
Generalized Ordinal Patterns and the KS-Entropy


Institute of Mathematics, University of Lübeck, D-23562 Lübeck, Germany
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(8), 1097; https://0-doi-org.brum.beds.ac.uk/10.3390/e23081097
Submission received: 1 July 2021
/
Revised: 18 August 2021
/
Accepted: 20 August 2021
/
Published: 23 August 2021
(This article belongs to the Special Issue Entropy Measures for Data Analysis II: Theory, Algorithms and Applications)
{kind=link}
{kind=link}
{kind=link}
Abstract
:Ordinal patterns classifying real vectors according to the order relations between their components are an interesting basic concept for determining the complexity of a measure-preserving dynamical system. In particular, as shown by C. Bandt, G. Keller and B. Pompe, the permutation entropy based on the probability distributions of such patterns is equal to Kolmogorov–Sinai entropy in simple one-dimensional systems. The general reason for this is that, roughly speaking, the system of ordinal patterns obtained for a real-valued “measuring arrangement” has high potential for separating orbits. Starting from a slightly different approach of A. Antoniouk, K. Keller and S. Maksymenko, we discuss the generalizations of ordinal patterns providing enough separation to determine the Kolmogorov–Sinai entropy. For defining these generalized ordinal patterns, the idea is to substitute the basic binary relation ≤ on the real numbers by another binary relation. Generalizing the former results of I. Stolz and K. Keller, we establish conditions that the binary relation and the dynamical system have to fulfill so that the obtained generalized ordinal patterns can be used for estimating the Kolmogorov–Sinai entropy.
1. Introduction
In 2002, Bandt and Pompe introduced so-called permutation entropy [1]. This entropy has been established in non-linear dynamical system theory and time series analysis, including applications in many fields from biomedicine to econophysics (compare with Zanin et al. [2]). It is a crucial point that permutation entropy is theoretically justified by asymptotic results relating it to Kolmogorov–Sinai entropy (KS entropy, also called metric entropy) which is the central complexity measure for dynamical systems. The important relationship of permutation entropy and KS entropy was first observed and mathematically founded for piece-wise monotone dynamical systems by Bandt et al. [3].
The (empirical) concept of permutation entropy is based upon analyzing the distribution of ordinal patterns in a time series or the underlying system. In this paper, we concentrate on a measure-preserving dynamical system , i.e., a probability space equipped with a measurable map satisfying for all .
Given a random variable , in this paper, an ordinal pattern of length with respect to X is considered as a subset of the state space . It is indicated by a permutation of and defined by
(Usually, ordinal patterns are defined in the range of X, i.e., for the vectors ). The collection of ordinal patterns:
is a partition of .
In the rest of this section, we assume that X preserves enough information about the given system in a certain sense. This is particularly the case if is contained in and X is the identity map. A precise general description of the assumption is given when presenting the results of this paper. It was shown in [4] that, under not too restrictive further conditions, the probability distribution on the partitions for can be used for determining the KS entropy of the given system. The reason is that, roughly speaking, under these conditions, is able to separate the orbits of the system if .
In order to address the problem that this paper is concerned with, we give a description of ordinal patterns being slightly different from the above. One can determine to which ordinal pattern of length n a point belongs to if, for all in:
one knows whether holds true or not. In other words, there exists a set such that:
where:
The above set contains all the points that satisfy for and for . Note that, given some arbitrary , the set on the right hand side of (3) can be empty. In the case that it is non-empty, it coincides with some ordinal pattern of length n.
While Equation (3) might be a bit more abstract than (1), it shows a way to generalize the concept of ordinal patterns on the basis of replacing the set R in (4) by some arbitrary Borel subset R of , also to investigate why ordinal patterns are so successful.
Definition 1.
We call a non-empty Borel subset R of discriminating relation.
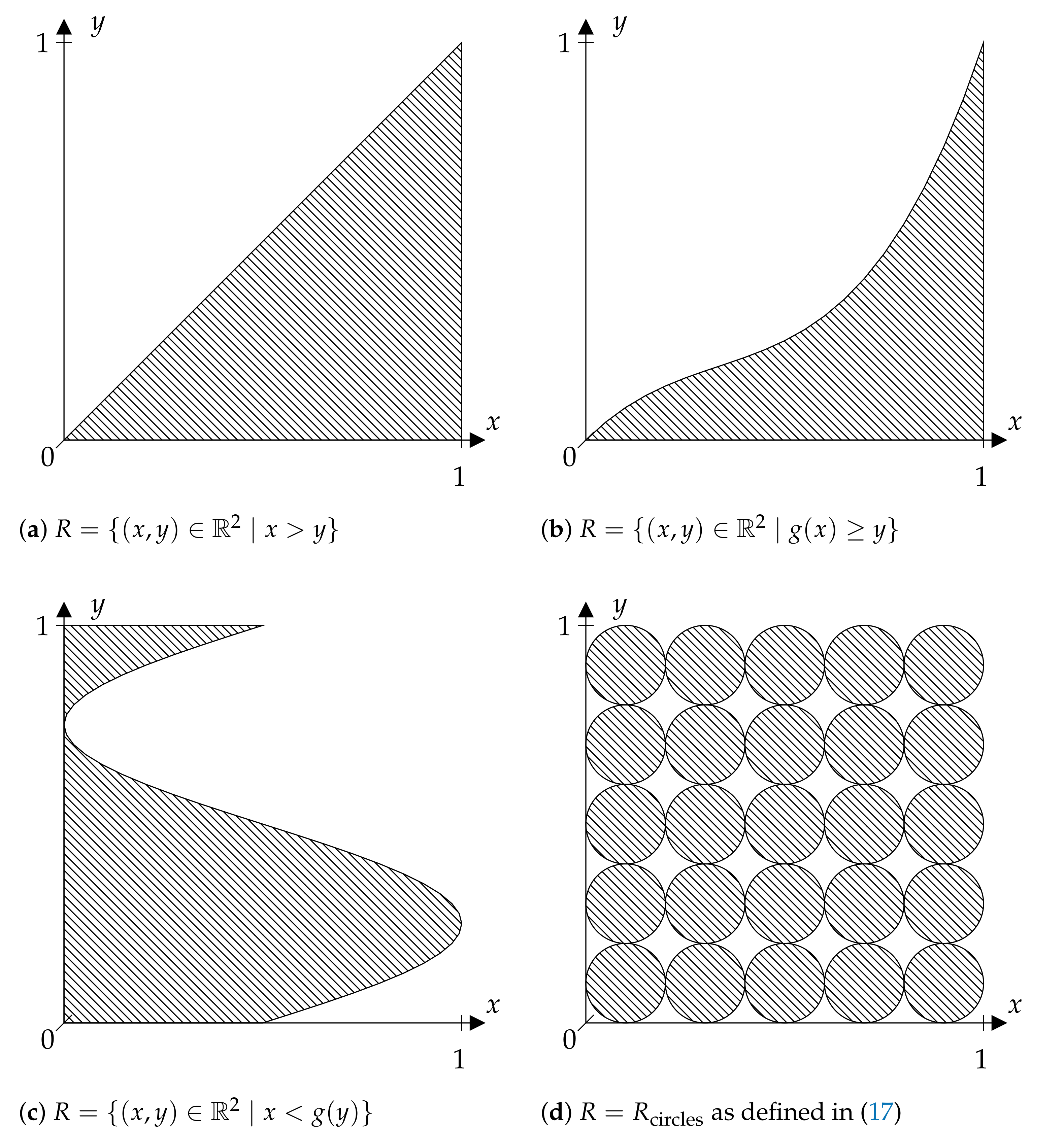
The figures given in this paper show different discriminating relations R. In each case, only the part of R contained in is presented. Note that in the case that X maps into , the restriction of R itself to this part would not change anything. Figure 1a illustrates R as given in (4), again only on . In the case of such an R, note that mapping into would not make a difference to a given X for our considerations, since order relations and associated partitions are preserved.
Given some discriminating relation, generalized ordinal patterns of length n with respect to X are given as the non-empty sets defined by the right hand side of (3) for some . Obviously, they also form a partition of . The question that arises is what a discriminating relation R should look like, such that those generalized ordinal patterns inhibit the same nice properties the original ordinal patterns had. More precisely, we ask the following question:
Main Question.
Under what conditions on a discriminating relation R the partitions given by the generalized ordinal patterns determine the KS entropy of a dynamical system?
Why is this determination of entropy, which is precisely described by formula (10) in Theorem 1 interesting? For answering this question, interpret X as an observable, as the initial state of the given system and as the measured values at times . Determining (generalized) ordinal patterns on the basis of those values is a symbolization, where a symbol obtained is the (generalized) ordinal pattern containing . Generally, symbolization means a coarse-graining of the state space underlying a system, where each point is assigned one of finitely many given symbols. Instead of considering the precise development of the system, one is interested in the change of symbols in the course of time, justifying the naming of the method symbolic dynamics. Note that a symbolization is equivalent to partitioning the state space into classes of states (with the same symbol).
The reason for obtaining the full entropy from the (generalized) ordinal patterns is, roughly speaking, that the symbol system obtained has high potential for separating orbits. Such kinds of successful symbolizations are important, for example, in big data analysis, see, e.g., Smith et al. [5].
The above question was first considered in [6], where the authors basically showed that sets of the form:
lead to generalized ordinal patterns that, under some conditions, can be used to determine the entropy if is measurable and one-to-one. Such an R is shown in Figure 1b and will be discussed in Section 4 as well as another R illustrated in Figure 1.
In this paper, we consider general sets that cannot necessarily be described by functions and inequalities and establish some conditions under which the entropy can be determined using those sets. As in [6], the discussion also includes a generalization of the sets given by (2) and is conducted in a multidimensional framework. In particular, the results give insights as to why the basic ordinal approach and generalizations are working.
It is instructive to discuss the partition of into R and from the viewpoint of symbolic dynamics. In contrast to classical symbolization approaches with symbolizing only in the range of single “measurements” x, the symbolization of pairs via the partition also regards some kind of link between x and y if R lies “diagonal” in a certain sense. We will discuss this constellation, which explains the success of ordinal patterns in a wider context, more precisely in Section 5.
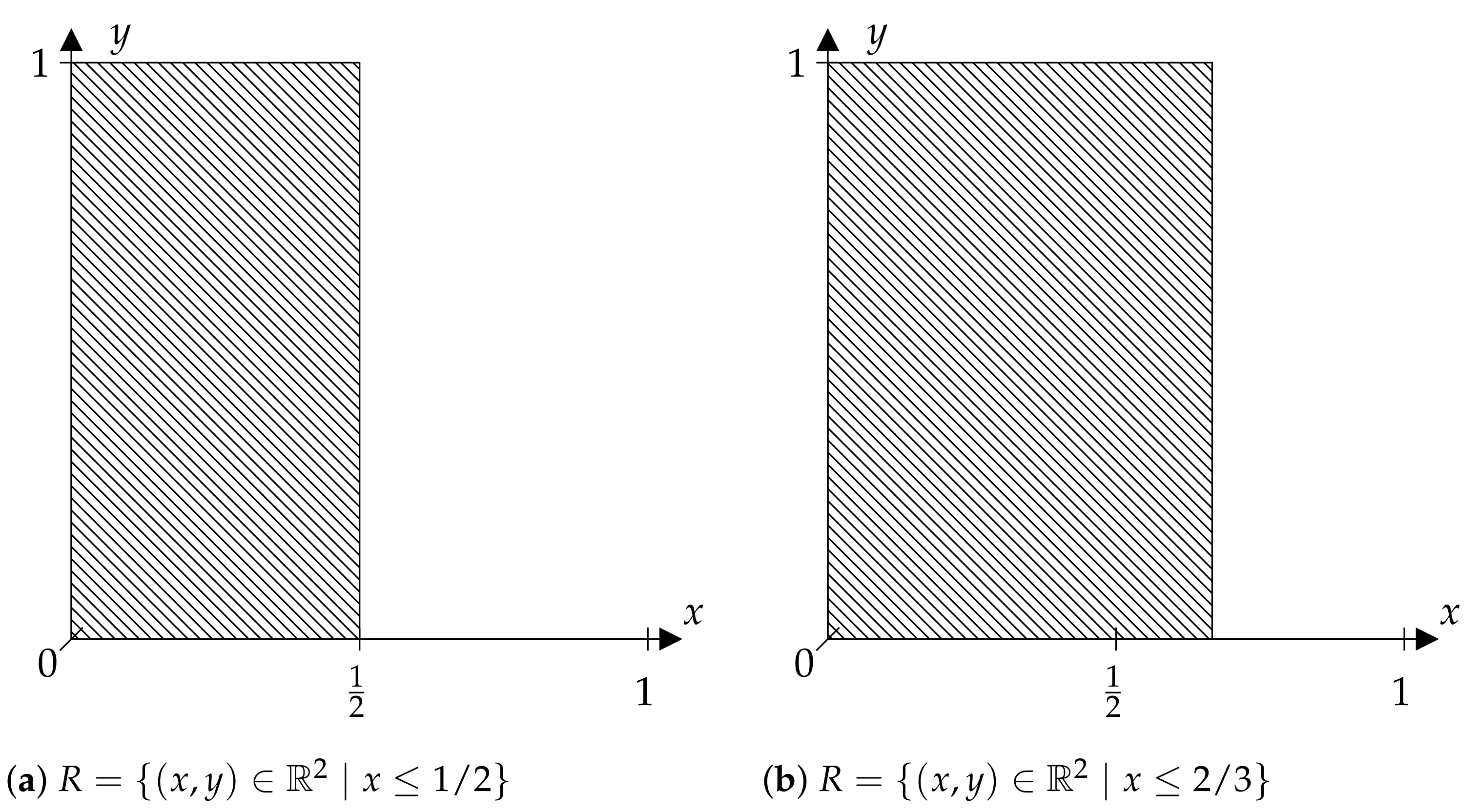
A completely different constellation is given for the sets R shown in Figure 2. Here, R is obtained as a half-plane from a “horizontal” division of . If, for example, , is the Borel -algebra and the Lebesgue measure on , and if T is the tent map on , meaning that:
and X is the identity map, then the location of the horizontal cut is substantial.
On the one hand, (Figure 2b) does not discriminate enough to obtain the KS entropy of the given system, and on the other hand, there is enough discrimination by (Figure 2a) due to the fact that is a generating partition for T. In the situation considered, there is no additional information given by the measurements relative to measurement x, hence R provides nothing more than a classical symbolization. For a detailed discussion of these facts, see [6].
The rest of this paper is organized as follows. Section 2 provides the notions and concepts being necessary for formulating the main statement of this paper in Section 3. This statement is rather abstract and general and has to be considered in relation to some special cases discussed in Section 4 and making our ideas and findings transparent. Section 5 is devoted to the proof of our main statement.
2. Preliminaries
Throughout this paper, will be a measure-preserving dynamical system.
2.1. Some Notions
We will write or for the Borel -algebra on or , respectively. Given a random variable , by we denote the push-forward measure of with regard to X, i.e., for all . The measure is the product measure, i.e., for all .
For some Borel set , we define the function by
If it is clear from the context which set is considered, we simply write instead of . The function can be represented as the integral:
Since is integrable with regard to , is integrable and therefore, also measurable by Fubini’s Theorem.
The complement of a set will be denoted by . The notation will be used for the boundary of a set R, i.e., the closure of R without its interior.
2.2. Entropy
The Shannon entropy of a finite partition of is defined as
The refinement of two partitions of is given by
For a finite collection of partitions of , one analogously defines:
The entropy rate of a finite partition of is defined as
where . For the existence of the limit in the formula, see, e.g., [7]. We are interested in determining the Kolmogorov–Sinai entropy of a system, which is defined as
where the supremum is taken over all finite partitions of in .
Note that the Kolmogorov–Sinai entropy serves as the central complexity measure for dynamical systems and can be considered as a reference for other complexity measures, including in data analysis. Roughly speaking, it measures the mean information obtained by each iteration step. Since the Kolmogorov–Sinai entropy is the supremum of the entropy rates of all finite partitions, its determination and its estimation in a practical context are not easy and it is of some interest to find natural finite partitions for which the entropy rate is near the Kolmogorov–Sinai entropy. This is also a motivation for considering ordinal patterns and its generalization in this paper.
2.3. -Algebras
Given a family of sets , by we denote the smallest -algebra containing all sets . Analogously, for a family of partitions of , we define as the smallest -algebra containing all partitions as subsets. Given d-dimensional random vectors , we define:
as the smallest -algebra containing all preimages of Borel sets. When comparing two -algebras , we ignore sets with measure 0, i.e., we write:
if for all there exists an with . In this sense, means that and .
3. The Main Statement
Recall that a measure-preserving dynamical system is ergodic if for each with it holds , meaning that the system does not divide into proper parts.
Referring to Section 1, we give some preparation for stating our main result. Recall that for defining (generalized) ordinal patterns it was basic to know whether or for and a random variable X on , where “time” pairs were taken from the sets (see (2)). In order to also allow reducing the number of necessary “comparisons”, we relax the definition of the sets leading to the following concept.
Definition 2.
We call a sequence with timing, if contains finitely many elements and if there exists a sequence with:
Formula (7) roughly says that nearly each “temporal” distance is available for “comparisons”. It guarantees that enough time-pairs are considered to not have any loss of information contained in the “thinned out” generalized ordinal patterns relative to the “full” generalized ordinal patterns.
Remark 1.
In the first paper on generalized ordinal patterns ([6]), a timing was differently defined: the authors of that paper called a sequence of finite sets timing, if there exists an increasing sequence such that for all :
- (i)
- ,
- (ii)
- for all , there exists a with and ,
- (iii)
- for all
hold true. Note that the last condition does not only depend on the timing but also on T and . Instead of those three conditions, we instead simply require that almost all differences can be found in the timing.
Given a random vector and , we define the partition:
for all , which is equal to:
Then, for as given in (2) the partition is no more than the partition of generalized ordinal patterns with respect to defined in Section 1 and can be considered as the partition of generalized ordinal patterns with respect to .
The proof of the following main theorem of the paper is given in Section 5.
Theorem 1.
Let be an ergodic measure-preserving dynamical system, be a random vector, be a discriminating relation and be a timing. Assume that the following conditions are valid:
Then:
holds true.
At first glance, conditions (8) and (9), being sufficient for (10), are looking very special. The considerations in the following section will, however, elucidate their role and show that they are relatively general. Roughly speaking, (8) says that the distribution of pairs of “independent measurements” with respect to is discrete on the boundary of R. Condition (9) is an orbit separation condition based on the involved “measurements” and the functions . In general:
holds true because all functions involved in (9) are measurable. Therefore, (9) is equivalent to
The inclusion of the random variable Y provides some further separation and allows the above inclusion to hold true for a wider class of dynamical systems than, for example, the ones considered in [6]. In the case that Y is constant, it can also be omitted. In theory, Y should be chosen to take different values on those sets on which takes the same values for and . In practice, the fact that such a random variable Y exists is sufficient and Y does not need to be explicitly specified. An example is given in Section 4.5.
4. Special Cases
In the following, we discuss some special situations where the assumptions of Theorem 1, i.e., (8) and (9), are satisfied. Lemma 2 provides an easy-to-check condition, that of when (8) holds true. It is more difficult to see, when the condition (9) is satisfied. Roughly speaking, this condition is fulfilled if together with Y can uniquely describe the outcomes of the whole dynamical system and applying to the results of is, in some sense, “reversible” for all . In other words, together with Y preserve the information of the system and there is no information loss for the symbolization. The first means that:
which obviously follows from
To describe the range of outcomes of the random variables X on a probability space , we will use its cumulative distribution functions defined by
When applying the cumulative distribution functions to the outcomes X of a system, we do not lose any essential information about the system, according to the following lemma. This lemma is a simple modification of Lemma A.3 in [6].
Lemma 1.
Let be a probability space, be a random variable and be a measurable function which maps Borel sets to Borel sets and satisfies the following property:
Then, . In particular, if or g is injective on .
Condition (11) in the above Lemma is a slightly weaker condition on g than injectivity. If g is injective, then will hold true for all and condition (11) will be satisfied. More general, condition (11) can still be true if g is not necessarily injective but if all sets on which g is not injective, which are given by for all , have measure 0. For example, this is true if g is equal to the cumulative distribution function.
4.1. On the Boundary of R
The condition (8) in Theorem 1, that the boundary of R apart from countably many points has measure 0, holds true for all “simple” sets R. In the following lemma, we specify what we mean by “simple”.
Lemma 2.
Let be a probability space, be a random vector and . If, for all :
then R satisfies (8), i.e., there exists a countable set with:
Proof.
Consider the sets:
for , which, obviously, are countable. Set:
Let . If is countable for -almost all , Fubini’s theorem implies:
Analogously, one can show the same if is countable for -almost all . □
Remark 2.
The patterns visualized in Figure 1 could also be defined on the whole real axis instead of a bounded interval by, for example, applying the transformation . Then, is a pattern defined on if R is defined on .
In the following three subsections, Y is assumed to be constant, and hence can be omitted.
4.2. Basic Ordinal Patterns
If:
(see Figure 1a), then is just the distribution function of , i.e., . Since is finite for all , (8) holds true by Lemma 2. According to Lemma 1, one has:
for all and . Therefore:
is equivalent to:
By Theorem 1, for ergodic systems, condition (14) implies (10). A more general statement also includes a large class of non-ergodic systems which was shown in [4]. Condition (14) is, for example, satisfied if and is the projection on the i-th coordinate for all , or if is a compact Hausdorff space and is injective and continuous. One can also use Taken’s theorem to argue that the set of maps that satisfy (14) is large in a certain topological sense. For both, see Keller [8].
4.3. Patterns Defined by “Injective” Functions
Let be a random vector and consider now:
for a measurable function (see Figure 1b). Since is finite for all , (8) holds true by Lemma 2. Moreover, one easily sees that .
Now, suppose that:
holds true for all . This directly yields:
for all and . Remember that holds true according to Lemma 1. Thus, (14) and (16) imply (10). When considering basic ordinal patterns in Section 4.2, we stated some conditions under which (14) holds true. It remains to consider when (16) is satisfied.
Assume that g maps Borel sets to Borel sets and is injective. This implies:
for all and . Now, suppose that:
holds true. This would then imply (16). However, the above equation only holds true -almost surely (see (13)). This can be a problem when applying the function g because there could exist sets with but . Additionally, we therefore need to require that implies for all .
Theorem 1 then provides the following statement:
Corollary 1.
Let be an ergodic measure-preserving dynamical system, be a random vector and be a timing. Let further be a measurable function which maps Borel sets to Borel sets, is injective on and satisfies for all and . Let .
Note that the statements in Corollary 1, in principle, were shown in [6]. The case of basic ordinal patterns is included by for all .
4.4. Patterns Defined by “Surjective” Functions
Swapping coordinates in (15) yields the set:
(see Figure 1c) with (8) following from Lemma 2 and with:
Corollary 2.
Let be an ergodic measure-preserving dynamical system, be a random vector and be a timing. Let further be a measurable function and let . Then, the following holds:
- (i)
- (ii)
- If and is the projection on the i-th coordinate for all or if Ω is a compact Hausdorff space and is injective and continuous, if further for every non-empty open set , g is continuous and , then (10) is valid in each of the following two cases:
- (1)
- For each and all with , there exists some with ,
- (2)
- Ω is connected.
Proof.
(i): If the above assumptions are satisfied and is injective on for all , then by Lemma 1 it holds that for all and . This implies (9), hence, by Theorem 1 the statement (10).
(ii): Given the assumptions of (ii), we have to show that is injective on for all . If is connected, then (1) is obviously satisfied. We can thus start from (1). Take with . Then, is non-empty and because is continuous, contains a non-empty open set. This implies that . because every non-empty open set was assumed to have a strictly positive measure. □
Notice that, unlike in (15), it is not necessary that g is one-to-one.
4.5. Piecewise Patterns
The previous subsection illustrates that (9) is fulfilled if, roughly speaking, preserves all information and if is a almost surely invertible function for all . The finite-valued random variable Y in (9) can be used to weaken the condition of invertibility in the sense that only piecewise invertibility is needed where the different pieces are induced by the random variable Y.
4.6. A Remark on the Work of Amigó et al.
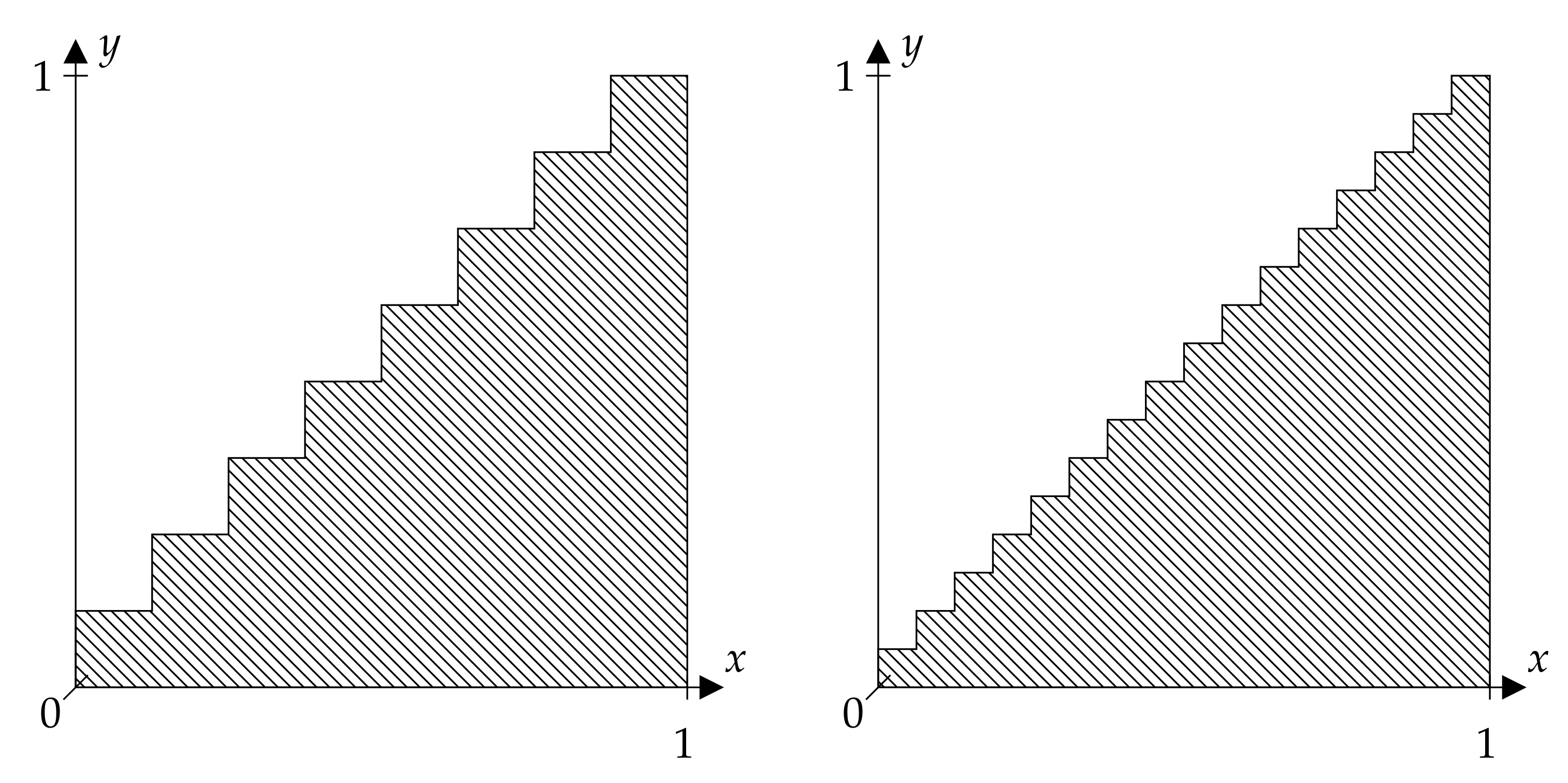
Consider the discriminating relation:
shown in Figure 3 for . Assume for simplicity that the dynamical system is defined on and that X is the identity map . It is easy to see that:
holds true, where . Therefore, (9) in Theorem 1 holds true if is a generating partition.
Additionally, one could consider the quantity:
which was introduced by Amigó et. al. [9]. They used finite-valued random variables to quantize the dynamical system into k parts and considered the ordinal patterns of the quantized systems while we directly apply the quantization to the discriminating relation. Both approaches only differ in their notation. They showed in their paper that the limit in (18) is equal to the Kolmogorov–Sinai entropy.
5. Proof of the Main Statement
We first recall some definitions and statements related to partitions and the conditional entropy. For two partitions of , the conditional entropy is defined as
Roughly speaking, the conditional entropy describes how much uncertainty is left in the outcomes described by the sets given in if one already has information about the outcomes described by the sets given in . For example, if , then . However, if and are independent, meaning that for all and , and .
Without explicitly referencing them, we will use the following properties of the conditional entropy:
- (i)
- ,
- (ii)
- ,
- (iii)
- .
See, for examples, [7] for proofs.
A sequence of partitions in of is said to be generating (the -algebra ), if for all and:
holds true. As a consequence of this property:
holds true for all partitions of . Using the properties of the conditional entropy implies:
For :
will denote the partition of in equally sized intervals.
We start the proof of Theorem 1 with two basic lemmata.
Lemma 3.
Let be a measure-preserving dynamical system, be a random vector and Y be a random variable satisfying (9). Then, there exists some constant with:
for all .
Proof.
Fix . Set:
Since Y was assumed to attain only a finite number of different values, is a finite partition of . Because the Borel -algebra of is generated by the partitions and due to (9), we have:
Thus, for any and any finite partition of , there exists an and a with:
for all . Hence:
for any , which implies:
□
Lemma 4.
Let be a probability space, be a random variable and . Then:
holds true.
Proof.
For all :
holds true. Analogously, one can show:
This implies:
and, by Fubini’s theorem:
□
Therefore, in particular, the above lemma implies that, if is a sequence of sets in with , then converges to in for .
Given and a random variable , consider the function with:
We want to show that converges to for all and -almost all . If is monotone in x for all and , this can be shown relatively easily using the pointwise ergodic theorem and the monotonicity of the considered functions. Monotonicity is guaranteed, if implies:
For example, if , the above implication holds true. For this special case, a proof of the statement in Lemma 5 can be found in [4].
However, we are interested in general sets and therefore, cannot use the monotonicity. Therefore, we have to prove this statement differently.
Lemma 5.
Let be an ergodic measure-preserving dynamical system, be a random vector and satisfy (8). Then, for all , there exist sets and with satisfying:
for all and .
Proof.
Fix . According to (8), there exists a countable set
with:
By the pointwise ergodic theorem (see, e.g., [10]), for all , there exists with and:
for all . It is easy to see that:
holds true for all and if . Hence:
for all and . Using Fatou’s lemma and the fact that C is countable implies:
for all and . We will use this fact later.
Since is open, there exists a countable collection of pairwise disjoint rectangles with:
Take for all . Using the pointwise ergodic theorem, for all there exists a set with and:
for all . Because is a rectangle, for all :
holds true for all with and:
holds true for all with . Together with (23), this implies:
for all and .
Set . Lemma 4 provides:
Therefore, there exists a set with and a sequence with:
for all . Thus:
for all and . Because is open as well, one can analogously show that there exist sets and with and:
for all and . This implies:
Hence:
for all and . □
Given a random vector and , we define the partition:
for all , which is equal to:
Lemma 1.
Let be an ergodic measure-preserving dynamical system, be a random vector, be a timing and satisfying (8). Then, there exists a sequence with:
for all and .
Proof.
Because is a timing, there exist a sequence with:
So one can find a strictly increasing sequence with:
for all and:
Now, fix . According to Lemma 5, there exist sets and with satisfying:
for all and . Set
Consider the function with:
Then:
for all .
We can now finalize the proof of Theorem 1.
Proof of Theorem 1.
Let and . Set:
and:
for all and . According to Lemma 1, there exists a sequence with:
for all . We have:
for all . This implies:
Using Lemma 3, we can conclude that there exists a constant with:
for all . Thus:
which is equivalent to:
On the other hand:
which, together with (31), finishes the proof. □
6. Conclusions
We discussed a special “two-dimensional” approach to symbolic dynamics differing from many usual approaches which was introduced in [6]. From the practical viewpoint, the difference can be illustrated as follows: given the time-dependent measurements of a real-valued quantity, a symbolization is not conducted for the measurements themselves as in usual approaches, but for pairs of measurements at two different times. This means that to each pair of possible measured values, a symbol from a finite symbol set is assigned. Here, we only considered two symbols which lead to a partitioning of the two-dimensional real space into a set R and its complement . In usual approaches, partitions of are considered. (Advantages of the “two-dimensional” approach are described in [6]).
The set R, called a discriminating relation, was considered as a basic building block for constructing partitions of the state space of a given dynamical system, having time-dependent measurements of finitely many quantities in mind. In addition to the discrimination relation, the second central concept was the concept of a timing which roughly describes which pairs of times are included in the symbolization process and guarantees that there are not too few such pairs. The central question of the paper was that of under which conditions on a discriminating relation R the partitions constructed from R determine the KS entropy of a measure-preserving dynamical system. With Theorem 1, we gave a relatively general statement partially answering this question. Some specifications of the theorem in Section 4 illustrate the nature of “successful” discriminating relations.
Although the statement of Theorem 1 appears relatively natural when looking at the proofs a little closer, we do not expect that all cases where the K-S entropy can be constructed based on a discriminating relation is covered by the statement; however, we have no counterexample. The main tool used in the proofs of the results is the pointwise ergodic theorem. It allows to establish a connection between the generalized ordinal patterns and the shape of the discriminating relation.
The results of this paper, being on a rather abstract level, give some insights as to why the idea of ordinal patterns is working well, as reported by several applied papers, with extracting those advantageous features being more general than in the original ordinal approach. Having many choices for a discriminating relation, for practical purposes such as, for example, in a classification context, one needs methods and criteria for finding good discrimination relations, adapted to given data and problems. This is an important challenge for further research related to the given approach to symbolic dynamics. A further aspect is to discuss the approach for partitioning the into more than two pieces.
Author Contributions
T.G. and K.K. designed and wrote the paper and T.G. provided the proofs. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation Entropy and Its Main Biomedical and Econophysics Applications: A Review. Entropy 2012, 14, 1553–1577. [Google Scholar] [CrossRef]
- Bandt, C.; Keller, G.; Pompe, B. Entropy of interval maps via permutations. Nonlinearity 2002, 15, 1595–1602. [Google Scholar] [CrossRef]
- Antoniouk, A.; Keller, K.; Maksymenko, S. Kolmogorov-Sinai entropy via separation properties of order-generated σ-algebras. Discret. Contin. Dyn. Syst. A 2014, 34, 1793–1809. [Google Scholar] [CrossRef]
- Smith, G.; Goulding, J.; Barrack, D. Towards Optimal Symbolization for Time Series Comparisons. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops, Dallas, TX, USA, 7–10 December 2013; pp. 646–653. [Google Scholar] [CrossRef]
- Stolz, I.; Keller, K. A General Symbolic Approach to Kolmogorov-Sinai Entropy. Entropy 2017, 19, 675. [Google Scholar] [CrossRef] [Green Version]
- Walters, P. An introduction to ergodic theory. In Graduate Texts in Mathematics; Springer: New York, NY, USA, 1982; Volume 79. [Google Scholar]
- Keller, K. Permutations and the Kolmogorov-Sinai entropy. Discret. Contin. Dyn. Syst. 2012, 32, 891–900. [Google Scholar] [CrossRef]
- Amigó, J.M.; Kennel, M.B.; Kocarev, L. The permutation entropy rate equals the metric entropy rate for ergodic information sources and ergodic dynamical systems. Phys. D 2005, 210, 77–95. [Google Scholar] [CrossRef] [Green Version]
- Cornfeld, I.P.; Fomin, S.V.; Sinai, Y.G. Ergodic Theory, 1st ed.; Springer: New York, NY, USA, 1982. [Google Scholar]
- Billingsley, P. Probability and Measure, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 1986. [Google Scholar]
Figure 1.
This figure illustrates some special discriminating relations R (striped areas) considered in Section 4. Only the part of R contained in [0, 1[2 is shown (compare the corresponding remarks in Section 4).

Figure 2.
“Non-diagonal” discriminating relations.

Figure 3.
for (left side) and (right side), only shown in .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gutjahr, T.; Keller, K. Generalized Ordinal Patterns and the KS-Entropy. Entropy 2021, 23, 1097. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081097
AMA Style
Gutjahr T, Keller K. Generalized Ordinal Patterns and the KS-Entropy. Entropy. 2021; 23(8):1097. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081097
Chicago/Turabian StyleGutjahr, Tim, and Karsten Keller. 2021. "Generalized Ordinal Patterns and the KS-Entropy" Entropy 23, no. 8: 1097. https://0-doi-org.brum.beds.ac.uk/10.3390/e23081097
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.