
A Technical Critique of Some Parts of the Free Energy Principle


1
Araya Inc., Tokyo 107-6024, Japan
2
School of Physics and Astronomy, Monash University, Clayton, VIC 3800, Australia
*
Authors to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2021, 23(3), 293; https://0-doi-org.brum.beds.ac.uk/10.3390/e23030293
Submission received: 16 September 2020
/
Revised: 19 December 2020
/
Accepted: 24 February 2021
/
Published: 27 February 2021
(This article belongs to the Section Entropy and Biology)
{kind=link}
Abstract
:We summarize the original formulation of the free energy principle and highlight some technical issues. We discuss how these issues affect related results involving generalised coordinates and, where appropriate, mention consequences for and reveal, up to now unacknowledged, differences from newer formulations of the free energy principle. In particular, we reveal that various definitions of the “Markov blanket” proposed in different works are not equivalent. We show that crucial steps in the free energy argument, which involve rewriting the equations of motion of systems with Markov blankets, are not generally correct without additional (previously unstated) assumptions. We prove by counterexamples that the original free energy lemma, when taken at face value, is wrong. We show further that this free energy lemma, when it does hold, implies the equality of variational density and ergodic conditional density. The interpretation in terms of Bayesian inference hinges on this point, and we hence conclude that it is not sufficiently justified. Additionally, we highlight that the variational densities presented in newer formulations of the free energy principle and lemma are parametrised by different variables than in older works, leading to a substantially different interpretation of the theory. Note that we only highlight some specific problems in the discussed publications. These problems do not rule out conclusively that the general ideas behind the free energy principle are worth pursuing.
1. Overview
In [1], it was argued that the internal coordinates of an ergodic random dynamical system with a Markov blanket necessarily appear to engage in active Bayesian inference. Here, we reproduce the argument supporting this interpretation in detail and highlight at which points it faces technical issues. In the course of our critique, we also mention issues of some closely related alternative arguments. In cases where our results have clear consequences for the more recent related publications [2,3], we also mention those. In particular, we point out a conceptual difference in these latter works that has not previously been acknowledged. However, our analysis thereof does not go beyond a few remarks. In an additional section, we discuss the effect of our argument on [4]. The logical structure of the present paper is depicted in Figure 1. We note that the technical issues presented here do not affect the validity of approaches where a (expected) free energy minimizing agent is assumed a priori, as presented in, e.g., [5]. None of [1,2,3,4] make this assumption; they instead aim to identify the conditions under which such agents will emerge within a given stochastic process. We criticize specific formal issues in the latter publications but leave open whether they can be fixed. We now briefly introduce the setting of [1] and then sketch the content of this paper. We now briefly introduce the setting of [1] and then sketch the content of this paper.
The starting point is a random dynamical system whose evolution is governed by the stochastic differential equation:
where the system state x and vector field are multi-dimensional and is a Gaussian noise term. There is an additional assumption that the system is ergodic, such that the steady state probability density is well defined (In the original paper, the ergodic density is simply denoted . We here add a star to highlight that it is a time independent probability density.). In this case, plays the role of a potential function, in the sense that f can be formulated in terms of its gradients [6,7].
It is then assumed that there is a coordinate system with , , , and , referred to as external, sensory, active, and internal coordinates (these are called “states” in [1]), respectively, such that the following condition holds:
Condition 1.
The function can be written as:
This particular structure is described as “[formalizing] the dependencies implied by the Markov blanket” [1]. In contrast, more recent works [2,3] formulated the Markov blanket in terms of the statistical dependencies of the ergodic density . Specifically, the following condition is presented:
Condition 2.
The ergodic density factorises as:
In other words, the internal and external coordinates are independently distributed when conditioned on the sensory and active coordinates. This means we have two different formal expressions of what constitutes a Markov blanket in these publications, and their relationship has not previously been established.
Taking Condition 1 to hold, the argument of [1] then proceeds along the following steps:
- Step 2
- Rewrite the vector field describing the dynamics of the system in terms of the gradient of the negative logarithm of the ergodic density of that system.
- Step 3
- Rewrite the components and of the vector field in terms of only partial gradients of the negative logarithm of .
- Step 4
- Assert (in the free energy lemma) the existence of a density over the external coordinates parameterized by the internal coordinates and that can again be rewritten, this time in terms of a free energy depending on (here, and whenever it would otherwise be ambiguous, we use a capitalized to indicate full distributions, rather than the probability density for a specific value of ).
- Step 5
- Claim that the equivalence of the equations of motion in Step 3 and Step 4 implies that certain partial gradients of the KL divergence between and the conditional ergodic density must vanish.
- Step 6
- Claim that it follows from Step 5 that and are “rendered” equal.
- Step 7
- Interpret:
- as a posterior over external coordinates given particular values of sensor, active, and internal coordinates,
- as encoding Bayesian beliefs about the external coordinates by the internal coordinates, and
- their equality as the internal coordinates appearing to “solve the problem of Bayesian inference”.
In the present paper, we make the following main observations:
- The re-expression of Equation (1) in the form chosen in Step 2 is derived under restrictive assumptions, including that the system is subject to Gaussian and Markov noise.
- Conditions 1 and 2 are independent of each other.
- Conditions 1 and 3 together lead to a system where the interpretation of s and a as sensory and active coordinates is questionable.
- Under both Conditions 1 and 2, the expressions of and resulting from Step 3 are not as general as those contained in the result of Step 2. The more general alternative expression derived in [2] remains insufficiently general.
- Under both Conditions 1 and 2, the free energy lemma, when taken at face value, is wrong and cannot be salvaged by using alternatives in Step 3.
- Under both Conditions 1 and 2, contrary to Step 6, the vanishing of the gradient of the KL divergence does not imply the equality of and .
- As a consequence, the basic preconditions for the interpretations in Step 7 are not implied by either of the two proposed Markov blankets Conditions 1 and 2.
2. Expression via the Gradient of the Ergodic Density
Here, we introduce the expression of the system’s dynamics Equation (1) in the form used for the free energy lemma (Lemma 2.1 in [1]). This form expresses the dynamics of the internal and active coordinates of the given ergodic random dynamical system in terms of the gradient of the ergodic density . In accordance with the results of [7], is rewritten as (see Equation (2.5) in [1]):
where is the diffusion matrix, which we will take to be block diagonal (in [1], and later work such as [2], is taken to be proportional to the identity matrix), and R is an antisymmetric matrix, defined through the relation:
with
Here, and in all of [1,2,3,4], both and R are assumed constant. We emphasise here that, for general nonlinear models, these matrices can vary with the coordinates and Equation (5) holds only approximately [8,9] (the exact conditions under which these matrices can be chosen to be constant can be found in [9,10] and, for the discrete state case, [11]). Moreover, Equation (4) is derived in the literature under the explicit assumption that the fluctuations be Gaussian and Markov [6,7]. For the counterexamples we present here, we restrict ourselves to the class of Ornstein–Uhlenbeck processes, for which R and are always constant, and the ergodic density is necessarily a multivariate Gaussian with zero mean. Specifically, following [7],
where is a row vector and Z is a suitable normalisation constant. From Equation (4), it can be seen that,
though we emphasise here that strict relations between M and U can only be made because of the assumption that and R are coordinate independent [12]. This concludes Step 2.
Before moving on to Step 3, we note that, under the assumptions implicit in Step 2, we can express Conditions 1 and 2 in terms of the matrices M and U (in the nonlinear case, these matrices can still be defined in terms of the derivatives of the force vector field and potential, respectively; however, they will be generally coordinate-dependent, even when and R are not [8]). Firstly, since it effectively states that ,
with a block sub-matrix of M in general. Secondly, because of the multivariate Gaussian nature of , the dependencies of conditional distributions are encoded in the inverse U of the covariance matrix; we therefore have that:
where is a block sub-matrix of U. These implications bring us to our first observation:
Observation 1.
Neither Condition 1 (the vector field dependency structure) nor Condition 2 (conditional independence in the ergodic distribution) imply the other:
Proof.
In Appendix A, we provide direct counterexamples, using the equivalent constraints on the matrices M and U in Equations (9) and (10), for the implication in either direction. That is, there exists a system obeying Condition 1 that does not obey Condition 2 (proving Equation (11)), and there exists one obeying Condition 2 that does not obey Condition 1 (proving Equation (12)). □
Henceforth, unless otherwise stated, we will assume both Conditions 1 and 2. Any implications that fail to hold in this special case cannot hold generally.
3. Re-Expression Using Only Partial Gradients
For Step 3, we focus on the components and of f. Without loss of generality, we can rewrite them from Equation (4) as:
where () is the block of (R) connecting derivatives with respect to the m coordinates to the time derivatives of the n coordinates. The expectation value with respect to leaves the left-hand side of these equations unchanged. A few manipulations ([2] cf. Equation (12.14), p. 129) reveal that, on the right-hand side, this leads to the ergodic density being replaced by the marginalised ergodic density so that we get:
Since , the terms involving drop out:
We are not aware of how to further simplify this equation without additional assumptions. However, in (Equations (2.5) and (2.6) of [1]), all of the off-diagonal terms are implicitly assumed to vanish, i.e., Equation (4) is equated with:
This equation is the result of Step 3.
More recently (Appendix B of [2]), a more detailed discussion of Equation (4) was presented, where it was claimed that Condition 1 implies Condition 2 (cf. our Observation 1) along with the following simplification of Equations (17) and (18) ([2], Equations (12.8)–(12.11), (12.15), pp. 126–129):
However, Equations (21) and (22) are still provably less general than Equations (13) and (14), even when both Conditions 1 and 2 are satisfied.
Observation 2.
Proof.
By counterexample, see Appendix B. There, we show explicitly that a model satisfying the above assumptions does not satisfy the equations in question. □
In order to arrive at Equations (21) and (22) from Equations (17) and (18) in general, one must remove the offending “solenoidal flow” terms by fiat. That is, one assumes . In [2], Equation (12.4), the following, even stronger, condition was assumed as an alternative starting point (along with Condition 2):
Condition 3.
The blocks of the R matrix appearing in Equation (4) coupling coordinates to λ and ψ coordinates and ψ coordinates to λ coordinates vanish, i.e.,
This is claimed to imply , but not the full Condition 1. However, in [3], both Conditions 1 and 3 were assumed (along with ). This prompts our next observation.
Observation 3.
In a system satisfying both Conditions 1 and 3, the internal coordinates cannot be directly influenced by the sensory coordinates: , and the external coordinates cannot be directly influenced by the active coordinates: .
Proof.
From Equation (5), it follows that:
with the inverse replaced by a pseudoinverse if is not invertible. Therefore, if and for blocks of coordinates labelled by and , then:
and .
In this case, the four sets of coordinates interact in a chain, and it is questionable whether the s and a coordinates can be meaningfully interpreted, respectively, as sensory inputs to the internal coordinates or their boundary-mediated influence on the external coordinates.
4. Free Energy Lemma
The relation of the dynamics of the internal coordinates to Bayesian beliefs is made by introducing a density (called the variational density) that is then interpreted as encoding a Bayesian belief. It is parameterized by the internal coordinates and claimed to be “arbitrary”. We take this “at face value” and consider to be parameterized only by and, therefore, to be independent of . (We note that there is a convention in the literature on variational Bayesian inference, e.g., in [13], to drop the observed variables/data in the variational density. It is possible that in [1], was seen as observed variables and dropped from the variational density as in this convention. However, the reason that dropping the observed variables is justified in the established convention is that those observed variables are fixed throughout the minimization of the variational free energy and the parameters of the variational density do not influence the observed data in any way. In other words, the variational density is optimized for a single data point. In [1], the data point was continuously changing and partially doing so with dependence on the parameter as . These differences and their consequences are non-trivial and beyond the scope of this paper, so we assume that the variational density does not depend on .) If is allowed to depend on , Observation 4 does not apply, and the free energy lemma is made trivially true by setting . The existence of the variational density is asserted by the free energy lemma (see Lemma 2.1 in [1]) (Explicitly, the free energy lemma asserts the existence of a free energy in terms of which can be expressed and not the existence of . However, since the free energy is defined as a functional of , it exists if and only if a suitable exists.).
More precisely, the free energy lemma (and Step 4) asserts that for every ergodic density (equivalently as expressed in [1], for every Gibbs energy ) of a system obeying Equations (19) and (20), there is a free energy , defined as:
in terms of the “posterior density” (here, we keep the conditioning argument , as in [1], and do not explicitly assume Condition 2, though our conclusions are unaffected by it), such that Equations (19) and (20) can be rewritten as:
It is worth considering what a proof of the free energy lemma could look like. A proof of the existence of a free energy (and therefore of the free energy lemma) would need to show that, for every system satisfying the given assumptions, there always exists a such that the right-hand sides of Equations (29) and (30) are equal to the right-hand sides of Equations (19) and (20). Expanding Equations (29) and (30) using (28) leads to:
For the equality of the right-hand sides to those of Equations (19) and (20), we need:
In other words, these equations say that the free energy lemma holds if any of the following three conditions (of strictly increasing strengths) are given:
- There is a such that the partial gradients and of the KL divergence between the variational density and the conditional ergodic density are elements of the nullspaces of and , respectively.
- There is a such that the gradients of the KL divergence to are equal to the nullvector:Then, they are always elements of the nullspaces of and , respectively.
- There is a such that (and hence, ), which implies that the KL divergence to vanishes for all and the two partial gradients are always nullvectors and therefore elements of the according nullspaces.
The free energy lemma can then be proven by showing that one of these three cases follows from the conditions of the lemma. However, no attempt was made in [1] to establish this. Instead, the given proof discusses the purported consequences of the existence of a suitable . These will be discussed in Steps 5 and 6.
Even if the free energy lemma does not hold for systems obeying Equations (19) and (20), one might expect that the systems instead only satisfy the more general Equations (21) and (22) or the most general Equations (17) and (18). For these systems, the free energy lemma would require that there is a such that:
or:
hold, respectively. However, we find this not to be the case in general.
Observation 4.
Given a random dynamical system obeying Equation (1), ergodicity, Conditions 1 and 2, there need not exist a free energy expressed in terms of a variational density such that:
- (i)
- (ii)
- (iii)
Proof.
In Appendix C, we derive a set of conditions on the R and U matrices and on the putative variational density , which follow from each of the pairs of equations in Cases (i–iii). We show that, in general, each pair leads to a contradiction, and in each case, we provide a counterexample that falls into the according system class. □
Before proceeding, we note that later works presented an alternative version of the free energy lemma, where the conditioning argument of was replaced by the most likely value of conditional on the coordinates [2,3]. We here concern ourselves with the version apparent in [1], where is parametrised by the internal states themselves, but we briefly comment on the interpretation of the alternative approach in Step 7.
5. Vanishing Gradients
As mentioned in Step 4, the proof of the free energy lemma in [1] only discussed its consequences. The first proposed consequence is that expressing the vector field in terms of a free energy as in Equations (29) and (30) “requires” that the gradients with respect to a and of the KL divergence vanish, i.e., that Equations (35) and (36) hold.
We mentioned in Step 4 that the implication in the opposite direction holds. This can be seen from Equations (33) and (34). However, if the nullspace of or is non-trivial, then the gradient may be a non-zero element of this subspace and Equations (29) and (30) will still hold. In that case, the vanishing gradients would not be necessary for the free energy lemma.
The conditions under which a non-trivial nullspace exists were discussed in [7]. In short, the nullspace is guaranteed to be trivial in the special case where is positive definite. Whether or not ergodic systems with a Markov blanket can ever admit a non-trivial nullspace, and hence divergences in Equations (31) and (32) with non-vanishing gradients, is not immediately clear. However, in order to establish the necessity of Equations (35) and (36), this remains to be proven.
6. Equality of and
The proof of the free energy lemma in [1] also proposes that the vanishing of the gradients of the KL divergence, of the variational density from the conditional ergodic density , implies the equality of these densities. We mentioned in Equations (5) that the implication in the opposite direction holds. This can also be seen from Equations (33) and (34). Concerning the implication in the direction proposed by [1], let us now assume that for a given system of Equations (19) and (20) holds, a variational density does exist, and the gradients of the KL divergence of the variational and ergodic densities vanish, i.e., Equations (35) and (36) hold. Then, consider the argument by [1] in this direct quote (comments in square brackets by us):
In other words, the flow of internal and active states minimizes free energy, rendering the variational density equivalent to the posterior density over external states.”
The first problem in the above quote is that the minimization of the divergence does not follow from the vanishing gradients. On the contrary, since Equations (35) and (36) must hold for all , the KL divergence:
cannot depend on ; it therefore has no extremum (and thus no minimum) with respect to either of these coordinates.
The second problem pertains to the identification of the two distributions at a minimum. In general, if we try to find the minimum of a KL divergence between a given probability density and a family of densities parameterized by , then the lowest possible value of zero is achieved only if there is a parameter such that . If there is no such , then the minimum value will be larger than zero. Therefore, even if the divergence were minimized, it would not need to be zero. More generally, the divergence need not be zero for any value of s.
There is therefore no satisfactory reason given why the variational density and the posterior density should be equal or have low KL divergence. In fact, they need not be (Note that, since any that does not depend on is an element of the set of those that do, Observation 5 remains true for the case where we allow this dependence. In that case, the free energy lemma holds because we can set , and thus, a q exists for which the densities are actually equal. However, the claim here is that for every q that obeys the conditions in Observation 5, we must have equality.).
Observation 5.
Given a random dynamical system obeying Equation (1), ergodicity, Conditions 1 and 2. Then if, additionally,
- (i)
- (ii)
- (iii)
then there is no for which it can be guaranteed that:
In particular, it does not follow from these conditions that:
Proof.
By example, see Appendix D. To show that the implication does not generally hold for a given system and densities that obey Equations (19), (20), (29), and (30), Equations (21), (22), (37), and (38), or Equations (17), (18), (39), and (40), we only have to consider a system that obeys all three pairs of equations, Equations (19) and (20), Equations (21) and (22), and Equations (21) and (22), and for which a suitable exist. For this system, we then need to show that the that obey Equations (29) and (30) are not necessarily equal (or similar) to .
We use a variant of the model used in Appendix B as such a counterexample. This system obeys all three of Equations (19) and (20), Equations (21) and (22), and Equations (21) and (22), and the nullspace of the associated is trivial. We identify a set of possible satisfying Equations (29) and (30), which implies that the gradients of the KL divergence between those and vanish, i.e., Equations (35) and (36) hold. We then demonstrate that for the in this set, the value of the KL divergence to can be arbitrarily large. □
7. Interpretation
Finally, we turn our attention to the interpretation in terms of Bayesian inference, i.e., Step 7. We again quote directly from [1]:
Because (by Gibbs inequality) this divergence [DKL] cannot be less than zero, the internal flow will appear to have minimized the divergence between the variational and posterior density. In other words, the internal states will appear to have solved the problem of Bayesian inference by encoding posterior beliefs about hidden (external) states, under a generative model provided by the Gibbs energy.
We showed that, in general, there is no suitable variational density that is only parameterized by the internal coordinate . We then showed that, even if there is a suitable variational density (including those parameterized by all of ), it can be arbitrarily different from the posterior density. Since the arguments for the internal flow appearing to minimize the divergence between variational and posterior density are therefore incorrect, there is no reason why the internal states should appear to have solved the problem of Bayesian inference.
As mentioned in Step 4, some newer works (e.g., [2,3]) formulated a different free energy principle, where the variational density of beliefs is parametrised not by the internal coordinates , but by , the most likely value of the internal coordinates given the sensory and active ones. In this case, Observations 4 and 5 do not apply. However, the new parameters are strictly a function of the sensory and active coordinates. This means we have a Markov chain (with capitalisations indicating random variables associated with the corresponding lower case coordinates (or functions of coordinates)) and, by the data processing inequality [14], the mutual information between the both sensory and active coordinates and the belief parameter upper bounds that are between the internal coordinates and the belief parameter. It is therefore not clear to what extent the internal coordinates , rather than the active and sensory coordinates themselves, can be said to be encoding beliefs about the external coordinates. Note also that, on any given trajectory, unless the distribution is sufficiently peaked and unimodal, the internal coordinates are not guaranteed to spend most of their time close to their most likely conditional value, and (by definition if Condition 2 holds) they will not be better predictors of the external coordinates than those in the Markov blanket.
Generally, , and is the solution to an optimization problem that is assumed to be solved in these later works. Using this optimized variable to parametrise beliefs is therefore a considerable departure from [1]. Contrary to the impression created by the way it was referenced in [2,3], the older theory in [1] should be clearly distinguished from the newer ones in these more recent papers.
8. Consequences for Friston, K. et al. 2014
Reference [4] argued for the same interpretation as [1], but there were some differences in the argument.
The differences were the following:
- The Markov blanket structure was not explicitly defined via Equation (2). Formally, it was introduced directly (see [4] Equation (10)) in a less general form corresponding to Equations (19) and (20) (at the same time, [1] is referenced in connection to the Markov blanket so there seems to be no intention to replace the original definition with the stronger one). Therefore, our observations concerning Steps 2 to 4 are not directly relevant to this paper.
- The internal coordinate was renamed to r, and the role of matrix R was played by the matrix .
- The proof of the free energy lemma given in [4] was different. It (implicitly) suggested setting the variational density equal to the ergodic conditional posterior.
- The proof of the free energy lemma no longer contained the proposition that the gradient of the KL divergence of the variational density and the ergodic conditional density vanish, i.e., Step 5.
- The proof also no longer contained the claim that the vanishing gradients of the KL divergence of the variational density and the ergodic conditional density imply the equality of those densities, i.e., Step 6 was not present.
The interpretation in terms of Bayesian inference was unchanged and still relied on the equality of the variational and the ergodic conditional density.
Since there were no explicit generalized coordinate versions of Steps 2, 3, 5 and 6 in [4], we do not discuss those steps here. We only disprove the free energy lemma and the claim that when the free energy lemma holds, the variational and ergodic conditional density become equal. For this, we present a way to translate the counterexamples used in Observations 4 and 5 into counterexamples in generalized coordinates. The interpretation in terms of Bayesian inference given in [4] is therefore equally as unjustified as the one in [1].
For completeness, we first state the generalized coordinate versions of the stochastic differential Equation (1):
the less general version of the Markov blanket structure Equation (2):
the expression of the and components of the vector field in terms of the marginalised ergodic density Equations (19) and (20):
and in terms of free energy Equations (29) and (30):
The free energy lemma then requires that there exists such that the KL divergence between vanishes. Without going into further details of the difference between the proof in [4] and that in [1], we can prove the former wrong by translating the counterexample used for the latter into generalised coordinates.
Observation 6.
There is a general way to translate a system in ordinary coordinates into a system of generalised coordinates that corresponds to an infinite number of independent copies of the original system. This means all properties of the original system (e.g., linearity, ergodicity, the Gaussian and Markovian property of the noise, Conditions 1 and 2, the properties of ) are preserved during this translation.
Proof.
By construction, see Appendix E. □
This implies that the counterexamples used in proving Observations 4 and 5 directly translate to the setting of the generalised coordinates. The free energy lemma is therefore also wrong for generalised coordinates, and the variational density is not “ensured” [4] to be equal to the conditional ergodic density .
9. Conclusions
We find that the two different Markov blanket conditions proposed in [1,2,3] are independent of each other. We then show that under both of those Markov blanket conditions, among the six steps contained in the argument in [1], three do not hold independently of each other. We also show that fixing the second of those steps (Step 3) does not provide a valid alternative. The line of reasoning of [1] therefore does not support its claim that the internal coordinates of a Markov blanket “appear to have solved the problem of Bayesian inference by encoding posterior beliefs about hidden (external) [coordinates], …”. We also show that using generalised coordinates as in [4] does not remedy the situation. Additionally, we identify a technical error in [2] and an interpretational issue resulting from possibly too strong assumptions (both Conditions 1 and 3) in [3]. We also highlight that the latter publications both argued that it is the most likely internal coordinates given sensory and active coordinates that encode posterior beliefs about external states instead of the internal coordinates themselves. The resulting free energy principle and lemma are therefore a different proposal. This is not subject to our technical critique.
Author Contributions
Conceptualization, M.B., F.A.P., and R.K.; formal analysis, M.B. and F.A.P.; funding acquisition, F.A.P. and R.K.; methodology, M.B., F.A.P., and R.K.; visualization, M.B. and F.A.P.; writing—original draft, M.B. and F.A.P.; writing—review and editing, M.B., F.A.P., and R.K. All authors read and agreed to the published version of the manuscript.
Funding
The work by Martin Biehl and Ryota Kanai on this publication was made possible through the support of a grant from Templeton World Charity Foundation, Inc. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of Templeton World Charity Foundation, Inc. Martin Biehl and Ryota Kanai are also funded by the Japan Science and Technology Agency (JST) CREST project. Felix A. Pollock acknowledges support from the Monash University Network of Excellence for Consciousness and Complexity in the Conscious Brain.
Acknowledgments
All authors are grateful to Karl Friston and Thomas Parr for constructive feedback on an earlier version of this work. We also want to thank Danijar Hafner for pointing us to [9]. Martin Biehl wants to thank Yen Yu for helpful discussions on generalized coordinates.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; nor in the decision to publish the results.
Appendix A. Counterexamples for Observation 1
Consider a four-dimensional linear system obeying Equation (1) for which there are coordinates with and:
with the parametrisation:
From Equation (9), it is clear that the system obeys Condition 1 if . In this case, taking to be the identity matrix, it is possible to show that:
For fixed, finite , this is zero only for a few discrete values of , such as ; that it is generically non-zero proves Equation (11). As a concrete example, the following:
has:
and (full rank and hence ergodic):
and hence ergodic density:
which does not conditionally factorise.
Taking the same parametrisation as in Equation (A2) and fixing , we can search for a non-zero value of that leads to (equivalent to Condition 2 through Equation (10)). We find such a value in the real root of the quintic equation ; that is, with:
which does not satisfy Condition 1, we have:
and:
which has a non-zero determinant (i.e., the dynamics is ergodic) and an ergodic density satisfying Condition 2. This proves Equation (12).
Appendix B. Counterexample for Step 3
Here, we consider a linear system, as in the previous Appendix. We again assume equal to the identity matrix and choose a force matrix of the form:
which explicitly satisfies Condition 1 and has full rank such that the system is ergodic. Using Equation (5), this leads to:
which shows that this system also satisfies Condition 2 since . We also find:
which shows that all entries or R that can be non-zero for an anti-symmetric matrix are non-zero. For the marginal ergodic density, we find:
The difference between the right-hand sides of Equations (17) and (19) is:
which shows that Equation (19) is wrong in this example and therefore not generally equivalent to Equation (17). Similarly, computing the difference between the right-hand sides of Equations (18) and (20), one finds:
and hence, Equation (20) is also incorrect in general.
Performing the same comparison for the difference between the general expression in Equations (17) and (18) and the expressions taken from [2], one finds:
for the difference between the right-hand sides of Equations (17) and (21), and:
for the difference between the right-hand sides of Equations (18) and (22). Therefore, Equations (21) and (22) are also incorrect in general, even when Conditions 1 and 2 both hold.
Appendix C. Counterexamples for Step 4
We saw in Appendix B that Equations (19) and (20) are not generally equivalent to Equation (4), even when Conditions 1 and 2 hold simultaneously. We now show that if we instead use Equations (17) and (18), which are generally equivalent to Equation (4), the free energy lemma does not hold in general.
The original free energy lemma requires that (see Equations (31) and (32)):
Replacing the partial gradient in Equations (29) and (30) with the full gradient and including the entire matrix lead to the corresponding requirement for the more general case:
Similarly, the version based on the equations taken from [2] implies:
Using the rules of Gaussian integration, we can write the logarithm of the conditional ergodic density as:
with C a constant (and remembering each of , s, a, and is a vector of coordinates in general). We can then expand the derivatives of the KL divergence to express them in terms of the coordinates:
with and H the Shannon entropy.
Substituting Equations (A27) and (A28) into Equations (A19) and (A20) leads to:
and:
Since these must hold for all values of the coordinates, they put strong requirements on the U and R matrices. Specifically,
In other words, since and must be nonzero for the dynamics to be ergodic, it must be that (This is equivalent to . Therefore, if Condition 2 also holds, we must have in order for there to be a suitable .). Specifically, consider the system specified by the force matrix:
which leads to:
and:
Here, M is full rank, so the system is ergodic; clearly, it also satisfies Condition 1 due to the structure of M. Since , it obeys Equations (19) and (20), and since , it also obeys Condition 2. Additionally, we find , which is a contradiction.
For the more general version, substituting Equations (A26)–(A28) into Equation (A21), one finds:
which, considering that the coordinates can take any values, implies that:
lies in a common (left) nullspace of , , and . However, the existence of such a nontrivial nullspace would imply that the corresponding subspace of coordinates is independent of the s, a, and coordinates (to see this, consider marginalising over their complement in Equation (A25)). In other words, if only coordinates that play a nontrivial role in the dynamics are considered, then Equation (A21) must imply that the quantity in Equation (A38) is zero and hence that:
However, through a similar procedure, one finds that Equation (A22) is equivalent to:
implying that:
Unless and share a common nullspace or the U and R matrices are finely tuned, then Equations (A39) and (A41) contradict one another. In this case, there cannot exist a that satisfies both Equations (A21) and (A22), and hence, the modified free energy lemma is invalid in general. In particular, using the example from Appendix B, if we solve Equation (A39) for , we find:
and from Equation (A41), we get:
which is a contradiction.
If we now perform the same procedure for Equations (A23) and (A24), we arrive at the following conditions on the gradient of the variational density:
and:
Even when Condition 2 holds and , these will be inconsistent in general. As a specific counterexample, take the system with force matrix:
with corresponding:
and:
This model is ergodic (full rank U), and it satisfies both Conditions 1 and 2. Moreover, the forces satisfy Equations (21) and (22). However, substituting the relevant elements of the U and R matrices into Equation (A44), we find:
but doing the same for Equation (A45) gives:
which is a contradiction.
Appendix D. Counterexample for Step 6
Here, we provide an example system for which Conditions 1 and 2, as well as Steps 2 to 5 are valid, but Step 6 fails. We use a system with:
where:
This system is ergodic, satisfies Condition 1, and as we will will see, satisfies Equations (19) and (20) as well. Using Equation (5), we find:
and from Equation (8):
which means that Condition 2 is also satisfied.
This leads to the ergodic density:
which can be used to check that Equations (19) and (20) hold for this example. The conditional ergodic density is:
If we now define as a Gaussian distribution with mean and variance one, we can compute the KL divergence to get:
Clearly, for this choice of , the gradients with respect to a and of the KL divergence vanish everywhere (Equations (35) and (36) hold). This also means we can express in terms of a free energy, i.e., the free energy lemma holds for this system. However, for any proposed bound on the KL divergence, there is a value of s for which it is exceeded, whatever the choice of . Moreover, we can choose a such that the KL divergence is larger than any given c, even when .
Appendix E. Translating Systems into Generalized Coordinate Systems
We show how to get a generalized coordinate system from a finite-dimensional system. By definition, the generalized coordinates are infinite-dimensional. For all and a coordinate x, they also include the n-th time derivative of x.
Assume as given an ergodic, linear, random dynamical system described by:
where is a k-dimensional vector, M is a real-valued matrix, and . We can look at the second time derivative of the state by differentiating both sides:
Similarly for the third time derivative:
Similarly for all higher derivatives:
Now, define the generalized coordinates as:
Define also:
Without further clarification, the derivatives of are not well defined when the latter is a Gaussian white noise process, as explicitly assumed in writing the vector field in terms of the ergodic density [6,7,8]. As discussed in [15], delta-correlated Markovian noise is always a limiting approximation of noise with a finite correlation time. Meaningfully taking the derivatives requires first choosing a functional form for the (co)variance whose limit is a delta function (another, more direct approach would be in terms of generalized functions, but here too, additional information is required to specify the derivatives [16]). However, different choices can lead to vastly different central moments of the generalized noise distribution, including those that vanish or diverge at all orders. In the former case, the process in terms of generalized coordinates may not be ergodic [17]; in the latter case, the process is not well defined. In general, it is not clear that Equation (4) holds in the non-Markovian case, since the standard derivations in [6,7] and related works rely on delta-correlated noise.
Here, we can therefore assume that the noise is such that the derivatives in Equation (A70) can be treated as Markov and Gaussian. We also assume that is independently and identically distributed to for all n. Finally, we can then define the (infinite) matrix as the block diagonal matrix with all blocks equal to M:
The time derivative of is independent of , as the changes are independent of the value of . Therefore, we actually get an infinite number of independent and identically distributed systems. Using these definitions, we have:
These equations describe a random dynamical system composed of an infinite number of independent linear random dynamical systems, all governed by the same matrix M and driven by independently and identically distributed noise. Since the first of these systems (for the variables x) is ergodic by assumption, all of the subsystems are also ergodic, and therefore, the whole system is ergodic with the ergodic density equal to a product of the original ergodic density:
Additionally, if M is such that:
(which is the case for the M in the counterexample to Step 6) then for:
and using Equation (8) and that the inverse of a block diagonal matrix is block diagonal:
we also have:
The ergodic density of such a system is a product of the ergodic densities of the original system Equation (A56):
Thus, any property of the original system is also a property of the generalized coordinate system.
References
- Friston, K. Life as we know it. J. R. Soc. Interface 2013, 10, 2013.0475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friston, K. A free energy principle for a particular physics. arXiv 2019, arXiv:1906.10184. [Google Scholar]
- Parr, T.; Da Costa, L.; Friston, K. Markov blankets, information geometry and stochastic thermodynamics. Philos. Trans. R. Soc. A 2019, 378, 2019.0159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friston, K.; Sengupta, B.; Auletta, G. Cognitive Dynamics: From Attractors to Active Inference. Proc. IEEE 2014, 102, 427–445. [Google Scholar] [CrossRef]
- Friston, K.; Rigoli, F.; Ognibene, D.; Mathys, C.; Fitzgerald, T.; Pezzulo, G. Active inference and epistemic value. Cogn. Neurosci. 2015, 6, 187–214. [Google Scholar] [CrossRef] [PubMed]
- Ao, P. Potential in stochastic differential equations: Novel construction. J. Phys. A 2004, 37, L25–L30. [Google Scholar] [CrossRef]
- Kwon, C.; Ao, P.; Thouless, D.J. Structure of stochastic dynamics near fixed points. Proc. Natl. Acad. Sci. USA 2005, 102, 13029–13033. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwon, C.; Ao, P. Nonequilibrium steady state of a stochastic system driven by a nonlinear drift force. Phys. Rev. E 2011, 84, 061106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Y.A.; Chen, T.; Fox, E.B. A complete recipe for stochastic gradient MCMC. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 2; MIT Press: Montreal, QC, Canada, 2015; pp. 2917–2925. [Google Scholar]
- Yuan, R.; Tang, Y.; Ao, P. SDE decomposition and A-type stochastic interpretation in nonequilibrium processes. Front. Phys. 2017, 12, 120201. [Google Scholar] [CrossRef]
- Ao, P.; Chen, T.Q.; Shi, J.H. Dynamical Decomposition of Markov Processes without Detailed Balance. Chin. Phys. Lett. 2013, 30, 070201. [Google Scholar] [CrossRef]
- Yuan, R.S.; Ma, Y.A.; Yuan, B.; Ao, P. Lyapunov function as potential function: A dynamical equivalence. Chin. Phys. B 2014, 23, 010505. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C. Pattern Recognition and Machine Learning; Information Science and Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- van Kampen, N.G. Stochastic Processes in Physics and Chemistry; North-Holland: Amsterdam, The Netherlands, 1981. [Google Scholar]
- Oberguggenberger, M. Generalized Functions and Stochastic Processes. In Seminar on Stochastic Analysis, Random Fields and Applications. Progress in Probability; Bolthausen, E., Dozzi, M., Russo, F., Eds.; Birkhäuser: Basel, Switzerland, 1995; Volume 36, pp. 215–230. [Google Scholar]
- Cornfeld, I.P.; Fomin, S.V.; Sinai, Y.G. Ergodic Theory; Springer: New York, NY, USA, 1982. [Google Scholar]
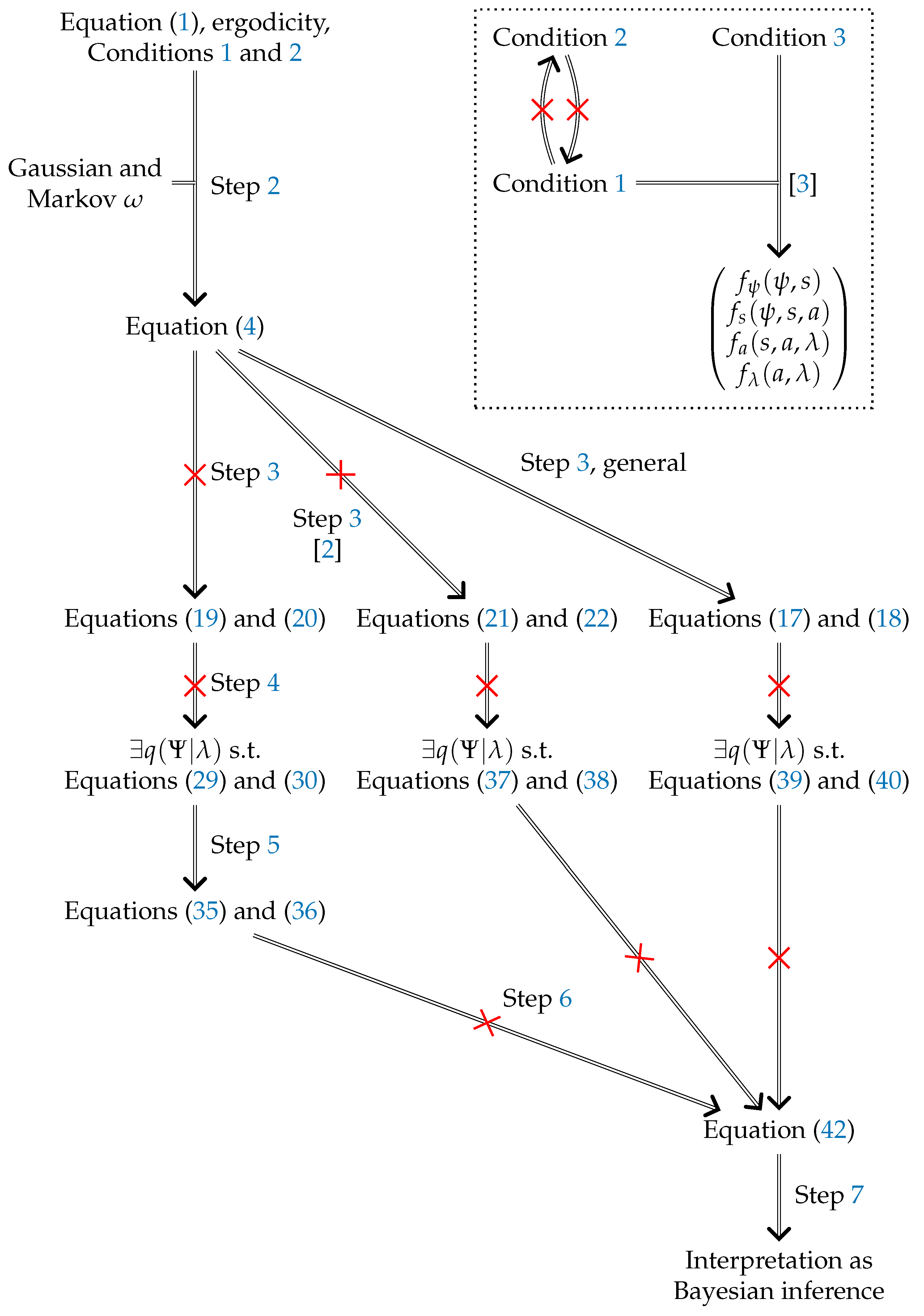
Figure 1.
Argument visualization. Numbers labelling edges indicate corresponding steps in this paper. Struck out edges indicate implications that we prove incorrect. The main argument in [1] takes the left path. The box in the top right indicates the relations between Conditions 1 to 3 and their role in [3]. Merged edges indicate a logical AND combination of the parent nodes.
Figure 1.
Argument visualization. Numbers labelling edges indicate corresponding steps in this paper. Struck out edges indicate implications that we prove incorrect. The main argument in [1] takes the left path. The box in the top right indicates the relations between Conditions 1 to 3 and their role in [3]. Merged edges indicate a logical AND combination of the parent nodes.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Biehl, M.; Pollock, F.A.; Kanai, R. A Technical Critique of Some Parts of the Free Energy Principle. Entropy 2021, 23, 293. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030293
AMA Style
Biehl M, Pollock FA, Kanai R. A Technical Critique of Some Parts of the Free Energy Principle. Entropy. 2021; 23(3):293. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030293
Chicago/Turabian StyleBiehl, Martin, Felix A. Pollock, and Ryota Kanai. 2021. "A Technical Critique of Some Parts of the Free Energy Principle" Entropy 23, no. 3: 293. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030293
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.