useful to introduce:
- The first entrance to : for a nonempty and , equals the number of paths of length n connecting i to j, without the appearance of any element of in between.
The first entrance to will provide us a new type of a generating function used in (37) and its applications.
Remark 11.
Let us denote by , the radius of convergence of the power series , . Since , for each and each , we always have , .
Proposition 6 has been stated in [8]. Since the argument showing Part (i) presented in [8] is not correct, we offer our own version of its proof.
Proposition 6
([8] (Proposition 2.6)). Let ; consider the graph , .
- (i)
- If there is a vertex j, such that then, there exists a strongly-connected subgraph , such that .
- (ii)
- If there is a vertex j, such that , then for all proper strongly-connected subgraphs , one has .
- (iii)
- If there is a vertex j, such that , then for all i.
Proof.
For the proof of Part (ii), see [8].
Let us prove (i). Fix a vertex for which and choose arbitrary . We can write:
where , resp. , denotes the number of -paths of length n that do not contain i, resp. contain i.
- I.
- If ,
- II.
- Assume that . Then, by our assumption and Equation (11):
Let us denote the number of paths of length n connecting i to j, without the appearance of after the initial i and before the final j. If we denote the number of -paths of length n connecting i to i with exactly one appearance of j after the initial i and before the final i, we can write for (the coefficients are defined analogously as ; compare the proof of Theorem 6):
By the formula of [10] (Lemma 4.3.6) and our assumption (12), for arbitrary , we obtain from (13) either:
or:
If Equation (14) is fulfilled for some i, the existence of a strongly-connected subgraph , such that , immediately follows. Otherwise, since:
we get for each , and the conclusion follows from [14] (Theorem 2.2). Assertion (iii) immediately follows from (i) and (ii). ☐
The behavior of the series , for was used in the Vere-Jones classification of irreducible aperiodic matrices [7]. Vere-Jones originally distinguished R-transient, null R-recurrent and positive R-recurrent cases. Later on, the classification was refined by Ruette in [8], who added the strongly-positive R-recurrent case. All is summarized in Table 1, which applies independently of the sites for M irreducible; compare the last row of Table 1 and Proposition 6. We call corresponding classes of matrices transient, null recurrent, weakly recurrent and strongly recurrent. The last three, resp. two, possibilities will occasionally be summarized by “M is recurrent”, resp. “M is positive recurrent”.
4.1.1. Salama’s Criteria
There are geometrical criteria (see [14] and also [8]) for cases of the Vere-Jones classification to apply depending on whether the underlying strongly-connected directed graph can be enlarged/reduced (in the class of strongly-connected directed graphs) without changing the entropy. We will use some of them in Section 7.
4.1.2. Further Useful Facts
In the whole paper, we are interested in nonzero nonnegative solutions of Equation (5). Analogously, in the next proposition, we consider nonzero nonnegative subinvariant λ-solutions for a matrix M, i.e., satisfying the inequality .
Theorem 5
([7] (Theorem 4.1)). Let be irreducible. There is no subinvariant λ-solution for . If M is transient, there are infinitely many linearly-independent subinvariant -solutions. If M is recurrent, there is a unique subinvariant -solution, which is in fact the -solution of Equation (5) proportional to the vector ( fixed), .
A general statement (a slight adaption of [15] (Theorem 2)) on the solvability of Equation (5) is as follows:
Theorem 6.
Let be irreducible. The system has a nonzero nonnegative solution v if and only if:
- (a)
- and M is recurrent or
- (b)
- when either or and M is transient, there is an infinite sequence of indices , such that ():
Proof.
Following Chung [16], we will use the analogues of the taboo probabilities: for , define , and for ,
Clearly, equals the number of paths of length n connecting i to j with no appearance of k between. Denote also the number of paths of length n connecting i to j with at least one appearance of k between. The usual convention that will be used. The following identities directly follow from the definitions of the corresponding generating functions (see before Table 1) or are easy to verify: for all and ,
Using Identities (i)–(vi), we can write Equation (17) as:
Since by (vi), , using (v), we obtain that:
if and only if:
The conclusion follows from [15] (Theorem 2). ☐
Corollary 1.
If for each i, except for a finite set of j values, then has a nonzero nonnegative solution if and only if .
4.1.3. Useful Matrix Operations in the Vere-Jones Classes
In order to be able to modify the nonnegative matrices in question, we will need the following observation. In some cases, it will enable us to produce transition matrices of maps from . Let E be the identity matrix; see Equation (2).
Proposition 7.
Let be irreducible. For an arbitrary pair of positive integer k and nonnegative integer ℓ, consider the matrix . Then:
- (i)
- ,
- (ii)
- if for each i, except for a finite set of j values, the matrix N belongs to the same class of the Vere-Jones classification as the matrix M.
Proof.
Both conclusions clearly hold if N is a multiple of M, i.e., when . Therefore, to show our statement, it is sufficient to verify the case when .
- (i)
- Since if and only if , Property (i) follows from Corollary 1.
- (ii)
- By our assumption, for each i, , except for a finite set of j values, so Theorem 6 and Corollary 1 can be applied. Notice that for any nonnegative v,so by Theorem 5, the matrix M is transient, resp. recurrent, if and only if is transient, resp. recurrent. In order to distinguish different recurrent cases, we will use Table 1. Since by (i) , we can write:
By Equation (10) for each k, and we can put . For each , there exists , such that whenever . Then, using the fact that:
we can write for any and sufficiently large :
hence . By Table 1, M is null, resp. positive recurrent, if and only if N is null, resp. positive recurrent.
Finally, let be positive recurrent, and assume its irreducible submatrix for some ; denote . Then, similarly as above, we obtain that , resp. . If M is weakly, resp. strongly recurrent, then for some K, resp. for each K, we obtain , resp. , and Theorem 4 can be applied.
This finishes the proof for . Now, the case when , , can be verified inductively. ☐
5. Entropy and the Vere-Jones Classification in
The following statement identifies the topological entropy of a map and the Perron value of its transition matrix.
Proposition 8.
Let . Then, , and if there is a summable λ-solution of Equation (5), then .
Proof.
For the first equality, we start by proving . We use Proposition 4(i) and Proposition 3(ii). By those statements, for any and for each sufficiently large n, the interval j contains intervals with pairwise disjoint interiors, such that for all . Clearly, the map has a -horseshoe [17], hence and . Since n can be arbitrarily large, the inequality follows.
Now, we look at the reverse inequality . A pair is a subsystem of T if is closed and . It has been shown in [18] (Theorem 3.1) that the entropy of T can be expressed as the supremum of entropies of minimal subsystems. Let us fix a minimal subsystem of T for which .
Claim 1.
There are finitely many elements , such that .
Proof.
Let us denote . Then, P is closed, at most countable and . Assume that . Then, , which is impossible for minimal of positive topological entropy. If intersected infinitely many elements of , then, since is closed, it would intersect also P, a contradiction. Thus, there are finitely many of the required property. ☐
Our claim together with Proposition 2 say that the connect-the-dots map of is piecewise monotone, and the finite submatrix of M corresponding to the elements satisfies . Now, the conclusion follows from Proposition 5.
The second statement follows from Theorem 3, Proposition 1 and the fact that topological entropy is a conjugacy invariant: . ☐
We would like to transfer the Vere-Jones classification to . That is why it is necessary to be sure that a change of Markov partition for the map in question does not change the Vere-Jones type of its transition matrix. This is guaranteed by the following proposition.
Given , consider the family of all Markov partitions for T. Write . The minimal Markov partition for T consists of the closures of connected components of .
Proposition 9.
Let with two Markov partitions , resp. , and corresponding matrices , resp. . The matrices and belong to the same class of the Vere-Jones classification.
Proof.
Since the map T is topologically mixing, each of the matrices , is irreducible and aperiodic. Moreover, by Proposition 8, the value guaranteed in Proposition 4(i) equals and, so, is the same for both the matrices , ; denote it λ. Let and .
First, let us assume that . Fix two elements , resp. , such that . Let us consider a path of the length n:
with respect to ; by Proposition 2, each interval contains intervals of monotonicity of T (denote them ), such that whenever . This implies that:
is the number of paths with respect to through the same vertices in order given by Equation (20), and at the same time, it is an upper bound of a number of paths:
with respect to finer , such that for each i. Considering all possible paths in Equation (20) and summing their numbers given by Equation (21), we obtain:
for each n. On the other hand, since T is topologically mixing and Markov, there is a positive integer , such that . It implies for each n,
Hence, by the third row of Table 1, is recurrent if and only if is recurrent. Again, from Equations (22) and (23), we can see that is positive if and only if is positive, and the fourth row of Table 1 for can be applied.
In order to distinguish weak, resp. strong, recurrence, for a , let be such that:
Using Equations (22) and (23), again, we can see that the Perron values of the irreducible aperiodic matrices and coincide; hence, the Gurevich entropies , are equal if and only if it is the case for , ; now, Theorem 4(ii) and (iii) applies.
Second, if and , let us consider the partition , where any element of equals the closure of a connected component of the set . The reader can easily verify that is a Markov partition for T. By the previous, the pairs of matrices , , resp. , belong to the same class of the Vere-Jones classification. Therefore, it is true also for the pair , . ☐
Remark 12.
Let . Applying Proposition 9 in what follows, we will call T transient, null recurrent, weakly recurrent or strongly recurrent, respectively, if it is the case for its transition matrix M. The last three, resp. two, possibilities will occasionally be summarized by “T is recurrent”, resp. “T is positive recurrent”. It is well known that if T is piecewise monotone, then it is strongly recurrent [12] (Theorem 0.16).
6. Linearizability
In this section, we investigate in more detail the set of maps from that are conjugate to maps of constant slope (linearizable, in particular). Relying on Theorems 3 and 5 and Proposition 9, our main tools will be local and global perturbations of maps from resulting in maps from . Some examples illustrating the results achieved in this section will be presented in Section 7.
We start with an easy, but rather useful observation. Its second part will play the key role in our evaluation using centralized perturbation: Formula (37) and its applications.
Proposition 10.
Proof.
- (i)
- Since T is leo, for a fixed element i of , there is an , such that . Then, by Proposition 3 (ii), for each . This implies that any λ-solution of Equation (5) satisfies:so .
- (ii)
- We assume that T is topologically mixing; see Definition 3. For any fixed element , there is an , such that : since T is topologically mixing, there exist positive integers and , such that for every , resp. for every . This implies that the interval contains whenever ; fix one such n. Then, for any element j of , such that ; hence:for any λ-solution of Equation (5).
The fundamental conclusion regarding the linearizability of a map from provided by the Vere-Jones theory follows.
Theorem 7.
If is leo and recurrent, then T is linearizable.
Proof.
By assumption, there exists a Markov partition for T, such that the transition matrix is recurrent. In such a case, Equation (5) has a -solution described in Theorem 5. Since T is leo, the -solution is summable by Proposition 10(i), and the conclusion follows from Theorem 3. ☐
Remark 13.
In Section 7, we present various examples illustrating Theorem 7. In particular, we show a strongly recurrent non-leo map of an operator type that is not conjugate to any map of constant slope.
6.1. Window Perturbation
In this section, we introduce and study two types of perturbations of a map T from : local and global window perturbation.
6.1.1. Local Window Perturbation
Definition 6.
For with Markov partition , let , such that is monotone. We say that is a window perturbation of S on j (of order k, ), if:
- T equals S on
- there is a nontrivial partition of j, such that and is monotone for each i.
Notice that due to Definition 6, a window perturbation does not change partition (but renders it slack). Using a sufficiently fine Markov partition for S, its window perturbation T can be arbitrarily close to S with respect to the supremum norm.
In the above definition, an element of monotonicity of a partition is used. Therefore, for example, we can take classical (i.e., non-slack), or to a given partition and a given maximal interval of monotonicity i of a map, we can consider a partition finer than , such that .
Proposition 11.
Let be a window perturbation of a map . The following is true.
- (i)
- If S is recurrent, then T is strongly recurrent and .
- (ii)
- If S is transient, then T is strongly recurrent for each sufficiently large k.
Proof.
Fix a partition for S, let T be a window perturbation of S on . Applying Proposition 9, it is sufficient to specify the Vere-Jones class of T with respect to . Consider generating functions , corresponding to S, resp. T, and with radius of the convergence , resp. . Notice that:
hence .
- (i)
- (ii)
Let M be a matrix indexed by the elements of some and representing a bounded linear operator on the Banach space ; see Section 2. It is well known [19] (p. 264, Theorem 3.3) that for , the formula:
defines the resolvent operator to the operator
We will repeatedly use this fact when proving our main results. The following theorem implies that in the space of maps from of the operator type, an arbitrarily small (with respect to the supremum norm) local change of a map will result in a linearizable map.
Theorem 8.
Let be a window perturbation of order k of a map of operator type. Then, T is linearizable for every sufficiently large k.
Proof.
We will use the same notation as in the proof of Proposition 11.
Let us denote the transition matrix of a considered window perturbation of S; let be the value ensured for by Proposition 4; put . Since S is of operator type, it is also the case for each . Using Proposition 11 and Theorem 5, we obtain that for some , the perturbation is recurrent, and Equation (5) is -solvable:
where , . Since by Equation (25) for each k,
we can deduce that is decreasing and:
By our definition of a window perturbation, for each ,
Denote the spectral radius of the operator represented by the matrix . Using Equation (27), we can consider a for which . Then, since the resolvent operator represented by the matrix (26) is defined well for each real as a bounded operator on [19] (p. 264), we obtain from Equation (28), Remark 11 and Equation (3):
Now, since is recurrent, Theorems 3 and 5 can be applied. ☐
Let . For any pair , we define the number:
In the corresponding strongly-connected directed graph , is the length of the shortest path from i to j. In particular, such a path contains neither i nor j inside, so at the same time:
and for every . Since:
for every pair , the suprema:
are either all finite or all infinite. Moreover, we have the following.
Proposition 12.
Let with two Markov partitions , resp. . Then, is finite for some if and only if is finite for some .
Proof.
Let and . First, let us assume that . Fix two elements , , such that . Since the map T is topologically mixing, there exists a positive integer m for which . For an and an satisfying , we obtain and ; hence:
Inequality (30) together with the property (29) show that if is finite for some , then is finite for some .
On the other hand, there has to exist an , , such that , i.e., . Since also , we can write for :
Inequality (31) together with the property (29) show that if is finite for some , then is finite for some .
If and , we can consider the partition for T:
Clearly, , and we can use the above arguments for the pairs and ; hence, the conclusion for the pair follows. ☐
Therefore, in (29), for fixed and , we compare the shortest path from j to i (numerator) to the shortest path from i to j (denominator) and take the supremum with respect to i. For example, for our map from Section 7.3, the values (29) are equal to one, when T is leo, and (29) is finite for every . Theorem 8 explains the role of a window perturbation in the case of maps of the operator type. In Theorem 9, we obtain an analogous statement for maps of the non-operator type under the assumption that the quantities in (29) are finite.
Theorem 9.
Let with a Markov partition and such that the supremum in (29) is finite for some . Let be a window perturbation of order k of S. Then, T is linearizable for every sufficiently large k.
Proof.
Fix a partition for S and . A perturbation of S on j of order will be denoted by . By our assumption, Proposition 12 and (29), the supremum is finite. The numbers , , do not depend on any window perturbation on an element of , because such a perturbation does not change ; we define , , , . Obviously, for every n,
To simplify our notation, using Proposition 11, we will assume that S is strongly recurrent, so this is also true for . Similarly as in the proof of Proposition 11, we obtain for each k
,
Moreover, as in (27), the sequence is decreasing, and , i.e., .
6.1.2. Global Window Perturbation
Let S be from . In this part, we will consider a perturbation of S with a Markov partition consisting of infinitely many window perturbations on elements of (and with independent orders) done due to Definition 6.
Definition 7.
A perturbation T of S on will be called centralized if there is an interval , , such that .
For technical reasons, we consider also an empty perturbation () as centralized.
Let T be a global (centralized) perturbation of S on ; denote . We can write for :
where the coefficients were defined before Remark 11. We use Formula (37) to argue in our proofs.
In the next theorem, the perturbation T need not be of an operator type.
Theorem 10.
Let be recurrent and linearizable. Assume that T is a recurrent centralized perturbation of S on . If there are finitely many elements of that are S-covered by elements of , then T is linearizable.
Proof.
Let be all elements of that are S-covered by elements of . Then:
Here, the last inequality follows from our assumption that the map S is recurrent and linearizable together with Theorems 3 and 5. Using (37), (38) and Proposition 10(ii), we obtain:
Therefore, by Theorems 3 and 5, the map T is linearizable. ☐
In the next theorem, the perturbation T need not be of the operator type.
Theorem 11.
Let be of the operator type. If the transition matrix represents an operator of the spectral radius , then any centralized recurrent perturbation T of S, such that , is linearizable. The entropy assumption is always satisfied when S is recurrent.
Proof.
Let T be a centralized perturbation of S on ; denote . From Proposition 8 and our assumption on the topological entropy of S and T, we obtain . We can write for :
where the last inequality follows from the fact that for each and ; for the definition of , see before Remark 11. By our assumption, Formula (26) represents the resolvent operator for every . In particular, is a bounded operator on [19] (p. 264); hence, with the help of Remark 11 we obtain:
and (39), (40) can be rewritten as:
because for topologically mixing T by Proposition 10(ii) and Theorem 5. The conclusion follows from Theorem 5 and (41), (42). It was shown in Proposition 11(i) that for a recurrent S, we always have . ☐
In order to apply Theorem 11, let us consider any map of the operator type; fix . By Theorem 8, there is a strongly recurrent linearizable map S of the operator type for which . Similarly, as in (27), we can conclude that the transition matrix of S satisfies the assumption of Theorem 11. By that theorem, any centralized perturbation T (operator/non-operator) of S is linearizable (such a centralized perturbation T can be taken to satisfy ).
7. Examples
7.1. Non-Leo Maps in the Vere-Jones Classes
For some , consider the matrix , given as:
Clearly, M is irreducible, but not aperiodic. It has period two, so we consider only . Obviously,
Using Stirling’s formula, we can write:
Therefore, . At the same time, we can see from (44) that:
so by Table 1, is null recurrent for each pair .
In the following statement, we describe a class of maps that are not conjugate to any map of constant slope. In particular, they are not linearizable. A rich space of such maps (not only Markov) has been studied by different methods in [20].
Proposition 13.
Let , k even and ℓ odd, consider the matrix defined in (43). Then, is a transition matrix of a non-leo map T from . The map T is null recurrent, and it is not conjugate to any map of constant slope. The matrix N represents an operator on and:
Proof.
Notice that the entries of N away from, resp. on, the diagonal are even, resp. odd. Draw a (countably piecewise affine, for example) graph of a map T from for which N is its transition matrix. Since is null recurrent, the matrix N is also null recurrent by Proposition 7. Solving the difference equation:
one can verify that Equation (5) with has a λ-solution if and only if (this follows also from Corollary 1), and none of these solutions is summable. Therefore, by Proposition 7 and Theorem 3, the map T is not conjugate to any map of constant slope. ☐
For some , let be given by:
Again, the matrix M is irreducible, but not aperiodic. It has period two, so we consider only the coefficients ; see Section 4.1. In order to find a λ-solution for M, we can use the difference Equation (46) for with the additional conditions and . Using Corollary 1 and the direct computation, one can show:
Proposition 14.
- (a)
- For any choice of ,so that .
- (b)
- If , then and M is transient. There is a summable -solution for M if and only if .
- (c)
- If , then and M is null recurrent. There is a summable -solution for M if and only if .
- (d)
- If , then , and M is strongly recurrent. There is a summable -solution for M if and only if .
Using the above observation and Proposition 7, we can conclude.
Proposition 15.
Let . The following hold:
- (i)
- The matrix is a transition matrix of a strongly recurrent non-leo map if and only if . The map T is not linearizable for .
- (ii)
- The matrix is a transition matrix of a transient non-leo map . The map T is linearizable if .
Proof.
Clearly, K and L are transition matrices of non-leo maps from . Property (i), resp. (ii) follows from the properties (a),(b),(d), resp. (a),(b),(c) of Proposition 14. ☐
7.2. Leo Maps in the Vere-Jones Classes
We have shown in Section 5 that the subset of maps from that are linearizable is sufficiently rich in the case of non-leo maps of the operator/non-operator type. In order to refine the whole picture, in this paragraph, we show how to detect interesting leo maps of the operator/non-operator type. In the next two collections of examples, we will use a simple countably-infinite Markov partition for the full tent map and test various possibilities of its global window perturbations.
7.2.1. Perturbations of the Full Tent Map of the Operator Type
For the full tent map , , consider the Markov partition:
We will study several global window perturbations of S of the following general form: let be a sequence of odd positive integers, and consider a global window perturbation of S, such that:
- the window perturbation on is of order (i.e., if we do not perturb S on ).
Then, using the notation of Section 4 and Remark 11, we can consider generating functions corresponding to the element : for each n. One can easily verify that:
With the help of Proposition 8, we denote , resp. , the topological entropy of , resp. the radius of convergence of ; also, we put .
- Strongly recurrent: First of all, consider the set and the choice:Then, by (48), for and for each , hence:
Therefore, by Table 1, , i.e., ; for the upper bound, see [10]. This implies that the map is strongly recurrent, hence, by Theorems 5 and 8, also linearizable for any ℓ.
- Transient: Denoting , let us define:
From (48), we obtain , i.e., . Moreover, by direct computation, we can verify that
since always . It means that the map defined by the choice (50) is transient, and by Table 1 from Section 4, in fact, , i.e., Proposition 8 implies . If we consider in (50) any set , such that the inequalities (51) are still satisfied, the same is true for a resulting perturbation .
Remark 14.
Misiurewicz and Roth [11] observed that the map is not conjugate to any map of constant slope. It can be shown that for each choice of a sequence , such that the corresponding T has finite topological entropy, the following dichotomy is true: either T is recurrent and then Equation (5) has no λ-solution for , or T is transient and then Equation (5) does not have any λ-solution.
Let us define inductively a new set as follows: put and ; assuming that for some , we have already defined and , to obtain , we omit from the least number, denoted , such that the choice:
still gives for the corresponding window perturbation of . Clearly, for each k. Let , and consider the global perturbation of S corresponding to given by Formula (50) with replaced by . The set contains infinitely many units (by (49), any choice gives ). Moreover, our definition of implies ,
Therefore, the corresponding perturbation of S is null recurrent; hence, by Theorem 8, it is linearizable. By Proposition 8, .
7.2.2. One More Collection of Perturbations of the Full Tent Map
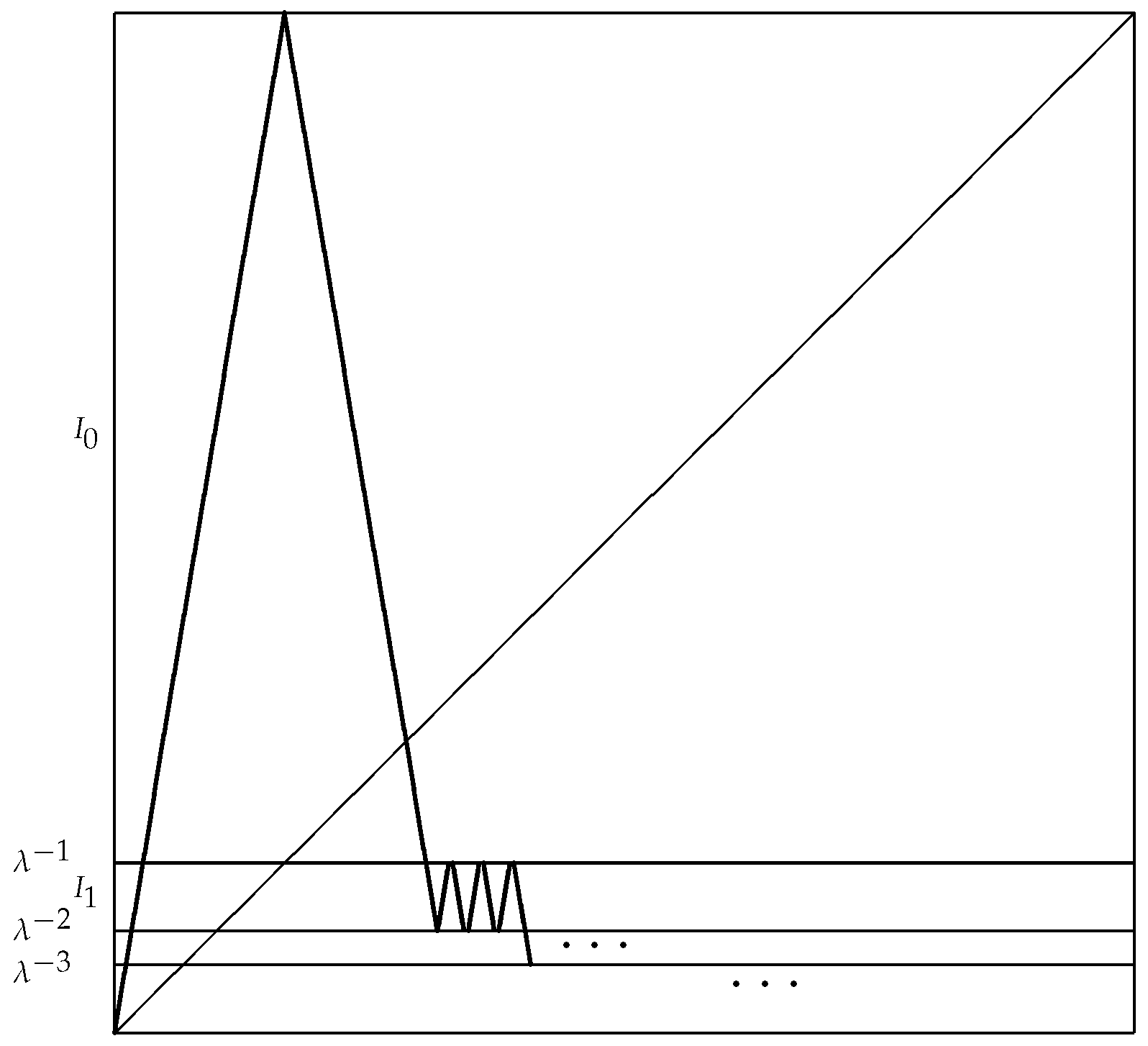
Expanding on the example of Ruette [8] (Example 2.9) (see also [15] (p. 1800)), we have the following construction. Let be a non-negative integer sequence with ; let a slope determined below in (52); and let , , be adjacent intervals converging to zero. Furthermore, let , , be adjacent intervals of length converging to one and such that is the left boundary point of .
We define the interval map with slope (see Figure 1) by:
To make sure that , we need to satisfy:
Therefore, any sequence , such that (52) has a positive finite solution λ, leads to the linearizable map . One can easily see that is a Markov (slack) partition for T as defined in Section 2.
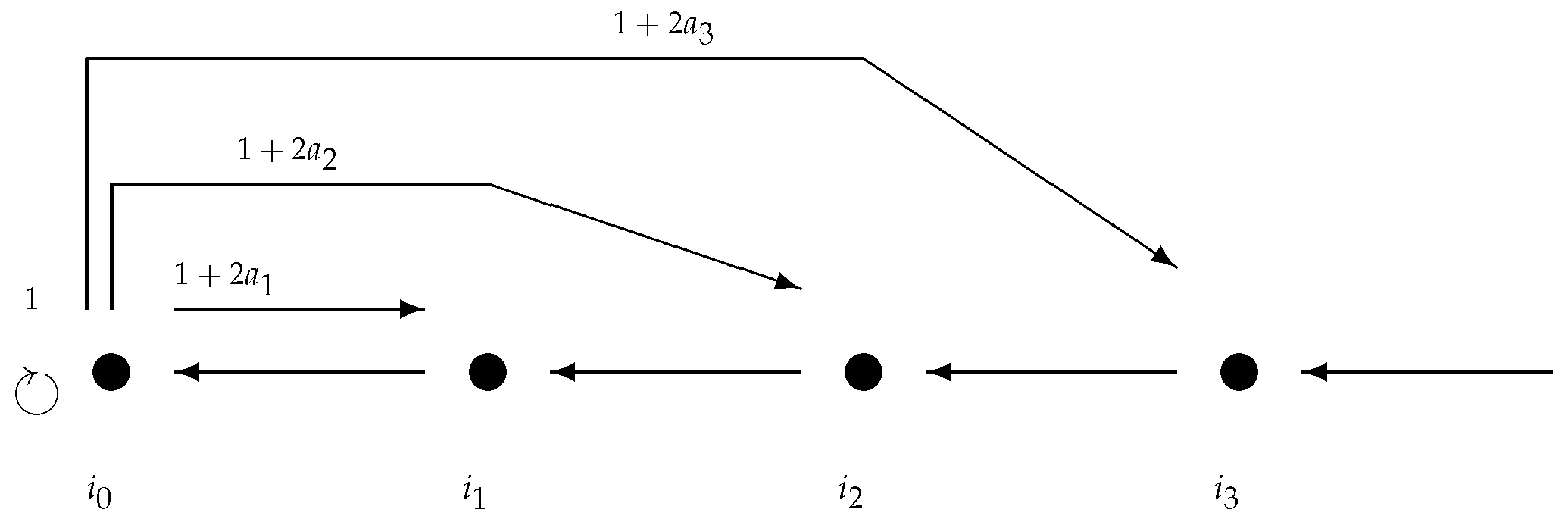
Applying Proposition 2, we associate with the transition matrix:
and also (see Figure 2) the corresponding strongly-connected directed graph :
In particular, the number of loops of length n from to itself is .
We use the Rometechnique from [21] (see also [22] (Section 9.3)) to compute the entropy of this graph: it is the leading root of the equation:
If we divide this equation by z, then we get:
From Table 1, it follows that the graph G (the matrix M, the map T) is recurrent for any choice of a sequence and corresponding finite . Proposition 8 and comparing Equations (52) and (53), we find that .
By Remark 5, the map T is of the operator type if and only if . In this case, by Table 1 and Proposition 8, , so the corresponding map is always strongly recurrent. For the choice for some fixed integer , the map T is of the non-operator type. In this case, , so ; hence, by Table 1, the map T is still strongly recurrent.
We can also take for some sublinearly-growing integer sequence chosen, such that (53) holds for , i.e., . In this case, and , and the system is null-recurrent or weakly recurrent (not strongly recurrent) depending on whether is infinite or finite.
7.2.3. Transient Non-Operator Example from [23]
Although up to now, all of our main results have been formulated and proven in the context of continuous maps, many statements remain true also for countably piecewise monotone Markov interval maps that are countably piecewise continuous (this example can be made continuous by replacing each branch with a tent-map of the same height. The λ will be twice as large, and the entropy increases accordingly in that case). We will present a countably-piecewise continuous, countably-piecewise monotone example adapted from [23], where it is studied in detail for its thermodynamic properties.
Let be a strictly-decreasing sequence in with and . We will consider the partition , where the interval map T (see Figure 3) is designed to be linear increasing on each interval for , , for and . With a slight modification of our definition from Section 2, is a Markov partition for T, and T is leo. Let be the matrix corresponding to ; see below. In order to have constant slope λ, we need to solve the recursive relation:
The characteristic equation has real solutions whenever . We obtain the solution:
and:
It is known that ; hence, by Proposition 8, . If we remove site (i.e., remove the first row and column) from M, the resulting matrix is M again, so strongly-connected directed graph contains its copy as a proper subgraph, and due to Theorem 4(i), M and also T are transient.
Writing , we have found, in accordance with Theorem 5, a positive summable λ-solution of Equation (5) for each . Summarizing, the map T is conjugate to a map of constant slope λ whenever . T is also linearizable, since .
7.2.4. Transient Non-Operator Example from [5]
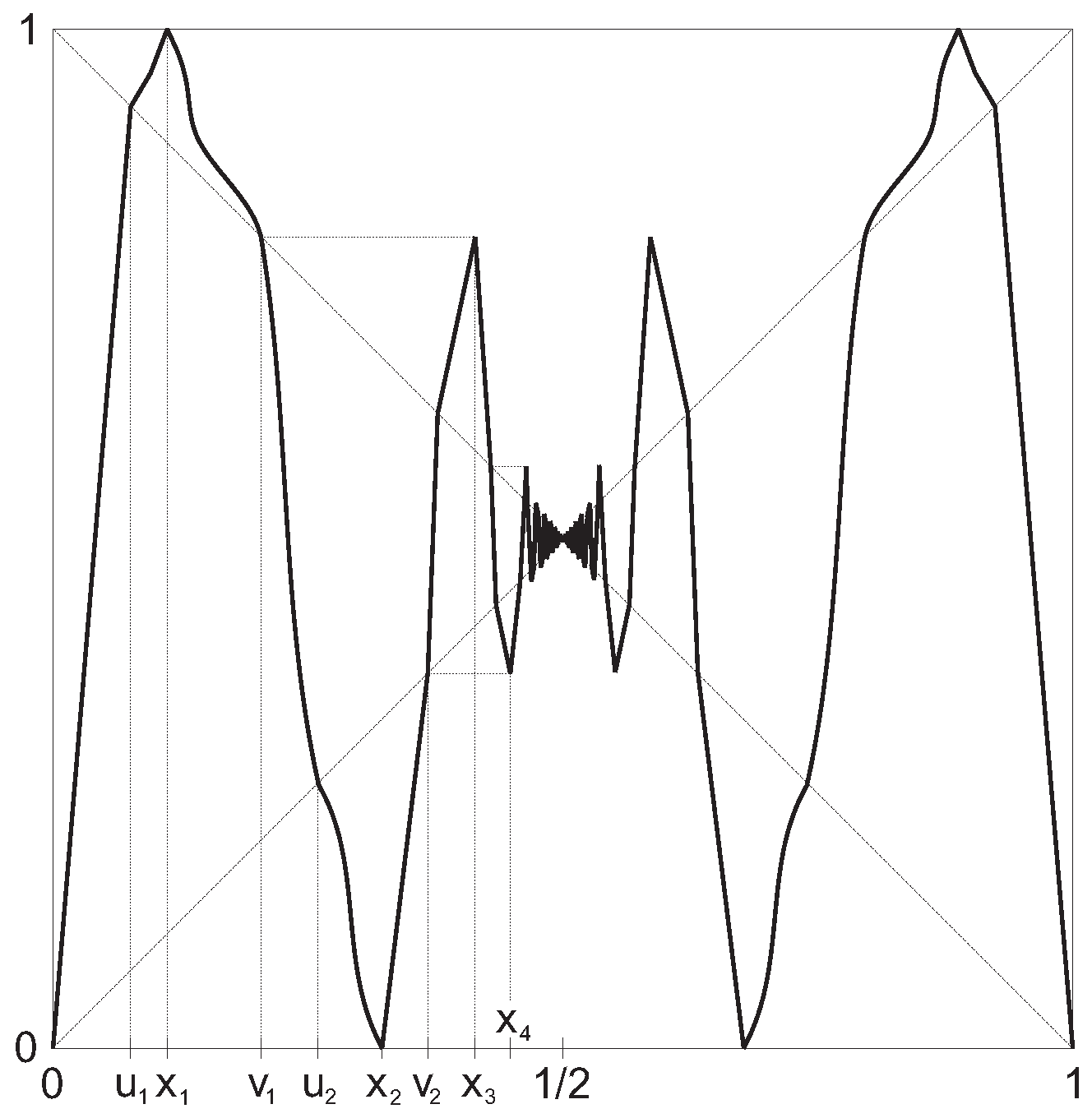
Let , converge to and ; the interval map satisfies (see Figure 4)
- (a)
- , , , ,
- (b)
- , , ,
- (c)
- for each interval ,
- (d)
- and for each .
Property (c) holds for our , since by (a), (b), we have for each .
Let us denote the set of all continuous interval maps fulfilling (a)–(d) for a fixed pair , and put . It was shown in [5] that:
- is a conjugacy class of maps in .
- The common topological entropy equals .
- Equation (5) has a positive summable λ-solution for each .
We can factor out the left-right symmetry of this map by using the semi-conjugacy , and the factor map has transition matrix:
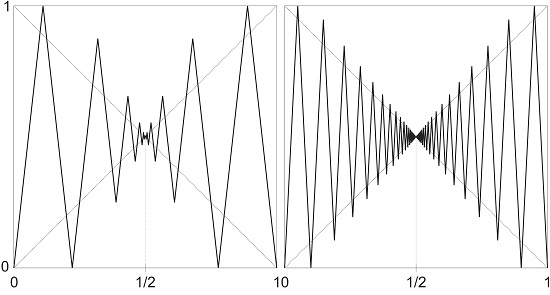
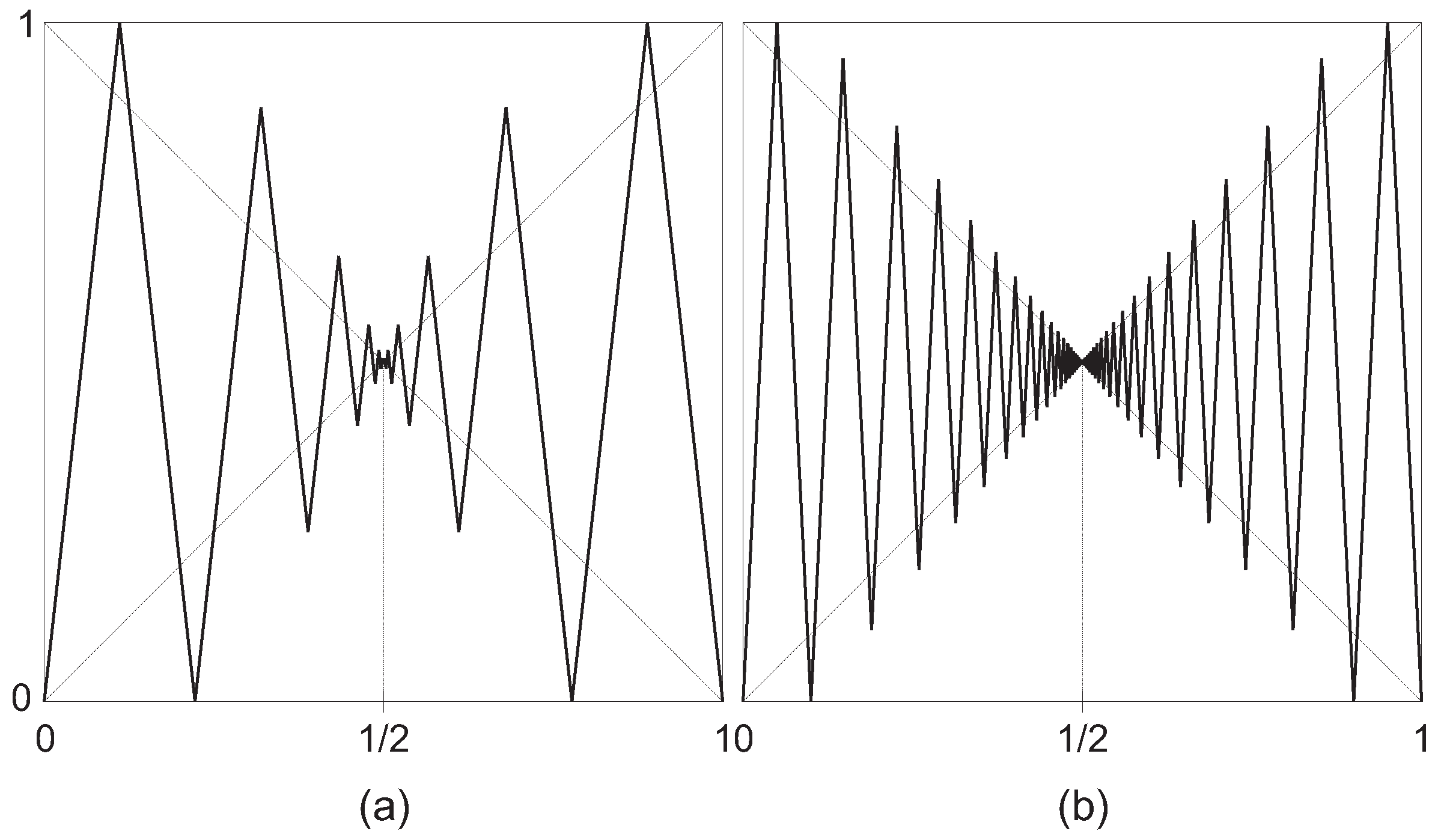
with similar properties as the previous example. Therefore, T is conjugate to a map of constant slope λ whenever (see Figure 5), and also linearizable, since .
7.3. One Application of Our Results
Using Proposition 13 let . We have discussed the fact that K is a transition matrix of a non-leo map with corresponding Markov partition denoted by . Clearly, by Remark 5, K represents a bounded linear operator, denoted it by , on , so T is of the operator type. We can conclude that:
- (i)
- , Propositions 8 and 13.
- (ii)
- (iii)
- T is not conjugate to a map of constant slope (is not linearizable), Proposition 13.
- (iv)
- T is null recurrent, Proposition 13.
- (v)
- Let be a Markov partition for T; denote the transition matrix of T with respect to representing a bounded linear operator on . Since:we have ; see (i), Section 2 and Proposition 8. Then, by Theorem 11, any recurrent centralized (operator/non-operator) perturbation of T is linearizable. In particular, it is true for any local window perturbation of T on some element of , Proposition 11(i).
- (vi)
- Let be a Markov partition for T, which equals outside of some interval . Let be a local window perturbation of T on some element of ; from the previous Paragraph (v), it follows that is strongly recurrent and linearizable. Consider a centralized (operator/non-operator) perturbation of on some . Then, if is recurrent, it is linearizable by Theorem 10. Otherwise, we can use either Theorem 8 (an operator case) or Theorem 9 (non-operator case; is finite for ) to show that a local window perturbation of of a sufficiently large order is linearizable.
Acknowledgments
We are grateful for the support of the Austrian Science Fund (FWF), Project Number P25975, and also for the Erwin Schrödinger International Institute for Mathematical Physics at the University of Vienna, where the final part of this research was carried out. Furthermore, we would like to thank the anonymous referees for the careful reading and valuable suggestions.
Author Contributions
Both authors equally contributed. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Milnor, J.; Thurston, W. On iterated maps of the interval. In Dynamical Systems, Lecture Notes in Math; Springer: Berlin/Heidelberg, Germany, 1988; Volume 1342, pp. 465–563. [Google Scholar]
- Parry, W. Symbolic dynamics and transformations of the unit interval. Trans. Am. Math. Soc. 1966, 122, 368–378. [Google Scholar] [CrossRef]
- Misiurewicz, M.; Szlenk, W. Entropy of piecewise monotone mappings. Stud. Math. 1988, 67, 45–63. [Google Scholar]
- Misiurewicz, M.; Raith, P. Strict inequalities for the entropy of transitive piecewise monotone maps. Discret. Contin. Dyn. Syst. 2005, 13, 451–468. [Google Scholar]
- Bobok, J.; Soukenka, M. On piecewise affine interval maps with countably many laps. Discret. Contin. Dyn. Syst. 2011, 31, 753–762. [Google Scholar] [CrossRef]
- Katok, A.; Hasselblatt, B. Introduction to the Modern Theory of Dynamical Systems; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Vere-Jones, D. Ergodic properties of non-negative matrices. I. Pac. J. Math. 1967, 22, 361–385. [Google Scholar] [CrossRef]
- Ruette, S. On the Vere-Jones classification and existence of maximal measures for countable topological Markov chains. Pac. J. Math. 2003, 209, 366–380. [Google Scholar] [CrossRef]
- Bobok, J. Semiconjugacy to a map of a constant slope. Stud. Math. 2012, 208, 213–228. [Google Scholar] [CrossRef]
- Alsedá, L.; Llibre, J.; Misiurewicz, M. Combinatorial Dynamics and the Entropy in Dimension One, 2nd ed.; World Scientific: Singapore, Singapore, 2000. [Google Scholar]
- Misiurewicz, M.; Roth, S. Constant slope maps on the extended real line. 2016; arXiv:1603.04198. [Google Scholar]
- Walters, P. An Introduction to Ergodic Theory; Springer: Berlin/Heidelberg, Germany, 1982. [Google Scholar]
- Gurevič, B.M. Topological entropy for denumerable Markov chains. Soviet Math. Dokl. 1969, 10, 911–915. [Google Scholar]
- Salama, I. Topological entropy and recurrence of countable chains. Pac. J. Math. 1988, 134, 325–341. [Google Scholar] [CrossRef]
- Pruitt, W.E. Eigenvalues of non-negative matrices. Ann. Math. Stat. 1964, 35, 1797–1800. [Google Scholar] [CrossRef]
- Chung, K.L. Markov Chains with Stationary Transition Probabilities; Springer: Berlin/Heidelberg, Germany, 1960. [Google Scholar]
- Misiurewicz, M. Horseshoes for mappings of an interval. Bull. Acad. Pol. Sci. 1979, 27, 167–169. [Google Scholar]
- Bobok, J. Strictly ergodic patterns and entropy for interval maps. Acta Math. Univ. Comen. 2003, 72, 111–118. [Google Scholar]
- Taylor, A.E.; Lay, D.C. Introduction to Fuctional Analysis, 2nd ed.; Robert, E., Ed.; Krieger Publishing Company: Malabar, FL, USA, 1980. [Google Scholar]
- Misiurewicz, M.; Roth, S. No semiconjugacy to a map of constant slope. Ergod. Theory Dyn. Syst. 2016, 36, 875–889. [Google Scholar] [CrossRef]
- Block, L.; Guckenheimer, J.; Misiurewicz, M.; Young, L.-S. Periodic points and topological entropy of one-dimensional maps. In Global Theory of Dynamical Systems; Springer: Berlin/Heidelberg, Germany, 1980; Volume 819, pp. 18–34. [Google Scholar]
- Brucks, K.; Bruin, H. Topics from One-Dimensional Dynamics (London Mathematical Society Student Texts); Cambridge University Press: Cambridge, UK, 2004; Volume 62. [Google Scholar]
- Bruin, H.; Todd, M. Transience and thermodynamic formalism for infinitely branched interval maps. J. Lond. Math. Soc. 2012, 86, 171–194. [Google Scholar] [CrossRef]
Figure 1.
The map .

Figure 2.
The Markov graph of ; indicates the number of edges in G from to .

Figure 3.
The transition matrix (left) and graph (right) of the map

Figure 4.
The leo map .

Figure 5.
is conjugate to a map with slope 9 (a) and slope 20 (b).


{kind=link}
{kind=link}
{kind=link}
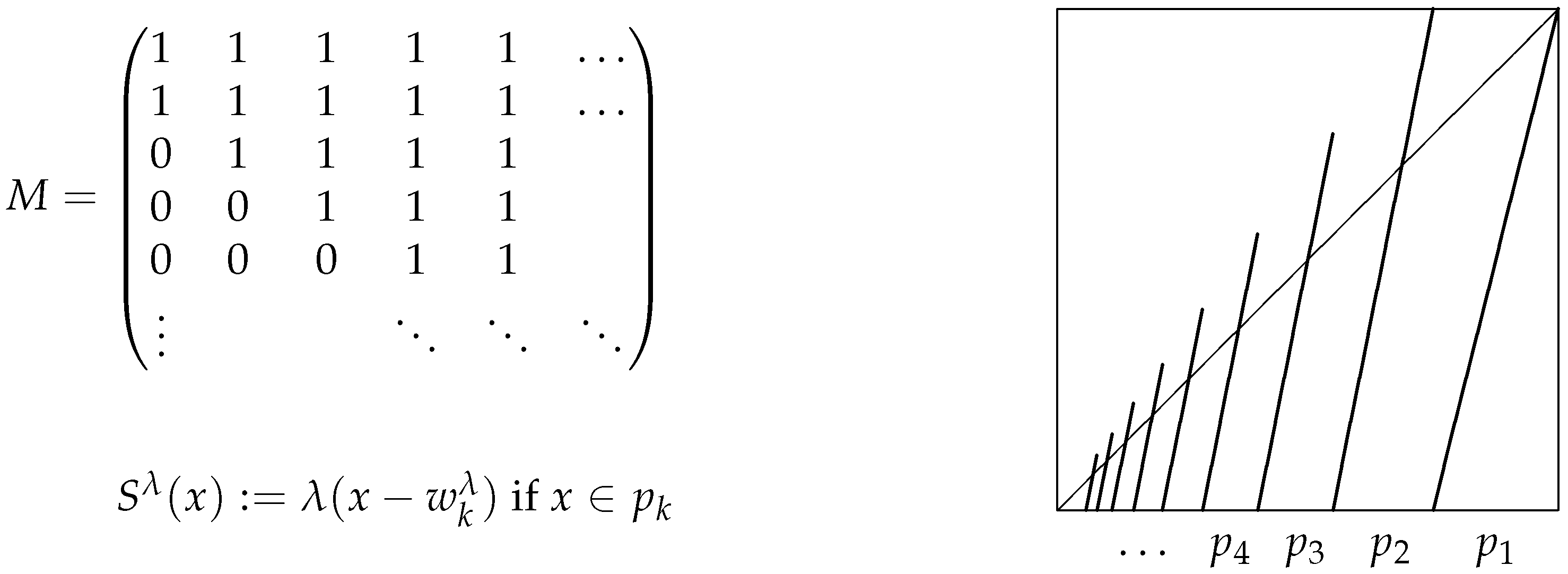{kind=link}
{kind=link}
{kind=link}
| Transient | Null Recurrent | Weakly Recurrent | Strongly Recurrent | |
|---|---|---|---|---|
| ∞ | ||||
| for all i |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bobok, J.; Bruin, H. Constant Slope Maps and the Vere-Jones Classification. Entropy 2016, 18, 234. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060234
AMA Style
Bobok J, Bruin H. Constant Slope Maps and the Vere-Jones Classification. Entropy. 2016; 18(6):234. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060234
Chicago/Turabian StyleBobok, Jozef, and Henk Bruin. 2016. "Constant Slope Maps and the Vere-Jones Classification" Entropy 18, no. 6: 234. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060234
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.