Semi-Supervised Minimum Error Entropy Principle with Distributed Method

1
School of Mathematics and Statistics, South-Central University for Nationalities, Wuhan 430074, China
2
School of Mathematics and Statistics, Wuhan University, Wuhan 430072, China
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(12), 968; https://0-doi-org.brum.beds.ac.uk/10.3390/e20120968
Submission received: 26 October 2018
/
Revised: 8 December 2018
/
Accepted: 10 December 2018
/
Published: 14 December 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:The minimum error entropy principle (MEE) is an alternative of the classical least squares for its robustness to non-Gaussian noise. This paper studies the gradient descent algorithm for MEE with a semi-supervised approach and distributed method, and shows that using the additional information of unlabeled data can enhance the learning ability of the distributed MEE algorithm. Our result proves that the mean squared error of the distributed gradient descent MEE algorithm can be minimax optimal for regression if the number of local machines increases polynomially as the total datasize.
1. Introduction
The minimum error entropy (MEE) principle is an important criterion proposed in information theoretical learning (ITL) [1] and was firstly addressed for adaptive system training by Erdogmus and Principe [2]. It has been applied to blind source separation, maximally informative subspace projections, clustering, feature selection, blind deconvolution, minimum cross-entropy for model selection, and some other topics [3,4,5,6,7,8]. Taking entropy as a measure of the error, the MEE principle can extract the information contained in data fully and produce robustness to outliers in the implementation of algorithms.
Let be an explanatory variable with values taken in a compact metric space Y be a real response variable with , and be a prediction function. For a given set of labeled examples (N denotes the sample size) and a windowing function the MEE principle is to find a minimizer of the empirical quadratic entropy:
where is the scaling parameter. Its goal is to solve the problem , where is the noise and is the target function. Taking a function MEE belongs to pairwise learning problems, which involves with the intersections of example pairs. Since logarithmic function is monotonic, we only consider the empirical information error of MEE:
in the optimization process. Borrowing the idea from Reference [9], we introduced the Mercer kernel and employed the reproducing kernel Hilbert space (RKHS) as our hypothesis space. With is defined as the linear span of the functions set which is equipped with the inner product and the reproducing property For the G nonconvex, we usually solve Equation (1) using the kernel-based gradient descent method as follows. It starts with and is updated by:
in the t-th step, where is a step size, ∇ is the gradient operator and:
as we know that the example pairs will grow quadratically with the increasing example size N, which will bring the computational burden in the MEE implementation. Thus, it is necessary to reduce the algorithmic complexity by the distributed method based on a divide-and-conquer strategy [10]. Semi-supervised learning (SSL) [11] has attracted extensive attention as an emerging field in machine learning research and data mining. Actually, in many practical problems, few data are given, but a large number of unlabeled data are available, since labeling data requires a lot of time, effort or money. In this paper, we study a distributed MEE algorithm in the framework of SSL and show that the learning ability of the MEE algorithm can be enhanced by the distributed method and the combination of labeled data with unlabeled data.
There are mainly three contributions in this paper. The first one is that we derive the explicit learning rate of the gradient descent method for distributed MEE in the context of SSL, which is comparable to the minimax optimal rate of the least squares in regression. This implies that the MEE algorithm can be an alternative of the least squares in SSL in the sense that both of them have the same prediction power. The second one is that we provide the theoretical upper bound for the number of local machines guaranteeing the optimal rate in the distributed computation. The last one is that we extend the range of the target function allowed in the distributed MEE algorithm.
In Table 1, we summarize some notations used in this paper.
2. Algorithms and Main Results
We considered MEE for the regression problem. To allow noise in sampling processes, we assumed that a Borel measure is defined on the product space Let be the conditional distribution of for any given , and the marginal distribution on For the semi-supervised MEE algorithm, our goal was to estimate the regression function , from labeled examples and unlabeled examples drawn from the distribution and , respectively.
Based on the divide-and-conquer strategy, both D and are partitioned equally into m subsets, and Here, we denote the size of subsets and , i.e., We construct a new dataset by:
where:
Based on the gradient descent algorithm (Equation (2)), we can get a set of local estimators for each subset Then, the global estimator averaging over these local estimators is given by:
In the pairwise setting, our target function which is the difference of the regression function Denote by the space of square integrable functions on the product space :
The goodness of is usually measured by the mean squared error
Throughout the paper, we assumed that and for some constant almost surely. Without generality, windowing function G is assumed to be differentiable and satisfies for and there exists some p such that and:
It is easy to check that the Gaussian kernel satisfies the assumptions above with
Before we present our main results, define an integral operator associated with the kernel K by:
Our error analysis for the distributed MEE algorithm (Equation (3)) is stated in terms of the following regularity condition:
where denotes the r-th power of on and is well defined, since the operator is positive and compact with the Mercer kernel We use the effective dimension [12,13] to measure the complexity of with respect to which is defined to be the trace of the operator as:
To obtain optimal learning rates, we need to quantify of . A suitable assumption is: that
Remark 1.
When Equation (6) always holds with For when is a Sobolev space on with all derivative of order up to then Equation (6) is satisfied with [14]. Moreover, if the eigenvalues of the operator decays as for some then The eigenvalues assumption is typical in the analysis of the performances of kernel methods estimators and recently used in References [13,15,16] to establish the optimal learning rate in the least square problems.
The following theorem shows that the distributed gradient descent algorithm (Equation (3)) can achieve the optimal rate by providing the iteration time T and the maximal number of local machines, whose proof can be found in Section 3.
Theorem 1. (Main Result)
Corollary 1.
Under the same conditions of Theorem 1, if the scaling parameter:
then for any with confidence at least :
Remark 2.
The rate in Equation (9) is optimal in the minimax sense for kernel regression problems [13]. When the result of Equation (9) shows that the kernel gradient descent MEE algorithm (Equation (2)) on a single big data set can achieve the minimax optimal rate for regression. Thus, MEE is a nice alternative of the classical least squares. Meanwhile, the upper bound (Equation (7)) for the number of local machines implies that the performance of the distributed MEE algorithm (Equation (3)) can be as good as the standard MEE algorithm (2) (acting on the whole data set ), provided that the subset ’s size is not too small.
Remark 3.
If no unlabeled data is engaged in the algorithm (Equation (3)), then and the upper bound (Equation (7)) for the number of local machines m that ensures the optimal rate is about So, when the regularity parameter r in Equation (5) is close to the upper bound reduces to a constant and then the distributed algorithm (Equation (3)) will not be feasible in real applications. A similar phenomenon is observed in various distributed algorithms [15,16,17,18]. When the size of unlabeled data we see from Equation (7) that the upper bound of m keeps growing with the increase of S when the size of labeled data N is fixed. For example, let and , then the upper bound in Equation (7) is and will not be a constant when Hence, with sufficient unlabeled data , the distributed algorithm (Equation (3)) will allow more local machines in the distributed method.
3. Proof of Main Result
In this section we prove our main results in Theorem 1. To this end, we introduce the data-free gradient descent method in for the least squares, defined as and:
Recalling the definition of , it can be written as:
Following the standard decomposition technique in leaning theory, we split the error into the sample error and the approximation error
3.1. Approximation Error
Firstly, we estimate the approximation error It has been proven in Reference [20] and shown in the lemmas as follows.
Moreover, we derive the uniform bound of the sequence by Equation (10) when , which is useful in our analysis. Here and in the sequel, denote as the polynomial operator associated with an operator L defined by and We use the conventional notation
Lemma 2.
3.2. Sample Error
Define the empirical operator by:
and for any :
In the sequel, denote:
With these preliminaries in place, we now turn to the estimates of the sample error presented in the following Lemma, whose proof can be found in the Appendix. Here and in the sequel, we use the conventional notation
Lemma 3.
Let and for any there holds:
where the constant :
and:
With the help of Lemma above, to bound the sample error we first need to estimate the quantities the quantities and Denote ( is the cardinality of D). In previous work [19,21,22,23], we have foundnd that each of the following inequality holds with confidence at least :
By Lemma 3, we also see that the function is crucial to determine To get a tight bound for the learning error, we should choose an appropriate according to the regularity of the target function. When and we take When is out of the space and we let
Now, we give the first main result when the target function is out of with
Theorem 2.
Assume Equation (5) for Let and Then, for any , with probability at least there holds:
where is a constant given in the proof,
Proof.
Decompose into:
The estimate of is presented in Lemma 1. We only need to handle by Lemma 3.
Noticing the elementary inequality then:
and:
Plugging the above inequalities into term 1 and term 2, then:
and:
where and .
Thus, for any fixed with confidence at least there holds:
and:
Therefore, with confidence at least there holds:
and:
Thus, by Equation (18), it follows that with confidence at least by scaling to , there holds:
where
Similarly, with confidence at least such that:
Next, we give the result when the target function is in with
Theorem 3.
Assume Equation (1) for Let and Then, for any , with probability at least there holds:
where and is a constant given in the proof.
The proof is similar to that of Theorem 2. Here we omit it.
With these preliminaries in place, we can prove our main result in Theorem 1.
Proof of Theorem 1.
We first prove Equation (8) by Theorem 2 when Let and . Notice that and for with and Equation (7), we obtain that:
and:
Thus:
It follows for :
Thus, by the above estimates:
Thus:
and:
Putting the above estimates into Theorem 2, we have the desired conclusion (Equation (8)) with:
When we apply Theorem 3 and take the same proof procedure a above. Then, the conclusion (Equation (8)) can be obtained. The proof is completed. □
4. Simulation and Conclusions
In this section, we provide the simulation to verify our theoretical statements. We assume that the inputs are independently drawn according to the uniform distribution on Consider the regression model , where is the independent Gaussian noise and:
Define the pairwise kernel by where:
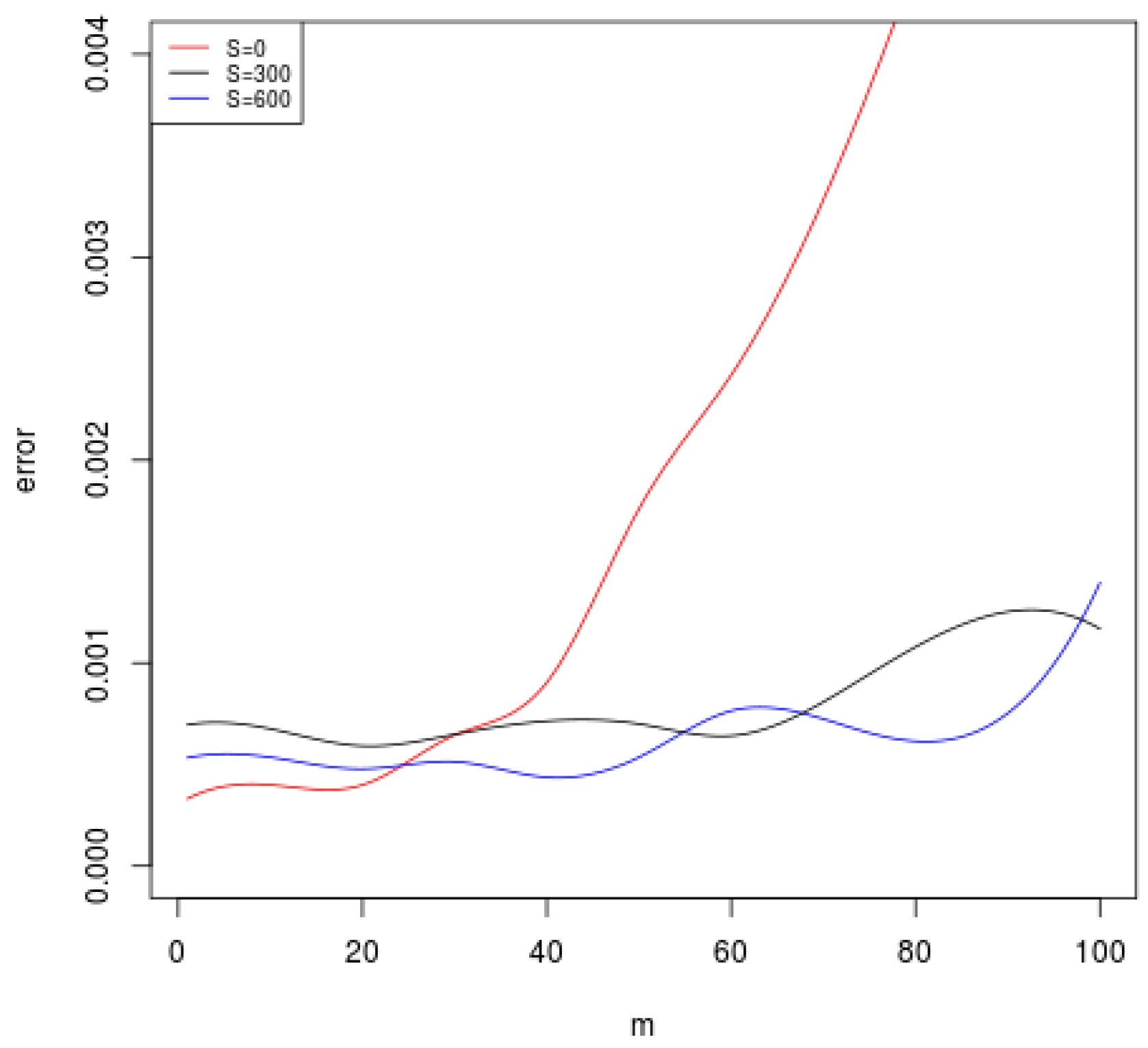
We apply the kernel K to the distributed algorithm (Equation (3)). In Figure 1, we plot the mean squared error of Equation (3) for and when the number of local machines m varies. Note that and it is a standard distributed MEE algorithm without unlabeled data. When m becomes large, the red curve increases dramatically. However, when we add 300 or 600 unlabeled data, the error curves begin to increase very slowly. This coincides with our theory that using unlabeled data can enlarge the range of m in the distributed method.
This paper studied the convergence rate of the distribute gradient descent MEE algorithm in a semi-supervised setting. Our results demonstrated that using additional unlabeled data can improve the learning performance of the distributed MEE algorithm, especially in enlarging the range of m to guarantee the learning rate. As we know, there are many gaps between theory and empirical studies. We regard this paper as mainly a theoretical paper and expect that the theoretical analysis give some guidance to real applications.
Author Contributions
B.W. conceived the presented idea. T.H. developed the theory and performed the computations. All authors discussed the results and contributed to the final manuscript.
Funding
The work described in this paper is partially supported by the National Natural Science Foundation of China [Nos. 11671307 and 11571078], the Natural Science Foundation of Hubei Province in China [No. 2017CFB523], and the Fundamental Research Funds for the Central Universities, South-Central University for Nationalities [No. CZY18033].
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemma 3
We state two useful lemmas as follows, whose proof can be found in Reference [22].
Lemma A1.
For , and , we have:
Lemma A2.
For any and there holds:
and:
where the constant
Proof of Lemma A2.
The first one is:
and the second one is:
Then, we can follow the proof procedure in Proposition 1 of Reference [24] to prove Equations (A2) and (A1). □
With the help of the lemmas above, we can prove Lemma 3.
Proof of Lemma 3.
Applying Equation (24) with for , we have that:
Firstly, we will bound which is most difficult to handle. It can be decomposed as:
Then, it is easy to get that by Lemma A1 and :
Applying Proposition A2 with and , we have that:
Thus:
By Lemma A1 again, we have:
and:
This completes the estimate of with Equations (A6), (A7), and (A8).
Now we turn to bound Then, by the definition of , the bound (Equation (A5)) of and Lemma A1, we obtain that:
and:
Together with the bound of Equations (A6), (A7), and (A8), we can get the desired conclusion (Equation (15)). □
References
- Principe, J.C. Renyi’s entropy and Kernel perspectives. In Information Theoretic Learning; Springer: New York, NY, USA, 2010. [Google Scholar]
- Erdogmus, D.; Principe, J.C. Comparison of entropy and mean square error criteria in adaptive system training using higher order statistics. In Proceedings of the International Conference on ICA and Signal Separation; Springer: Berlin, Germany, 2000; pp. 75–90. [Google Scholar]
- Erdogmus, D.; Hild, K.; Principe, J.C. Blind source separation using Renyi’s α-marginal entropies. Neurocomputing 2002, 49, 25–38. [Google Scholar] [CrossRef]
- Erdogmus, D.; Principe, J.C. Convergence properties and data efficiency of the minimum error entropy criterion in adaline training. IEEE Trans. Signal Process. 2003, 51, 1966–1978. [Google Scholar] [CrossRef]
- Gokcay, E.; Principe, J.C. Information theoretic clustering. IEEE Trans. Pattern Anal. Mach. Learn. 2002, 24, 158–171. [Google Scholar] [CrossRef]
- Silva, L.M.; Marques, J.; Alexandre, L.A. Neural network classification using Shannon’s entropy. In Proceedings of the European Symposium on Artificial Neural Networks; D-Side: Bruges, Belgium, 2005; pp. 217–222. [Google Scholar]
- Silva, L.M.; Marques, J.; Alexandre, L.A. The MEE principle in data classification: A perceptron-based analysis. Neural Comput. 2010, 22, 2698–2728. [Google Scholar] [CrossRef]
- Choe, Y. Information criterion for minimum cross-entropy model selection. arXiv, 2017; arXiv:1704.04315. [Google Scholar]
- Ying, Y.; Zhou, D.X. Online pairwise learning algorithms. Neural Comput. 2016, 28, 743–777. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Duchi, J.C.; Wainwright, M.J. Divide and conquer kernel ridge regression: A dis tributed algorithm with minimax optimal rates. J. Mach. Learn. Res. 2013, 30, 592–617. [Google Scholar]
- Chapelle, O.; Zien, A. Semi-Supervised Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Zhang, T. Learning bounds for kernel regression using effective data dimensionality. Neural Comput. 2005, 17, 2077–2098. [Google Scholar] [CrossRef] [PubMed]
- Caponnetto, A.; Vito, E.D. Optimal rates for the regularized least-squares algorithm. Found. Comput. Math. 2007, 7, 331–368. [Google Scholar] [CrossRef]
- Steinwart, I.; Hush, D.R.; Scovel, C. Optimal rates for regularized least squares regression. In Proceedings of the COLT 2009—the Conference on Learning Theory, Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]
- Lin, S.B.; Guo, X.; Zhou, D.X. Distributed learning with regularized least squares. J. Mach. Learn. Res. 2017, 18, 3202–3232. [Google Scholar]
- Guo, Z.C.; Lin, S.B.; Zhou, D.X. Learning theory of distributed spectral algorithms. Inverse Prob. 2017, 33, 074009. [Google Scholar] [CrossRef]
- Guo, Z.C.; Shi, L.; Wu, Q. Learning theory of distributed regression with bias corrected regu-larization kernel network. J. Mach. Learn. Res. 2017, 18, 4237–4261. [Google Scholar]
- M<i>u</i>¨cke, N.; Blanchard, G. Parallelizing spectrally regularized kernel algorithms. J. Mach. Learn. Res. 2018, 19, 1069–1097. [Google Scholar]
- Lin, S.B.; Zhou, D.X. Distributed kernel-based gradient descent algorithms. Constr. Approx. 2018, 47, 249–276. [Google Scholar] [CrossRef]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Chang, X.; Lin, S.B.; Zhou, D.X. Distributed semi-supervised learning with kernel ridge re-gression. J. Mach. Learn. Res. 2017, 18, 1493–1514. [Google Scholar]
- Hu, T.; Wu, Q.; Zhou, D.X. Distributed kernel gradient descent algorithm for minimum error entropy principle. Unpublished work. 2018. [Google Scholar]
- Guo, X.; Hu, T.; Wu, Q. Distributed minimum error entropy algorithms. Unpublished work. 2018. [Google Scholar]
- Wang, B.; Hu, T. Distributed pairwise algorithms with gradient descent methods. Unpublished work. 2018. [Google Scholar]
Figure 1.
The mean square errors for the size of unlabeled data as the number of local machines m varies.
Figure 1.
The mean square errors for the size of unlabeled data as the number of local machines m varies.


{kind=link}
Table 1.
List of notations used throughout the paper.
| Notation | Meaning of the Notation |
|---|---|
| X | the explanatory variable |
| Y | the response variable |
| , a compact subset of an Euclidian space | |
| , a subset of | |
| a Boreal measure on | |
| the marginal probability measure of on | |
| the conditional probability measure of given | |
| the mean regression function | |
| the target function of MEE induced by | |
| K | a reproducing kernel on |
| D | the labeled data set |
| N | the size of labeled data set D |
| the largest integer not exceeding | |
| the cardinality of | |
| the unlabeled data set | |
| S | the size of unlabeled data set |
| the cardinality of | |
| training data set used in the distributed MEE algorithm, consisting of D and | |
| the cardinality of | |
| m | the number of local machines |
| the lth subset of | |
| G | the loss function of MEE algorithm |
| the integral operator associated with K | |
| the empirical operator of on | |
| the function output by the kernel gradient descent MEE algorithm | |
| with data D and kernel K after t iterations | |
| the function output by the kernel gradient MEE algorithm | |
| with data and kernel K after t iterations | |
| the global output averaging over local outputs |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, B.; Hu, T. Semi-Supervised Minimum Error Entropy Principle with Distributed Method. Entropy 2018, 20, 968. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120968
AMA Style
Wang B, Hu T. Semi-Supervised Minimum Error Entropy Principle with Distributed Method. Entropy. 2018; 20(12):968. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120968
Chicago/Turabian StyleWang, Baobin, and Ting Hu. 2018. "Semi-Supervised Minimum Error Entropy Principle with Distributed Method" Entropy 20, no. 12: 968. https://0-doi-org.brum.beds.ac.uk/10.3390/e20120968
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.