Complexity as Causal Information Integration


1
Max Planck Institute for Mathematics in the Sciences, 04103 Leipzig, Germany
2
Faculty of Mathematics and Computer Science, University of Leipzig, PF 100920, 04009 Leipzig, Germany
3
Santa Fe Institute, Santa Fe, NM 87501, USA
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(10), 1107; https://0-doi-org.brum.beds.ac.uk/10.3390/e22101107
Submission received: 21 August 2020
/
Revised: 25 September 2020
/
Accepted: 27 September 2020
/
Published: 30 September 2020
(This article belongs to the Special Issue Entropy: The Scientific Tool of the 21st Century)
Abstract
:Complexity measures in the context of the Integrated Information Theory of consciousness try to quantify the strength of the causal connections between different neurons. This is done by minimizing the KL-divergence between a full system and one without causal cross-connections. Various measures have been proposed and compared in this setting. We will discuss a class of information geometric measures that aim at assessing the intrinsic causal cross-influences in a system. One promising candidate of these measures, denoted by , is based on conditional independence statements and does satisfy all of the properties that have been postulated as desirable. Unfortunately it does not have a graphical representation, which makes it less intuitive and difficult to analyze. We propose an alternative approach using a latent variable, which models a common exterior influence. This leads to a measure , Causal Information Integration, that satisfies all of the required conditions. Our measure can be calculated using an iterative information geometric algorithm, the em-algorithm. Therefore we are able to compare its behavior to existing integrated information measures.
1. Introduction
The theory of Integrated Information aims at quantifying the amount and quality of consciousness of a neural network. It was originally proposed by Tononi and went through various phases of evolution, starting with one of the first papers "Consciousness and Complexity" [1] in 1999 to "Consciousness as Integrated Information—a Provisional Manifesto" [2] in 2008 and Integrated Information Theory (IIT) 3.0 [3] in 2014 to ongoing research. Although important parts of the methodology of this theory changed or got extended the two key concepts determining consciousness that virtually stayed fixed are “Information” and “Integration”. Information refers to the number of different states a system can be in and Integration describes the amount to which the information is integrated among different parts of it. Tononi summarizes this idea in Reference [2] with the following sentence:
Therefore Integrated Information can be seen as a measure of the systems complexity. In this context it belongs to the class of theories that define complexity as to what extent the whole is more than the sum of its parts.In short, integrated information captures the information generated by causal interactions in the whole, over and above the information generated by the parts.
There are various ways to define a split system and the difference between them. Therefore, there exist different branches of complexity measures in the context of Integrated Information. The most recent theory, IIT 3.0 [3], goes far beyond the original measures and includes a different level of definitions corresponding to the quality of the measured consciousness, including the maximally irreducible conceptual structure (MICS) and the integrated conceptual information. In order to focus on the information geometric aspects of IIT, we follow the strategy of Oizumi et al. [4] and Amari et al. [5], restricting attention to measuring the integrated information in discrete n-dimensional stationary Markov processes from an information geometric point of view.
In detail we will measure the distance between the full and the split system using the KL-divergence as proposed in Reference [6], published in Reference [7]. This framework was further discussed in Reference [8]. Oizumi et al. [4] and Amari et al. [5] summarize these ideas and add a Markov condition and an upper bound to clarify what a complexity measure should satisfy. The Markov condition intends to model the removal of certain cross-time connections, which we call causal cross-connections. These connections are the ones that integrate information among the different nodes across different points in time. The upper bound was originally proposed in Reference [9] and is given by the mutual information, which aims at quantifying the total information flow from one timestep to the next. These conditions are defined as necessary and do not specify a measure uniquely. We will discuss the conditions in the next section.
Additionally Oizumi et al. [4] and Amari et al. [5] introduce one measure that satisfies all of these requirements. This measure is described by conditional independence statements and will be denoted here by . We will introduce along with two other existing measures, namely Stochastic Interaction [7] and Geometric Integrated Information [10]. The measure is not bounded from above by the mutual information and does not satisfy the postulated Markov condition.
Although fits perfectly in the proposed framework, this measure does not correspond to a graphical representation and it is therefore difficult to analyze the causal nature of the measured information flow. We focus on the notion of causality defined by Pearl in Reference [11], in which the correspondence between conditional independence statements and graphs, for instance DAGs or more generally chain graphs, is a key concept. Moreover, we demonstrate that it is not possible to express the conditional independence statements corresponding to using a chain graph even after adding latent variables. Following the reasoning of Pearls causality theory, however, this would be a desirable property.
The main purpose of this paper is to propose a more intuitive approach that ensures the consistency between graphical representation and conditional independence statements. This is achieved by using a latent variable that models a common exterior influence. Doing so leads to a new measure, which we call Causal Information Integration . This measure is specifically created to only measure the intrinsic causal cross-influences in a setting with an unknown exterior influence and it satisfies all the required conditions postulated by Oizumi et al. To assume the existence of an unknown exterior influence is not unreasonable, in fact one point of criticism concerning is that this measure does not account for exterior influences and therefore measures them erroneously as internal, see Section 6.9 in Reference [10]. In a setting with known external influences, these can be integrated in the model as visible variables. This leads to a model discussed in Section 2.1.1 that we call , which is an upper bound for .
We discuss the relationships between the introduced measures in Section 2.1.2 and present a way of calculating by using an iterative information geometric algorithm, the em-algorithm described in Section 2.1.3. This algorithm is guaranteed to converge to a minimum, but this might be a local minimum. Therefore we have to run the algorithm multiple times to find a global minimum. Utilizing this algorithm we are able to compare the behavior of to existing integrated information measures.
Integrated Information Measures
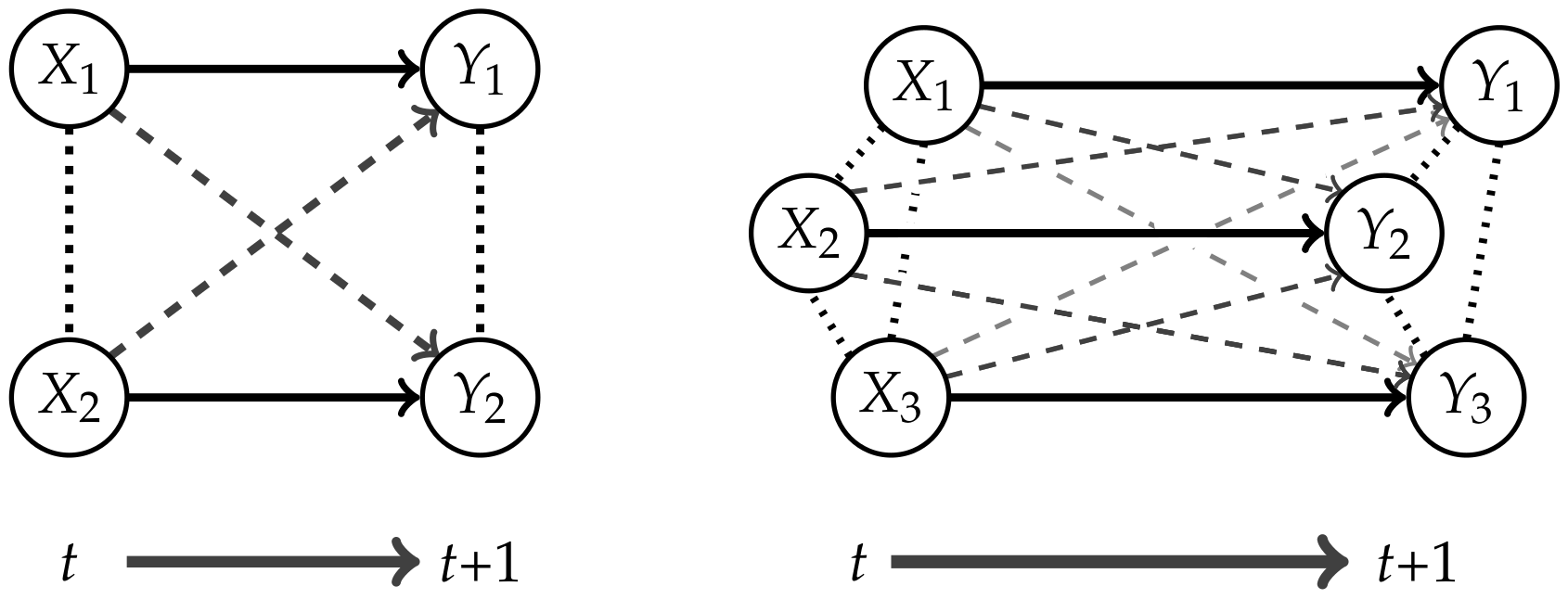
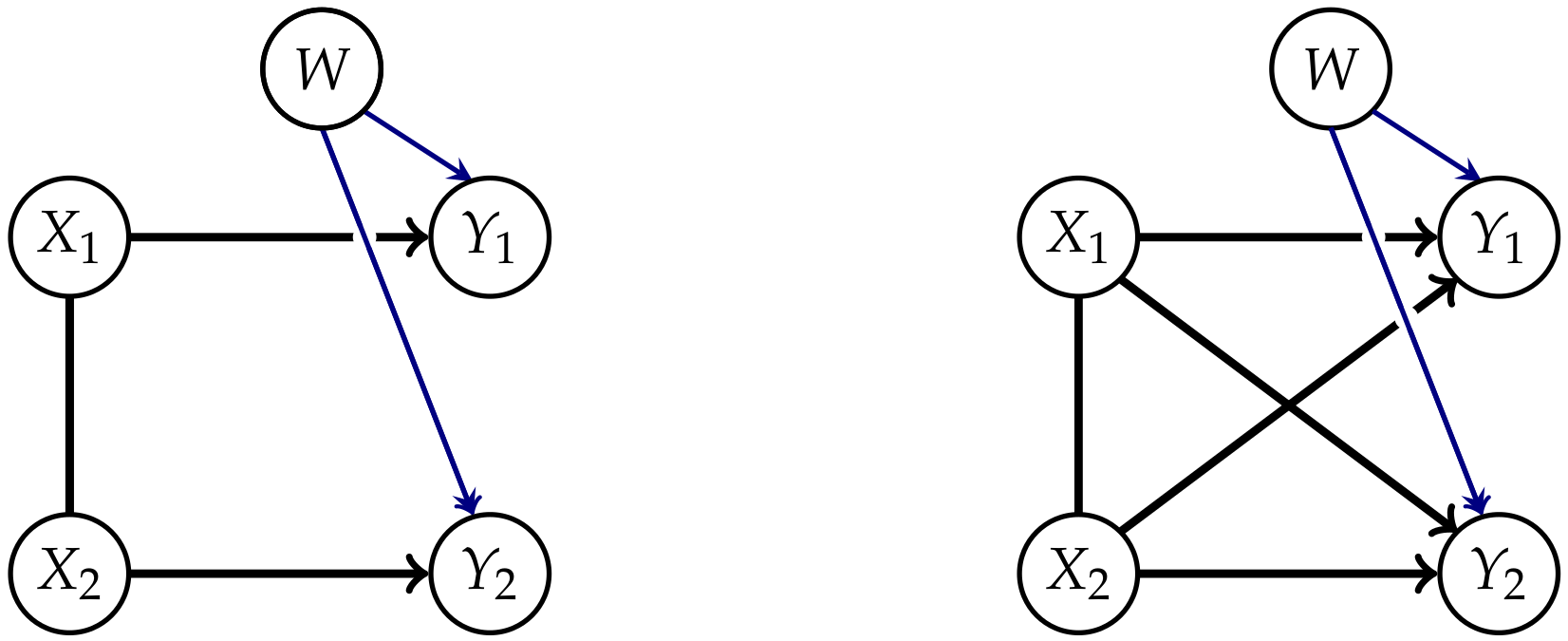
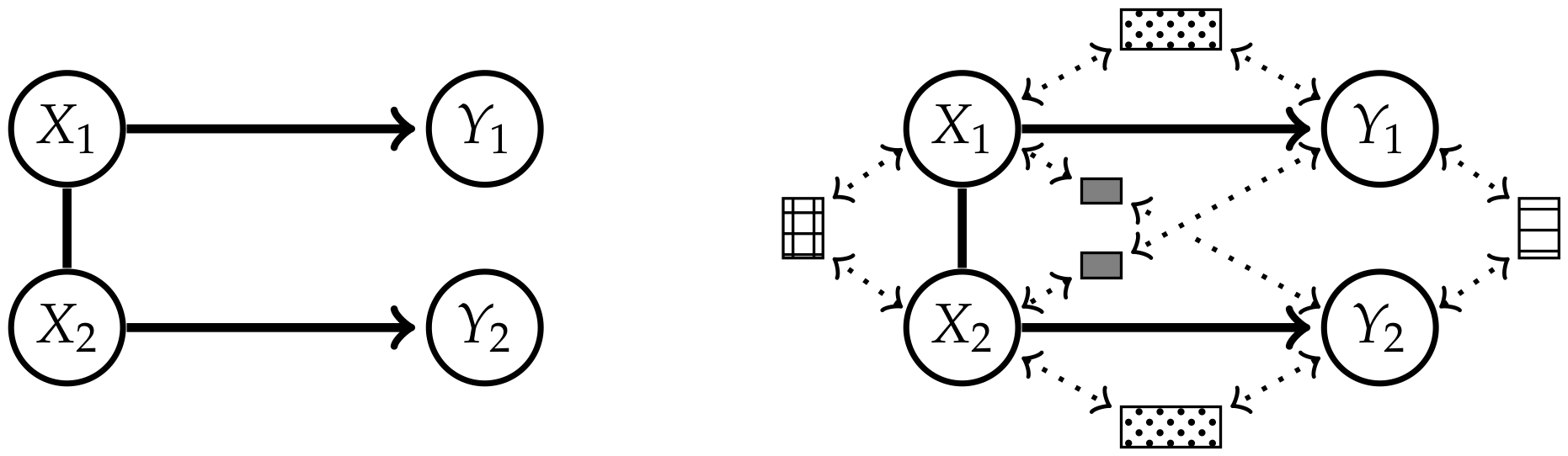
Measures corresponding to Integrated Information investigate the information flow in a system from a time t to . This flow is represented by the connections from the nodes in t to the nodes in as displayed in Figure 1.
The systems are modeled as discrete, stationary, n-dimensional Markov processes
on a finite set , which is the Cartesian product of the sample spaces of , denoted by
It is possible to apply the following methods to non-stationary distributions, but this assumption in addition to the process being Markovian allows us to restrict the discussion to one time step.
Let be set of distributions that belong to these Markov processes.
Denote the complement of in X by with . Corresponding to this notation describes the elementary events of . We will use the analogue notation in the case of Y and we will write instead of . The set of probability distributions on will be denoted by . Throughout this article we will restrict attention to strictly positive distributions.
The core idea of measuring Integrated Information is to determine how much the initial system differs from one in which no information integration takes place. The former will be called a “full” system, because we allow all possible connections between the nodes, and the latter will be called a “split” system. Graphical representations of the full systems for and their connections are depicted in Figure 1. In this article we are using graphs that describe the conditional independence structure of the corresponding sets of distributions. An introduction to those is given in Appendix A.
Graphs are not only a tool to conveniently represent conditional independence statements, but the connection between conditional independence and graphs is a core concept of Pearls causality theory. The interplay between graphs and conditional independence statements provides a consistent foundation of causality. In Reference [11] Section 1.3 Pearl emphasizes the importance of a graphical representation with the following statement:
Therefore, measures of the strength of causal cross-connections should be based on split models, that have a graphical representation.It seems that if conditional independence judgments are by-products of stored causal relationships, then tapping and representing those relationships directly would be a more natural and more reliable way of expressing what we know or believe about the world. This is indeed the philosophy behind causal Bayesian networks.
Following the concept introduced in References [6,7], the difference between the measures corresponding to the full and split systems will be calculated by using the KL-divergence.
Definition 1 (Complexity).
Let be a set of probability distributions on corresponding to a split system. Then we minimize the KL-divergence between and the distribution of the fully connected system to calculate the complexity
Minimizing the KL-divergence with respect to the second argument is called m-projection or rI-projection. Hence we will call with
the projection of to .
The question remains how to define the split model . We want to measure the information that gets integrated between different nodes in different points in time. In Figure 1 these are the dashed connections, also called cross-influences in Reference [4]. We will refer to the dashed connections as causal cross-connections.
In order to ensure that these connections are removed in the split system, the authors of Reference [4] and Reference [5] argue that should be independent of given , , leading to the following property.
Property 1.
A valid split system should satisfy the Markov condition
with . This can also be written in the following form
Now we take a closer look at the remaining connections. The dotted lines connect nodes belonging to the same point in time. These connections between the s might result from common internal influences, meaning a correlation between the s passed on to the next point in time via the dashed or solid connections. Additionally Amari points out in Section 6.9 in Reference [10] that there might exist a common exterior influence on the s. Although the measured integrated information should be internal and independent of external influences, the system itself is in general not completely independent of its environment.
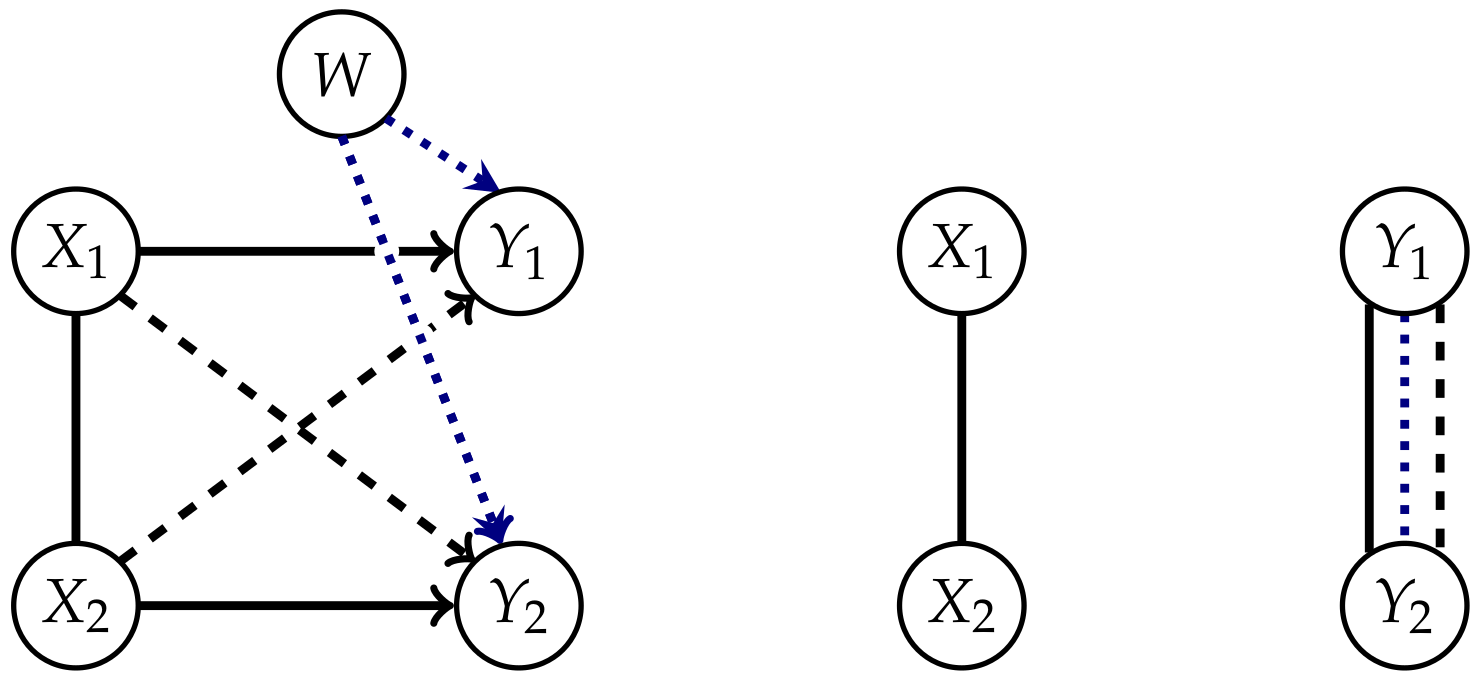
Since we want to measure the amount of integrated information between t and , the distribution in t, and therefore the connection between the s, should stay unchanged in the split system. The dotted connections between the s play an important role in Property 2. For this property, we will consider the split system in which the solid and dashed connections are removed.
The solid arrows represent the influence of a node in t on itself in and removing these arrows, in addition to the causal cross-connections, leads to a system with completely disconnected points in time as shown on the right in Figure 2. The distributions corresponding to this split system are
and the measure is given by the mutual information , which is defined in the following way
Since there is no information flow between the time steps Oizumi et al. argue in Reference [4] that an integrated information measure should be bounded from above by the mutual information.
Property 2.
The mutual information should be an upper bound for an Integrated Information measure
Oizumi et al. [4,9] and Amari et al. [5] state that this property is natural, because an Integrated Information measure should be bounded by the total amount of information flow between the different points in time. The postulation of this property led to a discussion in Reference [12]. The point of disagreement concerns the edge between the s. On the one hand this connection takes into account that the s might have a common exterior influence that affects all the s, as pointed out by Amari in Reference [10]. This is symbolized by the additional node W in Figure 2 and this should not contribute to the value of Integrated Information between the different points in time.
On the other hand, we know that if the s are correlated, then the correlation is passed to the s via the solid and dashed arrows. The edges created by calculating the marginal distribution on Y also contain these correlations. The question now is, how much of these correlations integrate information in the system and should therefore be measured. Kanwal et al. discuss this problem in Reference [12]. They distinguish between intrinsic and extrinsic influences that cause the connections between the s in the way displayed in Figure 2. By calculating the split system for the edge between the s might compensate for the solid arrows and common exterior influences, but also for the dashed, causal cross-connections, as shown in Figure 2 on the right. Kanwal et al. analyze an example of a full system without a common exterior influence with the result that there are cases in which a measure that only removes the causal cross-connections has a larger value than . This is only possible if the undirected edge between the s compensates a part of the causal cross-connections. Hence does not measure all the intrinsic causal cross-influences. Therefore Kanwal et al. question the use of the mutual information as an upper bound.
Then again, we would like to contribute a different perspective. Admitting to Property 2 does not necessarily mean that the connections between the s are fixed. It may merely mean that is a subset of the set of split distributions. We will see that the measures and do satisfy Property 2 in this way. Although the argument that measures all the intrinsic influences is no longer valid, satisfying Property 2 is still desirable in general. Consider an initial system with the distribution . This system has a common exterior influence on the s and no connection between the different points in time. Since there is no information flow between the points in time, a measure for Integrated Information should be zero for all distributions of this form. This is the case exactly when , hence when is an upper bound for . In order to emphasize this point we propose a modified version of Property 2.
Property 3.
The set should be a subset of the split model corresponding to the Integrated Information measure . Then the inequality
holds.
Note that the new formulation is stronger, hence Property 2 is a consequence of Property 3. Every measure discussed here that satisfies Property 2 also fulfills Property 3. Therefore we will keep referring to Property 2 in the following sections.
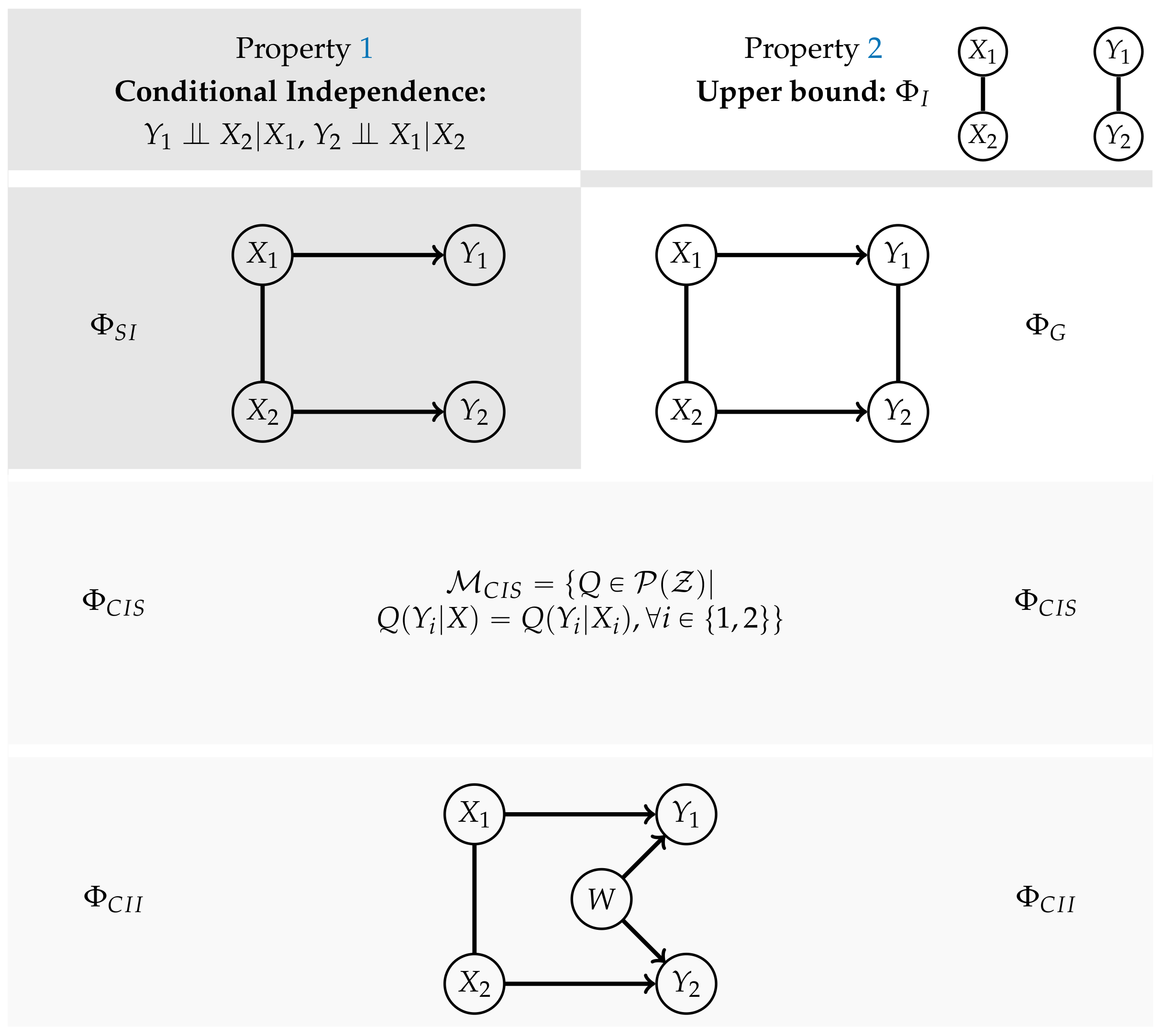
Figure 3 displays an overview over the different measures and whether they satisfy Properties 1 and 2.
The first complexity measure that we are discussing does not fulfill Property 2. It is called Stochastic Interaction and was introduced by Ay in Reference [6] in 2001, later published in Reference [7]. Barrett and Seth discuss it in Reference [13] in the context of Integrated Information. In Reference [5] the corresponding model is called “fully split model”.
The core idea is to allow only the connections among the random variables in t and additionally the connections between and , meaning the same random variable in different points in time. The last ones correspond to the solid arrows in Figure 1. A graphical representation for can be found in the first column of Figure 3.
Definition 2 (Stochastic Interaction).
The set of distributions belonging to the split model in the sense of Stochastic Interaction can be defined as
and the complexity measure can be calculated as follows
as shown in Reference [7]. In the definition above, H denotes the conditional entropy
This does not satisfy Property 2 and therefore the corresponding graph is displayed only in the first column of Figure 3. Amari points out in Reference [10] that this measure is not applicable in the case of an exterior influences on the s. Such an influence can cause the s to be correlated even in the case of independent s and no causal cross-connections.
Consider a setting without exterior influences, then quantifies the strength of the causal cross-connections alone and is therefore a reasonable choice for an Integrated Information measure. Accounting for an exterior influence that does not exist leads to a split system, which compensates a part of the removal of the causal cross-connections so that the resulting measure does not quantify all of the interior causal cross-influences.
To force the model to satisfy Property 2, one can add the interaction between and , which results in the measure Geometric Integrated Information [10].
Definition 3 (Geometric Integrated Information).
The graphical model corresponding to the graph in the second row and first column of Figure 3 is the set
and the measure is defined as
is called the diagonally split model in Reference [5]. This is not causally split in the sense that the corresponding distributions in general do not satisfy Property 1. It can be seen by analyzing the conditional independence structure of the graph as described in Appendix A. By introducing the edges between the s as fixed, might force these connections to be stronger than they originally are. A result of this might be that an effect of the causal cross-connections gets atoned for by the new edge. We discussed this above in the context of Property 2.
This measure has no closed form solution, but we are able to calculate the corresponding split system with the help of the iterative scaling algorithm, (see, for example, Section 5.1 in Reference [14]).
The first measure that satifies both properties is called “Integrated Information” [4], its model is referred to by “Causally split model” in Reference [5] and it is derived from the first property. Since we are able to define it using conditional independence statements, we will denote it by . It requires to be independent of given .
Definition 4 (Integrated Information).
The set of distributions, that belongs to the split system corresponding to integrated information, is defined as
and this leads to the measure
We write the requirements to the distributions in (3) as conditional independent statements
A detailed analysis of probabilistic independence statements can be found in Reference [15]. Unfortunately, these conditional independence statements can not be encoded in terms of a chain graph in general. The definition of this measure arises naturally from Property 1 by applying the relation (1)
to all pairs . This leads to
as shown in Appendix B.
Note that this implies that every model satisfying Property 1 is a submodel of . In order to show that satisfies Property 1, we are going to rewrite the condition in Property 1 as
The definition of allows us to write
for . Therefore satisfies Property 1 and since meets the conditional independence statements of Property 1 the relation holds and fulfills Property 2.
In Reference [4] Oizumi et al. derive an analytical solution for Gaussian variables, but there does not exist a closed form solution for discrete variables in general. Therefore they use Newton’s method in the case of discrete variables.
Due to the lack of a graphical representation, it is difficult to interpret the causal nature of the elements of . In Example 1 we will see a type of model that is part of , but which has a graphical representation. This model does not lie in the set of Markovian processes discussed in this article . Hence this implies that not all the split distributions in arise from removing connections from a full distribution, as depicted in Figure 1.
2. Causal Information Integration
Inspired by the discussion about extrinsic and intrinsic influences in the context of Property 2, we now utilize the notion of a common exterior influence to define the measure , which we call Causal Information Integration. This measure should be used in case of an unknown exterior influence.
2.1. Definition
Explicitly including a common exterior influence allows us to avoid the problems of a fixed edge between the s discussed earlier. This leads to the graphs in Figure 4.
The factorization of the distributions belonging to these graphical models is the following one
By marginalizing over the elements of we get a distribution on defining our new model.
Definition 5 (Causal Information Integration).
The set of distributions belonging to the marginalized model for is
We will define the split model for Causal Integrated Information as the closure (denoted by a bar) of the union of
This leads to the measure
Since the split system was defined by utilizing graphs, we are able to use the graphical representation to get a more precise notion of the cases in which holds. In those cases the initial distribution can be completely explained as a limit of marginalized distributions without causal cross-influences and with exterior influences.
Proposition 1.
The measure is 0 if and only if there exists a sequence of distributions with the following properties.
- 1.
- 2.
- For every there exists a distribution that has marginals equal toAdditionally factors according to the graph corresponding to the split system
In order to show that satisfies the conditional independence statements in Property 1, we will calculate the conditional distributions and of
This results in
for all . Hence , for every . Since every element in is a limit point of distributions that satisfy the conditional independence statements, also fulfills those. A proof can be found in Reference [16] Proposition 3.12. Therefore satisfies Property 1 and the set of all such distributions is a subset of
We are able to represent the marginalized model by using the methods from Reference [17]. Up to this point we have been using chain graphs. These are graphs consisting of directed and undirected edges such that there are no semi-directed cycles as described in Appendix A. In order to be able to gain a graph that represents the conditional independence structure of the marginalized model, we need the concept of chain mixed graphs (CMGs). In addition to the directed and undirected edges belonging to chain graphs, chain mixed graphs also have arcs ↔. Two nodes connected by an arc are called spouses. The connection between spouses appears when we marginalize over a common influence, hence spouses do not have a directed information flow from one node to the other but are affected by the same mechanisms. The Algorithm A3 from Reference [17] allows us to transform a chain graph with latent variables into a chain mixed graph that represents the conditional independence structures of the marginalized chain graph. Using this on the graphs in Figure 4 leads to the CMGs in Figure 5. Unfortunately, there exists no new factorization corresponding to the CMGs known to the authors.
In order to prove that satisfies Property 2, we will show that is a subset of . At first we will consider the following subset of
where we remove the connections between the different stages, as shown in Figure 6.
Now X and Y are independent of each other
with
for and since independence structures of discrete distributions are preserved in the limit we have . In order to gain equality it remains to show that can approximate every distribution on if the state space of W is sufficiently large. These distributions are mixtures of discrete product distributions, where
are the mixture components and are the mixture weights. Hence we are able to use the following result.
Theorem 1
(Theorem 1.3.1 from Reference [18]). Let q be a prime power. The smallest m for which any probability distribution on can be approximated arbitrarily well as mixture of m product distributions is .
Universal approximation results like the theorem above may suggest that the models and are equal. However we will present numerically calculated examples of elements belonging to , but not to , even with an extremely large state space. We will discuss this matter further in Section 2.1.2.
In conclusion, satisfies Property 1 and 2.
Note that using in cases without an exterior influence might not capture all the internal cross-influences, since the additional latent variable can compensate some of the difference between the initial distribution and the split model. This can only be avoided when the exterior influence is known and can therefore be included in the model. We will discuss that case in the next section.
2.1.1. Ground Truth
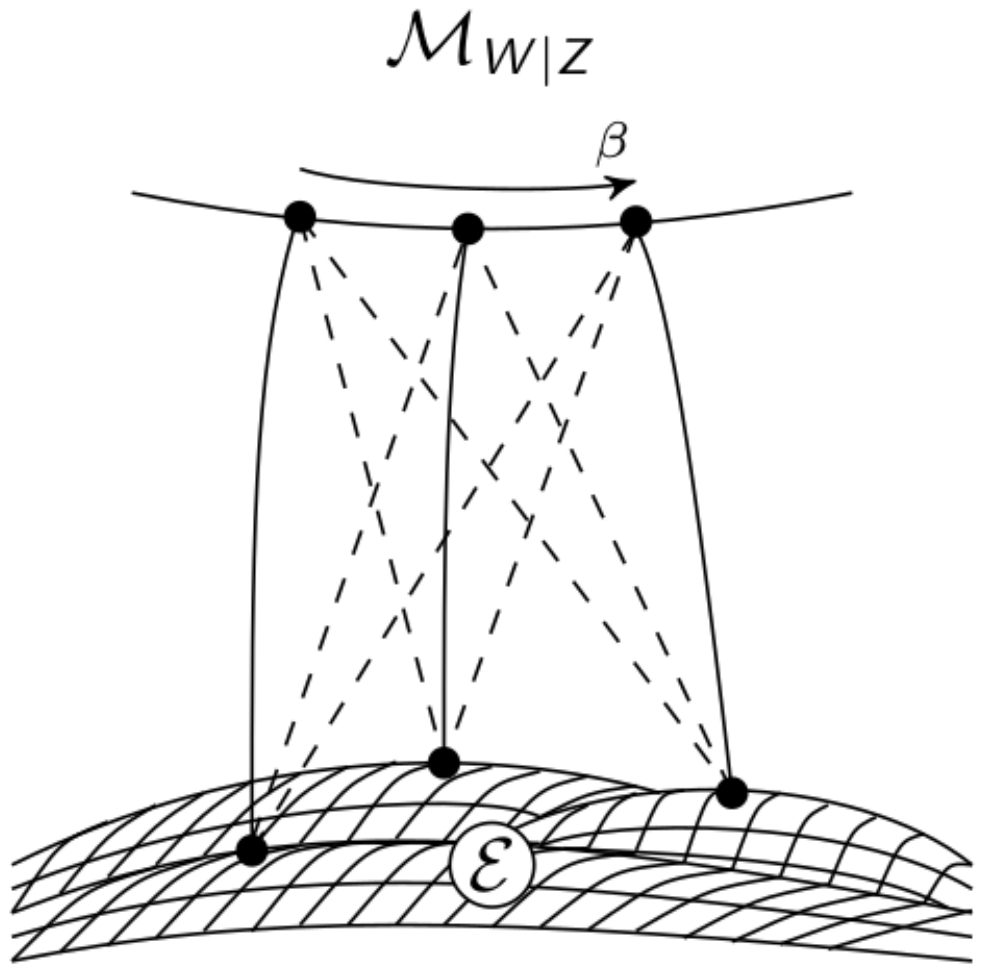
The concept of an exterior influence suggests that there exists a ground truth in a larger model in which W is a visible variable. This is shown in Figure 7 on the right.
Assuming that we know the distribution of the whole model, we are able to apply the concepts discussed above to define an Integrated Information measure on the larger space. This allows us to really only remove the causal cross-connections as shown in Figure 7 on the left. Thus we can interpret as the ultimate measure of Integrated Information, if the ground truth is available. Note that using the measure in the setting with no external influences is a special case of .
The set of distributions belonging to the larger, fully connected model will be called and the set corresponding to the graph on the left of Figure 7 depicts the split system which will be denoted by . Since W is now known, we are able to fix the state space to its actual size m.
Note that is the set of all the distributions that result in an element of after marginalization over
Calculating the KL-divergence between and results in the new measure.
Proposition 2.
Let . Minimizing the KL-divergence between P and leads to
In the definition above is the conditional mutual information defined by
It characterizes the reduction of uncertainty in due to when W and are given. Therefore this measure decomposes to a sum in which each addend characterizes the information flow towards one . Writing this as conditional independence statements, is 0 if and only if
Ignoring W would lead exactly to the conditional independence statements in Equation (3). For a more detailed description of the conditional mutual information and its properties, see Reference [19].
Furthermore, if and only if the initial distribution P factors according to the graph that belongs to . This follows from Proposition 2 and the fact that the KL-divergence is 0 if and only if both distributions are equal. Hence this measure truly removes the causal cross-connections.
Additionally, by using that , we are able to split up the conditional mutual information into a part corresponding to the conditional independence statements of Property 1 and another conditional mutual information.
Since the conditional mutual information is non-negative, is 0 if and only if the conditional independence statements of Equation (3) hold and additionally the reduction of uncertainty in W due to given is 0.
In general, we do not know what the ground truth of our system is and therefore we have to assume that W is a hidden variable. This leads us back to . Minimizing over all possible W might compensate a part of the causal information flow. One example, in which accounting for an exterior influence that does not exist leads to a value smaller than the true integrated information, was discussed earlier in the context of Property 2. There we refer to an example in Reference [12] where exceeds in a setting without an exterior influence. Similarly, is smaller or equal to the true value .
Proposition 3.
The new measure is an upper bound for
Hence by assuming that there exists a common exterior influence, we are able to show that is bounded from above by the true value, that measures all the intrinsic cross-influences. We are able to observe this behavior in Section 2.2.2.
2.1.2. Relationships between the Different Measures
Now we are going to analyze the relationship between the different measures and . We will start with and . Previously we already showed that satisfies Property 1 and since does not satisfy Property 1, we have
To evaluate the other inclusion, we will consider the more refined parametrizations of elements and as defined A1. These are
where are non-negative functions such that and
Since depends on more than and , does not factorize according to in general. Hence holds.
Furthermore, looking at the parametrizations allows us to identify a subset of distributions that lies in the intersection of and . Allowing P to only have pairwise interactions would lead to
with the non-negative functions such that and
This P is an element of .
In the next part we will discuss the relationship between and . The elements in satisfy the conditional independence statements of Property 1, therefore
Previously we have seen that making the state space of W large enough can approximate a distribution between the s, see Theorem 1. This gives the impression that and coincide. However, based on numerically calculated examples, we have the following conjecture.
Conjecture 1.
It is not possible to approximate every distribution with arbitrary accuracy by an element of . Therefore, we have that
The following example strongly suggests this conjecture to be true.
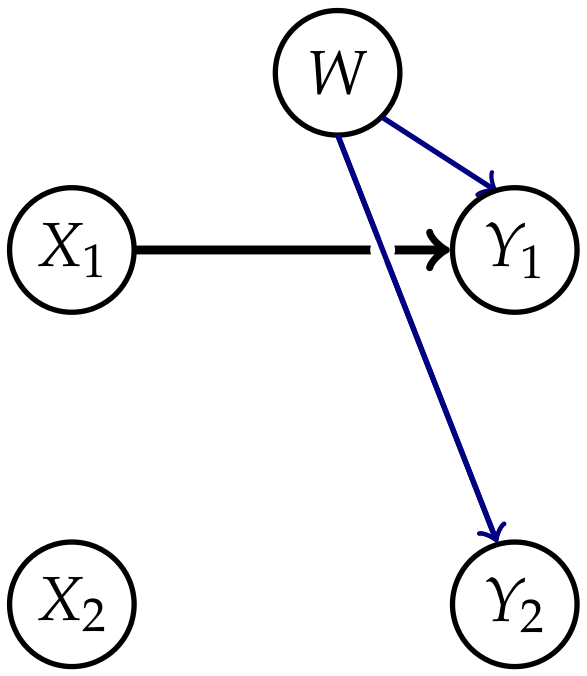
Example 1.
Consider the set of distributions that factor according to the graph in Figure 8
This model satisfies the conditional independence statements of Property 1 and is therefore a subset of the model . In this case and are independent of each other, hence from a causal perspective the influence of on should be purely external. Therefore we try to model this with a subset of
and this corresponds to Figure 9.
Using the em-algorithm described in Section 2.1.3 we took 500 random elements of and calculated the closest element of by using the minimum KL-divergence of 50 different random input distributions in each run. The results are displayed in Table 1.
This is an example of an element lying in , which cannot be approximated by an element in .
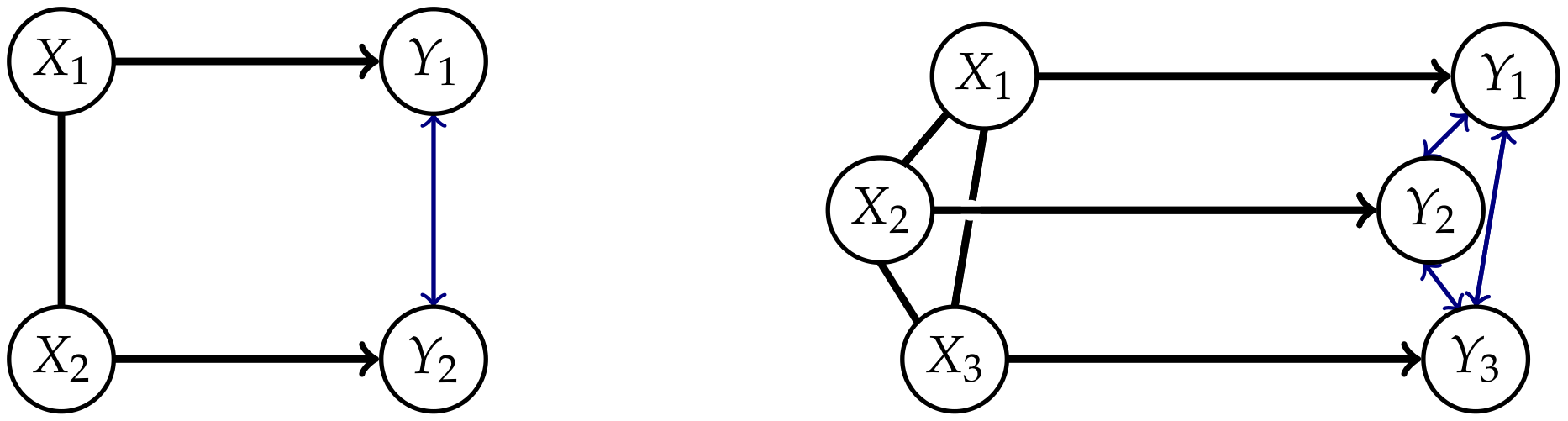
Now we are going to look at this example from the causal perspective. Proposition 1 states that is 0 if and only if is the limit of a sequence of distributions in corresponding to distributions on the extended space that factor according to the split model. Hence a distribution resulting in cannot be explained by a split model with an exterior influence. Taking into account that does not correspond to a graph, we do not have a similar result describing the distributions for which . Nonetheless, by looking at the graphical model , we are able to discuss the causal structure of a submodel of , a class of distributions for which holds.
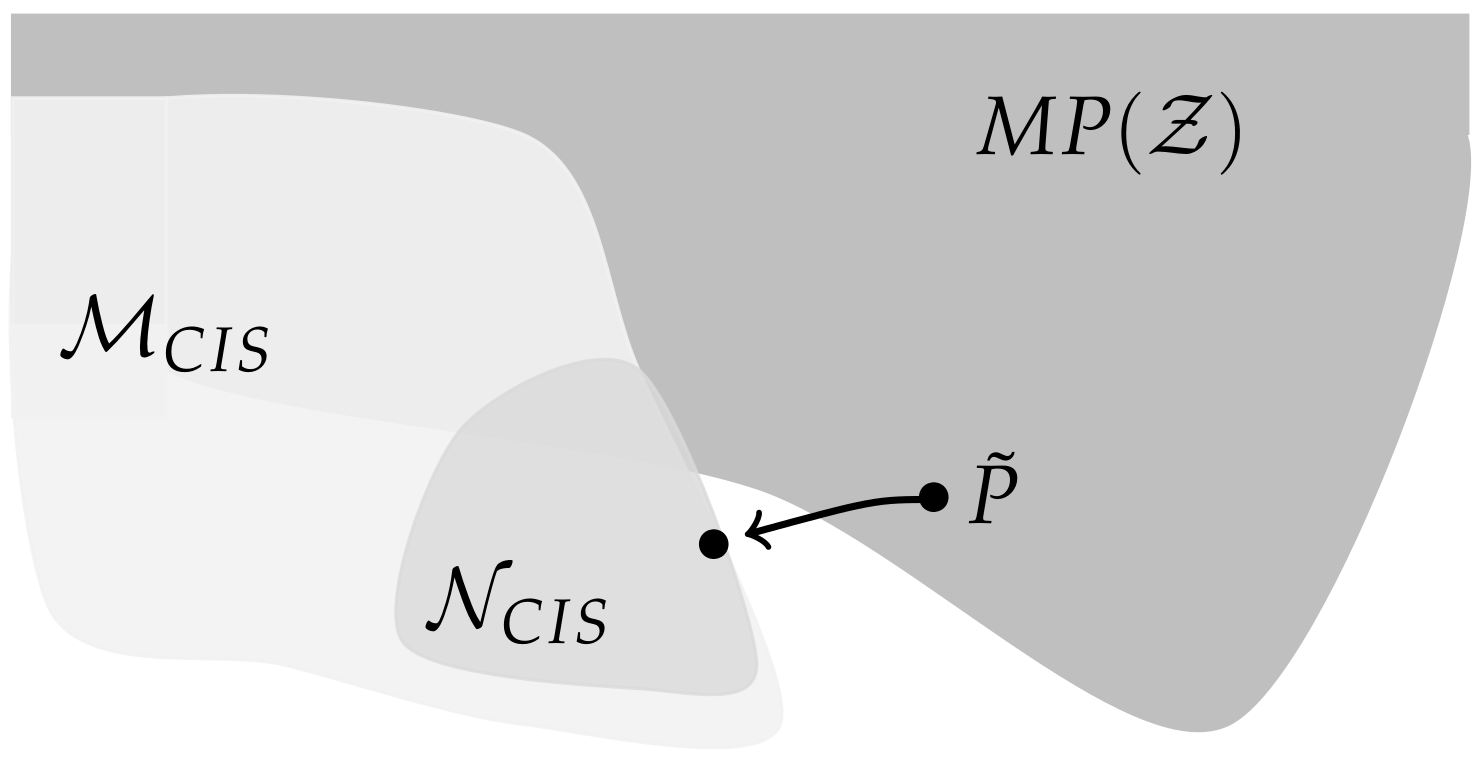
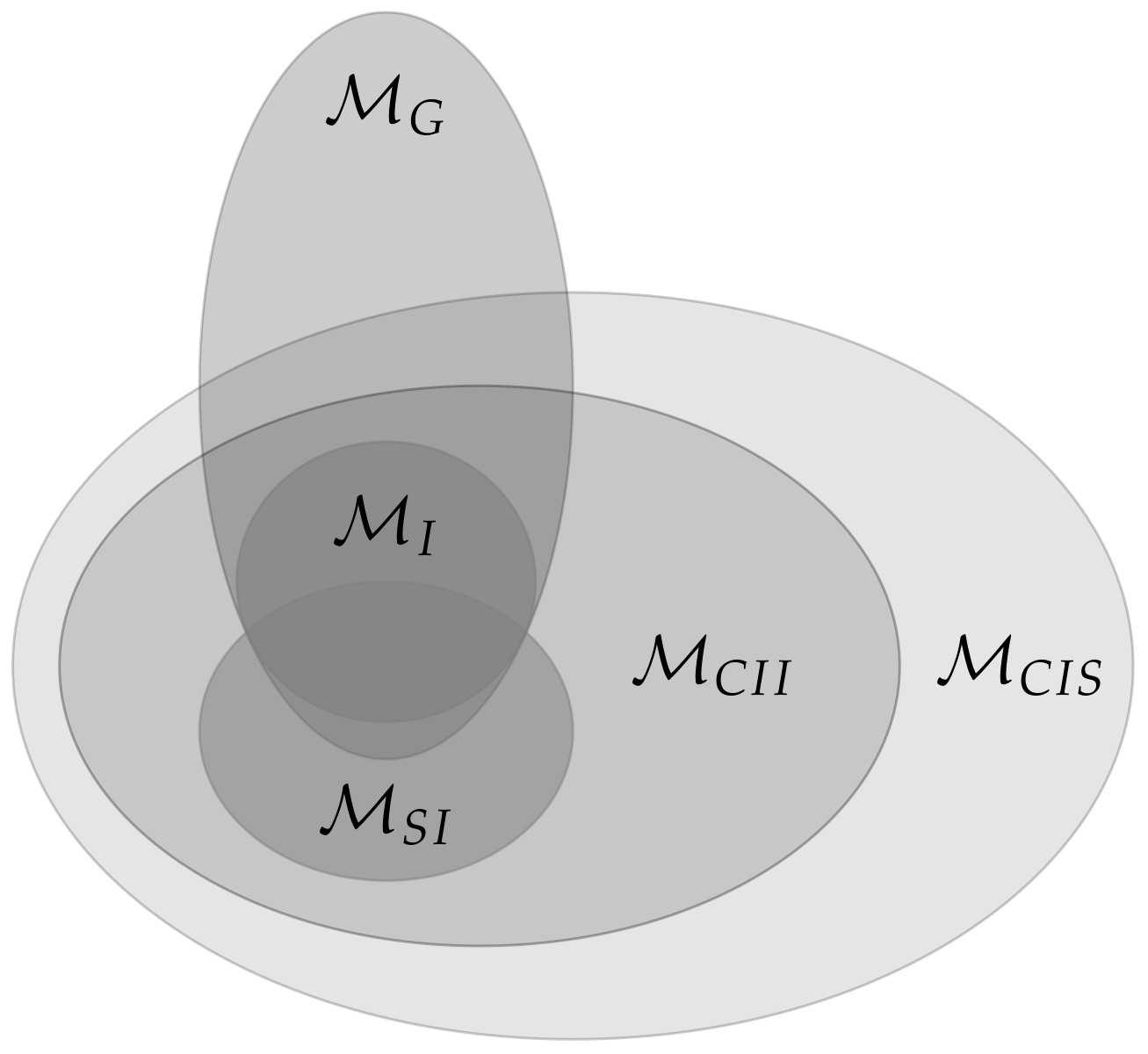
If we trust the results in Table 1, this would imply that the influence from to is not purely external, but that there suddenly develops an internal influence in timestep that did not exist in timestep t. Therefore the distributions in do not belong to the stationary Markovian processes , depicted in Figure 1, in general. For these Markovian processes the connections between the s arise from correlated s or external influences, as pointed out by Amari in Section 6.9 [10]. So from a causal perspective does not fit into our framework. Hence the initial distribution , which corresponds to a full model, will in general not be an element of . However, the projection of to might lie in as illustrated in Figure 10.
When this is the case, then is closer to an element with a causal structure that does not fit into the discussed setting, than to a split model in which only the causal cross-connections are removed. Hence a part of the internal cross-connections is being compensated by this type of model and therefore this does not measure all the intrinsic integrated information.
Further examples, which hint towards , can be found in Section 2.2.2.
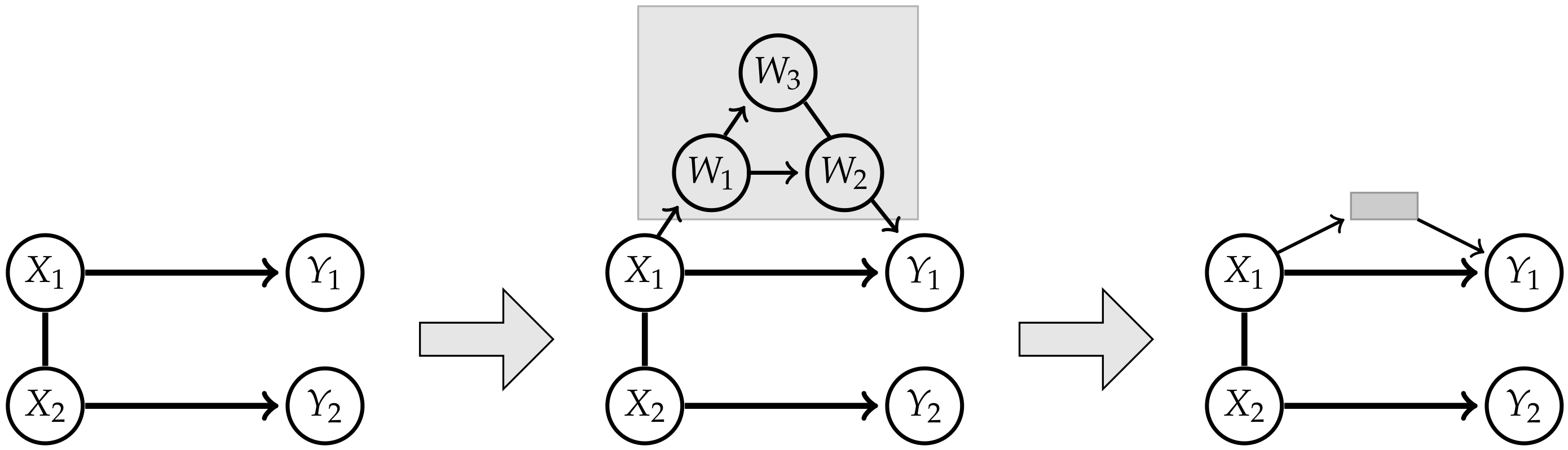
Adding the hidden variable W seems not to be sufficient to approximate elements of . Now the question naturally arises whether there are other exterior influences that need to be included in order to be able to approximate . We will explore this thought by starting with the graph corresponding to the split model , depicted in Figure 11 on the left. In the next step we add hidden vertices and edges to the graph in a way such that the whole graph is still a chain graph. An example for a valid hidden structure is given in Figure 11 in the middle. Since we are going to marginalize over the hidden structure, it is only important how the visible nodes are connected via the hidden nodes. In the case of the example in Figure 11 we have a directed path from to going through the hidden nodes. Therefore we are able to reduce the structure to a gray box shown on the right in Figure 11.
Then we use the Algorithm A3 mentioned earlier, which converts a chain graph with hidden variables to a chain mixed graph reflecting the conditional independence structure of the marginalized model. This leads to a directed edge from to by marginalizing over the nodes in the hidden structures. Seeing that this directed edge already existed, the resulting model now is a subset of and therefore does not approximate .
Following this procedure we are able to show that adding further hidden nodes and subgraphs of hidden nodes does not lead to a chain mixed graph belonging to a model that satisfies the conditional independence statements of Property 1 and strictly contains .
Theorem 2.
It is not possible to create a chain mixed graph corresponding to a model , such that its distributions satisfy Property 1 and , by introducing a more complicated hidden structure to the graph of .
In conclusion, assuming that Conjecture 1 holds, we have the following relations among the different presented models.
A sketch of the inclusion properties among the models is displayed in Figure 12.
Every set that lies inside satisfies Property 1 and every set that completely contains fulfills Property 2.
2.1.3. em-Algorithm
The calculation of the measure with
can be done by the em-algorithm, a well known information geometric algorithm. It was proposed by Csiszár and Tusnády in 1984 in Reference [20] and its usage in the context of neural networks with hidden variables was described for example by Amari et al. in Reference [21]. The expectation-maximization EM-algorithm [22] used in statistics is equivalent to the em-algorithm in many cases, including this one, as we will see below. A detailed discussion of the relationship of these algorithms can be found in Reference [23].
In order to calculate the distance between the distribution and the set on we will make use of the extended space of distributions on , . Let be the set of all distributions on that have -marginals equal to the distribution of the whole system
This is an m-flat submanifold since it is linear w.r.t . Therefore there exists a unique e-projection to .
The second set that we are going to use is the set of distributions that factor according to the split model including the common exterior influence. We have seen this set before in Section 2.1.1.
This set is in general not e-flat, but we will show that there is a unique m-projection to it. We are able to use these sets instead of and because of the following result.
Theorem 3
(Theorem 7 from Reference [21]). The minimum divergence between and is equal to the minimum divergence between and in the visible manifold
Proof of Theorem 3.
Let , using the chain-rule for KL-divergence leads to
with
This results in
□
The em-algorithm is an iterative algorithm that first performs an e-projection to and then an m-projection to repeatedly. Let be an arbitrary starting point and define as the e-projection of to
Now we define as the m-projection of to
Repeating this leads to
The correspondence between these projections in the extended space and one m-projection in is illustrated in Figure 13.
The algorithm iterates between the extended spaces and on the left of Figure 13. Using Theorem 2.1.3 we gain that this minimization is equivalent to the minimization between and . The convergence of this algorithm is given by the following result.
Proposition 4
(Theorem 8 from Reference [21]). The monotonic relations
hold, where equality holds only for the fixed points of the projections
Proof of Proposition 4.
This is immediate, because of the definitions of the e- and m-projections. □
Hence this algorithm is guaranteed to converge towards a minimum, but this minimum might be local. We will see examples of that in Section 2.2.2.
In order to use this algorithm to calculate we first need to determine how to perform an e- and m-projection in this case. The e-projection from to is given by
for all . This is the projection because of the following equality
The first addend is a constant for a fixed distribution and the second addend is equal to 0 if and only if . Note that this means that the conditional expectation of W remains fixed during the e-projection. This is an important point, because this guarantees the equivalence to the EM algorithm and therefore the convergence towards the MLE. For a proof and examples see Theorem 8.1 in Reference [10] and Section 6 in Reference [23].
After discussing the e-projection, we now consider the m-projection.
Proposition 5.
The m-projection from is given by
for all .
The last remaining decision to be made before calculating is the choice of the initial distribution. Since it depends on the initial distribution whether the algorithm converges towards a local or global minimum, it is important to take the minimal outcome of multiple runs. One class of starting points that immediately lead to an equilibrium, which is in general not minimal, are the ones in which Z and W are independent . It is easy to check that the algorithm converges here to the fixed point
Note that this is the result of the m-projection of to , the manifold belonging to .
2.2. Comparison
In order to compare the different measures, we need a setting in which we generate the probability distributions of full systems. We chose to use weighted Ising models as described in the next section.
2.2.1. Ising Model
The distributions used to compare the different measures in the next chapter are generated by weighted Ising models, also known as binary auto-logistic models as described in Reference [24] Example 3.2.3. Let us consider n binary variables , . The matrix contains the weights of the connection from to as displayed in Figure 14. Note that this figure is not a graphical model corresponding to the stationary distribution, but merely displays the connections of the conditional distribution of given with the respective weights
The inverse temperature regulates the coupling strength between the nodes. For close to zero the different nodes are almost independent and as grows the connections become stronger.
2.2.2. Results
In this section we are going to compare the different measures experimentally. Note that we do not have an exterior influence in these examples, so that holds.
To distinguish between the Causal Information Integration calculated with different sized state spaces of W, we will denote
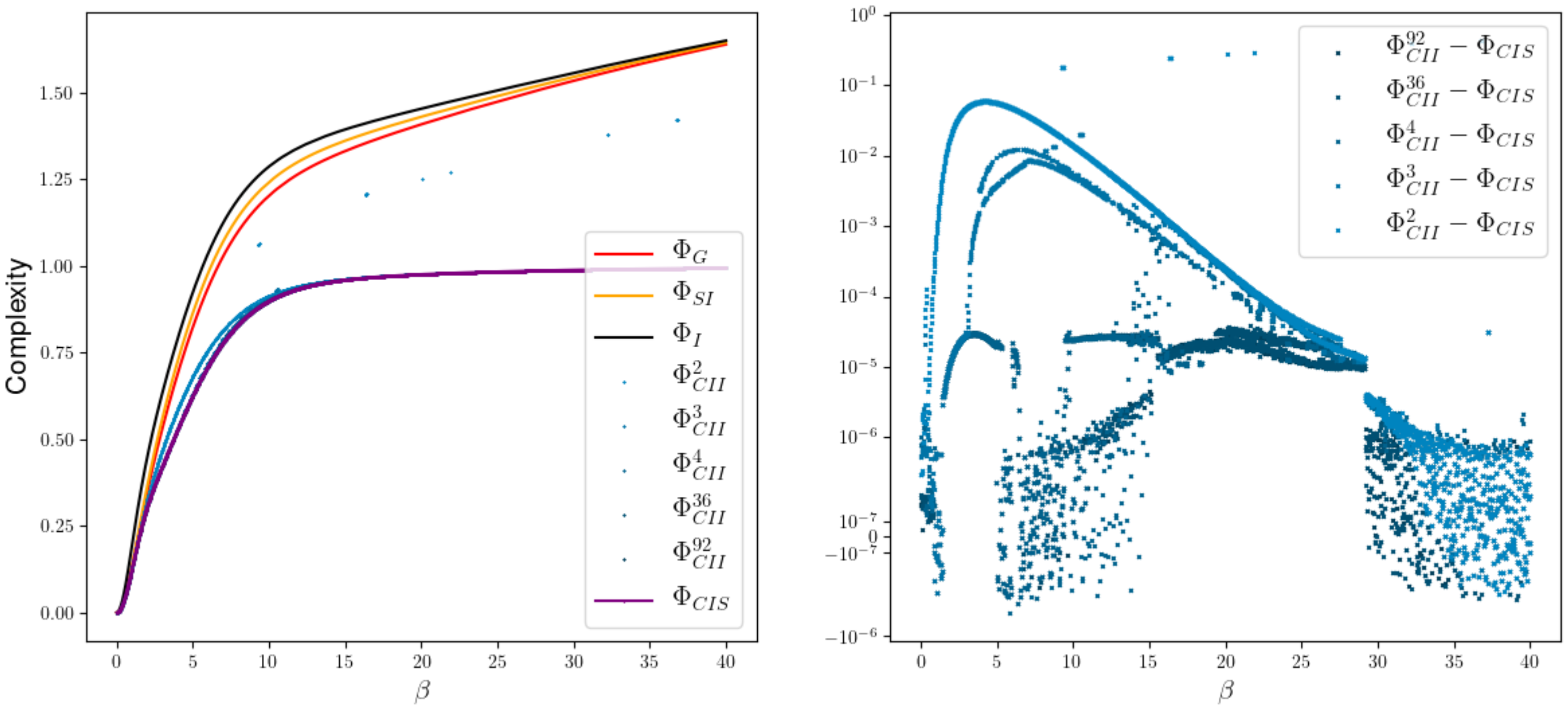
We start with the smallest example possible, with , and the weight matrix
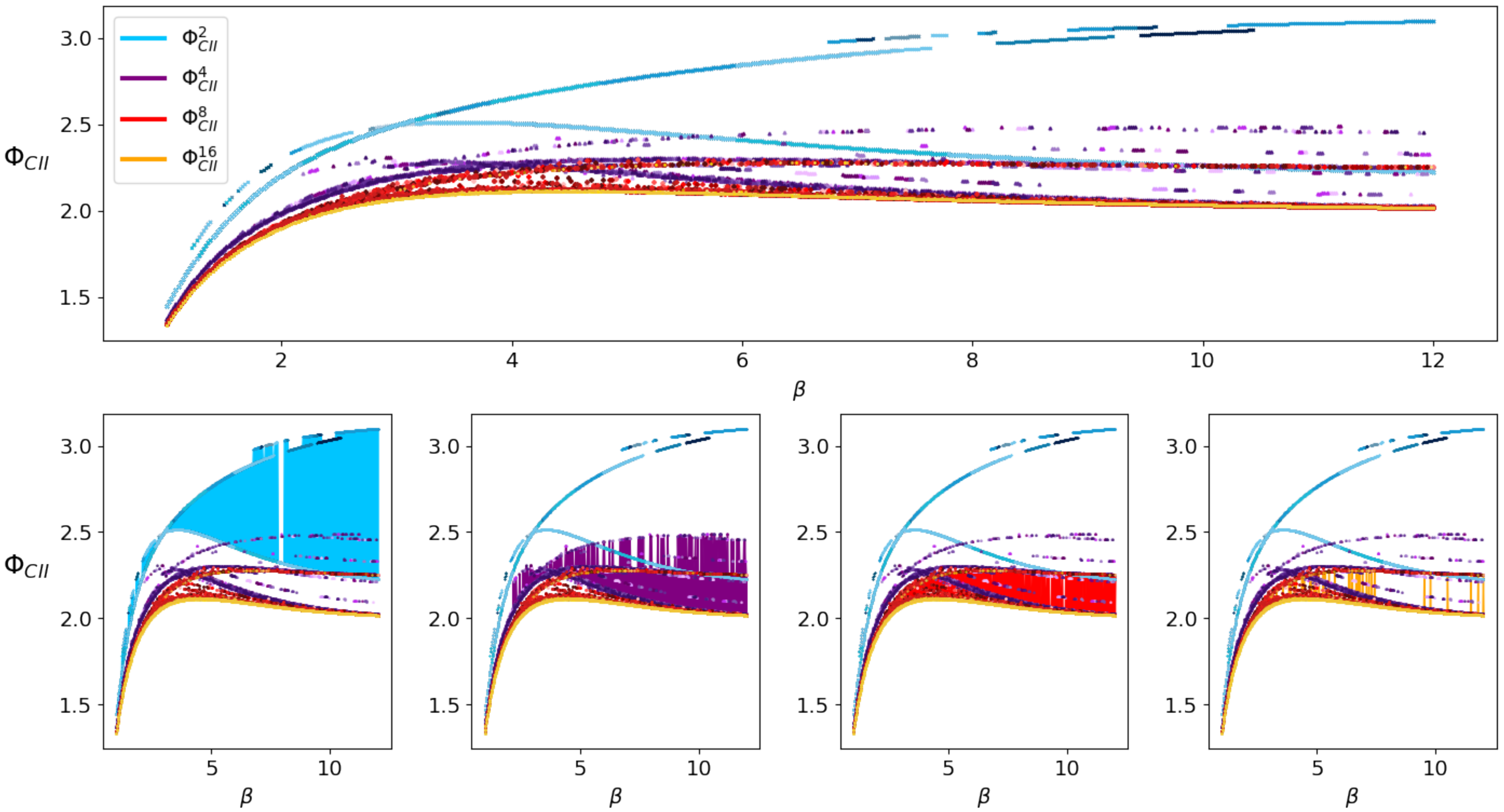
shown in Figure 15. In this example every measure is bounded by and the measures and display a limit behavior different from and the . The state spaces of W have the size 2, 3, 4, 36 and 92 and the respective measures are displayed in shades of blue that get darker as the state space gets larger. In every case the em-algorithm has been initiated 100 times with a random input distribution in order to find a global minimum. Minimizing over the outcome of 100 different runs turns out to be sufficient, at least empirically, to reveal the behavior of the global minima. On the right side of this figure, we are able to see the difference between and . Considering the precision of the algorithms we assume that a difference smaller than 5e-07 is approx. zero. We can see that in a region from to the measures differ even in the case of 92 hidden states. So this small case already hints towards .
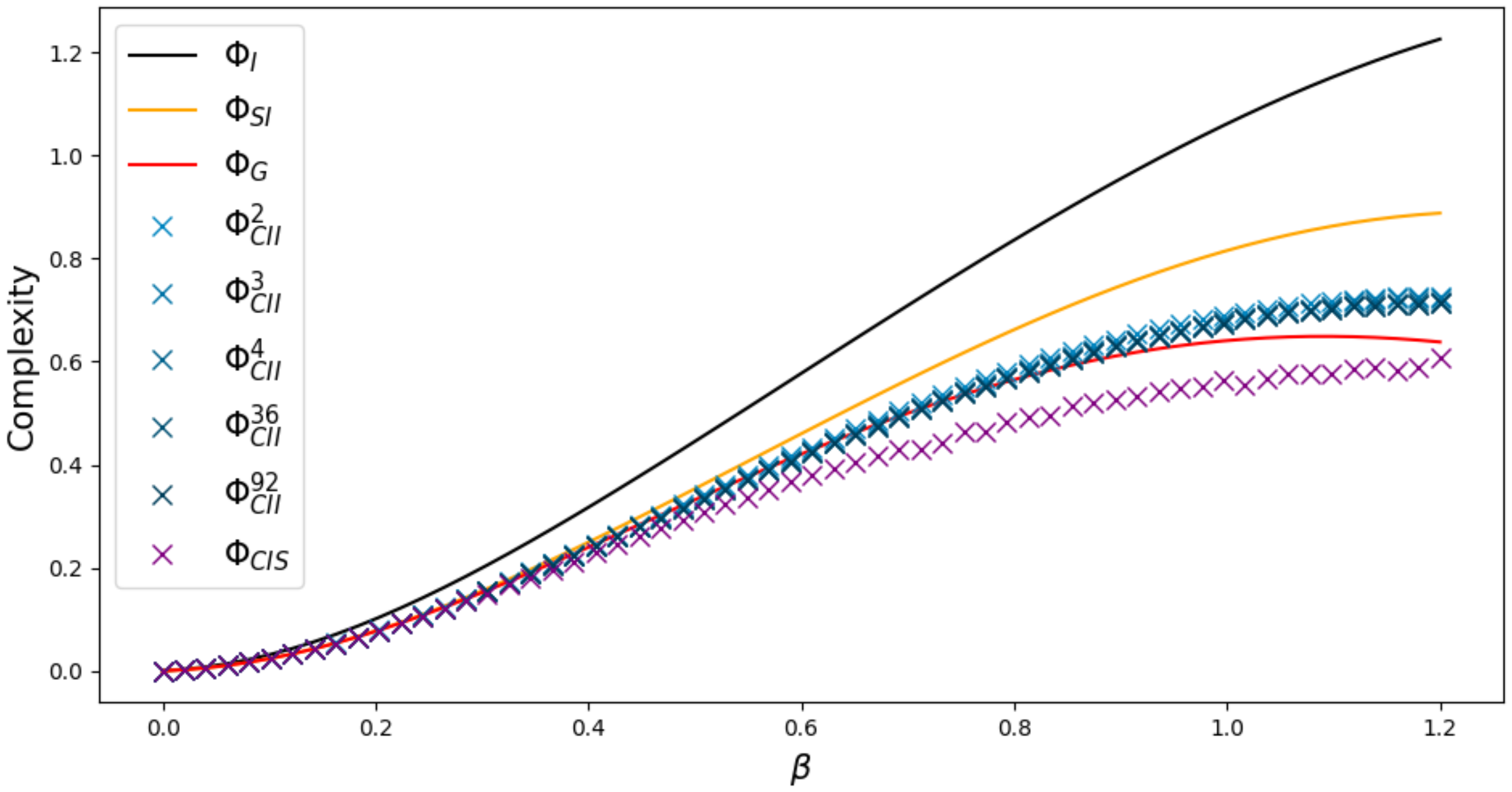
Increasing n from 2 to 3 makes the difference even more visible, as we can see in Figure 16 produced with the weight matrix
Here we are able to observe a difference in the behavior of compared to the other measures, since we see that , and are still increasing around , while starts to decrease.
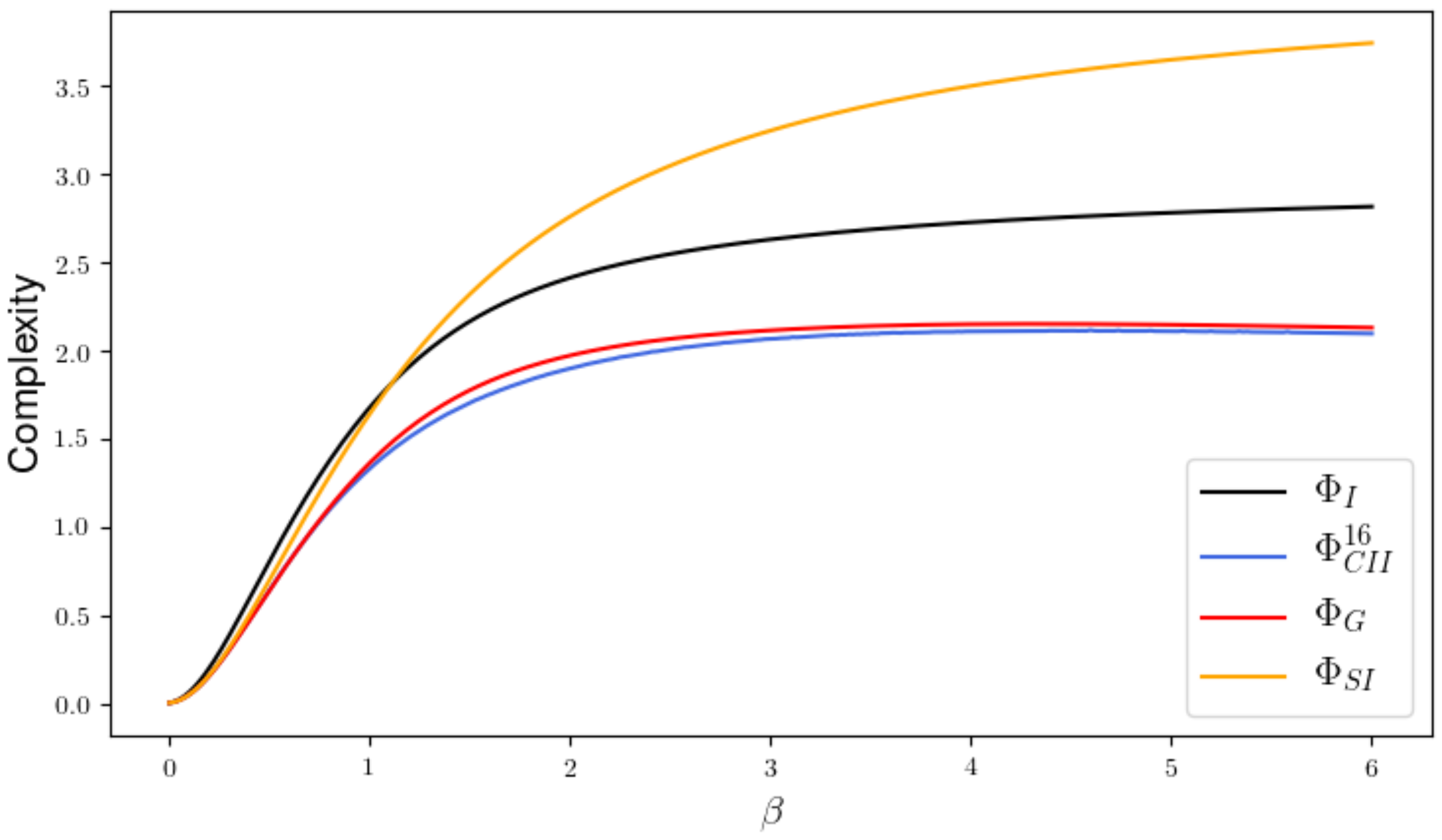
Now, we are going to focus on an example with 5 nodes. Since it is very time consuming to calculate for more than 3 nodes, we are going to restrict attention to , , and . The weight matrix
produces the Figure 17. This example shows that is not bounded by and therefore does not satisfy Property 2. Since the focus in this examples lies on the relationship between and , the em-algorithm was run with ten different input distributions for each step.
Using this example, we are going to take a closer look at the local minima the em-algorithm converges to. Considering only and varying the size of the state space leads to the upper part in Figure 18. This figure displays ten different runs of the em-algorithm with each size of state space in different shades of the respective color, namely blue for , violet for , red for and orange for . Note that we display the outcomes of every run in this case and not only the minimal one, since we are interested in the local minima. We are able to observe how increasing the state space leads to a smaller value of . Additionally, the differences between the minimal values corresponding to each state space grow smaller and converge as the state spaces increase.
The bottom half of Figure 18 highlights an observation that we made. Each of the four illustrations is a copy of the one above, where the difference between the minima are shaded in the respective color. By increasing the size of the state space the difference in value between the various local minima decreases visibly. We think this is consistent with the general observation made in the context of high dimensional optimization, for example, Reference [25] in which the authors conjecture that the probability of finding a high valued local minimum decreases when the network size grows.
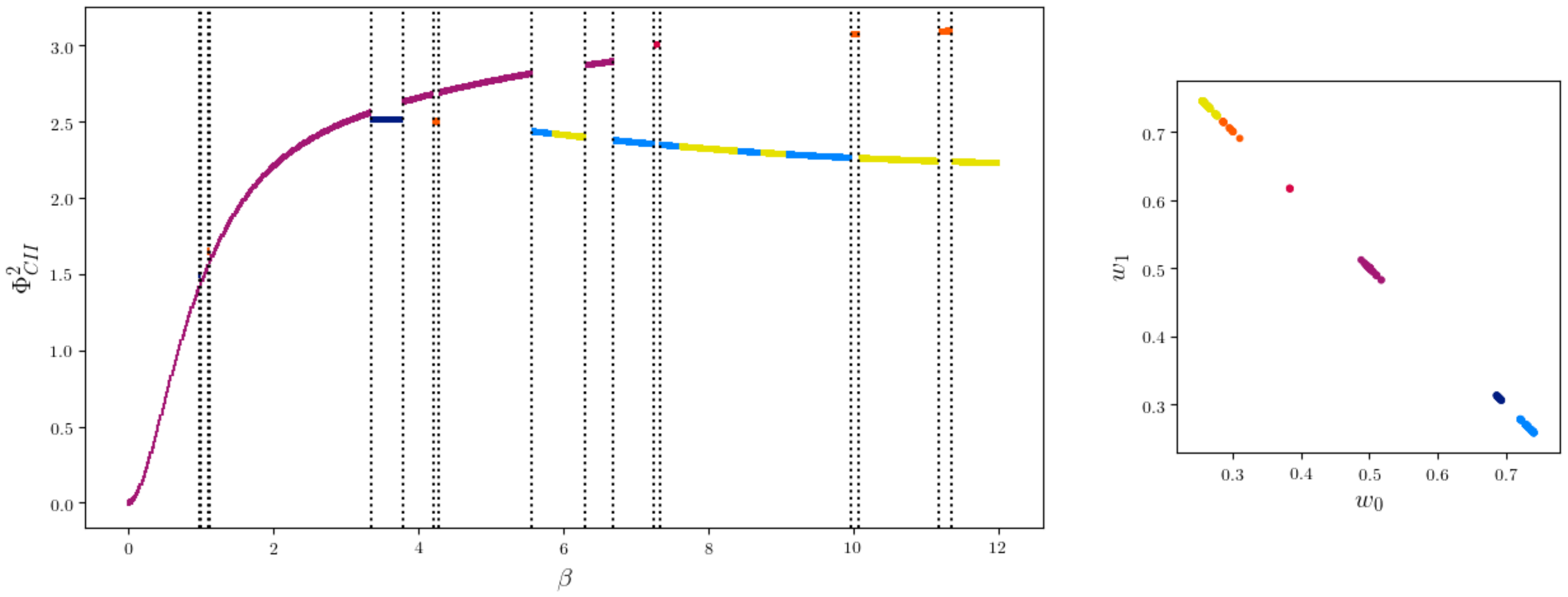
Letting the algorithm run only once with on the same data leads to a curve on the left in Figure 19.
The sets defined in (7) and (5) do not change for different values of and therefore we have a fixed set of local minima for a fixed state space of W. What does change with different is which of the local minima are global minima. The vertical dotted lines represent the steps to in which the KL-divergence between the projection to is greater than 0.2
meaning that inside the different sections of the curve, the projections to are close. As increases, a different region of local minima becomes global. A sketch of this is shown in Figure 20.
The curve is colored according to the distribution of W as shown on the right side of Figure 19. We see that a different distribution on results in a different minimum, except for the region between 7.5 and 8. The colors light blue and yellow refer to distributions on that are different, but symmetric in the following way. Consider two different distributions on such that
for all . Then the corresponding marginalized distributions in are equal
This symmetry is the reason for the different colors in the region between 7.5 and 8.
Using this geometric algorithm we therefore gain a notion of the local minima on .
3. Discussion
This article discusses a selection of existing complexity measures in the context of Integrated Information Theory that follow the framework introduced in Reference [7], namely and . The main contribution is the proposal of a new measure, Causal Information Integration .
In Reference [4] and Reference [5] the authors postulate a Markov condition, ensuring the removal of the causal cross-connections, and an upper bound, given by the mutual information , for valid Integrated Information measures. Although is not bounded by , as we see in Figure 17, it does measure the intrinsic causal cross-connections in a setting in which there exists no common exterior influences. Therefore the authors of Reference [12] criticize this bound. Since wrongly assuming the existence of a common exterior influence might lead to a value that does not measure all the intrinsic causal influences, the question which measure to use strongly depends on how much we know about the system and its environment. We argue that using as an upper bound in the cases in which we have an unknown common exterior influence is reasonable. The measure attempts to extend to a setting with exterior influences, but it does not satisfy the Markov condition postulated in Reference [4].
One measure that fulfills all the requirements of this framework is , but it has no graphical representation. Hence the causal nature of the measured information flow is difficult to analyze. We present in Example 1 a submodel of that has a causal structure, which does not lie inside the set of Markovian processes , that we discuss in this article. Therefore by projecting to we might project to a distribution that still holds some of the integrated information of the original system, although it does not have any causal cross-connections. Additionally we demonstrate that does not correspond to a graphical representation, even after adding any number of latent variables to the model of . This is conflicting with the strong connection between conditional independence statements and graphs in Pearls causality theory. For discrete variables does not have a closed form solution and has to be calculated numerically.
We propose a new measure that also satisfies all the conditions and has additionally a graphical and intuitive interpretation. Numerically calculated examples indicate that . The definition of explicitly includes an interior influence as a latent variable and therefore aims at only measuring intrinsic causal influences. This measure should be used in the setting in which there exists an unknown common exterior influence. By assuming the existence of a ground truth, we are able to prove that our new measure is bounded from above by the ultimate value of Integrated Information of this system. Although also has no analytical solution, we are able to use the information geometric em-algorithm to calculate it. The em-algorithm is guaranteed to converge towards a minimum, but this might be local. Even after letting our smallest example, depicted in Figure 15, run with 100 random input distributions, we still get local minima. On the other hand, in our experience the em-algorithm seems to be more reliable, and for larger networks faster, than the numerical methods we used to calculate . Additionally, by letting the algorithm run multiple times we are able to gain a notion on how the local minima in are related to each other as demonstrated in Figure 19.
4. Materials and Methods
The distributions used in the Section 2.2.2 were generated by a python program and the measures ans are implemented in C++. The python package scipy.mimimize has been used to calculate . The code is available at Reference [26].
Author Contributions
Conceptualization, N.A. and C.L.; methodology, N.A. and C.L.; software, C.L.; investigation, C.L.; writing, C.L.; supervision, N.A.; project administration, N.A.; funding acquisition, N.A. All authors have read and agreed to the published version of the manuscript.
Funding
The authors acknowledge funding by Deutsche Forschungsgemeinschaft Priority Programme “The Active Self” (SPP 2134).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Graphical Models
Graphical models are a useful tool to visualize conditional independence structures. In this method a graph is used to describe the set of distributions that factor according to it. In our case, we are considering chain graphs.These are graphs, with vertex set V and edge set , consisting of directed and undirected edges such that we are able to partition the vertex set into subsets , called chain components, with the properties that all edges between different subsets are directed, all edges between vertices of the same chain component are undirected and that there are no directed cycles between chain components. For a vertex set , we will denote by the set of parents of element in , which are vertices with a directed arrow from to an element of . Vertices connected by an undirected edge are called neighbours. A more detailed description can be found in Reference [16].
Definition A1.
Let T be the set of chain components. A distribution factorizes with respect to a chain graph G if the distribution can be written as follows
where the structure of can be described in more detail. Let be the set of all subsets of , that are complete in a graph , which is an undirected graph with the vertex set and the edges are the ones between elements in that exist in G and additionally the ones between elements in . An undirected graph is complete if every pair of distinct vertices is connected by an edge. Then there are non-negative functions such that
If is a singleton then is already complete. There are different kinds of independence statements a chain graph can encode, but we only need the global chain graph markov property. In order to define this property we need the concepts ancestral set and moral graph.
The boundary of a set is the set of vertices in that are parents or neighbours to vertices in A. If for all we call A an ancestral set. For any there exists a smallest ancestral set containing A, because the intersection of ancestral sets is again an ancestral set. This smallest ancestral set of A is denoted by .
Let G be a chain graph. The moral graph of G is an undirected graph denoted by that consists of the same vertex set as G and in which two vertices are connected if and only if either they were already connected by an edge in G or if there are vertices belonging to the same chain component such that and .
Definition A2.
(Global Chain Graph Markov Property). Let P be a distribution on and G a chain graph. P satisfies the global chain Markov property, with respect to G, if for any triple of disjoint subsets of Z such that separates from in , the moral graph of the smallest ancestral set containing ,
holds.
Since we are only considering positive discrete distributions, we have the following result.
Lemma A1.
The global chain Markov property and the factorization property are equivalent for positive discrete distributions.
Proof of Lemma A1.
In order to understand the conditional independence structure of a chain graph after marginalization, we need the following alogrithm from Reference [17]. This algorithm converts a chain graph with latent variables into a chain mixed graph with the conditional independence structure of the marginalized chain graph. A chain mixed graph has in addition to directed and undirected edges also bidirected edges, called arcs. The condition that there are no semi-directed cycles also applies to chain mixed graphs.
Definition A3.
Let M be the set of vertices over which we want to marginalize. The following algorithm produces a chain mixed graph (CMG) with the conditional independence structure of the marginalized chain graph.
- 1.
- Generate an ij edge as in Table A1, steps 8 and 9, between i and j on a collider trislide with an endpoint j and an endpoint in M if the edge of the same type does not already exist.
- 2.
- Generate an appropriate edge as in Table A1, steps 1 to 7, between the endpoints of every tripath with inner node in M if the edge of the same type does not already exist. Apply this step until no other edge can be generated.
- 3.
- Remove all nodes in M.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Types of edge induced by tripaths with inner node m ∈ M and trislides with endpoint m ∈ M.
Table A1.
Types of edge induced by tripaths with inner node m ∈ M and trislides with endpoint m ∈ M.
| 1 | i ← m ← j | generates | i ← j |
| 2 | i ← m – j | generates | i ← j |
| 3 | i ↔ m —j | generates | i ↔ j |
| 4 | i ← m → j | generates | i ↔ j |
| 5 | i ← m ↔ j | generates | i ↔ j |
| 6 | i – m ← j | generates | i ← j |
| 7 | i – m – j | generates | i–j |
| 8 | m → i – ⋯ – j | generates | i ← j |
| 9 | mj | generates | i ↔ j |
Conditional independence in CMGs is defined using the concept of c-separation, see for example Reference [17] in Section 4. For this definition we need the concepts of a walk and of a collider section. A walk is a list of vertices , such there is an edge or arrow from to . A set of vertices connected by undirected edges is called a section. If there exists a walk including a section such that an arrow points at the first and last vertices of the section
then this is called a collider section.
Definition A4 (c-separation).
Let and C be disjoint sets of vertices of a graph. A walk π is called a c-connecting walk given C, if every collider section of π has a node in C and all non-collider sections are disjoint. The nodes A and B are called c-separated given C if there are no c-connecting walks between them given C and we write .
Appendix B. Proofs
Proof of the Relationship (4).
Proof of Proposition 1.
If holds, then
Since is compact the infimum is an element of , so there exists such that . Therefore and the existence of a sequence follows from the definition of .
Assume that there exists a sequence that satisfies 1. and 2. Then every element per definition and the limit
Hence
□
Proof of Proposition 2.
Let and , then the KL-divergence between the two elements is
The inequality holds, because in the first and third addend, we are able to apply that the cross entropy is greater or equal to the entropy and in the second addend we use the log-sum inequality in the following way
Therefore the new integrated information measure results in
This can be rewritten to
□
Proof of Proposition 3.
By using the log-sum inequality we get
The fact that every element of corresponds via marginalization to an element in and every element in has at least one corresponding element in , leads to the equality in the last row. Since taking the infimum over a larger space can only decrease the value further, the relation
holds. □
Proof of Proposition 5.
The first addend is a constant for P and the others are cross-entropies which are greater or equal to entropy
Therefore this projection is unique. □
Proof of Theorem 2.
We need a way to understand the connections in a graph after marginalization. In Reference [17] Sadeghi presents an algorithm that converts a chain graph to a chain mixed graph that represents the markov properties of the original graph after marginalizing, see Definition A3.
Although the actual set of distributions after marginalizing might be more complicated, it is a subset of the distributions factorizing according to the new graph, if the new graph is still a chain graph. This is due to the equivalence of the global chain Markov property and the factorization property in Lemma A1.
At first we will consider the case of two nodes per time step, . We will take a close look at the possible ways a hidden structure could be connected to the left graph in Figure A1. At first we will look at the possible connections between two nodes, depicted on the right in Figure A1. The boxes stand for any kind of subgraph of hidden nodes such that the whole graph is still a chain graph and the two headed dotted arrows stand for a line, or an arrow in any direction. Consider two nodes A and B, then the connections including a box between the nodes can take one of the five following forms
- they form an undirected path between A and B,
- they can form a directed path from A to B,
- they can form a directed path form B to A,
- there exists a collider,
- A and B have a common exterior influence.
A collider is a node or a set of nodes connected by undirected edges that have an arrow pointing at the set at both ends
![Entropy 22 01107 g0a1]()
Figure A1.
Starting graph and possible two way interactions.

We will start with the gridded hidden structure connected to and . Since there already is an undirected edge between the s an undirected path would make no difference in the marginalized model. The cases (2) and (3) would form a directed cycle which violates the requirements of a chain mixed graph. A collider would also make no difference, since it disappears in the marginalized model. A common exterior influence leads to
Now let us discuss these possibilities in the case of a gray hidden structure between and , . An undirected edge or a directed edge (3) would create a directed cycle. A directed path (2) from to would lead to a chain graph in which and are not conditionally independent given . If there exists a collider (4) in the hidden structure, then nothing else in the graph depends on this part of the structure and it reduces to a factor one when we marginalize over the hidden variables. Therefore the path between and gets interrupted leaving a potential external influence or effect. Those do not have an additional impact on the marginalized model. A common exterior influence (5) leads to a chain mixed graph which does not satisfy the necessary conditional independence structure, because using the Algorithm A3 leads to an arc between and , hence they are c-connected in the sense of Definition A4.
The next possibility is a dotted hidden structure between and . An undirected path (1) and a directed path (3) would lead to a directed cycle. A directed path (2) would add no new structure to the model since there already is a directed edge between and . A collider (4) does not have an effect on the marginalized model. Adding a common exterior influence on results in a new model which is not symmetric in and does not include , therefore it does not fully contain . By adding additional common exterior influences on or , in order to include in the new model, violates the conditional independence statements since nodes in and are connected in the moralized graph.
The last hidden structure between two nodes is the striped one between the s. An undirected path (1) or any directed path (2), (3) lead to a graph that does not satisfy the conditional independence statements. A collider (4) has no impact on the model and a common exterior influence leads to the definition of Causal Information Integration.
Connecting and leads either to a violation of the conditional independence statements or contains a collider in which case the marginalized model reduces to one of the cases above.
All the possible ways a hidden structure could be connected to three nodes by directed edges are shown in Figure A2. Replacing any of these edges by an undirected edge would either make no difference or lead to a model that does not satisfy the conditional independence statements. In this case the black boxes represent sections. More complicated hidden structures reduce to this case, since these structures either contain a collider and correspond to one of the cases above or contain longer directed paths in the direction of the edges connecting the structure to the visible nodes, which does not change the marginalized model.
![Entropy 22 01107 g0a2]()
Figure A2.
The eight possible hidden structures between three nodes.

The models in (c), (d), (e), (f) and (g) contain either a collider and reduce therefore to one of the cases discussed above or induce a directed cycle. We see that (a) and (h) display structures that do not satisfy the conditional independence statements. The hidden structure in (b) has no impact on the model.
A hidden structure connected to all four nodes contains one of the structures above and therefore does not induce a new valid model.
Let us now consider a model with . Any hidden structure on this model either connects only up to four nodes and reduces therefore to one of the cases above, contains one of the connections discussed in Figure A2 or only connects nodes among one point in time. The only structures possible to add would be a common exterior influence on the s, a common exterior influence on the s or a collider section on any nodes. All these structures do not change the marginalized model. Therefore it is not possible to create a chain graph with hidden nodes in order to get a model strictly larger than . □
References
- Tononi, G.; Edelman, G.M. Consciousness and Complexity. Science 1999, 282, 1846–1851. [Google Scholar] [CrossRef]
- Tononi, G. Consciousness as Integrated Information: A Provisional Manifesto. Biol. Bull. 2008, 215, 216–242. [Google Scholar] [CrossRef]
- Oizumi, M.; Albantakis, L.; Tononi, G. From the Phenomenology to the Mechanisms of Consciousness: Integrated Information Theory 3.0. PLoS Comput. Biol. 2014, 10, 1–25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oizumi, M.; Tsuchiya, N.; Amari, S. Unified framework for information integration based on information geometry. Proc. Natl. Acad. Sci. USA 2016, 113, 14817–14822. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amari, S.; Tsuchiya, N.; Oizumi, M. Geometry of Information Integration. In Information Geometry and Its Applications; Ay, N., Gibilisco, P., Matúš, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–17. [Google Scholar]
- Ay, N. Information Geometry on Complexity and Stochastic Interaction. MPI MIS PREPRINT 95. 2001. Available online: https://www.mis.mpg.de/preprints/2001/preprint2001_95.pdf (accessed on 28 September 2020).
- Ay, N. Information Geometry on Complexity and Stochastic Interaction. Entropy 2015, 17, 2432–2458. [Google Scholar] [CrossRef]
- Ay, N.; Olbrich, E.; Bertschinger, N.A. Geometric Approach to Complexity. Chaos 2011, 21. [Google Scholar] [CrossRef] [PubMed]
- Oizumi, M.; Amari, S.; Yanagawa, T.; Fujii, N.; Tsuchiya, N. Measuring Integrated Information from the Decoding Perspective. PLoS Comput. Biol. 2016, 12. [Google Scholar] [CrossRef] [PubMed]
- Amari, S. Information Geometry and Its Applications; Springer Japan: Tokyo, Japan, 2016. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Kanwal, M.S.; Grochow, J.A.; Ay, N. Comparing Information-Theoretic Measures of Complexity in Boltzmann Machines. Entropy 2017, 19, 310. [Google Scholar] [CrossRef]
- Barrett, A.B.; Seth, A.K. Practical Measures of Integrated Information for Time- Series Data. PLoS Comput. Biol. 2011, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Csiszár, I.; Shields, P. Foundations and Trends in Communications and Information Theory. In Information Theory and Statistics: A Tutorial; Now Publishers Inc.: Delft, The Netherlands, 2004; pp. 417–528. [Google Scholar]
- Studený, M. Probabilistic Conditional Independence Structures; Springer: London, UK, 2005. [Google Scholar]
- Lauritzen, S.L. Graphical Models; Clarendon Press: Oxford, UK, 1996. [Google Scholar]
- Sadeghi, K. Marginalization and conditioning for LWF chain graphs. Ann. Stat. 2016, 44, 1792–1816. [Google Scholar] [CrossRef] [Green Version]
- Montúfar, G. On the expressive power of discrete mixture models, restricted Boltzmann machines, and deep belief networks—A unified mathematical treatment. Ph.D. Thesis, Universität Leipzig, Leipzig, Germany, 2012. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Csiszár, I.; Tusnády, G. Information geometry and alternating minimization procedures. Stat. Decis. 1984, Supplemental Issue Number 1, 205–237. [Google Scholar]
- Amari, S.; Kurata, K.; Nagaoka, H. Information geometry of Boltzmann machines. IEEE Trans. Neural Netw. 1992, 3, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. 1977, 39, 2–38. [Google Scholar]
- Amari, S. Information Geometry of the EM and em Algorithms for Neural Networks. Neural Netw. 1995, 9, 1379–1408. [Google Scholar] [CrossRef]
- Winkler, G. Image Analysis, Random Fields and Markov Chain Monte Carlo Methods; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Choromanska, A.; Henaff, M.; Mathieu, M.; Arous, G.B.; LeCun, Y. The Loss Surfaces of Multilayer Networks. PMLR 2015, 38, 192–204. [Google Scholar]
- Langer, C. Integrated-Information-Measures GitHub Repository. Available online: https://github.com/CarlottaLanger/Integrated-Information-Measures (accessed on 18 August 2020).
- Frydenberg, M. The Chain Graph Markov Property. Scand. J. Stat. 1990, 17, 333–353. [Google Scholar]
- Ay, N.; Jost, J.; Lê, H.V.; Schwachhöfer, L. Information Geometry; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
Figure 1.
The fully connected system for and .

Figure 2.
Interior and exterior influences on Y in the full and the split system corresponding to .

Figure 3.
The different measures and their properties in the case of .

Figure 4.
Split systems with exterior influences for and .

Figure 5.
Marginalized Model for and .

Figure 6.
Submodels of the split models with exterior influences for and .

Figure 7.
The graphs corresponding to and (right).

Figure 8.
Graph of the model .

Figure 9.
Graph of the model .

Figure 10.
Sketch of the relationships among and

Figure 11.
Example of an exterior influence on the initial graph.

Figure 12.
Sketch of the relationship between the manifolds corresponding to the different measures.
Figure 12.
Sketch of the relationship between the manifolds corresponding to the different measures.

Figure 13.
Sketch of the em-Algorithm.

Figure 14.
The weights corresponding to the connections for .

Figure 15.
Ising model with 2 nodes and the differences between and .

Figure 16.
Ising model with 3 nodes.

Figure 17.
Ising model with 5 nodes.

Figure 18.
The effect of a different sized state space.

Figure 19.
Curve of one run of the em-algorithm for each coloured according to the distribution of W.
Figure 19.
Curve of one run of the em-algorithm for each coloured according to the distribution of W.

Figure 20.
Sketch of different local Minima.

Table 1.
The results of the em-algorithm between and .
| Minimum | Maximum | Arithmetic Mean | |
|---|---|---|---|
| 2 | 0.011969035529826939 | 0.5028091152589176 | 0.15263592877594967 |
| 3 | 0.021348311360946 | 0.5499395859771526 | 0.1538653506807848 |
| 4 | 0.014762084688030863 | 0.3984635189946462 | 0.15139198568055212 |
| 8 | 0.017334311629729246 | 0.4383731978333986 | 0.15481967618112732 |
| 16 | 0.024306996171092318 | 0.4238222051787452 | 0.1490336847067273 |
| 300 | 0.016524177216064712 | 0.47733473380366764 | 0.15493896625208842 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Langer, C.; Ay, N. Complexity as Causal Information Integration. Entropy 2020, 22, 1107. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101107
AMA Style
Langer C, Ay N. Complexity as Causal Information Integration. Entropy. 2020; 22(10):1107. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101107
Chicago/Turabian StyleLanger, Carlotta, and Nihat Ay. 2020. "Complexity as Causal Information Integration" Entropy 22, no. 10: 1107. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101107
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.