Degrees-Of-Freedom in Multi-Cloud Based Sectored Cellular Networks


1
Institut National des Sciences Appliquées de Rennes, Université de Rennes, 20 Avenue des Buttes de Coesmes, 35708 Rennes, France
2
Laboratoire Traitement et Communication de l’Information (LTCI), Telecom Paris, Institut Polytechnique de Paris, 91120 Palaiseau, France
*
Authors to whom correspondence should be addressed.
Entropy 2020, 22(6), 668; https://0-doi-org.brum.beds.ac.uk/10.3390/e22060668
Submission received: 15 May 2020
/
Revised: 9 June 2020
/
Accepted: 11 June 2020
/
Published: 16 June 2020
(This article belongs to the Special Issue Wireless Networks: Information Theoretic Perspectives)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This paper investigates the achievable per-user degrees-of-freedom (DoF) in multi-cloud based sectored hexagonal cellular networks (M-CRAN) at uplink. The network consists of N base stations (BS) and base band unit pools (BBUP), which function as independent cloud centers. The communication between BSs and BBUPs occurs by means of finite-capacity fronthaul links of capacities with P denoting transmit power. In the system model, BBUPs have limited processing capacity . We propose two different achievability schemes based on dividing the network into non-interfering parallelogram and hexagonal clusters, respectively. The minimum number of users in a cluster is determined by the ratio of BBUPs to BSs, . Both of the parallelogram and hexagonal schemes are based on practically implementable beamforming and adapt the way of forming clusters to the sectorization of the cells. Proposed coding schemes improve the sum-rate over naive approaches that ignore cell sectorization, both at finite signal-to-noise ratio (SNR) and in the high-SNR limit. We derive a lower bound on per-user DoF which is a function of , , and r. We show that cut-set bound are attained for several cases, the achievability gap between lower and cut-set bounds decreases with the inverse of BBUP-BS ratio for irrespective of , and that per-user DoF achieved through hexagonal clustering can not exceed the per-user DoF of parallelogram clustering for any value of and r as long as . Since the achievability gap decreases with inverse of the BBUP-BS ratio for small and moderate fronthaul capacities, the cut-set bound is almost achieved even for small cluster sizes for this range of fronthaul capacities. For higher fronthaul capacities, the achievability gap is not always tight but decreases with processing capacity. However, the cut-set bound, e.g., at , can be achieved with a moderate clustering size.
1. Introduction
Interference is one of the fundamental obstacles for high data rate communications in current and future cellular networks because of restricting the effect on overall spectral efficiency in bits/sec/Hz/base station. Sectorization, which has been used in 4G networks, is one solution to alleviate intra-cell interference by using multiple antennas at base stations (BS) resulting in directional beams that cover an intended sector. In the literature, sectorization is often combined with hexagonal cell models, and mostly each cell is divided into three sectors [1,2]. Here, we follow the works in [3,4,5,6] that totally ignore the interference between the sectors in the same cell. In real systems, this is not the case since the side lobes of the radiation pattern cause to observe signals from adjacent inter-cell sectors. However, we ignore it in the current work since the interference is close to the noise level and our focus will be on the sum-capacity of the sectored hexagonal network in the high signal-to-noise ratio (SNR) and the degrees of freedom (DoF) per-user.
Together with sectorization, cooperation between BSs or mobile users is a well-known technique of decreasing the detrimental effect of interference in cellular networks (see e.g., [7] and references therein). In the context of cellular networks, cooperation has mostly been used to create alternate communication paths (by having mobile users or dedicated terminals relay the transmit signals of adjacent mobiles, see, e.g., [8,9]), or to provide BSs with quantized versions of the transmit/receive signals of other BSs via backhaul links (allowing for clustered decoding, see, e.g., [10,11,12,13,14,15,16]). Cooperation makes it possible for user data to be jointly processed by several BSs at both uplink and downlink, hence imitating the benefits of virtual multiple-input multiple-output (MIMO) architecture. This framework is also known as multi-cell processing (MCP) [7,16]. The study of MCP started for uplink with the works [12,13] and for downlink with the work [14] based on full cooperation assumption. In uplink, the received signals at all BSs are relayed to a central processor (CP) via perfect backhaul links (assumed to be of infinite capacity and error free). Then, the CP decodes all user messages jointly. In contrast, in downlink, the CP encodes all messages jointly and sends each transmit signal to its corresponding BS via backhaul links and each mobile user decodes the message itself. With such a full MCP through unlimited backhaul, there is no signal causing complete interference, that is, all received or transmitted signals provide useful information in decoding at the CP or mobile users. Then, interference becomes constructive rather than destructive. Thus, it is exploited.
The exploitation of interference is also possible by implementing the full MCP with limited capacity backhaul links, which is studied for uplink in [15,16] and for downlink in [17]. In [15,16], BSs share functions of their received signals using compress-and-forward protocol ([18], Theorem 6), where each BS first quantizes its received signal and then sends the quantization codeword to the CP. Then, the CP either decodes the quantization codewords and user messages jointly, or decompress quantization codewords first and then decodes the user messages. However, in the downlink [17], the CP precodes the interference across transmit signals of BSs through joint Dirty Paper Coding (DPC) [19] under individual power constraints for each BS. Therefore, each mobile user decodes its message by cancelling precoded interference. In [16,17], it is shown that the close to optimal performance can be achieved in some scenarios by full MCP with modest capacity backhaul links.
Cloud radio access network (CRAN) is a promising architecture for 5G wireless networks [20] to exploit the interference. For a single-CRAN, each BS in the network acts only as a relay and all BSs are connected to the single base-band-unit pool (BBUP) that performs encoding/decoding functionalities, which mimics the function of a CP, over dedicated rate-limited fronthaul links. Therefore, it allows for natural implementation of full MCP with limited capacity relaying links. In some works such as [3,21,22], the performance of single-CRAN is investigated. For downlink, it is shown in [3] that, when each mobile user and sector receiver have M antennas, DoF per-user is achievable with moderate fronthaul capacity by applying simple zero forcing scheme with smart assignment of the messages to different BSs. Similar performance can be achieved for uplink by applying the ideas in [21]. However, due to complexity, latency, connectivity, scalability, and synchronization problems, the deployment of multi-cloud radio-access-networks (M-CRAN) is recently considered in a few works such as [23,24,25,26,27,28,29,30]. For example, Reference [27] studies the problem of optimization of precoding and joint compression of baseband signals across multiple clusters of BSs in downlink. It demonstrates that the multivariate compression based solution reduces the inter-cluster interference. A similar model is studied in [28] by adding access channels from BSs to mobile users as a joint optimization parameter besides precoding and fronthaul compression optimization. Reference [29] handles the network sum power consumption minimization problem for downlink M-CRAN while fronthaul capacity, channel state information CSI error, quality of service and BS power are taken into account as optimization constraints in order to to determine the beamforming vector of each user across the network and the optimal quantization noise covariance matrix associated with each cluster. This work proposes a distributed iterative solution that achieves the performance of the case all BSs connected to a single BBUP. While the formerly mentioned works assume non-dynamic clustering for each BBUP, the authors of [30] propose and analyze dynamic clustering approach based on instantaneous CSI, where they also consider the allocation of computation resources of BBUPs as an optimization parameter.
In the present work, we consider uplink of an M-CRAN with multiple-antenna mobile users and multiple-antenna BSs. We assume BSs, BBUPs with limited processing capacity and limited fronthaul capacity. The main interest of this paper is to understand highest achievable per-DoF and sum-rate for limited fronthaul and BBUP processing capacity for given BBUP-BS ratio . We propose two coding schemes in each of which some mobile users are deactivated to decompose the network into isolated parallelogram and hexagonal clusters, respectively. For both clustering types, the minimum number of mobile users/sectors are determined regarding a BBUP-BS ratio due to one-to-one association between BBUPs and clusters. Each BBUP collects quantized versions of the received signals of the associated cluster through fronthaul links and decodes them jointly. The considered decoding scheme is thus reminiscent of clustered decoding as performed in [10,31].
The contributions of this paper are:
- We propose a specific non-dynamic way of silencing mobile users in parallelogram clustering. One could attempt to silence entire cells. We find an efficient way of dividing the network non-interfering parallelogram clusters by silencing mobile users mostly in single sectors of the considered cells;
- We propose achievability schemes for both parallelogram and hexagonal clusterings and derive lower bounds on per-user DoF for both schemes in a function of fronthaul and BBUP processing capacities and BBUP-BS ratio;
- We prove that the performance of parallelogram clustering can not be worse than hexagonal clustering for small and moderate fronthaul capacities;
- We show by simulations that, for high fronthaul capacities, the coding scheme proposed for hexagonal clustering can show better performance than parallelogram clustering if the processing capacity is large enough according to given BBUP-BS ratio.
The upper bound is obtained through cut-set argument. In several cases, upper and lower bounds are matched. For small and moderate fronthaul capacities, the achievability gap is given as a function of fronthaul capacity and BBUP-BS ratio, and it is shown that it decreases with the inverse of the BBUP-BS ratio irrespective of BBUP processing capacity.
In the finite SNR case, we compare the proposed coding schemes with the following schemes:
- Naive versions of both schemes where all mobile users in certain cells are deactivated,
- Interfering versions of both schemes where the network is decomposed into non-overlapping but interfering clusters,
- An opportunistic scheme where each message is decoded based on the received signals of three neighboring sectors that have the strongest channel gains.
Finite SNR analysis shows that, in the strong interference regime, the proposed schemes outperform all other schemes for almost all SNR range under all scenarios except two; for the 3-sector decoding scheme, low SNR range and scarce BBUP capacities and, for non-interfering schemes, moderate SNR range and high BBUP capacities.
An interesting outcome of the finite SNR analysis is that interfering clustering schemes show either close to or better performance than proposed schemes in the finite SNR range under both weak and strong interference regimes; therefore, the interfering clusterings can be employed at finite SNR values with minor performance losses, since they may be more convenient for practical systems.
1.1. Organization
The rest of the paper is organized as follows: This section ends with some remarks on notation. The following Section 2 describes the problem definition. Section 3 presents the main results of the paper. In Section 4 and Section 5, we present the coding schemes for the parallelogram and hexagonal clusterings, respectively. Section 6 presents the achievability results for the naive schemes and Section 7 presents simulation results for DoF per-user. In Section 8, we present the results regarding the finite SNR analysis. We conclude the paper with Section 9 and some technical proofs are presented in the appendices.
1.2. Notation
We denote the set of all integers by , the set of positive integers by , and the set of real numbers by . For other sets, we use calligraphic letters, for example, . We represent random variables by uppercase letters, for example, X, and their realizations by lowercase letters, for example, x. We use boldface notation for vectors, that is, upper case boldface letters such as for random vectors and lower case boldface letters such as for deterministic vectors.) Matrices are depicted with sans serif font, for example, . We also write for the tuple of random vectors .
2. Problem Definition
2.1. Network Model
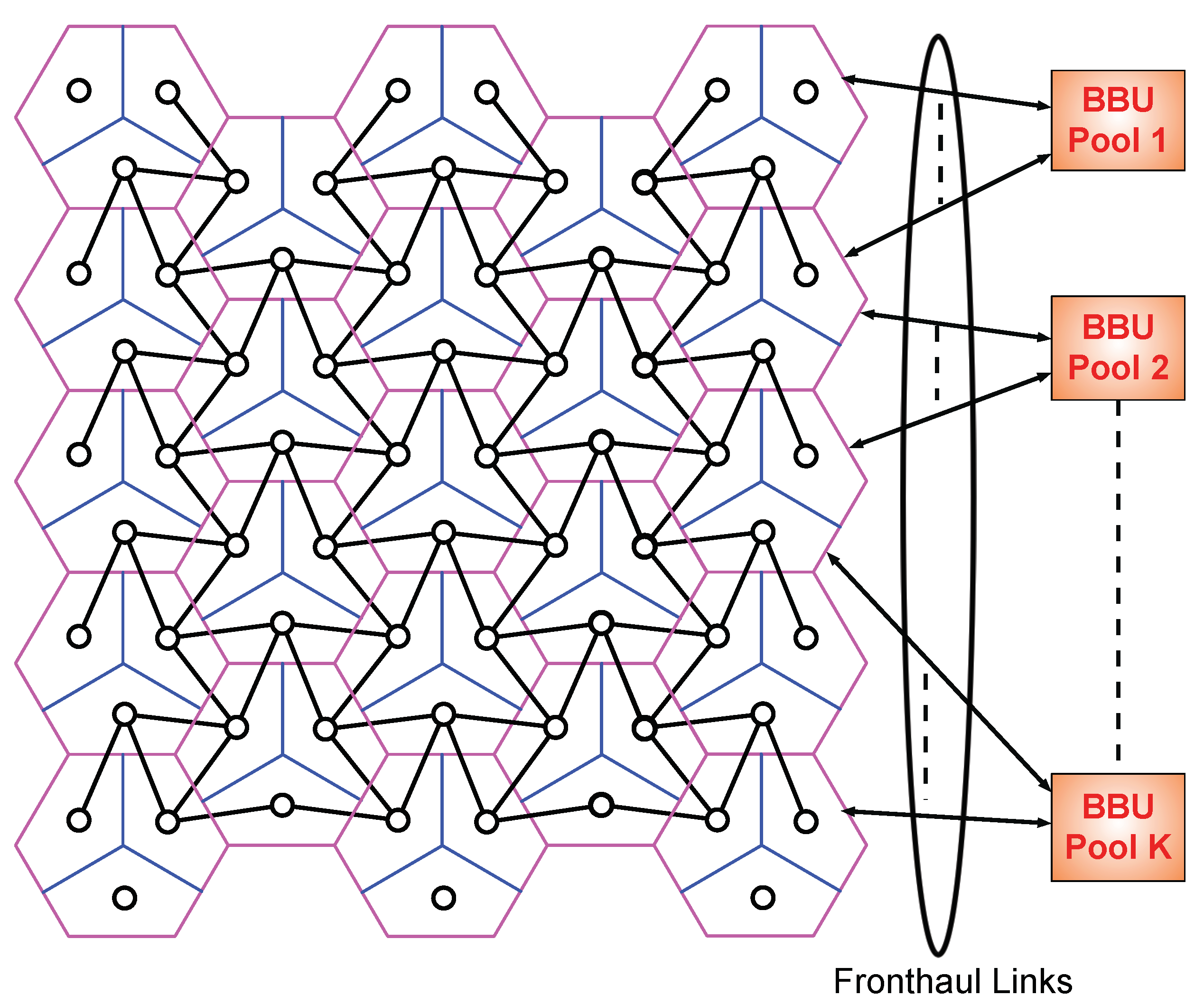
Consider the uplink communication in a cellular network consisting of hexagonal cells as depicted in Figure 1. Each single cell contains a base station (BS) equipped with directional receive antennas and is divided into three sectors, where each sector is covered by M receive antennas. Usage of directional antennas, where side lobe radiation patterns are negligible, implies that communications in the three sectors of a cell do not interfere with each other. It is assumed that different mobile users in the same sector perform orthogonal multiple-access as is typical for current 4G networks [32]. Thus, the model is restricted to a single mobile user per sector. For simplicity and symmetry, it is supposed that each mobile user is equipped with M transmit antennas.
It is assumed that the signal from a mobile user attenuates rapidly enough so that it cannot cause interference to sector receive antennas (Rx) in non-adjacent sectors. These assumptions lead to the interference graph in Figure 1, where each small circle depicts a mobile user and Rx pair. Solid black lines between any two circles represent symmetric interference between mobile users and Rxs of adjacent sectors. Let be an index set of all cells and associated BS in the network, and let be index set of all sectors and their corresponding users and Rxs. Then, the observed signal at the Rx is given by the following discrete-time input-output relation:
where
- n denotes the number of channel use;
- denotes the index set of mobile users whose transmitted signal is observed by Rx u (including mobile user u);
- denotes the M-dimensional time- signal sent by mobile user v;
- denotes the M-dimensional i.i.d. standard Gaussian noise vector corrupting the time- signal at Rx u; it is independent of all other noise vectors;
- and denotes an M-by-M dimensional random matrix with entries that are independently drawn according to a standard Gaussian distribution that models the channel from mobile user to Rx u.
Channel matrices are randomly drawn but assumed to be constant over the n channel uses employed for the transmission of a message. In other words, the block length of a transmission is assumed shorter than the coherence time of the channel. Realizations of the channel matrices are assumed to be known by corresponding BSs, but not by the mobile users.
2.2. Uplink Communication Model with M-CRAN Architecture
Consider the network model defined in Section 2.1. Assume that the mobile user in sector wishes to send its message , which is selected at random from the set , to the BS in which its sector is located. To this end, mobile user u encodes its message with the function
where , and is a column vector for , satisfying the power constraint:
We assume that the decoding processes of receive signals during the uplink communication is performed by BBUPs, and that any BS can have access to any BBUP through a one-hop fronthaul link which can be modeled as noise-free but capacity limited.
Definition 1.
Observation Function Let be the index set of BSs communicating with BBUP k. Each BS sends an observation function, , to BBUP k, where
and
with , , and denoting the three sectors of BS j.
To account for capacity limits of the fronthaul links, we require
where and is fronthaul capacity prelog, which is a positive constant.
Let be the index set of sectors whose messages are to be decoded at BBUP k. After receiving observation functions, for each BBUP k and each , BBUP k applies a deterministic and invertible function on the relevant observation functions to decode the message :
Decoding is successful if, for all :
Increasing computational power of a processor leads to an increase in complexity. Hence, to take the computational limitation into consideration, we impose a complexity constraint on the BBUPs in terms of bit processing capacity per channel use. We assume that any BBUP k can implement the decoding process if and only if the sum rate of all observation functions that is sent to BBUP k satisfies
where and is processing capacity prelog, which is a positive constant.
2.3. Capacity and Degrees of Freedom
A rate-tuple is said to be achievable if, for every and sufficiently large n, there exists encoding, observation, and decoding functions , , and satisfying (3), (6) and (9), such that
The capacity region is the closure of all achievable rate-tuples , and the maximum sum-rate is defined as
where the supremum is over all achievable rates .
Definition 2
(Per-User DoF). For any BBUP-BS ratio , fronthaul capacity prelog and processsing capacity prelog , the per user DoF is given as
Here, note that the allowed interval of r guarantees satisfying the proposed system model restriction . In the following, we use the abbreviation DoF to designate the per-user DoF.
3. Main Results
We derive two lower bounds and an upper bound on the DoF. As we will show, they match in some cases. The first and second lower bounds are achieved by the schemes described in Section 4 and Section 5, respectively. Both schemes are based on deactivating a set of mobile users. In the first scheme, the mobile users are deactivated so that the remaining active users form parallelogram-like clusters. In the second, the remaining active users form hexagon-like clusters. We name the two DoF lower bounds as parallelogram bound and hexagon bound, respectively.
Theorem 1
(Lower Bound). For any , , and , the achievable DoF is given by
where
Remark 1.
For and
Proof.
The proof is given in Appendix A. □
Theorem 2
(Cut-Set Bound). For any , and , the achievable DoF is upper bounded by
Proof.
The proof is given in Appendix B. □
Corollary 1
(Optimality in some special cases).
- If and , then
- If , and , then
- Forif and , where is the integer solution to .
- For
- -
- if , and , where is the integer solution to that minimizes , or
- -
- if and , where .
- For
- -
- if , and , where is the integer solution to that minimizes , or
- -
- if and where .
Proof.
The proofs are given in Appendix C. □
Theorem 3.
The achievability gap is upper bounded by
Proof.
The proof is given in Appendix D. □
4. Uplink Scheme with Parallelogram Clustering
In the proposed uplink scheme, we deactivate a subset of mobile users so as to partition the network into non-interfering clusters of active users. These clusters have parallelogram shapes and are parametrized by positive integer pair .
4.1. Construction of Parallelogram Clusters
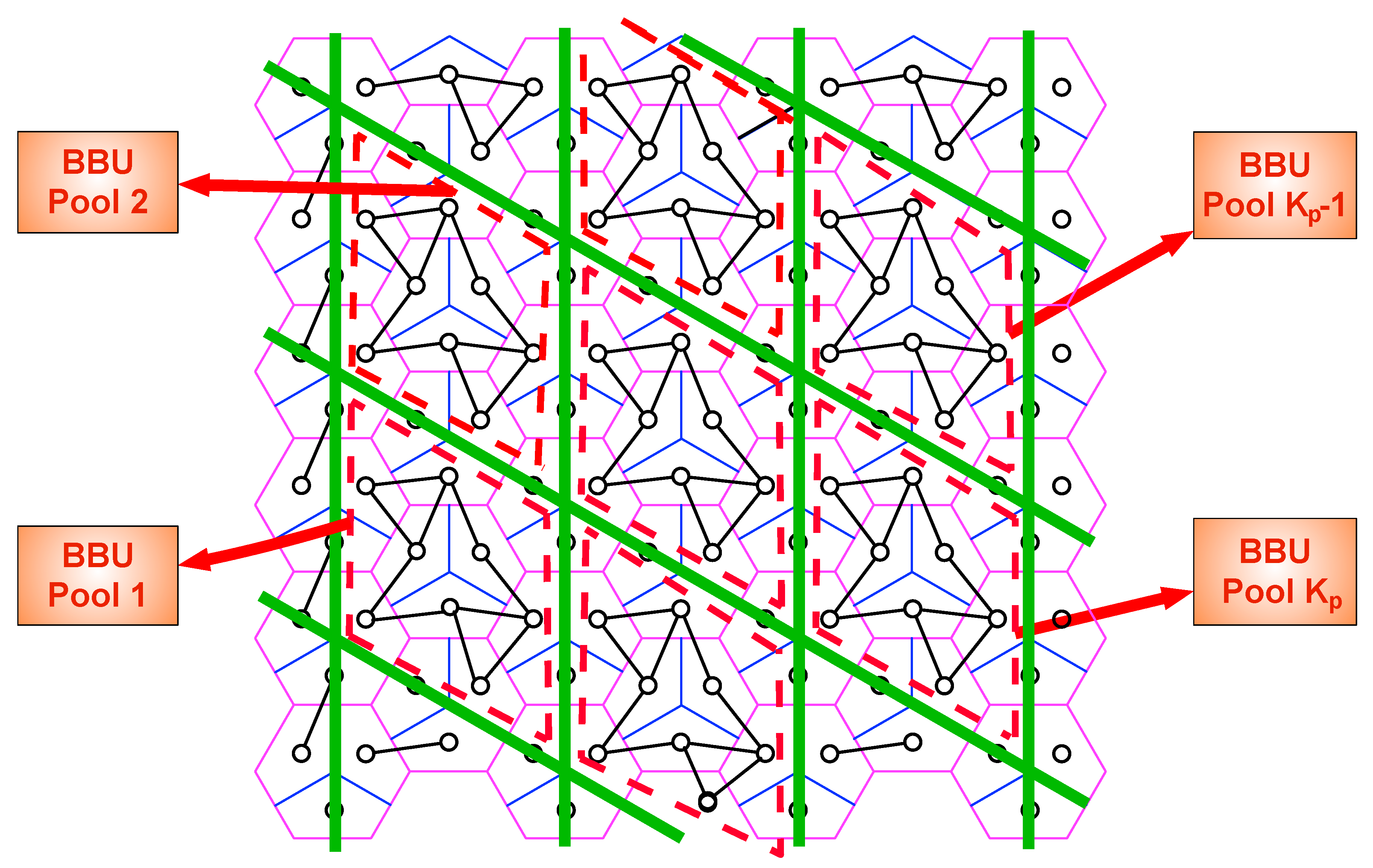
For a given pair, we define a regular parallelogram grid such that the length of sides of a parallelogram in the diagonal direction (−30 degree with horizontal axis) is cell-hop length, and the length of sides in the vertical direction is cell-hop length. Then, we fit this parallelogram grid into our figurative network in a way that the intersections of the parallelogram grid coincide with BSs, which are supposed to be at the center of the cells. Subsequently, we deactivate all mobile users coinciding with the sides of the grid. This process divides the network into parallelogram-like non-interfering clusters of active users and their sectors, and we refer to them shortly as p-clusters. In Figure 2, we present an example of parallelogram clustering for , where users coinciding with green lines are deactivated. Throughout this section, we refer to active users as only users. Users of a p-cluster are located in:
- BSs with three users,
- BSs with two users,
- Single BS with one user.
Therefore, the number of users in a p-cluster is:
Let , with , be index set of p-clusters. We associate each p-cluster with single BBUP and denote the associated BBUP with the same index of the p-cluster. Let be the index set of BSs whose users are elements of kth p-cluster. Each BS sends an observation function to BBUP, i.e., .
To be able to find a BBUP-BS ratio, we need to equally partition all BSs to BBUPs. Note that any BS with one user or three users is an element of a single index set , , and any BS with two users is an element of two different index sets, i.e., and , . Therefore, of the BSs of p-cluster k, we associate all of them with one user or three users, and half of them with two users to the BBUP k. This leads to the BBUP-BS ratio :
We can choose any pair to construct p-clusters that satisfies :
4.2. Coding Scheme
Each mobile user u encodes its message , which is uniformly distributed over the set , with a multi-antenna Gaussian codebook of power P. Since Rxs of silenced user observe only interference, each BS j generates its observation function for (active) Rxs through independent quantization codebooks. To generate quantization codebooks, each BS j applies a point-to-point Gaussian vector quantizer to receive signal of each Rx so that the noise-level quantization rates imposed in the following are satisfied. Let denote the sector index set of p-cluster k. We choose , where is an index set of sectors whose messages are to be decoded at BBUP k. Each BS with three users transmits a message consisting of three quantization messages of its Rxs to BBUP k and each BS with two users transmits only quantization message of Rx u to BBUP k if . The BS with a single user transmits the only quantization message of its cell to the BBUP k. Depending on the prelogs and , there are three different quantization rates: all BSs with three users quantize each receive signal at the rate and all BSs with two users quantize each receive signal at the rate , and all BSs with one active user quantize their receive signals at the rate . After receiving quantization messages, each BBUP k reconstructs all observations with quantization noise term, i.e., . The input–output relationship experienced by each BBUP k is a multi-user MIMO-MAC channel ([33], Chapter 9) and [34], where the effective noise is the sum of channel and quantization noises. Since the channel matrix from mobile users of to Rxs of is known by BBUP k and is square and full rank with probability 1, each BBUP k can perform joint decoding with vanishingly small average error probability, which leads to achieving the same DoFs as if each user message is decoded in a point-to-point communication. That is, the prelogs , and are achieved for respective mobile users.
To be able to find DoF for asymptotic case (The limit is only needed to eliminate edge effects.), i.e., while , we need to equally partition deactivated users of the network to p-clusters. Note that deactivated users around a p-cluster are located on green lines of four different sides and each side is on the border of two p-clusters. Therefore, when half of the deactivated users around a p-cluster, i.e., , are associated with the p-cluster itself, the equal partition of the deactivated users is performed. Then, the DoF of the scheme can be obtained as:
where the expression in the numerator refers to the sum-DoF in a given p-cluster and the expression in the denominator refers to the total number of active and deactivated users for a given p-cluster. In the following, we will give a policy to choose quantization rates for any satisfying (25).
4.2.1. Case 1:
The DoF of MIMO system with independently fading channels, which is our case, is M as given in [35]: the quantization rate is enough to describe message set of any user u asymptotically. Thus, here, we are not restricted by the processing capacity prelog , i.e., the only restricting factor is fronthaul capacity prelog . The main policy is to distribute transmission resources between (active) users of any given BS unless the per sector transmission capacity is more than the rate providing maximum DoF M, i.e., . To this end, we determine the quantization rates regarding :
- If , transmission resource of a fronthaul link is allocated equally among Rxs of a BS:and the achievable DoF is given as
- If , transmission resource of a fronthaul link is equally allocated among Rxs of a BS with two or three users; however, any BS with one user quantizes its received signal at the maximum rate since each fronthaul link has enough capacity to support that communication rate ():and the achievable DoF is given by
- If , transmission resource of a fronthaul link is equally allocated among Rxs of a BS with three users; however, any BS with one or two users quantizes their receive signals at the maximum rate for each Rx since each fronthaul link has enough capacity to support that communication rate ():and the achievable DoF is given by
- If , all BSs quantize their receive signal at the maximum rate at each sector ():and achievable DoF is given as:
4.2.2. Case 2:
Under this condition, the achievable sum-DoF of a p-cluster, which is given in the numerator of (26), can be restricted by the processing capacity prelog . If the is not smaller than the achievable sum-DoF of a p-cluster for the given interval of :
- If for ,
- If for ,
- If for ,
- If for ,
The process that has been implemented in Section 4.2.1 is applied and, hence, the DoF expressions are given as in (27), (28), (29) and (30), respectively. However, if the processing capacity prelog is smaller than the sum-DoF for the given :
- If for ,
- If for ,
- If for ,
- If for ,
We distribute the processing resource of a BBUP equally among sectors of a cluster and the quantization rate at each sector is chosen as
which leads to:
To provide fairness among the achievable DoFs of users, instances of the proposed scheme are time-shared so that each mobile user takes all relative positions in a p-cluster, which requires
different instances.
5. Uplink Scheme with Hexagon Clustering
The same as done in the last section, we deactivate a subset of mobile users so as to partition the network into non-interfering clusters of active users and their sectors. The shape of the clusters is hexagon and the size of the hexagons are set by a positive integer t.
5.1. Construction of Hexagon Clusters
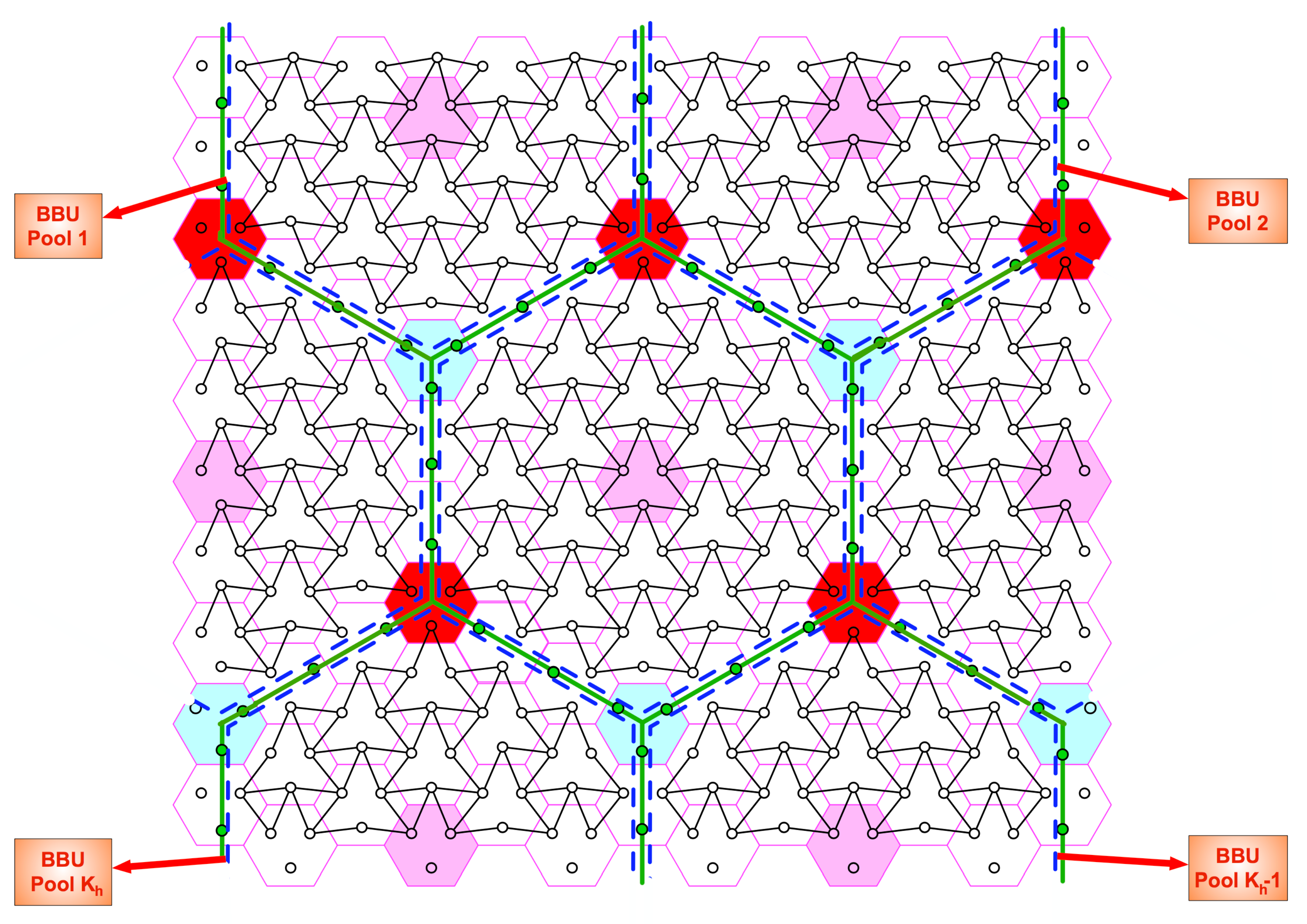
For a given design parameter t, we choose some BSs as center BSs to construct a regular grid of equilateral triangles where every three closest center BSs are cell-hops apart from each other. Therefore, the maximum distance to the closest center BS is t cell-hops and we name the BSs whose distance is ℓ cell-hops to the closest center BS as layer-“ℓ” BSs, for . We determine all BSs located at t cell-hops above and below of any center BS as corner and null BSs, respectively. Then, we create solid green lines between any closest null and corner BSs (t cell-hop apart from each other), which creates hexagon grids along the entire network. Subsequently, we deactivate mobile users coinciding with solid green lines. This process divides the network hexagon-like non-interfering clusters and we shortly name as h-clusters (The hexagonal clustering is first presented in [36].). Figure 3 shows an example of partition for . Later on, we refer to active users as only users. In an h-cluster,
- There are three users in center BS,
- There are layer-“ℓ”, , BSs with 3 users around center BS, i.e., in total ,
- There are users in layer-“t” BSs.
Therefore, the number of users in a h-cluster, , is:
Let , with , be index set of h-clusters. We associate each h-cluster with single BBUP and denote the associated BBUP with the same index of the h-cluster. Let be the index set of BSs whose users are elements of kth h-cluster. Each BS sends an observation function to kth BBUP, i.e., .
To be able to find a BBUP-BS ratio, , we need to equally partition all BSs to BBUPs. Note that each layer-t BS, except the one in the corner, belongs to two different index sets, i.e., and , . Each corner BS is an element of three different index sets, i.e., , and , . In addition, note that each null BS around a h-cluster k is on the border of three different h-clusters. To this end, of the BSs and null BSs around h-cluster k, we partition all layer-“ℓ”, , BSs including center BS, half of the layer-t BSs except corner and null BSs, and one third of corner and null BSs to the BBUP k, which leads to:
Since we have a given ratio r, we can choose any such that , i.e.,
5.2. Coding Scheme
Each mobile user u encodes its message , which is uniformly distributed over the set , with a multi-antenna Gaussian codebook of power P. As in Section 4, after observation at sector antennas, each BS j generates observation function for (active) Rxs through independent quantization codebooks. To generate quantization codebooks, each BS j applies a point-to-point Gaussian vector quantizer to a received signal of each Rx such that the following noise-level quantization rate constraints are met. Let denote the sector index set of h-cluster k. We choose . Each BS of layer-“ℓ”, , transmits a message consisting of three independent quantization messages of Rxs to BBUP k and each BS of layer-“t” transmits only quantization message of sector u to BBUP k if . Depending on the prelogs and , there are two different quantization rates: Each BS with three users quantize each receive signal at the rate and each BS with two users quantize each receive signal at the rate . That is, in h-cluster k, the receive signals of all layer-“ℓ” BSs, , and the receive signals of every corner BS is quantized at rate , i.e., , and receive signals of layer-“t” BSs other than corner BSs are quantized at , i.e., . After obtaining quantization messages, BBUP k reconstructs all with quantization error. The input–output relationship experienced at the BBUP k is multi-user Gaussian MIMO-MAC. Then, each BBUP k performs joint decoding with vanishingly small probability of error since the channel matrix from users of to Rxs of is known by BBUP k and is square and full rank with probability 1. This leads to achieving DoFs and for respective mobile users.
To be able to find DoF for asymptotic case, i.e., , we need to equally partition deactivated users of the network to h-clusters. The number of deactivated users around h-cluster k is . Since each deactivated user is on the border of two h-clusters, to be able to find DoF of the scheme, we partition half of them, i.e., , to users of h-cluster k, which gives the expression:
In the following, we will give the policy for choosing quantization rates.
5.2.1. Case 1:
In Section 4.2.1, is the only limiting factor since the quantization rate is enough to describe message of any user u in the asymptotic case. The policy is again to distribute transmission resources equally among (active) Rxs of any given BS. To this end, we choose the quantization rates regarding :
- If , transmission resource of a fronthaul link is equally allocated between Rxsand the achievable DoF is given as
- If , transmission resource of a fronthaul link is equally allocated among Rxs of a BS with three users; however, any BS with two users quantizes its receive signals at the maximum rate at each Rx since each fronthaul link has enough capacity to support that communication rate ():and the achievable DoF is given as
- If , all BSs quantize their receive signals at the maximum quantization rate ():and the achievable DoF is given as
5.2.2. Case 2:
Under this condition, depending on , the achievable sum-DoF of a h-cluster can be restricted by the processing capacity prelog . Achievable sum-DoF is given in the numerator of (36). Therefore, if the processing capacity prelog is not smaller than the achievable sum-DoF of a h-cluster for the given interval of :
- If for
- If for
- If for
The process that has been implemented in Section 5.2.1 is applied and, hence, the DoF expressions are given as in (38), (40) and (42), respectively. However, if the processing capacity prelog is smaller than the sum-DoF for the given :
- If for ,
- If for ,
- If for ,
We distribute the processing resource of a BBUP equally among sectors of a cluster and the quantization rate at each sector is chosen as
which leads to:
To provide fairness among the achievable DoFs of users, instances of the proposed scheme are time-shared so that each mobile user takes all relative positions in a h-cluster, which requires
different instances.
6. DoF without Sectorization
In the two proposed achievability schemes (“p-clustering” and “h-clustering”), we considered three non-interfering sectors in each cell. Now, if we consider cells without sectors, we can naively adapt our clustering by deactivating all users in the border cells of clusters. That is, for p-clustering, it requires deactivation of all users in the cells with one or two active mobile users and, for h-clustering, it requires deactivation of all users in the corner cells and the cells with two active users. This means that the network consists of only cells with three active users and cells with no active users for both schemes. This would again partition the network into non-interfering p-clusters and h-clusters without changing the and for any given pair or t, respectively.
By following the similar procedure introduced in Section 4 and Section 5, one can easily state the following result by simply distributing the available transmission resources equally among three Rxs of a given BS as long as the BBUP capacity is enough or, otherwise, distributing BBUP processing resources equally among the Rxs of a p-cluster/h-cluster. This leads to the following lemma:
Lemma 1
(DoF for naive scheme). For any , and , the achievable DoF in a multi cloud based non-sectored cellular network is given by
where
and above maximizations are over all positive integers , satisfying , and
where above maximizations are over all positive integers t satisfying .
Notice that the same cut-set bound, Theorem 2, applies for the naive schemes since the observation functions, Definition 1, are defined not on the sector basis but on the BS basis.
7. Numerical Results and Discussion
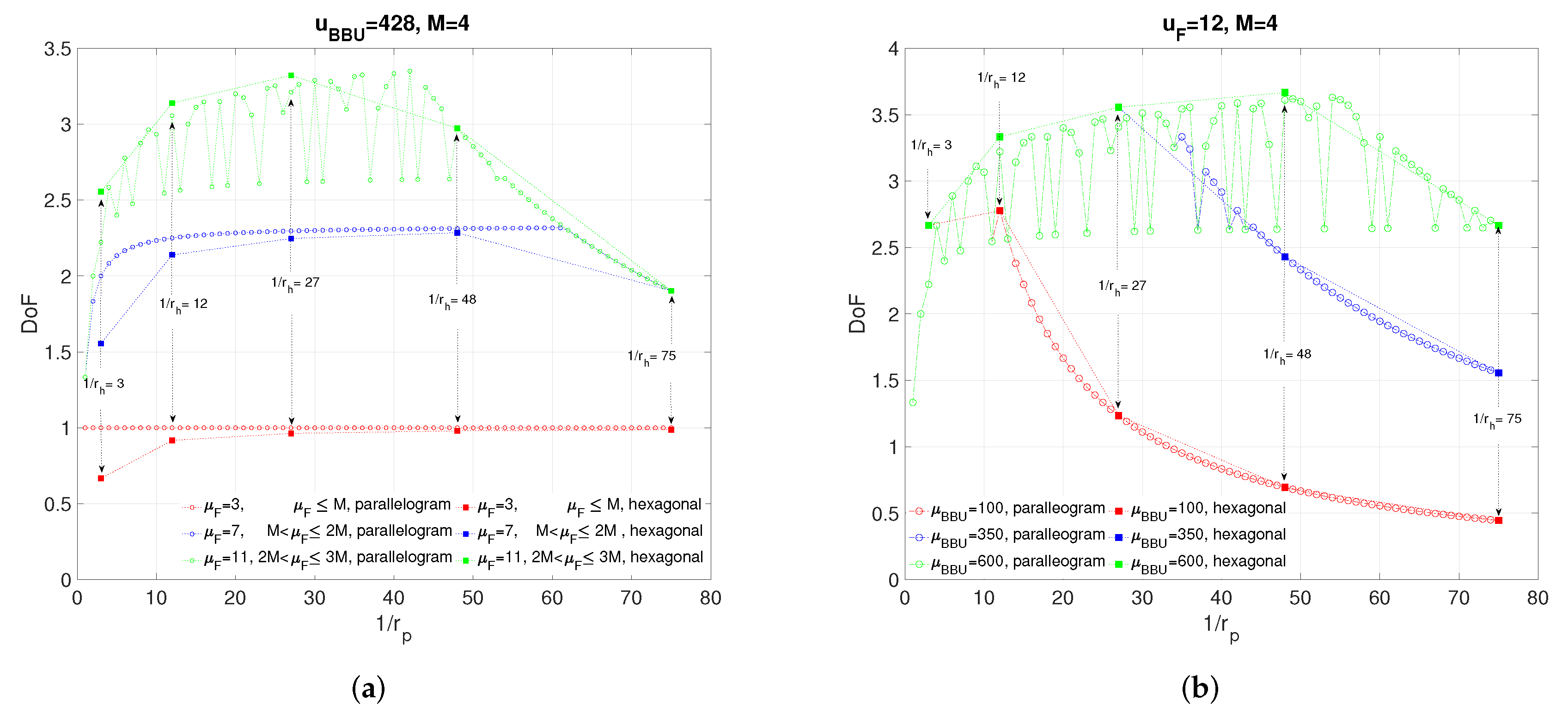
In this section, we present simulation results to evaluate the proposed coding schemes for p-clustering and h-clustering. In Figure 4a, we investigate effect of clustering size on the achievable DoF for several fronthaul capacities and . We define size of a p-cluster as inverse of , i.e., , and we denote it also with side length pair . We define size of a h-cluster as inverse , i.e., , and we denote it also with the parameter t. It is observed that, for p-clustering, when the fronthaul capacity is small, i.e., , clustering size has no effect on DoF since becomes a bottleneck. In general, we see that, for both p-clustering and h-clustering, the clustering size giving highest DoF decreases with . The figure verifies the Remark 1 since, for all , p-clustering outperforms h-clustering for . It is also interesting to note that, for p-clustering, the achievable DoF is not monotonically increasing(decreasing) until(after) reaching the maximum for (i.e., ) since not only the clustering size but also the side length of the p-cluster is important for exploiting interference. For any , choosing a pair that is the minimum in the sum gives the maximum DoF since it provides higher joint processing gain for a p-cluster for the given size (i.e., ), i.e., the more and becomes closer to each other the more mutual information clusters have. Therefore, larger p-cluster sizes may not result in higher DoF owing to the side length effect. However, for , the side lengths of p-cluster has no effect on achievable DoF for a given cluster size.
Figure 4b shows the effect of clustering size on DoF for various values of and . It is seen that, for each , achievable DoF increases with cluster size until it becomes a bottleneck, i.e., until becomes active in the achievability expression. Accordingly, the results clearly indicate that having more processing power makes possible larger cluster sizes and hence larger DoF.
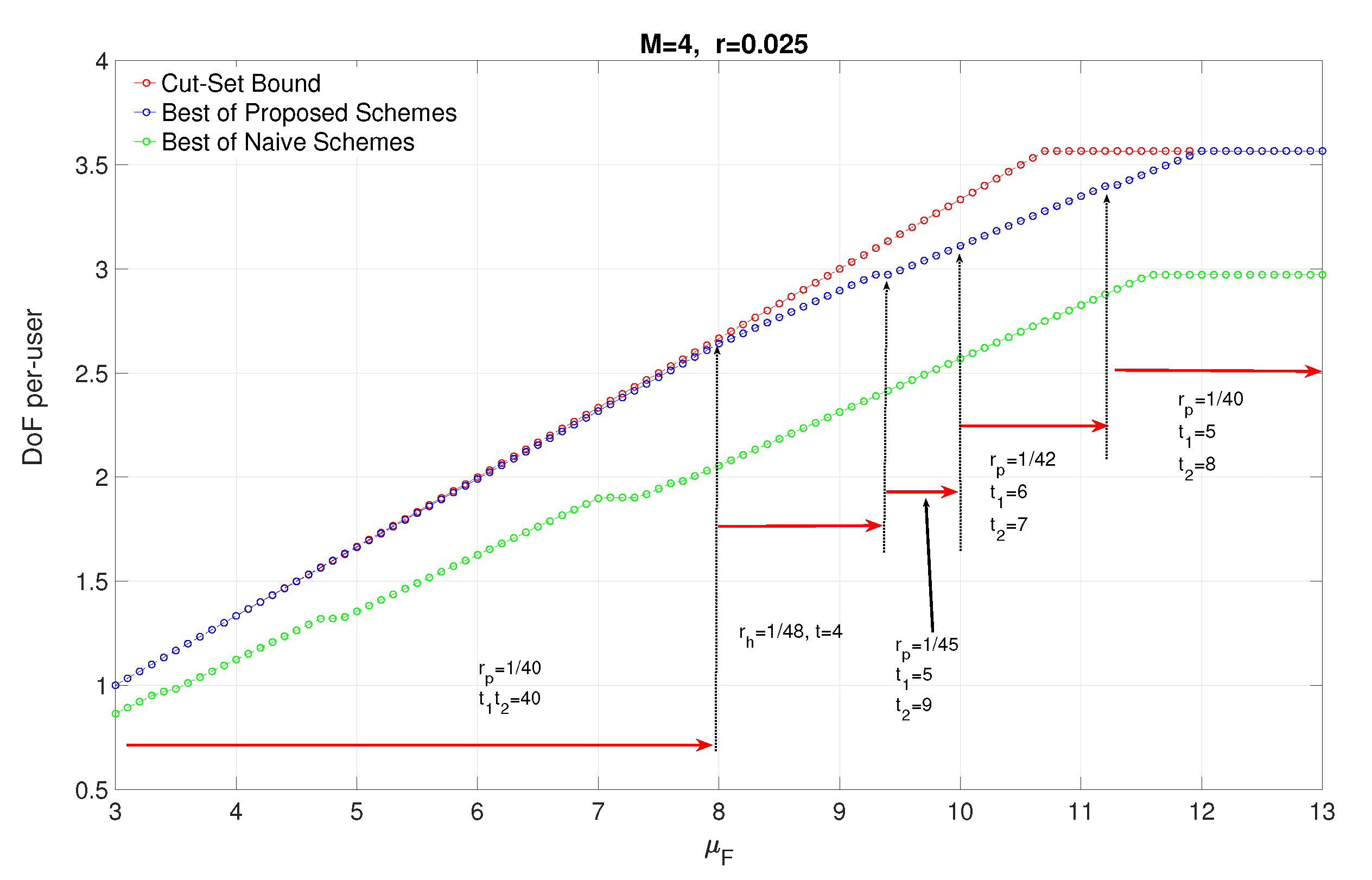
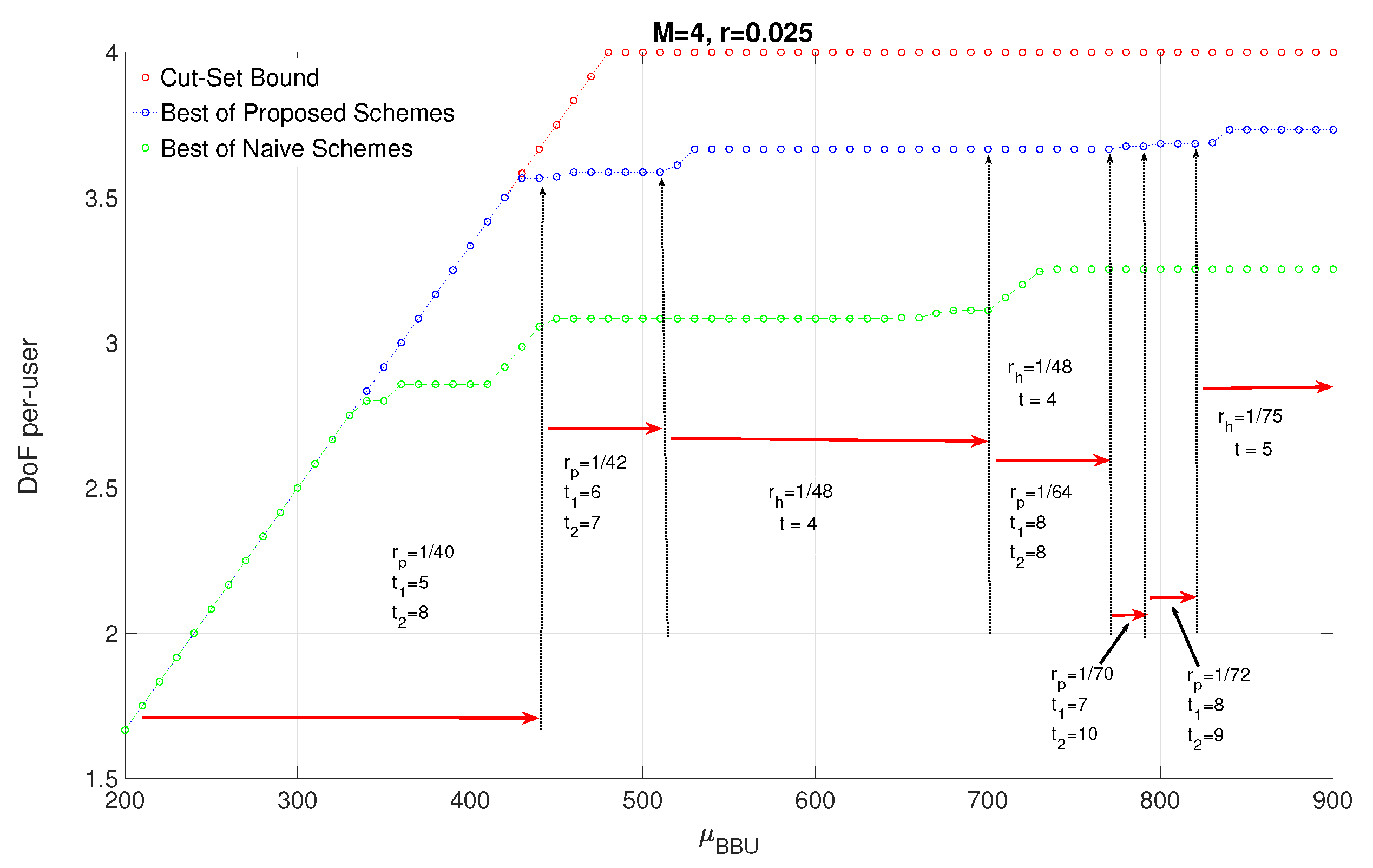
In Figure 5, we plot the achievable DoF and cut-set bound vs for , and , which refers the case BBUP processing capacity is equal to the required processing capacity when each receive signal in a p-cluster of size is quantized at the maximum quantization rate . From the figure, we can deduce that almost upper bound for can be reached, which means that DoF is almost achievable at given that processing capacity is high enough. In Figure 5, the operating points of clustering sizes is also depicted. For , equivalently , any p-clustering with gives the highest achievable DoF for the given system parameters. However, for , there are several different operating points. For example, for , the h-clustering of size is the optimal clustering size, which means, for , dividing the network into h-clusters provides higher joint processing gain than p-clustering for the same if the BBUP processing capacity is enough. For the rest, the clustering size is decreasing with due to the given BBUP capacity is not enough to handle the quantized data for larger cluster sizes. At the operating point , which allows maximum quantization rate for each receive signal, the p-clustering of size achieves capacity. This proves that the proposed scheme utilizes the system resources optimally at this operating point and almost DoF is achievable. We plot also the lower bound on DoF achieved by the naive scheme vs. for the same parameters. We can clearly see that the performance of the proposed schemes is considerably better than naive schemes due to the sectorization gain brought by nulling intra-cell interference.
In Figure 6, we plot the achievable DoF and cut-set bound as a function of processing capacity prelog , for and , which means that the fronthaul capacity has no restrictive effect on the achievable DoF. The operating points of clustering sizes regarding is also presented. The plot clearly indicates that the cut set bound is achieved until , i.e., the processing resources is used efficiently even until achieving DoF. At the rest of the range, it is seen that the optimal clustering sizes ( or ) increase with , and for most of , h-clustering provides highest DoF. This indicates the advantage of employing h-clustering when the processing capacity is high enough. For some range of , both h-clustering of size and p-clustering of size provide the highest DoF, which shows that h-clustering with lower clustering size provides higher joint processing gain than p-clustering with larger clustering sizes due to clustering geometry. The figure also depicts the lower bound achieved by the naive approach vs. for the same parameters and the gain of sectorization is clearly seen for higher values of processing capacity.
8. Finite SNR Analysis
In this section, we compare finite SNR performances of the proposed schemes with several other schemes, which will be introduced later on. For the finite SNR case, the quantization rates for both proposed clusterings are chosen as stated in Section 4.2 and Section 5.2, but the conditions regarding a high SNR regime are not applied, i.e., the prelog of any quantization rate is not reduced to the number of antennas M. Then, each BBUP implements joint decoding for the users of the associated cluster after reconstructing all sector receive signals of the cluster. For simplicity, we present the comparisons for throughout the section.
To evaluate the performance of the proposed schemes at finite SNR values, other than naive schemes, we compare our schemes with three different schemes:
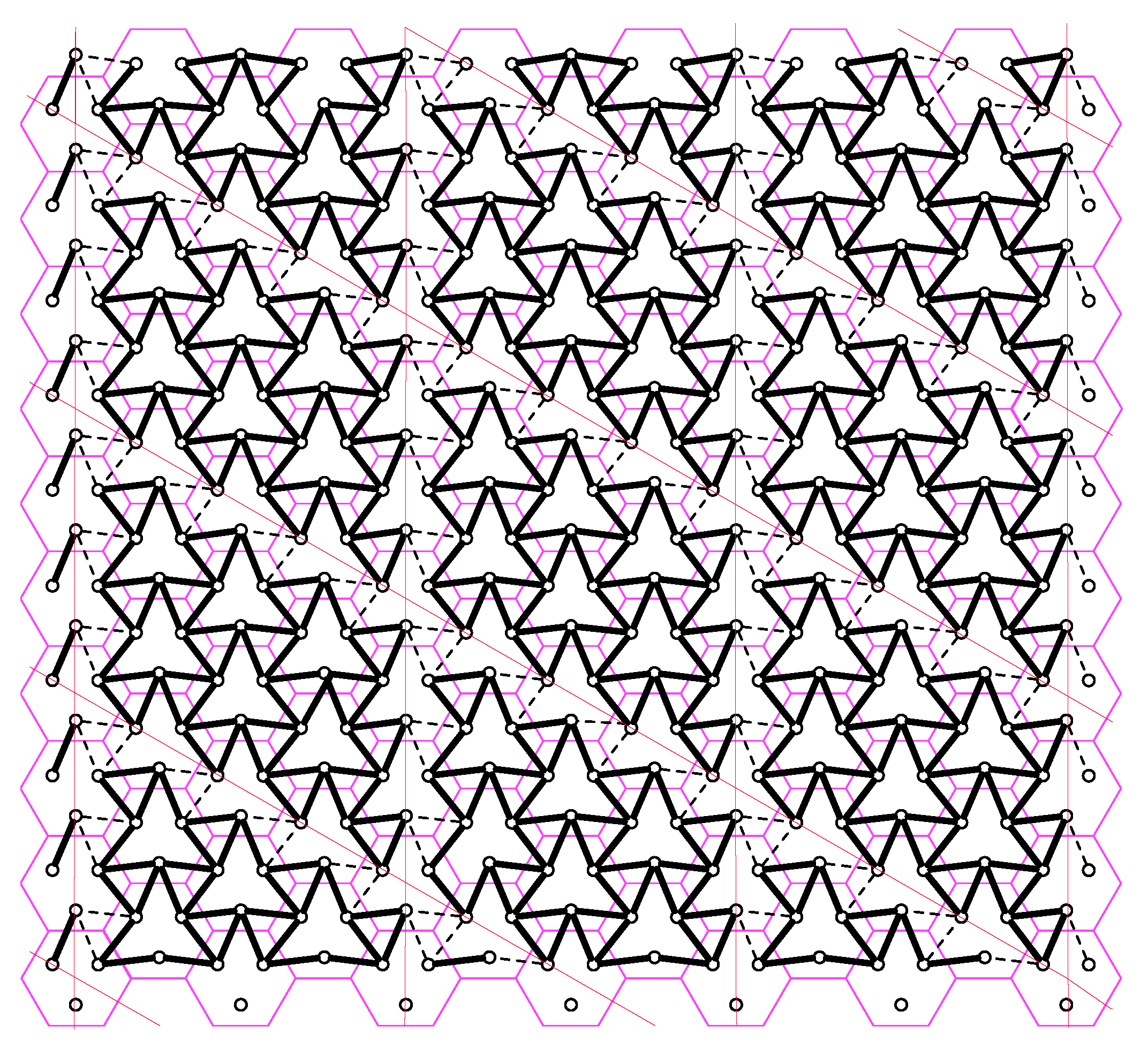
- Scheme 1 is a variation of the proposed p-clustering scheme. In p-clustering, each p-cluster is surrounded by deactivated users located on the sides of -hop parellelogram, where each side has and deactivated users, respectively. For each p-cluster, we associate all deactivated users on the lower side and right side of a -hop parellelogram to the p-cluster under consideration. Subsequently, we activate all deactivated users and allow each BBUP to collect quantization messages of reactivated user sectors associated with its own p-cluster. This process partitions the network into non-overlapping but interfering paralleogram-like clusters, which we call -clusters later on; see Figure 7 for an example of . Note that -clustering requires the same BBUP-BS ratio as for a p-clustering case. With reactivation of all deactivated mobile users, there are active users in each -cluster and all cells consists of three active users. Therefore, each BS equally partitions its fronthaul transmission resources to Rxs if BBU processing resources is enough to implement the joint decoding; otherwise, the processing resources is evenly distributed among all Rxs of the -cluster, i.e., the quantization rate is chosen asover all positive integer pairs satisfying . To be able to guess the user messages, each BBUP implement joint decoding by treating out-of-cluster interference as noise.
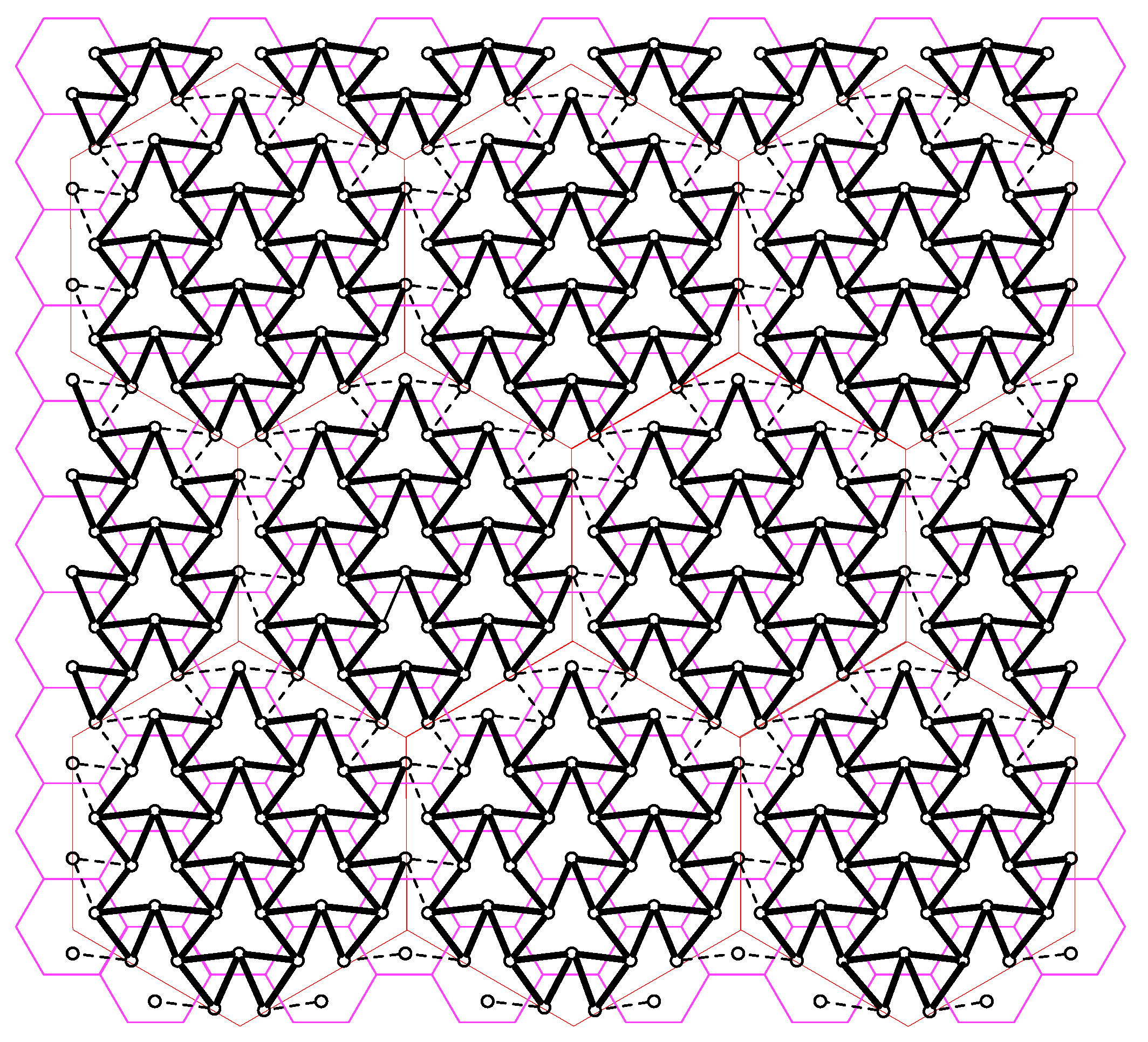
- Scheme 2 is a variation of the proposed h-clustering scheme. In h-clustering, there are 6t deactivated users around a cluster of size-t. For a specific h-cluster, we associate the deactivated users on the borders of any three adjacent h-clusters, e.g., east, southeast, and southwest, to the h-cluster under consideration. Then, we replicate this process for each h-cluster with the same relative directions of adjacent h-clusters. Subsequently, we reactivate all deactivated users and allow each BBUP k to collect the quantized received signals of sectors of reactivated users associated with its own h-cluster. This process partitions the network into interfering but non-overlapping clusters, which we call -cluster in the following, see Figure 8 for . Note that -clustering requires the same BBUP-BS ratio as for the h-clustering case. With reactivation of deactivated users, there are active users in each -cluster. Therefore, by applying similar arguments as stated above, the quantization rate for -clustering is chosen asover positive integers t satisfying . To be able to guess the user messages, each BBUP implement joint decoding by treating out-of-cluster interference as noise.
- Scheme 3 is a variation of the practical opportunistic schemes. The decoding depends on the realization of the channel coefficients. With the help of neighbors of the considered BS, the corresponding BBUP identifies for each user in the corresponding cell the three adjacent sectors that give the best joint decoding performance for the corresponding message. To be able to make a fair comparison between the proposed schemes and the 3-sector decoding scheme, we impose the same fronthaul rate constraint on the 3-sector decoding scheme as in the non-interfering clustering scheme (note that there is no silenced user in the 3-sector decoding case) by assuming all processing resources are used. That is, the quantization rates are chosen asThen, the BBUP collects the quantization messages and decodes the corresponding message based on them.
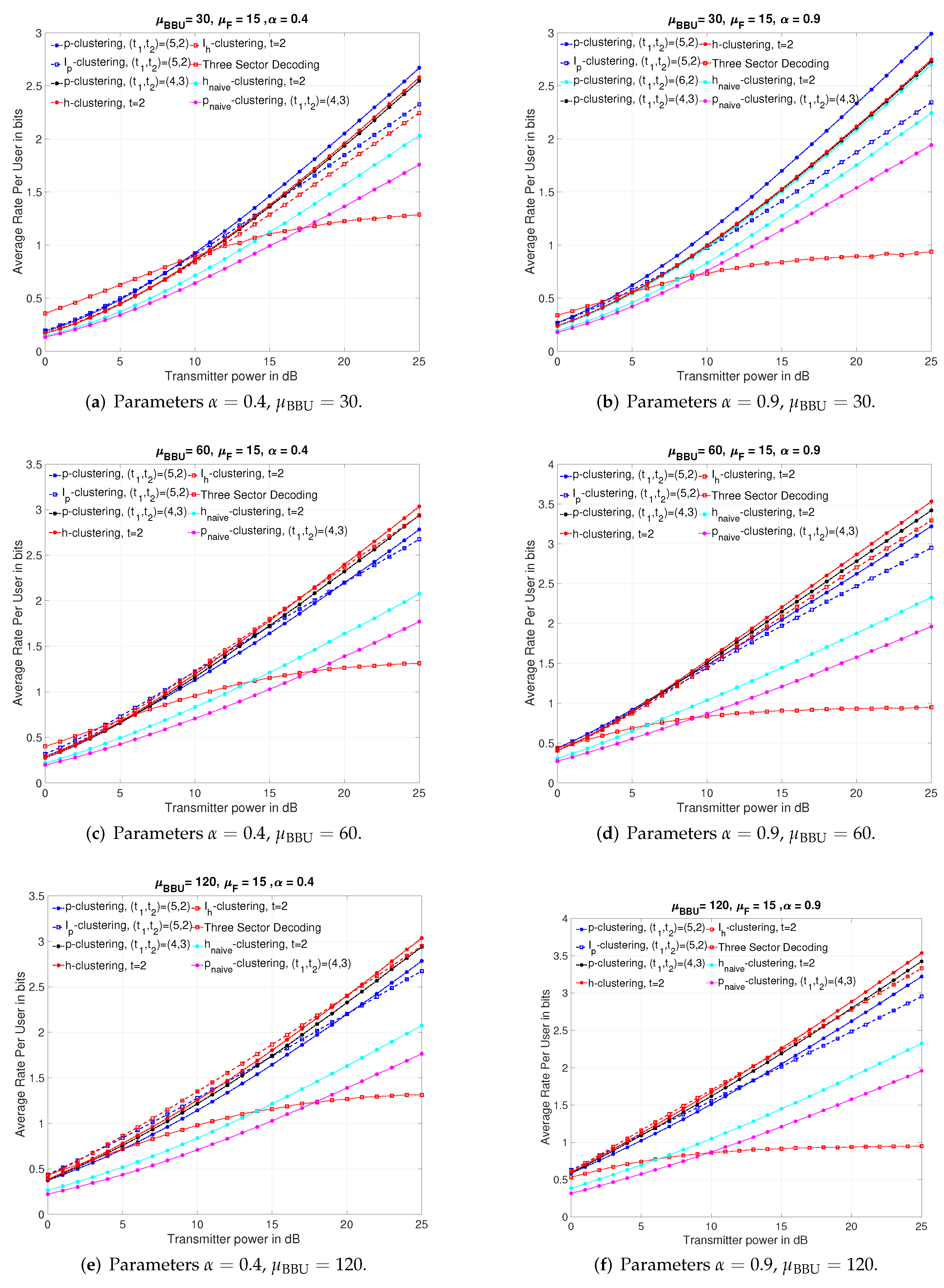
In our numerical comparison, we average the rate over 5000 independent channel realizations of the channel matrices, where for each realization all channel gains are drawn independently of each other according to a Gaussian distribution, by which we aim at modeling the random location of a mobile user. The direct channel gains of intra-sector links are drawn with variance 1 and the cross channel gains of inter-sector links are drawn with variance since any mobile user in adjacent sectors can not be closer to a sector receiver than the user in the considered sector, where is the channel attenuation coefficient. Figure 9 presents the comparison of the performances of the proposed schemes with naive schemes, -clustering, -clustering schemes and 3-sector decoding scheme vs. SNR when . The simulations are performed for different cluster sizes such that and . However, in all the subfigures of Figure 9, we present only the ones showing relatively better performance than others to make presentation better.
As seen from all the subfigures of Figure 9, the proposed schemes provides higher sum-rates than naive schemes for all SNR range and, under all scenarios, e.g., strong interference regime at low BBUP processing capacity as in Figure 9b, or low interference regime at high BBUP capacity as in Figure 9e.
By comparing the subfigures of Figure 9 for a given , we conclude that the proposed schemes become more efficient if the processing capacity of BBUPs increases, i.e., the allowed quantization rate increases. In addition, we can see that employing the smallest possible cluster for a given r is more advantageous for small processing capacities. For example, for , while the p-clustering scheme for shows better performance than other proposed schemes of larger cluster sizes at all SNR range for , it outperforms the h-clustering for only at low SNR values for , and it does not outperform either h-clustering for or p-clustering for at any SNR value for .
By comparing the subfigures of Figure 9 for a given , we can observe that, for each value, the SNR range in which the performance of the 3-sector decoding scheme is superior to or close to the proposed schemes decreases when the channel attenuation coefficient is higher. In addition, we see that, for , the SNR range in which the h-clustering for outperforms the -clustering for and/or -clustering for increases with the channel attenuation coefficient. We infer that the idea of isolated clustering is more advantageous at strong interference regime.
Another general conclusion that we can draw from simulation results presented in Figure 9 is that, if the processing capacity is high enough, i.e., the quantization rate is high enough, decomposing the network into hexagonal-type clusters achieves higher rates than paralellogram-type clusters especially at moderate and high SNR range even if . This is due to geometrical structure of hexagonal-type clustering that includes more users for both h-cluster/-cluster and less interfererers for -cluster in comparison with the parallelogram clusters for the same .
An interesting conclusion from the finite SNR analysis is that interfering clusterings show close performance to the proposed schemes in the finite SNR range; therefore, the interfering clusterings can also be employed at finite SNR values, since it may be more convenient for practical systems.
9. Conclusions
In this paper, we analyze the uplink per-user DoF of M-CRAN based sectored cellular networks. The main features of this paper are the following: it proposes efficient ways of decomposing the network into non-interfering clusters for M-CRAN scenarios, and it characterizes per-user DoF as a function of fronthaul and processing capacity prelogs, and BBUP-BS ratio. The lower bound is obtained through two coding schemes based on decomposing the network into non-interfering parallelogram and hexagonal clusters, respectively. In both schemes, BSs apply point-point quantization to receive signals and send the quantization messages to the associated BBUPs over fronthaul links for joint decoding.
Simulation results show that, for small and moderate fronthaul capacities, the achievability gap between lower and cut-set bounds decreases with an inverse of the BBUP-BS ratio. Therefore, the cut-set bound is almost achieved even for small cluster sizes at this range of fronthaul capacities. For higher fronthaul capacity prelogs, the achievability gap is not always tight but decreases with processing capacity prelog.
The finite SNR analysis shows that the proposed schemes outperform the naive schemes at all SNR ranges and, under all scenarios, the interfering clustering cases at all SNR range under strong interference regime when the BBUP processing capacity is scarce and moderate, and the 3-sector decoding case at all SNR range under strong interference regime if the BBUP processing capacity is moderate and high. In other scenarios for interfering clustering and 3-sector decoding cases, the proposed schemes always achieve higher sum-rates except low SNR values.
In general, the results provide valuable insights into appropriate clustering ways for mobile users/sectors, emphasizing the isolation of clusters, particularly if inter-cell interference is highly detrimental.
Author Contributions
S.G. put forward the original ideas. S.G. developed this work in discussion with G.R.-B.O.; S.G. wrote the paper with comments from G.R.-B.O. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Samet Gelincik is supported by Turkish Ministry of Education.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Remark 1
By (25), any pair that satisfies provides the maximum number of BBUP deployment for parallelogram clustering. By (35), is the minimum cluster size that can be created for the given r, and hence provides the maximum possible number of BBUP deployment for hexagon clustering. Note that for .
We now check the cases for and .
Appendix A.1. Case 1:
Proposition A1.
Proof.
The first part of the proposition, i.e., (A1), is straightforward. For (A2), note that, for a given , there is a unique that satisfies (A3) and the maximization term in (A2) comes from the fact that, to implement the hexagonal scheme, we choose the design parameter t that gives the maximum DoF of among minimums found for satisfying . From (15), we infer that the term is active in the minimization process for since , and that the term is active in lower bound for since . Therefore, the achievable DoF by hexagon scheme is given by the second term of (A2) if . □
Appendix A.1.1.
The DoF is given as:
since for any .
Appendix A.1.2.
The DoF is given as:
Proof.
Notice that the given condition on implies and ; otherwise, the imposed condition on is not possible. In addition, notice that, even for the , the following inequality holds:
and therefore
Then, we end up with:
since and . □
Appendix A.1.3.
The DoF is given as:
Proof.
The condition implies , then
□
Appendix A.1.4.
Thel DoF is given as:
Proof.
If is active in the inner maximization, then
If is active in the inner maximization, we infer that the term is active in hexagon bound when the design parameter is chosen as , which means
Therefore, the fact that
implies
□
Appendix A.2. Case 2:
Proposition A2.
Proof.
For any given , there is a unique positive integer that satisfies (A17). The maximization in (A16) can be inferred from (14)) by a similar approach given for (A2) in Appendix A.1. Note the DoF expression of hexagon case does not change for . □
Appendix A.2.1.
The DoF is given as:
since for any .
Appendix A.2.2.
The DoF is given as:
for satisfying (A19).
Proof.
Notice that the imposed condition on implies since there is a unique satisfying (A19) and . The rest is trivial. Since ,
and since the condition requires , then
□
Appendix A.2.3.
The DoF is given as:
for satisfying with (A17).
Appendix A.2.4.
Proof.
Notice that, for any given , Equations (A17) and (A19) hold for a unique positive integer and a unique . For any given , Equations (A17) and (A19) impose
which implies
We now check the following cases:
□
This completes the proof for Remark 1.
Appendix B. Proof of Theorem 2
For the sake of simplicity, define as the received signal of BBUP k:
We obtain the first two terms of the upper bound by choosing the cut set
and defining
In that case, for any fixed BBUP to BS association for any given network, the total rate of all users is upper bounded by:
where second inequality comes from applying (6) and (9) to received signals of BBUPs, which gives the first two terms by Definition 2. The third term comes from the fact that, by [35], the DoF a MIMO system is upper bounded by M.
Appendix C. Proof of Corollary 1
For the first item, the matching occurs when the term with is active in both lower and upper bounds. For the rest, the matching occurs with the term and is active in both lower and upper bounds. Due to Remark 1, if , showing the matching cases between parallelogram lower bound and cut-set upper bound is enough. For , we show the matching cases between both lower bounds and cut-set bound.
For , the term with is active in upper and lower bounds if and , respectively. Since , choosing implies . The term with is active in upper and lower bound if and , respectively, where the matching requires .
For , the term with is active in both upper and lower bounds if and , respectively, where the matching requires .
For , the term with is active in upper and parallelogram lower bound if and , respectively, where matching requires . If , there is at least one pair that results in . However, unless , the term with can not be active in lower bound. This imposes choosing the pair that minimizes . The term with is active in upper and hexagon lower bound if and , where matching requires .
For , the matching cases can be found by applying similar procedures as in the case.
Appendix D. Proof of Theorem 3
Due to Remark 1, we do the achievability gap analysis only for paralleogram clustering. We do the analysis for one of the cases which leads to the maximum achievability gap. For other cases, a similar procedure can be applied.
- If , the maximum gap occurs when and is active in upper and lower bounds, respectively. Note that this assumption imposes .where is due to and is due to by (25).
- If , the maximum gap occurs when and is active in upper and lower bound, respectively. Notice that this assumption imposes .where is due to by (25), and is due the fact that, if , there is equality, if , there is strict inequality.
References
- Nasri, R.; Jaziri, A. Analytical tractability of hexagonal network model with random user location. IEEE Trans. Wirel. Commun. 2016, 15, 3768–3780. [Google Scholar] [CrossRef] [Green Version]
- Tesfay, T.T.; Khalili, R.; Boudec, J.-Y.L.; Richter, F.; Fehske, A. Energy saving and capacity gain of micro sites in regular LTE networks. In Proceedings of the 6th ACM Workshop on Performance Monitoring and Measurement of Heterogeneous Wireless and Wired Networks—PM2HW2N ’11, Miami Beach, FL, USA, 31 October–4 November 2011. [Google Scholar]
- Bande, M.; El Gamal, A.; Veeravalli, V.V. Degrees of freedom in wireless interference networks with cooperative transmission and backhaul load constraints. IEEE Trans. Inf. Theory 2019, 65, 5816–5832. [Google Scholar] [CrossRef]
- Bande, M.; El Gamal, A.; Veeravalli, V.V. Flexible backhaul design with cooperative transmission in cellular interference networks. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 2431–2435. [Google Scholar]
- Veeravalli, V.V.; Gamal, A.E. Interference Management in Wireless Networks: Fundamental Bounds and the Role of Cooperation; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Ntranos, V.; Maddah-Ali, M.A.; Caire, G. Cellular interference alignment. IEEE Trans. Inf. Theory 2015, 61, 1194–1217. [Google Scholar] [CrossRef] [Green Version]
- Gesbert, D.; Hanly, S.; Huang, H.; Shamai, S.; Simeone, O.; Yu, W. Multi-cell MIMO cooperative networks: A new look at interference. IEEE J. Sel. Areas Commun. 2010, 28, 1380–1408. [Google Scholar] [CrossRef] [Green Version]
- Atsan, E.; Knopp, R.; Diggavi, S.; Fragouli, C. Towards integrating quantize-map-forward relaying into LTE. In Proceedings of the 2012 IEEE Information Theory Workshop (ITW), Lausanne, Switzerland, 3–7 September 2012; pp. 212–216. [Google Scholar]
- Chen, J.; Mitra, U.; Gesbert, D. Optimal UAV relay placement for single user capacity maximization over terrain with obstacles. In Proceedings of the IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, 2–5 July 2019; pp. 1–5. [Google Scholar]
- Katz, G.; Zaidel, B.M.; Shitz, S.S. On layered transmission in clustered cooperative cellular architectures. In Proceedings of the 2013 IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1162–1166. [Google Scholar]
- Simeone, O.; Poor, H.V.; Somekh, O.; Shamai, S. Local base station cooperation via finite-capacity links for the uplink of linear cellular networks. IEEE Trans. Inf. Theory 2009, 55, 190–204. [Google Scholar] [CrossRef]
- Hanly, S.V.; Whiting, P. Information-theoretic capacity of multi-receiver networks. Telecommun. Syst. 1993, 1, 1–42. [Google Scholar] [CrossRef]
- Wyner, A.D. Shannon-theoretic approach to a gaussian cellular multiple-access channel. IEEE Trans. Inf. Theory 1994, 40, 1713–1727. [Google Scholar] [CrossRef]
- Shamai, S.; Zaidel, B.M. Enhancing the cellular downlink capacity via co-processing at the transmitting end. In Proceedings of the IEEE VTS 53rd Vehicular Technology Conference, Spring 2001. Proceedings (Cat. No.01CH37202), Rhodes, Greece, 6–9 May 2001; Volume 3, pp. 1745–1749. [Google Scholar]
- Sanderovich, A.; Shamai, S.; Steinberg, Y.; Kramer, G. Communication via decentralized processing. IEEE Trans. Inf. Theory 2008, 54, 3008–3023. [Google Scholar] [CrossRef] [Green Version]
- Sanderovich, A.; Somekh, O.; Poor, H.V.; Shamai, S. Uplink macro diversity of limited backhaul cellular network. IEEE Trans. Inf. Theory 2009, 55, 3457–3478. [Google Scholar] [CrossRef] [Green Version]
- Simeone, O.; Somekh, O.; Poor, H.V.; Shamai, S. Downlink multicell processing with limited-backhaul capacity. EURASIP J. Adv. Signal Process. 2009, 2009, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; El Gamal, A. Capacity theorems for the relay channel. IEEE Trans. Inf. Theory 1978, 25, 572–584. [Google Scholar] [CrossRef] [Green Version]
- Costa, M. Writing on dirty paper (Corresp.). IEEE Trans. Inf. Theory 1983, 29, 439–441. [Google Scholar] [CrossRef]
- Checko, A.; Christiansen, H.L.; Yan, Y.; Scolari, L.; Kardaras, G.; Berger, M.S.; Dittmann, L. Cloud RAN for Mobile Networks: A Technology Overview. IEEE Commun. Surv. Tutor. 2015, 17, 405–426. [Google Scholar] [CrossRef] [Green Version]
- Singhal, M.; Seyfi, T.; El Gamal, A. Joint Uplink-Downlink Cooperative Interference Management with Flexible Cell Associations. arXiv 2018, arXiv:1811.11986. [Google Scholar]
- Kang, J.; Simeone, O.; Kang, J.; Shamai, S. Layered Downlink Precoding for C-RAN Systems With Full Dimensional MIMO. IEEE Trans. Veh. Technol. 2017, 66, 2170–2182. [Google Scholar] [CrossRef]
- Park, S.; Simeone, O.; Shamai, S. Uplink sum-rate analysis of C-RAN with interconnected radio units. In Proceedings of the IEEE Information Theory Workshop (ITW), Kaohsiung, Taiwan, 6–10 November 2017; pp. 171–175. [Google Scholar]
- Kim, J.; Park, S.-H. Layered Inter-Cluster Cooperation Scheme for Backhaul-Constrained C-RAN Uplink Systems in the Presence of Inter-Cluster Interference. Entropy 2020, 22, 554. [Google Scholar] [CrossRef]
- Douik, A.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M. Distributed hybrid scheduling in multi-cloud networks using conflict graphs. IEEE Trans. Commun. 2018, 66, 209–224. [Google Scholar] [CrossRef] [Green Version]
- Awais, M.; Ahmed, A.; Ali, S.A.; Naeem, M.; Ejaz, W.; Anpalagan, A. Resource management in multicloud iot radio access network. IEEE Internet Things J. 2019, 6, 3014–3023. [Google Scholar] [CrossRef]
- Park, S.; Simeone, O.; Sahin, O.; Shamai, S. Inter-cluster design of precoding and fronthaul compression for cloud radio access networks. IEEE Wirel. Commun. Lett. 2014, 3, 369–372. [Google Scholar] [CrossRef]
- Park, S.; Song, C.; Lee, K. Inter-cluster design of wireless fronthaul and access links for the downlink of c-ran. IEEE Wirel. Commun. Lett. 2017, 6, 270–273. [Google Scholar] [CrossRef]
- Dhif-Allah, O.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M. Distributed robust power minimization for the downlink of multi-cloud radio access networks. IEEE Trans. Green Commun. Netw. 2018, 2, 327–335. [Google Scholar] [CrossRef]
- Ferdouse, L.; Anpalagan, A.; Erkucuk, S. Joint Communication and Computing Resource Allocation in 5G Cloud Radio Access Networks. IEEE Trans. Veh. Technol. 2019, 68, 9122–9135. [Google Scholar] [CrossRef]
- Wigger, M.; Timo, R.; Shamai, S. Conferencing in Wyner’s asymmetric interference network: Effect of number of rounds. In Proceedings of the IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Sesia, S.; Toufik, I.; Baker, M. LTE-The UMTS Long Term Evolution: From Theory to Practice; Wiley: New York, NY, USA, 2009. [Google Scholar]
- El Gamal, A.; Kim, Y. Network Information Theory; Cambridge University Press: Cambridge, UK. [CrossRef] [Green Version]
- Jeon, S.; Suh, C. Degrees of Freedom of Uplink–Downlink Multiantenna Cellular Networks. IEEE Trans. Inf. Theory 2016, 62, 4589–4603. [Google Scholar] [CrossRef]
- Telatar, I.E. Capacity of multi-antenna gaussian channels. Eur. Trans. Telecommun. 1999, 10, 585–595. [Google Scholar] [CrossRef]
- Gelincik, S.; Wigger, M.; Wang, L. DoF in Sectored Cellular Systems with BS Cooperation Under a Complexity Constraint. In Proceedings of the IEEE 15th International Symposium on Wireless Communication Systems (ISWCS), Lisbon, Portugal, 28–31 August 2018; pp. 1–5. [Google Scholar]
Figure 1.
Multi-cloud based sectored cellular network.

Figure 2.
Parallelogram clustering for .

Figure 3.
Illustration of h-clusters for . Pink, red, and blue cells represent center, corner, and null cells, respectively. Green-filled circles refer to deactivated users. All users and their sectors inside a blue dashed hexagon are associated with the same BBUP.
Figure 3.
Illustration of h-clusters for . Pink, red, and blue cells represent center, corner, and null cells, respectively. Green-filled circles refer to deactivated users. All users and their sectors inside a blue dashed hexagon are associated with the same BBUP.

Figure 4.
The impact of : (a) For various values of . (b) For various values of .

Figure 5.
The impact of at .

Figure 6.
The impact of at .

Figure 7.
-clustering for . The red lines denote a paralleogram-like shape of the clusters. The interference pattern highlighted with solid black lines depict the users in in the same -clusters. The interference pattern highlighted with dashed lines between circles denote the borders between -clusters.
Figure 7.
-clustering for . The red lines denote a paralleogram-like shape of the clusters. The interference pattern highlighted with solid black lines depict the users in in the same -clusters. The interference pattern highlighted with dashed lines between circles denote the borders between -clusters.

Figure 8.
-clustering for . The interference pattern highlighted with solid black lines depict the users in in the same -clusters. The interference pattern highlighted with dashed lines between circles denote the borders between -clusters.
Figure 8.
-clustering for . The interference pattern highlighted with solid black lines depict the users in in the same -clusters. The interference pattern highlighted with dashed lines between circles denote the borders between -clusters.

Figure 9.
Comparison of the achieved rates for different channel attenuation parameters and processing capacities when and .
Figure 9.
Comparison of the achieved rates for different channel attenuation parameters and processing capacities when and .

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gelincik, S.; Rekaya-Ben Othman, G. Degrees-Of-Freedom in Multi-Cloud Based Sectored Cellular Networks. Entropy 2020, 22, 668. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060668
AMA Style
Gelincik S, Rekaya-Ben Othman G. Degrees-Of-Freedom in Multi-Cloud Based Sectored Cellular Networks. Entropy. 2020; 22(6):668. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060668
Chicago/Turabian StyleGelincik, Samet, and Ghaya Rekaya-Ben Othman. 2020. "Degrees-Of-Freedom in Multi-Cloud Based Sectored Cellular Networks" Entropy 22, no. 6: 668. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060668
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.