Stealthy Secret Key Generation


1
Information Theory and Communication Systems Department, Technische Universität Braunschweig, 38106 Braunschweig, Germany
2
Information Theory and Applications Chair, Technische Universität Berlin, 10623 Berlin, Germany
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(6), 679; https://0-doi-org.brum.beds.ac.uk/10.3390/e22060679
Submission received: 1 June 2020
/
Accepted: 15 June 2020
/
Published: 18 June 2020
(This article belongs to the Special Issue Wireless Networks: Information Theoretic Perspectives)
{kind=link}
{kind=link}
Abstract
:In order to make a warden, Willie, unaware of the existence of meaningful communications, there have been different schemes proposed including covert and stealth communications. When legitimate users have no channel advantage over Willie, the legitimate users may need additional secret keys to confuse Willie, if the stealth or covert communication is still possible. However, secret key generation (SKG) may raise Willie’s attention since it has a public discussion, which is observable by Willie. To prevent Willie’s attention, we consider the source model for SKG under a strong secrecy constraint, which has further to fulfill a stealth constraint. Our first contribution is that, if the stochastic dependence between the observations at Alice and Bob fulfills the strict more capable criterion with respect to the stochastic dependence between the observations at Alice and Willie or between Bob and Willie, then a positive stealthy secret key rate is identical to the one without the stealth constraint. Our second contribution is that, if the random variables observed at Alice, Bob, and Willie induced by the common random source form a Markov chain, then the key capacity of the source model SKG with the strong secrecy constraint and the stealth constraint is equal to the key capacity with the strong secrecy constraint, but without the stealth constraint. For the case of fast fading models, a sufficient condition for the existence of an equivalent model, which is degraded, is provided, based on stochastic orders. Furthermore, we present an example to illustrate our results.
1. Introduction
Consider the following motivating example. Two agents, Alice and Bob, want to establish a communication that does not raise the curiosity of a warden Willie, whose duty is to monitor if there is any suspicious activity and also decrypts the data. In order to realize a confidential transmission for such a scenario, we may adopt the following two steps. The first step is to make Willie unaware of the existence of the meaningful communication, which is embedded in the messages intended to be delivered to Bob. In contrast, in a meaningless communication, Bob does not care about the received signal, which is only used to confuse Willie. If Willie can successfully detect the existence of the meaningful transmission, then the second step is to use wiretap coding [1] to provide secrecy (or hidability [2]). There are two main concepts to attain the goal of the first step: (1) communications with a stealth constraint [2,3] and (2) communications with a covert constraint [2,4,5]. Both concepts make Willie unable to differentiate between the existence or nonexistence of the meaningful transmission, solely according to the probability distributions of his observations. More specifically, in the first concept, we transmit meaningful and meaningless signals non-overlapped in time. Note that the meaningful signal is the one Alice wants to communicate with Bob, while the meaningless signal is used to confuse Willie. If well designed, Willie cannot differentiate between those two signals, because the induced output distributions are close (the closeness can be defined in several different ways, e.g., by total variational distance, divergence, etc.) to each other. In the second concept, the meaningful signal can be superimposed on the meaningless one. Under the stealth constraint, we can have a positive capacity, while the covert transmission rate is zero, asymptotically. Even though the transmission rate of the second concept is in general zero, asymptotically, the second order rate is positive following the square root law [5,6].
For the aforementioned two concepts, if the channel between Alice and Bob (denoted by Bob’s channel in the following) is no better than the channel between Alice and Willie (denoted by Willie’s channel in the following), we need additional keys to conceal the meaningful signals, e.g., [4,5]. In particular, these additional keys are used to choose between codebooks to fool Willie. Our motivation is to design an achievable scheme for the source model secret key generation (SKG) for the above scenario, i.e., Bob has no channel advantage over Willie, while fulfilling both the security and stealth constraints, simultaneously. Note that the keys generated from the stealthy SKG can also be used to protect the data on top of concealing the behavior of transmission, e.g., encryption/one-time pad, etc. Note also that our design goal is violated if we directly apply common SKG schemes [7]. This is because common SKG schemes use public communications for several important operations including advantage distillation, information reconciliation, and privacy amplification ([7] Chapter 4.3).Without subtle modifications, these operations will raise Willie’s curiosity. To attain our objective, we focus on stealthy SKG, which is from its counterpart, stealth communications [3]. The main reason not to consider covertness but stealth for the SKG is that, under the assumption of a noiseless public discussion channel, there is no ambient noise to hide the discussion signal. Instead, covert SKG may be feasible if there is a noisy public channel. In addition, in general, the covert SKG suffers a sub-linear rate, e.g., [8], which is inherited from the covert communications. Recall that a channel-model SKG with a rate-unlimited public channel was considered in [8]. The authors applied the scheme from covert communication to the key transmission, while a stealth-like public discussion was used.
The main contributions of this work are summarized in the following:
- We investigate a source-model SKG under strong secrecy with an additional stealth constraint.
- We derive an achievable secret key (SK) rate under the stealth constraint, if , where X, Y, and Z are the observations of the common randomness source at Alice, Bob, and Willie, respectively. Moreover, if form a Markov chain , then the SK capacity with the additional stealth constraint can be achieved without extra cost, compared to the SKG without the stealth constraint.
- We prove that a sufficient condition to achieve the stealthy SK capacity can be relaxed from the physically degraded channel to a stochastically degraded one.
Notation: Lower case bold letters denote deterministic vectors, and upper case normal/bold letters denote random variables/random vectors (or matrices), which will be defined when they are first mentioned. We denote the probability mass function (pmf) by P. The entropy of X is denoted as . The mutual information between two random variables X and Y is denoted by . The divergence between distributions and is denoted by . denotes that the random variable X follows the distribution F, while The subscript i in denotes the ith symbol, and . denotes the Markov chain. denotes the ceiling operator. All logarithms are to base two. .
2. Preliminaries and System Model
2.1. Preliminaries
We first introduce some necessary definitions and results to develop our work.
Definition 1.
The strong secrecy and the stealth constraints are respectively defined as:
for arbitrarily small , where M, , , and are transmitted messages, the observed signal at Willie, and the output distributions at Willie induced by meaningful and meaningless signals, respectively.
The second constraint in the above definition can be explained by hypothesis testing as discussed in [3]. By this viewpoint, if the second constraint is fulfilled, the adversary’s best strategy is to blindly guess whether the current transmitted signal is meaningful or meaningless.
Definition 2.
Denote a common random source as , where are the alphabets of the observations at Alice, Bob, and Willie. The random source is stochastically degraded, if the marginal distributions and are identical to those of another source of common randomness following the physical degradedness, i.e., .
Corollary 1.
The same marginal property for one transmitter ([11] Theorem 13.9) Consider a discrete memoryless multiuser channel including one transmitter and two non-cooperative receivers with input and output alphabets and , respectively. The capacity region of such a channel depends only on the conditional marginal distributions and and not on the joint conditional distribution , where and and are the transmit signal and the two receive signals, respectively.
Definition 3.
δ-robust typicality ([12] Appendix)
The sequence is δ-robust typical for :
where is the number of occurrences of a in .
Definition 4.
([9] (1.A.3) For random variables A and B, if and only if for all a.
Let denote that A and have the same distribution.
Lemma 1.
Coupling [13]: if and only if there exists random variables and such that almost surely.
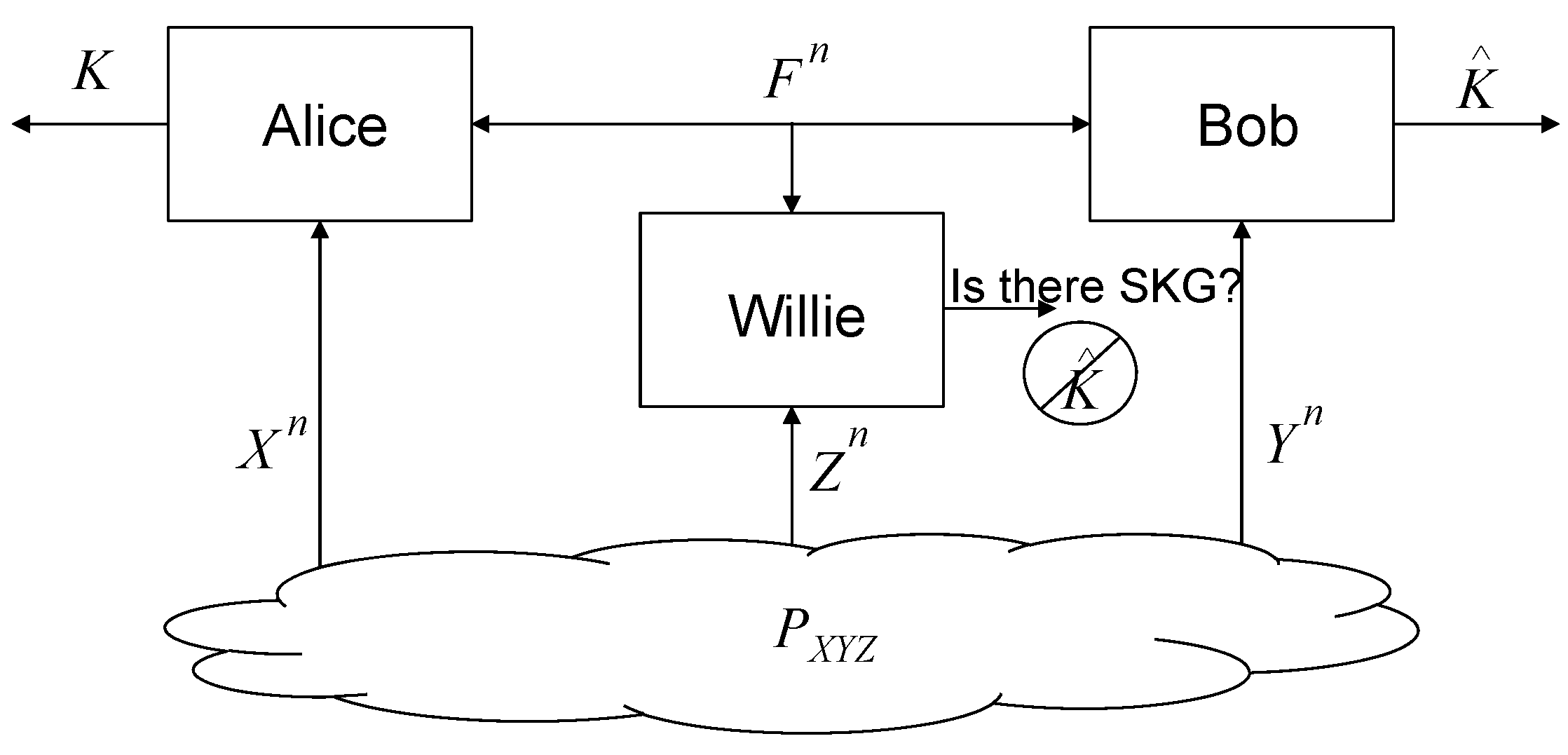
2.2. System Model
The considered system model is shown in Figure 1. We denote the n-time source observations at Alice, Bob, and Willie by , , and , respectively, which follow the independent and identically distributed (i.i.d.) joint distribution with alphabets , respectively. The public discussion between Alice and Bob through a noiseless channel is denoted by a random vector . We consider the case without rate limitation on the public discussion channel. Willie can perfectly observe . The joint distributions of the signals that Willie can observe when the SKG is meaningful and meaningless are denoted by and , respectively. Alice and Bob aim at sharing keys satisfying the constraints as follows:
for arbitrarily small , where (2) is the error probability having different keys at Bob from Alice, (3) is the keys’ uniformity constraint, while is the number of keys and (4) is the constraint for the strong secret key, which is an adaptation from the stealth communication in Definition 1. In particular, K is dual to M, and is dual to . The stealth constraint is considered in (5), which is again an adaptation from Definition 1, i.e., here, is what Willie can observe, instead of solely in stealth communications.
Definition 5.
Definition 6.
The maximum achievable stealthy strong SK rate is called the stealthy strong SK capacity.
3. Main Results
We show two main result in this section: (1) the stealthy strong SK rate and a condition to attain the capacity; (2) a scheme to identify the fast fading Gaussian Maurer’s model as a degraded one, so that the stealth SK capacity can be determined explicitly.
3.1. Stealthy Strong Secret Key Rate and Capacity
Our main result is described by the following theorem followed by discussions.
Theorem 1.
If drawn from the common random source , then the stealthy strong SK capacity of source model SKG with the stealth constraint can be bounded by:
Furthermore, if forms a Markov chain , the stealthy strong SK capacity is:
3.2. Sufficient Conditions for a Degraded Common Randomness
In this section, we derive a sufficient condition to obtain . In particular, we show that this sufficient condition, i.e., the common randomness forming a Markov chain , can be relaxed to be stochastically degraded. After that, we show that this relaxed condition can be satisfied under a quite common setting by, e.g., the fast fading Gaussian Maurer’s (satellite) model [10]. In particular, a central random source emits signals passing through fast fading additive white Gaussian noise (AWGN) channels, which are observed as X, Y, and Z at Alice, Bob, and Willie, respectively.
Theorem 2.
If a common random source is stochastically degraded such that and , where , then:
The proof is delegated to Appendix C.
Example: Consider the fast fading Gaussian Maurer’s (satellite) model [10] as a special case of Theorem 2:
where , , and are independent AWGNs at Bob and Willie, respectively, while both are with zero mean and unit variance; , , and follow CDFs , , and , respectively, and are the i.i.d. fast fading channel gains from the source to Alice and Willie, respectively. Note that intuitively, X, Y, and Z have no degradedness relation in general due to the random fading. This is because, by the definition of degradedness, the trichotomy order of all realizations between the two fading channels within a codeword length should be the same. We can invoke the same marginal property [14] to construct an equivalent channel, wherein by imposing the usual stochastic order constraint, we can identify those fading channels that can be re-ordered in the equivalent channel to keep the trichotomy order fixed.
If the random channels and fulfill for all x, where the subscripts denote the absolute square of the channel magnitudes, then from Lemma 1, we have equivalent (in the sense of having the same stealthy SK capacity) observations at Bob and Willie as and , respectively, where almost surely. Therefore, it is clear that is a relaxed sufficient condition to guarantee that Z is an equivalently stochastically degraded version of Y.
Assume that and in Equations (9a)–(9c) are fast fading magnitudes following the Nakagami-m distribution with shape parameters and and spread parameters and [15], respectively. From Theorem 2, we know that Z is a degraded version of X if:
where is the incomplete gamma function and is the ordinary gamma function. An example satisfying the above inequality is and .
4. Conclusions
In this work, we analyzed the performance of the secret key generation from a common random source, which satisfied the additional constraint that the generation of keys should not invoke the warden Willie’s attention. Our results showed that compared to the normal SKG, the additional stealth constraint could be fulfilled without extra cost. In particular, the stealthy SK capacity with strong secrecy constraint is , if the common random source satisfies . To emphasize the practical relevance, a sufficient condition was derived to attain the degradedness by the usual stochastic order for the Gaussian Maurer’s (satellite) model for the source of common randomness under fast fading. As a final note, we can also use Slepian–Wolf coding with a proper use of the binning code book to derive the same result.
Author Contributions
Formal analysis, P.-H.L.; investigation, P.-H.L., C.R.J., and E.A.J.; supervision, E.A.J.; validation, C.R.J. and R.F.S.; writing, review and editing, C.R.J., E.A.J., and R.F.S. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Pin-Hsun Lin was supported in part by German Research Foundation (DFG) LI 2886/2-1. The work of Eduard A. Jorswieck was supported in part by DFG, C. Janda was supported by DFG within the project Play Scate (DFG JO 801/21-1). We acknowledge support by the German Research Foundation and the Open Access Publication Funds of the Technische Universität Braunschweig. This work of R. F. Schaefer was supported by the German Federal Ministry of Education and Research (BMBF) within the national initiative for “Post Shannon Communication (NewCom)” under Grant 16KIS1004.
Acknowledgments
The authors would like to thank Matthieu Bloch for fruitful discussions and the anonymous reviewers’ efforts on Remark 1 and also on improving the quality of the presentation of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Our main idea for deriving the lower bound of the SK capacity in the second scheme is by constructing a conceptual WTC (CWTC) as in [16]. An equivalent wiretap codebook is constructed, where , , is the number of secure messages, and is the number of confusion messages; m and w are uniformly and independently selected; . In addition, are generated according to , where we consider the equivalent channel from Alice to Willie as:
where is the equivalent channel output at Willie. Similarly, is the equivalent channel output at Bob. We choose mutually independent of , and .
In order to analyze the stealth, the respective distributions of the meaningful and meaningless signals at the equivalent channel output at Willie are:
We first decompose the stealth secrecy constraint as follows:
where (a) follows the chain rule of divergence ([17] Th.2.2.2).
We then apply the channel resolvability analysis [18] to the CWTC, in order to find the rate constraint on the confusion messages, in order to guarantee the validity of the stealth secrecy constraint (A4).
From the analysis conducted in Appendix B, we know:
Recall that is the number of confusion messages inside each bin, and we need to design it such that (A6) is vanishing. The main difference between our proof and that in [3] is that we introduce an additional channel output at both Bob and Willie by constructing a CWTC for the considered SKG model, which makes the results from [3] not able to be directly applied.
Now, we reexpress the ratio in the logarithm on the right-hand side (RHS) of (A6) as follows:
where (a) is due to the fact that and are independent when a meaningless discussion is transmitted, which has a pmf denoted by ; (b) comes the fact that is independent of by selection, i.e., .
Note that even though and are independent and and are independent by assumption, that does not mean , , and are necessarily generated according to or . In fact, since pairwise independence does not imply mutual independence ([19] Chapter 7.1, 7.2), there exists joint distribution such that we can invoke tools from the joint asymptotic equipartition property [20].
Then, we can rewrite (A6) as follows:
The RHS of (A8) can be discussed in two cases as follows similar to [3], according to whether are jointly typical or not:
where follows the -robust typicality [12] definition for the subsequent derivation.
The Chernoff bound and an important upper bound, which will be used later, are restated in the following.
Lemma A1.
(Chernoff bound ([12] Lemma 16) For every , , and ,
Lemma A2.
Next, we derive the constraint (The constraint that Bob should successfully decode both the secret and confusion messages is a point-to-point transmission without secrecy, which can be seen from [12]. Therefore, we omit the proof here.) on as follows:
where (a) comes from ([12] Lemma 18, Lemma 20); (b) comes from the fact that the total probability of the jointly typical set is smaller than one; (c) is from definition of and . After that, we have if when the following constraint is fulfilled:
where (a) comes from a specific use of the public discussion following ([16] Theorem 3) and ⊕ is the modulo addition in . We can follow the argument in ([21] Appendix B) in order to apply the crypto lemma in (A12) or (A14) to unbounded X like the Gaussian case. (b) comes from the fact that U is uniformly distributed with the crypto lemma. In addition, we can derive that as as follows:
where (a) is due to the fact that , and therefore, ; (b) is by lower bounding with , where ; (c) by simple algebra; (d) is by definition of probability; (e) is by Lemma A2. Note that in (A13) is a constant, but not a function of n. Therefore, the RHS of (A13) can be easily seen to vanish exponentially fast, if . Then, from (A11) and (A13), it is clear that (4) and (5) are fulfilled.
By constructing the CWTC, the following rate between Alice and Bob is achievable:
where (a) again comes from the crypto lemma with the selection of being independent of . Then, from (A12) and (A14), the achievable stealthy strong SK rate can be derived as follows:
where (a) is by plugging (A12) with the assumption of a memoryless common randomness, which is independent and identically distributed (i.i.d.). We can interchange the roles of X and Y to get , which completes the proof.
Remark A1.
In addition to the channel resolvability scheme, we can also attain the proof by a modified SWC scheme, which is sketched as follows. We can first construct a binary auxiliary random variable S, which selects the meaningful or meaningless discussion when and , respectively. The stealth constraint is to avoid Willie successfully guessing the realization of S and can be formulated as By the data processing inequality for divergence [17], we can have the inequality , which is an effective secrecy constraint of the considered SKG model. It is the counterpart to the one of the wiretap channel with stealth constraint [3]. We can then construct two binning codebooks for and , where in each case, there is one corresponding binning codebook, in order to fulfill the secrecy constraint. In the error analysis, there are two cases: (1) when , the probability of Alice and Bob having different keys; (2) when , the probability of Bob generating a key that is not null. By vanishing enforcing the average error probability, we can attain the result in Theorem 1.
Remark A2.
In the analysis by the WTC scheme in Appendix A, we derive the stealthy strong SK rate by combining a tool based one channel resolvability developed in [3] with the CWTC. In particular, we first derive an upper bound of the averaged stealth secrecy constraint (A5) by the random coding analysis. By enforcing the upper bound to vanish, we can derive the constraints on the stealthy strong SK rate and the confusion rate in the codebook design. By this scheme, we can proceed with the derivation based on the result of the wiretap channel.
Appendix B. Proof of (A6)
In the following, we show the tedious derivation for (A6) from channel resolvability [3]:
where (a) is by constructing a CWTC, such that the key K is interchangeable with the message M; (b) is by definition of the conditional K-L distance ([17] Definition 2.2); (c) is due to the fact that is the marginalization of with respect to w, which is the index of the confusion message; in (d), we expand the expectation with respect to M; (e) is by defining and by and , respectively, to simplify the expression, where ; (f) is by definition of the expectation over . Since are generated independently and identically according to , the joint distribution of codewords in a codebook is the product of marginal distributions; in (g), we expand the summation with respect to m and w; in (h), we expand the product according to the form in step (g); in (i), we collect terms to form the expectation ; in (j), we collect the terms by introducing additional indices ; in (k), we apply Jensen’s inequality to the logarithm; (l) is by expanding the expectation ; (m) is by adding the term ; (n) is by the definition of marginalization over with respect to . In particular, the second term on the RHS of the numerator in (m) becomes from (A3); (o) is by definition of the expectation.
Appendix C. Proof of Theorem 2
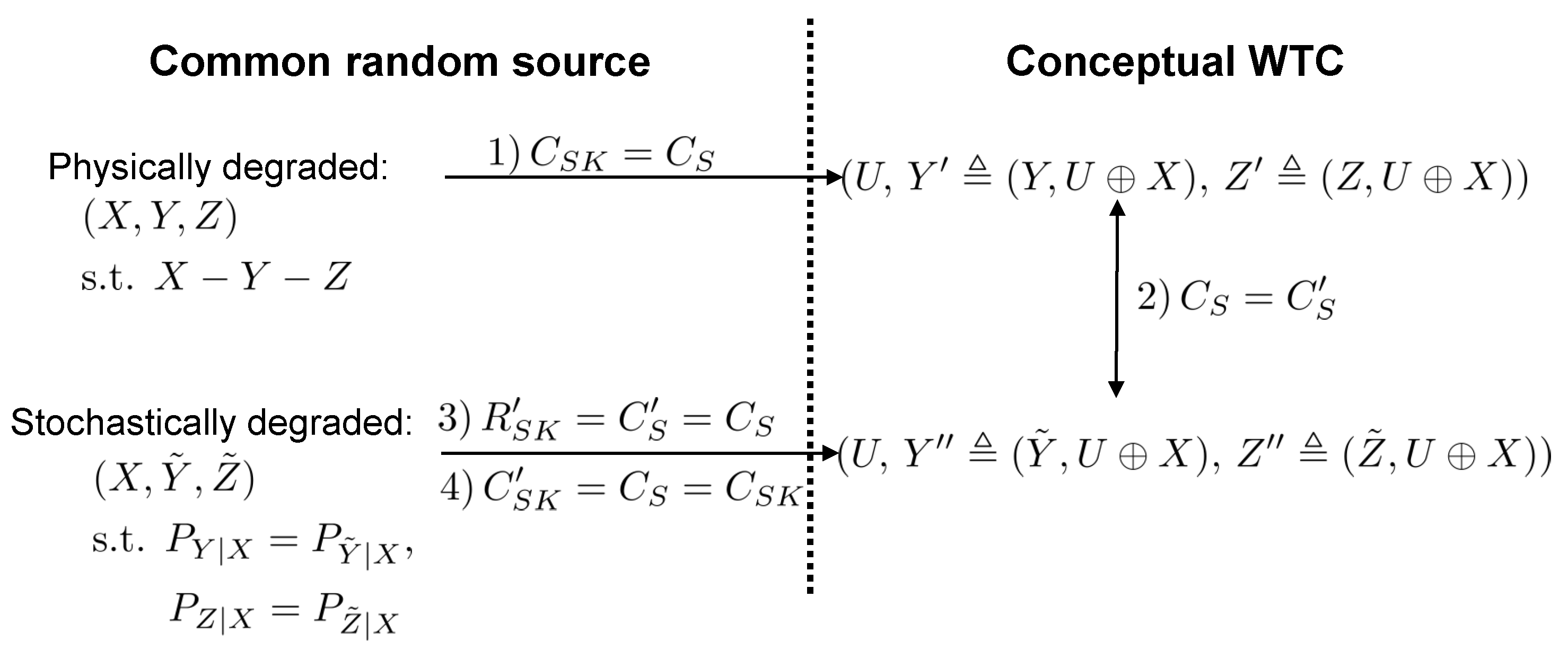
We sketch the proof as follows in three steps, while the main idea is summarized in Figure A1. The key is to show that the stochastically degraded source implies that the corresponding CWTC [16] is also stochastically degraded, then the secret key capacity of the source is the same as the secrecy capacity of a CWTC constructed from a physically degraded source . The first step is to construct the CWTC of the source and prove that, if , then , i.e., the corresponding CWTC is also physically degraded, where U is the conceptual code symbol, uniformly distributed in and independent of . The equivalently received signals at Bob and Willie in the CWTC are and , respectively, while is the signal transmitted through the public channel. The second step is to construct a stochastically degraded source from . After that, we construct the corresponding CWTC of as , where and . The third step is to show that the CWTC described by has the same marginals as the CWTC described by , i.e., the two CWTC’s have the same secrecy capacity. In addition to the fact that stochastic degradedness is no stronger than the physical degradedness, this results in that the former one should not have a higher secret key capacity than the latter one. We then know that the sources and have the same secret key capacity, which completes the proof.
Figure A1.
Key steps in the proof of Theorem 2. First is to show that the CWTCalso physically degraded if the source is physically degraded. Then, we show that the CWTC constructed from a stochastically degraded source corresponding to the physically degraded source is a stochastically degraded CWTC with the same marginal as that physically degraded CWTC. Finally, we show that the secrecy capacity of the second CWTC is indeed the secret key capacity of the stochastically degraded source. The key and secrecy capacities of the physically degraded source and the corresponding CWTC are denoted by and , respectively, while the key (rate) and secrecy capacities of the stochastic source and the corresponding CWTC are denoted by and , respectively.
Figure A1.
Key steps in the proof of Theorem 2. First is to show that the CWTCalso physically degraded if the source is physically degraded. Then, we show that the CWTC constructed from a stochastically degraded source corresponding to the physically degraded source is a stochastically degraded CWTC with the same marginal as that physically degraded CWTC. Finally, we show that the secrecy capacity of the second CWTC is indeed the secret key capacity of the stochastically degraded source. The key and secrecy capacities of the physically degraded source and the corresponding CWTC are denoted by and , respectively, while the key (rate) and secrecy capacities of the stochastic source and the corresponding CWTC are denoted by and , respectively.

In the following, we will prove that the stochastically degraded random source implies that the corresponding CWTC [16] is also stochastically degraded, which is constructed by the corresponding physically degraded source . We start from constructing the CWTC of the random source , where the equivalently received signals at Bob and Willie are and , respectively. If , then , i.e., the CWTC is also a physically degraded one, which can be shown as follows:
where (a) is by the definition of and ; (b) is by the crypto lemma [22], and U is selected to be independent of Y and Z; (c) is from the fact that given U, we can know X from ; (d) is by the same reason as (b); (e) is due to and by the definition of conditional mutual information.
Now, we consider the stochastically degraded source of common randomness fulfilling and . Similar to the first step, we construct the CWTC from , namely , where and are the equivalent channel outputs at Bob and Willie, respectively. To prove that the two CWTC’s and are equivalent, we can invoke the same marginal property in ([11] Theorem 16.6) to prove that and , which is shown in the following. By the definitions of and , we know that and , respectively, where we define as . Note that due to the closed operation ⊕ in , the distribution of is a left circular shift of that of X by u. Instead of directly proving , we can equivalently prove , as follows:
where the second equality is due to the assumption of forming a stochastically degraded source from the physically degraded one . Therefore, . Similarly, we can derive . Hence, we prove that the CWTC of a stochastic degraded source is also a degraded CWTC and the two CWTC’s have the same secrecy capacity.
Note that due to , we can derive the key capacity from the corresponding CWTC, not just an achievable key rate. For the source , till now, we may only claim the achievable secret key rate, but not the secret key capacity, namely , is the same as . That is because the CWTC is in general only an achievable scheme to derive the secret key rate. However, due to the fact that the stochastic degradedness is more general than the physical degradedness, i.e., less stringent on characterizing the order between and , the stochastic degradedness cannot result in a larger secret key capacity than the physically degraded one. Therefore, we attain that , which completes the proof.
References
- Wyner, A.D. The wiretap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Che, P.H.; Bakshi, M.; Jaggi, S. Reliable deniable communication: Hiding messages in noise. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 2945–2949. [Google Scholar]
- Hou, J.; Kramer, G. Effective secrecy: Reliability, confusion and stealth. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 601–605. [Google Scholar]
- Wang, L.; Wornell, G.W.; Zheng, L. Fundamental limits of communication with low probability of detection. IEEE Trans. Inf. Theory 2016, 62, 3493–3503. [Google Scholar] [CrossRef] [Green Version]
- Bloch, M.R. Covert Communication Over Noisy Channels: A Resolvability Perspective. IEEE Trans. Inf. Theory 2016, 62, 2334–2353. [Google Scholar] [CrossRef] [Green Version]
- Bash, B.A.; Goeckel, D.; Towsley, D. Limits of reliable communication with low probability of detection on AWGN channels. IEEE J. Sel. Areas Commun. 2013, 31, 1921–1930. [Google Scholar] [CrossRef] [Green Version]
- Bloch, M.; Barros, J. Physical-Layer Security From Information Theory to Security Engineering; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Tahmasbi, M.; Bloch, M.R. Covert Secret Key Generation. In Proceedings of the 2017 IEEE Conference on Communications and Network Security (CNS), Las Vegas, NV, USA, 9–11 October 2017; pp. 540–544. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Springer: Berlin/Heidelberger, Germany, 2007. [Google Scholar]
- Naito, M.; Watanabe, S.; Matsumoto, R.; Uyematsu, T. Secret key agreement by soft-decision of signals in Gaussian Maurer’s model. IEICE Trans. Fundam. 2009, E92-A, 525–534. [Google Scholar] [CrossRef] [Green Version]
- Moser, S.M. Advanced Topics in Information Theory-Lecture Notes. 2013. Available online: http://moser-isi.ethz.ch/docs/it_script_v46.pdf (accessed on 10 June 2020).
- Orlitsky, A.; Roche, J. Coding for computing. IEEE Trans. Inf. Theory 2001, 47, 903–917. [Google Scholar] [CrossRef]
- Thorisson, H. Coupling, Stationarity, and Regeneration; Springer: New York, NY, USA, 2000. [Google Scholar]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Simon, M.K.; Alouini, M.S. Digital Communication over Fading Channels; John Wiley & Sons: Chichester, UK, 2000. [Google Scholar]
- Maurer, U.M. Secret Key Agreement by Public Discussion from Common Information. IEEE Trans. Inf. Theory 1993, 39, 733–742. [Google Scholar] [CrossRef] [Green Version]
- Polyanskiy, Y.; Wu, Y. Lecture Notes on Information Theory 2019. Available online: http://www.stat.yale.edu/~yw562/teaching/itlectures.pdf (accessed on 10 June 2020).
- Hou, J.; Kramer, G. Informational divergence approximations to product distributions. In Proceedings of the 2013 13th Canadian Workshop on Information Theory, Toronto, ON, Canada, 18–21 June 2013. [Google Scholar]
- Stoyanov, J.M. Counterexamples in Probability, 3rd ed.; Dover: New York, NY, USA, 2013. [Google Scholar]
- Cover, T.M. Broadcast Channels. IEEE Trans. Inf. Theory 1972, 18, 2–14. [Google Scholar] [CrossRef] [Green Version]
- Bennatan, A.; Burshtein, D.; Caire, G.; Shamai, S. Superposition coding for side-information channels. IEEE Trans. Inf. Theory 2006, 52, 1872–1889. [Google Scholar] [CrossRef]
- Forney, G.D., Jr. On the Role of MMSE Estimation in Approaching the Information-Theoretic Limits of Linear Gaussian Channels: Shannon meets Wiener. 2004. Available online: https://arxiv.org/pdf/cs/0409053.pdf (accessed on 10 June 2020).
Figure 1.
The system model of the considered stealthy secret key generation (SKG).

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lin, P.-H.; Janda, C.R.; Jorswieck, E.A.; Schaefer, R.F. Stealthy Secret Key Generation. Entropy 2020, 22, 679. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060679
AMA Style
Lin P-H, Janda CR, Jorswieck EA, Schaefer RF. Stealthy Secret Key Generation. Entropy. 2020; 22(6):679. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060679
Chicago/Turabian StyleLin, Pin-Hsun, Carsten R. Janda, Eduard A. Jorswieck, and Rafael F. Schaefer. 2020. "Stealthy Secret Key Generation" Entropy 22, no. 6: 679. https://0-doi-org.brum.beds.ac.uk/10.3390/e22060679
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.