
On Supervised Classification of Feature Vectors with Independent and Non-Identically Distributed Elements


Electrical and Computer Systems Engineering, Monash University, Alliance Ln, Clayton, VIC 3168, Australia
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(8), 1045; https://0-doi-org.brum.beds.ac.uk/10.3390/e23081045
Submission received: 26 July 2021
/
Revised: 6 August 2021
/
Accepted: 10 August 2021
/
Published: 13 August 2021
(This article belongs to the Special Issue Information Theory and Machine Learning)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we investigate the problem of classifying feature vectors with mutually independent but non-identically distributed elements that take values from a finite alphabet set. First, we show the importance of this problem. Next, we propose a classifier and derive an analytical upper bound on its error probability. We show that the error probability moves to zero as the length of the feature vectors grows, even when there is only one training feature vector per label available. Thereby, we show that for this important problem at least one asymptotically optimal classifier exists. Finally, we provide numerical examples where we show that the performance of the proposed classifier outperforms conventional classification algorithms when the number of training data is small and the length of the feature vectors is sufficiently high.
1. Introduction
1.1. Background
Supervised classification is a machine learning technique that maps an input feature vector to an output label based on a set of correctly labeled training data. There is no single learning algorithm that works best on all supervised learning problems, as shown by the no free lunch theorem in [1]. As a result, there are many algorithms proposed in the literature whose performance depends on the underlying problem and the amount of training data available. The most widely used algorithms in the literature are decision trees [2,3], Support Vector Machines (SVM) [4,5], Rule-Based Systems [6], naive Bayes classifiers [7], k-nearest neighbors (KNN) [8], logistic regressions, and neural networks [9,10].
1.2. Motivation
In the following, we discuss the motivation for this work.
1.2.1. Lack of Tight Upper Bounds on the Performance of Classifiers
In general, there are no tight upper bounds on the performance of the classifiers used in practice. Many of the previous works only provide experimental performance results. However, this approach has drawbacks. For example, one has to rely on the trial-and-error approach in order to develop a good classifier for a given problem, which impacts the reliability. Next, the algorithms whose performance has been verified only experimentally may work for a given problem, but may fail to work when applied to a similar problem. Finally, experimental results do not provide intuition into the underlying problem, whereas the analytical results provide the understanding of the underlying problem and the corresponding solutions.
Motivated by this, in the paper, we aim to investigate classifiers with analytical upper bounds on their performance.
1.2.2. Independent and Non-Identically Distributed Features
In general, we can categorize the statistical properties of the feature vectors, which are the input to the classifier, into three types. To this end, let denote the input feature vector to the supervised classifier, where n is the length of the feature vector and X is the label to which the feature vector belongs. Then, we can distinguish the following three types of feature vectors depending on the statistics of the elements in the feature vector .
The first type of feature vector is when the elements of are independent and identically distributed (i.i.d.). This is the simplest features model, but also the least applicable in practice. This model is identical to hypothesis testing, which has been well investigated in the literature [11,12,13]. As a result, tight upper bounds on the performance of supervised learning algorithms for this type of feature vector are available in the hypothesis testing literature. For instance, the authors in [11] showed that the posterior entropy and the maximum a posterior error probability decay to zero with the length of the feature vector at the identical exponential rate, where the maximum achievable exponent is the minimum Chernoff information. In [12], the authors determine the requirements for the length of the vector and the number of labels m in order to achieve vanishing exponential error probability in testing m hypothesis that minimizes the rejection zone. In [13], the authors provide an upper bound and a lower-bound on the error probability of Bayesian m-ary hypothesis testing in terms of conditional entropy.
The second type of feature vectors is when the elements of are mutually dependent and non-identically distributed (d.non-i.d.). This type of features model is the most general model and the most applicable in practice. However, it is also the most difficult to tackle analytically. As a result, supervised learning algorithms proposed for this features model lack analytical tight upper bounds on their performance [14,15,16,17,18,19,20,21,22,23]. This is because there are not any frameworks that produce closed-form results when deriving statistics of vectors with d.non-i.d. elements when the underlying distributions are unknown. Then how can we investigate analytically classifiers for practical scenarios when the feature vectors have d.non-i.d. elements? A possible approach leads us to the third type of feature vectors, explained in the following.
The third type of feature vectors is when the elements of are mutually independent but non-identically distributed (i.non-i.d.). This features model is much simpler than the d.non-i.d. features model and, more importantly, it is analytically tractable, as we show in this paper. Furthermore, this features model is applicable in practice. Specifically, there exists a class of algorithms, known as Independent Component Analysis (ICA), that transform vectors with d.non-i.d. elements into vectors with i.non-i.d. elements with a zero or a negligible loss of information [24,25,26,27,28]. The origins of ICA can be traced back to Barlow [29], who argued that a good representation of binary data can be achieved by an invertible transformation that transform vectors with d.non-i.d. elements into vectors with i.non-i.d. elements. Finding such a transformation with no prior information about the distribution of the data has been considered an open problem until recently [28]. Specifically, the authors in [28] show that this hard problem can be accurately solved with a branch and bound search tree algorithm, or tightly approximated with a series of linear problems. Thereby, the authors in [28] provide the first efficient set of solutions to Barlow’s problem. So far, the complexity of the fastest such algorithm is [28]. Nevertheless, since there exist such invertible transformations (i.e., no loss of information) which can transform vectors with d.non-i.d. elements into vectors with i.non-i.d. elements, we can tackle the features model comprised of d.non-i.d. elements by first transforming it (without loss of information) into the features model comprised of i.non-i.d. elements and then tackling the i.non-i.d. features model.
Motivated by this, in this paper, we investigate supervised classification of feature vectors with i.non-i.d. elements.
1.2.3. Small Training Set
The main factor that impacts the accuracy of supervised classification is the amount of training data. In fact, most supervised algorithms are able to learn only if there is a very large set of training data available [30]. The main reason for this is the curse of dimensionality [31,32], which states that “the higher the dimensionality of the feature vectors, the more training data are needed for the supervised classifier” [33]. For example, supervised classification methods such as random forest [34,35] and KNN [36] suffer from the curse of dimensionality. However, having large training data sets is not always possible in practice. As a result, designing a supervised classification algorithm that exhibits good performance even when the training data set is extremely small is important.
Motivated by this, in this paper, we investigate supervised classifiers for the case when t training feature vectors per label are available, where
1.3. Contributions
In this paper, we propose an algorithm for supervised classification of feature vectors with i.non-i.d. elements when the number of training feature vectors per label is t, where Next, we derive an upper bound on the error probability of the proposed classifier for uniformly distributed labels and prove that the error probability exponentially decays to zero when the length of the feature vector, n, grows, even when only one training vector per label is available, i.e., when . Hence, the proposed classification algorithm provides an asymptotically optimal performance even when the number of training vectors per label is extremely small. We compare the performance of the proposed classifier with the naive Bayes classifier and to the KNN algorithm. Our numerical results show that the proposed classifier significantly outperforms the naive Bayes classifier and the KNN algorithm when the number of training feature vectors per label is small and the length of the feature vectors n is sufficiently high.
The proposed algorithm is a form of the nearest neighbor classification algorithm, where the nearest neighbor is searched in the domain of empirical distributions. As a result, we refer to the algorithm as the nearest empirical distribution. The nearest empirical distribution algorithm is not new and, to the best of our knowledge, it was first proposed in [37] for the case when the elements of are i.i.d., i.e., for the equivalent problem of hypothesis testing. However, in this paper, we propose the nearest empirical distribution algorithm for the case when the elements of are i.non-i.d., which is much more complex than the problem of hypothesis testing where the elements of are i.i.d.
To the best of our knowledge, this is the first paper that investigates the important problem of classifying feature vectors with i.non-i.d. elements and provides an upper bound on its error probability. The novelty of this paper is not with the classifier itself, but rather in showing the importance of the problem of classifying feature vectors with i.non-i.d elements and in showing analytically that at least one classifier with an asymptotically optimal error probability exists when at least one training feature vectors per label is available.
The remainder of this paper is structured as follows. In Section 2, we formulate the considered classification problem. In Section 3, we provide our classifier and derive an upper bound on its error probability. In Section 4, we provide numerical examples of the performance on the proposed classifier. Finally, Section 5 concludes the paper.
2. Problem Formulation
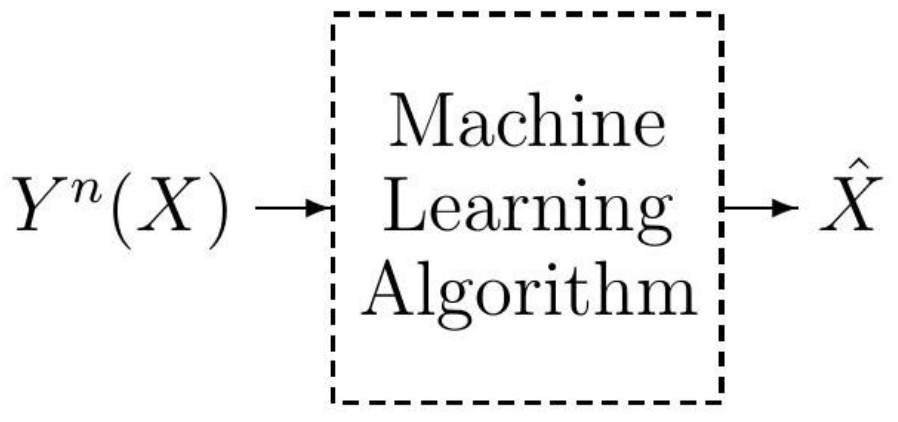
The machine learning model is comprised of a label X, a feature vector of length n mapped to the label X, and a learned label , as shown in Figure 1. In this paper, we adopt the information-theoretic style of notations and thereby random variables are denoted by capital letters and their realizations are denoted with small letters. The feature vector is the input to the machine learning algorithm whose aim is to detect the label X from the observed feature vector . The performance of the machine learning algorithm is measured by the error probability .
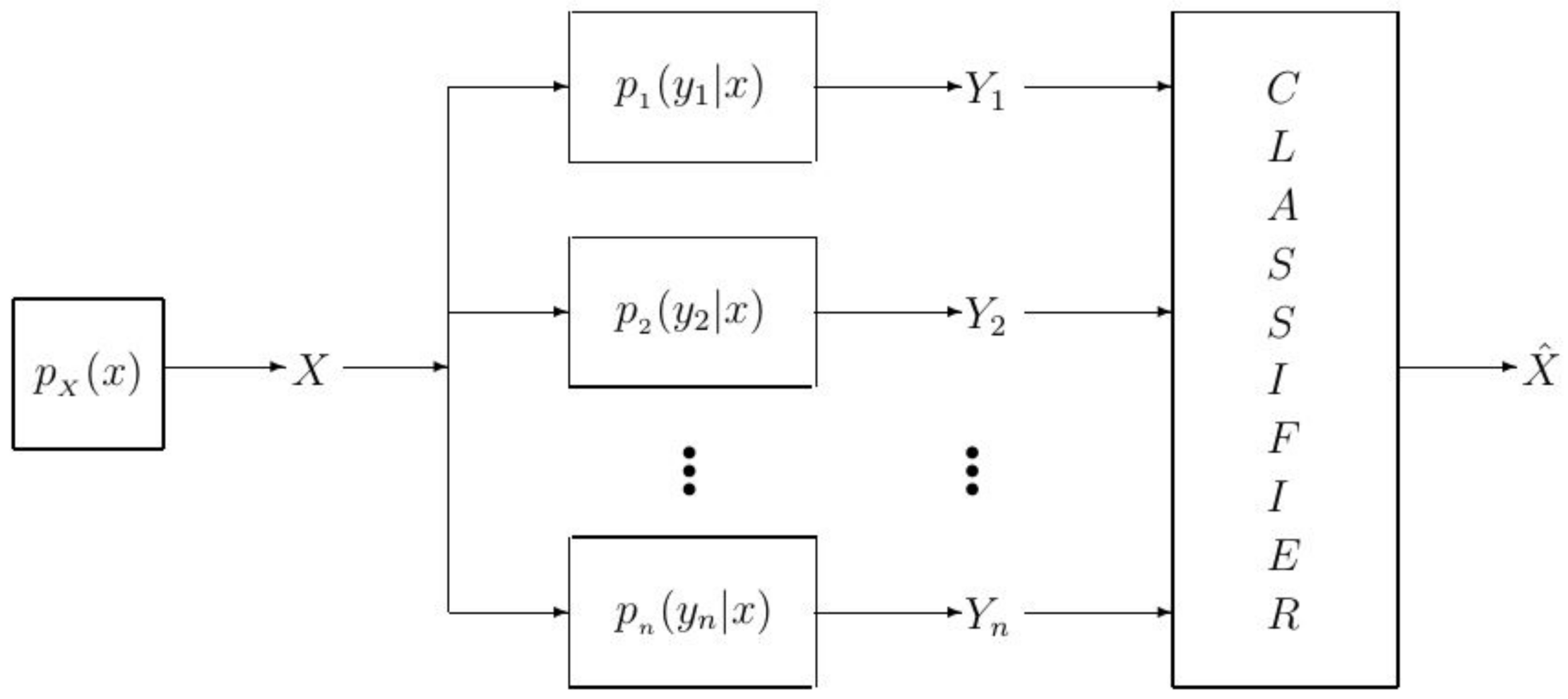
We adopt the modeling in [38,39,40] and represent the dependency between the label X and the feature vector via a joint probability distribution . Now, in order to gain a better understanding of the problem, we include the joint probability distribution into the model in Figure 1. To this end, since holds, instead of , we can include the conditional probability distribution and the probability distribution into the model in Figure 1, and thereby obtain the model in Figure 2.
Now, the classification learning model in Figure 2 is a system comprised of a label generating source X according to the distribution , a feature vector generator modelled by the conditional probability distribution , a feature vector , a classifier that aims to detect X from the observed feature vector , and the detected label . Note that the system model in Figure 2 can be seen equivalently as a communication system comprised of a source X, a channel with input X and output , and a decoder (i.e., detector) that aims to detect X from . The notation used in this paper, letter X for labels and letter Y for features, is based on the notation used in information theory for modelling communication systems. In the classification model shown in Figure 2, we assume that the label X can take values from the set , according to , where denotes the cardinality of a set. Next, we assume that the i-th element of the feature vector , , for , takes values from the set , according to the conditional probability distribution .
Moreover, we assume that the elements of the feature vector are i.non-i.d. As a result, the feature vector takes values from the set according to the conditional probability distribution given by
where comes from the fact that elements in the feature vector are mutually independent and is for the sake of notational simplicity, where is used instead of . As a result of (1), the considered classification model in Figure 2 can be represented equivalently as in Figure 3.
Next, we assume that , , and thereby are unknown to the classifier. Instead, the classifier knows , , and for each , where , it has access to a finite set of t correctly labelled input–output pairs , denoted by , referred to as the training set for label .
Finally, we assume that the following holds
The condition in (2) means that the distribution of the feature vectors for label is not a perturbation of distribution of the feature vectors for label . As a result, the proposed classifier only applies to the subset of data vectors with i.non-i.d. elements that satisfy (2).
For the classification system model defined above and illustrated in Figure 3, we wish to propose a classifier that exhibits an asymptotically optimal error probability with respect to the length of , n, for any , i.e., for any , as . Moreover, we wish to obtain an analytical upper bound on the error probability of the proposed classifier for a given t and n.
3. The Proposed Classifier and Its Performance
In this section, we propose our classifier, derive an analytical upper bound on its error probability, and prove that the classifier exhibits an asymptotically optimal performance when the length of the feature vector , n, satisfies . This is conducted in the following.
For a given vector , let the Minkowski distance r be defined as
Moreover, for a given feature vector , let be a function defined as
where is an indicator function assuming the value 1 if and 0 otherwise. Hence, counts the number of elements in that have the value y.
3.1. The Proposed Classifier
Let be a vector obtained by concatenating all training feature vectors for the input label as
Let be the empirical probability distribution of the concatenated training feature vector for label , , given by
Let be the observed feature vector at the classifier whose label it wants to detect and let denote the empirical probability distribution of , given by
Using the above notations, we propose the following classifier.
Proposition 1.
For the considered system model, we propose a classifier with the following classification rule
where and ties are resolved by assigning the label among the ties uniformly at random. (For example, if holds for, , we set or uniformly at random).
As seen from (8), the proposed classifier assigns the label if the empirical probability distribution of the concatenated training feature vector mapped to label , is the closest, in terms of Minkowski distance r, to the empirical probability distribution of the observed feature vector . In that sense, the proposed classifier can be considered as the nearest empirical distribution classifier.
3.2. Upper Bound on the Error Probability
The following theorem establishes an upper bound on the error probability of the proposed classifier.
Theorem 1.
Let , for , be a vector defined as
where is given by
Then, for a given , the error probability of the proposed classifier is upper bounded by
where ϵ is given by
Proof of Theorem 1.
Without loss of generality we assume that is the input to and is observed.
Let , for , be a set defined as
Furthermore, let , for , be a set defined as
Let and . Now, for any , we have
where follows from (13). Moreover, for , we have
where follows from (14). Next, we have the following upper bound
where follows from the Minkowski inequality. Combining (15)–(17), we obtain
Hence, the Minkowski distance between the empirical probability distribution of the observed vector and the empirical probability distribution of the concatenated training vector for label is upper bounded by the right hand side of (18). We now derive a lower bound for , where . For any , such that , we have
where follows from (15) and is again due to the Minkowski inequality. The expression in (19), can be written equivalently as
where . Now, using the definitions of and given by (6) and (9), respectively, into (20) we can replace the expression in the right-hand side of (20) by , and thereby for any we have
The expression in (21) represents a lower bound on the Minkowski r distance between the empirical probability distribution of the observed vector and the empirical probability distribution of the concatenated training vector for any label , where .
Using the bounds in (18) and (21), we now relate the left-hand sides of (18) and (21). As long as the following inequality holds for each ,
which is equivalent to the following for
where , , and follow from (18), (22), and (21), respectively. Thereby, from (24), we have the following for
Note that the right- and left-hand sides of (25) can be replaced by the Minkowski distance of the vectors
and
respectively. Now, (26) and (27) can be replaced by and , respectively, by the definitions of and given by (7) and (6), respectively. Therefore, (25) can be written equivalently as
Now, let us highlight what we have obtained. We obtained that there is an for which if (23) holds for , and for that there are sets and for which and then (28) holds for , and thereby our classifier will detect that is the correct label. Using this, we can upper bound the error probability as
where is a set defined as
In the following, we derive the expression in (29). The right-hand side of (29) can be upper bounded as -4.6cm0cm
where follows from Boole’s inequality. Now, note that we have the following upper bound for the first expression in the right-hand side of (31)
where is the complement of and follows from Boole’s inequality. Note that in (32) are n independent Bernoulli random variables with probabilities of success , respectively. Let be a binomial random variable with parameters . We proceed the proof by introducing the following well-known Hoefdding’s Theorem from [41]. □
Theorem 2
(Hoeffding [41]). Assume that and are n independent Bernoulli random variables with probabilities of success and , respectively. Next, let be defined as and, let be defined as . Let be a binomial random variable with parameters . Then, for a given a and b, where holds, we have
In other words, the probability distribution of is more dispersed around its mean than is the probability distribution of . Except in the trivial case when , the bound in (33) holds with equality if and only if .
Proof of Theorem 2.
Please refer to [41]. □
Setting and in (33), we obtain
We now turn to the proof of Theorem 1. According to Theorem 2, the probability distribution of is more dispersed around its mean than is the probability distribution of . Therefore, we can upper bound the probability in the last line of (32) as
where is defined in (30) and follows from (35). Now, let us introduce another well-known Hoeffding’s Theorem from [42].
Theorem 3
(Hoeffding’s inequality [42]). Let be n independent random variables such that for each , we have . Then for , defined as , we have
where is the expectation of .
Proof of Theorem 3.
Please refer to [42]. □
Back to (36), by using the result of (37) for and since the binomial random variable can take values 0 or 1, respectively, we have
where is defined in (30). Inserting (38) into (32), we obtain the following upper bound
Similarly, we have the following result for the second expression in the right-hand side of (31)
where again follows from Boole’s inequality. Note that due to (5), for any integer number l such that the random variables and in (40) are n independent Bernoulli random variables with the probabilities of success and , respectively are elements of . In addition, note that
Notice that for each , is the summation of the probabilities of success of the random variables and . Thereby, the last expression on the right-hand side of (41) is the average probability of success of random variables for . Now, let be a binomial random variable with parameters . Once again, according to Theorem 2, the probability distribution of is more dispersed around its mean than is the probability distribution of . Therefore, the probability in the last line of (40) can be upper bounded as
where , defined in (30), follows from (35) (in which n is replaced by ), and is the result of (37) for and since the binomial random variable can take values 0 or 1, respectively. Inserting (42) into (40), we have the following upper bound
Inserting (39) and (43) into (31), and then inserting (31) into (29), we obtain the following upper bound for the error probability
where
which is the optimal value of that exhibits the tightest upper bound for the error probability given by (44). This completes the proof of Theorem 1.
The following corollary provides a simplified upper bound on the error probability when .
Corollary 1.
When the number of training vectors per label reaches infinity, i.e., when , which is equivalently to the case when the probability distribution is known at the classifier, the error probability of the proposed classifier is upper bounded as
where ϵ is given by
Proof.
The proof is straightforward. □
As can be seen from (8) and (11), the performance of the proposed classifier depends on r. We cannot derive the optimal value of r that minimizes the error probability since we do not have the exact expression of the error probability, we only have its upper bound. On the other hand, in practice, the optimal r with respect to the upper bound on the error probability also cannot be derived since the upper bound depends on , which would be unknown in practice due to being unknown. As a result, for our numerical examples, we consider the Euclidean distance , which is one of the most widely used distance metrics in practice.
The following corollary establishes the asymptotic optimality of the proposed classifier with respect to n.
Corollary 2.
The proposed classifier has an error probability that satisfies as if , m is fixed, and . Here, indicates the dimension of our space, i.e., maximum number of alphabets each element in the feature vector can take. Thereby, the proposed classifier is asymptotically optimal.
Proof.
For the proof, please see Appendix A. □
4. Simulation Results
In this section, we provide simulation results of the performance of the proposed classifier for and compare it to benchmark schemes. The benchmark schemes that we adopt for comparison are the naive Bayes classifier and the KNN algorithm. We cannot adopt a classifier based on a neural network since neural networks require a very large training set, which we assume is not available. For the naive Bayes classifier, the probability distribution is estimated from the training vectors as follows. Let again be a vector obtained by concatenating all training feature vectors for the input label as in (5). Then, the estimated probability distribution of , denoted by , is found as
and the naive Bayes classifier decides according to
The main problem of the naive Bayes classifier occurs when an alphabet is not present in the training feature vectors. In that case, in (48) is , and, as a result, the right hand side of (49) is zero since at least one of the elements in the product in (49) is zero. In this case, the naive Bayes classifier fails to provide an accurate classification of the labels. In what follows, we see that this issue of the naive Bayes classifier appears frequently when we have a small number of training feature vectors. On the other hand, the KNN classifier works as follows. For the observed feature vector , the KNN classifier looks for the k nearest feature vectors to , among all training feature vectors , for all and . Then by considering a set of K input–output pairs , for and , the KNN classifier decides a label which is the most frequent among -s. The optimum value of k for is .
In the following, we provide numerical examples where we illustrate the performance of the proposed classifier when is artificially generated.
4.1. The I.I.D. Case with One Training Sample per Label
In the following examples, we assume that the classifiers have access to only one training feature vector for each label, the elements of the feature vectors are generated i.i.d., and the alphabet size of the feature vector, , is fixed.
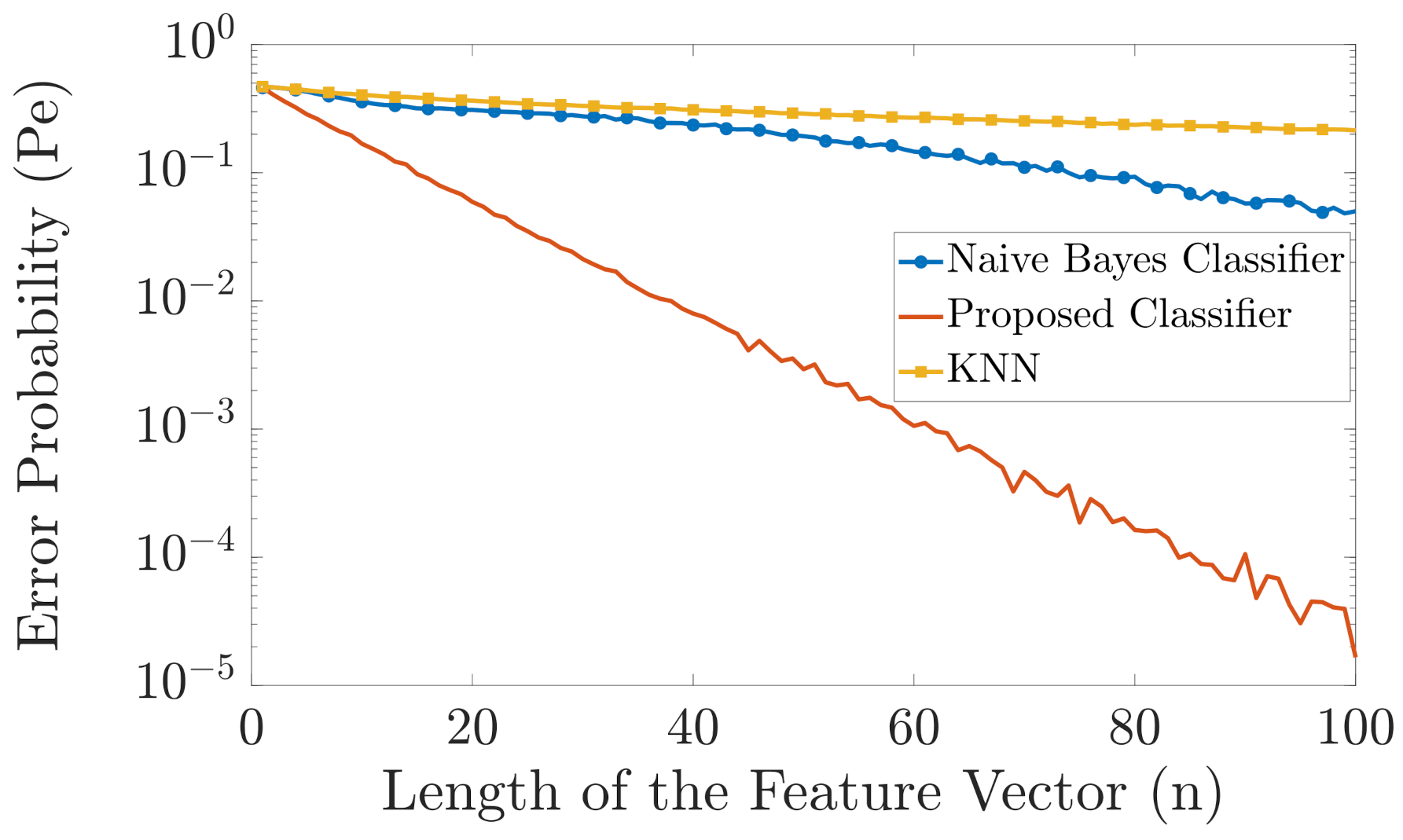
In Figure 4 and Figure 5, we compare the error probability of the proposed classifier with the naive Bayes classifier and the KNN algorithm for the case when and , respectively. In both examples, we have two different labels, i.e., . As a result, we have two different probability distributions and . The probability distributions and are randomly generated as follows. We first generate two random vectors of length 6 and length 20 for Figure 4 and Figure 5, respectively, where the elements of these vectors are drawn independently from a uniform probability distribution. Then we normalize these vectors such that the sum of their elements is equal to one. These two normalized randomly generated vectors then represent the two probability distributions and , . Then, is obtained as , for . The simulation is carried out as follows. For each n, we generate one training vector for each label, using the aforementioned probability distributions. Then, as test samples, we generate 1000 feature vectors for each label and pass these feature vectors through our proposed classifier, the naive Bayes classifier, and the KNN algorithm, and compute the errors. The length of the feature vector n is varied from to . We repeat the simulation 5000 times and then plot the error probability. Figure 4 and Figure 5 show that the proposed classifier outperforms both the naive Bayes classification and KNN. The main reason for this performance gain is because when only one training vector per label is available, the proposed classifier is more resilient to errors than the naive Bayes classifier, whereas the KNN algorithm has very poor performance because of the “curse of dimensionality”. Specifically, the naive Bayes classifier cannot perform an accurate classification for small n compared to since the chance that an alphabet will not be present in one of the training feature vectors is close to 1. On the other hand, the KNN algorithm cannot perform an accurate classification for large n since the dimension of the input feature vector becomes much larger than the training data and the “curse of dimensionality” occurs.
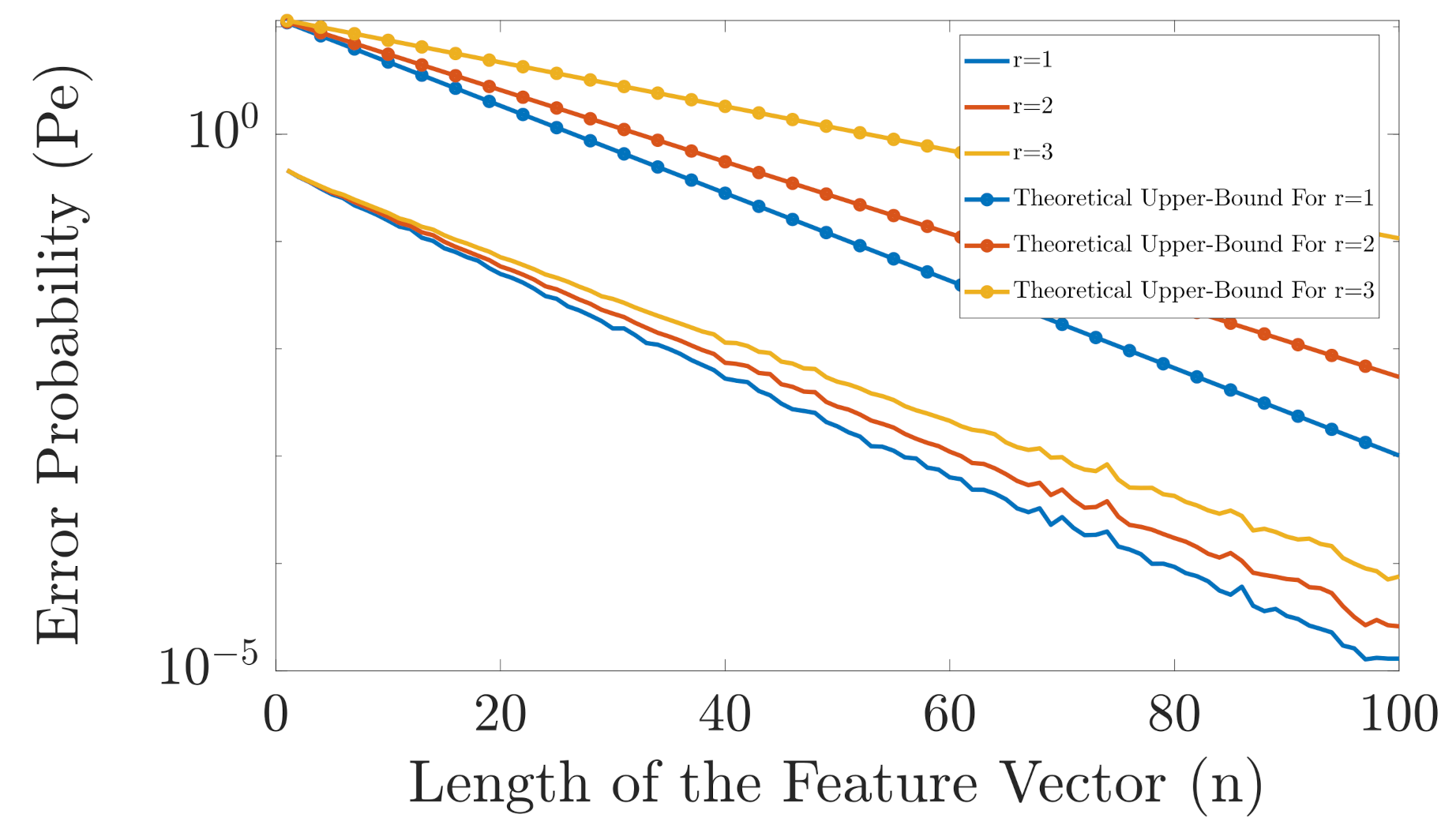
In Figure 6, we compare the performance of the proposed classifier for different values of r when with the derived upper bounds. As can be seen, for this example, the derived theoretical upper bounds have similar slope as the exact error probabilities. Moreover, we can see that for this example, the optimal r is . However, this is not always the case and it depends on , , and .
4.2. The Overlapping I.Non-I.D. Case with One Training Sample per Label
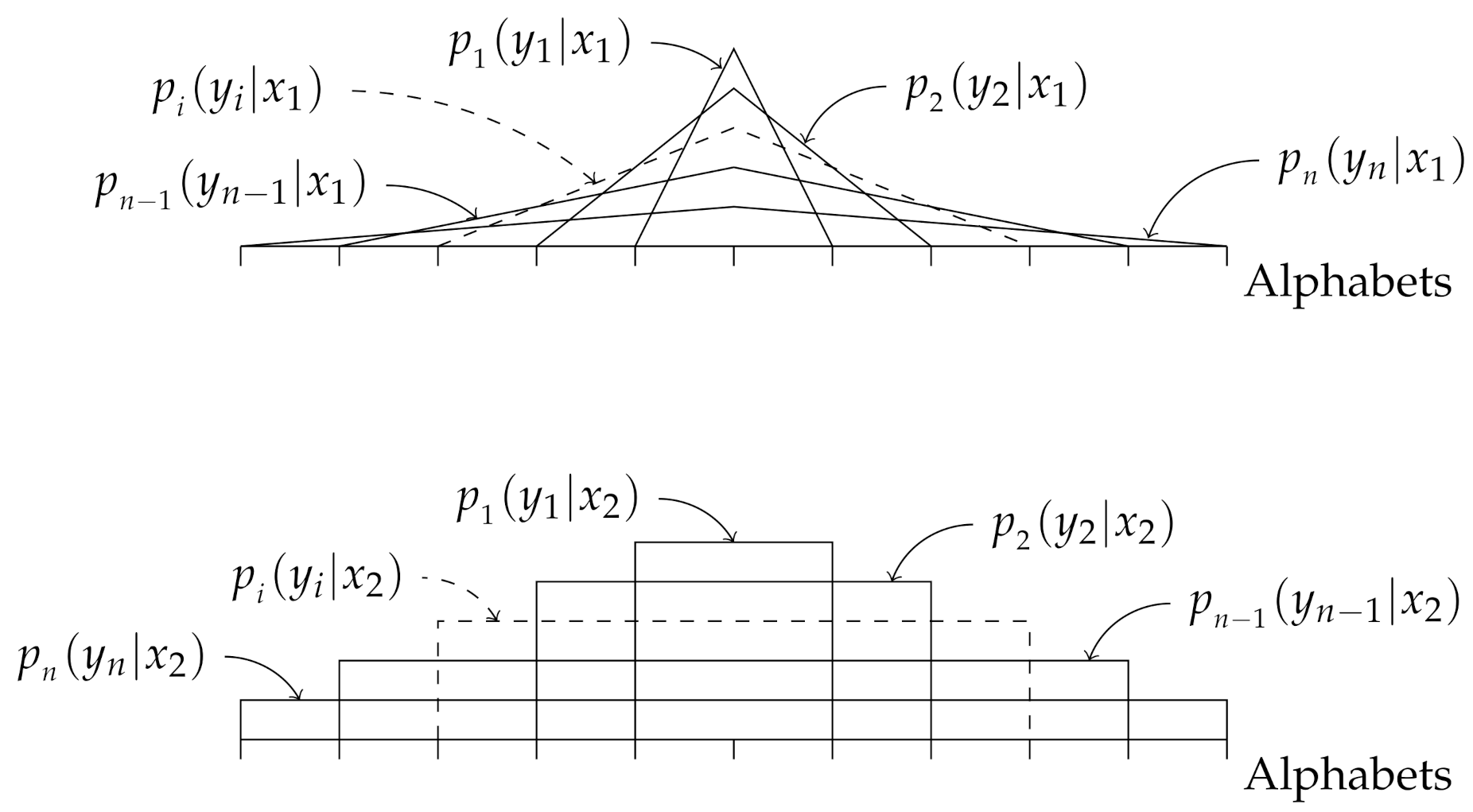
In this example, we consider the i.non-i.d. case where the probability distributions are overlapping for all i, as shown in Figure 7. The small orthogonal lines on the x-axis in Figure 7 represent alphabets, i.e., the elements in , and the probability of occurrence of an alphabet is equal to the intersection between the corresponding orthogonal line to the represented probability distribution for . By “overlapping”, we mean the following. Let and denote the set of outputs generated by and , respectively. If for any v and u, holds, we say that the output alphabets are overlapping.
To demonstrate the performance of our proposed classifier in the overlapping case, we assume that we have two different labels, , where the corresponding conditional probability distributions and are obtained as follows. For a given n, let be the set of all alphabets. Note that the size of grows with n. Moreover, let and be vectors of length , given by
The number of zeros in each side of the vectors and is . To generate a feature vector from label , we generate the vector , where takes values from the set , with a probability distribution .
The simulation is carried out as follows. For each n, we generate one training feature vector for each label. Then, we generate 1000 feature vectors for each label and pass them through our proposed classifier, the naive Bayes classifier, and the KNN algorithm and calculate the error probability. We change the length of the feature vector from to and repeat the simulation 1000 times and then plot the error probability.
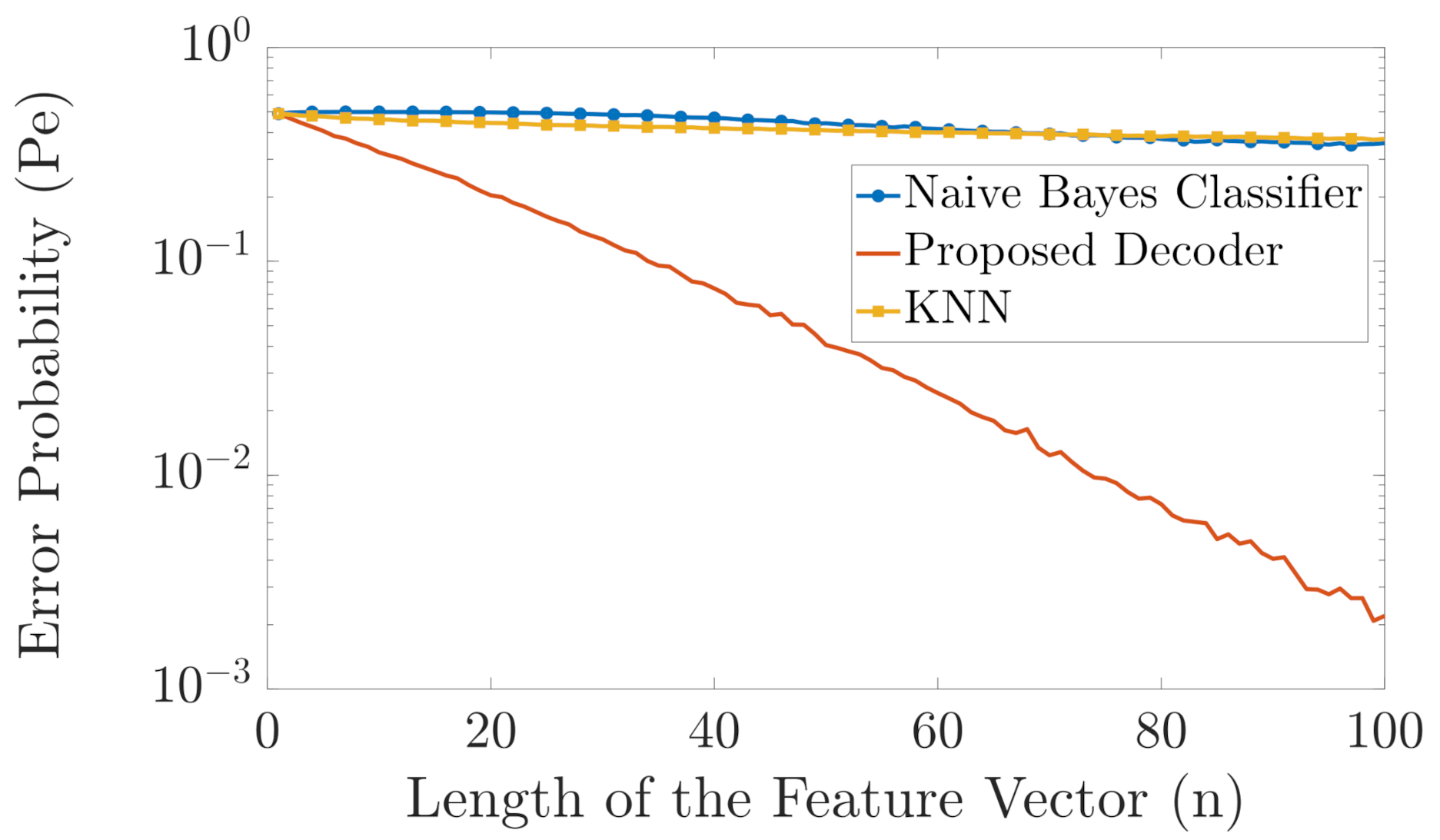
As shown in Figure 8, there is a huge difference between the performance of the two benchmark classifiers and the proposed classifier. The error probability of the naive Bayes classifier is almost for all shown values of n as it is susceptible to the problem of unseen alphabets in the training vectors. The error probability of the KNN classifier is also almost for as it is susceptible to the “curse of dimensionality”. However, the error probability of our proposed classifier continuously decays as n increases.
In Figure 9, we run the same experiments as in Figure 8 but with , i.e., 100 training feature vectors per label. As can be seen from Figure 9, the performance of the proposed classifier is better than the naive Bayes classifier, for . Since , for small values of n, the naive Bayes classifier has access to many training samples and, thereby, its performance is very close to the case when the probability distribution is known, i.e., to the maximum-likelihood classifier, and hence it has the optimal performance. As n increases, the number of alphabets rises, i.e., rises, and due to the aforementioned issue of the naive Bayes classifier with unseen alphabets, our proposed classifier performs much better classification than the naive Bayes classifier. Furthermore, note that the error probability of our proposed classifier decays exponentially as n increases which is not the case with the naive Bayes classifier. Moreover, Figure 9 also shows the theoretical upper bound on the error probability we derived in (11).
4.3. The Non-Overlapping I.Non-I.D. Case with One Training Sample for Each Label
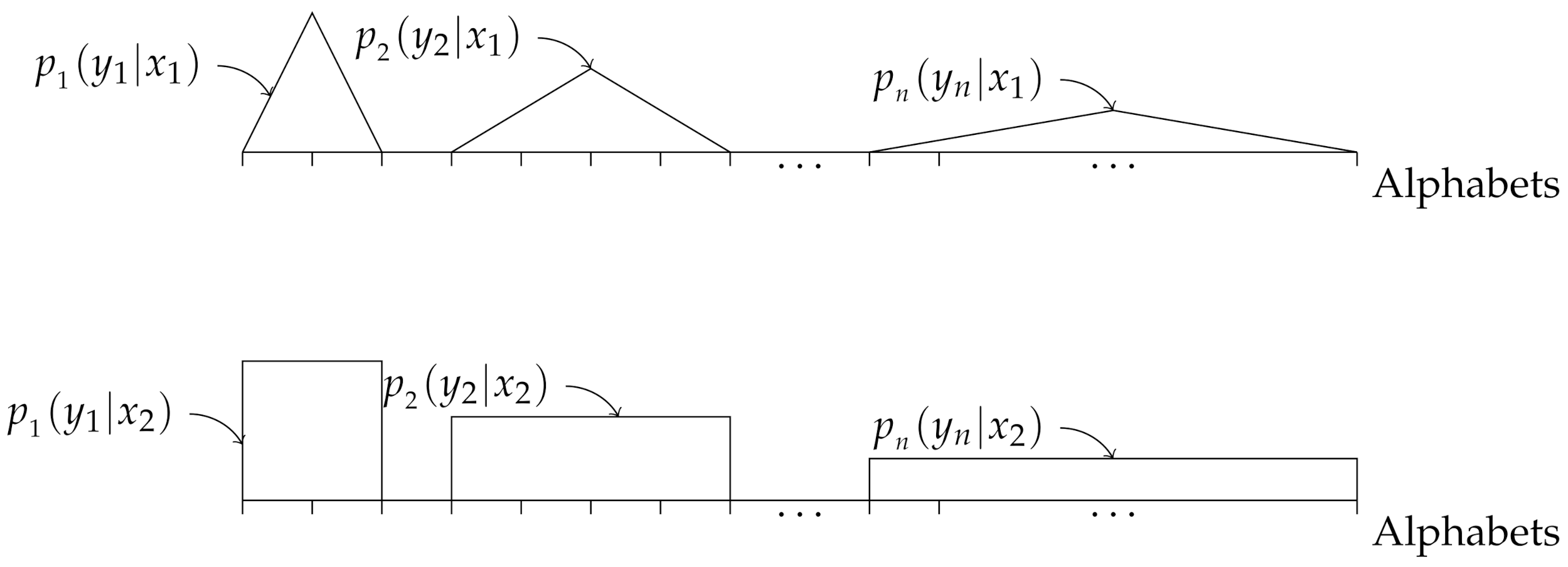
In this example, we consider the i.non-i.d. case where the probability distributions are non-overlapping for all j as shown in Figure 10, where we defined “overlapping” in Section 4.2. Hence, we test the other extreme in terms of possible distribution of the elements in the feature vectors .
To demonstrate the performance of our proposed classifier in the non-overlapping case, we assume that we have two different labels , the corresponding conditional probability distributions and are obtained as follows. For a given n, let be the set of all alphabets of the element in the feature vectors. Note again that the size of grows with n. in addition, let and for , be vectors of length , given by
The number of zeros in the left-hand sides of and is . To generate a feature vector from the label , we generate the vector , where take values from the set , with probability distribution .
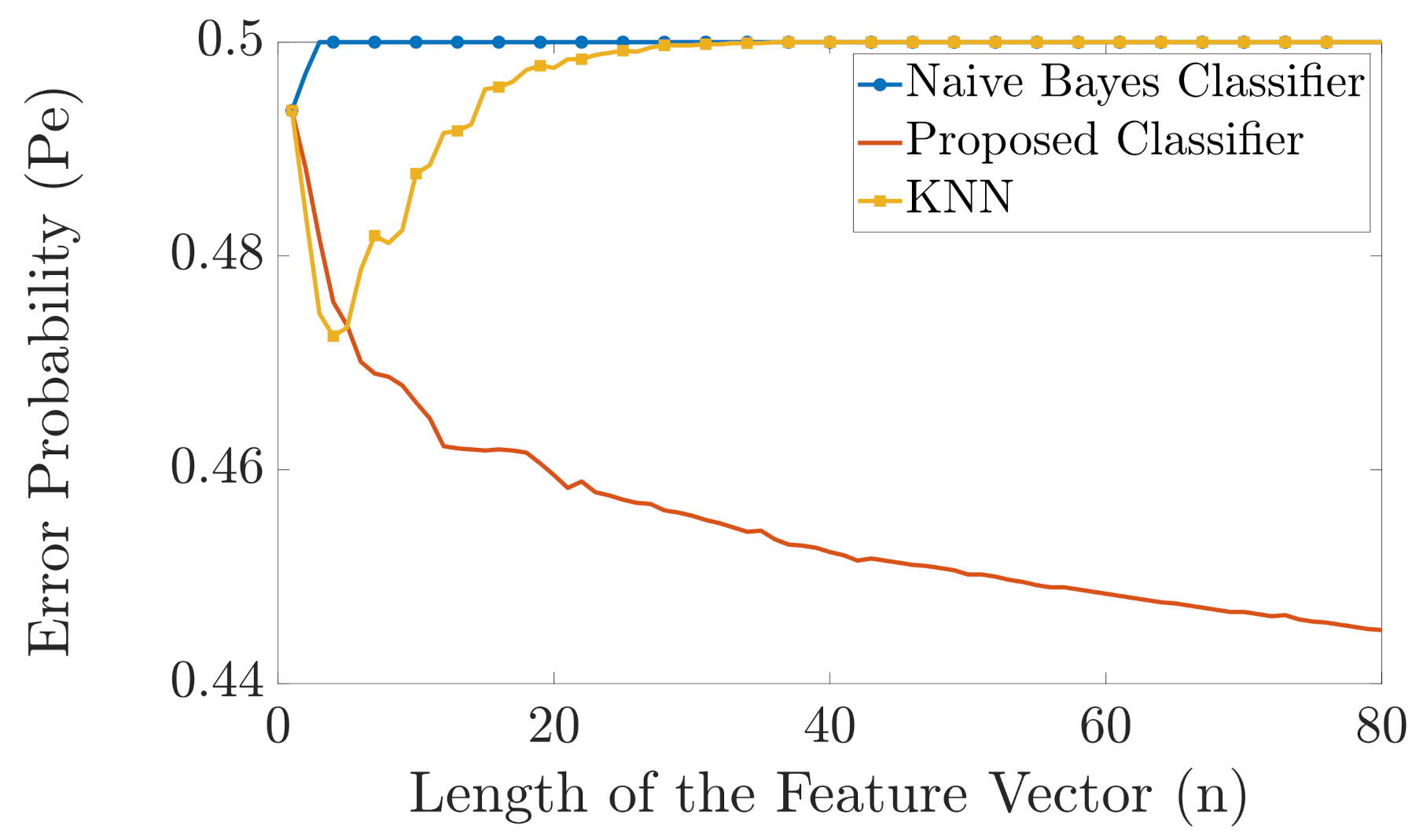
The simulation is carried out as follows. For each n, we generate one training feature vector for each label. Then we generate 250 feature vectors for each label and pass it through our proposed classifier, the naive Bayes classifier and KNN and calculate the error probabilities. We change the length of the vector from 1 to 80 and repeat the simulation 250 times and then plot the error probability. As shown in Figure 11, there is a huge difference between the performance of the proposed classifier and the two benchmark classifiers. The error probability of the naive Bayes classifier is almost for all shown values of n as it is susceptible to the issue with unseen alphabets in the training feature vector. The error probability of the KNN classifier is almost for all shown values of as it becomes susceptible to the “curse of dimensionality”. However, the error probability of our proposed classifier still decays continuously as n increases.
Note that, in our numerical examples, we compared our algorithm with the benchmark schemes on two extreme cases of i.non-i.d. vectors, referred to as “overlapping” and “non-overlapping”. Any other i.non-i.d. vector can be represented as a combination of the “overlapping” and “non-overlapping” vectors. Since our algorithm works better than the benchmark schemes for small t on both these cases, it will work better than the benchmark schemes on any combination between “overlapping” and “non-overlapping” vectors, i.e., for any other i.non-i.d. vectors.
5. Conclusions
In this paper, we proposed a supervised classification algorithm that assigns labels to input feature vectors with independent but non-identically distributed elements, a statistical property found in practice. We proved that the proposed classifier is asymptotically optimal since the error probability moves to zero as the length of the input feature vectors grows. We showed that this asymptotic optimality is achievable even when one training feature vector per label is available. In the numerical examples, we compared the proposed classifier with the naive Bayes classifier and the KNN algorithm. Our numerical results show that the proposed classifier outperforms the benchmark classifiers when the number of training data is small and the length of the input feature vectors is sufficiency large.
Author Contributions
Methodology, F.S. and N.Z.; software, F.S.; formal analysis, F.S. and N.Z.; investigation, F.S.; supervision, N.Z.; writing—original draft preparation, F.S.; writing—review and editing, N.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Corollary 2
The proof is almost identical to the proof of Theorem 1; however, here we derive a looser upper-bound on the error-probability than that in (11), which is independent of .
Without loss of generality we assume that is the input to and is observed at the classifier.
Let , for and , be a set defined as
Let . For , we have
Using the same derivation as (18), for any and for , we have:
On the other hand, the same as the derivation in (21), for each , we have:
Now, for any , we have
where follows from (A1) and is again due to the Minkowski inequality. The expression in (A5), can be written equivalently as
where . Using the bounds in (A6) and (A4), for any we have
Using the bounds in (A3) and (A7), we now relate the left-hand sides of (A3) and (A7) as follows. As long as the following inequality holds for each ,
which is equivalent to the following for
we have the following for
where , , and follow from (A3), (A8), and (A7), respectively. Thereby, from (A10), we have the following for
or equivalently as
Once again, we obtained that if there is an for which (A9) holds for and for that there are sets and for which and for all , then (A12) holds for , and thereby our classifier will detect that is the correct label. Using this, we can upper-bound the error probability as
where is a set defined as
The right-hand side of (A13) can be upper-bounded as
Using the same derivation as (39), we have:
Similarly, we have the following result for the second expression in the right-hand side of (A15), which is the same as the derivation in (43)
Inserting (A16) and (A17) into (A15), and then inserting (A15) into (A13), we obtain the following upper-bound for the error probability
where
Now, if , (A18) can be written as
References
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Quinlan, J.R. Learning Efficient Classification Procedures and Their Application to Chess End Games; Springer: Berlin/Heidelberg, Germany, 1983; pp. 453–482. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth and Brooks: Monterey, CA, USA, 1984. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, San Jose, CA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Lallich, S.; Teytaud, O.; Prudhomme, E. Association Rule Interestingness: Measure and Statistical Validation; Studies in Computational Intelligence; Springer: Berlin, Germany, 2007; Volume 43, pp. 251–275. [Google Scholar]
- Langley, P.; Iba, W.; Thompson, K. An analysis of bayesian classifiers. In Proceedings of the Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 14–16 July 1992; AAAI Press: San Jose, CA, USA, 1992; p. 223228. [Google Scholar]
- Aha, D.W. Lazy learning. In Artificial Intelligent Review; Kluwer Academic Publishers: Cambridge, MA, USA, 1997; p. 710. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Kanaya, F.; Han, T.S. The asymptotics of posterior entropy and error probability for bayesian estimation. IEEE Trans. Inf. Theory 1995, 41, 1988–1992. [Google Scholar] [CrossRef]
- Gutman, M. Asymptotically optimal classification for multiple tests with empirically observed statistics. IEEE Trans. Inf. Theory 1989, 35, 401–408. [Google Scholar] [CrossRef]
- Sason, I.; Verd, S. Arimotornyi conditional entropy and bayesian hypothesis testing. IEEE Trans. Inf. Theory 2018, 64, 4–25. [Google Scholar] [CrossRef]
- Wang, C.; She, Z.; Cao, L. Coupled attribute analysis on numerical data. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 2–9 August 2013; AAAI Press: Beijing, China, 2013; p. 17361742. [Google Scholar]
- Wang, C.; Dong, X.; Zhou, F.; Cao, L.; Chi, C.H. Coupled attribute similarity learning on categorical data. IEEE Trans. Neural Networks Learn. Syst. 2015, 26, 781–797. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Cao, L.; Wang, M.; Li, J.; Wei, W.; Ou, Y. Coupled nominal similarity in unsupervised learning. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–28 October 2011; Association for Computing Machinery: Glasgow, Scotland, UK, 2011; p. 973978. [Google Scholar]
- Liu, C.; Cao, L. A coupled k-nearest neighbor algorithm for multi-label classification. In PAKDD; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Liu, C.; Cao, L.; Yu, P. A hybrid coupled k-nearest neighbor algorithm on imbalance data. In Proceedings of the International Joint Conference on Neural Networks, Beijing, China, 6–11 July 2014; pp. 2011–2018. [Google Scholar]
- Liu, C.; Cao, L.; Yu, P.S. Coupled fuzzy k-nearest neighbors classification of imbalanced non-iid categorical data. In Proceedings of the 2014 International Joint Conference on Neural Networks IJCNN, Beijing, China, 8–13 July 2014; pp. 1122–1129. [Google Scholar]
- Cao, L. Non-IIDness Learning in Behavioral and Social Data. Comput. J. 2013, 57, 1358–1370. [Google Scholar] [CrossRef]
- Cao, L. Coupling learning of complex interactions. Inf. Process. Manag. 2015, 51, 167–186. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, H.; Zhao, Y.; Luo, D.; Zhang, C. Combined mining discovering informative knowledge in complex data. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 41, 699–712. [Google Scholar]
- Getoor, L.; Taskar, B. Introduction to Statistical Relational Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Abed-Meraim, K.; Loubaton, P.; Moulines, E. A subspace algorithm for certain blind identification problems. IEEE Trans. Inf. Theory 2006, 43, 499–511. [Google Scholar] [CrossRef]
- Almeida, L. Linear and nonlinear ica based on mutual information—The misep method. IEEE Trans. Signal Process. 2004, 84, 231–245. [Google Scholar] [CrossRef]
- Hyvarinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411430. [Google Scholar] [CrossRef] [Green Version]
- Yeredor, A. Independent component analysis over galois fields of prime order. IEEE Trans. Inf. Theory 2011, 57, 53425359. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.; Zheng, R. Binary independent component analysis with or mixtures. IEEE Trans. Signal Processing 2011, 59, 31683181. [Google Scholar] [CrossRef] [Green Version]
- Barlow, H.B. Unsupervised learning. Neural Comput. 1989, 1, 295311. [Google Scholar] [CrossRef]
- Nakhaeizadeh, G.; Taylor, C.C.; Kunisch, G. Dynamic Supervised Learning: Some Basic Issues and Application Aspects. In Classification and Knowledge Organization; Springer: Berlin/Heidelberg, Germany, 1997; pp. 123–135. [Google Scholar]
- Koppen, M. The Curse of Dimensionality; SAGE: London, UK, 2000; pp. 4–8. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2000. [Google Scholar]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 437. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Huang, J.; Williams, G.; Wang, Q.; Ye, Y. Classifying very high-dimensional data with random forests built from small subspaces. Int. J. Data Warehous. Min. 2012, 8, 44–63. [Google Scholar] [CrossRef]
- Ye, Y.; Wu, Q.; Huang, J.Z.; Ng, M.K.; Li, X. Stratified sampling for feature subspace selection in random forests for high dimensional data. Pattern Recognit. 2013, 46, 769–787. [Google Scholar] [CrossRef]
- Kouiroukidis, N.; Evangelidis, G. The effects of dimensionality curse in high dimensional knn search. In Proceedings of the 15th Panhellenic Conference on Informatics, Kastoria, Greece, 30 September–2 October 2011; pp. 41–45. [Google Scholar]
- Matusita, K. Classification based on distance in multivariate gaussian cases. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; Volume 1: Statistics; University of California Press: Regents, CA, USA, 1967; pp. 299–304. [Google Scholar]
- Collins, M.; Schapire, R.E.; Singer, Y. Logistic regression, adaboost and bregman distances. Mach. Learn. 2002, 48, 253285. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Warsaw, Poland, 2020. [Google Scholar]
- Lebanon, G.; Lafferty, J. Cranking: Combining rankings using conditional probability models on permutations. In Proceedings of the 19th International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 2002; pp. 363–370. [Google Scholar]
- Hoeffding, W. On the distribution of the number of successes in independent trials. Ann. Math. Statist. 1956, 27, 713–721. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. J. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]
Figure 1.
A typical structural modelling of the classification learning problem.

Figure 2.
An alternative modeling of the classification learning problem.

Figure 3.
An alternative modelling of the classification learning problem when the elements of are mutually independent but non-identically distributed (i.non-i.d.).
Figure 3.
An alternative modelling of the classification learning problem when the elements of are mutually independent but non-identically distributed (i.non-i.d.).

Figure 4.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier.
Figure 4.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier.

Figure 5.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier.
Figure 5.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier.

Figure 6.
Comparison in error probability of the proposed classifier for different values of r when . The related theoretical upper bounds for each value of r are also given.
Figure 6.
Comparison in error probability of the proposed classifier for different values of r when . The related theoretical upper bounds for each value of r are also given.

Figure 7.
Illustration of the probability distributions (upper figure) and (lower figure), for .

Figure 8.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier .
Figure 8.
Comparison in error probability between the naive Bayes classifier, KNN, and the proposed classifier .

Figure 9.
Comparison in error probability between the naive Bayes classifier and the proposed classifier .
Figure 9.
Comparison in error probability between the naive Bayes classifier and the proposed classifier .

Figure 10.
Illustration of the probability distributions (upper figure) and (lower figure), for .

Figure 11.
Comparison in error probability between the naive Bayes classifier and the proposed classifier .
Figure 11.
Comparison in error probability between the naive Bayes classifier and the proposed classifier .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shahrivari, F.; Zlatanov, N. On Supervised Classification of Feature Vectors with Independent and Non-Identically Distributed Elements. Entropy 2021, 23, 1045. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081045
AMA Style
Shahrivari F, Zlatanov N. On Supervised Classification of Feature Vectors with Independent and Non-Identically Distributed Elements. Entropy. 2021; 23(8):1045. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081045
Chicago/Turabian StyleShahrivari, Farzad, and Nikola Zlatanov. 2021. "On Supervised Classification of Feature Vectors with Independent and Non-Identically Distributed Elements" Entropy 23, no. 8: 1045. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081045
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.