Aside from the presented data collection approaches further digitalization techniques are currently under investigation by the authors to make the process more efficient. In the following, we discuss the challenges and possibilities of digitalization and the generation of factory models. The economic potential of automating the digitalization process and the process of model generation is highlighted for a number of exemplary plants. Finally, a brief conclusion completes our work.
5.1. Discussion
In the presented modelling approach plant digitalization is carried out during production free times, which has the advantage of the assembly line standing still and hardly any people being in the plant except maintenance workers. Due to privacy protection regulations, the faces of people that are captured by the laser scanner or the cameras have to be disguised, which is easier during production free time, as fewer people are in the building. However, personal data displayed on process boards and shift schedules still needs to be handled. In this work we collect our data using stationary laser scanners, which usually take some time to capture their surroundings. Thus, in practice it is advisable to use a combination of mobile and static laser scanners, which can still be complemented by photogrammetry if necessary. The plant is ideally digitalized using a mobile laser scanner in order to save time. Only in places where higher accuracy is needed the mobile laser scan can be complemented with a stationary one, for example, when accurate height information plays an important role. In addition, drone technologies are investigated for digitalization purposes, however, the risk of a drone falling down and hurting employees or damaging assembled customer products has to be addressed. Further, we look into technologies using only cameras to generate a 3D model. Generally, these methods are useful for creating a quick and rough overview of the plant. Yet, they are inadequate for most of the planning tasks due to a comparatively low accuracy.
Another consideration is to place laser scanners on a fleet of vehicles that are routinely used within production plants like forklifts, autonomous platforms or hangers on the production line. An incremental model of hundreds or even thousands of laser scans could be built. However, this approach causes scan activities to be carried out during the running production. On the one hand, several challenges like the registration of a high number of laser scans created by different mobile scanners, attached to different vehicle types at different heights and moving with different speeds arise. On the other hand, changes to the facility are detected quickly. Yet, not all the changes are relevant for planning projects. For instance, changes to the building structure are important for planning tasks in terms of spatial restrictions. In contrast to that the different parking positions of a forklift are irrelevant for factory planning. After the detection of a relevant change, a partial update of the factory point cloud is favorable, that is, only the area where a change is detected is updated, in order to keep the computational and storage overhead as low as possible.
At the moment, static simulation scenes are built from laser scans, which correspond to a snap-shot of the production plant at the time of data collection. In future, it is thinkable to generate animated simulation scenes based on a stream of input data in certain parts of the plant, that is, process simulations are generated automatically based on periodical digitalization and data collection. For the time being, this will only be possible for smaller parts of the plant, where special sensory equipment is installed. In order to generate process simulations, the frequency of laser scans must be high. Thus, an efficient scanning strategy is a prerequisite.
The transition from 2D to 3D planning introduces a lot of changes in the IT and process landscape that are necessary for various planning tasks. Hence, dedicated measures of employee training need to be provided in order to support a smooth transition. Generally, the whole process from data collection over final storage to the management of access rights needs to be detailed. Further, an optimized database for point cloud storage, updating and versioning is needed. Software products that are apt for point cloud streaming could be connected to this database as they allow for efficient visualization of the point clouds even on resource constrained devices.
The potential that lies in automating the factory digitalization process and model generation is huge. On the basis of quotes from three different service providers, we conclude that laser scanning of an assembly plant costs about 1–4 € per square metre depending on how much surface geometry is modelled into the scan, thus, we calculate with a low degree of modelling resulting in 1.50 €/m
2. Assuming an average area of 950,000 m
2 per production plant we calculate the potential yearly savings of 10 plants. Further, we assume that about 60% of the total plant area is relevant for assembly and needs to be digitalized. We aim at digitalizing a plant once a year and target a degree of automation of about 70%. A higher degree of automation would of course be favorable, however, there are certain aspects that can hardly be automated. For instance, monitoring the digitalization process, checking on the registration targets and the quality of registration will still be handled manually. The above-mentioned assumptions result in a yearly saving of about 6 million Euros.
Table 9 summarizes the calculation. Note that the numbers in the above example are hypothetical and do not reflect the real volume and number of the automotive production plants under investigation in this text.
Thus, the economic potential of automating the digitalization process is big. However, these are only the obvious savings gained by the automation of data collection. The availability of a comprehensive digital 3D model of big parts of the assembly area, which reflects the current state of the plant, holds an even bigger potential, when it comes to planning tasks. As already mentioned, planning mistakes can be found in the digital model rather than during the implementation of the changes, which saves a tremendous amount of money and potentially prevents production downtimes. Further, travelling efforts of planners are reduced considerably, thus, they are relieved from this additional burden and can focus on their core business.
5.2. Conclusions
In this paper, we describe a holistic and methodical approach to generate a static simulation model in a partially automated fashion from a point cloud of a factory environment. We start with the collection of point clouds in large-scale industrial production plants using laser scanning and photogrammetry techniques. Further, the data pre-processing steps of point cloud registration, cleaning and labelling are described. The data processing steps of segmentation, pose estimation and the final simulation model generation are discussed in detail. For point cloud segmentation the application of a Bayesian neural network is evaluated as it allows the quantification of uncertainty in the network predictions. To this end, three entropy based uncertainty measures as well as the predictive variance and a credible interval based method of uncertainty estimation are discussed.
An automotive factory data set is collected in order to evaluate the digitalization strategy. The different technologies and hardware equipment are evaluated with respect to the resulting point cloud accuracy, completeness and point density. Based on this evaluation we conclude that laser scan point clouds are more accurate than photogrammetric point clouds but they have a lower completeness and point density. Further, the use of wide-angle instead of fish-eye lenses for photogrammetry is highly recommended as the former outperforms the latter with respect to all the evaluation metrics. Thus, in terms of data collection we recommend to combine the point clouds generated by laser scanners and photogrammetry techniques.
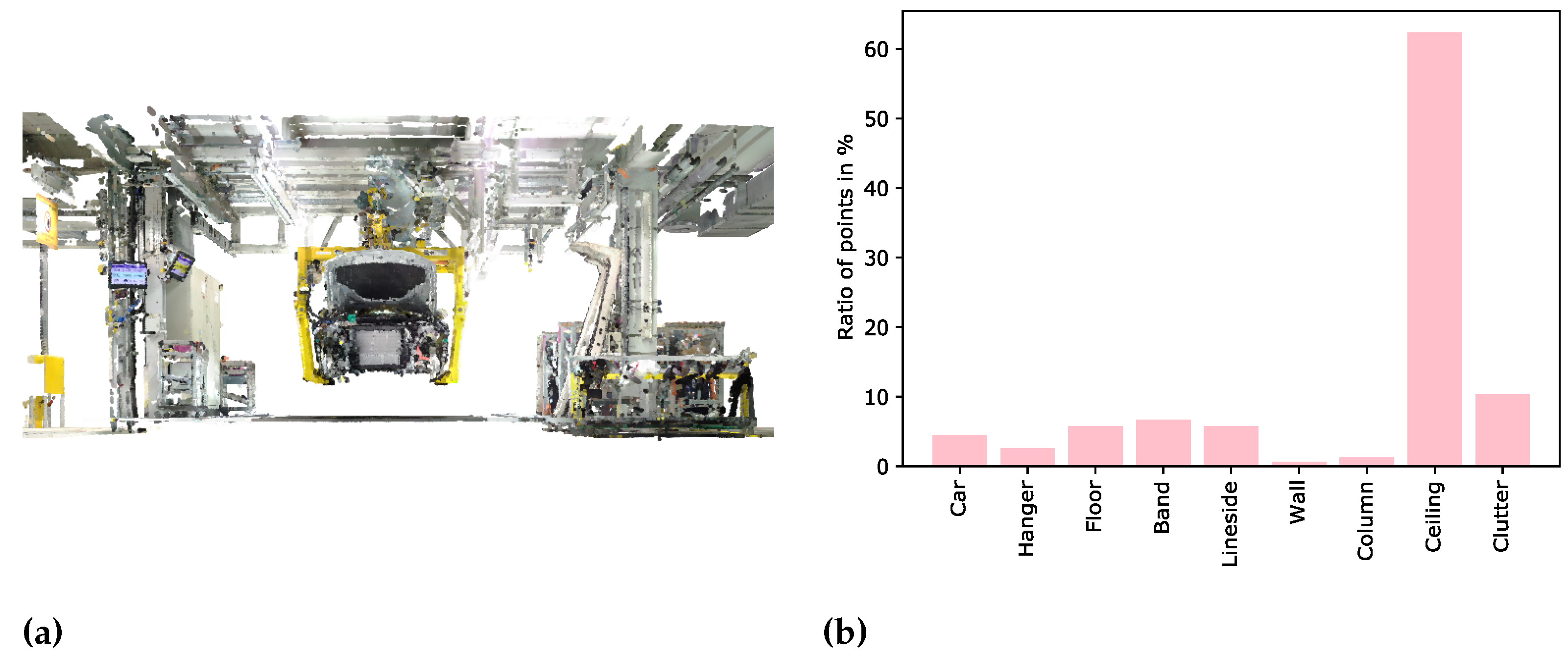
The subsequent steps of the proposed modelling approach are evaluated on the collected data set as well. The Bayesian segmentation network clearly outperforms the frequentist model even without considering the additional information provided by the uncertainty in the network predictions. Taking into account the network’s uncertainty in its predictions and evaluating the segmentation accuracy only on certain points increases the network performance considerably using any of the described uncertainty measures. In this case uncertain predictions are discarded. The notions of predictive and aleatoric uncertainty lead to the best results. In the given use case, we decide to focus on the measure of predictive uncertainty as it allows us to control the ratio of points dropped by setting an uncertainty threshold, which is not the case for the credible interval based method. As predictive uncertainty combines the information of both aleatoric and epistemic uncertainty, we prefer this measure over aleatoric uncertainty alone. Based on the segmented point cloud we estimate the poses of relevant objects using, among other methods, clustering techniques. Therefore, the common clustering algorithms k-means and fuzzy c-means, the density based methods DBSCAN and OPTICS as well as spectral clustering are compared. Even though k-means and fuzzy c-means clustering achieve superior performance when knowing the number of clusters in advance we advise not to use these methods for an automated solution. All the remaining methods automatically determine the number of clusters. The OPTICS algorithm provides the best trade-off between runtime and clustering accuracy. Thus, we apply this algorithm for the final evaluation of the placement accuracy. The object placement is carried out on the basis of the segmented point cloud using the frequentist and the Bayesian neural network. Additionally, the Bayesian neural network including uncertainty information is used for object placement. The placement in the frequentist case is by far the worst, not producing any reasonable simulation scene without adding additional hand-crafted constraints for object placement. Astonishingly, the placement accuracy is highest for the Bayesian neural network not considering network uncertainty, even though the segmentation accuracy is considerably improved by incorporating uncertainty information. Most probably, the reason is that by considering network uncertainty relevant features of the point cloud are classified as uncertain and thus dropped. Therefore, we conclude that the Bayesian neural network without removing uncertain points is best suited for our use case.
In summary, the major advantage of the proposed modelling approach is the ability to reconstruct a factory environment on object rather than on building level, which extends state-of-the-art reconstruction techniques. Further, this approach does not necessarily require the availability of CAD models of the objects in the scene like the majority of frameworks do. However, the reconstruction results are more reliable under the presence of CAD models. Additionally, the input point cloud is partitioned into meaningful subsets of points early in the process, which allows us to process subsets of points aside from simulation generation within the respective departments.
The proposed modelling approach is applied in a real-world industrial prototype that aims at the reconstruction of automotive assembly plants on the basis of 3D point clouds. On the process side, this paves the way for an automated target-actual comparison of plant assets. For instance, layouts and construction measures can be verified automatically on the basis of the generated factory model. Further, the differences in the environment between two arbitrary digitalization dates can be determined, which is favorable to indicate changes in the building or process structure. These points will be covered in future research. Additionally, the generation of an asset library is supported by our approach, as objects for which CAD models are unavailable can be extracted from the point cloud and their surface can be reconstructed. Currently, this reconstruction is automated for geometrically simple objects like walls or columns. In future work, we study the automatic reconstruction of more complex process related structures. With respect to mathematical concepts, the suitability of uncertainty information for removing noise in point clouds will be analysed. Further, the parameters of the prior distribution in the applied network will no longer be treated as hyper parameters during network optimization. They will rather be estimated in a Bayesian way by the definition of a separate prior and calculation of their posterior.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}