Entropy Analysis of a Flexible Markovian Queue with Server Breakdowns


1
Department of Mathematics, King Saud University, Riyadh 11451, Saudi Arabia
2
Department of Industrial Engineering, Alfaisal University, Riyadh 12714, Saudi Arabia
3
Department of Computer Engineering, King Saud University, Riyadh 11453, Saudi Arabia
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(9), 979; https://0-doi-org.brum.beds.ac.uk/10.3390/e22090979
Submission received: 6 July 2020
/
Revised: 16 August 2020
/
Accepted: 25 August 2020
/
Published: 3 September 2020
(This article belongs to the Special Issue Entropy: The Scientific Tool of the 21st Century)
Abstract
:In this paper, a versatile Markovian queueing system is considered. Given a fixed threshold level c, the server serves customers one a time when the queue length is less than c, and in batches of fixed size c when the queue length is greater than or equal to c. The server is subject to failure when serving either a single or a batch of customers. Service rates, failure rates, and repair rates, depend on whether the server is serving a single customer or a batch of customers. While the analytical method provides the initial probability vector, we use the entropy principle to obtain both the initial probability vector (for comparison) and the tail probability vector. The comparison shows the results obtained analytically and approximately are in good agreement, especially when the first two moments are used in the entropy approach.
1. Introduction
The concept of entropy was introduced by Shannon in his seminal papers, Shannon [1]. In information theory, entropy refers to a basic quantity associated to a random variable. Among a number of different probability distributions that express the current state of knowledge, the maximum entropy principle allows to choose the best one, that is the one with maximum entropy.
Originally, the entropy was created by Shannon as part of his theory of communication. However, since then, the principle of maximum entropy has found applications in a multitude of other areas such as statistical mechanics, statistical thermodynamics, business, marketing and elections, economics, finance, insurance, spectral analysis of time series, image reconstruction, pattern recognition, operations research, reliability theory, biology, medicine, and so forth, see Kapur [2].
In operations research, and particularly in queueing theory, a large number of papers has used the maximum entropy principle to determine the steady-state probability distribution of some process. The earliest document using entropy maximization in the context of queues that came to our attention is that of Bechtold et al. [3]. Among the latest theoretical papers applying the maximum entropy principle we cite Yen et al. [4], Shah [5], and Singh et al. [6], while She et al. [7], Giri and Roy [8], and Lin et al. [9] present recent applications.
The intention of this paper is to resume work on a paper started by Bounkhel et al. [10], who studied a flexible queueing system and used an analytical method to obtain the initial steady state probability vector. For other possible approaches to calculate the probabilities see the references in Reference [10]. The objective of this paper is threefold. First, the maximum entropy principle is used to derive the initial steady state probability vector and make sure it is in agreement with the one obtained by Bounkhel et al. [10]. Second, we use the maximum entropy principle to obtain the tail steady state probability vector. Third, improve both initial and tail probability vectors by providing more information to the maximum entropy technique.
The rest of this paper is structured as follows. In Section 2, we describe the flexible queueing system and recall the results obtained by Bounkhel et al. [10]. Our main results are presented in Section 3 where we use the maximum entropy principle to obtain the different probabilities. The theoretical results are verified with numerical illustrations. The paper is concluded in Section 4.
2. Model Formulation and Previous Results
Bounkhel et al. [10] studied a versatile single-server queueing system where service is regulated by an integer threshold level , and can be either single or batch as follows—if the queue length is less than c, then service is single and exponential with parameter . If the queue length is equal to c, then service is batch of size c and follows the exponential distribution with parameter . Finally, if the queue size is greater than c, then service is again batch of fixed size c and follows the exponential distribution with parameter . The server is subject to breakdowns which happen according to a Poisson process with rate when service is single and when service is batch. Repairs that follow breakdowns are exponentially distributed with rate when service is single and when service is batch. Assume that costumers arrive according to a Poisson process with positive rate .
We let represent the number of customers in the system at time t and introduce , the probability of n customers in the system in the steady-state when the server is in a working state, and the probability of n customers in the system in the steady-state regardless of the server state. Also, for , we introduce the probability generating functions:
Then,
where
The c unknown probabilities , are determined by solving the system of c equations:
where are the roots inside the open unit ball of the equation
and
with
Writing , the expected number of customers in the system in the steady-state is
where
with
and
3. Entropy Approach
By solving the system of Equations (3)–(4), only the probabilities are obtained. The rest of the probabilities can be obtained by successive differentiations of (1). Note that using (2), we have
Therefore, the initial probability vector is completely determined while the tail probability vector is yet to be determined. However, since the first moment of the process has been found in (5), we can use this information, along we the maximum entropy principle, to obtain approximate values for the components of the tail probability vector .
3.1. Entropy Solution Using the First Moment
In a first step, we will calculate the initial probability vector using the maximum entropy principle and compare it with the initial probability vector obtained in the previous section to make sure they are in agreement. To this end, consider the following nonlinear maximization problem:
Constraint (8) is the summability-to-one condition while constraint (9) is the mean system size equation. This maximization problem can be solved by the method of Lagrange multipliers, see for example Luenberger and Ye [11]. The Lagrangian function associated with problem is given by:
where the vector stands for the Lagrange multipliers. Setting the derivative of with respect to to zero yields
All we need to do now is solve numerically the nonlinear system (11) and (12) to find and then and then substitute in (10) to obtain the probabilities .
Example 1.
Some numerical tests are conducted here to see how good is the solution procedure proposed in this section. In this sequel, we will refer to the solution obtained analytically as the exact solution, and to the solution obtained using the entropy approach with the first moment as the approximate solution 1. To compare these solutions, we will use the percentage error ():
Let us take a numerical example where and calculate the initial probability vector . Assume , , , , , and . Table 1 shows the exact solution, the approximate solution 1, and the percentage error for two different values of the arrival rate λ.
When , the average is and when , the average is . The overall average percentage error is , which can be greatly improved.
3.2. Entropy Solution Using the Second Moment
In this subsection, we use (2) to calculate the second moment and we will show that the use of the second moment instead of the first moment as an extra constraint leads to an initial steady state probability vector that is also closer to the initial steady state probability vector obtained analytically. We find that the second moment is given by
where
with
The nonlinear maximization problem to solve in this case is the following:
Similarly to the case where we only used the first moment, we use the classical method of Lagrange. The following system of nonlinear equations, where the unknowns are the Lagrange multipliers is obtained:
This system can be solved numerically. Once we have the values of , we replace these values in the following formula to obtain the probabilities :
Example 2.
Some numerical tests are conducted here to see how good is the solution procedure proposed in this subsection. Similarly to the previous subsection, we will refer to the percentage error obtained using the entropy approach with the second moment as . Then we compare the two approximate solutions using the percentage errors. Let us take a numerical example with the same data in Example 1, that is, , , , , , , and . Table 2 shows the exact solution, the approximate solution obtained in Section 3.1, the approximate solution obtained in this subsection, the percentage errors and , for two different values of the arrival rate λ.
When , the average of is and the average of is , and when , the average of is and the average of is . The overall average percentage error of and , respectively, are and , which can be greatly improved in the next subsection.
3.3. Entropy Solution Using Both First and Second Moments
Our objective here is to improve the probability vector obtained in the previous subsections. This is realized by including both first and second moments to the previous formulation. We will show that the use of the two moments as extra constraints leads to best approximation to the initial steady state probability vector obtained analytically. The nonlinear maximization problem to solve in this case is the following:
Similarly to the previous cases, we use the classical method of Lagrange. The following system of nonlinear equations, where the unknowns are the Lagrange multipliers is obtained:
This system can be solved numerically. The values of obtained numerically will be replaced in the following formula to obtain the probabilities :
Example 3.
Let us take the same data as in Examples 1 and 2 and calculate the initial probability vector using the analytical method (exact), entropy approach with first moment only (Entropy 1), entropy approach with second moment only (Entropy 2), and entropy approach with both first and second moments (Entropy 1&2). Table 3 and Table 4 show the exact solution and the approximate solutions along with the corresponding percentage errors for and , respectively.
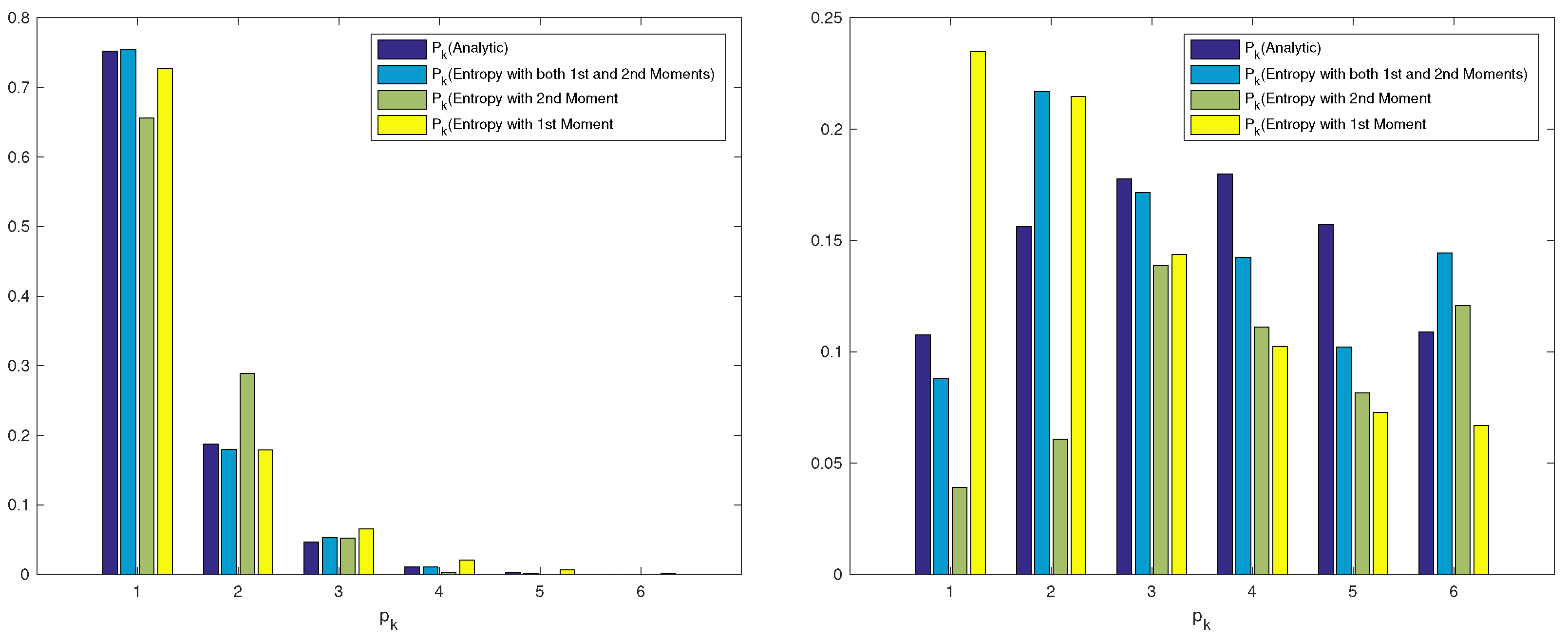
We denote by the percentage error when Entropy 1 is used, by the percentage error when Entropy 2 is used, and by the percentage error when Entropy is used. The overall average percentage error using the entropy approach with the first moment is , while the overall average percentage error using the entropy approach with the second moment is which represents a slight improvement of . However, the overall average percentage using both moments is , which represents a substantial improvement of . We show in Figure 1 the two distributions for a better visualisation. We can see that the entropy approach with both moments always outperforms the entropy approach with only the first moment or only second moment.
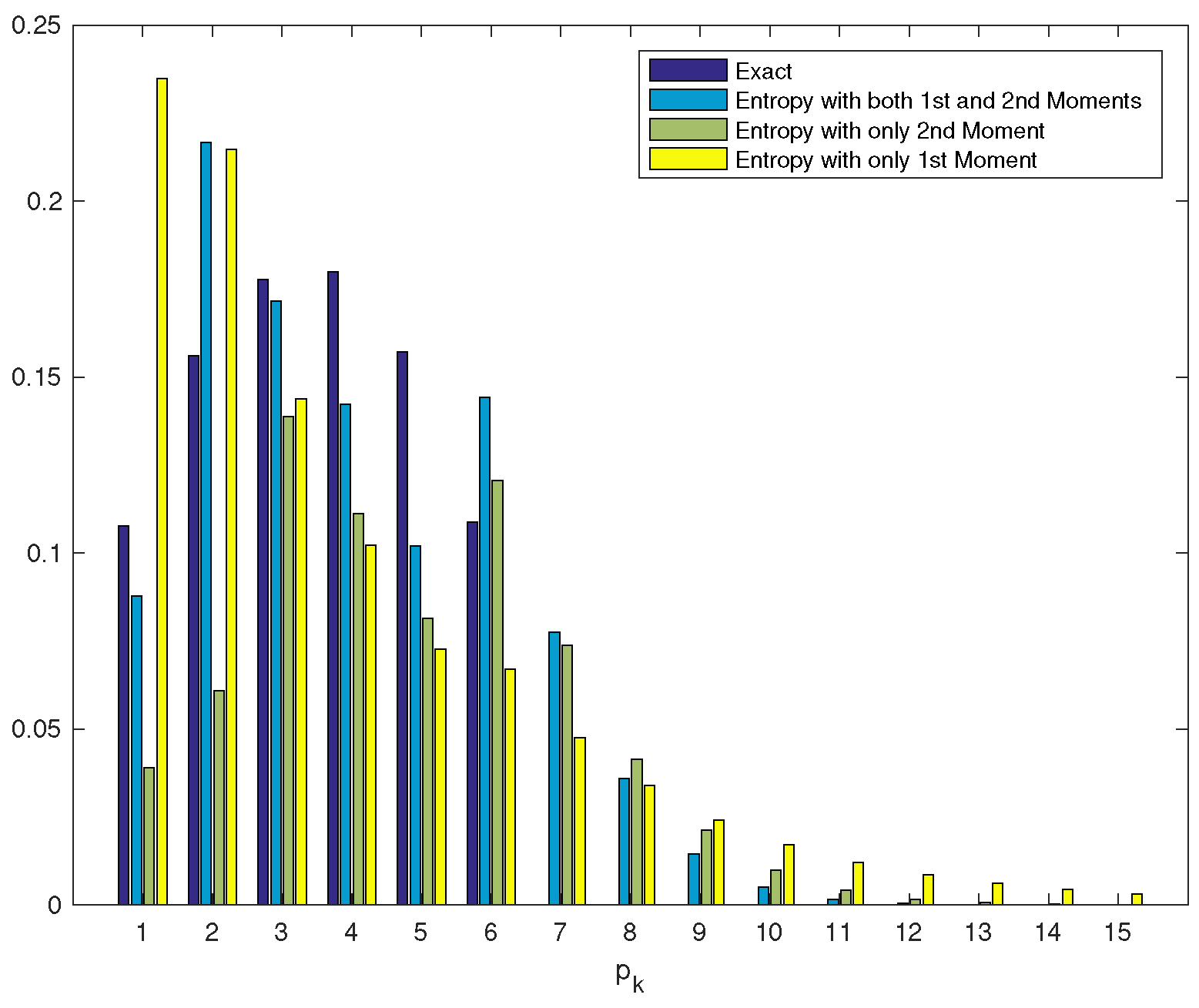
Since the results obtained by the entropy method with both two moments are satisfactory, we also calculated the tail probability vector and present in Figure 2 both initial and tail probability vectors. For comparison, we present the distribution obtained when only one moment (first or second moment) is used and when both first and second moments are used.
One other remark we make when looking at Table 2, Table 3 and Table 4 is that the probability mass function is concentrated at for small values of λ and as λ increases, this distribution becomes more evenly distributed and the value of decreases. Intuitively, this makes sense since we expect the probability of no customers in the system to decrease as the arrival rate increases. Therefore, to further compare the approximate entropy approaches, we conduct next a sensitivity analysis to investigate the effect of λ on the percentage errors of . We also explore the effect of other parameters, namely c, and . The parameters and do not seem to have any effect on the deviations. For the sensitivity analysis, we keep the base values of Example 1 and change one parameter at a time.
Effect of on the Percentage Error of .
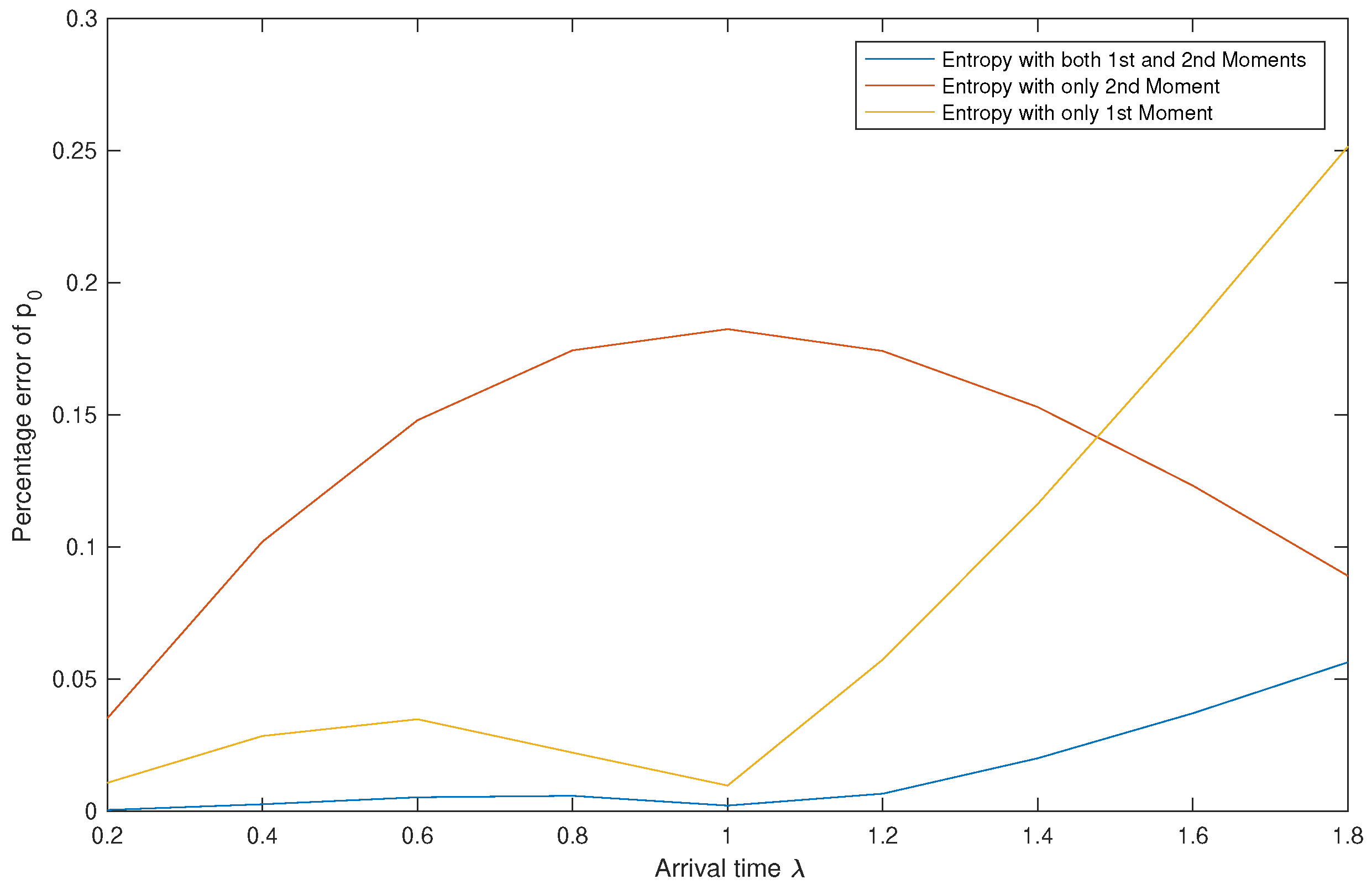
Table 5 shows the values of calculated using the three methods, while Figure 3 shows the variations of the percentage errors as λ changes.
We read from Table 5 two points: First, the approximation results obtained using Entropy 1&2 are clearly better than the ones obtained by the two other methods. Second, the efficiency of the best method is inversely proportional to the values of λ.
Figure 3 shows that Entropy 1&2 always has the lowest , however, there are values of λ for which . In other words, if we are using a single moment, then better use the first moment for small values of λ and the second moment for larger values of λ.
Effect of on the Percentage Error of .
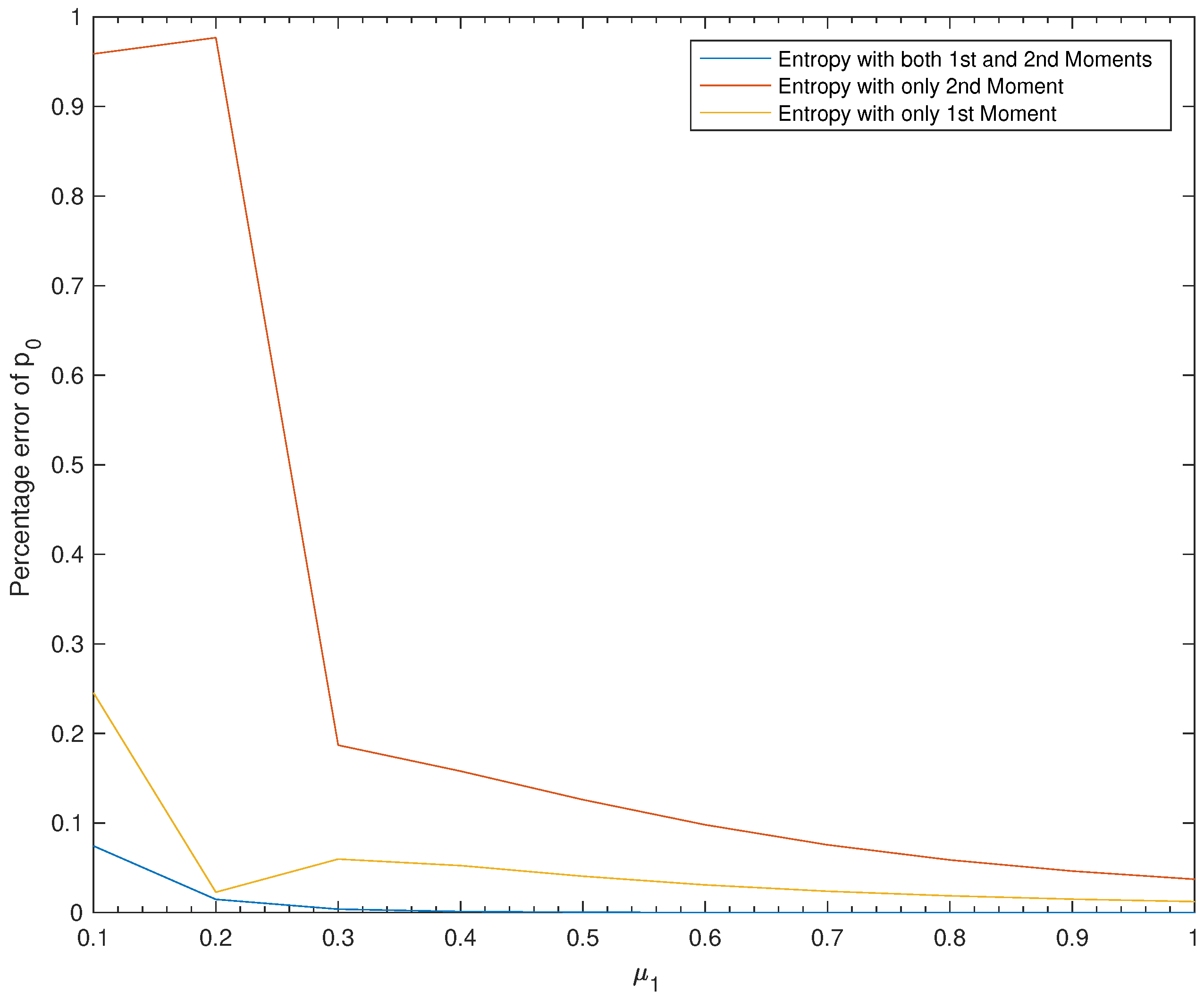
We read from Table 6 three points: First, the approximation results obtained using Entropy 1&2 are clearly better than the ones obtained by the two other methods. Second, Entropy 1 is much better than Entropy 2, that is, if we are using a single moment, then better use the first moment than the second moment. Third, the efficiency of all three methods is directly proportional to the values of .
We can see from Figure 4 that we always have , which confirms our conclusions from Table 6 stated above.
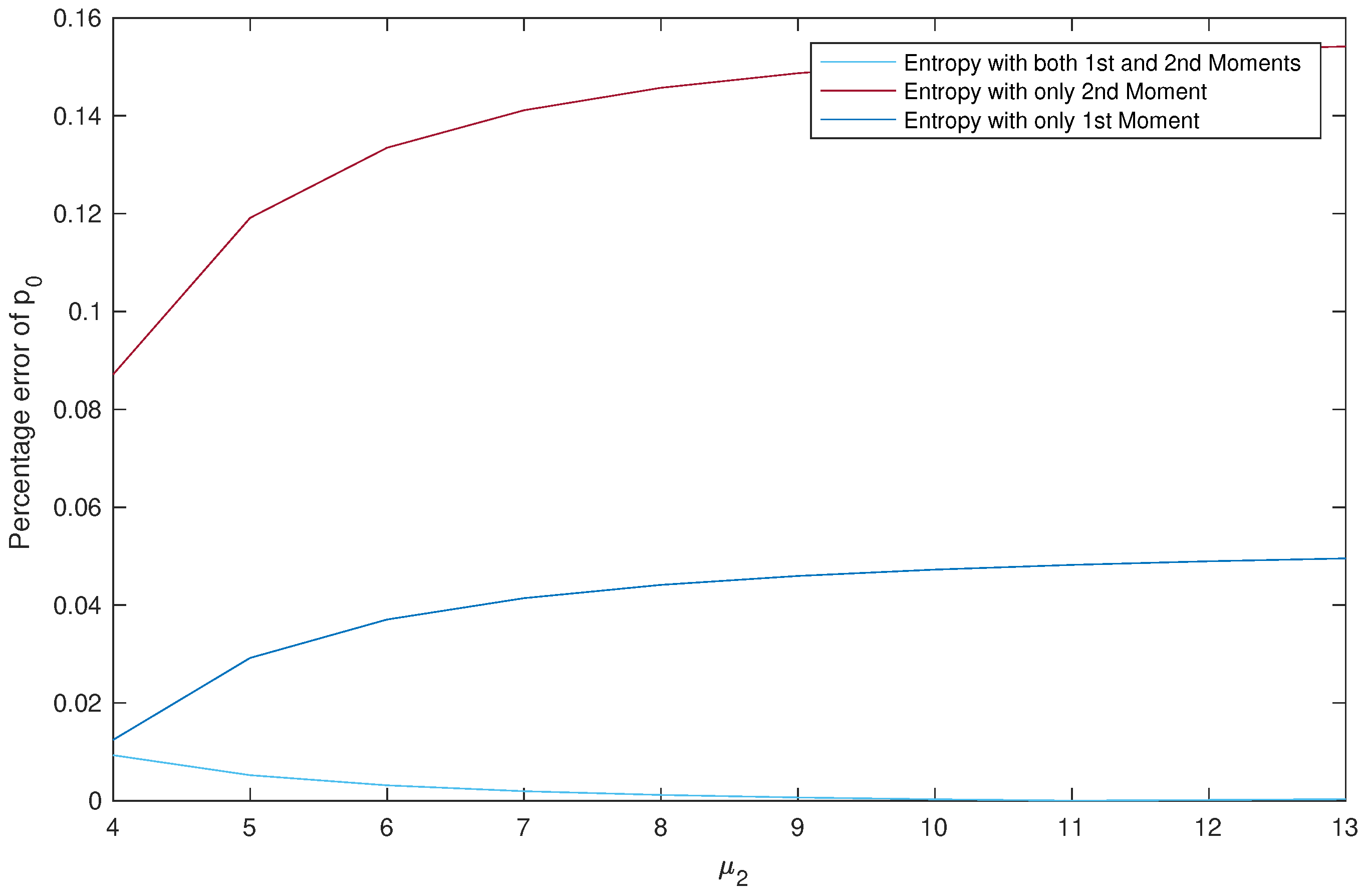
Effect of on the Percentage Error of .
We read from Table 7 three points: First, the approximation results obtained using Entropy 1&2 are much better than the ones obtained by the two other methods. Second, if we are using a single moment, then better use Entropy 1 than Entropy 2. Third, the efficiency of the best method is directly proportional to the values of and the efficiency of the other two methods is inversely proportional.
Again observe from Figure 5 that we always have , which confirms our conclusions from Table 7 stated above.
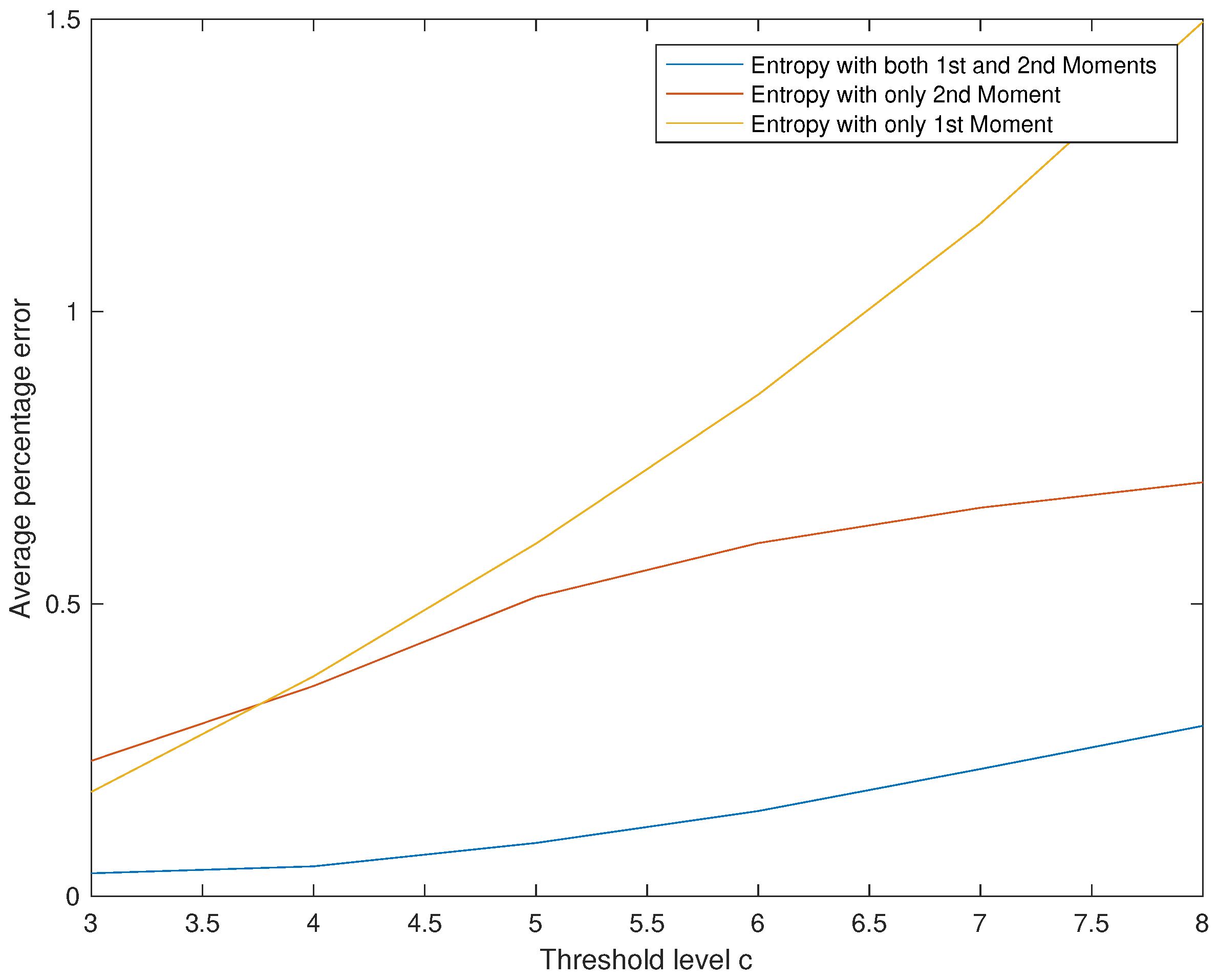
Effect of on The Initial Probability Vector .
The results are summarized in Table 8 and Figure 6. Superiority of Entropy 1&2 is demonstrated for all values of c.
We read from Table 8 and Figure 6 three points: First, obviously the approximation results obtained using Entropy 1&2 are clearly better than the ones obtained by the two other methods. Second, if we are using a single moment, then better use Entropy 2 than Entropy 1 for large values of c and for small values of c there is no big difference between the two methods. Third, the efficiency of all three methods is inversely proportional to the values of c.
From our previous sensitivity analysis, we conclude that if a single moment is used to estimate the probabilities, then it makes a difference whether we use the first moment or the second moment. Also, the more information we feed the maximum entropy technique, the more accurate the results are. Although we did not do it, we conjecture that inclusion of the third moment would confirm our findings that including more information would result in higher accuracy.
4. Conclusions
An analytical and the maximum entropy principle are used in this paper to calculate the steady-state initial probabilities of the number of customers in a Markovian queueing system. The entropy solution is further improved by including second moment information. When the analytical and entropy solutions are in agreement, the entropy solution is used to obtain the tail probabilities of the number of customers in the system. These probabilities cannot be obtained analytically.
The number of customers in the system is a discrete random variable. This paper can be followed by one where a continuous random variable such as the waiting time or the busy period is studied. In this case, the probability density function, instead of the probability mass function, needs to be calculated.
Author Contributions
All authors contributed equally to this article. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deanship of Scientific Research at King Saud University for funding the work through the research group Project No. RGP-024.
Acknowledgments
The authors would like to thank the referees for the com-plete reading of the first version of this work and for their suggestions allowing us to improve the presentation of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Kapur, J.N. Maximum Entropy Models in Science and Engineering; Wiley Eastern Limited: New Delhi, India, 1989. [Google Scholar]
- Bechtold, W.R.; Medlin, J.E.; Weber, D.R. PCM Telemetry Data Compression Study, Phase 1 Final Report, Prepared by Lockheed Missiles & Space Company Sunnyvale, California for Goddard Space Flight Center Greenbelt, Maryland. 1965. Available online: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19660012530.pdf (accessed on 6 July 2020).
- Yen, T.-C.; Wang, K.-H.; Chen, J.-Y. Optimization Analysis of the N Policy M/G/1 Queue with Working Breakdowns. Symmetry 2020, 12, 583. [Google Scholar] [CrossRef] [Green Version]
- Shah, N.P. Entropy Maximisation and Queues with or without Balking. Ph.D. Thesis, School of Electrical Engineering and Computer Science, Faculty of Engineering and Informatics, University of Bradford, Bradford, UK, 2014. [Google Scholar]
- Singh, C.J.; Kaur, S.; Jain, M. Unreliable server retrial G-queue with bulk arrival, optional additional service and delayed repair. Int. J. Oper. Res. 2020, 38, 82–111. [Google Scholar] [CrossRef]
- She, R.; Liu, S.; Fan, P. Recognizing information feature variation: Message importance transfer measure and its applications in big data. Entropy 2018, 20, 401. [Google Scholar] [CrossRef] [Green Version]
- Giri, S.; Roy, R. On NACK-based rDWS algorithm for network coded broadcast. Entropy 2019, 21, 905. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.; Wang, H.; Deng, Z.; Wang, K.; Zhou, X. State machine with tracking tree and traffic allocation scheme based on cumulative entropy for satellite network. Chin. J. Electron. 2020, 29, 185–189. [Google Scholar] [CrossRef]
- Bounkhel, M.; Tadj, L.; Hedjar, R. Steady-state analysis of a flexible Markovian queue with server breakdowns. Entropy 2019, 21, 259. [Google Scholar] [CrossRef] [Green Version]
- Luenberger, D.G.; Ye, Y. Introduction to Linear and Nonlinear Programming, 4th ed.; Springer: Cham, Switzerland, 2016. [Google Scholar]
Figure 1.
Initial probability vectors comparison (left and right ).

Figure 2.
Initial and tail probability vectors.

Figure 3.
Effect of λ on the percentage errors of .

Figure 4.
Effect of on the percentage errors of .

Figure 5.
Effect of on the percentage errors of .

Figure 6.
Effect of c on the average percentage error.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Initial probability vectors comparison.
| Exact | Approx. 1 | Exact | Approx. 1 | |||
|---|---|---|---|---|---|---|
| 0.7519 | 0.7265 | 0.0338 | 0.1077 | 0.2349 | 1.1815 | |
| 0.1876 | 0.1794 | 0.0441 | 0.1561 | 0.2147 | 0.3748 | |
| 0.0465 | 0.0653 | 0.4049 | 0.1776 | 0.1438 | 0.1906 | |
| 0.0112 | 0.0206 | 0.8346 | 0.1799 | 0.1023 | 0.4316 | |
| 0.0024 | 0.0065 | 1.6986 | 0.1572 | 0.0727 | 0.5373 | |
| Average | 0.6032 | 0.5432 | ||||
Table 2.
Initial probability vectors comparison.
| Exact | Appr. 1 | Appr. 2 | Exact | Appr. 1 | Appr. 2 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.7519 | 0.7265 | 0.0338 | 0.6560 | 0.1275 | 0.1077 | 0.2349 | 1.1815 | 0.0391 | 0.6372 | |
| 0.1876 | 0.1794 | 0.0441 | 0.2892 | 0.5414 | 0.1561 | 0.2147 | 0.3748 | 0.0608 | 0.6108 | |
| 0.0465 | 0.0653 | 0.4049 | 0.0523 | 0.1237 | 0.1776 | 0.1438 | 0.1906 | 0.1387 | 0.2191 | |
| 0.0112 | 0.0206 | 0.8346 | 0.0025 | 0.7810 | 0.1799 | 0.1023 | 0.4316 | 0.1112 | 0.3821 | |
| 0.0024 | 0.0065 | 1.6986 | 0.0000 | 0.9858 | 0.1572 | 0.0727 | 0.5373 | 0.0815 | 0.4812 | |
| Average | 0.6032 | 0.5119 | 0.5432 | 0.4661 | ||||||
Table 3.
Initial probability vectors comparison ().
| Exact | Entropy 1 | Entropy 2 | Entropy | ||||
|---|---|---|---|---|---|---|---|
| 0.7519 | 0.7265 | 0.0338 | 0.6560 | 0.1275 | 0.7550 | 0.0040 | |
| 0.1876 | 0.1794 | 0.0441 | 0.2892 | 0.5414 | 0.1795 | 0.0431 | |
| 0.0465 | 0.0653 | 0.4049 | 0.0523 | 0.1237 | 0.0527 | 0.1324 | |
| 0.0112 | 0.0206 | 0.8346 | 0.0025 | 0.7810 | 0.0108 | 0.0346 | |
| 0.0024 | 0.0065 | 1.6986 | 0.0000 | 0.9858 | 0.0018 | 0.2421 | |
| Average | 0.6032 | 0.5119 | 0.0912 |
Table 4.
Initial probability vectors comparison ().
| Exact | Entropy 1 | Entropy 2 | Entropy | ||||
|---|---|---|---|---|---|---|---|
| 0.1077 | 0.2349 | 1.1815 | 0.0391 | 0.6372 | 0.0878 | 0.1843 | |
| 0.1561 | 0.2147 | 0.3748 | 0.0608 | 0.6108 | 0.2167 | 0.3881 | |
| 0.1776 | 0.1438 | 0.1906 | 0.1387 | 0.2191 | 0.1716 | 0.0341 | |
| 0.1799 | 0.1023 | 0.4316 | 0.1112 | 0.3821 | 0.1423 | 0.2090 | |
| 0.1572 | 0.0727 | 0.5373 | 0.0815 | 0.4812 | 0.1021 | 0.3503 | |
| Average | 0.5432 | 0.4661 | 0.2332 |
Table 5.
Effect of λ on .
| Exact | Entropy 1 | Entropy 2 | Entropy 1&2 | |
|---|---|---|---|---|
| 0.2 | 0.5341 | 0.5393 | 0.4366 | 0.5352 |
| 0.4 | 0.2894 | 0.3826 | 0.2739 | 0.2673 |
| 0.6 | 0.1937 | 0.3189 | 0.1279 | 0.1618 |
| 0.8 | 0.1468 | 0.2794 | 0.1256 | 0.1169 |
| 1.0 | 0.1183 | 0.2486 | 0.0111 | 0.0949 |
| 1.2 | 0.0986 | 0.2219 | 0.1435 | 0.0821 |
| 1.4 | 0.0838 | 0.1974 | 0.1330 | 0.0733 |
| 1.6 | 0.0721 | 0.1744 | 0.0880 | 0.0660 |
| 1.8 | 0.0627 | 0.1523 | 0.0339 | 0.0597 |
Table 6.
Effect of on .
| Exact | Entropy 1 | Entropy 2 | Entropy 1&2 | |
|---|---|---|---|---|
| 0.1 | 0.3312 | 0.4124 | 0.0136 | 0.3065 |
| 0.2 | 0.5429 | 0.5306 | 0.0126 | 0.5349 |
| 0.3 | 0.6756 | 0.6353 | 0.5493 | 0.6730 |
| 0.4 | 0.7526 | 0.7131 | 0.6338 | 0.7517 |
| 0.5 | 0.8009 | 0.7685 | 0.7000 | 0.8007 |
| 0.6 | 0.8337 | 0.8080 | 0.7520 | 0.8337 |
| 0.7 | 0.8573 | 0.8369 | 0.7925 | 0.8574 |
| 0.8 | 0.8751 | 0.8587 | 0.8237 | 0.8752 |
| 0.9 | 0.8889 | 0.8756 | 0.8478 | 0.8890 |
| 1 | 0.9000 | 0.8890 | 0.8665 | 0.9001 |
Table 7.
Effect of on .
| Exact | Entropy 1 | Entropy 2 | Entropy 1&2 | |
|---|---|---|---|---|
| 4 | 0.7516 | 0.7422 | 0.6861 | 0.7586 |
| 5 | 0.7518 | 0.7299 | 0.6623 | 0.7558 |
| 6 | 0.7520 | 0.7241 | 0.6516 | 0.7544 |
| 7 | 0.7521 | 0.7210 | 0.6460 | 0.7536 |
| 8 | 0.7522 | 0.7190 | 0.6426 | 0.7531 |
| 9 | 0.7523 | 0.7177 | 0.6404 | 0.7528 |
| 10 | 0.7523 | 0.7168 | 0.6389 | 0.7525 |
| 11 | 0.7523 | 0.7161 | 0.6378 | 0.7524 |
| 12 | 0.7524 | 0.7155 | 0.6370 | 0.7523 |
| 13 | 0.7524 | 0.7151 | 0.6364 | 0.7522 |
Table 8.
Effect of c on initial probability vector .
| Exact | 0.7687 | 0.1863 | 0.0400 | ||||||
| Entropy 1 | 0.7582 | 0.1707 | 0.0575 | ||||||
| Entropy 2 | 0.7052 | 0.2625 | 0.0318 | ||||||
| Entropy 1&2 | 0.7701 | 0.1824 | 0.0438 | ||||||
| Exact | 0.7562 | 0.1876 | 0.0453 | 0.0097 | |||||
| Entropy 1 | 0.7348 | 0.1773 | 0.0633 | 0.0197 | |||||
| Entropy 2 | 0.6723 | 0.2810 | 0.0449 | 0.0017 | |||||
| Entropy 1&2 | 0.7582 | 0.1819 | 0.0500 | 0.0091 | |||||
| Exact | 0.7519 | 0.1876 | 0.0465 | 0.0112 | 0.0024 | ||||
| Entropy 1 | 0.7265 | 0.1794 | 0.0653 | 0.0206 | 0.0065 | ||||
| Entropy 2 | 0.6560 | 0.2892 | 0.0523 | 0.0025 | 0.0000 | ||||
| Entropy 1&2 | 0.7550 | 0.1795 | 0.0527 | 0.0108 | 0.0018 | ||||
| Exact | 0.7506 | 0.1876 | 0.0468 | 0.0116 | 0.0028 | 0.0006 | |||
| Entropy 1 | 0.7236 | 0.1801 | 0.0662 | 0.0209 | 0.0066 | 0.0021 | |||
| Entropy 2 | 0.6488 | 0.2927 | 0.0557 | 0.0028 | 0.0000 | 0.0000 | |||
| Entropy 1&2 | 0.7544 | 0.1777 | 0.0536 | 0.0117 | 0.0022 | 0.0003 | |||
| Exact | 0.7502 | 0.1875 | 0.0469 | 0.0117 | 0.0029 | 0.0007 | 0.0001 | ||
| Entropy 1 | 0.7224 | 0.1804 | 0.0665 | 0.0211 | 0.0067 | 0.0021 | 0.0007 | ||
| Entropy 2 | 0.6457 | 0.2941 | 0.0571 | 0.0030 | 0.0000 | 0.0000 | 0.0000 | ||
| Entropy 1&2 | 0.7545 | 0.1766 | 0.0540 | 0.0121 | 0.0023 | 0.0004 | 0.0001 | ||
| Exact | 0.7500 | 0.1875 | 0.0469 | 0.0117 | 0.0029 | 0.0007 | 0.0002 | 0.0000 | |
| Entropy 1 | 0.7219 | 0.1805 | 0.0668 | 0.0211 | 0.0067 | 0.0021 | 0.0007 | 0.0002 | |
| Entropy 2 | 0.6445 | 0.2947 | 0.0577 | 0.0031 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | |
| Entropy 1&2 | 0.7547 | 0.1761 | 0.0541 | 0.0122 | 0.0024 | 0.0004 | 0.0001 | 0.0000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bounkhel, M.; Tadj, L.; Hedjar, R. Entropy Analysis of a Flexible Markovian Queue with Server Breakdowns. Entropy 2020, 22, 979. https://0-doi-org.brum.beds.ac.uk/10.3390/e22090979
AMA Style
Bounkhel M, Tadj L, Hedjar R. Entropy Analysis of a Flexible Markovian Queue with Server Breakdowns. Entropy. 2020; 22(9):979. https://0-doi-org.brum.beds.ac.uk/10.3390/e22090979
Chicago/Turabian StyleBounkhel, Messaoud, Lotfi Tadj, and Ramdane Hedjar. 2020. "Entropy Analysis of a Flexible Markovian Queue with Server Breakdowns" Entropy 22, no. 9: 979. https://0-doi-org.brum.beds.ac.uk/10.3390/e22090979
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.