Information-Theoretic Generalization Bounds for Meta-Learning and Applications



Department of Engineering, King’s College London, London WC2R 2LS, UK
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(1), 126; https://0-doi-org.brum.beds.ac.uk/10.3390/e23010126
Submission received: 17 November 2020
/
Revised: 13 January 2021
/
Accepted: 14 January 2021
/
Published: 19 January 2021
(This article belongs to the Special Issue The Role of Signal Processing and Information Theory in Modern Machine Learning)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Meta-learning, or “learning to learn”, refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that use either separate within-task training and test sets, like model agnostic meta-learning (MAML), or joint within-task training and test sets, like reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed for the two classes via novel individual task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
1. Introduction
As formalized by the “no free lunch theorem”, any effective learning procedure must be based on prior assumptions on the task of interest [1]. These include the selection of a model class and of the hyperparameters of a learning algorithm, such as weight initialization and learning rate. In conventional single-task learning, these assumptions, collectively known as inductive bias, are fixed a priori relying on domain knowledge or validation [1,2,3]. Fixing a suitable inductive bias can significantly reduce the sample complexity of the learning process, and is thus crucial to any learning procedure. The goal of meta-learning is to automatically infer the inductive bias, thereby learning to learn from past experiences via the observation of a number of related tasks, so as to speed up learning a new and unseen task [4,5,6,7,8].
In this work, we consider the meta-learning problem of inferring the hyperparameters of a learning algorithm. The learning algorithm (henceforth, called base-learning algorithm or base-learner) is defined as a stochastic mapping from the input training set of m samples to a model parameter for a fixed hyperparameter vector u. The meta-learning algorithm (or meta-learner) infers the hyperparameter vector u, which defines the inductive bias, by observing a finite number of related tasks.
For example, consider the well-studied algorithm of biased regularization for supervised learning [9,10]. Let us denote each data point as a tuple of input features and label . The loss function is given as the quadratic measure that quantifies the loss accrued by the inferred model parameter w on a data sample z. Corresponding to each per-task data set , the biased regularization algorithm is a Kronecker delta function centered at the minimizer of the following optimization problem
which corresponds to an empirical risk minimization problem with a biased regularizer. Here, is a regularization constant that weighs the deviation of the model parameter w from a bias vector u. The bias vector u can be then thought of as a common “mean” among related tasks. In the context of meta-learning, the objective then is to infer the bias vector u by observing data sets from a number of similar related tasks. Different meta-learning algorithms have been developed for this problem [11,12].
In the meta-learning problem under study, we follow the standard setting of Baxter [13] and assume that the learning tasks belong to a task environment, which is defined by a probability distribution on the space of learning tasks , and per-task data distributions . The data set for a task is then generated i.i.d. according to the distribution . The meta-learner observes the performance of the base-learner on the meta-training data from a finite number of meta-training tasks, which are sampled independently from the task environment, and infers the hyperparameter U such that it can learn a new task, drawn from the same task environment, from fewer data samples.
The quality of the inferred hyperparameter U is measured by the meta-generalization loss, , which is the average loss incurred on the data set of a new, previously unseen task T sampled from the task distribution . The notation will be formally introduced in Section 2.2. While the goal of meta-learning is to infer a hyperparameter U that minimizes the meta-generalization loss , this is not computable, since the underlying task and data distributions are unknown. Instead, the meta-learner can evaluate an empirical estimate of the loss, , using the meta-training set of data from N tasks, which is referred to as meta-training loss. The difference between the meta-generalization loss and the meta-training loss is the meta-generalization gap,
and measures how well the inferred hyperparameter U generalizes to a new, previously unseen task. In particular, if the meta-generalization gap is small, on average or with high probability, then the performance of the meta-learner on the meta-training set can be taken as a reliable estimate of the meta-generalization loss.
In this paper, we study information-theoretic upper bounds on the average meta-generalization gap , where the average is with respect to the meta-training set and the meta-learner defined by the stochastic kernel . Specifically, we extend the recent line of work initiated by Russo and Zhou [14], and Xu and Raginsky [15], which obtain mutual information (MI)-based bounds on the average generalization gap for conventional learning, to meta-learning. To the best of our knowledge, this is the first work that studies information-theoretic bounds for meta-learning.
The bounds on average meta-generalization gap, studied in this work, are distinct from the other well-known bounds on meta-generalization gap in literature. Broadly speaking, existing bounds on the meta-generalization gap can be grouped into two—high probability, probably approximately correct (PAC) bounds, and high probability PAC-Bayesian bounds. These upper bounds take the general form, , that hold with probability at least , for , over the meta-training set . In contrast, our work focuses on bounding on average also over the meta-training set. Notable PAC bounds on meta-generalization gap include the bound of Baxter [13] obtained using the framework of Vapnik–Chervonenkis (VC) dimensions; and of Maurer [16], which employs the algorithmic stability [17,18] properties. In contrast, the PAC-Bayesian bounds also incorporate prior beliefs on the base-learner and the meta-learner posteriors via an auxiliary data-independent prior distribution and a hyper-prior distribution , respectively. Most notably, PAC-Bayesian bounds include that of Pentina and Lambert [19], the tighter bound of Amit and Meir [20], and most recently, the bounds of Rothfuss et al. [21]. While the high-probability bounds are agnostic to task and data distributions, our information-theoretic bounds depend explicitly on the task and per-task data distributions, on the loss function, and on the meta-training algorithm, in accordance to prior work on information-theoretic generalization bounds.
Another general property inherited from the information-theoretic approach adopted in this paper is that the bounds on the average meta-generalization gap under study are designed to hold for arbitrary base-learners and meta-learners. As such, they generally do not result in tighter bounds as compared to non-information theoretic generalization guarantees obtained for specific meta-learning problems, such as the ridge regression problem with meta-learned bias vector mentioned above [22]. In contrast, the general purpose of the bounds in this paper is to provide insights into the number of tasks, and the number of samples per task required to ensure that the training-based metrics are a good approximation to their population counterparts.
1.1. Main Contributions
The derivation of bounds on average meta-generalization gap differs from conventional learning owing to two levels of uncertainties—environment-level uncertainty and within-task uncertainty. While within-task uncertainty results from observing a finite number m of data samples per task as in conventional learning, environment-level uncertainty results from observing a finite number N of tasks from the task-environment. The relative importance of these two forms of uncertainty depend on the use made by the meta-learner of the meta-training data. In fact, depending on how the meta-training data are used by the meta-learner, we identify two main classes of meta-training algorithms—with separate within-task training and test sets, and joint within-task training and test sets. The former class includes the state-of-the-art meta-learning algorithms, such as model agnostic meta-learning (MAML) [23], that splits the training data corresponding to each task into training and test sets, with the latter reserved for within-task validation. In contrast, the second class of algorithms, such as reptile [24], use the entire per-task data both for training and testing. Our main contributions are as follows.
- In Theorem 1, we show that, for the case with separate within-task training and test sets, the average meta-generalization gap contains only the contribution of environment-level uncertainty. This is captured by a ratio of the mutual information (MI) between the output of the meta-learner U and the meta-training set , and the number of tasks N, aswhere is the sub-Gaussianity variance factor of the meta-loss function. This is a direct parallel of the MI-based bounds for single-task learning [25].
- In Theorem 3, we then show that, for the case with joint within-task training and test sets, the bound on the average meta-generalization gap also contains a contribution due to the within-task uncertainty via the ratio of the MI between the output of the base-learner and within-task training data and the per-task data sample size m. Specifically, we have the following boundwhere is the sub-Gaussianity variance factor of the loss function for task T.
- In Theorems 2 and 4, we extend the individual sample MI (ISMI) bound of [26] to obtain novel individual task MI (ITMI)-based bounds on the meta-generalization gap for both separate and within-task training and test sets asand
- Finally, we study the applications of the derived bounds to two meta-learning problems. The first is a parameter estimation setup that involves one-shot meta-learning and base-learning procedures, for which a closed form expression for meta-generalization gap can be derived. The second application covers a broad range of noisy iterative meta-learning algorithms and is inspired by the work of Pensia et al. [27] for conventional learning.
1.2. Related Work
For conventional learning, there exists a rich literature on diverse frameworks for deriving upper bounds on the generalization gap, i.e., on the difference between generalization and training losses. Classical bounds from statistical learning theory quantify the generalization gap in terms of measures of complexity of the model class, most notably VC dimension [28] and Radmacher complexity [29]. This approach obtains high-probability, probably approximate correct (PAC) bounds on the generalization gap with respect to the training set. An alternate line of high-probability bounding techniques relies on the notion of algorithmic stability, which measures the sensitivity of the output of a learning algorithm to the replacement of individual samples from the training data set. The pioneering work [30] has been extended to include various notions of algorithmic stability [31,32,33]. As a notable example, a distributional notion of stability in terms of differential privacy, which quantifies the sensitvity of the distribution of algorithm’s output to data set, has been studied in [34,35]. The high-probability PAC–Bayesian bounds rely on change of measure arguments and uses the Kullback–Leibler (KL) divergence between the algorithm and a data-independent prior to quantifying the algorithmic sensitivity [36,37,38].
Following the initial work of Russo and Zou [14], information-theoretic bounds on the average generalization gap for conventional learning have been widely investigated in recent years. Xu and Raginsky [25] showed that the MI between the output of the learning algorithm and its training data set yields an upper bound in expectation on the generalization gap. The bound has been shown to offer computable generalization gaurentees for noisy iterative algorithms, including stochastic gradient Langevin dynamics (SGLD) in [27]. Various refinements of the MI-based bound have since been analyzed to obtain tighter bounds. In particular, the bounds in [39] employ chaining mutual information techniques to tighten the bounds in [25], while the bound in [26] depends on the MI between the output of the algorithm and an individual data sample. The MI between the output of the algorithm and a random subset of the data set appears in the bounds introduced in [40]. The total variation information between the joint distribution of the training data and algorithmic output and the product of marginals was shown in [41] to yield a bound on the generalization gap for any bounded loss function. Subsequent works in [42,43,44] consider other information-theoretic measures, such as maximum leakage and lautum information. Most recently, a conditional mutual information (CMI)-based approach has been proposed in [45] to develop generalization bounds.
1.3. Notation
Throughout this paper, upper case letters, e.g., X, denote random variables and lower case letters, e.g., x, their realizations. We use to denote the set of all probability distributions on the argument set or vector space. For a discrete or continuous random variable X taking values in a set or vector space denotes its probability distribution, with being the probability mass or density value at . We denote as the n-fold product distribution induced by . The conditional distribution of a random variable X given random variable Y is similarly defined as , with representing the probability mass or density at conditioned on the event . We use to denote the Euclidean norm of the argument vector, and to denote a d-dimensional identity matrix. We define the Kronecker delta if and otherwise.
2. Problem Definition
In this section, we define the problem of interest by introducing the key definitions of generalization gap for conventional, or single-task, learning and for meta-learning.
2.1. Generalization Gap for Single-Task Learning
Consider first the conventional problem of learning a task .
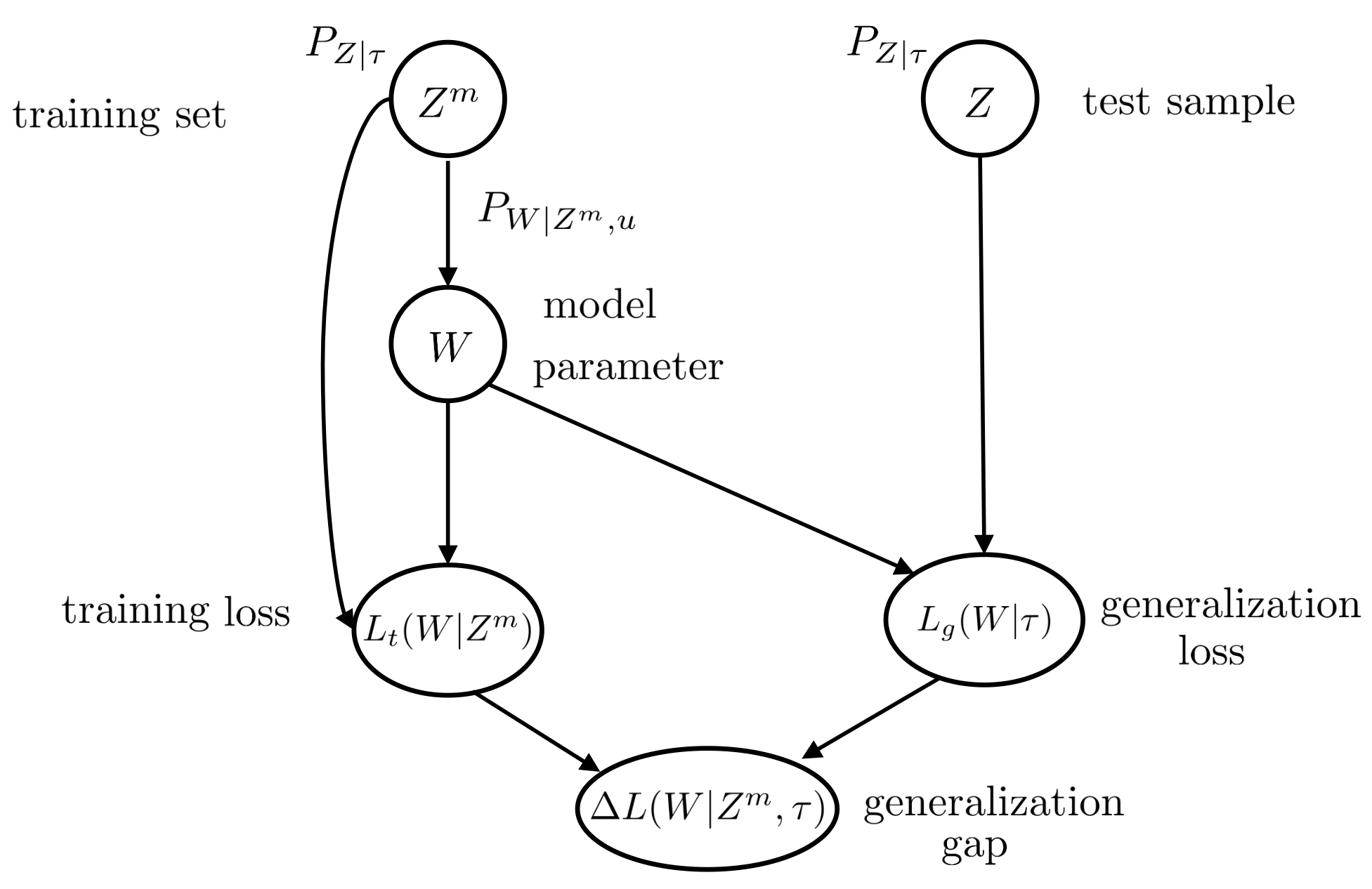
As illustrated in Figure 1, each task is associated with an underlying unknown data distribution, , defined in a subset or vector space. Henceforth, we use to denote for notational convenience.
The training procedure, which is referred to as the base-learner, has access to a training data set of m independent and identically distributed (i.i.d.) samples drawn from distribution . The base-learner uses this data set to choose a model, or hypothesis, W from the model class by using a randomized training procedure defined by a conditional distribution as
The conditional distribution defines a stochastic mapping from the training data set to the model class . The training procedure (7) is parameterized by a vector of hyperparameters, which defines the inductive bias. As an example, the base-learner may follow stochastic gradient descent (SGD) updates with hyperparameters u, including the learning rate and the initialization point.
The performance of a parameter vector on a data sample is measured by a loss function . The generalization loss for a model parameter vector is the average
over a test example Z independently drawn from the data distribution . The subscript g is used to distinguish the generalization loss from the training loss defined below. The generalization loss cannot be computed by the learner, given that the data distribution is unknown. Instead, the learner can evaluate the training loss on the data set , which is defined as the empirical average
The subscript t specifies that the loss is the empirical training loss.
The difference between generalization loss (8) and training loss (9) is known as generalization gap,
and is a key metric that quantifies the level of uncertainty (This type of uncertainty is known as epistemic.) at the learner regarding the data distribution . The average generalization gap for the data distribution and base-learner is defined as
where the expectation is taken with respect to the joint distribution . A summary of the variables involved in the Definition of the generalization gap (11) can be found in Figure 1.
Intuitively, if the generalization gap is small, on average or with high probability, then the base-learner can take the performance (9) on the training set as a reliable measure of the generalization loss (8) of the trained model W. Furthermore, data-dependent bounds on the generalization gap can be used as regularization terms to avoid overfitting, yielding generalized Bayesian inference problems [46,47].
2.2. Generalization Gap for Meta-Learning
As discussed, in single-task learning, the inductive bias u, defining the hyperparameters of the training procedure, must be selected a priori, i.e., without having access to task-specific data. The inductive bias determines the training data set size m needed to ensure a small generalization loss (8), since, generally speaking, richer models require more data to be trained [1]. The sample complexity can be generally reduced if one selects a suitable inductive bias based on prior information. Such prior information is typically obtained from domain knowledge on the problem under study. In contrast, meta-learning aims at automatically inferring an effective inductive bias based on data from related tasks.
To elaborate, we follow the setting of [13], in which a meta-learner observes data from a number of tasks, known as meta-training tasks, from the same task environment. A task environment is defined by a task distribution , supported on the space of tasks, and by a per-task data distribution for each task . Using the meta-training data drawn from a randomly selected subset of tasks, the meta-learner infers a hyperparameter vector defining the inductive bias. This is done with the goal of ensuring that, using hyperparameter u, the base-learner can efficiently learn on a new task, referred to as meta-test task, drawn independently from the same task distribution .
To elaborate, the meta-training data consist of N data sets . Each ith data set is generated independently by first drawing a task from the task environment and then a task-specific training data set . The meta-learner uses the meta-training data set to infer a hyperparameter vector . To this end, we consider a randomized meta-learner
where is a stochastic mapping from the meta-training set to the space of hyperparameters. We distinguish two different formulations of meta-learning that are often considered in the literature. In the first, the per-task data set is split into training, or support, and test, or query subsets [23,48]; while, in the second, the entire data set is used for both within-task training and testing [13,19,20].
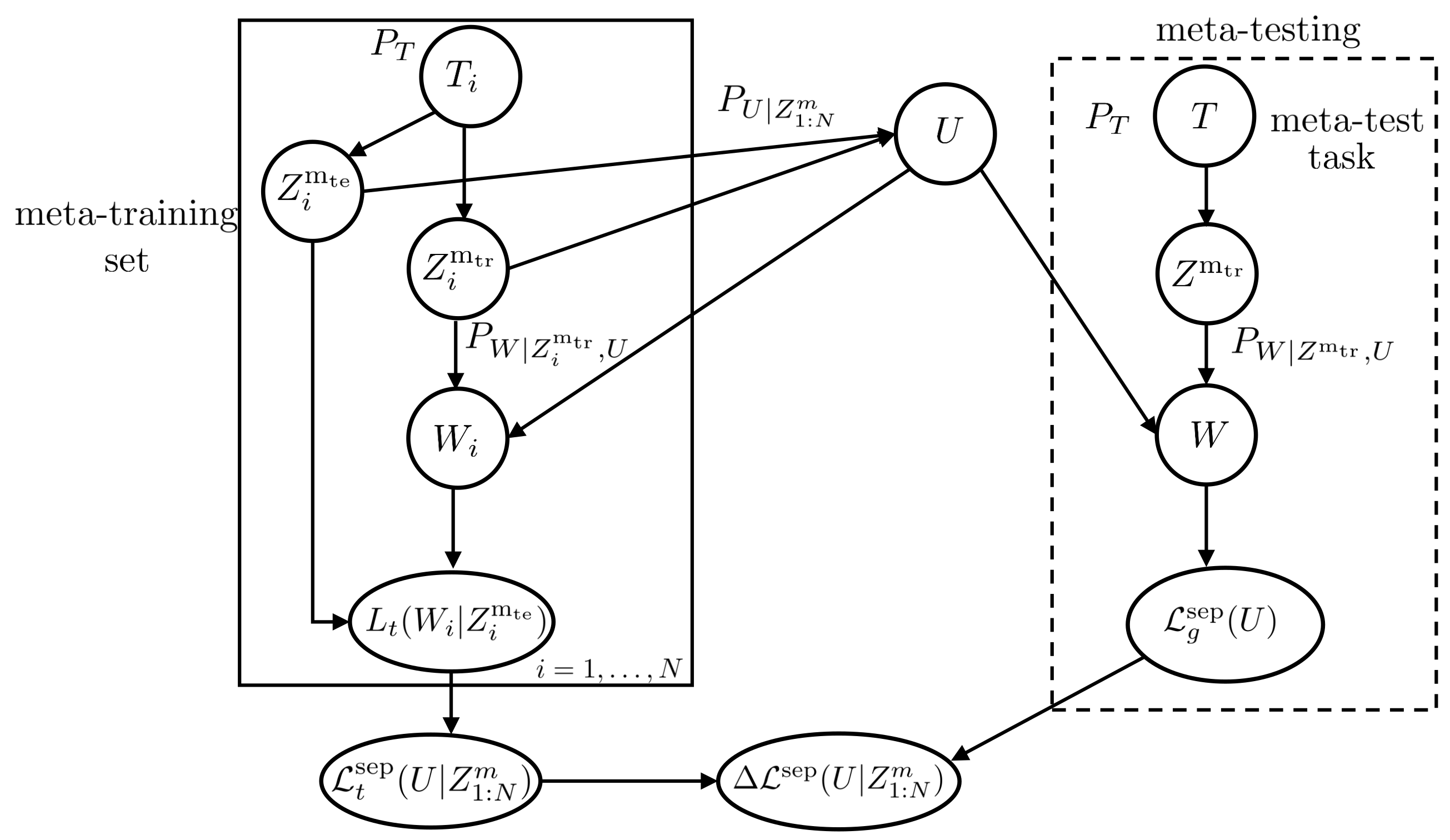
2.2.1. Separate Within-Task Training and Test Sets
As seen in Figure 2, in this first approach to meta-learning, each meta-training sub data set is split into a training set and a test set as , where contains i.i.d. training examples and contains i.i.d. test examples, with . The within-task base-learner maps the per-task training subset to random model parameter for a given hyperparameter . The test subset is used to evaluate the empirical training loss of a model w for task as
where denote the jth example of the test subset . Furthermore, the overall empirical meta-training loss for a hyperparameter u is computed by summing up all meta-training tasks as
where
is the average per-task training loss over the base-learner.
We emphasize that the meta-training loss (14) can be computed by the meta-learner and used as a criterion to select the meta-learning procedure (12), since it is obtained from the meta-training data . We also note that the rationale of splitting training and test sets is that the average training loss is an unbiased estimate of the corresponding average generalization loss .
The true goal of the meta-learner is to minimize the meta-generalization loss,
where and are as defined in (8). Unlike the meta-training loss (14), the meta-generalization loss is evaluated on a new, meta-test task T and on the corresponding training data . We distinguish the meta-generalization loss and meta-training loss by the subscripts g and t, respectively in (16) and (14). The difference between the meta-generalization loss (16) and the meta-training loss (14), known as the meta-generalization gap, is defined as
The quantity of interest to us is the average meta-generalization gap, defined as
where the expectation is with respect to the joint distribution , of the meta-training set and of the hyperparameter U. Note that is the marginal of the joint distribution .
Intuitively, if the meta-generalization gap is small, on average or with high probability, the meta learner can take the performance (14) on the meta-training data as a reliable measure of the accuracy of the inferred hyperparameter vector in terms of the meta-generalization loss (16). Furthermore, data-dependant bounds on the meta-generalization gap can be used as regularization terms to avoid meta-overfitting. Meta-overfitting occurs when the meta-trained hyperparameter yields a small meta-training loss but a large meta-test loss, due to an excessive dependence on the meta-training set [13].
2.2.2. Joint Within-Task Training and Test Sets
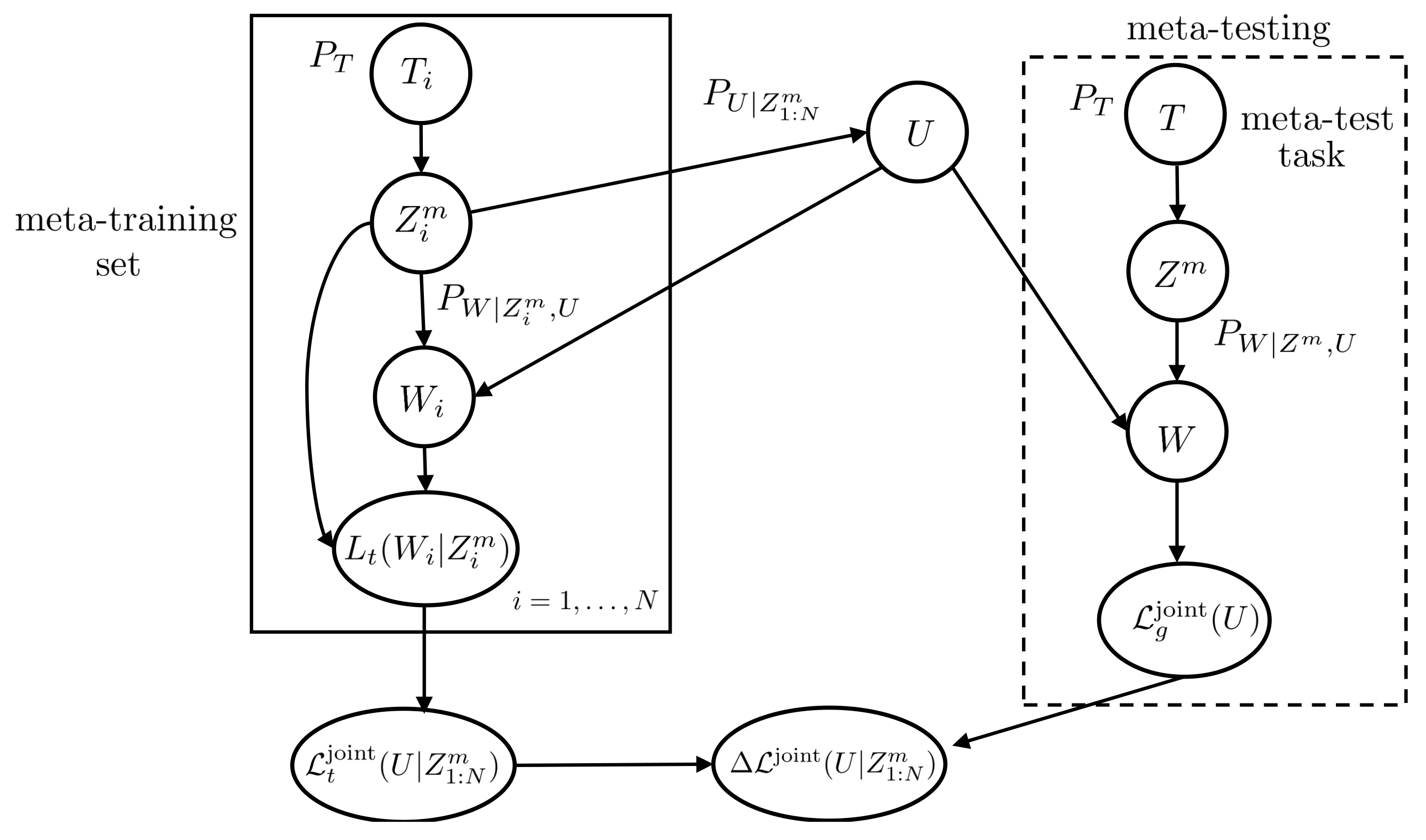
In the second formulation of meta-learning, as illustrated in Figure 3, the entire data set is used for within-task training and testing. Accordingly, the meta-learner computes the meta-training loss
where
is the average per-task training loss. Note here that in evaluating the meta-training loss in (19), the data set is used to infer model parameters W and to evaluate the per-task training loss. The expectation in (20) is taken over the output of the base-learner W given the hyperparameter vector u. As discussed, the meta-generalization loss for hyperparameter is computed by randomly selecting a novel task as
where and is as defined in (8). In a manner similar to (17), the meta-generalization gap for a task distribution , data distribution , meta-learning algorithm , and base-learner is defined as
The average meta-generalization gap is then given as , where the expectation is taken over all meta-training sets and over the output of the meta-learner.
3. Information-Theoretic Generalization Bounds for Single-Task Learning
In this section, we review two information-theoretic bounds on the generalization gap (11) for conventional learning derived in [25,26]. The material covered in this section provides the necessary background for the analysis of the meta-generalization gap to be studied in the rest of the paper. Throughout this section, we fix a task . Since the generalization and meta-generalization gaps measure the deviation of empirical-mean random variables representing training and meta-training losses from reference values, we will make use of tools and definitions from large-deviation theory (see, e.g., [49]). We discuss the key essential definitions below.
3.1. Preliminaries
To start, the cumulant generating function (CGF) of a random variable is defined as . If it is well-defined, the CGF is convex and it satisfies the equalities . A random variable X with finite mean, i.e., with , is said to -sub-Gaussian if its CGF is bounded as
As a special case, if X is bounded in the interval , i.e., if the inequality holds for some constants a and b, then X is -sub-Gaussian.
3.2. Mutual Information (MI) Bound
We first present the mutual information (MI)-based upper bound obtained in [25]. Key to this result is the following Assumption.
Assumption 1.
The loss function is -sub-Gaussian under for all model parameters .
In particular, if the loss function is bounded, i.e., if the inequalities hold for all for and , Assumption 1 is satisfied with . The main result is as follows.
Lemma 1
([25]). Under Assumption 1, the following bound on the generalization gap holds for any base-learner
The proof of Lemma 1 is based on a decoupling estimate Lemma, which is reported for completeness in Lemma A1. We also note that the result in Lemma 1 can be extended to account for loss function with bounded CGF [14].
The bound (24) on the generalization gap is in terms of the mutual information , which quantifies the overall dependence between the base-learner output W and the input training data set . The mutual information in (24) is hence a measure of the sensitivity of the base-learner output to the data set. Using the terminology in [25], if , the base-learner is said to be -MI stable, in which case the bound in (24) evaluates to . The relationship between generalization and stability of a training algorithm is well-established [1], and the result (24) amounts to a formulation of this link in information-theoretic terms.
The traditional notion of algorithmic stability measures how much the base-learner output changes with the replacement of an individual training sample [30,50]. In the next section, we review the bound in [26] that translates this per-sample stability concept within an information-theoretic framework.
3.3. Individual Sample MI (ISMI) Bound
The MI-based bound in Lemma 1 has the disadvantage of being vacuous, i.e., , for deterministic base-learning algorithms defined on continuous parameter space . An individual sample MI (ISMI)-based bound that address this shortcoming was introduced in [26]. The ISMI bound borrows the standard algorithmic stability notion of sensitivity of the base-learner output to the replacement of any individual training sample [17,18]. Accordingly, the resulting bound is in terms of the MI between the trained parameter W and each data point of the training data set . The bound, summarized in Lemma 2, applies under the following assumption.
Assumption 2.
The loss function satisfies either of the following two conditions:
- (a)
- Assumption 1, or
- (b)
- is a -sub-Gaussian random variable when , where is the marginal of the joint distribution .
We note that, in general, Assumption 1 does not imply Assumption 2 (see ([40], Appendix C)), and vice versa (see [26]). There are, however, loss functions and relevant distributions for which both the assumptions hold, including the case of loss functions which takes values in a bounded interval .
Lemma 2
([26]). Under Assumption 2, the following bound on the average generalization gap holds for any base-learner
4. Information-Theoretic Generalization Bounds for Meta-Learning
In this section, we first derive novel MI-based bounds on the meta-generalization gap with separate within-task training and test sets, as introduced in Section 4.1, and then we consider joint within-task training and test sets, as described in Section 4.2.
4.1. Bounds on Meta-Generalization Gap with Separate Within-Task Training and Test Sets
In this section, we present two novel MI-based bounds on the meta-generalization gap (18) for the setup with separate within-task training and testing sets. The first is an MI-based bound, which is akin to Lemma 1, and the second is an individual task MI (ITMI) bound, which resembles Lemma 2 for conventional learning.
4.1.1. MI-Based Bound
In order to derive the MI-based bound, we make the following assumption on in (15). Throughout, we use to denote the marginal of the joint distribution .
Assumption 3.
For all , the average per-task training loss is -sub-Gaussian under .
Distinct from the assumptions in Section 3 on loss function , we note that Assumption 3 is on the average per-task training loss . This is because the loss function satisfying Assumption 1 do not in general guarantee the sub-Gaussianity of with respect to . However, if the loss function is bounded, Assumption 3 can be easily verified to hold, as given in the following lemma.
Lemma 3.
If the loss function is bounded, then is also bounded for all . Consequently, is -sub-Gaussian under for all .
Under Assumption 3, the following theorem presents an upper bound on the meta-generalization gap (18).
Theorem 1.
Let Assumption 3 hold for the base-learner . Then, for any meta learner such that the inequality holds, we have the following bound on the average meta-generalization gap
Proof.
See Appendix B. □
The technical lemmas required for the proof of Theorem 1 and the theorems that follow are included in Appendix A.
In order to prove Theorem 1, one needs to overcome an additional challenge as compared to the derivation of bounds for learning reviewed in Section 3. In fact, the meta-generalization gap is caused by two distinct sources of uncertainty: environment-level uncertainty due to a finite number N of observed tasks, and within-task uncertainty resulting from the finite number m of per-task data samples. Our proof approach involves applying the single-task MI-based bound in Lemma 1 to bound the effect of both sources of uncertainties.
Towards this, we start by introducing the average training loss for the randomly selected meta-test task as
The subscript denotes that the loss is generalization (g) with expectation over at the environment level, and training (t) at the task level with . Note that this differs from the meta-test loss in (16) in that the per-task loss is evaluated in (28) on the training set. With this definition, the meta-generalization gap can be decomposed as
In (29), the second difference corresponds to the environment-level uncertainty and arises from the observation of a finite number N of tasks. In fact, as N increases, the meta-training loss almost surely tends to by the law of large numbers. However, the average is not equal to zero in general for finite values of N. The within-task generalization gap is instead measured by the difference . In the setup under study with separate within-task training and test sets, this term equals zero, since, as we discussed, the average empirical loss is an unbiased estimate of the corresponding average test loss (cf. (28)). This is no longer true for joint within-task training and test sets, as we discuss in Section 4.2.
The decomposition approach adopted here follows the main steps of the bounding techniques introduced in ([16], Equation (6)). In contrast, the PAC-Bayesian bounds in [20,21] rely on a different decomposition of the meta-generalization gap. The environment and within-task generalization gaps are then separately bounded in high probability, and are combined via union bound to obtain the required PAC-Bayesian bounds.
The bound (27) relates the meta-generalization gap to the information-theoretic stability of the meta-training procedure. As first introduced here, this stability is measured by the MI between the hyperparameter U and the meta-training data set , in a manner similar to the MI-based bounds in Lemma 1 for conventional learning. Importantly, as we will discuss in Section 4.2, this direct parallel between learning and meta-learning no longer applies with joint within-task training and test data sets.
4.1.2. ITMI Bound
We now present the ITMI bound, which holds under the following assumption.
Assumption 4.
Either of the following assumptions on the average per-task training loss, holds:
- (a)
- satisfies Assumption 3, or
- (b)
- is -sub-Gaussian under , where is the marginal of the joint distribution and is the marginal of the joint distribution .
Assumption 4 can be seen to be implied by the sufficient conditions in Lemma 3.
Theorem 2.
Let Assumption 4 hold for the base-learner . Then, for any meta learner , the following bound on the meta-generalization gap (18) holds
where the MI is computed with respect to the joint distribution obtained by marginalizing the probability distribution .
Proof.
See Appendix B. □
As can be seen from (30), the ITMI bound on the meta-generalization gap is in terms of the MI between the output U of the meta learner and each per-task data set . This, in turn, quantifies the sensitivity of the meta learner output to the replacement of a single per-task data set. Moreover, under Assumption 3, the ITMI bound (30) yields a tighter bound than the MI-based bound (27). This can be seen from the following sequence of relations
where ; follows, since is independent of ; and follows from Jensen’s inequality.
4.2. Bounds on Generalization Gap with Joint Within-Task Training and Test Sets
We now derive MI and ITMI-based bounds on the meta-generalization gap in (22) for the case with joint within-task training and test sets. As we will see, the key difference with respect to the case with separate within-task training and test sets is that the uncertainty due to finite number of per-task samples, measured by the second term in the decomposition (29), contributes in a non-negligible way to the meta-generalization gap. Since there is no split into separate within-task training and test sets, the average training loss with respect to the learning algorithm is given by in (20).
4.2.1. MI-Based Bound
In order to derive the MI-based bound, we make the following assumptions.
Assumption 5.
We consider the following assumptions.
- (a)
- For each task , the loss function satisifies Assumption 1, and
- (b)
An easily verifiable sufficient condition for the above assumption to hold is the boundedness of loss function , which follows in a manner similar to Lemma 3.
Theorem 3.
Let Assumption 5 hold for a base-learner . Then, for any meta learner , we have the following bound on the meta-generalization gap (22)
where the MI is evaluated with respect to the distribution obtained by marginalizing the joint distribution .
Proof.
See Appendix C. □
With joint within-task training and test sets, the bound (32) on the meta-generalization gap contains the contributions of two mutual informations. The first, , quantifies the sensitivity of the meta learner output U to the meta-training data set . This term also appeared in the bound (27) with separate within-task training and test sets. Decomposing the meta-generalization gap in a manner analogous to (29), it corresponds to a bound on the average of the second difference. The second contribution, , quantifies the sensitivity of the output of the base-learner to the data set of the meta-test task T, when the hyperparameter is randomly selected by the meta-learner using the meta-training set . This second term is in line with the single-task generalization gap bounds (24), and it bounds the corresponding first difference in the decomposition (29).
We finally note that the dependence of the bound in (32) on the number of tasks N and per-task samples m is of the order . Meta-generalization bounds with similar dependence have been derived in [20] using PAC-Bayesian arguments. The bounds on excess risk for representation learning also follow a similar order of dependence on N and m (c.f [51], [Thm. 2]).
4.2.2. ITMI Bound on (22)
For deriving the ITMI bound on the meta-generalization gap (22), we assume the following.
Assumption 6.
Either of the following assumptions hold:
- (a)
- Assumption 5 holds, or
- (b)
- For each task , the loss function is -sub-Gaussian when , where is the marginal of the joint distribution . The average per-task training loss is -sub-Gaussian when .
As in Section 4.1.2, Assumption 6 can be seen to be implied by the sufficient conditions in Lemma 3.
Theorem 4.
Under Assumption 6, for any meta learner , the following bound holds on the average meta-generalization gap
where the MI is evaluated with respect to obtained by marginalizing , and the MI is with respect to obtained by marginalizing .
Proof.
See Appendix C. □
Similar to the bound in (32), the bounds on meta-generalization gap in (33) are in terms of two types of mutual information, the first describing the sensitivity of the meta-learner and the second the sensitivity of the base-learner. Specifically, the MI quantifies the sensitivity of the output of the meta learner to per-task data set , and the MI measures the sensitivity of the output of the base-learner, to each data sample within the training set of the meta-test task T. Moreover, it can be shown, in a manner similar to (31c), that, under Assumption 5, the ITMI bound in (33) is tighter than the MI bound in (32).
4.3. Discussion on Bounds
The bounds on the average meta-generalization gap obtained in this section generalize the bounds for conventional single-task learning in Section 3. To see this, consider the task distribution to be centered at some task . Recall that in conventional learning, the hyperparameter u is fixed a priori. As such, the mutual information (for MI-based bounds) and (for ITMI-based bounds) vanishes. For the separate within-task training and test sets, this implies that the average generalization gap is zero, which follows since the per-task test loss is an unbiased estimate of per-task generalization loss . The MI- and ITMI-based bounds for the joint within-task training and test sets then reduce to
and
respectively, where is evaluated with respect to the joint distribution and with respect to .
The MI- and ITMI-based bounds derived in this section point that a smaller correlation between hyperparameters and meta-training set and thus small mutual information improves the meta-generalization gap, although this seems deleterious to performance. To clarify this contradiction, we would like to emphasize that these bounds quantify the difference between meta-generalization loss and empirical training loss, which in turn depends on the sensitivity of the meta-learner and base-learner to their input meta-training set and per-task training set, respectively. The mutual information terms in our bounds capture these sensitivities. Consequently, our bounds suggest that a meta-learner that is highly correlated to the input meta-training set (i.e., when is large) does not generalize well (i.e., yields large meta-generalization gap). This property aligns with a previous information-theoretic analysis for generalization in conventional learning [25].
To the best of our knowledge, the MI- and ITMI-based bounds studied here are the first bounds on the average meta-generalization gap. As discussed in the introduction, these bounds are distinct from the high-probability PAC and PAC-Bayesian bounds on the meta-generalization gap studied previously on meta-learning. Consequently, the bounds studied in this work are not directly comparable with the existing high-probability bounds.
Finally, we note that similarity between tasks is crucial to meta-learning. If the per-task data distributions in the task environment are ‘closer’ to each other, a meta-learner can efficiently learn the shared characteristics of tasks, and can generalize well to new tasks from the task environment. In our setting, the statistical properties of the task environment dictate this similarity. Although our MI- and ITMI-based bounds do not explicitly capture this, we note that the properties of task environment are implicitly accounted for by the mutual information terms and , where the meta-training data set is generated from the task environment, and also by the sub-Gaussianity considerations in Assumptions 3–6. From preliminary studies, we believe that information-theoretic bounds that explicitly capture the impact of task similarity require a different performance metric than the average meta-generalization gap considered here, and is left to future work.
5. Applications
In this section, we consider two applications of the information-theoretic bounds proposed in Section 4.1. The first, simpler, example concerns a parameter estimation problem for which an optimized meta-learner can be obtained in closed form. In contrast, the second application covers a broad class of iterative meta-training schemes.
5.1. Parameter Estimation
To illustrate the bounds on the meta-generalization gap derived in Section 4.1, we first consider the problem of prediction for a Bernoulli process with a ‘soft’ predictor that uses only a few samples from the process, as well as meta-training data. Towards this, we consider an arbitrary discrete finite set of tasks . The data distribution for each task , , is given as with mean parameter . The task distribution is then defined over the finite set of mean parameters . The base-learner uses training data, distributed i.i.d. from to determine the parameter , which is used as a predictor of new observation at test time. The loss function is defined as , measuring the quadratic error between prediction and realized test input z. Note that the optimal (Bayes) predictor, computable in the ideal case of known distribution , is given as . We now distinguish the two cases with separate and joint within-task training and test sets.
5.1.1. Separate Within-Task Training and Test Sets
The base-learner for task , deterministically selects the prediction
where is an empirical average over the training set , u is a hyperparameter defining a bias that can be meta-trained, and is a fixed scalar. Here, denote the jth data sample in the training set of task . The bias term in (36) may help approximate the ideal Bayes predictor in the presence of limited data .
The objective of the meta-learner is to infer the hyperparameter u. For a given meta-training data set , comprising of data sets from N tasks sampled according to , the meta-learner can compute the empirical meta-training loss as
where denote the jth example in the test set of , the kth sub-data set of . The meta-learner then deterministically selects the minimizing hyperparameter u of the meta-training empirical loss function in (37). This optimization yields
where . Note that and are binomial random variables and by (38), U takes finitely many discrete values and is bounded as . The meta-test loss can be explicitly computed as
where , and the average meta-generalization gap evaluates to
where is the variance of .
To compute the MI- and ITMI-based bounds on the meta-generalization gap (40), it is easy to verify that the average training loss is bounded, i.e., for all and . Thus, Assumption 3 for the MI bound and also Assumption 4 for the ITMI bound hold with . For the MI bound, we note that, since the meta-learner is deterministic, we have that . The ITMI bound (30) is given as
The information-theoretic measures in (41) can be evaluated numerically as discussed in Appendix D.
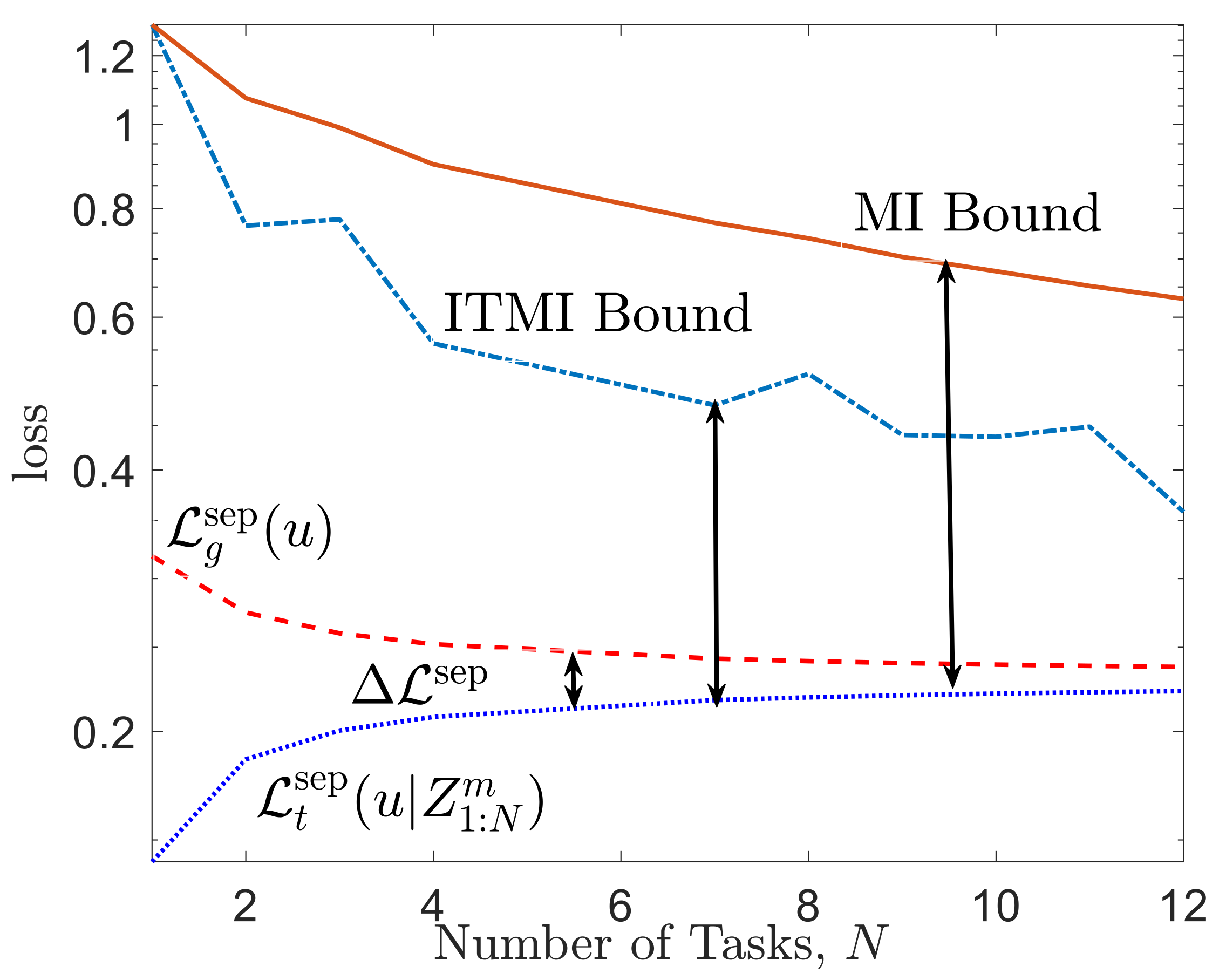
For a numerical illustration, Figure 4 plots the average of the meta-generalization loss (39) and average meta-training loss (A16) along with the ITMI bound in (41) and MI bound in (27). It can be seen that the ITMI bound is tighter than MI bound and correctly predicts the decrease in the meta-generalization gap as the number N of tasks increases.
5.1.2. Joint Within-Task Training and Testing sets
We now consider the case with joint within-task training and test sets. The base-learner for task still uses the predictor (36), but now the empirical average over the training set is given as As before, the meta-learner deterministically selects the minimizing hyperparameter u of the meta-training empirical loss function, yielding As discussed in Appendix D, the meta-generalization loss for this example can also be explicitly computed and the meta-generalization gap bounds in (32) and (33) can be evaluated numerically. Figure 5 plots the average meta-generalization loss and average meta-training loss along with the MI bound in (32) and ITMI bound in (A18), as a function of per-task data samples m. The ITMI bound is seen to better reflect the decrease of the meta-training loss as a function of m.
5.2. Noisy Iterative Meta-Learning Algorithms
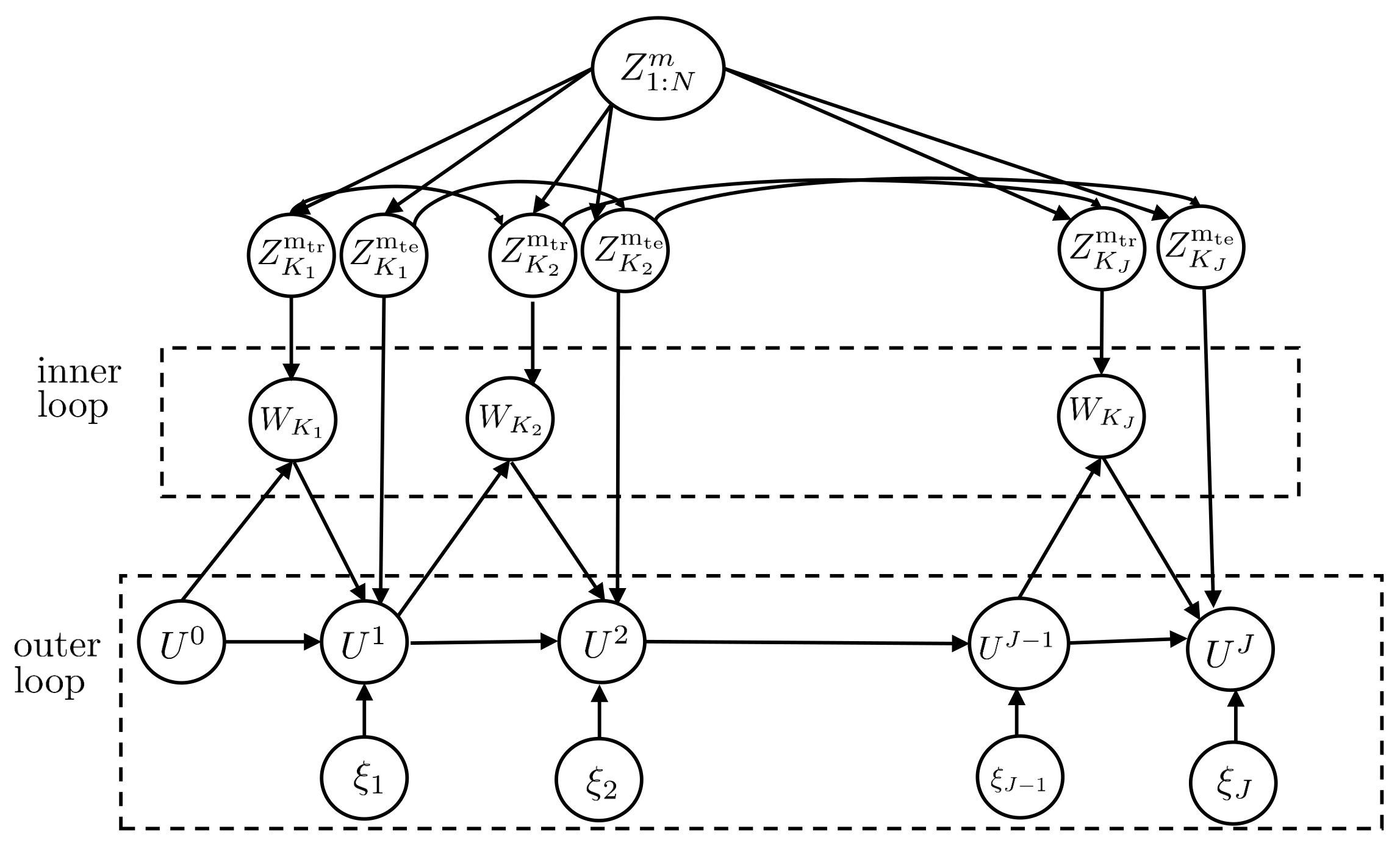
Most meta-learning algorithms are built around a nested loop structure, with the inner loop applying the base-learner on the meta-training set and the outer loop updating the hyperparameters U. In this section, we focus on a vast class of such meta-learning algorithms in which the inner loop applies training procedures dependent on the current iterate of the hyperparameter, while the outer loop updates the hyperparameter using a stochastic rule. This class includes stochastic variants of state-of-the-art algorithms such as MAML [23] and reptile [24]. We apply the derived information-theoretic bounds to study the meta-generalization performance of the mentioned class of meta-training iterative stochastic rules by focusing on the case of separate within-task training and test sets here, which is assumed e.g., by MAML. The analysis for the setup with joint within-task training and test sets can also be carried out at the cost of a more cumbersome notation.
To start, let denote the hyperparameter vector at outer iteration j, with being an arbitrary initialization. For example, in MAML, the hyperparameter U defines the initial iterate used by each base-learner in the inner loop to update the model parameter corresponding to task . At each iteration , we randomly select a mini-batch of task indices from the meta-training data , obtaining the corresponding data set , where and are the separate training and test sets for the selected tasks. For each index , in the inner loop, the base-learner selects the model parameter as a possibly stochastic function
For instance, in MAML, the function in (42) represents the output of an SGD procedure that starts from initialization and uses the task training data to iteratively update the model parameters, producing the final iterate . We denote as the collection of the base-learners’ outputs for all task indices at outer iteration j.
In the outer loop, the meta-learner uses the task-specific adapted parameters from the inner loop and the meta-test set to update the past iterate according to the general update rule
where and are arbitrary deterministic functions; is the step-size; and is an isotropic Gaussian noise, independently drawn for . As an example, in MAML, the function is the identity function and function equals the gradient of the empirical loss in (14) with respect to . Note, however, that MAML does not add noise, i.e., for all j.
The final output of the meta-learning algorithm is then defined as an arbitrary function of all iterates. Examples of function f include the last update and average of the updates . A graphical model representation of the variables involved is shown in Figure 6.
We now derive an upper bound on the meta-generalization gap for the general class of iterative meta-learning algorithm satisfying (42) and (43) under the following assumptions.
Assumption 7.
- (1)
- (2)
- The meta-training data set sampled at each iteration j is conditionally independent of the history of model-parameter vectors and hyperparameter , i.e.,
- (3)
- The meta-parameter update function is uniformly bounded, i.e., for some .
Lemma 4.
Proof.
See Appendix E. □
The bound in (45) has the same form as the generalization gap derived in [27] for conventional learning. From (45), the generalization gap can be reduced by increasing the variance of the injected Gaussian noise. In particular, the meta-generalization gap depends on the ratios between squared step size and variance . For example, SGLD sets , and a step size decaying over time according to the standard Robbins–Monro conditions, in order to ensure convergence of the output samples to the generalized posterior distribution of the hyperparameters [52].
Example: To illustrate bound (45), we now consider a simple logistic regression problem that generalizes the example studied in Section 5.1. Accordingly, each data point Z corresponds to labelled data , where represents the input vector and represents the corresponding binary label. The data distribution for each task is such that is a d-dimensional Bernoulli vector obtained via d independent draws from and Y is distributed as , where is the sigmoid function and , with . The task distribution then defines a distribution over the parameter vectors . The base-learner uses training data generated i.i.d. from to obtain a prediction w of the parameter vector for task . The loss function is taken as the quadratic error
At each iteration j, starting from initialization point , the base-learner in (42) uses a one-step projected gradient descent algorithm on the training data set to obtain the prediction as
where is the step-size is the set of feasible model parameters and is the projection operator. The meta-learner (43) updates the initialization vector according to the noisy gradient descent rule
where is the step-size; and is isotropic Gaussian noise. This update rule corresponds to performing a first order MAML (FOMAML) [23] with the addition of noise.
For this problem, it is easy to verify that Assumption 7 is satisfied, since the loss function is bounded in the interval , whereby is also -bounded. We also have the inequality
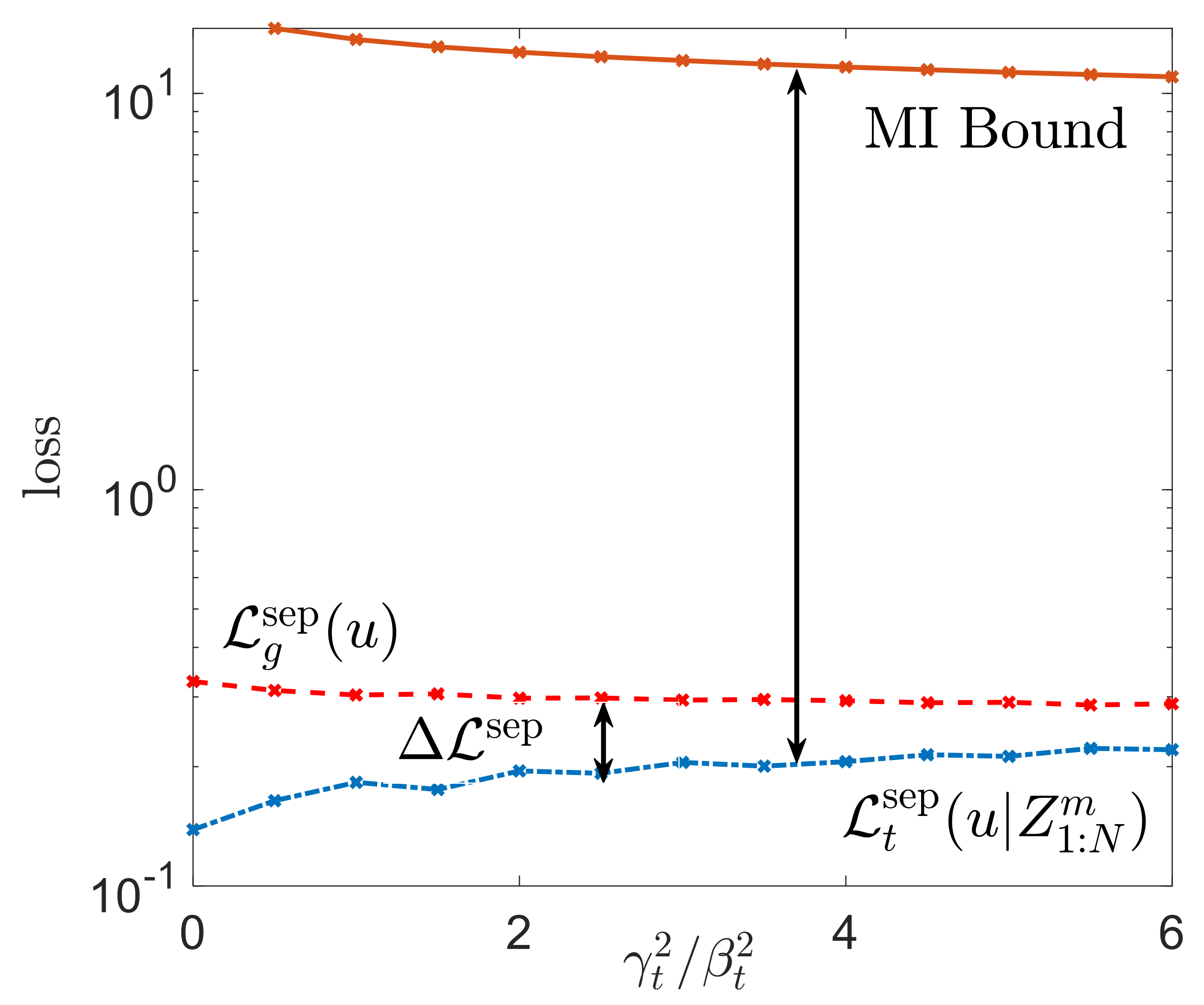
The MI bound in (45) then evaluates to
We now evaluate the meta-training and meta-test loss, along with the bound (49) as a function of the ratio in Figure 7. For the experiment, we considered a task environment of tasks with , , meta-training tasks with training data samples and test data samples. For the inner-loop (46), we fixed step-size and for the outer-loop (47), we set , and iterations.
6. Conclusions
This work has presented novel information-theoretic upper bounds on the average generalization gap of meta-learning algorithms, thereby extending the well-studied information-theoretic approaches in conventional learning to meta-learning. The proposed bounds capture two sources of uncertainty-environment-level uncertainty and within-task uncertainty—and bound them via separate mutual information terms. Applications were also discussed, with the aim of elucidating the use of the bounds to quantify meta-overfitting and guide the choice of the meta-inductive bias, i.e., the class of inductive biases. The derived bounds are amenable to further refinements, such as those along the lines of [39,40,45]. It would also be interesting to study the meta-generalization bounds on noisy iterative meta-learning algorithms using the tighter information-theoretic bounds such as [26,40].
Author Contributions
Conceptualization, formal analysis, writing—original draft, S.T.J.; conceptualization, funding acquisition and supervision, O.S. Both authors have read and agreed to the published version of the manuscript.
Funding
The authors have received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 Research and Innovation Programme (Grant Agreement No. 725731).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Decoupling Estimate Lemmas
The proofs of the main results rely on the following decoupling estimate lemmas, which bound the difference in expectations under a change of measure from the joint to the product of the marginals . In order to state the most general form of decoupling estimate lemmas, we first define a generalized sub-Gaussian random variable.
Definition A1.
A random variable X is said to be -generalized sub-Gaussian if there exist convex functions and that satisfy the equalities and bound the CGF of X as
for some constants and .
For a -generalized sub-Gaussian random variable, we also introduce the following standard definitions. First, the Legendre dual of function is defined as
It can be easily seen that is a non-negative, convex, and non-decreasing function on with Second, the inverse Legendre dual of function is defined as . This function is concave, and it can be equivalently written as [26]
Similar definitions and results apply for .
A -sub-Gaussian random variable X is a generalized sub-Gaussian variable with , and . Furthermore, the Legendre dual functions are given as , and the inverse Legendre dual functions evaluate to
We are now ready to state the decoupling estimate lemmas.
Lemma A1
(Decoupling Estimate [14]). Let and be two jointly distributed random variables with joint distribution , and let be a real valued function such that is -generalized sub-Gaussian for all when . Then we have the following inequalities
where .
Lemma A2
Note that in Lemma A2, the random variables are jointly distributed according to . Assuming that the function is generalized sub-Gaussian under and with and being the marginals of , the lemma provides an upper bound on the difference between average of when is jointly distributed according to and the average of when is independent with and . The resultant bound thus provides an estimate of the effect of decoupling of the joint distribution to its marginals with respect to function .
Appendix B. Proofs of Theorems 1 and 2
For the proof of Theorem 1, we use the decomposition (29) of the meta-generalization gap into average environment-level and within-task generalization gaps as
where (A6) follows since the average within-task generalization gap for a random meta-test task can be equivalently written as , with denoting the generalization gap of the meta-test task T, and the joint distribution factorizes as . To obtain an upper bound on the average meta-generalization gap , we bound each of the two differences in (A6) separately.
We first bound the second difference in (A6) , which represents the expected environment-level uncertainty measured using the average per-task training loss defined in (15). To this end, we extend the single-task learning generalization bound of Lemma 1 by resorting to the decoupling estimate in Lemma A1 with , and , so that and .
Recall from Assumption 3 that for a given , is the average of -sub-Gaussian i.i.d. random variables under for all . It then follows that is -sub-Gaussian under for all [53]. Applying Lemma A1 with specialized to the -sub-Gaussian loss in (A4) gives that
We now evaluate the first difference in (A6). It can be seen that for a fixed task , the average within-task uncertainty evaluates to
where (a) follows, since W and are conditionally independent given , whereby . Substituting (A7) and (A8) in (A6), then concludes the proof.
For Theorem 2, the proof follows along the same line, bounding the average environment-level uncertainty . Towards this, we note that the environment-level uncertainty can be equivalently written as
where and U in the first term are conditionally independent random variables distributed as , while, in the second term, they are jointly distributed according to , which is obtained by marginalizing the joint distribution . Under Assumption 4(a), we can bound the difference by resorting to the decoupling estimate in Lemma A1 with , such that and . Since is sub-Gaussian under Assumption 4(a) for all , Lemma A1 yields the following bound
Appendix C. Proofs of Theorems 3 and 4
For Theorem 3, we start from the following decomposition of the average meta-generalization gap analogous to (A6)
where is the average training loss for the randomly selected meta-test task as a function of the hyperparameter u, and is the generalization gap for the meta-test task T. The MI bound on the expected environment-level uncertainty, , can be obtained by using Lemma A1 and the Assumption 5(b) as in (A7).
The main difference between the separate and joint within-task training and test sets scenarios is that while the average within-task uncertainty vanishes in the former scenario, this is not the case for joint within-task training and training sets. Consequently, we now bound the average within-task generalization gap denoted by the first difference in (A11). For given task , to bound the within-task generalization gap , we resort to Lemma A1 with , and , so that . It can be then verified that , where . Since is the sum of i.i.d -sub-Gaussian random variables (from Assumption 5(a)), we have that is -sub-Gaussian under for all [53]. Consequently, Lemma A1 yields the following bound
Averaging with respect to on both sides of (A12), and combining with the bound on average environment-level uncertainty yields the required bound in (32) via Jensen’s inequality.
For Theorem 4, the proof follows along the same line. The ITMI bound on the expected environment-level uncertainty can be obtained along the lines of (A10), using the assumption on in either Assumption 6(a) or Assumption 6(b). We now show that we can similarly bound the within-task uncertainty using the assumption on loss function in either Assumption 6(a) or Assumption 6(b). Towards this, for fixed task , we write the average within-task uncertainty equivalently as
where W and in the second term are jointly distributed according to , which is the marginal of the joint distribution . In contrast, W and in the first term are conditionally independent random variables distributed as where is the marginal distribution of . Now, fixing , and so that and in Lemma A1 under the assumption on in Assumption 6(a), or in Lemma A2 under the assumption on in Assumption 6(b) yields the following bound,
Appendix D. Details of Example
We first give details of the derivation of meta-generalization gap for the case with separate within-task training and test sets. The average meta-generalization loss can be computed as
where the equality in (a) follows since , and . In a similar manner, the average meta-training loss can be computed as
with U defined as in (38). The meta-generalization gap in (40) then results by taking the difference of (A15) and (A16), and using that and with .
We now evaluate the mutual pieces of information and . For the first MI, note that, since the meta-learner is deterministic (see (38)), and thus . For the second MI, we can write . It can be seen that random variables U and are mixtures of probability distributions, whose entropies can be evaluated following standard methods [54].
For the case with joint within-task training and test sets, the meta-generalization gap can be obtained in a similar way as
For the MI- and ITMI-based bounds, note that with , the loss function is -bounded, and for the deterministic base-learner in (36) with , the average training loss, is also -bounded for all . Thus, Assumptions 5 and 6 hold with . For the MI bound in (32), we have and . For the ITMI bound (33), we have
All information measures can be easily evaluated numerically [54].
Appendix E. Proof of Lemma 4
From the update rule of the meta-learner in (43), we get the Markov dependency
where is the history vector of hyperparameters. The sampling strategy in (44) together with (A19) then implies the following relation
Using to denote the set of all updates, we have the following relations
where, the inequality in (a) follows from data processing inequality on Markov chain ; (b) follows from the Markov chain ; and the equality in (c) follows from and (A20). Finally, the computation of bound in (A24) follows similar to Lemma 5 in [27].
References
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Simeone, O. A Brief Introduction to Machine Learning for Engineers. Found. Trends Signal Process. 2018, 12, 200–431. [Google Scholar] [CrossRef]
- Schmidhuber, J. Evolutionary Principles in Self-Referential Learning, or On Learning How to Learn: The Meta-meta-... Hook. Ph.D. Thesis, Technische Universität München, München, Germany, 1987. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to Learn: Introduction and Overview. In Learning to Learn; Springer: Berlin/Heidelberg, Germany, 1998; pp. 3–17. [Google Scholar]
- Thrun, S. Is Learning the N-th Thing Any Easier Than Learning the First? In Proceedings of the Advances in Neural Information Processing Systems(NIPS); MIT Press: Cambridge, MA, USA, 1996; pp. 640–646. [Google Scholar]
- Vilalta, R.; Drissi, Y. A Perspective View and Survey of Meta-Learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Simeone, O.; Park, S.; Kang, J. From Learning to Meta-Learning: Reduced Training Overhead and Complexity for Communication Systems. arXiv 2020, arXiv:2001.01227. [Google Scholar]
- Kuzborskij, I.; Orabona, F. Fast rates by transferring from auxiliary hypotheses. Mach. Learn. 2017, 106, 171–195. [Google Scholar] [CrossRef] [Green Version]
- Kienzle, W.; Chellapilla, K. Personalized handwriting recognition via biased regularization. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 457–464. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Grazzi, R.; Pontil, M. Learning-to-learn stochastic gradient descent with biased regularization. arXiv 2019, arXiv:1903.10399. [Google Scholar]
- Denevi, G.; Pontil, M.; Ciliberto, C. The advantage of conditional meta-learning for biased regularization and fine-tuning. arXiv 2020, arXiv:2008.10857. [Google Scholar]
- Baxter, J. A Model of Inductive Bias Learning. J. Artif. Intell. Res. 2000, 12, 149–198. [Google Scholar] [CrossRef]
- Russo, D.; Zou, J. Controlling Bias in Adaptive Data Analysis Using Information Theory. In Proceedings of the Artificial Intelligence and Statistics (AISTATS), Cadiz, Spain, 9–11 May 2016; pp. 1232–1240. [Google Scholar]
- Xu, H.; Farajtabar, M.; Zha, H. Learning Granger causality for Hawkes processes. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 20–22 June 2016; pp. 1717–1726. [Google Scholar]
- Maurer, A. Algorithmic Stability and Meta-Learning. J. Mach. Learn. Res. 2005, 6, 967–994. [Google Scholar]
- Devroye, L.; Wagner, T. Distribution-Free Performance Bounds for Potential Function Rules. IEEE Trans. Inf. Theory 1979, 25, 601–604. [Google Scholar] [CrossRef] [Green Version]
- Rogers, W.H.; Wagner, T.J. A Finite Sample Distribution-Free Performance Bound for Local Discrimination Rules. Ann. Stat. 1978, 6, 506–514. [Google Scholar] [CrossRef]
- Pentina, A.; Lampert, C. A PAC-Bayesian Bound for Lifelong Learning. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 991–999. [Google Scholar]
- Amit, R.; Meir, R. Meta-Learning by Adjusting Priors Based on Extended PAC-Bayes Theory. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2018; pp. 205–214. [Google Scholar]
- Rothfuss, J.; Fortuin, V.; Krause, A. PACOH: Bayes-Optimal Meta-Learning with PAC-Guarantees. arXiv 2020, arXiv:2002.05551. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Stamos, D.; Pontil, M. Incremental learning-to-learn with statistical guarantees. arXiv 2018, arXiv:1803.08089. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Xu, A.; Raginsky, M. Information-Theoretic Analysis of Generalization Capability of Learning Algorithms. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 2524–2533. [Google Scholar]
- Bu, Y.; Zou, S.; Veeravalli, V.V. Tightening Mutual Information Based Bounds on Generalization Error. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 587–591. [Google Scholar]
- Pensia, A.; Jog, V.; Loh, P.L. Generalization Error Bounds for Noisy, Iterative Algorithms. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Veil, CO, USA, 17–22 June 2018; pp. 546–550. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities. In Theory of Probability and Its Applications; SIAM: Philadelphia, PA, USA, 1971; Volume 16, pp. 264–280. [Google Scholar]
- Koltchinskii, V.; Panchenko, D. Rademacher Processes and Bounding the Risk of Function Learning. In High Dimensional Probability II; Springer: Berlin/Heidelberg, Germany, 2000; Volume 47, pp. 443–457. [Google Scholar]
- Bousquet, O.; Elisseeff, A. Stability and Generalization. J. Mach. Learn. Res. 2002, 2, 499–526. [Google Scholar]
- Kearns, M.; Ron, D. Algorithmic Stability and Sanity-Check Bounds for Leave-One-Out Cross-Validation. Neural Comput. 1999, 11, 1427–1453. [Google Scholar] [CrossRef]
- Poggio, T.; Rifkin, R.; Mukherjee, S.; Niyogi, P. General Conditions for Predictivity In Learning Theory. Nature 2004, 428, 419–422. [Google Scholar] [CrossRef]
- Kutin, S.; Niyogi, P. Almost-Everywhere Algorithmic Stability and Generalization Error. In Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence (UAI’02); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2002; pp. 275–282. [Google Scholar]
- Dwork, C.; Feldman, V.; Hardt, M.; Pitassi, T.; Reingold, O.; Roth, A.L. Preserving Statistical Validity in Adaptive Data Analysis. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing (STOC), Portland, OR, USA, 15–17 June 2015; pp. 117–126. [Google Scholar]
- Bassily, R.; Nissim, K.; Smith, A.; Steinke, T.; Stemmer, U.; Ullman, J. Algorithmic Stability for Adaptive Data Analysis. In Proceedings of the Forty-Eighth Annual ACM Symposium on Theory of Computing (STOC), Cambridge, MA, USA, 19–21 June 2016; pp. 1046–1059. [Google Scholar]
- McAllester, D.A. PAC-Bayesian Model Averaging. In Proceedings of the Twelfth Annual Conference on Computational Learning Theory (COLT), Santa Cruz, CA, USA, 7–9 July 1999; pp. 164–170. [Google Scholar]
- Seeger, M. PAC-Bayesian Generalization Error Bounds for Gaussian Process Classification. J. Mach. Learn. Res. 2002, 3, 233–269. [Google Scholar]
- Alquier, P.; Ridgway, J.; Chopin, N. On the Properties of Variational Approximations of Gibbs Posteriors. J. Mach. Learn. Res. 2016, 17, 8374–8414. [Google Scholar]
- Asadi, A.; Abbe, E.; Verdú, S. Chaining Mutual Information and Tightening Generalization Bounds. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018; pp. 7234–7243. [Google Scholar]
- Negrea, J.; Haghifam, M.; Dziugaite, G.K.; Khisti, A.; Roy, D.M. Information-Theoretic Generalization Bounds for SGLD via Data-Dependent Estimates. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 11013–11023. [Google Scholar]
- Alabdulmohsin, I. Towards a Unified Theory of Learning and Information. Entropy 2020, 22, 438. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Han, Y.; Weissman, T. Dependence Measures Bounding the Exploration Bias for General Measurements. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1475–1479. [Google Scholar]
- Issa, I.; Gastpar, M. Computable Bounds On the Exploration Bias. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 576–580. [Google Scholar]
- Issa, I.; Esposito, A.R.; Gastpar, M. Strengthened Information-Theoretic Bounds on the Generalization Error. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 582–586. [Google Scholar]
- Steinke, T.; Zakynthinou, L. Reasoning About Generalization via Conditional Mutual Information. arXiv 2020, arXiv:2001.09122. [Google Scholar]
- Knoblauch, J.; Jewson, J.; Damoulas, T. Generalized Variational Inference. arXiv 2019, arXiv:1904.02063. [Google Scholar]
- Bissiri, P.G.; Holmes, C.C.; Walker, S.G. A General Framework for Updating Belief Distributions. J. R. Stat. Soc. Ser. Stat. Methodol. 2016, 78, 1103–1130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, M.; Tucker, G.; Zhou, M.; Levine, S.; Finn, C. Meta-Learning Without Memorization. arXiv 2019, arXiv:1912.03820. [Google Scholar]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019; Volume 48. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Learnability, Stability and Uniform Convergence. J. Mach. Learn. Res. 2010, 11, 2635–2670. [Google Scholar]
- Maurer, A.; Pontil, M.; Romera-Paredes, B. The Benefit of Multitask Representation Learning. J. Mach. Learn. Res. 2016, 17, 2853–2884. [Google Scholar]
- Welling, M.; Teh, Y.W. Bayesian Learning via Stochastic Gradient Langevin Dynamics. In Proceedings of the 28th International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011; pp. 681–688. [Google Scholar]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Michalowicz, J.V.; Nichols, J.M.; Bucholtz, F. Handbook of Differential Entropy; CRC Press: New York, NY, USA, 2013. [Google Scholar]
Figure 1.
Directed graph representing the variables involved in the definition of generalization gap (11) for single-task learning.
Figure 1.
Directed graph representing the variables involved in the definition of generalization gap (11) for single-task learning.

Figure 2.
Directed graph representing the variables involved in the definition of meta-generalization gap (18) for separate within-task training and testing sets.
Figure 2.
Directed graph representing the variables involved in the definition of meta-generalization gap (18) for separate within-task training and testing sets.

Figure 3.
Directed graph representing the variables involved in the definition of meta-generalization gap (22) for joint within-task training and testing sets.
Figure 3.
Directed graph representing the variables involved in the definition of meta-generalization gap (22) for joint within-task training and testing sets.

Figure 4.
Comparison of the MI bound in (27) and ITMI-based bound obtained in (41) with the meta-generalization gap for meta-learning with separate within-task training and test sets. The task environment is defined by tasks. Other parameters are set as , , .

Figure 5.
Comparison of the MI- and ITMI-based bound obtained in (A18) with the meta-generalization gap for meta-learning with joint within-task training and test sets, as a function of the per-task data samples m for and . The task environment is defined by tasks.
Figure 5.
Comparison of the MI- and ITMI-based bound obtained in (A18) with the meta-generalization gap for meta-learning with joint within-task training and test sets, as a function of the per-task data samples m for and . The task environment is defined by tasks.

Figure 6.
A graphical model representation of the variables involved in the Definition of noisy iterative algorithms.
Figure 6.
A graphical model representation of the variables involved in the Definition of noisy iterative algorithms.

Figure 7.
Comparison of the meta-generalization gap with the MI-based bound in (49) as function of the ratio .
Figure 7.
Comparison of the meta-generalization gap with the MI-based bound in (49) as function of the ratio .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jose, S.T.; Simeone, O. Information-Theoretic Generalization Bounds for Meta-Learning and Applications. Entropy 2021, 23, 126. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010126
AMA Style
Jose ST, Simeone O. Information-Theoretic Generalization Bounds for Meta-Learning and Applications. Entropy. 2021; 23(1):126. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010126
Chicago/Turabian StyleJose, Sharu Theresa, and Osvaldo Simeone. 2021. "Information-Theoretic Generalization Bounds for Meta-Learning and Applications" Entropy 23, no. 1: 126. https://0-doi-org.brum.beds.ac.uk/10.3390/e23010126
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.