
Solvable Model for the Linear Separability of Structured Data


1
Department of Physics, Università degli Studi di Milano, via Celoria 16, 20133 Milano, Italy
2
Istituto Nazionale di Fisica Nucleare Sezione di Milano, via Celoria 16, 20133 Milano, Italy
Entropy 2021, 23(3), 305; https://0-doi-org.brum.beds.ac.uk/10.3390/e23030305
Submission received: 2 February 2021
/
Revised: 22 February 2021
/
Accepted: 25 February 2021
/
Published: 4 March 2021
{kind=link}
{kind=link}
{kind=link}
Abstract
:Linear separability, a core concept in supervised machine learning, refers to whether the labels of a data set can be captured by the simplest possible machine: a linear classifier. In order to quantify linear separability beyond this single bit of information, one needs models of data structure parameterized by interpretable quantities, and tractable analytically. Here, I address one class of models with these properties, and show how a combinatorial method allows for the computation, in a mean field approximation, of two useful descriptors of linear separability, one of which is closely related to the popular concept of storage capacity. I motivate the need for multiple metrics by quantifying linear separability in a simple synthetic data set with controlled correlations between the points and their labels, as well as in the benchmark data set MNIST, where the capacity alone paints an incomplete picture. The analytical results indicate a high degree of “universality”, or robustness with respect to the microscopic parameters controlling data structure.
1. Introduction
Linear classifiers are quintessential models of supervised machine learning. Despite their simplicity, or possibly because of it, they are ubiquitous: they are building blocks of more complex architectures, for instance, in deep learning and support vector machines, and they provide testing grounds of new tools and ideas in learning theory and statistical mechanics, in both the study of artificial neural networks and in neuroscience [1,2,3,4,5,6,7,8,9]. Recently, interest in linear classifiers was rekindled by two outstanding results. First, deep neural networks with wide layers can be well approximated by linear models acting on a well defined feature space, given by what is called “neural tangent kernel” [10,11]. Second, it was discovered that deep linear networks, albeit identical to linear classifiers for what concerns the class of realizable functions, allow it to reproduce and explain complex features of nonlinear learning and gradient flow [12].
In spite of the central role that linear separability plays in our understanding of machine learning, fundamental questions still remain open, notably regarding the predictors of separability in real data sets [13]. How does data complexity affect the performance of linear classifiers? Data sets in supervised machine learning are usually not linearly separable: the relations between the data points and their labels cannot be expressed as linear constraints. The first layers in deep learning architectures learn to perform transformations that enhance the linear separability of the data, thus providing downstream fully-connected layers with data points that are more adapted for linear readout [14,15]. The role of “data structure” in machine learning is a hot topic, involving computer scientists and statistical physicists, and impacting both applications and fundamental research in the field [16,17,18,19,20,21,22].
Before attempting to assess the effects of data specificities on models and algorithms of machine learning, and, in particular, on the simple case of linear classification, one should have available (i) a quantitative notion of linear separability and (ii) interpretable parameterized models of data structure. Recent advances, especially within statistical mechanics, mainly focused on point (ii). Different models of structured data have been introduced to express different properties that are deemed to be relevant. For example, the organization of data as the superposition of elementary features (a well-studied trait of empirical data across different disciplines [23,24,25]) leads to the emergence of a hierarchy in the architecture of Hopfield models [26]. Another example is the “hidden manifold model”, whereby a latent low-dimensional representation of the data is used to generate both the data points and their labels in a way that introduces nontrivial dependence between them [19]. An important class of models assumes that data points are samples of probability distributions that are supported on extended object manifold, which represent all possible variations of an input that should have no effect on its classification (e.g., differences in brightness of a photo, differences in aspect ratio of a handwritten digit) [27]. Recently, a useful parameterization of object manifolds was introduced that is amenable to analytical computations [28]; it will be described in detail below. In a data science perspective, these approaches are motivated by the empirical observation that data sets usually lie on low-dimensional manifolds, whose “intrinsic dimension” is a measure of the number of latent degrees of freedom [29,30,31].
The main aims of this article are two: (i) the discussion of a quantitative measure of linear separability that could be applied to empirical data and generative models alike; and, (ii) the definition of useful models expressing nontrivial data structure, and the analytical computation, within these models, of compact metrics of linear separability. Most works concerned with data structure and object manifolds (in particular, Refs. [8,27,28]) focus on a single descriptor of linear separability, namely the storage capacity . Informally, the storage capacity measures the maximum number of points that a classifier can reliably classify; in statistical mechanics, it signals the transition, in the thermodynamic limit, between the SAT and UNSAT phases of the random satisfiability problem related to the linear separability of random data [32]. Here, I will present a more complete description of separability than the sole storage capacity (a further motivation is the discovery, within the same model of data structure, of other phenomena lying “beyond the storage capacity” [33]).
2. Linear Classification of Data
Let us first review the standard definition of linear separability for a given data set. In supervised learning, data are given in the form of pairs , where is a data point and is a binary label. We focus on dichotomies, i.e., classifications of the data into two subsets (hence, the binary labels); of course, this choice does not exclude datasets with multiple classes of objects, as one can always consider the classification of one particular class versus all the other classes. Given a set of points , a dichotomy is a function . A data set is linearly separable (or equivalently the dichotomy , , is linearly realizable) if there exists a vector , such that
where is the ith component of the th element of the set. In the following, I will simply write for the scalar product appearing in the sgn function when it is obvious that w and are vectors.
In machine learning, the left hand side of Equation (1) is the definition of a linear classifier, or perceptron. The points x, such that define a hyperplane, which is the separating surface, i.e., the boundary between points that are assigned different labels by the perceptron. By viewing the perceptron as a neural network, the vector w is the collection of the synaptic weights. “Learning” in this context refers to the process of adjusting the weight vector w so as to satisfy the m constraints in Equation (1). Because of the fact that the sgn function is invariant under multiplication of its argument by a positive constant, I will always consider normalized vectors, i.e., both the weight vector w and data points will lie on the unit sphere.
A major motivation behind the introduction of the concept of data structure and the combinatorial theory that is related to it (reviewed in Section 5 and Section 6 below) is the fact that the definition of linear separability above is not very powerful per se. Empirically relevant data sets are usually not linearly separable. Knowing whether a data set is linearly separable does not convey much information on its structure: crucially, it does not allow quantifying “how close” to being separable or nonseparable the data set really is. To fix the ideas, let us consider a concrete case: the data set MNIST [34]. MNIST is a collection of handwritten digits, digitized as greyscale images, each labelled by the corresponding digit (“0” to “9”). I will use the “training” subset of MNIST, containing 6000 images per digit. To simplify the discussion, I will mainly focus on a single dichotomy within MNIST: that expressed by the labels “3” and “7”. The particular choice of digits is unimportant for this discussion; I will give an example of another dichotomy below, when subtle differences between the digits can be observed.
One may ask the question as to whether the MNIST training set, as a whole, is linearly separable. However, the answer is not particularly informative: the MNIST training set is not linearly separable [34]. But how unexpected is this answer? Can we measure the surprise of finding out a given training set is or is not linearly separable? Intuitively, there are three different properties of a data set that facilitate or hinder its linear separability: size, dimensionality, and structure.
- Size. The number of elements m of a data set is a simple indication of its complexity. While a few data points are likely linearly separable, they convey little information on the “ground truth”, the underlying process that generated the data set. On the contrary, larger data sets are more difficult to classify, but the information that is stored in the weights after learning is expected to be more faithful to the ground truth (this is related to the concept of “sample complexity” in machine learning [35]).
- Dimensionality. There are two complementary aspects when considering dimensionality in a data oriented framework. First, the embedding dimension is the number of variables that a single data point comprises. For instance, MNIST points are embedded in , i.e., each of them is represented by 784 real numbers. The embedding dimension is n in Equation (1); therefore, n is also the number of degrees of freedom that a linear classifier can adjust to find a separating hyperplane. Hence, one expects that a large embedding dimension promotes linear separability. Second, the data set itself does not usually uniformly occupy the embedding space. Rather, points lie on a lower-dimensional manifold, whose dimension d is called the intrinsic dimension of the data set. The concept of general position discussed below is related to the intrinsic dimension; however, beyond that, I will not explicitly consider this type of data complexity in this article (for analytical results on the linear separability of manifolds of varying intrinsic dimension, see [27]).
- Structure. As I will show in a moment, the effects of size and dimensionality on linear separability are easily quantified in a simple null model. Data structure, on the other hand, has proved more challenging, and it is the main focus of the theory described here. There is no single definition of data structure; different definitions are useful in different contexts. A common characterization can be given like this: data have structure whenever the data points and their labels are not independent variables. I will specify a more precise definition in Section 5. Intuitively, the data structure can both promote or preclude linear separability. If points that are close to one another tend to have the same label then linear separability is improved; if, instead, there are many differently labeled points in a small region of space, then linear separability is obstructed.
Let us get back to the question “how surprising is it that MNIST is not linearly separable?”. This question should be answered by at least taking into account the first two properties described above, the size of the data set and its dimensionality, which are readily computed from the raw data. In fact, the surprise, i.e., the divergence from what is expected based on size and dimensionality, may be interpreted as a beacon of the third property: data structure. I will show in the next section that the answer to our question is “exceedingly unsurprising”. Yet, a slightly modified question will reveal that MNIST, albeit unremarkable in it not being linearly separable, is exceptionally structured.
3. Null Model of Linear Separability
Let us consider a null model of data that fixes the dimension n and the size p. I use a different letter (p instead of m), because it will be useful below to have two different symbols for the size of the whole data set (m) and for the size of its subsets. Consider a data set , where the vectors are random independent variables that are uniformly distributed on the unit sphere, and the labels are independent Bernoulli random variables (also independent from every ). These choices are suggested by a maximum entropy principle, when only the parameters m and n are fixed. What is the probability that a data set generated by this model is linearly separable? This problem was addressed and solved more than half a century ago [36,37,38]; In Section 6 I will describe an analytical technique that allows this computation. The fraction of dichotomies of a random data set that are linearly realizable is
where is the binomial coefficient. Thus, a random (uniform) dichotomy has probability of being linearly realizable. In this article, I will refer to the probability as the separability, or probability of separation. A related quantity is the number of dichotomies (here, is the total number of dichotomies of p points).
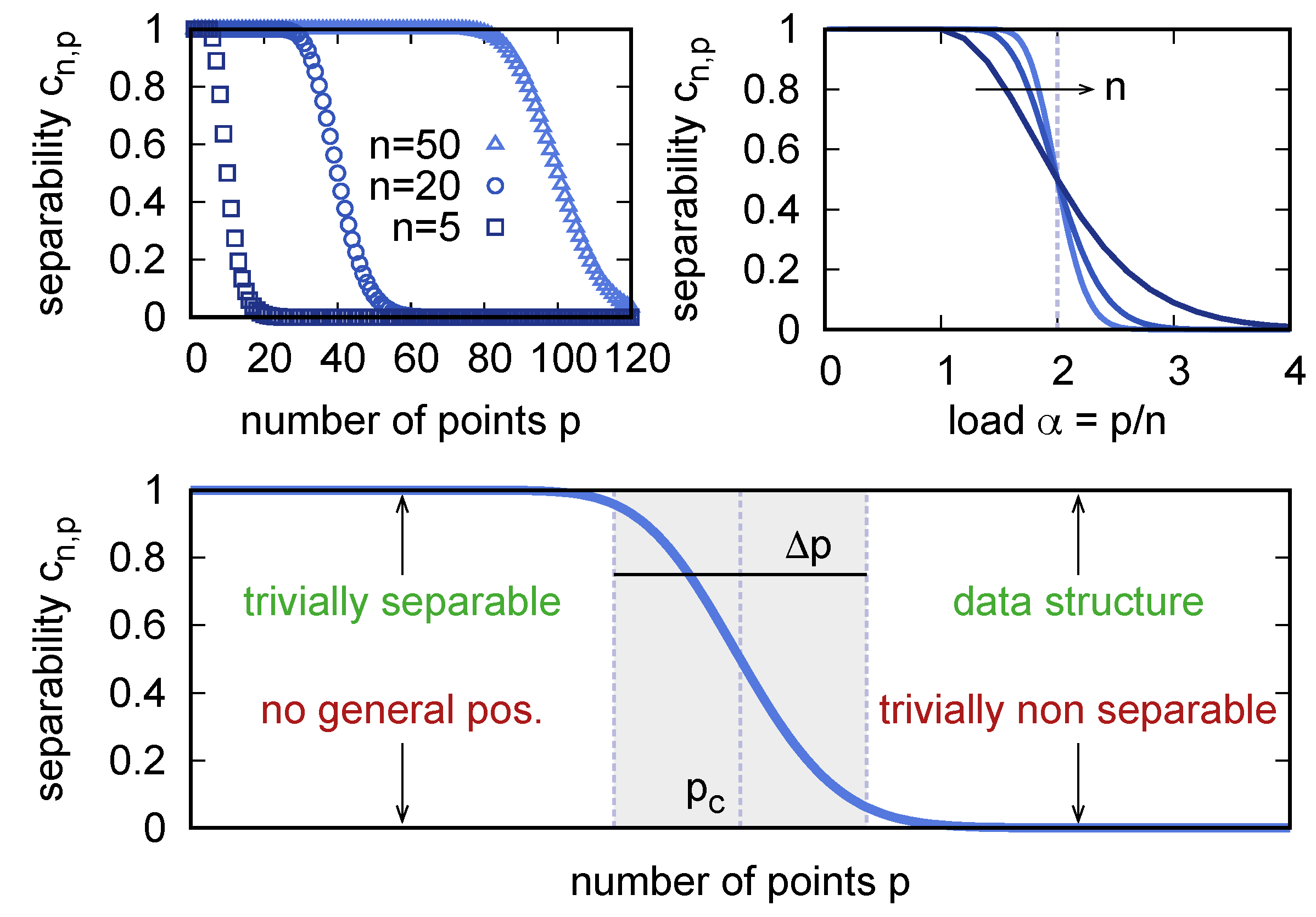
Figure 1 shows the sigmoidal shape of as a function of p at fixed n. The separability is exactly equal to 1 up to (which pinpoints what is known as the Vapnik–Chervonenkis dimension in statistical learning theory [35]), and it stays close to 1 up to a critical value , which increases with n. At , the curve steeply drops to asymptotically vanishing values, the more abruptly the larger is n. Rescaling the number of points p with the dimension n yields the load . As a function of , the probability of separation has the remarkable property of being equal to at the critical value (that is known as the storage capacity) , independently of n. Such an absence of finite size corrections to the location of the critical point is an unusual feature, which will be lost when we consider structured data below. In the large-n limit, converges to a step function that transitions from 1 to 0 at .
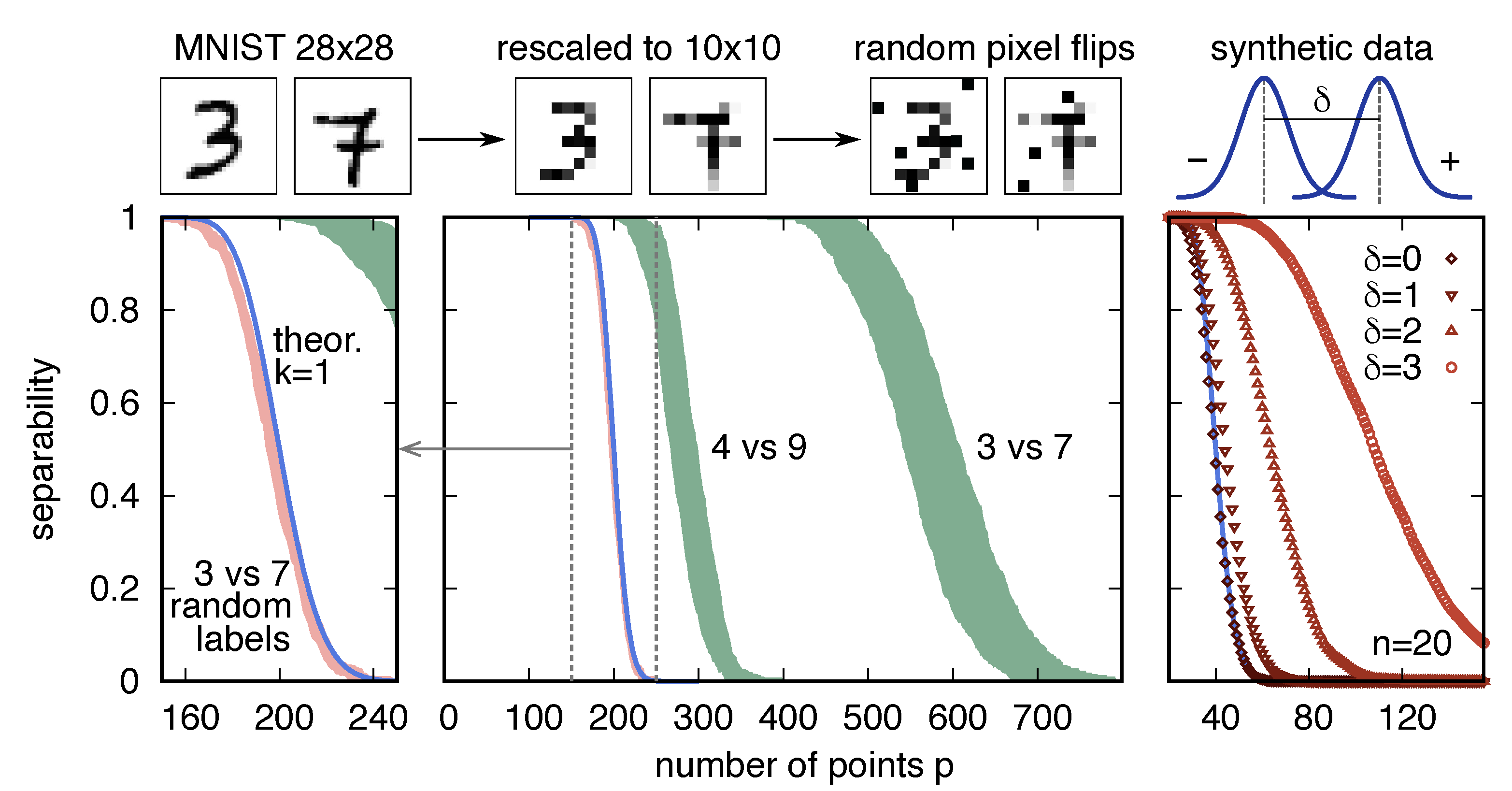
How large is the probability of separation that is given by Equation (2) when one substitutes the sample size m = 12,000 and the dimensionality , i.e., those of the dichotomy “3”/“7” in the data set MNIST? The probability, as anticipated, is utterly small, less than : it should be no surprise that MNIST is not linearly separable. This comparison is not completely fair, because of the assumption, underlying Equation (2), of general position. The concept of general position is an extension of that of linear independence, which is useful for sets larger than the dimension of the vector space. A set X of vectors in is in a general position if there is no linearly dependent subset of cardinality less than or equal to n. MNIST is quite possibly not in general position. To make sure that it is, I downscaled each image to pixels and only considered 1000 images per class (to allow for faster numerical computations), and applied mild multiplicative random noise, by flipping of the pixels around the middle grey value (see Figure 2); I will refer to this modified dataset as “rescaled MNIST”. Running the standard perceptron algorithm on rescaled MNIST did not show signs of convergence after iterations, which indicated that the data set is likely not linearly separable. For and , the separability is less than .
The null model provides a simple concise interpretation of the linear separability of a given data set, given its size m and dimensionality n, in terms of 5 possible outcomes (see Figure 1, bottom panel):
- The set is linearly separable and it lies in the region where . Separability here is trivial: almost all data sets are separable in this region, provided that the points are in general position.
- The set is not linearly separable and it lies in the region where . The only way this can happen for is if the points are not in a general position. For , but still in this region, the lack of separability could also be attributed to a non-trivial data structure.
- The set is not linearly separable and it lies in the region where . Almost no dichotomy is linearly realizable in this region; therefore, the lack of separability is trivial here.
- The set is linearly separable and it lies in the region where . This situation is the hallmark of data structure. The fact that the data set happens to represent one of the few dichotomies that are linearly realizable in this region indicates a non-null dependence between the labels and the points in the data set.
- The set lies in the region where is significantly different from 0 and 1. Here, knowing that a data set is linearly separable or not is unsurprising either way. The location and the width of this “transition region” are the two main parameters that summarize the shape of the separability curve. In Section 6 I will show how to compute these quantities within a more general model that includes data structure.
4. Quantifying Linear Separability via Relative Entropy
In order to make a step further in the characterization of the linear separability of (rescaled) MNIST, we can consider its subsets. While there is only one subset with points (focusing on the dichotomy “3”/“7”), and only one yes/no answer to the question of its linear separability, there are many subsets of size , which can provide more detailed information. To quantify such information, let us formulate a more precise notion of surprise with respect to a model expressing prior expectation [39]. Let us again fix an empirical data set and fix . Now, consider the set of all subsets of p indices , with for . Additionally, consider the set of all dichotomies of p elements. (I use curly braces for both sets and indexed families.) For each pair , we can construct the corresponding synthetic dataset
similarly, for each , we can construct the corresponding subset of the empirical data set :
The main tool for defining the surprise will be probability distributions on a space , which is defined as the union of all synthetic data sets:
The empirical space can be defined similarly:
Essentially, contains all collections of p point/label pairs in the data set , while contains all the collections of p point/label pairs where the p points are chosen among the ones in the data set and the labels are all possible combinations on those p points. Notice that and have different cardinalities: and , where is the number of subsets of size p in the data set.
Interpreted as a probability distribution on , the empirical data are uniform distributed on ; likewise, the null model defined above induces, by conditioning on the points , the uniform distribution on the whole . In general, not every data set in (nor in ) is linearly separable. Let us define the subsets for which this property holds:
Let us call and the uniform probability distributions on and , respectively. The Kullback–Leibler (KL) divergence from to (or relative entropy)
then measures the surprise carried by the data with respect to the prior belief regarding its linear separability expressed by . Because and are defined on sets ( and ) of different cardinality, I define the (signed) surprise by subtracting the reference KL divergence between the uniform distributions on these spaces:
Notice that the summand in the definition of KL divergence, Equation (8), is only nonzero for ; one then obtains
where I have defined the empirical separability as the fraction of linearly separable subsets of size p in :
The signed surprise is positive (respectively negative) when the fraction of linearly separable subsets of size p is smaller (respectively larger) than expected in the null model.
Separability in a Synthetic Data Set and in MNIST
The discussion above encourages the use of the empirical separability as a detailed description of the linear separability of a data set in an information theoretic framework. Despite being one of the simplest benchmark data sets used in machine learning, MNIST is already rather complex; its classes are known to have small intrinsic dimensions and varied geometries [15]. Therefore, before turning to MNIST, let us consider a simple controlled experiment, where the data are extracted from a simple one-parameter mixture distribution, defined, as follows. Let be a Bernoulli random variable with parameter , which generates the labels. The data points are extracted from a multivariate normal distribution with -dependent mean. The joint probability distribution of each point-label pair is
where is the probability density function of the multivariate normal distribution with mean and identity covariance matrix. The parameter measures the distance between the two means: . Figure 2 shows the empirical separability , as a function of the size p of the subsets, for such a data set containing data points in dimensions. When , all of the data points are extracted from the same distribution, regardless of their labels: the data have no structure and the separability follows the null model, as in Equation (2). While increases, equally labelled points start to cluster, and the separability at any given increases, as expected from the qualitative discussion in Section 2. It is interesting to note that the width of the transition region ( in Figure 1) is also an increasing function of . This dependence was not expected a priori; In Section 7, I will show that the theory of structured data presented below allows for explaining this behavior.
Let us now compute for the rescaled MNIST data set. Figure 2 shows the results of three numerical experiments, as compared with the null model prediction (2), and elicits four observations. (i) MNIST data are significantly more separable than the null model. For instance, the signed surprise, with respect to the null model, of the empirical dichotomies separating the digits “3” and “7” takes the values , , . (ii) Even within the same data set, different classifications can have different probabilities of separation; the dichotomy separating the digits “4” and “9” in rescaled MNIST is closer to the null model than the dichotomy of “3” and “7” (e.g., ). (iii) Destroying the structure by random reshuffling of the labels makes the separability collapse onto that of the null model; the surprise in this case is, at most, of order for all p. (iv) Similarly to what happens in the more controlled experiment with the synthetic data above, the separability curve of the “3”/“7” dichotomy, which has its transition point at a larger value of p than the “3”/“9” dichotomy, also has a wider transition region.
This analysis shows that, contrary to what appeared by looking solely at the whole data set, the dichotomies of rescaled MNIST are much more likely to be realized by a linear separator than random ones. In relation to the separability as a function of p, the null model has a single parameter, the dimension n. Is it possible to interpret the empirical curves as those of the null model with an effective dimension ? Increasing n has the effect of increasing proportionally the value because the storage capacity is fixed to . However, while fixing indeed aligns the critical number of points with the empirical one, it yields a much smaller width of the transition region ( for the null model and in the data). Furthermore, notice that the values of the surprise for the “3”-vs.-“7” and “4”-vs.-“9” experiments are not very different. The reason is the ingenuousness of the null model, which hardly captures the properties of the empirical sets, and whose term therefore dominates in . These observations, together with the motivations that are discussed above, are a spur for the definition of a more nuanced and versatile model of the separability of structured data.
5. Parameterized Model of Structured Data
Fixing a model of data structure in this context means fixing a generative model of data. Here, I use the model first introduced in [28]. This should not be considered to be a realistic model of real data sets. It is useful as an effective or phenomenological parameterization of data structure. It has two main advantages: (i) it allows the analytical computation, within a mean field approximation, of the probability of separation ; and, (ii) it naturally points out the relevant geometric-probabilistic parameters that control the linear separability.
The model is expressed in the form of constraints between the points and the labels. The synthetic data set is constructed as a collection of q “multiplets”, i.e., subsets of k points with prescribed geometric relations between them, and such that the labels are constant within each multiplet:
The total number of point/label pairs is . Observe that, if one considers the set of all points , not every dichotomy of X is admitted by the parameterization of in Equation (13). If a dichotomy assigns different labels to two elements of the same multiplet, it cannot be written in this form. The dichotomies that agree with the parameterization of Equation (13) are termed as admissible.
The relations between the points within each multiplet can be fixed, for instance, by prescribing that the overlaps be fixed and independent of (remember that ). The statistical ensemble for , as specified by the probability density , is chosen in accordance with the maximum entropy principle: it is the uniform probability distribution on the points and the labels independently, given the constraints:
where is the partition function, fixed by the normalization condition
The null (unstructured) model of Section 3 is recovered in this parameterization in two different limits. First, if each multiplet is composed of a single point, and no contraints are imposed other than the normalization. Second, for any k, if all overlaps are fixed to 1, then all points in each overlap coincide, , and the model is equivalent to the null model with .
The theory that will be described below depends on a natural set of parameters , with . These quantities are conditional probabilities of geometric events that are related to single multiplets. They characterize the properties of the multiplets that are relevant for the linear separability of the whole set. Consider a multiplet . is a measure of the likelihood that a subset of points is classified coherently by a random weight vector. More precisely, is the probability that the scalar product has the same sign for all , being conditioned on the event that has the same sign for all . This probability is computed in the ensemble where the vector w is uniformly distributed on the unit sphere , is uniformly distributed on the subsets of X of m points, and is uniformly distributed on the elements of . This is coherent with the mean field nature of the combinatorial theory, which assumes uniformly distributed and uncorrelated quantities (see below).
In a few cases, can be computed explicitly. For instance, for a doublet at fixed overlap ,
This is the probability that a random hyperplane does not intersect the segment that connects two points at overlap . It is an increasing function of , from to . If , then the quantity that enters the equations will be the mean of over all the pairs in the multiplet. It can be shown that , as a function of the overlaps , does not explicitly depend on the dimensionality n [28]; this property greatly simplifies the analytical computations.
In summary, the parameters of the model are the following: the dimensionality n, the multiplicity k, and the probabilities . Actually, only two special combinations of the parameters emerge as relevant from the theory that is presented in the next sections:
I will call them structure parameters. Other functions of the probabilities are relevant for other purposes, for instance, when considering the large-p asymptotics of , which relates to the generalization properties of the linear separator [32].
6. Combinatorial Computation of the Separability for Structured Data
Cover popularized a powerful combinatorial technique to compute the number of linearly realizable dichotomies in an old and highly cited paper [38]. Despite its appeal, the combinatorial approach (while certainly not extraneous to contemporary statistical physics, both theoretical and applied [40,41,42,43]) remained somewhat confined to very few papers in discrete mathematics, and it was only very recently extended to more modern questions, when it was used to obtain an equation for , the number of admissible dichotomies of q multiplets, for structured data of the type that is defined in the previous section. Ref. [28] first presented the arguments and computations leading to this equation. To make this article as self-contained as possible, I repeat most of the derivation here.
6.1. Exact Approach for Unstructured Data (k = 1 Points per Multiplet)
First, I recall the classic computation for unstructured data ( in our notation). The idea is to write a recurrence relation for the number of linearly realizable dichotomies and, consequently, for the probability , by considering the addition of the th element to the set that was composed of the first p elements.
Consider one of the dichotomies of , let us call it ; how many linearly realizable dichotomies of agree with (i.e., take the same values) on the points of ? When the point is added to the set, two different things can happen: (i) is the same for all possible weight vectors w that realize ; and, (ii) there is at least one weight vector realizing , such that . These two cases lead to different contributions to . In the first case, there is only one dichotomy of agreeing with , as the value that is assigned to is fixed. In the second case, the value that is assigned to can be either or ; therefore, the number of dichotomies of agreeing with is 2.
Let us call the number of those dichotomies, among the dichotomies of , such that (ii) holds for the new point; the number of those satisfying (i) will be . The reasoning above then leads to . Here lies the keystone that allows for the closure of the recurrence equation: is the number of dichotomies conditioned to satisfy a linear constraint; therefore, it is equal to the number of dichotomies, of the same number of points p, in dimensions: . Finally, the recurrence relation is , which translates into the following equation for the probability :
The boundary conditions of the recurrence (19) are
which come from the conditions (there are only two normalized weight vectors in one dimension) and (there is always a weight vector w, such that ). The solution of Equation (19) is Equation (2), as can be checked directly. However, the more complicated equations that are satisfied by the probabilities for structured data are not as easily solvable. For this reason, in Section 7, below, I will show a method to compute useful quantities that are related to the shape of directly from the recurrence relations, with no need for a closed solution.
6.2. Mean-Field Approach for Pairs of Points (k = 2 Points per Multiplet)
The simplest non-trivial extension of Cover’s computation to structured data is . From here on I will use and to denote the fraction and number of linearly realizable admissible dichotomies of q multiplets because the symbols and were reserved to denote the fraction and number of linearly realizable dichotomies of p points.
Notice that all the quantities appearing above are notated with no explicit dependence on the points . This is because the unstructured case enjoys a strong universality property (as proved in [38]): is independent of the points of , as long as they are in a general position. Such generality breaks down for structured data. In this case, the recurrence equations that will be obtained are not valid for all sets ; rather, they are satisfied by the ensemble averages of and , in the spirit of the mean-field approximation of statistical physics.
The set of points is now , where is a set of q points and is a set of partners , where for all (remember that all of the points are on the unit sphere). Consider the addition of the points and to and , respectively. By repeating the reasoning described above for with respect to the point , one finds a formula for the number of dichotomies of the set that are admissible on the first q pairs (and are unconstrained on ): . These dichotomies can be separated into two classes, similarly to the two cases (i) and (ii) above: those that can be realized by a weight vector orthogonal to (let us denote their number by ) and those that cannot (their number is then ). For each dichotomy of the first class, there exists one and only one admissible dichotomy of the full set that agrees with and can be realized linearly. In fact, thanks to the orthogonality constraint, there is always, among the weight vectors realizing , one vector w, such that
thus satisfying the admissibility condition on the pair . The remaining dichotomies do not allow this freedom. How many of them are realized by weight vectors w, such that the admissibility condition (21) is satisfied can be estimated at the mean field level by the probability that, given a random weight vector w chosen uniformly on the unit sphere, the scalar products and have the same sign. This probability does not depend on the actual points, but only on their overlap , and it is exactly the quantity that is defined in the previous section, Equation (16). I will denote it by in the following, with the dependence on being understood.
The foregoing argument brings the following equation:
Similarly to what happens in the unstructured case, the unknown term can be expressed in terms of variables by considering the same problem in a lower dimension. In fact, remember that above was computed by applying Cover’s argument for , because it counts how the number of dichotomies is affected when the single point is added to the set. must be computed in the same way, since it, again, counts the number of dichotomies that are admissible on the first q pairs and free on . However, these dichotomies must satisfy the additional linear constraint ; therefore, the whole argument must be applied in dimensions. This leads to
Finally, substituting this expression of into Equation (22) yields
As above, this translates to a similar equation for the probability :
The boundary conditions of this recurrence are slightly different than for . They are discussed in the Appendix A, together with those for the general case.
6.3. General Case Parameterized by k
It is possible to extend the method that is described above to all k. I will only sketch the derivation; the details can be found in [28]. Just as the case can be treated by making use of the recurrence formula for , the idea here is to construct the case k recursively by using the formula (yet to be found) for , therefore obtaining a recurrence relation in k as well as in n and q. To this aim, the th multiplet is split into the two subsets and . The formula for allows for applying the argument to the set , thus obtaining the number of dichotomies of the set that are admissible on the first q complete multiplets and are admissible on the th incomplete multiplet . More formally, is the number of linearly realizable dichotomies , such that
Now the argument goes exactly as for the case : some of these dichotomies (their number being ) can be realized by a weight vector orthogonal to the point ; therefore, each of them contributes a single admissible dichotomy of the whole set ; the remaining contribute with probability . Again, can be expressed by applying the same argument in dimensions.
7. Computation of Compact Metrics of Linear Separability
The model of data structure leading to the foregoing equations is very detailed, in that it allows for the independent specification of a large number of parameters. However, the influence of each parameter on the separability is not equal, with some combinations of parameters being more relevant than others. In this section, I compute two main descriptors of the shape of as a function of q at n fixed: the transition point (equivalently, the capacity ) and the width of the transition region; they are defined more precisely below. We will see that only the structure parameters and , the special combinations defined in Section 5, are needed to fix and .
7.1. Diagonalization of the Recurrence Relation
Notice that, while the quantity that is given by the theory is expressed as a function of the number of multiplets q, the definition of separability that is discussed in Section 5 is given in terms of the number of points . This is not really a problem in the thermodynamic limit
whereby the separability is expressed as a function of the load . In the following, I will define the location and the width of the transition region in the parameterization by the number of multiplets q; the corresponding quantities that are parameterized by p are obtained by rescaling:
Let us consider the discrete derivative of with respect to n:
As will be clear momentarily, working with is convenient because it is normalized, as I will prove below. satisfies the same recurrence relation as :
The boundary conditions, in accordance with (20), are
The right hand side of Equation (33) has the form of a discrete convolution between and :
The convolution is diagonalized in Fourier space, by defining the characteristic functions
Multiplying both sides of Equation (35) by and summing over n yields
From the definition (36) and boundary conditions (34), one gets ; hence, the solution of the recurrence equation is
7.2. Defining the Location and Width of the Transition Region
As mentioned above, is normalized, which means that
or, equivalently, . To prove this, it suffices to show that , i.e., that is normalized. Summing both sides of Equation (28) in l from 0 to ∞ shows that is constant in k, therefore
as can be computed from the boundary conditions (29).
Because it is normalized, can be interpreted as a probability distribution, whose cumulative distribution function is . The ath moment of the distribution is
The same holds for , whose moments can be obtained from its characteristic function . Let us focus on the mean and the variance ,
Equation (39) allows for expressing these quantities in terms of the mean and variance of :
as can be checked by using Equation (42).
We can now define the two main descriptors, and , which summarize the separability as a function of q:
7.3. Expression in Terms of the Structure Parameters
To compute these quantities, all we need is and , or and . Solving Equation (45) for gives
Solving Equations (46) and (47) for gives
The corresponding expressions to leading order in n are the following
The moments of satisfy the following equation, which can be obtained by multiplying both sides of Equation (28) by and summing over l:
The boundary conditions are (computed above) and , as given by Equation (29). In particular, for , we obtain
whose solution is
where the structure parameter , as defined in Equation (17), implicitly depends on k. For , the recurrence Equation (51) becomes
By substituting given by Equation (53) and solving the recurrence we obtain, after some algebra,
where is the second structure parameter that is defined in Equation (18). Finally, by combining the leading order expansions (50) and the moments (53) and (55), and by rescaling, as in Equation (31), we have the following explicit expressions for the two main metrics of separability as functions of the multiplicity k and the structure parameters and :
For data that are structured as pairs of points, , Equation (56) gives the storage capacity of an ensemble of segments; this special result was first obtained, by means of replica calculations, in [44], and it was then rediscovered in other contexts in [8,45].
7.4. Dependence on the Structure Parameters and Scaling
The two structure parameters and , which control the two main metrics of linear separability, belong to k-dependent ranges:
The two quantities are not independent, since they are constructed from the same set of quantities . When conditioned on a fixed value of , has a lower bound and an upper bound that can be computed by considering the two following extreme cases. First, the supremum of is realized in the maximum entropy case, where the value of is uniformly distributed among the . Second, the infimum of corresponds to the minimum entropy case, where is distributed on the fewest possible ’s. Explicitly,
The definition of , Equation (18), can be rewritten, as follows:
Substituting (59) and (60) into (61), we obtain
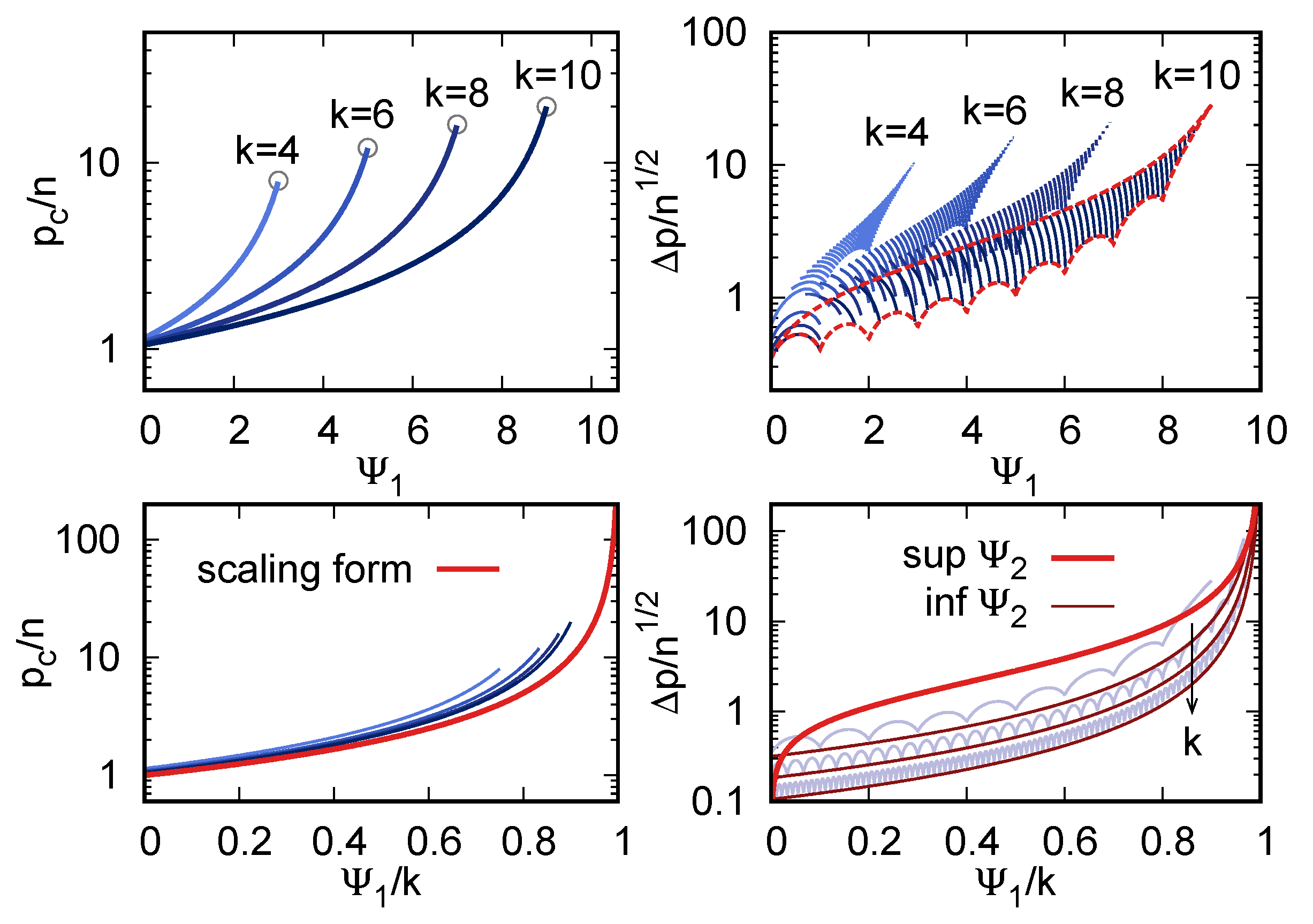
Figure 3 shows the location of the transition, , and the width of the region, , as functions of and for a few values of k. Notice that the range of at fixed k and is itself bounded because of the limited range of .
There is an interesting observation to be made on a semi-quantitative level. At fixed k and n, is an increasing function of . The width depends on both structure parameters, but, since the range of at fixed is so limited, one expects that, in practice, will be approximately an increasing function of . Therefore, will be, in most cases, an increasing function of . This is exactly the phenomenology that is observed in Figure 2, in both the synthetic data and MNIST.
The rescaled location of the transition , Equation (56), does not depend on , and it depends on only through the rescaled value . For large k, it takes the scaling form
The width , on the contrary, depends on both and . Because it is a monotonically increasing function of , its upper bound and lower bound at fixed can be obtained by substituting (62) and (63) in Equation (57). Expressing again as a function of the rescaled parameter , and only keeping the leading term in , one obtains the scaling form
Doing the same for yields a complicated function, which is plotted in Figure 3. A simpler expression for the bound can be obtained by observing that ; using this more regular bound yields, at leading order in k,
Figure 3 shows the large-k scaling behavior of , , and .
The two metrics are insensitive on most of the microscopic parameters of the theory, and they only depend on the two structure parameters, as shown analytically above. In addition, they display a large degree of robustness, even as functions of and : measuring from the data fixes (up to corrections in k) the quantity , which, in turn, significantly narrows down the range of values that are attainable by , the more so the smaller is k.
8. Discussion
The discussion above focused on the quantification of linear separability within a model that encodes simple relations between data points and their labels, in the form of constraints. Such a model has the advantage of being analytically tractable and allows the explicit expression of and in terms of model parameters. Moreover, the parameters appearing in the theory have direct interpretations as probabilities of geometric events, thus suggesting routes for further generalization.
In the face of its convenience for theoretical investigations, the definition of data structure used here does not aim at a realistic description of any specific data set. It must be interpreted as a phenomenological or effective parameterization of basic features of data structure that have a distinct effect on linear separability. The limited numerical experiments on MNIST data reported above are a proof of concept, showing a real data set with unexpectedly high linear separability, and they serve as a notable motivation for the investigation of data structure. The main goal of this article is the theoretical analysis; therefore, I postpone any comparison of theory and data. Moreover, MNIST is a relatively simple and clean data set. The numerical analysis signals the highly constrained nature of these data, where points that are close with respect to the Euclidean distance in are more likely to have the same label. However, more complex data sets, such as ImageNET, are expected to be less constrained at the level of raw data, due to the higher variability within each category, and due to what are referred to as “nuisances”, i.e., elements that are present, but do not contribute to the classification. Yet, even in these cases, the aggregation of equally-labelled points emerges in the feature spaces towards the last layers of deep neural networks, which improves the efficacy of the linear readout downstream, as empirically observed [14,15].
An interesting, and perhaps unexpected, outcome of the theory concerns the universal properties of the probability of separation . Here, I use the term “universality” in a much weaker sense than what is usually intended in statistical mechanics: I use it to denote (i) the qualitative robustness of the sigmoidal shape of the separability curve on the details of the model, and (ii) the quantitative insensitivity of the separability metrics on all but a few special combinations of parameters [46]. Importantly, the two metrics of data structure that are computed for the model, and , are the only two important parameters that fix in the thermodynamic limit, apart from the rescaling by k. The central limit theorem suggests this universality property. In fact, is the probability distribution of the sum of independent and identically distributed variables, as expressed by Equation (39). Therefore, will converge to a Gaussian distribution with linearly increasing mean and variance. This indicates that and are the only two nonzero cumulants in the thermodynamic limit and, thus, and are the only two nontrivial metrics that are related to . This does not, by any means, imply that the model of data structure itself can be reduced to only two degrees of freedom. In fact, the phenomenology is richer if one considers the combinatorial quantity instead of the intensive one , see [32]; still, regarding the probability of separation, the relevant metrics are the location and width of the transition region.
Funding
The author acknowledges support from the University of Milan through the APC initiative.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. The MNIST data set can be found here: yann.lecun.com/exdb/mnist/ (accessed on 20 May 2019).
Acknowledgments
I am grateful to Pietro Rotondo for countless stimulating discussions.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Boundary Conditions
The boundary conditions of the recurrence Equation (27) require some care. When a single () multiplet is considered in dimension , both its admissible dichotomies are linearly realizable. This is because all dichotomies of k points can be realized in dimensions, as I mentioned above. Therefore
The boundary conditions for are not simply the same as for . To see this, consider for instance what happens in dimensions when dealing with a single () multiplet of points, and . Two problems arise: (i) if the two points lie on opposite sides of the origin, a linearly realized dichotomy will always assign them different signs, ; (ii) there are not enough degrees of freedom to fix the overlap while keeping and normalized.
These obstructions are problematic when trying to define the value of for . This quantity appears in the right hand side of the recurrence Equation (25) when and , where it is needed, alongside , to compute . Retracing the derivation for shows that in this context occurs when imposing a linear constraint in 2 dimensions, where it represents the fraction of admissible dichotomies of the doublet that can be realized by a weight versor w satisfying . In 2 dimensions, the orthogonality condition fixes w up to its sign. If this constrained w is such that
then exactly 2 admissible dichotomies of are realizable, otherwise the only realizable dichotomies are not admissible. Therefore expresses the probability that Equation (A2) is satisfied; in the mean field approximation, this is . The foregoing argument actually applies for all . The probability that all k points in a multiplet lie in the same half-space with respect to the hyperplane realized by a random versor fixes the first non-trivial boundary condition .
For this fixes everything. Let us now consider . In this case Equation (A1) omits . What should its value be? Again, going back to the argument in Section 6.3 is helpful. appears in the recurrence when and a linear constraint is imposed on w. This fixes w up to rotations around an axis, identified by a versor v. Now, whether the multiplet allows 2 or 0 admissible dichotomies depends on whether there exists a vector w satisfying the constraint and such that . This happens if and only if the axis of rotation v lies outside the solid angle subtended by the three vectors . This characterization allows to compute by elementary methods of solid geometry. One finds
where
For larger values of k, the same reasoning allows to express the non trivial boundary conditions as geometric probabilities. Fortunately, the hassle of computing all these probabilities can be bypassed by using the boundary conditions (20), which are approximate for , but still provide asymptotically correct results [28]. In fact, as is evident from the discussion in Section 7, if one takes the thermodynamic limit (30) the contribution of the approximate values of becomes negligible. Other ways of taking the thermodynamic limit (e.g., if k is extensive in n) may not enjoy this simplification, and may require a different analysis of the boundary conditions.
References
- Yuan, G.X.; Ho, C.H.; Lin, C.J. Recent Advances of Large-Scale Linear Classification. Proc. IEEE 2012, 100, 2584–2603. [Google Scholar] [CrossRef] [Green Version]
- Elizondo, D. The linear separability problem: Some testing methods. IEEE Trans. Neural Netw. 2006, 17, 330–344. [Google Scholar] [CrossRef] [PubMed]
- Baldassi, C.; Della Vecchia, R.; Lucibello, C.; Zecchina, R. Clustering of solutions in the symmetric binary perceptron. J. Stat. Mech. Theory Exp. 2020, 2020, 073303. [Google Scholar] [CrossRef]
- Baldassi, C.; Malatesta, E.; Negri, M.; Zecchina, R. Wide flat minima and optimal generalization in classifying high-dimensional Gaussian mixtures. J. Stat. Mech. Theory Exp. 2020, 2020, 124012. [Google Scholar] [CrossRef]
- Cui, H.; Saglietti, L.; Zdeborová, L. Large deviations for the perceptron model and consequences for active learning. In Proceedings of the First Mathematical and Scientific Machine Learning Conference, Princeton, NJ, USA, 20–24 July 2020; pp. 390–430. [Google Scholar]
- Aubin, B.; Perkins, W.; Zdeborová, L. Storage capacity in symmetric binary perceptrons. J. Phys. Math. Theor. 2019, 52, 294003. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [Green Version]
- Chung, S.; Lee, D.D.; Sompolinsky, H. Linear readout of object manifolds. Phys. Rev. E 2016, 93, 060301. [Google Scholar] [CrossRef] [Green Version]
- Astrand, E.; Enel, P.; Ibos, G.; Dominey, P.F.; Baraduc, P.; Ben Hamed, S. Comparison of classifiers for decoding sensory and cognitive information from prefrontal neuronal populations. PLoS ONE 2014, 9, e86314. [Google Scholar] [CrossRef]
- Jacot, A.; Gabriel, F.; Hongler, C. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. In Advances in Neural Information Processing Systems 31; NIPS: Montreal, QC, Canada, 2018. [Google Scholar]
- Lee, J.; Xiao, L.; Schoenholz, S.S.; Bahri, Y.; Novak, R.; Sohl-Dickstein, J.; Pennington, J. Wide neural networks of any depth evolve as linear models under gradient descent. J. Stat. Mech. Theory Exp. 2020, 2020, 124002. [Google Scholar] [CrossRef]
- Saxe, A.M.; Mcclelland, J.L.; Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural network. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Basu, M.; Ho, T. Data Complexity in Pattern Recognition; Springer: London, UK, 2006. [Google Scholar]
- Cohen, U.; Chung, S.; Lee, D.D.; Sompolinsky, H. Separability and geometry of object manifolds in deep neural networks. Nat. Commun. 2020, 11, 746. [Google Scholar] [CrossRef] [Green Version]
- Ansuini, A.; Laio, A.; Macke, J.; Zoccolan, D. Intrinsic dimension of data representations in deep neural networks. In Advances in Neural Information Processing Systems 32; NIPS: Vancouver, BC, Canada, 2019. [Google Scholar]
- Ingrosso, A. Optimal learning with excitatory and inhibitory synapses. PLoS Comput. Biol. 2021, 16, e1008536. [Google Scholar]
- Zdeborová, L. Understanding deep learning is also a job for physicists. Nat. Phys. 2020, 16, 602–604. [Google Scholar] [CrossRef]
- Bahri, Y.; Kadmon, J.; Pennington, J.; Schoenholz, S.S.; Sohl-Dickstein, J.; Ganguli, S. Statistical Mechanics of Deep Learning. Annu. Rev. Condens. Matter Phys. 2020, 11, 501–528. [Google Scholar] [CrossRef] [Green Version]
- Goldt, S.; Mézard, M.; Krzakala, F.; Zdeborová, L. Modeling the Influence of Data Structure on Learning in Neural Networks: The Hidden Manifold Model. Phys. Rev. X 2020, 10, 041044. [Google Scholar] [CrossRef]
- Erba, V.; Ariosto, S.; Gherardi, M.; Rotondo, P. Random geometric graphs in high dimension. Phys. Rev. E 2020, 102, 012306. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Poole, B.; Lahiri, S.; Raghu, M.; Sohl-Dickstein, J.; Ganguli, S. Exponential expressivity in deep neural networks through transient chaos. In Advances in Neural Information Processing Systems 26; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29, pp. 3360–3368. [Google Scholar]
- Mazzolini, A.; Gherardi, M.; Caselle, M.; Cosentino Lagomarsino, M.; Osella, M. Statistics of Shared Components in Complex Component Systems. Phys. Rev. X 2018, 8, 021023. [Google Scholar] [CrossRef] [Green Version]
- Mazzolini, A.; Grilli, J.; De Lazzari, E.; Osella, M.; Lagomarsino, M.C.; Gherardi, M. Zipf and Heaps laws from dependency structures in component systems. Phys. Rev. E 2018, 98, 012315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gherardi, M.; Rotondo, P. Measuring logic complexity can guide pattern discovery in empirical systems. Complexity 2016, 21, 397–408. [Google Scholar] [CrossRef] [Green Version]
- Mézard, M. Mean-field message-passing equations in the Hopfield model and its generalizations. Phys. Rev. E 2017, 95, 022117. [Google Scholar] [CrossRef] [Green Version]
- Chung, S.; Lee, D.D.; Sompolinsky, H. Classification and Geometry of General Perceptual Manifolds. Phys. Rev. X 2018, 8, 031003. [Google Scholar] [CrossRef] [Green Version]
- Rotondo, P.; Cosentino Lagomarsino, M.; Gherardi, M. Counting the learnable functions of geometrically structured data. Phys. Rev. Res. 2020, 2, 023169. [Google Scholar] [CrossRef]
- Erba, V.; Gherardi, M.; Rotondo, P. Intrinsic dimension estimation for locally undersampled data. Sci. Rep. 2019, 9, 17133. [Google Scholar] [CrossRef] [PubMed]
- Facco, E.; d’Errico, M.; Rodriguez, A.; Laio, A. Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Sci. Rep. 2017, 7, 12140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pastore, M.; Rotondo, P.; Erba, V.; Gherardi, M. Statistical learning theory of structured data. Phys. Rev. E 2020, 102, 032119. [Google Scholar] [CrossRef] [PubMed]
- Rotondo, P.; Pastore, M.; Gherardi, M. Beyond the Storage Capacity: Data-Driven Satisfiability Transition. Phys. Rev. Lett. 2020, 125, 120601. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Schläfli, L. Gesammelte Mathematische Abhandlungen; Springer: Basel, Switzerland, 1950. [Google Scholar]
- Cameron, S. An Estimate of the Complexity Requisite in a Universal Decision Network; WADD Technical Report; Bionics Symposium: Dayton, OH, USA, 1960. [Google Scholar]
- Cover, T.M. Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition. IEEE Trans. Electron. Comput. 1965, EC-14, 326–334. [Google Scholar] [CrossRef] [Green Version]
- Baldi, P. A computational theory of surprise. In Information, Coding and Mathematics: Proceedings of Workshop Honoring Prof. Bob McEliece on His 60th Birthday; Blaum, M., Farrell, P.G., van Tilborg, H.C.A., Eds.; The Springer International Series in Engineering and Computer Science; Springer: Boston, MA, USA, 2002; pp. 1–25. [Google Scholar]
- McCoy, B.M. Advanced Statistical Mechanics; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Caracciolo, S.; Di Gioacchino, A.; Gherardi, M.; Malatesta, E.M. Solution for a bipartite Euclidean traveling-salesman problem in one dimension. Phys. Rev. E 2018, 97, 052109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dell’Aquila, G.; Ferrante, M.I.; Gherardi, M.; Cosentino Lagomarsino, M.; Ribera d’Alcalà, M.; Iudicone, D.; Amato, A. Nutrient consumption and chain tuning in diatoms exposed to storm-like turbulence. Sci. Rep. 2017, 7, 1828. [Google Scholar] [CrossRef] [PubMed]
- Gherardi, M.; Amato, A.; Bouly, J.P.; Cheminant, S.; Ferrante, M.I.; d’Alcalá, M.R.; Iudicone, D.; Falciatore, A.; Cosentino Lagomarsino, M. Regulation of chain length in two diatoms as a growth-fragmentation process. Phys. Rev. E 2016, 94, 022418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopez, B.; Schroder, M.; Opper, M. Storage of correlated patterns in a perceptron. J. Phys. Math. Gen. 1995, 28, L447. [Google Scholar] [CrossRef] [Green Version]
- Borra, F.; Lagomarsino, M.C.; Rotondo, P.; Gherardi, M. Generalization from correlated sets of patterns in the perceptron. J. Phys. Math. Theor. 2019, 52, 384004. [Google Scholar] [CrossRef] [Green Version]
- Machta, B.B.; Chachra, R.; Transtrum, M.K.; Sethna, J.P. Parameter Space Compression Underlies Emergent Theories and Predictive Models. Science 2013, 342, 604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
(Top left) The probability of separation, Equation (2), as a function of the number of points p for three values of the embedding dimension n. (Top right) As a function of the load , the probability of separation converges, for large n, to a step function. (Bottom) Depending on the values of n and p, a data set being separable or nonseparable can convey information about its structure. The location and the width of the transition region are the two main descriptors of the shape of a separability curve.
Figure 1.
(Top left) The probability of separation, Equation (2), as a function of the number of points p for three values of the embedding dimension n. (Top right) As a function of the load , the probability of separation converges, for large n, to a step function. (Bottom) Depending on the values of n and p, a data set being separable or nonseparable can convey information about its structure. The location and the width of the transition region are the two main descriptors of the shape of a separability curve.

Figure 2.
Linear separability (y axis) for subsets of varying size p (x axis), computed in a modified MNIST data set, generated by downscaling and applying multiplicative noise (left and center panels), and in synthetic data sets generated from a mixture of two normal distributions (right panel). (Left panel) If the labels are reshuffled, MNIST data (pink area) almost perfectly follow the prediction of the null model (blue line). (Center panel) The separabilities of two representative dichotomies in the data set (digits “4” versus “9”, and digits “3” versus “7”) are far removed from the null model, as is apparent from the location (and the width) of their transition regions (green areas). The shaded areas denote the 95% variability intervals. (Right panel) By increasing the distance between the means of the two Gaussian distributions that define the synthetic data set (here in dimensions), the separability increases. For (squares), one recovers the prediction of the null model (blue line). Error bars (not shown) are approximately the same size as the symbols.
Figure 2.
Linear separability (y axis) for subsets of varying size p (x axis), computed in a modified MNIST data set, generated by downscaling and applying multiplicative noise (left and center panels), and in synthetic data sets generated from a mixture of two normal distributions (right panel). (Left panel) If the labels are reshuffled, MNIST data (pink area) almost perfectly follow the prediction of the null model (blue line). (Center panel) The separabilities of two representative dichotomies in the data set (digits “4” versus “9”, and digits “3” versus “7”) are far removed from the null model, as is apparent from the location (and the width) of their transition regions (green areas). The shaded areas denote the 95% variability intervals. (Right panel) By increasing the distance between the means of the two Gaussian distributions that define the synthetic data set (here in dimensions), the separability increases. For (squares), one recovers the prediction of the null model (blue line). Error bars (not shown) are approximately the same size as the symbols.

Figure 3.
(Top left) The dependence of the rescaled location of the transition region (y axis) on the structure parameter (x axis), for a few values of the multiplicity k. Circles pinpoint the tips of the curves, which correspond to the unstructured case, where (i.e., for all m) and . (Top right) The rescaled width of the transition region (y axis). Segments correspond to 50 fixed values of , which were equally spaced in ; their range in (x axis) is obtained by inverting the relations (62) and (63). The dashed red lines are the upper and lower bounds of , obtained by substituting (62) and (63) into (57). (Bottom left) The large-k scaling form (red line) of (y axis) as a function of the rescaled parameter (x axis); the blue lines are the same as in the top left panel. (Bottom right) The large-k behavior of the upper (thick red line) and lower (thin red and grey lines) bounds (y axis) as functions of (x axis). Grey lines are the tight lower bounds as in the top right panel and thin red lines are the simpler bound Equation (66); different lower bounds correspond to .
Figure 3.
(Top left) The dependence of the rescaled location of the transition region (y axis) on the structure parameter (x axis), for a few values of the multiplicity k. Circles pinpoint the tips of the curves, which correspond to the unstructured case, where (i.e., for all m) and . (Top right) The rescaled width of the transition region (y axis). Segments correspond to 50 fixed values of , which were equally spaced in ; their range in (x axis) is obtained by inverting the relations (62) and (63). The dashed red lines are the upper and lower bounds of , obtained by substituting (62) and (63) into (57). (Bottom left) The large-k scaling form (red line) of (y axis) as a function of the rescaled parameter (x axis); the blue lines are the same as in the top left panel. (Bottom right) The large-k behavior of the upper (thick red line) and lower (thin red and grey lines) bounds (y axis) as functions of (x axis). Grey lines are the tight lower bounds as in the top right panel and thin red lines are the simpler bound Equation (66); different lower bounds correspond to .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gherardi, M. Solvable Model for the Linear Separability of Structured Data. Entropy 2021, 23, 305. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030305
AMA Style
Gherardi M. Solvable Model for the Linear Separability of Structured Data. Entropy. 2021; 23(3):305. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030305
Chicago/Turabian StyleGherardi, Marco. 2021. "Solvable Model for the Linear Separability of Structured Data" Entropy 23, no. 3: 305. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030305
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.