Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information

Abstract
:1. Introduction
2. Related Work
2.1. Embedding Models for Knowledge Graph Completion
2.2. Neural Network-Based Models for Knowledge Graph Completion
2.3. Language Models for Knowledge Graph Completion
2.4. Multisource Information Incorporation for Knowledge Graph Completion
3. Methodology
3.1. Bidirectional Encoder Representations from Transformers (BERT)
3.2. BERT-KGC Model with Entity-Type Information
4. Experiments
4.1. Dataset and Baselines
4.1.1. Dataset
4.1.2. Baselines
- TransE, the classical link embedding model proposed by Bordes et al. [21].
- TransH, an extension of TransE [22].
- TransR, an extension of TransE [23].
- TransD, an improvement of TransR [24].
- TEKE, a knowledge graph representation learning method taking advantage of the rich context information in a text corpus [8].
- NTN, the neural tensor network proposed by Socher et al. [25].
- TKRL, knowledge graph embeddings with hierarchical entity types and constraint information between entity types and relations [19].
- ConvE, based on the CNN model proposed by Dettmers et al. [11].
- ConvKB, an extension of ConvE proposed by Nguyen et al. [10].
- CapsE, which added a capsule network layer on top of the convolution layer, proposed by Nguyen et al. [12].
- KG-BERT, a knowledge graph completion framework based on pre-trained language models, which was proposed and applied to English text by Yao et al. [29].
4.2. Experimental Settings
4.3. Experimental Results
4.3.1. Performance Comparison of BERT-KGC and the Baselines in Triple Classification
4.3.2. Performance Comparison of BERT-KGC and the Baselines for Link Prediction
4.3.3. Performance Comparison of BERT-KGC and the Baselines for Relation Prediction
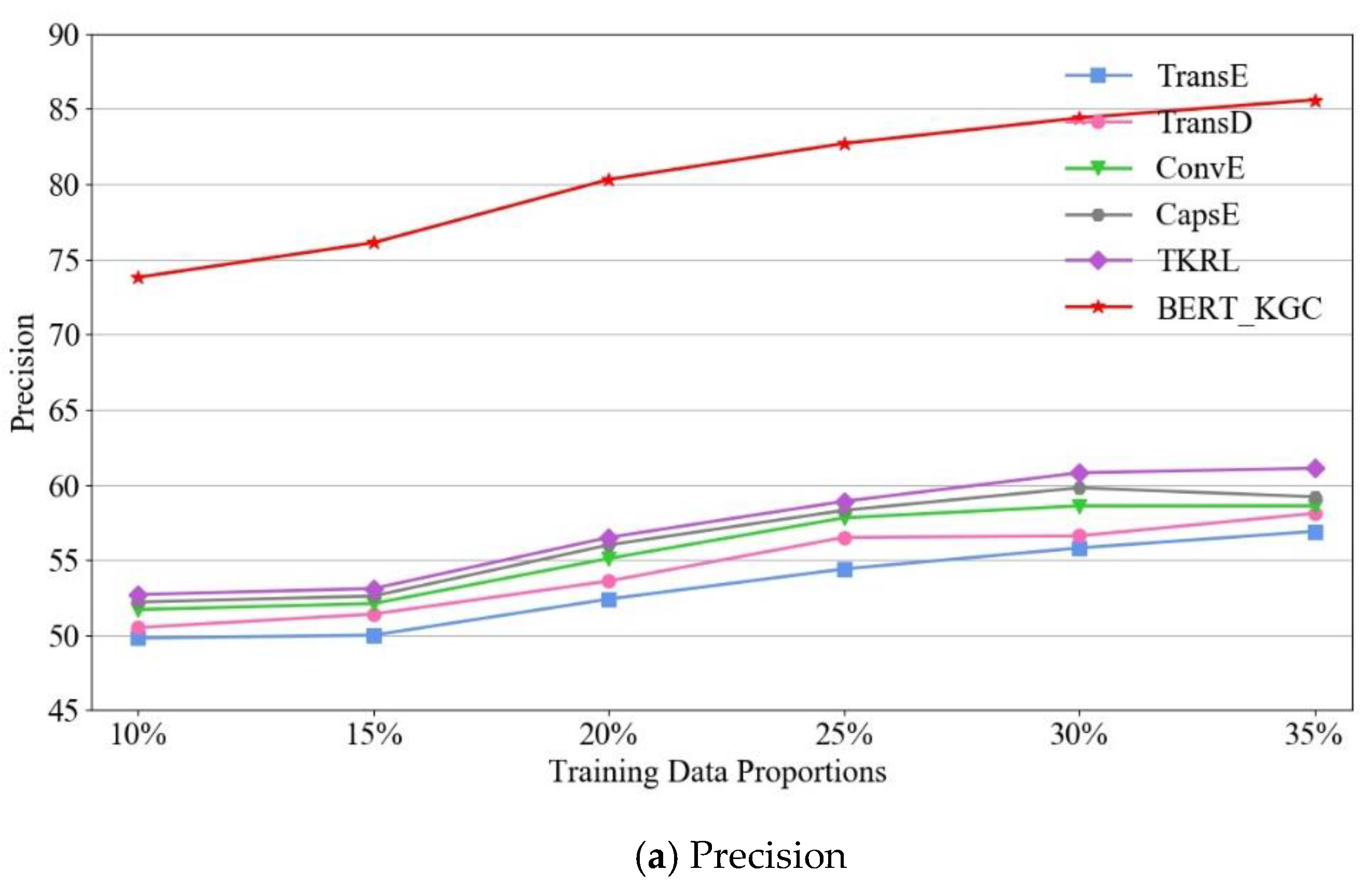
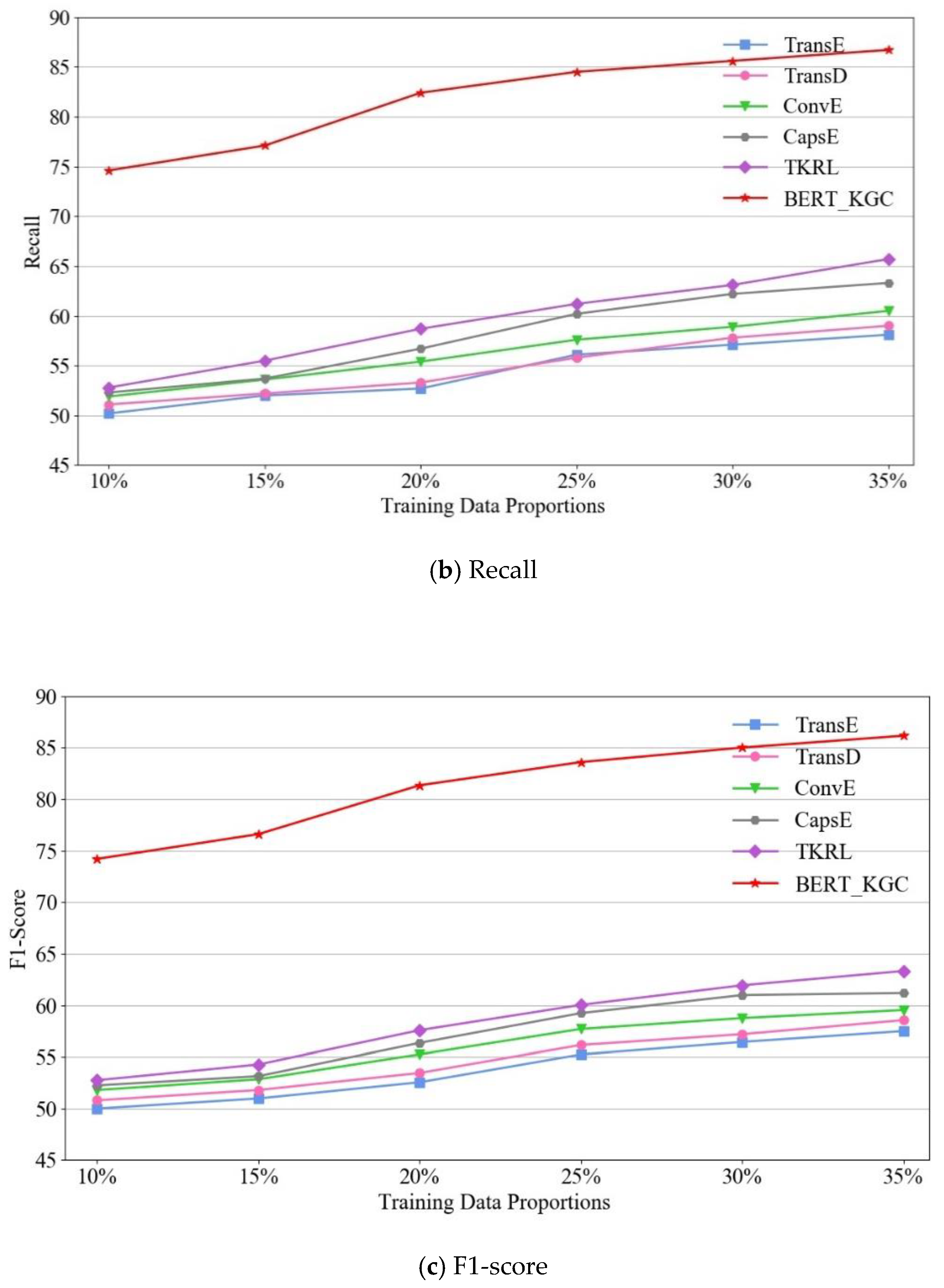
4.3.4. The Influence of Training Data Proportions on Triple Classification
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Robert, W.; Evgeniy, G.; Kevin, M.; Sun, S.; Rahul, G.; Lin, D. Knowledge Base Completion via Search-based Question Answering. In Proceedings of the 23rd international conference on Machine learning-ICML’06, Seoul, Korea, 7–11 April 2014; pp. 515–526. [Google Scholar]
- Sancheti, A.; Maheshwari, P.; Chaturvedi, R.; Monsy, A.V.; Goyal, T.; Srinivasan, B.V. Harvesting Knowledge from Cultural Heritage Artifacts in Museums of India. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2018); Springer: Cham, Switzerland, 2018; pp. 312–324. [Google Scholar]
- Krompaß, D.; Baier, S.; Tresp, V. Type-Constrained Representation Learning in Knowledge Graphs. In Proceedings of the 14th International Semantic Web Conference (ISWC), Bethlehem, PA, USA, 28 August 2015; pp. 640–655. [Google Scholar]
- Minkov, E.; Kahanov, K.; Kuflik, T. Graph-based recommendation integrating rating history and domain knowledge: Application to onsite guidance of museum visitors. J. Assoc. Inf. Sci. Technol. 2017, 68, 1911–1924. [Google Scholar] [CrossRef]
- Matt, G.; Partha, P.T.; Jayant, K.; Tom, M.M. Incorporating Vector Space Similarity in Random Walk Inference over Knowledge Bases. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 397–406. [Google Scholar]
- Antoine, B.; Jason, W.; Ronan, C.; Yoshua, B. Learning Structured Embeddings of Knowledge Bases. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; pp. 301–306. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 2016, 104, 11–33. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.-Z. Text-Enhanced Representation Learning for Knowledge Graph. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1293–1299. [Google Scholar]
- Xu, J.; Qiu, X.; Chen, K.; Huang, X. Knowledge Graph Representation with Jointly Structural and Textual Encoding. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1318–1324. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Novel Embedding Model for Knowledge base Completion based on Convolutional Neural Network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; pp. 327–333. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d Knowledge Graph Embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Vu, T.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Long and Short Papers), Minneapolis, MN, USA,, 13 August 2019; Volume 1, pp. 2180–2189. [Google Scholar]
- Lin, Y.; Liu, Z.; Luan, H.; Sun, M.; Rao, S.; Liu, S. Modeling Relation Paths for Representation Learning of Knowledge Bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 705–714. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-Supervised Sequence Learning. In Proceedings of the Advances in neural information processing systems (NIPS 2015), Montréal, QC, Canada, 7–10 December 2015; pp. 3079–3087. [Google Scholar]
- Yang, B.; Yih, W.-T.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inferencein Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; pp. 2227–2237. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; Technical Report; OpenAI: San Francisco, CA, USA, June 2018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation Learning of Knowledge Graphs with Hierarchical Types. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Nguyen, D.Q. An overview of embedding models of entities and relationships for knowledge base completion. arXiv 2017, arXiv:1703.08098. [Google Scholar]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Zheng, C. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI), Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligenc, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding Via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE TKDE 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS 2013), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 926–934. [Google Scholar]
- Wang, H.; Kulkarni, V.; Wang, W.Y. Dolores: Deep contextualized knowledge graph embeddings. arXiv 2018, arXiv:1811.00147. 2018. [Google Scholar]
- Davison, J.; Feldman, J.; Rush, A.M. Commonsense Knowledge Mining from Pretrained Models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1173–1178. [Google Scholar]
- Yao, L.; Mao, C.S.; Luo, Y. KG-BERT: BERT for Knowledge Graph Completion. arXiv 2019, arXiv:1909.03193v2. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph and Text Jointly Embedding. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1591–1601. [Google Scholar]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation Learning of Knowledge Graphs with Entity Descriptions. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12 May 2016; pp. 2659–2665. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Zhang, M.; Geng, G.; Chen, J. Semi-Supervised Bidirectional Long Short-Term Memory and Conditional Random Fields Model for Named-Entity Recognition Using Embeddings from Language Models Representations. Entropy 2020, 22, 252. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Geng, G. Capsule Networks with Word-attention Dynamic Routing for Cultural Relics Relation Extraction. IEEE Access 2020, 8, 94236–94244. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Rel | # Ent | # Train | # Dev | # Test |
|---|---|---|---|---|---|
| CCR20 | 16 | 34,877 | 69,642 | 2908 | 3069 |
| Method | P | R | F1 |
|---|---|---|---|
| TransE (Bordes et al. 2013) [21] | 70.3 | 72.2 | 71.2 |
| TransH (Wang et al. 2014) [22] | 72.3 | 70.4 | 71.3 |
| TransR (Lin et al. 2015b) [23] | 75.5 | 77.6 | 76.5 |
| TEKE (Wang and Li 2016) [8] | 75.8 | 78.3 | 77.1 |
| NTN (Socher et al. 2013) [25] | 76.0 | 79.4 | 77.7 |
| TransD (Ji et al. 2015) [24] | 76.7 | 80.9 | 78.7 |
| ConvE (Dettmers et al. 2018) [11] | 77.3 | 81.6 | 79.4 |
| ConvKB (Nguyen et al. 2017) [10] | 77.9 | 84.3 | 81.1 |
| CapsE (Nguyen et al. 2019) [12] | 80.4 | 84.4 | 82.3 |
| TKRL (Xie et al. 2016) [19] | 81.1 | 85.0 | 83.3 |
| KG-BERT(a) (Yao et al. 2019) [29] | 83.8 | 86.6 | 85.2 |
| BERT-KGC | 86.3 | 88.7 | 87.5 |
| Method | MR | Hits@10 |
|---|---|---|
| TransE (Bordes et al. 2013) [21] | 2594 | 47.3 |
| TransH (Wang et al. 2014) [22] | 2965 | 46.2 |
| TransR (Lin et al. 2015b) [23] | 3272 | 48.4 |
| NTN (Socher et al. 2013) [25] | 3315 | 47.2 |
| TransD (Ji et al. 2015) [24] | 3303 | 47.3 |
| ConvE (Dettmers et al. 2018) [11] | 3298 | 49.3 |
| ConvKB (Nguyen et al. 2017) [10] | 2592 | 50.3 |
| CapsE (Nguyen et al. 2019) [12] | 2945 | 51.3 |
| TKRL (Xie et al. 2016) [19] | 2108 | 51.9 |
| KG-BERT(a) (Yao et al. 2019) [29] | 1136 | 52.2 |
| BERT-KGC | 897 | 53.5 |
| Method | MR | Hits@10 |
|---|---|---|
| TransE (Bordes et al. 2013) [21] | 379 | 78.2 |
| TransH (Wang et al. 2014) [22] | 370 | 79.4 |
| TransR (Lin et al. 2015b) [23] | 369 | 78.9 |
| NTN (Socher et al. 2013) [25] | 387 | 77.6 |
| TransD (Ji et al. 2015) [24] | 332 | 79.1 |
| ConvE (Dettmers et al. 2018) [11] | 259 | 79.4 |
| ConvKB (Nguyen et al. 2017) [10] | 264 | 80.6 |
| CapsE (Nguyen et al. 2019) [12] | 260 | 81.8 |
| TKRL (Xie et al. 2016) [19] | 246 | 80.2 |
| KG-BERT(b) (Yao et al. 2019) [29] | 132 | 82.1 |
| BERT-KGC | 98 | 84.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Geng, G.; Zeng, S.; Jia, H. Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information. Entropy 2020, 22, 1168. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101168
Zhang M, Geng G, Zeng S, Jia H. Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information. Entropy. 2020; 22(10):1168. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101168
Chicago/Turabian StyleZhang, Min, Guohua Geng, Sheng Zeng, and Huaping Jia. 2020. "Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information" Entropy 22, no. 10: 1168. https://0-doi-org.brum.beds.ac.uk/10.3390/e22101168