Interacting Particle Solutions of Fokker–Planck Equations Through Gradient–Log–Density Estimation


1
Artificial Intelligence Group, Technische Universität Berlin, Marchstraße 23, 10587 Berlin, Germany
2
Institute of Mathematics, University of Potsdam, Karl-Liebknecht-Str. 24/25, 14476 Potsdam, Germany
*
Authors to whom correspondence should be addressed.
Entropy 2020, 22(8), 802; https://0-doi-org.brum.beds.ac.uk/10.3390/e22080802
Submission received: 7 June 2020
/
Revised: 7 July 2020
/
Accepted: 15 July 2020
/
Published: 22 July 2020
(This article belongs to the Special Issue Entropy Methods for Stochastic Dynamical Systems and Evolution Equations)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Fokker–Planck equations are extensively employed in various scientific fields as they characterise the behaviour of stochastic systems at the level of probability density functions. Although broadly used, they allow for analytical treatment only in limited settings, and often it is inevitable to resort to numerical solutions. Here, we develop a computational approach for simulating the time evolution of Fokker–Planck solutions in terms of a mean field limit of an interacting particle system. The interactions between particles are determined by the gradient of the logarithm of the particle density, approximated here by a novel statistical estimator. The performance of our method shows promising results, with more accurate and less fluctuating statistics compared to direct stochastic simulations of comparable particle number. Taken together, our framework allows for effortless and reliable particle-based simulations of Fokker–Planck equations in low and moderate dimensions. The proposed gradient–log–density estimator is also of independent interest, for example, in the context of optimal control.
1. Introduction
Many biological and physical systems are characterised by the presence of stochastic forces that influence their dynamics. These forces may be attributed either to intrinsic or extrinsic sources [1,2,3], i.e., arising either from random fluctuations of constituent subsystems [4,5], or from fluctuating interactions with the environment [6,7].
Often, deterministic analysis of these systems suffices to describe their macroscopic behaviour, and the fluctuations contribute only negligible perturbations around the deterministic dynamics. In systems biology, for example, rate equations describing mean concentrations of considered system’s species have provided a useful description of chemical reaction networks’ dynamics, and have enabled answering invaluable questions pertaining chemical systems comprising large numbers of molecules [8].
However, in several settings, the effect of stochastic forces influences considerably the resulting system’s behaviour by qualitatively altering its evolution. In those settings, random fluctuations have to be accounted for, and thus stochastic analysis becomes essential [9,10]. Phenomena such as stochastic resonance [11,12], noise induced transitions [13,14,15], and stochastic synchronisation, to name a few, are prevalent in many physical systems, and highlight the importance of considering fluctuating forces in the analysis of a system’s behaviour. Manifestations of these phenomena abound in nature and have been encountered in genetics [16], neuroscience [17,18], climate science [12,19,20] and other fields.
Indispensable tools for the analysis of stochastic systems are Kolmogorov equations, and in particular the Fokker–Planck equation (FPE) [21,22]. FPEs characterise the evolution of the probability density functions (PDF) for the state variables of dynamical systems described by stochastic differential equations (SDE). SDEs commonly arise in modeling random effects in systems with continuous state variables [23], or after diffusion approximation of Master equations for systems involving discrete state transitions in time [8,24,25]. The associated FPEs have been widely used for modelling stochastic phenomena in various fields, such as, for example, in physics, finance, biology, neuroscience, traffic flow [26].
Yet, although commonly used, explicit closed-form solutions of FPEs are rarely available [27], especially in settings where the underlying dynamics is nonlinear. In particular, exact analytic solutions may be obtained only for a restricted class of systems following linear dynamics perturbed by white Gaussian noise, and for some nonlinear Hamiltonian systems [21,28]. Further systems that admit analytical treatment independent of system dimension are those with discrete state transitions approximated via van Kampen expansion (linear noise approximation), resulting thus in linear SDEs with time dependent coefficients [9].
Existing numerical approaches for computing Fokker–Planck solutions may be grouped into three broad categories: grid-based, semi-analytical, and sample-based methods. The first category comprises mainly finite difference and finite element methods [29,30,31,32]. These frameworks, based on integration of FPEs employing numerical solvers for partial differential equations, entail computationally demanding calculations with inherent finite spatial resolution [33].
Conversely, semi-analytical approaches try to reduce the number of required computations by assuming conditional Gaussian structures [34], or by employing cumulant neglect closures [35], statistical linearisation [36,37], or stochastic averaging [38]. Although efficient in the settings they are devised for, their applicability is limited since the resulting solutions are imprecise or unstable in certain settings.
On the other hand, in the sample-based category, Monte Carlo methods resort to stochastic integration of a large number of independent stochastic trajectories that as an ensemble represent the probability density [39,40]. These methods are appropriate for computing unbiased estimates of exact expectations from empirical averages. Nevertheless, as we show in the following, cumulants of resulting distributions exhibit strong temporal fluctuations when the number of simulated trajectories is not sufficiently large.
Surprisingly, there is an alternative sample-based approach built on deterministic particle dynamics. In this setting, the particles are not independent, but they rather interact via an (approximated) probability density, and the FPE describes the mean field limit when their number grows to infinity. This approach introduces a bias in the approximated expectations, but significantly reduces the variance for a given particle number.
Recent research, see e.g., [41,42,43,44], has focused on particle methods for models of thermal equilibrium, where the stationary density is known analytically. For these models, interacting particle methods have found interesting new applications in the field of probabilistic Bayesian inference: by treating the Bayesian posterior probability density as the stationary density of a FPE, the particle dynamics provides posterior samples in the long time limit. For this approach, the particle dynamics are constructed by exploiting the gradient structure of the probability flow of the FPE. This involves the relative entropy distance to the equilibrium density as a Lyapunov function. Unfortunately, this structure does not apply to general FPEs in non–equilibrium settings, where the stationary density is usually unknown.
In this article, we introduce a framework for interacting particle systems that may be applied to general types of Fokker–Planck equations. Our approach is based on the fact that the instantaneous effective force on a particle due to diffusion is proportional to the gradient of the logarithm of the exact probability density (GLD). Rather than computing a differentiable estimate of this density (say by a kernel density estimator), we estimate the GLD directly without requiring knowledge of a stationary density. Therefore, we introduce an approximation to the effective force acting on each particle, which becomes exact in the large particle number limit given the consistency of the estimator.
Our approach is motivated by recent developments in the field of machine learning, where GLD estimators have been studied independently and are used to fit probabilistic models to data. An application of these techniques to particle approximations for FPE is, to our knowledge, new. (The approach in [45] uses a GLD estimator different from ours for particle dynamics but with a probability flow towards equilibrium which is not given by a standard FPE.) Furthermore, our method provides straightforward approximations of entropy production rates, which are of primary importance in non–equilibrium statistical physics [46].
This article is organised as follows: Section 2 describes the deterministic particle formulation of the Fokker–Planck equation. Section 3 shows how a gradient of the logarithm of a density may be represented as the solution of a variational problem, while in Section 4 we discuss an empirical approximation of the gradient-log-density. In Section 5, we introduce function classes for which the variational problem may be solved explicitly, while in Section 6 we compare the temporal derivative of empirical expectations based on the particle dynamics with exact results derived from the Fokker–Planck equation. Section 7 is devoted to the class of equilibrium Fokker–Planck equations, where we discuss relations to Stein Variational Gradient Descent and other particle approximations of Fokker–Planck solutions. In Section 8, we show how our method may be extended to general diffusion processes with state-dependent diffusion, while Section 9 discusses how our framework may be employed to simulate second order Langevin dynamics. In Section 10 we demonstrate various aspects of our method by simulating Fokker–Planck solutions for different dynamical models. Finally, we conclude with a discussion and an outlook in Section 11.
2. Deterministic Particle Dynamics for Fokker–Planck Equations
We consider Fokker–Planck equations of the type
Given an initial condition , Equation (1) describes the temporal development of the density for the random variable following the stochastic differential equation
In Equation (2), denotes the drift function characterising the deterministic part of the driving force, while represents the differential of a vector of independent Wiener processes capturing stochastic, Gaussian white noise excitations. For the moment, we restrict ourselves to state independent and diagonal diffusion matrices, i.e., diffusion matrices independent of (additive noise) with diagonal elements characterising the noise amplitude in each dimension. Extensions to more general settings are deferred to Section 8.
We may rewrite the FPE Equation (1) in the form of a Liouville equation
for the deterministic dynamical system
(dropping the time argument in for simplicity) with velocity field
Hence, by evolving an ensemble of N independent realisations of Equation (4) (to be called ’particles’ in the following) according to
we obtain an empirical approximation to the density .
Since the only source of randomness in Equation (4) can be attributed to the initial conditions , averages computed from the particle approximation (Equation (6)) are expected to have smaller variance compared to N independent realisations of the SDE (Equation (2)). Unfortunately, this approach requires perfect knowledge of the unknown instantaneous density (Equation (5)), which is actually the unknown quantity of interest.
Here, we circumvent this issue by introducing statistical estimators for the term , computed from the entire ensemble of particles at time t. Although this additional approximation introduces interactions among the particles via the estimator, for sufficiently large particle number N, fluctuations of the estimator are expected to be negligible and the limiting dynamics should converge to its mean field limit (Equation (4)) provided the estimator is asymptotically consistent. Thus, rather than computing a differentiable approximation to from the particles, e.g., by a kernel density estimator, we show in the following section, how the function may be directly estimated from samples of .
3. Variational Representation of Gradient–Log–Densities
To construct a gradient–log–density (GLD) estimator we rely on a variational representation introduced by Hyvärinen in his score–matching approach for the estimation of non–normalised statistical models [47]. We favoured this approach over other estimators [48,49] due to its flexibility to adapt to different function classes chosen to approximate the GLD.
Here, we use a slightly more general representation compared to [47] allowing for an extra arbitrary reference function such that the component of the gradient is represented as
where stands for the partial derivative with respect to coordinate of the vector .
The cost function is defined as an expectation with respect to the density by
with representing the volume element in . To obtain this relation, we use integration by parts (assuming appropriate behaviour of densities and at boundaries), and get
Minimisation with respect to yields Equation (7).
4. Gradient–Log–Density Estimator
To transform the variational formulation into a GLD estimator based on N sample points , we replace the density in Equation (8) by the empirical distribution , i.e.,
and
where is an appropriately chosen family of functions with controllable complexity. By introducing the estimator of Equation (11) in Equation (6), we obtain a particle representation for the Fokker–Planck equation
for , with
Although in this article, we use reference functions for all simulated examples, the choice , which cancels the first two terms in Equation (12), leads to interesting relations with other particle approaches for simulating Fokker–Planck solutions for equilibrium systems (c.f. Section 7) and impacts on the numerical approximation of (c.f. Section 5). In particular, when considering Brownian dynamics, where , the choice leads to once the system has reached thermal equilibrium. More generally speaking, one may choose , where is an appropriate reference measure such as the equilibrium measure of the underlying stochastic process.
Estimating the Entropy Rate
Interestingly, the variational approach provides us with a simple, built in method for computing the entropy rate (temporal change of entropy) of the stochastic process (Equation (2)).
The first term on the right hand side is usually called entropy production, whereas the second term corresponds to the entropy flux. In the stationary state, the total entropy rate vanishes. For equilibrium dynamics, both terms vanish individually at stationarity. This should be compared to the minimum of the cost function (Equation (9)), which for , equals
Thus, we obtain the estimator
We will later see for the case of equilibrium dynamics that a similar method may be employed to approximate the relative entropy distance to the equilibrium density.
5. Function Classes
In the following, we discuss choices for families of functions leading to explicit, closed form solutions for estimators.
5.1. Linear Models
A simple possibility is to choose linearly parametrised functions of the form
where the are appropriate basis functions, e.g., polynomials, radial basis functions or trigonometric functions. For this linear parametrisation, the empirical cost (Equation (10)) is quadratic in the parameters and can be minimised explicitly. A straightforward computation from Equation (12) shows that
with .
Here, we require the number of samples to be greater than the number of employed basis functions, i.e., , to have a non–singular matrix C. This restriction may be lifted by adding a penalty to the empirical cost (Equation (10)) for regularisation, similar to ridge regression estimators. Equation (17) is independent of the reference function r, when r belongs to the linear span of the selected basis functions. However, this model class with a finite parameter number has limited complexity.
When the particle number N grows large, we expect convergence of the dynamics to a mean field limit which would be given by
where the brackets denote expectation with respect to the limiting density and . Since the linear model class (Equation (16)) exhibits limited complexity for fixed m, we do not expect the approximated solution to equal the exact solution of the FPE. Nevertheless, for rare cases, where both and also are linear combinations of the employed basis functions for all times t, would provide an exact solution. For example, in a setting with linear drift function , reference function , and dimensionality , a basis consisting of a constant and a linear function , would be able to perfectly represent the GLD of the Gaussian density .
5.2. Kernel Approaches
Here, we consider a family of functions for which the effective number of parameters to be computed is not fixed beforehand, but rather increases with the sample number N: a reproducing kernel Hilbert space (RKHS) of functions defined by a positive definite (Mercer) kernel . Statistical models based on such function spaces have played a prominent role in the field of machine learning in recent years [51].
A common, kernel-based approach to regularise the minimisation of empirical cost functions is via penalisation using the RKHS norm of functions in . This can also be understood as a penalised version of a linear model (Equation (16)) with infinitely many feature functions . For so-called universal kernels [52], this unbounded complexity suggests that we could expect asymptotic convergence of the GLD estimator (see [53] for related results) and a corresponding convergence of the particle model to the FPE as its mean field limit. However, a rigorous proof may not be trivial, since particles in our setting are not independent.
The explicit form of the kernel-based approximation is given by
where the parameter controls the strength of the penalisation. Again, this optimisation problem can be solved in closed form in terms of matrix inverses. One can prove a representer theorem which states that the minimiser in Equation (18) is a linear combination of kernel functions evaluated at the sample points , i.e.,
For such functions, the RKHS norm is given by
Hence, this representation leads again to a quadratic form in the N coefficients.
The solution of the minimisation problem is given by
where . Similar approaches for kernel-based GLD estimators have been discussed in [48,49]. For , Equation (21) agrees with the GLD estimator of [48] derived by inverting Stein’s equation, or by minimising the Kernelised Stein discrepancy.
The resulting particle dynamics is given by
Please note that here the inverse matrix also depends on the particles .
We may simplify Equation (22) by adding and subtracting a term in the summation over l, with denoting the Kronecker delta. This yields
In the limit of small , the right hand side becomes independent of the reference function r.
In the present article, we employ Gaussian radial basis function (RBF) kernels given by
with a length scale l. A different possibility would be given by kernels with a finite dimensional feature representation
which may also be interpreted as a linear model as in Equation (16) with a penalty on the unknown coefficients.
5.3. A Sparse Kernel Approximation
Since the inversions of the matrices in Equation (22) have to be performed at each step of a time discretised ODE system (Equation (22)), for large particle number N, the cubic complexity becomes too computationally demanding. Hence, here, we resort to a well established approximation in machine learning to overcome this issue, by applying a sparse approximation to the optimisation problem of Equation (18), see e.g., [54]. In particular, we introduce a smaller set of inducing points that need not necessarily be a subset of the N particles. We then minimise the penalised cost function (Equation (18)) in the finite dimensional family of functions
This may also be understood as a special linear parametric approximation. To keep matrices well conditioned, in practice we add a small ’jitter’ term to Equation (18), i.e., we use
as the total penalty. In the limit , this representation reduces to an approximation of the form of Equation (16) with M basis functions for .
Hence, for this approximation we have to invert only matrices. For fixed M, the complexity of the GLD estimator is limited. Results for log–density estimators in machine learning (obtained for independent data) indicate that for a moderate growth of the number of inducing points M with the number of particles N, similar approximation rates may be obtained as for full kernel approaches.
6. A Note on Expectations
In this section, we present a preliminary discussion of the quality of the particle method to approximate expectations of scalar functions h of the random variable . We concentrate on the temporal development of . While it would be important to obtain an estimate of the approximation error over time, we will defer such an analysis to future publications and only concentrate on a result for the first time derivative of expectations, i.e., the evolution over infinitesimal times.
Using the FPE (Equation (1)) and integrations by parts, one derives the exact result
where denotes the expectation with respect to and the operator is defined as
In Equation (32), denotes the generator of the diffusion process defined by the corresponding stochastic differential equation (Equation (2)). To obtain a related result for the particle dynamics and the empirical expectations denoted by , we employ the relation
where we have used the chain rule for the time derivative.
We will focus initially on the dynamics based on basis functions. Expressing the sum over in Equation (17) as an expectation, we obtain
Hence, by inserting Equation (34) into Equation (33) and adding and subtracting the term we obtain
where the remainder term is given by
For the approximation of the vectorial function we have
A simple comparison shows that each component of the vector can be written as the minimiser of where is a linear combination of basis functions. Hence, equals the best approximation of the vectorial function based on the ’data’ using regression with basis functions. Thus, if is well approximated by basis functions, the remainder is small. If indeed , for some , the remainder term vanishes, . By its similarity to the finite basis function model, this result should also be valid for the sparse kernel dynamics of Equation (30), when the penalty is small. One might conjecture that the temporal development of expectations for reasonably smooth functions might be faithfully represented by the particle dynamics. This conjecture is supported by our numerical results.
7. Equilibrium Dynamics
An important class of stochastic dynamical systems describe thermal equilibrium, for which the drift function f is the negative gradient of a potential U, while the limiting equilibrium density is explicitly given by a Gibbs distribution:
For this class of models, our method provides a simple and built-in estimator for the relative entropy between the instantaneous and the equilibrium density, and respectively. As we discuss here, our framework may also be related to two other particle approaches that converge to the (approximate) equilibrium density.
7.1. Relative Entropy
The relative entropy or Kullback–Leibler divergence is defined as
Following a similar calculation that led to Equation (13), we obtain
where indicates the velocity field of the particle system defined in Equation (4). The first equality holds for arbitrary drift functions. To obtain the second equality, we have inserted the explicit result for .
Hence, we may compute the relative entropy at any time T as a time integral
where the inner expectation is easily approximated by our particle algorithm. This result shows that the exact velocity field converges to 0 for , and one expects particles to also converge to fixed points. For other non–equilibrium systems, asymptotic fixed points are, however, the exception.
7.2. Relation to Stein Variational Gradient Descent
Recently, Stein variational gradient descent (SVGD), a kernel-based particle algorithm, has attracted considerable attention in the machine learning community [55,56]. The algorithm is designed to provide approximate samples from a given density as the asymptotic fixed points of a deterministic particle system. Setting , SVGD is based on the dynamics
This may be compared to our approximate FPE dynamics (Equation (22)) for the equilibrium case by setting and . For this setting, both algorithms have in fact, the same conditions
for the ’equilibrium’ fixed points. See [44] for a discussion of these fixed points for different kernel functions. However, both dynamics differ for finite times t, where a single time step of SVGD is computationally simpler, being free of the matrix inversion required by our framework. The mean field limit of Equation (44) differs from the FPE limit, and the resulting partial differential equation is nonlinear [57]. Nevertheless, it is possible to interpolate between the two particle dynamics. In fact, in the limit of a large regularisation parameter , the inverse matrix in Equation (22) becomes diagonal, i.e., , and we recover SVGD (Equation (44)) by introducing a rescaled time . This result could be of practical importance when the goal is to approximate the stationary distribution, irrespective of the finite-time dynamics. The SVGD combines faster matrix operations with slower relaxation times to equilibrium compared to the FPE dynamics. It would be interesting to see if an optimal computational speed of a particle algorithm might be achieved at some intermediate regularisation parameter .
7.3. Relation to Geometric Formulation of FPE Flow
Following Otto [58] and Villani [59], the FPE for the equilibrium case can be viewed as a gradient flow on the manifold of probability densities with respect to the Wasserstein metric. This formulation can be used to define an implicit Euler time discretisation method for the dynamics of the density . For small times (and ) this is given by the variational problem
in terms of the Kullback–Leibler divergence and the Wasserstein distance. The latter gives the minimum of for two random variables and X, where the expectation is over the joint distribution with fixed marginals and p. Using the dual formulation for a regularised Wasserstein distance, approximate numerical algorithms for solving Equation (46) have been developed by [60] and by [61] with applications to simulations of FPE.
We show in the following that Equation (46) may be cast into a form closely related to our variational formulation (Equation (7)) for . Assuming that X and are related through deterministic (transport) mappings of the form
we may represent the Wasserstein distance in terms of and the variational problem in Equation (46) may be reformulated as
where
To proceed, we expand the relative entropy in Equation (48) to first order in , inserting the representation of Equation (49) for , thereby obtaining
Minimisation ignoring the terms (employing integration by parts) yields
which is related to our cost function (Equation (8)) if we formally identify . More precisely, by replacing by samples, the empirical cost function may be regularised with a RKHS norm penalty resulting in a nonparametric estimator for unnormalised log–density , as shown in [62]. One could use this estimator as an alternative to our approach. This would lead to a simultaneous estimate of all components of the GLD. In our approach, each of the d components of the gradient is computed individually. In this way, we avoid additional second derivatives of kernels, which would increase the dimensionality of the resulting matrices.
8. Extension to General Diffusion Processes
The Fokker–Planck equations for an SDE with arbitrary drift and general, state-dependent diffusion matrix is given by
This may again be written in the form of a Liouville equation (Equation (3)) where the effective force term equals
9. Second Order Langevin Dynamics (Kramer’s Equation)
For second-order Langevin equations, the system state comprises positions and velocities following the coupled SDE
In Equation (54), the dynamics describe the effect of a friction force, , an external force, , and a fluctuating force, where denotes the dissipation constant. In this setting, the effective deterministic ODE system is given by
Considering here the equilibrium case, we set for which the stationary density equals
where and denotes the Hamiltonian function. Inserting into Equation (56), we find that for , the damping and the density-dependent part of the force cancel and we are left with pure Hamiltonian dynamics
for which all particles become completely decoupled, with each one conserving energy separately. Of course, this result also precludes fixed point solutions to the particle dynamics. However, this limiting dynamics captured by Equation (58) assumes the mean field limit together with a consistent estimate of the GLD before taking the limit . For GLD estimators at finite N, we expect reasonably small stationary fluctuations of individual particle energies, which were also evident in our numerical experiments.
The exact asymptotic behaviour is also reflected in the expression for the change of the relative entropy for Kramer’s equation. Similar to Equation (42) we obtain
When the system approaches equilibrium, both terms in the norm cancel out and the entropy production rate converges to 0.
10. Simulating Accurate Fokker–Planck Solutions for Model Systems
To demonstrate the accuracy of our approach, we simulated solutions of FPEs for a range of model systems and compared the results with those obtained from direct stochastic simulations (Monte Carlo sampling) with the same particle number, as well as with analytic solutions where relevant. We tested our framework on systems with diverse degrees of nonlinearity and dimensionality, as well as with various types of noise (additive/multiplicative). We quantified the accuracy of transient and steady state solutions resulting from our method in terms of 1-Wasserstein distance [59] and Kullback–Leibler (KL) divergence (Appendix C and Appendix D), along with the squared error of distances between distribution cumulants. For evaluating particle solutions for nonlinear processes, where analytical solutions of the Fokker–Planck equation are intractable, we simulated a very large number () of stochastic trajectories that we considered to be ground truth Fokker–Planck solutions. We employed an Euler–Maruyama and forward Euler integration scheme of constant step size for stochastic and deterministic simulations respectively. We provide a description of the employed algorithm along with analysis of its computational complexity in Appendix H, while further numerical experiments on the influence of hyperparameter values on the performance of the estimator are provided in Appendix G and Appendix F.
10.1. Linear Conservative System with Additive Noise
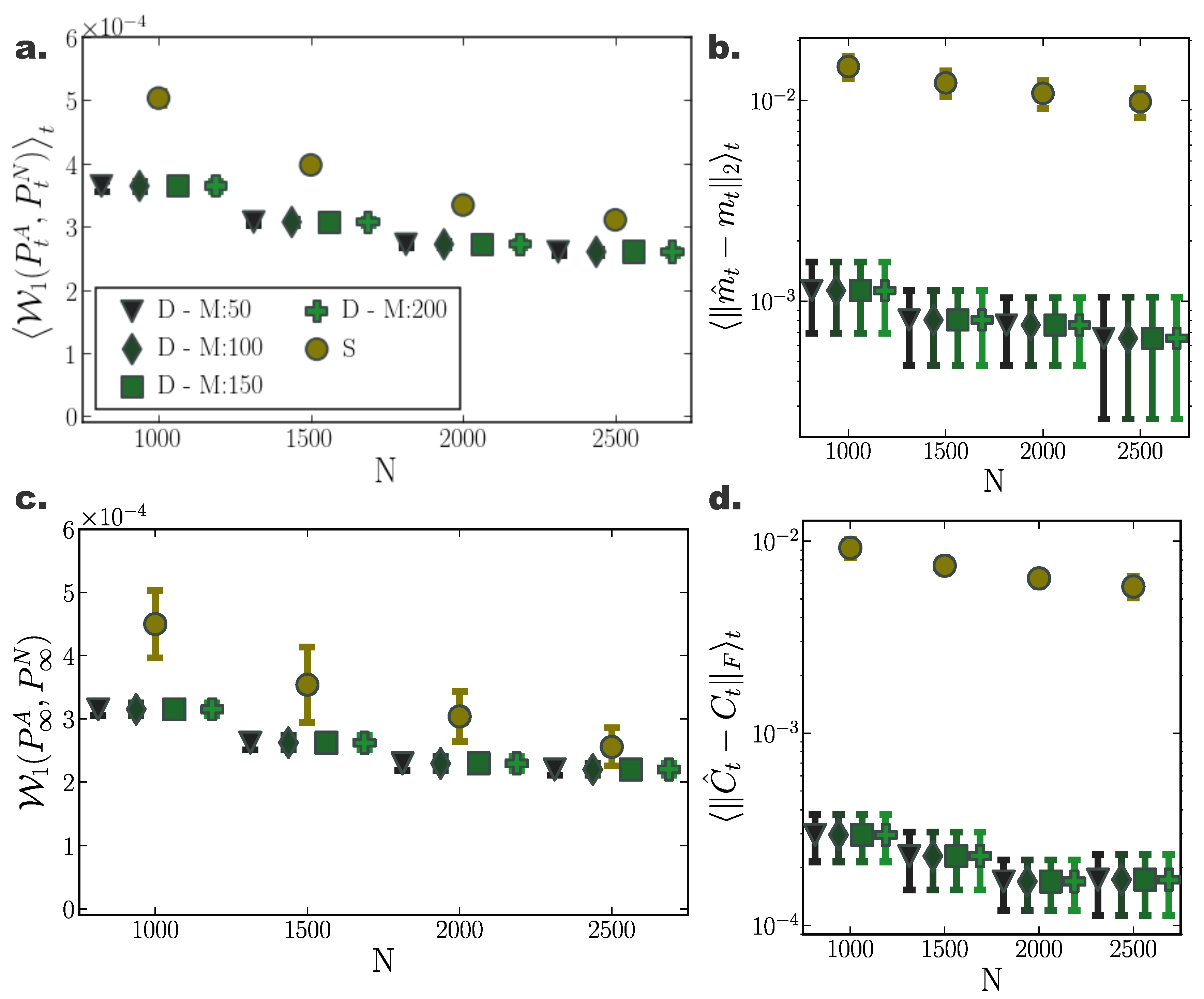
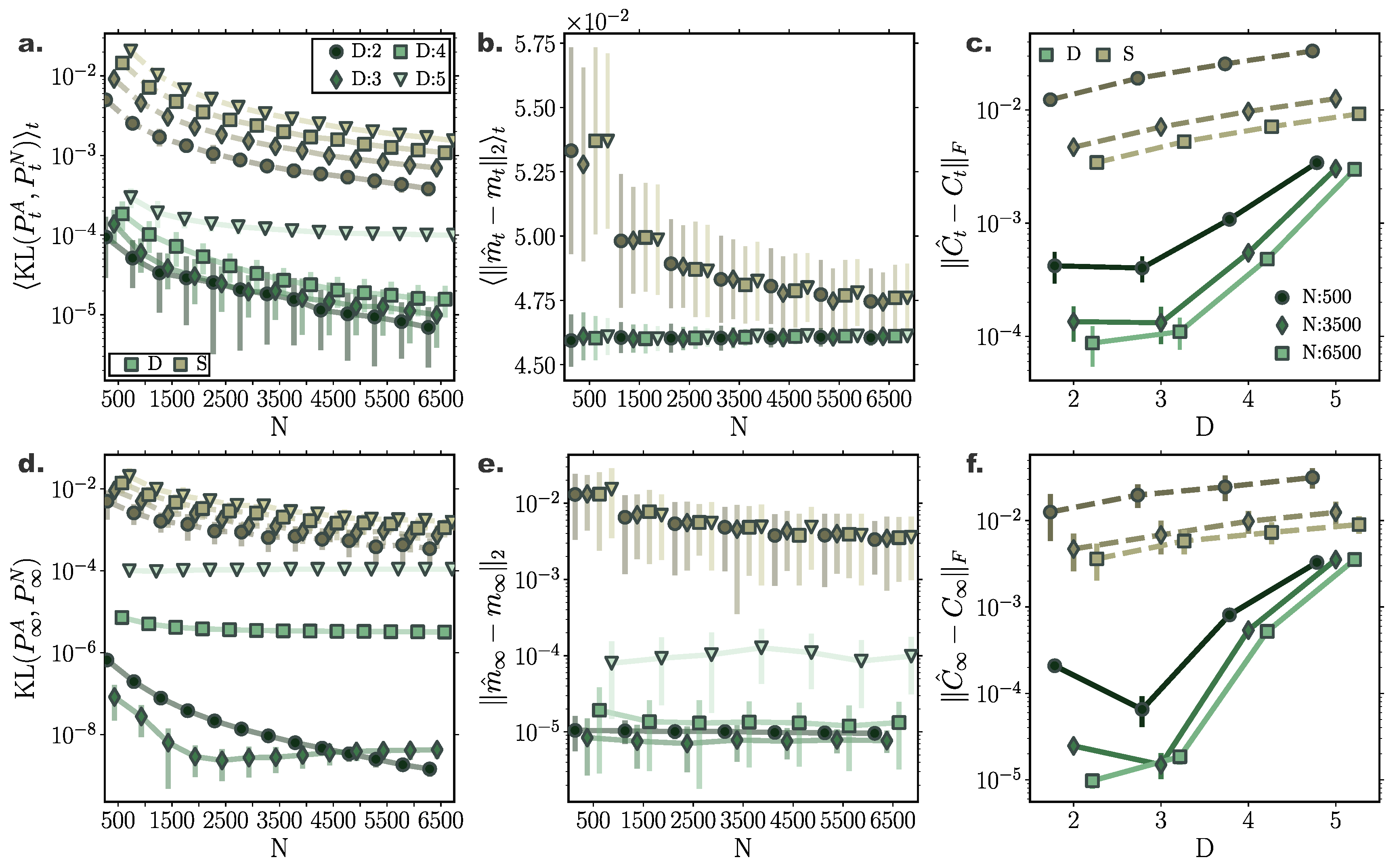
For a two dimensional Ornstein-Uhlenbeck process (Appendix A.1) transient and stationary densities evolved through deterministic particle simulations (D) consistently outperformed their stochastic counterparts (S) comprising the same number of particles in terms accuracy in approximating the underlying density (Figure 1). In particular, comparing the 1-Wasserstein distance between samples from analytically derived densities () (Appendix B)—considered here to reflect the ground truth—and the deterministically (D) or stochastically (S) evolved densities (), , we observed smaller Wasserstein distances to ground truth for densities evolved according to our deterministic particle dynamics, both for transient (Figure 1a) and stationary (Figure 1c) solutions. Specifically, we quantified the transient deviation of simulated densities from ground truth by the average temporal 1-Wasserstein distance, (Appendix D). For small particle number, deterministically evolved interacting particle trajectories represented more reliably the evolution of the true probability density compared to independent stochastic ones, as portrayed by smaller average Wasserstein distances. For increasing particle number, the accuracy of the simulated solutions with the two approaches converged. Yet, while for particles the stochastically evolved densities suggest on average (over trials) comparable approximation precision with their deterministic counterparts, the deterministically evolved densities more reliably delivered densities of a certain accuracy, as proclaimed by the smaller dispersion of Wasserstein distances among different realisations (Figure 1a,c).
Likewise, we observed similar results when comparing only the stationary distributions, (Figure 1c). While for small particle number, the interacting particle system more accurately captured the underlying limiting distribution, for increasing particle number the accuracy of both approaches converged, with our method consistently delivering more reliable approximations among individual repetitions.
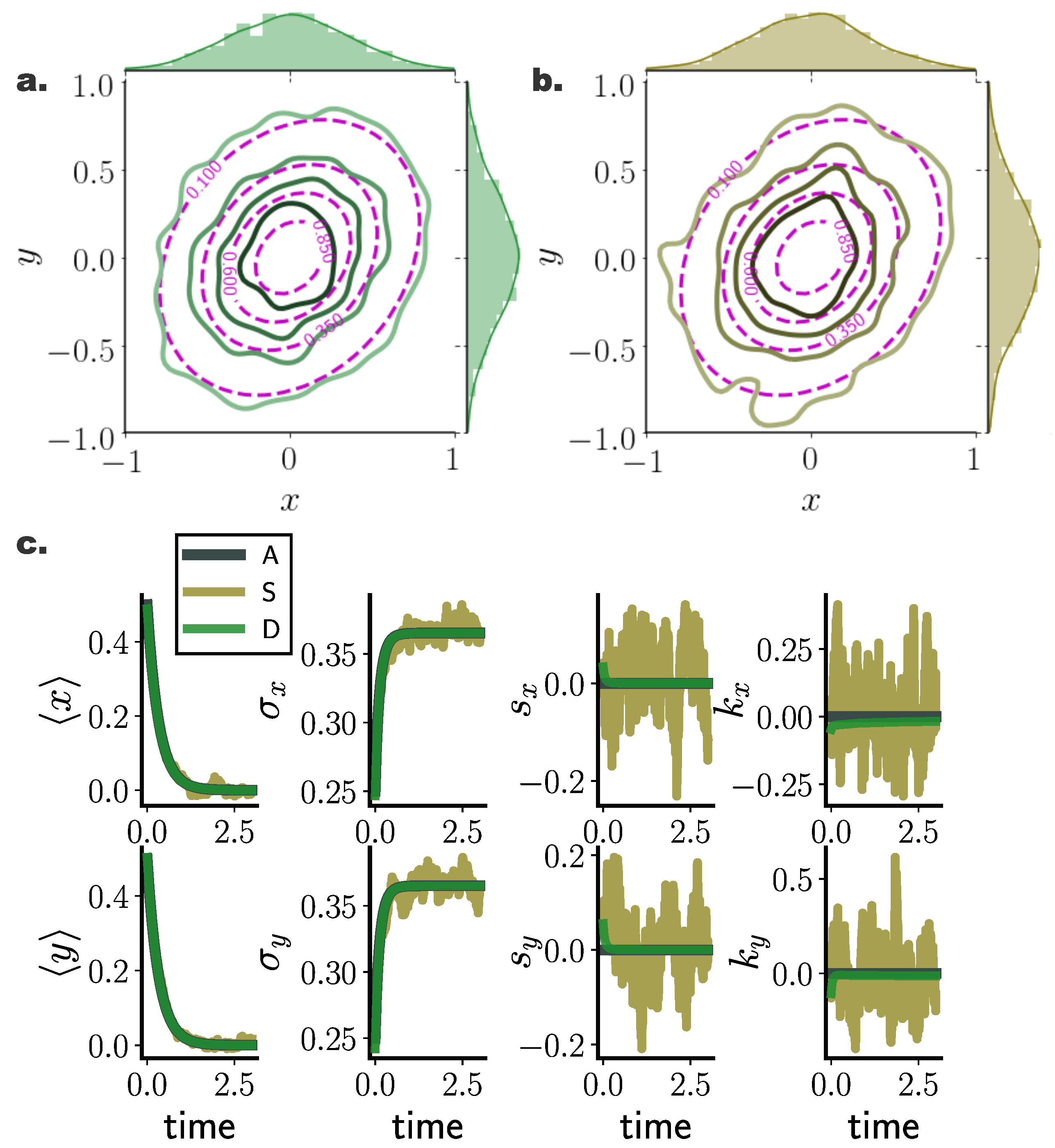
Moreover, densities evolved with our deterministic framework exhibited less fluctuating cumulant trajectories in time, compared to their stochastic counterparts (Figure 2c). In particular, even for limited particle number, cumulants calculated over deterministically evolved particles progressed smoothly in time, while substantially more particles for the stochastic simulations were required for the same temporal cumulant smoothness. To further quantify the transient accuracy of Fokker–Planck solutions computed with our method, we compared the average transient discrepancy between the first two analytic cumulants ( and ) to those estimated from the particles ( and ), (Figure 1b) and (Figure 1d), where stands for the Frobenious norm (Appendix E). In line with our previous results, our deterministic framework delivered considerably more accurate transient cumulants when compared to stochastic simulations, with more consistent results among individual realisations, denoted by smaller dispersion of average cumulant differences. (Notice the logarithmic y-axis scale in Figure 1b,d. Error bars for the stochastic solutions were in fact larger than those for the deterministic solutions on a linear scale.)
Interestingly, the number of sparse points M employed in the gradient–log–density estimation had only minor influence on the quality of the solution (Figure 1a,c). This hints to substantially low computational demands for obtaining accurate Fokker–Planck solutions, since our method is computationally limited by the inversion of the matrix in Equation (29).
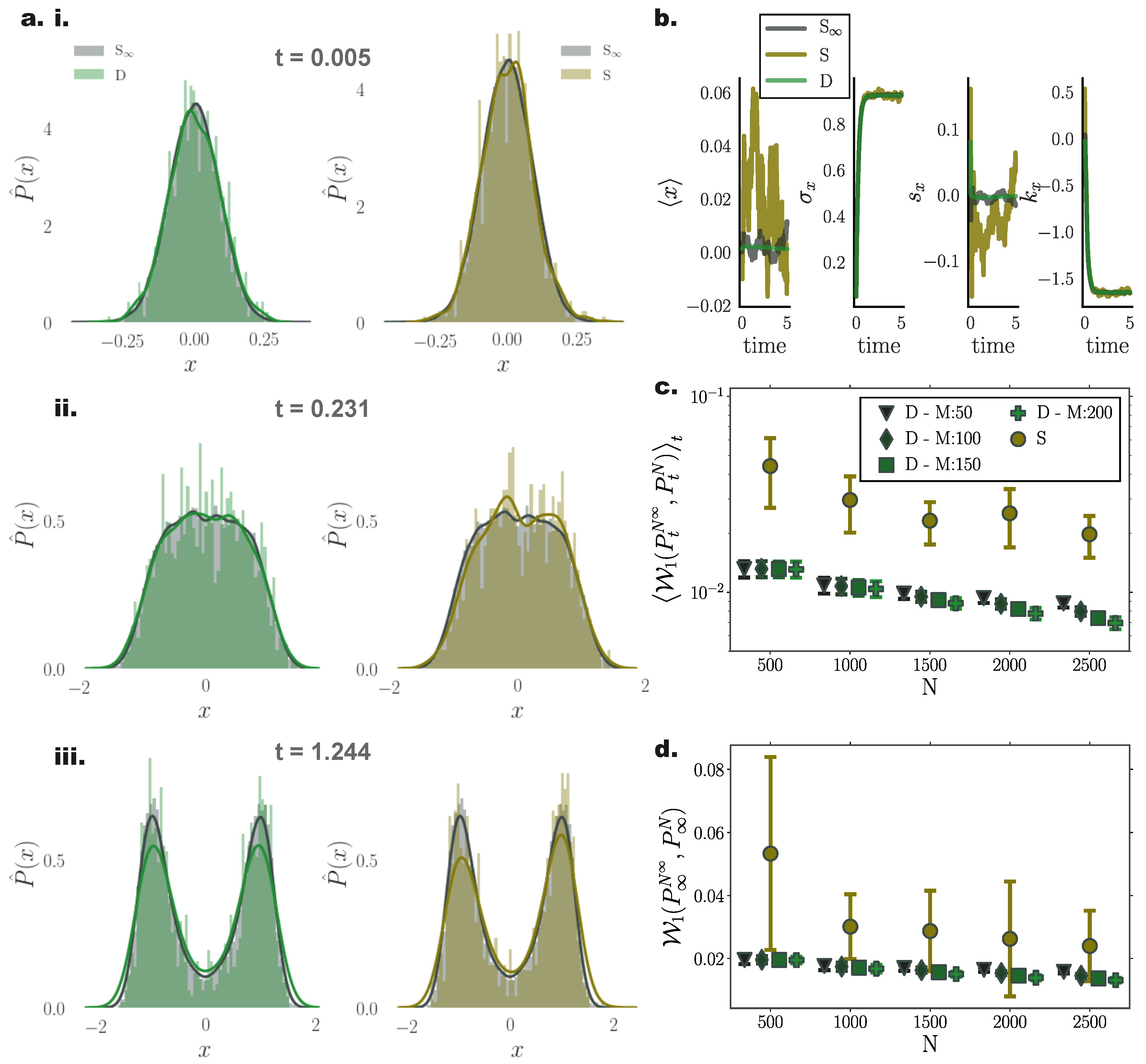
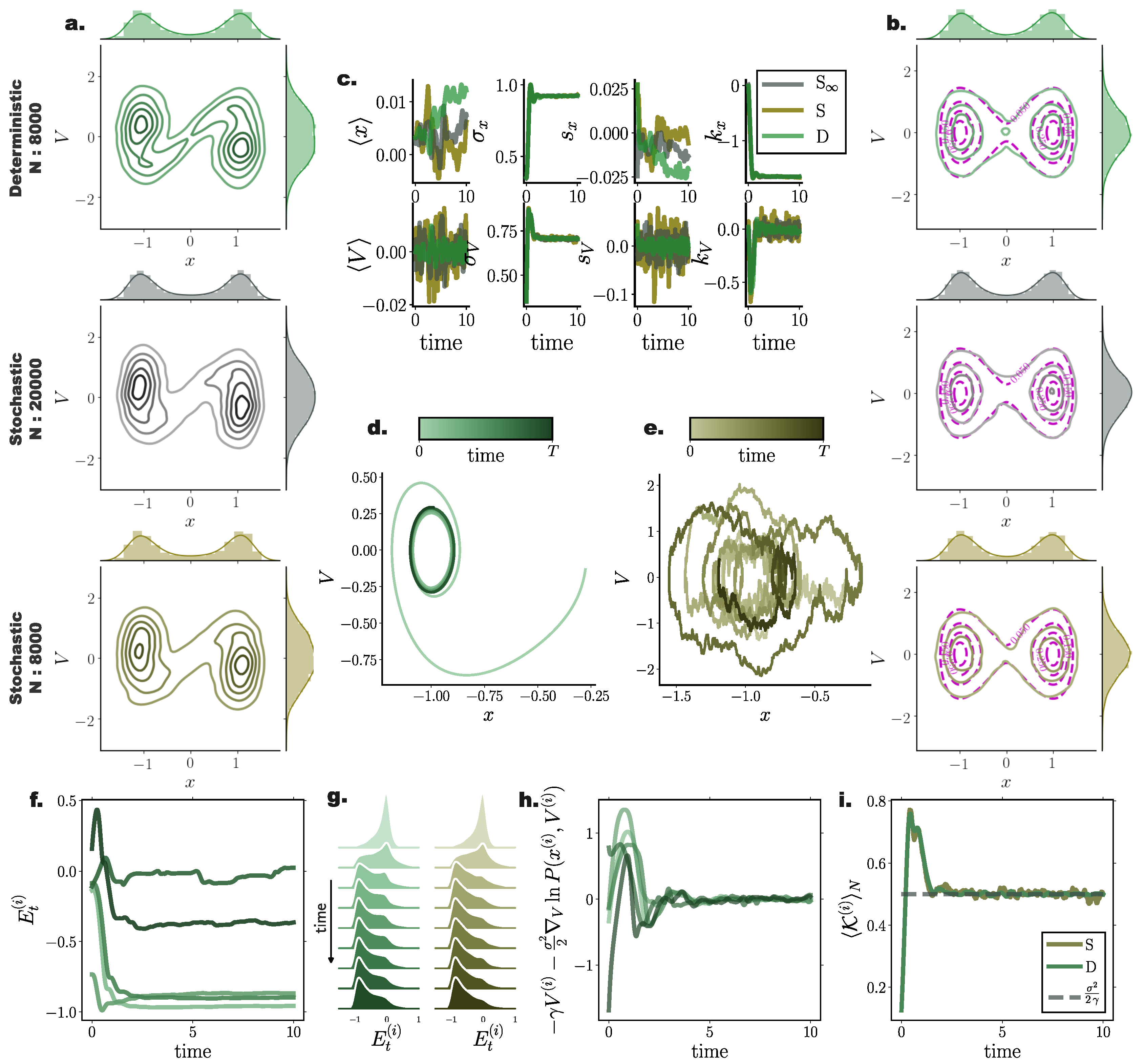
10.2. Bi-Stable Nonlinear System with Additive Noise
For nonlinear processes, since the transient solution of the FPE is analytically intractable, we compared the transient and stationary densities estimated by our method with those returned from stochastic simulations of = 26,000 particles, and contrasted them against stochastic simulations with the same particle number.
For a system with bi-modal stationary distribution (Appendix A.2), the resulting particle densities from our deterministic framework closely agreed with those arising from the stochastic system with = 26,000 particles (Figure 3a). In particular, deterministically evolved distributions respected the symmetry of the underlying double–well potential, while the stochastic system failed to accurately capture the potential symmetric structure Figure 3a (iii).
Systematic comparisons of the 1-Wasserstein distance between deterministic and stochastic N particle simulations with the “” stochastic simulation comprising particles revealed that our approach efficiently captured the underlying PDF already with particles (Figure 3c,d). For increasing particle number, the stationary solutions of both systems converged to the “” one. However, we observed a systematically increasing approximation accuracy delivered from the deterministic simulations compared to their stochastic counterparts.
It is noteworthy that, on average, deterministic simulations of particles conveyed a better approximation of the underlying transient PDF compared to stochastic simulations of particles (Figure 3c).
Interestingly, for small particle number, the number of employed inducing points M did not significantly influence the accuracy of the approximated solution. However for increasing particle number, enlarging the set of inducing points contributed to more accurate approximation of Fokker–Planck equation solutions (Figure 3c), with the trade off of additional computational cost.
Similar to the Ornstein Uhlenbeck process (Section 10.1), comparing cumulant trajectories computed from both the deterministic and stochastic particle systems revealed less fluctuating cumulant evolution for densities evolved with our deterministic framework also in this nonlinear setting (Figure 3b).
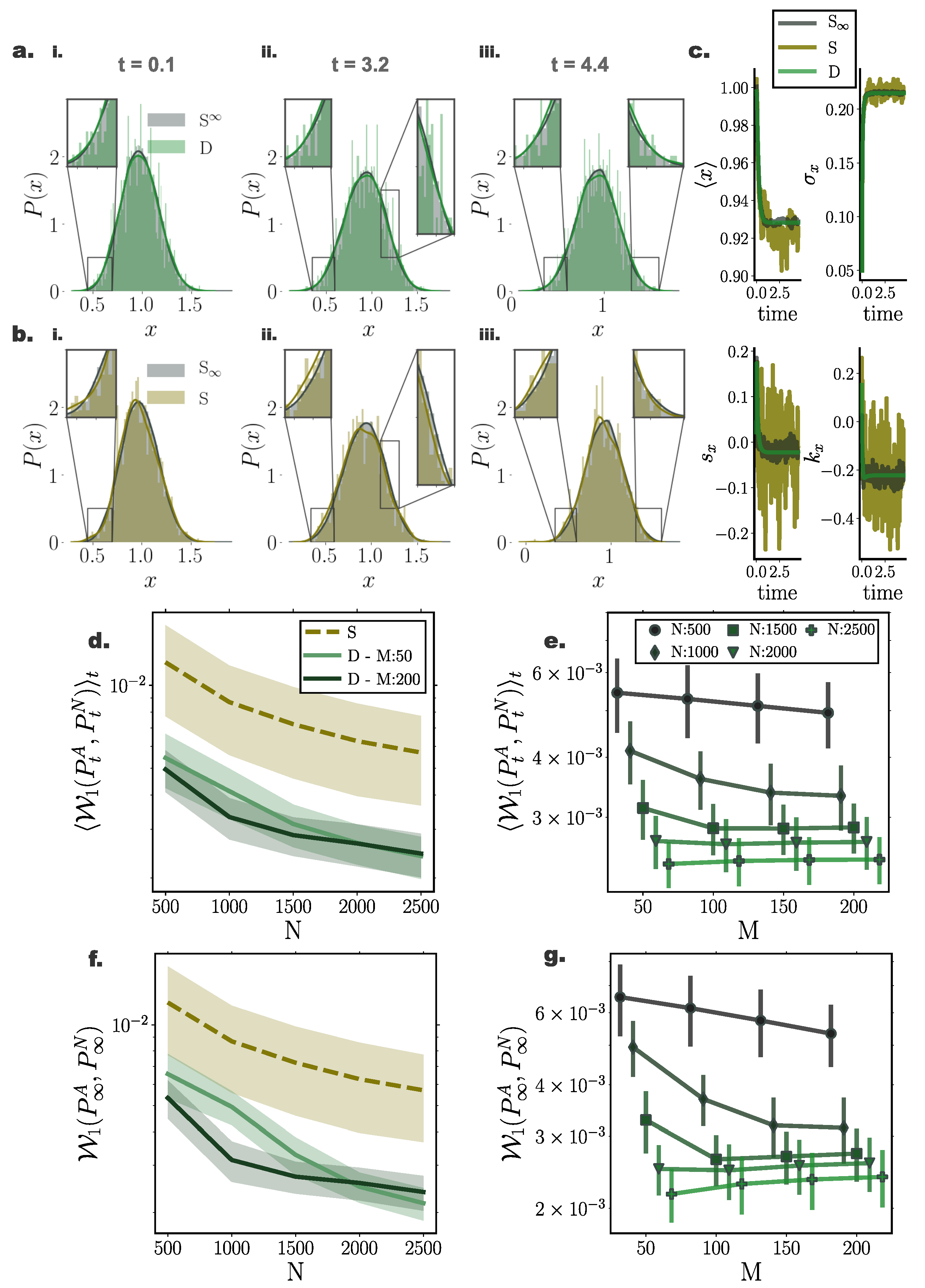
10.3. Nonlinear System Perturbed by Multiplicative Noise
To assess the accuracy of our framework on general diffusion processes perturbed by state-dependent (multiplicative) noise, we simulated a bi-stable system with dynamics governed by Equation (A3) with diffusion function according to Equation (53). Similarly, in this setting, deterministic particle distributions delivered a closer approximation of the underlying density when compared to direct stochastic simulations. In particular, we found that in this setting, deterministically evolved distributions more accurately captured the tails of the underlying distribution, mediated here by stochastic simulations of = 35,000 particles (Figure 4a,b).
Similar to the previously examined settings, the deterministic framework delivered more reliable and smooth trajectories for the marginal statistics of the underlying distribution (Figure 4c).
Comparing the temporal average and stationary 1-Wasserstein distance (Figure 4d,f) between the optimal stochastic distributions and the deterministic and stochastic particle distributions of size N, we found that the deterministic system delivered consistently more accurate approximations, as portrayed by smaller 1-Wasserstein distances.
Interestingly, we found that for deterministic particle simulations, the number of employed sparse points in the gradient–log–density estimation mediated a moderate approximation improvement for small system sizes, while for systems comprising more than particles, the number of sparse points had minimal or no influence on the accuracy of the resulting distribution (Figure 4e,g).
10.4. Performance in Higher Dimensions
To quantify the scaling and performance of the proposed framework for increasing system dimension, we systematically compared simulated densities with analytically calculated ones for Ornstein–Uhlenbeck processes of dimension following the dynamics of Equation (A4) for inducing point number (Figure 5) and (Figure 6). To evaluate simulated Fokker–Planck solutions, we calculated the Kullback–Leibler divergence between analytically evolved densities (Appendix B) and particle densities. We employed the closed-form equation for estimating KL divergence between two Gaussian distributions (Appendix C) for empirically estimated mean, , and covariance, , for particle distributions.
For all dimensionalities, the deterministic particle solutions approximated transient and stationary densities remarkably accurately with Kullback–Leibler divergence between the simulated and analytically derived densities below for all dimensions, both for transient and stationary solutions (Figure 5a,d and Figure 6a,d). In fact, the deterministic particle solutions delivered more precise approximations of the underlying densities compared to direct stochastic simulations of the same particle number. Remarkably, even for processes of dimension , deterministically evolved solutions mediated through particles resulted in approximately the same KL divergence of stochastic particle solutions of particles.
Our deterministic particle method delivered consistently better approximations of the mean of the underlying densities compared to stochastic particle simulations (Figure 5b,e). Specifically, estimations of the stationary mean of the underlying distributions were more than two orders of magnitude accurate that their stochastically approximated counterparts already for small particle number (Figure 5e).
Yet, the accuracy of our deterministic framework deteriorated for increasing dimension (Figure 5a,d). More precisely, while for low dimensionalities the covariance matrices of the underlying densities were accurately captured by deterministically evolved particles, for increasing system dimension approximations of covariance matrices became progressively worse. Yet, even for systems of dimension , covariance matrices computed from deterministically simulated solutions of particles were at the same order of magnitude as accurate as covariances delivered by stochastic particle simulations of size .
However, comparing the resulting performance of solutions delivered by employing different number of inducing points (Figure 5 and Figure 6) reveals that for increasing dimension more inducing points are required to attain accurate FPE solutions. In particular, both transient and stationary KL divergences to ground truth improved remarkably for dimensions and by employing inducing points in the gradient–log–density estimation (Figure 5a,d and Figure 6a,d). In more detail, for nearly all dimensions, the estimation of the covariance of the underlying distribution improved considerably, both for transients and stationary solutions (Figure 5c,f and Figure 6c,f), while only the stationary mean of dimension showed significant improvement (Figure 5b,e and Figure 6b,e). Figure 6c,f reveals that by increasing the number of inducing points our framework is able to capture more effectively the spread of the underlying distribution, clearly surpassing in approximation accuracy solutions mediated by stochastic particle simulations.
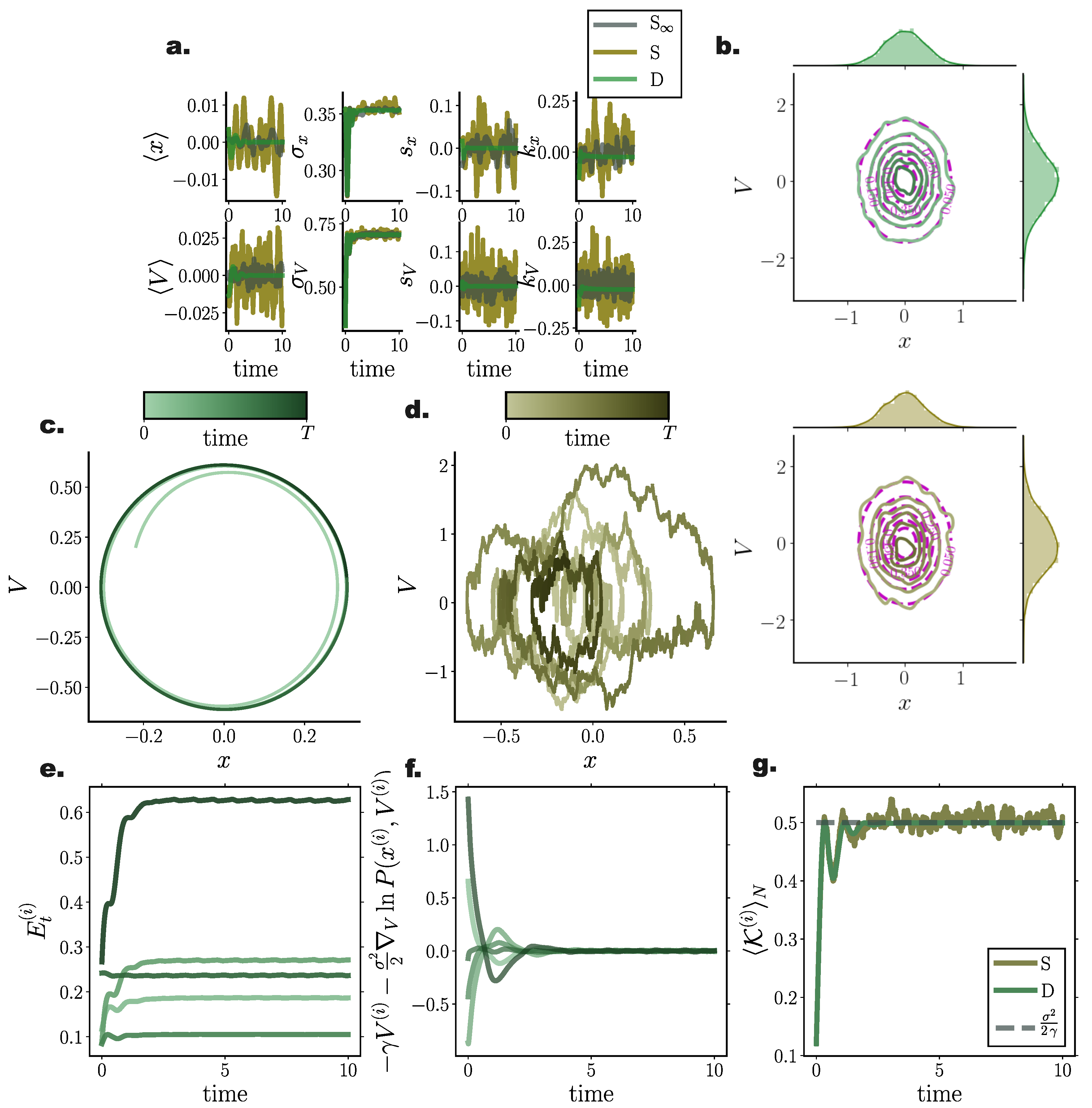
10.5. Second order Langevin Systems
To demonstrate the performance of our framework for simulating solutions of the FPEs for second order Langevin systems as described in Section 9, we incorporated our method in a symplectic Verlet integrator (Equations (A10)–(A12)) simulating the second-order dynamics captured by Equation (56) for a linear and a nonlinear, , drift function (Equation (A10)), and compared the results with stochastic simulations integrated by a semi-symplectic framework [63]. In agreement with previous results, cumulant trajectories evolved smoother in time for deterministic particle simulations when compared to their stochastic counterparts (Figure 7a and Figure 8c). Stationary densities closely matched analytically derived ones (see Equation (A7)) (purple contour lines in Figure 7b and Figure 8b), while transient densities captured the fine details of simulated stochastic particle densities comprising (Figure 8a).
Furthermore, the symplectic integration contributed to the preservation of energy levels for each particle after the system reached equilibrium (Figure 7e and Figure 8f), which was also evident when observing individual particle trajectories in the state space (Figure 7c,d and Figure 8d,e).
As already conveyed in Section 9, the velocity term and the gradient–log–density term canceled out in the long time limit (Figure 7f and Figure 8g) for each particle individually, while the average kinetic energy in equilibrium exactly resorted to the value dictated by the fluctuation–dissipation relation and the equipartition of energy property, i.e., (Figure 7g and Figure 8h).
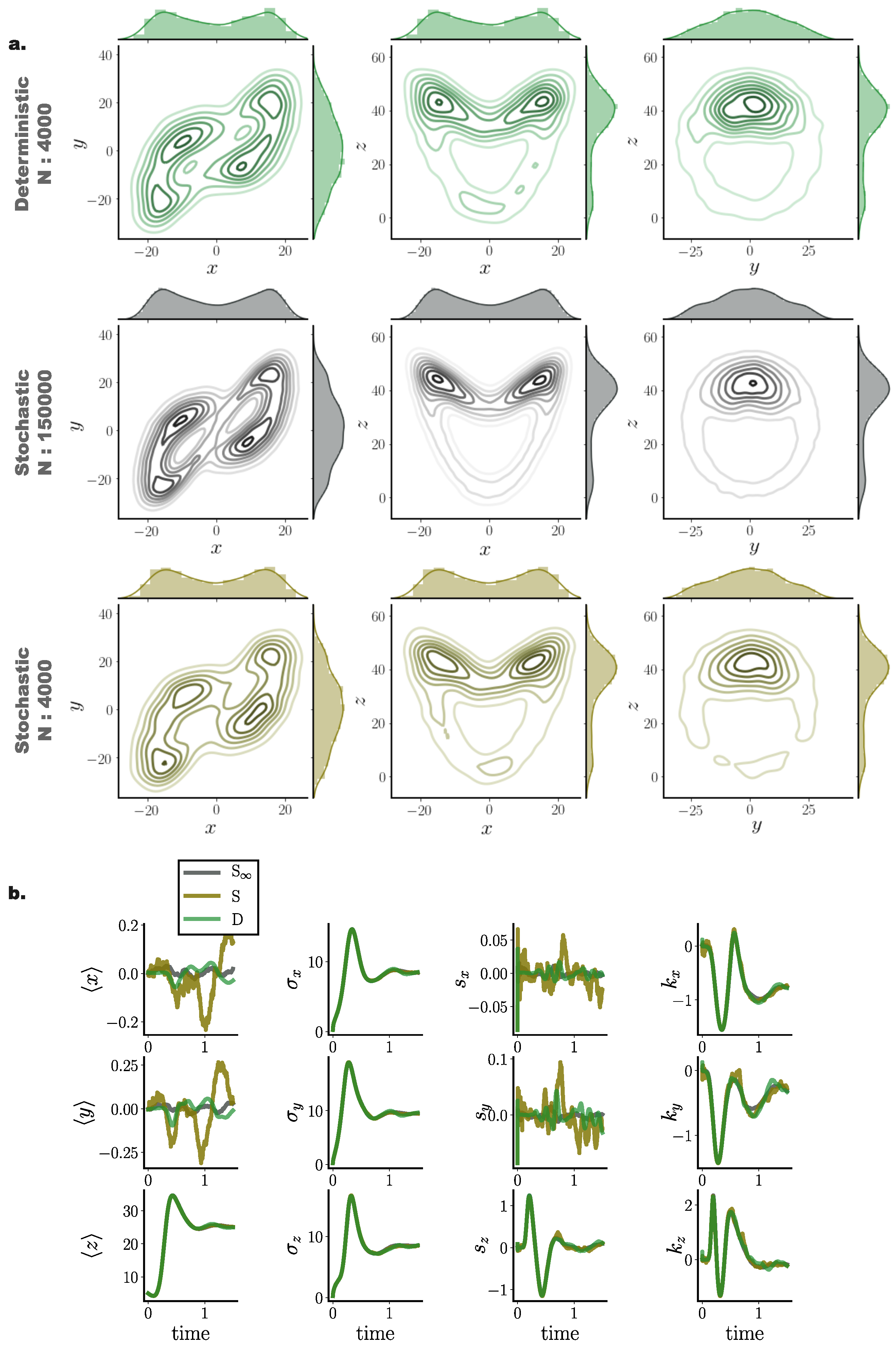
10.6. Nonconservative Chaotic System with Additive Noise (Lorenz Attractor)
As a final assessment of our framework for simulating accurate solutions of Fokker–Planck equations, we employed a Lorenz attractor model with parameters rendering the dynamics chaotic, perturbed by moderate additive Gaussian noise (Equation (A13)). By comparing stochastic simulations of = 150,000 particles and deterministic and stochastic simulations of particles (Figure 9), we observed that the deterministic framework more precisely captured finer details of the underlying distribution (Figure 9a), represented here by the stochastic simulation. While both stochastic and deterministic simulations capture the overall butterfly profile of the Lorenz attractor, the deterministic system indeed delivered a closer match to the underlying distribution.
Similar to the previously examined models, cumulant trajectories computed from deterministically evolved particles show closer agreement with those computed from the stochastic system, compared to the stochastic system comprising N particles (Figure 9b). In particular, cumulants for the x and y states exhibited high temporal fluctuations when computed from stochastically evolved distributions, while our framework conveyed more accurate cumulant trajectories, closer to those delivered by the stochastic system.
11. Discussion and Outlook
We presented a particle method for simulating solutions of FPEs governing the temporal evolution of the probability density for stochastic dynamical systems of the diffusion type. By reframing the FPE in a Liouville form, we obtained an effective dynamics in terms of independent deterministic particle trajectories. Unfortunately, this formulation requires the knowledge of the gradient of the logarithm of the instantaneous probability density of the system state, which is actually the unknown quantity of interest. We circumvented this complication by introducing statistical estimators for the gradient–log–density based on a variational formulation. To combine high flexibility of estimators with computational efficiency, we employed kernel-based estimation together with an additional sparse approximation. For the case of equilibrium systems, we related our framework to Stein Variational Gradient Descent, a particle-based dynamics to approximate the stationary density, and to a geometric formulation of Fokker–Planck dynamics. We further discussed extensions of our method to settings with multiplicative noise and to second order Langevin dynamics.
To demonstrate the performance of our framework, we provided detailed tests and comparisons with stochastic simulations and analytic solutions (when possible). We demonstrated the accuracy of our method on conservative and non-conservative model systems with different dimensionalities. In particular, we found that our framework outperforms stochastic simulations both in linear and nonlinear settings by delivering more accurate densities for small particle number when the dimensionality is small enough. For increasing particle number, the accuracy of both approaches converges. Yet, our deterministic framework consistently delivered results with smaller variance among individual repetitions. Furthermore, we showed that our method, even for small particle numbers, exhibits low-order cumulant trajectories with significantly less temporal fluctuations when compared against to stochastic simulations of the same particle number.
We envisage several ways to improve and extend our method. There is room for enhancement by optimising hyperparameters of our algorithm such as inducing point position and kernel length scale. Current grid-based and uniform random selection of inducing point position may contribute to the deterioration of solution accuracy in higher dimensions. Other methods, such as subsampling or clustering of particle positions may lead to further improvements. On the other hand, a hyperparameter update may not be at all necessary at each time step in certain settings, such that a further speedup of our algorithm could be achieved.
The implementation of our method depends on the function class chosen to represent the estimator. In this paper we have focused on linear representations, leading to simple closed form expressions. It would be interesting to see if other, nonlinear parametric models, such as neural networks, (see e.g., [64]) could be employed to represent estimators. While in this setting, there would be no closed-form solutions, the small changes in estimates between successive time steps suggest that only a few updates of numerical optimisation may be necessary at each step. Moreover, the ability of neural networks to automatically learn relevant features from data might help to improve performance for higher dimensional problems when particle motion is typically restricted on lower dimensional submanifolds.
From a theoretical point of view, rigorous results on the accuracy of the particle approximation would be important. These would depend on the speed of convergence of estimators towards exact gradients of log–densities. However, to obtain such results may not be easy. While rates of convergence for kernel-based estimators have been studied in the literature, the methods for proofs usually rely on the independence of samples and would not necessarily apply to the case of interacting particles.
We have so far addressed only the forward simulation of FPEs. However, preliminary results indicate that related techniques may be applied to particle based simulations for smoothing (forward–backward) and related control problems for diffusion processes [65]. Such problems involve computations of an effective, controlled drift function in terms of gradient–log–densities. We defer further details and discussions on subsequent publications on the topic.
Taken together, the main advantage of our framework is its minimal requirement in simulated particle trajectories for attaining reliable Fokker–Planck solutions with smoothly evolving transient statistics. Moreover, our proposed method is nearly effortless to set up when compared to classical grid-based FPE solvers, while it delivers more reliable results than direct stochastic simulations.
Author Contributions
Conceptualization, S.R. and M.O.; methodology, D.M. and M.O.; software, D.M.; validation, D.M. and M.O.; formal analysis, D.M. and M.O.; investigation, D.M.; resources, M.O.; data curation, D.M.; writing—original draft preparation, D.M. and M.O.; writing—review and editing, D.M., S.R. and M.O.; visualization, D.M.; supervision, M.O.; project administration, M.O.; funding acquisition, S.R. and M.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been partially funded by Deutsche Forschungsgemeinschaft (DFG)-SFB1294/ 1-318763901.
Acknowledgments
We would like to thank Paul Rozdeba for constructive criticism on the manuscript.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Simulated Systems
Appendix A.1. Two Dimensional Ornstein-Uhlenbeck Process
For comparing Fokker-Planck solutions computed with our approach with solutions derived from stochastic simulations, we considered the two dimensional Ornstein-Uhlenbeck process captured by the following equations
where the related potential is . The simulation time was set to with Euler–Maruyama integration step . For estimating the instantaneous gradient log density we employed inducing points, randomly selected at every time point from a uniform distribution spanning the state space volume covered by the particles at the current time point.
Appendix A.2. Bistable Nonlinear System
For testing our framework on nonlinear settings, we simulated
with for evaluating solutions with additive Gaussian noise, and with for multiplicative noise FP solutions. The associated potential is .
Appendix A.3. Multi-Dimensional Ornstein-Uhlenbeck Processes
For quantifying the scaling of our method for increasing system dimension, we simulated systems of dimensionality according to the following equation
for . Simulation time was determined by the time required for analytic mean to converge to its stationary solution within precision , while the integration step was set to .
Appendix A.4. Second Order Langevin Dynamics
For demonstrating the energy preservation properties of our method for second-order Langevin dynamics, we incorporated our framework into a Verlet symplectic integration scheme (Equation (A10)), and compared the results with stochastic simulations integrated according to a semi-symplectic scheme [63].
We consider a system with dynamics for positions X and velocities V captured by
where the velocity change (acceleration) is the sum of a deterministic drift f, a velocity-dependent damping , and a stochastic noise term .
In conservative settings, the drift is the gradient of a potential . Here we used a quadratic (harmonic) potential and a double-well potential .
In equilibrium, the Fokker–Planck solution is the Maxwell–Boltzmann distribution, i.e.,
with partition function .
We may compute the energy of each particle at each time point as the sum of its kinetic and potential energies
Here the superscripts denote individual particles. After the system has reached equilibrium, energy levels per particle are expected to remain constant.
From the equipartition of energy and the fluctuation–dissipation relation, in the long time limit the average kinetic energy of the system is expected to resort to
Appendix A.5. Lorenz attractor
For simulating trajectories of the noisy Lorenz system, we employed the following equations
with parameters , , and , that render the deterministic dynamics chaotic [66], employing moderate additive Gaussian noise.
Appendix B. Computing Central Moment Trajectories for Linear Processes
For a linear process
the joint density of the state vector X remains Gaussian for all times when the initial density is Gaussian. The mean vector m and covariance matrix C may be computed by solving the ODE system
Appendix C. Kullback–Leibler Divergence for Gaussian Distributions
We calculated the KL divergence between the theoretical and simulated distributions with
where .
Appendix D. Wasserstein Distance
We employed the 1-Wasserstein distance [59] as a distance metric for comparing pairs of empirical distributions.
For two distributions P and Q, we denote with all joint distributions J for a pair of random variables with marginals P and Q. Then the Wasserstein distance between these distributions is
where for the 1-Wasserstein distances (used in the present manuscript) .
Interestingly, the Wasserstein distance between two one dimensional distributions P and Q obtains a closed form solution
with and indicating the cumulative distribution functions of P and Q.
Moreover, for one dimensional empirical distributions P and Q with samples of same size and , the Wasserstein distance simplifies into computation of differences of order statistics
where and indicates the i-th order statistic of the sample and , i.e., and [67].
We calculated the average temporal 1-Wasserstein distance as the time average of instantaneous 1-Wasserstein distances between the two distributions under comparison, and , i.e.,
where as before T stands for the duration of the simulation and for the time discretisation step.
Appendix E. Frobenious Norm
For comparing covariance matrices of the simulated particle systems with ground truth we employed the Frobenious norm of the relevant matrices difference. The Frobenious norm of a matrix A may be calculated from
where denote the entries of matrix A, and stands for the conjugate transpose of A.
Appendix F. Influence of Hyperparameter Values on the Performance of the Gradient–Log–Density Estimator
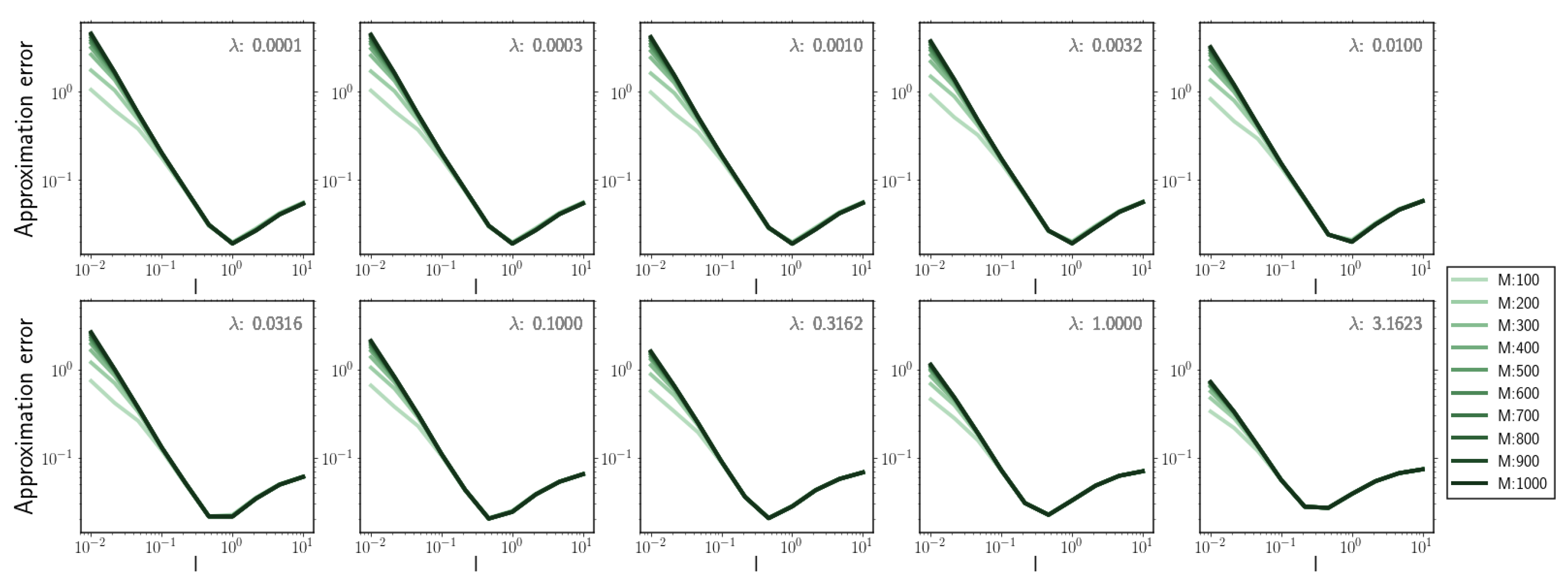
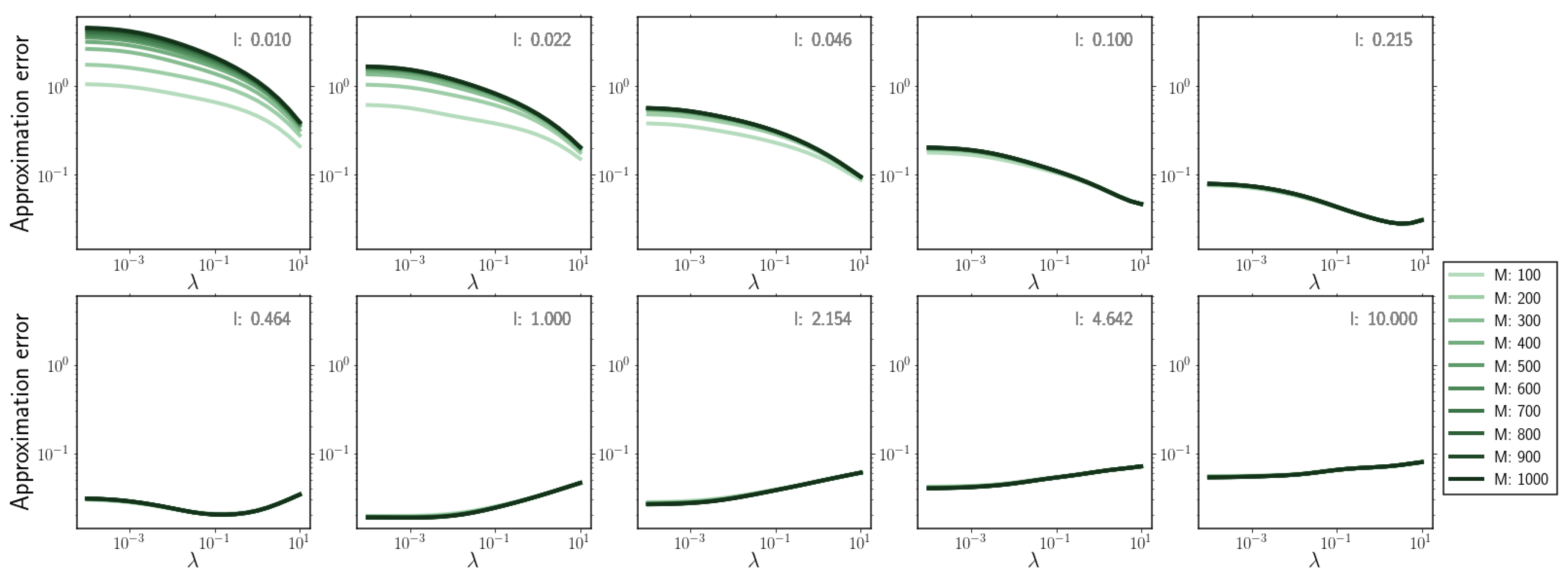
To determine the influence of the hyperparameter values on the performance of the gradient–log–density estimator, we systematically evaluated the approximation error of our estimator for samples of a one dimensional log–normal distribution with mean and standard deviation for 20 independent realisations.
We quantified the approximation error as the average error between the analytically calculated and predicted gradient-log-density on each sample, i.e.,
where the analytically calculated gradient-log-density was determined as .
By systematically varying the regularisation parameter , the kernel length scale l, and the inducing point number M we observed the following:
- -
- The hyperparameter that strongly influences the approximation accuracy is the kernel length scale l (Figure A1).
- -
- Underestimation of kernel length scale l has stronger impact on approximation accuracy than overestimation (Figure A1).
- -
- -
- For overestimation of the kernel length scale l, the regularisation parameter and inducing point number M have nearly no effect on the resulting approximation error (Figure A1).
- -
- For underestimation of kernel length scale l, increasing the number of inducing points M in the estimator results in larger approximation errors (Figure A2 (upper left)).
Figure A1.
Approximation error for increasing kernel length scale l for different regularisation parameter values and inducing point number M.
Figure A1.
Approximation error for increasing kernel length scale l for different regularisation parameter values and inducing point number M.

Figure A2.
Approximation error for increasing regularisation parameter value for different kernel length scale l and inducing point number M.
Figure A2.
Approximation error for increasing regularisation parameter value for different kernel length scale l and inducing point number M.

Appendix G. Required Number of Particles for Accurate Fokker–Planck Solutions
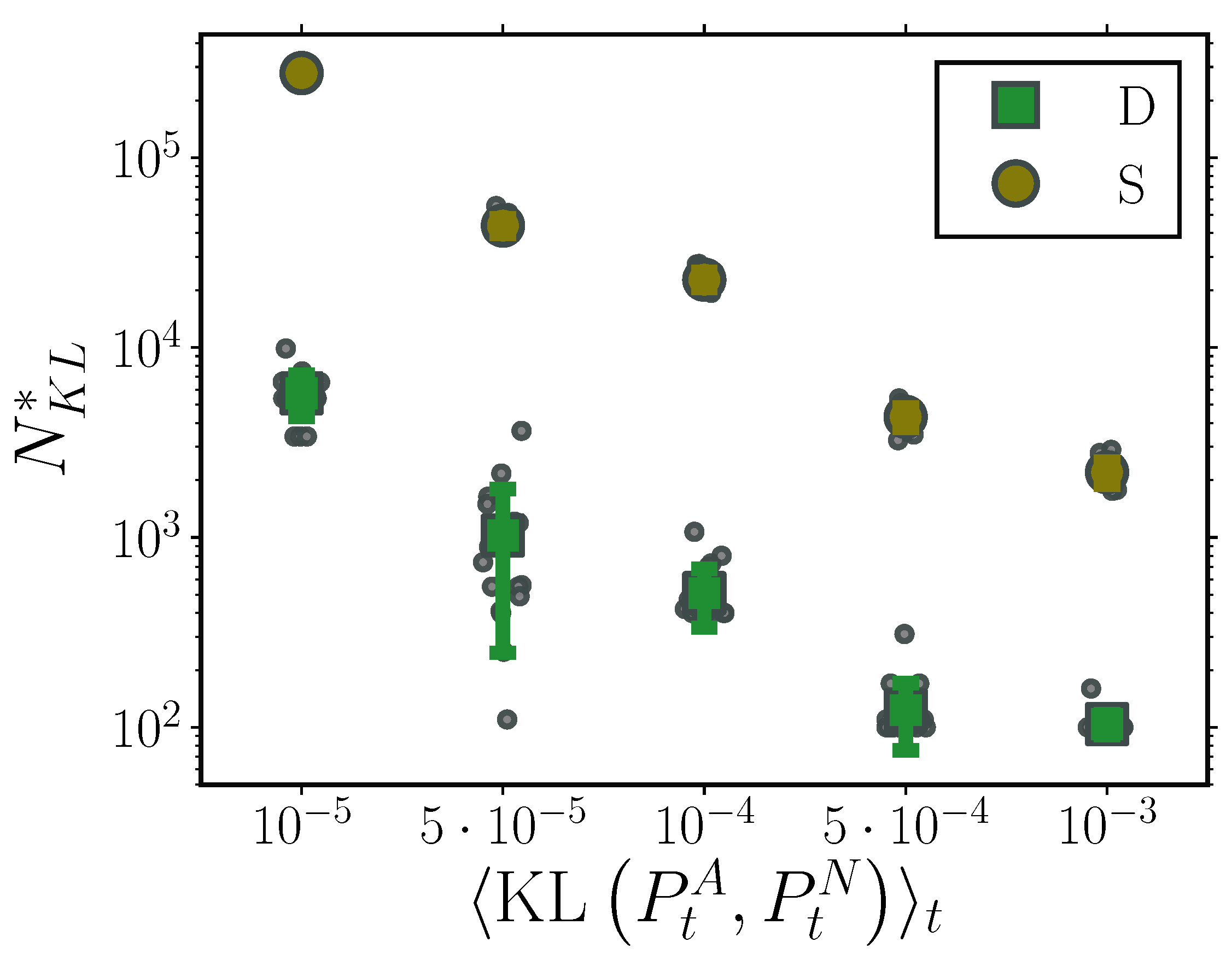
To compare the computational demands of the deterministic and stochastic particle systems, we determined the required particle number each system needed to attain a specified accuracy compared to ground truth transient solutions. In particular, for a two dimensional Ornstein–Uhlenbeck process, we identified the minimal number of particles both systems required to achieve a certain time-averaged Kullback–Leibler distance to ground truth transient solutions, . As already indicated in the previous sections, the stochastic system required considerably larger particle number to achieve the same time averaged KL distances to ground truth when compared to our proposed framework. In fact, for the entire range of examined KL distances, our method consistently required at least one order of magnitude less particles compared to the its stochastic counterpart.
Figure A3.
Required particle number, , to attain time averaged Kullback–Leibler divergence to ground truth, , for deterministic (green) and stochastic (brown) particle systems for a two dimensional Ornstein-Uhlenbeck process. Markers indicate mean required particle number, while error bars denote one standard deviation over 20 independent realisations. Grey circles indicate required particle number for each individual realisation. The deterministic particle system consistently required at least one order of magnitude less particles compared to its stochastic counterpart. (Further parameter values: regularisation constant , inducing point number , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure A3.
Required particle number, , to attain time averaged Kullback–Leibler divergence to ground truth, , for deterministic (green) and stochastic (brown) particle systems for a two dimensional Ornstein-Uhlenbeck process. Markers indicate mean required particle number, while error bars denote one standard deviation over 20 independent realisations. Grey circles indicate required particle number for each individual realisation. The deterministic particle system consistently required at least one order of magnitude less particles compared to its stochastic counterpart. (Further parameter values: regularisation constant , inducing point number , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Appendix H. Algorithm for Simulating Deterministic Particle System
Here we provide the algorithm for simulating deterministic particle trajectories according to our proposed framework (Algorithms A1 and A2). In the comments, we denote the computational complexity of each operation in the gradient–log–density estimation in terms of big- notation. Since the inducing point number M employed in the gradient–log–density estimation is considerably smaller than sample number N, i.e., , the overall computational complexity of a single gradient-log-density evaluation amounts to .
| Algorithm A1: Gradient Log Density Estimator | |
| Input: X: state vector Z: inducing points vector d: dimension for gradient l: RBF Kernel length scale Output: G: vector for gradient-log-density at each position X in d dimension | |
| 1 | // |
| 2 | // |
| 3 | // |
| 4 | // |
| 5 | // |
| 6 | // |
| // | |
| Algorithm A2: Deterministic Particle Simulation |
 |
References
- Swain, P.S.; Elowitz, M.B.; Siggia, E.D. Intrinsic and extrinsic contributions to stochasticity in gene expression. Proc. Natl. Acad. Sci. USA 2002, 99, 12795–12800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pimentel, J.A.; Aldana, M.; Huepe, C.; Larralde, H. Intrinsic and extrinsic noise effects on phase transitions of network models with applications to swarming systems. Phys. Rev. E 2008, 77, 061138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hilfinger, A.; Paulsson, J. Separating intrinsic from extrinsic fluctuations in dynamic biological systems. Proc. Natl. Acad. Sci. USA 2011, 108, 12167–12172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elowitz, M.B.; Levine, A.J.; Siggia, E.D.; Swain, P.S. Stochastic gene expression in a single cell. Science 2002, 297, 1183–1186. [Google Scholar] [CrossRef] [Green Version]
- White, J.A.; Rubinstein, J.T.; Kay, A.R. Channel noise in neurons. Trends Neurosci. 2000, 23, 131–137. [Google Scholar] [CrossRef]
- Volfson, D.; Marciniak, J.; Blake, W.J.; Ostroff, N.; Tsimring, L.S.; Hasty, J. Origins of extrinsic variability in eukaryotic gene expression. Nature 2006, 439, 861–864. [Google Scholar] [CrossRef]
- Fellous, J.M.; Rudolph, M.; Destexhe, A.; Sejnowski, T.J. Synaptic background noise controls the input/output characteristics of single cells in an in vitro model of in vivo activity. Neuroscience 2003, 122, 811–829. [Google Scholar] [CrossRef]
- Schnoerr, D.; Sanguinetti, G.; Grima, R. Approximation and inference methods for stochastic biochemical kinetics—A tutorial review. J. Phys. Math. Theor. 2017, 50, 093001. [Google Scholar] [CrossRef]
- Van Kampen, N.G. The expansion of the master equation. Adv. Chem. Phys. 1976, 34, 245–309. [Google Scholar]
- Suzuki, M. Passage from an initial unstable state to a final stable state. Adv. Chem. Phys. 1981, 46, 195–278. [Google Scholar]
- Gammaitoni, L.; Hänggi, P.; Jung, P.; Marchesoni, F. Stochastic resonance. Rev. Mod. Phys. 1998, 70, 223. [Google Scholar] [CrossRef]
- Benzi, R.; Parisi, G.; Sutera, A.; Vulpiani, A. Stochastic resonance in climatic change. Tellus 1982, 34, 10–16. [Google Scholar] [CrossRef]
- Horsthemke, W. Noise induced transitions. In Non-Equilibrium Dynamics in Chemical Systems; Springer: Berlin/Heidelberg, Germany, 1984; pp. 150–160. [Google Scholar]
- Adorno, D.P.; Pizzolato, N.; Valenti, D.; Spagnolo, B. External noise effects in doped semiconductors operating under sub-THz signals. Rep. Math. Phys. 2012, 70, 171–179. [Google Scholar] [CrossRef] [Green Version]
- Assaf, M.; Roberts, E.; Luthey-Schulten, Z.; Goldenfeld, N. Extrinsic noise driven phenotype switching in a self-regulating gene. Phys. Rev. Lett. 2013, 111, 058102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balázsi, G.; van Oudenaarden, A.; Collins, J.J. Cellular decision making and biological noise: From microbes to mammals. Cell 2011, 144, 910–925. [Google Scholar] [CrossRef] [Green Version]
- Hughes, S.W.; Cope, D.W.; Toth, T.I.; Williams, S.R.; Crunelli, V. All thalamocortical neurones possess a T-type Ca2+ ‘window’current that enables the expression of bistability-mediated activities. J. Physiol. 1999, 517, 805–815. [Google Scholar] [CrossRef]
- Rose, J.E.; Brugge, J.F.; Anderson, D.J.; Hind, J.E. Phase-locked response to low-frequency tones in single auditory nerve fibers of the squirrel monkey. J. Neurophysiol. 1967, 30, 769–793. [Google Scholar] [CrossRef]
- Nicolis, C. Solar variability and stochastic effects on climate. Sol. Phys. 1981, 74, 473–478. [Google Scholar] [CrossRef]
- Nicolis, C. Stochastic aspects of climatic transitions–response to a periodic forcing. Tellus 1982, 34, 1–9. [Google Scholar] [CrossRef]
- Risken, H. Fokker-Planck equation. In The Fokker-Planck Equation; Springer: Berlin/Heidelberg, Germany, 1996; pp. 63–95. [Google Scholar]
- Wang, M.C.; Uhlenbeck, G.E. On the theory of the Brownian motion II. Rev. Mod. Phys. 1945, 17, 323. [Google Scholar] [CrossRef]
- Särkkä, S.; Solin, A. Applied Stochastic Differential Equations; Cambridge University Press: Cambridge, UK, 2019; Volume 10. [Google Scholar]
- Gillespie, D.T. The chemical Langevin equation. J. Chem. Phys. 2000, 113, 297–306. [Google Scholar] [CrossRef]
- Melykuti, B.; Burrage, K.; Zygalakis, K.C. Fast stochastic simulation of biochemical reaction systems by alternative formulations of the chemical Langevin equation. J. Chem. Phys. 2010, 132, 164109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schadschneider, A.; Chowdhury, D.; Nishinari, K. Stochastic Transport in Complex Systems: From Molecules to Vehicles; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Kumar, P.; Narayanan, S. Solution of Fokker-Planck equation by finite element and finite difference methods for nonlinear systems. Sadhana 2006, 31, 445–461. [Google Scholar] [CrossRef]
- Brics, M.; Kaupuzs, J.; Mahnke, R. How to solve Fokker-Planck equation treating mixed eigenvalue spectrum? arXiv 2013, arXiv:1303.5211. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.; Cooper, G. A practical difference scheme for Fokker-Planck equations. J. Comput. Phys. 1970, 6, 1–16. [Google Scholar] [CrossRef]
- Pichler, L.; Masud, A.; Bergman, L.A. Numerical solution of the Fokker–Planck equation by finite difference and finite element methods—A comparative study. In Computational Methods in Stochastic Dynamics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 69–85. [Google Scholar]
- Harrison, G.W. Numerical solution of the Fokker Planck equation using moving finite elements. Numer. Methods Partial Differ. Equ. 1988, 4, 219–232. [Google Scholar] [CrossRef]
- Epperlein, E. Implicit and conservative difference scheme for the Fokker-Planck equation. J. Comput. Phys. 1994, 112, 291–297. [Google Scholar] [CrossRef]
- Leimkuhler, B.; Reich, S. Simulating Hamiltonian Dynamics; Cambridge University Press: Cambridge, UK, 2004; Volume 14. [Google Scholar]
- Chen, N.; Majda, A.J. Efficient statistically accurate algorithms for the Fokker–Planck equation in large dimensions. J. Comput. Phys. 2018, 354, 242–268. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Cai, G. Probabilistic Structural Dynamics: Advanced Theory and Applications; McGraw-Hill: New York, NY, USA, 1995. [Google Scholar]
- Roberts, J.B.; Spanos, P.D. Random Vibration and Statistical Linearization; Courier Corporation: Chelmsford, MA, USA, 2003. [Google Scholar]
- Proppe, C.; Pradlwarter, H.; Schuëller, G. Equivalent linearization and Monte Carlo simulation in stochastic dynamics. Probab. Eng. Mech. 2003, 18, 1–15. [Google Scholar] [CrossRef]
- Grigoriu, M. Stochastic Calculus: Applications in Science and Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- ØKsendal, B. Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Kroese, D.P.; Taimre, T.; Botev, Z.I. Handbook of Monte Carlo Methods; John Wiley &; Sons: Hoboken, NJ, USA, 2013; Volume 706. [Google Scholar]
- Carrillo, J.; Craig, K.; Patacchini, F. A blob method for diffusion. Calc. Var. Partial Differ. Equ. 2019, 58, 1–53. [Google Scholar] [CrossRef] [Green Version]
- Pathiraja, S.; Reich, S. Discrete gradients for computational Bayesian inference. J. Comp. Dyn. 2019, 6, 236–251. [Google Scholar] [CrossRef] [Green Version]
- Reich, S.; Weissmann, S. Fokker-Planck particle systems for Bayesian inference: Computational approaches. arXiv 2019, arXiv:1911.10832. [Google Scholar]
- Liu, Q.; Lee, J.; Jordan, M. A kernelized Stein discrepancy for goodness-of-fit tests. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 276–284. [Google Scholar]
- Taghvaei, A.; Mehta, P.G. Accelerated flow for probability distributions. arXiv 2019, arXiv:1901.03317. [Google Scholar]
- Velasco, R.M.; Scherer García-Colín, L.; Uribe, F.J. Entropy production: Its role in non-equilibrium thermodynamics. Entropy 2011, 13, 82–116. [Google Scholar] [CrossRef]
- Hyvärinen, A. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res. 2005, 6, 695–709. [Google Scholar]
- Li, Y.; Turner, R.E. Gradient estimators for implicit models. arXiv 2017, arXiv:1705.07107. [Google Scholar]
- Shi, J.; Sun, S.; Zhu, J. A spectral approach to gradient estimation for implicit distributions. arXiv 2018, arXiv:1806.02925. [Google Scholar]
- Tomé, T.; De Oliveira, M.J. Stochastic Dynamics and Irreversibility; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Sutherland, D.J.; Strathmann, H.; Arbel, M.; Gretton, A. Efficient and principled score estimation with Nyström kernel exponential families. arXiv 2017, arXiv:1705.08360. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning; Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Liu, Q.; Wang, D. Stein variational gradient descent: A general purpose Bayesian inference algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2378–2386. [Google Scholar]
- Liu, Q. Stein variational gradient descent as gradient flow. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3115–3123. [Google Scholar]
- Garbuno-Inigo, A.; Nüsken, N.; Reich, S. Affine invariant interacting Langevin dynamics for Bayesian inference. arXiv 2019, arXiv:1912.02859. [Google Scholar]
- Otto, F. The geometry of dissipative evolution equations: The porous medium equation. Commun. Partial Differ. Equ. 2001, 26, 101–174. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Frogner, C.; Poggio, T. Approximate inference with Wasserstein gradient flows. arXiv 2018, arXiv:1806.04542. [Google Scholar]
- Caluya, K.; Halder, A. Gradient flow algorithms for density propagation in stochastic systems. IEEE Trans. Autom. Control 2019. [Google Scholar] [CrossRef] [Green Version]
- Batz, P.; Ruttor, A.; Opper, M. Variational estimation of the drift for stochastic differential equations from the empirical density. J. Stat. Mech. Theory Exp. 2016, 2016, 083404. [Google Scholar] [CrossRef] [Green Version]
- Milstein, G.; Tretyakov, M. Computing ergodic limits for Langevin equations. Phys. D Nonlinear Phenom. 2007, 229, 81–95. [Google Scholar] [CrossRef]
- Saremi, S.; Mehrjou, A.; Schölkopf, B.; Hyvärinen, A. Deep energy estimator networks. arXiv 2018, arXiv:1805.08306. [Google Scholar]
- Reich, S.; Cotter, C. Probabilistic Forecasting and Bayesian Data Assimilation; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef] [Green Version]
- Bobkov, S.; Ledoux, M. One-Dimensional Empirical Measures, Order Statistics and Kantorovich Transport Distances; Amer Mathematical Society: Providence, RI, USA, 2014. [Google Scholar]
Figure 1.
Accuracy of Fokker–Planck solutions for two dimensional Ornstein Uhlenbeck process. (a) Mean, , and (c) stationary , 1-Wasserstein distance, between analytic solution and deterministic(D)/stochastic(S) simulations of N particles (for different inducing point number M). (b) Average temporal deviations from analytic mean and (d) covariance matrix for deterministic and stochastic system for increasing particle number N. Deterministic particle simulations consistently outperformed stochastic ones in approximating the temporal evolution of the mean and covariance of the distribution for all examined particle number settings. (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 1.
Accuracy of Fokker–Planck solutions for two dimensional Ornstein Uhlenbeck process. (a) Mean, , and (c) stationary , 1-Wasserstein distance, between analytic solution and deterministic(D)/stochastic(S) simulations of N particles (for different inducing point number M). (b) Average temporal deviations from analytic mean and (d) covariance matrix for deterministic and stochastic system for increasing particle number N. Deterministic particle simulations consistently outperformed stochastic ones in approximating the temporal evolution of the mean and covariance of the distribution for all examined particle number settings. (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 2.
Stationary and transient Fokker–Planck solutions computed with deterministic (green) and stochastic (brown) particle dynamics for a two dimensional Ornstein Uhlenbeck process. (a,b) Estimated stationary PDFs arising from deterministic () (green), and stochastic () (brown) particle dynamics. Purple contours denote analytically calculated stationary distributions, while top and side histograms display marginal distributions for each dimension. (c) Temporal evolution of marginal statistics, mean , standard deviation , skewness , and kurtosis , for analytic solution (A), and for stochastic (S) and deterministic (D) particle systems comprising , with initial state distribution , for randomly selected inducing points employed in the gradient–log–density estimation. Deterministic particle simulations deliver smooth cumulant trajectories, as opposed to highly fluctuating stochastic particle cumulants. (Further parameter values: regularisation constant , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 2.
Stationary and transient Fokker–Planck solutions computed with deterministic (green) and stochastic (brown) particle dynamics for a two dimensional Ornstein Uhlenbeck process. (a,b) Estimated stationary PDFs arising from deterministic () (green), and stochastic () (brown) particle dynamics. Purple contours denote analytically calculated stationary distributions, while top and side histograms display marginal distributions for each dimension. (c) Temporal evolution of marginal statistics, mean , standard deviation , skewness , and kurtosis , for analytic solution (A), and for stochastic (S) and deterministic (D) particle systems comprising , with initial state distribution , for randomly selected inducing points employed in the gradient–log–density estimation. Deterministic particle simulations deliver smooth cumulant trajectories, as opposed to highly fluctuating stochastic particle cumulants. (Further parameter values: regularisation constant , and RBF kernel length scale l estimated at every time point as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 3.
Performance of deterministic (green) and stochastic (brown) N particle solutions compared to (grey) stochastic particle densities for a nonlinear bi-stable process. (a) Instances of estimated pdfs arising from (left) stochastic ( = 26,000) (grey) and deterministic () (green), and (right) stochastic () (grey) and stochastic () (brown) particle dynamics at times (i) , (ii) , and (iii) . (b) Temporal evolution of first four distribution cumulants, mean , standard deviation , skewness , and kurtosis , for stochastic ( and S) and deterministic (D) systems comprising = 26,000, , with initial state distribution , by employing inducing points in the gradient–log–density estimation. (c) Mean, , and (d) stationary, , 1-Wasserstein distance, between = 26,000 stochastic, and deterministic (D)/stochastic (S) simulations of N particles (for different inducing point number M). (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 3.
Performance of deterministic (green) and stochastic (brown) N particle solutions compared to (grey) stochastic particle densities for a nonlinear bi-stable process. (a) Instances of estimated pdfs arising from (left) stochastic ( = 26,000) (grey) and deterministic () (green), and (right) stochastic () (grey) and stochastic () (brown) particle dynamics at times (i) , (ii) , and (iii) . (b) Temporal evolution of first four distribution cumulants, mean , standard deviation , skewness , and kurtosis , for stochastic ( and S) and deterministic (D) systems comprising = 26,000, , with initial state distribution , by employing inducing points in the gradient–log–density estimation. (c) Mean, , and (d) stationary, , 1-Wasserstein distance, between = 26,000 stochastic, and deterministic (D)/stochastic (S) simulations of N particles (for different inducing point number M). (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 4.
Accuracy of Fokker–Planck solutions for a nonlinear system perturbed with state-dependent noise. (a) Instances of particle distributions resulting from deterministic (green) and (b) stochastic (brown) simulations against stochastic particle distributions comprising = 35,000 particles (grey) for (i) , (ii) , and (iii) . Insets provide a closer view of details of distribution for visual clarity. Distributions resulting from deterministic particle simulations closer agree with underlying distribution for all three instances. (c) Temporal evolution of first four cumulants for the three particle systems (grey: —stochastic with = 35000 particles, brown: S - stochastic with N = 1000 particles, and green: D—deterministic with N = 1000 particles). Deterministically evolved distributions result in smooth cumulant trajectories. (d,e) Temporal average and (f,g) stationary 1-Wasserstein distance between distributions mediated through stochastic simulations of = 35000, and through deterministic (green) and stochastic (brown) simulations of N particles against particle number N and inducing point number M. Shaded regions and error bars denote one standard deviation among 20 independent repetitions. Different green hues designate different inducing point number M employed in the gradient–log–density estimation. (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale . Inducing points were arranged on a regular grid spanning the instantaneous state space volume captured by the state vector).
Figure 4.
Accuracy of Fokker–Planck solutions for a nonlinear system perturbed with state-dependent noise. (a) Instances of particle distributions resulting from deterministic (green) and (b) stochastic (brown) simulations against stochastic particle distributions comprising = 35,000 particles (grey) for (i) , (ii) , and (iii) . Insets provide a closer view of details of distribution for visual clarity. Distributions resulting from deterministic particle simulations closer agree with underlying distribution for all three instances. (c) Temporal evolution of first four cumulants for the three particle systems (grey: —stochastic with = 35000 particles, brown: S - stochastic with N = 1000 particles, and green: D—deterministic with N = 1000 particles). Deterministically evolved distributions result in smooth cumulant trajectories. (d,e) Temporal average and (f,g) stationary 1-Wasserstein distance between distributions mediated through stochastic simulations of = 35000, and through deterministic (green) and stochastic (brown) simulations of N particles against particle number N and inducing point number M. Shaded regions and error bars denote one standard deviation among 20 independent repetitions. Different green hues designate different inducing point number M employed in the gradient–log–density estimation. (Further parameter values: regularisation constant , Euler integration time step , and RBF kernel length scale . Inducing points were arranged on a regular grid spanning the instantaneous state space volume captured by the state vector).

Figure 5.
Accuracy of Fokker-Planck solutions for multi-dimensional Ornstein–Uhlenbeck processes for inducing points. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems and analytic solutions for multi-dimensional Ornstein–Uhlenbeck process of D = {2, 3, 4, 5} dimensions. (a) Time-averaged and (d) stationary Kullback–Leibler (KL) divergence between simulated particle solutions (green: deterministic, brown: stochastic) and analytic solutions for different dimensions. Deterministic particle simulations outperform stochastic particle solutions even for increasing system dimensionality. (b) Time averaged and (e) stationary error between analytic, , and sample mean, , for increasing particle number. (c) Time averaged and (f) stationary discrepancy between simulated, , and analytic covariances, , as captured by the Frobenius norm of the relevant covariance matrices difference. The accuracy of the estimated covariance decreases for increasing dimensionality. (Further parameter values: regularisation constant , Euler integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 5.
Accuracy of Fokker-Planck solutions for multi-dimensional Ornstein–Uhlenbeck processes for inducing points. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems and analytic solutions for multi-dimensional Ornstein–Uhlenbeck process of D = {2, 3, 4, 5} dimensions. (a) Time-averaged and (d) stationary Kullback–Leibler (KL) divergence between simulated particle solutions (green: deterministic, brown: stochastic) and analytic solutions for different dimensions. Deterministic particle simulations outperform stochastic particle solutions even for increasing system dimensionality. (b) Time averaged and (e) stationary error between analytic, , and sample mean, , for increasing particle number. (c) Time averaged and (f) stationary discrepancy between simulated, , and analytic covariances, , as captured by the Frobenius norm of the relevant covariance matrices difference. The accuracy of the estimated covariance decreases for increasing dimensionality. (Further parameter values: regularisation constant , Euler integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 6.
Accuracy of Fokker-Planck solutions for multi-dimensional Ornstein–Uhlenbeck processes for inducing points. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems and analytic solutions for multi-dimensional Ornstein–Uhlenbeck process of D = {2,3,4,5} dimensions. (a) Time-averaged and (d) stationary Kullback–Leibler (KL) divergence between simulated particle solutions (green: deterministic, brown: stochastic) and analytic solutions for different dimensions. Deterministic particle simulations outperform stochastic particle solutions even for increasing system dimensionality. (b) Time averaged and (e) stationary error between analytic, , and sample mean, , for increasing particle number. (c) Time averaged and (f) stationary discrepancy between simulated, , and analytic covariances, , as captured by the Frobenius norm of the relevant covariance matrices difference. The accuracy of the estimated covariance decreases for increasing dimensionality. (Further parameter values: regularisation constant , Euler integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 6.
Accuracy of Fokker-Planck solutions for multi-dimensional Ornstein–Uhlenbeck processes for inducing points. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems and analytic solutions for multi-dimensional Ornstein–Uhlenbeck process of D = {2,3,4,5} dimensions. (a) Time-averaged and (d) stationary Kullback–Leibler (KL) divergence between simulated particle solutions (green: deterministic, brown: stochastic) and analytic solutions for different dimensions. Deterministic particle simulations outperform stochastic particle solutions even for increasing system dimensionality. (b) Time averaged and (e) stationary error between analytic, , and sample mean, , for increasing particle number. (c) Time averaged and (f) stationary discrepancy between simulated, , and analytic covariances, , as captured by the Frobenius norm of the relevant covariance matrices difference. The accuracy of the estimated covariance decreases for increasing dimensionality. (Further parameter values: regularisation constant , Euler integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 7.
Energy preservation for second order Langevin dynamics in a quadratic potential. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems for a harmonic oscillator (a) First four cumulant temporal evolution for deterministic (green) and stochastic (brown) system. (b) Stationary joint and marginal distributions for deterministic (green) and stochastic (brown) systems. Purple lines denote analytically derived stationary distributions. (c,d) State space trajectory of a single particle for deterministic (green) and stochastic (brown) system. Color gradients denote time. (e) Temporal evolution of individual particle energy for deterministic system for 5 particles. (f) Difference between velocity and gradient–log–density term for individual particles. After the system reaches stationary state the particle velocity and GLD term cancel out. (g) Ensemble average kinetic energy through time resorts to (grey dashed line) after equilibrium is reached. (Further parameter values: regularisation constant , integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 7.
Energy preservation for second order Langevin dynamics in a quadratic potential. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems for a harmonic oscillator (a) First four cumulant temporal evolution for deterministic (green) and stochastic (brown) system. (b) Stationary joint and marginal distributions for deterministic (green) and stochastic (brown) systems. Purple lines denote analytically derived stationary distributions. (c,d) State space trajectory of a single particle for deterministic (green) and stochastic (brown) system. Color gradients denote time. (e) Temporal evolution of individual particle energy for deterministic system for 5 particles. (f) Difference between velocity and gradient–log–density term for individual particles. After the system reaches stationary state the particle velocity and GLD term cancel out. (g) Ensemble average kinetic energy through time resorts to (grey dashed line) after equilibrium is reached. (Further parameter values: regularisation constant , integration time step , and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 8.
Energy preservation for second order Langevin dynamics in a double well potential. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems for a bistable process. (a,b) Joint and marginal distributions of system states mediated by particles evolved with our framework (green) and with direct stochastic simulations comprising = 20,000 (grey) and (brown) particles at (a) , and (b) . Purple lines denote the analytically derived stationary density. (c) First four cumulant temporal evolution for deterministic (green) and stochastic (brown) system. (d) State space trajectory of a single particle for deterministic and (e) stochastic system. Color gradients denote time. (f) Temporal evolution of individual particle energy for deterministic system for 5 particles. (g) Temporal evolution of distribution of particle energies for deterministic (green) and stochastic (brown) system. (h) Difference between velocity and gradient log density term for individual particles. (i) Ensemble average kinetic energy through time resorts to (grey dashed line) after equilibrium is reached. (Further parameter values: regularisation constant , integration time step and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 8.
Energy preservation for second order Langevin dynamics in a double well potential. Comparison of deterministic particle Fokker–Planck solutions with stochastic particle systems for a bistable process. (a,b) Joint and marginal distributions of system states mediated by particles evolved with our framework (green) and with direct stochastic simulations comprising = 20,000 (grey) and (brown) particles at (a) , and (b) . Purple lines denote the analytically derived stationary density. (c) First four cumulant temporal evolution for deterministic (green) and stochastic (brown) system. (d) State space trajectory of a single particle for deterministic and (e) stochastic system. Color gradients denote time. (f) Temporal evolution of individual particle energy for deterministic system for 5 particles. (g) Temporal evolution of distribution of particle energies for deterministic (green) and stochastic (brown) system. (h) Difference between velocity and gradient log density term for individual particles. (i) Ensemble average kinetic energy through time resorts to (grey dashed line) after equilibrium is reached. (Further parameter values: regularisation constant , integration time step and adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

Figure 9.
Deterministic (green) and stochastic (brown) Fokker–Planck particle solutions for a three dimensional Lorenz attractor system in the chaotic regime perturbed by additive Gaussian noise. (a) Joint and marginal distributions of system states mediated by particles evolved with our framework (green) and with direct stochastic simulations comprising N = 150,000 (grey) and (brown) particles at . (b) Cumulant trajectories for the three particle systems. Cumulants derived from deterministic particle simulations (green) closer match cumulant evolution of the underlying distribution (grey) compared to stochastic simulations (brown). (Further parameter values: regularisation constant , Euler integration time step , adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points: . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).
Figure 9.
Deterministic (green) and stochastic (brown) Fokker–Planck particle solutions for a three dimensional Lorenz attractor system in the chaotic regime perturbed by additive Gaussian noise. (a) Joint and marginal distributions of system states mediated by particles evolved with our framework (green) and with direct stochastic simulations comprising N = 150,000 (grey) and (brown) particles at . (b) Cumulant trajectories for the three particle systems. Cumulants derived from deterministic particle simulations (green) closer match cumulant evolution of the underlying distribution (grey) compared to stochastic simulations (brown). (Further parameter values: regularisation constant , Euler integration time step , adaptive RBF kernel length scale l calculated at every time step as two times the standard deviation of the state vector. Number of inducing points: . Inducing point locations were selected randomly at each time step from a uniform distribution spanning the state space volume covered by the state vector).

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Maoutsa, D.; Reich, S.; Opper, M. Interacting Particle Solutions of Fokker–Planck Equations Through Gradient–Log–Density Estimation. Entropy 2020, 22, 802. https://0-doi-org.brum.beds.ac.uk/10.3390/e22080802
AMA Style
Maoutsa D, Reich S, Opper M. Interacting Particle Solutions of Fokker–Planck Equations Through Gradient–Log–Density Estimation. Entropy. 2020; 22(8):802. https://0-doi-org.brum.beds.ac.uk/10.3390/e22080802
Chicago/Turabian StyleMaoutsa, Dimitra, Sebastian Reich, and Manfred Opper. 2020. "Interacting Particle Solutions of Fokker–Planck Equations Through Gradient–Log–Density Estimation" Entropy 22, no. 8: 802. https://0-doi-org.brum.beds.ac.uk/10.3390/e22080802
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.