
Information Measure in Terms of the Hazard Function and Its Estimate


1
Department of Statistics and Data Science, Yonsei University, Shinchon Dong 134, Seoul 03722, Korea
2
Department of Applied Statistics, Yonsei University, Shinchon Dong 134, Seoul 03722, Korea
Entropy 2021, 23(3), 298; https://0-doi-org.brum.beds.ac.uk/10.3390/e23030298
Submission received: 14 January 2021
/
Revised: 22 February 2021
/
Accepted: 25 February 2021
/
Published: 28 February 2021
(This article belongs to the Special Issue Applications of Information Theory in Statistics)
Abstract
:It is well-known that some information measures, including Fisher information and entropy, can be represented in terms of the hazard function. In this paper, we provide the representations of more information measures, including quantal Fisher information and quantal Kullback-leibler information, in terms of the hazard function and reverse hazard function. We provide some estimators of the quantal KL information, which include the Anderson-Darling test statistic, and compare their performances.
1. Introduction
Suppose that X is a random variable with a continuous probability density function (p.d.f.) , where is a real-valued scalar parameter. It is well-known that the Fisher information plays an important role in statistical estimation and inference, which is defined as
Fisher information identity in terms of the hazard function has been provided by Efron and Johnstone [1] as
where is the hazard function defined as and is the cumulative distribution function.
It is also well-known that the entropy (Teitler et al., 1986) and Kullback-Leibler information [2] can be represented in terms of the hazard function, respectively, as
and
where and are the hazard functions defined as and , respectively.
The quantal (randomly censored) Fisher information and the quantal (randomly censored) Kullback-Leibler information have been defined [3], respectively, as
and
where is an appropriate weight function which satisfies .
The quantal Fisher information is related with the Fisher information in the ranked set sample, and the quantal Kullback-Leibler information is related with the cumulative residual entropy [4] and cumulative entropy [5], defined as
and
The information representation in terms of the cumulative functions enables us to estimate the information measure by employing the empirical distribution function.
The organization of this article is as follows: In Section 2, we discuss the relation between the quantal Fisher information and quantal Kullback-Leibler information. In Section 3, we provide the expression of the quantal Fisher information in terms of the hazard and reverse hazard functions as
where and are the hazard and reverse hazard functions, respectively.
We also provide the expression of the quantal (randomly censored) KL information in terms of the hazard and reverse hazard functions as
where and are the reverse hazard functions defined as and , respectively.
This representation enables us to estimate the quantal information by employing the nonparametric hazard function estimator. In Section 4, we discuss the choice of the weight function in terms of maximizing the related Fisher information. In Section 5, we provide the estimator of (2) and evaluate its performance as a goodness-of-fit test statistic. Finally, in Section 6, some concluding remarks are provided.
2. Quantal Fisher Information and Quantal Kullback-Leibler Information
If we define the quantal response variable Y at t as
its density function is
Then, the conditional Fisher information in the quantal response at t about can be obtained as
This conditional Fisher information has been studied in terms of censoring by Gertsbakh [6] and Park [7], and its weighted average has been defined to be the quantal randomly censored Fisher information [3] as
where is an appropriate weight function.
The expression (5) says that may be called cumulative Fisher information and can be written in a simpler way, as
Remark 1.
If we take to be , is related with the Fisher information in the ranked set sample [8] as
where is the Fisher information in a simple random sample of size n, which is equal to , and is the Fisher information in a ranked set sample.
The result means that the ranked set sample has additional ordering information in the pairs to the simple random sample. Hence, represents the efficiency level of the ranked set sample relative to the simple random sample.
In a similar way, the Kullback-Leibler (KL) information between two quantal random variables can be obtained as
Then, the weighted average of has been defined to be quantal (randomly censored) divergence [3], as
We note that the quantal KL information (quantal divergence) with is equal to the addition of the cumulative KL information (Park, 2015) and cumulative residual KL information [9]. This quantal Kullback-Leibler information has been discussed in constructing goodness-of-fit test statistics by Zhang [10].
The following approximation of the KL information in terms of the Fisher information is well-known [11], as
Hence, we can also apply Taylor’s expansion to (2) to have the approximation of the quantal KL information in terms of the quantal Fisher information as follows:
Lemma 1.
Proof of Lemma 1.
By applying the Taylor expansion, we have
Then, we can show that
□
3. Quantal Fisher Information in Terms of the (Reversed) Hazard Function
It is well-known that the Fisher information can be represented in terms of the hazard function [1] as
where is the hazard function defined as .
The mirror image of (1) provides another representation of the Fisher information in terms of the reverse hazard function [12] as
where is the reverse hazard function defined as .
Then, (6) can be written again in terms of both hazard function and reversed hazard function in view of (7) and (8) as follows:
Lemma 2.
Now, we show that the quantal Fisher information can also be expressed in terms of both hazard function and reversed hazard function, as follows.
Theorem 1.
Suppose that is bounded and the regularity conditions for the existence of the Fisher information hold.
Proof of Theorem 1.
Example 1.
If is taken to be , (9) can be written as
because it has been shown in Park (1996) that
where is the Fisher information in the ith order statistic from an independently and identically distributed sample of size n.
4. Quantal KL Information and Choice of the Weight Function in Terms of Maximizing the Quantal Fisher Information
Because Lemma 2 shows that the approximation of the Kullback-Leibler information can be represented in terms of the hazard function and reverse hazard function, the following representations of the KL information in terms of the hazard function and reverse hazard function have been shown in Park and Shin [2] as
and
In a similar context, Lemma 2 and Theorem 1 says that the approximation of the quantal Kullback-Leibler information can also be represented in terms of the hazard function and reverse hazard function; hence, we can expect the following quantal KL information representation in terms of the hazard function and reverse hazard function.
Theorem 2.
Proof of Theorem 2.
We can show that
Then, we can apply the integration by parts to (2) to get the result. □
Equation (13) can be rewritten in terms of the cumulative distribution function as follows:
Hence, the quantal KL information has another representation in terms of the cumulative distribution function, which measures the weighted differences in distribution functions and the log odds ratio.
Now, we consider the choice of the weight function in , which has not been discussed much so far. Here, we consider the criterion of maximizing the quantal Fisher information in Theorem 1. For the multi-parameter case, we have the quantal Fisher information matrix and can consider its determinant, which is called generalized Fisher information.
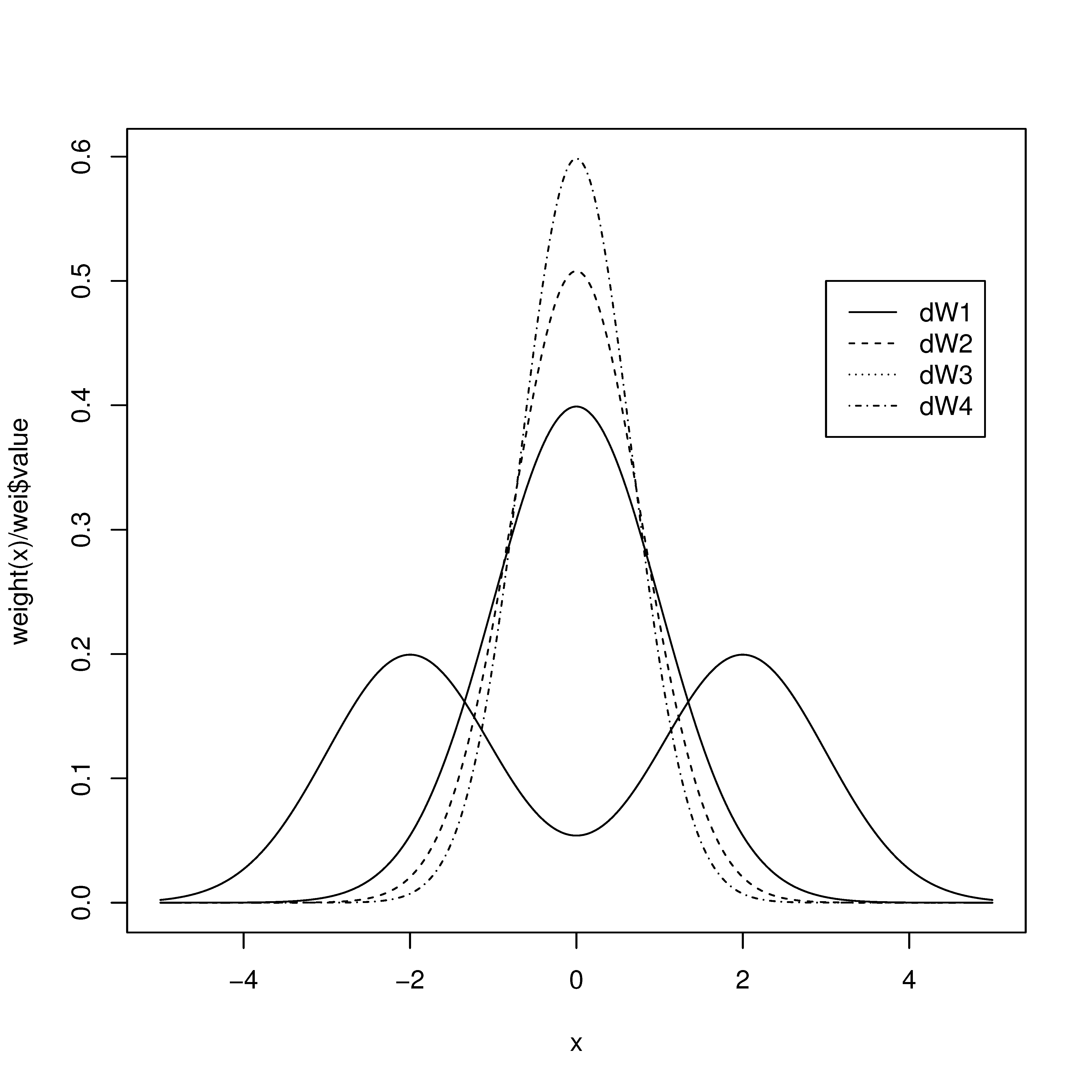
For illustration, we take to be the normal distribution. Then we consider the following ’s and plotted their shapes in Figure 1 where is the bimodal weight function and the shapes get more centralized as i in increases.
- ,
where is the cumulative distribution function of the normal random variable.
We calculate the corresponding quantal Fisher information and summarize the results in Table 1. We can see from Table 1 that about the location parameter gets larger as the weight function becomes more centralized. We also note that we have the maximum about the scale parameter at the bimodal weight function. However, we can see that we have the maximum generalized quantal Fisher information at .
5. Estimation of the Quantal KL Information
Suppose that we have an independently and identically distributed (IID) sample of size n, , from an assumed density function , and are their ordered values. Then, the distance between the sample distribution and the assumed distribution can be measured as , where is an appropriate nonparametric density function estimator, and its estimate has been studied as a goodness-of-fit test statistic by lots of authors, including Pakyari and Balakrishnan [13], Noughabi and Arghami [14], and Qiu and Jia [15] by considering a piecewise uniform density function estimator or nonparametric kernel density function estimator. In the same manner, the estimate of (12) has been studied by Park and Shin (2015) for the same purpose by considering a nonparametric hazard function estimator. However, we note that the critical values based on those nonparametric density (hazard) function estimators depend on the choice of the bandwidth-type parameter.
We can also measure the distance between the sample distribution and the assumed distribution with , if we choose the weight function to be in view of Section 4, which can be written as
where is the empirical distribution function.
Then, can be obtained as , and is obtained as only at ’s, and (14) can be written as
where , and , and .
However, because the empirical distribution function is only right-continuous, we also consider to be so that to be , then we have
Hence, we may obtain the average of both and obtain
which is actually equivalent to the Anderson-Darling test.
For example, we consider the performance of the above statistics for testing the following hypothesis:
: The true distribution function is
versus
: The true distribution function is not .
The unknown parameters, and , are estimated with the sample mean and sample standard deviation, respectively. We also consider the classical Kolmogorov-Smirnov test statistic (Lilliefors test) for comparison as
where and and s are the sample mean and the sample standard deviation, respectively.
We provide the critical values of the above test statistics for in Table 2, which are obtained by employing the Monte Carlo simulations of size 200,000.
Then, we compare the power estimates of the above test statistics, for illustration, against the following alternatives to compare the powers:
- Symmetric alternatives: Logistic, , Uniform, Beta(0.5,0.5), Beta(2,2);
- Asymmetric alternatives: Beta(2,5), Beta(5,2), Exponential, Lognormal(0,0.5), Lognormal(0,1).
We also employed the Monte Carlo simulation to estimate the powers against the above alternatives for , respectively, where the simiulation size is 100,000. The numerical results are summarized in Table 3, Table 4 and Table 5. These show that performs better than and against symmetric alternatives, and the powers of against asymmetric alternatives are in between and . They all outperform the classical Kolmogorov-Smirnov test statistic. generally performs better than against asymmetric alternatives, but the simulation result shows that seems to be a biased test, which can be known from the power estimate against for .
6. Concluding Remarks
It is well-known that both Fisher information and Kullback-Leibler information can be in terms of the hazard function or reverse hazard function. We considered the quantal response variable and showed that the quantal Fisher information and quantal KL information can also be represented in terms of both hazard function and reverse hazard function. We also provided the criterion of maximizing the standardized quantal Fisher information in choosing the weight function in the quantal KL information. For illustration, we considered the normal distribution and studied the choice of weight function, and compared the performance of the estimators of the quantal KL information as a goodness-of-fit test.
Funding
This research was supported by Basic Science Research Program through the National Research Foundation of Korea(NRF) funded by the Ministry of Education(2018R1D1A1B07042581).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- Efron, B.; Johnstone, I. Fisher information in terms of the hazard rate. Ann. Stat. 1990, 18, 38–62. [Google Scholar] [CrossRef]
- Park, S.; Shin, M. Kullback-Libler information of a censored variable and its applications. Statistics 2014, 48, 756–765. [Google Scholar] [CrossRef]
- Tsairidis, C.; Zogfrafos, K.; Ferentinos, K.; Papaioannou, T. Information in quantal response data and random censoring. Ann. Inst. Stat. Math. 2001, 53, 528–542. [Google Scholar] [CrossRef]
- Rao, M.; Chen, Y.; Vemuri, B.C.; Wang, F. Cumulative residual entropy: A new measure of information. IEEE Trans. Inf. Theory 2004, 50, 1220–1228. [Google Scholar] [CrossRef]
- Di Crescenzo, A.; Longobardi, M. On cumulative entropies. J. Stat. Plan. Inference 2009, 139, 4072–4087. [Google Scholar] [CrossRef]
- Gertsbakh, I. On the Fisher information in the type-I censored and quantal response data. Stat. Probab. Lett. 1995, 32, 297–306. [Google Scholar] [CrossRef]
- Park, S. On the asymptotic Fisher information in order statistics. Metrika 2003, 57, 71–80. [Google Scholar] [CrossRef]
- Chen, Z. The efficiency of ranked-set sampling relative to simple random sampling under multi-parameter families. Stat. Sin. 2000, 10, 247–263. [Google Scholar]
- Baratpour, S.; Rad, A.H. Testing goodness-of-fit for exponential distribution based on cumulative residual entropy. Commun. Stat. Theory Methods 2012, 41, 1387–1396. [Google Scholar] [CrossRef]
- Zhang, J. Powerful goodness-of-fit tests based on the likelihood ratio. J. R. Stat. Soc. B 2002, 64, 281–294. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Gupta, R.D.; Gupta, R.C.; Sankaran, P.G. Some Characterization Results Based on Factorization of the (Reversed) Hazard Rate Function. Commun. Stat. Theory Methods 2004, 33, 3009–3031. [Google Scholar] [CrossRef]
- Pakyari, R.; Balakrishnan, N. A general purpose approximate goodness-of-fit test for progressively Type-II censored data. IEEE Trans. Reliab. 2012, 61, 238–244. [Google Scholar] [CrossRef]
- Noughabi, H.A.; Arghami, N.R. Goodness-of-Fit Tests Based on Correcting Moments of Entropy Estimators. Commun. Stat. Simul. Comput. 2013, 42, 499–513. [Google Scholar] [CrossRef]
- Qiu, G.; Jia, K. Extropy estimators with applications in testing uniformity. J. Nonparametric Stat. 2018, 30, 182–196. [Google Scholar] [CrossRef]
Figure 1.
Shapes of the chosen weight functions.


{kind=link}
Table 1.
Quantal FI for some weight functions.
| Specification | |||||
|---|---|---|---|---|---|
| Distribution | Parameter | ||||
| Normal | Location | 0.1983 | 0.4205 | 0.4805 | 0.5513 |
| Normal | Scale | 0.3497 | 0.3014 | 0.2701 | 0.1883 |
| Normal | Generalized FI | 0.0693 | 0.1267 | 0.1298 | 0.1013 |
Table 2.
Critical values of test statistics.
| n | |||||
|---|---|---|---|---|---|
| 10 | 0.4360 | 0.4350 | 0.4322 | 2.7395 | 0.2619 |
| 20 | 0.4131 | 0.4141 | 0.4115 | 3.9108 | 0.1920 |
| 30 | 0.4028 | 0.4025 | 0.4008 | 4.6310 | 0.1586 |
| 40 | 0.3977 | 0.3978 | 0.3960 | 5.1486 | 0.1385 |
| 50 | 0.3928 | 0.3924 | 0.3918 | 5.5000 | 0.1244 |
| 60 | 0.3901 | 0.3905 | 0.3892 | 5.8764 | 0.1138 |
| 70 | 0.3914 | 0.3914 | 0.3905 | 6.1723 | 0.1060 |
| 80 | 0.3872 | 0.3873 | 0.3867 | 6.3988 | 0.0991 |
| 90 | 0.3874 | 0.3874 | 0.3867 | 6.6307 | 0.0935 |
| 100 | 0.3858 | 0.3851 | 0.3851 | 6.8319 | 0.0888 |
Table 3.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
Table 3.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
| Alternatives | |||||
|---|---|---|---|---|---|
| N(0,1) | 5.01 | 5.01 | 5.00 | 5.08 | 4.96 |
| Logistic(0,1) | 10.54 | 10.35 | 10.48 | 12.34 | 8.55 |
| t(5) | 16.98 | 16.86 | 17.04 | 19.69 | 13.15 |
| t(3) | 32.15 | 31.96 | 32.35 | 34.56 | 26.03 |
| t(1) | 88.06 | 88.04 | 88.23 | 86.49 | 84.63 |
| Uniform | 16.57 | 16.40 | 16.78 | 13.57 | 9.71 |
| Beta(0.5,0.5) | 60.66 | 60.52 | 61.10 | 66.55 | 31.82 |
| Beta(1,1) | 16.73 | 16.55 | 16.91 | 13.53 | 9.89 |
| Beta(2,2) | 5.52 | 5.41 | 5.52 | 3.26 | 5.08 |
| Beta(2,5) | 11.53 | 17.47 | 14.64 | 17.26 | 11.54 |
| Beta(5,2) | 17.92 | 11.48 | 14.77 | 17.62 | 11.51 |
| Exponential(1) | 72.62 | 81.23 | 77.59 | 86.72 | 58.54 |
| Log normal(0,0.5) | 40.64 | 51.40 | 46.64 | 53.98 | 34.29 |
| Log normal(0,1) | 88.03 | 92.20 | 90.48 | 94.32 | 79.20 |
Table 4.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
Table 4.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
| Alternatives | |||||
|---|---|---|---|---|---|
| N(0,1) | 5.06 | 5.12 | 5.05 | 5.16 | 5.05 |
| Logistic(0,1) | 16.13 | 16.21 | 16.20 | 18.49 | 11.45 |
| t(5) | 30.25 | 30.31 | 30.41 | 33.63 | 21.10 |
| t(3) | 60.86 | 60.85 | 60.99 | 61.60 | 48.57 |
| t(1) | 99.72 | 99.72 | 99.73 | 99.48 | 99.33 |
| Uniform | 57.43 | 57.61 | 57.73 | 80.08 | 25.92 |
| Beta(0.5,0.5) | 99.06 | 99.08 | 99.08 | 99.97 | 80.21 |
| Beta(1,1) | 57.54 | 57.59 | 57.80 | 80.04 | 26.07 |
| Beta(2,2) | 13.18 | 13.30 | 13.33 | 14.75 | 8.21 |
| Beta(2,5) | 35.09 | 43.79 | 39.67 | 59.41 | 25.65 |
| Beta(5,2) | 43.56 | 35.09 | 39.47 | 59.03 | 25.57 |
| Exponential(1) | 99.50 | 99.76 | 99.65 | 99.99 | 96.05 |
| Log normal(0,0.5) | 84.70 | 89.52 | 87.40 | 94.16 | 71.05 |
| Log normal(0,1) | 99.94 | 99.97 | 99.96 | 100.00 | 99.52 |
Table 5.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
Table 5.
Power estimate (%) of 0.05 tests against 10 alternatives of the normal distribution based on 100,000 simulations; .
| Alternatives | |||||
|---|---|---|---|---|---|
| N(0,1) | 5.06 | 5.08 | 5.04 | 5.05 | 5.05 |
| Logistic(0,1) | 24.15 | 24.16 | 24.19 | 24.99 | 15.57 |
| t(5) | 48.18 | 48.23 | 48.26 | 50.34 | 33.23 |
| t(3) | 84.94 | 84.97 | 84.97 | 83.52 | 73.09 |
| t(1) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Uniform | 95.02 | 95.07 | 95.07 | 99.93 | 59.20 |
| Beta(0.5,0.5) | 100.00 | 100.00 | 100.00 | 100.00 | 99.47 |
| Beta(1,1) | 94.82 | 94.89 | 94.88 | 99.95 | 58.92 |
| Beta(2,2) | 31.96 | 32.10 | 32.10 | 54.81 | 15.39 |
| Beta(2,5) | 72.88 | 78.80 | 76.00 | 96.22 | 50.56 |
| Beta(5,2) | 78.73 | 72.98 | 76.04 | 96.11 | 50.70 |
| Exponential(1) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Log normal(0,0.5) | 99.28 | 99.59 | 99.47 | 99.94 | 95.07 |
| Log normal(0,1) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Park, S. Information Measure in Terms of the Hazard Function and Its Estimate. Entropy 2021, 23, 298. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030298
AMA Style
Park S. Information Measure in Terms of the Hazard Function and Its Estimate. Entropy. 2021; 23(3):298. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030298
Chicago/Turabian StylePark, Sangun. 2021. "Information Measure in Terms of the Hazard Function and Its Estimate" Entropy 23, no. 3: 298. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030298
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.