1. Introduction
Ecological Momentary Assessments (EMAs) are utilized to capture the immediate behavioral experience for a medical phenomenon. The behavioral experience can range from the present moment to a few minutes earlier, or can be a recollection of events that occurred at earlier, longer time frames. Presently, EMAs are mainly recorded with help of mobile technology, namely, by digital devices that notify the users multiple times for a period of days or weeks, so that they record current or recent medical states, behaviors, or environmental conditions [
1]. By using this approach, the period of recall can be reduced to hours or minutes. Hence, EMAs allow observing the natural set of behaviors and moods of the participants [
2]. EMAs are used for behavioral monitoring and tracking the progression of bipolar disorders [
3,
4], for studying tinnitus distress [
5], and for monitoring mood in major depressive disorders [
6]. Importantly, EMAs reduce the recall bias [
7,
8,
9], and can thus be exploited by physicians for reliable patient monitoring and decision support. Comprehensible Artificial Intelligence (cAI) [
10] is a transition framework that encompasses multiple disciplines such as AI, Human-Computer Interaction (HCI), and End User explanations, along with the combinations of techniques and approaches such as visual analytics, interactive ML, and dialog systems. Visual analytics act as an intersection between AI and end-user explanations to provide rich visualizations, which are helpful for humans to understand, interpret and further improve the trust of a developed system. A Clinical Decision Support System (CDSS) involves the provision of effective assistance to clinicians during the process of patient treatment and diagnosis [
11]. It was utilized for effective and interactive communication between a physician and patients through alerts that are provided during self-monitoring [
12]. The ability for the patients to make clinical decisions are also utilized in CDSS [
13]. Recently, Intellicare [
14] platforms attempt to provide remote therapies for anyone at any point in their mental health journey through smartphone-based applications to reduce stress, depression, and anxiety. By including the parts of cAI transition framework, the existing systems can be enhanced.
Note that considerations of mHealth data in the context of well-being are not fundamentally new. Studies and concepts can be found that deal with the combined perspective of well-being and mHealth. In [
15], for example, a technical concept is discussed, in which mHealth monitoring is related to well-being monitoring in general, concretely by a comparison with an online social network scenario. The results shown by [
16], in turn, reveal that emotional bonding with mHealth apps can be related to the well-being of the users. Many other recent and related works can be found in this context [
17,
18,
19]. However, the decision to investigate the similarity among the users to assess their well-being is not considered so far, to the best of the authors’ knowledge. In addition, to accomplish the similarity inspection based on advanced visualization techniques is not being pursued in the same way by other works.
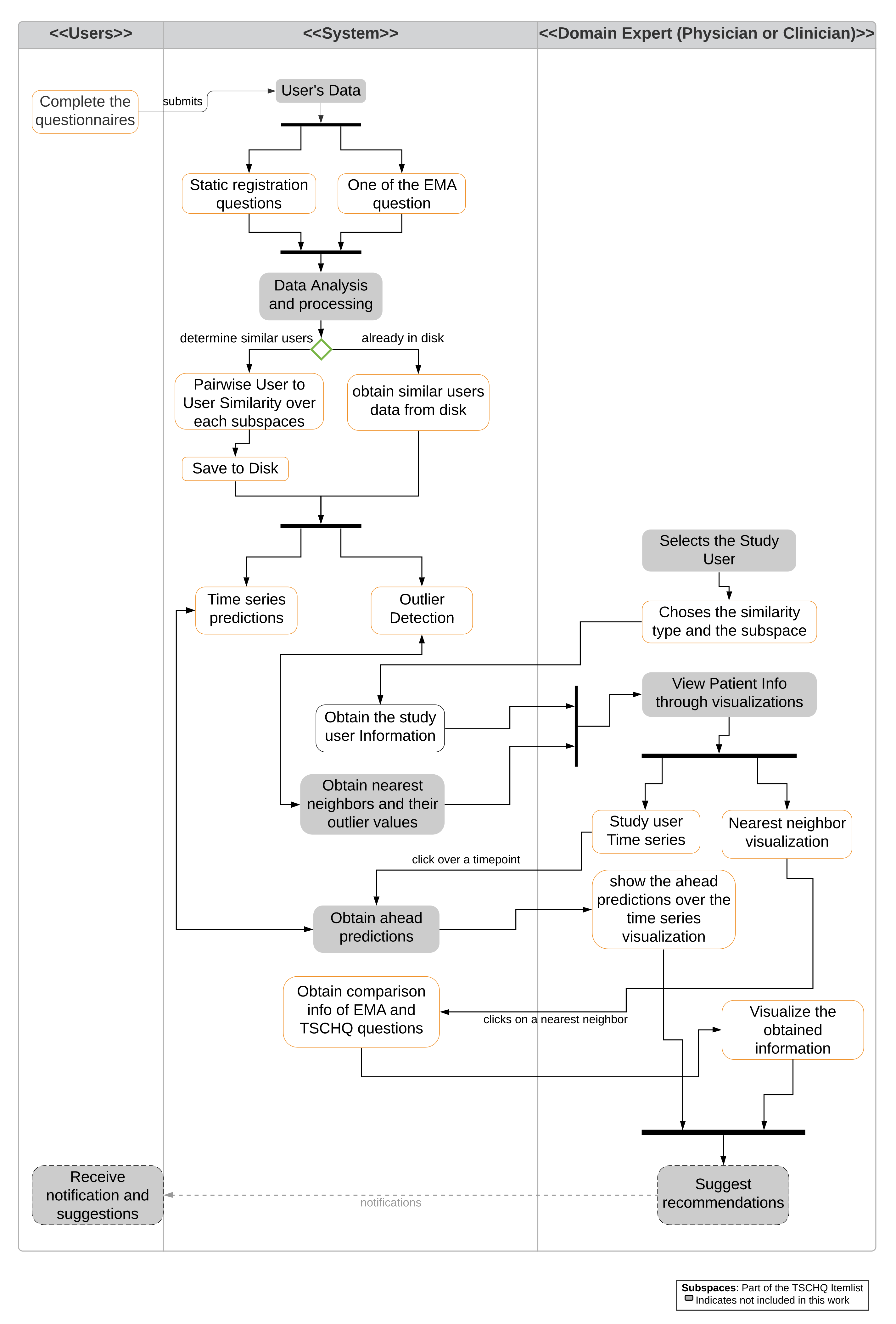
In this work, we contribute to CDSS through a medical analytics interactive tool that facilitates the inspection of a user’s EMA and clinical data. It juxtaposes timestamped EMA recordings of users with related clinical data, and predicts future user recordings with respect to symptoms of interest. In particular, we investigate the following research questions:
- RQ1-
How to predict a user’s EMA in the near and far future, on the basis of similarities to other users?
- RQ2-
How to identify and show outlierness in users’ EMAs?
- RQ3-
How to show similarities and differences in the EMAs of users who are similar in their clinical data?
The core idea of our approach is the exploitation of similarity among users in their static clinical data as well as in their dynamic, timestamped EMAs. We build upon similarity for prediction in time series (see RQ1), upon identification of users with outlier behavior (see RQ2), and upon visual and quantitative juxtaposition among users (see RQ3). For the validation of our work, we use the data of a pilot study on the role of mHealth tools for patient empowerment. The study involved 72 tinnitus patients, who recorded EMAs with the mHealth tool TinnitusTipps over an 8-weeks period between 2018 and 2019.
Our contributions can be summarized as follows:
We demonstrate the users neighborhood comparisons over data (i.e., both static, dynamic, and timestamped EMA) and utilize them for predicting user’s EMA recordings and show that users neighborhood are indeed useful in making the ahead predictions.
We introduce a voting-based outlier detection methodology to identify users who behave differently in their interaction with the app and also introduce tailored interactive visualizations that can be inspected.
We introduce a medical analytics tool with the introduction of tailored interactive visualizations to demonstrate the nearest neighboring user’s behaviors recorded through the app, and a visualization to show the ahead predictions for a study based on the identified nearest neighbors by constructing pathways.
The remainder of this paper is structured as follows. In
Section 2 we provide the necessary information about the mobile health app and data of the pilot study on TinnitusTipps. In
Section 3,
Section 5 and
Section 6 we detail the methods introduced for answering our RQ’s. In
Section 7 we report on the results of our analysis. In
Section 8 we elaborate on the obtained findings and discuss improvements and limitations.
3. Methods
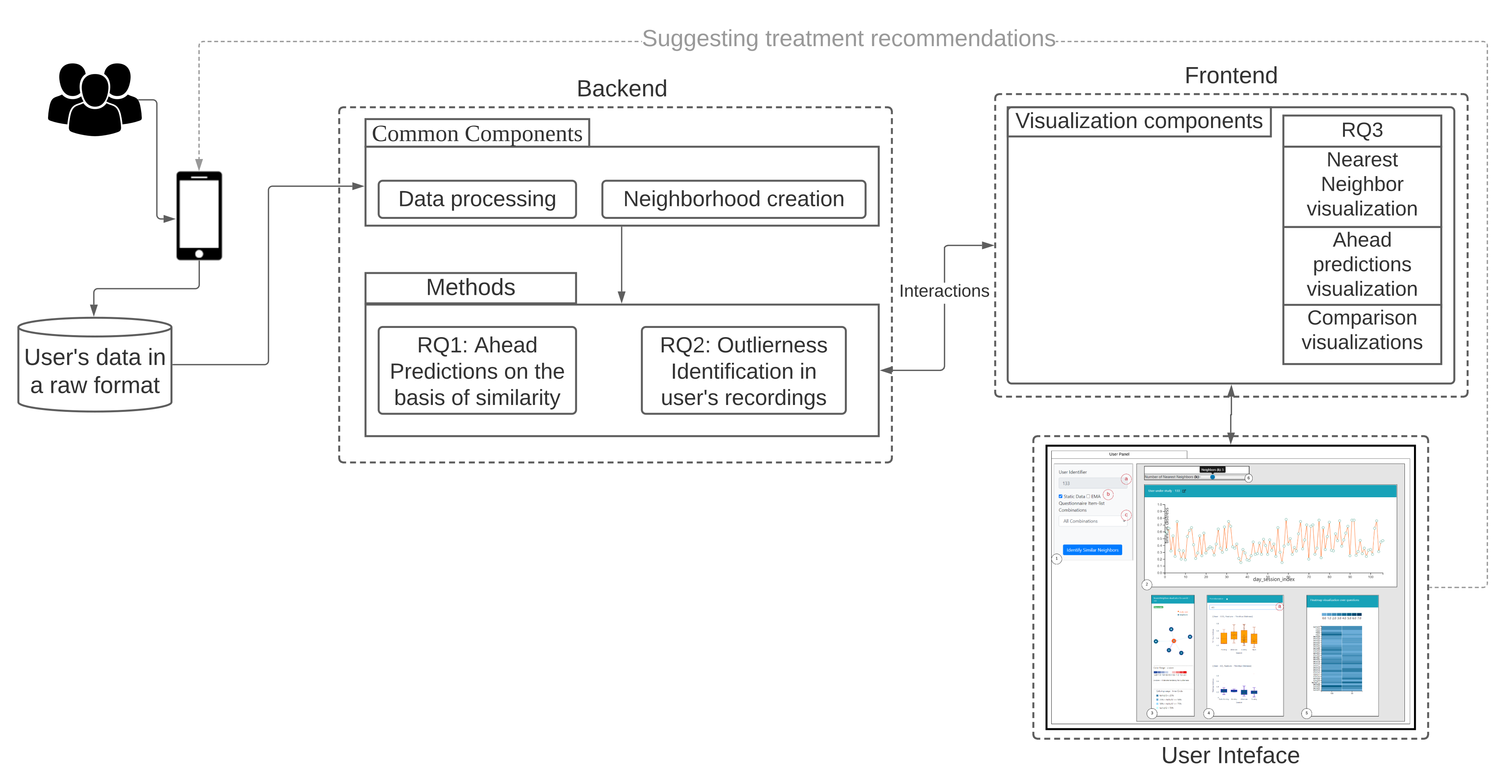
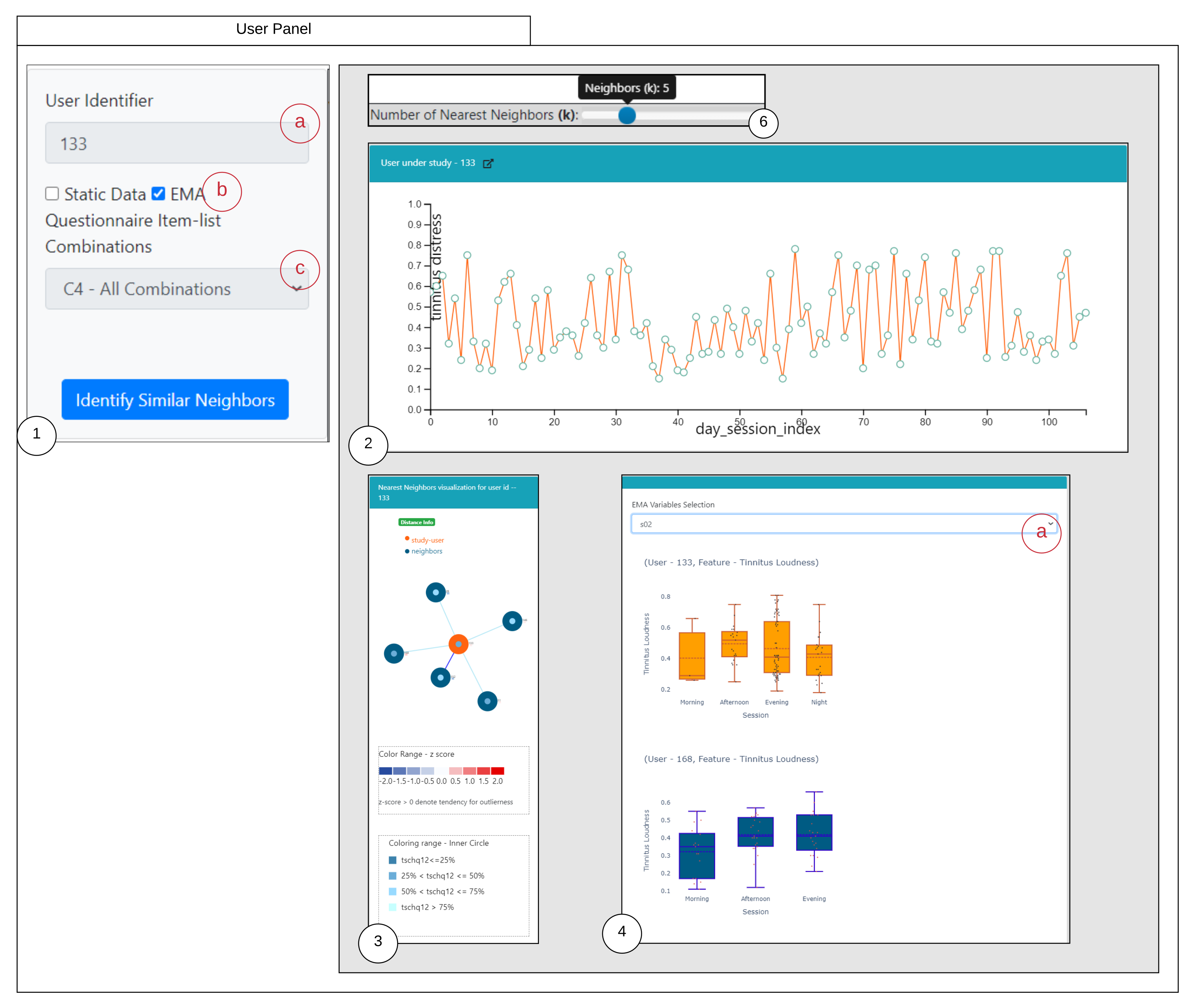
Our workflow consists of methods for data conversion (1), neighborhood creation (2), and generation of question combinations as features (3), which are used for all three RQs. The backend and frontend components of our workflow are shown in
Figure 1 and explained hereafter.
On
Table 1 we summarize the notation we used throughout this paper.
3.1. Data Conversion
The collected user data were stored in the JavaScript Object Notation (JSON) format, from which they were converted into Comma Separated Values (CSV) format. The processed data encompass two types of user answers: the static data from the two registration questionnaires and the time series data from the EMA questionnaire. The numeric values of the EMA variables were rescaled to be between 0 and 1. We used the time series on loudness (s02) and tinnitus distress (s03) for prediction, and the time series of the items s02, s03, …, s08 for visualizations.
3.2. Time Series Alignment
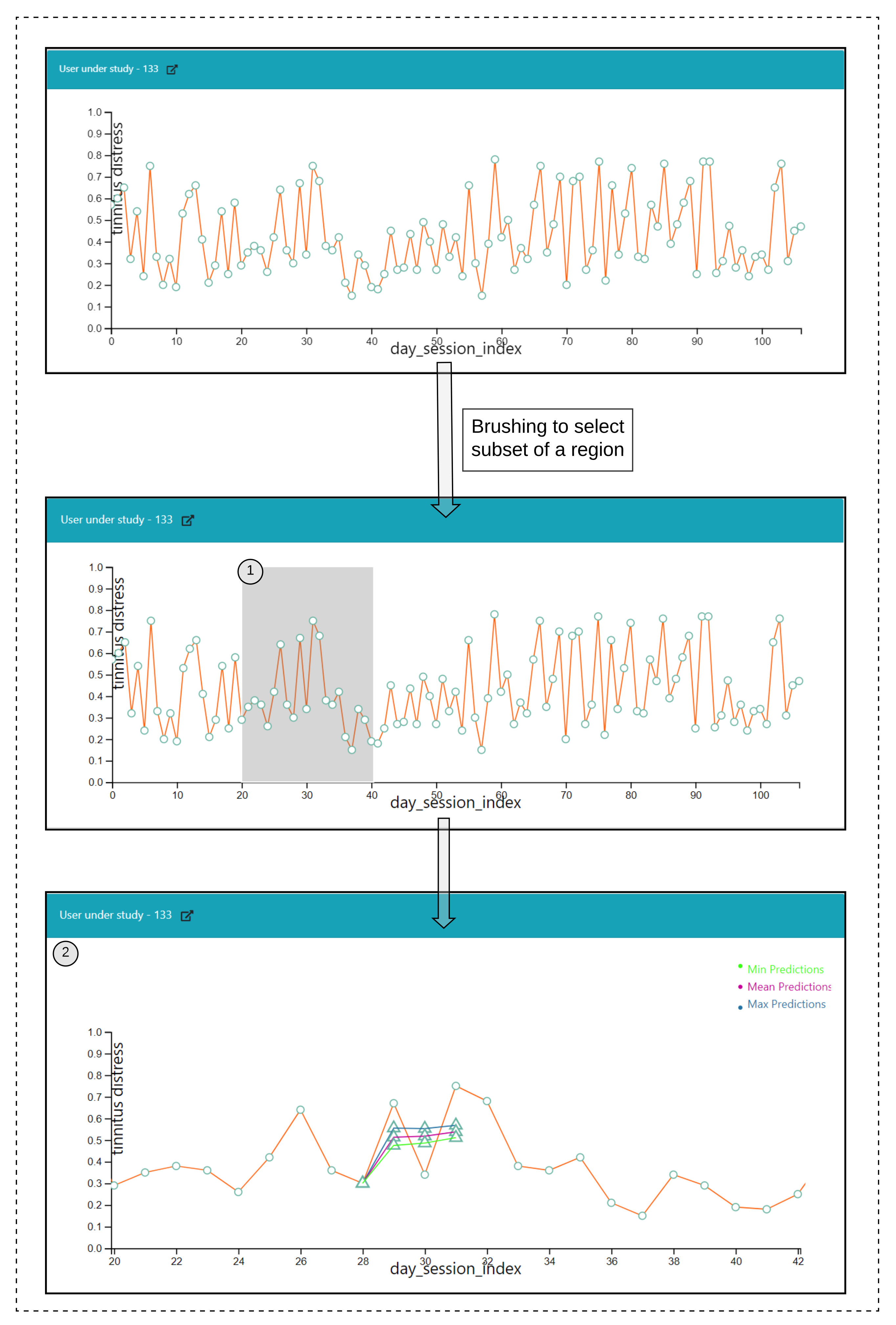
The users start recording their observations over different time periods and after a few days, there are possibilities to stop. To deal with such gaps and variations in the user’s time series recordings, a time series alignment approach is taken into account. The approach involves the aggregating the time series at a daily-level using either mean, maximum or minimum. The first observation within a given month is initialized to 0, and is assigned to the variable. For the next observation within the given month, the is incremented and the updated value is reassigned to . For the first observations for the next month, the last day index value of is obtained and incremented accordingly until the last recording for a user. For the ahead predictions, minimum, maximum and mean aggregations are investigated.
3.3. Creation of Neighborhood
We created two types of neighborhoods—using static data and using time series data, as described hereafter.
3.3.1. Neighborhoods on Static Data
Let represent a set of users, with n being the number of users and features of a user is denoted by , with || is the total number of features in the static data. The response attributes in contain the user’s static information (age, background, and comorbidities) and their past medical conditions (presence/absence of neck pain, etc.).
For each user, we compute the set of k-nearest neighbors subject to a threshold, namely, the average of the distances over all pairs of users, so that only closer neighbors contribute to the similarity.
The Heterogeneous Euclidean Overlap Metric (HEOM) is used to measure the similarity. The definitions hereafter come from [
23,
24], but we use a different notation.
Let
sr(
x),
sr(
z) be the feature values of
, then the overlap metric distance for the users
is defined as:
with,
When the attributes value of
sr(
x),
sr(
z) are continuous, then we define the range difference between the two attribute values as follows:
where,
is used to normalize the attributes.
From the overlap metric and range difference, we derive
HEOM as:
with,
3.3.2. Neighborhoods on the Dynamic Data of the EMA Time Series—One per EMA Item
Next to the static information, the users also record an ordered sequence of observations that constitute the EMA recordings. Let represent the set of users with the EMA recordings. We denote the sequence of observations of an as , where each observation contains a set of features along with a timestamp = {, }, where represents the timestamp of the user , represent the feature space of EMA recordings which is denoted as ,for ; = 8, and m represents the total number of EMA recordings recorded by over the days denoting the length of the time series. The multiple observed values recorded by the user within a given day for the considered EMA variable are averaged for the neighborhood computations.
We compute the similarity between a user x and user z for each EMA item separately, after aligning their time series at the same (nominal) day 0:
‘Day matching’ between x and z: number of days from day 0 onward and until the last day of the shortest between the two time series. For example, if x has EMA observations for 30 days and z for 60 days, then the matching is on the first 30 days, with day of x matched to the corresponding day of z.
For each of the matched days for x and z, a euclidean distance is computed. A counter is maintained to capture the number of days when both the users have reported their observations, denoted by, and the distance obtained for each day is summed up and is denoted as .
Finally, a fraction of the is returned as the similarity between the user x and z.
3.4. Creation of Feature Combinations
The similarity between users and, accordingly, their neighborhoods over static data, can be computed using the whole set of registration items or a subset of them. To assess the effect of different aspects of a user’s recordings, we construct the following overlapping ‘subspaces’, i.e., combinations of features from the set of registration items:
- C1:
user background and tinnitus complaints information (items tschq02-04); tinnitus historical information (items tschq05-18), including the initial onset of tinnitus, loudness, tinnitus awareness, and different past treatments
- C2:
experienced effects of tinnitus (tschq19-25), and questions on hearing quality/loss (hq01, hq03)
- C3:
further conditions, such as neck pain, dizziness etc. (tschq28-35), as well as the items on hearing quality/hearing loss (hq02, hq04)
- C4:
all the TSCHQ and HQ items
Along with these combinations, the numerical value loudness (tschq12) is also included, so that there are no ties in the computation of user similarity.
By using these combinations, a similarity is built for the specified neighborhood size (k); i.e., for each of the user and the obtained similar users are utilized for the prediction of tinnitus distress by computing the k nearest neighbors over the registration data.
4. RQ1: How to Predict a User’s EMA in the Near and Far Future, on the Basis of Similarity to Other Users?
A prediction of a class label for a test user u, for an EMA recording at a timepoint is performed through obtaining the nearest neighbor users of u and by utilizing the nearest neighbors EMA recordings until . The work focuses on the prediction of a numeric class label only.
4.1. Ahead Prediction of the Target Variable
Let be the set of test users, let u be a test user, and let be the timepoint at which we want to predict the values of future EMA recordings for u. We first compute the set of nearest neighbors of u for a given k. We denote it as . Then, we consider the following options:
4.2. Evaluation for RQ1
We investigate how the value of k, the choice of subspace (from the registration data), the kind of neighborhood (static vs dynamic) and the aggregation function over the EMA within a day (min, mean, max) affect the quality of the prediction. For the evaluation, we consider Root Mean Squared Error (RMSE) over a set test users. In particular:
For a test user , the nearest neighbors are obtained (either for static or dynamic). Once after obtaining the nearest neighbors of , their respective time series are aligned, and wherever multiple observations are present for a given day, they are aggregated using either the minimum(), mean(), or maximum() functions.
Next, based upon ahead prediction timepoint (in a day), future EMA recordings (l), and the nearest neighbors time series information; ahead predictions are obtained based on the proposed methodologies as per
Section 4.1.
For a test user, the error for a feature
is measured using Root Mean Squared Error (RMSE) against the true value of that feature as follows:
where
denotes the predicted values obtained for a feature
, and
l denotes the number of ahead days to predict.
Let the above three steps of evaluation be denoted as
. The same process is carried out for all the test users and compute the final quality value for a given neighborhood size
k as
and the achieved RMSE for all the test users is averaged for the provided neighborhood size (
k).
To assess the changes in ahead-prediction from earlier days to days in the distant future, a comparison between near predictions (earlier days) and far predictions (far-future days) are also done based on the concepts of [
25]. The neighborhood size from 1 to 30 is chosen in this work.
8. Discussion
The previous
Section 7 highlighted some important results of the research questions concerning the ability to predict user’s EMA based on similarity, identification of individuals whose properties are different, and the overview of key usage scenarios addressed in the visualization tool.
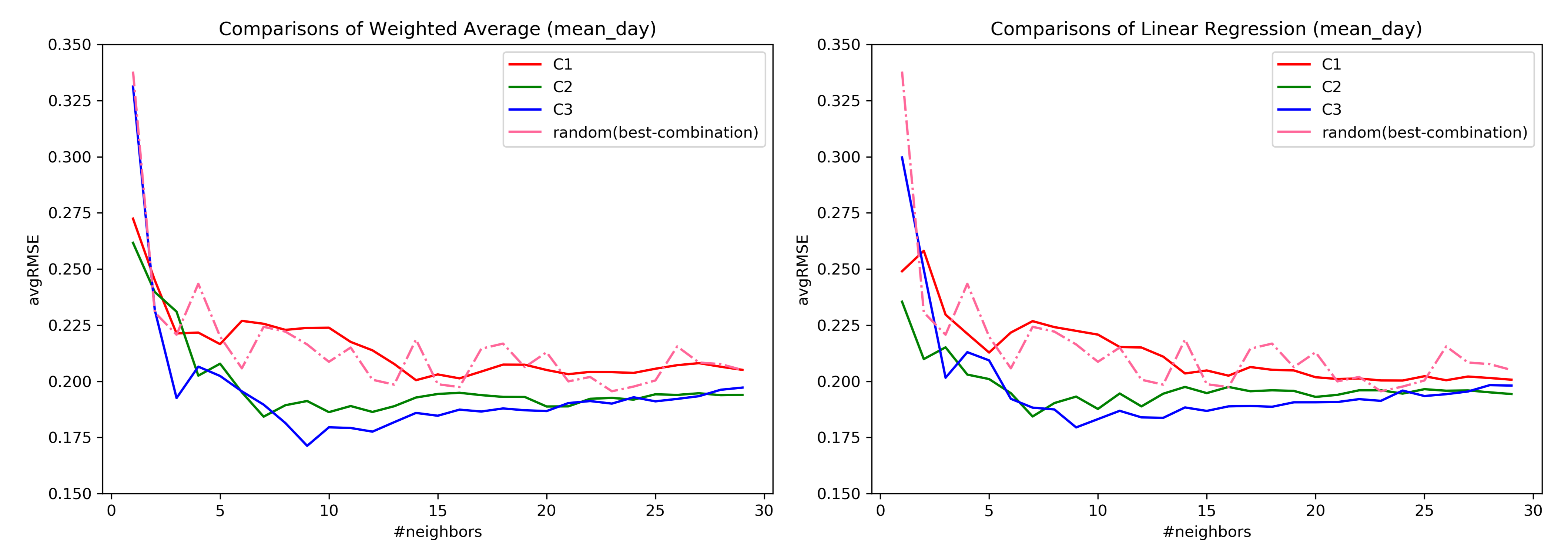
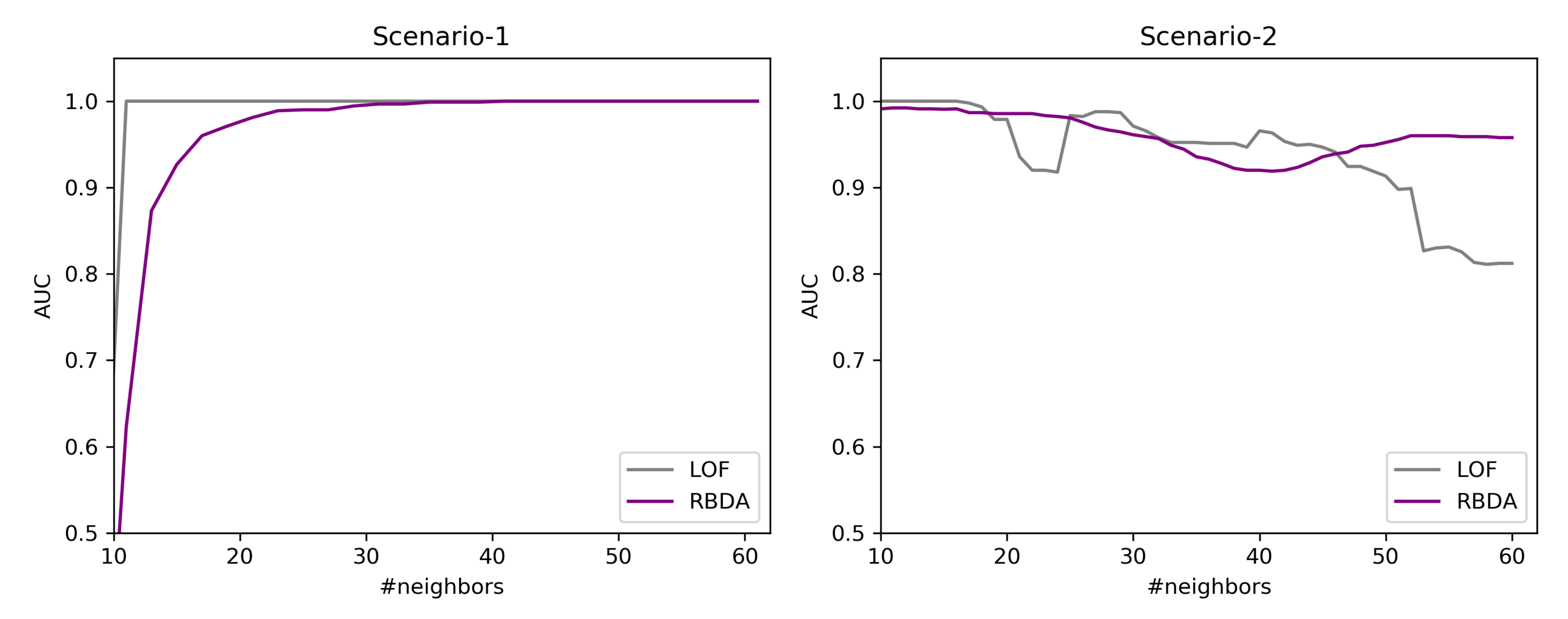
Regarding the RQ1, from the
Figure 7 it confirms that the subspaces do help in the ahead predictions of the user’s EMA recordings as opposed to considering all the questions. Similar behavior was also observed in [
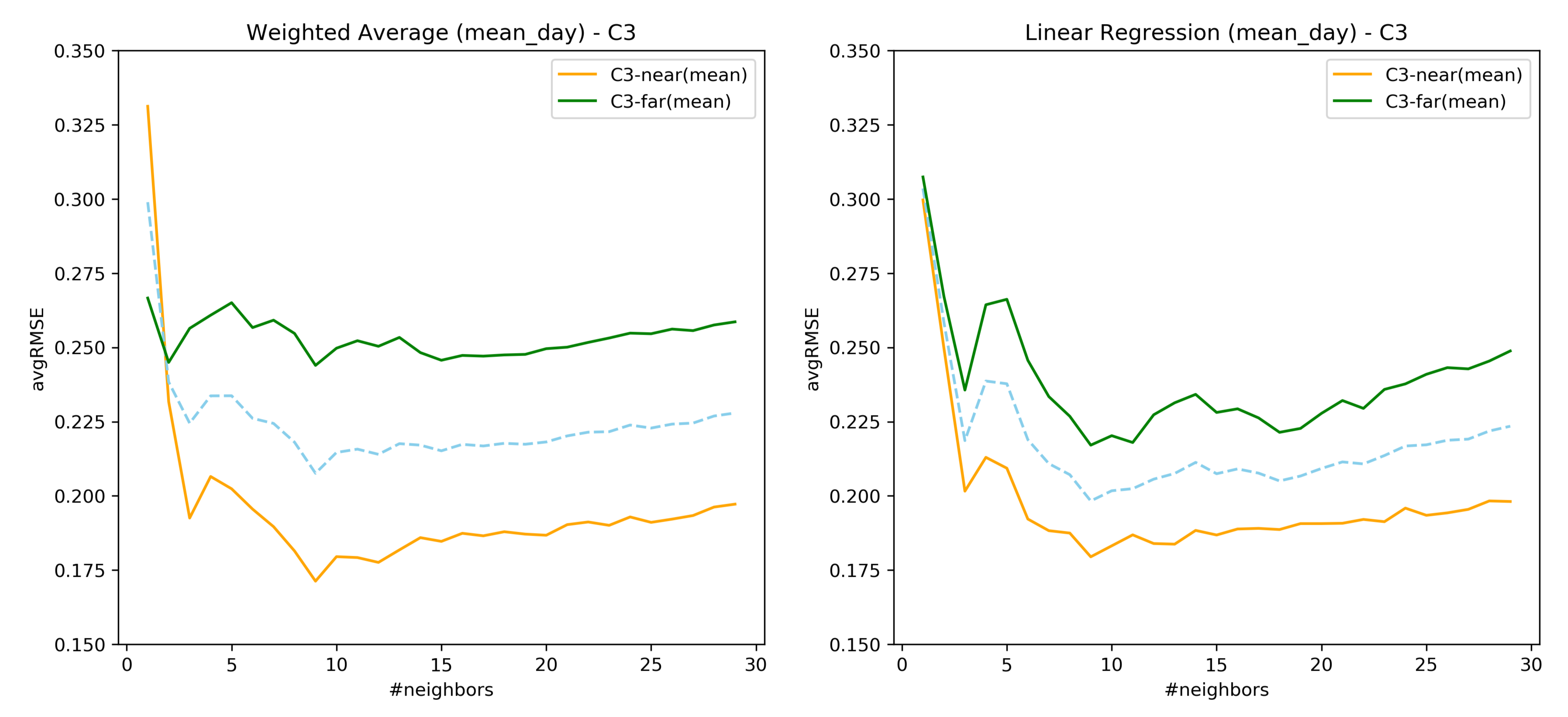
34] where the predictive power of the model was assessed through clustering. However, considering only the user’s EMA recordings to construct similarity has a lower error rate as compared to considering the registration data. Therefore, it can be inferred that a similarity measure considering both forms of data together must be explored. As seen from
Figure 8, the prediction of user’s EMA for the far future is indeed difficult, which is in agreement with the findings of [
25].
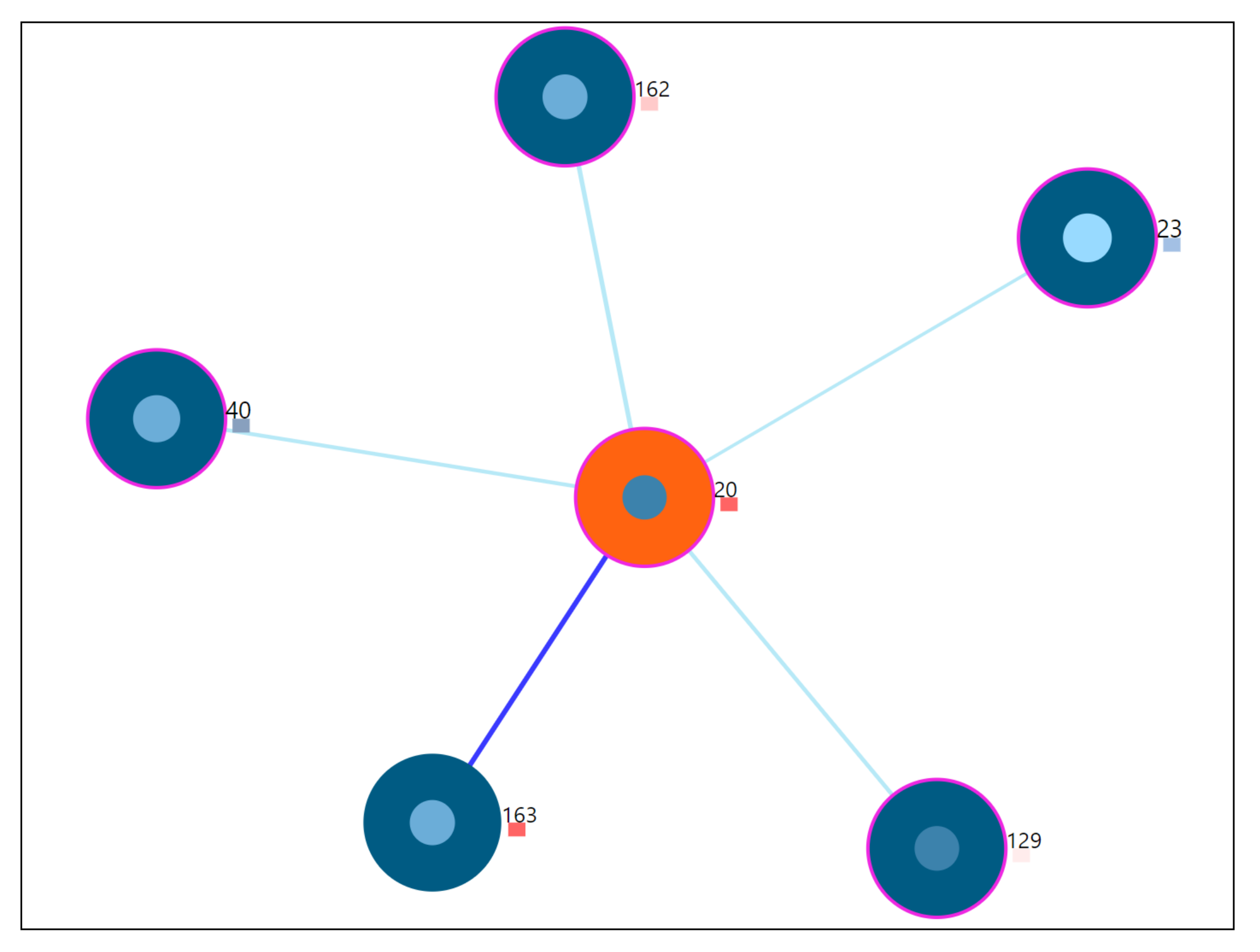
Regarding the RQ2, we showed that there exist users whose EMA observations deviate from most of the other users. For example, it is already known that there are users with high tinnitus loudness and low distress [
35]. These users behave differently in their interaction with the app, and closer inspection are of interest to the domain expert through interacting with the tool. The predictive mechanism introduced in [
34] can be enhanced by including our outlier detection methodology within the workflow.
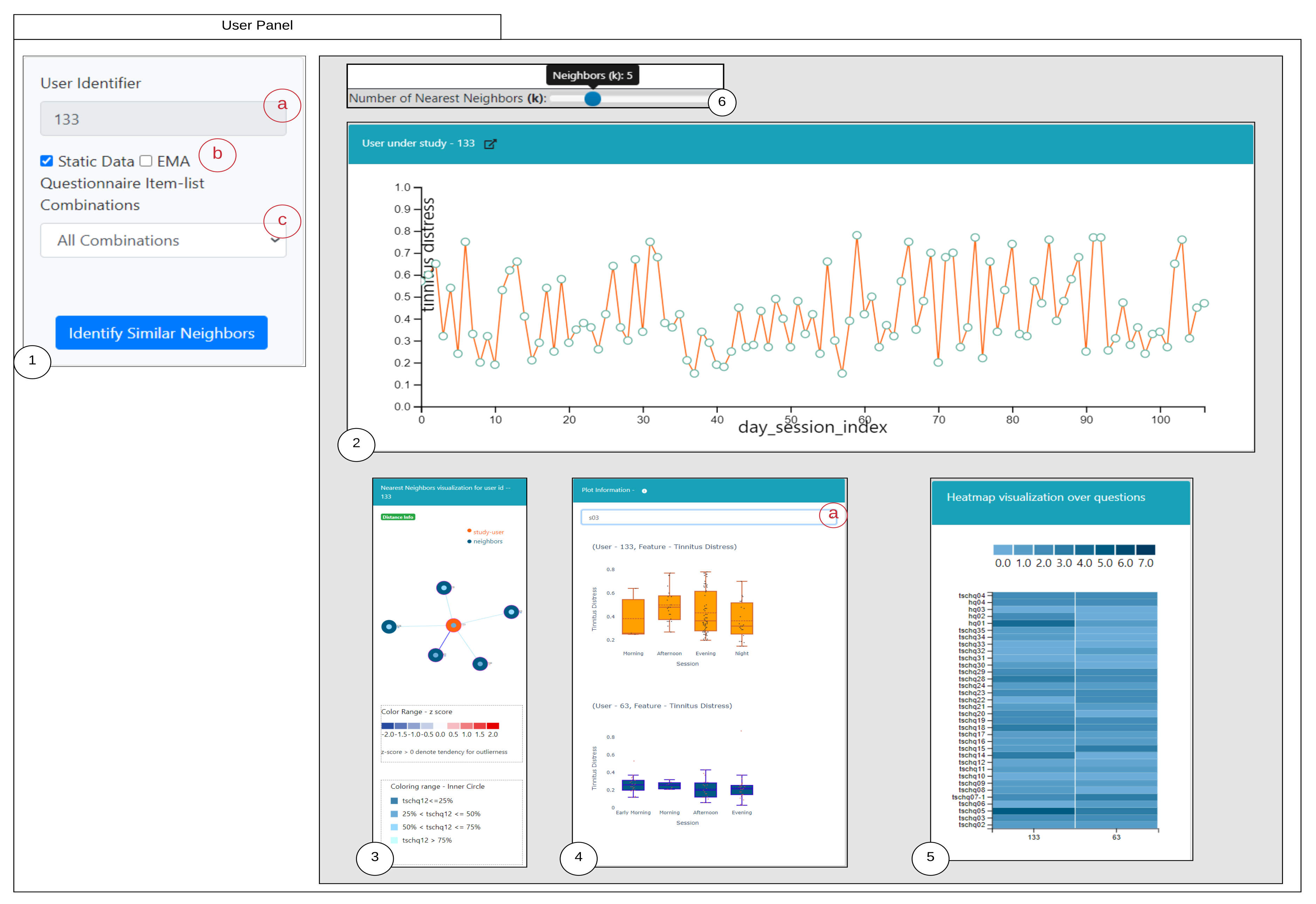
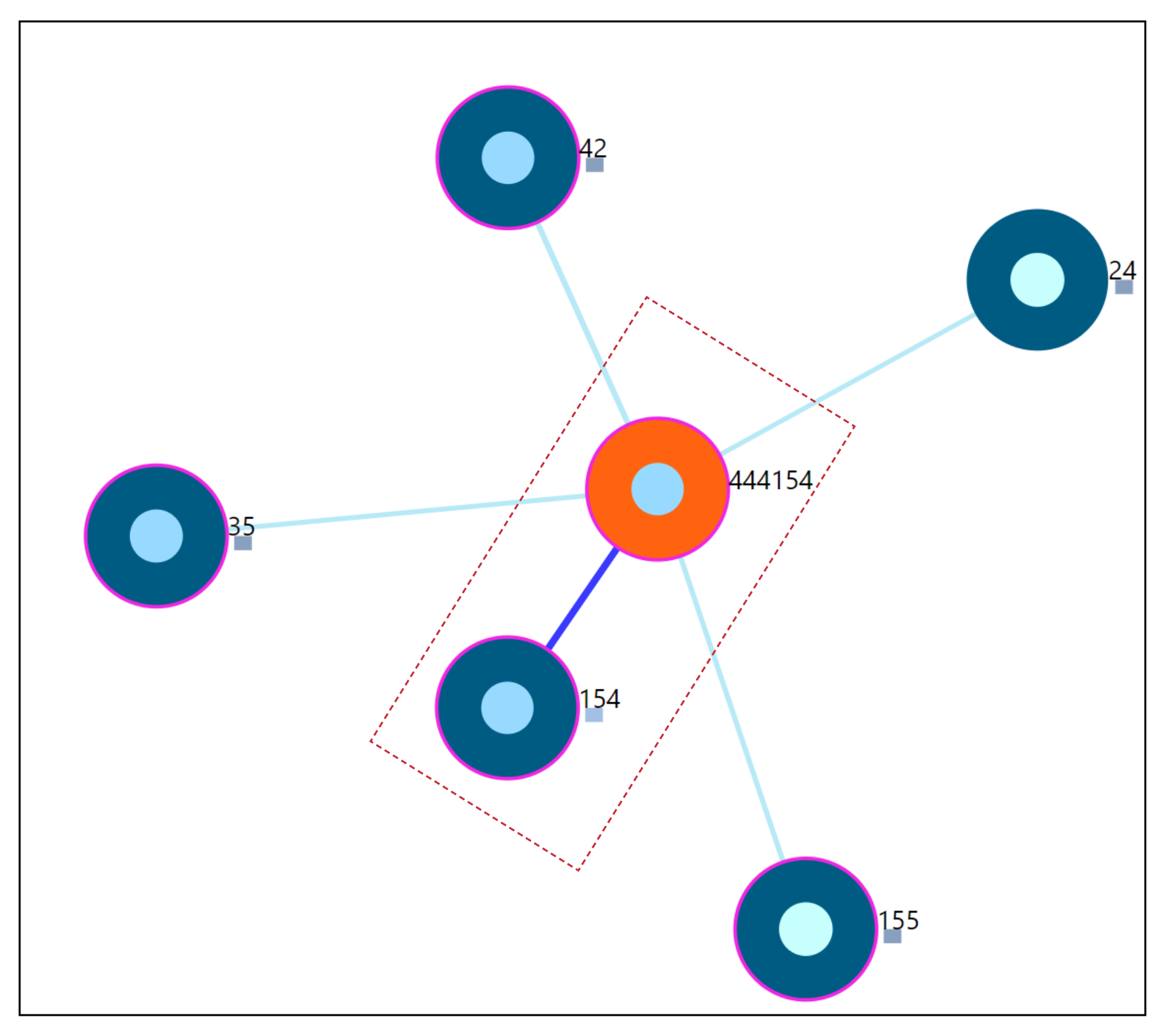
The proposed medical analytics interactive tool introduces two innovative visualizations regarding RQ3. As seen from the user-scenarios in the
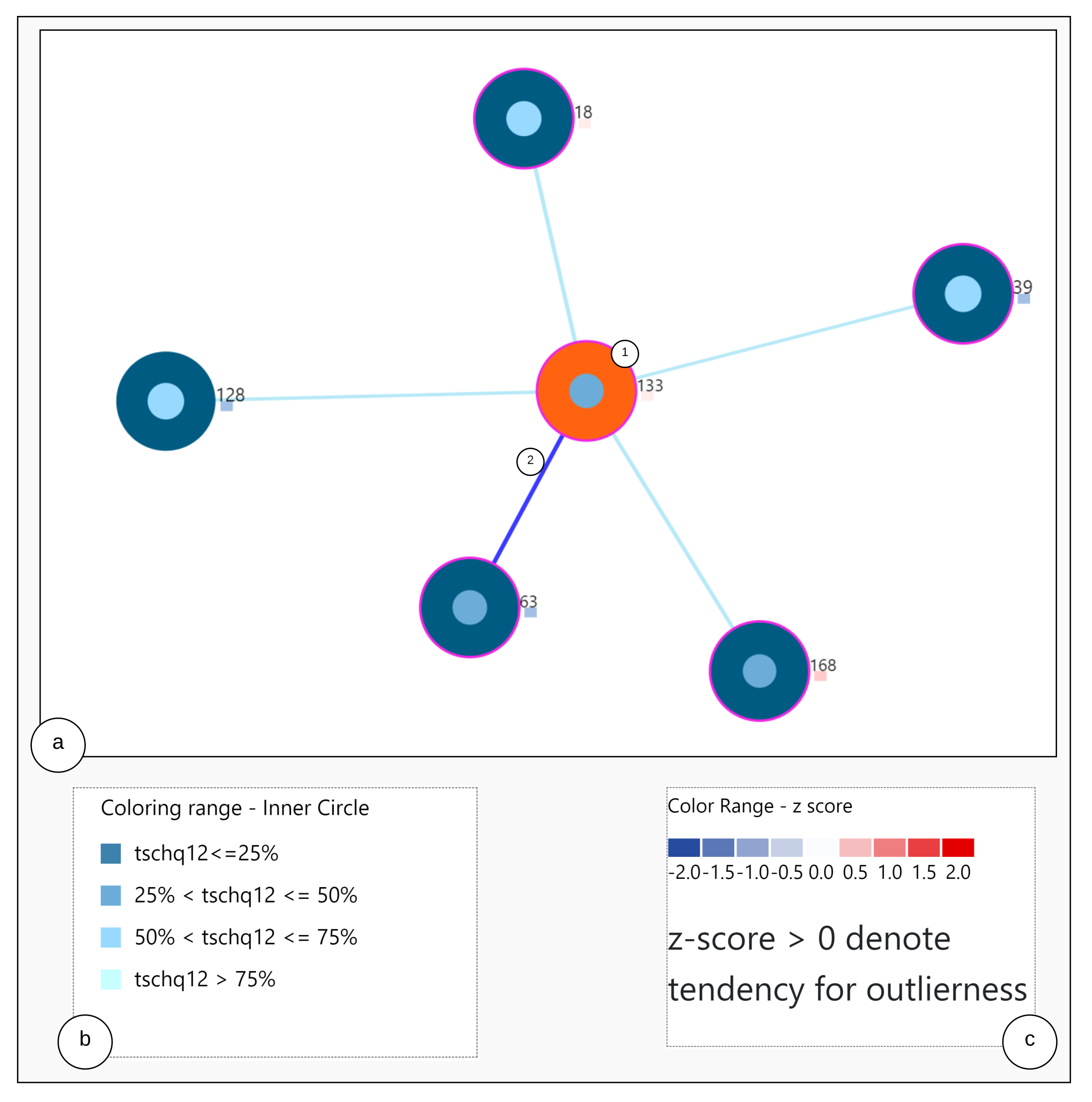
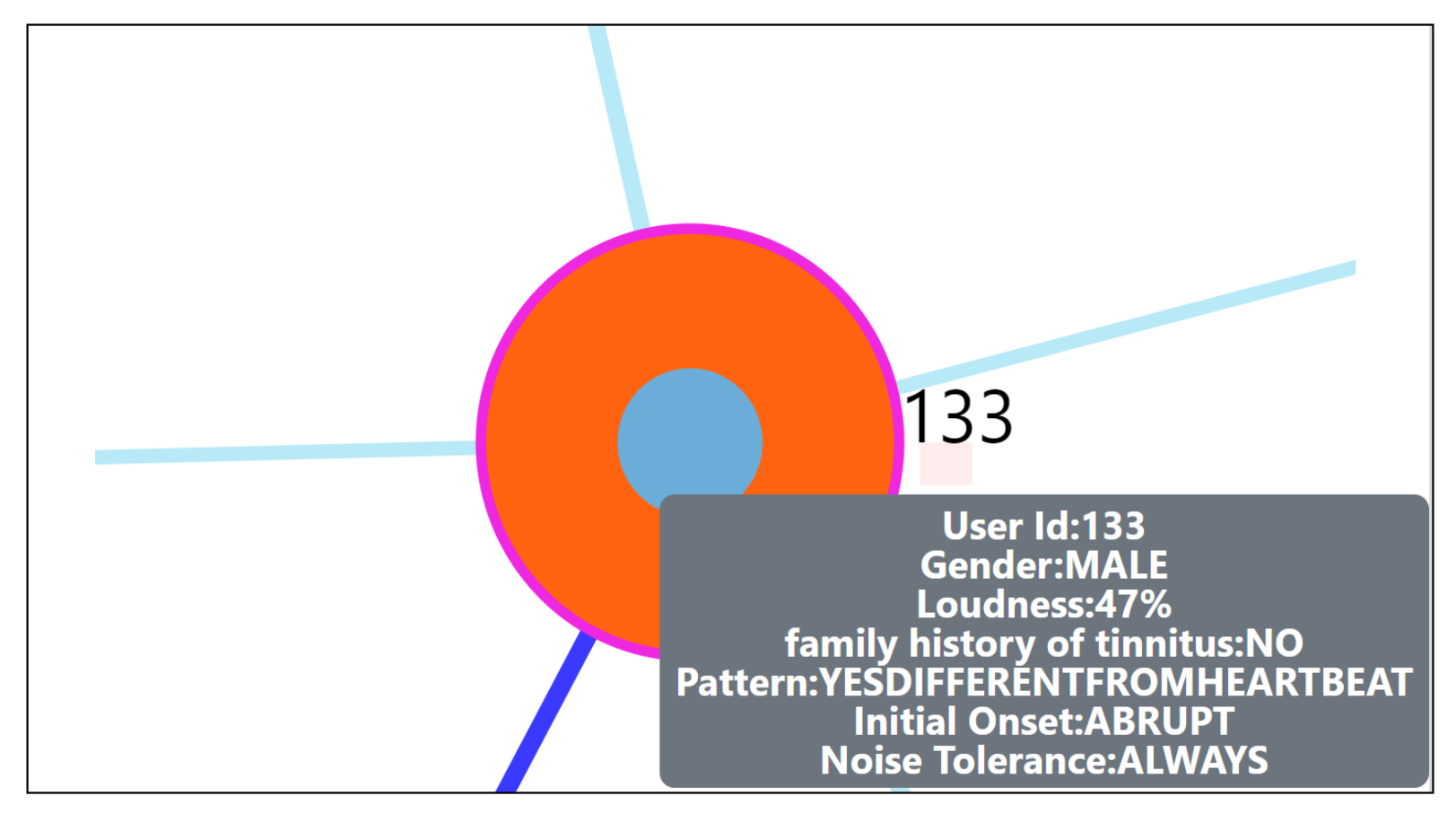
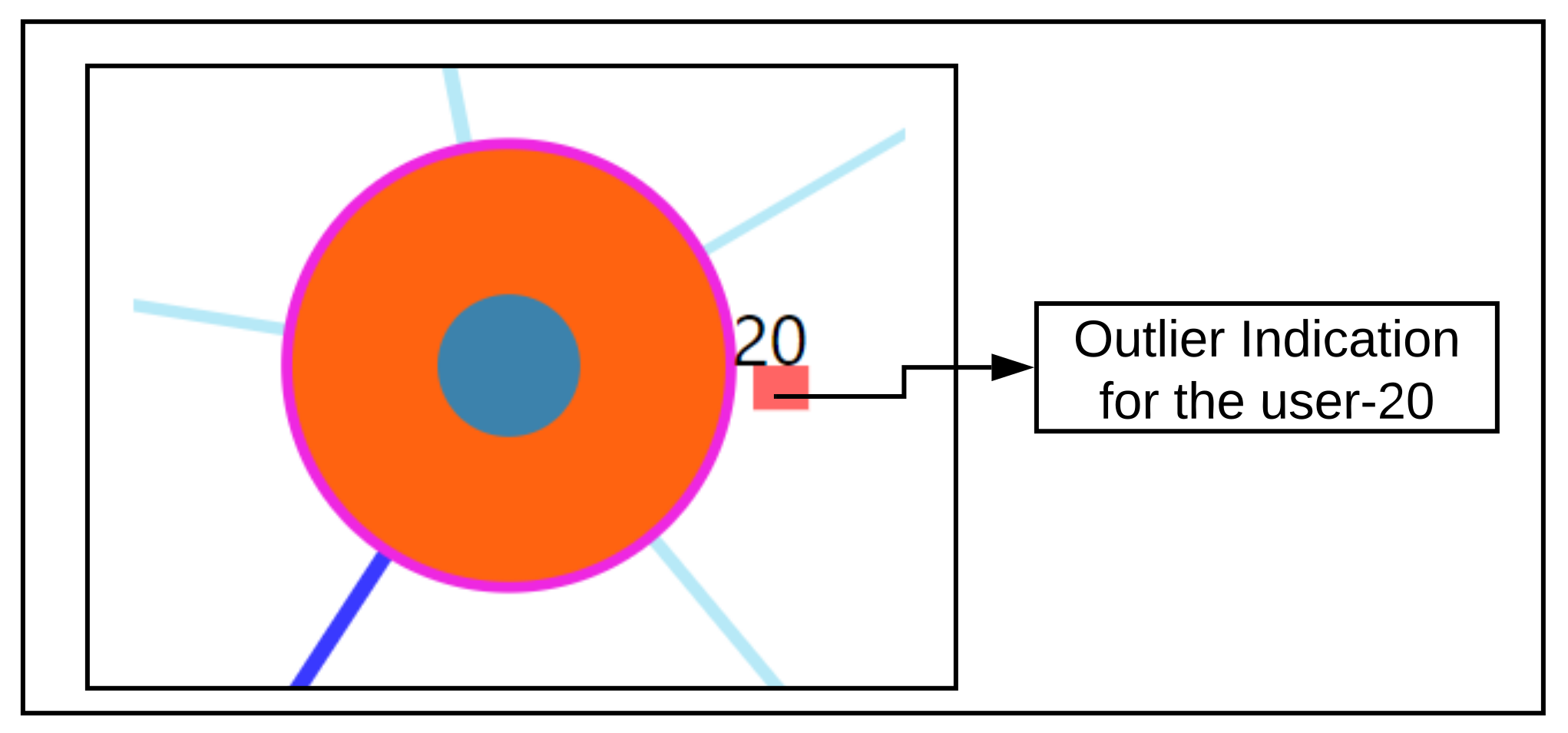
Section 7.7, we were able to correctly detect the nearest neighboring user’s based on their daily life behaviors recorded through the app. As seen from the outlier scenario, the visual encoding of the color code provides useful information to the physician about a user’s outlierness. The proposed ahead prediction visualization can help in reconsidering the patient treatment or monitoring policy.
Finally, the results are briefly reflected in a broader scope. In general, we have learned in recent years that mHealth can deliver interesting results for medical purposes [
36]. However, the use of mHealth has revealed too many flavors without comparable construction principles like presented by [
37]. Consequently, we have to investigate comparable and powerful tools to approximate ourselves to tangible medical results based on the use of mHealth. The idea to compare users might open one more perspective to learn more about mHealth behaviour and users. In this light, with this work, we may enable both computer scientists to create new algorithms better and empower medical experts to more quickly reveal user differences. As tinnitus is a very heterogeneous phenomenon, works like this may help to better demystify this heterogeneity.
From a practitioner point of view, the proposed method could be useful to identify those patients that need special care or will need additional special care any time soon. Especially in the case of sparse resources, it would allow focusing on those patients that need more or specific care to prevent more severe clinical conditions (and associated costs). By preventing higher costs and severe conditions, a commercial solution could gain market share over others that were not able to predict future data based on currently available patient information.
Threats to validity: The experimental design for RQ2 did not contain class labels to verify whether a user is behaving differently or not. To truly assess RQ2, an experiment setup must be made over a labeled dataset and verified. The underlying data did not have user answers for Mini-TQ questionnaire, and we firmly believe that making this mandatory in the app can help to better assess the user’s EMA recordings [
34]. In the proposed interactive tool, our ahead prediction visualization is concerned with only one of the EMA variables. Including predictions for the other EMA variables will be of greater benefit to the physician. The use cases explored in our interactive tool were developed with limited input from very few physicians, and a wider user study with more experts would give better insights into whether the use cases are exhaustive and sufficient from the point of view of a physician.
Future actions: As part of the future work, we are looking forward to exploring and exploiting similarity methods that can work on both static and dynamic data, and perform a comparison experiment on our introduced and existing approaches. In terms of the visualization, we look to explore new approaches of visualization to compare EMA recordings as event sequences.
9. Conclusions
To conclude, we showed from the tool that it is possible to predict a user’s future EMA based on the data of similar users, with the ability to identify outlying individuals. Our findings on outlierness indicate how important it is to closely monitor the users’ EMAs as a medical practitioner, who can assess whether action is needed as EMA values change. Our findings on the evolution of users with similar registration data over time show that registration data alone are not adequate to assess similarity during EMA recordings. Apart from the quality of predictions, we also see that the results of such an interactive system to explore the usefulness of neighborhoods and the outlierness of an individual can help bring scientists in two fields come closer together. The medical practitioner can use such a system to better intuit factors that make users different, which researchers in computer science can use to develop better algorithms to discover these differences and visualize them in a way that non-experts can intuitively understand.
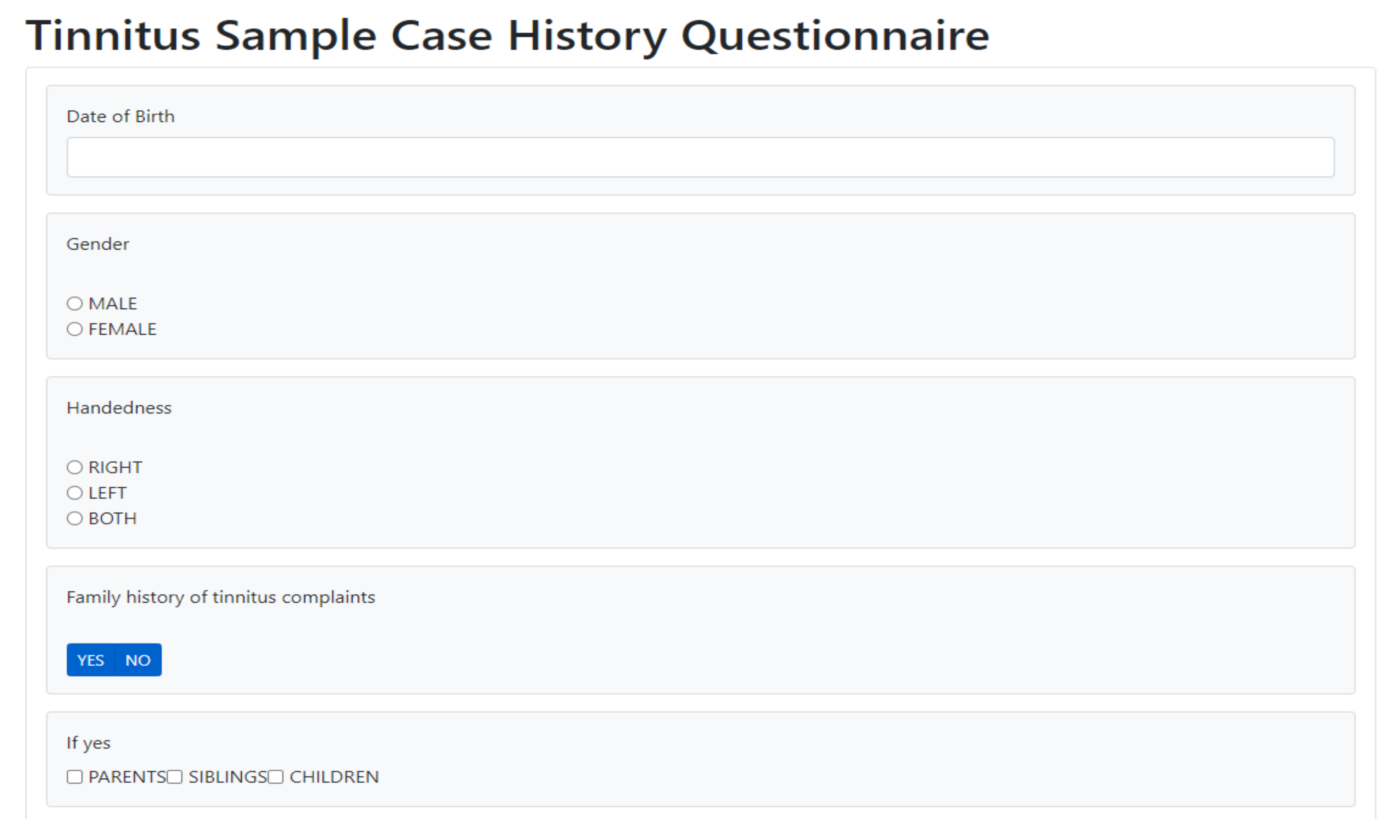
On a technical front, we discuss some opportunities for extensions on both the prediction of EMAs in the near and far future, and also the possibility to simultaneously exploit static and dynamic data during the neighborhood discovery process. The results of these methods can be compared against the current proposed method, which can serve as a baseline. The design of the visualization can be adapted to this special case with minimal effort. We also make an initial attempt with the facilitation for collecting tinnitus static data (Refer:
Figure A3). We further look to improvise regarding automatic collection, information processing and visualize within the tool itself.
More work is needed to understand whether there are subpopulations of users who have similar registration data and evolve similarly. Our findings on near and far future prediction of EMA indicate that after the first days of interaction with the mHealth app, the involvement of the users may decrease. Hence, mHealth app developers and medical practitioners should think of incentives to stimulate regular interaction (for example, gamification).


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















