
Wealth Rheology
by
 , , and
, , and
Zdzislaw Burda
1,† ,
,
Malgorzata J. Krawczyk
1,†,
Krzysztof Malarz
1,*,† and
and
Malgorzata Snarska
2,† 1
Faculty of Physics and Applied Computer Science, AGH University of Science and Technology, Mickiewicza 30, PL-30059 Kraków, Poland
2
Department of Financial Markets, Cracow University of Economics, Rakowicka 27, PL-31510 Kraków, Poland
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2021, 23(7), 842; https://0-doi-org.brum.beds.ac.uk/10.3390/e23070842
Submission received: 20 May 2021
/
Revised: 27 June 2021
/
Accepted: 28 June 2021
/
Published: 30 June 2021
(This article belongs to the Special Issue Entropy and Social Physics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We study wealth rank correlations in a simple model of macroeconomy. To quantify rank correlations between wealth rankings at different times, we use Kendall’s and Spearman’s , Goodman–Kruskal’s , and the lists’ overlap ratio. We show that the dynamics of wealth flow and the speed of reshuffling in the ranking list depend on parameters of the model controlling the wealth exchange rate and the wealth growth volatility. As an example of the rheology of wealth in real data, we analyze the lists of the richest people in Poland, Germany, the USA and the world.
1. Introduction
The problem of wealth inequality is the subject of intense research in economics [1,2,3,4,5], sociology and econophysics [6], but it also arouses great interest outside of science [7,8,9,10,11,12,13]. Parallel to empirical studies, theoretical research is carried out to explain the main features of wealth statistics and wealth dynamics observed in macroeconomic data, like the presence of Pareto tails in wealth distribution or increasing wealth inequality in the world.
In theoretical models, wealth dynamics is often described by stochastic equations representing the evolution of wealth of a typical individual in a given economic environment. In physical terminology, this can be called the one-body approach. Even today this approach is used in mainstream economics, for example, in studies of wealth inequality [14]. An alternative is to use population dynamics, which in this context is often referred to as agent-based modelling. It was introduced in [15] and popularised in [16]. In agent-based modelling, the economy is perceived as a complex system consisting of many entities interacting with each other under given macroeconomic conditions. Unlike the one-body approach, this can be called the multi-body approach. The main idea of agent-based modelling is to statistically look at the problem of wealth distribution from the perspective of the entire system. This allows studying collective effects, like correlations between agents, or emergent phenomena, such as the formation of wealth classes, or self-organisation of the economy, or instability of the system. This perspective is in many aspects similar to that used in statistical physics, aiming at deriving macroscopic physical laws from microscopic rules by applying laws of large numbers. This is probably why the problem of wealth distribution has been intensively studied in the econophysical literature [6]. Many ideas behind agent-based modelling have been derived from concepts like kinetic theory [17,18], scattering [19], rate equations [20], random matrix theory [21,22], Brownian motion [23] which were developed in statistical physics. Using this type of ideas, one was able to model wealth or income distributions [24], dynamics of wealth inequality [25,26], wealth concentration [27], structure emergence [28,29], economic instability and corruption mechanisms [30,31,32], systemic risk in economic networks [33], emergence of heavy tails in wealth and income distributions [24,34], and herding behaviour [35], or to analyse statistical behaviour or rational agents [36].
Since the time of Keynes, it has been widely believed that a closed economy eventually reaches a stationary state, also known as a steady state or saturation. What is usually meant as a stationary state economy is a system where macroeconomic quantities have stationary distributions. A typical example is the wealth distribution that does not change over time after reaching a steady state. This does not mean that each person’s wealth is constant in time, but that the system as a whole has a stationary distribution in a statistical sense. In fact, the wealth of individuals may change all the time even in the stationary state. Wealth flows from one individual to another: some people get richer, some poorer—panta rhei. In this article, we will take a closer look at the flow of wealth. We call this class of phenomena wealth rheology. To be specific, in the paper we study the dynamics of wealth rank correlations using the Bouchaud–Mézard model of macroeconomy [24]. The model is implemented as a stochastic process based on Gibrat’s law of proportionate growth [37] which is combined with dynamics representing agents’ interactions. The model generates Pareto’s tail in the wealth distribution [38]. The stochastic process belongs to the class of Kesten processes [39], which is a class of multiplicative contracting stochastic processes. It is a generic feature of Kesten processes that they lead to a stationary state with a power-law tail.
2. The Model
In this section, we briefly recall the Bouchaud–Mézard model [24]. The model describes evolution of wealth of N interacting agents in a closed macroeconomic system. The evolution is given by N stochastic differential equations for wealth of agents at time t. In the continuous time formalism the equations read
where , are independent Wiener processes (continuous Brownian motions). The above equations are written in the Itô formalism (in the Stratonovich approach the term would be replaced with ). In this paper, we shall use the discrete time formalism. Equation (1) can be discretised by introducing an elementary time interval relating physical time t to discrete time as follows . In the leading order, up to -terms, the discretisation of Equation (1) gives
where , and are independent identically distributed random variables with the normal distribution with and . In the limit , Equation (1) is restored. The first term on the right hand side of Equation (2) corresponds to random multiplicative fluctuations of wealth. In the economic literature, it is referred to as the law of proportionate effect [37] stating that growth rates are independent of wealth. In the simplest version of the model it is assumed that the growth rates have the same mean and the same variance for all agents throughout evolution of the system. The first term on the right hand side of Equation (2) reflects spontaneous changes in wealth due to changing market conditions and expectations. The second one describes the flow of wealth between individuals, resulting from interactions and trading. Coefficient is the fraction of wealth of agent a which is transferred to agent b within a single time interval . Equations (2) are invariant under rescaling of wealth by a common factor for all . In particular, this means that the equations do not change when the monetary units change. Therefore, it is convenient to express wealth in units of the mean wealth . We denote the corresponding quantities by small letters
The normalised wealth values (3) are insensitive to the parameter controlling the mean growth rate, because it cancels in the numerator and the denominator of Equation (3). The change can be interpreted as a change of the inflation rate by .
The model can be solved in the mean-field approximation assuming that all agents interact with each other with the same intensity for all pairs . For , in the limit and , the normalised wealth (3) can be shown to approach a stationary state with the distribution given by the inverse gamma distribution with the following probability density function [24]:
where the parameter is
One can easily check that the mean of this distribution is equal to one, that is in accordance with the normalisation (3). The distribution has a Pareto tail for with the exponent , given by Equation (5). The index depends on the ratio of the flow intensity parameter j and the volatility of growth rates , so the stationary distribution does not change when and j are simultaneously re-scaled by the same factor and . The parameters and j can be interpreted as economic activity parameters. The flow parameter j reflects the intensity of trade and wealth exchange. The parameter is the growth rate volatility and it reflects the degree of economic freedom: the larger the more liberal economy. Large values of mean that the state does not intervene and does not help if economic entities need support. On the contrary it supports and encourages a free market, new ideas, bold businesses and the foundation of start-ups, etc. In effect, some companies may quickly grow, while some large established companies can shrink or go bankrupt quickly. For a large , large changes in the wealth of individuals are expected. In such circumstances, the economic landscape is changing rapidly. On the other hand, small values of mean that the economy is very conservative, that is, the system discourages risky investments and the state intervenes when established companies need help, the system supports economic status quo and the economy is more predictable in the short term.
The aim of this paper is to compare the wealth dynamics in steady state for systems having the same stationary distribution (4), but different economic activity parameters and j. To get an insight into wealth flow dynamics in the steady state, we study temporal evolution of wealth rank correlations and quantify them by measuring Kendall’s [40] and Spearman’s [41] for wealth distributions separated by k steps of evolution (2). Standard definitions of rank correlations are recalled in Appendix A.
3. Monte Carlo Simulations
We perform Monte Carlo simulations to generate evolution of the system. In practice we find it more convenient to use a slightly modified version of the evolution Equation (2), where a single step of evolution is split into two
with some intermediate values . The first equation in (6) corresponds to Gibrat’s rule of proportionate growth, while the second one to wealth’s flow which preserves the total wealth in the system . One can easily show that the two representations of the evolution (2), (6) are identical up to -order so they have the same continuous time limit (1) for . Here, for the sake of simplicity, we focus on the mean field system where each agent interacts with all the others with the same intensity . In this case, Equation (6) simplify to
The flow rate j can be interpreted as the average fraction of wealth that can flow from an agent to others over a period of time .
We simulated systems up to agents, but the results presented in this paper are for . We used two types of initial configurations:
- a complete equality configuration where for all ;
- an equilibrium configuration, where are drawn independently of each other from the inverse gamma distribution (4).
We call them ‘cold’ and ‘hot’ starts, respectively.
4. Results
In Figure 1a, we compare a theoretical prediction for the Gini coefficient with the values obtained in Monte Carlo simulations of the system with and . The theoretical prediction for the distribution (4) reads [26]
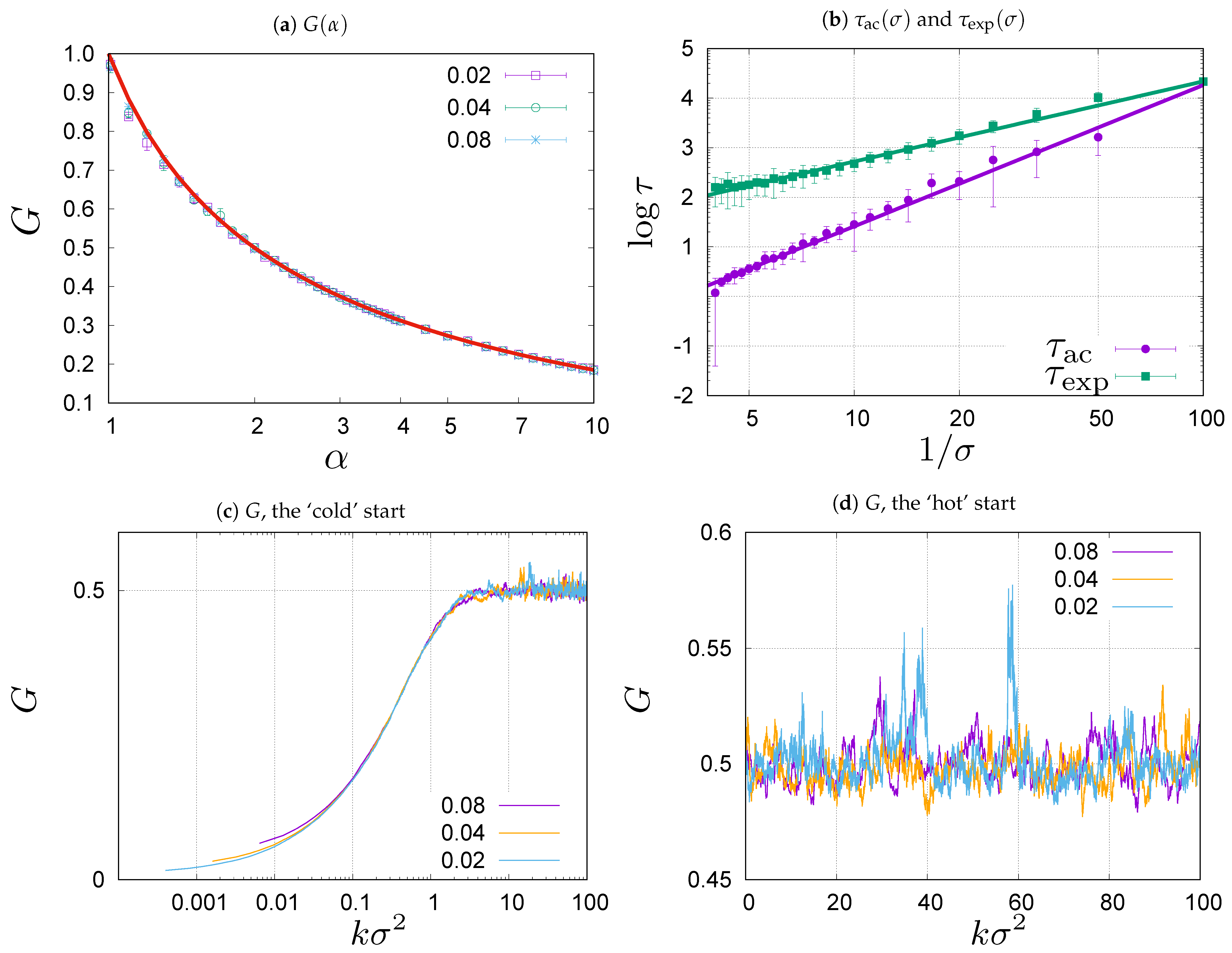
where is the hypergeometric function [42]. One can see in Figure 1a that the experimental and theoretical values are consistent. This means that the evolution Equation (7) bring the system to the predicted steady state. In fact, there are some slight deviations from the theoretical prediction which can be attributed to the fact that the theoretical results are derived in the continuous time formalism, while the Monte Carlo simulations are done for discrete time. The deviations grow with the volatility .
The main conclusion from the comparison shown in Figure 1a is that the stationary state in the first-order approximation depends on the combination and not on itself, exactly as predicted by the theoretical Formula (8). Let us now address the question how the dynamic properties of evolution depend on . First, we will study the rate of relaxation towards the steady state by measuring the exponential auto-correlation time [43] for the Gini coefficient. Roughly speaking the exponential time corresponds to the time needed for the system to reach the stationary state. To measure we initiate the system from a uniform wealth distribution (cold start), for which the Gini coefficient is , and wait till the Gini coefficient of the current configuration exceeds the steady state value for the first time. In Figure 1b we show the mean exponential auto-correlation time as a function of for and averaged over a sample of 100 values obtained from independent simulations. We see that grows as decreases. This effect is clearly seen in Figure 1c which shows examples of the evolution of the Gini coefficient for , from cold starts for , and . In all three cases the Gini coefficient evolves from the initial value towards the stationary state value (5) which is equal to for . The values of G during the evolution are plotted against in Figure 1c. The variable on the horizontal axis is proportional to physical time , for given in Equation (1), because . The curves in Figure 1c correspond to different time intervals used in the discretization of Equation (1). The small variations between the curves, seen in Figure 1c for small , can be attributed to the higher-order corrections in that occur in the discretization of Equation (1), skipped in Equation (2). Generally, we can expect that in the presented range of the evolution is universally described by the parameter , that we shall use from here on.
Once the stationary state is reached, the value of the Gini coefficient fluctuates about the steady state value. This is illustrated in Figure 1d where we show evolution of the Gini coefficient in systems initiated from hot starts, that correspond to the stationary wealth distribution given by Equation (4). The Gini coefficient fluctuates about the stationary value but the way it fluctuates about this value slightly depends on the volatility . The reason for this is related to the presence of a heavy tail in the limiting distribution (4), which for , leads to an infinite variance. In effect, the curves representing the evolution in Figure 1d exhibit strong fluctuations which depart from mean value. For the simulations shown in the figure, the length of evolution measured in the discrete time steps, k, is sixteen and four times longer for and , respectively, than for . Therefore, we observe more fluctuations and larger deviations for and than for . To quantify the degree of correlation between the values of the Gini coefficient at different times, we measure the integrated auto-correlation time [43] which gives a typical timescale for the length of temporal fluctuations. Coming back to Figure 1b we show there the dependence of the integrated auto-correlation time on for the system with and . It can be compared in the figure to the relaxation time that we previously discussed. As you can see, both and grow when decreases. The straight lines in Figure 1b are to guide the eye. They are determined as the best power-law fits: , where and , where .
As mentioned in the introduction, we are mainly interested in the dynamic aspects of the evolution of wealth distribution, such as wealth flow and wealth ranking reshuffling. We are now going to analyse the wealth rank correlations for different systems having the same stationary state, by studying systems with different ’s and j’s but identical ’s (5).
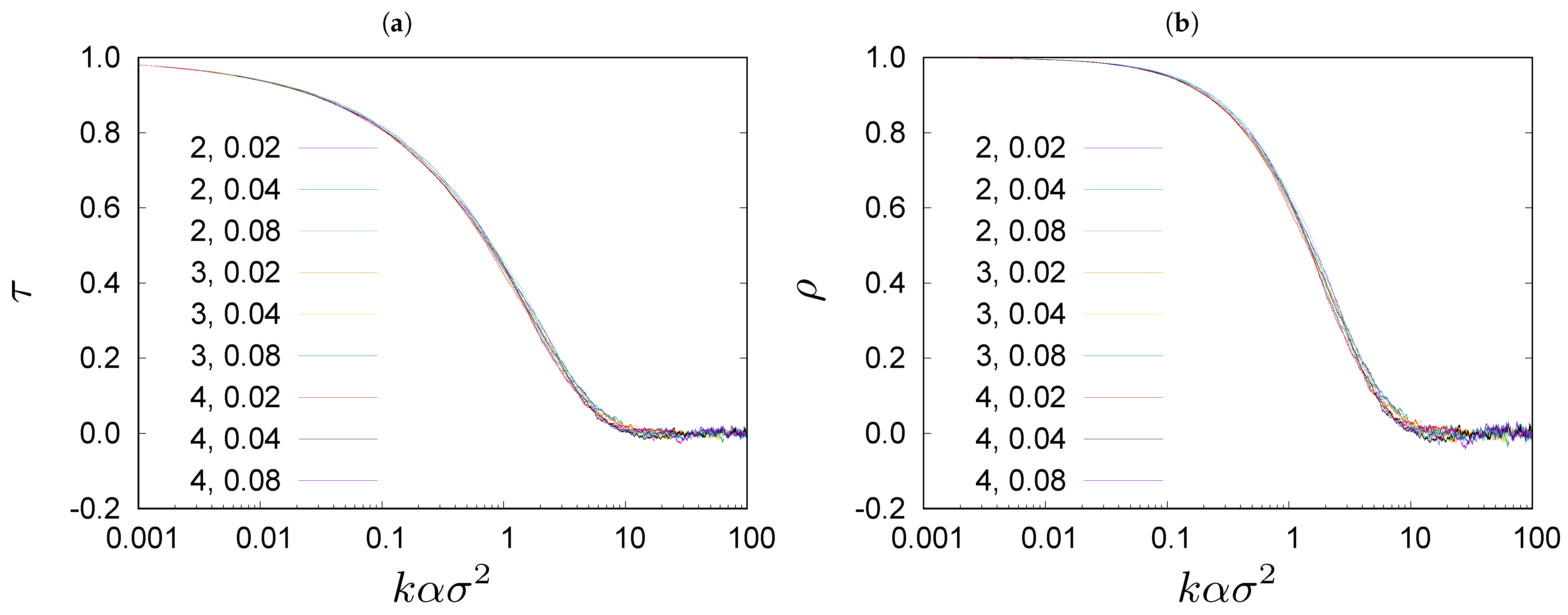
Wealth rank is a position on the ranking list ordered from the richest to the poorest individuals. The wealth ranking is continuously reshuffling, even in the stationary state. The rate of reshuffling depends on and j: the larger and j the faster is the reshuffling. Changes in wealth ranking are faster when is larger. In Figure 2, we show rank correlations between wealth ranking lists obtained in the Monte Carlo simulations of the Bouchaud–Mézard model [24], for configurations separated by k steps of evolution (7), in the stationary state of the system with , and , and , and , and . The degree of rank correlations is quantified by Kendall’s [40] and Spearman’s [41] (see Appendix A). In Figure 2, we plot and against a rescaled variable . We can see that the curves lie on top of each other, reflecting some universality of the wealth rheology in the model (1).
Another quantity which captures rank correlations is the overlap ratio which is defined as the percentage of people which are among n richest people at times and . For example, you may be interested in how many people from the top 100 richest list in some year, are in the top 100 richest list one or two years later. If denotes the set of people being in the top-n richest list in the ranking at time and at time , the overlap ratio is:
where the symbol ∩ denotes sets’ intersection, and # is the set’s cardinality. If the dynamics describing the wealth evolution is Markovian, then the overlap ratio depends on the time difference . In such a case, the overlap ratio can be estimated numerically as follows
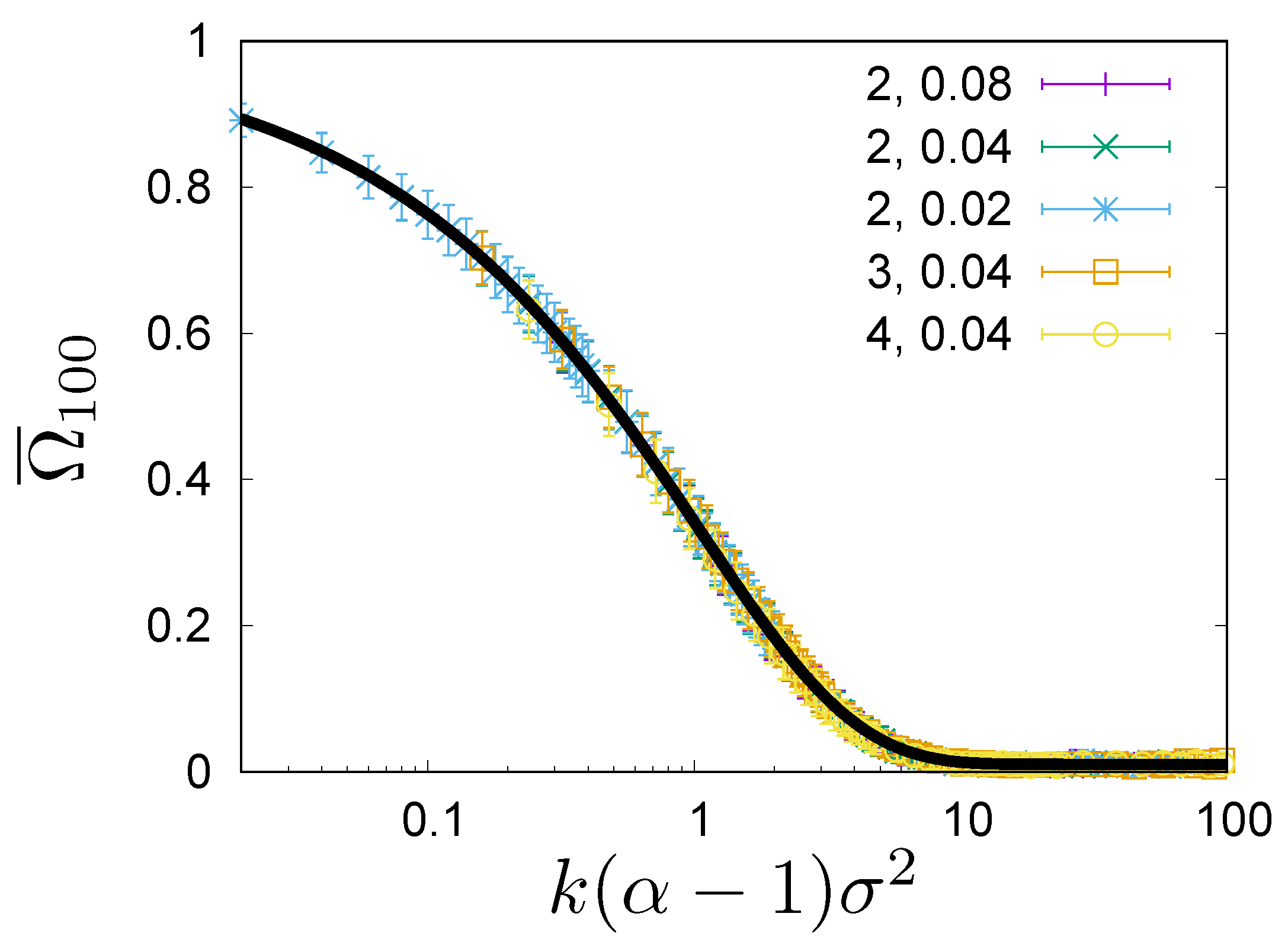
where k is the discrete time, which refers to consecutive configurations (rankings), and K is the number of configurations in the sample. In Figure 3, we show the expected overlap for the top 100 richest list, estimated from the steady state configurations in Monte Carlo simulations for three values of (4) and for three values of , for . We see that all curves collapse to a single universal curve. By listing explicitly all arguments of the overlap ratio , we see that the overlap ratio becomes a universal function of the argument :
The function interpolates monotonically between for and for . A simple phenomenological formula
gives a very good fit to the data (see Figure 3). Notice that the scaling variable is not the same as the scaling variable for and .
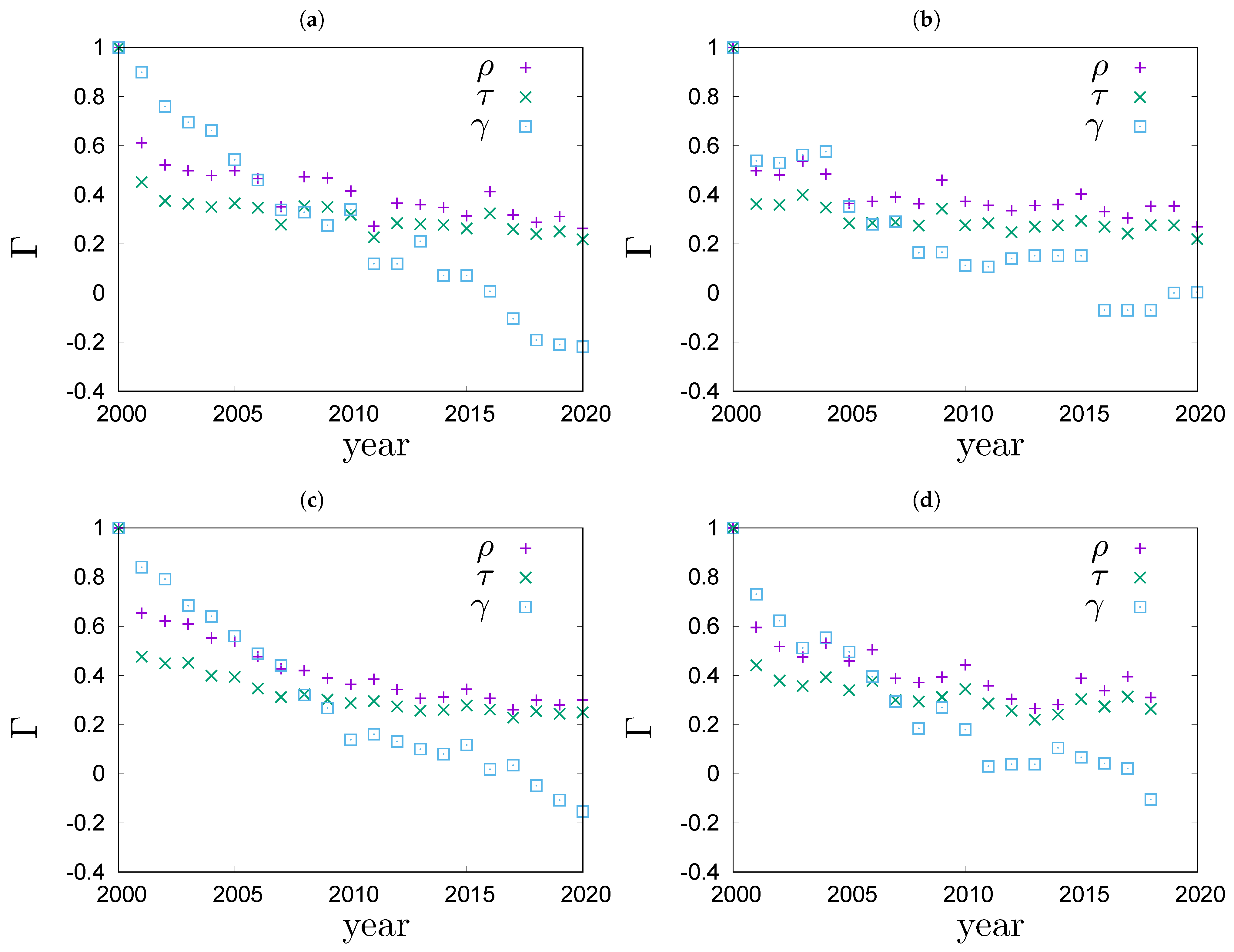
In the remainder of this section, we will investigate the rheology of wealth in real world systems. People’s wealth data are very sensitive, so it is almost impossible to collect them. Therefore we restrict ourselves to data on the richest people that is publicly available. To be specific, we focus on the top 100 lists of richest people in Poland, Germany, the USA and the world [11,12,13]. The top 100 richest lists are a small part of the whole picture but it is the part that usually gets the most attention. Data that we analyse covers the period 2000–2020 for Poland [11], Germany [12] and the USA [13], and the period 2000–2018 for the world [13]. We are going to determine the rank correlation coefficients (A2), (A4), and (A5) between the top 100 richest lists in years 2000 and . The sets of people present in the top 100 richest lists vary from year to year: there are people who are in the top 100 richest list in some years but not in others. To compare the lists we must first standardize them so that they include the same set of people every year. To do so, we determine a full set of people who have been present on the top 100 list at least once in the studied period. The full set is then used to complete the annual top 100 lists in the following way: if a person from the full set is not in the top 100 richest list for a given year, s/he is added to this list with a unique random rank in the range between 101 and the number of people in the full set. In the analysed period, the full sets contain 360 people in Poland, 342 in Germany, 319 in the USA and 323 in the world. For each system, all standardized lists are of the same size and contain the same people every year. The standardized lists are used as input to calculations of and . The results are shown in Figure 4. In the figure you can also see the results for Goodman–Kruskal’s (A5) computations. To compute we used a slightly different algorithm to complement the annual lists. The algorithm assigns the same ex aequo rank to all people added as a complement, to the list. By design, the coefficient omits ex aequo ranks, thus minimizing the statistical bias coming from the artificial completion of lists. Analysing the plots in Figure 4 we see for example, that the values of drop between and much less than the corresponding values of and . The big drop of and is related to the large number of additional rank pairs, created by the complement algorithm. The number of pairs is less in the complement algorithm for . When the sets of elements vary from year to year, the Goodman–Kruskal’s coefficient better captures rank correlations of the original ranking lists. Therefore, we find it more reliable to use to compare rank correlations for lists of different lengths.
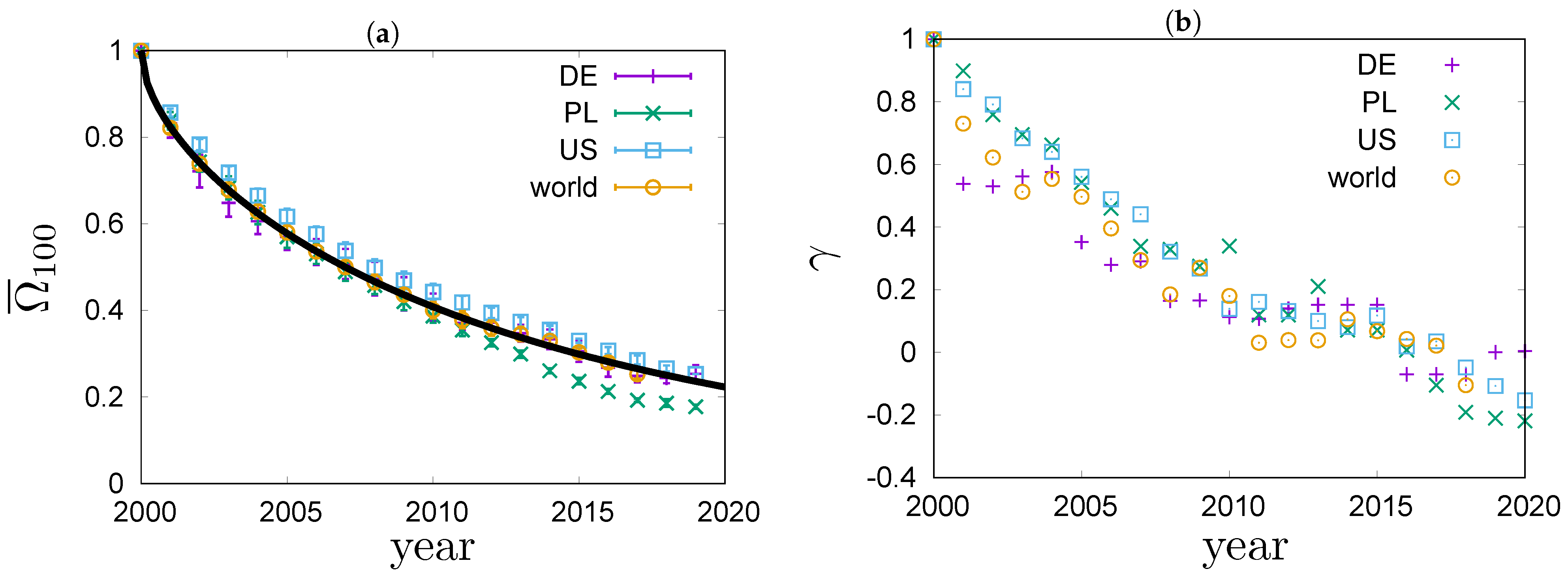
In Figure 5a, values of the overlap ratio of the annual top 100 richest lists in Poland, Germany, the US and the world are compared. The overlap ratios exhibit a fairly universal behaviour that is well described by the phenomenological Formula (12). The best fit to the top 100 richest people in the world is shown with a solid line in Figure 5a. It fits the data very well. We can see that in the four systems the overlap ratio drops to after years. In Figure 5b, values of the Goodman–Kruskal’s rank correlation coefficient for the four systems are compared. We can see that the rank correlations fall off from one to zero roughly within 20 years. The rate of decay for is quite similar in all the studied systems. For Germany, the dependence of on time exhibits an interesting pattern. The values of stay roughly constant for a couple of years, then significantly drop and again stay roughly constant for a couple of years. This motif repeats a couple of times, forming a stairway shape.
5. Conclusions
Steady-state macroeconomic systems are characterized by no statistical changes in the distribution of wealth and macroeconomic parameters. This does not mean that there are no changes in the system. On the contrary, in the microscale the system undergoes continuous dynamical changes. As far as the wealth distribution is concerned, the internal dynamics can be observed as a continuous process which manifests as reshuffling of wealth ranks of people on the wealth ranking lists: some people get richer, some get poorer. In this paper, we have studied the dynamical properties of macroeconomic systems related to the flow of wealth, and wealth rheology. We used the Bouchaud–Mézard model and the agent-based modelling approach to simulate the evolution of wealth in a closed macroeconomy. An interesting property of the Bouchaud–Mézard model is that it generates steady states with a Pareto tail in the wealth distribution, and that different combinations of economic activity parameters may lead to the same limiting wealth distribution. This allowed us to investigate the dependence of wealth rank correlations on the wealth activity parameters for various scenarios but the same wealth distribution. We have seen that the wealth rank correlations depend mainly on the growth rate volatility. The smaller the volatility, the larger the correlations. The rank correlations are closely related to auto-correlations in the system. We have also studied rank correlations on the top 100 richest lists in Poland, Germany, the US and the world using the Goodman–Kruskal’s and the lists overlap ratio . We have observed that the rank correlations in the studied systems exhibit a certain degree of universality, for example, the overlap ratio gets reduced by half within and the Goodman–Kruskal’s decreases to zero within two decades. We have focused on the top 100 richest lists because they are easily available. It would be interesting to perform a similar analysis for top-n lists for larger n and for longer periods, years, in the future to get a full picture on wealth rank dynamics.
There are also some theoretical questions—regarding the scaling and universality of results—that are extremely interesting. We have seen that the correlation coefficients and depend on a universal variable while the overlap ratio on . The question is if this scaling is the general feature of the Kesten processes? To solve this problem we have considered an alternative implementation of Kesten dynamics, where the wealth of agents is generated as exponents of independent random walks , on the positive semi-axis with the drift towards the reflective wall located at . Such a stochastic process is probably the simplest implementation of the Kesten process. It leads to a stationary state with a power law in the probability density function of wealth distribution for , with the exponent , where are the drift and the volatility of the underlying random walk. The rank statistics of W’s and x’s are the same because the map is monotonic. The Kesten dynamics is thus mapped onto the dynamics of a gas of particles performing independent random walks on the positive semiaxis. The gas of particles is much easier to analyse. For instance, one can give a simple argument that the overlap ratio for this system depends on the combination , so the scaling is different than for the model discussed in this paper. Thus, the scaling is not universal. It would be interesting to find an analytical way to calculate the rank correlation measures in the models discussed in this paper. For the gas of random walkers on the positive semi-axis one can maybe use the spectral methods [44].
Author Contributions
Conceptualization, Z.B.; Data curation, M.J.K., K.M. and M.S.; Formal analysis, K.M.; Investigation, K.M. and M.S.; Methodology, Z.B.; Resources, K.M. and M.S.; Software, M.J.K.; Visualization, K.M.; Writing—original draft, Z.B.; Writing—review & editing, Z.B., M.J.K., K.M. and M.S. All authors have read and agreed to the published version of the manuscript.
Funding
MS has been partially supported by the Ministry of Education and Science within the “Regional Initiative of Excellence” Program for 2019–2022.
Data Availability Statement
Acknowledgments
We thank the anonymous reviewer who drew our attention to the scaling of dynamics in the model.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Rank Correlations
Consider a set of N elements, each being characterised by two real quantities , , . For example, one can think of the weight and height of pupils in a class. The elements (pupils) can be ranked with respect to the property X (weight) and Y (height). For sake of simplicity assume that all values , are distinct, so that the elements can be unambiguously ranked with respect to X, and assume that the same holds for Y. Denote the corresponding ranks by ’s and ’s. To quantify correlations between the ranks one can introduce a rank score function f to define a rank correlation coefficient associated with this score function
The score function is a monotonic odd function . The standard choices of the rank score function are the sign function or the identity function . In the former case the corresponding rank correlation coefficient is usually called Kendall’s . It is calculated as follows:
where and are the numbers of concordant and discordant pairs. A pair is concordant if the elements i and j are ranked in the same order for X and Y. Otherwise, the pair is discordant. For the identity function the rank correlation coefficient is usually called Spearman’s
Using elementary algebraic operations one can find that
This formula is particularly useful in practice since instead of a double sum it involves only a single sum. The computational complexity to determine increases linearly with N in contrast to the complexity to compute (A2) which increases quadratically with N.
We conclude this appendix by mentioning that there are rank correlation measures that apply also for the case when there are ex aequo ranks in the sample. In the example given above, you can think of two or more pupils having the same weight or height within a given accuracy. In this case, one can replace Kendall’s by Goodman–Kruskal’s [45]
Clearly, if there are no ex aequo ranks in the sample then is equivalent to (A2).
References
- Davis, J.B.; Shorrocks, A.E. The distribution of wealth. In Handbook of Income Distribution; Atkinson, A.B., Bourguignon, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Benhabib, J.; Bisin, A. Skewed Wealth Distributions: Theory and Empirics; Working Paper 21924; National Bureau of Economic Research: Cambridge, MA, USA, 2016. [Google Scholar]
- Nardi, M.D. Models of Wealth Inequality: A Survey. Available online: http://www.nber.org/papers/w21106 (accessed on 26 February 2021).
- Berman, Y.; Peters, O.; Adamou, A. Far from equilibrium: Wealth reallocation in the United States. arXiv 2016, arXiv:1605.05631. [Google Scholar]
- Berman, Y.; Ben-Jacob, E.; Shapira, Y. The dynamics of wealth inequality and the effect of income distribution. PLoS ONE 2016, 11, e0154196. [Google Scholar] [CrossRef]
- Chakrabarti, B.K.; Chakraborti, A.; Chakravarty, S.R.; Chatterjee, A. Income and wealth distribution data for different countries. In Econophysics of Income and Wealth Distributions; Cambridge University Press: Cambridge, MA, USA, 2013; pp. 7–34. [Google Scholar]
- Hardoon, D. An Economy for the 99%. Available online: https://www.oxfam.org/en/research/economy-99 (accessed on 26 February 2021).
- World Inequality Report 2018. Available online: https://wir2018.wid.world/ (accessed on 26 February 2021).
- Piketty, T. Capital in the Twenty-First Century; Harvard University Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Piketty, T. About ‘Capital in the Twenty-First Century’. Am. Econ. Rev. 2015, 105, 48–53. [Google Scholar] [CrossRef] [Green Version]
- Wprost. Top 100 Richest People in Poland. Available online: https://rankingi.wprost.pl/100-najbogatszych-polakow/2020 (accessed on 23 February 2021).
- Manager Magazin (Spiegel Group). Die 500 Reichsten Deutschen. Available online: https://www.manager-magazin.de (accessed on 20 April 2021).
- Forbes. The Richest People in the World. Available online: https://www.forbes.com/billionaires/ (accessed on 20 April 2021).
- Piketty, T.; Saez, E. A Theory of Optimal Capital Taxation; Working Paper 17989; National Bureau of Economic Research: Cambridge, MA, USA, 2012. [Google Scholar]
- Angle, J. The surplus theory of social stratification and the size distribution of personal wealth. Soc. Forces 1986, 65, 293–326. [Google Scholar] [CrossRef]
- Samanidou, E.; Zschischang, E.; Stauffer, D.; Lux, T. Agent-based models of financial markets. Rep. Prog. Phys. 2007, 70, 409–450. [Google Scholar] [CrossRef] [Green Version]
- Dragulescu, A.; Yakovenko, V.M. Statistical mechanics of money. Eur. Phys. J. B Condens. Matter Complex Syst. 2000, 17, 723–729. [Google Scholar] [CrossRef] [Green Version]
- Yakovenko, V.M.; Rosser, J.B. Colloquium: Statistical mechanics of money, wealth, and income. Rev. Mod. Phys. 2009, 81, 1703–1725. [Google Scholar] [CrossRef] [Green Version]
- Slanina, F. Inelastically scattering particles and wealth distribution in an open economy. Phys. Rev. E 2004, 69, 046102. [Google Scholar] [CrossRef] [Green Version]
- Ispolatov, S.; Krapivsky, P.; Redner, S. Wealth distributions in asset exchange models. Eur. Phys. J. B Condens. Matter Complex Syst. 1998, 2, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Burda, Z.; Jurkiewicz, J.; Nowak, M.A. Is econophysics a solid science? Acta Phys. Pol. B 2003, 34, 87–131. [Google Scholar]
- Bouchaud, J.P.; Potters, M. Financial applications of random matrix theory: A short review. In The Oxford Handbook of Random Matrix Theory; Akemann, G., Baik, J., Di Francesco, P., Eds.; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry, 3rd ed.; Elsevier: Amsterdam, The Netherland, 2007. [Google Scholar]
- Bouchaud, J.P.; Mézard, M. Wealth condensation in a simple model of economy. Phys. A Stat. Mech. Its Appl. 2000, 282, 536–545. [Google Scholar] [CrossRef] [Green Version]
- Adamou, A.; Peters, O. Dynamics of inequality. Significance 2016, 13, 32–35. [Google Scholar] [CrossRef]
- Burda, Z.; Wojcieszak, P.; Zuchniak, K. Dynamics of wealth inequality. Comptes Rendus Phys. 2019, 20, 349–363. [Google Scholar] [CrossRef]
- Cieśla, M.; Snarska, M. A simple mechanism causing wealth concentration. Entropy 2020, 22, 1148. [Google Scholar] [CrossRef] [PubMed]
- Waśko, M.; Kułakowski, K. Efficiency of pair formation in a model society. Acta Phys. Pol. B 2006, 37, 3171–3176. [Google Scholar]
- Karpińska, J.; Malarz, K.; Kułakowski, K. How pairs of partners emerge in an initially fully connected society. Int. J. Mod. Phys. C 2004, 15, 1227–1233. [Google Scholar] [CrossRef] [Green Version]
- Burda, Z.; Johnston, D.; Jurkiewicz, J.; Kamiński, M.; Nowak, M.A.; Papp, G.; Zahed, I. Wealth condensation in Pareto macroeconomies. Phys. Rev. E 2002, 65, 026102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ball, P. Wealth spawns corruption. Physicists are explaining how politics can create the super-rich. Nature 2002. [Google Scholar] [CrossRef]
- Malarz, K.; Kułakowski, K. Game of collusions. Phys. A Stat. Mech. Its Appl. 2016, 457, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Diem, C.; Pichler, A.; Thurner, S. What is the minimal systemic risk in financial exposure networks? J. Econ. Dyn. Control 2020, 116, 103900. [Google Scholar] [CrossRef]
- Levy, M.; Solomon, S. Power laws are logarithmic Boltzmann laws. Int. J. Mod. Phys. C 1996, 7, 595–601. [Google Scholar] [CrossRef] [Green Version]
- Cont, R.; Bouchaud, J.P. Herd behavior and aggregate fluctuations in financial markets. Macroecon. Dyn. 2000, 4, 170–196. [Google Scholar] [CrossRef] [Green Version]
- Venkatasubramanian, V.; Luo, Y.; Sethuraman, J. How much inequality in income is fair? A microeconomic game theoretic perspective. Phys. A Stat. Mech. Its Appl. 2015, 435, 120–138. [Google Scholar] [CrossRef] [Green Version]
- Gibrat, R. Les Inégalités Économiques; Recueil Sirey: Paris, France, 1931. [Google Scholar]
- Pareto, V. Cours d’Économie Politique; F. Rouge: Lausanne, Switzerland, 1897; Volume II. [Google Scholar]
- Kesten, H. Random difference equations and Renewal theory for products of random matrices. Acta Math. 1973, 131, 207–248. [Google Scholar] [CrossRef]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Arfken, G.B.; Weber, H.J.; Harris, F.E. Mathematical Methods for Physicists, 7th ed.; Academic Press: Boston, MA, USA, 2013; pp. 871–933. [Google Scholar]
- Madras, N.; Sokal, A.D. The pivot algorithm: A highly efficient Monte Carlo method for the self-avoiding walk. J. Stat. Phys. 1988, 50, 109–186. [Google Scholar] [CrossRef]
- Karlin, S.; McGregor, J. Random walks. Ill. J. Math. 1959, 3, 66–81. [Google Scholar] [CrossRef]
- Goodman, L.A.; Kruskal, W.H. Measures of association for cross classifications. J. Am. Stat. Assoc. 1954, 49, 732–764. [Google Scholar] [CrossRef]
Figure 1.
(a) Gini coefficient G (8) plotted as a function of (solid line) and computed numerically from samples generated in Monte Carlo simulations for (symbols). Different symbols correspond to , and . (b) The auto-correlation time (1) and the exponential time (2) for the Gini coefficient G measured for consecutive configurations in the stationary state for for different . When decreases grows as with , and grows as with . (c) Evolution of the Gini coefficient G from the ‘cold’ start, , towards the stationary state’s value for . The plots correspond to , and . Please note logarithmic scale on the time axis. (d) Evolution of the Gini coefficient G from the ‘hot’ start. The values fluctuate about the stationary state value for . The plots correspond to , and .
Figure 1.
(a) Gini coefficient G (8) plotted as a function of (solid line) and computed numerically from samples generated in Monte Carlo simulations for (symbols). Different symbols correspond to , and . (b) The auto-correlation time (1) and the exponential time (2) for the Gini coefficient G measured for consecutive configurations in the stationary state for for different . When decreases grows as with , and grows as with . (c) Evolution of the Gini coefficient G from the ‘cold’ start, , towards the stationary state’s value for . The plots correspond to , and . Please note logarithmic scale on the time axis. (d) Evolution of the Gini coefficient G from the ‘hot’ start. The values fluctuate about the stationary state value for . The plots correspond to , and .

Figure 2.
Rank correlations coefficients (a) and (b) for steady state configurations separated by k time steps in the simulated systems for and for various values of , 3, 4 and for various values of , and . Please note logarithmic scale on the time axis. The first parameter in the legend is the value of and the second is the value of .
Figure 2.
Rank correlations coefficients (a) and (b) for steady state configurations separated by k time steps in the simulated systems for and for various values of , 3, 4 and for various values of , and . Please note logarithmic scale on the time axis. The first parameter in the legend is the value of and the second is the value of .

Figure 3.
Dependence of the overlap of top 100 lists at times and on the separation time . The overlap is measured as the percentage of people that are on both the lists. The data points are obtained by averaging over pairs of , such that . They are plotted against the universal argument . The data is obtained by simulations of the model for , and for different combinations of , 3, 4 and , , . The first parameter in the legend is the value of and the second is the value of . The data is fitted with the Formula (12) with and . The fit is shown with a solid line.
Figure 3.
Dependence of the overlap of top 100 lists at times and on the separation time . The overlap is measured as the percentage of people that are on both the lists. The data points are obtained by averaging over pairs of , such that . They are plotted against the universal argument . The data is obtained by simulations of the model for , and for different combinations of , 3, 4 and , , . The first parameter in the legend is the value of and the second is the value of . The data is fitted with the Formula (12) with and . The fit is shown with a solid line.

Figure 4.
Time evolution of various rank correlations for top 100 richest people in (a) Poland, data from [11], (b) Germany, data from [12], (c) the USA, data from [13] and (d) the world, data from [13].

Figure 5.
Rank coefficients for the richest people in Germany, Poland, the US and the world based on real-world data published in Refs. [11,12,13]. (a) Overlap ratios for the four systems. The best fit of the Formula (12), with and , to the world data is shown with a solid line. (b) Goodman–Kruskal’s coefficients for the four system.
Figure 5.
Rank coefficients for the richest people in Germany, Poland, the US and the world based on real-world data published in Refs. [11,12,13]. (a) Overlap ratios for the four systems. The best fit of the Formula (12), with and , to the world data is shown with a solid line. (b) Goodman–Kruskal’s coefficients for the four system.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Burda, Z.; Krawczyk, M.J.; Malarz, K.; Snarska, M. Wealth Rheology. Entropy 2021, 23, 842. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070842
AMA Style
Burda Z, Krawczyk MJ, Malarz K, Snarska M. Wealth Rheology. Entropy. 2021; 23(7):842. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070842
Chicago/Turabian StyleBurda, Zdzislaw, Malgorzata J. Krawczyk, Krzysztof Malarz, and Malgorzata Snarska. 2021. "Wealth Rheology" Entropy 23, no. 7: 842. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070842
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.