
No-Reference Quality Assessment for 3D Synthesized Images Based on Visual-Entropy-Guided Multi-Layer Features Analysis


Abstract
:1. Introduction
- (1)
- The metric elaborately classifies geometric distortions into bottom-up and top-down layers via visual entropy, and integrates multi-layer features to regress quality score.
- (2)
- In the bottom-up layer, the strong geometric distortion is measured by calculating area proportion plus transition threshold.
- (3)
- In the top-down layer, key regions of weak geometric distortions are extracted by the relative total variation model, and the features are measured by the interaction of decentralized attention (entropy, secondary Gaussian blur similarity, and horizontal pixels correlation) and concentrated attention (Gaussian mixture models).
2. Motivation
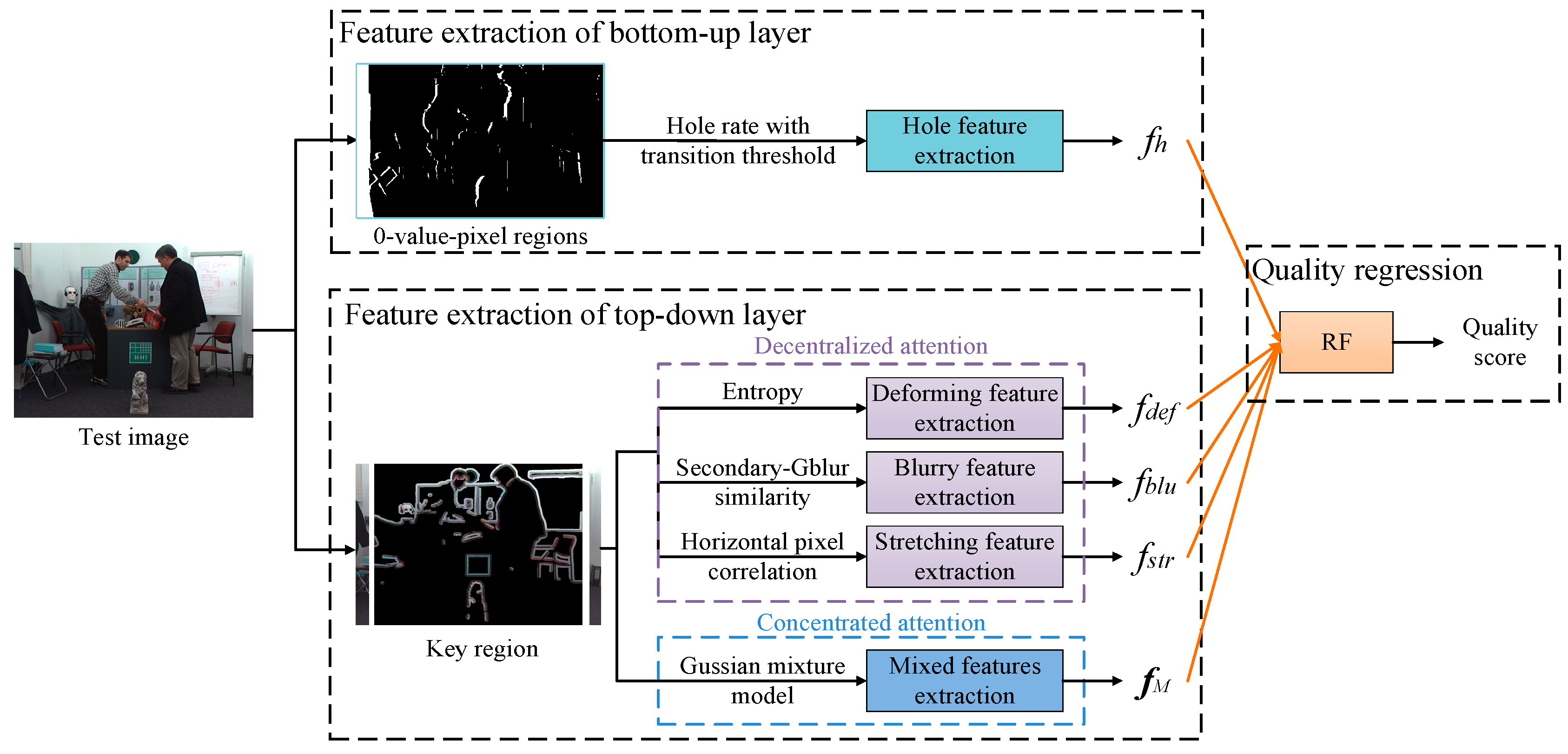
3. The Proposed Visual-Entropy-Guided MLFA Method
3.1. Feature Extraction of the Bottom-Up Layer
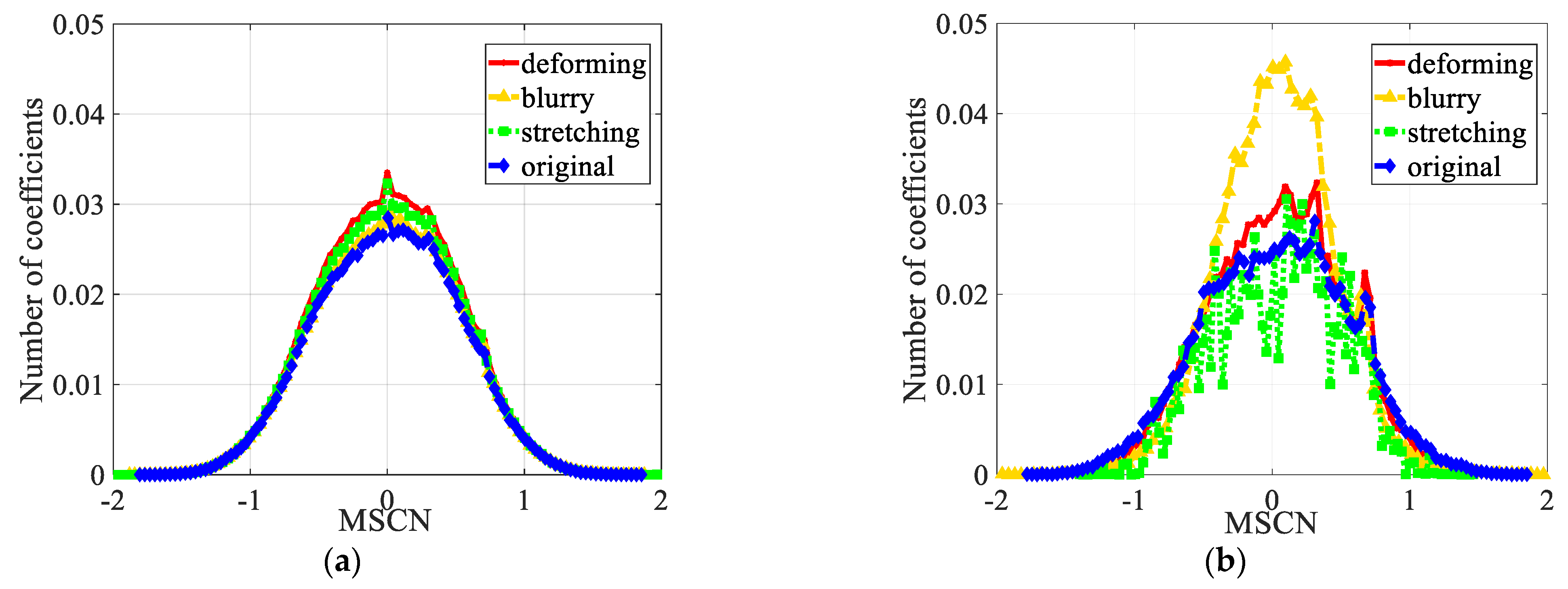
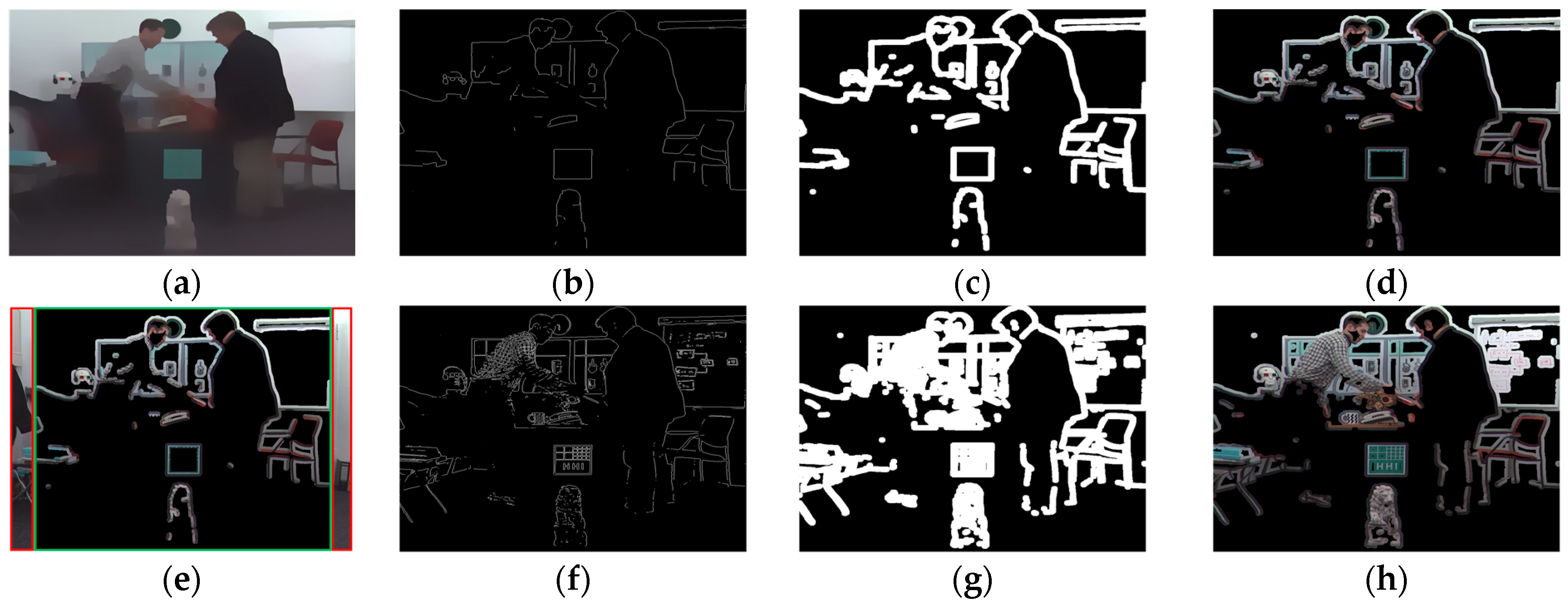
3.2. Feature Extraction of a Top-Down Layer
3.3. Quality Regression
4. Experimental Results and Analysis
4.1. Databases and Evaluation Criteria
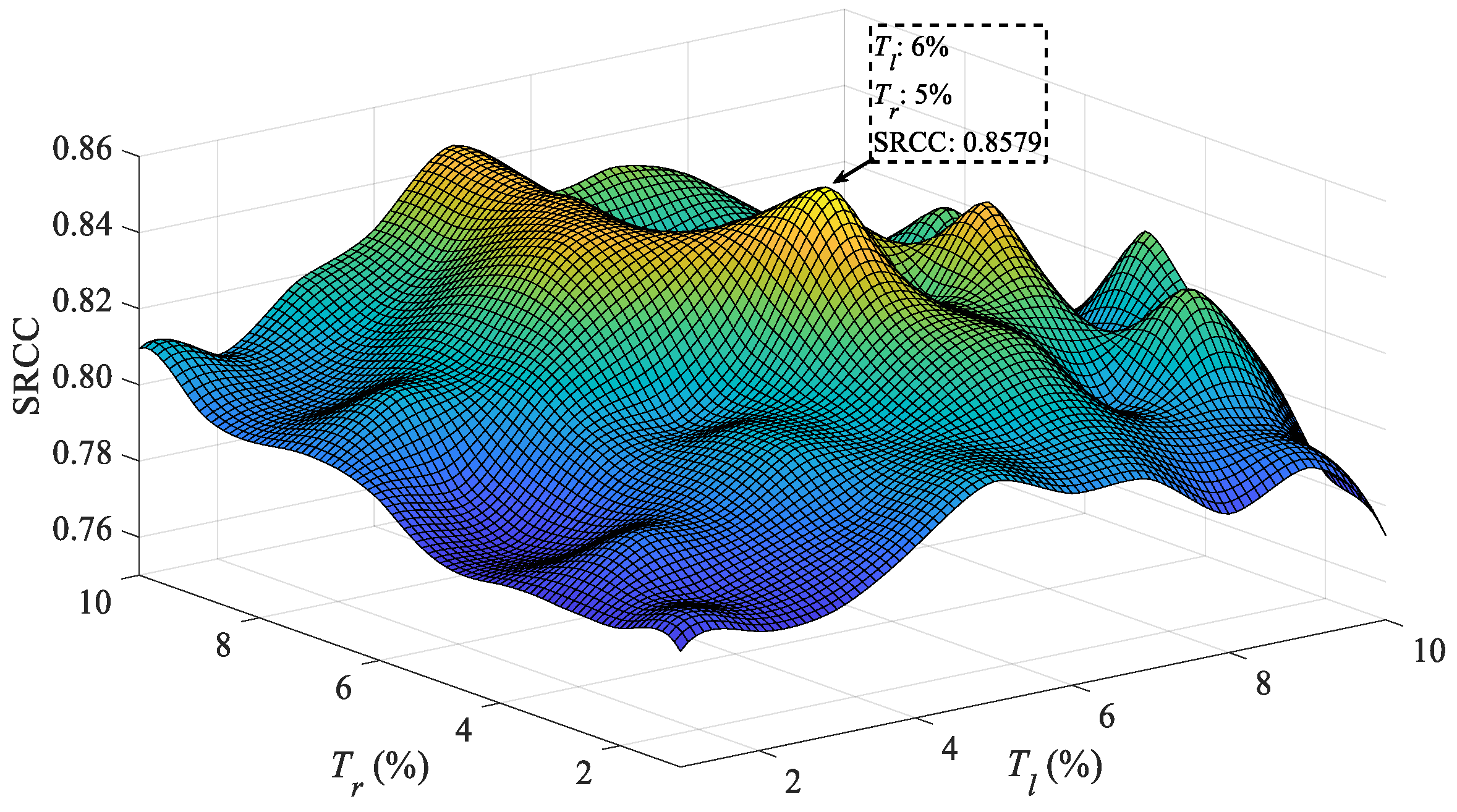
4.2. Parameters Determination
4.3. Performance Comparison
- (1)
- The traditional metrics, like PSNR and SSIM, are not effective for 3D synthesized images. The performance of PSNR and SSIM is poor because they have not been conceived for dealing with the local specificity of geometric distortions (e.g., the PLCC is less than 0.5).
- (2)
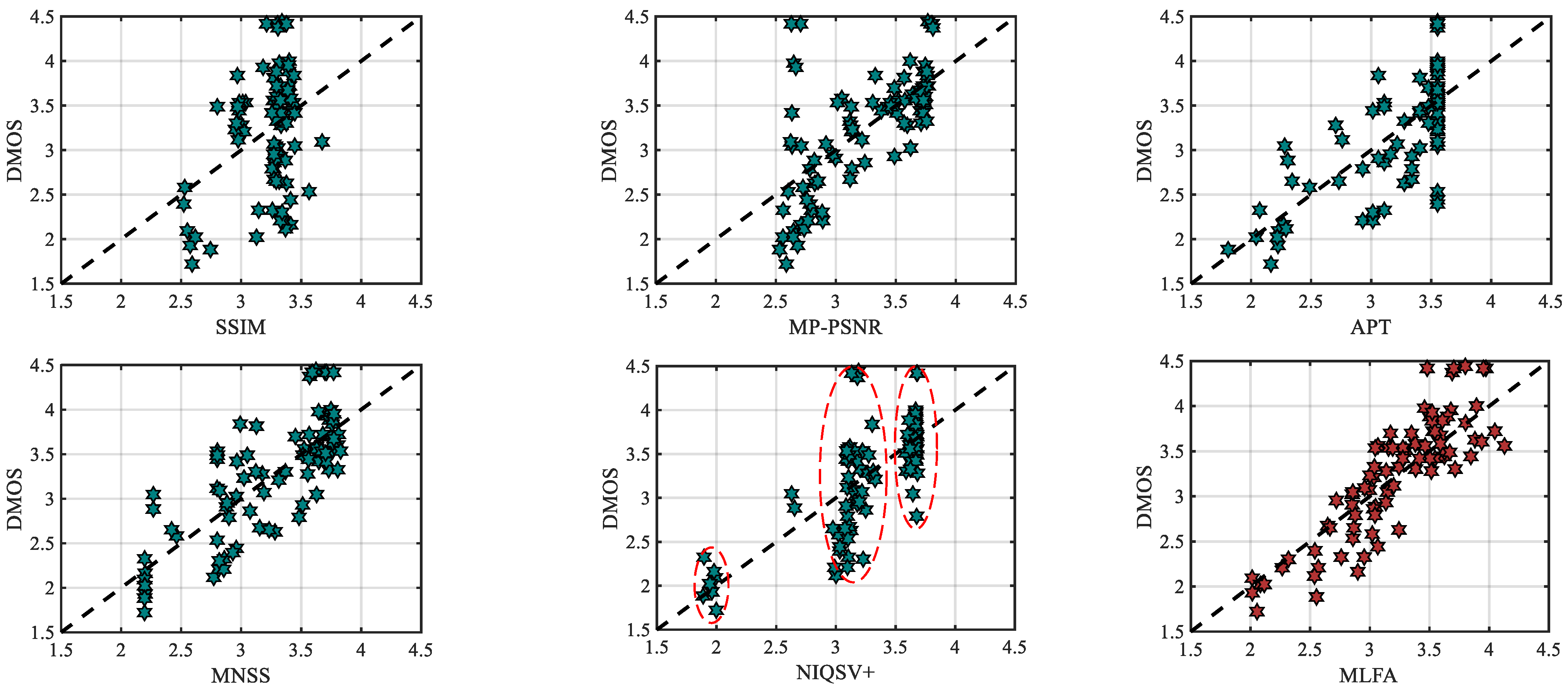
- The performance of metrics designed for 3D synthesized images is better than traditional metrics, but not sufficient. The metrics, VSQA, 3DSwIM, ST-SIAQ, EM-IQA, and NIQSV, are mainly designed for the object shifting and blurry distortions (parts of the top-down layer). The metrics, MW-PSNR, MP-PSNR, APT, MNSS, and OUT, are mainly sensitive to hole distortion. The above-mentioned metrics ignore the diversity of geometric distortions. Among them, the MNSS metric shows the best performance, and PLCC, SRCC, and RMSE are 0.7700, 0.7850, and 0.4120. A few metrics consider multiple distortions, such as SC-IQA, IDEA, NR-MWT, SET, NIQSV+, and CLGM. However, the weak geometric distortions are inadequately and ambiguously classified, and merely measured via decentralized attention. In addition, only a few metrics (e.g., IDEA) emphasize the utilization of local distortion distribution characteristics. These limitations lead these metrics to fail to effectively estimate weak distortions. Even for SET, the best among these metrics, the corresponding PLCC, SRCC, and RMSE are 0.8586, 0.8109, and 0.3015, and can be further improved. The performance of deep-learning-based metrics, such as GANs-NRM and Wang, is also unsatisfactory due to the limitation of insufficient training samples.
- (3)
- The proposed method MLFA is superior to the state-of-the-art metrics, and PLCC, SRCC, and RMSE are 0.8757, 0.8579, and 0.4106. It affirms the effectiveness of MLFA method for 3D synthesized images.
4.4. Generalization Ability
4.5. Impact of Training Percentages
4.6. Performance Analysis of a Multi-Layer Strategy
4.7. Performance Analysis of Key Region Extraction
- (1)
- S3 and S4 have similar PLCC performance on the bottom-up layer (i.e., fh). However, the performance of S3 is reduced on the top-down layer, especially for fM. Theoretically, most regions of the 3D synthesized images are not geometrically distorted. In S3, the features are extracted throughout the entire image, and the local geometric distortions are too subtle to be extracted. However, S4 adopts key region extraction, which highlights the regions of weak geometric distortion. Hence, the interference of most non-geometric distortion regions is effectively eliminated. The experimental data indeed verifies this theoretical explanation, i.e., the PLCC of S4 is nearly twice as high as S3 in fM on two databases.
- (2)
- Different from fM, the PLCC performance of fdef, fblu, and fstr on the top-down layer is slightly affected by key region extraction. fM is a multi-dimensional feature and is obtained by concentrated attention. By contrast, fdef, fblu, and fstr, are single-dimensional features, and extracted from corresponding distortions via decentralized attention. Thus, the latter features are more distortion-specific, and insensitive to the regional interference in different scenes. The analysis is validated by the experimental results, which the PLCC of S3 slightly decreases within 0.04 compared to S4 in terms of fdef, fblu, and fstr.
4.8. Feature Ablation Experiments
- (1)
- M1–M5, composed of one feature, have poor performance, i.e., PLCC is below 0.7 roughly. In M6–M11, the feature components reach three, and the PLCC ranges from 0.7465 to 0.8174. For M12–M16, the feature components are increased to four, and the PLCC is further improved and stabilized in 0.8294 to 0.8538. In M17, PLCC is the best and equals 0.8757, when the feature components are five. The experimental data show that the performance increases in steps and gradually stabilizes with the addition of feature components. Hence, each feature is an essential part of the MLFA method and can significantly increase the accuracy and stability of the IQA model.
- (2)
- Among these models, M12 and M17 are emphatically compared. In M12, the features are merely obtained by decentralized attention (as traditional distortion-classification-based 3D synthesized IQA metrics do). In M17, the features are acquired via feature integration theory, i.e., the interaction of decentralized attention and concentrated attention (as the MLFA method does). Obviously, the performance of M17 is better than M12, i.e., PLCC and SRCC are 0.0353 and 0.0988 higher than M12, and RMSE is 0.0145 lower than M12. The performance comparison demonstrates that the MLFA method, which uses the strategy of feature integration theory, achieves higher feature utilization and improves the consistency with the subjective scores.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Buisine, J.; Bigand, A.; Synave, R.; Delepoulle, S.; Renaud, C. Stopping Criterion during Rendering of Computer-Generated Images Based on SVD-Entropy. Entropy 2021, 23, 75. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Y.; Jiao, L.; Yang, S.; Hou, B.; Feng, J. Color Correction and Depth-Based Hierarchical Hole Filling in Free Viewpoint Generation. IEEE Trans. Broadcast. 2019, 65, 294–307. [Google Scholar] [CrossRef]
- Lin, Y.; Yu, M.; Chen, K.; Jiang, G.; Chen, F.; Peng, Z. Blind Mesh Assessment Based on Graph Spectral Entropy and Spatial Features. Entropy 2020, 22, 190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Tian, M.; Zhang, W.; Yao, H.; Wang, X. Learning to Predict the Quality of Distorted-then-Compressed Images via a Deep Neural Network. J. Vis. Commun. Image Represent. 2021, 76, 103004. [Google Scholar] [CrossRef]
- Cui, X.; Peng, Z.; Jiang, G.; Chen, F.; Yu, M. Perceptual Video Coding Scheme Using Just Noticeable Distortion Model Based on Entropy Filter. Entropy 2019, 21, 1095. [Google Scholar] [CrossRef] [Green Version]
- Deng, C.; Wang, S.; Bovik, A.C.; Huang, G.; Zhao, B. Blind Noisy Image Quality Assessment Using Sub-Band Kurtosis. IEEE Trans. Cybern. 2020, 50, 1146–1156. [Google Scholar] [CrossRef]
- Guan, X.; He, L.; Li, M.; Li, F. Entropy based Data Expansion Method for Blind Image Quality Assessment. Entropy 2020, 22, 60. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Y.; Zhang, R. No-Reference JPEG Image Quality Assessment Based on Blockiness and Luminance Change. IEEE Signal Process. Lett. 2017, 24, 760–764. [Google Scholar] [CrossRef]
- Soltani, M.; Pourahmadi, V.; Mirzaei, A.; Sheikhzadeh, H. Deep Learning-Based Channel Estimation. IEEE Commun. Lett. 2019, 23, 652–655. [Google Scholar] [CrossRef] [Green Version]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Saha, A.; Wu, Q. Full-reference image quality assessment by combining global and local distortion measures. Signal Process. 2016, 128, 186–197. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Mou, X.; Chandler, D.M. Learning No-Reference Quality Assessment of Multiply and Singly Distorted Images with Big Data. IEEE Trans. Image Process. 2020, 29, 2676–2691. [Google Scholar] [CrossRef] [PubMed]
- Bosc, E.; Callet, P.L.; Morin, L.; Pressigout, M. An edge-based structural distortion indicator for the quality assessment of 3D synthesized views. In Proceedings of the Picture Coding Symposium (PCS), Krakow, Poland, 7–9 May 2012; pp. 249–252. [Google Scholar]
- Conze, P.-H.; Robert, P.; Morin, L. Objective view synthesis quality assessment. In Proceedings of the International Society for Optical Engineering (SPIE), Burlingame, CA, USA, 27 February 2012; pp. 8256–8288. [Google Scholar]
- Battisti, F.; Bosc, E.; Carli, M.; Callet, P.L.; Perugia, S. Objective image quality assessment of 3D synthesized views. Signal Process. Image Commun. 2015, 30, 78–88. [Google Scholar] [CrossRef]
- Ling, S.; Callet, P.L. Image quality assessment for free viewpoint video based on mid-level contours feature. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 79–84. [Google Scholar]
- Ling, S.; Callet, P.L. Image quality assessment for DIBR synthesized views using elastic metric. In Proceedings of the 17th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1157–1163. [Google Scholar]
- Sandić-Stanković, D.; Kukolj, D.; Callet, P.L. DIBR synthesized image quality assessment based on morphological wavelets. In Proceedings of the 2015 Seventh International Workshop on Quality of Multimedia Experience (QoMEX), Pylos-Nestoras, Greece, 26–29 May 2015; pp. 1–6. [Google Scholar]
- Sandić-Stanković, D.; Kukolj, D.; Callet, P.L. Multi-scale synthesized view assessment based on morphological pyramids. J. Elect. Eng. 2016, 67, 9–11. [Google Scholar] [CrossRef] [Green Version]
- Tian, S.; Zhang, L.; Morin, L.; Déforges, O. SC-IQA: Shift compensation based image quality assessment for DIBR-synthesized views. In Proceedings of the IEEE International Conference on Visual Communication and Image Processing (VCIP), Taiwan, China, 7–10 October 2018; pp. 1–4. [Google Scholar]
- Li, L.; Zhou, Y.; Wu, J.; Li, F.; Shi, G. Quality Index for View Synthesis by Measuring Instance Degradation and Global Appearance. IEEE Trans. Multimed. 2021, 23, 320–332. [Google Scholar] [CrossRef]
- Gu, K.; Jakhetiya, V.; Qiao, J.; Li, X.; Lin, W.; Thalmann, D. Model-based referenceless quality metric of 3D synthesized images using local image description. IEEE Trans. Image Process. 2018, 27, 394–405. [Google Scholar] [CrossRef]
- Gu, K.; Qiao, J.; Lee, S.; Liu, H.; Lin, W.; Callet, P.L. Multiscale Natural Scene Statistical Analysis for No-Reference Quality Evaluation of DIBR-Synthesized Views. IEEE Trans. Broadcast. 2020, 66, 127–139. [Google Scholar] [CrossRef]
- Jakhetiya, V.; Gu, K.; Singhal, T.; Guntuku, S.C.; Xia, Z.; Lin, W. A highly efficient blind image quality assessment metric of 3d synthesized images using outlier detection. IEEE Trans. Ind. Inform. 2019, 15, 4120–4128. [Google Scholar] [CrossRef]
- Jakhetiya, V.; Gu, K.; Jaiswal, S.P.; Singhal, T.; Xia, Z. Kernel-Ridge Regression-Based Quality Measure and Enhancement of Three-Dimensional-Synthesized Images. IEEE Trans. Ind. Electron. 2021, 68, 423–433. [Google Scholar] [CrossRef]
- Sandić-Stanković, D.D.; Kukolj, D.D.; Callet, P.L. Fast Blind Quality Assessment of DIBR-Synthesized Video Based on High-High Wavelet Subband. IEEE Trans. Image Process. 2019, 28, 5524–5536. [Google Scholar] [CrossRef]
- Wang, G.; Wang, Z.; Gu, K.; Li, L.; Xia, Z.; Wu, L. Blind Quality Metric of DIBR-Synthesized Images in the Discrete Wavelet Transform Domain. IEEE Trans. Image Process. 2020, 29, 1802–1814. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, L.; Wang, S.; Wu, J.; Fang, Y.; Gao, X. No-Reference Quality Assessment for View Synthesis Using DoG-Based Edge Statistics and Texture Naturalness. IEEE Trans. Image Process. 2019, 28, 4566–4579. [Google Scholar] [CrossRef]
- Tian, S.; Zhang, L.; Morin, L.; Déforges, O. NIQSV: A no reference image quality assessment metric for 3D synthesized views. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Los Angeles, CA, USA, 5–9 March 2017; pp. 1248–1252. [Google Scholar]
- Tian, S.; Zhang, L.; Morin, L.; Déforges, O. NIQSV+: A No-Reference Synthesized View Quality Assessment Metric. IEEE Trans. Image Process. 2018, 27, 1652–1664. [Google Scholar] [CrossRef]
- Yue, G.; Hou, C.; Gu, K.; Zhou, T.; Zhai, G. Combining Local and Global Measures for DIBR-Synthesized Image Quality Evaluation. IEEE Trans. Image Process. 2019, 28, 2075–2088. [Google Scholar] [CrossRef]
- Ling, S.; Li, J.; Wang, J.; Callet, P.L. Gans-nqm: A generative adversarial networks based no reference quality assessment metric for RGB-D synthesized views. arXiv 2019, arXiv:1903.12088. [Google Scholar]
- Wang, X.; Liang, X.; Yang, B.; Li, F. No-reference synthetic image quality assessment with convolutional neural network and local image saliency. Comput. Vis. Media 2019, 5, 193–208. [Google Scholar] [CrossRef] [Green Version]
- Bosc, E.; Pepion, R.; Callet, P.L.; Koppel, M.; Ndjiki-Nya, P.; Pressigout, M.; Morin, L. Towards a new quality metric for 3-D synthesized view assessment. IEEE J. Sel. Top. Signal Process. 2011, 5, 1332–1343. [Google Scholar] [CrossRef] [Green Version]
- Fehn, C. Depth-image-based rendering (DIBR), compression and transmission for a new approach on 3D-TV. In Proceedings of the Society of Photo-Optical Instrumentation Engineers (SPIE), San Jose, CA, USA, 21 May 2004; pp. 93–104. [Google Scholar]
- Ndjiki-Nya, P.; Koppel, M.; Doshkov, D.; Lakshman, H.; Merkle, P.; Muller, K.; Wiegand, T. Depth Image-Based Rendering with Advanced Texture Synthesis. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo (ICME), Suntec City, Singapore, 19–23 July 2010; pp. 424–429. [Google Scholar]
- Köppel, M.; Ndjiki-Nya, P.; Doshkov, D.; Lakshman, H.; Merkle, P.; Müller, K.; Wiegand, T. Temporally consistent handling of disocclusions with texture synthesis for depth-image-based rendering. In Proceedings of the 2010 IEEE International Conference on Image Processing (ICIP), Hong Kong, China, 26–29 September 2010; pp. 1809–1812. [Google Scholar]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Mori, Y.; Fukushima, N.; Yendo, T.; Fujii, T.; Tanimoto, M. View generation with 3D warping using depth information for FTV. Signal Process. Image Commun. 2009, 24, 65–72. [Google Scholar] [CrossRef]
- Müller, K.; Smolic, A.; Dix, K.; Merkle, P.; Kauff, P.; Wiegand, T. View synthesis for advanced 3D video systems. EURASIP J. Image Video Process. 2009, 2008, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Miller, E.K. The prefrontal cortex and cognitive control. Nat. Rev. Neurosci. 2000, 1, 59–65. [Google Scholar] [CrossRef]
- Crick, F.; Koch, C. Constraints on cortical and thalamic projections: The no-strong-loops hypothesis. Nature 1998, 391, 245–250. [Google Scholar] [CrossRef]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Varga, D. No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features. J. Imaging 2020, 6, 75. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Xu, L.; Yan, Q.; Xia, Y.; Jia, J. Structure Extraction from Texture via Relative Total Variation. ACM Trans. Graph. 2012, 31, 139:1–139:10. [Google Scholar] [CrossRef]
- Cui, Y. No-Reference Image Quality Assessment Based on Dual-Domain Feature Fusion. Entropy 2020, 22, 344. [Google Scholar] [CrossRef] [Green Version]
- Tian, S.; Zhang, L.; Morin, L.; Deforges, O. A benchmark of DIBR synthesized view quality assessment metrics on a new database for immersive media applications. IEEE Trans. Multimed. 2018, 21, 1235–1247. [Google Scholar] [CrossRef]
- Tanimoto, M.; Fujii, T.; Suzuki, K.; Fukushima, N.; Mori, Y. Reference softwares for depth estimation and view synthesis. In ISO/IEC JTC1/SC29/WG11; MPEG: Archamps, France, 2008; doc. M15377. [Google Scholar]
- Zhu, C.; Li, S. Depth image based view synthesis: New insights and perspectives on hole generation and filling. IEEE Trans. Broadcast. 2016, 62, 82–93. [Google Scholar] [CrossRef]
- Criminisi, A.; Perez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Luo, G.; Zhu, Y.; Li, Z.; Zhang, L. A hole filling approach based on background reconstruction for view synthesis in 3-D video. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, CA, USA, 27–30 June 2016; pp. 1781–1789. [Google Scholar]
- Solh, M.; AlRegib, G. Hierarchical hole-filling for depth-based view synthesis in FTV and 3-D video. IEEE J. Sel. Top. Signal Process. 2012, 6, 495–504. [Google Scholar] [CrossRef]
- Jantet, V.; Guillemot, C.; Morin, L. Object-based layered depth images for improved virtual view synthesis in rate-constrained context. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 125–128. [Google Scholar]
- Ahn, I.; Kim, C. A novel depth-based virtual view synthesis method for free viewpoint video. IEEE Trans. Broadcast. 2013, 59, 614–6268. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 3 | 5 | 7 | 9 | 11 |
|---|---|---|---|---|---|
| Standard deviation of hole | 17.87 | 17.16 | 18.32 | 18.33 | 18.55 |
| Standard deviation of non-hole | 1.67 | 2.06 | 4.56 | 7.63 | 11.74 |
| T | 32 | 33 | 42 | 47 | - |
| Computational time (s) | 2.83 | 3.71 | 4.40 | 4.74 | 4.92 |
| Category | Distortion Type | Metric | PLCC | SRCC | RMSE |
|---|---|---|---|---|---|
| FR | 2D traditional distortion | PSNR | 0.4515 | 0.4589 | 0.5527 |
| SSIM [11] | 0.4850 | 0.4368 | 0.5823 | ||
| FR | 3D synthesized distortion | VSQA [16] | 0.5742 | 0.5233 | 0.5451 |
| 3DSwIM [17] | 0.6584 | 0.6156 | 0.5011 | ||
| ST-SIAQ [18] | 0.6914 | 0.6746 | 0.4812 | ||
| EM-IQA [19] | 0.7430 | 0.6282 | 0.4455 | ||
| MW-PSNR [20] | 0.5622 | 0.5757 | 0.5506 | ||
| MP-PSNR [21] | 0.6174 | 0.6227 | 0.5238 | ||
| SC-IQA [22] | 0.8496 | 0.7640 | 0.3511 | ||
| IDEA [23] | 0.7796 | 0.6652 | 0.3533 | ||
| NR | 3D synthesized distortion | APT [24] | 0.7307 | 0.7157 | 0.4546 |
| MNSS [25] | 0.7700 | 0.7850 | 0.4120 | ||
| OUT [26] | 0.7243 | 0.7010 | 0.4591 | ||
| NR-MWT [28] | 0.7343 | 0.5169 | 0.4520 | ||
| SET [30] | 0.8586 | 0.8109 | 0.3015 | ||
| NIQSV [31] | 0.6346 | 0.6167 | 0.5146 | ||
| NIQSV+ [32] | 0.7114 | 0.6668 | 0.4679 | ||
| CLGM [33] | 0.6750 | 0.6528 | 0.4620 | ||
| GANs-NRM [34] | 0.8262 | 0.8072 | 0.3861 | ||
| Wang [35] | 0.8112 | 0.7520 | 0.3820 | ||
| MLFA | 0.8757 | 0.8579 | 0.4106 |
| Category | Distortion Type | Metric | PLCC | SRCC | RMSE |
|---|---|---|---|---|---|
| FR | 2D traditional distortion | PSNR | 0.6012 | 0.5356 | 0.1985 |
| SSIM [11] | 0.4016 | 0.2395 | 0.2275 | ||
| FR | 3D synthesized distortion | VSQA [16] | 0.5576 | 0.4719 | 0.2062 |
| ST-SIAQ [18] | 0.3345 | 0.4232 | 0.2336 | ||
| EM-IQA [19] | 0.5627 | 0.5670 | 0.2020 | ||
| MW-PSNR [20] | 0.5301 | 0.4845 | 0.2106 | ||
| MP-PSNR [21] | 0.5753 | 0.5507 | 0.2032 | ||
| SC-IQA [22] | 0.6856 | 0.6423 | 0.1805 | ||
| NR | 3D synthesized distortion | APT [24] | 0.4225 | 0.4187 | 0.2252 |
| MNSS [25] | 0.3387 | 0.2281 | 0.2333 | ||
| OUT [26] | 0.2007 | 0.1924 | 0.2429 | ||
| NR-MWT [27] | 0.4769 | 0.4567 | 0.2179 | ||
| NIQSV [31] | 0.1759 | 0.1473 | 0.2446 | ||
| NIQSV+ [32] | 0.2095 | 0.2190 | 0.2429 | ||
| CLGM [33] | 0.1146 | 0.0860 | 0.2463 | ||
| MLFA | 0.7378 | 0.7036 | 0.1899 |
| Training Database | Testing Database | Method | PLCC | SRCC | RMSE |
|---|---|---|---|---|---|
| IETR DIBR image | IRCCyN_IVC_DIBR_images | APT | 0.6745 | 0.5817 | 0.4916 |
| MNSS | 0.6539 | 0.6147 | 0.5037 | ||
| NIQSV | 0.4989 | 0.0889 | 0.5494 | ||
| NIQSV+ | 0.5921 | 0.2680 | 0.5365 | ||
| MLFA | 0.8645 | 0.8562 | 0.3945 | ||
| IRCCyN_IVC_DIBR_images | IETR DIBR image | APT | 0.3838 | 0.2198 | 0.2249 |
| MNSS | 0.2829 | 0.2196 | 0.2335 | ||
| NIQSV | 0.1216 | 0.0839 | 0.2416 | ||
| NIQSV+ | 0.0292 | 0.0569 | 0.2433 | ||
| MLFA | 0.7046 | 0.6720 | 0.2181 |
| Database | Training–Testing | PLCC | SRCC | RMSE |
|---|---|---|---|---|
| IRCCyN_IVC_DIBR_images | 90–10% | 0.8895 | 0.8585 | 0.2967 |
| 80–20% | 0.8757 | 0.8579 | 0.3106 | |
| 70–30% | 0.8620 | 0.8330 | 0.3871 | |
| 60–40% | 0.8467 | 0.8073 | 0.4339 | |
| 50–50% | 0.8303 | 0.7970 | 0.5010 | |
| IETR DIBR image | 90–10% | 0.7473 | 0.7158 | 0.1642 |
| 80–20% | 0.7378 | 0.7036 | 0.1899 | |
| 70–30% | 0.7180 | 0.6845 | 0.1928 | |
| 60–40% | 0.7055 | 0.6644 | 0.2027 | |
| 50–50% | 0.6899 | 0.6473 | 0.2092 |
| Scheme | IRCCyN_IVC_DIBR_Images | IETR DIBR Image | ||||
|---|---|---|---|---|---|---|
| PLCC | SRCC | RMSE | PLCC | SRCC | RMSE | |
| S1 | 0.8558 | 0.8004 | 0.4269 | 0.7133 | 0.6861 | 0.2061 |
| S2 | 0.8757 | 0.8579 | 0.4106 | 0.7378 | 0.7036 | 0.1899 |
| Database | Scheme | fh | fdef | fblu | fstr | fM |
|---|---|---|---|---|---|---|
| IRCCyN_IVC_DIBR_images | S3 | 0.5409 | 0.5760 | 0.6248 | 0.3956 | 0.3535 |
| S4 | 0.5416 | 0.6108 | 0.6358 | 0.4331 | 0.6906 | |
| IETR DIBR image | S3 | 0.4278 | 0.2972 | 0.4092 | 0.3367 | 0.2094 |
| S4 | 0.4271 | 0.3365 | 0.4165 | 0.3681 | 0.4544 |
| Models | Features | IRCCyN_IVC_DIBR_Images | ||||||
|---|---|---|---|---|---|---|---|---|
| fh | fdef | fblu | fstr | fM | PLCC | SRCC | RMSE | |
| M1 | √ | 0.5416 | 0.3670 | 0.7050 | ||||
| M2 | √ | 0.6108 | 0.3543 | 0.6248 | ||||
| M3 | √ | 0.6358 | 0.5375 | 0.6420 | ||||
| M4 | √ | 0.4331 | 0.3829 | 0.7605 | ||||
| M5 | √ | 0.6906 | 0.5639 | 0.6022 | ||||
| M6 | √ | √ | √ | 0.8174 | 0.7558 | 0.4518 | ||
| M7 | √ | √ | √ | 0.7465 | 0.6680 | 0.5366 | ||
| M8 | √ | √ | √ | 0.8029 | 0.7301 | 0.4856 | ||
| M9 | √ | √ | √ | 0.8103 | 0.7085 | 0.4698 | ||
| M10 | √ | √ | √ | 0.7895 | 0.7088 | 0.4850 | ||
| M11 | √ | √ | √ | 0.7781 | 0.6887 | 0.5049 | ||
| M12 | √ | √ | √ | √ | 0.8404 | 0.7591 | 0.4251 | |
| M13 | √ | √ | √ | √ | 0.8378 | 0.7735 | 0.4353 | |
| M14 | √ | √ | √ | √ | 0.8294 | 0.7511 | 0.4537 | |
| M15 | √ | √ | √ | √ | 0.8373 | 0.7598 | 0.4497 | |
| M16 | √ | √ | √ | √ | 0.8538 | 0.7997 | 0.4146 | |
| M17 | √ | √ | √ | √ | √ | 0.8757 | 0.8579 | 0.4106 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, C.; Peng, Z.; Zou, W.; Chen, F.; Jiang, G.; Yu, M. No-Reference Quality Assessment for 3D Synthesized Images Based on Visual-Entropy-Guided Multi-Layer Features Analysis. Entropy 2021, 23, 770. https://0-doi-org.brum.beds.ac.uk/10.3390/e23060770
Jin C, Peng Z, Zou W, Chen F, Jiang G, Yu M. No-Reference Quality Assessment for 3D Synthesized Images Based on Visual-Entropy-Guided Multi-Layer Features Analysis. Entropy. 2021; 23(6):770. https://0-doi-org.brum.beds.ac.uk/10.3390/e23060770
Chicago/Turabian StyleJin, Chongchong, Zongju Peng, Wenhui Zou, Fen Chen, Gangyi Jiang, and Mei Yu. 2021. "No-Reference Quality Assessment for 3D Synthesized Images Based on Visual-Entropy-Guided Multi-Layer Features Analysis" Entropy 23, no. 6: 770. https://0-doi-org.brum.beds.ac.uk/10.3390/e23060770