
Entropic Dynamics on Gibbs Statistical Manifolds


Department of Physics, University at Albany (SUNY), Albany, NY 12222, USA
*
Authors to whom correspondence should be addressed.
Entropy 2021, 23(5), 494; https://0-doi-org.brum.beds.ac.uk/10.3390/e23050494
Submission received: 2 March 2021
/
Revised: 15 April 2021
/
Accepted: 19 April 2021
/
Published: 21 April 2021
(This article belongs to the Special Issue Entropy: The Scientific Tool of the 21st Century)
Abstract
:Entropic dynamics is a framework in which the laws of dynamics are derived as an application of entropic methods of inference. Its successes include the derivation of quantum mechanics and quantum field theory from probabilistic principles. Here, we develop the entropic dynamics of a system, the state of which is described by a probability distribution. Thus, the dynamics unfolds on a statistical manifold that is automatically endowed by a metric structure provided by information geometry. The curvature of the manifold has a significant influence. We focus our dynamics on the statistical manifold of Gibbs distributions (also known as canonical distributions or the exponential family). The model includes an “entropic” notion of time that is tailored to the system under study; the system is its own clock. As one might expect that entropic time is intrinsically directional; there is a natural arrow of time that is led by entropic considerations. As illustrative examples, we discuss dynamics on a space of Gaussians and the discrete three-state system.
1. Introduction
The original method of Maximum Entropy (MaxEnt) is usually associated with the names of Shannon [1] and Jaynes [2,3,4,5], although its roots can be traced to Gibbs [6]. The method was designed to assign probabilities on the basis of partial information in the form of expected value constraints and the central quantity, called entropy, which was interpreted as a measure of uncertainty or as an amount of missing information. In a series of developments starting with Shore and Johnson [7], with further contributions from other authors [8,9,10,11,12], the range of applicability of the method was significantly extended. In its new incarnation, the purpose of the method of Maximum Entropy, which will be referred as ME to distinguish it from the older version, is to update the probabilities from arbitrary priors when new information in the form of constraints is considered [13]. Highlights of the new method include: (1) A unified treatment of Bayesian and entropic methods which demonstrates their mutual consistency. (2) A new concept of entropy as a tool for reasoning that requires no interpretation in terms of heat, multiplicities, disorder, uncertainty, or amount of information. Indeed, entropy in ME needs no interpretation; it is a tool designed to perform a certain function—to update probabilities to accommodate new information. (3) A Bayesian concept of information defined in terms of its effects on the beliefs of rational agents—the constraints are the information. (4) The possibility of information that is not in the form of expected value constraints (we shall see an example below).
The old MaxEnt was sufficiently versatile for providing the foundations to equilibrium statistical mechanics [2] and to find application in a wide variety of fields such as economics [14], ecology [15,16], cellular biology [17,18], network science [19,20], and opinion dynamics [21,22]. As is the case with thermodynamics, all these applications are essentially static. MaxEnt has also been deployed to non-equilibrium statistical mechanics (see [23,24] and subsequent literature in maximum caliber, e.g., [25,26,27]) but the dynamics is not intrinsic to the probabilities; it is induced by the underlying Hamiltonian dynamics of the molecules. For problems beyond physics there is a need for more general dynamical frameworks based on information theory.
The ME version of the maximum entropy method offers the possibility of developing a true dynamics of probabilities. It is a dynamics driven by entropy—an Entropic Dynamics (ED)—which is automatically consistent with the principles for updating probabilities. ED naturally leads to an “entropic” notion of time. Entropic time is a device designed to keep track of the accumulation of changes. Its construction involves three ingredients: one must introduce the notion of an instant, verify that these instants are suitably ordered, and finally one must define a convenient notion of duration or interval between successive instants. A welcome feature is that entropic time is tailored to the system under study; the system is its own clock. Another welcome feature is that such an entropic time is intrinsically directional—an arrow of time is generated automatically.
ED has been successful in reconstructing dynamical models in physics such as quantum mechanics [28,29], quantum field theory [30], and the renormalization group [31]. Beyond physics, it has been recently applied to the rhw fields of finance [32,33] and neural networks [34]. Here, we aim for a different class of applications of ED: to describe the dynamics of Gibbs distributions, also known as canonical distribution (exponential family) in statistical physics (statistics), since they are the distributions that are defined by a set of expected values constraint, namely sufficient statistics. Unlike the other cited papers on ED, here we will not focus on what the distributions are meant to represent. Other assumptions that would be specific to the modeled system are beyond the scope of the present article.
The goal is to study the ED that is generated by transitions from one distribution to another. The main assumptions are that changes happen and that they are not discontinuous. We do not explain why changes happen—this is a mechanics without a mechanism. Our goal is to venture an educated estimate of what changes one expects to happen. The second assumption is that systems evolve along continuous trajectories in the space of probability distributions. It also implies that the study of motion involves two tasks. The first is to describe how a single infinitesimal step occurs. The second requires a scheme for keeping track of how a large number of these short steps accumulate to produce a finite motion. It is the latter task that involves the introduction of the concept of time.
The fact that the space of macrostates is a statistical manifold—each point in the space is a probability distribution—has a profound effect on the dynamics. The reason is that statistical manifolds are naturally endowed with a Riemannian metric structure that is given by the Fisher–Rao information metric (FRIM) [35,36]; this structure is known as information geometry [37,38,39]. The particular case of Gibbs distributions leads to additional interesting geometrical properties (see e.g., [40,41]), which have been explored in the extensive work relating statistical mechanics to information geometry [42,43,44,45,46,47,48,49]. Information geometry has also been used as a fundamental concept for complexity measures [50,51,52].
In this paper, we tackle the more formal aspects of an ED on Gibbs manifolds and offer a couple of illustrative examples. The formalism is applied to two important sets of probability distributions: the space of Gaussians and the space of distributions for a three-state system, both of which can be written in the exponential form. Because these distributions are both well-studied and scientifically relevant, they can give us a good insight into how the dynamics work.
It is important to emphasize that Gibbs distributions are not restricted to the description of a system in thermal equilibrium. While it is true that, if one chooses the conserved quantities in Hamiltonian motion as the sufficient statistics, the resultant Gibbs distributions are the ones that are associated to equilibrium statistical mechanics, the Gibbs distribution can be defined for arbitrary choices of sufficient statistics, and the modeling endeavour includes identifying the ones that are relevant to the problem at hand. On the same note, the dynamics developed here are not a form of nonequilibrium statistical mechanics, which is driven by a underlying physical molecular dynamics, while the ED is completely agnostic of any microstate dynamics.
The article is organized, as follows: the next section discusses the space of Gibbs distributions and its geometric properties; Section 3 considers the ideas of ED; Section 4 tackles the difficulties associated with formulating ED on the curved space of probability distributions; Section 5 introduces the notion of entropic time; Section 6 describes the evolution of the system in the form of a differential equation; in Section 7, we offer two illustrative examples of ED on a Gaussian manifold and on a two-simplex.
2. The Statistical Manifold of Gibbs Distributions
2.1. Gibbs Distributions
The canonical or Gibbs probability distributions are the macrostates of a system. They describe a state of uncertainty regarding the microstate of the macroscopic system. A canonical distribution is assigned by maximizing the entropy
relative to the prior subject to n expected value constraints
and the normalization of . Typically, the prior is chosen to be a uniform distribution over the space so that it is maximally non-informative, but this is not strictly necessary. The n constraints, on the other hand, reflect the information that happens to be relevant to the problem. The resulting canonical distribution is
where are the Lagrange multipliers that are associated to the expected value constraints, and we adopt the Einstein summation convention. The normalization constant is
where plays a role analogous to the free energy. The Lagrange multipliers are implicitly defined by
Evaluating the entropy (1) at its maximum yields
which we shall call the macrostate entropy or (when there is no risk of confusion) just the entropy. Equation (6) shows that is the Legendre transform of : a small change in the constraints shows that is indeed a function of the expected values ,
One might think that defining dynamics on the family of canonical distributions might be too restricted to be of interest; however, this family has widespread applicability. Here, it has been derived using the method of maximum entropy, but historically it has also been known as the exponential family, namely the only family of distributions that possesses sufficient statistics. Interestingly, this was a problem that was proposed by Fisher [53] in the primordium of statistics and later proved independently by Pitman [54], Darmois [55], and Koopman [56]. The sufficient statistics turn out to be the functions in (1). In Table 1, we give a short list of the priors and the functions that lead to well-known distributions [41,57].
Naturally, the method of maximum entropy assumes that the various constraints are compatible with each other, so that the set of multipliers exists. It is further assumed that the constraints reflect physically relevant information, so that the various functions, such as and , which appear in the formalism, are both invertible and differentiable, and so that the space of Gibbs distributions is indeed a manifold. However, the manifold may include singularities of various kinds that are of particular interest, as they may describe phenomena, such as phase transitions [42,46].
2.2. Information Geometry
We offer a brief review of well known results concerning the information geometry of Gibbs distributions in order to establish the notation and recall some results that will be needed in later sections [38,40].
To each set of expected values , or to the associated set of Lagrange multipliers , there corresponds a canonical distribution. Therefore the set of distributions or, equivalently, is a statistical manifold in which each point can be labelled by the coordinates or by A. Whether we choose or A as coordinates is purely a matter of convenience. The change of coordinates is implemented using
where we recognize the covariance tensor,
Its inverse is given by
that means the inverse covariant matrix is the Hessian of negative entropy in (6). This implies
Statistical manifolds are endowed with an essentially unique quantity to measure the extent to which two neighboring distributions and can be distinguished from each other. This measure of distinguishability provides a statistical notion of distance, which is given by FRIM, where
For a broader discussion on the existence, derivation, and consistency of this metric, as well as its properties, see [38,39,40]. Here, it suffices to say that FRIM is the unique metric structure that is invariant under Markov embeddings [58,59] and, therefore, is the only way of assigning a differential geometry structure that is in accordance to the grouping property of probability distributions.
To calculate for canonical distributions, we use
and
so that, using (8)–(11), we have
Therefore, the metric tensor is the inverse of the covariance matrix , which, by (10), is the Hessian of the entropy.
As mentioned above, instead of , we could use the Lagrange multipliers as coordinates. Subsequently, the information metric is the covariance matrix,
Therefore, the distance between neighboring distributions can be written in either of two equivalent forms,
Incidentally, the availability of a unique measure of volume implies that there is a uniquely defined notion of the uniform distribution over the space of macrostates. The uniform distribution assigns equal probabilities to equal volumes, so that
To conclude this overview section, we note that the metric tensor can be used to lower the contravariant indices of a vector to produce its dual covector. Using (10) and (12), the covector dual to the infinitesimal vector with components is
which shows that not only are the coordinates A and related through a Legendre transformation, which is a consequence of entropy maximization, but also through a vector-covector duality, i.e., is the covector dual to , which is a consequence of information geometry.
3. Entropic Dynamics
Having established the necessary background, we can now develop an entropic framework to describe the dynamics on the space of macrostates.
3.1. Change Happens
Our starting assumption is that changes happen continuously, which is supported by observation in nature. Therefore, the dynamics that we wish to formulate assumes that the system evolves along continuous paths. This assumption of continuity represents a significant simplification, because it implies that a finite motion can be analyzed as the accumulation of a large number of infinitesimally short steps. Thus, our first goal will be to find the probability that the system takes a short step from the macrostate A to the neighboring macrostate . The transition probability will be assigned by maximizing an entropy. This first requires that we identify the particular entropy that is relevant to our problem. Next, we must decide on the prior distribution: what short steps we might expect before we know the specifics of the motion. Finally, we stipulate the constraints that are meant to capture the information that is relevant to the particular problem at hand.
To settle the first item—the choice of entropy—we note that not only are we are uncertain about the macrostate at A, but we are also uncertain about the microstates . This means that the actual universe of discourse is the joint space and the appropriate statistical description of the system is in terms of the joint distribution
Where is of form (3), which means that we impose to be canonical and the distribution represents our lack of knowledge about the macrostates. Note that what we did in (20) is nothing more than assuming a probability distribution for the macrostates. This description is sometimes referred to as superstatistics [60].
Our immediate task is to find the transition probability of a change by maximizing the entropy
relative to the prior and subject to constraints to be discussed below (to simplify the notation in multidimensional integrals we write and ).
Although S in (6) and in (21) are both entropies, in the information theory sense, they represent two very distinct statistical objects. The in (6) is the entropy of the macrostate—which is what one may be used to from statistical mechanics —while the in (21) is the entropy to be maximized, so that we find the transition probability that better matches the information at hand, which means that is a tool to select the dynamics of the macrostates.
3.2. The Prior
We adopt a prior that implements the idea that the system evolves by taking short steps at the macrostate level, but is otherwise maximally uninformative. We write
and analyze the two factors in turn. We shall assume that a priori, before we know the relation between the microstates x and the macrostate A, the prior distribution for is the same uniform underlying measure that is introduced in (1),
Next, we tackle the second factor . As shown in Appendix A, using the method of maximum entropy, the prior that enforces short steps, but is otherwise maximally uninformative, is spherically symmetric as
so the joint prior is
We see that steps of length
have negligible probability. Eventually, we will take the limit to enforce short steps. The prefactor ensures that is a probability density. Later, we will show how this choice of priors, which only comes from the assumption of continuous motion, leads to a diffusion structure.
3.3. The Constraints
The piece of information that we wish to codify through the constraints is the simple geometric idea that the dynamics remains confined to the statistical manifold . This is implemented by writing
and imposing that the distribution for is a canonical distribution
This means that, given , the distribution of is independent of the initial microstate x and macrostate A. The second factor in (27), , is the transition probability we seek, which leads to the constraint
We note that this constraint is not, as is usual in applications of the method of maximum entropy, in the form of an expected value. It may appear from (29) that the transition probability will be largely unaffected by the underlying space of microstates. To the contrary, as we shall see below—(31) and (32)—the macrostate dynamics turns out to be dominated by the entropy of the microstate distribution .
Depending on the particular system under consideration, one could formulate richer forms of dynamics by imposing additional constraints. To give just one example, one could introduce some drift relative to the direction that is specified by a covector by imposing a constraint of the form (see [29,30]). However, in this paper, we shall limit ourselves to what is perhaps the simplest case, the minimal ED that is described by the single constraint (29).
3.4. Maximizing the Entropy
Substituting (25) and (29) into (21) and rearranging, we find
where is the macrostate entropy that is given in (6). Maximizing subject to normalization gives
It is noteworthy that turned out to be independent of x, which is not surprising, since neither the prior nor the constraints indicate any correlation between and x.
We perform a linear approximation of S because the transition from A to has to be an arbitrarily small continuous change. This makes the exponential factor in (31) quadratic in , as
where was absorbed in the normalization factor . This is the transition probability found by maximizing the entropy (21). However, some mathematical difficulties arise from the fact that (32) is defined over a curved manifold. We are going to explore these mathematical issues and their consequences to motion in the following section.
4. The Transition Probability
Because the statistical manifold is a curved space, we must understand how the transition probability (32) behaves under a change of coordinates. Because (25) and (32) describe an arbitrarily small step, we wish to express the transition probability, as well as the quantities derived from it, which are calculated up to the order of . Because the exponent in (32) is manifestly invariant, one can complete squares and obtain
If were uniform, it would imply that the first two moments and are of order . Therefore, even in the limit , the transition will be affected by curvature effects. This can be verified for an arbitrary metric tensor by a direct calculation of the first moment,
where . And the second moment
It is convenient to write (32) in normal coordinates at A in order to facilitate the calculation of the integrals in (34) and (35). This means that, for a smooth manifold, one can always make a change of coordinates —we will label the normal coordinates with Greek letter indexes ()—so that the metric in this coordinate system is so that
allowing for us to approximate for a short step. For a general discussion and rigorous proof of the existence of normal coordinates, see [61]. Although normal coordinates are a valuable tool for geometrical analysis at this point, it is not clear whether they can be given a deeper statistical interpretation—this is unlike other applications of differential geometry, such as general relativity, where the physical interpretation of normal coordinates turns out be of central importance. A displacement in these coordinates can be related to the original coordinates by a Taylor expansion in terms of as (see [62,63])
To proceed, it is interesting to recall the Christoffel symbols ,
which transform as
Because, in normal coordinates, we have , this allows us to isolate up to the order obtaining
By squaring (40), we have
Because the exponent in (34) is invariant and in a coordinate transformation we have , it separates into two terms.
The integrals can be evaluated from the known properties of a Gaussian. The integral in the first term gives and the integral in the second term gives , so that
Therefore, in natural coordinates, the first two moments up to order of are
where . Here, we see the dependence on curvature for in the Christoffel symbol term. Note that it is a consequence of the dependance between and the quadratic term in (40), which per (44) does not vanish, even for small steps. Hence, fluctuations in cannot be ignored in the ED motion, and this is the reason why the motion probes curvature. It also follows from (44) that, even in the limit , the average change does not transform covariantly.
Note that we used several words, such as “transitions”, “short step”, “continuous”, and “dynamics” without any established notion of time. In the following section, we will discuss time not as an external parameter, but as an emergent parameter from the maximum entropy transition (32) and its moments (44).
5. Entropic Time
Having described a short step transition, the next challenge is to study how these short steps accumulate.
5.1. Introducing Time
In order to introduce time, we note that and A are elements of the same manifold; therefore, and are two probability distributions over the same space. Our established solution for describing the accumulation of changes (see [28]) is to introduce a “book-keeping” parameter t that distinguishes the said distributions as labelled by different parameters, i.e., and .
In this formalism, we will refer to these different labels as a description of the system at particular instants t and . This allows us to call a transition probability.
where .
As the system changes from A to and then to . The probability will be constructed from , not explicitly dependent on . This means that (45) represents a Markovian process: conditioned on the present , the “future” is independent of the “past” , where . It is important to notice that, under this formalism, (45) is not used to show that the process is Markovian in an existing time, but rather the concept of time that was developed here makes the dynamics Markovian by design.
It is also important to notice that the parameter t that is presented here is not necessarily the “physical” time (as it appears in Newton’s laws of motion or the Schrödinger equation). Our parameter t, which we call entropic time, is an epistemic well-ordered parameter in which the dynamics are defined.
5.2. The Entropic Arrow of Time
It is important to note that the marginalization process from (20) to (45) could also lead to
where the conditional probabilities are related by Bayes’ Theorem,
showing that a change “forward” will not happen the same way as a change “backwards” unless the system is in some form of stationary state, . Another way to present this is that probability theory alone gives no intrinsic distinction of the change “forward” and “backward”. The fact that we assigned the change “forward” by ME implies that, in general, the change “backward” is not an entropy maximum. Therefore, the preferential direction of the flow of time arises from the entropic dynamics naturally.
5.3. Calibrating the Clock
One needs to define the duration with respect to the motion in order to connect the entropic time to the transition probability. Time in entropic dynamics is defined so as to simplify the description of the motion. This notion of time is tailored to the system under discussion. The time interval will be chosen, so that the parameter that first appeared in the prior (25) takes the role of a time interval,
where is a constant, so that t has the units of time. For the remainder of this article, we will adopt . In principle, any monotonic function serves as an parameter for ordering. Our choice is a matter of convenience, as required by simplicity. Here this is implemented so that for a short transition we have the dimensionless time interval
This means that the system’s fluctuations measure the entropic time. Rather than having the changes in the system represented in terms of given time intervals (as measured by an external clock), here the system is its own clock.
The moments in (44) can be written, up to order , as
With this, we have established a concept of time and it is convenient to write the trajectory of the expected values in terms of a differential equation.
6. Diffusion and the Fokker–Planck Equation
Our goal of designing the dynamics from entropic methods is accomplished. The entropic dynamics equation of evolution is written in integral form as a Chapman–Kolmogorov Equation (45) with a transition probability given by (32). In this section, we will conveniently rewrite it in the differential form. The computed drift and the fluctuation in (50) describe the dynamical process as a smooth diffusion—meaning, as defined by [63], a stochastic process in which the first two moments are calculated to the order of , , , and . Therefore, for a short transition, it is possible to write the evolution of , as a Fokker–Planck (diffusion) equation,
where
The derivation of (51) and (52) takes into account the fact that the space in which the diffusion happens is curved and it is given in Appendix B. In equation (52), we see that the current velocity consists of two components. The first term is the drift velocity that is guided by the entropy gradient and the second term is an osmotic velocity, which is a term that is driven by differences in probability density. The examples that are presented in the following section will show how these terms interact and the dynamical properties that are derived from each.
Derivatives and Divergence
Because the entropy S is a scalar, the velocity that is defined in (52) is a contravariant vector. However, (51) is not a manifestly invariant equation. To check its consistency, it is convenient to write it in terms of the invariant object p, being defined as
meaning that p is the probability of A divided by the volume element, in terms of which (51) becomes
We can recognize, on the right-hand side, the covariant divergence of the contravariant vector , which can be written in the manifestly covariant form
where is the covariant derivative. The fact that the covariant derivative arises from the dynamical process is the direct indication that even when evolving the invariant object p the curvature of the space is taken into account. We can identify (55) as a continuity equation—generalized to the parallel transport in a curved space, as evidenced by the covariant divergence—where the flux, , can be written from (52) and (53) as
The second term, which is related to the osmotic velocity, is a Fick’s law with diffusion tensor . Note that this is identified from purely probabilistic arguments, rather than assuming a repulsive interaction from the microstate dynamics.
Having the dynamics fully described, we can now study its consequences, as will be done in the following section.
7. Examples
We established the entropic dynamics by finding the transition probability (32), presenting it as a differential equation in (51), (52), and presenting it as the invariant Equation (55). We want to show some examples of how it would be applied and what are the results achieved. Our present goal is not to search for realistic models, but to search for models that are both mathematically simple and general enough so it can give insight on how to use the formalism.
We will be particularly interested in two properties: the drift velocity,
which is the first term in (52), and the static states, , which are a particular subset of the dynamical system’s equilibrium . These are obtained from (52) as
allowing for one to write the static probability
where the factor of 2 in the exponent comes from the diffusion tensor that is explained in Section 6. This result shows that the invariant stationary probability density (53) is
7.1. A Gaussian Manifold
The statistical manifold defined by the mean values and correlations of a random variable, the microstate x, is the space of Gaussian distribution, which is an example of a canonical distribution. Here, we consider the dynamics of a two-dimensional spherically symmetric Gaussian with a non-uniform variance, , as defined by
These Gaussians are of the form,
The entropy of (62) relative to a uniform background measure is given by
The space of Gaussians with a uniform variance, constant, is flat and the dynamics turn out to be a rather trivial spherically symmetric diffusion. Choosing the variance to be non-uniform yields richer and more interesting dynamics. Because this example is pursued for purely illustrative purposes, we restrict to two dimensions and spherically symmetric Gaussians. The generalization is immediate.
The FRIM for a Gaussian distribution is found using (12) (see also [13]), to be
so that, using
the induced metric leads to
Gaussian Submanifold around an Entropy Maximum
We present an example of our dynamical model that illustrates the motion around an entropy maximum. A simple way to manifest it is to recognize that, in (52), plays a role analogous to a potential. A rotationally symmetric quadratic potential can then be sustituted in (63), leading to
which, substituted in (66), yields the metric
so that
The scalar curvature for the Gaussian submanifold can be calculated from (68) as
The static distribution results from the dynamical equilibrium between two opposite tendencies. One is the drift velocity field that drives the distribution along the entropy gradient towards the entropy maximum at the origin. The other is the osmotic diffusive force that we identified earlier as the ED analogue of Fick’s law. This osmotic force drives the distribution against the direction of the probability gradient and prevents it from becoming infinitely concentrated at the origin. At equilibrium, the cancellation between these two opposing forces results in the Gaussian distribution, Equation (72).
7.2. 2-Simplex Manifold
Here, we discuss an example of discrete microstates. The macrostate coordinates, being expected values, are continuous variables. Our subject matter will be a three-state system, , such as, for example, a 3-sided die. The statistical manifold is the 2-dimensional simplex and the natural coordinates are the probabilities themselves,
The distributions on the two-simplex are Gibbs distributions defined by the sufficient statistics of functions
The entropy relative to the uniform discrete measure is
and the information metric is given by
The two-simplex arises naturally from probability theory due to normalization when one identifies the macrostate of interest to be the probabilities themselves. The choice of sufficient statistics (74) implies that the manifold is a two-dimensional surface, since, due to the normalization, one can write . We will use the the tuple as our coordinates and as a function of them. In this scenario, one finds a metric tensor
which induces the volume element
As is well known, the simplex is characterized by a constant curvature ; the two-simplex is the positive octant of a sphere. From (57), the drift velocity (Figure 3) is
Additionally, the static probability is
From the determinant of the metric, we note that the static probability (80) diverges at the boundary of the two-simplex. This reflects the fact that a two-state system (say, ) is easily distinguishable from a three-state system (). Indeed, a single datum will tell us that we are dealing with a three-state system.
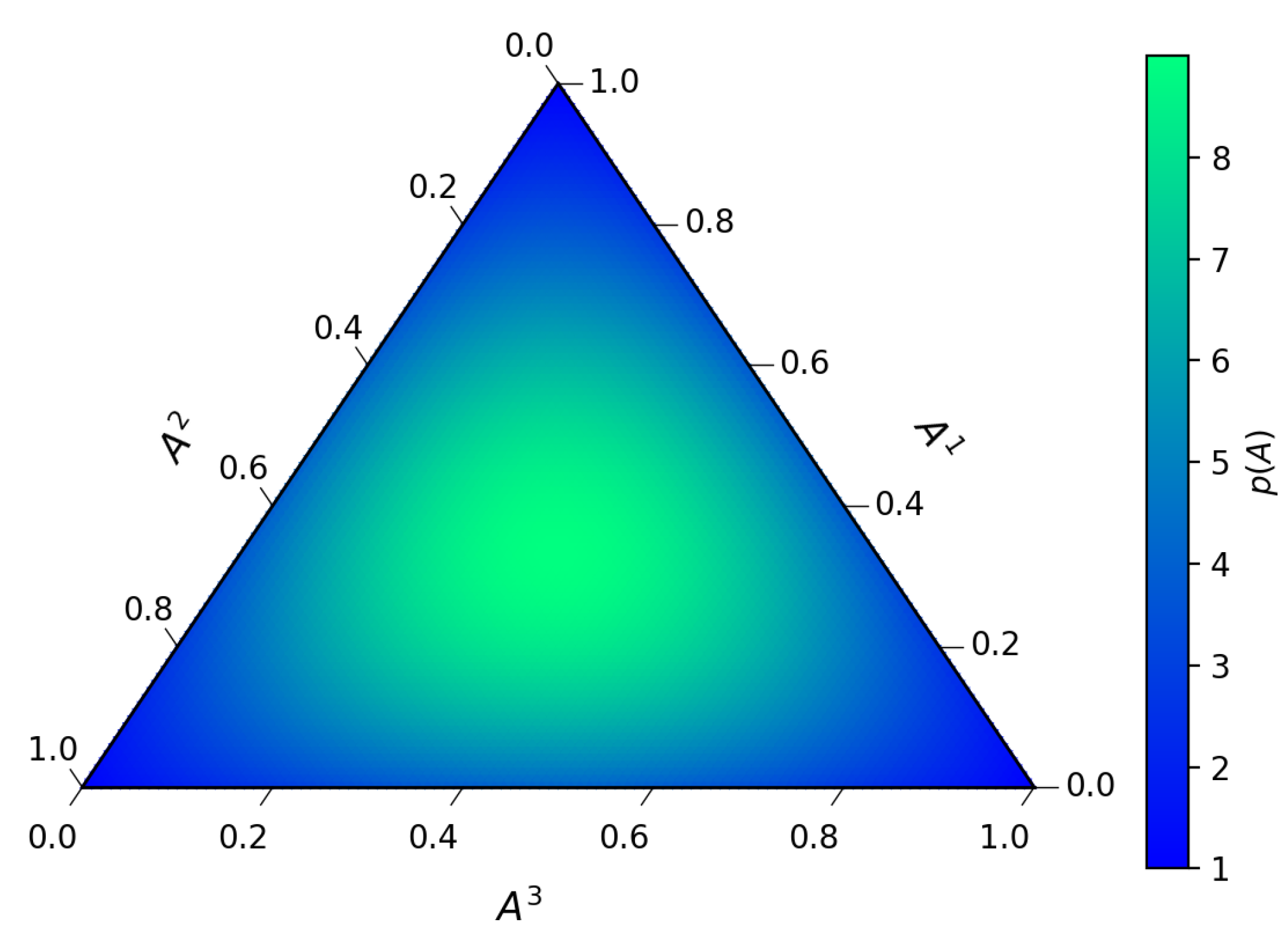
On the other hand, we can see (Figure 4) that this divergence is not present in the invariant stationary probability (53).
As in the Gaussian case discussed in the previous section, the static equilibrium results from the cancellation of two opposing forces: the entropic force along the drift velocity field towards the center of the simplex is cancelled by the osmotic diffusive force away from the center.
8. Conclusions
We conclude with a summary of the main results. In this paper, the entropic dynamics framework has been extended to describe dynamics on a statistical manifold. ME played an instrumental role in that it allowed us to impose constraints that are not in the standard form of expected values.
The resulting dynamics, which follow from purely entropic considerations, take the form of a diffusive process on a curved space. The effects of curvature turn out to be significant. We found that the probability flux is the result of two components. One describes a flux along the entropy gradient and the other is a diffusive or osmotic component that turns out to be the curved-space analogue of Fick’s law with a diffusion tensor that is given by information geometry.
A highlight of the model is that it includes an “entropic” notion of time that is tailored to the system under study; the system is its own clock. This opens the door to the introduction of a notion of time that transcends physics and it might be useful for social and ecological systems. The emerging notion of entropic time is intrinsically directional. There is a natural arrow of time that manifests itself in a simple description of the approach to equilibrium.
The model developed here is rather minimal in the sense that the dynamics could be extended by taking additional relevant information into account. For example, it is rather straightforward to enrich the dynamics by imposing additional constraints
involving system-specific functions that carry information regarding correlations. This is the kind of further developments that we envisage in future work.
As illustrative examples, the dynamics were applied to two general spaces of probability distributions. A submanifold of the space of two-dimensional Gaussians and the space of probability distributions for a three-state system (two-simplex). In each of these, we were able to provide insight on the dynamics by presenting the drift velocity (57) and the equilibrium stationary states (59). Additionally, as future work, we intend to apply the dynamics developed here in the distributions found in network sciences [65].
Author Contributions
All authors contributed equally. All authors have read and agreed to the published version of the manuscript.
Funding
P. Pessoa was financed in part by CNPq—Conselho Nacional de Desenvolvimento Científico e Tecnológico– (scholarship GDE 249934/2013-2).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We would like to thank N. Caticha, C. Cafaro, S. Ipek, N. Carrara, and M. Abedi for valuable discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
Appendix A. Obtaining the Prior
In this appendix we derive the prior transition probability from A to seen in (25). This is achieved by maximizing the entropy
where , the prior for (A1), encodes information about an unbiased transition of the systems. The posterior of (A1), , becomes the prior in (21).
At this stage A could evolve into any and the only assumption is that the assigned prior for (A1) leads to equal probabilities for equal volumes; thus, ignoring biases. That is achieved by a prior proportional to the volume element , where . There is no need to address the normalization of R since it will have no effect on the posterior.
The chosen constraint represents an isotropic and continuous motion on the manifold. This will be imposed by
where K is a small quantity, since is invariant only in the limit for short steps . Therefore, eventually, .
The result of maximizing (A1) under (A2) and normalization is
where is the Lagrange multiplier associated to (A2). As the result requires to make it geometrically invariant, the conjugated Lagrange multiplier should be allowed to be taken to infinity. This allows us to define , such that the short step limit will lead to .
Note that, since no motion in x and no correlation between x and is induced by the constraints, the result does not depend on the previous microstate x, .
Appendix B. Derivation of the Fokker-Planck Equation
The goal of this appendix is to show that for a dynamics that is a smooth diffusion in a curved space, can be written as a Fokker-Planck equation and to obtain its velocity (52) from the moments for the motion (50). In order to do so, it is convenient to define a drift velocity
First, let us analyze the change of a smooth integrable function as the system transitions from A to . A smooth change in the function will be
since a cubic term, would be . In a smooth diffusion we can take the expected value of (A5) with respect to as
which can be further averaged in . The left-hand side will be
while the right hand is
such that they equate to
As established in Section 5, and are distributions at the instants t and respectively.
which can be partially integrated in the limit of small steps
Due to the generality of f as test function, we identify the integrants,
and substitute (A4) for general coordinates,
and the contracted Christoffel symbols can be substituted in the identity
Here we see that the effect of curvature—encoded by the Christoffel symbols—substitute in the differential Equation (A13) obtaining
where the second term inside the parenthesis above is the result of taking the curvature into account. The result is a Fokker-Planck equation that is usefully written in the continuity form
where
completing the derivation.
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information theory and statistical mechanics: I. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. II. Phys. Rev. 1957, 108, 171. [Google Scholar] [CrossRef]
- Rosenkrantz, R.D. (Ed.) E. T. Jaynes: Papers on Probability, Statistics and Statistical Physics; Reidel: Dordrecht, The Netherlands, 1983. [Google Scholar] [CrossRef]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Gibbs, J. Elementary Principles in Statistical Mechanics; Yale University Press: New Haven, Connecticut, 1902; Reprinted by Ox Bow Press: Woodbridge, Connecticut, 1981. [Google Scholar]
- Shore, J.; Johnson, R. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Trans. Inf. Theory 1980, 26, 26–37. [Google Scholar] [CrossRef] [Green Version]
- Skilling, J. The Axioms of Maximum Entropy. In Maximum-Entropy and Bayesian Methods in Science and Engineering; Erickson, G.J., Smith, C.R., Eds.; Springer: Dordrecht, The Netherlands, 1988; Volumes 31–32, pp. 173–187. [Google Scholar] [CrossRef]
- Caticha, A. Relative Entropy and Inductive Inference. AIP Conf. Proc. Am. Inst. Phys. 2004, 707, 75–96. [Google Scholar] [CrossRef]
- Caticha, A. Information and Entropy. AIP Conf. Proc. Am. Inst. Phys. 2007, 954, 11–22. [Google Scholar] [CrossRef] [Green Version]
- Caticha, A.; Giffin, A. Updating Probabilities. AIP Conf. Proc. Am. Inst. Phys. 2006, 872, 31–42. [Google Scholar] [CrossRef] [Green Version]
- Vanslette, K. Entropic Updating of Probabilities and Density Matrices. Entropy 2017, 19, 664. [Google Scholar] [CrossRef] [Green Version]
- Caticha, A. Entropic Physics: Probability, Entropy, and the Foundations of Physics. Available online: https://www.albany.edu/physics/faculty/ariel-caticha (accessed on 19 April 2021).
- Caticha, A.; Golan, A. An entropic framework for modeling economies. Phys. A Stat. Mech. Appl. 2014, 408, 149–163. [Google Scholar] [CrossRef]
- Harte, J. Maximum Entropy and Ecology: A Theory of Abundance, Distribution, and Energetics; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Banavar, J.R.; Maritan, A.; Volkov, I. Applications of the principle of maximum entropy: From physics to ecology. J. Phys. Condens. Matter 2010, 22, 063101. [Google Scholar] [CrossRef] [Green Version]
- De Martino, A.; De Martino, D. An introduction to the maximum entropy approach and its application to inference problems in biology. Heliyon 2018, 4, e00596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dixit, P.D.; Lyashenko, E.; Niepel, M.; Vitkup, D. Maximum entropy framework for predictive inference of cell population heterogeneity and responses in signaling networks. Cell Syst. 2020, 10, 204–212. [Google Scholar] [CrossRef]
- Cimini, G.; Squartini, T.; Saracco, F.; Garlaschelli, D.; Gabrielli, A.; Caldarelli, G. The statistical physics of real-world networks. Nat. Rev. Phys. 2019, 1, 58–71. [Google Scholar] [CrossRef] [Green Version]
- Radicchi, F.; Krioukov, D.; Hartle, H.; Bianconi, G. Classical information theory of networks. J. Phys. Complex. 2020, 1, 025001. [Google Scholar] [CrossRef]
- Vicente, R.; Susemihl, A.; Jericó, J.P.; Caticha, N. Moral foundations in an interacting neural networks society: A statistical mechanics analysis. Phys. A Stat. Mech. Its Appl. 2014, 400, 124–138. [Google Scholar] [CrossRef] [Green Version]
- Alves, F.; Caticha, N. Sympatric Multiculturalism in Opinion Models; AIP Conference Proceedings; AIP Publishing LLC.: New York, NY, USA, 2016; Volume 1757, p. 060005. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Where do we stand on maximum entropy? In The Maximum Entropy Principle; Levine, R.D., Tribus, M., Eds.; MIT Press: Cambridge, MA, USA, 1979. [Google Scholar] [CrossRef]
- Balian, R. From Microphysics to Macrophysics: Methods and Applications of Statistical Mechanics. Volumes I and II; Springer: Heidelberg, Germany, 1991–1992. [Google Scholar]
- Pressé, S.; Ghosh, K.; Lee, J.; Dill, K.A. Principles of maximum entropy and maximum caliber in statistical physics. Rev. Mod. Phys. 2013, 85, 1115–1141. [Google Scholar] [CrossRef] [Green Version]
- Davis, S.; González, D. Hamiltonian formalism and path entropy maximization. J. Phys. A Math. Theor. 2015, 48, 425003. [Google Scholar] [CrossRef] [Green Version]
- Cafaro, C.; Ali, S.A. Maximum caliber inference and the stochastic Ising model. Phys. Rev. E 2016, 94. [Google Scholar] [CrossRef] [Green Version]
- Caticha, A. Entropic dynamics, time and quantum theory. J. Phys. A Math. Theor. 2011, 44, 225303. [Google Scholar] [CrossRef] [Green Version]
- Caticha, A. The Entropic Dynamics Approach to Quantum Mechanics. Entropy 2019, 21, 943. [Google Scholar] [CrossRef] [Green Version]
- Ipek, S.; Abedi, M.; Caticha, A. Entropic dynamics: Reconstructing quantum field theory in curved space-time. Class. Quantum Gravity 2019, 36, 205013. [Google Scholar] [CrossRef] [Green Version]
- Pessoa, P.; Caticha, A. Exact renormalization groups as a form of entropic dynamics. Entropy 2018, 20, 25. [Google Scholar] [CrossRef] [Green Version]
- Abedi, M.; Bartolomeo, D. Entropic Dynamics of Exchange Rates and Options. Entropy 2019, 21, 586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abedi, M.; Bartolomeo, D. Entropic Dynamics of Stocks and European Options. Entropy 2019, 21, 765. [Google Scholar] [CrossRef] [Green Version]
- Caticha, N. Entropic Dynamics in Neural Networks, the Renormalization Group and the Hamilton-Jacobi-Bellman Equation. Entropy 2020, 22, 587. [Google Scholar] [CrossRef]
- Fisher, R.A. Theory of Statistical Estimation. Proc. Camb. Philos. Soc. 1925, 122, 700. [Google Scholar] [CrossRef] [Green Version]
- Rao, C.R. Information and the accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81. [Google Scholar] [CrossRef]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA, 2000. [Google Scholar]
- Amari, S. Information Geometry and Its Applications; Springer International Publishing: Berlin, Germany, 2016. [Google Scholar] [CrossRef]
- Ay, N.; Jost, J.; Lê, H.V.; Schwachhöfer, L. Information Geometry; Springer International Publishing: Berlin, Germany, 2017. [Google Scholar] [CrossRef]
- Caticha, A. The basics of information geometry. AIP Conf. Proc. Am. Inst. Phys. 2015, 1641, 15–26. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Garcia, V. Statistical exponential families: A digest with flash cards. arXiv 2009, arXiv:cs.LG/0911.4863. [Google Scholar]
- Ruppeiner, G. Riemannian geometry in thermodynamic fluctuation theory. Rev. Mod. Phys. 1995, 67, 605. [Google Scholar] [CrossRef]
- Janyszek, H.; Mrugala, R. Riemannian geometry and stability of ideal quantum gases. J. Phys. A Math. Gen. 1990, 23, 467. [Google Scholar] [CrossRef]
- Brody, D.; Rivier, N. Geometrical aspects of statistical mechanics. Phys. Rev. E 1995, 51, 1006. [Google Scholar] [CrossRef]
- Oshima, H.; Obata, T.; Hara, H. Riemann scalar curvature of ideal quantum gases obeying Gentiles statistics. J. Phys. A Math. Gen. 1999, 32, 6373–6383. [Google Scholar] [CrossRef]
- Brody, D.; Hook, D.W. Information geometry in vapour–liquid equilibrium. J. Phys. A Math. Theor. 2008, 42, 023001. [Google Scholar] [CrossRef]
- Yapage, N.; Nagaoka, H. An information geometrical approach to the mean-field approximation for quantum Ising spin models. J. Phys. A Math. Theor. 2008, 41, 065005. [Google Scholar] [CrossRef]
- Tanaka, S. Information geometrical characterization of the Onsager-Machlup process. Chem. Phys. Lett. 2017, 689, 152–155. [Google Scholar] [CrossRef]
- Nicholson, S.B.; del Campo, A.; Green, J.R. Nonequilibrium uncertainty principle from information geometry. Phys. Rev. E 2018, 98, 032106. [Google Scholar] [CrossRef] [Green Version]
- Ay, N.; Olbrich, E.; Bertschinger, N.; Jost, J. A geometric approach to complexity. Chaos Interdiscip. J. Nonlinear Sci. 2011, 21, 037103. [Google Scholar] [CrossRef] [PubMed]
- Felice, D.; Mancini, S.; Pettini, M. Quantifying networks complexity from information geometry viewpoint. J. Math. Phys. 2014, 55, 043505. [Google Scholar] [CrossRef] [Green Version]
- Felice, D.; Cafaro, C.; Mancini, S. Information geometric methods for complexity. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 032101. [Google Scholar] [CrossRef]
- Fisher, R.A. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. Lond. 1922, 222, 309–368. [Google Scholar] [CrossRef] [Green Version]
- Pitman, E.J.G. Sufficient statistics and intrinsic accuracy. Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1936; Volume 32, pp. 567–579. [Google Scholar] [CrossRef]
- Darmois, G. Sur les lois de probabilitéa estimation exhaustive. CR Acad. Sci. Paris 1935, 260, 85. [Google Scholar]
- Koopman, B.O. On distributions admitting a sufficient statistic. Trans. Am. Math. Soc. 1936, 39, 399–409. [Google Scholar] [CrossRef]
- Brody, D. A note on exponential families of distributions. J. Phys. A Math. Theor. 2007, 40, F691. [Google Scholar] [CrossRef] [Green Version]
- Cencov, N.N. Statistical decision rules and optimal inference. Am. Math. Soc. 1981, 53. [Google Scholar] [CrossRef]
- Campbell, L.L. An extended Cencov characterization of the information metric. Proc. Am. Math. Soc. 1986, 98, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Beck, C.; Cohen, E.G.D. Superstatistics. Phys. A Stat. Mech. Appl. 2003, 322, 267–275. [Google Scholar] [CrossRef] [Green Version]
- Kobayashi, S.; Nomizu, K. Foundations of Differential Geometry (Wiley Classics Library); John Wiley and Sons: New York, NY, USA, 1963; Volume 1. [Google Scholar]
- Nawaz, S.; Abedi, M.; Caticha, A. Entropic Dynamics on Curved Spaces; AIP Conference Proceedings; AIP Publishing LLC.: New York, NY, USA, 2016; Volume 1757, p. 030004. [Google Scholar] [CrossRef] [Green Version]
- Nelson, E. Quantum Fluctuations; Princeton University Press: Princeton, NJ, USA, 1985. [Google Scholar]
- Python-ternary: Ternary Plots in Python. GitHub Repository. Available online: https://github.com/marcharper/python-ternary/ (accessed on 19 April 2021).
- Costa, F.X.; Pessoa, P. Entropic dynamics of networks. Northeast J. Complex Syst. 2021, 3, 5. [Google Scholar] [CrossRef]
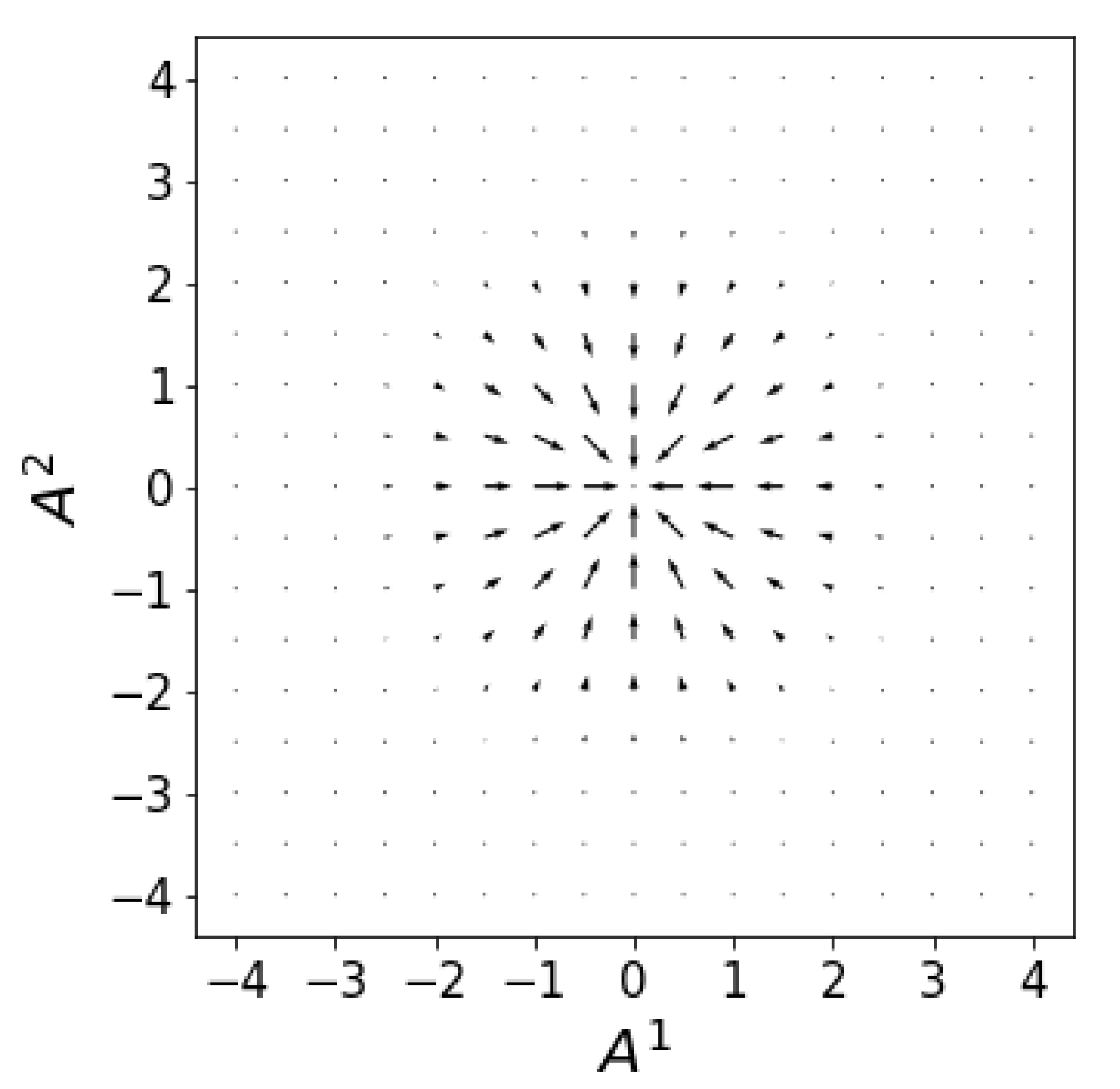
Figure 1.
The drift velocity field (71) drives the flux along the entropy gradient.
Figure 1.
The drift velocity field (71) drives the flux along the entropy gradient.

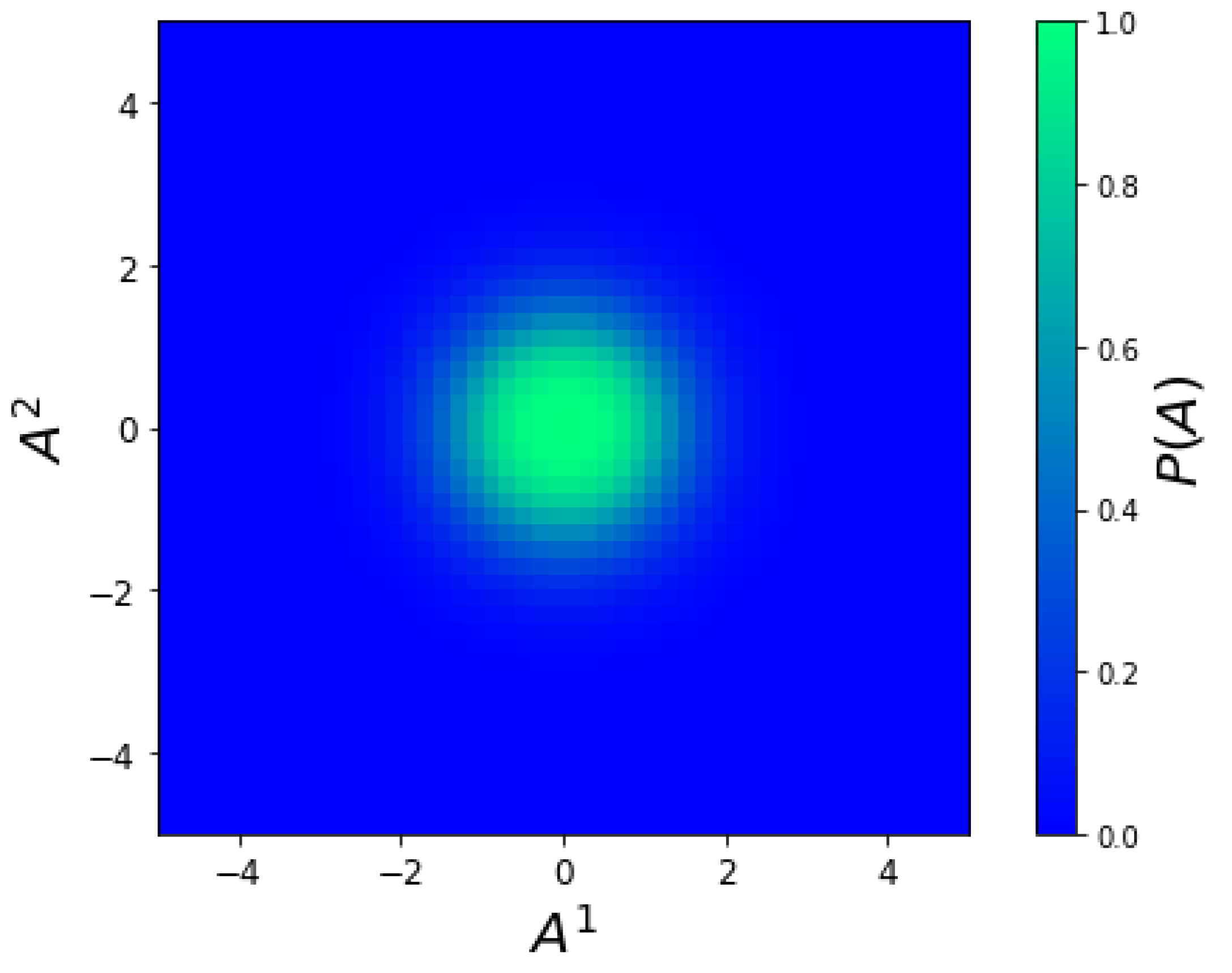
Figure 2.
Equilibrium stationary probability (72).
Figure 2.
Equilibrium stationary probability (72).

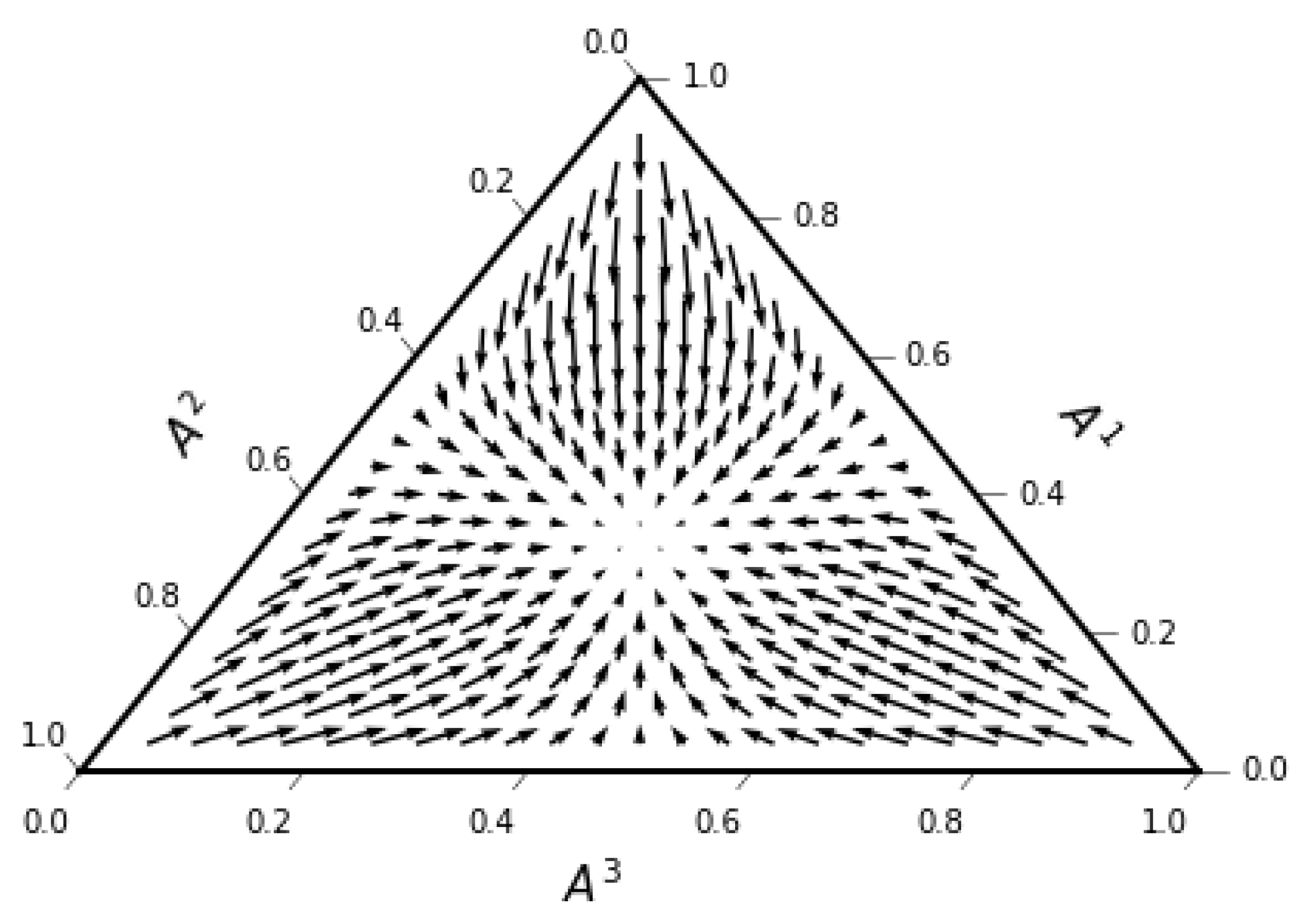
Figure 3.
Drift velocity field for the two-simplex in (79). The ternary plots ware created using python-ternary library [64].

Figure 4.
Static invariant stationary probability for the three-state system.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Identification of sufficient statistics, priors and Lagrange multipliers for some well-known probability distributions.
Table 1.
Identification of sufficient statistics, priors and Lagrange multipliers for some well-known probability distributions.
| Distribution | Parameter | Suff. Stat. | Prior |
|---|---|---|---|
| Exponent Polynomial | uniform | ||
| Gaussian | uniform | ||
| Multinomial (k) | |||
| Poisson | |||
| Mixed power laws | uniform |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pessoa, P.; Costa, F.X.; Caticha, A. Entropic Dynamics on Gibbs Statistical Manifolds. Entropy 2021, 23, 494. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050494
AMA Style
Pessoa P, Costa FX, Caticha A. Entropic Dynamics on Gibbs Statistical Manifolds. Entropy. 2021; 23(5):494. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050494
Chicago/Turabian StylePessoa, Pedro, Felipe Xavier Costa, and Ariel Caticha. 2021. "Entropic Dynamics on Gibbs Statistical Manifolds" Entropy 23, no. 5: 494. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050494
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.