
Generalisations of Fisher Matrices


Imperial Centre for Inference and Cosmology (ICIC), Imperial College London, Blackett Laboratory, Prince Consort Road, London SW7 2AZ, UK
Entropy 2016, 18(6), 236; https://0-doi-org.brum.beds.ac.uk/10.3390/e18060236
Submission received: 3 May 2016
/
Revised: 16 June 2016
/
Accepted: 18 June 2016
/
Published: 22 June 2016
(This article belongs to the Special Issue Applications of Fisher Information in Sciences)
{kind=link}
{kind=link}
{kind=link}
Abstract
:Fisher matrices play an important role in experimental design and in data analysis. Their primary role is to make predictions for the inference of model parameters—both their errors and covariances. In this short review, I outline a number of extensions to the simple Fisher matrix formalism, covering a number of recent developments in the field. These are: (a) situations where the data (in the form of () pairs) have errors in both x and y; (b) modifications to parameter inference in the presence of systematic errors, or through fixing the values of some model parameters; (c) Derivative Approximation for LIkelihoods (DALI) - higher-order expansions of the likelihood surface, going beyond the Gaussian shape approximation; (d) extensions of the Fisher-like formalism, to treat model selection problems with Bayesian evidence.
1. Introduction
Fisher information matrices are widely used for making predictions for the errors and covariances of parameter estimates. They characterise the expected shape of the likelihood surface in parameter space, subject to an assumption that the likelihood surface is a multivariate Gaussian when viewed as a function of the model parameters. Diagonal terms are the inverse variances of the parameters, conditional on all others being known, and non-zero off-diagonal terms indicate correlations between inferred parameters. Diagonal terms of the inverse Fisher matrix yield the variances of parameters when all others are marginalised over. The Cramér–Rao inequality shows that the variances deduced from the Fisher matrix are lower bounds.
Fisher matrices have been extensively used in cosmology, where future experiments have been designed in order to deduce as precisely as possible the parameters of the standard cosmological model, so-called ΛCDM (Cold Dark Matter, with a cosmological constant Λ), and are routinely used to give “figures-of-merit” [1] for the power of each experiment. Normally, these studies are standard applications of Fisher matrix theory, often simplified by an approximation (which is very good for observations of the Early Universe) that the data are Gaussian-distributed.
In this article, I review a number of generalisations of the Fisher matrix approach. In Section 2 the derivation of the Fisher matrix for Gaussian data is sketched out; in Section 3 we consider Fisher matrices for data pairs that have errors in both x and y; in Section 4 we show how Fisher matrices may be used to estimate biases when some parameters are fixed at incorrect values; in Section 5 we explore better approximations for the likelihood surface (“DALI”), from expansions to higher order in derivatives, and in Section 6 we generalise the use of Gaussian likelihood surfaces to model selection and Bayesian evidence.
2. Gaussian Fields
In cosmology, one is very often dealing with Gaussian random fields, which are characterised statistically entirely by their mean and covariance. A pedagogical derivation for the Fisher matrix when the data are Gaussian appears in [2]. The negative log-likelihood is
where in general both the mean vector and the covariance matrix depend on the model parameters . If represents 1-point statistics, such as Fourier coefficients, then typically , and all the parameter dependence is in . If represents 2-point statistics, then for Gaussian fields they have only approximately a Gaussian distribution, and the analysis is only approximately correct. In this case, the covariance matrix has some parameter dependence through the 4-point function, which for Gaussian fields can be written as products of the 2-point function.
The Gaussian assumption is widely applicable in cosmology, since the quantum fluctuations that are thought to give rise to the density and radiation fields should ensure this, and limits on departures from gaussianity are very tight [3]. Defining the data matrix and using the matrix identity for positive definite square matrices , where Tr indicates trace, we can re-write Equation (1) as
Using standard comma notation for partial derivatives, , and using the matrix identities and , we find after taking two derivatives and then the expectation value,
The great advantage of the Fisher matrix approach is seen in this example: no data (real or simulated) are required to compute the expected log-likelihood surface, only the statistical properties of the data. This can be a big advantage if simulation is computationally expensive.
3. Fisher Matrix with Errors in x as Well as y
The previous section gives the standard analysis where only the covariance of the y values is considered. Let us now consider the fairly general case where the data consists of data pairs , where we have errors in both X and Y. We can compute the Fisher matrix via the application of a Bayesian hierarchical model, provided that the errors in X are small (this will be defined later). The full analysis is given in [4].
We assume and are length m and n vectors (for data pairs, , but in fact the analysis is more general), and have Gaussian errors, around true values , , with a covariance matrix , which also allows correlations between and . and are not observed, being latent variables, and are essentially nuisance parameters. In fact the are not independent nuisance parameters as they are assumed to be related precisely to through a deterministic theoretical model (however, a stochastic element could easily be included). Given the observed data, , we seek the posterior . With a uniform prior for , this is proportional to the likelihood . We write this as the marginalised distribution over and as
A deterministic relation gives a delta function, , and assuming a uniform prior for (a more general prior is considered in [4]), integration over gives
We now assume that the errors in are small, for which we require that we can truncate at the linear term of the Taylor expansion of :
where
is diagonal for data consisting of pairs.
We assume a multivariate Gaussian for (independent of ), and write the covariance matrix of the data in block form as
Note that is not symmetrical, nor invertible or even square in general; although and are. The covariance matrix may include a number of elements, such as intrinsic scatter and measurement noise, with individual covariance matrices adding to give the final . We also assume that the function is linear across the width of the Gaussian error distribution of , in which case the likelihood may be integrated analytically, as follows. We write
where , and and are -dimensional vectors: and for , and . The inverse of in block form is
where
Defining , and , we find that Q has the quadratic form
where
With the definition of Q in Equation (12), the Gaussian integral of Equation (9) can be performed, using
and noting that is independent of . The likelihood then simplifies to
where the inverse of the marginal covariance matrix of is . This is obtained using the Woodbury formula [5] , giving
This is a key result. We see that this looks just like a standard Gaussian (in terms of data) likelihood, but with the covariance matrix ( in our current notation) replaced by . Hence to compute the Fisher matrix, we can use the standard formula found in Equation (3) and Equation (15) of [2], and simply replace by :
Note that depends not only on the standard covariance, but also on the covariance in the independent variable, , the meta-covariance, , and the first partial derivatives of the model function . In the case of uncorrelated data pairs, the result reduces to that found in [6]. For the simple case of no correlations between and values , and with diagonal covariance matrices and we recover the propagation of error result that the variance of for each data point is effectively
where and can be replaced in the standard Fisher expression, Equation (3), by a diagonal matrix with these enhanced entries.
Generalising Still Further
The analysis above is applicable not just to the simple case of data with errors in x as well as y, but to any system where the “data” depend (in a locally linear way) on any parameters that have some error associated with them.
4. Systematic Errors, or Errors from Simplified Nested Models
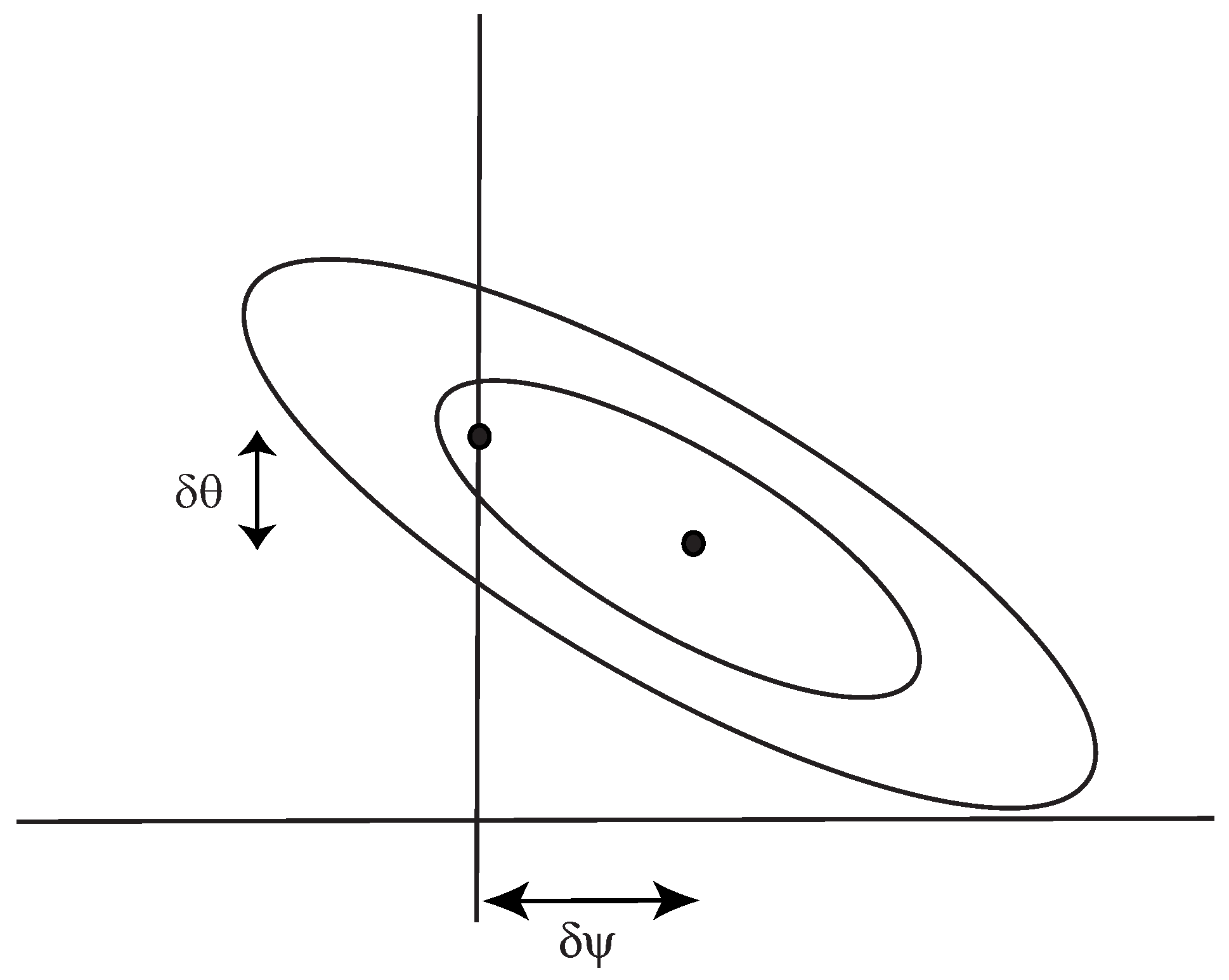
The Fisher matrix can also be useful to determine the errors in parameter inference that arise if one parameter is fixed at an erroneous value. This could arise in a number of contexts, such as a nuisance parameter (e.g., a calibration setting) being fixed at an incorrect value, or when considering nested models. An example of the latter would be cosmological models where the Universe is assumed to be flat. This is an example of a nested model, being a subset of a more general model, but with the curvature parameter (usually given the symbol ) set to zero. In these cases, the maximum likelihood values of all the other parameters are, in general, shifted from their maximum likelihood values in the more general model. See Figure 1 for an illustration of this in two dimensions. With the usual Fisher assumption that the likelihood surface is a Gaussian function of the parameters, these shifts can be computed using the Fisher matrix.
We consider two models, M, which has more () parameters than a simpler nested model , which has . The extra parameters are designated , and these are fixed in at values that are from their maximum likelihood values in M. In this case, the maximum likelihood values of all other parameters of , , are systematically shifted by [7,8]
where
which we recognise as a subset of the Fisher matrix.
5. Beyond the Gaussian Approximation—DALI
The Fisher matrix approach assumes that the likelihood surface is a multivariate Gaussian, which will be asymptotically true near the peak, but may not be a good approximation over the range of parameter values of interest. A generalisation of the Fisher matrix is DALI, Derivative Approximation for LIkelihoods [9], which expands the likelihood surface to include higher-order derivatives than the second. This is a rather elegant expansion, in derivatives rather than parameters, that ensures that the approximate distribution is a genuine probability distribution—i.e., it is non-negative and normalisable, non-divergent and asymptotically approaches the true likelihood.
The starting point is a Taylor expansion of the likelihood:
where is a normalization constant and , and .
If the expansion is arranged in order of derivatives, the expressions are normalisable and positive-definite. For example, to second order in the derivatives, and assuming is independent of , we have
6. The Expected Bayesian Evidence—Generalising Fisher Matrices to Model Selection
At the root of the Fisher matrix formalism is the Laplace approximation, i.e., the assumption that the likelihood surface is a multivariate Gaussian when viewed as a function of the model parameters. We can generalise this to the higher-level question of model selection, where we compute the posterior probabilities of different models, given the data collected, but regardless of the model parameters . The ratio of these probabilities is the ratio of the prior model probabilities, multiplied by the “Bayes factor”, which is the ratio of the marginal likelihoods (or Bayesian evidence) of the models, where the evidence for a model M is
With the Laplace approximation for the first, likelihood term, and a uniform prior (which can be generalised to a Gaussian prior), we can compute the expected evidence (conditional on some fiducial set of parameters) by performing Gaussian integrals. For nested models (with and parameters respectively), the considerations of Section 4 on the locations of the peak likelihood is relevant, and the result depends on the shifts of the fiducial parameters away from the values that are fixed in the lower-dimensional model, . If we further approximate that the expected Bayes factor is the ratio of the expected evidences, then the expected Bayes factor is (see [7] for details)
where are the prior ranges of the additional p parameters in the extended model, and the offsets are given by Equation (19). Note that is an matrix, is , and is an block of the full Fisher matrix , given by Equation (20). The expression we find is a specific example of the Savage-Dickey density ratio [11]; here we explicitly use the Laplace approximation to compute the offsets in the parameter estimates which accompany the wrong choice of model.
Figure 3 shows the ratio of expected evidences, assuming the Laplace approximation (as the Fisher matrix does), for nested cosmological models. Details are in the caption, but essentially one parameter is fixed in the simpler model, but allowed to vary in the more complex model. If the more complex model applies, then the data will favour the simpler model if the parameter is close to the fixed value. This is shown in the figure by the cusp in the graph. is positive to the left of the cusp, and negative to the right.
7. Discussion
This article reviews some recent developments in Fisher matrix theory, which have been motivated by cosmology. The Fisher matrix for data consisting of pairs that have errors in both x and y is derived, as a specific example of a general result where the data can depend on arbitrary variables x that may be measured with some error. The Fisher matrix is shown to be able to determine biases in some parameters when others are set to fixed values (such as in nested models where the simpler model does not allow some parameters to vary). DALI, which goes beyond the Laplace approximation by using higher-order derivatives, is found to allow much more accurate predictions for the expected shape of the likelihood surface. Finally, the concept of expected probabilities in the Laplace approximation is generalised to model selection, by computing the expected Bayesian evidence.
Acknowledgments
The author thanks Elena Sellentin for useful discussions about DALI.
Conflicts of Interest
The author declares no conflict of interest.
References
- Albrecht, A.; Bernstein, G.; Cahn, R.; Freedman, W.L.; Hewitt, J.; Hu, W.; Huth, J.; Kamionkowski, M.; Kolb, E.W.; Knox, L.; et al. Report of the Dark Energy Task Force. 2006. [Google Scholar]
- Tegmark, M.; Taylor, A.N.; Heavens, A.F. Karhunen-Loeve eigenvalue problems in cosmology: How should we tackle large data sets? Astrophys. J. 1997. [Google Scholar] [CrossRef]
- Ade, P.A.R.; Aghanim, N.; Arnaud, M.; Arroja, F.; Ashdown, M.; Aumont, J.; Baccigalupi, C.; Ballardini, M.; Banday, A.J.; Barreiro, R.B.; et al. Planck 2015 results. XVII. Constraints on primordial non-Gaussianity. 2015. [Google Scholar]
- Heavens, A.F.; Seikel, M.; Nord, B.D.; Aich, M.; Bouffanais, Y.; Bassett, B.A.; Hobson, M.P. Generalised Fisher Matrices. Mon. Not. Roy. Astron. Soc. 2014. [Google Scholar] [CrossRef]
- Woodbury, M.A. Inverting Modified Matrices (Statistical Research Group, Memorandum Report 42). Available online: http://www.ams.org/mathscinet-getitem?mr=38136 (accessed on 20 June 2016).
- March, M.C.; Trotta, R.; Berkes, P.; Starkman, G.D.; Vaudrevange, P.M. Improved constraints on cosmological parameters from SNIa data. Mon. Not. Roy. Astron. Soc. 2011. [Google Scholar] [CrossRef]
- Heavens, A.F.; Kitching, T.D.; Verde, L. On model selection forecasting, Dark Energy and modified gravity. Mon. Not. Roy. Astron. Soc. 2007. [Google Scholar] [CrossRef] [Green Version]
- Taylor, A.N.; Kitching, T.D.; Bacon, D.J.; Heavens, A.F. Probing dark energy with the shear-ratio geometric test. Mon. Not. Roy. Astron. Soc. 2007. [Google Scholar] [CrossRef]
- Sellentin, E.; Quartin, M.; Amendola, L. Breaking the spell of Gaussianity: Forecasting with higher order Fisher matrices. Mon. Not. Roy. Astron. Soc. 2014, 441, 1831–1840. [Google Scholar] [CrossRef]
- Sellentin, E. A fast, always positive definite and normalizable approximation of non-Gaussian likelihoods. Mon. Not. Roy. Astron. Soc. 2014. [Google Scholar] [CrossRef]
- Dickey, J.M. The weighted likelihood ratio, linear hypotheses on normal location parameters. Ann. Math. Stat. 1971, 42, 204–223. [Google Scholar] [CrossRef]
Figure 1.
Illustration of the shift in the maximum likelihood value of a parameter, if another parameter is set at a specific value (e.g., a calibration parameter, or a nested model which does not allow a parameter to vary from some fixed value. The Fisher matrix may be used to determine the shift. Reproduced from Figure 1 of “On model selection forecasting, Dark Energy and modified gravity” published in Mon. Not. Roy. Astron. Soc. [7].
Figure 1.
Illustration of the shift in the maximum likelihood value of a parameter, if another parameter is set at a specific value (e.g., a calibration parameter, or a nested model which does not allow a parameter to vary from some fixed value. The Fisher matrix may be used to determine the shift. Reproduced from Figure 1 of “On model selection forecasting, Dark Energy and modified gravity” published in Mon. Not. Roy. Astron. Soc. [7].

Figure 2.
The extended Fisher likelihood of DALI as applied to a sample of supernovae, as a function of the matter density parameter of the Universe, , and the equation of state parameter of dark energy. From left-to-right this shows the Fisher approximation, the “doublet-DALI” expansion, and the “triplet-DALI” expansion, all compared with the likelihood evaluated on a grid. Reproduced from Figure 1 of “Breaking the Spell of Gaussianity: Forecasting with Higher Order Fisher Matrices” published in Mon. Not. Roy. Astron. Soc. [9].
Figure 2.
The extended Fisher likelihood of DALI as applied to a sample of supernovae, as a function of the matter density parameter of the Universe, , and the equation of state parameter of dark energy. From left-to-right this shows the Fisher approximation, the “doublet-DALI” expansion, and the “triplet-DALI” expansion, all compared with the likelihood evaluated on a grid. Reproduced from Figure 1 of “Breaking the Spell of Gaussianity: Forecasting with Higher Order Fisher Matrices” published in Mon. Not. Roy. Astron. Soc. [9].

Figure 3.
The ratio of expected evidences B for two cosmological models. One is based on Einstein Gravity; the other is a more general model where the growth rate of perturbations is allowed to be a free parameter, rather than fixed. The graph shows the ratio as a function of the true shift of the growth rate away from the General Relativity value, for weak lensing data expected from ESA’s Euclid satellite. If the growth rate is close to Einstein’s (left of the figure; ), Bayesian evidence is expected to favour Einstein gravity, whereas if the deviation is large enough (right of the cusp; ), it favours the more complex model. Adapted from Figure 2 of “On model selection forecasting, Dark Energy and modified gravity” published in Mon. Not. Roy. Astron. Soc. [7].
Figure 3.
The ratio of expected evidences B for two cosmological models. One is based on Einstein Gravity; the other is a more general model where the growth rate of perturbations is allowed to be a free parameter, rather than fixed. The graph shows the ratio as a function of the true shift of the growth rate away from the General Relativity value, for weak lensing data expected from ESA’s Euclid satellite. If the growth rate is close to Einstein’s (left of the figure; ), Bayesian evidence is expected to favour Einstein gravity, whereas if the deviation is large enough (right of the cusp; ), it favours the more complex model. Adapted from Figure 2 of “On model selection forecasting, Dark Energy and modified gravity” published in Mon. Not. Roy. Astron. Soc. [7].

© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Heavens, A. Generalisations of Fisher Matrices. Entropy 2016, 18, 236. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060236
AMA Style
Heavens A. Generalisations of Fisher Matrices. Entropy. 2016; 18(6):236. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060236
Chicago/Turabian StyleHeavens, Alan. 2016. "Generalisations of Fisher Matrices" Entropy 18, no. 6: 236. https://0-doi-org.brum.beds.ac.uk/10.3390/e18060236
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.