Assessing the Relevance of Specific Response Features in the Neural Code


1
Department of Computer Science and Helsinki Institute for Information Technology, University of Helsinki Gustaf Hällströmin katu 2b, FI00560 Helsinki, Finland
2
Department of Medical Physics, Centro Atómico Bariloche and Instituto Balseiro, 8400 San Carlos de Bariloche, Argentina
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(11), 879; https://0-doi-org.brum.beds.ac.uk/10.3390/e20110879
Submission received: 1 October 2018
/
Revised: 12 November 2018
/
Accepted: 13 November 2018
/
Published: 15 November 2018
(This article belongs to the Special Issue Information Theory in Neuroscience)
Abstract
:The study of the neural code aims at deciphering how the nervous system maps external stimuli into neural activity—the encoding phase—and subsequently transforms such activity into adequate responses to the original stimuli—the decoding phase. Several information-theoretical methods have been proposed to assess the relevance of individual response features, as for example, the spike count of a given neuron, or the amount of correlation in the activity of two cells. These methods work under the premise that the relevance of a feature is reflected in the information loss that is induced by eliminating the feature from the response. The alternative methods differ in the procedure by which the tested feature is removed, and the algorithm with which the lost information is calculated. Here we compare these methods, and show that more often than not, each method assigns a different relevance to the tested feature. We demonstrate that the differences are both quantitative and qualitative, and connect them with the method employed to remove the tested feature, as well as the procedure to calculate the lost information. By studying a collection of carefully designed examples, and working on analytic derivations, we identify the conditions under which the relevance of features diagnosed by different methods can be ranked, or sometimes even equated. The condition for equality involves both the amount and the type of information contributed by the tested feature. We conclude that the quest for relevant response features is more delicate than previously thought, and may yield to multiple answers depending on methodological subtleties.
1. Introduction
Understanding the neural code involves, among other things, identifying the relevant response features that participate in the representation of information. Different studies have proposed several candidates, for example, the spiking rate [1,2], the response latency [3], the temporal organisation of spikes [4], the amount of synchrony in a given brain area [5], the amount of correlation between the activity of different neurons [6], or the phase of the local field potential at the time of spiking [7], to cite a few. One way of evaluating the relevance of each candidate feature is to assess how much information is lost by ignoring that feature. This strategy involves the comparison of the mutual information between the stimulus and the so-called full response (a collection of response features including the tested one) and the same information calculated with a reduced response, obtained by dropping the tested feature from the full response. If the tested feature is relevant, the information encoded by the reduced response should be smaller than that of the full response.
The procedure is fairly straightforward when the response features are defined in terms of variables that take definite values in each stimulus presentation, as for example, the spike count C fired in a fixed time window, or the latency L between the stimulus and the first spike. The full response in this case is a two-component vector , the value of which is uniquely defined for each stimulus presentation—let us assume that in this example, C is never equal to 0, so L is always well defined. The reduced response is a one-component vector, either C or L, depending whether we are evaluating the relevance of the latency or the spike count, respectively. If the latency or the spike count are relevant, then the information encoded by C or L, respectively, should be smaller than that of the pair . Throughout this paper, we often use C and L as examples of response features that take a precise value in each trial, to contrast with other features that are only defined in the whole collection of trials, as discussed below.
The method becomes more controversial when applied to response properties that can only be defined in multiple stimulus presentations, as for example, the amount of correlation in the activity of two or more neurons, or the temporal precision of the elicited spikes. These properties cannot be calculated from single responses, so more sophisticated methods are required to delete the tested feature. There are several alternative procedures to perform such deletion, and several are also the ways in which the lost information can be calculated. Interestingly, the lost information depends markedly on the chosen method, implying that the so-called relevance of a given feature is a subtle concept, that needs to be specified precisely. When assessing the relevance of noise correlations, two different sets of strategies have been proposed by the seminal works of Nirenberg et al. [8] and Schneidman et al. [9]. The first proposal evaluated the role of noise correlations in decoding the information represented in neural activity, whereas the second, in the amount of encoded information. Quite surprisingly, the contribution of correlations to the decoded information was shown to sometimes exceed the amount of encoded information [9], seemingly contradicting the intuitive idea that the encoded information constitutes an upper bound to the decoded information. The apparent inconsistency between the two measures has not been observed in later extensions of the technique, where the relevance of other response aspects was evaluated, such as spike-time precision, spike-counts or spike-onsets. Moreover, it has even been argued that the inconsistency was exclusively observed when assessing the role of noise correlations [10,11,12,13].
In this paper, for the first time, the different methods used in the literature to delete a given response feature are distinguished, and the implications of each method are discussed and compared. We show that the data processing inequality, stating that the decoded information cannot surpass the encoded information, can only be invoked with some - and not all - deletion procedures. The distinction between such procedures allows us to identify the conditions in which the decoded information can exceed the encoded information, and to demonstrate that there was no logical inconsistency in previous studies. We also show explicit examples where the decoded information surpasses the encoded information also when assessing the role of other response aspects different from noise correlations. In order to explain why such behaviours have not been identified until now, we scrutinise the arguments given in the literature to claim that only noise correlations could exhibit such syndrome. We conclude that although the measures employed to assess the relevance of individual response features initially distinguished clearly between the relevance for encoding and the relevance for decoding, this distinction was eventually lost in later modifications of the measures. By diagnosing the confusion, we prove that indeed, the response features for which the decoded information can surpass the encoded information are not restricted to noise correlations.
More generally, we discuss a wide collection of strategies employed to assess the relevance of individual response features, ranging from those encoded-oriented to those decoded-oriented. This distinction is related to the way the tested feature contributes to the performance of decoders, which can be mismatched or not. The relevance of the tested feature obtained with some of the measures is always bounded by the relevance of another measure. Yet, not all measures can be ordered hierarchically. There are examples where the relevance of a feature obtained with one method may surpass or be surpassed by the relevance of another, depending on the specific values taken by the prior stimulus probability and the conditional response probabilities. We analyse a collection of carefully chosen examples to identify the cases where this is so. In certain restricted conditions, however, the hierarchy, or even the equality, can be ensured. Here we establish these conditions by means of analytic reasoning, and discuss their implications in terms of the amount and type of information encoded by the tested feature.
We also present examples in which the measures to assess the relevance of a given feature can be used to extract qualitative knowledge about the type of information encoded by the feature. In other words, we assess not only how much information is encoded by an individual feature, but also what kind of information is provided, with respect to individual stimulus attributes. Again, we prove that the type of encoded information depends on the method employed to assess it.
Finally, given that one important property of measures of relevance hinges on whether they represent the operation of matched or mismatched decoders, we also explore the consequences of operating mismatched decoders on noisy responses, instead of real responses. We conclude that it may be possible to improve the performance of a mismatched decoder by adding noise. From the theoretical point of view, this observation underscores the fact that the conditions for optimality for matched decoders need not hold for mismatched decoders. From the practical perspective, our results open new opportunities for potentially simpler, more efficient and more resilient decoding algorithms.
In Section 2.1, we establish the notation, and we introduce some of the key concepts that will be used throughout the paper. These concepts are employed in Section 2.2 to determine the cases where the data-processing inequality can be ensured. In Section 2.3 we introduce 9 measures of feature relevance that were previously defined in the literature, and briefly discuss their meaning, similarities and discrepancies. A numeric exploration of a set of carefully chosen examples is employed in Section 2.4 to detect the pairs of measures for which no general hierarchical order exists. In Section 2.5 we discuss the consequences of employing measures that are conceptually linked to matched or mismatched decoders. Later, in Section 2.6, we explore the way in which different measures of feature relevance arrogate different qualitative meaning to the type of information encoded by the tested feature. In Section 2.7 we discuss the conditions under which encoding-oriented measures provide the same amount of information as their decoding-oriented counterparts, and also the conditions under which the equality extends also to the content of that information. Then, in Section 2.8, we observe that sometimes, mismatched decoders may improve their performance when operating upon noisy responses. We discuss some relations of our work with other approaches and to the limiting sampling problem in Section 3, and we close with a summary of the main results of the paper in Section 4.
2. Results
2.1. Definitions
2.1.1. Statistical Notation
When no risk of ambiguity arises, we here employ the standard abbreviated notation of statistical inference [14], denoting random variables with letters in upper case, and their values, in lower case. For example, the symbol always denotes the conditional probability of the random variable X taking the value x given that the random variable Y takes the value y. This notation may lead to confusion or be inappropriate, for example, when the random variable X takes the value u given that the random variable Y takes the value v. In those cases, we explicitly indicate the random variables and their values, as for example .
In the study of the neural code, the relevant random variables are the stimulus S and the response generated by the nervous system. In this paper, we discuss the statistics of the true responses observed experimentally, and compare them with a theoretical model that describes how responses would be, if the encoding strategy were different. To differentiate these two situations, we employ the variable for the experimental responses (the real ones), and for the surrogate responses (the fictitious ones). The associated conditional probability distributions are and , which are often abbreviated as and , respectively. Once these distributions are known, and given the prior stimulus probabilities , the joint probabilities and can be deduced, as well as the marginals and . When interpreting the abbreviated notation, readers should keep in mind that governs the variable , and , . If a statement is made about a distribution P or a response variable that has no sub-index, the argument is intended for both the real and surrogate distributions or variables.
2.1.2. Encoding
The process of converting stimuli S into neural responses (e.g., spike-trains, local-field potentials, electroencephalographic or other brain signals, etc.) is called “encoding” [9,15]. The encoding process is typically noisy, in the sense that repeated presentations of the same stimulus may yield different neural responses, and is characterised by the joint probability distribution . The associated marginal probabilities are
from which the conditional response probability , and the posterior stimulus probability can be defined.
The mutual information that contains about S is
More generally, the mutual information about S contained in any random variable X, including but not limited to , can be computed using the above formula with replaced by X. For compactness, we denote as unless ambiguity arises.
2.1.3. Data Processing Inequalities
When the response is a post-processed version of the response , the joint probability distribution can be written as . This decomposition implies that is conditionally independent of S. In these circumstances, the information about S contained in cannot exceed the information about S contained in [16]. In addition, the accuracy of the optimal decoder operating on cannot exceed the accuracy of the optimal decoder operating on [17]. These results constitute the data processing inequalities.
2.1.4. Decoding
The process of transforming responses into estimated stimuli is called “decoding” [9,15]. More precisely, a decoder is a mapping defined by a function . The inverse of this function is , and when D is not injective, is a multi-valued mapping. The joint probability of the presented and estimated stimuli, also called “confusion matrix” [12], is
where the sum runs over all responses that are mapped onto by D. The information that preserves about S is , and can be calculated from the confusion matrix of Equation (2). The decoding accuracy above chance level is here defined as
2.1.5. Optimal Decoding
Although all mappings D are formally admissible as decoders, not all are useful. The aim of a decoder is to make a good guess of the external stimulus S from the neural response . It is therefore important to be able to construct decoders that make good guesses, or at least, as good as the mapping from stimuli to responses allows. Optimal decoders (also called Bayesian or maximum-a-posteriori decoders, as well as ideal homunculus, or observer, among other names) are defined as [18,19]
This mapping selects, for each response , the stimulus that most likely generated . It is optimal in the sense that any other decoding algorithm yields a confusion matrix with lower decoding accuracy. Equation (4) depends on , so the decoder cannot be defined before knowing the functional shape of the joint probability distribution between stimuli and responses. The process of estimating from real data, and the subsequent insertion of the obtained distribution in Equation (4) is called the training of the decoder. The word “training” makes reference to a gradual process, originally stemming from a computational strategy employed to estimate the distribution progressively, while the data was being gathered. However, in this paper we do not discuss estimation strategies from limited samples, so for us, “training a decoder” is equivalent to constructing a decoder from Equation (4).
2.1.6. Extensions of Optimal Decoding
The study of Ince et al. [20] introduced the concept of ranked decoding, in which each response is mapped onto a list of K stimuli ordered according to their posterior probabilities so that (with , and the total number of stimuli in the experiment). Ranked decoding can provide useful models for intermediate stages in the decision pathway, and the information loss induced by ranked decoding was computed recently [17]. The joint probability associated with ranked decoding is
where the sum runs over all response vectors that produce the same ranking . Although can be used to compute the information between S and , it cannot be used to compute the decoding accuracy above chance level because the support of (i.e., the set of stimulus lists) is not contained in the support of S (i.e., the set of stimuli).
2.1.7. Approximations to Optimal Decoding
For given probabilities and , Equation (4) defines a mapping between each response and a candidate stimulus . In the study of the neural code, scientists often wonder what would happen if responses were not governed by the experimentally recorded distribution , but by some other surrogate distribution . If we replace by in Equation (4), we define a new decoding algorithm
which, as discussed below, may or may not be optimal, depending on how the decoder is used.
2.1.8. Two Different Decoding Strategies
One alternative, here referred to as “decoding method ” is that, for each response obtained experimentally, one decodifies a stimulus using the new mapping of Equation (6). In this case, the chain gives rise to the confusion matrix
where the sum runs over all response vectors that are mapped onto by the new decoding algorithm , and the probability appearing in the right-hand side is the real one, since responses are generated experimentally. It is easy to see that in this case, the decoding accuracy of the new algorithm is suboptimal, since responses are generated with the original distribution , and for that distribution, the optimal decoder is given by Equation (4) with . In the literature, training a decoder with a probability and then operating it on variables that are generated with is called mismatched decoding. In what follows, information values calculated from the distribution of Equation (7) are noted as .
A second alternative, “decoding method ,” is that, for each stimulus s, a surrogate response is drawn using the new distribution . If the sampled value is , the stimulus is decoded. In this case, the confusion matrix is
where as before, the sum runs over all response vectors that are mapped onto by the decoding algorithm , but now the probability appearing in the right-hand side is the surrogate one, since responses are not generated experimentally. In this case, there is no mismatch between the construction and operation of the decoder, and is optimal, in the sense that no other algorithm decodes with higher decoding accuracy. One should bear in mind, however, that the surrogate responses are not the responses observed experimentally, that they may well take values in a response set that does not coincide with the set of real responses, and that is not necessarily obtained by transforming the real response with a stimulus-independent mapping (see below). In what follows, information values calculated from the distribution of Equation (8) are noted as . Methods and can be easily extended to encompass also ranked decoding, mutatis mutandis.
The two alternative decoding methods yield two different decoding accuracies. To distinguish them, we use the notation . The superscript indicates the variable whose probability distribution is used to construct the decoder in Equation (4), and consequently, determines the set of that contribute to the sums of Equations (7) and (8). The subscript indicates the variable upon which the decoder is applied, and its probability distribution is summed in the right-hand side of Equations (7) and (8). That is, is computed through Equation (3) with
so that and .
2.2. The Applicability of the Data-Processing Inequality
Assessing the relevance of a response feature typically involves a subtraction , where I and represent the mutual information between stimuli and a set of response features containing or not containing the tested feature, respectively. The magnitude of is often interpreted as the information provided by the tested feature. This interpretation requires to be positive, since intuitively, one would imagine that removing a response feature cannot increase the encoded information. As shown below, a formal proof of this intuition may or may not be possible invoking the data processing inequality (see Section 2.1.3 and reference [16]), depending on the method used to eliminate the tested feature. As a consequence, there are cases in which is indeed negative (see below). In these cases, the tested feature is detrimental to information encoding [9].
2.2.1. Reduced Representations
There are several procedures by which the tested feature can be removed from the response. The validity of the data-processing inequalities (see definition in Section 2.1.3) depends on the chosen procedure. In order to specify the conditions in which the inequalities hold, we here introduce the concept of reduced representations. When the response feature under evaluation is removed from by a deterministic mapping , we call the obtained variable a reduced representation of . A required condition for a mapping to be a reduced representation is that the function f be stimulus-independent, that is, that the value of be conditionally independent from s. Mathematically, this means that . If the mapping f and the conditional response distribution are known, the distribution can be derived using standard methods. The data processing inequality ensures that for all reduced representations, .
Reduced representations are usually employed when the response feature whose relevance is to be assessed takes a definite value in each trial, as happens for example, with the number of spikes in a fixed time window, the latency of the firing response, or the activity of a specific neuron in a larger population of neurons. In these cases it is easy to construct simply by dropping from the tested feature, or by fixing its value with some deterministic rule.
Reduced representations can also be used in other cases, for example, when the relevance of the feature response accuracy is assessed. This feature does not take a specific value in each trial; only by comparing multiple trials can the response accuracy be determined. A widely-used strategy is to represent spike trains with temporal bins of increasing duration, and to evaluate how the amount of information decreases as the representation becomes coarser. A sequence of surrogate responses is thereby defined, by progressively disregarding the fine temporal precision with which spike trains were recorded (Figure 1).
Several studies have reported an information that decreases monotonically with the duration of the time bin (for example [21,22,23]). If there is a specific temporal scale in which spike-time precision is relevant—the alleged argument goes—a sudden drop in appears at the relevant scale. It should be noted, however, that the data processing inequality does not ensure that be a monotonically decreasing function of . In the example of Figure 1, representations and are defined with long temporal bins, the durations of which are integer multiples of the bin used for . Hence, and are reduced representations of , and the data processing inequality does indeed guarantee that and . However, is not a reduced representation of , so there is no reason why should be smaller than , and indeed, Figure 1b shows an example where it is not. The representation constructed with bins of intermediate duration, namely 10 ms, does not distinguish between the two stimuli, whereas those of shorter and longer duration, 5 and 15 ms, do. A similar effect can be observed in the experimental data (freely available online) of Lefebvre et al. [24], when analysed with bins of sizes 5, 10 and 15 ms in windows of total duration 60 ms. Although these examples are rare, they demonstrate that there is no theoretical substantiation to the expectation of to drop monotonically with increasing .
2.2.2. Stochastically Reduced Representations
When the response feature under evaluation is removed from the response variable by a stochastic mapping , the obtained variable is called a stochastically reduced representation of . A required condition for a mapping to be a stochastically reduced representation is that the probability distribution of each be dependent on , but conditionally independent from s. In these circumstances, the data processing inequality ensures that . If the statistical properties of the noisy components of the mapping are known, as well as the conditional response probability distribution , the distribution can be derived using standard methods. Formally, stochastic representations are obtained through stimulus-independent stochastic functions of the original representation . After observing that adopted the value , these functions produce a single value for chosen with transition probabilities such that
To illustrate the utility of stochastically reduced representations, we discuss their role in providing alternative strategies when assessing the relevance of spike-timing precision, not by changing the bin size as in Figure 1, but by randomly manipulating the responses, as illustrated in Figure 2.
The method of Figure 2a yields the same information and response accuracy as the method producing in Figure 1. Each method yields responses that can be related to the responses of the other method through a stimulus-independent deterministic or stochastic function. Both methods suffer from the same drawback: They treat spikes differently depending on their location within the 15 ms time window. Indeed, both methods preserve the distinction between two spikes located in different windows, but not within the same window, even if the separation between the spikes is the same. The mapping illustrated in Figure 2a has transition probabilities
where rows enumerate the elements of the ordered set from where is sampled, and columns enumerate the elements of the ordered set from where is sampled.
A third method, jittering, consists in shuffling the recorded spikes within time windows centered at each spike (Figure 2b). The responses generated by this method need not be obtainable from the responses generated by the mappings of Figure 2a or Figure 1 through stimulus-independent stochastic functions. Still, the method of Figure 2b inherently yields a stochastic code, and, unlike the methods discussed previously, treats all spikes in the same manner. The mapping illustrated in Figure 2b has transition probabilities
where rows enumerate the elements of the ordered set from where is sampled, and columns enumerate the elements of the ordered set from where is sampled.
As a fourth example, consider the effect of response discrimination, as studied in the seminal work of Victor and Purpura [25]. There, two responses were considered indistinguishable when some measure of distance between the responses was less than a predefined threshold. However, neural responses were transformed through a method based on cross-validation that is not guaranteed to be stimulus-independent. Depending on the case, hence, this fourth method may or may not be a stochastically reduced representation. The case chosen in Figure 2c is a successful example, and the associated matrix of transition probabilities is
where rows and columns enumerate the elements of the ordered set from where both and are sampled.
Other methods exist which merge indistinguishable responses, thereby yielding reduced representations. These methods, however, are limited to notions of similarity that are transitive, a condition not fulfilled, for example, by those based on Euclidean distance, edit distance, or by the case of Figure 2c.
Stochastically reduced representations include reduced representations as limiting cases. Indeed, when for each there is a such that , stochastic representations become reduced representations (Figure 3). The possibility to include stochasticity, however, broadens the range of alternatives. Consider for example the hypothetical experiment in Figure 3a, in which the neural responses can be completely characterized by the first-spike latencies (L) and the spike counts (C). The importance of C can be studied for example by using a reduced code that replaces all C-values with a constant (Figure 3b). In this case,
where rows enumerate the elements of the ordered set from where is sampled, and columns enumerate the elements of the ordered set from where is sampled.
Another alternative is to assess the relevance of C by means of a stochastic code that shuffles the values of C across all responses with the same L (Figure 3c). In this case,
where rows enumerate the elements of the ordered set from where is sampled, and columns enumerate the elements of the ordered set from where is sampled. The parameter a is arbitrary, as long as . We use the notation .
A third option is to use a stochastic code that preserves the original value of L but chooses the value of C from some possibly dependent probability distribution (Figure 3d), for which
where rows enumerate the elements of the ordered set from where is sampled, and columns enumerate the elements of the ordered set from where is sampled. The parameters and d are arbitrary, as long as ; and we have used the notation for any number x.
2.2.3. Modification of the Conditional Response Probability Distribution
When the response feature under evaluation is removed by altering the real conditional response probability distribution , and transforming it into a surrogate distribution , the obtained response model is here said to implement a probabilistic removal of the tested feature. Probabilistic removals are usually employed when assessing the relevance of correlations between neurons in a population, since correlations are not a variable that can be deleted from each individual response. For example, if represents the spike count of n different neurons, the real distribution is replaced by a new distribution in which all neurons are conditionally independent, that is,
where, following the notation introduced previously [17], the generic subscript “” was replaced by “” to indicate “noise-independent”.
The probabilistic removal of a response feature may or may not be describable in terms of a deterministically or a stochastically reduced representation. In other words, there may or may not exist a mapping , or equivalently, a matrix of transition probabilities , that captures the replacement of by . It is important to assess whether such a matrix exists, since the data processing inequality is only guaranteed to hold with reduced representations, stochastic or not. If no reduced representation can capture the effect of a probabilistic removal, the data processing inequality may not hold, and may well be larger than .
In order to determine whether a stochastically reduced representation exists, the first step is to discern whether Equation (10) constitutes a compatible or an incompatible linear system for the matrix elements . If the system is incompatible, there is no solution. In the compatible case, which is often indeterminate, a solution entirely composed of non-negative numbers that sum up to unity in each row is required. Given enough time and computational power, the problem can always be solved in the framework of linear programming [27]. In practical cases, however, the search is often hampered by the curse of dimensionality. To facilitate the labour, here we list a few necessary (though not sufficient) conditions that must be fulfilled for the mapping to exist. If any of the following properties does not hold, Equation (10) has no solution, so there is no need to begin a search.
Property 1.
Proof.
If we multiply both sides of the inequality by and sum over , we obtain an inequality between the mutual informations . If , this result reduces to the data-processing inequality .
Property 2.
If exists, then whenever and for at least some s.
Proof.
Suppose that when for some s. Then, Equation (10) yields , contradicting the hypothesis that . Hence, must vanish. □
For example, in Figure 4a, we decorrelate first-spike latencies (L) and spike counts (C) by replacing the true conditional distribution (left panel) by its noise-independent version defined in Equation (17) (middle panel). Before searching for a mapping , we verify that the condition holds. Moreover, for several choices of (◯) and (□), one may confirm that , as well as . These results motivate the search for a solution of Equation (10) for . The transition probability must be zero at least whenever and (Property 2). One possible solution is
where each response is defined by a vector , and rows and columns enumerate the elements of the ordered sets and from where and are sampled, respectively. In Equation (19), ; ; and .
However, stochastically reduced representations are not always guaranteed to exist. For example, in Figure 4b, it is easy to verify that the condition holds for any . Therefore, no stochastic mapping can transform into in such a way that is converted into . Schneidman et al. [9] employed an analogous example, but involving different neurons instead of response aspects. The two examples of Figure 4 motivate the following theorem:
Theorem 1.
No deterministic mapping exists transforming the conditional probability into its noise-independent version defined in Equation (17). Stochastic mappings may or may not exist, depending on the conditional probability .
Proof.
See Appendix B.2. □
In addition, when a stochastic mapping exists, the values of the probabilities may well depend on the discarded response aspect, as well as on the preserved response aspects. We mention this fact, because when assessing the relevance of noise correlations, the marginals suffice for us to write down the surrogate distribution , with no need to know the full distribution containing the noise correlations. One could have hoped that perhaps also the mapping (assuming that such a mapping exists) could be calculated with no knowledge of the noise correlations. This is, however, not always true, as stated in the theorem below. Two experiments with the same marginals and different amounts of noise correlations may require different mappings to eliminate noise correlations, as illustrated in the the example of Figure 5. More formally:
Theorem 2.
The transition probabilities of stochastic codes that ignore noise correlations may depend both on the marginal likelihoods (preserved at the output of the mapping), and on the noise correlations (eliminated at the output of the mapping).
Proof.
See Appendix B.3. □
The solution of Equation (10) for the example of Figure 5 is
where each response is defined by a vector , and rows and columns enumerate the elements of the ordered sets and from where and are sampled, respectively. In Equation (20), ; and . The fact that the matrix in Equation (20) bears an explicit dependence on these parameters–and not only on and –implies that the transformation between and depends on the amount of noise correlations in .
2.3. Multiple Measures to Assess the Relevance of a Specific Response Feature
The importance of a specific response feature has been previously quantified in many ways (see [17,30] and references therein), which have oftentimes led to heated debates about their merits and drawbacks [9,11,12,17,31,32,33]. Here we consider several measures, to underscore the diversity of the meanings with which the relevance of a given feature has been assessed so far. They are mathematically defined as
Equations (22)–(24) are based on matched decoders, that is, decoders operating on responses governed by the same probability distribution involved in their construction (method ). Instead, Equations (25)–(28) are based on the operation of mismatched decoders (method ). Each measure of Equations (21)–(24) has one or two homologous measures in Equations (25)–(29), as illustrated in Figure 6.
We here describe the measures briefly, and refer the interested reader to the original papers.
In Equation (21), and are the mutual informations between the set of stimuli and a set of responses governed by the distributions and , respectively. Thus, is the simplest way in which the information encoded by the true responses can be compared with that of the surrogate responses. This comparison has been employed for more than six decades in neuroscience [34,35] to study, for example, the encoding of different stimulus features in spike counts, in synchronous spikes, and in other forms of spike patterns, both in single neurons and populations (see [30] and references therein).
The measure defined in Equation (25) was introduced by Nirenberg et al. [8] to study the role of noise correlations, and was later extended to arbitrary deterministic mappings [10,12,13]. Here we use the supra-script D to indicate that the measure is the “divergence” (in the Kullback-Leibler sense) between the posterior stimulus distributions calculated with the real and the surrogate responses, respectively. In [10], Nirenberg and Latham argued that the important feature of is that it represents the information loss of a mismatched decoder trained with but operated on the real responses, sampled from . Not before long, Schneidman et al. [9] noticed that can exceed . The interpretation of as a measure of information loss would imply that decoders trained with surrogate responses can lose more information than the one encoded by the real response. In fact, tends to infinity if when for some s. In the limit, becomes undefined when and . To avoid this peculiar behavior, Latham and Nirenberg generalized the theoretical framework used to derive [11], giving rise to the measure of Equation (26). Here, the supra-script makes reference to “Divergence Lowest”, since the measure was presented as the lowest possible information loss of a decoder trained with . In the definition of , the parameter is a real scalar. The distribution was defined by Latham and Nirenberg [11] as proportional to . This definition has several problems, as discussed in [11,17,36,37,38,39]. In Appendix B.1 we demonstrate a theorem that resolves the issues appearing in previous definitions, and justifies the use of
From the conceptual point of view, represents the information loss of a mismatched decoder trained with and operated on . Latham and Nirenberg [11] showed that, unlike , it is possible to demonstrate that . Hence, never yields a tested feature encoding more information than the full response. The proof in [11] ignored a few specific cases that we discuss in the Theorem A1 of Appendix B.1. Still, even in those additional cases, the inequality holds.
In Equations (22) and (23), and denote a sorted stimulus list and the most-likely stimulus, respectively, both decoded by evaluating Equation (6) (or its ranked version) on a response sampled from the surrogate distribution (method ). Estimating mutual informations using decoders can be traced back at least to Gochin et al. [40], and comparing the estimations of two decoders that take different response features into account, at least to Warland et al. [41].
The measures and are paired with and , respectively, since the latter are obtained from the former when replacing the decoding method from to . The measure was introduced by Ince et al. [20], and quantifies the difference between the information in , and the one in the output of decoders that, after observing a variable sampled with distribution (method ), produce a stimulus list sorted according to . The supra-script indicates “List of Stimuli”. Similarly, , quantifies the difference between the information encoded in and that encoded in the output of a decoder trained by inserting into Equation (6), and operated on sampled with distribution (method ). The supra-script B stands for the “Bayesian” nature of the involved decoder. The use of these measures can be traced back at least to Nirenberg et al. [8], although in that case, decoders were restricted to be linear. The measure of Equation (22) is new, and we have introduced it here as the homologous of . When the number of stimuli is two, , since selecting the optimal stimulus is (as a computation) in one-to-one correspondence with ranking the two candidate stimuli.
The accuracy loss defined in Equation (24) entails the comparison between the performance of two decoders, one trained with and applied on , and one trained with and applied on . Such comparisons have also a long history in neuroscience [42,43] (see [9,12] for further discussion). The accuracy loss also compares two decoders. The first, is the same as for , but the second is trained with and applied on .
The measures , , and are undefined if the actual responses are not contained in the set of surrogate responses . In other words, a decoder constructed with does not know what output to produce when evaluated in a response for which . This situation never happens when evaluating the relevance of noise correlations with , but it may well be encountered in more general situations, as for example, in Figure 3B.
2.4. Relating the Values Obtained with Different Measures
If a mapping exists transforming into , we may use the decoding procedure of Equation (6) to construct the transformation chain [17,44]. Consequently, , and can be interpreted as accumulated information losses after the first, second and third transformations, respectively, and , as the accuracy loss after the first transformation. The data processing theorems (Section 2.1.3) ensure that these measures are never negative. This property, however, cannot be guaranteed in the absence of a reduced transformation , stochastic or deterministic. Indeed, in the example of Figure 4b, if both stimuli are equiprobable, and both responses associated with ◯ are equiprobable, then of , implying that the surrogate responses encode more information about the stimulus than the original, experimental responses. Removing the correlations between spike count and latency, hence, increases the information, so correlations can be concluded to be detrimental to information encoding.
Irrespective of whether a (deterministic or stochastic) mapping exists, the data processing inequality guarantees that , since is a deterministic function of , and is a deterministic function of . The inequality holds irrespective of the sign of each measure.
All decoder-oriented measured are guaranteed to be non-negative. The very definitions of and of imply they cannot be negative, since they are both Kullback-Leibler divergences between two probability distributions. The sequence of reduced transformations , in turn, guarantees the non-negativity of and , through the Data Processing Inequalities.
In order to assess whether decoding-oriented measures are always larger or smaller than their encoding (or gray) counterparts, we performed a numerical exploration comparing each encoding/gray-oriented measure with its decoding-oriented homologue. The exploration was conducted by calculating the values of these measures for a large collection of possible stimulus prior probabilities , and response conditional probabilities in the examples of Figure 2, Figure 3, Figure 4 and Figure 7. The details of the numerical exploration are in Appendix A. The measures in the first group were sometimes greater and sometimes smaller than those of the second group, depending on the case and the probabilities (Table 1). Consequently, our results demonstrate that there is no general rule by which measures of one type bound the measures of the other type.
The exploration also included the example of Figure 7a. In panel (a), the transition probabilities are
where rows and columns enumerate the elements of the ordered sets from where both and are sampled. For panel b,
with , rows enumerating the elements of , and columns those of .
An important issue is to identify the situations in which gives exactly the same result as either or . It is not easy to determine the conditions for the equality between and . Yet, for the equality between and , and in the specific case in which as given by Equation (17), the following theorem holds.
Theorem 3.
When assessing the relevance of noise correlations, if and only if
Moreover, implies that .
Proof.
See Appendix B.4. □
Equation (33) implies that neither the prior stimulus probabilities nor the conditional response probabilities intervene in the condition for the equality, beyond the effect they have in fixing the value of and . Each response makes a contribution to the value of , which favours whenever , and in the opposite case. As pointed out by [10], all responses for which and give a null contribution to , and a negative contribution to , implying that correlations in such responses are irrelevant for decoding, and detrimental to encoding.
The fact that encoding-oriented measures neither bound nor are bounded by decoding-oriented measures is a daunting result. If, when working in a specific example, one gets a positive value with one measure and a negative value with another, the interpretation must carefully distinguish between the two paradigms. One may wonder, however, if such distinction is also required when correlations are absolutely essential for one of the measures, in that they capture the whole of the encoded information. Could the other measure conclude that they are irrelevant? Or that they are only mildly relevant? Luckily, in this case, the answer is negative. In other words, when the tested feature is fundamental, then and coincide, and no conflict arises between encoding and decoding, as proven by the following theorem:
Theorem 4.
if and only if , regardless of whether stochastic codes exist that map the actual responses into the surrogate responses generated assuming noise independence.
Proof.
See Appendix B.5. □
The conclusion is that if a given feature is 100% relevant for encoding, then it is also 100% relevant for decoding, and vice versa. Hence, although and often differ in the relevance they ascribe to a given feature, the discrepancy is only encountered when the tested feature is not the only informative feature in play. When the removal of the feature is catastrophic (in the sense that it brings about a complete information loss), then both and diagnose the situation equally.
2.5. Relation between Measures Based on Decoding Strategies and
The results of Table 1 may seem puzzling because decoding happens after encoding. Therefore—one may naively reason—the data processing theorems should have forbidden both to surpass , , or , as well as to surpass . However, even though decoding indeed happens after encoding, the data processing theorem is not violated. The theorem certainly ensures that and constitute lower bounds for measures related to decoders that operate on responses generated by , but not for measures related to decoders that operate on responses generated by , such as happens with , , , and .
This observation about the validity of the data processing inequality is different from the one discussed in Section 2.2. There, we discussed the conditions under which could be guaranteed to be non-negative, the crucial factor being the existence of a stochastic mapping . Now we are discussing a different aspect, regarding whether decoding-related measures can or cannot be bounded by encoding-oriented measures. The conclusion is that in general terms, the answer is negative, because decoding-related measures operate with decoding strategy , a strategy never addressed by the encoding measures. The surrogate variable participating in the encoding measure is not the response decoded by the measures of Equations (25)–(28), so the data processing inequalities need not hold. That being said, there are specific instances in which both types of measures coincide, two of them discussed in Theorems 3 and 4 and a third case later in Theorem 5.
Other explanations have been given in the literature for the fact that sometimes, decoding oriented measures surpass their encoding counterparts. For example, it has been alleged [10] that when or are smaller than , this is either due to (a) the impossibility to define a stimulus-independent reduction that yields (and therefore the data-processing inequality is not guaranteed to hold), or due to (b) the fact that surrogate responses often sample values of response space that are never reached by real responses (and therefore, the losses of matched decoders may be larger than the ones of mismatched ones). However, Figure 2c constitutes a counterexample of both arguments, since there, the stimulus-independent stochastic reduction exists, and the response set of and coincide.
One could also wonder whether the discrepancy between the values obtained with encoding-oriented measures and decoding-oriented measures only occurs in examples where a stochastic reduction exists, and the involved transition matrix depends on the joint probabilities , and not only on the marginals, as discussed in Theorem 2. However, Figure 2b,c provide examples in which does not depend on , and yet, the discrepancies are still observed.
The distinction between decoding strategies and is also crucial when using the measure . This measure was introduced by Nirenberg et al. [8] for the specific case in which the tested feature is the amount of noise correlations, that is, when . The measure was later extended to arbitrary deterministic mappings [10,12,13], with the instruction to use an expression like Equation (25), but with replaced by . It should be noted, however, that as soon as this replacement is made, becomes exactly equal to . Specifically, the measure now describes the information loss of a decoder that operates on a response variable generated with the surrogate distribution (decoding method ). If we want to keep the original spirit, and associate with a decoder that operates on a response variable generated with the real distribution (decoding method ), in Equation (25), should not be modified. Only the evaluation of the surrogate variable in the experimentally observed value describes a mismatched decoder constructed with and operated on (mathematical details in Appendix C).
2.6. Assessing the Type of Information Encoded by Individual Response Features
When the stimulus contains several attributes (as shape, color, sound, etc.), by removing a specific response feature it is possible to assess not only how much information is encoded by the feature, but also, what type of information. Identifiying the type of encoded information implies determining the stimulus feature represented by the tested response feature. As shown in this section, the type of encoded information is as dependent on the method of removal as is the amount. In other words, the different measures defined in Equations (21)–(29) sometimes associate a feature with the encoding of different stimulus attributes.
In the example of Figure 8, we use four compound stimuli , generated by choosing independently a frame ( or ) and a letter ( or ), thereby yielding ![Entropy 20 00879 i001]() , Ⓐ,
, Ⓐ, ![Entropy 20 00879 i002]() , and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .
, and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .
 , Ⓐ,
, Ⓐ,  , and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .
, and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .The transformation causes some responses to occur for all stimuli, so when decoding with method , some information about frames is lost (that is, of ), as well as some information about letters (that is, of ). In other words, decoding causes a partial information loss that is composed of both frame and letter information. Instead, when decoding with method , there is no information loss about letters: For the responses that actually occur, the decoder trained with can perfectly identify the letters, because . The information about frames, on the other hand, is completely lost, since whenever l adopts a value that actually occurs in , namely 2 or 3. This example shows that the fact that two decoding procedures give the same numerical loss does not mean that they draw the same conclusions regarding the role of the tested feature in the neural code. Ananalogous computations yield analogous results for the hypothetical experiment shown in Figure 7b.
If responses and are written as vectors , and the values of are arranged in a rectangular structure, in Figure 8c the transition probabilities are
where rows and columns indicate the ordered sets and , where × denotes the Cartesian product with colexicographical order, that is, ordered as , etc. In Figure 8e
with rows and columns with the same convention as in Equation (34).
2.7. Conditions for Equality of the Amount and Type of Information Loss Reported by Different Measures
We now derive the conditions under which encoding/gray-oriented measures coincide with their decoding-oriented counterparts, as observed in Figure 2a and Figure 3d. That is, we derive the conditions under which the following equalities hold:
The example in Figure 7a showed that the existence of deterministic mappings does not suffice for a qualitative and quantitative equivalence of different measures. Furthermore, the example of Figure 3b showed that the equalities require the space of to include the space of , or else the decoding method may be undefined. We demonstrate that the Equations (37)–(40) arise, and moreover, that there is no discrepancy in the type of information assessed by these different measures, whenever the mapping from into can be described using positive-diagonal idempotent stochastic matrices [45]. Specifically, we prove the following theorem:
Theorem 5.
Consider a stimulus-independent stochastic function f from a representation into another representation , such that the range of includes that of , and with transition probabilities that can be written as positive-diagonal idempotent right stochastic matrices with row and column indices that enumerate the elements of in the same order. Then, Equations (37)–(40) hold.
Proof.
See Appendix B.6. □
The theorem states that the equalities of Equations (37)–(40) can be guaranteed whenever the removal of the tested response feature involves a (deterministic or) stochastic mapping that induces a partition within the set of real responses , and is obtained by rendering all responses inside each partition indistinguishable (but not across partitions). To sample , the probabilities of individual responses inside each partition are re-assigned, rendering their distinction uninformative [30].
This theorem provides sufficient but not necessary conditions for the equalities to hold. The important aspect, however, is that it ensures that the equalities hold not only in numerical value, but also, in the type of information that different measures ascribe to the tested feature. Two different methods preserve or lose information of different type if, when decoding a stimulus, the trials with decoding errors tend to confound different attributes of the stimulus, as in the example of Figure 8. The conditions of Theorem 5, however, ensure that the strategies and always decode exactly the same stimulus (see Appendix B.6), so there can be no difference in the confounded attributes. Pushing the argument further, one could even argue that responses (real or surrogate) encode more information than the identity of the stimulus that originated them. For a fixed decoded stimulus, the response still contains additional information [46], that refers to (a) the degree of certainty with which the stimulus is decoded, and (b) the rank of the alternative stimuli, in case the decoded stimulus was mistaken [20]. Both meanings are embodied in the whole rank of a posteriori probabilities , not just the maximal one. Yet, under the conditions of the theorem, the entire rankings obtained with methods and coincide (see Appendix B.6). Therefore, even within this broader interpretation, there can be no difference in the qualitative aspects of the information preserved or lost by one and the other.
For example, in Figure 7b, we found that all information losses are equal (that is, , , , , , , and are all ), and both accuracy losses are equal (that is, and are both ). However, the conditions of Theorem 5 do not hold. The matrix of Equation (32) is not block-diagonal, nor it can be taken to that shape by incorporating new rows (to make it square), and permuting both rows and columns, in such a way that the response vectors are enumerated in the same order by both indices. For this reason, the losses are not guaranteed to be of the same type.
Instead, the transition probabilities of Equations (15) and (16) can be turned into positive-diagonal idempotent right stochastic matrices. Equation (15) is already in the required format. To take Equation (16) to the conditions of Theorem 5, two new rows need to be incorporated, associated to the responses and , that do not occur experimentally. Those rows can contain arbitrary values, since the condition renders them irrelevant. Arranging the columns so that both rows and columns enumerate the same list of responses, Equation (16) can be written as
with . Hence, in these two examples, both the amount and type of information of encoding and decoding-based measures coincide.
2.8. Improving the Performance of Decoders Operating with Strategy
In a previous paper [17], we demonstrated that neither nor constitute lower bounds on the information loss induced by decoders constructed by disregarding the tested response feature. This means that some decoders may exist, that perform better than defined in Equation (6). In this section we discuss one possible way in which some of these improved decoders may be constructed, inspired in the example of Figure 8. Quite remarkably, the construction involves the addition of noise to the real responses, before feeding them to the decoder of Equation (6). Panel (a) shows a decoder constructed with noisy data (), and then employed to decode quality data (; Figure 8b), thereby yielding information losses . These losses can be decreased by feeding the decoder with a degraded version of the quality data (Figure 8d) generated through a stimulus-independent transformation that adds latency noise (Figure 8e). Decoding as if it were by first transforming into results in , thereby recovering of the information previously lost. On the contrary, adding spike-count noise will tend to increase the losses. Thus, adding suitable amounts and type of noise can increase the performance of approximate decoders, and the result is not limited to the case in which the response aspect is the amount of noise correlations. In addition, this result also indicates that, contrary to previously thought [47], decoding algorithms need not match the encoding mechanisms for performing optimally from an information-theoretical standpoint. All these results are a consequence of the fact that decoders operating with strategy are not optimal, so it is possible to improve their performance by deterministic or stochastic manipulations of the response. In practice, our results open up the possibility of increasing the efficiency of decoders constructed with approximate descriptions of the neural responses, usually called approximate or mismatched decoders, by adding suitable amounts and types of noise to the decoder input.
3. Related Issues
3.1. Relation to Decomposition-Based Methods
Many measures of different types have been developed to assess how different response features of the neural code interact with each other. Some are based on direct comparisons between the information encoded by individual features, or collections of features (see for example [48,49,50], to cite just a few among many). Others distinguish between two or more potential dynamical models of brain activity [51], for example, by differentiating between conditional and unconditional correlations between neurons in the frequency domain [52]. Yet others, rely on decompositions or projections based on information geometry. In those, the mutual information between stimuli and responses is broken down as , where represents the information contributed by the individual response feature , and the remaining terms incorporate the synergy or redundancy between them. In the original approaches [53,54,55,56,57], the terms represented the information encoded in single response aspects irrespective of what be encoded in other aspects. In later studies, [58,59,60,61,62], these terms accounted for the information that is only encoded in individual aspects, taking care of excluding whatever be redundant with other aspects. The approach discussed in this paper is in the line of the studies Nirenberg et al. [8] and Schneidman et al. [9] and all their consequences. This line has some similarities and some discrepancies with the decomposition-based studies. We here comment on some of these relations.
- -
- First, the measure quantifies the relevance of a given feature with the difference . When the surrogate response is equal to the original response with just a single component eliminated, is equal to , where is the collection of all response aspects except . In this case, coincides with the sum of the unique and the synergistic contributions of the dual decompositions in the newest set of methods [63].
- -
- Second, when assessing the relevance of a given response feature, we are often inclined to draw conclusions about the cost of ignoring the tested feature when aiming to decode the original stimulus. As shown in this paper, those conclusions depend not only on how stimuli are encoded, but also, on how they are decoded. The decomposition-based methods are mainly focused in the encoding problem, so they are less suited to draw conclusions about decoding.
- -
- Finally, as discussed in Figure 8, not only the amount of (encoded or decoded) information matters, but also, what type. Decomposition-based methods, although not yet reaching a full consensus in their formulation, provide a valuable attempt to characterize how both the type and the amount of information is structured within the set of analyzed variables, in a way that is complementary to the present approach, specifically in analyzing the structure of the lattices obtained by associating different response features [58,63].
3.2. The Problem of Limited Sampling
Throughout the paper we assumed that the distribution is known, or is accessible to the experimenter. In the examples, when we calculated information values, we plugged the true distributions into the formulas, without discussing the fact that such distribution may not be easily estimated with finite amounts of data. Whichever method is used to estimate , to a larger or lesser degree, the outcome is no more than an approximation. Hence, even (which is supposed to be the full information) is estimated approximately. Since is a modified version of , also can only be estimated approximately. Information measures, including Kullback-Leibler divergences, are highly sensitive to variations in the involved probabilities [20,32,64,65,66,67,68,69], and the latter are unavoidable in high-dimensional response spaces. The assessment of the relevance of a given feature, hence, requires experiments that contain sufficient samples so as to ensure that the correcting methods work. When the response space is large, the measures , and the loss of accuracies are less sensitive to limited sampling than , and .
In addition, the problem of finite sampling can also be formulated as an attempt to determine the relevance of the feature “Accuracy in the estimation of ”. This feature is not a property of the nervous system, but rather, of our ability to characterise it. Still, the framework developed here can also handle this methodological problem. The estimated distribution can be interpreted as a stochastic modification of the true distribution . As long as the caveats discussed in this paper are taken into account, the measures of Equations (21)–(29) may serve to evaluate the cost of modeling out of finite amounts of data.
4. Conclusions
Several measures have been proposed in the literature to assess the relevance of specific response features in the neural code. All proposals are based on the idea that by removing the tested feature from the response, the neural code deteriorates, and the lost information is a useful measure of the relevance of the feature. In this paper, we demonstrated that the neural code may or may not deteriorate when removing a response feature, depending on the nature of the tested feature, and on the method of removal, in ways previously unseen. First, we determined the conditions under which the data processing inequality can be invoked. Second, we showed that decoding-oriented measures may result in larger or smaller losses than their encoding (or gray) counterparts, even for response aspects that, unlike noise correlations, can be modeled as stimulus-independent transformations of the full response. Third, we demonstrated that both types of measures coincide under the conditions of Theorem 5. Fourth, we showed that evaluating the role of a response feature in the neural code involves not only an assessment of its contribution to the amount of encoded information, but also, to the meaning of that information. Such meaning is as dependent as the amount on the measure employed to assess it. Finally, our results open up the possibility that simple and cheap decoding strategies, based on the addition of an adequate type and amount of noise, be more efficient and resilient than previously thought. We conclude that the assessment of the relevance of a specific response feature cannot be performed without a careful justification for the selection of a specific method of removal.
Author Contributions
Conceptualization, methodology, software, validation, formal analysis, investigation, writing, visualization: H.G.E. Formal analysis, resources, writing, editing: I.S.
Funding
This work was supported by the Ella and Georg Ehrnrooth Foundation, Consejo Nacional de Investigaciones Científicas y Técnicas of Argentina (06/C444), Universidad Nacional de Cuyo (PIP 0256), and Agencia Nacional de Promoción Científica y Tecnológica (grant PICT Raíces 2016 1004).
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
Appendix A. On the Information and Accuracy Differences
Each value in Table 1 (except for those associated with Figure 3b; see below) was computed using the Nelder-Mead simplex algorithm for optimization, as implemented by the function fminsearch of Matlab 2016. For accuracy reasons, only examples in which and were considered. Furthermore, parameters defining the joint stimulus-response probabilities and the transition matrices were restricted to the interval . Each difference between two measures defined in Equations (21)–(29) was computed repeatedly, with random initial values for the stimulus-response probabilities and the transition matrices, until the value of the difference failed to increase or decrease in 20 consecutive runs.
The values in Table 1 for Figure 3b were computed analytically with or , but not both. In those cases, the measures , , and are undefined, whereas , for the reasons given in Section 2.4. However, and can vary between and , for example, attaining when , and when and . The information equals the stimulus entropy, regardless of the response probabilities. The values in Table 1 for Figure 3d were computed by setting in Equation (16). The values in Section 2.4 for Figure 7b were obtained by setting for the stimulus-response pairs shown in the figure, and are valid for any transition probability matrix set as in Equation (32) with . The values in Section 2.4 for Figure 8 were obtained by setting for the stimulus-response pairs shown in the figure.
Appendix B. Proofs
Appendix B.1. Derivation of Equation (30)
The definition of involves the probability defined in [11,36,38] as proportional to , where the exponent is chosen so as to maximize . This definition has been recently shown to be invalid when such that for a stimulus s or a response for which [17]. This problem never appears when evaluating the relevance of noise correlations with as stated by Equation (17). Yet, it may well appear in more general cases, including those arising from stochastically reduced codes. To overcome it, we prove the theorem
Theorem A1.
The probability that appears in the definition of is
Proof.
According to Latham and Nirenberg [11], the probability is the one that minimizes the Kullback-Leibler divergence with respect to the distribution , subject to the constraints
The minimization problem can be formulated in terms of an objective function to be minimized, in which the constraints appear with Lagrange multipliers, and is the one accompanying Equation (A1). Using the standard conventions that and for , Equation (A1) is fulfilled if such that if . The first part of the theorem immediately follows by solving Equation (B15) in [11] as there indicated with . If such that , then Equation (A1) is fulfilled only if when . The second and third parts of the theorem immediately follows using Bayes’ rule. □
Appendix B.2. Proof of Theorem 1
Proof.
The second part is proved by the two examples in Figure 4. The first part was proved in [9], at least for cases in which the set of the surrogate responses differ from the set of the real responses . When they both coincide, we can prove the first part by contradiction, assuming that a deterministic mapping exists from into . If both variables sample the same response space, the deterministic mapping must be one-to-one, otherwise the variable would sample a smaller set. Therefore, both and maximize the conditional entropy given S over the probability distributions with the same marginals, since one-to-one mappings do not modify the entropy, and is defined as the distribution with maximal conditional entropy with fixed marginals. Because the probability distribution achieving this maximum is unique [16], and must be the same, thereby proving the theorem. □
Appendix B.3. Proof of Theorem 2
Proof.
We prove the dependency on the marginal likelihoods by computing for the hypothetical experiment of Figure 4a, and observing that the result depends on the marginal likelihood . To that end, we rewrite Equation (10) for as
Note that and . Using this and rearranging the terms, we obtain the quadratic equation
that is solved by
where . Hence, any change in must be followed by some change in , thereby proving the first part.
We prove the dependency on the noise correlations by computing for the hypothetical experiment of Figure 5, and observing that the result not only depends on the marginal likelihoods and , but in many cases, it also depends on the joint distributions . Hence, varying the amount of noise correlations, even if keeping the marginals fixed, yields a variation in the mapping .
We proceed by reductio ad absurdum. If does not depend on the amount of noise correlations in , we may assume that if we vary but keep the marginals fixed, the transition probabilities remain unchanged. Under this hypothesis, Equation (10) is valid for many choices of . In this context, consider the set of all response distributions with the same marginals as that can be turned into through . This set includes , and therefore, should be able to transform into itself. In addition, Property 2 requires that when because either or for those responses. Normalization yields . Furthermore, computing Equation (10) for yields
which shows that when . Consequently, the resulting yields through Equation (10) that . After noticing that
and that
we can show that, after some straightforward algebra, Equation (10) only holds if for all . Thus, the initial hypothesis yields a transition matrix that is unable to transform into when is noise correlated, and thus necessarily depends on the amount of noise correlations in . □
Appendix B.4. Proof of Theorem 3
Proof.
The condition implies that
However,
Hence, Equation (A3) becomes
In addition, when evaluating the relevance of noise correlations, as established by Equation (17). Hence,
Replacing Equations (A5) and (A6) in Equation (A4),
Summing in s, and rearranging,
If instead of an equality, we start with an inequality, that same inequality can be kept all through the proof. □
Appendix B.5. Proof of Theorem 4
Proof.
Consider a neural code and recall that the range of includes that of . Therefore, implies that the minimum in Eqution (26) is attained when . In that case, Equation (B13a) in [11] yields
After some more algebra and recalling that the Kullback-Leibler divergence is never negative, this equation becomes , implying that when read isolatedly, single responses contain no information about the stimulus. Consequently , thereby proving the “only if” part. For the “if” part, it is sufficient to notice that the last equality implies that . □
Appendix B.6. Proof of Theorem 5
Proof.
The conditions on f and ensure that can be written as a block-diagonal matrix, each block composed of the same rows with no zeros, and that each block can be associated with a non-overlapping partition of the range of f. Under these conditions, when . Hence, for , , yielding and . Recomputing Equations (21)–(29) with these equalities in mind immediately yields the equalities in the theorem.
Even when the amount of information is equal, differences in the type of information may arise because the measures are based on different decoding strategies, here denoted and . However, under the conditions of the theorem, decoding strategy and decoding strategy are one and the same. Because , both decoding strategies choose s only based on the partition of or , respectively. Mathematically, both choose s according to
where denotes the mapping from into , which is the same regardless of whether is or . Because maps each partition onto itself, the responses within each partition of is completely generated by the responses in each partition of , and thus the decoding strategies are applied to the same set of . Hence, both decoding strategies are defined and operate in the same manner, yielding the same information. □
Appendix C. On the Computation of ΔID
The information loss caused by mismatched decoders (decoding strategy ) when has previously been computed as but with replaced by [10,12,13]. The latter represents the probability of s given that takes the value , thereby limiting f to deterministic mappings. However, the probabilities and are not equivalent, since
These two definitions raise the question of which alternative is the appropriate one when computing the information loss caused by mismatched decoders.
To resolve this question, notice that replacing with in Equation (6) yields the decoding algorithm
This algorithm entails first transforming the observed into , and then choosing the stimulus with a matched probability. Hence, its operation is analogous to the decoding algorithm , and not, as originally intended, to the decoding algorithm .
To illustrate the difference, recall the experiment in Figure 7a and suppose that the observed response is . The decoding algorithm reads this value, computes , and decodes . Instead, the decoding algorithm proposed in [10,12,13], first transforms the value of into , then computes , and finally decodes . This mode of operation corresponds to the decoding algorithm .
The above discrepancy can also be seen from the change in the operational meaning of caused by the replacement. To that end, recall that was first introduced as a comparison between the average number of binary questions required to identify s after observing when using two optimal question-asking strategies, one tailored for and the other for [8]. Mathematically, this difference can be written as
In each term, the argument of the logarithms is determined by the question-asking strategy, whereas the weight of the averages is determined by the probability distribution of the variables on which the strategy is applied [8,10,16]. Equation (A7) describes the decoding strategy .
Replacing with turns Equation (A7) into
Unlike , this difference compares the average number of binary questions required to identify s after observing using a question-asking strategy that is optimal for , with the average number of binary questions required to identify s after observing using the a question-asking strategy that is optimal for . This is the way the decoding strategy operates, not .
Naively, one may think that a change in , regardless of its size, may turn the measure , typically regarded as an encoding-oriented measure and here linked to the decoding algorithm , into the decoding-oriented measure . However, notice that this change cannot occur through the equations above due to the change induced in . For that to actually occur, one must write differently, as for example:
In this reformulation, the second term can be interpreted as the average number of binary questions required to identify s after observing using a question-asking strategy that is optimal for , but only after converting into . Any change in immediately renders a mismatched probability for , and makes the second term represent the average number of binary questions required to identify s after observing using the question-asking strategy that is optimal for an altered version of but only after converting into , which need not resemble the meaning of the second term in .
References
- Adrian, E.D. The impulses produced by sensory nerve endings. J. Physiol. 1926, 61, 49–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 173–180. [Google Scholar] [CrossRef]
- Thorpe, S.; Fize, D.; Marlot, C. Speed of processing in the human visual system. Nature 1996, 6582, 520–522. [Google Scholar] [CrossRef] [PubMed]
- Abeles, M. Corticonix: Neural Circuits of the Cerebral Cortex; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Gray, C.M.; König, P.; Engel, A.K.; Singer, W. Oscillatory responses in cat visual cortex exhibit inter-columnar synchronization which reflects global stimulus properties. Nature 1989, 6213, 334–337. [Google Scholar] [CrossRef] [PubMed]
- Franke, F.; Fiscella, M.; Sevelev, M.; Roska, B.; Hierlemann, A.; da Silveira, R.A. Structures of Neural Correlation and How They Favor Coding. Neuron 2016, 89, 409–422. [Google Scholar] [CrossRef] [PubMed]
- O’Keefe, J. Hippocampues, theta, and spatial memory. Curr. Opin. Neurobiol. 1993, 6, 917–924. [Google Scholar] [CrossRef]
- Nirenberg, S.; Carcieri, S.M.; Jacobs, A.L.; Latham, P.E. Retinal ganglion cells act largely as independent encoders. Nature 2001, 411, 698–701. [Google Scholar] [CrossRef] [PubMed]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, redundancy, and independence in population codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [CrossRef] [PubMed]
- Nirenberg, S.; Latham, P.E. Decoding neuronal spike trains: How important are correlations? Proc. Natl. Acad. Sci. USA 2003, 100, 7348–7353. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Latham, P.E.; Nirenberg, S. Synergy, redundancy, and independence in population codes, revisited. J. Neurosci. 2005, 25, 5195–5206. [Google Scholar] [CrossRef] [PubMed]
- Quiroga, R.Q.; Panzeri, S. Extracting information from neuronal populations: Information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef] [PubMed]
- Latham, P.E.; Roudi, Y. Role of correlations in population coding. In Principles of Neural Coding; Panzeri, S., Quian Quiroga, R., Eds.; CRC Press: Boca Raton, FL, USA, 2013; Chapter 7; pp. 121–138. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Duxbury, MA, USA, 2002. [Google Scholar]
- Panzeri, S.; Brunel, N.; Logothetis, N.K.; Kayser, C. Sensory neural codes using multiplexed temporal scales. Trends Neurosci. 2010, 33, 111–120. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Eyherabide, H.G.; Samengo, I. When and why noise correlations are important in neural decoding. J. Neurosci. 2013, 33, 17921–17936. [Google Scholar] [CrossRef] [PubMed]
- Knill, D.C.; Pouget, A. The Bayesian brain: The role of uncertainty in neural coding and computation. Trends Neurosci. 2004, 27, 712–719. [Google Scholar] [CrossRef] [PubMed]
- Van Bergen, R.S.; Ma, W.J.; Pratte, M.S.; Jehee, J.F.M. Sensory uncertainty decoded from visual cortex predicts behavior. Nat. Neurosci. 2015, 18, 1728–1730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ince, R.A.A.; Senatore, R.; Arabzadeh, E.; Montani, F.; Diamond, M.E.; Panzeri, S. Information-theoretic methods for studying population codes. Neural Netw. 2010, 23, 713–727. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reinagel, P.; Reid, R.C. Temporal coding of visual information in the thalamus. J. Neurosci. 2000, 20, 5392–5400. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Petersen, R.S.; Schultz, S.R.; Lebedev, M.; Diamond, M.E. The Role of Spike Timing in the Coding of Stimulus Location in Rat Somatosensory Cortex. Neuron 2001, 29, 769–777. [Google Scholar] [CrossRef] [Green Version]
- Rokem, A.; Watzl, S.; Gollisch, T.; Stemmler, M.; Herz, A.V.M.; Samengo, I. Spike-timing precision underlies the coding efficiency of auditory receptor neurons. J. Neurophysiol. 2006, 95, 2541–2552. [Google Scholar] [CrossRef] [PubMed]
- Lefebvre, J.L.; Zhang, Y.; Meister, M.; Wang, X.; Sanes, J.R. γ-Protocadherins regulate neuronal survival but are dispensable for circuit formation in retina. Development 2008, 135, 4141–4151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Victor, J.D.; Purpura, K.P. Nature and precision of temporal coding in visual cortex: A metric-space analysis. J. Neurophysiol. 1996, 76, 1310–1326. [Google Scholar] [CrossRef] [PubMed]
- Victor, J.D. Spike train metrics. Curr. Opin. Neurobiol. 2005, 15, 585–592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Fano, R.M. Transmission of Information; The MIT Press: Cambridge, MA, USA, 1961. [Google Scholar]
- DeWeese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Eyherabide, H.G.; Samengo, I. Time and category information in pattern-based codes. Front. Comput. Neurosci. 2010, 4, 145. [Google Scholar] [CrossRef] [PubMed]
- Eckhorn, R.; Pöpel, B. Rigorous and extended application of information theory to the afferent visual system of the cat. I. Basic concepts. Kybernetik 1974, 16, 191–200. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Treves, A. Analytical estimates of limited sampling biases in different information measures. Network 1996, 7, 87–107. [Google Scholar] [CrossRef] [PubMed]
- Eyherabide, H.G. Disambiguating the role of noise correlations when decoding neural populations together. arXiv, 2016; arXiv:1608.05501. [Google Scholar]
- MacKay, D.M.; McCulloch, W.S. The limiting information capacity of a neuronal link. Bull. Math. Biophys. 1952, 14, 127–135. [Google Scholar] [CrossRef]
- Fitzhugh, R. The statistical detection of threshold signals in the retina. J. Gen. Physiol. 1957, 40, 925–948. [Google Scholar] [CrossRef] [PubMed]
- Merhav, N.; Kaplan, G.; Lapidoth, A.; Shamai Shitz, S. On information rates for mismatched decoders. IEEE Trans. Inf. Theory 1994, 40, 1953–1967. [Google Scholar] [CrossRef]
- Oizumi, M.; Ishii, T.; Ishibashi, K.; Hosoya, T.; Okada, M. A general framework for investigating how far the decoding process in the brain can be simplified. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2009; pp. 1225–1232. [Google Scholar]
- Oizumi, M.; Ishii, T.; Ishibashi, K.; Hosoya, T.; Okada, M. Mismatched decoding in the brain. J. Neurosci. 2010, 30, 4815–4826. [Google Scholar] [CrossRef] [PubMed]
- Oizumi, M.; Amari, S.I.; Yanagawa, T.; Fujii, N.; Tsuchiya, N. Measuring Integrated Information from the Decoding Perspective. PLoS Comput. Biol. 2016, 12, e1004654. [Google Scholar] [CrossRef] [PubMed]
- Gochin, P.M.; Colombo, M.; Dorfman, G.A.; Gerstein, G.L.; Gross, C.G. Neural ensemble coding in inferior temporal cortex. J. Neurophysiol. 1994, 71, 2325–2337. [Google Scholar] [CrossRef] [PubMed]
- Warland, D.K.; Reinagel, P.; Meister, M. Decoding visual information from a population of retinal ganglion cells. J. Neurophysiol. 1997, 78, 2336–2350. [Google Scholar] [CrossRef] [PubMed]
- Optican, L.M.; Richmond, B.J. Temporal encoding of two-dimensional patterns by single units in primate inferior temporal cortex. III. Information theoretic analysis. J. Neurophysiol. 1987, 57, 162–178. [Google Scholar] [CrossRef] [PubMed]
- Salinas, E.; Abbott, L.F. Transfer of coded information from sensory neurons to motor networks. J. Neurosci. 1995, 10, 6461–6476. [Google Scholar] [CrossRef]
- Geisler, W.S. Sequential ideal-observer analysis of visual discriminations. Psychol. Rev. 1989, 96, 267–314. [Google Scholar] [CrossRef] [PubMed]
- Högnäs, G.; Mukherjea, A. Probability Measures on Semigroups: Convolution Products, Random Walks and Random Matrices, 2nd ed.; Springer: New York, NY, USA, 2011. [Google Scholar]
- Samengo, I.; Treves, A. The information loss in an optimal maximum likelihood decoding. Neural Comput. 2002, 14, 771–779. [Google Scholar] [CrossRef] [PubMed]
- Shamir, M. Emerging principles of population coding: In search for the neural code. Curr. Opin. Neurobiol. 2014, 25, 140–148. [Google Scholar] [CrossRef] [PubMed]
- Gawne, T.J.; Richmond, B.J. How independent are the messages carried by adjacent inferior temporal cortical neurons? J. Neurosci. 1993, 13, 2758–2771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gollisch, T.; Meister, M. Rapid Neural Coding in the Retina with Relative Spike Latencies. Science 2008, 5866, 1108–1111. [Google Scholar] [CrossRef] [PubMed]
- Reifenstein, E.T.; Kemptner, R.; Schreiber, S.; Stemmler, M.B.; Herz, A.V.M. Grid cells in rat entorhinal cortex encode physical space with independent firing fields and phase precession at the single-trial level. Proc. Natl. Acad. Sci. USA 2012, 109, 6301–6306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, H.J.; Friston, K. Nonlinear multivariate analysis of neurophysiological signals. Science 2013, 6158, 1238411. [Google Scholar] [CrossRef] [PubMed]
- Dahlhaus, R.; Eichler, M.; Sandkühler, J. Identification of synaptic connections in neural ensembles by graphical models. J. Neurosci. Methods 1997, 77, 93–107. [Google Scholar] [CrossRef] [Green Version]
- Panzeri, S.; Schultz, S.R.; Treves, A.; Rolls, E.T. Correlations and the encoding of information in the nervous system. Proc. R. Soc. B Biol. Sci. 1999, 266, 1001–1012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schultz, S.R.; Panzeri, S. Temporal Correlations and Neural Spike Train Entropy. Phys. Rev. Lett. 2001, 25, 5823–5826. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Schultz, S.R. A Unified Approach to the Study of Temporal, Correlational, and Rate Coding. Neural Comput. 2001, 13, 1311–1349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pola, G.; Thiele, A.; Hoffmann, K.P.; Panzeri, S. An exact method to quantify the information transmitted by different mechanisms of correlational coding. Network 2003, 14, 35–60. [Google Scholar] [CrossRef] [PubMed]
- Hernández, D.G.; Zanette, D.H.; Samengo, I. Information-theoretical analysis of the statistical dependencies between three variables: Applications to written language. Phys. Rev. E. 2015, 92, 022813. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate Measure of Redundant Information. Phys. Rev. E. 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Prokopenko, M., Ed.; Springer: New York, NY, USA, 2014; Chapter 6; pp. 159–190. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Ince, R.A.A. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Wolf, D.R. Estimating functions of probability distributions from a finite set of samples. Phys. Rev. E. 1996, 52, 6841–6973. [Google Scholar] [CrossRef]
- Samengo, I. Estimating probabilities from experimental frequencies. Phys. Rev. E 2002, 65, 046124. [Google Scholar] [CrossRef] [PubMed]
- Nemenman, I.; Bialek, W.; de Ruyter van Steveninck, R. Entropy and information in neural spike trains: Progress on the sampling problem. Phys. Rev. E. 2004, 69, 056111. [Google Scholar] [CrossRef] [PubMed]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 6, 1191–1253. [Google Scholar] [CrossRef]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the sampling bias problem in spike train information measures. J. Neurophysiol. 2007, 98, 1064–1072. [Google Scholar] [CrossRef] [PubMed]
- Montemurro, M.A.; Senatore, R.; Panzeri, S. Tight data-robust bounds to mutual information combining shuffling and model selection techniques. Neural Comput. 2007, 11, 2913–2957. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Assessing the relevance of response accuracy by varying the duration of the temporal bin. (a) Hypothetical intracellular recording of the spike patterns elicited by a single neuron after presenting in alternation two visual stimuli, □ and ◯, each of which triggers two possible responses displayed in columns 1 and 3 for □, and 2 and 4 for ◯. Stimulus probabilities and conditional response probabilities are arbitrary. Time is discretized in bins of 5 ms. The responses are recorded within 30 ms time-windows after stimulus onset. Spikes are fired with latencies that are uniformly distributed between 0 and 10 ms after the onset of □, and between 20 and 30 ms after the onset of ◯. Responses are represented by counting the number of spikes within consecutive time-bins of size 5, 10 and 15 ms starting from stimulus onset, thereby yielding discrete-time sequences , and , respectively; (b) Same as a, but with stimuli producing two different types of response patterns composed of 2 or 3 spikes.
Figure 1.
Assessing the relevance of response accuracy by varying the duration of the temporal bin. (a) Hypothetical intracellular recording of the spike patterns elicited by a single neuron after presenting in alternation two visual stimuli, □ and ◯, each of which triggers two possible responses displayed in columns 1 and 3 for □, and 2 and 4 for ◯. Stimulus probabilities and conditional response probabilities are arbitrary. Time is discretized in bins of 5 ms. The responses are recorded within 30 ms time-windows after stimulus onset. Spikes are fired with latencies that are uniformly distributed between 0 and 10 ms after the onset of □, and between 20 and 30 ms after the onset of ◯. Responses are represented by counting the number of spikes within consecutive time-bins of size 5, 10 and 15 ms starting from stimulus onset, thereby yielding discrete-time sequences , and , respectively; (b) Same as a, but with stimuli producing two different types of response patterns composed of 2 or 3 spikes.

Figure 2.
Examples of stochastic codes. Alternative ways of assessing the relevance of spike-timing precision. (a) Stochastic function (arrows on the left) modeling the encoding process. The elicited response is turned into a surrogate response with a transition probability given by Equation (11). This function turns into a stochastic representation by shuffling spikes and silences within bins of starting from stimulus onset; (b) Responses in panel (a) are transformed by a stochastic function with given by Equation (12), which introduces jitter uniformly distributed within windows centered at each spike; (c) Responses in panel (a) are transformed by a stochastic function with given by Equation (13), which models the inability to distinguish responses with spikes occurring in adjacent bins, or equivalently, with distances or (see [25,26] for further remarks on these distances). Notice that samples the same response set as .
Figure 2.
Examples of stochastic codes. Alternative ways of assessing the relevance of spike-timing precision. (a) Stochastic function (arrows on the left) modeling the encoding process. The elicited response is turned into a surrogate response with a transition probability given by Equation (11). This function turns into a stochastic representation by shuffling spikes and silences within bins of starting from stimulus onset; (b) Responses in panel (a) are transformed by a stochastic function with given by Equation (12), which introduces jitter uniformly distributed within windows centered at each spike; (c) Responses in panel (a) are transformed by a stochastic function with given by Equation (13), which models the inability to distinguish responses with spikes occurring in adjacent bins, or equivalently, with distances or (see [25,26] for further remarks on these distances). Notice that samples the same response set as .

Figure 3.
Stochastically reduced representations include and generalize deterministically reduced representations. (a) Analogous description to Figure 1a, but with responses characterized using a representation based on the first-spike latency (L) and the spike-count (C); (b) Deterministic transformation (arrows) of in panel a into a reduced code , which ignores the additional information carried in C by considering it constant and equal to unity. This reduced code can also be reinterpreted as a stochastic code with transition probabilities defined by Equation (14); (c) The additional information carried in C is here ignored by shuffling the values of C across all trails with the same L, thereby turning in panel a into a stochastic code with transition probabilities defined by Equation (15); (d) The additional information carried in C is here ignored by replacing the actual value of C for one chosen with some possibly L-dependent probability distribution (Equation (16)).
Figure 3.
Stochastically reduced representations include and generalize deterministically reduced representations. (a) Analogous description to Figure 1a, but with responses characterized using a representation based on the first-spike latency (L) and the spike-count (C); (b) Deterministic transformation (arrows) of in panel a into a reduced code , which ignores the additional information carried in C by considering it constant and equal to unity. This reduced code can also be reinterpreted as a stochastic code with transition probabilities defined by Equation (14); (c) The additional information carried in C is here ignored by shuffling the values of C across all trails with the same L, thereby turning in panel a into a stochastic code with transition probabilities defined by Equation (15); (d) The additional information carried in C is here ignored by replacing the actual value of C for one chosen with some possibly L-dependent probability distribution (Equation (16)).

Figure 4.
Relation between probabilistic removal and stochastic codes. (a) Cartesian coordinates depicting: on the left, responses of a neuron for which L and C are positively correlated when elicited by ◯, and negatively correlated when elicited by □; in the middle, the surrogate responses that would occur should L and C be noise independent (middle); and on the right, a stimulus-independent stochastic function that turns into with given by Equation (19); (b) Same description as in (a), but with L and C noise independent given □, and with the stochastic function depicted on the right turning into given ◯ but not □.
Figure 4.
Relation between probabilistic removal and stochastic codes. (a) Cartesian coordinates depicting: on the left, responses of a neuron for which L and C are positively correlated when elicited by ◯, and negatively correlated when elicited by □; in the middle, the surrogate responses that would occur should L and C be noise independent (middle); and on the right, a stimulus-independent stochastic function that turns into with given by Equation (19); (b) Same description as in (a), but with L and C noise independent given □, and with the stochastic function depicted on the right turning into given ◯ but not □.

Figure 5.
Stochastically reduced representations that ignore noise correlations may depend on them.(a) Cartesian coordinates representing a hypothetical experiment in which two different stimuli, □ and ◯, elicit single neuron responses () that are completely characterized by their first-spike latency (L) and spike counts (C). Both L and C are noise independent; (b) Cartesian coordinates representing a hypothetical experiment with the same marginal probabilities and as in panel (a), with one among many possible types of noise correlations between L and C; (c) Stimulus-independent stochastic function transforming the noise-correlated responses of panel (b) into the noise-independent responses of panel (a). The transition probabilities are given in Equation (20), and they bear an explicit dependence on the amount of noise correlations.
Figure 5.
Stochastically reduced representations that ignore noise correlations may depend on them.(a) Cartesian coordinates representing a hypothetical experiment in which two different stimuli, □ and ◯, elicit single neuron responses () that are completely characterized by their first-spike latency (L) and spike counts (C). Both L and C are noise independent; (b) Cartesian coordinates representing a hypothetical experiment with the same marginal probabilities and as in panel (a), with one among many possible types of noise correlations between L and C; (c) Stimulus-independent stochastic function transforming the noise-correlated responses of panel (b) into the noise-independent responses of panel (a). The transition probabilities are given in Equation (20), and they bear an explicit dependence on the amount of noise correlations.

Figure 6.
Relations between the measures defined in Equations (21)–(29). The four measures on the left are either encoding-oriented (, on a pink background), or half-way between encoding- and decoding-oriented (the last three, gray background). The five measures on the right are all decoding-oriented (light-blue background). Each measure on the left has a conceptually related measure on the right on the same line, except for , which has two associated decoding-oriented measures: and . The distinction between the measures on pink and on gray background relies on the fact that does not involve a decoding process. Instead, and decode a stimulus (or rank the stimuli) with decoding method . This decoding is not meant to be applicable to real experiments, since (as opposed to the truly decoding-oriented measures on the right, that operate with method ) the decoding is applied to the surrogate responses , not the real ones .
Figure 6.
Relations between the measures defined in Equations (21)–(29). The four measures on the left are either encoding-oriented (, on a pink background), or half-way between encoding- and decoding-oriented (the last three, gray background). The five measures on the right are all decoding-oriented (light-blue background). Each measure on the left has a conceptually related measure on the right on the same line, except for , which has two associated decoding-oriented measures: and . The distinction between the measures on pink and on gray background relies on the fact that does not involve a decoding process. Instead, and decode a stimulus (or rank the stimuli) with decoding method . This decoding is not meant to be applicable to real experiments, since (as opposed to the truly decoding-oriented measures on the right, that operate with method ) the decoding is applied to the surrogate responses , not the real ones .

Figure 7.
Stochastic codes may play different roles in encoding and decoding. (a) Hypothetical experiment with two stimuli □ and ◯, which are transformed (solid and dashed lines) into neural responses containing a single spike () fired at different phases () with respect to a cycle of 20 ms period starting at stimulus onset. The phases have been discretized in intervals of size and wrapped to the interval . The encoding process is followed by a circular phase-shift that transforms into another code with transition probabilities defined by Equation (31). The set of all coincides with the set of all ; (b) Same as (a), except that stimuli are four ( ![Entropy 20 00879 i001]() , Ⓐ,
, Ⓐ, ![Entropy 20 00879 i002]() , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
Figure 7.
Stochastic codes may play different roles in encoding and decoding. (a) Hypothetical experiment with two stimuli □ and ◯, which are transformed (solid and dashed lines) into neural responses containing a single spike () fired at different phases () with respect to a cycle of 20 ms period starting at stimulus onset. The phases have been discretized in intervals of size and wrapped to the interval . The encoding process is followed by a circular phase-shift that transforms into another code with transition probabilities defined by Equation (31). The set of all coincides with the set of all ; (b) Same as (a), except that stimuli are four ( ![Entropy 20 00879 i001]() , Ⓐ,
, Ⓐ, ![Entropy 20 00879 i002]() , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
Figure 8.
Assessing the amount and type of information encoded by. (a) Noisy data recorded in response of the compound stimulus ; (b) Quality data recorded in the case of panel (a), but without noise; (c) Stimulus-independent stochastic transformation with transition probabilities given by Equation (34), that introduces independent noise both in the latencies and in the spike counts, thereby transforming into and rendering a stochastic code; (d) Degraded data obtained by adding latency noise to the quality data; (e) Representation of the stimulus-independent stochastic transformation with transition probabilities given by Equation (35) that adds latency noise in panel (d).
Figure 8.
Assessing the amount and type of information encoded by. (a) Noisy data recorded in response of the compound stimulus ; (b) Quality data recorded in the case of panel (a), but without noise; (c) Stimulus-independent stochastic transformation with transition probabilities given by Equation (34), that introduces independent noise both in the latencies and in the spike counts, thereby transforming into and rendering a stochastic code; (d) Degraded data obtained by adding latency noise to the quality data; (e) Representation of the stimulus-independent stochastic transformation with transition probabilities given by Equation (35) that adds latency noise in panel (d).


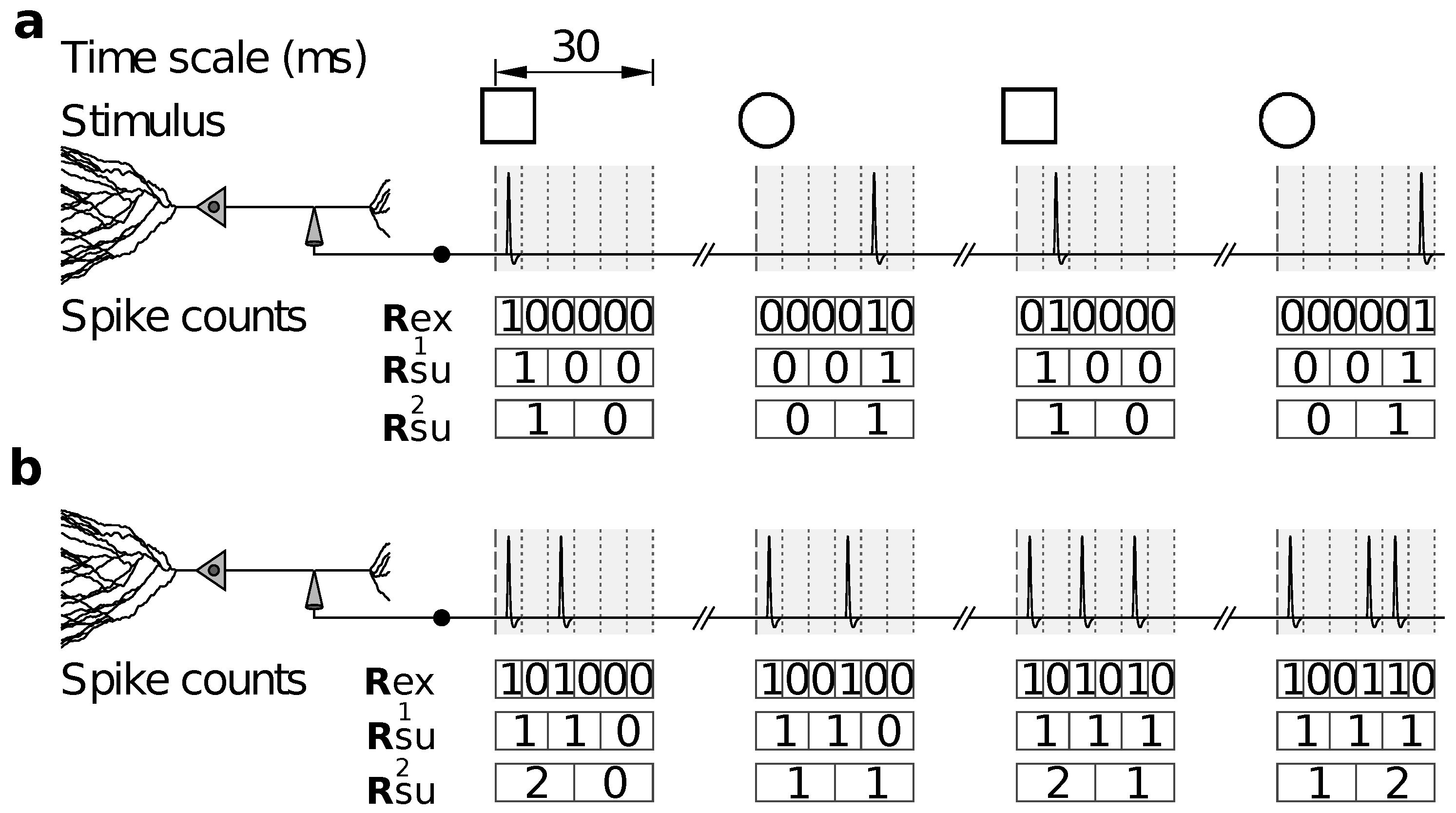{kind=link}
{kind=link}
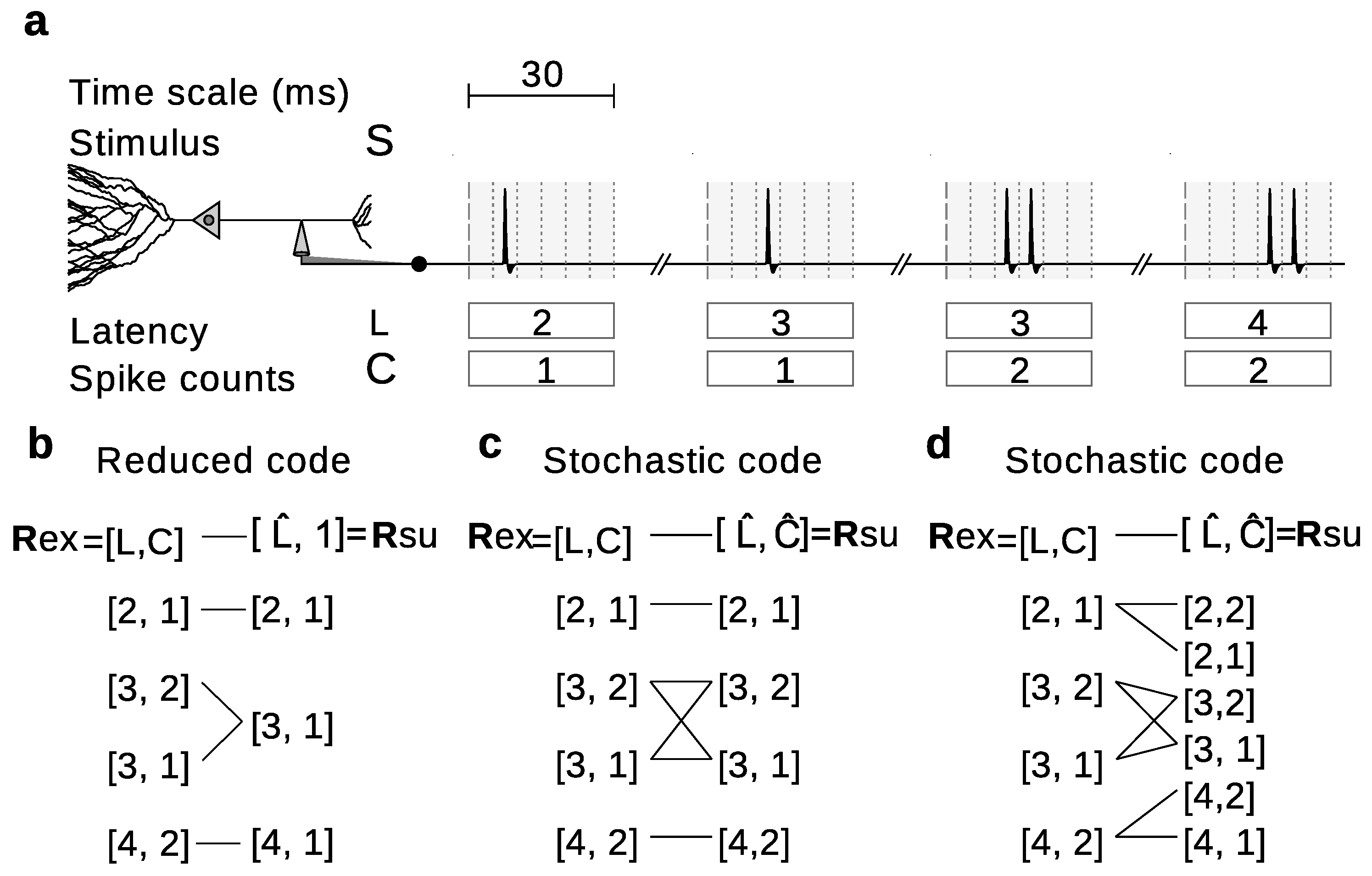{kind=link}
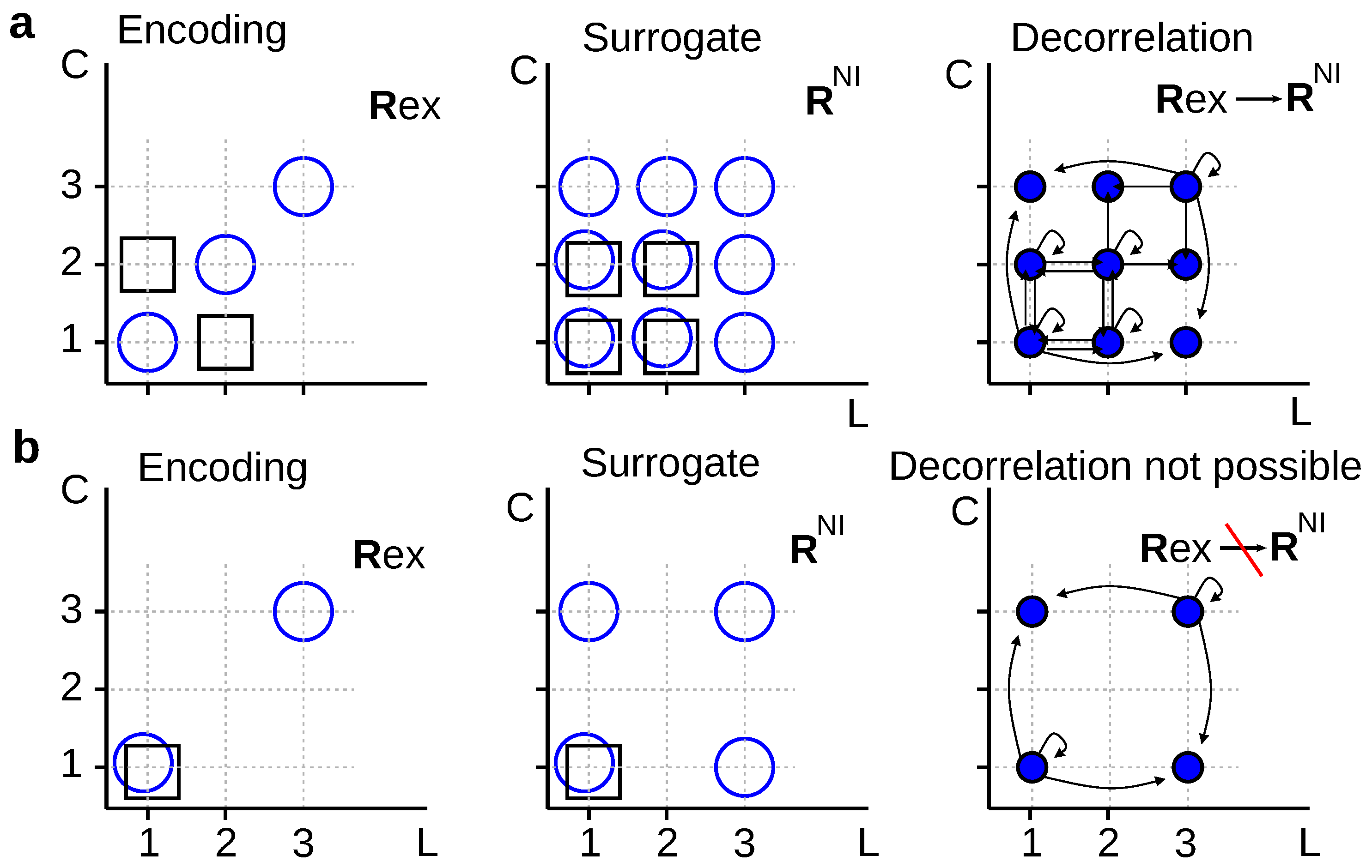{kind=link}
{kind=link}
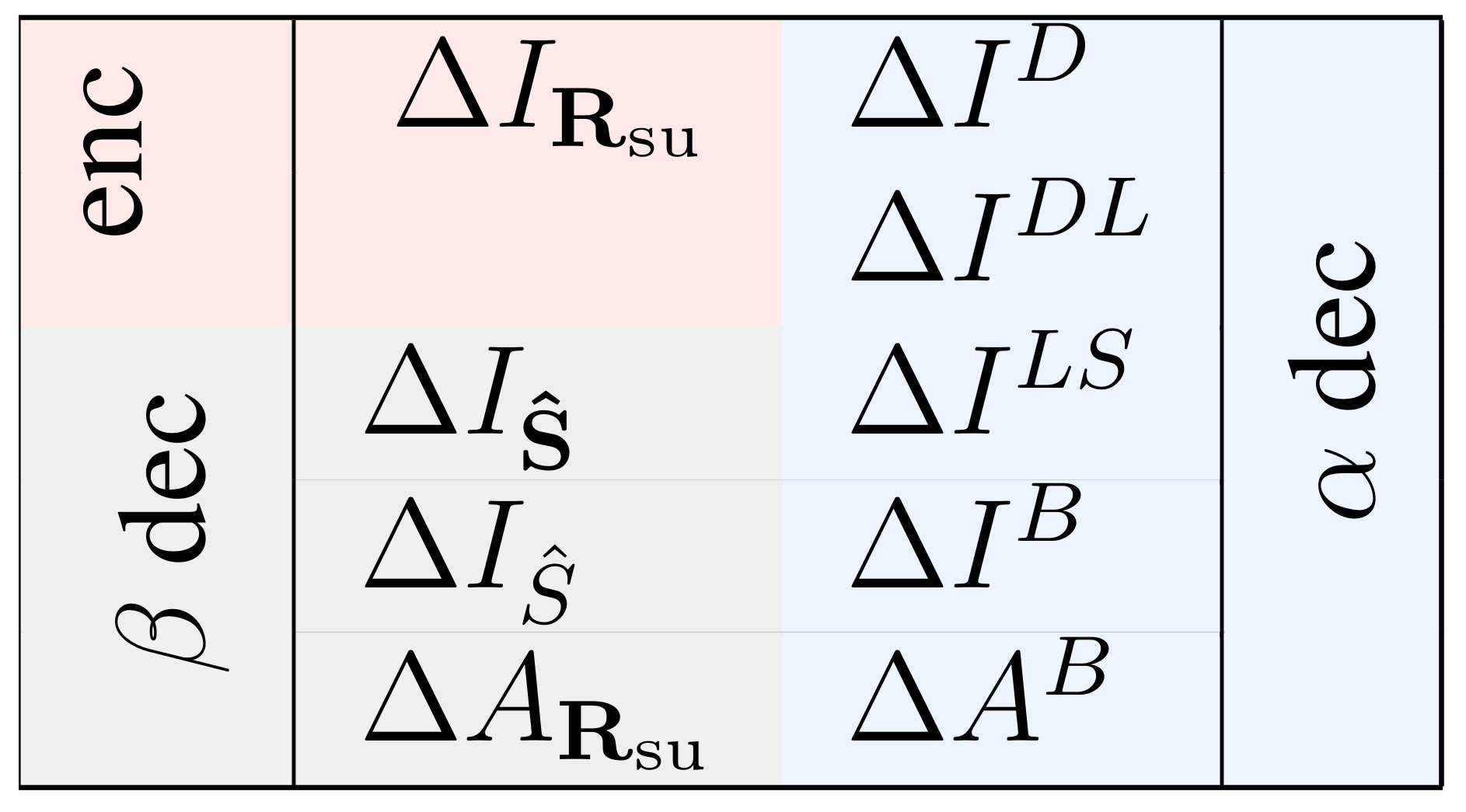{kind=link}
{kind=link}
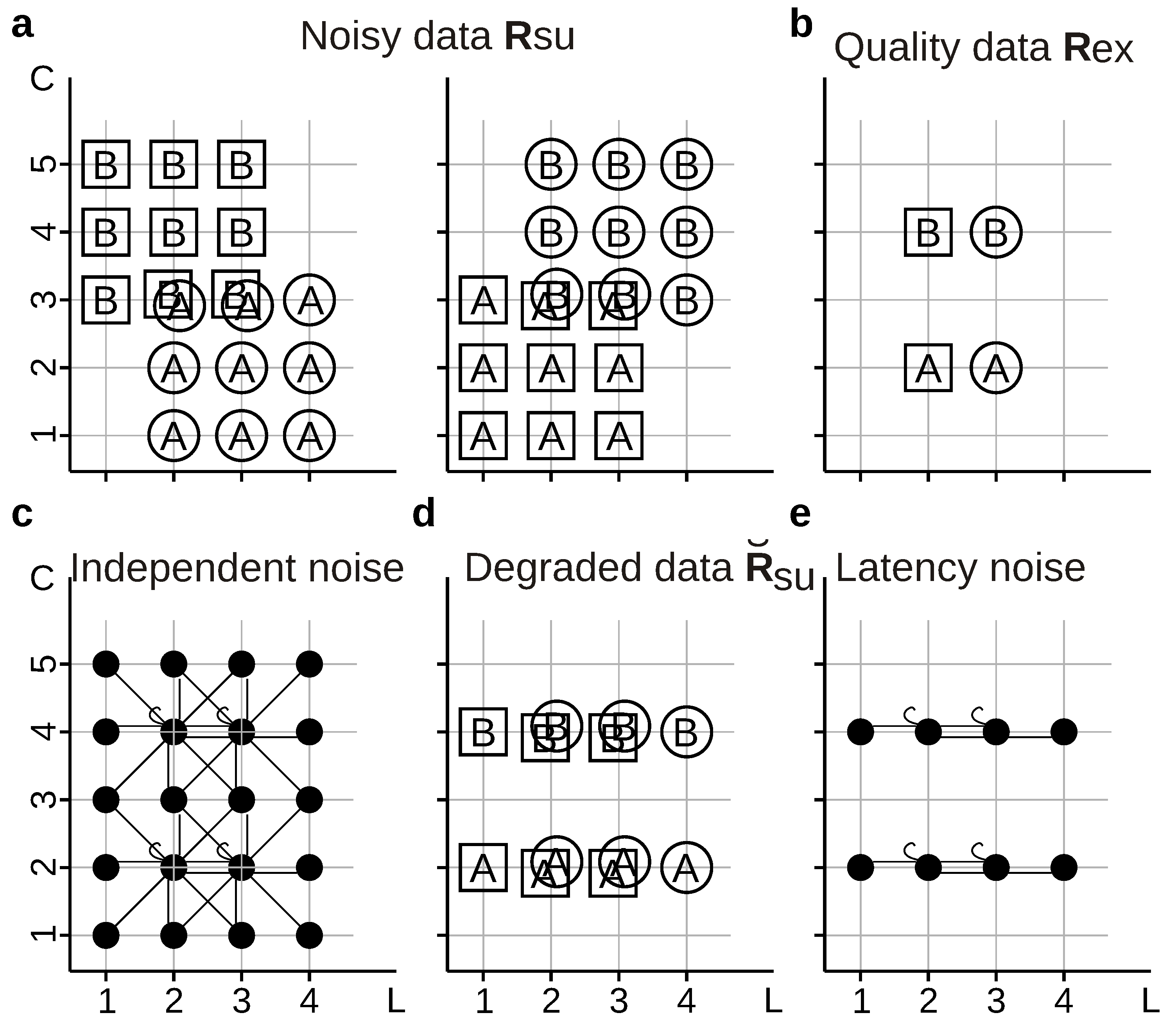{kind=link}
Table 1.
Numerical exploration of the maximum and minimum differences between several measures of information and accuracy losses. The values are expressed as percentages of (the information encoded in ) or (the maximum accuracy above chance level when decoders operate on ). All examples involve two stimuli, so and . The absolute value of can become extremely large when . Dashes represent cases in which decoding-oriented measures are undefined, as explained in Section 2.4.
Table 1.
Numerical exploration of the maximum and minimum differences between several measures of information and accuracy losses. The values are expressed as percentages of (the information encoded in ) or (the maximum accuracy above chance level when decoders operate on ). All examples involve two stimuli, so and . The absolute value of can become extremely large when . Dashes represent cases in which decoding-oriented measures are undefined, as explained in Section 2.4.
| Cases | Figure 4a | Figure 2b | Figure 2c | Figure 3d | Figure 2a | Figure 3b | Figure 7a | |
|---|---|---|---|---|---|---|---|---|
| min | −79 | −51 | −34 | 0 | 0 | — | ≤999 | |
| max | 26 | 32 | 51 | 0 | 0 | — | −20 | |
| min | −34 | −32 | −16 | 0 | 0 | −100 | −100 | |
| max | 59 | 41 | 98 | 0 | 0 | 0 | 0 | |
| min | −67 | −62 | −46 | −63 | −87 | — | −100 | |
| max | 57 | 81 | 96 | 0 | 0 | — | 0 | |
| min | −79 | −48 | −34 | 0 | 0 | — | ≤999 | |
| max | 67 | 92 | 93 | 63 | 87 | — | 70 | |
| min | −34 | −27 | −16 | 0 | 0 | −100 | −100 | |
| max | 91 | 92 | 99 | 63 | 87 | 0 | 97 | |
| min | −51 | −31 | −17 | 0 | 0 | — | −100 | |
| max | 59 | 91 | 98 | 0 | 0 | — | 100 | |
| min | −386 | −200 | −150 | 0 | 0 | — | ≤999 | |
| max | 95 | 67 | 100 | 0 | 0 | — | 0 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Eyherabide, H.G.; Samengo, I. Assessing the Relevance of Specific Response Features in the Neural Code. Entropy 2018, 20, 879. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110879
AMA Style
Eyherabide HG, Samengo I. Assessing the Relevance of Specific Response Features in the Neural Code. Entropy. 2018; 20(11):879. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110879
Chicago/Turabian StyleEyherabide, Hugo Gabriel, and Inés Samengo. 2018. "Assessing the Relevance of Specific Response Features in the Neural Code" Entropy 20, no. 11: 879. https://0-doi-org.brum.beds.ac.uk/10.3390/e20110879
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.