Robust Signaling for Bursty Interference


1
Signal Theory and Communications Department, Universidad Carlos III de Madrid, 28911 Leganés, Spain
2
Gregorio Marañón Health Research Institute, 28007 Madrid, Spain
3
Electrical Engineering and Information Technology Department, Ruhr-Universität Bochum, 44780 Bochum, Germany
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(11), 870; https://0-doi-org.brum.beds.ac.uk/10.3390/e20110870
Submission received: 3 September 2018
/
Revised: 25 October 2018
/
Accepted: 6 November 2018
/
Published: 12 November 2018
(This article belongs to the Special Issue Multiuser Information Theory II)
Abstract
:This paper studies a bursty interference channel, where the presence/absence of interference is modeled by a block-i.i.d. Bernoulli process that stays constant for a duration of T symbols (referred to as coherence block) and then changes independently to a new state. We consider both a quasi-static setup, where the interference state remains constant during the whole transmission of the codeword, and an ergodic setup, where a codeword spans several coherence blocks. For the quasi-static setup, we study the largest rate of a coding strategy that provides reliable communication at a basic rate and allows an increased (opportunistic) rate when there is no interference. For the ergodic setup, we study the largest achievable rate. We study how non-causal knowledge of the interference state, referred to as channel-state information (CSI), affects the achievable rates. We derive converse and achievability bounds for (i) local CSI at the receiver side only; (ii) local CSI at the transmitter and receiver side; and (iii) global CSI at all nodes. Our bounds allow us to identify when interference burstiness is beneficial and in which scenarios global CSI outperforms local CSI. The joint treatment of the quasi-static and ergodic setup further allows for a thorough comparison of these two setups.
1. Introduction
Interference is a key limiting factor for the efficient use of the spectrum in modern wireless networks. It is, therefore, not surprising that the interference channel (IC) has been studied extensively in the past; see, e.g., [1] (Chapter 6) and references therein. Most of the information-theoretic work developed for the IC assumes that interference is always present. However, certain physical phenomena, such as shadowing, can make the presence of interference intermittent or bursty. Interference can also be bursty due to the bursty nature of data traffic, distributed medium access control mechanisms, and decentralized networking protocols. For this reason, there has been an increasing interest in understanding and exploring the effects of burstiness of interference.
Seminal works in this area were performed by Khude et al. in [2] for the Gaussian channel and in [3] by using a model which corresponds to an approximation to the two-user Gaussian IC. They tried to harness the burstiness of the interference by taking advantage of the time instants when the interference is not present to send opportunistic data. Specifically, [2,3] considered a channel model where the interference state stays constant during the transmission of the entire codeword, which corresponds to a quasi-static channel. Motivated by the idea of degraded message sets by Körner and Marton [4], Khude et al. studied the largest rate of a coding strategy that provides reliable communication at a basic rate R and allows an increased (opportunistic) rate when there is no interference. The idea of opportunism was also used by Diggavi and Tse [5] for the quasi-static flat fading channel and, recently, by Yi and Sun [6] for the K-user IC with states.
Wang et al. [7] modeled the presence of interference using an independent and identically distributed (i.i.d.) Bernoulli process that indicates whether interference is present or not, which corresponds to an ergodic channel. They further assume that the interference links are fully correlated. Wang et al. mainly studied the effect of causal feedback under this model, but also presented converse bounds for the non-feedback case. Mishra et al. considered the generalization of this model to multicarrier systems, modeled as parallel two-user bursty ICs, for the feedback [8] and non-feedback case [9].
The bursty IC is related to the binary fading IC, for which the four channel coefficients are in the binary field according to some Bernoulli distribution. Note, however, that neither of the two models is a special case of the other. While a zero channel coefficient of the cross link corresponds to intermittence of interference, the bursty IC allows for non-binary signals. Conversely, in contrast to the binary fading IC, the direct links in the bursty IC cannot be zero, since only the interference can be intermittent. Vahid et al. [10,11,12,13,14] studied the capacity region of the binary fading IC. Specifically, [11,14] study the capacity region of the binary fading IC when the transmitters do not have access to the channel coefficients, and [12] study the capacity region when the transmitters have access to the past channel coefficients. Vahid and Calderbank additionally study the effect on the capacity region when certain correlation is available to all nodes as side information [13].
The focus of the works by Khude et al. [3] and Wang et al. [7] was on the linear deterministic model (LDM), which was first introduced by Avestimehr [15], but falls within the class of more general deterministic channels whose capacity was obtained by El Gamal and Costa in [16]. The LDM maps the Gaussian IC to a channel whose outputs are deterministic functions of their inputs. Bresler and Tse demonstrated in [17] that the generalized degrees of freedom (first-order capacity approximation) of the two-user Gaussian IC coincides with the normalized capacity of the corresponding deterministic channel. The LDM thus offers insights on the Gaussian IC.
1.1. Contributions
In this work, we consider the LDM of a bursty IC. We study how interference burstiness and the knowledge of the interference states (throughout referred to as channel-state information (CSI)) affects the capacity of this channel. We point out that this CSI is different from the one sometimes considered in the analysis of ICs (see, e.g., [18]), where CSI refers to knowledge of the channel coefficients. (In this regard, we assume that all transmitters and receivers have access to the channel coefficients). For the sake of compactness, we focus on non-causal CSI and leave other CSI scenarios, such as causal or delayed CSI, for future work.
We consider the following cases: (i) only the receivers know the corresponding interference state (local CSIR); (ii) transmitters and receivers know their corresponding interference states (local CSIRT); and (iii) both transmitters and receivers know all interference states (global CSIRT). For each CSI level we consider both (i) the quasi-static channel and (ii) the ergodic channel. Specifically, in the quasi-static channel the interference is present or absent during the whole message transmission and we harness the realizations when the channel experiences better conditions (no presence of interference) to send extra messages. In the ergodic channel the presence/absence of interference is modeled as a Bernoulli random variable which determines the interference state. The interference state stays constant for a certain coherence time T and then changes independently to a new state. This model includes the i.i.d. model by Wang et al. as a special case, but also allows for scenarios where the interference state changes more slowly. Note, however, that when the receivers know the interference state (as we shall assume in this work), then the capacity of this model becomes independent of T and coincides with that of the i.i.d. model. The proposed analysis is performed for the two extreme cases where the states of each of the interfering links are independent, and where states of the interfering links are fully correlated. Hence we unify the scenarios already treated in the literature [2,3,7]. Nevertheless, some of our presented results can be extended to consider an arbitrary correlation between the interfering states. The works by Vahid and Calderbank [13] and Yeh and Wang [19] characterize the capacity region of the two-user binary IC and the MIMO X-channel, respectively. While [13,19] consider a general spatial correlation between communication and interfering links, they do not consider the correlation between interfering links.
Our analysis shows that, for both the quasi-static and ergodic channels, for all interference regions except the very strong interference region, global CSIRT outperforms local CSIR/CSIRT. This result does not depend on the correlation between the states of the interfering links. For local CSIR/CSIRT and the quasi-static scenario, the burstiness of the channel is of benefit only in the very weak and weak interference regions. For the ergodic case and local CSIR, interference burstiness is only of clear benefit if the interference is either weak or very weak, or if it is present at most half of the time. This is in contrast to local CSIRT, where interference burstiness is beneficial in all interference regions.
Specific contributions of our paper include:
- A joint treatment of the quasi-static and the ergodic model: Previous literature on the bursty IC considers either the quasi-static model or the ergodic model. Furthermore, due to space constraints, the proofs of some of the existing results were either omitted or contain little details. In contrast, our paper discusses both models, allowing for a thorough comparison between the two.
- Novel achievability and converse bounds: For the ergodic model, the achievability bounds for local CSIRT, and the achievability and converse bounds for global CSIRT, are novel. In particular, novel achievability strategies are proposed that exploit certain synchronization between the users. To keep the paper self-contained, we further present the proof of the achievability bound for local CSIR that has appeared in the literature without proof.
- Novel converse proofs for the quasi-static model: In contrast to existing converse bounds, which are based on Fano’s inequality, our proofs of the converse bounds for the rates of the worst-case and opportunistic messages are based on an information density approach (more precise, they are based on the Verdú-Han lemma). This approach does not only allow for rigorous yet clear proofs, but it would also enable a more refined analysis of the probabilities that worst-case and opportunistic messages can be decoded correctly.
- A thorough comparison of the sum capacity of various scenarios: Inter alia, the obtained results are used to study the advantage of featuring different levels of CSI, the impact of the burstiness of the interference, and the effect of the correlation between the channel states of both users.
The rest of this paper is organized as follows. Section 2 introduces the system model, where we define the bursty IC quasi-static setup, the ergodic setup, and briefly summarize previous results on the non-bursty IC. In Section 3, Section 4 and Section 5 we present our results for local CSIR, local CSIRT and global CSIRT, respectively. Section 6 studies the impact of featuring different CSI levels. Section 7 analyzes in which scenarios exploiting burstiness of interference is beneficial. Section 8 concludes the paper with a summary of the results. Most proofs of the presented results are deferred to the appendix.
1.2. Notation
To differentiate between scalars, vectors, and matrices we use different fonts: scalar random variables and their realizations are denoted by upper and lower case letters, respectively, e.g., B, b; vectors are denoted using bold face, e.g., , ; random matrices are denoted via a special font, e.g., ; and for deterministic matrices we shall use yet another font, e.g., . For sets we use the calligraphic font, e.g., . We denote sequences such as by . We define as .
We use to denote the binary Galois field and ⊕ to denote the modulo 2 addition. Let the down-shift matrix , a matrix of dimension , be defined as
with the all-zero vector and the identity matrix.
Similarly, we define the matrix of dimension that selects the d lowest components of a vector of dimension q:
We shall denote by the entropy of a binary random variable X with probability mass function (), i.e.,
Similarly, we denote by the entropy where X and are two independent binary random variables with probability mass functions and , respectively:
For this function it holds that . Finally, denotes the indicator function, i.e., is 1 if the statement is true and 0 if it is false.
2. System Model
Our analysis is based on the LDM, introduced by Avestimehr et al. [15] for some relay network. This model is, on the one hand, simple to analyze and, on the other hand, captures the essential structure of the Gaussian channel in the high signal-to-noise ratio regime.
We consider a bursty IC where (i) the interference state remains constant during the whole transmission of the codeword of length N (quasi-static setup) or (ii) the interference state remains constant for a duration of T consecutive symbols and then changes independently to a new state (ergodic setup). For one coherence block, the two-user bursty IC is depicted in Figure 1, where and are the channel gains of the direct and cross links, respectively. We assume that and are known to both the transmitter and receiver and remain constant during the whole transmission of the codeword. For simplicity, we shall assume that and are equal for both users. Nevertheless, most of our results generalize to the asymmetric case. More precisely, all converse and achievability bounds generalize to the asymmetric case, while the direct generalization of the proposed achievability schemes may be loose in some asymmetric regions.
For the k-th block, the input-output relation of the channel is given bys
Let . In (3) and (4), and , . The interference states , , , are sequences of i.i.d. Bernoulli random variables with activation probability p.
Regarding the sequences and , we consider two cases: (i) and are independent of each other and (ii) and are fully correlated sequences, i.e., . For both cases we assume that the sequences are independent of the messages and .
We shall define the normalized interference level as , based on which we can divide the interference into the following regions (a similar division was used by Jafar and Vishwanath [20]):
- very weak interference (VWI) for ,
- weak interference (WI) for ,
- moderate interference (MI) for ,
- strong interference (SI) for ,
- very strong interference (VSI) for .
2.1. Quasi-Static Channel
The channel defined in (3) and (4) may experience a slowly-varying change on the interference state. In this case, the duration of each of the transmitted codewords of length is smaller than the coherence time T of the channel and the interference state stays constant over the duration of each codeword, i.e., , . In the wireless communications literature such a channel is usually referred to as a quasi-static channel [21] (Section 5.4.1). In this scenario, the rate pair of achievable rates is dominated by the worst case, which corresponds to the presence of interference at both receivers. However, in absence of interference, it is possible to communicate at a higher date rate, so planning a system for the worst case may be too pessimistic. Assuming that the receivers have access to the interference states, the transmitters could send opportunistic messages that are decoded only if the interference is absent, in addition to the regular messages that are decoded irrespective of the interference state. We make the notion of opportunistic messages and rates precise in the subsequent paragraphs.
Let indicate the level of CSI available at the transmitter side in coherence block k, and let indicate the level of CSI at the receiver side in coherence block k:
- local CSIR: ,
- local CSIRT: ,
- global CSIRT: .
We define the set of opportunistic messages according to the level of CSI at the receiver as , where denotes the set of possible interference states . Specifically,
- for local CSIR: ,
- for local CSIRT: ,
- for global CSIRT: .
Then, we define an opportunistic code as follows.
Definition 1
(Opportunistic code for the bursty IC).
An opportunistic code for the bursty IC is defined as:
- 1.
- two independent messages and uniformly distributed over the message sets ;
- 2.
- two independent sets of opportunistic messages and uniformly distributed over the message sets , ,
- 3.
- two encoders:
- 4.
- two decoders: .
Here and denote the decoded message and the decoded opportunistic message, respectively. We set , (for local CSIR/CSIRT) and (for global CSIRT).
To better distinguish the rates from the opportunistic rates , , we shall refer to as worst-case rates, because the corresponding messages can be decoded even if the channel is in its worst state (see also Definition 2).
Definition 2
(Achievable opportunistic rates).
A rate tuple is achievable if there exists a sequence of codes such that
and
The capacity region is the closure of the set of achievable rate tuples [1](Sec. 6.1). We define the worst-case sum rate as and the opportunistic sum rate as . The worst-case sum capacity C is the supremum of all achievable worst-case sum rates, the opportunistic sum capacity is the supremum of all opportunistic sum rates, and the total sum capacity is defined as . Note that the opportunistic sum capacity depends on the worst-case sum rate.
Remark 1.
The worst-case sum rate and opportunistic sum rates in the quasi-static setting depend only on the collection of possible interference states: for independent interference states we have , and for fully correlated interference states we have . In principle, our proof techniques could also be applied to analyze other collections of interference states.
Remark 2.
In the CSIRT setting the transmitters have access to the interference state. Therefore, in this setting the messages are strictly speaking not opportunistic. Instead, transmitters can adapt their rate based on the state of the interference links, which is sometimes referred to as rate adaptation in the literature.
2.2. Ergodic Channel
In this setup, we shall restrict ourselves to codes whose blocklength N is an integer multiple of the coherence time T. A codeword of length thus spans K independent channel realizations.
Definition 3
(Code for the bursty IC).
A code for the bursty IC is defined as:
- 1.
- two independent messages and uniformly distributed over the message sets
- 2.
- two encoders:
- 3.
- two decoders:
Here denotes the decoded message, and and indicate the level of CSI at the transmitter and receiver side, respectively, which are defined as for the quasi-static channel in Section 2.1.
Definition 4
(Ergodic achievable rates). A rate pair is achievable for a fixed T if there exists a sequence of codes (parametrized by K) such that
The capacity region is the closure of the set of achievable rate pairs. We define the sum rate as , the sum capacity C is the supremum of all achievable sum rates.
2.3. The Sum Capacities of the Non-Bursty and the Quasi-Static Bursty IC
When the activation probability p is 1, we recover in both the ergodic and quasi-static scenarios the deterministic IC. For a general deterministic IC the capacity region was obtained in [16] (Theorem 1) and then by Bresler and Tse in [17] for a specific deterministic IC. For completeness, we present the sum capacity region for the deterministic non-bursty IC in the following theorem.
Theorem 1.
The sum capacity region of the two-user deterministic IC is equal to the union of the set of all sum rates R satisfying
Proof.
The proof is given in [16] (Section II). For the achievability bounds, El Gamal and Costa [16] (Theorem 1) use the Han-Kobayashi scheme [22] for a general IC. Bresler and Tse [17] (Section 4) use a specific Han-Kobayashi strategy for the special case of the LDM. Jafar and Vishwanath [20] present an alternative achievability scheme for the K-user IC, which particularized for the two-user IC will be referenced in this work. □
We can achieve the sum rates (9) and (11) over the quasi-static channel by treating the bursty IC as a non-bursty IC. The following theorem demonstrates that this is the largest achievable worst-case sum rate irrespective of the availability of CSI and the correlation between and .
Theorem 2
(Sum capacity for the quasi-static bursty IC). For , the worst-case sum capacity of the bursty IC is equal to the supremum of the set of sum rates R satisfying
- For ,
- For
Proof.
The converse bounds are proved in Appendix A.1. Achievability follows directly from Theorem 1 by treating the bursty IC as a non-bursty IC. □
Theorem 2 shows that the worst-case sum capacity does not depend on the level of CSI available at the transmitter and receiver side. However, this is not the case for the opportunistic rates as we will see in the next sections.
Remark 3.
In principle, one could reduce the worst-case rates in order to increase the opportunistic rates. However, it turns out that such a strategy is not beneficial in terms of total rates , . In other words, setting , (for local CSIR/CSIRT) and (for global CSIRT), as we have done in Definition 2, incurs no loss in total rate. Furthermore, in most cases it is preferable to maximize the worst-case rate, since it can be guaranteed irrespective of the interference state.
3. Local CSIR
For the quasi-static and ergodic setups, described in Section 2.1 and Section 2.2, respectively, we derive converse and achievability bounds for the independent and fully correlated scenarios when the interference state is only available at the receiver side.
3.1. Quasi-Static Channel
3.1.1. Independent Case
We present converse and achievability bounds for local CSIR when and are independent. The converse bounds are derived for local CSIRT, hence they also apply to this case. Since converse and achievability bounds coincide, this implies that local CSI at the transmitter is not beneficial in the quasi-static setup.
Theorem 3 (Opportunistic sum capacity for local CSIR/CSIRT).
Assume that and are independent of each other. For , the opportunistic sum capacity region is the union of the set of rate tuples , where , and R, and satisfy (12)–(14) and
Proof.
The converse bounds are proved in Appendix A.2 and the achievability bounds are proved in Appendix A.3. □
Remark 4.
The converse bounds in Theorem 3 coincide with those in [3] (Theorem 2.1), particularized for the symmetric setting. Theorem 3, however, is proven for local CSIRT, which is not considered in the model from [3]. The proof included in Appendix A.2 is based on an information density approach and provides a unified framework for treating local CSIR, local CSIRT and global CSIRT, as will be shown in Section 5.
As discussed in Remark 3, one could reduce the worst-case sum rate R and increase the opportunistic rates . However, in the case of one-shot transmission this is not desirable, since the worst-case sum rate is the only rate that can be guaranteed irrespective of the interference state. (With one-shot transmission we refer to the case where we transmit one codeword of length N over the quasi-static channel. This is in contrast to the case discussed, e.g., in Section 3.3, where we are interested in transmitting many codewords, each over N channel uses of independent quasi-static channels.) Thus, one is typically interested in the opportunistic sum capacity when the worst-case rate R is maximized. For this case, the results of Theorem 3 are summarized in Table 1 for the VWI, WI, MI and SI regions.
Observe that converse and achievability bounds coincide. Further observe that opportunistic messages can only be transmitted reliably for VWI or WI. In the other interference regions, the opportunistic sum capacity is zero.
3.1.2. Fully Correlated Case
Assume now that the sequences and are fully correlated (). For local CSIR, the correlation between and has no influence on the opportunistic sum capacity region. Indeed, in this case the channel inputs are independent of and the opportunistic sum capacity region of the quasi-static bursty IC depends on only via the marginal distributions of , . Hence, it follows that Theorem 3 as well as Table 1 apply also to the fully correlated case and local CSIR scenario. For completeness, a proof of the converse part is given in Appendix A.4. The achievability part is included in Appendix A.3.
3.2. Ergodic Channel
3.2.1. Independent Case
For the case where the sequences and are independent of each other, we have the following theorems.
Theorem 4
(Converse bounds for local CSIR).
Assume that and are independent of each other. The sum rate R for the bursty IC is upper-bounded by
and
Proof.
Bound (18) coincides with [7] (Equation (3)). Specifically, [7] (Equation (3)) derives (18) for the considered channel model with and feedback. The proof for this bound under local CSIRT (without feedback) is given in Appendix B.1. Bound (19) coincides with [23] (Lemma A.1). Specifically, [23] (Lemma A.1) derives (19) for the model considered with . The proof of [23] (Lemma A.1) directly generalizes to arbitrary T. □
Theorem 5 (Achievability bounds for local CSIR).
Assume that and are independent of each other. The following sum rate R is achievable over the bursty IC:
Proof.
The achievability scheme for VWI for all values of p, and for WI and MI when , is described in Appendix B.2.1. The achievability scheme for WI and is described in Appendix B.2.2. The scheme for SI and is summarized in Appendix B.2.3. For MI and SI when , the achievability bound in the theorem corresponds to the one of the non-bursty IC [20]. This also implies that in this sub-region we do not exploit the burstiness of the IC. □
Remark 5.
The achievability schemes presented in Theorem 5 are similar to those described in [11,14]. They achieve the capacity region by applying point-to-point erasure codes with appropriate rates at each transmitter and using either treating-interference-as-erasure or interference-decoding at each receiver. Specifically, we apply treating-interference-as-erasure in the VWI region and for all values of p, and for all interference regions, except VSI, and . Interference-decoding at each receiver is applied in the MI and SI regions for .
Remark 6.
Wang et al. claim in [23] (Lemma A.1) that the converse bound (18) is tight for without providing an achievability bound. Instead, they refer to Khude et al. [3] for the inner bound which, alas, does not apply to the ergodic setup. While it is possible to adapt the achievability schemes considered in [3] to prove (20), a number of steps are required. For completeness, we include the achievability schemes for the ergodic setup and in Appendix B.2.1.
3.2.2. Fully Correlated Case
For local CSIR, the dependence between and has no influence on the capacity region. Indeed, in this case the channel inputs are independent of and decoder i has only access to and , , and . Furthermore, vanishes as if, and only if, , , vanishes as . Since depends only on , the capacity region of the bursty IC depends on only via the marginal distributions of and . Hence, Theorems 4 and 5 as well as Table 2 apply also to the case where . This is consistent with the observation by Sato [24] that “the capacity region is the same for all two-user channels that have the same marginal probabilities”.
3.3. Quasi-Static vs. Ergodic Setup
In general, the sum capacities of the quasi-static and ergodic channels cannot be compared, because in the former case we have a set of sum capacities (worst case and opportunistic), whereas in the latter case only one is defined. To allow for a comparison, we introduce for the quasi-static channel the average sum capacity as
where the suprema is over all tuples that satisfy (12)–(17). Intuitively, the average rate corresponds to the case where we send many messages over independent quasi-static fading channels. By the law of large numbers, a fraction of p transmissions will be affected by interference, the remaining transmissions will be interference-free. Table 3 summarizes the average sum capacity for the different interference regions.
By comparing Table 2 and Table 3, we can observe that for and all interference regions, and for and VWI/WI, the average sum capacity in the quasi-static setup coincides with the sum capacity in the ergodic setup. For , and MI/SI (where converse and achievability bounds do not coincide), the average sum capacities in the quasi-static setup coincide with the achievability bounds of the ergodic setup.
4. Local CSIRT
For the quasi-static and ergodic setups, we present converse and achievability bounds when transmitters and receivers have access to their corresponding interference states. We shall only consider the independent case here, because when local CSIRT coincides with global CSIRT, which will be discussed in Section 5.
4.1. Quasi-Static Channel
For the quasi-static channel, the converse and achievability bounds were already presented in Theorem 3 in Section 3.1.1. Indeed, the converse bounds were derived for local CSIRT, whereas the achievability bounds in that theorem were derived for local CSIR. Since these bounds coincide for all interference regions and all probabilities of it follows that, for the quasi-static channel, availability of local CSI at the transmitter in addition to local CSI at the receiver is not beneficial. The converse and achievability bounds are then given in Theorem 3.
4.2. Ergodic Channel
The converse bound (18) presented in Theorem 4 was derived for local CSIRT, so it applies to the case at hand. We next present achievability bounds for this setup that improve upon those for CSIR. The aim of these bounds is to provide computable expressions showing that local CSIRT outperforms local CSIR in the whole range of the parameter. While the particular achievability schemes are sometimes involved, the intuition behind these schemes can be explained with the following toy example.
Example 1.
Let us assume that , and suppose that at time k the transmitters send the bits . If there is no interference, then receiver i receives . If there is interference, then receiver i receives . Consequently, the channel flips if , and it flips if . It follows that each transmitter-receiver pair experiences a binary symmetric channel (BSC) with a given crossover probability that depends on p and on the probabilities that are one. Specifically, let
and define and , which are the crossover probabilities of the BSCs experienced by receivers 1 and 2, respectively, when they are affected by interference. By drawing for each user two codebooks (one for and one for ) i.i.d. at random according to the probabilities , , , and , and by following a random-coding argument, it can be shown that this scheme achieves the sum rate
This expression holds for any set of parameters , and the largest sum rate achieved by this scheme is obtained by maximizing over .
In the following, we present the achievable sum rates that can be obtained by generalizing the above achievability scheme to general and . The achievability schemes that achieve these rates are presented in Appendix D. The largest achievable sum rates can then be obtained by numerically maximizing over the parameters (which depend on the interference region).
- For the VWI region, we achieve the sum rate
- For the WI region, we can achieve for anywhere and .
- To present the achievable rates for MI, we need to divide the region into the following four subregions:
- (a)
- For , we can achieve for any andwhere , , , and , andwhere , , , and .Remark 7. After combining (32) and (33), and appear only through the functions and , respectively. Hence, and can be optimized separately from the remaining terms.
- (b)
- For , we can achieve for any andwhere , , , and , andwhere , , , and . Remark 7 also applies to the parameters and in (34) and (35).
- (c)
- For , we can achieve for any andwhere , , and , andwhere , , and .
- (d)
- For we can achieve for any andwhere , , and , andwhere , , and .
- To present the achievable rates for SI, we divide the region into the following four subregions:
- (a)
- For , we can achieve for any andwhere and , andwhere and .
- (b)
- For , we can achieve for any andwhere , and , andwhere , and . Remark 7 also applies to the parameters and in (42) and (43).
- (c)
- For , we can achieve for any and ,where , , and . Remark 7 also applies to the parameters and in (44) and (45).
- (d)
In each region, we optimize numerically over the set of parameters, exploiting in some cases that there is symmetry (except for ) between the corresponding parameters of both users.
4.3. Local CSIRT vs. Local CSIR
To evaluate the effect of exploiting local CSI at the transmitter side, we plot in Figure 2, Figure 3 and Figure 4 the converse and achievability bounds for local CSIR and local CSIRT. For each interference region, we choose one value of . We omit the VWI region because in this region both local CSIR and local CISRT coincide. We observe that for all interference regions, except in the VWI region, local CSIRT outperforms local CSIR. We further observe that the largest improvement is obtained for . This is not surprising, since in this case the uncertainty about the interference states is the largest.
4.4. Quasi-Static vs. Ergodic Setup
As observed in the previous subsection, for the ergodic setup local CSIRT outperforms local CSIR in all interference regions (except VWI). In contrast, the opportunistic rates achievable in the quasi-static setup for local CSIRT coincide with those achievable for local CSIR. In other words, the availability of local CSI at the transmitter is only beneficial in the ergodic setup but not in the quasi-static one. This remains to be true even if we consider the average sum capacity rather than the sum rate region. Intuitively, in the coherent setup, the achievable rates depend on the input distributions of and , and adapting these distributions to the interference state yields a rate gain. In contrast, in the quasi-static setup, we treat the two interference states separately: the worst-case rates are designed for the worst case (where both receivers experience interference), and the opportunistic rates are designed for the best case (where the corresponding receiver is interference-free).
Given that the opportunistic rate region is not enhanced by the availability of local CSI at the transmitter, it follows directly that the same is true for the average sum capacity, defined in (23). Note, however, that it is unclear whether (23) corresponds to the best strategy to transmit several messages over independent uses of a quasi-static channel when the transmitters have access to local CSI. Indeed, in this case transmitter i may choose the values for and as a function of the interference state , potentially giving rise to a larger average sum capacity. Yet, the set of achievable rate pairs depends on the choice of of transmitter , which transmitter i may not deduce since it has no access to the other transmitter’s CSI. How the transmitters should adapt their rates to the interference state remains therefore an open question.
5. Global CSIRT
We next present converse and achievability bounds for global CSIRT. In this scenario, the transmitters may agree on a specific coding scheme that depends on the realization of . This allows for a more elaborated cooperation between the transmitters and strictly increases the sum capacity compared to the local CSIR/CSIRT scenarios.
5.1. Quasi-Static Channel
In the quasi-static scenario with global CSIRT, the messages are, strictly speaking, not opportunistic. Instead, transmitters can choose the message depending on the true state of the interference links, so the strategy is perhaps better described as rate adaptation. Nevertheless, the definitions of worst-case sum rate and opportunistic sum rate in Section 2.1 still apply in this case. To keep notation consistent, we use the definition of “opportunism” also for global CSIRT.
5.1.1. Independent Case
Assume first that the sequences and are independent of each other.
Theorem 6
(Opportunistic sum capacity for global CSIRT). Assume that and are independent of each other. For , the opportunistic sum capacity region is the union of the set of rate tuples satisfying (12)–(14) and
Proof.
The converse bounds are proved in Appendix A.5. The achievability bounds are achieved by the following achievability scheme: For we use all the sub-channels of both parallel channels. For and and the VWI/WI regions, we use all sub-channels and the receivers decode them only if they are not affected by interference. For the MI/SI regions, we treat the bursty IC as a non-bursty IC and use the achievability schemes of the IC proposed in [20]. The details can be found in Appendix A.6. □
Remark 8.
The proofs of Theorems 3 and 6 merely require that the joint distribution satisfies , , and . Thus, these theorems also apply to the case where and are dependent, as long as they are not fully correlated.
Table 4 summarizes the results of Theorem 6. Observe that for VWI and WI opportunistic messages can be transmitted reliably at a positive rate, while for MI and SI this is only the case if both links are interference-free.
5.1.2. Fully Correlated Case
Next, we consider the case in which the interference states are fully correlated. In this scenario, local CSIRT coincides with global CSIRT.
Theorem 7
(Opportunistic sum capacity for global CSIRT).
Assume that and are fully correlated. For , the opportunistic sum capacity region is the union of the set of rate pairs satisfying (12)–(14) and
Proof.
For the converse bound, we note that the analysis in Appendix A.5 applies directly to the case where the states and are fully correlated, with the only difference that there are only two possible cases and . The result follows then from (A59), (A60) and (A62). For the achievability bound, we use an achievability scheme where the opportunistic messages are only decoded in absence of interference at the intended receiver. In this case, we have two parallel interference-free channels, for which the optimal strategy consists of transmitting uncoded bits in the sub-channels. □
Table 5 summarizes the results of Theorem 7. Observe that the worst-case sum capacity C and the opportunistic sum capacity when the channel is interference-free do not depend on the correlation between and . The only difference between the independent and fully correlated case is that the interference states and are impossible if .
5.2. Ergodic Channel
5.2.1. Independent Case
When the sequences and are independent of each other, we have the following theorems.
Theorem 8
(Converse bounds for global CSIRT).
Assume that and are independent of each other. The sum rate R for the bursty IC is upper-bounded by
and
Proof.
The proof of (52) follows along similar lines as (18) but noting that, for global CSIRT, depends on both and . The proof of (53) is based on pairing the interference states according the four possible combinations of (). See Appendix B.3 for details. □
Remark 9.
The proof of Theorem 8 can be extended to consider an arbitrary joint distribution . In this case (52) is replaced by
and (53) becomes
Theorem 9
(Achievability bounds for global CSIRT).
Assume that and are independent of each other. The following sum rates R are achievable over the bursty IC:
where .
Proof.
The sum rate (54) is achieved by using the optimal scheme for the non-bursty IC when any of the two receivers is affected by interference [20], and by using uncoded transmission when there is no interference. The sum rates (55) and (56) are novel. See Appendix B.4 for details. □
Remark 10.
In contrast to the local CSIR scenario, the achievability schemes presented in Theorem 9 differ noticeably from those in [12] for the binary IC. Indeed, while both works exploit global CSIRT to enable cooperation between users, [12] assumes that only delayed CSI is present. The achievability schemes presented in Theorem 9 thus cannot be applied directly to the model considered in [12].
5.2.2. Fully Correlated Case
We next discuss the case where the sequences and are fully correlated, i.e., .
Theorem 10 (
Converse bounds for global CSIRT).
Assume that and are fully correlated. The sum rate R for the bursty IC is upper-bounded by
Proof.
The proof of (59) follows similar steps as in Appendix B.3.1 but considering . The proof of (60) is given in Appendix B.5. See also Remark 9. □
Theorem 11 (Achievability bounds for global CSIRT).
Assume that and are fully correlated. The following sum rates R are achievable over the bursty IC:
Proof.
The sum rates (61) and (62) are achieved by using the optimal scheme for the non-bursty IC when the two receivers are affected by interference [20], and by using uncoded transmission in absence of interference. □
Table 7 summarizes the results of Theorems 10 and 11. For global CSIRT and fully correlated and , converse and achievability bounds coincide. Thus, (61) and (62) indicate the sum capacity.
5.3. Quasi-Static vs. Ergodic Setup
Similar to the average sum capacity for local CSIR defined in Section 3.3, we define the average sum capacity for global CSIRT when and are independent as
where the suprema are over all rate tuples that satisfy Theorems 2 and 6. The intuition behind (63) is the same as that behind (23) for local CSIR, but with global CSIRT the transmitters can adapt their rates to the interference state. For example, the first term on the right-hand side (RHS) of (63) corresponds to the interference state , in which case we transmit at total sum rate R; the second term corresponds to the interference state , in which case we transmit at total sum rate ; and so on.
Table 8 summarizes the average sum capacity for the different interference regions. The average sum capacities for VWI and WI coincide with the sum capacities in the ergodic setup (see Table 6). In contrast, for MI and SI, the average sum capacities are smaller than the sum capacities in the ergodic setup.
Similarly, in the fully correlated case, we define the average sum capacity as
where the suprema are over all rate pairs that satisfy Theorems 2 and 7. The corresponding results are summarized in Table 9.
We observe that the average sum capacities coincide with the sum capacities of the ergodic setup.
6. Exploiting CSI
In this section, we study how the level of CSI affects the sum rate in the quasi-static and ergodic setups.
For the quasi-static channel, Figure 5 and Figure 6 show the total sum capacity presented in Theorems 3, 6 and 7. Specifically, we plot the normalized total sum capacity versus , comparing scenarios of local CSIR/CSIRT and global CSIRT. We analyze separately the cases and . For the case where and global CSIRT, the total sum capacity is for all interference regions. For and local CSIR/CSIRT, the total sum capacity is for VWI and VSI, but is strictly smaller in the remaining interference regions. Hence, in these regions global CSIRT outperforms local CSIR/CSIRT. For the case where , the total sum capacity is equal to irrespective of the level of CSI.
We further observe that the opportunistic-capacity region for local CSIRT is equal to that for local CSIR. Thus, local CSI at the transmitter is not beneficial. As we shall see later, this is in stark contrast to the ergodic setup, where local CSI at the transmitter-side is beneficial. Intuitively, in the ergodic case the input distributions of and depend on the realizations of and , respectively. Hence, adapting the input distributions to these realizations increases the sum capacity. In contrast, in the quasi-static case, the worst-case scenario (presence of interference) and the best-case scenario (absence of interference) are treated separately. Hence, there is no difference to the case of local CSIR.
For the ergodic setup, Figure 7, Figure 8, Figure 9 and Figure 10 show the converse and achievability bounds presented in Theorems 4, 5, 8 and 9. We further include the results on local CSIRT presented in Section 4. Specifically, we plot the normalized sum capacity versus the probability of presence of interference p, comparing scenarios of local CSIR, local CSIRT and global CSIRT when and are independent of each other. The shadowed areas correspond to the regions where achievability and converse bounds do not coincide.
Figure 7 reveals that in the VWI region the sum capacity is equal to , irrespective of the availability of CSI (see Figure 7). Thus, in this region access to global CSIRT is not beneficial compared to the local CSIR scenario. In the VSI region, the sum capacity of the non-bursty IC is equal to , which is that of two parallel channels without interference [15] (Section II-A). Therefore, burstiness of the interference (and hence CSI) does not affect the sum capacity.
In the WI region, shown in Figure 8, the converse and achievability bounds for local CSIR and global CSIRT coincide and it is apparent that global CSIRT outperforms local CSIR. In the MI and SI regions, the converse and achievability bounds only coincide for certain regions of p. Nevertheless, Figure 9 and Figure 10 show that, in almost all cases, global CSIRT outperforms local CSIR. (For the case presented in Figure 9, we also present the local CSIRT converse bound (18), although it is looser for some values of p, with respect to the one depicted for global CSIRT.) Local CSIRT outperforms local CSIR in all interference regions (except VWI). We stress again the fact that this was not the case in the quasi-static scenario, where both coincide.
We next consider the case where and are fully correlated. For this scenario, [7,23] studied the effect of perfect feedback on the bursty IC. For comparison, the non-bursty IC with feedback was studied by Suh et al. in [25], where it was demonstrated that the gain of feedback becomes arbitrarily large for certain interference regions (VWI and WI) when the signal-to-noise-ratio increases. This gain corresponds to a better resource utilization and thereby a better resource sharing between users. Specifically, [7,23] (bursty IC) and [25] (non-bursty IC) assume that noiseless, delayed feedback is available from receiver i to transmitter i. For the symmetric setup treated in this paper, [7] (Theorem 3.2) or [23] (Theorem 3.2) showed the following:
Theorem 12
Observe that (65) for coincides with (18). This implies that local CSIRT can never outperform delayed feedback. Intuitively, feedback contains not only information about the channel state, but also about the previous symbols transmitted by the other transmitter, which can be exploited to establish a certain cooperation between the transmitters. Figure 11, Figure 12, Figure 13 and Figure 14 show the bounds on the normalized sum capacity, , comparing the scenarios of local CSIR versus global CSIRT when the interference states are fully correlated, i.e., . They further show the sum capacity for the case where the transmitters have noiseless delayed feedback [7]. The shadowed areas correspond to the regions where achievability and converse bounds do not coincide.
Figure 11 reveals that feedback in the VWI region outperforms the non-feedback case, irrespective of the availability of CSI. Wang et al. [7] have further shown that feedback also outperforms the non-feedback case in the VSI region. The order between global CSIRT and the feedback scheme is not obvious. There are regions where global CSIRT outperforms the feedback scheme and vice versa. Indeed, on the one hand, feedback contains information about the previous interference states and previous symbols transmitted by the other transmitter, permitting the resolution of collisions in previous transmissions. On the other hand, global CSIRT provides non-causal information about the interference states, allowing a better adaptation of the transmission strategy to the interference burstiness.
7. Exploiting Interference Burstiness
To better illustrate the benefits of interference burstiness, we show the normalized sum capacity as a function of , in order to appreciate all the interference regions. In the non-bursty IC (), this curve corresponds to the well-known W-curve obtained by Etkin et al. in [26]. We next study how burstiness affects this curve in the different considered scenarios.
In the quasi-static setup, burstiness can be exploited by sending opportunistic messages. We consider the total sum capacity for the case where the worst-case rate R is maximized. For local CSIR/CSIRT, Theorem 3 suggests that the use of an opportunistic code is only beneficial if the interference region is VWI or WI. For other interference regions there is no benefit. In contrast, for global CSIRT an opportunistic code is beneficial for all interference regions (except for VSI where the sum capacity corresponds to that of two parallel channels without interference).
Figure 15 and Figure 16 illustrate these observations. Specifically, in Figure 15 and Figure 16 we show the normalized total sum capacity achieved under local CSIR/CSIRT and global CSIRT when the interference states are independent. We observe that, for local CSIR, the opportunistic rates and , are only positive in the VWI and WI regions. In these regions, if only one of the receivers is affected by interference the sum capacity is given by the worst-case rate R plus one opportunistic rate of the user which is not affected by interference. In absence of interference at both receivers, both receivers can decode opportunistic messages. Hence, the total sum capacity is equal to . For global CSIRT we can observe that, when only one of the receivers is affected by interference, we achieve the same total sum capacity as in the local CSIR/CSIRT. However, in absence of interference at both receivers, we achieve the trivial upper bound corresponding to two parallel channels. The fully correlated scenario can be considered as a subset of the independent scenario. Indeed, for the case and we obtain the same total sum capacity as for the independent scenario. The main difference is that in the fully correlated scenario the interference states and are impossible.
For the ergodic case, Figure 17 and Figure 18 show the bounds on the normalized sum capacity, , as a function of when and are independent. The shadowed areas correspond to the regions where achievability and converse bounds do not coincide. We further show the W-curve. Observe that for the sum capacity as a function of forms a V-curve instead of the W-curve. Further observe how the sum capacity approaches the W-curve as p tends to one.
In Figure 19 we show the bounds on the normalized sum capacity, , as a function of for global CSIRT when and are fully correlated. (For local CSIR the sum capacity is not affected by the correlation between and , so the curve for as a function of coincides with the one obtained in Figure 17.) We observe that, for all values of , the sum capacity forms a W-curve similar to the W-curve for . This is the case because, when both interference states are fully correlated, the bursty IC is a combination of an IC and two parallel channels.
We observe that for global CSIRT the burstiness of the interference is beneficial for all interference regions and all values of p. For local CSIR, burstiness is beneficial for all values of p for VWI and WI. However, for MI and SI, burstiness is only of clear benefit for . It is yet unclear whether burstiness is also beneficial in these interference regions when . To shed some light on this question, note that evaluating the converse bound in [23] (Lemma A.1), which yields (21), for inputs and that are temporally independent, we recover the achievability bound (20). Since for MI/SI and this bound coincides with the rates achievable over the non-bursty IC, this implies that an achievability scheme can only exploit the burstiness of the interference in this regime if it introduces some temporal correlation (this observation is also revealed by considering the average sum capacity for the quasi-static case). In fact, for global CSIRT the achievability schemes proposed in Theorem 9 for MI and SI copy the same bits over several coherence blocks, i.e., they exhibit a temporal correlation, which cannot be achieved using temporally independent distributions. However, the temporal pattern of these bits requires knowledge of both interference states, so this approach cannot be adapted to the cases of local CSIR/CSIRT. In contrast, for global CSIRT in the fully correlated case where converse and achievability bounds coincide, it is not necessary to introduce temporal memory. This scenario is simpler, since in this case the channel exhibits only two channel states, a non-bursty IC and two parallel channels.
8. Summary and Conclusions
In this work, we considered a two-user bursty IC in which the presence/absence of interference is modeled by a block-i.i.d. Bernoulli process while the power of the direct and cross links remains constant during the whole transmission. This scenario corresponds, e.g., to a slow-fading scenario in which all the nodes can track the channel gains of the different links, but where the interfering links are affected by intermittent occlusions due to some physical process. While this model may appear over-simplified, it yields a unified treatment of several aspects previously studied in the literature and gives rise to several new results on the effect of the CSI in the achievable rates over the bursty IC. Our channel model encompasses both the quasi-static scenario studied in [3,5] and the ergodic scenario (see, e.g., [7,12]). While the model recovers several cases studied in the literature, it also presents scenarios which have not been previously analyzed. This is the case, for example, for the ergodic setup with local and global CSIRT. Our analysis in these scenarios does not yield matching upper and lower bounds for all interference and burstiness levels. Yet, examining the obtained results, we observe that the best strategies in these scenarios often require elaborated coding strategies for both users that feature memory across different interference. This fact probably explains why no previous results exist in these scenarios. Furthermore, several of our proposed achievability schemes require complex correlation among signal levels. Thus, while the LDM in general provides insights on the Gaussian IC, the proposed schemes may actually be difficult to convert to the Gaussian case.
In the quasi-static scenario, the highest sum rate R that can be achieved is limited by the worst realization of the channel and thus coincides with that of the (non-bursty) IC. We can however transmit at an increased (opportunistic) sum rate when there is no interference at any of the interfering links. For the ergodic setup, we showed that an increased rate can be obtained when local CSI is present at both transmitter and receiver, compared to that obtained when CSI is only available at the receiver side. This is in contrast to the quasi-static scenario, where the achievable rates for local CSIR and local CSIRT coincide. Featuring global CSIRT at all nodes yields an increased sum rate for both the quasi-static and the ergodic scenarios. In the quasi-static channel, global CSI yields increased opportunistic rates in all the regions except in the very strong interference region, which is equivalent to having two parallel channels with no interference.
Both in the quasi-static and ergodic scenarios, global CSI exploits interference burstiness for all interference regions (except for very strong interference), irrespective of the level of burstiness. When local CSI is available only at the receiver side, interference burstiness is of clear benefit if the interference is either weak or very weak, or if the channel is ergodic and interference is present at most half of the time. When local CSI is available at each transmitter and receiver and the channel is ergodic, interference burstiness is beneficial in all interference regions except in the very weak and very strong interference regions.
In order to compare the achievable rates of the quasi-static and ergodic setup, one can define the average sum rate of the quasi-static setup for local CSIR/CSIRT as , with a similar definition for the average sum rate for global CSIRT. The average sum rate corresponds to a scenario where several codewords are transmitted over independent quasi-static bursty ICs. This, in turn, could be the case if a codeword spans several coherence blocks, but no coding is performed over these blocks. This is in contrast to the ergodic setup where coding is typically performed over different coherence blocks. By the law of large numbers, roughly a fraction of p codewords experiences interference, the remaining codewords are transmitted free of interference. Consequently, an opportunistic transmission strategy achieves the rate , which corresponds to the average sum rate. Our results demonstrate that, for local CSIR, the average sum capacity, obtained by maximizing the average sum rate over all achievable rate pairs , coincides with the achievable rates in the ergodic setup for all interference regions. In contrast, for local CSIRT, the average sum capacity is strictly smaller than the sum capacity in the ergodic setup. For global CSIRT, average sum capacity and sum capacity coincide for all interference regions when the interference states are fully correlated, and they coincide for VWI and WI when the interference states are independent. For global CSIRT, MI/SI, and independent interference states, the average sum capacity is smaller than the sum capacity in the ergodic setup. In general, the average sum capacity defined for the quasi-static setup never exceeds the sum capacity in the ergodic setup. This is perhaps not surprising if we recall that the average sum capacity corresponds to the case where no coding is performed over coherence blocks. Interestingly, the average sum capacity is not always achieved by maximizing the worst-case rate. For small values of p, it is beneficial to reduce the worst-case rate in order to achieve a larger opportunistic rate.
In our work we considered both the case where the interference states of the two users are independent and the case where the interference states are fully correlated. In both ergodic and quasi-static setups, the results for local CSIR are independent of the correlation between interference states. For other CSI levels, dependence between the interference states helps in all interference regions except very weak and very strong interference regions.
Author Contributions
Conceptualization, G.V., T.K., A.S. and G.V.-V.; Funding acquisition, T.K., A.S. and G.V.-V.; Investigation, G.V., T.K., A.S. and G.V.-V.; Methodology, G.V., T.K., A.S. and G.V.-V.; Project administration, T.K., A.S. and G.V.-V.; Resources, T.K. and A.S.; Software, G.V. and G.V.-V.; Supervision, T.K., A.S. and G.V.-V.; Validation, G.V., T.K., A.S. and G.V.-V.; Visualization, G.V. and G.V.-V.; Writing—original draft, G.V., T.K., A.S. and G.V.-V.; Writing—review & editing, G.V., T.K., A.S. and G.V.-V.
Funding
This work has been funded in part by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement number 714161), from the Spanish Ministerio de Economía y Competitividad under Grants TEC2013-41718-R, RYC-2014-16332, IJCI-2015-27020, TEC2016-78434-C3-3-R (AEI/FEDER, EU), from the Comunidad de Madrid under Grant S2103/ICE-2845, and from ‘Ayudas para la Movilidad del Programa Propio de Investigación UC3M 2016”.
Acknowledgments
Fruitful discussions with S. Gherekhloo are gratefully acknowledged. We further thank the anonymous reviewers for their insightful comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs for the Quasi-Static Case
We define . Clearly, when are independent, we have , and , and when are fully correlated , and .
The converse bounds in the quasi-static case are based on an information density approach [27]. In particular, we define the information densities for the bursty IC
Here and throughout the appendices, we use the notations , , , and to highlight the fact that, in the quasi-static setting, we transmit N symbols in one coherence block.
We further consider the individual error events
and the joint error event
The proofs of the converse results are based on the following lemmas.
Lemma A1 (Verdú-Han lemma)
Every code over a channel satisfies
for every , where places probability mass on each codeword and .
Proof.
See [27] (Theorem 4). □
Lemma A2.
Suppose that as . Then, for each pair , the threshold Γ must satisfy the following conditions:
Proof.
See Appendix C. □
Appendix A.1. Proof of Theorem 2
In this section we prove the IC channel converse bounds for . This proof assumes global CSIRT, hence the resulting bounds also apply to local CSIR and local CSIRT. Let , and let us denote by and the error probabilities at decoders one and two, respectively:
Clearly, the error probabilities , and are related by the following sets of inequalities
Using these inequalities we conclude that
We now rewrite (A9) and (A10) as
and apply the Verdú-Han lemma (Lemma A1) to each of the probability terms , , in (A13) and (A14). This yields
We set and . Then, using the definition of in (A3), we can write (A15) and (A16) as
Using (A20) and the union bound, we thus obtain
Combining this result with (A12), (A17) and (A18) gives
The remainder of this section is devoted to an analysis of . Indeed, by (A22) we have for any that
where . When , the probability is strictly positive both when are independent and when they are fully correlated. Since does not depend on N, it follows that the only way that is that as . The conditions on R under which this happens are summarized in Lemma A2. Specifically, recalling that , we obtain from Lemma A2 that only if
Since are arbitrary, we obtain the converse bounds (13) and (14) in Theorem 2 from (A24)–(A26) upon letting and then and .
When , the only positive probability is . A necessary condition for is that as . By following the same approach as for the case , we obtain the converse bound (12) in Theorem 2.
Appendix A.2. Converse Proof of Theorem 3
In this section, we analyze the opportunistic rate for local CSIRT and independent and . Let us denote by and the error probabilities at decoders one and two, defined in (6) and (7), i.e.,
Before we apply the Verdú-Han lemma, we have to deal with the fact that (A27) and (A28) are conditioned on two different variables but we need to analyze the probability of error jointly. To solve this problem, we expand the probability of error (A27) as
Since, by assumption, , it follows that
if, and only if,
We shall lower-bound (A29) by considering only one of the two terms in the sum. Proceeding analogously for the second user and applying the Verdú-Han lemma (Lemma A4), we obtain
Let , and . Then, (A31) and (A32) can be written as
Proceeding analogously as in (A19)–(A22), and using that , we obtain
Since , the left-hand side (LHS) of (A35) only tends to zero as if as . It thus follows from Lemma A2 that as only if conditions (A6)–(A8) are satisfied. Letting and then gives the following constraints:
- For
- For ,
- For , using that ,
- For , using that ,
The constraints (A39)–(A41) yield (15)–(17). This proves Theorem 3.
Appendix A.3. Achievability Proof of Theorem 3
In this section, we present the achievability bounds in Theorem 3 for the regions in which it is possible to transmit opportunistic messages, namely the VWI and WI regions. The presented bounds are valid for local CSIR and local CSIRT.
Appendix A.3.1. Very Weak Interference
Transmitter 1 (Tx) and transmitter 2 (Tx) transmit in the most significant levels a block of bits, and they transmit in the least significant levels a block of bits. The same construction is used for both transmitters. Figure A1 depicts the signal levels of the transmitted signals (normalized by ) as observed at receiver 1 (Rx), when it is affected by interference.
Figure A1.
Normalized signal levels at Rx for .

At the receiver side, we have the following procedure:
- In presence of interference: decode block
![Entropy 20 00870 i001]() in the desired signal which is interference free, and treat the block
in the desired signal which is interference free, and treat the block ![Entropy 20 00870 i002]() as noise. We thus obtain the individual rate
as noise. We thus obtain the individual rate
- In absence of interference: decode blocks
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i002]() . We thus obtain the individual rate
where corresponds to the opportunistic rate.
. We thus obtain the individual rate
where corresponds to the opportunistic rate.
The bounds (A42) and (A43) coincide with the bounds for the bounds of user 2. In order to obtain the possible sum rates according to the interference states, we combine (A42) (which corresponds to ) and (A43) (which corresponds to ) to obtain the converse bounds (15)–(16).
Appendix A.3.2. Weak Interference
The symbol transmitted by Tx (normalized by ) is depicted in Figure A2a. Specifically, we transmit in the most significant levels a block of bits. In the subsequent levels we transmit a block of zeros, followed by opportunistic bits. Finally, in the least significant levels, we transmit a block of bits. The same construction is used for both transmitters.
Figure A2b depicts the normalized signal levels of the transmitted signals as observed by Rx. At the receiver side, we have the following procedure:
- In presence of interference: The channel pushes the interference level by bits. Thus, the least significant bits of the desired signal (block
![Entropy 20 00870 i001]() ) align with the zeros of the interference signal and can be decoded free from interference. Since , the most significant bits (block
) align with the zeros of the interference signal and can be decoded free from interference. Since , the most significant bits (block ![Entropy 20 00870 i002]() ) are also free from interference. Thus, we achieve the rate
) are also free from interference. Thus, we achieve the rate
- In absence of interference: The bits in blocks
![Entropy 20 00870 i001]() ,
, ![Entropy 20 00870 i002]() , and
, and ![Entropy 20 00870 i004]() can be decoded free from interference. Thus, we achieve the rate
where corresponds to the opportunistic rate.
can be decoded free from interference. Thus, we achieve the rate
where corresponds to the opportunistic rate.
By symmetry, the bounds (A44) and (A45) also apply for the achievable rates of user 2. In order to obtain the possible sum rates according to the interference states, we combine (A44) (which corresponds to ) and (A45) (which corresponds to ) to obtain the achievability bounds in Theorem 3.
Figure A2.
(a) Normalized transmitted symbol at Tx; (b) Normalized signal levels at Rx.

Appendix A.4. Converse Proof of Theorem 3 when B1 = B2
The proof of the converse bound (15) for local CSIR when is similar to the proof when and are independent; see Appendix A.2. However, to prove the converse bound (16) for the case where we cannot simply reproduce the steps for the independent case. The reason is that, in the correlated case, we only have the interference states and , but the derivation of (16) for the independent case follows from the analysis of the states and (see (A40) and (A41) in Appendix A.2). To sidestep this problem, we follow a slightly different approach. Specifically, we combine the error probability of user 1 when with that of user 2 when . This approach yields a tighter converse bound compared to the one obtained by simply considering in both probabilities.
Consider and defined in (A27) and (A28). Applying the Verdú-Han lemma (Lemma A1) with and , and using (A29), we obtain the lower bounds
Note that compared to the derivation in Section A.2, the two error events and are conditioned on different interference states. In order to derive a joint error event for and , we use the next lemma.
Lemma A3.
For local CSIR, the information density , depends only on and the corresponding state , i.e.,
Proof.
We prove (A48) for user 1. By the definition of the information density (A1), it follows that
Evaluating for , and , we obtain that both cases are independent of . The identity (A48) can be proven in the same way. □
We next analyze the probability terms in (A46) and (A47). It follows from (A48) in Lemma A3 that is independent of . Consequently,
Analogously, using (A49) in (A47), we obtain
Adding (A46) and (A47), using (A51) and (A52), and lower-bounding and by , we obtain
where . We next apply Lemma A2 with . Since is strictly positive for , and since as for any fixed , a necessary condition for (A53) going to zero is that as . This is the case if, and only if, (A7) in Lemma A2 is fulfilled. Since are arbitrary, we conclude the proof by letting and and using that to obtain
Given the symmetry of the problem, a bound on follows by swapping the roles of users 1 and 2, yielding in this case
Finally, combining (A54) and (A55), we obtain the bound (16) in Theorem 3 for the fully correlated scenario.
Appendix A.5. Converse Proof of Theorem 6
In this section, we analyze the opportunistic rates for global CSIRT and independent and . Let us denote by and the error probabilities at decoders 1 and 2, defined in (6) and (7), namely,
We shall follow analogous steps as in Section A.2 and set , , and . Proceeding analogously as in (A19)–(A21), we obtain
By invoking Lemma A2 for fixed (but arbitrary) , and letting then and , we obtain that the RHS of (A58) vanishes as only if the following constraints are satisfied:
- For ,
- For ,
- For ,
- For ,
This proves the converse bounds in Theorem 6.
Appendix A.6. Achievability Proof of Theorem 6
In this section, we present the achievability schemes for global CSIRT when and are independent. In contrast to the local CSIR/CSIRT case, we can adapt our transmission strategy to the interference states.
When , the capacity-achieving scheme consists of sending uncoded bits in all level. We thus achieve the sum rate .
When or , the achievability schemes coincide with the schemes described in Section A.3. In this case, we can only send opportunistic messages when we have VWI or WI.
Appendix A.6.1. Very Weak Interference
This proves the achievability bounds in Theorem 6 for VWI.
Appendix A.6.2. Weak Interference
Combining (A67) and (A68), we obtain the achievability bounds in Theorem 6 for WI.
Appendix B. Proofs for the Ergodic Case
Appendix B.1. Proof of (18) in Theorem 4
The bound (18) coincides with [7] (Theorem 3.1). However, [7] (Theorem 3.1) derives (18) for the considered channel model with and feedback. In this section we show that (18) also holds for general T in the no-feedback case. We follow along the lines of the proof of [7] (Theorem 3.1). We begin by applying Fano’s inequality to obtain
where as . Here, follows because () determine , so we can subtract the contribution of in the second entropy and by evaluating the entropy for different interference states. Step follows because are independent of (which in turn follows because only depends on , which is independent of ) and because conditioning reduces entropy.
Likewise, we have
where as . Here, follows because , and are independent. Step (b) follows because determines , so we can subtract its contribution from , because has a lower entropy than , and because conditioning reduces entropy. Step follows by the chain rule, and because conditioning reduces entropy.
By maximizing the individual entropies in (A71) over all input distributions, dividing both sides of (A71) by , and by letting then K tend to infinity, we obtain that
By symmetry, the same bound also holds for . Thus, by averaging over the two cases, it follows that (A72) is also an upper bound on . The final result (18) follows by dividing (A72) by .
Appendix B.2. Achievability Proof of Theorem 5
In this section, we describe the achievability schemes that yield the rates presented in Theorem 5 for local CSIR. The bursty IC described in Section 2 is treated here as a set of parallel sub-channels.
Appendix B.2.1. Scheme 1 (VWI; WI, MI for 0 ≤ p ≤ )
The achievability scheme is illustrated in Figure A3a. In the figure, we present the normalized received signal at Rx, i.e., we represent graphically the time-k channel output given by (3), where the signal level from Tx corresponds to and the signal level from Tx corresponds to , both normalized by . In our scheme, the upper sub-channels (block ![Entropy 20 00870 i001]() in the figure) carry uncoded data (rate 1 bits/sub-channel use), while in the lower channels (block
in the figure) carry uncoded data (rate 1 bits/sub-channel use), while in the lower channels (block ![Entropy 20 00870 i002]() in the figure) a capacity-achieving code of blocklength for a binary erasure channel (BEC) with erasure probability p is used (with asymptotic rate bits/sub-channel use) [28] (Section 7.1.5). Block
in the figure) a capacity-achieving code of blocklength for a binary erasure channel (BEC) with erasure probability p is used (with asymptotic rate bits/sub-channel use) [28] (Section 7.1.5). Block ![Entropy 20 00870 i001]() is received free of interference and can be directly decoded at the receiver. Block
is received free of interference and can be directly decoded at the receiver. Block ![Entropy 20 00870 i002]() is affected by interference with probability (w.p.) p. Since the fading state is known to the i-th receiver, interfered slots are treated as erasures. Consequently, when K tends to infinity, user i achieves the rate . The sum rate R is thus given by
is affected by interference with probability (w.p.) p. Since the fading state is known to the i-th receiver, interfered slots are treated as erasures. Consequently, when K tends to infinity, user i achieves the rate . The sum rate R is thus given by
 in the figure) carry uncoded data (rate 1 bits/sub-channel use), while in the lower channels (block
in the figure) carry uncoded data (rate 1 bits/sub-channel use), while in the lower channels (block  in the figure) a capacity-achieving code of blocklength for a binary erasure channel (BEC) with erasure probability p is used (with asymptotic rate bits/sub-channel use) [28] (Section 7.1.5). Block is received free of interference and can be directly decoded at the receiver. Block is affected by interference with probability (w.p.) p. Since the fading state is known to the i-th receiver, interfered slots are treated as erasures. Consequently, when K tends to infinity, user i achieves the rate . The sum rate R is thus given by
in the figure) a capacity-achieving code of blocklength for a binary erasure channel (BEC) with erasure probability p is used (with asymptotic rate bits/sub-channel use) [28] (Section 7.1.5). Block is received free of interference and can be directly decoded at the receiver. Block is affected by interference with probability (w.p.) p. Since the fading state is known to the i-th receiver, interfered slots are treated as erasures. Consequently, when K tends to infinity, user i achieves the rate . The sum rate R is thus given by
This scheme is tight for VWI and for WI and MI when .
Appendix B.2.2. Scheme 2 (WI, < p ≤ 1)
We next consider the achievability scheme illustrated in Figure A3b. In blocks ![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i002]() uncoded data is transmitted (rate 1 bits/sub-channel use), block
uncoded data is transmitted (rate 1 bits/sub-channel use), block ![Entropy 20 00870 i003]() carries the deterministic all-zeros sequence (rate 0 bit/sub-channel use) and in block
carries the deterministic all-zeros sequence (rate 0 bit/sub-channel use) and in block ![Entropy 20 00870 i004]() a capacity-achieving code for the BEC (with asymptotic rate bits/sub-channel use) is used. As in Scheme 1, blocks
a capacity-achieving code for the BEC (with asymptotic rate bits/sub-channel use) is used. As in Scheme 1, blocks ![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i002]() can be decoded without interference, and block
can be decoded without interference, and block ![Entropy 20 00870 i004]() is decoded by treating interfered symbols as erasures. The rate achieved by this scheme at user i is , so
is decoded by treating interfered symbols as erasures. The rate achieved by this scheme at user i is , so
and uncoded data is transmitted (rate 1 bits/sub-channel use), block  carries the deterministic all-zeros sequence (rate 0 bit/sub-channel use) and in block
carries the deterministic all-zeros sequence (rate 0 bit/sub-channel use) and in block  a capacity-achieving code for the BEC (with asymptotic rate bits/sub-channel use) is used. As in Scheme 1, blocks and can be decoded without interference, and block is decoded by treating interfered symbols as erasures. The rate achieved by this scheme at user i is , so
a capacity-achieving code for the BEC (with asymptotic rate bits/sub-channel use) is used. As in Scheme 1, blocks and can be decoded without interference, and block is decoded by treating interfered symbols as erasures. The rate achieved by this scheme at user i is , so
Figure A3.
Normalized signal levels at Rx. (a) VWI; WI; MI, ; (b) WI, .

Appendix B.2.3. Scheme 3 (SI, 0 ≤ p ≤ )
We use an achievability scheme similar to Scheme 1. Now, the upper sub-channels carry a capacity-achieving code for a BEC with erasure probability p, and the lower sub-channels carry uncoded data. Consequently, when K tends to infinity, user i achieves the rate . The sum rate is thus given by
This proves Theorem 5.
Appendix B.3. Proof of Theorem 8
In this section, we prove the converse bounds for global CSIRT and independent and .
Appendix B.3.1. Converse Bound (52) for Global CSIRT
By Fano’s inequality, we have
where as . Here, follows because determines , so we can subtract its contribution from the second entropy. Likewise,
where as . Here, step follows because and are independent. Step follows because determines , so we can subtract its contribution from and , and because conditioning reduces entropy. Step follows by evaluating the entropies for different interference states and because conditioning reduces entropy. Combining (A76) and (A77) yields
By maximizing the entropies in (A78) over all input distributions, dividing by , and letting K tend to infinity, we obtain that
which is (52).
Appendix B.3.2. Converse Bound (53) for Global CSIRT
Let denote the realizations of the interference states . We label the set of time indices where the pair takes the value (0,1) by ; (1,1) by ; (1,0) by ; and (0,0) by . We denote the length of each of these states by and , respectively. For example,
and
These states are schematically shown in Figure A4, where shaded areas correspond to .
Figure A4.
Possible interference states.

For global CSIRT, may depend on . We shall denote by and the ’s with indices in and . For example, . At time k, the interference states can be in one of the 4 possible cases, as depicted in Figure A4. The converse bound (53) is proved as follows. We begin by applying Fano’s inequality to obtain
where and as . For every , we have
where step follows by the chain rule for entropy and because determines , so we can subtract its contribution from the second and fourth entropy. Step follows because conditioning reduces entropy. We next upper-bound (A81) by combining the positive and negative entropies in areas and for user 1 and user 2; and areas and for user 2 and user 1:
where step follows because for any random variables F and G. By maximizing the entropies in (A82) over all input distributions, we obtain
By dividing (A83) by , and taking the limit as , we obtain
where follows because as . Next, we apply the dominated convergence theorem (DCT) [29] (Section 1.34) to interchange limit and expectation. By the law of large numbers, we have that , , , and almost surely as . By replacing these probabilities in (A84), we thus obtainx
This yields (53).
Appendix B.4. Proof of Theorem 9
In this section, we present the achievability schemes for global CSIRT and independent and . Let denote the realizations of the interference states , and define . Consider the following achievable schemes.
Appendix B.4.1. Scheme 1 (MI, 0 ≤ p ≤ 1)
Both transmitters employ uncoded transmission in the first indices of regions and , respectively, and in the whole region . Tx copies the first indices of region in region , while Tx copies the first indices of region in , aligned with those of user 1. The remaining indices are treated as a non-bursty IC attaining rate [20].
To illustrate the decoding process, Figure A5 shows the different normalized signals at the Rx when . Tx transmits the signals ![Entropy 20 00870 i008]() ,
, ![Entropy 20 00870 i010]() , and
, and ![Entropy 20 00870 i011]() , in channel state and , , and , respectively. Similarly, Tx transmits the signal
, in channel state and , , and , respectively. Similarly, Tx transmits the signal ![Entropy 20 00870 i009]() in states and . Rx has access to a clean copy of signal
in states and . Rx has access to a clean copy of signal ![Entropy 20 00870 i008]() in region , which can then be subtracted in state to recover the interfering signal
in region , which can then be subtracted in state to recover the interfering signal ![Entropy 20 00870 i009]() . Since Tx transmits the same signal in state , the interference can then be canceled. Hence, signals
. Since Tx transmits the same signal in state , the interference can then be canceled. Hence, signals ![Entropy 20 00870 i010]() and
and ![Entropy 20 00870 i011]() are recovered. For a given interference state and general and , , and , the rate attained by user i with this scheme is
are recovered. For a given interference state and general and , , and , the rate attained by user i with this scheme is
 ,
,  , and
, and  , in channel state and , , and , respectively. Similarly, Tx transmits the signal
, in channel state and , , and , respectively. Similarly, Tx transmits the signal  in states and . Rx has access to a clean copy of signal in region , which can then be subtracted in state to recover the interfering signal . Since Tx transmits the same signal in state , the interference can then be canceled. Hence, signals and are recovered. For a given interference state and general and , , and , the rate attained by user i with this scheme is
in states and . Rx has access to a clean copy of signal in region , which can then be subtracted in state to recover the interfering signal . Since Tx transmits the same signal in state , the interference can then be canceled. Hence, signals and are recovered. For a given interference state and general and , , and , the rate attained by user i with this scheme is
Figure A5.
Normalized by signal levels at Rx for MI and .

Averaging (A86) over , and letting , we obtain for the sum rate
where we changed the order of limit and expectation by appealing to the DCT, and used that, by the law of large numbers, , , and almost surely as .
Appendix B.4.2. Scheme 2 (SI, 0 ≤ p ≤ 1)
Both transmitters employ uncoded transmission in the first indices of states and . Tx copies the lowest sub-channels of the first indices of region into the highest sub-channels and uses uncoded transmission in the lowest sub-channels of the corresponding sub-region in . Tx proceeds analogously but from region to . Both transmitters employ uncoded transmission in region and treat the remaining indices as a non-bursty IC [20] with rate .
To illustrate the decoding process, Figure A6 shows the different normalized signals at the Rx when . Tx transmits the signals ( ![Entropy 20 00870 i008]() ,
, ![Entropy 20 00870 i009]() ), (
), ( ![Entropy 20 00870 i008]() ,
, ![Entropy 20 00870 i010]() ),
), ![Entropy 20 00870 i012]() and
and ![Entropy 20 00870 i013]() in channel state and , , and , respectively. Similarly, Tx transmits the signal (
in channel state and , , and , respectively. Similarly, Tx transmits the signal ( ![Entropy 20 00870 i011]() ,
, ![Entropy 20 00870 i014]() ) and (
) and ( ![Entropy 20 00870 i011]() ,
, ![Entropy 20 00870 i015]() ) in states and , respectively. Rx has access to a clean copy of signals
) in states and , respectively. Rx has access to a clean copy of signals ![Entropy 20 00870 i008]() and
and ![Entropy 20 00870 i009]() in region , signal
in region , signal ![Entropy 20 00870 i008]() can then be subtracted in state to recover the interfering signals
can then be subtracted in state to recover the interfering signals ![Entropy 20 00870 i011]() and
and ![Entropy 20 00870 i014]() . In state , Rx has access to signal
. In state , Rx has access to signal ![Entropy 20 00870 i010]() . Since Tx transmits signal
. Since Tx transmits signal ![Entropy 20 00870 i011]() in state , the interference can then be canceled. Hence, signal
in state , the interference can then be canceled. Hence, signal ![Entropy 20 00870 i012]() can be recovered. Finally, signal
can be recovered. Finally, signal ![Entropy 20 00870 i013]() is recovered without interference. For a given interference state, and general , the rate attained by user i with this scheme is
is recovered without interference. For a given interference state, and general , the rate attained by user i with this scheme is
, ), ( , ),  and
and  in channel state and , , and , respectively. Similarly, Tx transmits the signal ( ,
in channel state and , , and , respectively. Similarly, Tx transmits the signal ( ,  ) and ( ,
) and ( ,  ) in states and , respectively. Rx has access to a clean copy of signals and in region , signal can then be subtracted in state to recover the interfering signals and . In state , Rx has access to signal . Since Tx transmits signal in state , the interference can then be canceled. Hence, signal can be recovered. Finally, signal is recovered without interference. For a given interference state, and general , the rate attained by user i with this scheme is
) in states and , respectively. Rx has access to a clean copy of signals and in region , signal can then be subtracted in state to recover the interfering signals and . In state , Rx has access to signal . Since Tx transmits signal in state , the interference can then be canceled. Hence, signal can be recovered. Finally, signal is recovered without interference. For a given interference state, and general , the rate attained by user i with this scheme is
Averaging (A88) over , and letting , we obtain for the sum rate
where we changed the order of limit and expectation by appealing to the DCT, and used that, by the law of large numbers, , , and almost surely as .
Figure A6.
Normalized by signal levels at Rx for SI.

Appendix B.5. Proof of Theorem 10
The converse bound (59) for global CSIRT follows similar steps as in Appendix B.3.1 but considering . We next present the converse bound (60) for global CSIRT when . This bound follows by giving the extra information to Rx. By Fano’s inequality, we have
where as . Analogously, by giving the extra information to Rx, we obtain
where as . Thus, (A90) and (A91) yield
where we have used that conditioning reduces entropy. By maximizing the entropies in (A92) over all input distributions, dividing by , and letting K tend to infinity, we obtain that
This proves (60).
Appendix C. Proof of Lemma A2
In this section, we prove the Lemma A2. To this end, we first introduce definitions and properties that will be used in the proof of the lemma.
Definition A1
(Sup-entropy rate). The sup-entropy rate is defined as the limsup in probability of . Analogously, the conditional sup-entropy rate is the limsup in probability (according to ) of .
Lemma A4
(Sup-entropy rate properties).
Suppose (X,Y) takes values in . The sup-entropy rate has the following properties:
where denotes the cardinality of Y.
Proof.
We recall the information densities and defined in (A1) and (A2), respectively. By decomposing the logarithms and applying the Bayes rule to both probability terms, we obtain
To shorten notation, we shall omit the arguments and write , wherever the arguments are clear from the context.
Recall the error events , , and , with , as defined in (A3) and (A4), respectively. We first note that
where (A97) follows because the conditions and imply that . Then, (A98) follows by applying basic set operations. Using (A97) and (A98), and computing the probability of the corresponding events, we obtain
For clarity of exposition, we define
and analyze the necessary conditions on such that as . We next consider separately the four possible realizations of .
Appendix C.1. Case B = [0,0]
When , the channel corresponds to two parallel channels with no interference links. Then, the underlying distribution of the probability (A100) is
as the outputs and must coincide with the corresponding inputs according to the deterministic model. To prove the constraint (A6), we use (A96) in (A100) to obtain
where we used that, according to (A101), w.p. 1, for .
We consider now the conditional sup-entropy rates , . According to (A95) in Lemma A4, we have that , . With these considerations, if we set for some arbitrary in (A102), we obtain
where the last step follows from (A99).
Recalling the definitions of the conditional sup-entropy rates we have that, for any ,
This implies that the first probability on the RHS of (A103) tends to 1 as , and the second probability on the RHS of (A103) tends to 0 as . We conclude that for any the lower bound in (A103) tends to 1 as . Thus, as only if .
Appendix C.2. Case B = [0,1]
When , the channel corresponds to a two-user IC where only one of the transmitters interferes its non-intended receiver. In this case, the underlying distribution in (A100) is given by
Appendix C.2.1. Proof of Constraint (A6)
We lower-bound the probability by that of 2 parallel channels and follow the steps in Appendix C.1. Indeed, by using (A96) in (A100) and lower-bounding , , we obtain that
The RHS of (A106) coincides with (A102) conditioned in . The proof then follows the one in Appendix C.1, with the probabilities and sup-entropy rates conditioned on instead of .
Appendix C.2.2. Proof of Constraint (A7)
According to (A105), the following identities hold w.p. 1:
- (i1)
- (i2)
- (i3)
Using (A96) in (A100) and the identities (i1)–(i3), we obtain
We next define and apply the chain rule of probability to obtain
Using (A108) in (A107) and canceling the term , we obtain
Consider the sup-entropy rates and . By (A94) and (A95) in Lemma A4, we have that
Let for some arbitrary . It follows that , so (A109) can be lower-bounded as
where the second step follows from (A99). By the definition of the conditional sup-entropy rate, it follows that the first probability on the RHS of (A112) tends to 1 as , and the second probability on the RHS of (A112) tends to 0 as . This implies that as only if and proves conditions (A6) and (A7) in Lemma A2.
Appendix C.3. Case B = [1,1]
This scenario corresponds to a non-bursty IC. The underlying distribution in (A100) is given by
where the last step follows from the deterministic model since, for given and , the outputs and are given by the equations appearing in the corresponding indicator functions. We next obtain the constraints (A6)–(A8) in Lemma A2.
Appendix C.3.1. Proof of Constraint (A6)
To prove this constraint, we lower-bound the probability by that of 2 parallel channels. Indeed, using (A96) in (A100), we obtain that
where the inequality follows because . As this expression coincides with (A102) conditioned on , the proof then follows the one in Appendix C.1, with the probabilities and sup-entropy rates conditioned on instead of .
Appendix C.3.2. Proof of Constraint (A7)
We next lower-bound the probability by that of an interference channel, in which only one of the transmitters interferes its non-intended receiver. Using the information densities and in (A96), we have that
where the second step follows from adding and subtracting
and simplifying the resulting terms via the Bayes rule and using that since and are independent conditioned on .
According to the underlying distribution (A113), the following identities hold w.p. 1:
- (i1)
- (i2)
- (i3)
- (i4)
- (i5)
- (i6)
- .
Using (A115) and the identities (i1)–(i6), we obtain for (A100)
Using (A108) in (A116), canceling the term , and using that , we obtain the lower bound
The RHS of (A117) coincides with (A109) conditioned on . The proof then follows the one in Appendix C.2.2, with the probabilities and sup-entropy rates conditioned on instead of .
Appendix C.3.3. Proof of Constraint (A8)
We begin this proof by using (A96) to write
where (a) follows by adding and subtracting
and by rearranging terms. Step (b) follows by applying the Bayes rule and by decomposing the logarithm terms.
We analyze the second and the seventh terms in (A118). To this end, we define and and apply the chain rule of probability to obtain
and
The probabilities (A119) and (A120) were simplified by recalling the underlying distribution (A113). Indeed, we have w.p. 1 that and , since is not affected by interference, so it is determined by . Similarly, we have that and .
We next note that, for the underlying distribution in (A113), the following identities hold w.p. 1:
- (i1)
- (i2)
- (i3)
- (i4)
- (i5)
- (i6)
We combine these identities with (A100) and (A118)–(A120) to obtain
where in the last step we canceled the terms and and we used that, w.p. 1, and .
By (A94) and (A95) in Lemma A4, the conditional sup-entropy rates satisfy
Then, setting for some arbitrary , we obtain from (A99) that (A121) can be lower-bounded by
By the definition of , the fist probability on the RHS of (A123) tends to 1 as . Similarly, by the definition of , the second probability on the RHS of (A123) tends to 0 as . This demonstrates that if , then the lower bound in (A121) tends to 1 as . Thus, as only if
Appendix D. Achievability for Local CSIRT
In this appendix we present the achievability schemes for local CSIRT.
Appendix D.1. Very Weak Interference
The sum rate (29) coincides with that of local CSIR, which in this interference region is equal to the sum rate of global CSIRT. The achievability scheme presented in Appendix B.2.1 is thus optimal for local CSIRT and VWI.
Appendix D.2. Weak Interference
We follow a random-coding argument where the codebooks of Tx and Tx are drawn i.i.d. at random according to the distribution depicted in Figure A7. Specifically, we divide the transmitted signal by Tx into three regions. For each symbol (corresponding to a coherence block) we denote the bits in regions ![Entropy 20 00870 i001]() ,
, ![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i003]() by , and , respectively. In each region the bits are i.i.d. but they follow a different distribution.
by , and , respectively. In each region the bits are i.i.d. but they follow a different distribution.
, and by , and , respectively. In each region the bits are i.i.d. but they follow a different distribution.
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i003]() : The bits and are i.i.d. with marginal probability mass function (pmf)
: The bits and are i.i.d. with marginal probability mass function (pmf)
- Region
![Entropy 20 00870 i002]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
We further assume that and are mutually independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions but with probabilities instead of , with . Evaluating for these distributions, it follows that user 1 achieves the rate
Similarly, for user 2, we obtain (31).
Figure A7.
Normalized signal levels at Rx (WI).

Appendix D.3. Moderate Interference
We follow along similar lines to obtain the achievable rates for MI. However, in contrast to WI, for MI we need to consider different input distributions, depending on the value of . In the proofs, we shall make use of the following auxiliary results, which can be proven by direct evaluation of the entropies considered.
Lemma A5.
Let X and be two binary random variables with joint pmf , and . Then,
Lemma A6.
Let and B be binary random variables with joint pmf , , , and . Then,
and
Lemma A7.
Let and be two binary random variables with joint pmf and . Similarly, let the pair of binary random variables and be independent of and have the same joint pmf but with parameter . Further let . Then,
and
To derive the achievable rates for MI, we again follow a random-coding argument where the codebooks are drawn i.i.d. at random. We next describe the input distributions for different values of :
Appendix D.3.1. MI, < α ≤
Consider the regions shown in Figure A8 for the received signal at Rx. For the transmitted signal , we denote the bits in region ![Entropy 20 00870 i007]() by , . In each of these regions we consider the following input distributions:
by , . In each of these regions we consider the following input distributions:
 by , . In each of these regions we consider the following input distributions:
by , . In each of these regions we consider the following input distributions:- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : We group the bits and in pairs, and we let each of these pairs be i.i.d. and have the distribution from Lemma A6 with , i.e., their marginal pmf is
where .
: We group the bits and in pairs, and we let each of these pairs be i.i.d. and have the distribution from Lemma A6 with , i.e., their marginal pmf is
where . - Regions
![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i006]() : The bits and are i.i.d. with marginal pmf
: The bits and are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i003]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i004]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i005]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf


Furthermore, we assume that , are independent. For user 2, the input distributions coincide with that of user 1 in the corresponding regions, but with parameters instead of , instead of , instead of , and instead of .
Figure A8.
Normalized signal levels at Rx (MI) for .

From the random-coding argument, we know that the rate is achievable. Since the distributions considered are temporally i.i.d., it suffices to evaluate for one coherence block, obtaining
By Lemma A6, we have that
Furthermore, by Lemma A7, we have that
because for the bits , . Similarly, we have
The terms in the other regions follow analogously. Therefore, using (A150) we obtain the rate
Similarly, user 2 achieves the rate (33).
Appendix D.3.2. MI,
We use a similar transmission strategy as for the case where (Section D.3.1), but where the regions have different sizes; see Figure A9a. Following the same steps as in Section D.3.1, we obtain the achievable rates (34) for and (35) for .
Figure A9.
Normalized signal levels at Rx. (a) (MI) for ; (b) (MI) for .

Appendix D.3.3. MI,
In this subsection we consider the particular case . The proposed achievability scheme features two nested regions with a certain correlation. In particular, we consider the division of the bit-pipes for the transmitted signal Tx in the subregions shown in Figure A9b. The input distributions considered in each of these regions are described next (for Tx, we shall consider the same input distributions parametrized by , , and , instead of , , and ):
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits and are grouped in i.i.d. pairs with the marginal pmf given by (A135)–(A139).
: The bits and are grouped in i.i.d. pairs with the marginal pmf given by (A135)–(A139). - Regions
![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i017]() : The bits and are grouped in i.i.d. pairs with marginal pmf
where .
: The bits and are grouped in i.i.d. pairs with marginal pmf
where . - Region
![Entropy 20 00870 i003]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i004]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i005]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf

Furthermore, we assume that , i = 1,2, are mutually independent. For the input distributions described above, we obtain for user 1 that
We next evaluate the different terms in (A167) by applying Lemmas A6 and A7 to obtain
Similarly, using Lemma A7, and since for we have that , we obtain
Combining (A168)–(A171) with (A176) yields
Following along similar lines, it can be shown that user 2 achieves the rate
Appendix D.3.4. MI, < α <
We consider the input distribution depicted in Figure A10a with:
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits are i.i.d. with marginal pmf given by (A135)–(A139).
: The bits are i.i.d. with marginal pmf given by (A135)–(A139). - Regions
![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i017]() : The bits are i.i.d. with marginal pmf given by (A155)–(A159).
: The bits are i.i.d. with marginal pmf given by (A155)–(A159). - Region
![Entropy 20 00870 i003]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i004]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i005]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
Furthermore, we assume that , are independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions, but with parameters instead of , instead of , instead of and instead of . Following similar steps as in the previous sections, we obtain (36) for and (37) for .
Appendix D.3.5. MI, < α < 1
The transmission strategy is similar to the one for (Section D.3.4), but with different sizes for the regions ![Entropy 20 00870 i001]() -
- ![Entropy 20 00870 i005]() , see Figure A10b. Following similar steps as in previous sections, we obtain (38) for and (39) for .
, see Figure A10b. Following similar steps as in previous sections, we obtain (38) for and (39) for .
-  , see Figure A10b. Following similar steps as in previous sections, we obtain (38) for and (39) for .
, see Figure A10b. Following similar steps as in previous sections, we obtain (38) for and (39) for .Appendix D.4. Strong Interference
To obtain the achievable rates for SI, we again need to consider different input distributions, depending on the value of .
Appendix D.4.1. SI, 1 ≤ α ≤
We consider the input distribution depicted in Figure A11a with:
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits are i.i.d. with marginal pmf given by (A135)–(A139).
: The bits are i.i.d. with marginal pmf given by (A135)–(A139). - Regions
![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i017]() : The bits are i.i.d. with marginal pmf given by (A155)–(A159).
: The bits are i.i.d. with marginal pmf given by (A155)–(A159). - Region
![Entropy 20 00870 i003]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
Furthermore, we assume that , are independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions, but with parameters instead of , instead of and instead of . Following similar steps as in previous sections, we obtain the achievable rate pair (40) and (41).
Figure A10.
Normalized signal levels at Rx. (a) (MI) for ; (b) (MI) for .

Figure A11.
Normalized signal levels at Rx. (a) (SI) for .; (b) (SI) for .

Appendix D.4.2. SI, ≤ α ≤
We consider the input distribution depicted in Figure A11b with the following distributions:
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits are i.i.d. with marginal pmf given by (A135)–(A139).
: The bits are i.i.d. with marginal pmf given by (A135)–(A139). - Regions
![Entropy 20 00870 i002]() and
and ![Entropy 20 00870 i004]() : The bits and are independent and temporally i.i.d. with marginal pmf
: The bits and are independent and temporally i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i003]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
Furthermore, we assume that , are independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions, but with parameters instead of , instead of and instead of . Following similar steps as in previous sections, we obtain the achievable rate pair (42) and (43).
Appendix D.4.3. SI, ≤ α ≤
We consider the input distribution depicted in Figure A12a with the following distributions:
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits are i.i.d. with marginal pmf given by (A135)–(A139).
: The bits are i.i.d. with marginal pmf given by (A135)–(A139). - Regions
![Entropy 20 00870 i002]() ,
, ![Entropy 20 00870 i003]() ,
, ![Entropy 20 00870 i005]() and
and ![Entropy 20 00870 i006]() : The bits , , and are independent and temporally i.i.d. with marginal pmf
: The bits , , and are independent and temporally i.i.d. with marginal pmf
- Region
![Entropy 20 00870 i004]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
Furthermore, we assume that , are independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions, but with parameters instead of and instead of . Following similar steps as in previous sections, we obtain an achievable rate pair for which is given by (44) and (45).
Appendix D.4.4. SI, ≤ α ≤ 2
We consider the input distribution depicted in Figure A12b with the following distributions:
- Regions
![Entropy 20 00870 i001]() and
and ![Entropy 20 00870 i016]() : The bits are i.i.d. with marginal pmf given by (A135)–(A139).
: The bits are i.i.d. with marginal pmf given by (A135)–(A139). - Region
![Entropy 20 00870 i002]() : The bits are i.i.d. with marginal pmf
: The bits are i.i.d. with marginal pmf
Furthermore, we assume that , are independent. For Tx, the input distributions coincide with that of Tx in the corresponding regions, but with parameters instead of , instead of and instead of . Proceeding as in the previous sections we obtain the achievable rate pair (46) and (47).
Figure A12.
Normalized signal levels at Rx. (a) (SI) for ; (b) (SI) for .

References
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Khude, N.; Prabhakaran, V.; Viswanath, P. Harnessing bursty interference. In Proceedings of the 2009 IEEE Information Theory Workshop on Networking and Information Theory (ITWNIT), Volos, Greece, 12–10 June 2009; pp. 13–16. [Google Scholar] [CrossRef]
- Khude, N.; Prabhakaran, V.; Viswanath, P. Opportunistic interference management. In Proceedings of the 2009 IEEE International Symposium on Information Theory (ISIT), Seoul, South Korea, 28 June–3 July 2009; pp. 2076–2080. [Google Scholar] [CrossRef]
- Korner, J.; Marton, K. General broadcast channels with degraded message sets. IEEE Trans. Inf. Theory 1977, 23, 60–64. [Google Scholar] [CrossRef]
- Diggavi, S.N.; Tse, D.N.C. On opportunistic codes and broadcast codes with degraded message sets. In Proceedings of the 2006 IEEE Information Theory Workshop (ITW), Punta del Este, Uruguay, 13–17 March 2006; pp. 227–231. [Google Scholar] [CrossRef]
- Yi, X.; Sun, H. Opportunistic treating interference as noise. arXiv, 2018; arXiv:1808.08926. [Google Scholar]
- Wang, I.H.; Suh, C.; Diggavi, S.; Viswanath, P. Bursty interference channel with feedback. In Proceedings of the 2013 IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 21–25. [Google Scholar] [CrossRef]
- Mishra, S.; Wang, I.H.; Diggavi, S.N. Harnessing bursty interference in multicarrier systems with output feedback. IEEE Trans. Inf. Theory 2017, 63, 4430–4452. [Google Scholar] [CrossRef]
- Mishra, S.; Wang, I.H.; Diggavi, S.N. Opportunistic interference management for multicarrier systems. In Proceedings of the 2013 IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 389–393. [Google Scholar] [CrossRef]
- Vahid, A.; Maddah-Ali, M.A.; Avestimehr, A.S. Interference channel with binary fading: Effect of delayed network state information. In Proceedings of the 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 28–30 September 2011; pp. 894–901. [Google Scholar] [CrossRef]
- Vahid, A.; Maddah-Ali, M.A.; Avestimehr, A.S. Binary fading interference channel with no CSIT. In Proceedings of the 2014 IEEE International Symposium on Information Theory (ISIT), Honolulu, HI, USA, 29 June–4 July 2014; pp. 666–670. [Google Scholar] [CrossRef]
- Vahid, A.; Maddah-Ali, M.A.; Avestimehr, A.S. Capacity results for binary fading interference channels with delayed CSIT. IEEE Trans. Inf. Theory 2014, 60, 6093–6130. [Google Scholar] [CrossRef]
- Vahid, A.; Calderbank, R. When does spatial correlation add value to delayed channel state information? In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2624–2628. [Google Scholar] [CrossRef]
- Vahid, A.; Maddah-Ali, M.A.; Avestimehr, A.S.; Zhu, Y. Binary fading interference channel with no CSIT. IEEE Trans. Inf. Theory 2017, 63, 3565–3578. [Google Scholar] [CrossRef]
- Avestimehr, A.S.; Diggavi, S.N.; Tse, D.N.C. Wireless network information flow: A deterministic approach. IEEE Trans. Inf. Theory 2011, 57, 1872–1905. [Google Scholar] [CrossRef]
- El Gamal, A.; Costa, M. The capacity region of a class of deterministic interference channels. IEEE Trans. Inf. Theory 1982, 28, 343–346. [Google Scholar] [CrossRef]
- Bresler, G.; Tse, D. The two-user Gaussian interference channel: A deterministic view. Trans. Emerg. Telecommun. Technol. 2008, 19, 333–354. [Google Scholar] [CrossRef]
- Kao, D.T.H.; Sabharwal, A. Two-user interference channels with local views: On capacity regions of TDM-dominating policies. IEEE Trans. Inf. Theory 2013, 59, 7014–7040. [Google Scholar] [CrossRef]
- Yeh, S.Y.; Wang, I. Degrees of freedom of the bursty MIMO X channel without feedback. arXiv, 2016; arXiv:1611.07630. [Google Scholar]
- Jafar, S.A.; Vishwanath, S. Generalized degrees of freedom of the symmetric Gaussian K user interference channel. IEEE Trans. Inf. Theory 2010, 56, 3297–3303. [Google Scholar] [CrossRef]
- Tse, D.; Viswanath, P. Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Han, T.S.; Kobayashi, K. A new achievable rate region for the interference channel. IEEE Trans. Inf. Theory 1981, 27, 49–60. [Google Scholar] [CrossRef]
- Wang, I.H.; Suh, C.; Diggavi, S.; Viswanath, P. Bursty Interference Channel with Feedback. 2013. Available online: https://sites.google.com/site/ihsiangw/isit13preprintburstyic (accessed on 8 November 2018).
- Sato, H. Two-user communication channels. IEEE Trans. Inf. Theory 1977, 23, 295–304. [Google Scholar] [CrossRef]
- Suh, C.; Tse, D.N.C. Feedback capacity of the Gaussian interference channel to within 2 bits. IEEE Trans. Inf. Theory 2011, 57, 2667–2685. [Google Scholar] [CrossRef]
- Etkin, R.H.; Tse, D.N.C.; Wang, H. Gaussian interference channel capacity to within one bit. IEEE Trans. Inf. Theory 2008, 54, 5534–5562. [Google Scholar] [CrossRef]
- Verdú, S.; Han, T.S. A general formula for channel capacity. IEEE Trans. Inf. Theory 1994, 40, 1147–1157. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Rudin, W. Real and Complex Analysis, 3rd ed.; McGraw-Hill, Inc.: New York, NY, USA, 1987. [Google Scholar]
Figure 1.
Channel model of the bursty interference channel.

Figure 2.
Local CSIRT vs. local CSIR for (WI).

Figure 3.
Local CSIRT vs. local CSIR for (MI).

Figure 4.
Local CSIRT vs. local CSIR for (SI).

Figure 5.
Total sum capacity for , for local CSIR/CSIRT and global CSIRT.

Figure 6.
Total sum capacity for , for local CSIR/CSIRT and global CSIRT.

Figure 7.
Sum capacity for local CSIR/CSIRT and global CSIRT when and are independent and (VWI).

Figure 8.
Sum capacity for local CSIR/CSIRT and global CSIRT when and are independent and (WI).

Figure 9.
Sum capacity for local CSIR/CSIRT and global CSIRT when and are independent and (MI).

Figure 10.
Sum capacity for local CSIR/CSIRT and global CSIRT when and are independent and (SI).

Figure 11.
Sum capacity for local CSIR and global CSIRT when and (VWI).

Figure 12.
Sum capacity for local CSIR and global CSIRT when and (WI).

Figure 13.
Sum capacity for local CSIR and global CSIRT when and (MI).

Figure 14.
Sum capacity for local CSIR and global CSIRT when and (SI).

Figure 15.
Normalized total sum capacity as a function of for local CSIR/CSIRT when and are independent.
Figure 15.
Normalized total sum capacity as a function of for local CSIR/CSIRT when and are independent.

Figure 16.
Normalized total sum capacity as a function of for global CSIRT when and are independent.
Figure 16.
Normalized total sum capacity as a function of for global CSIRT when and are independent.

Figure 17.
Normalized sum capacity as a function of for local CSIR/CSIRT when and are independent.

Figure 18.
Normalized sum capacity as a function of for global CSIRT when and are independent.

Figure 19.
Normalized sum capacity as a function of for global CSIRT when .


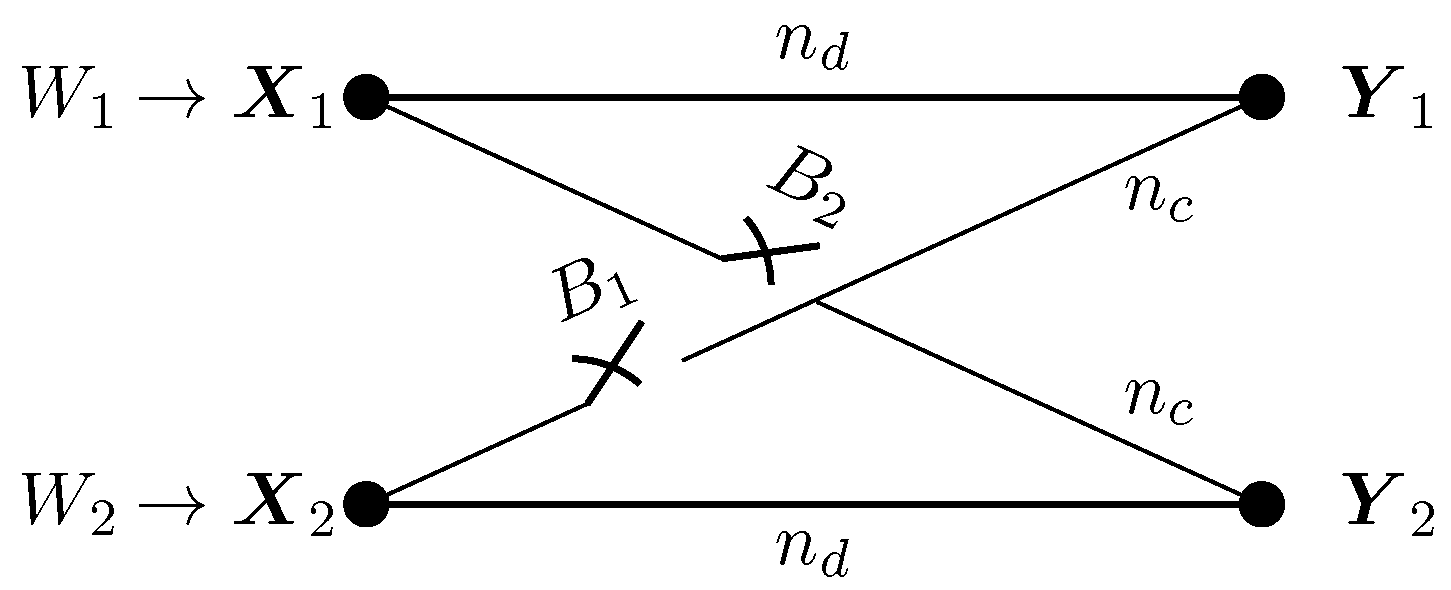{kind=link}
{kind=link}
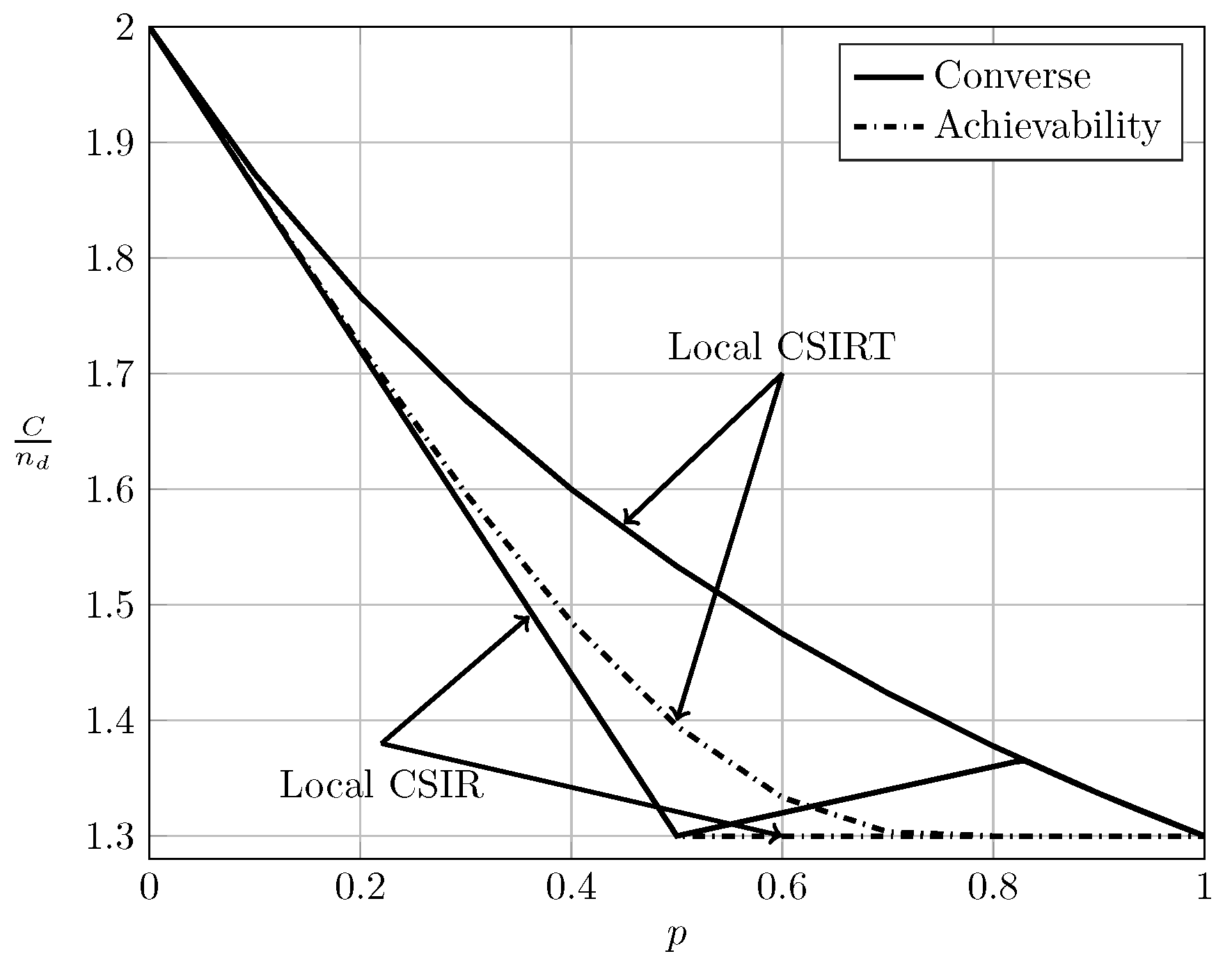{kind=link}
{kind=link}
{kind=link}
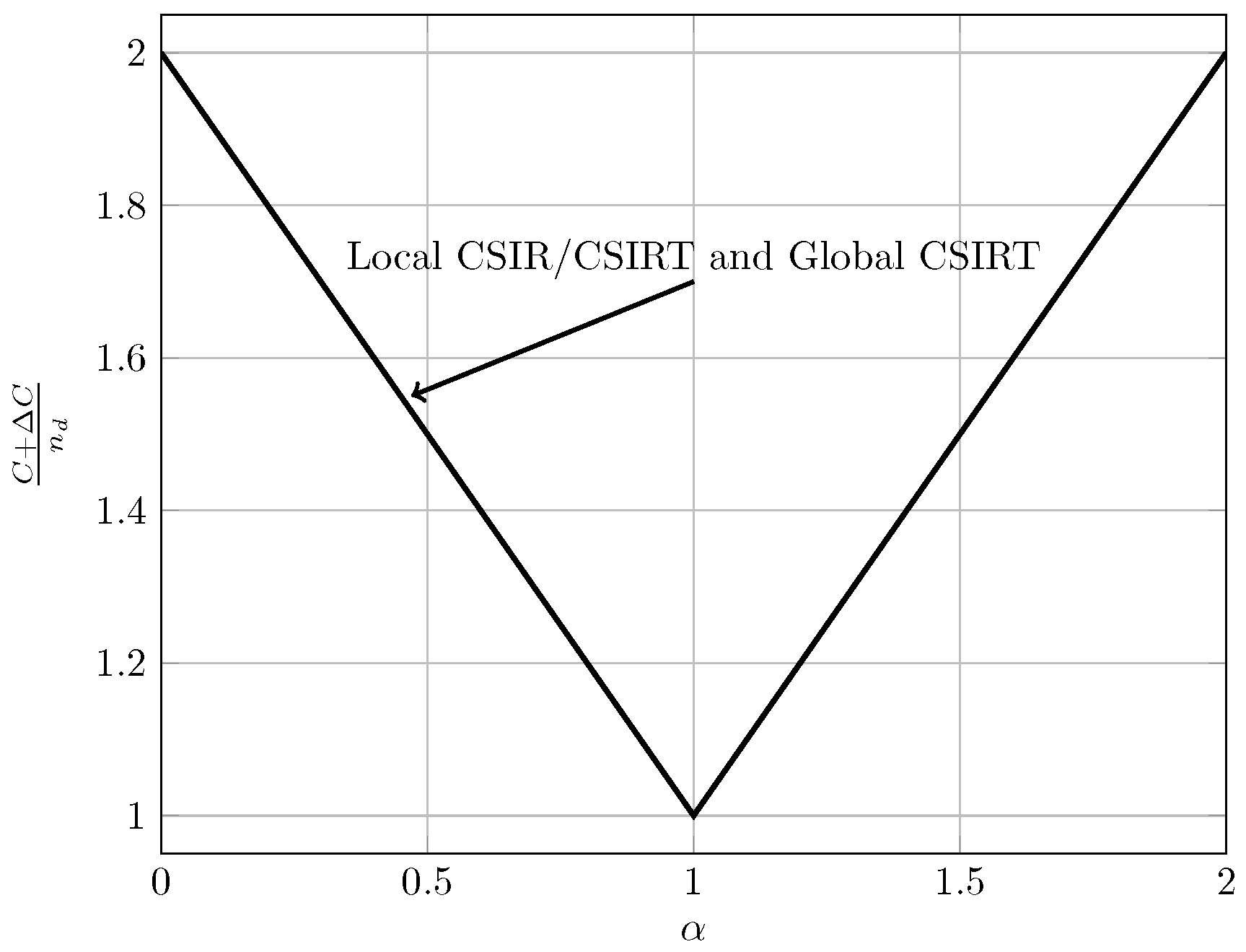{kind=link}
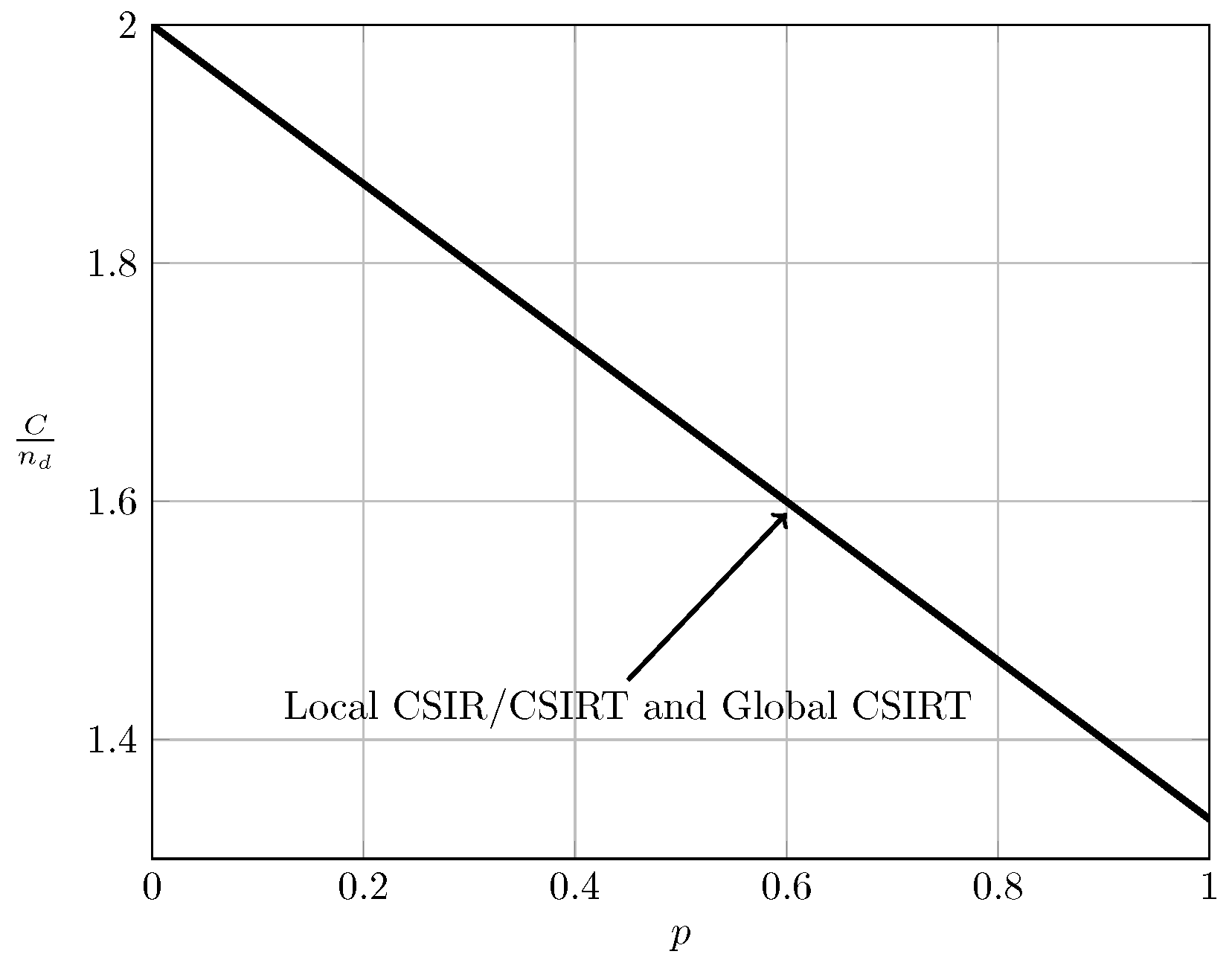{kind=link}
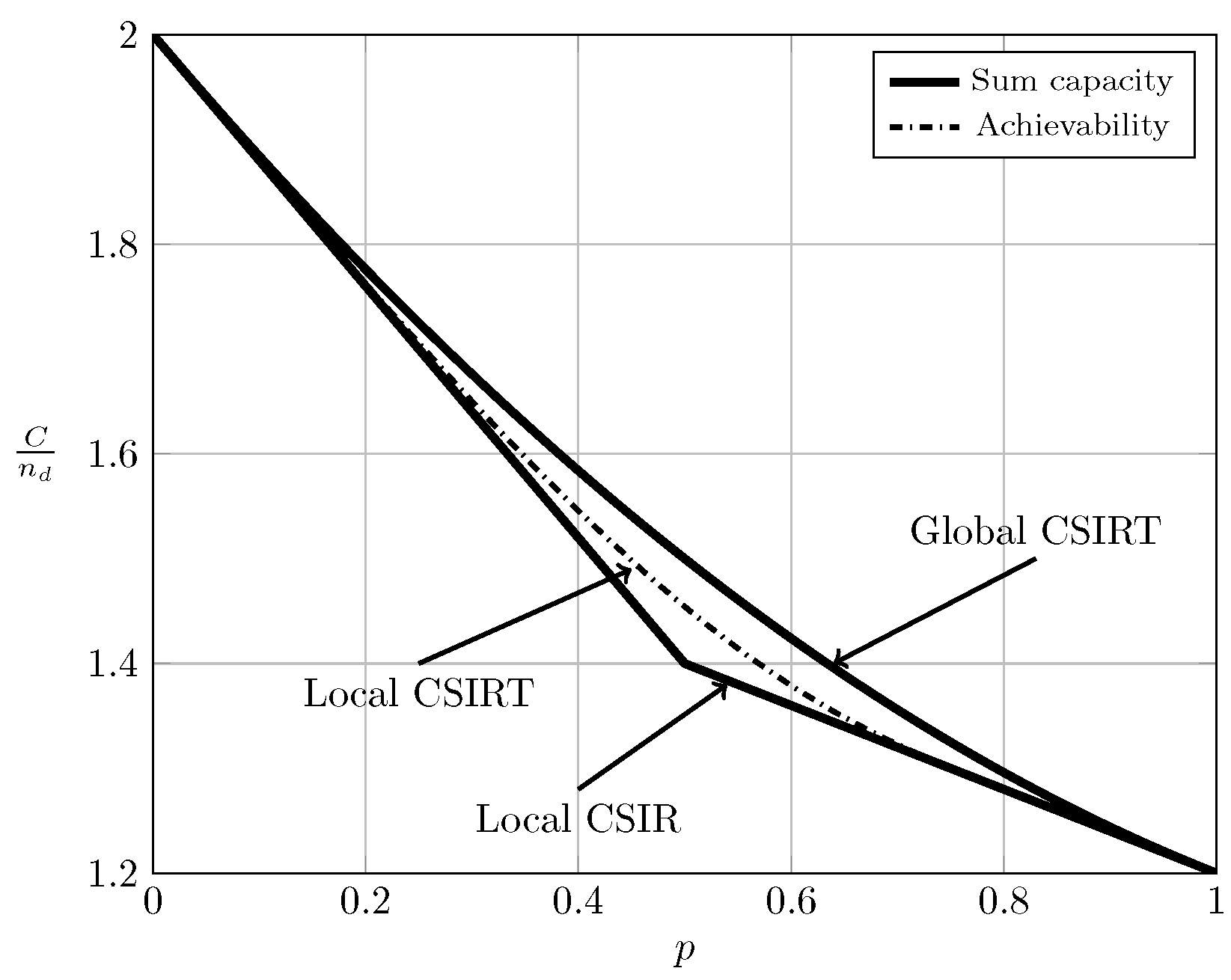{kind=link}
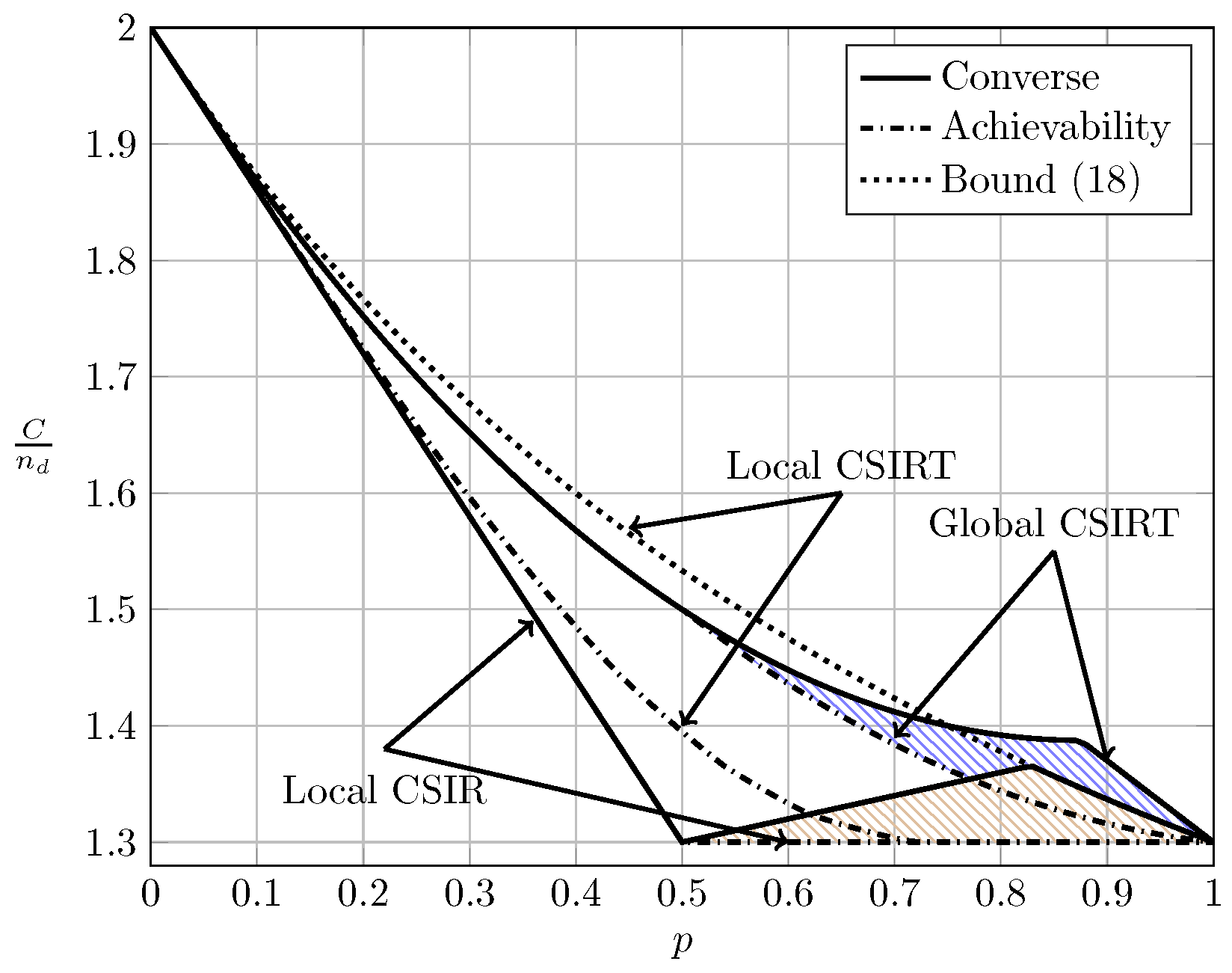{kind=link}
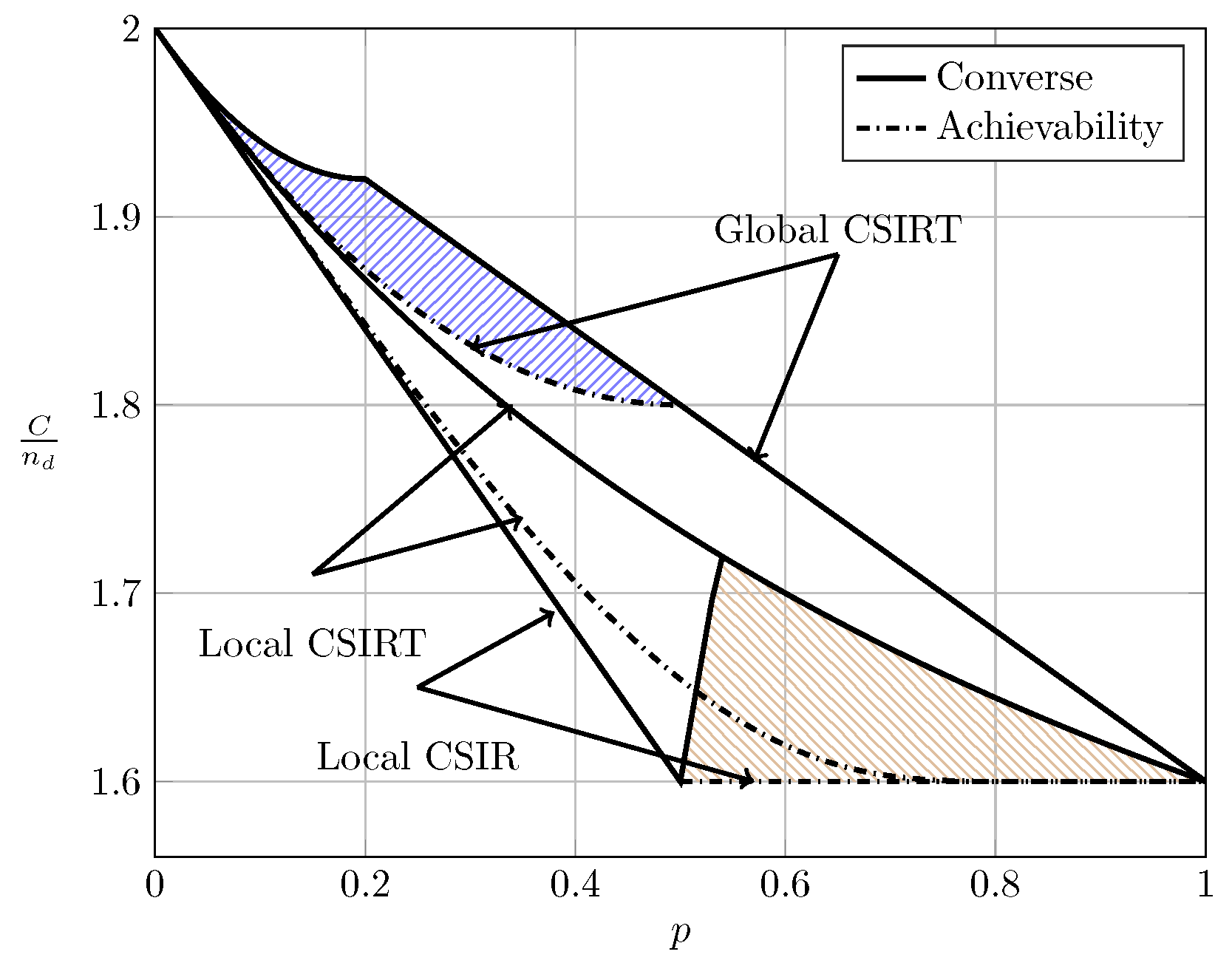{kind=link}
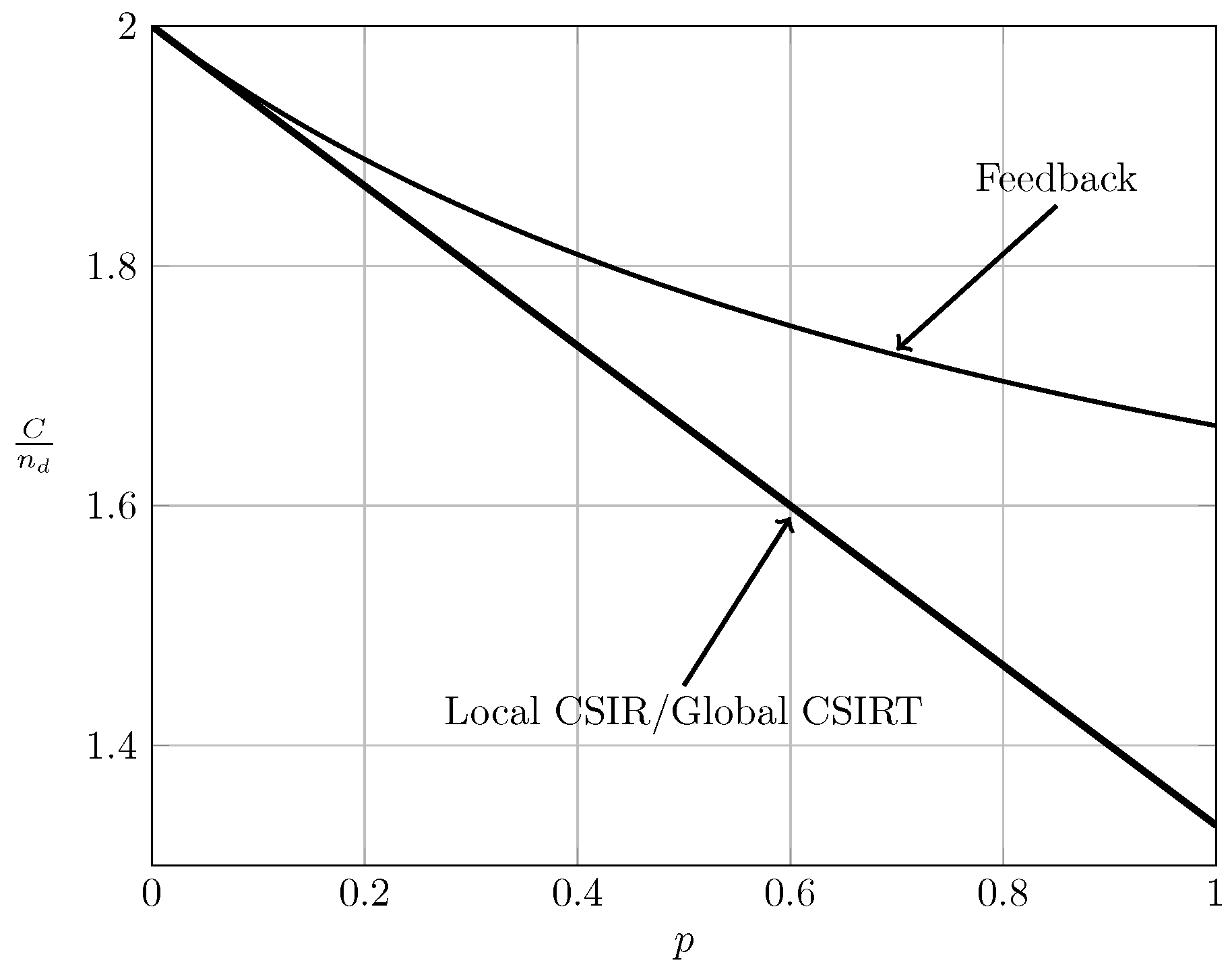{kind=link}
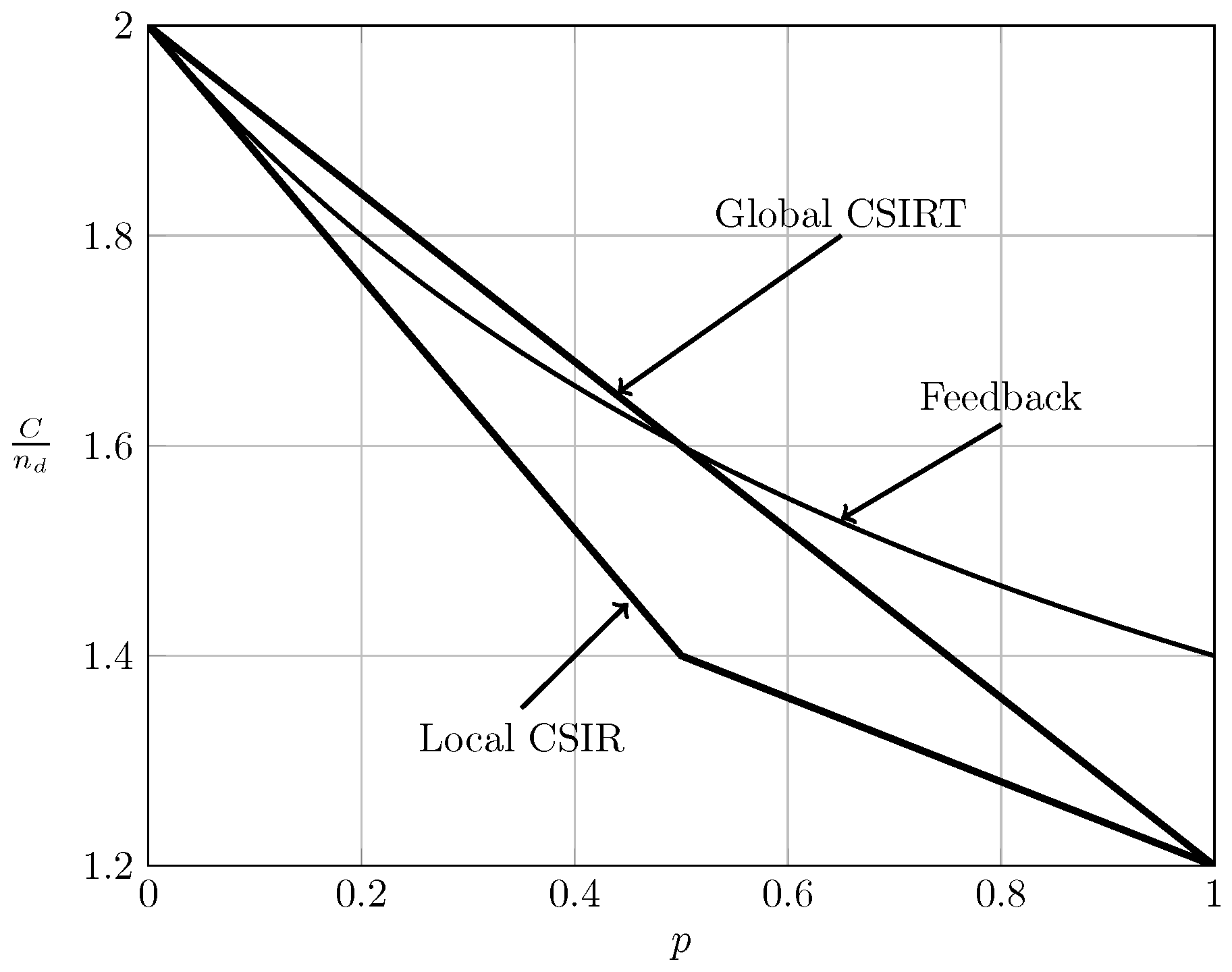{kind=link}
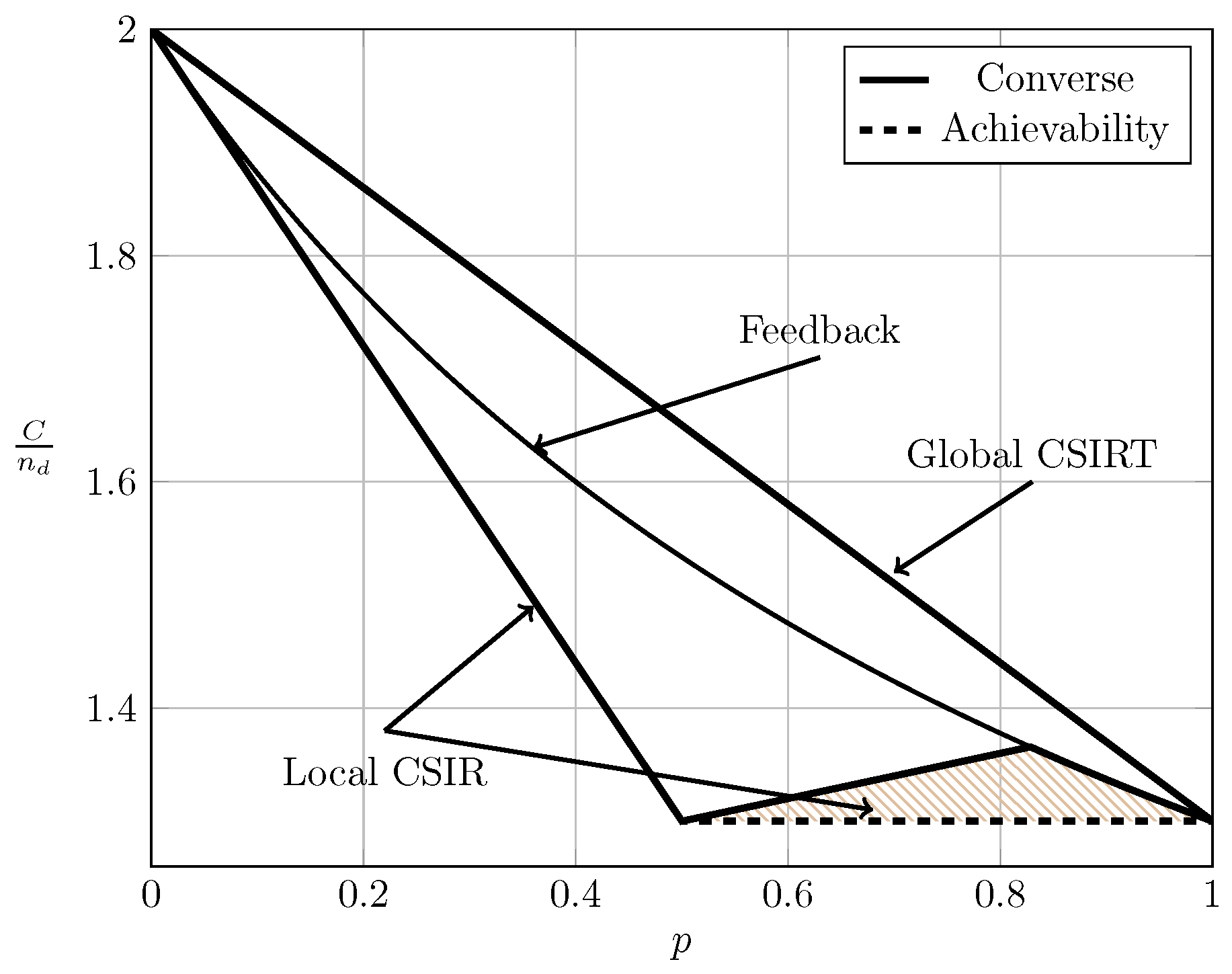{kind=link}
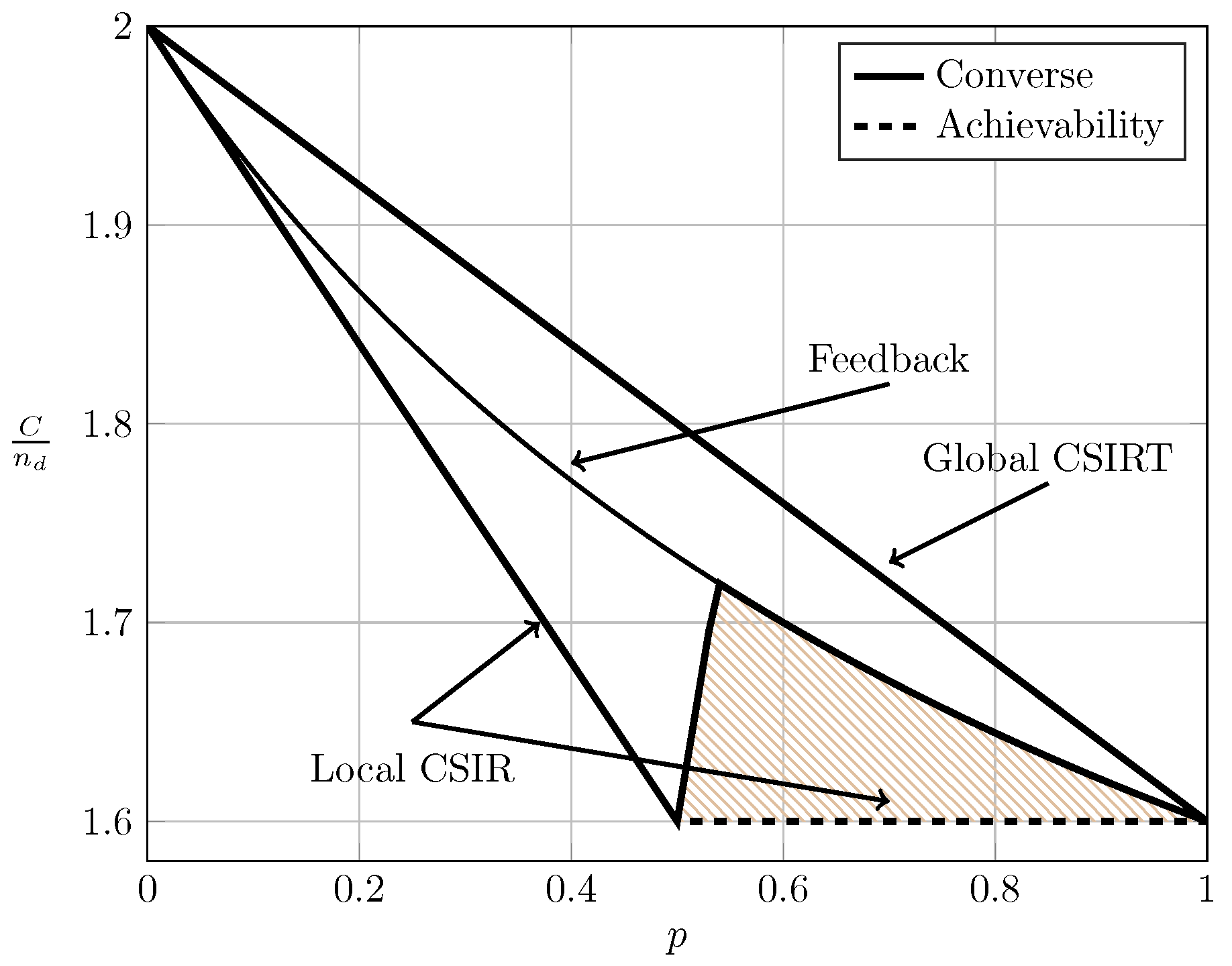{kind=link}
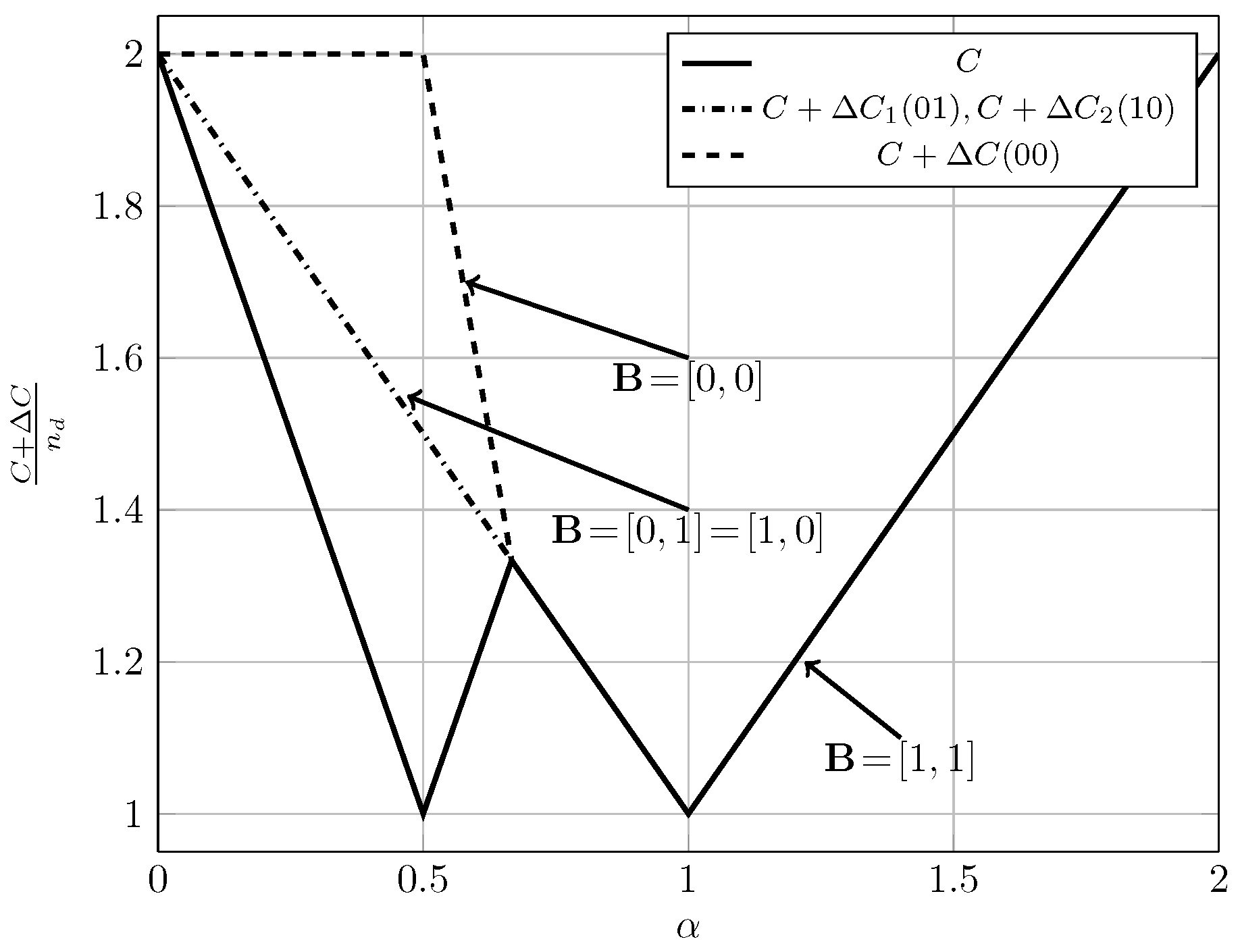{kind=link}
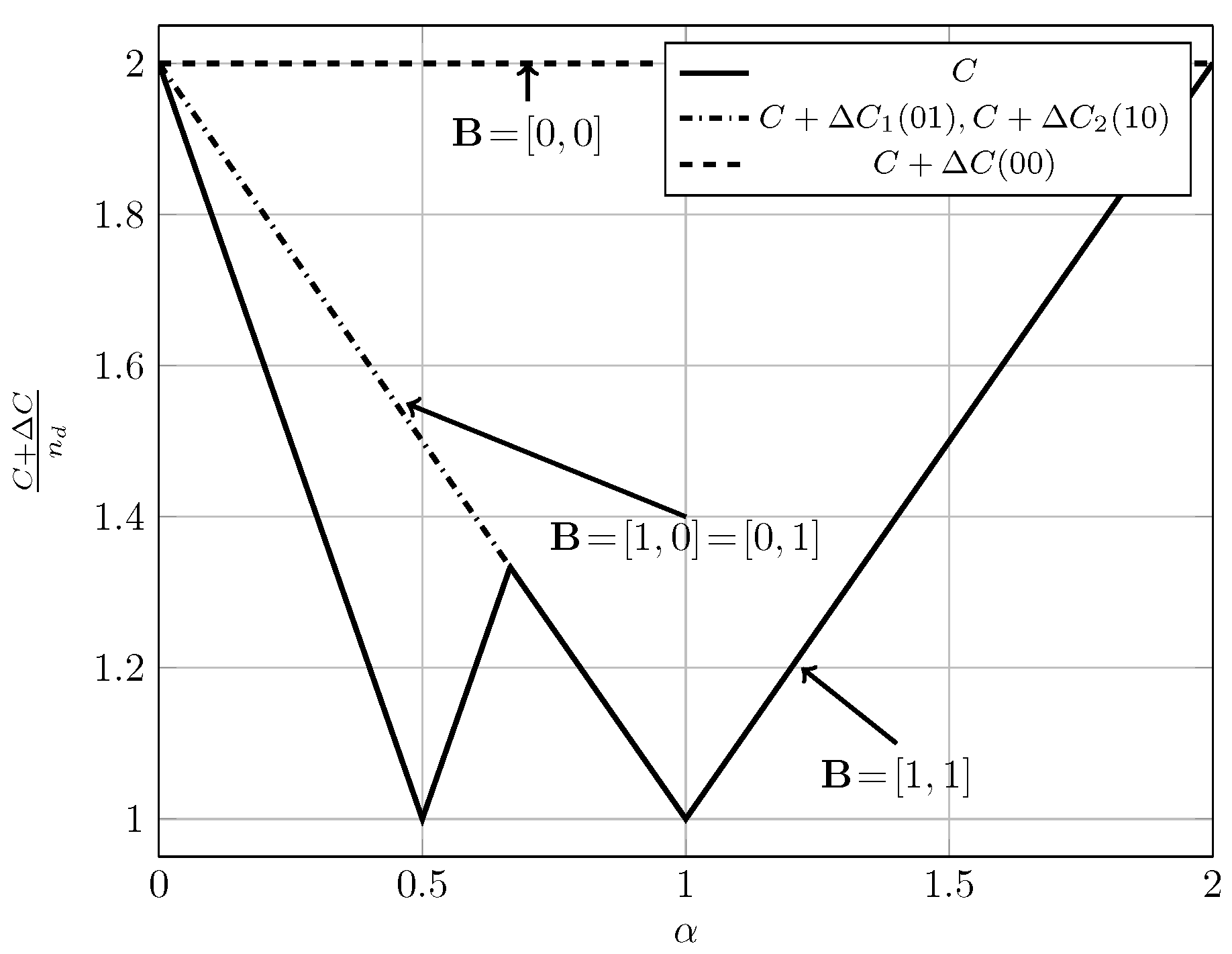{kind=link}
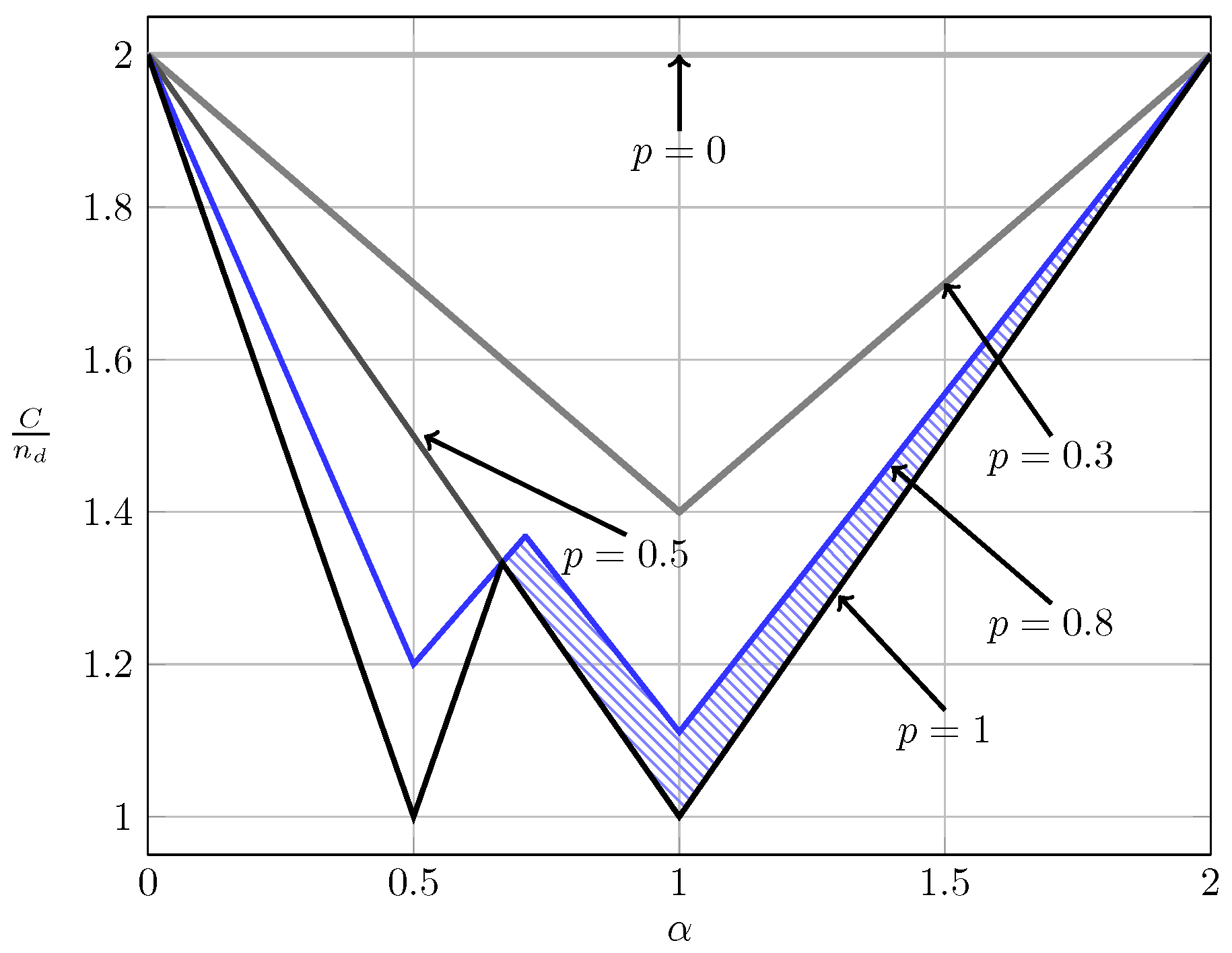{kind=link}
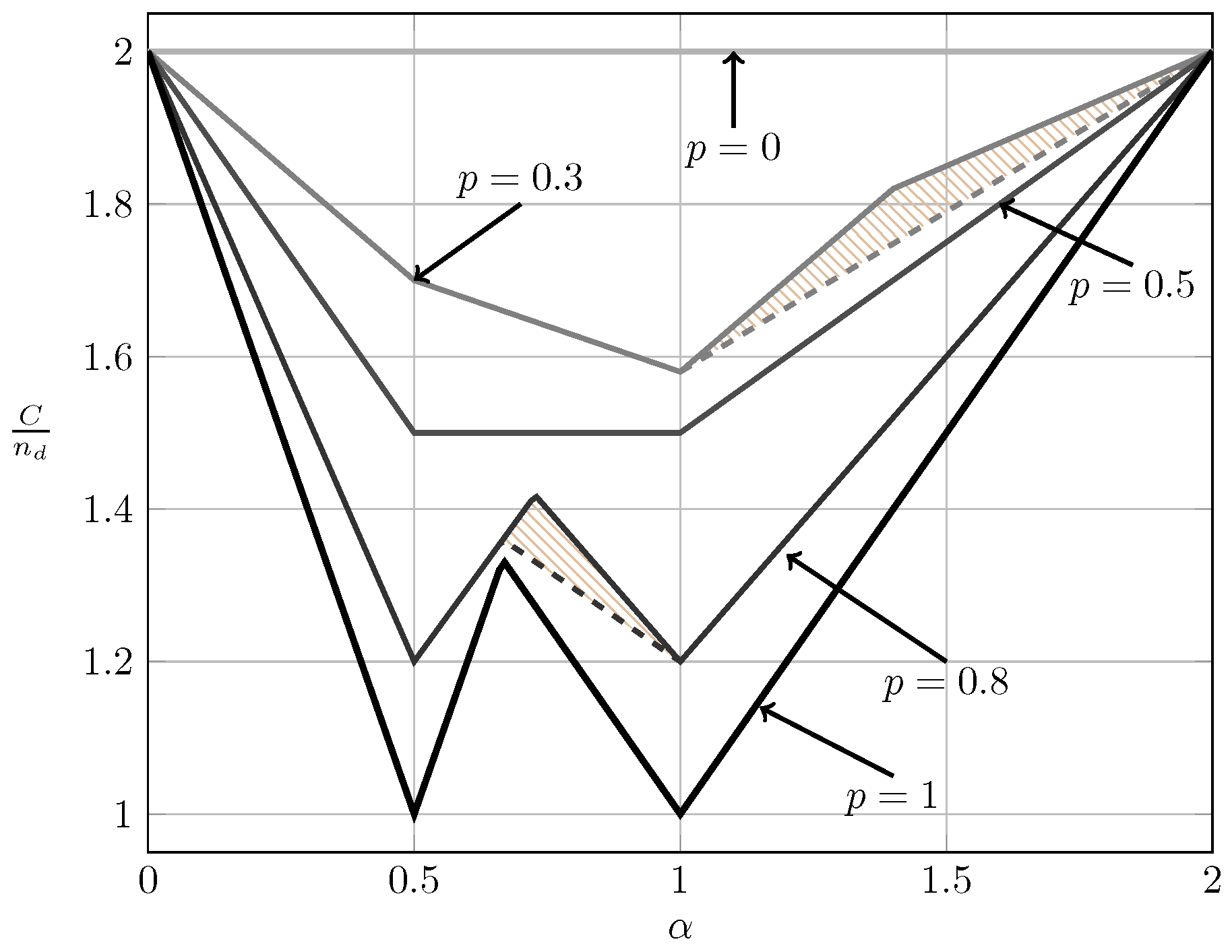{kind=link}
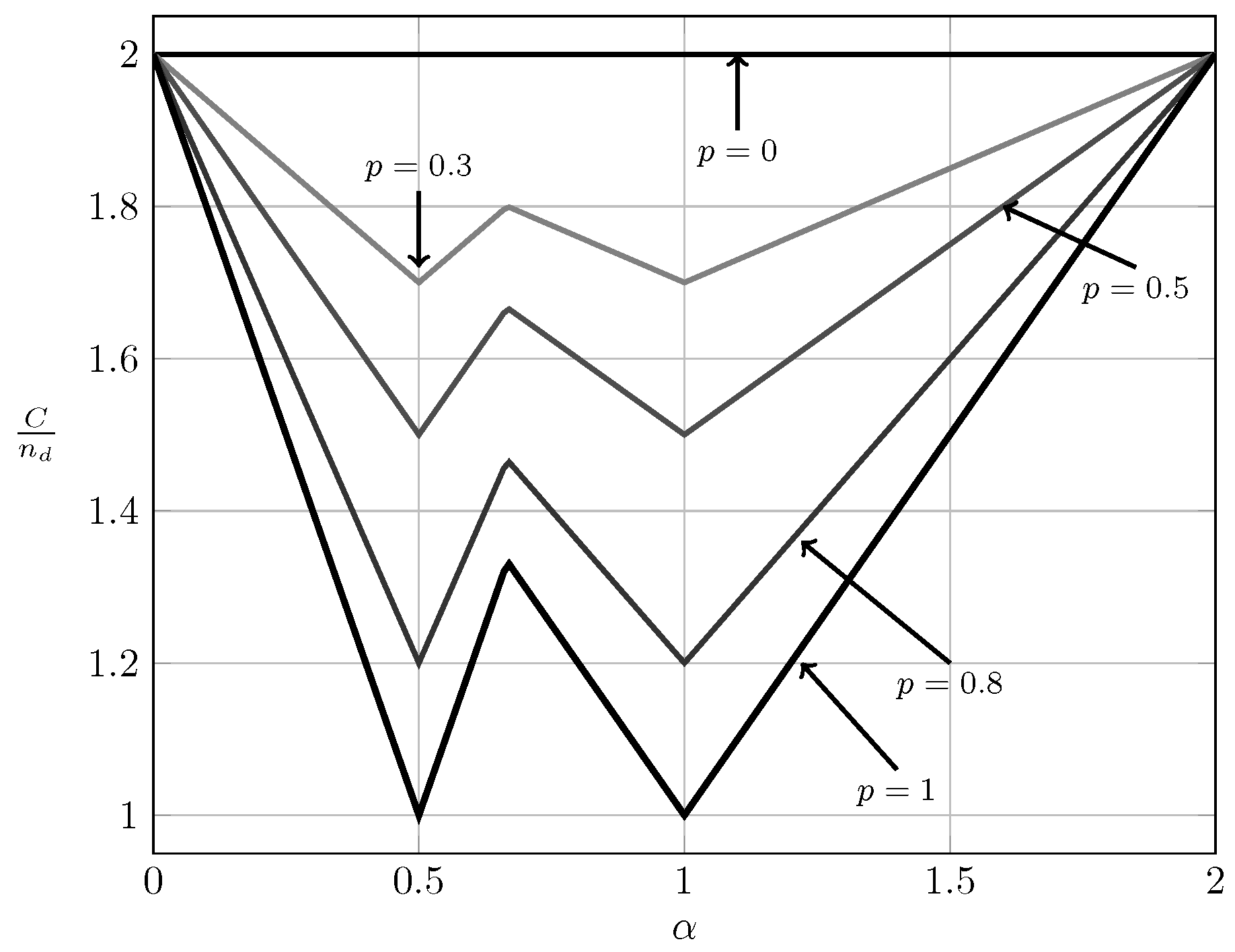{kind=link}
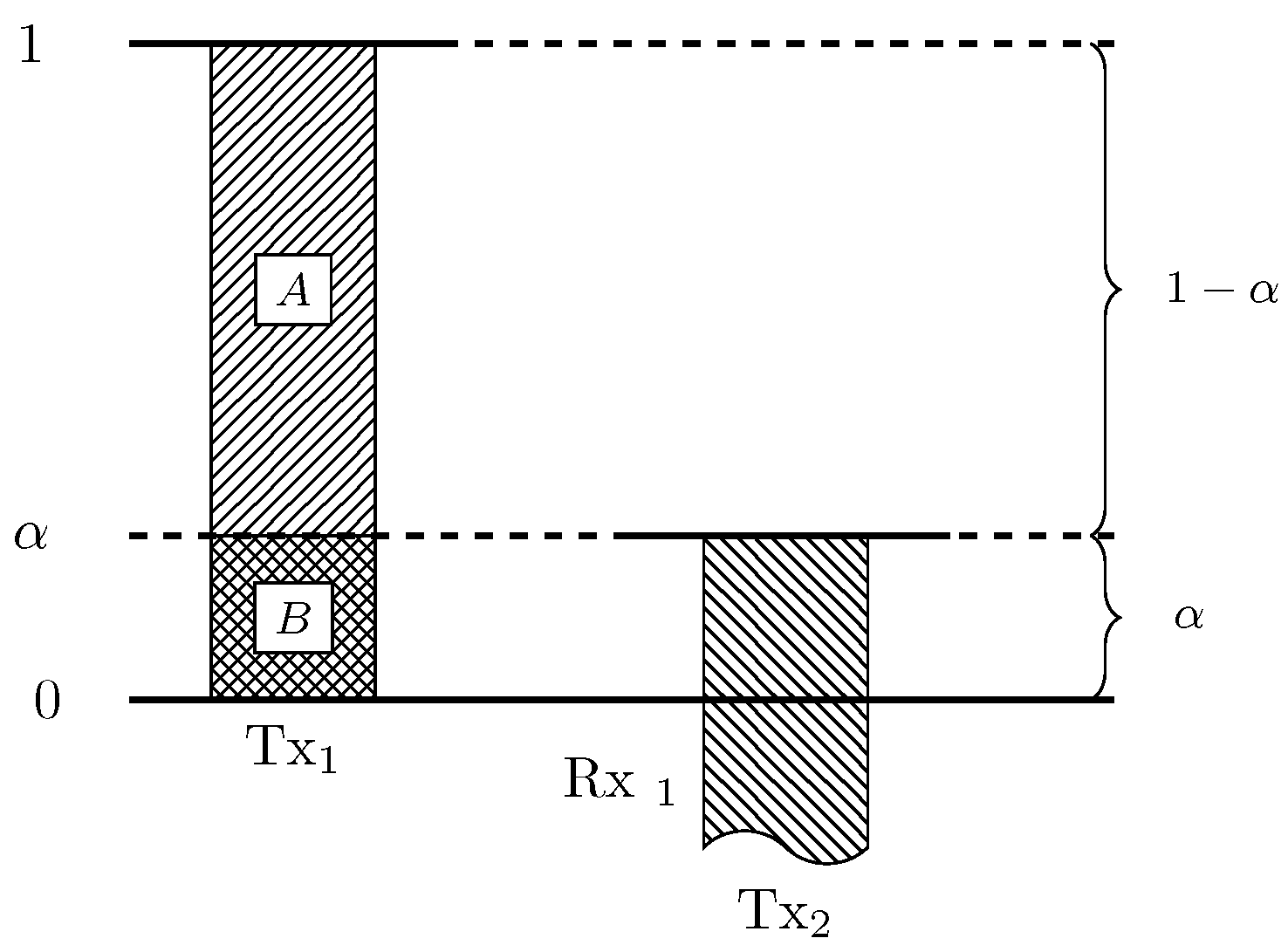{kind=link}
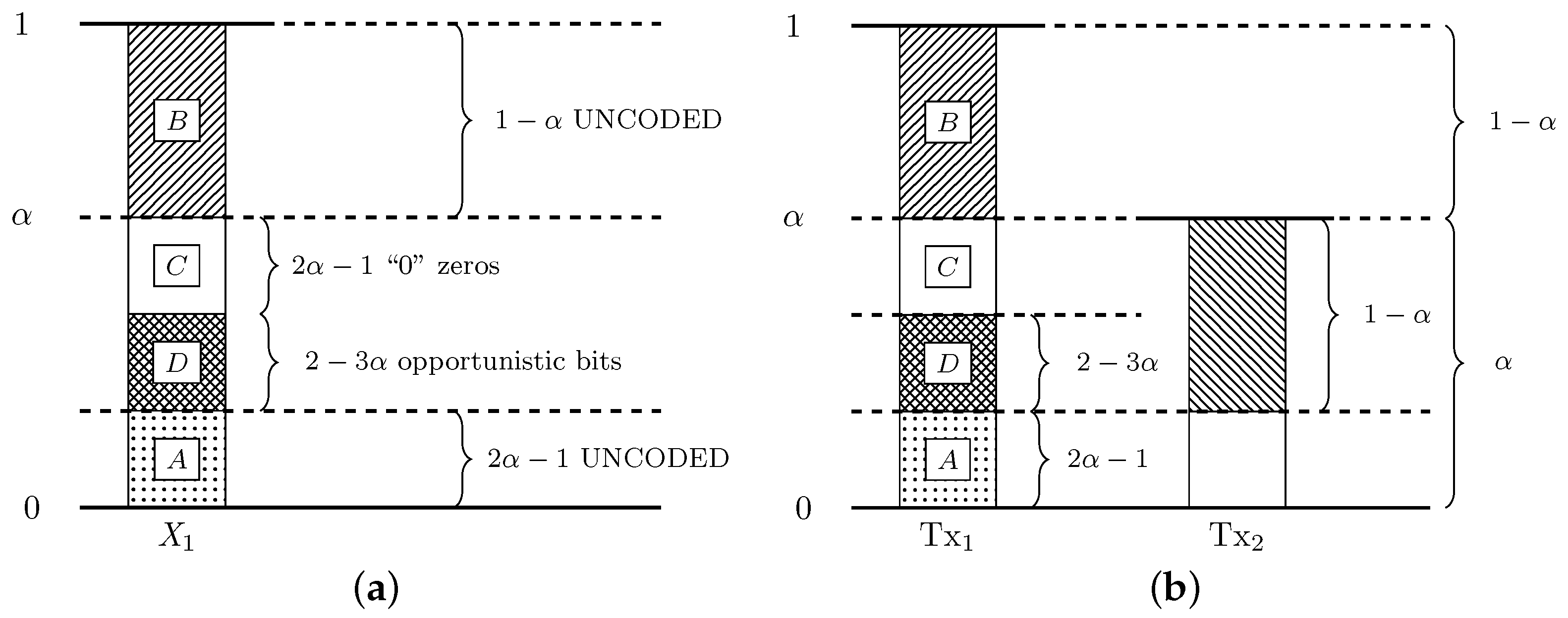{kind=link}
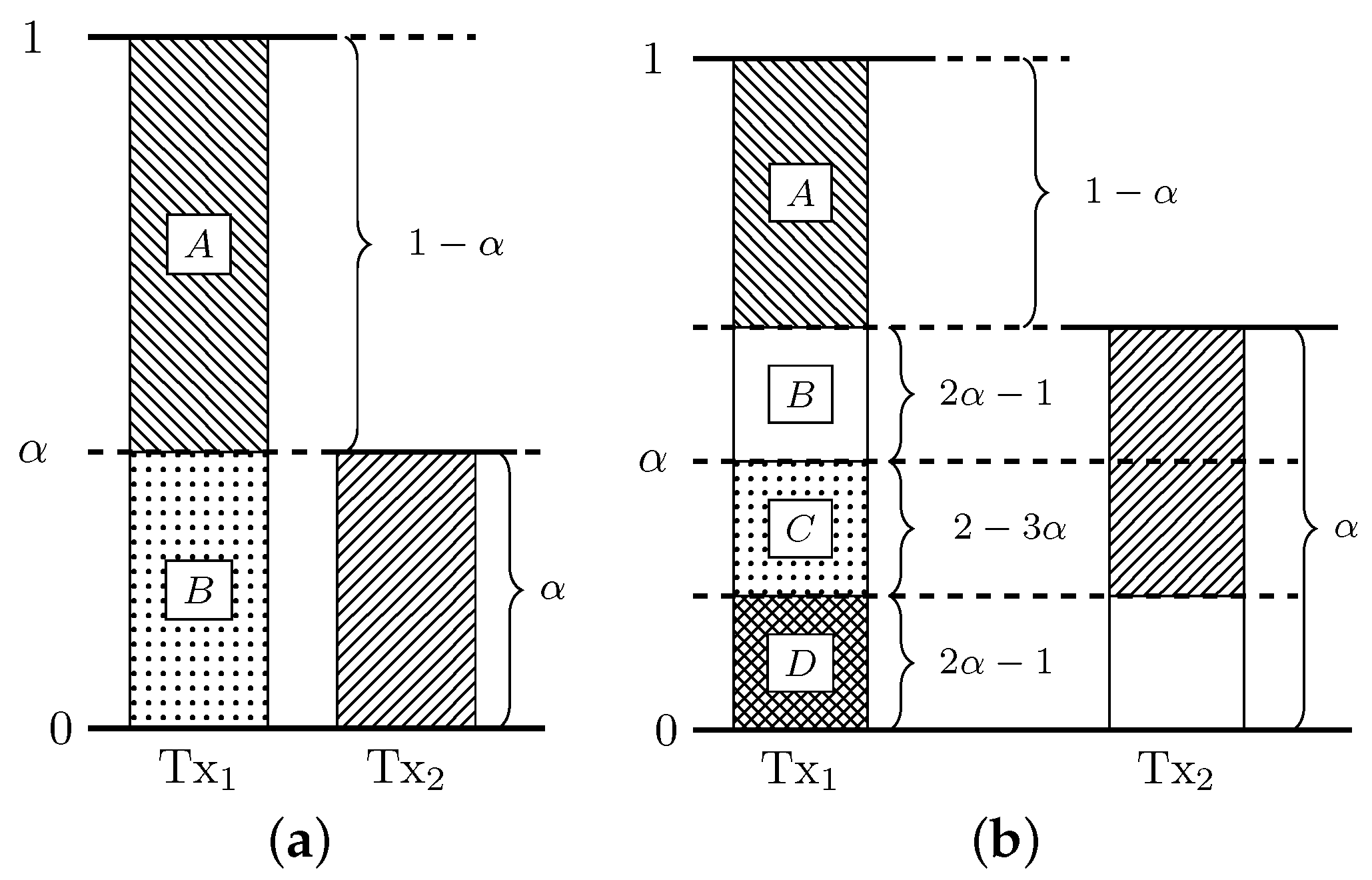{kind=link}
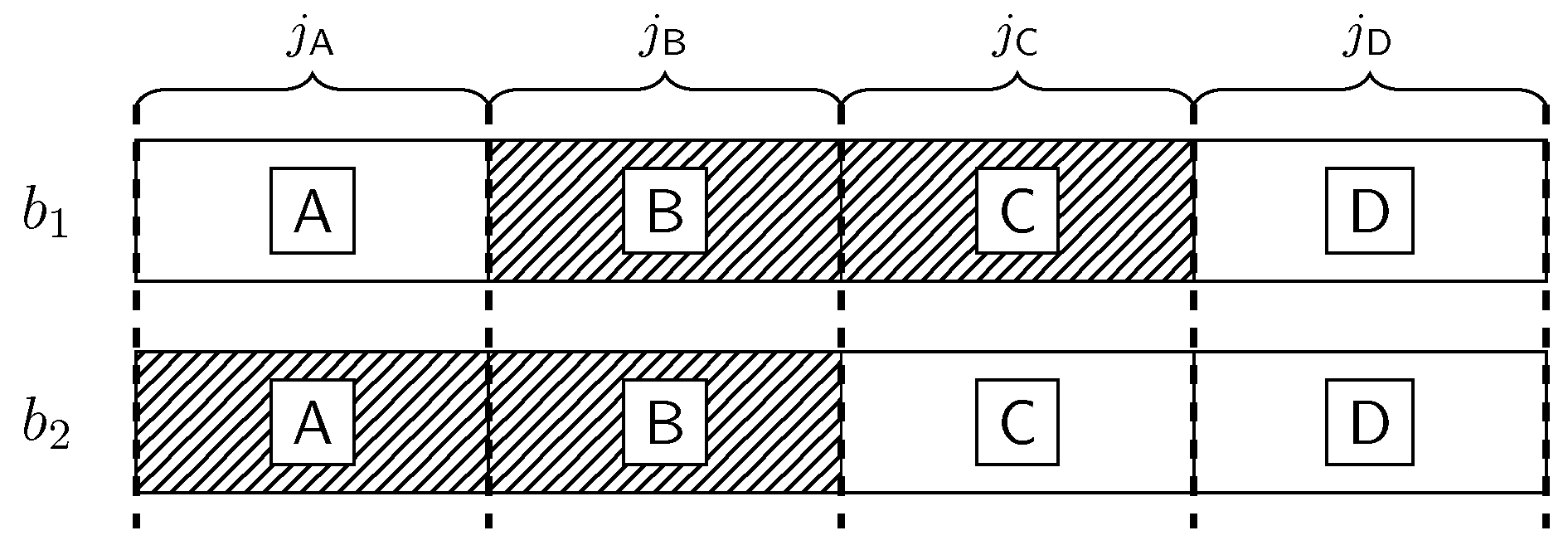{kind=link}
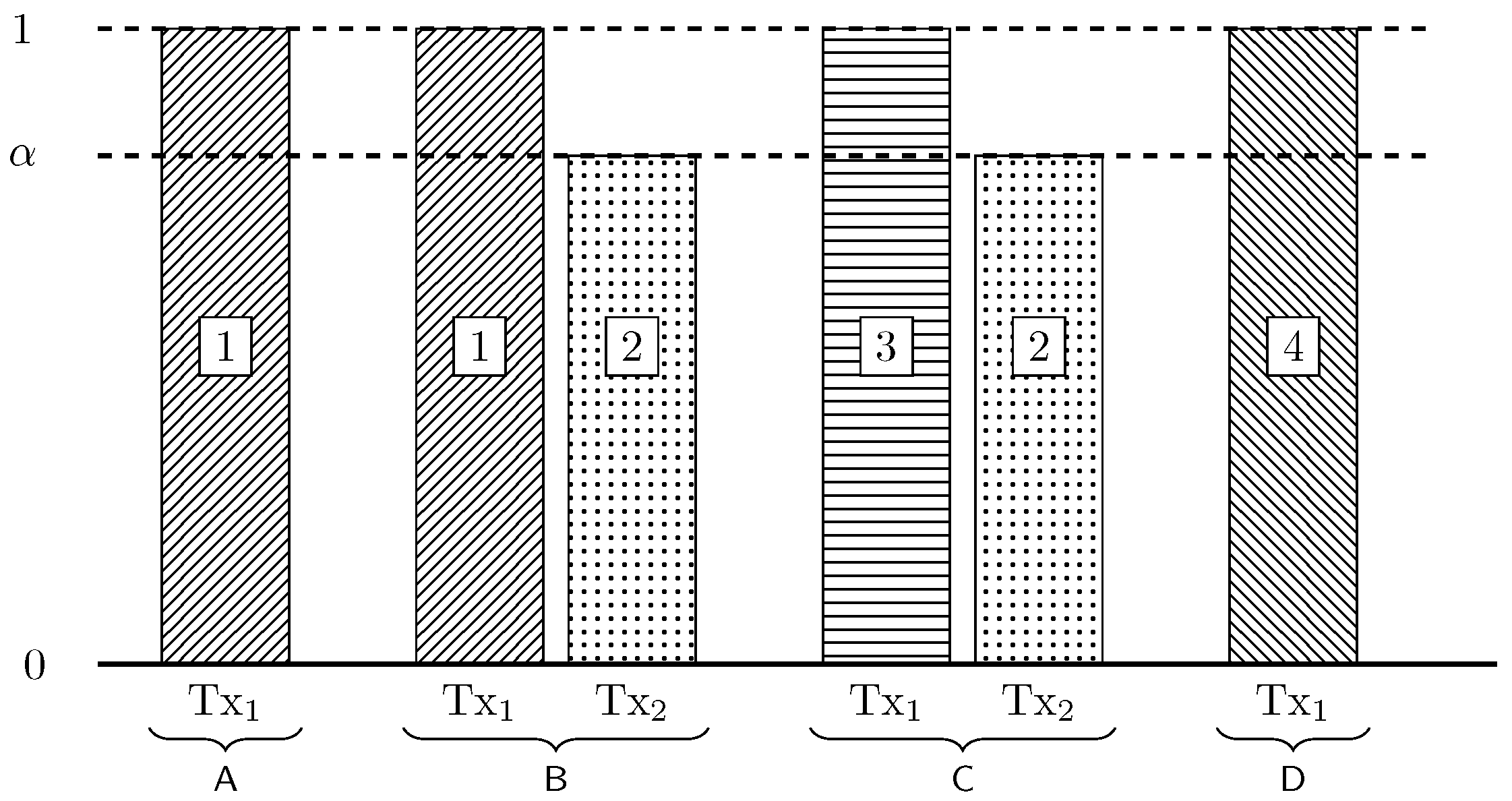{kind=link}
{kind=link}
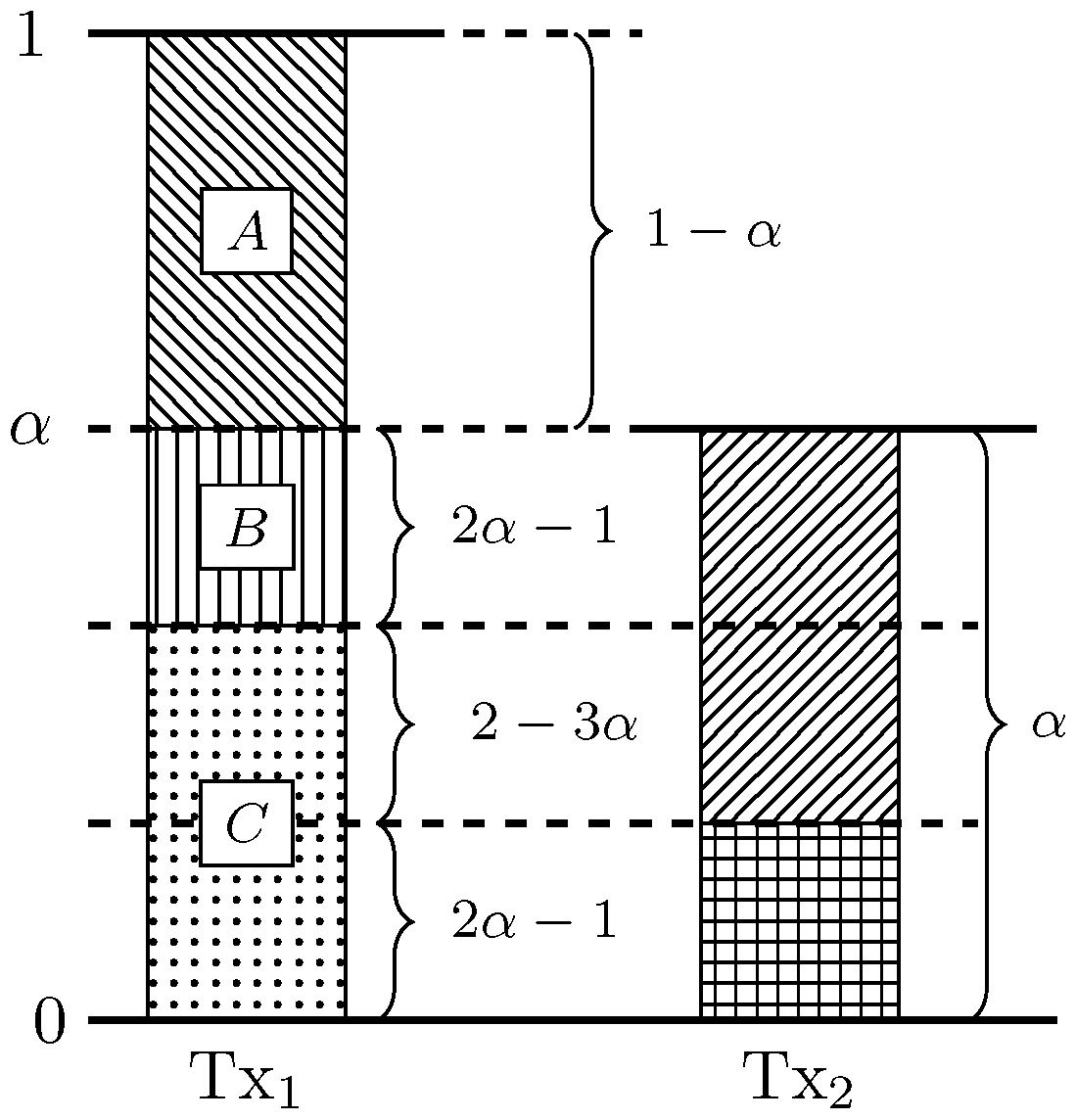{kind=link}
{kind=link}
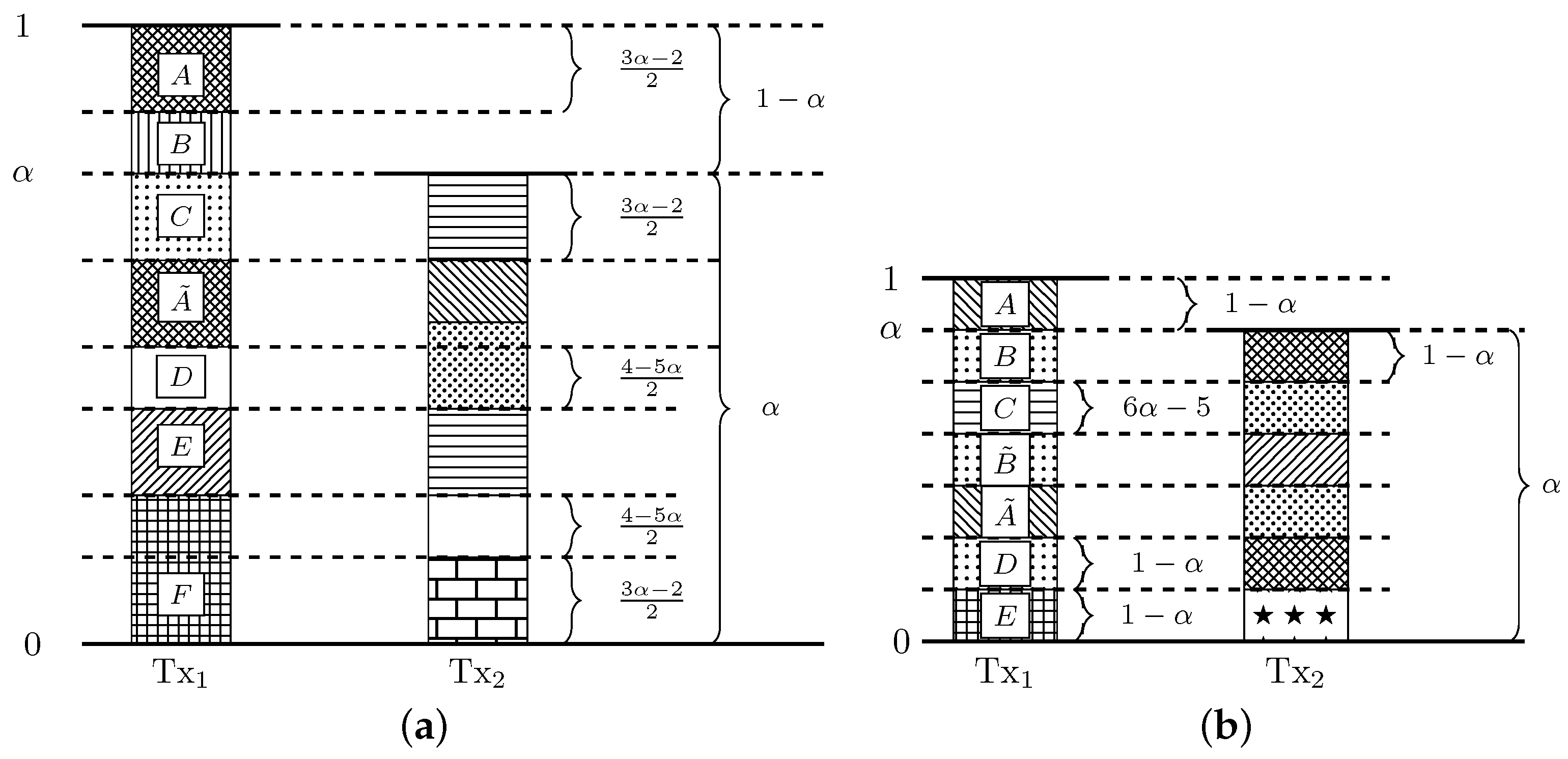{kind=link}
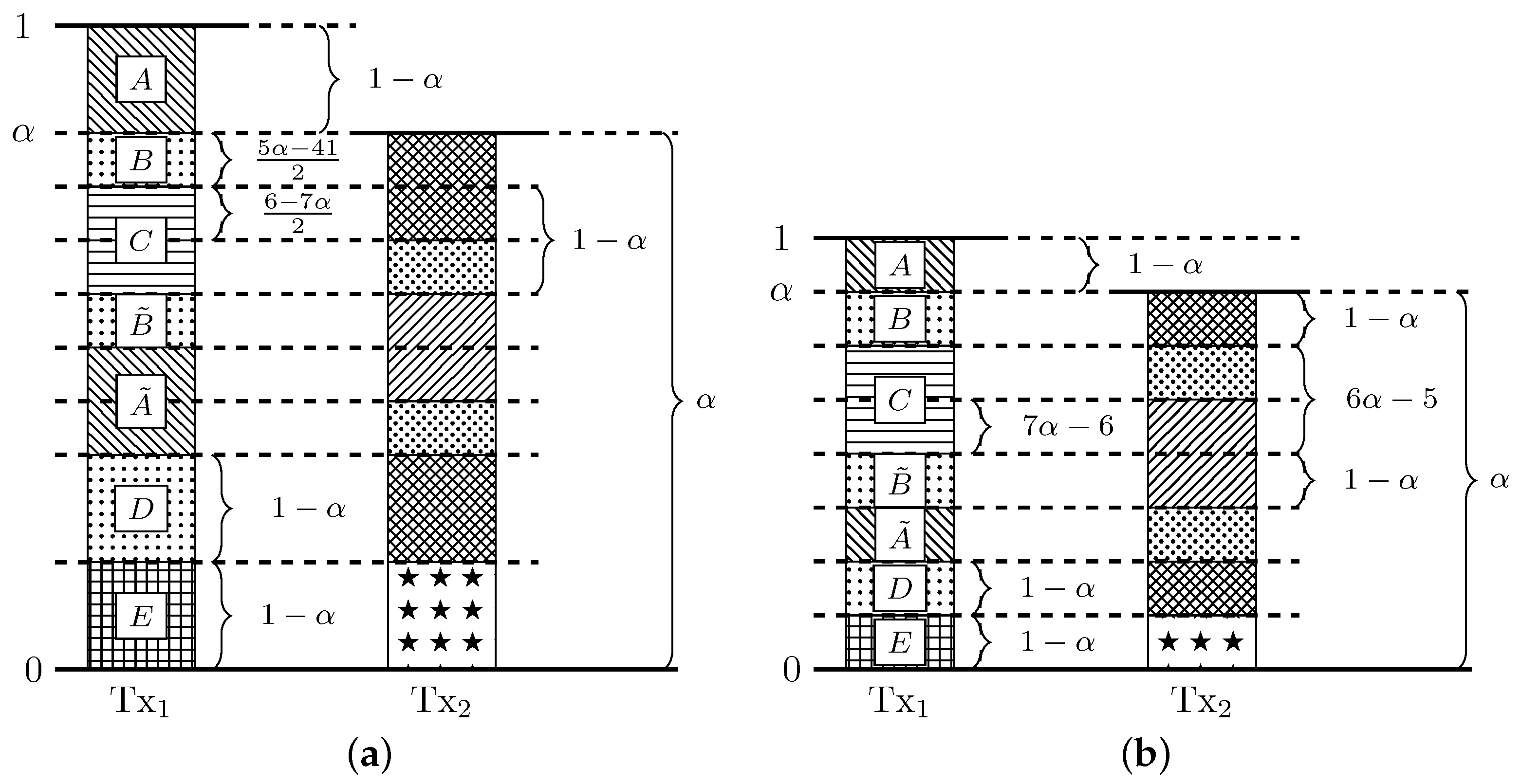{kind=link}
{kind=link}
{kind=link}
Table 1.
Opportunistic sum capacity for local CSIR when the worst-case sum rate is maximized.
| Rates | VWI | WI | MI | SI |
|---|---|---|---|---|
| C | ||||
| 0 | 0 | |||
| 0 | 0 |
Table 2.
Sum capacity for local CSIR.
| Regions | |||
|---|---|---|---|
| VWI | |||
| WI | |||
| MI | |||
| SI | |||
Table 3.
Average sum capacities for local CSIR.
| Regions | |||
|---|---|---|---|
| VWI | |||
| WI | |||
| MI | |||
| SI | |||
Table 4.
Opportunistic sum capacity for global CSIRT when the worst-case sum rate is maximized and and are independent.
Table 4.
Opportunistic sum capacity for global CSIRT when the worst-case sum rate is maximized and and are independent.
| Rates | VWI | WI | MI | SI |
|---|---|---|---|---|
| C | ||||
| 0 | 0 |
Table 5.
Opportunistic sum capacity for global CSIRT when the worst-case sum rate is maximized and and are fully correlated.
Table 5.
Opportunistic sum capacity for global CSIRT when the worst-case sum rate is maximized and and are fully correlated.
| Rates | VWI | WI | MI | SI |
|---|---|---|---|---|
| C | ||||
Table 6.
Bounds on the sum capacity C for global CSIRT when and are independent.
| Regions | Achievability | Converse |
|---|---|---|
| VWI | ||
| WI | ||
| MI | ||
| SI | ||
Table 7.
Bounds on the sum capacity C for global CSIRT when and are fully correlated.
| Regions | Bounds |
|---|---|
| VWI | |
| WI | |
| MI | |
| SI |
Table 8.
Average sum capacity when and are independent.
| Regions | Bounds |
|---|---|
| VWI | |
| WI | |
| MI | |
| SI |
Table 9.
Average sum capacity when and are fully correlated.
| Regions | Bounds |
|---|---|
| VWI | |
| WI | |
| MI | |
| SI |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Villacrés, G.; Koch, T.; Sezgin, A.; Vazquez-Vilar, G. Robust Signaling for Bursty Interference. Entropy 2018, 20, 870. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110870
AMA Style
Villacrés G, Koch T, Sezgin A, Vazquez-Vilar G. Robust Signaling for Bursty Interference. Entropy. 2018; 20(11):870. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110870
Chicago/Turabian StyleVillacrés, Grace, Tobias Koch, Aydin Sezgin, and Gonzalo Vazquez-Vilar. 2018. "Robust Signaling for Bursty Interference" Entropy 20, no. 11: 870. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110870
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.