
Fuzzy Entropy-Based Spatial Hotspot Reliability



1
Dipartimento di Architettura, Università degli Studi di Napoli Federico II, Via Toledo 402, 80134 Napoli, Italy
2
Centro Interdipartimentale di Ricerca in Urbanistica Alberto Calza Bini, Università degli Studi di Napoli Federico II, Via Toledo 402, 80134 Napoli, Italy
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(5), 531; https://0-doi-org.brum.beds.ac.uk/10.3390/e23050531
Submission received: 8 April 2021
/
Accepted: 22 April 2021
/
Published: 26 April 2021
(This article belongs to the Special Issue Entropy Method for Decision Making)
Abstract
:Cluster techniques are used in hotspot spatial analysis to detect hotspots as areas on the map; an extension of the Fuzzy C-means that the clustering algorithm has been applied to locate hotspots on the map as circular areas; it represents a good trade-off between the accuracy in the detection of the hotspot shape and the computational complexity. However, this method does not measure the reliability of the detected hotspots and therefore does not allow us to evaluate how reliable the identification of a hotspot of a circular area corresponding to the detected cluster is; a measure of the reliability of hotspots is crucial for the decision maker to assess the need for action on the area circumscribed by the hotspots. We propose a method based on the use of De Luca and Termini’s Fuzzy Entropy that uses this extension of the Fuzzy C-means algorithm and measures the reliability of detected hotspots. We test our method in a disease analysis problem in which hotspots corresponding to areas where most oto-laryngo-pharyngeal patients reside, within a geographical area constituted by the province of Naples, Italy, are detected as circular areas. The results show a dependency between the reliability and fluctuation of the values of the degrees of belonging to the hotspots.
1. Introduction
Hotspot detection is an emerging spatial analysis feature that allows for the detection of areas in which events representing a certain phenomenon are present with greater insistence (hotspots) and follows their spatial distribution and displacement over time. Cluster techniques are proposed by various researchers to locate hotspots in the study area for many problems. For example, in crime analysis, it is used specifically to locate as hotspots the areas with greater presence and frequency of criminal events in city contexts; in disease analysis, it is used to evaluate the formation and displacement of disease strains over time; in monitoring problems of natural and environmental disasters, such as the monitoring of developments of fires in wooded areas in summer, it is applied to analyze where and with what frequency and intensity natural and malicious phenomena of fires develop.
Cluster algorithms are proposed by some authors to detect hotspots in various spatial analysis problems.
K-means [1] is applied by some authors to detect hotspots in crime analysis [2,3] and fire analysis [4,5]. K-medoids [6] is applied in disease analysis [7]. Fuzzy C-means (for short, FCM) [8,9,10] is applied to detect hotspots in crime analysis [11,12,13,14], road traffic crashes [15], and disease analysis [16]. Kernel density-based algorithms [17] are applied in crime analysis [18], soil pollution [19], and traffic accident analysis [20].
Kernel density algorithms have the advantage of detecting even hotspots of irregular geometric shape, but they are computationally more expensive than K-means and FCM; on the other hand, K-means and FCM detect only cluster centers and are less robust than the presence of noise in the data. Furthermore, in K-means and FCM, the number of clusters must be fixed in advance and validity measures must be used to evaluate what the suitable number of clusters might be.
In [21], a new hotspot detection technique is proposed, based on an extension of FCM, called Extended Fuzzy C-means (for short, EFCM) [22]. EFCM detect cluster as hyper-spheres in the space of the features; the number of clusters must not be set a priori as it is obtained through merging processes of the most similar clusters carried out during each iteration. In [21], the authors show that EFCM can approximate the shape of hotspots on the map and is robust with respect to the presence of noise and outliers. The EFCM hotspot detection method was applied in disease analysis [23,24] and in earthquake disaster analysis [25].
One of the main needs in hotspot detection is to evaluate the reliability of the results by measuring how significant the detected hotspots are. EFCM detects circular hotspots on the map but does not give information about their reliability. This assessment is sometimes interpretative; it is left to the expert who assesses whether the analyzed event persists more frequently in the region where the hotspot was detected. An effective measure of reliability of a hotspot is critical to understanding how accurate the location of the area in which the analyzed phenomenon exists is, in order to monitor it and follow its movements over time. Currently, no hotspot detection method proposed in the literature allows us to measure the reliability of the detected hotspots; a quantitative assessment of the reliability of the detected hotspots is crucial because it would allow the decision maker to evaluate how accurate the geographic location and areal size of a hotspot can be.
In this research we propose a measure of the reliability of the hotspots detected by running the EFCM algorithm, in which the De Luca & Termini fuzzy entropy [26,27] is applied; the reliability of the hotspot is higher if the fuzzy entropy measured for the corresponding cluster is lower.
Recently, measures of fuzzy entropy of clustering in FCM have been proposed in [28,29]. Following [28], in this work each fuzzy cluster constitutes a fuzzy set in the domain of the data points and a measure of the fuzzy entropy is applied to each fuzzy cluster to evaluate its fuzziness.
If is the fuzziness of the ith cluster, normalized in the interval [0,1], we assign a reliability of the correspondent hotspot given by:
The reliability of is normalized in the interval [0,1]. It holds 1 when the fuzziness of is null (the cluster is a not null crisp set) and 0 when the fuzziness is maximum (all the data points belong to the cluster with a membership degree ½n).
We’ve implemented our method in a GIS-framework in which the EFCM-based hotspot detection algorithm was encapsulated. After executing EFCM, the detected hotspots are shown as circles on the map and the reliability of each hotspot is calculated as in (1). Finally, the hotspot reliability map is constructed.
2. Preliminaries
2.1. The EFCM Algorithm
The EFCM algorithm [22] is a variation of FCM in which the cluster prototypes are hyper-spheres in the space of the features; each cluster is characterized by a vector characterizing its center and its radius.
Let X = {x1, …, xN} ⊂ Rn be a set of N data points in the n-dimensional space of the features Rn where xk = (xk1, …, xkn). Let V = {v1, …, vC} ⊂ Rn be the set of centers of the C clusters. Let U be the C × N partition matrix where uik is the membership degree of the kth data point xk to the jth cluster vj. Let r = {r1, …, rC} be the set of radii of the C clusters.
EFCM minimize the following objective function:
where m is the fuzzifier parameter and δij, interpreted as the distance between the ith cluster and the jth data point, is given by:
In (2) dij is the Euclidean distance between the center of the ith cluster and the jth pattern and ri is the radius of the ith cluster.
If Pi is the covariance matrix of the ith cluster:
then the radius ri of the ith cluster is given by:
Applying the Lagrange multiplier method to the (1) we obtain the solutions for V and U:
where is the number of cluster whose distance from the jth data point is equal to 0.
In [22], with the aim to ensure the separation between clusters, the radius of the ith cluster calculated at the tth iteration, ri(t) is increased by a factor , where C(t−1) is the number of clusters detected during the previous iteration and β(t−1) is the value calculated at the previous iteration of a parameter defined recursively, where .
The optimal number of clusters is found merging at any iteration with the two most similar clusters, under some conditions.
The similarity between two clusters is measured by the following inclusion index:
where the similarity cluster matrix S is a symmetric matrix.
Let S(t) be the similarity cluster matrix calculated at the tth iteration and let i* and k* be the indices of the two most similar clusters; these two clusters are merged if their similarity is greater than an adaptive similarity threshold α(t) = 1/(C(t) − 1), and the absolute difference is less than an error η.
When two clusters are merged, the number of clusters is reduced by one unit and the parameter β remains unchanged, otherwise, if , the parameter β is increased, by setting .
If the two most similar clusters are merged:
otherwise:
The EFCM algorithm (Algorithm 1) is described in the following pseudocode.
| Algorithm 1: EFCM. |
| 1. Set m, ε, η, the initial number of clusters C(0) |
| 2. β ← 1, S* ← 0, S*prev ← 1 |
| 3. Initialize randomly the partition matrix U and the centers vi |
| 4. Repeat |
| 5. For i = 1 to C //calculate centers and radius of clusters |
| 6. Calculate the center of the ith cluster vi by (4) |
| 7. Calculate the radius of the ith cluster ri by (12) |
| 8. ri ← ri ∙ β/C //enlarge the radius of the i-th cluster |
| 9. For i = 1 to C //calculate new partition matrix |
| 10. For j = 1 to N |
| 11. Calculate the membership degree component uij by (14) |
| 12. For i = 1 to C 1 //Find the two most similar clusters |
| 13. For k = i + 1 to C |
| 14. Calculate Sik by (15) |
| 15. If Sik > S* Then |
| 16. S* ← Sik |
| 17. If |S* − S*prev| < η |
| 18. α = 1/(C 1) |
| 19. If S* > α //merge the two most similar clusters |
| 20. For j = i + 1 to N |
| 21. uij ← uij + ukj |
| 22. Remove the kth row from U |
| 23. C← C 1 |
| 24. Else |
| 25. β ← min(C, β + 1) |
| 26. Until |
| 27. Return the partition matrix and the volume prototypes of the final C Clusters |
2.2. De Luca & Termini Fuzzy Entropy and the Measure of Fuzziness
Let F(X) = {A: X → [0,1]} be the family of fuzzy sets defined on a universe of discourse X.
Let h: [0,1] → [0,1] be a continuous function called fuzzy entropy function. The following restrictions are required for the function h:
- h(1) = 0
- h(u) = h(1 u)
- h is monotonically increasing in in [0, ½]
- h is monotonically decreasing in in [½, 1]
The fuzzy entropy function has a minimal value of 0 when u is 0 or 1, and a maximum value when u = ½.
De Luca and Termini in [26,27] propose the following fuzzy entropy function:
which has the maximum value 1 when u = ½; it is called Shannon’s function.
If X = {} is a discrete set, we define the entropy measure of fuzziness of the fuzzy set A as:
where K is a multiplicative constant. If H(A) = 0, then for each element xi, i = 1, …, N, A(xi) = 0 or A(xi) = 1 and A coincides with a subset of the set X; if for each element xi, i = 1, …, N, A(xi) = ½ and the fuzziness of A is maximum.
If A is a crisp set, its fuzziness is null and H(A) = 0. The higher the fuzziness of a fuzzy set, the closer the mean membership degree to the fuzzy set of X’s elements approaches ½.
In [28], a fuzziness measure (12) is used to construct a new validity index, which is applied to evaluate the optimal number of clusters in FCM. If Ai is the ith fuzzy cluster where i = 1, …, C considered as a fuzzy set and uij is the membership degree of the jth data point to the ith cluster, the authors use the following fuzzy entropy measure of Ai:
where N is the number of data points and the De Luca & Termini fuzzy entropy function (11) is used.
3. The Proposed Framework
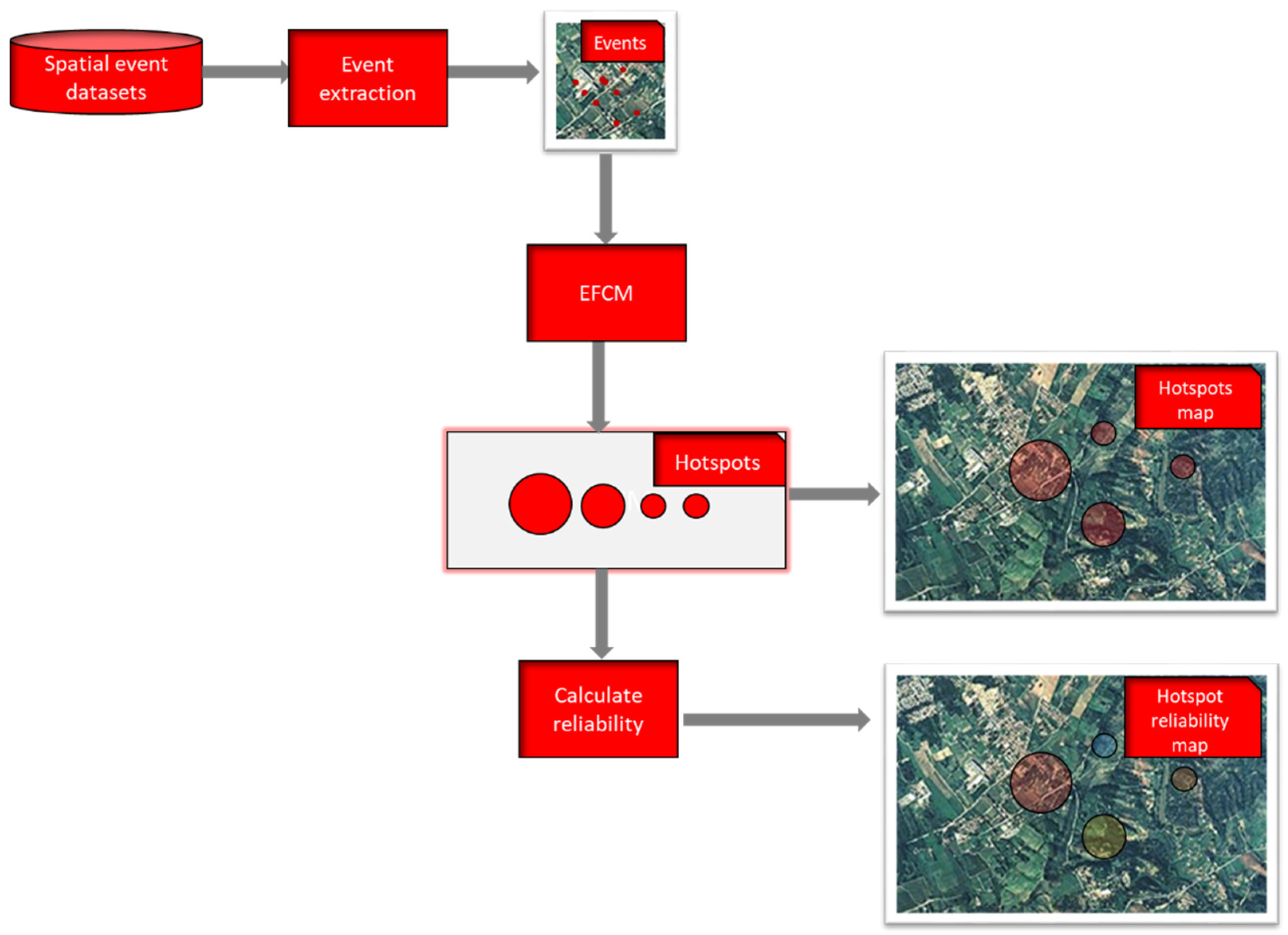
We constructed a GIS-based framework in which EFCM is implemented to detect hotspots and the fuzzy entropy measure (13) is calculated to evaluate the reliability of the detected hotspots. The framework is schematized in Figure 1.
The set of spatial events is extracted from the spatial event datasets. Each event is a data point given by its latitude and longitude coordinates. The event extraction functionality builds the set of data points by extracting the event data located in the study area and transforming them into a single system of geographic coordinates.
The set of spatial events is given by a set of N events X = {x1, …, xN} RN. Each data point is given by a pair xj = (xj1, xj2), j = 1, …, N; xj1 and xj2 are the latitude and longitude coordinates where the event is located.
EFCM was executed to detect circles C as clusters; each cluster is identified by its center vj = (vi1, vi2), j = 1, …, C and its radius ri and the component uij of the C × N partition matrix U gives the membership degree of the jth data point to the ith cluster. The cluster prototypes constitute hotspots of circular areas which are shown on the map.
The Calculate reliability function calculates the reliability of each hotspot by applying the Formula (13) to assess the fuzziness of the hotspots. The reliability R(Ai), i = 1, …, C, assigned to the ith hotspot is given by the Formula (1); it is a value in the range [0,1].
Finally, the reliability thematic map was produced. Below we show the algorithm applied to extract the hotspots assessing their reliabilities (Algorithm 2).
| Algorithm 2: Hotspots reliability evaluation. |
| 1. Extract the dataset of event X = {x1, …, xN} ⊂ R2 |
| 2. Execute EFCM (X) |
| 3. For i = 1 to C |
| 4. H ← 0 |
| 5. For j = 1 to N |
| 6. Hi ← Hi + h(uij)//where the Equation (11) is applied for the function h(u) |
| 7. H ← H/N |
| 8. Ri ← 1 − H |
| 9. Return the centers vi, the radius ri and the reliability Ri i = 1, …, C |
In next section we show the obtained results.
4. Test Results
We tested our framework on an area of study given by the district of Naples, Italy. The extension of the district is 1171 km2. The event dataset was constructed by considering the places of residence of patients who have been diagnosed with oto-laryngo-pharyngeal disease diagnosis in the last four years. These data were collected by entering only non-sensitive information and transmitted by hospitals and medical facilities. An address locator geocoding function was used to geo-refer the data points.
The event dataset is made from about 4000 data points. The GIS framework was constructed using the tool GIS Esri ArcGis Desktop 10.8; the EFCM algorithm was implemented in the GIS platform using Python libraries.
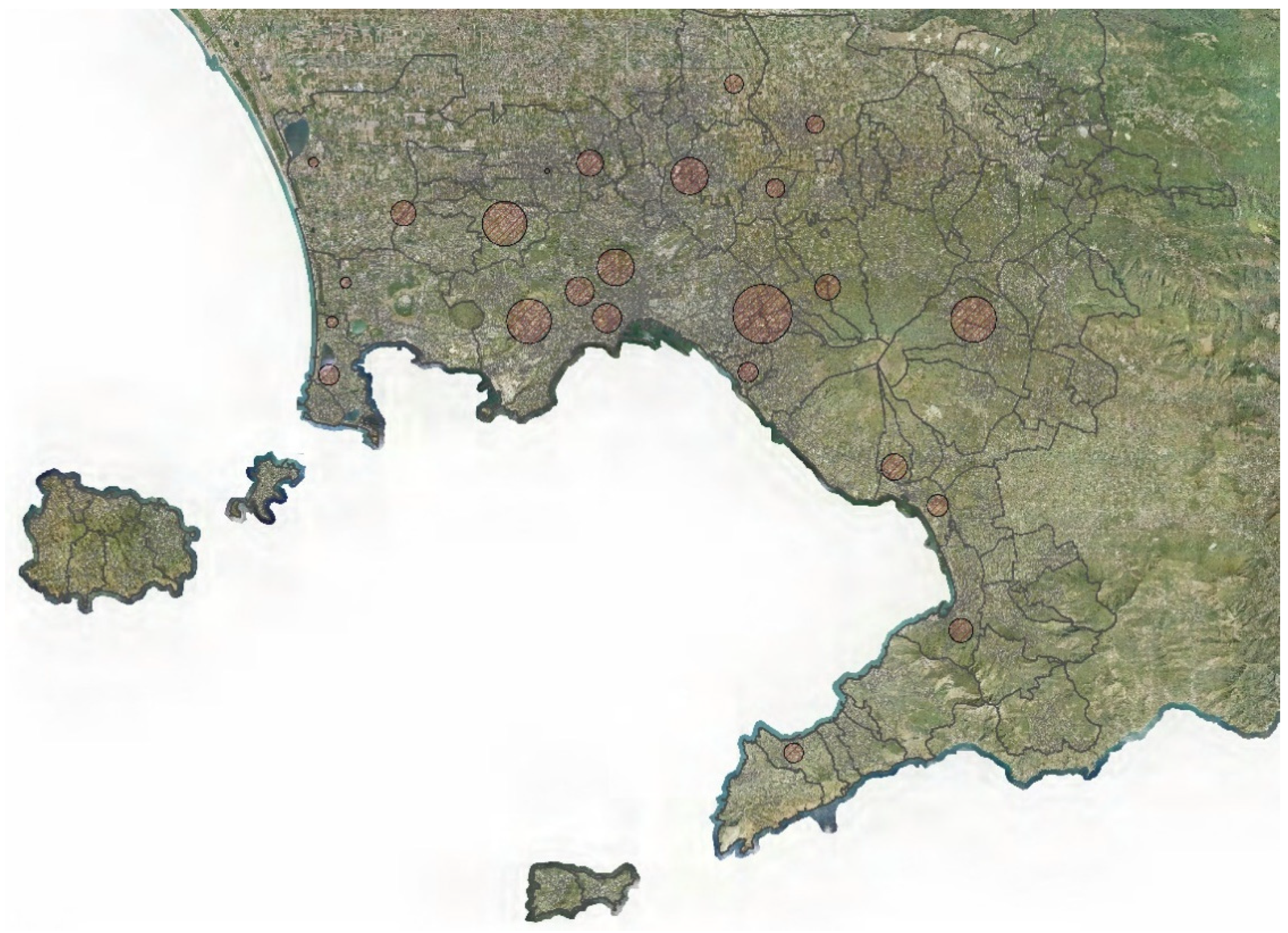
After executing EFCM, 24 hotspots were detected and plotted as circles on the map.
The thematic map with the hotspots is shown in Figure 2.
The detected hotspots have an extension between 0.6 and about 9 km2. The area and the reliability of each hotspots are shown in Table 1.
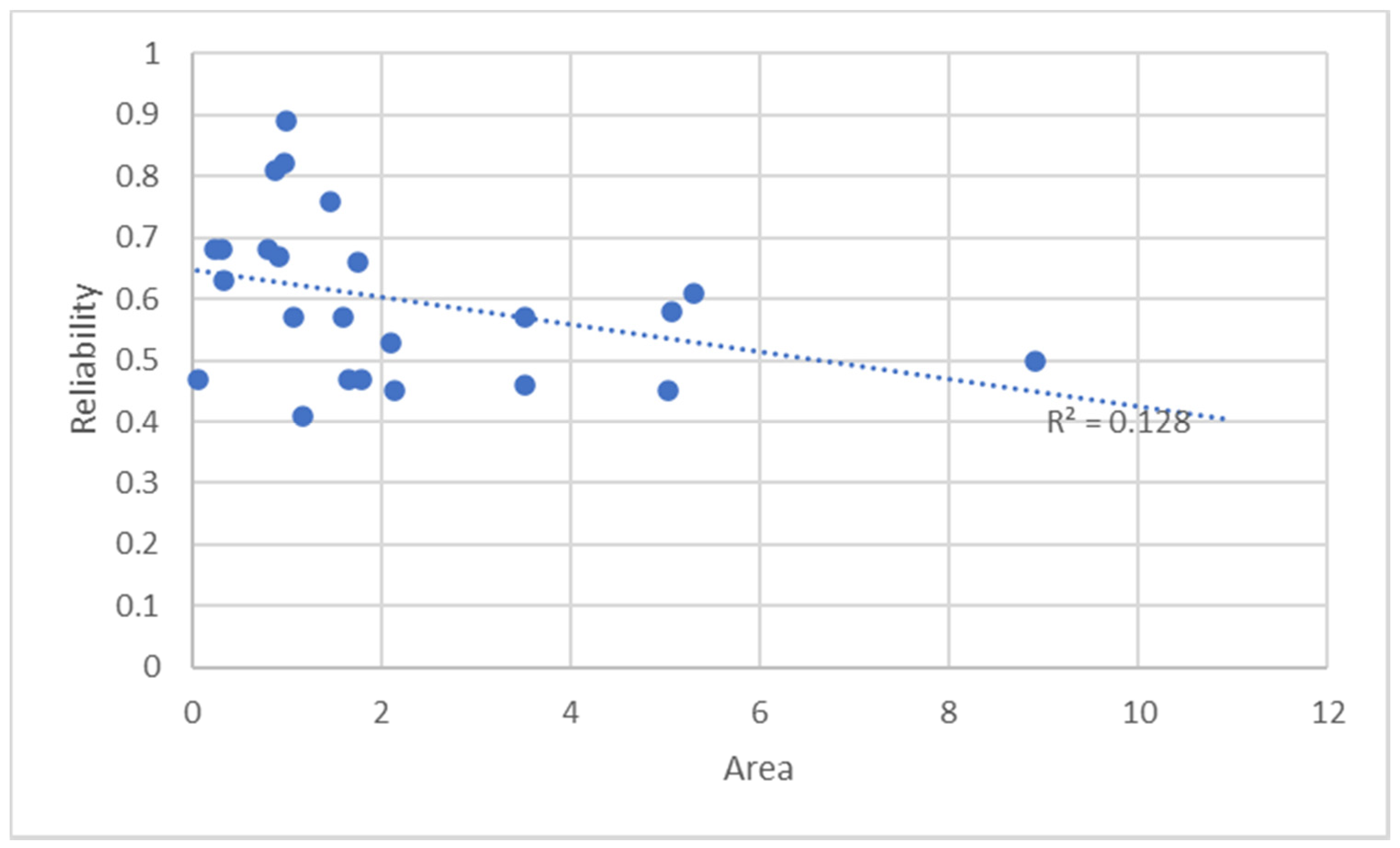
Figure 3 shows a plot graph in which the reliability dependency on hotspots area is analyzed.
Figure 3 shows that there is no linear dependency between the area of hotspots and their reliability; the very low value of the coefficient of determination R2 (=0.128) means that the smaller and more compact hotspots do not necessarily have greater reliability.
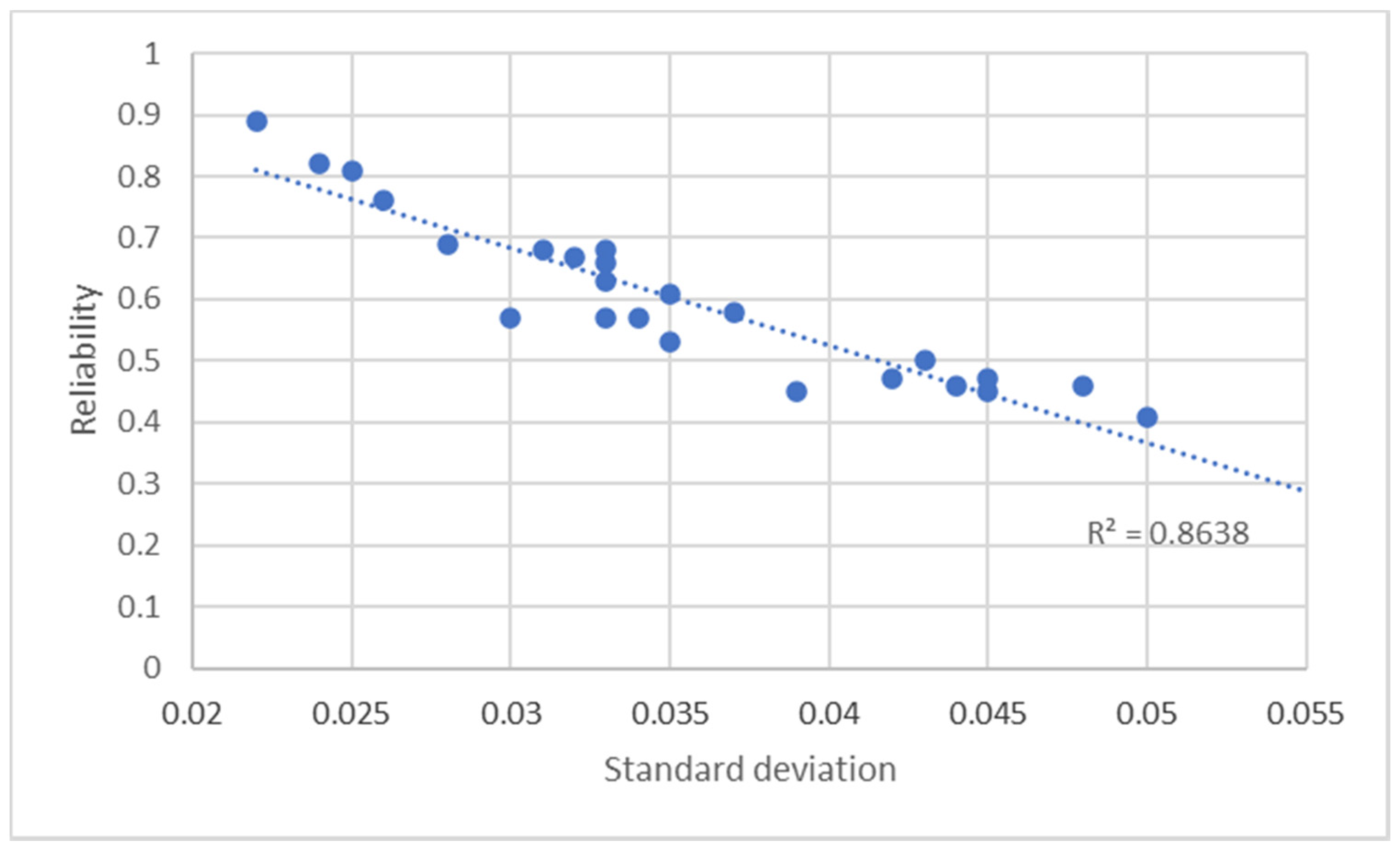
In Figure 4, the graph analyzes the linear dependency of reliability on the standard deviation. The graph shows the presence of a linear relationship between standard deviation and reliability with a mean-high value of the coefficient of determination R2 (=0.864): this result means that, on average, the greater the fluctuation of the values of the degrees of belonging of the data points to the hotspot, the greater the fuzzy entropy of the hotspot, therefore the lower its reliability.
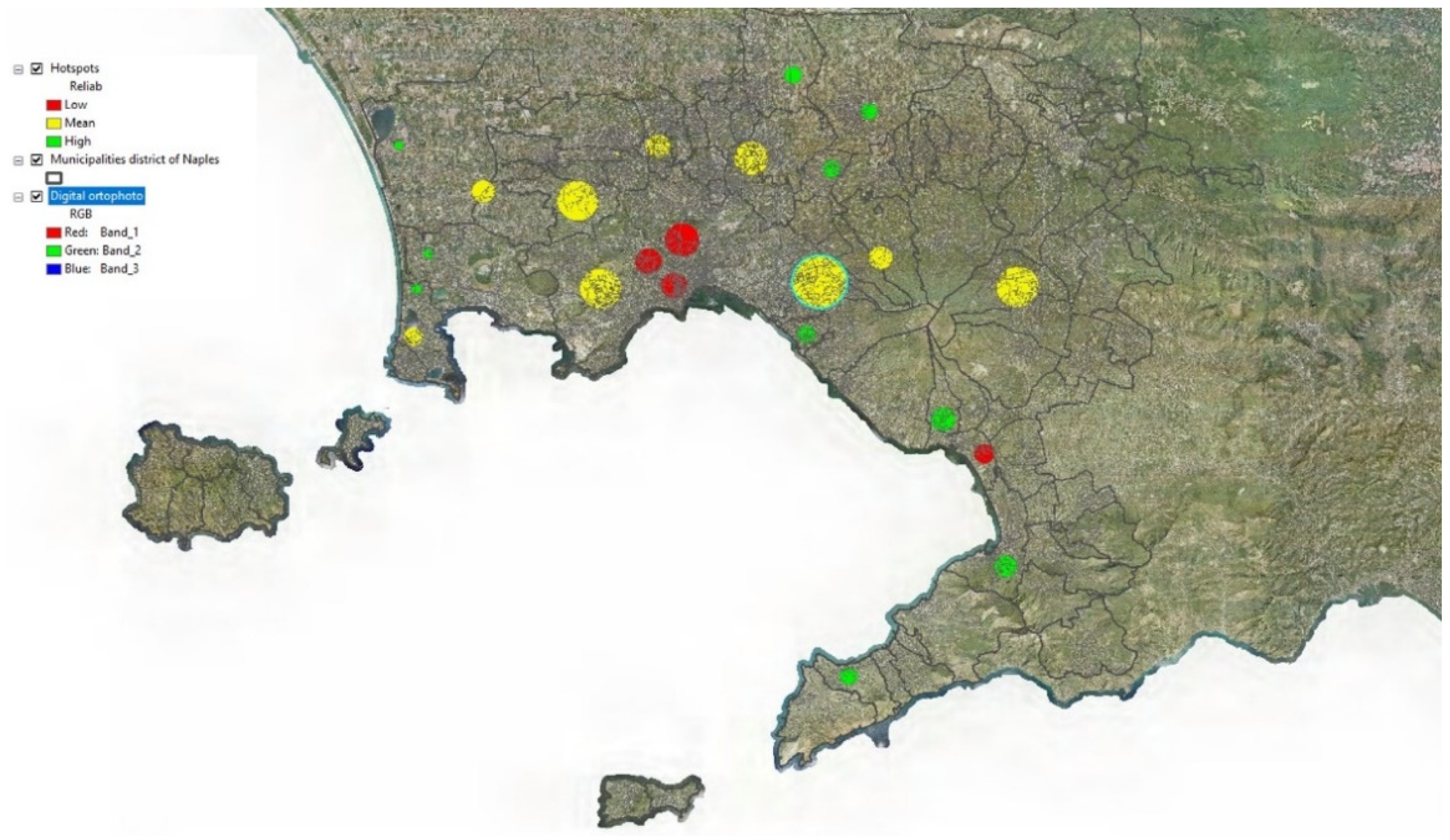
Figure 5 shows a thematic map of the hotspots in which three thematic classes are used, obtained by applying the Jenks Natural Breaks Classification method [30]:
- -
- Low, which includes hotspots with reliability less than 0.45
- -
- Mean, which includes hotspots with reliability between 0.45 and 0.6
- -
- High, which includes hotspots with reliability greater than 0.6
This can provide information on the distribution in the study area of hotspots with different reliabilities. Hotspots with low reliability can be interpreted as hotspots in which there is greater uncertainty regarding their location and extent; on the contrary, hotspots with high reliability are hotspots whose location and extent have been detected with greater certainty.
The map in Figure 5 shows a concentration of hotspots with low reliability within the municipality of Naples; they are located in an area corresponding to the historic center of the city.
We asked a team of expert doctors who analyzed the dataset of the locations of patients diagnosed with the disease to evaluate how accurate the location and width of each hotspot detected on the map was, assigning one of the three labels: Low, Mean, and High, to each hotspot. In Table 2, the evaluations of the experts are compared with the results obtained in the thematic map in Figure 5.
The results obtained are correlated with the deductions made by the team of experts. The four hotspots rated with reliability Low, are also evaluated with Low reliability by the pool of experts, who found it more difficult to locate disease strains in the areas including the historic center of the municipality of Naples, due mainly to a high population density, on average homogeneous to the entire area of the historic city center.
5. Final Considerations
To assess the reliability of the hotspots detected in spatial analysis, we propose a framework in which the EFCM hotspot detection algorithm is used to detect the hotspots, and the De Luca and Termini’s fuzzy entropy is applied to measure the reliability of the detected hotspots.
We tested our framework in a disease analysis problem; the results show that the presence of an approximately linear dependence between the reliability of the detected hotspots and the fluctuation of the membership degrees of the event data points to the corresponding fuzzy clusters. Furthermore, the spatial distribution of the reliability of the detected hotspots corresponds to the assessments made by the pool of experts.
In the future, we intend to adapt and apply our framework on massive event datasets, and to test the proposed method for measuring the reliability of predictions of future locations and displacements of hotspots.
Author Contributions
Conceptualization, F.D.M. and S.S.; methodology, F.D.M. and S.S.; software, F.D.M. and S.S.; validation, F.D.M. and S.S.; formal analysis, F.D.M. and S.S.; investigation, F.D.M. and S.S.; resources, F.D.M. and S.S.; data curation, F.D.M. and S.S.; writing—original draft preparation, F.D.M. and S.S.; writing—review and editing, F.D.M. and S.S.; visualization, F.D.M. and S.S.; supervision, F.D.M. and S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study did not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- MacQueen, J.B. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the fifth Berkeley Symposium on Mathematical Statistics and Probability; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Oakland CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Levine, N. CrimeStat: A Spatial Statistical Program for the Analysis of Crime Incidents. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Zhou, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Vadrevu, K.V.; Csiszar, I.; Ellicott, E.; Giglio, L.; Badarinath, K.V.S.; Vermote, E.; Justice, C. Hotspot Analysis of Vegetation Fires and Intensity in the Indian Region. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 224–228. [Google Scholar] [CrossRef]
- Hajela, G.; Chawla, M.; Rasool, A. A Clustering Based Hotspot Identification Approach For Crime Prediction. Procedia Comput. Sci. 2020, 167, 1462–1470. [Google Scholar] [CrossRef]
- Khairani, N.A.; Sutoyo, E. Application of K-Means Clustering Algorithm for Determination of Fire-Prone Areas Utilizing Hotspots in West Kalimantan Province. Int. J. Adv. Data Inf. Syst. 2020, 1, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005; 342p, ISBN 978-0471735786. [Google Scholar]
- Tabarej, M.S.; Minz, S. Rough-Set Based Hotspot Detection in Spatial Data. In Advances in Computing and Data Sciences. ICACDS 2019. Communications in Computer and Information Science; Singh, M., Gupta, P., Tyagi, V., Flusser, J., Ören, T., Kashyap, R., Eds.; Springer: Singapore, 2019; Volume 1046. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981; 272p, ISBN 978-0306406713. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. The fuzzy C-means Clustering Algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Pal, S.K. Fuzzy Models for Pattern Recognition: Methods that Search for Structure in Data; IEEE Press: New York, NY, USA, 1992; 544p, ISBN 978-0780304222. [Google Scholar]
- Grubesic, T.H. On the Application of Fuzzy Clustering for Crime HotSpot Detection. J. Quant. Criminol. 2006, 22, 77–105. [Google Scholar] [CrossRef]
- Kaur, R.; Sehera, S.S. Analyzing and Displaying of Crime Hotspots using Fuzzy Mapping Method. Int. J. Comput. Appl. 2014, 103, 25–28. [Google Scholar] [CrossRef]
- Ansari, M.Y.; Prakash, A. Application of Spatio-temporal Fuzzy C-Means Clustering for Crime Spot Detection. Def. Sci. J. 2018, 68, 374–380. [Google Scholar] [CrossRef] [Green Version]
- Win, K.N.; Chen, J.; Chen, Y.; Fournier-Viger, P. PCPD: A Parallel Crime Pattern Discovery System for Large-Scale Spatio-temporal Data Based on Fuzzy Clustering. Int. J. Fuzzy Syst. 2019, 21, 1961–1974. [Google Scholar] [CrossRef]
- Bandyopadhyaya, R.; Mitra, S. Fuzzy Cluster–Based Method of Hotspot Detection with Limited Information. J. Transp. Saf. Secur. 2015, 7, 307–323. [Google Scholar] [CrossRef]
- Besag, J.; Newell, J. The detection of clusters in rare diseases. J. R. Stat. Soc. A 1991, 154, 143–155. [Google Scholar] [CrossRef]
- Devroye, L.; Rugosi, G. Combinatorial Methods in Density Estimation; Springer: Berlin/Heidelberg, Germany, 2001; 208p, ISBN 978-0387951171. [Google Scholar]
- Chaney, S.; Ratcliffe, J. GIS and Crime Mapping Chap. 6, Identifying Crime Hotspots; John Wiley & Sons: Hoboken, NJ, USA, 2013; 402p, ISBN 978-0-470-86099-1. [Google Scholar]
- Lin, Y.-P.; Chu, H.-J.; Wu, C.-F.; Chang, T.-K.; Chen, C.-Y. Hotspot Analysis of Spatial Environmental Pollutants Using Kernel Density Estimation and Geostatistical Techniques. Int. J. Environ. Res. Public Health 2011, 8, 75–88. [Google Scholar] [CrossRef] [PubMed]
- Harirforoush, H.; Bellalite, L. A New Integrated GIS-based Analysis to Detect Hotspots: A Case Study of the City of Sherbrooke. Accid. Anal. Prev. 2019, 130, 62–74. [Google Scholar] [CrossRef] [PubMed]
- Di Martino, F.; Sessa, S. The Extended Fuzzy C-means Algorithm for Hotspots in Spatio-temporal GIS. Expert Syst. Appl. 2011, 38, 11829–11836. [Google Scholar] [CrossRef]
- Kaymak, U.; Setnes, M. Fuzzy Clustering with Volume Prototype and Adaptive Cluster Merging. IEEE Trans. Fuzzy Syst. 2002, 10, 705–712. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S.; Barillari, E.S.; Barillari, M.S. Spatio-temporal Hotspots and Application on a Disease Analysis Case via GIS. Soft Comput. 2014, 18, 2377–2384. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S.; Mele, R.; Barillari, U.E.; Barillari, M.R. WebGIS Based on Spatio-temporal Hotspots: An Application to Oto-laryngo-pharyngeal Diseases. Soft Comput. 2015, 20, 2135–2147. [Google Scholar]
- Di Martino, F.; Pedrycz, W.; Sessa, S. Hierarchical Granular Hotspots Detection. Soft Comput. 2020, 24, 1357–1376. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. Entropy and energy measures of fuzzy sets. In Advances in Fuzzy Set Theory and Applications; Gupta, M.M., Ragade, R.K., Yager, R.R., Eds.; North-Holland: Amsterdam, The Netherlands, 1979; pp. 321–338. [Google Scholar]
- De Luca, A.; Termini, S. A Definition of Non-probabilistic Entropy in the Setting of Fuzzy Sets Theory. Inf. Control 1972, 20, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Di Martino, F.; Sessa, S. A New Validity Index Based on Fuzzy Energy and Fuzzy Entropy Measures in Fuzzy Clustering Problems. Entropy 2020, 22, 1200. [Google Scholar] [CrossRef] [PubMed]
- Cardone, B.; Di Martino, F. A Novel Fuzzy Entropy-Based Method to Improve the Performance of the Fuzzy C-Means Algorithm. Electronics 2020, 9, 554. [Google Scholar] [CrossRef] [Green Version]
- Jenks, G.F. The Data Model Concept in Statistical Mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
Figure 1.
The proposed framework.

Figure 2.
Thematic map with the detected hotspots.

Figure 3.
Linear dependency analysis results of the reliability on the area of the hotspots.

Figure 4.
Linear dependency analysis results of the reliability on the standard deviation.

Figure 5.
Thematic map with the detected hotspots.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Area and reliability of the detected hotspots.
| ID | Area (km2) | Standard dev. | Reliability |
|---|---|---|---|
| 01 | 0.06 | 0.045 | 0.47 |
| 02 | 0.24 | 0.028 | 0.69 |
| 03 | 0.31 | 0.031 | 0.68 |
| 04 | 0.34 | 0.033 | 0.63 |
| 05 | 0.81 | 0.033 | 0.68 |
| 06 | 0.89 | 0.025 | 0.81 |
| 07 | 0.92 | 0.032 | 0.67 |
| 08 | 0.97 | 0.024 | 0.82 |
| 09 | 1.00 | 0.022 | 0.89 |
| 10 | 1.08 | 0.033 | 0.57 |
| 11 | 1.18 | 0.050 | 0.41 |
| 12 | 1.47 | 0.026 | 0.76 |
| 13 | 1.59 | 0.034 | 0.57 |
| 14 | 1.66 | 0.044 | 0.42 |
| 15 | 1.76 | 0.033 | 0.66 |
| 16 | 1.79 | 0.042 | 0.43 |
| 17 | 2.10 | 0.035 | 0.53 |
| 18 | 2.14 | 0.039 | 0.47 |
| 19 | 3.51 | 0.030 | 0.57 |
| 20 | 3.52 | 0.048 | 0.46 |
| 21 | 5.03 | 0.045 | 0.43 |
| 22 | 5.07 | 0.037 | 0.58 |
| 23 | 5.30 | 0.035 | 0.61 |
| 24 | 8.91 | 0.043 | 0.50 |
Table 2.
Hotspot reliability Comparison results.
| ID | Reliability | Reliability Class | Expert Evaluation |
|---|---|---|---|
| 01 | 0.47 | Mean | Mean |
| 02 | 0.69 | High | High |
| 03 | 0.68 | High | High |
| 04 | 0.63 | High | Mean |
| 05 | 0.68 | High | Mean |
| 06 | 0.81 | High | High |
| 07 | 0.67 | High | Mean |
| 08 | 0.82 | High | High |
| 09 | 0.89 | High | High |
| 10 | 0.57 | Mean | Mean |
| 11 | 0.41 | Low | Low |
| 12 | 0.76 | High | High |
| 13 | 0.57 | Mean | High |
| 14 | 0.43 | Low | Low |
| 15 | 0.66 | High | Mean |
| 16 | 0.42 | Low | Low |
| 17 | 0.53 | Mean | Mean |
| 18 | 0.47 | Mean | Mean |
| 19 | 0.57 | Mean | Mean |
| 20 | 0.46 | Mean | Mean |
| 21 | 0.43 | Low | Low |
| 22 | 0.58 | Mean | Mean |
| 23 | 0.61 | Mean | High |
| 24 | 0.50 | Mean | Mean |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Di Martino, F.; Sessa, S. Fuzzy Entropy-Based Spatial Hotspot Reliability. Entropy 2021, 23, 531. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050531
AMA Style
Di Martino F, Sessa S. Fuzzy Entropy-Based Spatial Hotspot Reliability. Entropy. 2021; 23(5):531. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050531
Chicago/Turabian StyleDi Martino, Ferdinando, and Salvatore Sessa. 2021. "Fuzzy Entropy-Based Spatial Hotspot Reliability" Entropy 23, no. 5: 531. https://0-doi-org.brum.beds.ac.uk/10.3390/e23050531
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.