Classification of MRI Brain Images Using DNA Genetic Algorithms Optimized Tsallis Entropy and Support Vector Machine



Abstract
:1. Introduction
2. Feature Extraction with DWT and Tsallis Entropy
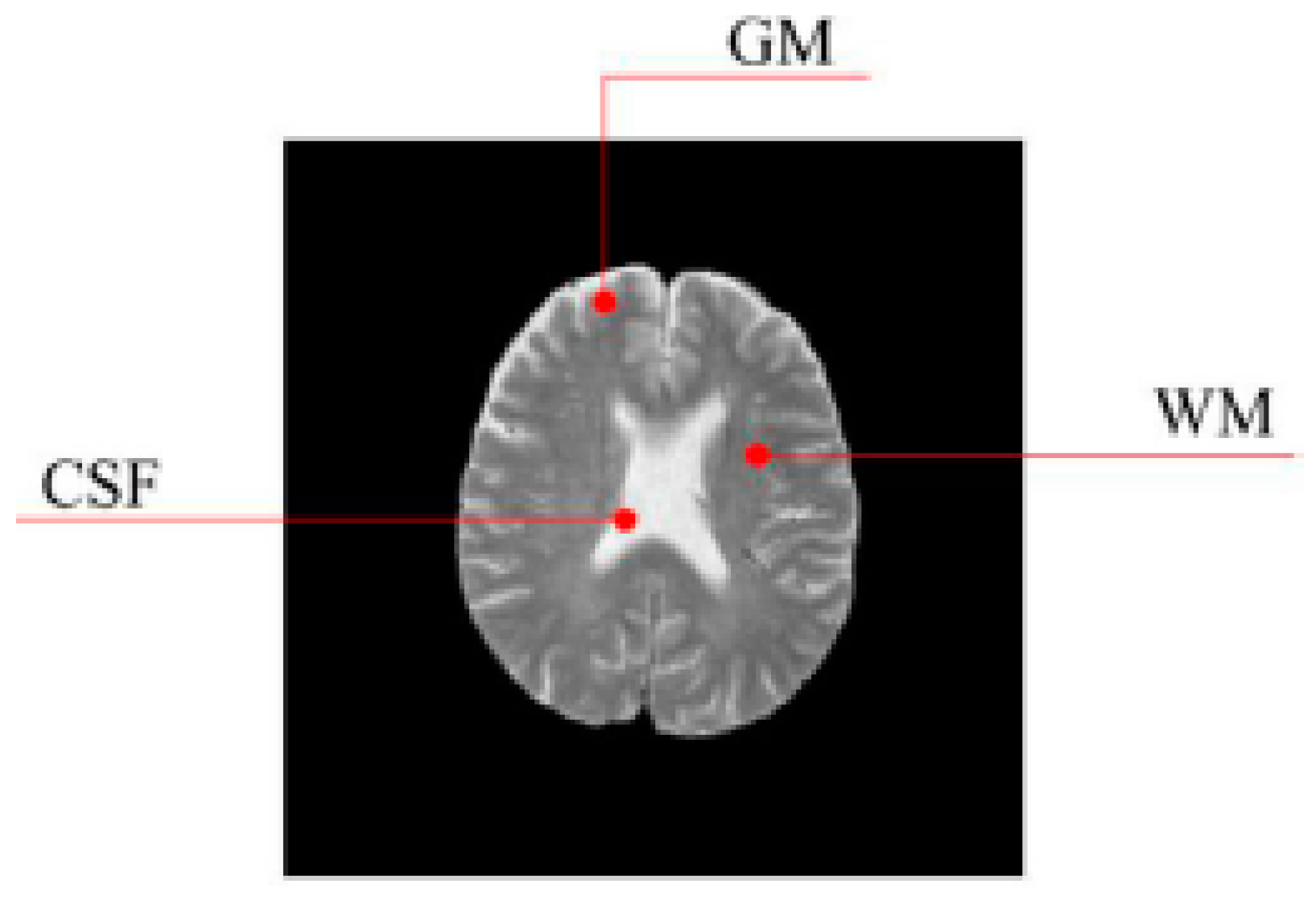
2.1. Feature Extraction
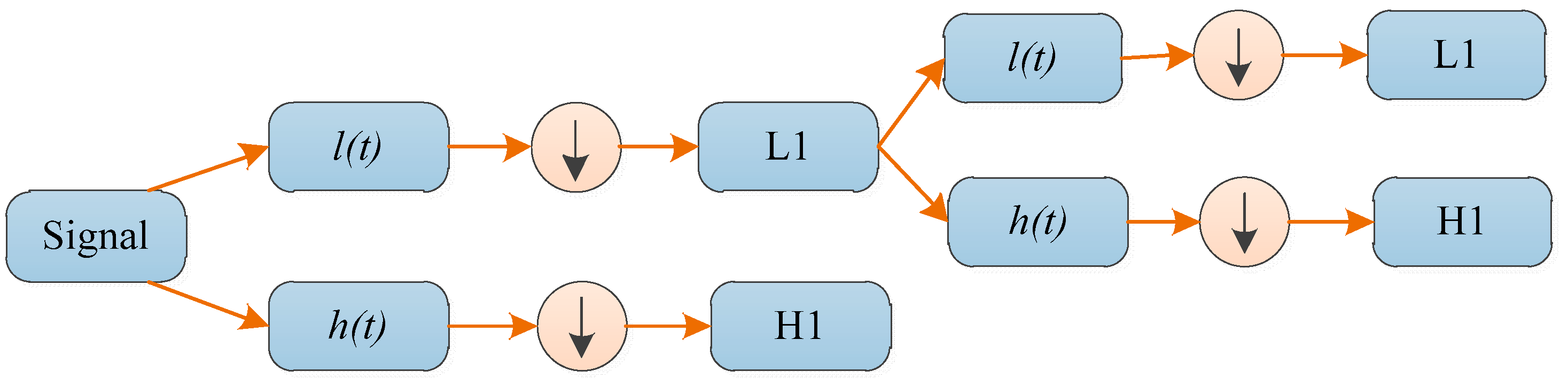
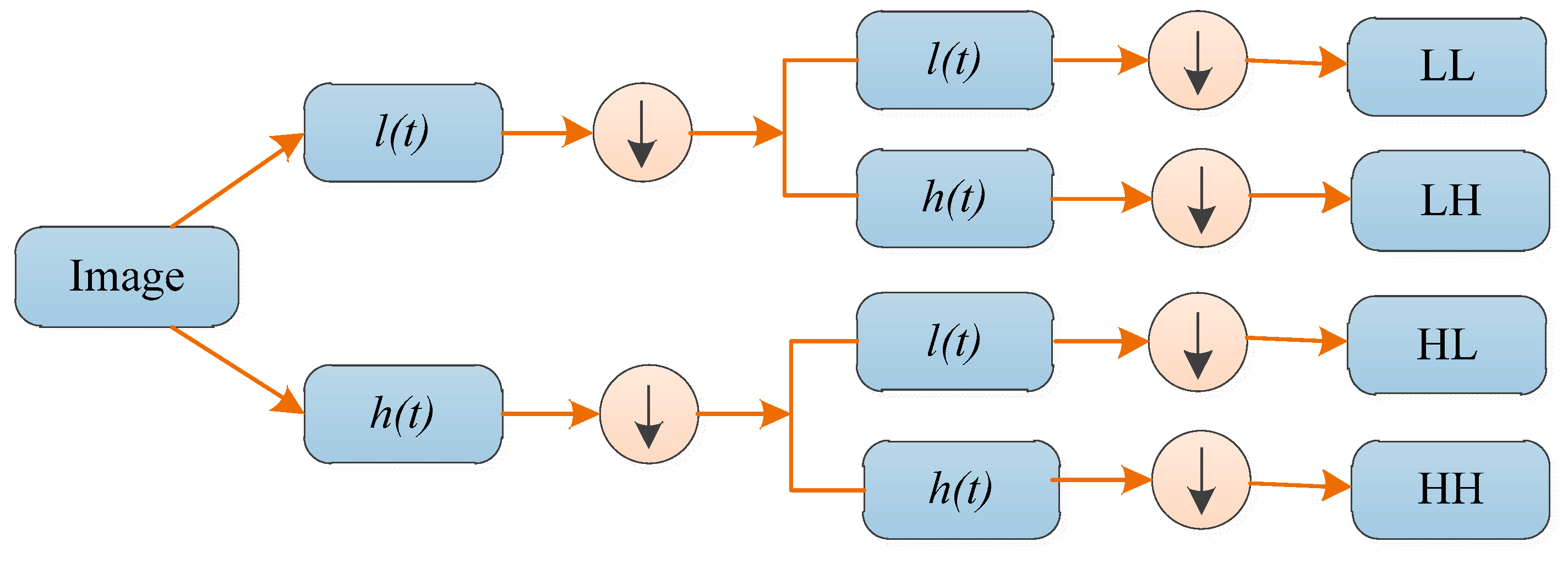
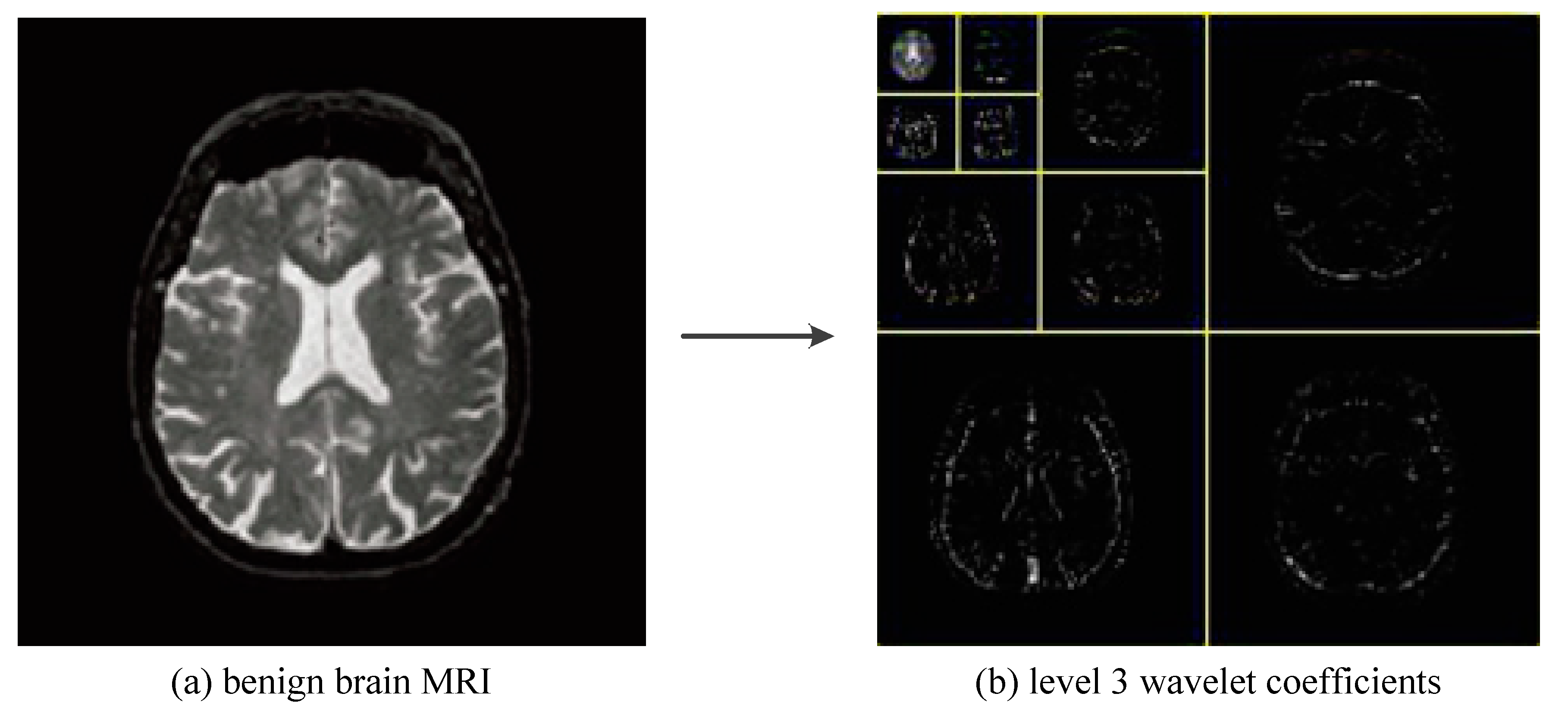
2.2. Discrete Wavelet Transform
2.3. Tsallis Entropy
3. SVMs and Parameters
3.1. Support Vector Machine
3.2. Kernel Functions
4. DNA-GA for Optimal Parameters
4.1. The Proposed Algorithm
4.2. DNA Encoding and Decoding
4.3. DNA Genetic Operators
4.3.1. The Selection Operation
4.3.2. The Crossover Operations
4.3.3. The Mutation Operations
4.4. Fitness Function
5. Experimental Study
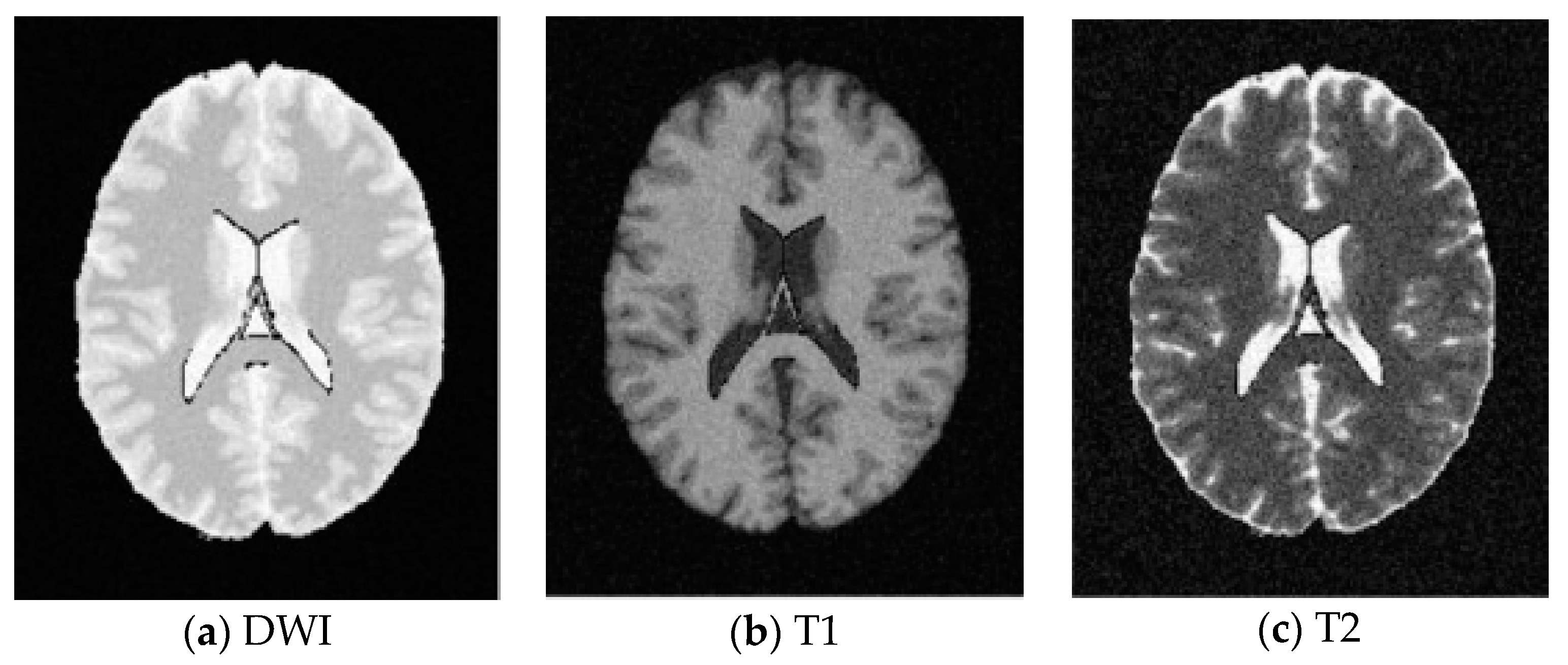
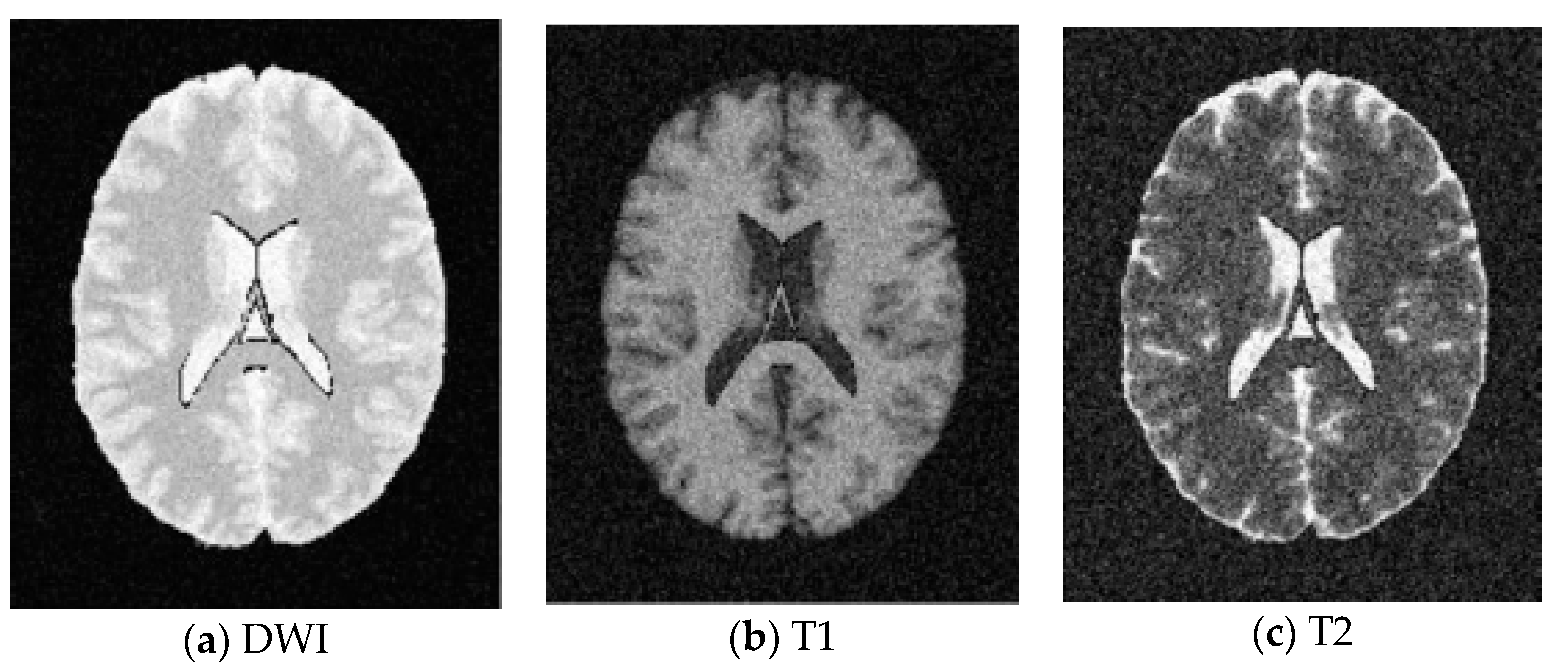
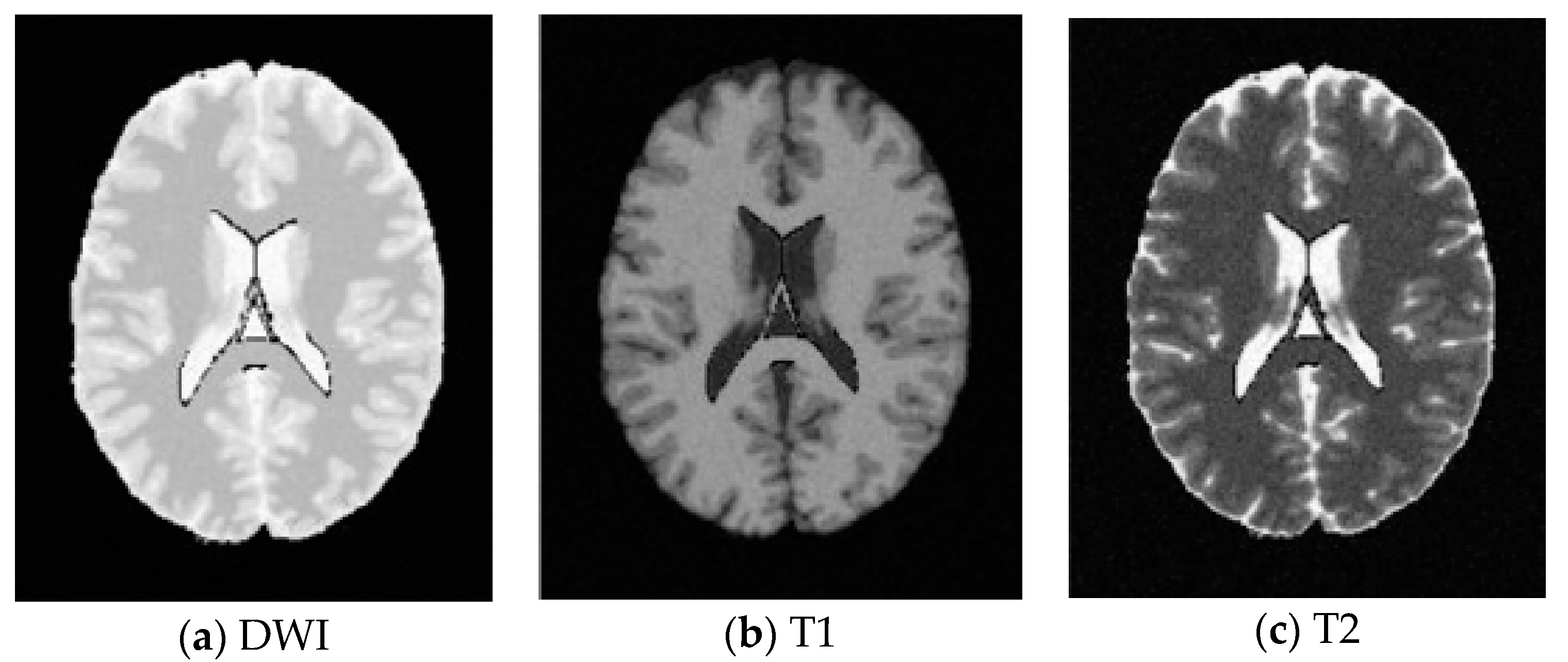
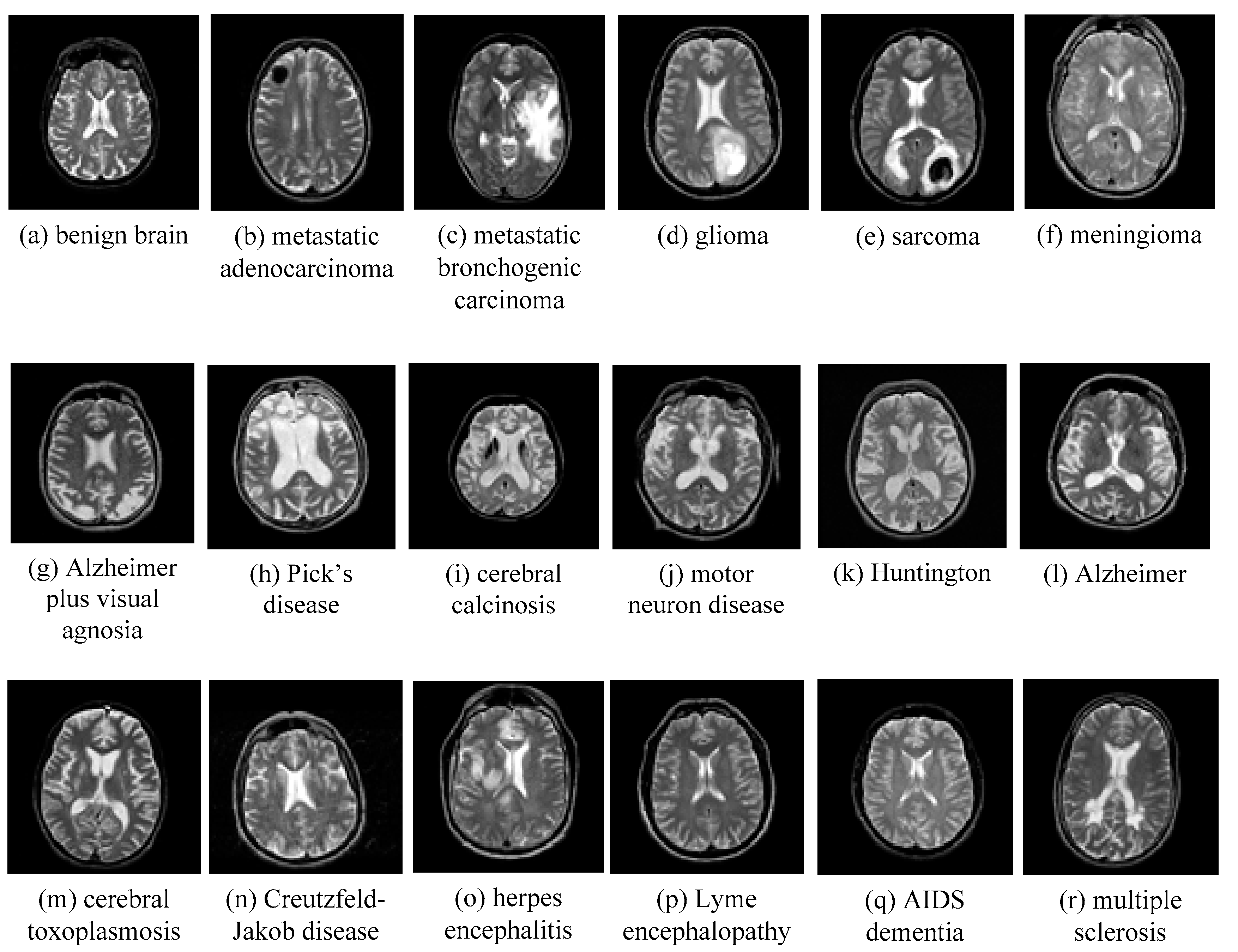
5.1. Database
5.2. Feature Extraction
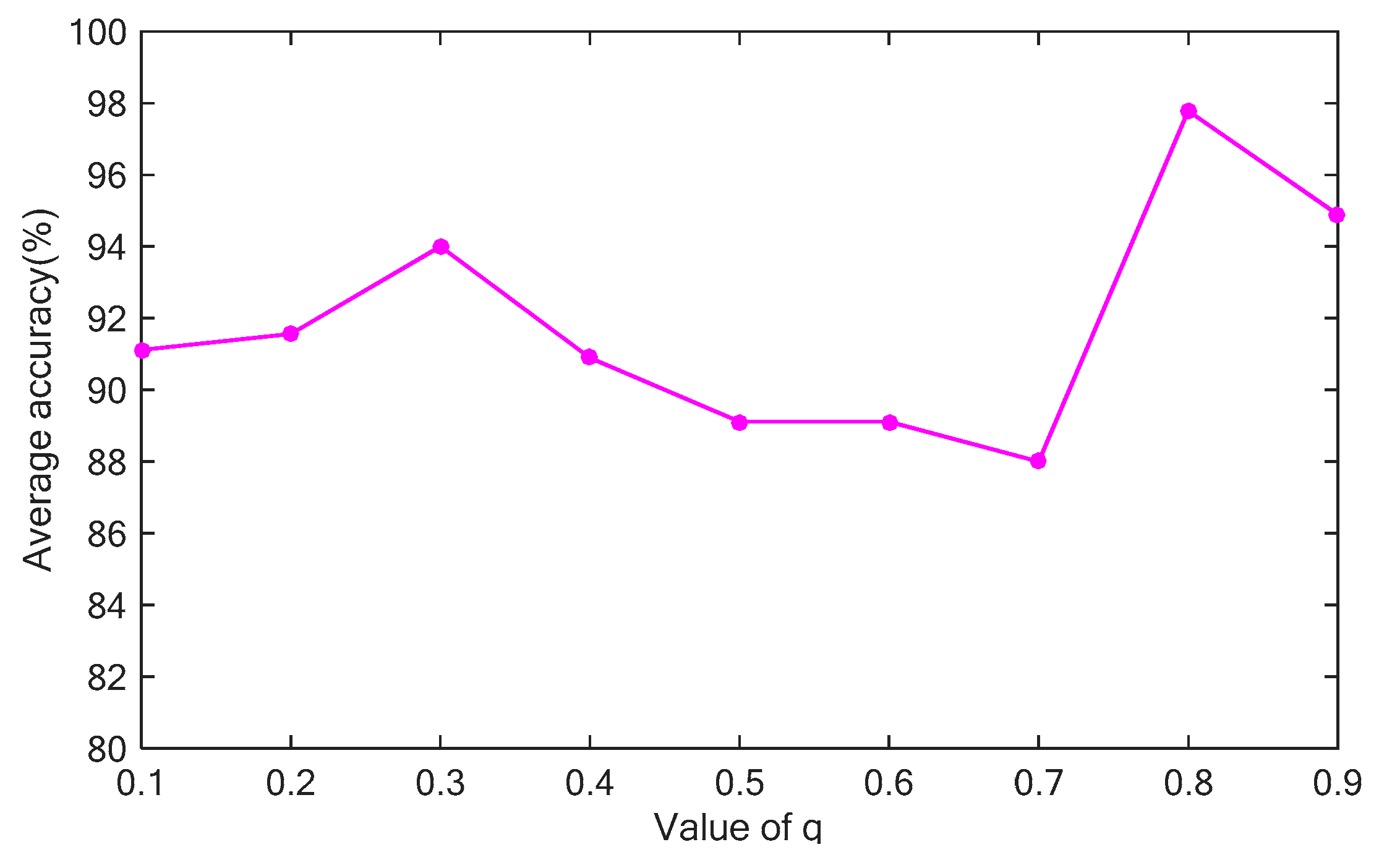
5.3. Results on SBD
5.4. Results on AANLIB
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Da Silva, A.R.F. A Dirichlet process mixture model for brain MRI tissue classification. Med. Image Anal. 2007, 11, 169–182. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Wang, W.; Wang, C.; Sun, S. Automated classification of multi-spectral MR images using linear discriminant analysis. Comput. Med. Imag. Graph. 2010, 34, 251–268. [Google Scholar] [CrossRef] [PubMed]
- Tagluk, M.E.; Akin, M.; Sezgin, N. Classification of sleep apnea by using wavelet transform and artificial neural networks. Expert Syst. Appl. 2010, 37, 1600–1607. [Google Scholar] [CrossRef]
- Zhang, Y.; Dong, Z.; Wu, L.; Wang, S. A hybrid method for MRI brain image classification. Exp. Syst. Appl. 2011, 38, 10049–10053. [Google Scholar] [CrossRef]
- Singh, B.; Singh, J. Classification of brain MRI in wavelet domain. Int. J. Electron. Comput. Sci. Eng. 2012, 1, 879–885. [Google Scholar]
- El-Dahshan, E.S.A.; Hosny, T.; Salem, A.B.M. Hybrid intelligent techniques for MRI brain images classification. Digit. Signal Process. 2010, 20, 433–441. [Google Scholar] [CrossRef]
- Chaplot, S.; Patnaik, L.M.; Jagannathan, N.R. Classification of magnetic resonance brain images using wavelets as input to support vector machine and neural network. Biomed. Signal Process. Control 2006, 1, 86–92. [Google Scholar] [CrossRef]
- Maitra, M.; Chatterjee, A. A Slantlet transform based intelligent system for magnetic resonance brain image classification. Biomed. Signal Process. Control 2006, 1, 299–306. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Gaur, A.; Yadav, S. Handwritten Hindi character recognition using k-means clustering and SVM. In Proceedings of the 2015 4th International Symposium on Emerging Trends and Technologies in Libraries and Information Services (ETTLIS), Noida, India, 6–8 January 2015; pp. 65–70. [Google Scholar]
- Nguyen, V.; Huy, H.; Tai, P.; Hung, H. Improving multi-class text classification method combined the SVM classifier with OAO and DDAG strategies. J. Converg. Inf. Technol. 2015, 10, 62–70. [Google Scholar]
- Sharma, S.; Sachdeva, K. Face recognition using PCA and SVM with surf technique—A review. Int. J. Res. Dev. Innov. 2015, 1, 138–141. [Google Scholar]
- Beebe, N.; Maddox, L.; Liu, L.; Sun, M. Sceadan: Using concatenated n-gram vectors for improved file and data type classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1519–1530. [Google Scholar] [CrossRef]
- Sonar, R.; Deshmukh, P. Multiclass classification: A review. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 65–69. [Google Scholar]
- Hable, R. Asymptotic normality of support vector machine variants and other regularized kernel methods. J. Multivar. Anal. 2012, 106, 92–117. [Google Scholar] [CrossRef]
- Hsu, C.; Chang, C.; Lin, C. A Practical Guide to Support Vector Classification. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 12 December 2018).
- Goldberg, D. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Adleman, L. Molecular computation of solution to combinatorial problems. Science 1994, 266, 1021–1024. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Ren, L.; Shao, S. DNA computation and soft computation. J. Syst. Simul. 2001, 13, 198–201. [Google Scholar]
- Dai, K.; Wang, N. A hybrid DNA based genetic algorithm for parameter estimation of dynamic systems. Chem. Eng. Res. Des. 2012, 90, 2235–2246. [Google Scholar] [CrossRef]
- Tsallis, C. Nonadditive entropy: The concept and its use. Eur. Phys. J. A 2009, 40, 257–266. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wu, L. Classification of fruits using computer vision and a multiclass support vector machine. Sensors 2012, 12, 12489–12505. [Google Scholar] [CrossRef]
- Saravanan, N.; Ramachandran, K.I. Incipient gear box fault diagnosis using discrete wavelet transform (DWT) for feature extraction and classification using artificial neural network (ANN). Exp. Syst. Appl. 2010, 37, 4168–4181. [Google Scholar] [CrossRef]
- Durak, L. Shift-invariance of short-time Fourier transform in fractional Fourier domains. J. Frankl. Inst. 2009, 346, 136–146. [Google Scholar] [CrossRef]
- Stanković, R.S.; Falkowski, B.J. The Haar wavelet transform: Its status and achievements. Comput. Electr. Eng. 2003, 29, 25–44. [Google Scholar] [CrossRef]
- Campos, D. Real and spurious contributions for the Shannon, Rényi and Tsallis entropies. Phys. A 2010, 389, 3761–3768. [Google Scholar] [CrossRef]
- Tsallis, C. The nonadditive entropy S-q and its applications in physics and elsewhere: Some Remarks. Entropy 2011, 13, 1765–1804. [Google Scholar] [CrossRef]
- Amaral-Silva, H.; Wichert-Ana, L.; Murta, L.O.; Romualdo-Suzuki, L.; Itikawa, E.; Bussato, G.F.; Azevedo-Marques, P. The superiority of Tsallis entropy over traditional cost functions for brain MRI and SPECT registration. Entropy 2014, 16, 1632–1651. [Google Scholar] [CrossRef]
- Hussain, M. Mammogram enhancement using lifting dyadic wavelet transform and normalized Tsallis entropy. J. Comput. Sci. Technol. 2014, 29, 1048–1057. [Google Scholar] [CrossRef]
- Zuo, R.; Carranza, E. Support vector machine: A tool for mapping mineral prospectively. Comput. Geosci. 2011, 37, 1967–1975. [Google Scholar] [CrossRef]
- Xiao, Y.; Wang, H.; Xu, W. Parameter selection of gaussian kernel for one-class SVM. IEEE Trans. Cybern. 2015, 45, 927–939. [Google Scholar] [PubMed]
- Blaxter, M.; Danchin, A.; Savakis, B.; Fukami-Kobayashi, K.; Kurokawa, K.; Sugano, S.; Roberts, R.J.; Salzberg, S.L.; Wu, C.-I. Reminder to deposit DNA sequences. Science 2016, 352, 780. [Google Scholar] [CrossRef] [PubMed]
- May, R.J.; Maier, H.R.; Dandy, G.C. Data splitting for artificial neural networks using SOM-based stratified sampling. Neural Netw. 2010, 23, 283–294. [Google Scholar] [CrossRef]
- Messina, A. Refinements of damage detection methods based on wavelet analysis of dynamical shapes. Int. J. Solids Struct. 2008, 45, 4068–4097. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR = 5 db | SNR = 10 db | SNR = 15 db | SNR = 20 db | |
|---|---|---|---|---|
| Average | 0.8341 | 0.937 | 0.9567 | 0.9684 |
| Best | 0.8671 | 0.948 | 0.9723 | 0.9795 |
| Worst | 0.7128 | 0.8844 | 0.8919 | 0.932 |
| Success Cases | Classification Rate (%) | ||||
|---|---|---|---|---|---|
| Random 1 | 124.71 | 0.625 | 0.1 | 410 | 91.11 |
| Random 2 | 185.13 | 1.439 | 0.2 | 412 | 91.56 |
| Random 3 | 136.2 | 1.491 | 0.3 | 423 | 94 |
| Random 4 | 176.78 | 1.595 | 0.4 | 409 | 90.89 |
| Random 5 | 160.8 | 1.836 | 0.5 | 401 | 89.11 |
| Random 6 | 137.9 | 1.973 | 0.6 | 401 | 89.11 |
| Random 7 | 87.01 | 1.654 | 0.7 | 396 | 88 |
| Random 8 DNAGA-TE+KSVM | 149.96 143.3 | 1.372 1.132 | 0.9 0.8 | 427 440 | 94.89 97.78 |
| Method | Confusion Matrix | Success Cases | Sensitivity | Specificity | Classification Accuracy |
|---|---|---|---|---|---|
| BP-NN | 374 11 51 14 | 388 | 88% | 56% | 86.22% |
| RBF-NN | 393 7 32 18 | 411 | 92.47% | 72% | 91.33% |
| DNAGA-TE+KSVM | 417 2 8 23 | 440 | 98.12% | 92% | 97.78% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, W.; Wang, Z.; Jiang, D.; Liu, X.; Jiang, Z. Classification of MRI Brain Images Using DNA Genetic Algorithms Optimized Tsallis Entropy and Support Vector Machine. Entropy 2018, 20, 964. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120964
Zang W, Wang Z, Jiang D, Liu X, Jiang Z. Classification of MRI Brain Images Using DNA Genetic Algorithms Optimized Tsallis Entropy and Support Vector Machine. Entropy. 2018; 20(12):964. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120964
Chicago/Turabian StyleZang, Wenke, Zehua Wang, Dong Jiang, Xiyu Liu, and Zhenni Jiang. 2018. "Classification of MRI Brain Images Using DNA Genetic Algorithms Optimized Tsallis Entropy and Support Vector Machine" Entropy 20, no. 12: 964. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120964