
Understanding Changes in the Topology and Geometry of Financial Market Correlations during a Market Crash


1
Center for Crystal Researches, National Sun Yet-Sen University, No. 70, Lien-hai Rd., Kaohsiung 80424, Taiwan
2
Division of Mathematical Sciences, School of Physical and Mathematical Sciences, Nanyang Technological University, 21 Nanyang Link, Singapore 637371, Singapore
3
Division of Physics and Applied Physics, School of Physical and Mathematical Sciences, Nanyang Technological University, 21 Nanyang Link, Singapore 637371, Singapore
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2021, 23(9), 1211; https://0-doi-org.brum.beds.ac.uk/10.3390/e23091211
Submission received: 19 July 2021
/
Revised: 5 September 2021
/
Accepted: 6 September 2021
/
Published: 14 September 2021
(This article belongs to the Special Issue Three Risky Decades: A Time for Econophysics?)
Abstract
:In econophysics, the achievements of information filtering methods over the past 20 years, such as the minimal spanning tree (MST) by Mantegna and the planar maximally filtered graph (PMFG) by Tumminello et al., should be celebrated. Here, we show how one can systematically improve upon this paradigm along two separate directions. First, we used topological data analysis (TDA) to extend the notions of nodes and links in networks to faces, tetrahedrons, or k-simplices in simplicial complexes. Second, we used the Ollivier-Ricci curvature (ORC) to acquire geometric information that cannot be provided by simple information filtering. In this sense, MSTs and PMFGs are but first steps to revealing the topological backbones of financial networks. This is something that TDA can elucidate more fully, following which the ORC can help us flesh out the geometry of financial networks. We applied these two approaches to a recent stock market crash in Taiwan and found that, beyond fusions and fissions, other non-fusion/fission processes such as cavitation, annihilation, rupture, healing, and puncture might also be important. We also successfully identified neck regions that emerged during the crash, based on their negative ORCs, and performed a case study on one such neck region.
1. Introduction
At the turn of the 20th century, Bachelier suggested in his PhD thesis that stock prices follow geometric Brownian motions and worked out some of the consequences [1]. This was a major breakthrough at that time, when few expected any theoretical understanding of the stock market. In his thesis, Bachelier assumed that the prices of term contracts follow a normal distribution. Osborn then proposed that it is the rate of return that follows a normal distribution [2]. Later, Mandelbrot and Fama independently found early evidence to suggest that this is not true, and the return distribution has fat tails better fitted by a Levy stable distribution with [3,4]. Mandelbrot then proposed modeling financial returns using fractional Brownian motion [5] and, later, multifractals [6]. Parallel efforts to understand the complexity of financial markets using agent-based models and evolutionary computing were also undertaken at the Santa Fe Institute by Palmer et al. [7]. Up until this point in time, physicists studied economics problems sporadically, and this body of knowledge was not yet known as econophysics.
Widely recognized to be the start of econophysics are the 1991 paper by Mantegna [8] and the 1992 paper by Takayasu and his co-workers [9]. Then, in 1995, Stanley coined the name econophysics during the Statphys-Kolkata conference at Kolkata, India [10]. This marked a watershed moment in the field. After 1995, more physicists worked on economic and financial problems, publishing their results and findings in physics journals. These events ushered in the field of econophysics, where physicists (and mathematicians, as well as computer scientists) brought insights from their own fields to the study of economics and finance. Over the next two decades, econophysicists witnessed several breakthroughs. The earliest success of econophysics is the application of random matrix theory (RMT, which is a statistical theory developed to explain the energy spectra of heavy nuclei) to the stock market [11,12,13,14]. In RMT, one treats noise as a kind of symmetry, and thus information represents some form of symmetry breaking. This allows physicists to discriminate between noise and signal in financial markets. The next significant milestone in econophysics was a more compelling demonstration of fat tails in return distributions by Mantegna and Stanley [15,16], and also by Mittnik et al. [17]. These two groups estimated for the Levy stable distribution.
Many other breakthroughs then followed, including the fitting of price time series to a log-periodic power-law (LPPL), which allowed precise predictions of market crashes [18,19], as well as the discovery of dragon kings [20] by Sornette, understanding and modeling of the Gibbs–Pareto distribution of wealth and income by Chakrabarti et al. [21] and Yakovenko [22], characterization of the actual Brownian motion in the price fluctuations [23,24], and the development of the DebtRank metric for measuring systemic risk in financial networks [25]. Other network approaches have also started appearing in econophysics recently. These include recurrence networks (RNs), visibility graphs (VGs), and transition networks (TNs). Recurrence networks were proposed by Marwan, Donner and their co-workers in 2009 [26,27] and are used to study the statistical properties of daily exchange rates [27]. Since the seminal work by Lacasa in 2008 [28], many groups have started using VGs to analyze financial time series, including exchange rates [29], stock indices across different countries [30], the macroeconomics series of China [31], and market indices in the US [32]. A recent article by Antoniades et al. [33] used the TN to investigate the Vosvrda macroeconomic model, but thus far no one has tested the approach on real financial time series data.
Other recent breakthroughs include the application of inverse statistics (IS) in finance. IS, which is deeply rooted in fluid dynamics, and related in particular to the phenomenon of turbulence, is an old yet challenging problem. For the last two decades, many concepts have been borrowed from past studies on turbulence and applied to financial problems. One of them was the use of forward statistics, which aims to answer the question “given a fixed time horizon, what are the typical returns that an investor will realize in that period?”. In addition, Jensen [34] proposed the inverse statistics, by turning the question around, to ask “for a given return on an investment, what is the typical time required to realize it?”. This latter question is no less pertinent and is more relevant to practical financial management. If IS such as the above can be computed, investors could earn market-beating profits.
Using the IS as a probe, Jensen, Simonsen, and Johansen, published a series of papers starting in the mid-2000s [35,36,37,38] to study many economic phenomena. They focused particularly on the Gain-Loss Asymmetry (GLA) in financial markets. GLA refers to the observation that, in a financial market, positive prices have different dynamics from the negative ones. After testing stock indices in the US such as the DJIA [35], Nasdaq, and the S&P 500 [37,39], those in other countries such as Austria [40], Korea [41], and 40 other world indices [39], and other instruments such as FOREX [38], mutual funds [42], it was found empirically that negative returns took shorter average times to realize compared to positive returns of the same magnitude. To explain how GLA occurs in real markets, models with a fear factor have been developed [43,44,45,46]. However, factors other than fear of loss might also explain the GLA [47]. A comprehensive survey on IS can be found in the review article by Ahlgren et al. [48].
In this Special Issue, we celebrate the breakthrough that is one of Mantegna’s crowning achievements, which is the application of the minimal spanning tree (MST) to unravel hierarchical structures in financial markets [49]. We will start by reviewing the essence of Mantegna’s insight, and the body of works that followed him (including the systematic embedding of cross correlations onto a hierarchy of surfaces with different genera [50]). We then describe attempts to overcome the limitations of the MST by going to hypergraph approaches [51,52,53,54]. A hypergraph is a natural extension of a graph, where instead of having each edge join only two nodes, an edge can join any number of nodes. Unfortunately, the hypergraph approach is difficult to implement starting from pairwise correlations, so we argue that the more promising approach to extract deeper insights into the hierarchical structure in financial markets is through topological data analysis (TDA) [55,56,57,58]. In TDA, the idea is to go beyond the concepts of nodes (0-simplex), links (1-simplex), and the network that they form to a simplicial complex, which can contain -simplices as constituents.
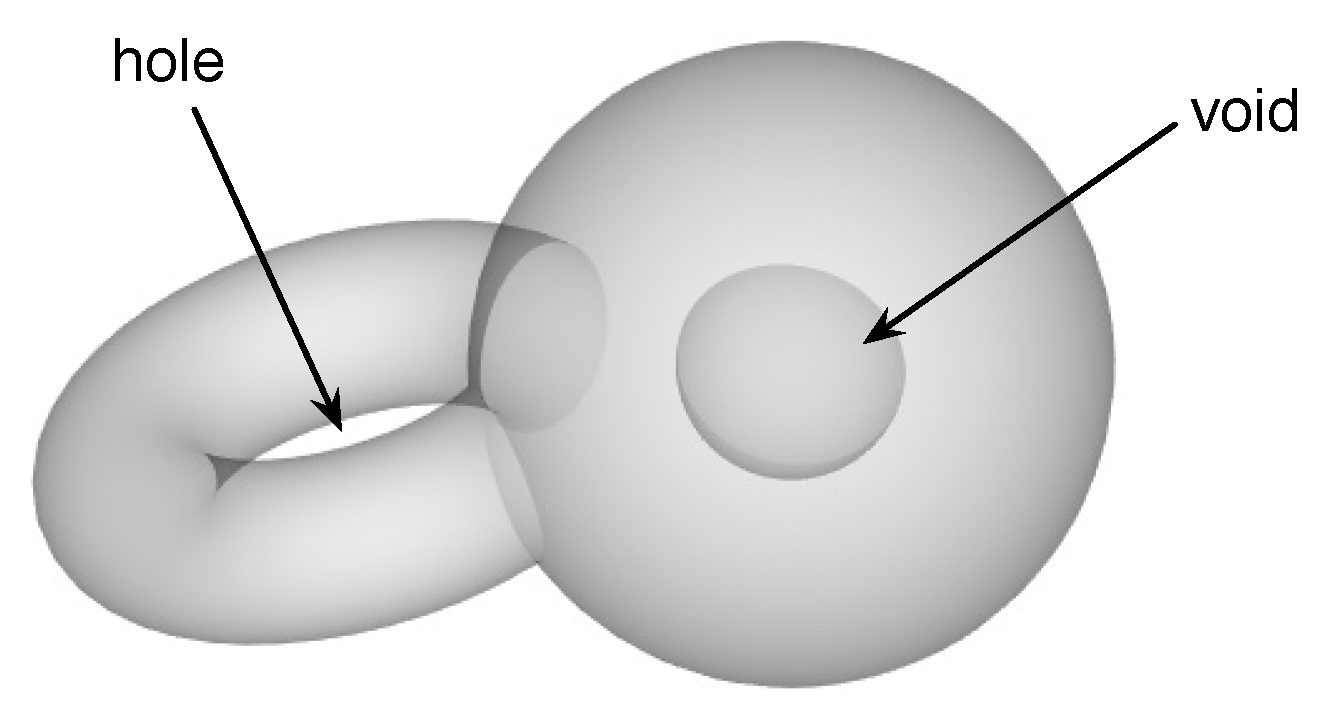
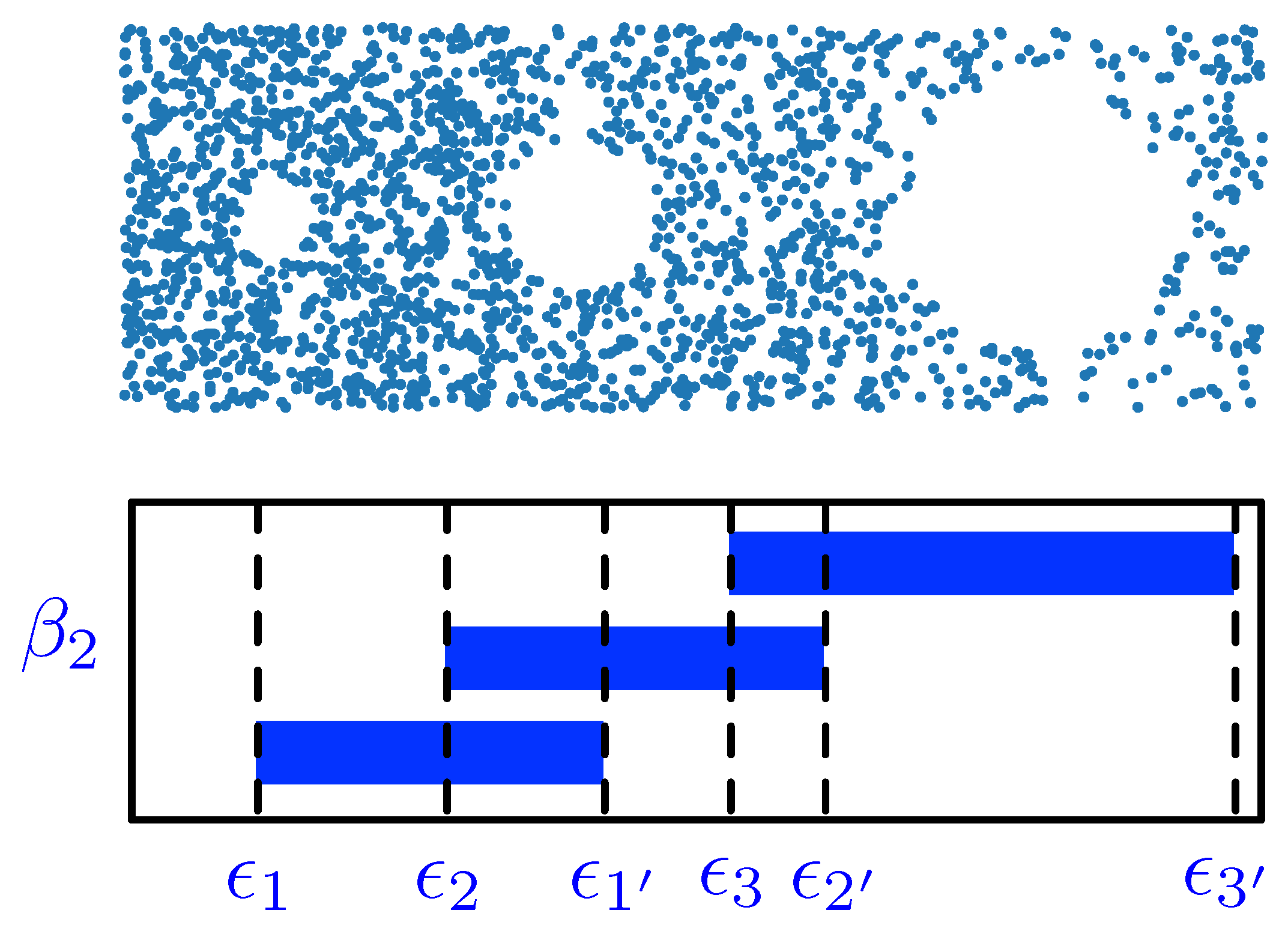
In a recent paper [59], we demonstrated how TDA can be used to understand the topological changes that accompany market crashes. For such extreme events in financial markets, one of the key questions not well answered through the use of MSTs or planar maximally filtered graphs (PMFGs) is how the hierarchy of cross correlations between stocks re-organizes itself. In particular, an important class of topological changes is the merging between disjoint clusters (or their time reversal—the splitting of a cluster into disjoint clusters). We found, by tracking how the Betti numbers , , and change over market crashes, that (the number of connected components) is small at the beginning of a market crash and increases as the market crash progresses. This tells us that we have a giant connected component in the market just before the crash, and as the market crashed, this broke up into many smaller components. The nature of this breaking up can be understood in greater detail through (the number of “holes” in the connected components), and (the number of “voids” in the connected components) (see Figure 1). Based on and , we realized that a particular crash occurred in two stages. In the first stage, the topology of the giant connected component became more complex, as some “voids” grew outwards to become “holes”. In the second stage, the number of “holes” decreased precipitously, presumably the result of handle-breaking events. These handle-breaking events are not simple, because the number of “voids” increases in this stage. Finally, the giant connected component broke up completely into many connected components that have simple topologies (few “holes” and “voids”).
In addition to the TDA, we found another promising approach for extending the information filtering paradigm of MSTs and PMFGs. This is through calculating discrete versions of the Ricci curvature, either the Ollivier-Ricci curvature (ORC) for networks, or the Forman-Ricci curvature (FRC) for simplicial complexes. To identify which stocks in a network or simplicial complex make up the neck or bridge region between two densely connected clusters, the naive approach would be to identify them visually. Naturally, this is laborious and inefficient. It turns out the ORC is ideal for this task, because links in the neck regions have negative ORC. More importantly, the breaking up of a manifold into two involved the stretching and narrowing of the neck region through a process called Ricci flow. Physical fission processes closely resemble Ricci flow, even when the objects undergoing fragmentation are networks or simplicial complexes. In such discrete Ricci flows, the ORC or FRC become more negative over time to produce finite-time singularities. Our motives in computing the ORC are threefold: First, we would like to identify the neck regions by looking for where in the network the ORCs are negative. Second, by looking at how the negative ORCs are changing, we would like to predict when we run into finite-time singularities. These are when the fissions occur. Finally, from the natures of the singularities, we would like to understand the drivers for the different fissions.
To make the case for TDA and Ricci curvature analysis, we organized our paper as follows. In Section 2, we will review applications of the MST in econophysics. In Section 3, we will explain how the PMFG can provide more details on correlations between stocks, by keeping more links than in the MST. In fact, there is a hierarchy of maximally filtered networks on closed surfaces with increasing genera (the PMFG being the simplest, on a sphere with genus ) that we can explore to understand the structure of correlations between stocks. Unfortunately, the algorithms for obtaining higher-order filtered networks become increasingly difficult to implement, which explains why the PMFG is not as popular as the MST. In fact, we found only one previous work that demonstrated how to filter the weighted links of an artificial complex network onto a torus (with genus ) [60]. In Section 4, we describe the ideas behind TDA, and suggest that this is the natural extension going beyond MST and PMFG. To make our case, we explore four toy models for fusions and fissions, and thereafter use their TDA signatures to explain non-trivial topological changes observed in the cross correlations between stocks during a market crash in the Taiwan Stock Exchange (TWSE). In Section 5, we define what Ricci curvature is for smooth surfaces, and describe how this can be generalized to discrete networks and simplicial complexes, in the form of Ollivier-Ricci curvature and Forman-Ricci curvature, respectively. We then explain why we need Ricci curvature analysis to distinguish between different stages of fission processes that are topologically equivalent, before demonstrating this power for one of the toy models. Finally, we use the Ollivier-Ricci curvature to analyze a sequence of PMFGs obtained from the cross correlations of TWSE stocks in overlapping time windows leading up to the market crash of interest, before ending with a comparative case study of two neck regions. In Section 6, we present the conclusions.
2. The Minimal Spanning Tree
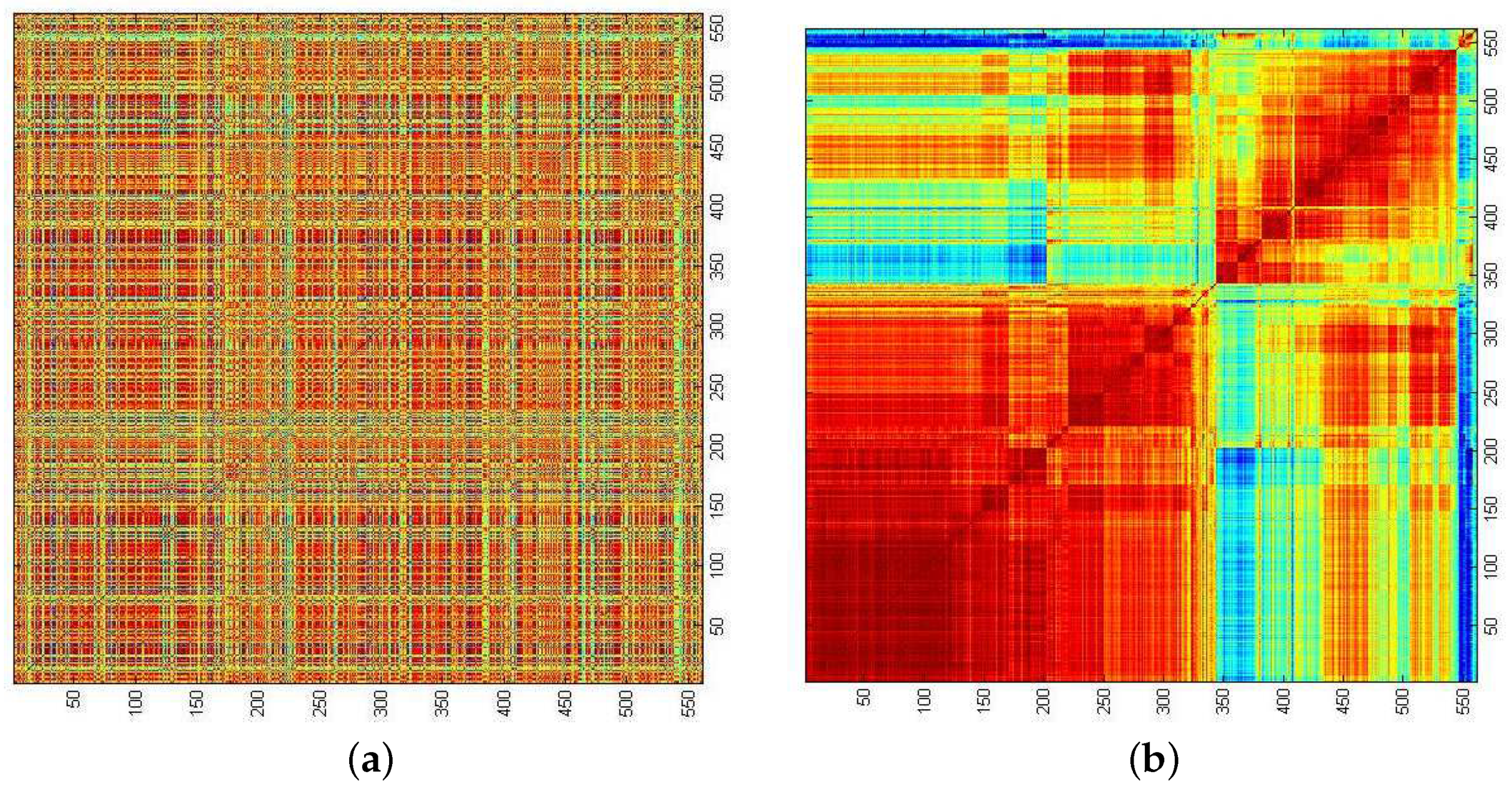
In Figure 2, we show the matrix of Pearson cross correlations
between 561 stocks in the Singapore Exchange (SGX) within the period January 2008 to December 2009. In Equation (1), the time series and with average can be the daily prices, daily price differences (also known as the daily returns), or daily log-returns (which are practically identical to the daily fractional returns) of stocks i and j. Their time averages are and . In Section 4.3, we used the daily returns for our topological data analysis. This is acceptable for short time periods, e.g., six months, because the price levels do not change by much. For longer time periods, for example, two years, as in the example associated with Figure 2, we used the daily fractional returns, so that we do not have the problem of increasing weights when the price levels become significantly higher at the end of the time period.
Before the rows and columns are reordered, it is impossible to discern any correlational structures in the SGX stocks. After reordering the rows and columns, we find the strong correlations organized into diagonal blocks, with weaker correlations between them. We also see that within the largest diagonal block in Figure 2b, the correlations are not uniform, but are further organized into diagonal sub-blocks. In hindsight, doing the reordering of rows and columns to reveal these correlational structures in the SGX was a straightforward task, since they have been shown to exist in other markets [61,62,63,64,65]. Mantegna was the first to suspect such hierarchical organizations exist in stock markets and proposed methods to elucidate such structures. Like us, Mantegna employed hierarchical clustering methods to carry out the reordering of rows and columns. However, clustering methods are based on pairwise distances, so the first problem that he had to solve was mapping the conventional Pearson cross correlations, which do not satisfy the three axioms of a distance metric, to pairwise distances. After discussions with Sornette (see Ref. 14 in [49]), Mantegna adopted the mapping
going from a cross correlation between stock i and stock j to a pairwise distance , which satisfies the strong triangle inequality. Mantegna then investigated the correlational structures in the component stocks of the Dow Jones Industrial Average (DJIA) and Standards and Poors 500 (S&P 500) indices, using single-linkage hierarchical clustering. Based on these results, Mantegna argued that US stocks do not react equally strongly to the various economic factors, but do so in groups synonymous with those discovered by random matrix theory [66]. This corroboration between Mantegna’s 1999 MST paper and Plerou et al.’s 1999 RMT paper was an important discovery at that time.
However, the greatest impact of this 1999 paper was the use of the minimal spanning tree (MST) as a caricature of the correlational structures between stocks. A tree is a graph with no cycles, and the MST was introduced as early as the 1950s as a special subgraph of a weighted graph containing cycles. In Figure 3a, we show the algorithm attributed to Kruskal [68] for constructing an MST, as well as an example in Appendix A. Following Mantegna’s lead, many others (including ourselves) started publishing papers on the MSTs of different markets in, for example, the US [69,70,71,72,73,74,75], UK [76], Korea [77,78], Japan [79], China [80], India [81], Indonesia [82], and Africa [83]. We also find the MST applied to different classes of financial instruments: market indices [81,84,85,86], bonds and interest rates [87,88,89], currencies [90,91,92,93,94,95], commodities [96,97,98,99,100,101], overnight loans in an interbank network [102], housing market indices of different countries [103], to name just a few. Beyond Mantegna’s test of the temporal stability of the MST representation (where he changed the time period slightly, recomputed the cross correlations, and drew the MST again) [69], Onnela et al. also used the MST to visualize the progression of a market crash [70,104]. Other applications include Sun et al. [105,106] and Jiang et al. [107] using the MST to detect insider trading in stock markets, as well as Onnela et al. [70,73], Tola et al. [108], and Coelho et al. [109] using the MST for portfolio selection. The popularity of the MST in econophysics should be clear from this quick survey, and interested readers can refer to the reviews [110,111] for even more references.
3. The Planar Maximally Filtered Graph (PMFG)
The successes of the MST in econophysics inspired many other network studies. For example, to understand the same finance and economics problems, many groups experimented with other types of networks [112,113,114,115,116,117,118,119]. Others, such as Chen et al. [120], experimented with artificial markets on small world networks, scale-free networks, and multilayer networks, to find noticeable differences in market sentiments on these different networks. We even found work focusing on developing complex network metrics that can be used to track the evolution of financial markets across different states (for further information, see the review by Kennett and Havlin [121]). Working more or less separately from network scientists, economists approach the network structure of financial markets from the broader perspective of market microstructure. The National Bureau of Economic Research has a market microstructure research group that, it says, “⋯ is devoted to theoretical, empirical, and experimental research on the economics of securities markets, including the role of information in the price discovery process, the definition, measurement, control, and determinants of liquidity and transactions costs, and their implications for the efficiency, welfare, and regulation of alternative trading mechanisms and market structures” [122]. According to a quant school [123], market microstructure deals with issues of market structure and design, price formation and price discovery, transaction and timing cost, volatility, information and disclosure, and market maker and investor behavior. In short, market microstructure is a sub-field of economics that assumes a network structure as a given in financial markets, but introduces additional economic metrics that would help policy makers regulate market dynamics. To this end, we see more network metrics used in economics, and they have become more widely accepted by traditional economists. For example, in a recent paper, Tellez et al. distinguished between secured and unsecured interbank loans, and concluded that the Katz centrality and DebtRank are appropriate measures of systemic risk for the unsecured interbank network, while PageRank is more correlated with the interest rate spread in a secured interbank network [124].
Against this backdrop, one of the most important developments following the popularization of the MST was by Tumminello et al., who took the correlation filtering approach one step further. In econophysics, the MST is typically constructed starting from the cross-correlation matrix, which has independent components. However, the MST only keeps of these. These MST links are clearly important, but we may also wonder whether some of the discarded links might be just as important. Tumminello et al. realized that we can obtain a hierarchy of filtered graphs by projecting the strongest cross correlations onto surfaces with different genera g [50]. The simplest such projection onto a sphere () is the planar maximally filtered graph (PMFG). This keeps links, which is more than in the MST but still small. In fact, all the MST links are contained in the PMFG. One advantage of using the MST (which is also true for the PMFG) is that we keep exactly the same number of links for the same number of nodes. This can be less biased than using a correlation threshold value because a small change in the threshold value may lead to a large change in the number of links kept. After the PMFG was introduced, we found the following econophysics papers applying it [86,125,126,127,128,129]. Unfortunately, the PMFG algorithm (see Figure 3b for said algorithm, and an example in Appendix A) is difficult to parallelize. Therefore, for larger data sets, Massara et al. developed a related algorithm called the triangulated maximally filtered graph (TMFG) [130].
4. Topological Data Analysis
In this section, we explain how to go beyond MSTs and PMFGs in our understanding of complex dynamics in financial markets by making use of methods developed for topological data analysis (TDA). In Section 4.1, we explain what the shortcomings of MSTs and PMFGs are, what we can understand and what we cannot, and why it is natural to turn to TDA. Following this, in Section 4.2 we briefly explain the ideas behind different TDA methods. We also describe three contrasting toy models for two manifolds to merge together, and a fourth toy model that is like a combination of the first three in Appendix B, before using the TDA signatures for each toy model to understand a real-world market crash in Section 4.3.
4.1. Why Topological Data Analysis?
In most of the MST and PMFG papers, econophysicists merely correlated the topologies of the networks obtained with events in the market, with little or no further explanation. When the MSTs or PMFGs of two successive time periods were compared, analysis is in terms of links created or deleted, but the market may have different numbers of connected components in the two time periods. A more thorough analysis would be to superimpose these connected components and the filtered graphs, to better understand the underlying reasons for link-level changes to the networks. However, when we project market cross correlations onto a MST or a PMFG, we always worry that we may be throwing out important information. Furthermore, by focusing on link-level changes, we are also implicitly assuming that changes to cross correlations can be understood in terms of pairwise interactions between stocks. Already, there are suggestions on the existence of important complex system dynamics that have to be described in terms of many-body interactions. For example, in gene expression networks, there are signs that important functions involve interactions between three or more genes [131,132,133,134]. The same is possibly also true for financial markets, but to identify such interactions, we must go beyond network descriptions of such systems.
The explanation for complex topological changes to the cross correlations between stocks lies ultimately with overlapping portfolios [135,136,137,138,139,140]. Simply put, each entity on the market owns multiple stocks, and because there are more entities than there are stocks, their portfolios necessarily overlap. Even for this bipartite system of entities and stocks, a network description would be an over-simplification. Based on the signals it receives and is capable of processing, an entity periodically optimizes its portfolio by buying and selling stocks. These trading activities generate signals for other entities in the market, who then react to optimize their own portfolios. These interactions at the portfolio level are not open information, but we can observe changes to the prices of stocks, and hence the cross correlations that these interactions produce. Over time, portfolios may accumulate so many changes that the cross correlations between stocks at different times become topologically distinct. Signatures of these topological changes can be seen in the MST [73,104,141] and PMFG [75,86,142] representations.
In their seminal work, Tumminello et al. explained how to project more and more cross correlations onto the surfaces of manifolds with increasing genera [50]. By keeping more links, we keep more of the information in the cross correlations. At the same time, we admit more complex groups (such as simplices) of cross correlations. Then, instead of asking about degree distributions and hubs, we can examine the distribution of k-simplices in the network, and how different simplices are connected to each other. The network obtained from the projection of cross correlations to a manifold with a large genus g should then be treated as a simplicial complex, i.e., a connected graph of simplices. In fact, in one of the PMFG papers [130], the authors pointed out that MSTs and PMFGs should already be recognized as simplicial complexes. There is thus potential for an improved understanding of the topological structure of cross correlations in terms of simplices, but somehow Massara et al. did not pursue it further to the natural TDA conclusion.
Recently, we published a TDA paper in the Frontier in Physics Special Issue “From Physics to Econophysics back to Physics: Methods and Insights” [59]. In this paper, we worked out the TDA signatures for (1) coalescing spheres, (2) torus to horn torus to spindle torus to sphere, and (3) sphere to ellipsoids, and used these toy models to develop a hypothesis on market crashes corresponding to the fragmentation of a multiply connected manifold with a non-zero genus. In this hypothesis, we have the creation of holes as well as handle-breaking events that accompany fragmentations associated with market crashes. We then presented preliminary evidence confirming the existence of hole creation and handle-breaking events. In this paper, we would like to go deeper to understand how a handle breaks, or its time-reversed event, which is how two disjoint manifolds fuse with each other.
4.2. What Is Topological Data Analysis?
TDA is a suite of mathematical tools developed by Edelsbrunner, Zomorodian, Carlsson, and Singh to analyze the topological properties of complex data sets [55,56,57]. Built on the foundations of topology [143,144,145,146,147], group theory [148,149], linear algebra [150,151], and graph theory [152,153,154], TDA has since became a popular field in applied mathematics, and has also found many applications in data analytics [58]. For more information on the history and developments of TDA, readers can consult these review articles [155,156,157,158].
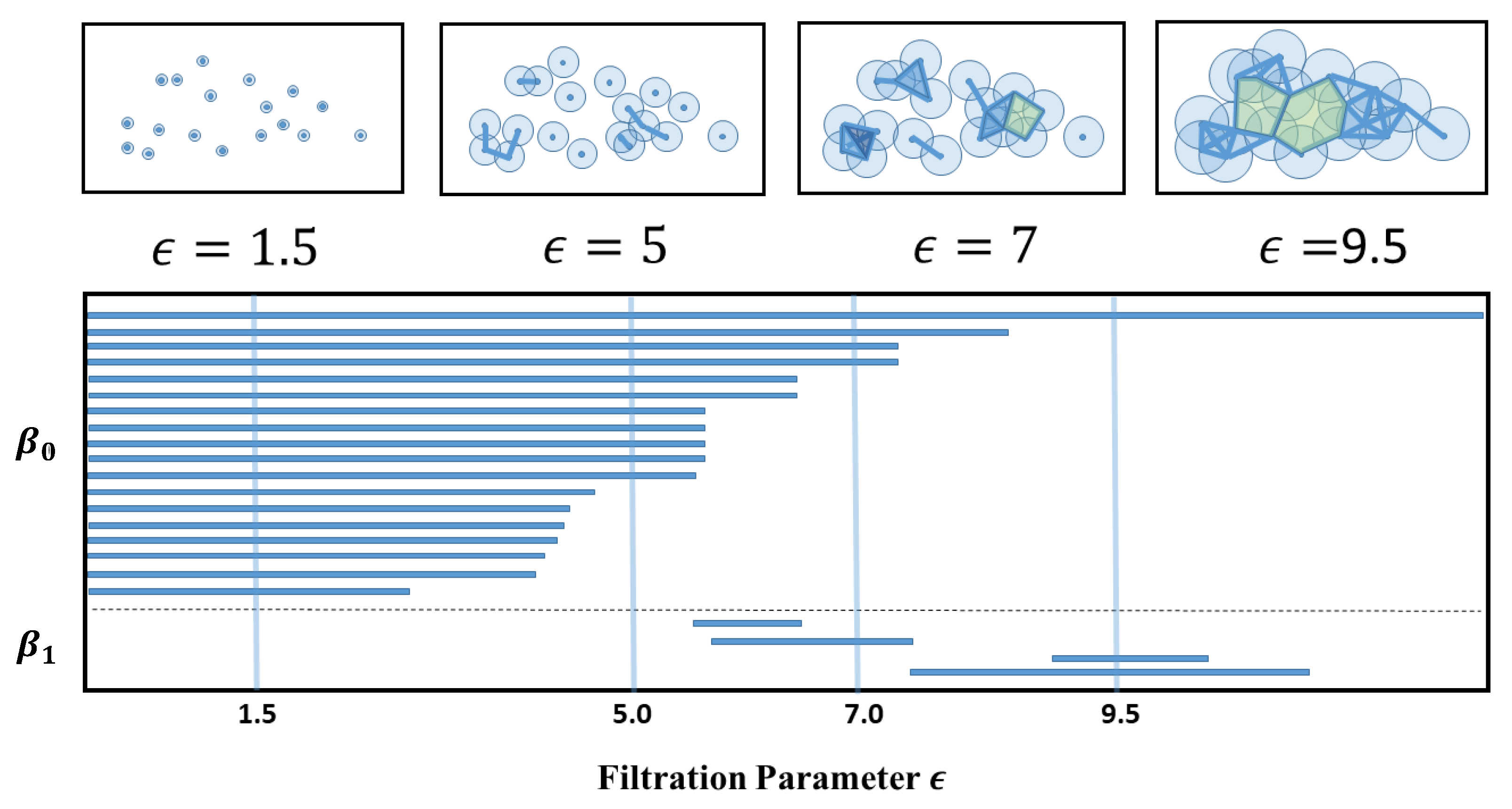
In its simplest terms, TDA is a novel way to unravel the topological features of raw data, which can be in the form of point clouds, distance matrices, networks, or digital images. To perform a TDA, we first imagine a control parameter called the proximity parameter or filtration parameter . This is the radius of an imaginary ball centered at each of the data points, which we call 0-simplices. When we increase , the balls will grow outwards and eventually overlap with other balls. When the balls of data points i and j overlap, we draw a link between i and j, and say that the two data points now form a 1-simplex . As increases further, there will be more overlaps, and if the data points are such that the balls of and overlap, for all pairs of in the set, then we say that forms a k-simplex. The topological information contained in the data set can then be expressed in terms of the distribution of k-simplices, , and how they are connected to each other into a simplicial complex. For different , we have different connected subsets of the simplicial complex. The homology groupH of a simplicial complex summarizes, in a group-theoretic way, the connectivities between k-simplices of different dimensions. As we analyze , the n-dimensional subgroup of H, for over the filtration process, we will discover simplices that remain the same over a large range of , as well as those that exist fleetingly over very small ranges of . We call the former the persistent homology of the data set, and based on these we construct useful TDA metrics such as barcodes, persistent diagrams, persistent landscapes, and also persistent Betti numbers. In addition, we combine these to design other tools, such as persistence-weighted kernels, or persistent entropy, and other persistent functions. To allow readers to more easily to grasp the general idea, we show cartoons in Figure 4 to demonstrate how TDA can be applied to a data cloud.
Recently, TDA has found applications in many areas. These include computer network structures [159,160,161], computational biology [162,163,164,165,166,167,168], image analysis [169,170,171,172], vision [170], data analysis [58,173,174,175,176], shape recognition [177], and amorphous material structures [178,179]. More recently, we found the use of TDA in the reconstruction of brain functional networks [180,181], the analysis of financial markets [182,183], and haze detections [184,185]. In fact, TDA has become so much of a cottage industry that many softwares have become available for non-experts. These include Javaplex [186], Dipha [187], jHoles [188], Simpers [189], R-TDA [190], GUDHI [191], PHAT [192], Persus [193], Dinoysus [194], Ripser [195], as well as those reviewed by Otter et al. [155], and Pun et al. [158].
To the best of our knowledge, so far only very few works [182,183,196,197] had applied persistent homology and TDA to the study of trading networks, banking systems, and market crashes. The work closest to ours is that by Gidea and Katz in 2018, who treated the daily log-returns of S&P 500, DJIA, NASDAQ, and Russell 2000 as a four-dimensional data point [183]. They then slided a w-day time window one day at a time to create a sequence of point-cloud data sets that covered the Dotcom Crash of 2000, as well as the Global Financial Crisis of 2007–2009. The topological features they identified from the filtration process are high-order temporal correlations at various time scales. They then devised an norm that can differentiate between persistent landscapes in two time windows, revealing early warning signals preceding crashes. Building on top of this work by Gidea and Katz, as well as the econophysics literature on MSTs and PMFGs, we will report in this paper an understanding of market crashes at levels of detail never before accomplished.
4.3. Using TDA to Understand Market Crashes
In this subsection, we examine the cross-correlation matrices of 671 stocks in the Taiwan Stock Exchange (TWSE) in successive six-month time windows that are seven days apart, and attempt to use the toy-model results in Appendix B to understand the fusion and fission processes associated with the March 2020 crash in greater details. In particular, we would like to ask “how many of each kind of processes do we find?” and “are there combinations of more than one kind of processes?” To answer these questions, we first organize in Table 1 the Betti numbers read off at the largest filtration parameters, for time windows between 1 August 2019 and 31 March 2020. Here, we see that, over the four time windows of August 2019, we have , , and on average. Then, in the first two time windows of September 2019, while and remained similar to those in August 2019, changed from an average of to . For the next three time windows, the topological changes appear to have accelerated. Using the same over the five time windows, we found that the number of simplices increased dramatically from 10 million in the first time window of September 2019 to 85 million in the last time window of September 2019. In this last time window of September 2019, the Javaplex program failed to return any Betti numbers. It was only when we decreased the maximum filtration parameter from to , that the number of simplices was reduced to 17 million, giving us , , and .
To put these changes in the proper context, let us recall that we analyzed 671 stocks in the TWSE. When , none of these would be within the -ball of each other, and thus we found . As increases, links start to form between stocks, and would decrease. After some point, the change in would be dominated by the gaps between clusters of stocks. If there are three such clusters, we would find over a wide range of , before it drops to 2, and then eventually to 1. This is the picture we should have in mind when we say that the persistent Betti number is . However, for the last few time windows, we cannot be sure that the found by Javaplex are its persistent values. Physically, it is meaningful to compare persistent Betti numbers. It is also meaningful (but less so) to compare Betti numbers for a given value of . However, it is meaningless to compare Betti numbers obtained with different filtration parameters if they are not all persistent. Based on our past experience, there seems to be an analogy between the filtration parameter and the temperature of a thermodynamic system. Normally, a 10% change in the filtration parameter results in a corresponding 10% change in the number of simplices (akin to the number of arrangements whose logarithm gives us the entropy [181,198]), and hardly any changes to the Betti numbers, if we have already arrived at their persistent values. However, when the system is close to a critical point, a small change in temperature can produce a large change in the number of accessible states (analogous to simplices). To put it simply, our analysis of the Betti numbers suggests that the cross correlations in the first six time windows were more or less similar topologically, whereas for (15 September 2019, 15 March 2020) and subsequent time windows, the Betti numbers became extremely sensitive to over a broad range of , suggesting a non-trivial topological transition over the last three time windows. Another signature of this topological transition is the persistence weakening phenomenon that we observed in our earlier paper [59], where we found first a slow increase in the number of simplices, and then a rapid increase in the number of simplices after some threshold.
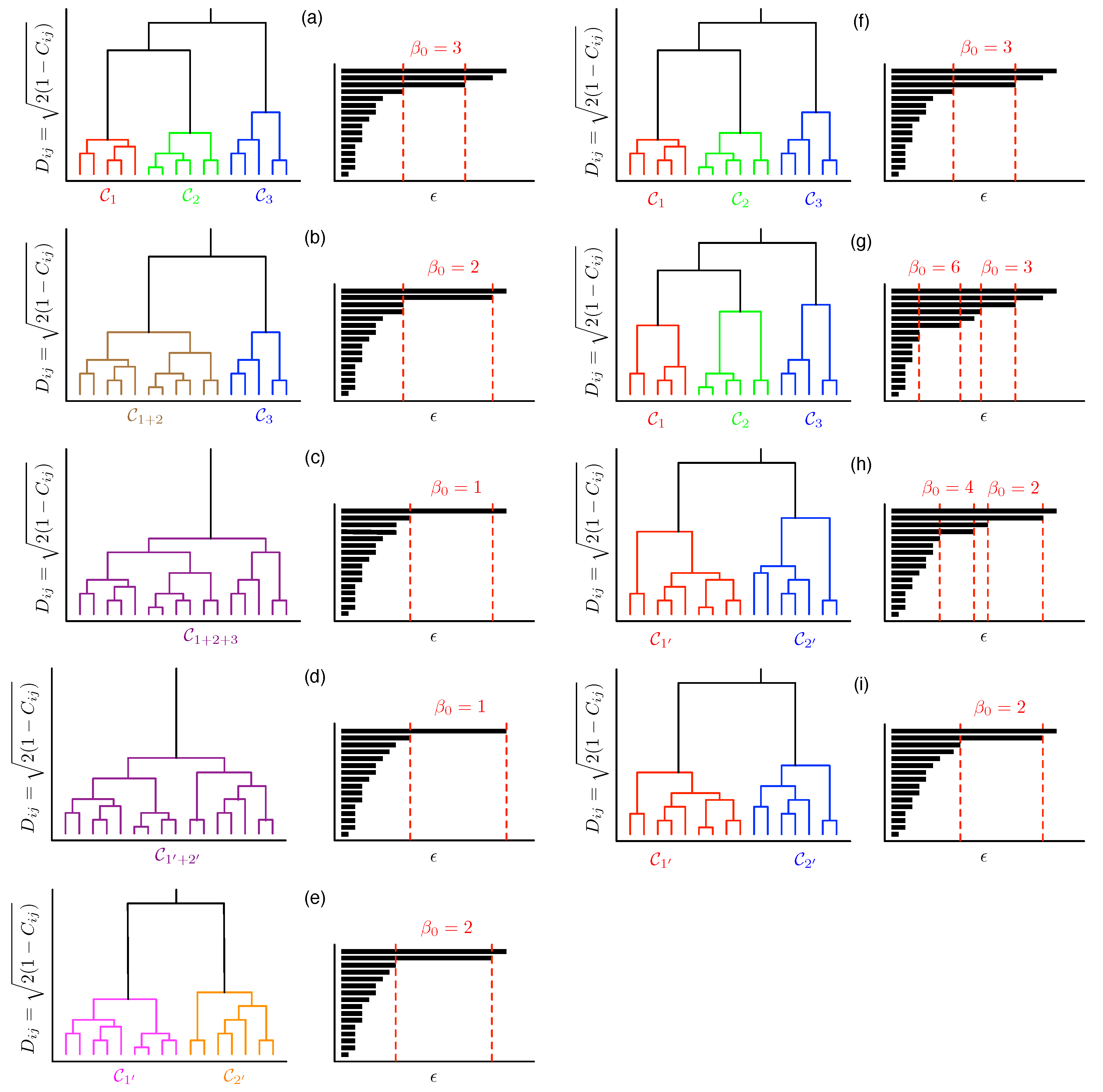
With the above in mind, let us consider the topological changes going from the second time window to the third time window, where we are confident that the Betti numbers obtained are persistent. Between these two time windows, we found that , , and . Comparing these against the results of Appendix B, we realized that there were no fusions () or fissions (), and therefore, none of the toy models we considered in Appendix B would be able to explain the changes to and . In fact, for these first few time windows, the changes to appeared to be independent of changes to , i.e., the creation/annihilation of holes seems to be independent of the creation/annihilation of voids. Some possible mechanisms for doing so are shown in Figure 5a–f. Although these time windows were still far from the crash, the picture of the market dynamics they suggest is more complex than we expected. We might need to go to higher-order Betti numbers to fully elucidate this dynamics.
In Appendix C, we showed that it is possible to have persistent Betti numbers (and thus equally meaningful pictures) at different scales. However, this makes the identification of the persistent more difficult, because we need to identify the filtration parameter values at which the lifetimes change most rapidly. Frequently, these are close to the largest scale, and cannot be easily seen from a full barcode (see Supplementary Material). To perform this multiscale analysis, we need to restrict ourselves to the longest-living barcodes, as shown in Figure 6 for the seventh of our nine time periods, i.e., (15 September 2019, 15 March 2020). In this figure, we find four persistent values at different scales. For the lowest of these four scales, from , we have . Thereafter, from , we have , and then for , and for . In Figure 6, the filtration parameter ends at . If we continue to increase , it is likely that we would find another persistent at a higher scale. Unlike for the seventh time period, which illustrated our ideas in Figure A6 very well, similar analyses for the eighth (22 September 2019, 22 March 2020) and ninth (1 October 2019, 31 March 2020) time periods would not yield equally convincing results, because the number of simplices at is far too large for Javaplex to handle. We also do not expect to find strongly persistent to emerge at the scales of for the eighth time window, and for the ninth time window.
To wrap up this section, we now understand that it is only meaningful to compare persistent Betti numbers or the Betti numbers at a fixed . However, we also realized from our analysis in Figure A6 that persistent Betti numbers can emerge at multiple scales, and the way to find them is to check where the lifetimes change most rapidly in the barcodes. Although we could not elucidate the persistent Betti number changes for the eighth and ninth time periods (for the March 2020 crash in the TWSE), our analyses of the first few time periods, as well as the seventh time period, are already a testament to the power of TDA. Without TDA, we would not have even guessed the roles of non-fission processes. Certainly, analyses based on the MST and PMFG would not be able to detect nucleation, rupture, and puncture events. Naturally, we need to ask whether such events are important, since these topological changes are not as drastic as fusion or fission. In any case, we must first be able to detect these events before we can evaluate how important they are relative to fusions and fissions. One hint that they might not be of negligible importance is the observed sequences of changes to and then to before changes. Therefore, any method that can detect and has the potential to provide early warning for fusion or fission events with .
5. Going Beyond TDA: Ricci Curvature
Up to this point, we have a very detailed picture of global topological changes to the TWSE over the March 2020 crash. However, metrics such as Betti numbers cannot tell us which stocks participate in which stage of the changes. We can of course manually inspect the output of Javaplex to identify persistent simplices and then track their changes over the time windows. As can be imagined, this is extremely laborious. We would certainly like to have a metric that would automatically pick out not all persistent simplices, but those in the midst of rapid changes. It turns out that such a metric exists, after applied mathematicians recently adapted the idea of Ricci curvature to networks.
5.1. Ricci Curvature and Ricci Flow
To understand Ricci curvature and Ricci flow, we need to start with the Riemannian metric , which allows us to specify the distance between any two points x, y on a surface. The Riemannian metric is also important for the calculation of area. To explain this, let us introduce a disk of radius r centered at x. This is the set of all points y whose distance to x is less than r. On a Euclidean plane, the area of would be . On a Riemannian surface, however, this area can deviate from . To understand this deviation, let us imagine a disk on the surface of a sphere. Through elementary calculus, we can show that the area of such a disk is a little less than , and we can understand this deficit as due to the scalar curvature
on the surface of the sphere. One of the main disadvantages of using the scalar curvature is that we do not know whether the curvatures along different directions are the same, or different. Therefore, we extend the notion of the scalar curvature to directional curvatures by defining the Ricci curvature as
for an angular sector inside a small disk , which has a small angular aperture (measured in radians) centered around some direction (a unit vector) emanating from x. Here, is the area of the small angular sector, and is the inner product of the Ricci curvature tensor along the direction. If has the same value for all , we say that the curvature of the surface is isotropic at x. Otherwise, the curvature at x is anisotropic.
The definition in Equation (4) allows the Ricci curvature to be computed intrinsically, i.e., without embedding the surface in a higher-dimensional space. This property is important when we generalize the Ricci curvature to networks. Going back to surface of a sphere, we will find that has the same positive value at every x, and for every direction . Therefore, the Ricci curvature on the surface of a sphere is not only isotropic, it is also positive. For a planar surface, the Ricci curvature is also isotropic at all points, but its value is zero. For an arbitrary two-dimensional surface, the Ricci curvature at a given point will vary from some maximum value to some minimum value. These two values are called the principal curvatures of the surface at the given point. In general, for an n-dimensional surface, the Ricci curvature will vary between n principal curvatures, each of which can be positive, negative, or zero. A highly readable explanation can be found in Terence Tao’s blog [199].
The Ricci curvature plays an important role in Einstein’s theory of general relativity [200]. Even though Einstein worked through the Riemann curvature tensor , to get to the Ricci curvature and the scalar curvature , we note that the Riemann curvature tensor is coordinate-dependent, while the Ricci curvature and scalar curvature are both coordinate-independent. It therefore makes perfect sense that only coordinate-independent quantities can enter Einstein’s field equations. Another application of the Ricci curvature is its use to measure the growth of volumes of distance balls, transportation distances between balls, divergence of geodesics, and meeting probabilities in coupled random walks [201].
Due to its intrinsic character, the Ricci curvature is also the central concept behind the theory of Ricci flow,
which is the mathematical theory that describes how manifolds deform. Informally, Ricci flow is the process of stretching the Riemannian metric g (increasing distance between points) in directions of negative Ricci curvature, and contracting g (decreasing distance between points) in directions of positive Ricci curvature. The stronger the curvature, the faster the stretching or contracting of the metric. In principle, one can use this equation to perform Ricci flow on a manifold for as long a period of time as one wished. In practice, however, it is possible for a manifold to develop singularities (where the curvature becomes infinite) during the Ricci flow. In three dimensions, many complicated singularities are possible. For instance, one can have a neck pinch, in which a cylinder-like “neck” of the manifold shrinks under Ricci flow, until at one or more places along the neck, the cylinder has tapered down to a point.
In pure mathematics, the theory of Ricci flow was instrumental in the proof of the Poincare conjecture (see Appendix D). So how does Ricci flow connect to what we care about in complex systems, or econophysics in particular? Conventionally, before one looks into the dynamics of a complex system, the first parsimonious step will always be to examine only the backbone (the “topology”) of the dynamics. From this perspective, MSTs, PMFGs, graphs, networks, manifolds, or simplicial complexes are different constructs to inform us what this backbone is like. After constructing the backbone, and making sure that it is roughly correct, we then add the “geometry” of the dynamics in as a natural second step, and a natural and coordinate-independent way to quantify this would be to use the Ricci curvature. Therefore, it is important not to go directly into the geometry, before getting a perspective on the topological panorama, because the same curvature value can often mean different things when they are put onto different topologies. For example, the n-sphere and the n-torus are topologically different manifolds, but they could still have similiar average curvatures. Therefore, the use of curvature alone cannot distinguish them. This is also why the correct procedure should always work on the topologies first, before putting the curvatures back, to acquire the correct geometrical information.
From the viewpoint of theorists, the use of differentiable manifolds to describe complex system dynamics is rigorous. In real-world problems, however, manifold constructs are difficult to implement, due to computational limitations. Hence, our plan B often involves the coarse-graining of smooth manifolds. The way this works is to first collect real-world time series cross-section data and calculate their correlation matrices, before visualizing them in terms of networks or simplicial complexes to extract their topological characteristics. From this perspective, we are interested in the breaking of bridges, or the fusion of clusters. For differentiable manifolds, the different types of singularities that can be encountered in two-dimensional Ricci flow have been completely worked out [202], and partially so for Ricci flow in three dimensions [203,204]. For higher dimensions, these are still poorly understood [205]. For networks and simplicial complexes, we need to start with discrete versions of the Ricci curvature. These are the Ollivier-Ricci curvature (ORC) [206,207] and the Forman-Ricci curvature (FRC) [208,209]. The former is applied to networks, whereas the latter is devised for simplicial complexes. It has been found that the ORC is “related to” various graph invariants, ranging from local measures, such as the node degree and clustering coefficient, to global measures, such as betweenness centrality and network connectivity [210]. Thus far, ORC has been used to broadly investigate properties of the internet [210], gene expression networks related to cancer [211], and the structural connectivity of an animal brain [212], as well as to assist in specific tasks such as community detection [213,214], the measurement of market fragility, and the estimation of systemic risk [215]. In this work, we focus on using the ORC, and defer the application of the FRC to future works.
To define the ORC in mathematical terms, we start with an unweighted graph with vertex set and edge set , where n is the total number of vertices and m is the total number of edges. Let be the neighborhood of a vertex . To introduce a curvature measure on a graph, Ollivier associated curvature with transport processes, much like the original concept of curvature being related to the parallel transport of one tangent vector along another. On a graph, the natural transport process to consider is a random walk, and the natural analog of parallel transport is how the hopping probabilities from a vertex to its neighbors change to the hopping probabilities from a vertex to its neighbors as we move the geodesic distance from x to y. This change can be quantified by the first Wasserstein distance, also known as the earth mover distance
where inf is the infimum, and represent the amount of “mass” moved from to , so that, after all movements, the hopping probabilities change from to . In the original paper by Ollivier, and others after him, the hopping probabilities are defined as
where is the total number of neighbors in . In the eighth example of his 2009 paper [207], Ollivier considered a lazy random walk, and used a modified set of hopping probabilities
This modification is useful, because in general, random walk on a graph G does not always lead to a stationary probability distribution, whereas a lazy random walk always do. Finally, in terms of , the ORC can be defined as
This can be obtained using a linear programming procedure to optimize , as shown in Appendix E. In this Appendix, we computed for two arbitrary nodes x and y on the network G, but in Equation (9), as part of the definition for , we compute only for edges . For the more common graphs, i.e., tree graphs, grid graphs, complete graphs, or bipartite graphs, can be evaluated in simple mathematical forms.
5.2. Ollivier-Ricci Curvature Analysis of TWSE
After confirming using the toy model in Appendix F the utility of negative ORCs to identify neck regions, we turn our attention to the TWSE March 2020 crash. The neck regions in the simplicial complexes across this market crash should also be thin and weakly connected parts that are most likely to be associated with rapid changes. Since the ORC computation requires a graph as input, we have to produce one starting from the Pearson cross correlations. Therefore, in the first part of this subsection, we limited ourselves to one time period (1 October 2019, 31 March 2020), and explore different ways to create the input graph.
Naively, we can create a complete network in which all links are present, but with different weights. However, such a network will always look like a fur ball when visualized, making it difficult for us to discern the various neck regions. Therefore, the first thing we tried is threshold filtering, i.e., we draw a link between stocks i and j if . The Python function that computes the ORC can accept as input disconnected graphs, but we adjusted until we obtain a fully connected graph. Unfortunately, for this (1 October 2019, 31 March 2020) time period, the fully connected graph obtained for the TWSE has 166,831 links. After visualization it still looks like a fur ball, impeding our investigations of topological changes in the network.
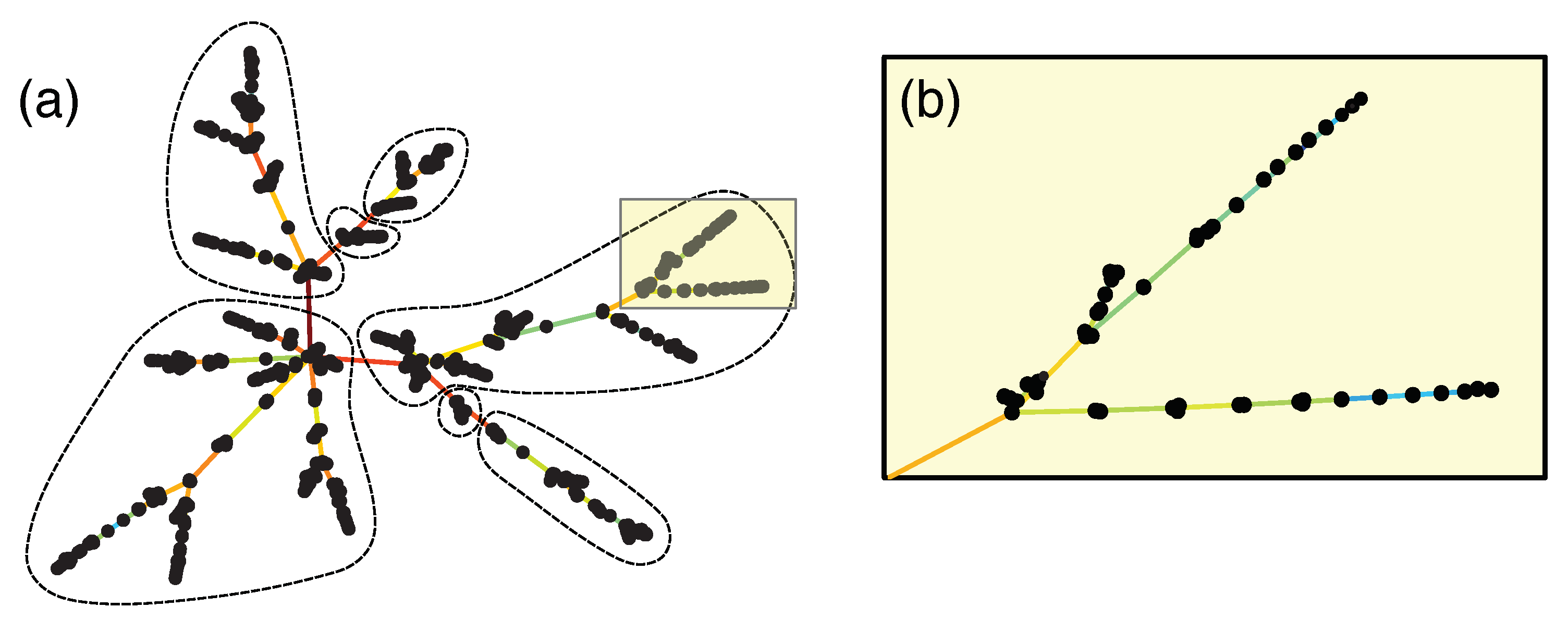
The next thing we tried is the minimal spanning tree, which can be constructed using the Kruskal algorithm shown in Figure 3a. Compared to a fur ball, the MST is more informative, especially when we used the force atlas layout [216]. In this layout, shown in Figure 7, nodes that are connected by short links have strong Pearson cross correlations, whereas those that are connected by long links have weak Pearson cross correlations. This geometrical feature of the layout allows us to discern clusters of strongly correlated nodes, separated from each other by weak correlations with bridging nodes. However, in the MST only, links are retained for N nodes. These are very few, so we checked how many important links were rejected by the MST in the nine periods, using two measures of importance: (1) correlations larger than the minimum correlation incorporated into the MST, and (2) correlations larger than the minimum correlation associated with the hub of the MST. These are shown in Table 2. Indeed, a large number of cross correlations larger than (1) were rejected in all nine time periods, and especially in the last two time periods. However, the importance measure (1) may be too strict, since we know that for all nodes to be connected in the MST, we frequently have to incorporate weak cross correlations. Based on importance measure (2), which is the correlation level set by the hub, the number of rejected cross correlations is significantly fewer, except during the fifth, seventh, and ninth time periods.
Therefore, the last filtering we tried is the planar maximally filtered graph (PMFG), adapting the Python example in https://gmarti.gitlab.io/networks/2018/06/03/pmfg-algorithm.html, accessed on 5 May 2021. As we have described in Section 3, this information filtering method was first proposed by Tumminello et al. [50]. We should add that in recent implementations, the Boyer–Myrvold planarity test [217] has replaced the Kuratowski theorem [153] for checking that the graph remains planar at different stages. The resulting PMFG is shown in Figure 8i. By allowing cycles, clusters are more compact in the PMFG. Additionally, links were kept. This is an intermediate number that is still easy to visualize, and contains more of the important cross correlations. In particular, we observed that the cluster at the bottom of the visualization is connected to the rest of the network through two necks (instead of one). However, if we use the same two measures of link importance as for the MST, we see in Table 3 even more important cross correlations rejected in the PMFGs.
After deciding to use the PMFG visualization across all time periods, we tried to identify neck regions that persisted over several time periods to better understand how the market crash proceeded. Therefore, we used the final layout of the first time period as the initial layout of the second time period, the final layout of the second time period as the initial layout of the third time period, and so on and so forth. We had hoped that the PMFGs for successive periods would be sufficiently similar that we could identify features across them. Unfortunately, as we can see from Figure 8, this is not the case, even when we reduced the number of iterations to 100 for the force atlas layout algorithm.
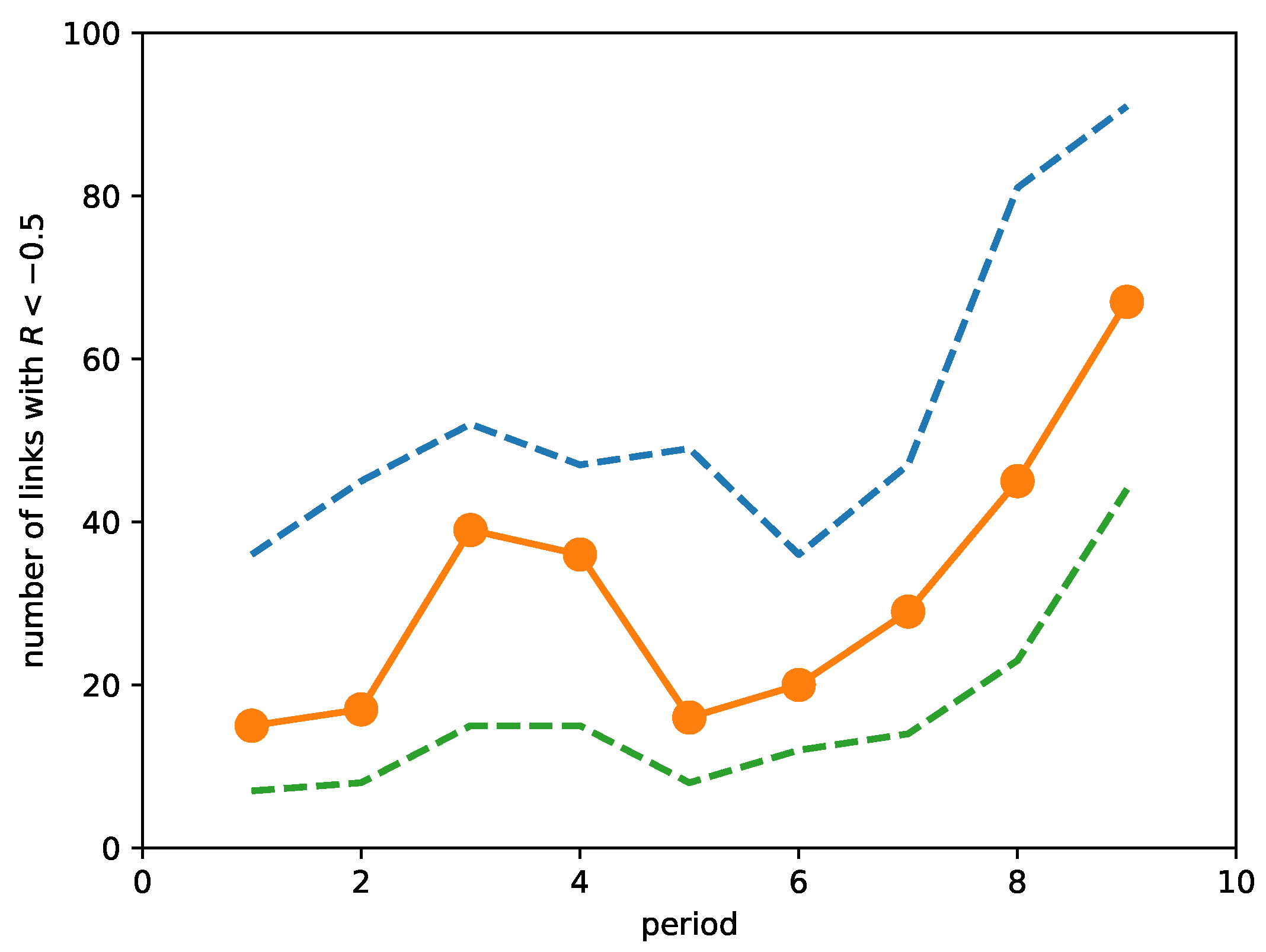
Due to this problem, we abandoned our original ambitious plan to automatically identify all neck regions and their changes. Instead, we manually analyzed the neck region that changed the most dramatically over the market crash. To begin, we first plotted in Figure 9 the number of links with strongly negative ORCs (<) over the time periods. As we can see, the number of such links increased as we approached the March 2020 market crash, but the number also increased in the third and fourth periods before falling back to levels close to the first and second periods. By checking the number of links with ORC < and the number of links with ORC < , we see that these features are robust and associated with strongly negative ORCs. It appears therefore that a rising number of links with strongly negative ORCs is also an early warning indicator of a market crash. This was first observed by Sandhu et al. [215].
After inspecting the lists of links with , we focused on two links, (176, 193) and (176, 393), which (1) appeared frequently in the PMFGs across the nine time periods, and (2) had consistently negative curvatures. These three stocks are: (176) Tung Thih Electronic Co., Ltd., Taoyuan City, Taiwan (3552.TWO); (193) C-Tech United Corp., New Taipei City, Taiwan (3625.TWO); and (393) Taiwan Semiconductor Co., Ltd., New Taipei City, Taiwan (5425.TWO). (176) Tung Thih Electronic Co., Ltd. is a large company in the Auto Parts industry, with market capitalization 15.11 billion TWD, whereas (193) C-Tech United Corp. is a medium-size company in the Electrical Equipments & Parts industry, with market capitalization of 1.45 billion TWD. The last company, (393) Taiwan Semiconductor Co., Ltd., is another large company in the Semiconductors industry, with a market capitalization of 10.5 billion TWD. To put the sizes of these companies into the proper perspective, we compare them against TSMC (2330.TWO), the largest chip maker in the world and one of the largest companies in Taiwan, with a market capitalization of 14.73 trillion TWD. The ORCs of these links over the nine periods are shown in Table 4. Over the period of study, there are no PMFG links between 193 and 393.
From Table 4 we see that is less strongly negative, and change more slowly than . Since the link did not appear in the last time period, we suspect that the cluster associated with 193 has completely broken off from the cluster associated with 176. More importantly, comparing Table 4 and Figure 9, we see that the appearance of in the PMFG coincided with the periods when the number of links with strongly negative curvature was increasing. This suggests that the link might have formed in the third time period, broke off in the fifth time period and thereafter reformed in the sixth time period, before finally breaking up in the last time period. Such a sequence of events would surely be interesting to elucidate, but a detailed story might be better suited for a future study that we hope to do using the Generalized Forman-Ricci curvature [218] to more closely track how these fusions and fissions unfold. To wrap this paper up, let us visualize the clusters that these three nodes participate in over the last three time periods.
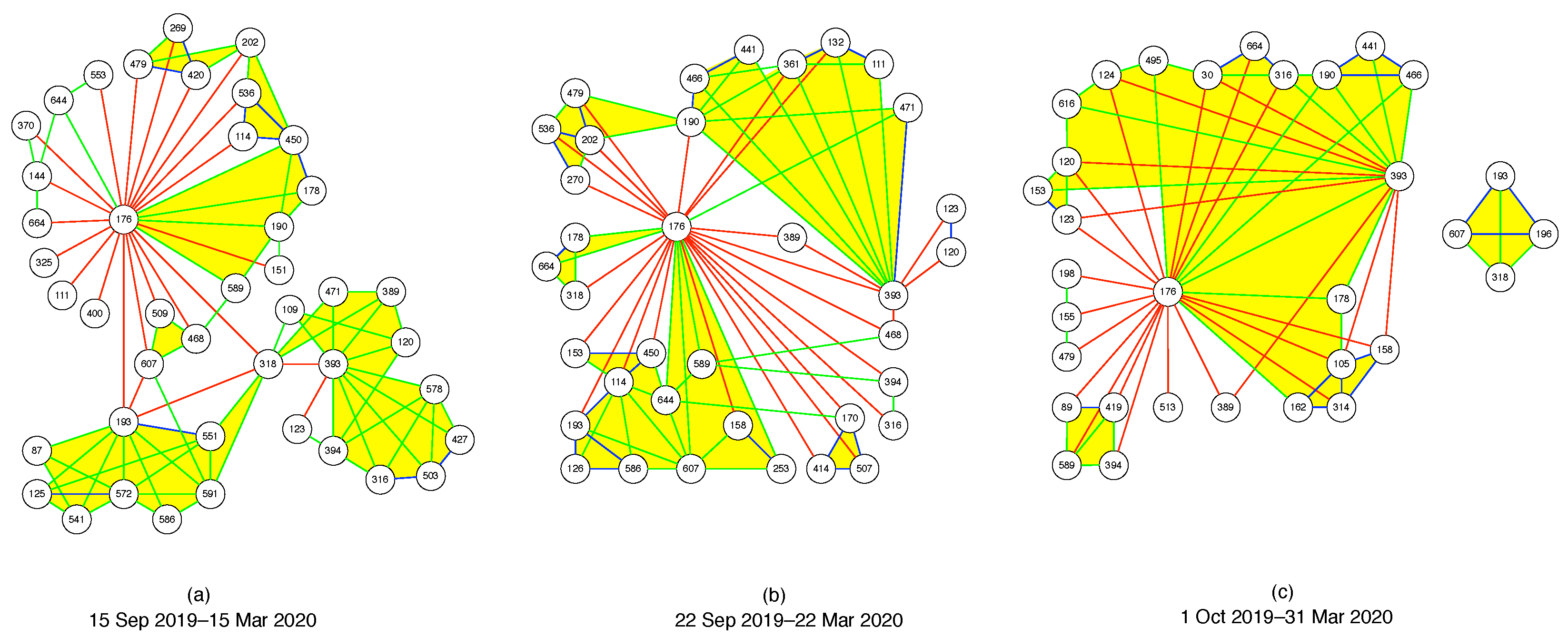
In network science, in addition to global layout algorithms for visualizing entire networks, we also find ego-centric visualizations centered on a node that are of interest. In Figure 10, we chose 176, 193, and 393 to be the three centers we would like to visualize around. Then, we included all nodes in the immediate neighborhoods of 176, 193, and 393, and colored the links they have with 176, 193, and 393 red if they have (strongly negative), green if (roughly zero), and blue if (strongly positive). Next, we drew only green and blue links between the neighbors of 176, 193, and 393, omitting red links between them. Finally, we colored simplices bound by green or blue links yellow. In this way, we keep the number of nodes and number of links to be visualized in Figure 10 to manageable numbers.
From this figure, we see in the seventh time period (15 September 2019–15 March 2020) that 176, 193, and 393 lied at the peripheries of the clusters they belong to respectively. We know that these nodes were at the peripheries of their respective clusters, because in their ego-centric visualizations, they would be surrounded by mostly green or blue links if they were part of the cores of their clusters. In this time period, 176 and 193 were connected directly through a red link, but the two of them were connected to 393 through 318 (Asia Electronic Material Co., Ltd., Zhubei, Taiwan (4939.TWO), Electronic Components). In the eighth time period (22 September 2019–22 March 2020), we see that the clusters containing 176 and 193 had merged, even though the two nodes were still at the fringe of this merged cluster, and still connected by a red link. 193 remained unlinked to 393, but 176 had “robbed” 318 from 393, but was now directly linked to 393 through a red link, as well as via 389 (AVY Precision Technology Inc., Taipei City, Taiwan (5392.TWO), Electronic Components) and 468 (Netronix Inc., Hsinchu City, Taiwan (6143.TWO), Communication Equipment). 176 also had other red links with the cluster 393 belonged to. Finally, in the last time period (1 October 2019–31 March 2020), we see that the cluster 193 belonged to had completely broken off from 176 (within the PMFG visualization for the entire network). Interestingly, 193 retained its link to 607 (Firich Enterprises Co., Ltd., New Taipei City, Taiwan (8076.TWO), Computer Hardware) from the eighth time period, and regained its connection to 318, at the same time made a new connection to 196 (Newmax Technology Co., Ltd., Taichung, Taiwan (3630.TWO), Electronic Components). Going from the eighth time period to the ninth time period, the biggest change (related to 176, 193, and 393) would be the clusters associated with 176 and 393 merging into a giant cluster. In this giant cluster, 176 and 393 were still peripheral nodes, but there was now a green link between them. In addition, 176 and 393 were also connected by green links through 178 (eGalax_eMPIA Technology Inc., Taipei City, Taiwan (3556.TWO), Semiconductors) and 190 (AimCore Technology Co., Ltd., Hsinchu City, Taiwan (3615.TWO), Electronic Components). In the eighth time period, 178 was connected to 176 by a green link, but not connected to 393, whereas 190 was connected to 393 by a green link, and to 176 by a red link in this time period.
To summarize, changes to the neck regions between 176, 193, and 393 appeared to be very sudden, even when we slid the time window by only seven days. This suggests the need to slide the time window through a smaller time step, to properly track changes to the network of stocks. However, to use such small time steps meaningfully, we will have to use intra-day time series data, instead of the daily data that we used in this paper. Furthermore, none of the fusions and fissions in Figure 10 resemble the simple toy models A or C (single neck, with fixed or varying dimensionality) described in the Appendix, even though it appears that these do start at the periheries of clusters. However, some aspects (multiple distant necks) of these events are similar to what happens in toy models B or D. In this sense, we are starting to understand why re-organizations of cross correlations in the financial market lead frequently to topological features such as voids.
6. Conclusions
Over the past 20 years, state-of-the-art information filtering methods such as the MST and the PMFG have revolutionized the field of econophysics, and also made contributions to other closely related disciplines. In this paper, we suggested two related directions to extend this information-filtering paradigm. The first is through topological data analysis (TDA), and the second is through the calculation of Ollivier-Ricci curvature. The former improves our understanding of the topological backbones of financial networks, whereas the latter puts the geometrical information back onto the topological backbones.
In the TDA, we explored four toy models of fusions, namely (1) the merging of two ellipsoidal surfaces, (2) the merging of two biconvex surfaces, (3) the merging of two anisotropic ellipsoidal surfaces through a sequence of higher-dimensional connections, and finally (4) the merging of two random irregular surfaces. By applying the insights extracted from this exploration to a recent crash in the TWSE, we found the number of simplices increasing slowly with increasing filtration parameter half a year before the market crash, and rapidly with increasing close to the crash. This suggests a non-trivial topological transition accompanied the market crash. However, we found that the four fusion/fission models proposed were not able to fully explain the topological changes, and additional processes (cavitation, annihilation, rupture, healing, and puncture) that do not involve fusion or fission, were needed to explain the changes in Betti numbers.
Moving beyond TDA, we used the Ollivier-Ricci curvature to quantify the distribution of curvatures in PMFGs constructed from the correlation matrices of the TWSE. We explained that positive ORCs correspond to stock components deep within a cluster, whereas negative ORCs pinpointed the neck (bridge) regions that connect distinct clusters. When we examined the PMFGs for nine periods between August 2019 and March 2020, we found dramatic topological changes between successive periods. This prevented us from systematically identifying all topological changes that were specifically associated with neck regions in the PMFGs. Instead, we look only at two neck regions—associated with the links (176, 193) and (176, 393)—that featured prominently during this period. These three nodes are: (176) Tung Thih Electronic Co., Ltd, (193) C-Tech United Corp., and (393) Taiwan Semiconductor Co., Ltd. During the last time period, (176, 193) was no longer found in the PMFG, while the curvature of (173, 393) became nearly zero. Using ego-network visualizations of these three nodes and selective visualization of links between them, we saw that all three nodes lie on the peripheries of the clusters they belonged to. In the seventh time period, all three clusters were distinct. In the eighth time period, the cluster containing 176 merged with the cluster containing 193. Finally, in the ninth time period, this cluster broke up into a small cluster containing 193, while the larger cluster containing 176 proceeded to merge with the cluster containing 393.
Supplementary Materials
MATLAB and Python scripts for TDA are available at https://0-doi-org.brum.beds.ac.uk/10.21979/N9/8XMZGF, accessed on 21 February 2021, whereas MATLAB and Python scripts and data files for Ricci curvature analysis are available at https://0-doi-org.brum.beds.ac.uk/10.21979/N9/EO5QON, accessed on 19 July 2021. The barcodes for the four toy models in Appendix B and the barcodes for the nine time periods of the TWSE in Section 4.3 are also available online at https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/e23091211/s1.
Author Contributions
Conceptualization, S.A.C. and K.X.; methodology, S.A.C. and P.T.-W.Y.; software, K.X.; writing—original draft preparation, S.A.C. and P.T.-W.Y.; writing—review and editing, S.A.C., K.X. and P.T.-W.Y.; visualization, S.A.C. and P.T.-W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All Python and Matlab scripts are provided, along with instructions on how to use them. This will download the raw data from Yahoo! Finance and perform the necessary computations to give the final results. See the links listed in Supplementary Material.
Acknowledgments
P.T.-W.Y. thanks the National Center for High-Performance Computing, Hsinchu, Taiwan for their technical support on providing high performance computing resources on Taiwania 1 server.
Conflicts of Interest
The authors declare no conflict of interest.
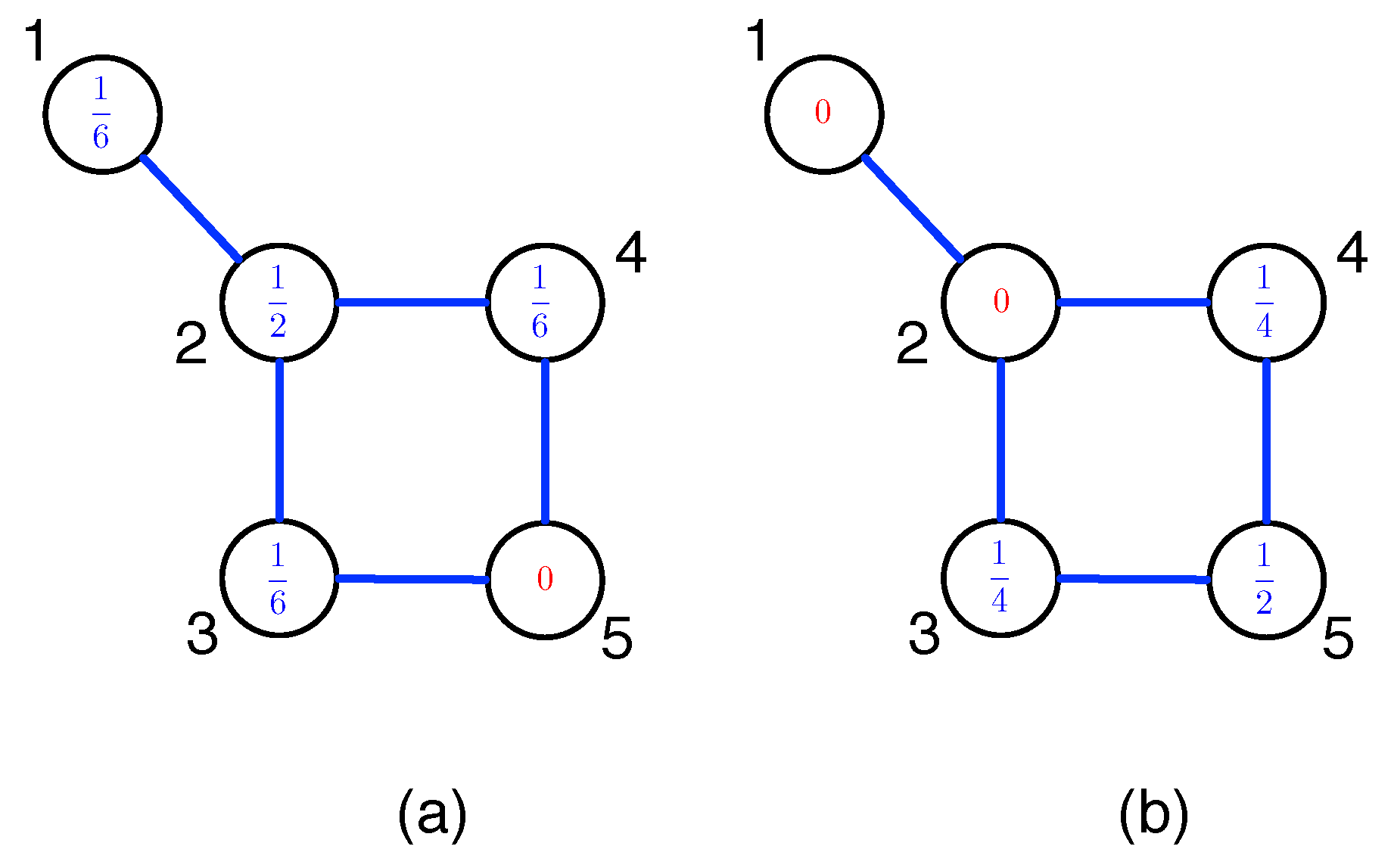
Appendix A. Construction of MST and PMFG
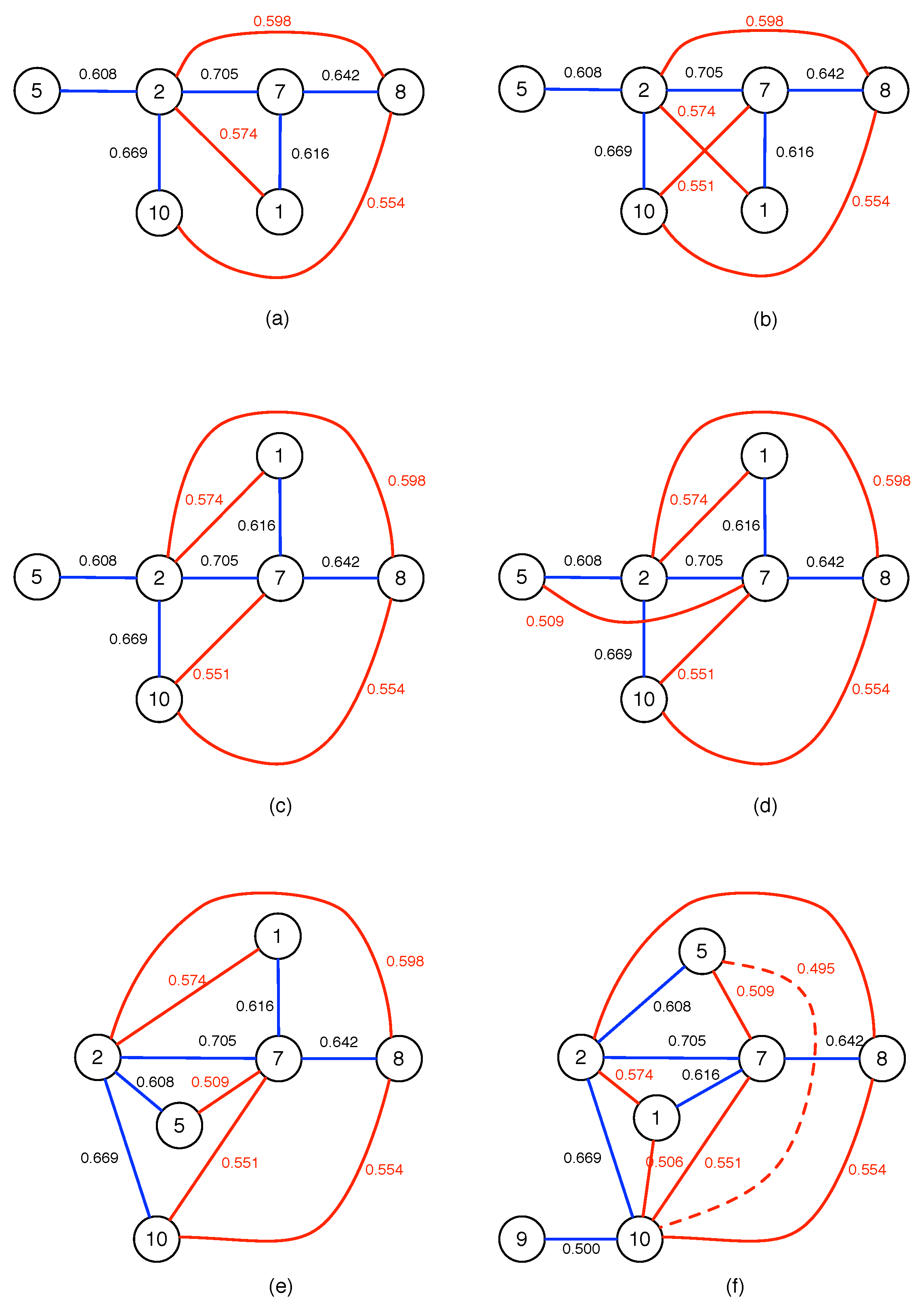
For readers interested in how to put the algorithms in Figure 3 into practice, let us use the Pearson cross correlations between 10 Asian stock market indices as an example. These 10 stock market indices are shown in Table A1, and their ordered cross correlations are shown in Table A2.
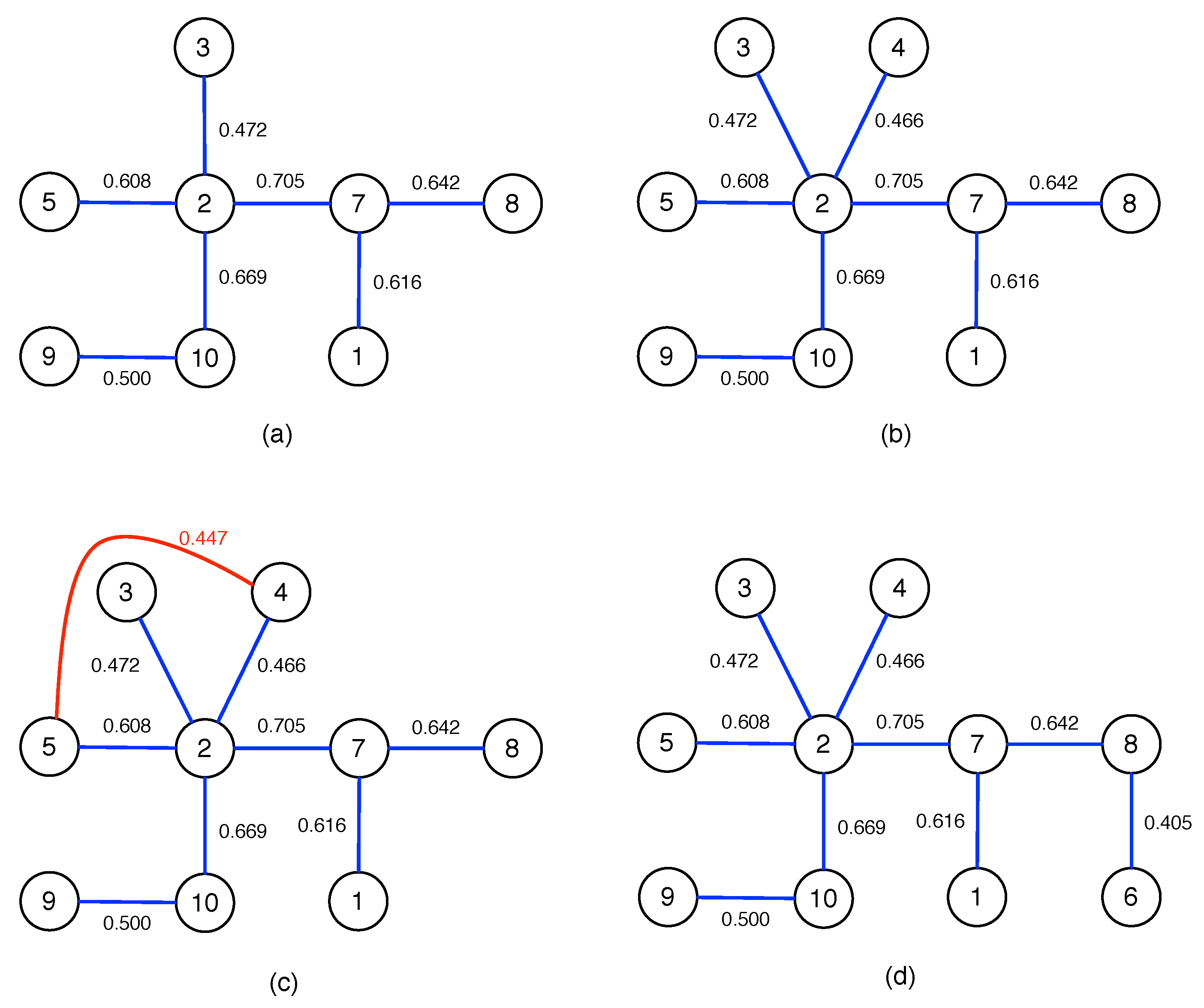
To construct the MST for these 10 Asian indices, we start from the largest cross correlation in Table A2, to draw a link between node 2 (Hong Kong) and node 7 (South Korea). We then proceed to go through the cross correlations within Table A2 in decreasing order, to add a link between node 2 and node 10 (Singapore), node 7 and node 8 (Taiwan), node 1 (Japan) and node 7, ..., until we reach between node 2 and node 3. To arrive at the tree graph shown in Figure A1a, we have rejected eight links, because they would result in cycles if we accepted them.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
List of ten Asian stock market indices.
| i | Country/Region | Index |
|---|---|---|
| 1 | Japan | Nikkei 225 Index |
| 2 | Hong Kong | Hang Seng |
| 3 | China | Shanghai Stock Market Composite Index |
| 4 | Thailand | SET Index |
| 5 | India | BSE Sensex Index |
| 6 | Indonesia | Jakarta Stock Index |
| 7 | South Korea | KOSPI Index |
| 8 | Taiwan | TSE Index |
| 9 | Malaysia | Kuala Lumpur Composite Index |
| 10 | Singapore | Straits Times Index |
According to Table A2, is the next cross correlation to be considered. Indeed, if we add a link between node 2 and the new node 4 (Thailand), no cycles are created. Therefore, we accept this new link, to end up with the tree graph shown in Figure A1b.
After adding the link between node 2 and node 4, the next link we should consider is according to Table A2. However, as we can see, adding this link that is colored red in Figure A1c, accepting this link between node 4 and node 5 (India) leads to a cycle in the network. Therefore, we reject the link between node 4 and node 5. Thereafter, we reject six more links, before adding a link between node 6 (Indonesia) and node 8 to complete the MST in Figure A1d.
Table A2.
Ordered list of Pearson cross correlations between the ten Asian indices shown in Table A1.
Table A2.
Ordered list of Pearson cross correlations between the ten Asian indices shown in Table A1.
| i | j | i | j | i | j | |||
|---|---|---|---|---|---|---|---|---|
| 2 | 7 | 0.705 | 2 | 4 | 0.466 | 5 | 9 | 0.331 |
| 2 | 10 | 0.669 | 4 | 5 | 0.447 | 5 | 6 | 0.316 |
| 7 | 8 | 0.642 | 8 | 9 | 0.438 | 1 | 4 | 0.304 |
| 1 | 7 | 0.616 | 5 | 8 | 0.426 | 4 | 8 | 0.295 |
| 2 | 5 | 0.608 | 7 | 9 | 0.421 | 3 | 7 | 0.277 |
| 2 | 8 | 0.598 | 4 | 7 | 0.413 | 4 | 6 | 0.275 |
| 1 | 2 | 0.574 | 2 | 9 | 0.412 | 3 | 8 | 0.267 |
| 8 | 10 | 0.554 | 1 | 5 | 0.410 | 3 | 10 | 0.258 |
| 7 | 10 | 0.551 | 6 | 8 | 0.405 | 4 | 9 | 0.253 |
| 5 | 7 | 0.509 | 1 | 9 | 0.395 | 3 | 9 | 0.228 |
| 1 | 10 | 0.506 | 4 | 10 | 0.385 | 3 | 5 | 0.227 |
| 9 | 10 | 0.500 | 2 | 6 | 0.383 | 1 | 6 | 0.222 |
| 5 | 10 | 0.495 | 6 | 10 | 0.382 | 3 | 4 | 0.199 |
| 1 | 8 | 0.474 | 6 | 9 | 0.378 | 1 | 3 | 0.197 |
| 2 | 3 | 0.472 | 6 | 7 | 0.364 | 3 | 6 | 0.129 |
Figure A1.
Intermediate and final stages in constructing the MST of 10 Asian indices: (a) after adding a link between node 2 and node 3; (b) after adding a link between node 2 and node 4; (c) after rejecting the red link between node 4 and node 5, due to the appearance of the cycle in the network. Finally, (d) all 10 nodes are linked in the MST, after adding the link between node 6 and node 8.
Figure A1.
Intermediate and final stages in constructing the MST of 10 Asian indices: (a) after adding a link between node 2 and node 3; (b) after adding a link between node 2 and node 4; (c) after rejecting the red link between node 4 and node 5, due to the appearance of the cycle in the network. Finally, (d) all 10 nodes are linked in the MST, after adding the link between node 6 and node 8.

Next, we construct the PMFG for the 10 Asian indices. Again, we start from the largest cross correlation in Table A2, to draw a link between node 2 and node 7. Then, we go through the cross correlations within Table A2 in decreasing order, and arrive at the network shown in Figure A2a after adding a link between node 8 and node 10, without rejecting any stronger links.
According to Table A2, the next link that we should add is between node 7 and node 10. When we first draw this in Figure A2b, the link between node 7 and node 10 overlaps the link between node 1 and node 2. However, this does not necessarily imply that the link must be rejected. If we move node 1 to the other side of 5–2–7–8, but keeping it within the loop formed by the 2–8 link, as shown in Figure A2c, we find no overlaps between links.
Similarly, when we add the next link between node 5 and node 7 in Figure A2d, the new link overlaps with the link between node 2 and node 10. Just like when we add the link between node 7 and node 10, we do not immediately reject this new link, but check if the network obtained thus far can be redrawn to accommodate the new link. Indeed, by moving node 5 into the triangle formed by nodes 2, 7, and 10, we show that the network with the new link continues to be planar, as shown in Figure A2e.
Finally, when we attempt to add the next link between node 5 and node 10, as shown in Figure A2f, we see that there is no rearrangement of the existing nodes and links that we can do, for the new link to not overlap with existing links (and remain planar). Therefore, this link has to be rejected.
Figure A2.
Intermediate stages in constructing the PMFG of 10 Asian indices: (a) after adding the link between node 8 and node 10; (b) after adding the link between node 7 and node 10, before checking for planarity; (c) after adding the link between node 7 and node 10, and after checking for planarity; (d) after adding the link between node 5 and node 7, before checking for planarity; (e) after adding the link between node 5 and node 7, and after checking for planarity; (f) after adding the link between node 5 and node 10, before checking for planarity. After checking for planarity, this link between node 5 and node 10 is rejected. In this figure, MST links are colored blue, PMFG links are colored red, while links that are rejected are shown as red dashed curves.
Figure A2.
Intermediate stages in constructing the PMFG of 10 Asian indices: (a) after adding the link between node 8 and node 10; (b) after adding the link between node 7 and node 10, before checking for planarity; (c) after adding the link between node 7 and node 10, and after checking for planarity; (d) after adding the link between node 5 and node 7, before checking for planarity; (e) after adding the link between node 5 and node 7, and after checking for planarity; (f) after adding the link between node 5 and node 10, before checking for planarity. After checking for planarity, this link between node 5 and node 10 is rejected. In this figure, MST links are colored blue, PMFG links are colored red, while links that are rejected are shown as red dashed curves.

Appendix B. Topological Data Analysis of Toy Models of Fusions
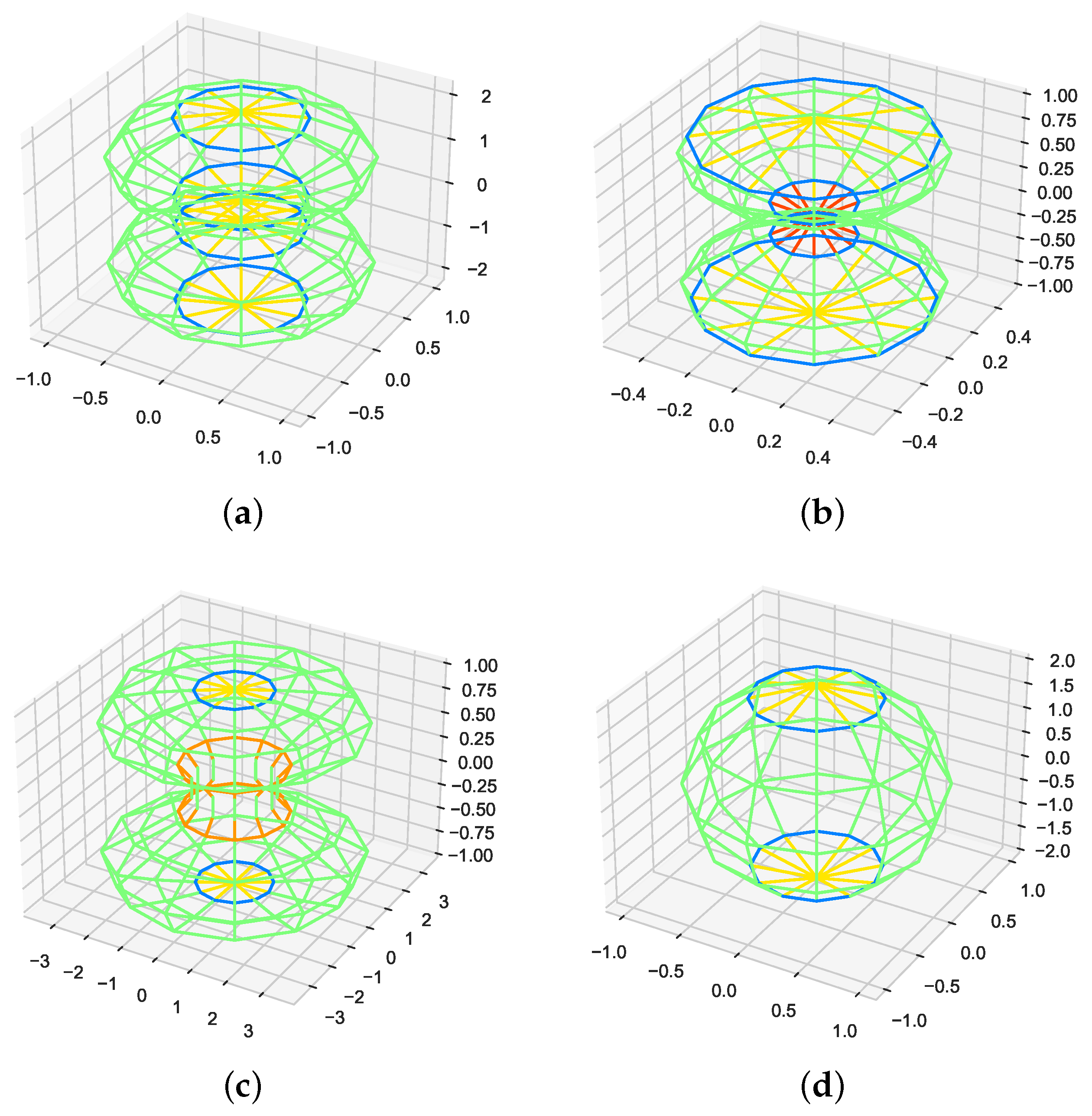
Before we attempt to understand the complex events underlying a market crash, we should first understand the simplest topological changes associated with the fusion between two manifolds, or the breaking up of a manifold into multiple pieces. In this paper, we worked out the TDA signatures of four toy models (see Figure A3): (1) fusion through a single point of contact, (2) fusion through a 1-dimensional set, (3) fusion through a set with increasing dimensionality, and (4) random. For these toy models, we first normalize the distance matrices by dividing them by the largest distance, so that when we do filtrations, the threshold will always terminate at . According to some researchers in this field, TDA may detect artifacts or noise due to specific data sampling methods. To eliminate these artifacts due to data sampling, we randomized and reshuffled the data points. This helps us focus on the more meaningful topological features in the data set. For each toy model, we used the Javaplex software to compute the persistent Betti numbers at each stage of the fusion. The barcodes for all stages of all toy models are also shown in the Supplementary Material, and the persistent Betti numbers are read off from the barcodes at the largest filtration parameter used.
Figure A3.
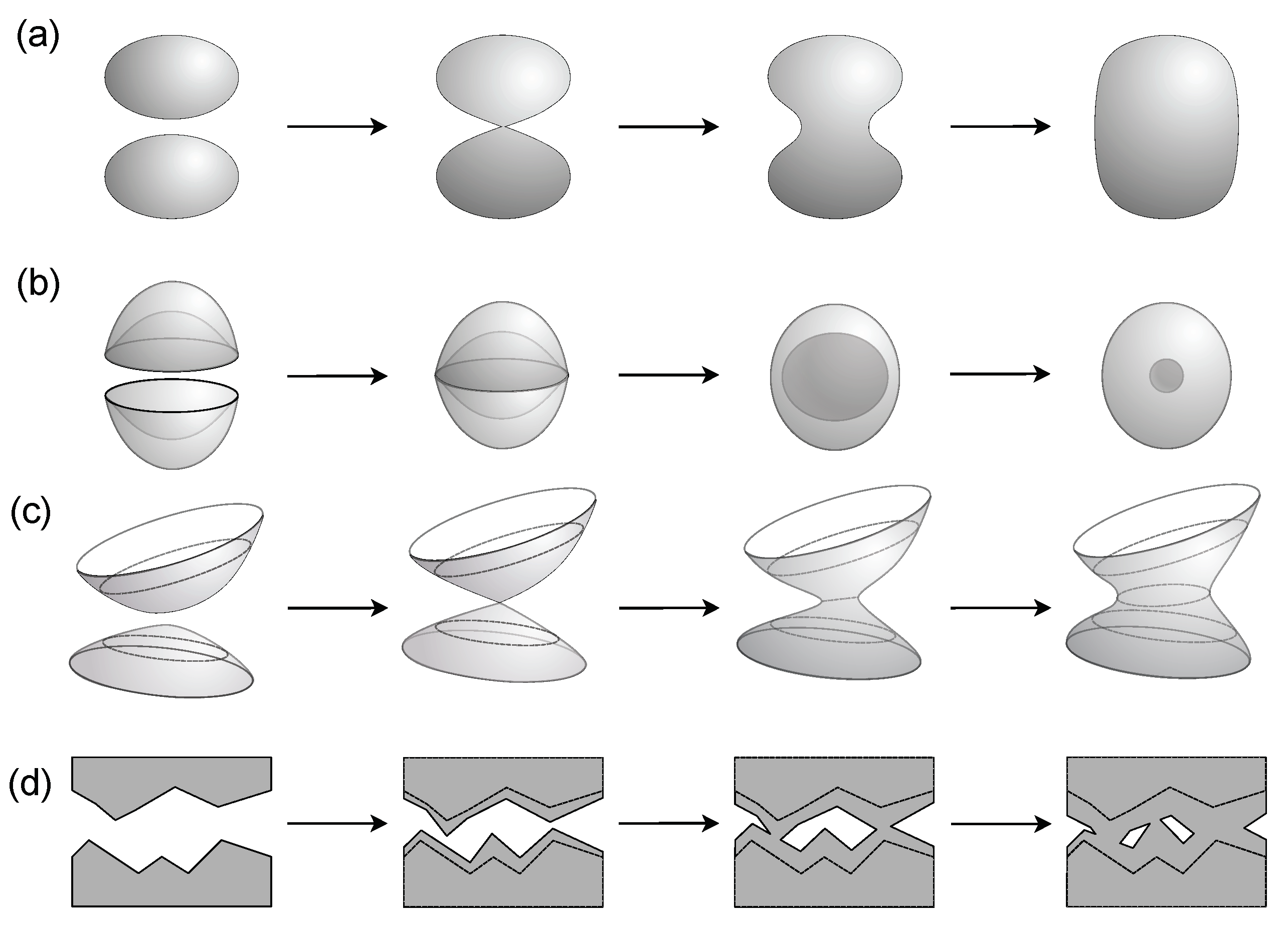
The four fusion models investigated: (a) two elliptical manifolds merging by first touching at a point, before developing a hyperbolic neck, and eventually having positive curvature everywhere; (b) two biconvex manifolds merging through their rims touching to form a void that shrinks in size; (c) a variation of (a), where the two anisotropic elliptical manifolds merging with their principal axes not aligned. After touching at a point, the neck between the two merging manifolds first becomes quasi-one-dimensional, before becoming fully two-dimensional; (d) the merging between two rough surfaces with random irregularities, which can be thought of as combinations of all of the above, plus emergent features like a hole that eventually becomes a void.
Figure A3.
The four fusion models investigated: (a) two elliptical manifolds merging by first touching at a point, before developing a hyperbolic neck, and eventually having positive curvature everywhere; (b) two biconvex manifolds merging through their rims touching to form a void that shrinks in size; (c) a variation of (a), where the two anisotropic elliptical manifolds merging with their principal axes not aligned. After touching at a point, the neck between the two merging manifolds first becomes quasi-one-dimensional, before becoming fully two-dimensional; (d) the merging between two rough surfaces with random irregularities, which can be thought of as combinations of all of the above, plus emergent features like a hole that eventually becomes a void.

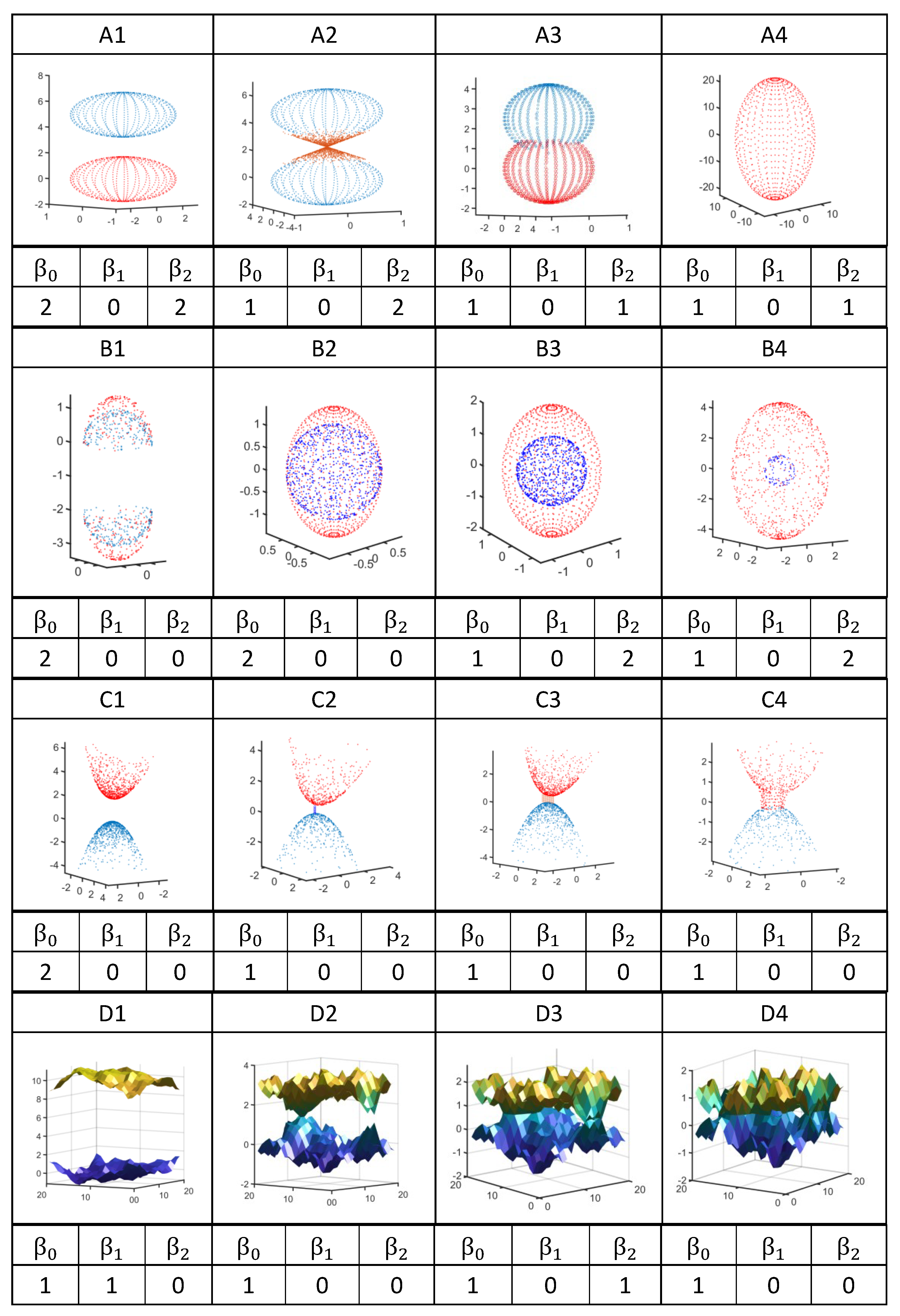
We show the results in Figure A4. For model (A), which is the reverse of the one studied by Santos et al. [181], we found in Figure A4(A1) that while the two ellipsoids are well separated, (two distinct objects), (no irreducible loops on either ellipsoids), and (one void enclosed by each ellipsoid). Then, in Figure A4(A2), the two deformed ellipsoids are just touching, and the point of contact has the form of a Dirac cone, which we expect to have non-trivial topological signatures of its own. As expected, the fusing of the two ellipsoids into a single manifold is reflected in . We also found , which tells us that there are no irreducible loops. Finally, the Dirac point kept the two voids separated, and hence . As shown in Figure A4(A3), the fusion is complete, but the neck region joining the original two ellipsoids has negative curvature. In this situation, we found that (one distinct object), , and (the two voids have merged). This is indeed what we expected, and it is indistinguishable from Figure A4(A4), which is the last stage of the whole coalescence process. The neck region has completely disappeared, and the curvature on the fused manifold is everywhere positive. Indeed, we found that , , and . These Betti numbers are identical to those of a sphere.
For model (B), we found in Figure A4(B1) that when the two biconvex shells are separated, we have (two distinct objects), (no irreducible loops), and . We were surprised that since each shell should still enclose a void. We increased the number of data points for this case, but remains zero, presumably because the typical gap in the voids is small, and the filtration procedure connects points across the voids. To test this hypothesis, we sliced the point cloud of (B3) into the top and bottom halves, moved them apart, and covered the gap in the equatorial plane between the inner and outer shells (see Figure A5a). For the top half, we found that , , and . In terms of symmetry, this tells us that for the two parts together, we will have , , and . This means that a void can indeed be identified if its narrowest part is distinctly larger than the typical distance between data points. In the next stage of the fusion, the two biconvex shells just touched in Figure A4(B2) to form an inner spherical shell and an outer ellipsoidal shell. As with (A2), the two two-dimensional shells also touched on a set of measure zero (even though the set is a one-dimensional ring, instead of a zero-dimensional point). This probably explains why (i.e., the shells remain topologically distinct). The other Betti numbers also remained the same as in (B1). Thereafter, with regard to (B3) and (B4), we expected them to have identical topological features, and found indeed that (one distinct object), (no irreducible loops), and (two voids enclosed) for the two cases. An observation we feel compelled to share is that for (B4), the density of red points (outer ellipsoid) and the density of blue points (inner sphere) are initially not the same, because we kept roughly the same number of blue and red points over the whole series of point clouds from (B1) to (B4). We then found the TDA calculations for (B4) were not complete even after four days (in contrast to (B1) to (B3), which took on average of two days). We suspected that this was because in the filtration process, the dense blue points at larger led to the emergence of very high-dimensional k-simplices. With every increase in dimension, the total number of simplices grew exponentially, and Javaplex slowed down. Indeed, when we performed an alternate TDA calculation in which we reduced the number of blue points, so that their density is comparable to the density of red points, the calculation became much faster: from longer than four days expected for the former, to roughly four hours in the latter.
Figure A4.
Point clouds generated using MATLAB for different stages (1) to (4) of the four fusion models (A–D), and their associated Betti numbers. For different cases, the number of data points are different. For example, (A2) has more data points than the other stages of model (A), because we implemented it as a combination of two spheroids, plus a pair of Dirac cones.
Figure A4.
Point clouds generated using MATLAB for different stages (1) to (4) of the four fusion models (A–D), and their associated Betti numbers. For different cases, the number of data points are different. For example, (A2) has more data points than the other stages of model (A), because we implemented it as a combination of two spheroids, plus a pair of Dirac cones.

Figure A5.
(a) To study how the typical gaps between data points affect the value of TDA produces, we split the point cloud in (B3) into top and bottom halves (blue points), moved them apart, and cover the gap in the equatorial plane between the inner and outer shells with green points. Such a structure would have a well-defined void whose average length scale is much larger than the distance between data points. (b) To show the channel formed in the neck region of (C4), we zoomed in to the green data points around the neck, and also rotated the view so that the channel formed by the two connected shells can be seen clearly, especially after the data points are meshed.
Figure A5.
(a) To study how the typical gaps between data points affect the value of TDA produces, we split the point cloud in (B3) into top and bottom halves (blue points), moved them apart, and cover the gap in the equatorial plane between the inner and outer shells with green points. Such a structure would have a well-defined void whose average length scale is much larger than the distance between data points. (b) To show the channel formed in the neck region of (C4), we zoomed in to the green data points around the neck, and also rotated the view so that the channel formed by the two connected shells can be seen clearly, especially after the data points are meshed.

Next, for model (C), we emulated the change in dimensionality during the fusion of two initially separated parabolic shells (Figure A4(C1)) approaching each other, by first connecting them with a one-dimensional line (Figure A4(C2)). As the fusion progressed, we connected the two parabolic shells with a two-dimensional rectangular sheet (Figure A4(C3)), and finally connected them with a two-dimensional cylindrical shell (Figure A4(C4)). In (C4), we removed points from the original parabolic shells that are within the neck region formed by the cylindrical shell to form the single surface with a channel shown in Figure A5b. We created this toy model as an alternative to model (A), in which the neck formation is locally isotropic. In physics, we know of materials and processes which are anisotropic, i.e., there are easy as well as hard axes. In these materials or processes, the neck formation is expected to go through a sequence of dimensionality changes. For (C1) in this model, we found that , , and . It is understandable that , because there are two distinct parabolic shells. We also understand why (because there are no irreducible closed loops) and (because the shells do not enclose any void). When we reached (C2), the two shells became connected. Therefore, we were not surprised to find that (one distinct object). We were also not surprised to find and remaining the same as for (C1). As we moved to (C3) and (C4), we found , , and , the same as in (C2). We had expected differences between (C2), (C3), and (C4), but it seems that these differences do not manifest themselves in the persistent Betti numbers, but require us to look more closely at the Betti curves.
Finally, for model (D), we first generated two rugged surfaces on a square grid. In Figure A4(D1), the two rugged surfaces were initially far apart, and then gradually moved closer, until they overlap at some parts, as shown in Figure A4(D2). We did not remove data points from the top rugged surface that penetrated the bottom rugged surface, or data points from the bottom rugged surface that penetrated the top rugged surface. In (D1), we have (as opposed to that we expected), (as opposed to that we expected), and (which is what we expected). In contrast, for (D2), we have , , and , which are all as we expected. As the two rugged surfaces were brought closer and started to have more overlaps as in Figure A4(D3), their Betti numbers became , and , which were as expected, but we now had (a void has been formed between the two surfaces.). As we made the two surfaces merge further, we witnessed the change of from 1 to 0 (see Figure A4(D4)). This implies that the wrapped void formed by the two rugged surfaces in (D3), had disappeared in (D4). We believe this observation is the result of scale-dependence of , discussed at the end of Appendix C.
Appendix C. Multiscale Analysis of Persistent Betti Numbers
We cannot directly apply the results of Appendix B, and Figure 5 to analyze the TDA results of the last three time windows, because we cannot be sure the Betti numbers are persistent. To better understand under what conditions we can have persistent Betti numbers, we visualize two contrasting mechanisms for fusion and fission in Figure A6. In Figure A6a–e, fusion occurs when thresholds decrease. Since , these events correspond to increases in cross correlations. To put it more simply, we started out having two clusters with strong intra-cluster correlations, and weak inter-cluster correlations. When the inter-cluster correlations also become strong, the two clusters merge into one larger cluster. In contrast, for Figure A6f–i, fusion occurs when thresholds increase. These events are the result of correlations within the two original clusters weakening, to become comparable to the intra-cluster correlations. Without strong intra-cluster correlations to distinguish between their members, the two clusters effectively merged into a large but weakly correlated cluster. In the first sequence (Figure A6a–e), the persistent Betti number is the number of 0-simplexes where the lifetime changes most rapidly in the barcode. As we can see from Figure A6a–e, it is not difficult to identify the persistent for this sequence.
In the second sequence, the situation is more interesting. Instead of just one set of persistent , we find two sets of persistent emerging at different scales. This means that we have one picture at the lower scale, but an equally meaningful picture at the higher scale. This also means that we need to be cautious when interpreting changes in as the result of fusions and fissions.
Similar scale-dependence can also occur for . Consider the situation shown in Figure A7, where we can visually discern three voids in a (three-dimensional) point cloud. The three voids have different sizes, and are such that the smallest void occurs in the densest part of the point cloud, while the biggest void occurs in the sparsest part of the point cloud. When we perform TDA on this point cloud, the smallest void would be the first to emerge, when the filtration parameter is just large enough to create a 2-simplex that encapsulates this smallest void. At this value of , the points around the medium void and the biggest void are too far apart for the simplices formed around them to fully encapsulate. Therefore, over a fairly large range of filtration parameters, this is the only persistent void we will find, and thus .
When we continue to increase the filtration parameter, we will eventually reach the value , which is just large enough to create a 2-simplex encapsulating the medium void. At , the smallest void remains intact, while the sparse data points around the biggest void are still too far apart for the void to be encapsulated. If we continue to increase the filtration parameter, then at some point , the filtration parameter would become comparable to the size of the smallest void, and this void disappears. Therefore, over the range , there are two persistent voids, and hence .
Finally, at some other point , the biggest void become fully encapsulated and emerge as a topological feature. Later on, when the filtration parameter becomes large enough, we will find the medium void disappearing at , and the biggest void disappearing at . Therefore, depending on what scale we are at, the persistent may be 1 or 2, before dropping down to 1, and then eventually becoming 0.
This phenomenon of being scale-dependent explains the small values of in (D3) and (D4), where we expect from the rugged surfaces approaching each together to produce lots of small voids. In other words, by the time these small voids are produced, the filtration parameter would become so large that points on opposite sides of the void will be linked, and thus, the small voids will disappear.
Figure A6.
Using hierarchical clustering dendrograms and their corresponding barcodes to understand two fusion-and-fission sequences. In the first sequence, we first have the merging threshold between clusters and decreased going from (a–b), and thereafter the merging threshold between clusters and decreased going from (b–c). There is then a rearrangement in (d), before the merging threshold between clusters and increased going from (d–e). The fusion thus occurs with decreasing threshold, while the fission occurs with increasing threshold. In the second sequence, the thresholds of , , and first increased going from (f–g), before a rearrangement occurs in (h) with comparable thresholds. Finally, the thresholds of and decreased in (i) to give two distinct clusters. In this figure, a large distance is associated with a small cross correlation , and vice versa. For each dendrogram, we also show the persistent Betti number in the corresponding barcode.
Figure A6.
Using hierarchical clustering dendrograms and their corresponding barcodes to understand two fusion-and-fission sequences. In the first sequence, we first have the merging threshold between clusters and decreased going from (a–b), and thereafter the merging threshold between clusters and decreased going from (b–c). There is then a rearrangement in (d), before the merging threshold between clusters and increased going from (d–e). The fusion thus occurs with decreasing threshold, while the fission occurs with increasing threshold. In the second sequence, the thresholds of , , and first increased going from (f–g), before a rearrangement occurs in (h) with comparable thresholds. Finally, the thresholds of and decreased in (i) to give two distinct clusters. In this figure, a large distance is associated with a small cross correlation , and vice versa. For each dendrogram, we also show the persistent Betti number in the corresponding barcode.

Figure A7.
In this stylized depiction of a three-dimensional point cloud, we can visually discern three (persistent) voids. The smallest of these occurs in the densest part of the point cloud, whereas the biggest of these occurs in the sparsest part of the point cloud. (bottom) The barcodes associated with the emergences and disappearances of the three voids.
Figure A7.
In this stylized depiction of a three-dimensional point cloud, we can visually discern three (persistent) voids. The smallest of these occurs in the densest part of the point cloud, whereas the biggest of these occurs in the sparsest part of the point cloud. (bottom) The barcodes associated with the emergences and disappearances of the three voids.

Appendix D. Ricci Flow and the Poincare Conjecture
In addition to its role in helping us understand dynamical reorganizations within complex systems, Ricci flow was also at the center of a major recent breakthrough in pure mathematics. In 1904, the French mathematician Poincare conjectured that “any closed simply connected 3-manifold is diffeomorphic to the standard 3-dimensional sphere ” [219], but later believed that the same is true in any dimension. Between 1960 and 1980, the Poincare conjectures for all dimensions were proven [220,221,222,223], except for three dimension. This problem was recognized as mathematically hard, but also of fundamental importance, that it was included as one of the seven Millenium Prize problems identified by the Clay Mathematics Institute in 2000. Later, the Poincare conjecture for three dimensions was stated in a more general form by Thurston, who conjectured that “any closed orientable 3-manifold can be canonically cut along embedded 2-spheres and 2-tori so as to decompose into eight different geometrical pieces” [224]. In response to this challenge, Hamilton crafted the Ricci flow model [225], and initiated a program to apply Ricci flow to solve Thurston’s geometrization conjecture [224]. After the Poincare conjecture in three dimensions was stated in more general terms, the original problem and Thurston’s generalized geometrization conjecture went unsolved for 20 more years, until Perelman cracked the final puzzle. With his original and ingenious “Ricci flow with surgery” approach, he successfully expunged the singular region as a work around for solving the geometrization conjecture, and ultimately resolved the Poincare conjecture in three dimensions [226,227]. This achievement not only won him the 2007 Fields Medal, but also made him the recipient of the first Millennium Prize. Since 2007, many mathematicians started dabbling into Ricci flow and related fields, creating something of a “gold rush” in this field over the past 15 years.
Appendix E. Computing the First Wasserstein Distance Using Linear Programming
In Equation (6), we defined the first Wasserstein distance (also known as the earth mover distance) conceptually, so that it can be used in the definition of the Ollivier-Ricci curvature. In this appendix, let us describe how the first Wasserstein distance on a network can be computed using linear programming.
First, consider a network G with five nodes. To compute the first Wasserstein distance between the lazy random walk probability distribution (Figure A8a) and the lazy random walk probability distribution (Figure A8b), let us consider all possible redistributions from to , such that
These are our constraints.
Next, let be the geodesic distance between node i and node j. On an unweighted network such as the one shown in Figure A8, the geodesic distance is the number of hops needed to go from node i to node j, and can therefore only take on integer values from 0 to 3. If there is more than one way to get from node i to node j, is the smallest number of hops. With this, we can write down the matrix of geodesic distances as
Following this, let us define the cost of moving from node i to node j to be . The total cost to make into is thus
Our goal is to minimize , subject to the constraints in Equation (A1).
This constrained minimization problem can be recasted into a linear programming problem, if we change the indices from i and j to a fused index . In terms of this fused index, the cost function can be rewritten as
while the constraints can be written as
In this formulation, if the first index in k is i, and otherwise, whereas if the second index in k is j, and otherwise.
The standard method for solving a high-dimensional linear programming problem is the simplex method, which can be found in numerous textbooks [228,229,230]. There are many variants for the simplex method, depending on whether the optimization is a maximization or minimization, and whether we are dealing with equality or inequality constraints. In general, the simplex method and its variants introduce auxiliary variables called slack variables, excess variables, or artificial variables. To illustrate how we can compute the first Wasserstein distance described above using the simplex method, we will also have to introduce artificial variables. Therefore, we should first eliminate redundant variables from with the list of 25 .
Figure A8.
(a) The probability distribution for lazy random walk starting from node 2, and (b) the probability distribution for lazy random walk starting from node 5, on a network with five nodes. In (a), the probability of hopping from is , while the probability of hopping from 2 to its neighbors 1, 3, 4 are . These are shown in blue within the destination nodes. To complete the probability distribution , we also need to specify . Since it is not possible for the lazy random walk from node 2 to reach node 5 in a single hop, we set , and show this probability in red within the destination node. In (b), we continue to have , but since node 5 has only two neighbors, we find , and show these in blue within the destination nodes. We also show in red within the destination nodes.
Figure A8.
(a) The probability distribution for lazy random walk starting from node 2, and (b) the probability distribution for lazy random walk starting from node 5, on a network with five nodes. In (a), the probability of hopping from is , while the probability of hopping from 2 to its neighbors 1, 3, 4 are . These are shown in blue within the destination nodes. To complete the probability distribution , we also need to specify . Since it is not possible for the lazy random walk from node 2 to reach node 5 in a single hop, we set , and show this probability in red within the destination node. In (b), we continue to have , but since node 5 has only two neighbors, we find , and show these in blue within the destination nodes. We also show in red within the destination nodes.

First of all, . This cannot be broken down any further for redistribution to the various nodes in , and so we can just drop the variables , for . Additionally, , so none of the nodes in can make contributions to . Hence, we can drop the variables and , for . After eliminating these variables, we are then left with the 12 variables
Next, in terms of these remaining variables, we write the cost function as
We also write the seven equality constraints out explicitly as
To solve the minimization problem iteratively, we need to start from an initial feasible solution. This is not easy to guess, if we limit ourselves to the 12 variables. Therefore, we introduce one artificial variable for each of the seven equality constraints, such that
This allows us to set , , , , , , , and all the variables to zero as our initial solution. However, as their names imply, to are artificial variables, so we must be able to set their values to zero at the end of our minimization. To ensure that this will happen, let us also add to the cost function
where M is a large number. For this reason, this variant of the simplex method is called the big M method.
After years of teaching the simplex method to undergraduates, mathematicians have learned how to present the procedure in simple matrix/tabular form. The starting point is shown Table A3, where the coefficients of unknowns in the equality constraints have been organized into the first seventh rows of a matrix, and the coefficients of unknowns in the cost function organized into the eighth row. Initially, the columns V and r are not populated. To populate column V, we inspect the coefficient matrix to identify the basic variables. A basic variable is one that appears in one and only one row. At this start of the optimization, it should be clear that the basic variables are the artificial variables to .
Starting from , , , , , , , and all the variables set to zero, we want to ultimately be able to obtain a value of C that does not depend on the artificial variables to . This can be achieved by subtracting M times the rows where the artificial variables appear from the last row where C appears, to produce the table shown in Table A4. In the last row of Table A4, all the coefficients associated with the variables are negative, so this is not a feasible solution. To improve the solution, we need one of the values to replace one of a as a basic variable. Looking for the most negative entry in the last row of Table A4, we find that this is , in the columns associated with and . We can pick either one as the entering variable to replace one of the a’s, which will be the leaving variable. Since we will surely pick in the next iteration, let us for concreteness pick as the entering variable. The final solution will not depend on the order we pick our entering variables. For to become an entering variable, we determine the leaving variable by dividing the constants b by the coefficients in the column, if this is possible, and populate the last column r. Since only two coefficients in the column are non-zero, we compute r only along these two rows, to obtain the ratios and . Since is the smaller of the two, we choose to be the leaving variable.
However, for to replace as a basic variable, it must appear only in one row. In Table A4 it also appears in the row associated with , as well as the last row. Therefore, we must perform elementary row operations to eliminate from the row, as well as to eliminate from the last row. After this is completed, we end up with the table shown in Table A5. Here we see also that the cost function has improved from to . Since there are still negative coefficients in the last row, we know that we can continue to improve the cost function. In Table A5, the most negative coefficient is , which appears in the column associated with . We skipped in favor of the last iteration, so this is the right time to choose as the entering variable. Thereafter, we divide the constants b’s by the coefficients in the row associated with , if this is possible, and look for the smallest ratio. In this case, we find only two ratios, and , and the smallest ratio is associated with , which will therefore be our new leaving variable.
Again, for to become a basic variable, we must zero its coefficient in all other rows using elementary row operations. The matrix of coefficients then become the one shown in Table A6. We are making progress, because the cost function has improved to , and many of the coefficients associated with ’s have become positive in the last row. To find the next entering variable, we continue to look in the last row for the most negative coefficient. This would be , which appears in the column associated with , as well as the column associated with . As explained earlier, choosing or as the next entering variable will not change the solution, so let us make the next entering variable. Then, from the ratios of the constants divided by the coefficients in the row associated with , we see that will become the leaving variable.
Table A3.
Matrix of coefficients at the start of the big M method to solve the linear programming problem for the 12 redistribution variables . In this table, the column V consists of basic variables, the column b consists of constraint values, while the column r consists of constraint values divided by elements in the column of the entering variable.
Table A3.
Matrix of coefficients at the start of the big M method to solve the linear programming problem for the 12 redistribution variables . In this table, the column V consists of basic variables, the column b consists of constraint values, while the column r consists of constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 2 | 2 | 3 | 1 | 1 | 2 | 0 | 1 | 2 | 2 | 0 | 1 | M | M | M | M | M | M | M | 1 | 0 |
Table A4.
Matrix of coefficients after subtracting M times the constraint equations from the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable. In this table, the most recent changes are highlighted in bold.
Table A4.
Matrix of coefficients after subtracting M times the constraint equations from the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable. In this table, the most recent changes are highlighted in bold.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Table A5.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable. In this table, the most recent changes are highlighted in bold.
Table A5.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable. In this table, the most recent changes are highlighted in bold.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Table A6.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
Table A6.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||||||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 0 | 1 | 2 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Performing elementary row operations to make a proper basic variable, we obtained the table shown in Table A7. Again, the cost was improved, and more coefficients in the last row became positive. At this stage in the iterations, the most negative coefficient is , appearing in the column associated with , which we postponed handling in the previous iteration. Therefore, we choose the next entering variable to be . Thereafter, dividing the constants by coefficients in the column associated with , we find the next leaving variable to be .
After another round of elementary row operations, we obtained the table shown in Table A8. In this table, the most negative coefficient in the last row is , appearing in the columns associated with , and . Let us choose to be the entering variable. For this variable, we find the ratio for the row associated with , and in the row associated with . Since , we identify as the leaving variable.
After elementary row operations to make a basic variable, we obtained the table shown in Table A9. The steady improvement to the cost function is obvious, and there are also fewer negative coefficients in the last row. To choose the next entering variable, let us inspect those columns with in the last row. These are associated with , , and . Since node 5 is the most important destination node, let us choose as the next entering variable. The ratios are associated with , and associated with . Since they are the same, let us choose to be our next leaving variable.
After one last round of elementary row operations, making a basic variable, we obtained the table shown in Table A10. Now, none of the coefficients in the last row are negative. This means that we have found our solution, and the iterations can end. From Table A10, we can read off the basic variables as
We can check that , satisfying the second constraint. Additionally, since , this means that . Furthermore, , satisfying the third constraint. Similarly, since , we also have , and satisfies the fourth constraint. As in the cases of the third and fourth constraints, satisfies the first constraint by itself, meaning that . More importantly, , which already satisfy the seventh constraint, so we must have . We also have , satisfying the fifth constraint, and satisfying the sixth constraint.
Table A7.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
Table A7.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | ||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||||||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
Table A8.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
Table A8.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | |||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||||||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |||
| 1 | 1 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
Table A9.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
Table A9.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | |||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||||||
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | ||||||
| 0 | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
Table A10.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
Table A10.
Matrix of coefficients after elementary row operations to subtract appropriate multiples of the row associated with from the row associated with and the last row. In this table, the column V refers to basic variables, the column b refers to constraint values, while the column r refers to constraint values divided by elements in the column of the entering variable.
| V | C | b | r | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | |||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ||||||
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | ||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 1 | 1 | 0 | 1 |
Let us observe that the above solution implies that . Let us also observe that , , , , , did not make it onto the list of basic variables, and are thus non-basic variables. In the simplex method, non-basic variables are automatically set to zero at the end of the optimization. We also observe that we started out with seven artificial variables as basic variables, and iteratively replaced them with the redistribution variables. This means that at most seven redistribution variables can become basic, i.e., take on non-zero values at the end of the optimization. In this example, the optimization stopped after six redistribution variables became basic. The remaining six redistribution variables remained non-basic, and were thus set to zero, as dictated by the simplex method.
Finally, let us observe that after we prepared the coefficient matrix for the constraints and the cost function, including however many auxiliary variables as we need, the steps involved in each iteration are mechanical and easy to automate. In fact, most variants of the simplex method have been implemented in MATLAB, Python SciPy, and R as functions that users can call with minimal preparations.
Appendix F. Ollivier-Ricci Curvature Analysis of a Toy Model Sequence of Fusion
In Section 4.3, we saw that the Betti numbers—being topological quantities—are not able to distinguish between parts of some models. There is, therefore, the need to go beyond TDA. Most notably, (A3) and (A4) have the same Betti numbers, but whereas the curvature is positive everywhere in (A4), the neck region in (A3) has negative curvature. In this subsection, we will use model (A) to illustrate the power of the ORC.
To compute the ORC for the different phases of model (A), we created wire meshes for the surfaces involved from (A1) to (A4) (see Figure A9), as instances of the Graph class from networkx. We then installed GraphRicciCurvature and all the Python packages that this depends on, before creating instances of the OllivierRicci class using the networkx graphs as inputs, using for the self-transition parameter. Finally, we called on the compute_ricci_curvature() method in the OllivierRicci class to compute the ORCs of all edges in the graphs.
As expected, the curvature ranged from slightly negative to slightly positive to significantly positive in (A1). Negative curvatures started appearing in (A2), at the Dirac point, and intensified in (A3). Finally, we have the curvature again ranging from slightly negative to slightly positive to significantly positive in (A4), thereby allowing us to distinguish between (A2), (A3), and (A4). The ORC changed most rapidly between (A2) and (A3).
Figure A9.
The sequence of topological changes going from (a) two disjoint spheres, to (b) them touching at a point to form a Dirac cone, to (c) them fusing to form a smoothed neck, to (d) eventually rounding off to an ellipsoid with no neck. In these figures, the links are colored according to their Ollivier-Ricci curvatures, standardized across the four scenarios from (deep red) to (green (slightly negative) and yellow (slightly positive)) to (deep blue).
Figure A9.
The sequence of topological changes going from (a) two disjoint spheres, to (b) them touching at a point to form a Dirac cone, to (c) them fusing to form a smoothed neck, to (d) eventually rounding off to an ellipsoid with no neck. In these figures, the links are colored according to their Ollivier-Ricci curvatures, standardized across the four scenarios from (deep red) to (green (slightly negative) and yellow (slightly positive)) to (deep blue).

References
- Bachelier, L. Théorie de la spéculation. In Annales Scientifiques de l’École Normale Supérieure; Société Mathématique de France: Marseille, France, 1900; Volume 17, pp. 21–86. [Google Scholar]
- Osborne, M.F. Brownian motion in the stock market. Oper. Res. 1959, 7, 145–173. [Google Scholar] [CrossRef]
- Mandelbrot, B.B. The variation of certain speculative prices. In Fractals and Scaling in Finance; Springer: Berlin/Heidelberg, Germany, 1997; pp. 371–418. [Google Scholar]
- Fama, E.F. The behavior of stock-market prices. J. Bus. 1965, 38, 34–105. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Van Ness, J.W. Fractional Brownian motions, fractional noises and applications. SIAM Rev. 1968, 10, 422–437. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Fisher, A.J.; Calvet, L.E. A Multifractal Model of Asset Returns; Cowles Foundation: New Haven, CT, USA, 1997. [Google Scholar]
- Palmer, R.G.; Arthur, W.B.; Holland, J.H.; LeBaron, B.; Tayler, P. Artificial economic life: A simple model of a stockmarket. Phys. D Nonlinear Phenom. 1994, 75, 264–274. [Google Scholar] [CrossRef] [Green Version]
- Mantegna, R.N. Lévy walks and enhanced diffusion in Milan stock exchange. Phys. A Stat. Mech. Its Appl. 1991, 179, 232–242. [Google Scholar] [CrossRef]
- Takayasu, H.; Miura, H.; Hirabayashi, T.; Hamada, K. Statistical properties of deterministic threshold elements-the case of market price. Phys. A Stat. Mech. Its Appl. 1992, 184, 127–134. [Google Scholar] [CrossRef]
- Stanley, H.E.; Afanasyev, V.; Amaral, L.A.N.; Buldyrev, S.V.; Goldberger, A.L.; Havlin, S.; Leschhorn, H.; Maass, P.; Mantegna, R.N.; Peng, C.K.; et al. Anomalous fluctuations in the dynamics of complex systems: From DNA and physiology to econophysics. Phys. A Stat. Mech. Its Appl. 1996, 224, 302–321. [Google Scholar] [CrossRef]
- Laloux, L.; Cizeau, P.; Bouchaud, J.P.; Potters, M. Noise dressing of financial correlation matrices. Phys. Rev. Lett. 1999, 83, 1467. [Google Scholar] [CrossRef] [Green Version]
- Plerou, V.; Gopikrishnan, P.; Rosenow, B.; Amaral, L.A.N.; Stanley, H.E. Universal and nonuniversal properties of cross correlations in financial time series. Phys. Rev. Lett. 1999, 83, 1471. [Google Scholar] [CrossRef] [Green Version]
- Plerou, V.; Gopikrishnan, P.; Rosenow, B.; Amaral, L.N.; Stanley, H.E. A random matrix theory approach to financial cross-correlations. Phys. A Stat. Mech. Its Appl. 2000, 287, 374–382. [Google Scholar] [CrossRef]
- Junior, L.S.; Franca, I.D.P. Correlation of financial markets in times of crisis. Phys. A Stat. Mech. Its Appl. 2012, 391, 187–208. [Google Scholar]
- Mantegna, R.N.; Stanley, H.E. Stochastic process with ultraslow convergence to a Gaussian: The truncated Lévy flight. Phys. Rev. Lett. 1994, 73, 2946. [Google Scholar] [CrossRef] [PubMed]
- Mantegna, R.N.; Stanley, H.E. Scaling behaviour in the dynamics of an economic index. Nature 1995, 376, 46–49. [Google Scholar] [CrossRef]
- Mittnik, S.; Rachev, S.T.; Paolella, M.S. Stable Paretian modeling in finance: Some empirical and theoretical aspects. In A Practical Guide to Heavy Tails; Birkhäuser: Basel, Switzerland, 1998; pp. 79–110. [Google Scholar]
- Sornette, D.; Sammis, C.G. Complex critical exponents from renormalization group theory of earthquakes: Implications for earthquake predictions. J. Phys. I 1995, 5, 607–619. [Google Scholar] [CrossRef]
- Sornette, D.; Johansen, A.; Bouchaud, J.P. Stock market crashes, precursors and replicas. J. Phys. I 1996, 6, 167–175. [Google Scholar] [CrossRef] [Green Version]
- Sornette, D. Dragon-kings, black swans and the prediction of crises. arXiv 2009, arXiv:0907.4290. [Google Scholar] [CrossRef]
- Chatterjee, A.; Chakrabarti, B.K.; Manna, S. Money in gas-like markets: Gibbs and Pareto laws. Phys. Scr. 2003, 2003, 36. [Google Scholar] [CrossRef] [Green Version]
- Dragulescu, A.; Yakovenko, V.M. Statistical mechanics of money. Eur. Phys. J.-Condens. Matter Complex Syst. 2000, 17, 723–729. [Google Scholar] [CrossRef] [Green Version]
- Yura, Y.; Takayasu, H.; Sornette, D.; Takayasu, M. Financial brownian particle in the layered order-book fluid and fluctuation-dissipation relations. Phys. Rev. Lett. 2014, 112, 098703. [Google Scholar] [CrossRef] [Green Version]
- Yura, Y.; Takayasu, H.; Sornette, D.; Takayasu, M. Financial Knudsen number: Breakdown of continuous price dynamics and asymmetric buy-and-sell structures confirmed by high-precision order-book information. Phys. Rev. E 2015, 92, 042811. [Google Scholar] [CrossRef] [Green Version]
- Battiston, S.; Puliga, M.; Kaushik, R.; Tasca, P.; Caldarelli, G. Debtrank: Too central to fail? financial networks, the fed and systemic risk. Sci. Rep. 2012, 2, 541. [Google Scholar] [CrossRef] [Green Version]
- Marwan, N.; Donges, J.F.; Zou, Y.; Donner, R.V.; Kurths, J. Complex network approach for recurrence analysis of time series. Phys. Lett. A 2009, 373, 4246–4254. [Google Scholar] [CrossRef] [Green Version]
- Donner, R.V.; Donges, J.F.; Zou, Y.; Marwan, N.; Kurths, J. Recurrence-based evolving networks for time series analysis of complex systems. In Proceedings of the International Symposium on Nonlinear Theory and its Applications (NOLTA), Krakow, Poland, 5–8 September 2010; IEICE: Tokyo, Japan, 2010. [Google Scholar]
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuno, J.C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wang, J.; Yang, H.; Mang, J. Visibility graph approach to exchange rate series. Phys. A Stat. Mech. Its Appl. 2009, 388, 4431–4437. [Google Scholar] [CrossRef]
- Qian, M.C.; Jiang, Z.Q.; Zhou, W.X. Universal and nonuniversal allometric scaling behaviors in the visibility graphs of world stock market indices. J. Phys. A Math. Theor. 2010, 43, 335002. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Li, D.; Wang, Q. Visibility graph analysis on quarterly macroeconomic series of China based on complex network theory. Phys. A Stat. Mech. Its Appl. 2012, 391, 6543–6555. [Google Scholar] [CrossRef]
- Stephen, M.; Gu, C.; Yang, H. Visibility graph based time series analysis. PLoS ONE 2015, 10, e0143015. [Google Scholar] [CrossRef]
- Antoniades, I.; Stavrinides, S.; Hanias, M.; Magafas, L. Complex network time series analysis of a macroeconomic model. In Dynamics on and of Complex Networks III; Springer Science and Business Media LLC: Cham, Switzerland, 2020; pp. 135–147. [Google Scholar]
- Jensen, M.H. Multiscaling and structure functions in turbulence: An alternative approach. Phys. Rev. Lett. 1999, 83, 76. [Google Scholar] [CrossRef] [Green Version]
- Simonsen, I.; Jensen, M.H.; Johansen, A. Optimal investment horizons. Eur. Phys. J.-Condens. Matter Complex Syst. 2002, 27, 583–586. [Google Scholar] [CrossRef] [Green Version]
- Jensen, M.H.; Johansen, A.; Simonsen, I. Inverse statistics in economics: The gain–loss asymmetry. Phys. A Stat. Mech. Its Appl. 2003, 324, 338–343. [Google Scholar] [CrossRef] [Green Version]
- Johansen, A.; Simonsen, I.; Jensen, M.H. Optimal investment horizons for stocks and markets. Phys. A Stat. Mech. Its Appl. 2006, 370, 64–67. [Google Scholar] [CrossRef] [Green Version]
- Jensen, M.H.; Johansen, A.; Petroni, F.; Simonsen, I. Inverse statistics in the foreign exchange market. Phys. A Stat. Mech. Its Appl. 2004, 340, 678–684. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.X.; Yuan, W.K. Inverse statistics in stock markets: Universality and idiosyncracy. Phys. A Stat. Mech. Its Appl. 2005, 353, 433–444. [Google Scholar] [CrossRef] [Green Version]
- Karpio, K.; Załuska-Kotur, M.A.; Orłowski, A. Gain–loss asymmetry for emerging stock markets. Phys. A Stat. Mech. Its Appl. 2007, 375, 599–604. [Google Scholar] [CrossRef]
- Lee, C.Y.; Kim, J.; Hwang, I. Inverse statistics of the Korea composite stock price index. J. Korean Phys. Soc. 2008, 52, 517–523. [Google Scholar] [CrossRef]
- Grudziecki, M.; Gnatowska, E.; Karpio, K.; Orlowski, A.; Zaluska-Kotur, M. New results on gain-loss asymmetry for stock markets time series. Acta Phys.-Pol.-Ser. Gen. Phys. 2008, 114, 569. [Google Scholar] [CrossRef]
- Donangelo, R.; Jensen, M.H.; Simonsen, I.; Sneppen, K. Synchronization model for stock market asymmetry. J. Stat. Mech. Theory Exp. 2006, 2006, L11001. [Google Scholar] [CrossRef]
- Simonsen, I.; Ahlgren, P.T.H.; Jensen, M.H.; Donangelo, R.; Sneppen, K. Fear and its implications for stock markets. Eur. Phys. J. B 2007, 57, 153–158. [Google Scholar] [CrossRef]
- Ahlgren, P.T.H.; Jensen, M.H.; Simonsen, I.; Donangelo, R.; Sneppen, K. Frustration driven stock market dynamics: Leverage effect and asymmetry. Phys. A Stat. Mech. Its Appl. 2007, 383, 1–4. [Google Scholar] [CrossRef]
- Siven, J.; Lins, J.; Hansen, J.L. A multiscale view on inverse statistics and gain/loss asymmetry in financial time series. J. Stat. Mech. Theory Exp. 2009, 2009, P02004. [Google Scholar] [CrossRef] [Green Version]
- Sornette, D. Stock market speculation: Spontaneous symmetry breaking of economic valuation. Phys. A Stat. Mech. Its Appl. 2000, 284, 355–375. [Google Scholar] [CrossRef] [Green Version]
- Ahlgren, P.T.H.; Dahl, H.; Jensen, M.H.; Simonsen, I. What Can Be Learned from Inverse Statistics? In Econophysics Approaches to Large-Scale Business Data and Financial Crisis; Springer: Berlin/Heidelberg, Germany, 2010; pp. 247–270. [Google Scholar]
- Mantegna, R.N. Hierarchical structure in financial markets. Eur. Phys. J.-Condens. Matter Complex Syst. 1999, 11, 193–197. [Google Scholar] [CrossRef] [Green Version]
- Tumminello, M.; Aste, T.; Di Matteo, T.; Mantegna, R.N. A tool for filtering information in complex systems. Proc. Natl. Acad. Sci. USA 2005, 102, 10421–10426. [Google Scholar] [CrossRef] [Green Version]
- Berge, C.; Minieka, E., Translators; Graphs and Hypergraphs; North-Holland Publishing Company: Amsterdam, The Netherlands, 1976.
- Gallo, G.; Longo, G.; Pallottino, S.; Nguyen, S. Directed hypergraphs and applications. Discret. Appl. Math. 1993, 42, 177–201. [Google Scholar] [CrossRef] [Green Version]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. Adv. Neural Inf. Process. Syst. 2006, 19, 1601–1608. [Google Scholar]
- Klamt, S.; Haus, U.U.; Theis, F. Hypergraphs and cellular networks. PLoS Comput. Biol. 2009, 5, e1000385. [Google Scholar] [CrossRef] [Green Version]
- Zomorodian, A.; Carlsson, G. Computing persistent homology. Discret. Comput. Geom. 2005, 33, 249–274. [Google Scholar] [CrossRef] [Green Version]
- Singh, G.; Mémoli, F.; Carlsson, G.E. Topological methods for the analysis of high dimensional data sets and 3d object recognition. SPBG 2007, 91, 100. [Google Scholar]
- Edelsbrunner, H.; Letscher, D.; Zomorodian, A. Topological persistence and simplification. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science, Redondo Beach, CA, USA, 12–14 November 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 454–463. [Google Scholar]
- Carlsson, G. Topology and data. Bull. Am. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef] [Green Version]
- Yen, P.T.W.; Cheong, S.A. Using topological data analysis (TDA) and persistent homology to analyze the stock markets in Singapore and Taiwan. Front. Phys. 2021, 9, 20. [Google Scholar] [CrossRef]
- Aste, T.; Di Matteo, T.; Hyde, S. Complex networks on hyperbolic surfaces. Phys. A Stat. Mech. Its Appl. 2005, 346, 20–26. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, A.; Kichikawa, Y.; Iino, T.; Iyetomi, H.; Inoue, H.; Fujiwara, Y.; Aoyama, H. Hierarchical communities in the walnut structure of the Japanese production network. PLoS ONE 2018, 13, e0202739. [Google Scholar] [CrossRef] [PubMed]
- Fujiwara, Y.; Aoyama, H. Large-scale structure of a nation-wide production network. Eur. Phys. J. B 2010, 77, 565–580. [Google Scholar] [CrossRef]
- Iino, T.; Iyetomi, H. Community structure of a large-scale production network in japan. In The Economics of Interfirm Networks; Springer: Berlin/Heidelberg, Germany, 2015; pp. 39–65. [Google Scholar]
- Chakraborty, A.; Krichene, H.; Inoue, H.; Fujiwara, Y. Characterization of the community structure in a large-scale production network in Japan. Phys. A Stat. Mech. Its Appl. 2019, 513, 210–221. [Google Scholar] [CrossRef] [Green Version]
- Krichene, H.; Chakraborty, A.; Inoue, H.; Fujiwara, Y. Business cycles’s correlation and systemic risk of the Japanese supplier-customer network. PLoS ONE 2017, 12, e0186467. [Google Scholar] [CrossRef] [Green Version]
- Plerou, V.; Gopikrishnan, P.; Rosenow, B.; Amaral, L.A.N.; Guhr, T.; Stanley, H.E. Random matrix approach to cross correlations in financial data. Phys. Rev. E 2002, 65, 066126. [Google Scholar] [CrossRef] [Green Version]
- Teh, B.K.; Cheong, S.A. Cluster fusion-fission dynamics in the Singapore stock exchange. Eur. Phys. J. B 2015, 88, 1–14. [Google Scholar] [CrossRef]
- Kruskal, J.B. On the shortest spanning subtree of a graph and the traveling salesman problem. Proc. Am. Math. Soc. USA 1956, 7, 48–50. [Google Scholar] [CrossRef]
- Bonanno, G.; Lillo, F.; Mantegna, R.N. High-frequency cross-correlation in a set of stocks. Quant. Finance 2001, 1, 96–104. [Google Scholar] [CrossRef]
- Onnela, J.P.; Chakraborti, A.; Kaski, K.; Kertiész, J. Dynamic asset trees and portfolio analysis. Eur. Phys. J.-Condens. Matter Complex Syst. 2002, 30, 285–288. [Google Scholar] [CrossRef] [Green Version]
- Miccichè, S.; Bonanno, G.; Lillo, F.; Mantegna, R.N. Degree stability of a minimum spanning tree of price return and volatility. Phys. A Stat. Mech. Its Appl. 2003, 324, 66–73. [Google Scholar] [CrossRef] [Green Version]
- Bonanno, G.; Caldarelli, G.; Lillo, F.; Mantegna, R.N. Topology of correlation-based minimal spanning trees in real and model markets. Phys. Rev. E 2003, 68, 046130. [Google Scholar] [CrossRef] [Green Version]
- Onnela, J.P.; Chakraborti, A.; Kaski, K.; Kertesz, J.; Kanto, A. Dynamics of market correlations: Taxonomy and portfolio analysis. Phys. Rev. E 2003, 68, 056110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brida, J.G.; Risso, W.A. Multidimensional minimal spanning tree: The Dow Jones case. Phys. A Stat. Mech. Its Appl. 2008, 387, 5205–5210. [Google Scholar] [CrossRef]
- Zhang, Y.; Lee, G.H.T.; Wong, J.C.; Kok, J.L.; Prusty, M.; Cheong, S.A. Will the US economy recover in 2010? A minimal spanning tree study. Phys. A Stat. Mech. Its Appl. 2011, 390, 2020–2050. [Google Scholar] [CrossRef] [Green Version]
- Coronnello, C.; Tumminello, M.; Lillo, F.; Micciche, S.; Mantegna, R.N. Sector identification in a set of stock return time series traded at the London Stock Exchange. arXiv 2005, arXiv:cond-mat/0508122. [Google Scholar]
- Jung, W.S.; Chae, S.; Yang, J.S.; Moon, H.T. Characteristics of the Korean stock market correlations. Phys. A Stat. Mech. Its Appl. 2006, 361, 263–271. [Google Scholar] [CrossRef] [Green Version]
- Eom, C.; Oh, G.; Kim, S. Topological properties of the minimal spanning tree in Korean and American stock markets. arXiv 2006, arXiv:physics/0612068. [Google Scholar] [CrossRef] [Green Version]
- Cheong, S.A.; Fornia, R.P.; Lee, G.H.T.; Kok, J.L.; Yim, W.S.; Xu, D.Y.; Zhang, Y. The Japanese economy in crises: A time series segmentation study. Econ. Open-Access Open-Assess. E-J. 2012, 6, 1–81. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, R.; Hu, B.; Ye, Z. Minimal spanning tree for Shanghai-Shenzhen 300 stock index. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1417–1424. [Google Scholar]
- Bonanno, G.; Vandewalle, N.; Mantegna, R.N. Taxonomy of stock market indices. Phys. Rev. E 2000, 62, R7615. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.S.; Djauhari, M.A. Network topology of Indonesian stock market. In Proceedings of the 2012 International Conference on Cloud Computing and Social Networking (ICCCSN), Bandung, Indonesia, 26–27 April 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–4. [Google Scholar]
- Majapa, M.; Gossel, S.J. Topology of the South African stock market network across the 2008 financial crisis. Phys. A Stat. Mech. Its Appl. 2016, 445, 35–47. [Google Scholar] [CrossRef]
- Coelho, R.; Gilmore, C.G.; Lucey, B.; Richmond, P.; Hutzler, S. The evolution of interdependence in world equity markets-Evidence from minimum spanning trees. Phys. A Stat. Mech. Its Appl. 2007, 376, 455–466. [Google Scholar] [CrossRef] [Green Version]
- Gilmore, C.G.; Lucey, B.M.; Boscia, M. An ever-closer union? Examining the evolution of linkages of European equity markets via minimum spanning trees. Phys. A Stat. Mech. Its Appl. 2008, 387, 6319–6329. [Google Scholar] [CrossRef]
- Song, D.M.; Tumminello, M.; Zhou, W.X.; Mantegna, R.N. Evolution of worldwide stock markets, correlation structure, and correlation-based graphs. Phys. Rev. E 2011, 84, 026108. [Google Scholar] [CrossRef] [Green Version]
- Di Matteo, T.; Aste, T. How does the eurodollar interest rate behave? Int. J. Theor. Appl. Financ. 2002, 5, 107–122. [Google Scholar] [CrossRef] [Green Version]
- Dias, J. Sovereign debt crisis in the European Union: A minimum spanning tree approach. Phys. A Stat. Mech. Its Appl. 2012, 391, 2046–2055. [Google Scholar] [CrossRef]
- Dias, J. Spanning trees and the Eurozone crisis. Phys. A Stat. Mech. Its Appl. 2013, 392, 5974–5984. [Google Scholar] [CrossRef]
- McDonald, M.; Suleman, O.; Williams, S.; Howison, S.; Johnson, N.F. Detecting a currency’s dominance or dependence using foreign exchange network trees. Phys. Rev. E 2005, 72, 046106. [Google Scholar] [CrossRef] [Green Version]
- Mizuno, T.; Takayasu, H.; Takayasu, M. Correlation networks among currencies. Phys. A Stat. Mech. Its Appl. 2006, 364, 336–342. [Google Scholar] [CrossRef] [Green Version]
- Górski, A.; Drozdz, S.; Kwapien, J. Minimal spanning tree graphs and power like scaling in FOREX networks. arXiv 2008, arXiv:0809.0437. [Google Scholar] [CrossRef]
- Jang, W.; Lee, J.; Chang, W. Currency crises and the evolution of foreign exchange market: Evidence from minimum spanning tree. Phys. A Stat. Mech. Its Appl. 2011, 390, 707–718. [Google Scholar] [CrossRef]
- Wang, G.J.; Xie, C.; Han, F.; Sun, B. Similarity measure and topology evolution of foreign exchange markets using dynamic time warping method: Evidence from minimal spanning tree. Phys. A Stat. Mech. Its Appl. 2012, 391, 4136–4146. [Google Scholar] [CrossRef]
- Wang, G.J.; Xie, C.; Chen, Y.J.; Chen, S. Statistical properties of the foreign exchange network at different time scales: Evidence from detrended cross-correlation coefficient and minimum spanning tree. Entropy 2013, 15, 1643–1662. [Google Scholar] [CrossRef]
- Sieczka, P.; Hołyst, J.A. Correlations in commodity markets. Phys. A Stat. Mech. Its Appl. 2009, 388, 1621–1630. [Google Scholar] [CrossRef] [Green Version]
- Barigozzi, M.; Fagiolo, G.; Garlaschelli, D. Multinetwork of international trade: A commodity-specific analysis. Phys. Rev. E 2010, 81, 046104. [Google Scholar] [CrossRef] [Green Version]
- Tabak, B.; Serra, T.; Cajueiro, D. Topological properties of commodities networks. Eur. Phys. J. B 2010, 74, 243–249. [Google Scholar] [CrossRef]
- Kristoufek, L.; Janda, K.; Zilberman, D. Correlations between biofuels and related commodities before and during the food crisis: A taxonomy perspective. Energy Econ. 2012, 34, 1380–1391. [Google Scholar] [CrossRef]
- Zheng, Z.; Yamasaki, K.; Tenenbaum, J.N.; Stanley, H.E. Carbon-dioxide emissions trading and hierarchical structure in worldwide finance and commodities markets. Phys. Rev. E 2013, 87, 012814. [Google Scholar] [CrossRef] [Green Version]
- Kazemilari, M.; Mardani, A.; Streimikiene, D.; Zavadskas, E.K. An overview of renewable energy companies in stock exchange: Evidence from minimal spanning tree approach. Renew. Energy 2017, 102, 107–117. [Google Scholar] [CrossRef]
- Iori, G.; De Masi, G.; Precup, O.V.; Gabbi, G.; Caldarelli, G. A network analysis of the Italian overnight money market. J. Econ. Dyn. Control 2008, 32, 259–278. [Google Scholar] [CrossRef]
- Wang, G.J.; Xie, C. Correlation structure and dynamics of international real estate securities markets: A network perspective. Phys. A Stat. Mech. Its Appl. 2015, 424, 176–193. [Google Scholar] [CrossRef]
- Onnela, J.P.; Chakraborti, A.; Kaski, K.; Kertesz, J. Dynamic asset trees and Black Monday. Phys. A Stat. Mech. Its Appl. 2003, 324, 247–252. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.Q.; Cheng, X.Q.; Shen, H.W.; Wang, Z.Y. Distinguishing manipulated stocks via trading network analysis. Phys. A Stat. Mech. Its Appl. 2011, 390, 3427–3434. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.Q.; Shen, H.W.; Cheng, X.Q.; Zhang, Y. Detecting anomalous traders using multi-slice network analysis. Phys. A Stat. Mech. Its Appl. 2017, 473, 1–9. [Google Scholar] [CrossRef]
- Jiang, Z.Q.; Xie, W.J.; Xiong, X.; Zhang, W.; Zhang, Y.J.; Zhou, W.X. Trading networks, abnormal motifs and stock manipulation. Quant. Financ. Lett. 2013, 1, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Tola, V.; Lillo, F.; Gallegati, M.; Mantegna, R.N. Cluster analysis for portfolio optimization. J. Econ. Dyn. Control 2008, 32, 235–258. [Google Scholar] [CrossRef] [Green Version]
- Coelho, R.; Hutzler, S.; Repetowicz, P.; Richmond, P. Sector analysis for a FTSE portfolio of stocks. Phys. A Stat. Mech. Its Appl. 2007, 373, 615–626. [Google Scholar] [CrossRef] [Green Version]
- Iori, G.; Mantegna, R.N. Empirical analyses of networks in finance. In Handbook of Computational Economics; Elsevier: Amsterdam, The Netherlands, 2018; Volume 4, pp. 637–685. [Google Scholar]
- Marti, G.; Nielsen, F.; Bińkowski, M.; Donnat, P. A review of two decades of correlations, hierarchies, networks and clustering in financial markets. arXiv 2017, arXiv:1703.00485. [Google Scholar]
- Onnela, J.P.; Kaski, K.; Kertész, J. Clustering and information in correlation based financial networks. Eur. Phys. J. B 2004, 38, 353–362. [Google Scholar] [CrossRef]
- Gao, Y.C.; Zeng, Y.; Cai, S.M. Influence network in the Chinese stock market. J. Stat. Mech. Theory Exp. 2015, 2015, P03017. [Google Scholar] [CrossRef] [Green Version]
- Kenett, D.Y.; Tumminello, M.; Madi, A.; Gur-Gershgoren, G.; Mantegna, R.N.; Ben-Jacob, E. Dominating clasp of the financial sector revealed by partial correlation analysis of the stock market. PLoS ONE 2010, 5, e15032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kenett, D.Y.; Preis, T.; Gur-Gershgoren, G.; Ben-Jacob, E. Dependency network and node influence: Application to the study of financial markets. Int. J. Bifurc. Chaos 2012, 22, 1250181. [Google Scholar] [CrossRef]
- Billio, M.; Getmansky, M.; Lo, A.W.; Pelizzon, L. Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ. 2012, 104, 535–559. [Google Scholar] [CrossRef]
- Vỳrost, T.; Lyócsa, Š.; Baumöhl, E. Granger causality stock market networks: Temporal proximity and preferential attachment. Phys. A Stat. Mech. Its Appl. 2015, 427, 262–276. [Google Scholar] [CrossRef] [Green Version]
- Tu, C. Cointegration-based financial networks study in Chinese stock market. Phys. A Stat. Mech. Its Appl. 2014, 402, 245–254. [Google Scholar] [CrossRef]
- Tumminello, M.; Micciche, S.; Lillo, F.; Piilo, J.; Mantegna, R.N. Statistically validated networks in bipartite complex systems. PLoS ONE 2011, 6, e17994. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.H.; Chang, C.L.; Tseng, Y.H. Social networks, social interaction and macroeconomic dynamics: How much could Ernst Ising help DSGE? Res. Int. Bus. Financ. 2014, 30, 312–335. [Google Scholar] [CrossRef]
- Kenett, D.Y.; Havlin, S. Network science: A useful tool in economics and finance. Mind Soc. 2015, 14, 155–167. [Google Scholar] [CrossRef]
- National Bureau of Economic Research. Market Microstructure. Available online: https://web.archive.org/web/20080722025938/http://www.nber.org/workinggroups/groups_desc.html (accessed on 29 June 2021).
- Schools, Q. Market Microstructure. Available online: https://www.quantschools.co.uk/module/market-microstructure/ (accessed on 29 June 2021).
- Téllez-León, I.E.; Martínez-Jaramillo, S.; Escobar-Farfán, L.O.; Hochreiter, R. How are network centrality metrics related to interest rates in the Mexican secured and unsecured interbank markets? J. Financ. Stab. 2021, 55, 100893. [Google Scholar] [CrossRef]
- Aste, T.; Shaw, W.; Di Matteo, T. Correlation structure and dynamics in volatile markets. New J. Phys. 2010, 12, 085009. [Google Scholar] [CrossRef]
- Pozzi, F.; Di Matteo, T.; Aste, T. Spread of risk across financial markets: Better to invest in the peripheries. Sci. Rep. 2013, 3, 1665. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.J.; Xie, C.; Chen, S. Multiscale correlation networks analysis of the US stock market: A wavelet analysis. J. Econ. Interact. Coord. 2017, 12, 561–594. [Google Scholar] [CrossRef]
- Musmeci, N.; Aste, T.; Di Matteo, T. Relation between financial market structure and the real economy: Comparison between clustering methods. PLoS ONE 2015, 10, e0116201. [Google Scholar] [CrossRef] [Green Version]
- Wen, F.; Yang, X.; Zhou, W.X. Tail dependence networks of global stock markets. Int. J. Financ. Econ. 2019, 24, 558–567. [Google Scholar] [CrossRef] [Green Version]
- Massara, G.P.; Di Matteo, T.; Aste, T. Network filtering for big data: Triangulated maximally filtered graph. J. Complex Netw. 2016, 5, 161–178. [Google Scholar] [CrossRef]
- Li, Z.; Pinson, S.; Marchetti, M.; Stansel, J.; Park, W. Characterization of quantitative trait loci (QTLs) in cultivated rice contributing to field resistance to sheath blight (Rhizoctonia solani). Theor. Appl. Genet. 1995, 91, 382–388. [Google Scholar] [CrossRef]
- Tong, A.H.Y.; Lesage, G.; Bader, G.D.; Ding, H.; Xu, H.; Xin, X.; Young, J.; Berriz, G.F.; Brost, R.L.; Chang, M.; et al. Global mapping of the yeast genetic interaction network. Science 2004, 303, 808–813. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taylor, M.B.; Ehrenreich, I.M. Higher-order genetic interactions and their contribution to complex traits. Trends Genet. 2015, 31, 34–40. [Google Scholar] [CrossRef] [Green Version]
- Kuzmin, E.; VanderSluis, B.; Wang, W.; Tan, G.; Deshpande, R.; Chen, Y.; Usaj, M.; Balint, A.; Usaj, M.M.; Van Leeuwen, J.; et al. Systematic analysis of complex genetic interactions. Science 2018, 360, 128800. [Google Scholar] [CrossRef] [Green Version]
- Cifuentes, R.; Ferrucci, G.; Shin, H.S. Liquidity risk and contagion. J. Eur. Econ. Assoc. 2005, 3, 556–566. [Google Scholar] [CrossRef]
- Huang, X.; Vodenska, I.; Havlin, S.; Stanley, H.E. Cascading failures in bi-partite graphs: Model for systemic risk propagation. Sci. Rep. 2013, 3, 1–9. [Google Scholar]
- Caccioli, F.; Shrestha, M.; Moore, C.; Farmer, J.D. Stability analysis of financial contagion due to overlapping portfolios. J. Bank. Financ. 2014, 46, 233–245. [Google Scholar] [CrossRef] [Green Version]
- Caccioli, F.; Farmer, J.D.; Foti, N.; Rockmore, D. Overlapping portfolios, contagion, and financial stability. J. Econ. Dyn. Control 2015, 51, 50–63. [Google Scholar] [CrossRef]
- Corsi, F.; Marmi, S.; Lillo, F. When micro prudence increases macro risk: The destabilizing effects of financial innovation, leverage, and diversification. Oper. Res. 2016, 64, 1073–1088. [Google Scholar] [CrossRef]
- Guo, W.; Minca, A.; Wang, L. The topology of overlapping portfolio networks. Stat. Risk Model. 2016, 33, 139–155. [Google Scholar] [CrossRef]
- Yan, X.G.; Xie, C.; Wang, G.J. Stock market network’s topological stability: Evidence from planar maximally filtered graph and minimal spanning tree. Int. J. Mod. Phys. B 2015, 29, 1550161. [Google Scholar] [CrossRef]
- Eryiğit, M.; Eryiğit, R. Network structure of cross-correlations among the world market indices. Phys. A Stat. Mech. Its Appl. 2009, 388, 3551–3562. [Google Scholar] [CrossRef]
- Hatcher, A. Algebraic Topology; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Edelsbrunner, H.; Harer, J. Computational Topology: An Introduction; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Ghrist, R.W. Elementary Applied Topology; Createspace: Seattle, WA, USA, 2014. [Google Scholar]
- Eilenberg, S.; Steenrod, N. Foundations of Algebraic Topology; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Munkres, J.R. Elements of Algebraic Topology; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Cotton, F.A. Chemical Applications of Group Theory; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Dresselhaus, M.S.; Dresselhaus, G.; Jorio, A. Group Theory: Application to the Physics of Condensed Matter; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Strang, G. Linear Algebra and Its Applications, 4th ed.; Cengage Learning: Boston, MA, USA, 2006. [Google Scholar]
- Lay, D.; Lay, S.; McDonald, J. Linear Algebra and Its Applications, 5th ed.; Pearson: London, UK, 2014. [Google Scholar]
- Barabási, A.; PÃ3sfai, M. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- West, D.B. Introduction to Graph Theory; Prentice Hall: Upper Saddle River, NJ, USA, 2001; Volume 2. [Google Scholar]
- Newman, M. Networks: An Introduction; OUP Oxford: Oxford, UK, 2010. [Google Scholar]
- Otter, N.; Porter, M.A.; Tillmann, U.; Grindrod, P.; Harrington, H.A. A roadmap for the computation of persistent homology. EPJ Data Sci. 2017, 6, 1–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gholizadeh, S.; Zadrozny, W. A short survey of topological data analysis in time series and systems analysis. arXiv 2018, arXiv:1809.10745. [Google Scholar]
- Salnikov, V.; Cassese, D.; Lambiotte, R. Simplicial complexes and complex systems. Eur. J. Phys. 2018, 40, 014001. [Google Scholar] [CrossRef] [Green Version]
- Pun, C.S.; Xia, K.; Lee, S.X. Persistent-Homology-based Machine Learning and its Applications—A Survey. arXiv 2018, arXiv:1811.00252. [Google Scholar] [CrossRef] [Green Version]
- De Silva, V.; Ghrist, R.; Muhammad, A. Blind Swarms for Coverage in 2-D. In Robotics: Science and Systems; MIT Press: Cambridge, MA, USA, 2005; pp. 335–342. [Google Scholar]
- Horak, D.; Maletić, S.; Rajković, M. Persistent homology of complex networks. J. Stat. Mech. Theory Exp. 2009, 2009, P03034. [Google Scholar] [CrossRef]
- Lee, H.; Kang, H.; Chung, M.K.; Kim, B.N.; Lee, D.S. Persistent brain network homology from the perspective of dendrogram. IEEE Trans. Med. Imaging 2012, 31, 2267–2277. [Google Scholar]
- Kasson, P.M.; Zomorodian, A.; Park, S.; Singhal, N.; Guibas, L.J.; Pande, V.S. Persistent voids: A new structural metric for membrane fusion. Bioinformatics 2007, 23, 1753–1759. [Google Scholar] [CrossRef]
- Yao, Y.; Sun, J.; Huang, X.; Bowman, G.R.; Singh, G.; Lesnick, M.; Guibas, L.J.; Pande, V.S.; Carlsson, G. Topological methods for exploring low-density states in biomolecular folding pathways. J. Chem. Phys. 2009, 130, 04B614. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xia, K.; Wei, G.W. Persistent homology analysis of protein structure, flexibility, and folding. Int. J. Numer. Methods Biomed. Eng. 2014, 30, 814–844. [Google Scholar] [CrossRef] [PubMed]
- Gameiro, M.; Hiraoka, Y.; Izumi, S.; Kramar, M.; Mischaikow, K.; Nanda, V. A topological measurement of protein compressibility. Jpn. J. Ind. Appl. Math 2015, 32, 1–17. [Google Scholar] [CrossRef]
- Xia, K.; Feng, X.; Tong, Y.; Wei, G.W. Persistent homology for the quantitative prediction of fullerene stability. J. Comput. Chem. 2015, 36, 408–422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xia, K.; Wei, G.W. Multidimensional persistence in biomolecular data. J. Comput. Chem. 2015, 36, 1502–1520. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Wei, G.W. Object-oriented persistent homology. J. Comput. Phys. 2016, 305, 276–299. [Google Scholar] [CrossRef] [Green Version]
- Carlsson, G.; Ishkhanov, T.; De Silva, V.; Zomorodian, A. On the local behavior of spaces of natural images. Int. J. Comput. Vis. 2008, 76, 1–12. [Google Scholar] [CrossRef]
- Singh, G.; Memoli, F.; Ishkhanov, T.; Sapiro, G.; Carlsson, G.; Ringach, D.L. Topological analysis of population activity in visual cortex. J. Vis. 2008, 8, 11. [Google Scholar] [CrossRef] [Green Version]
- Bendich, P.; Edelsbrunner, H.; Kerber, M. Computing robustness and persistence for images. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1251–1260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pachauri, D.; Hinrichs, C.; Chung, M.K.; Johnson, S.C.; Singh, V. Topology-based kernels with application to inference problems in Alzheimer’s disease. IEEE Trans. Med. Imaging 2011, 30, 1760–1770. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niyogi, P.; Smale, S.; Weinberger, S. A topological view of unsupervised learning from noisy data. SIAM J. Comput. 2011, 40, 646–663. [Google Scholar] [CrossRef]
- Wang, B.; Summa, B.; Pascucci, V.; Vejdemo-Johansson, M. Branching and circular features in high dimensional data. IEEE Trans. Vis. Comput. Graph. 2011, 17, 1902–1911. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Xie, Z.; Yi, D. A fast algorithm for constructing topological structure in large data. Homol. Homotopy Appl. 2012, 14, 221–238. [Google Scholar] [CrossRef] [Green Version]
- Rieck, B.; Mara, H.; Leitte, H. Multivariate data analysis using persistence-based filtering and topological signatures. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2382–2391. [Google Scholar] [CrossRef]
- Di Fabio, B.; Landi, C. A Mayer–Vietoris formula for persistent homology with an application to shape recognition in the presence of occlusions. Found. Comput. Math. 2011, 11, 499–527. [Google Scholar] [CrossRef] [Green Version]
- Hiraoka, Y.; Nakamura, T.; Hirata, A.; Escolar, E.G.; Matsue, K.; Nishiura, Y. Hierarchical structures of amorphous solids characterized by persistent homology. Proc. Natl. Acad. Sci. USA 2016, 113, 7035–7040. [Google Scholar] [CrossRef] [Green Version]
- Saadatfar, M.; Takeuchi, H.; Robins, V.; Francois, N.; Hiraoka, Y. Pore configuration landscape of granular crystallization. Nat. Commun. 2017, 8, 15082. [Google Scholar] [CrossRef] [PubMed]
- Reimann, M.W.; Nolte, M.; Scolamiero, M.; Turner, K.; Perin, R.; Chindemi, G.; Dłotko, P.; Levi, R.; Hess, K.; Markram, H. Cliques of neurons bound into cavities provide a missing link between structure and function. Front. Comput. Neurosci. 2017, 11, 48. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Santos, F.A.; Raposo, E.P.; Coutinho-Filho, M.D.; Copelli, M.; Stam, C.J.; Douw, L. Topological phase transitions in functional brain networks. Phys. Rev. E 2019, 100, 032414. [Google Scholar] [CrossRef]
- Gidea, M. Topological data analysis of critical transitions in financial networks. In International Conference and School on Network Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 47–59. [Google Scholar]
- Gidea, M.; Katz, Y. Topological data analysis of financial time series: Landscapes of crashes. Phys. A Stat. Mech. Its Appl. 2018, 491, 820–834. [Google Scholar] [CrossRef] [Green Version]
- Zulkepli, N.; Noorani, M.; Razak, F.; Ismail, M.; Alias, M. Haze detection using persistent homology. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2019; Volume 2111, p. 020012. [Google Scholar]
- Zulkepli, N.F.S.; Noorani, M.S.M.; Razak, F.A.; Ismail, M.; Alias, M.A. Topological characterization of haze episodes using persistent homology. Aerosol Air Qual. Res. 2019, 19, 1614–1624. [Google Scholar] [CrossRef] [Green Version]
- Adams, H.; Tausz, A.; Vejdemo-Johansson, M. JavaPlex: A research software package for persistent (co) homology. In International Congress on Mathematical Software; Springer: Berlin/Heidelberg, Germany, 2014; pp. 129–136. [Google Scholar]
- Bauer, U.; Kerber, M.; Reininghaus, J. Distributed computation of persistent homology. In 2014 Proceedings of the Sixteenth Workshop on Algorithm Engineering and Experiments (ALENEX); SIAM: Philadelphia, PA, USA, 2014; pp. 31–38. [Google Scholar]
- Binchi, J.; Merelli, E.; Rucco, M.; Petri, G.; Vaccarino, F. jholes: A tool for understanding biological complex networks via clique weight rank persistent homology. Electron. Notes Theor. Comput. Sci. 2014, 306, 5–18. [Google Scholar] [CrossRef]
- Dey, T.K.; Fan, F.; Wang, Y. Computing topological persistence for simplicial maps. In Proceedings of the Thirtieth Annual Symposium on Computational Geometry, Kyoto, Japan, 8–11 June 2014; ACM: New York, NY, USA, 2014; pp. 345–354. [Google Scholar]
- Fasy, B.T.; Kim, J.; Lecci, F.; Maria, C. Introduction to the R package TDA. arXiv 2014, arXiv:1411.1830. [Google Scholar]
- Maria, C. Filtered Complexes. Available online: https://gudhi.inria.fr/doc/3.4.1/group__simplex__tree.html (accessed on 20 April 2020).
- Bauer, U.; Kerber, M.; Reininghaus, J.; Wagner, H. Phat–persistent homology algorithms toolbox. J. Symb. Comput. 2017, 78, 76–90. [Google Scholar] [CrossRef]
- Nanda, V. Perseus, the Persistent Homology Software. Available online: http://www.sas.upenn.edu/~vnanda/perseus (accessed on 20 April 2020).
- Dionysus. Dionysus: The Persistent Homology Software. Available online: https://mrzv.org/software/dionysus2/ (accessed on 20 April 2020).
- Bauer, U. Ripser: A Lean C++ Code for the Computation of Vietoris-Rips Persistence Barcodes. 2017. Available online: https://github.com/Ripser/ripser (accessed on 20 April 2020).
- Schauf, A.; Cho, J.B.; Haraguchi, M.; Scott, J.J. Discrimination of Economic Input-Output Networks Using Persistent Homology; The Santa Fe Institute CSSS Working Paper; The Santa Fe Institute: Santa Fe, NM, USA, 2016. [Google Scholar]
- de la Concha, A.; Martinez-Jaramillo, S.; Carmona, C. Multiplex financial networks: Revealing the level of interconnectedness in the banking system. In Proceedings of the International Conference on Complex Networks and their Applications, Lyon, France, 29 November–1 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1135–1148. [Google Scholar]
- Santos, F.; Da Silva, L.; Coutinho-Filho, M. Topological approach to microcanonical thermodynamics and phase transition of interacting classical spins. J. Stat. Mech. Theory Exp. 2017, 2017, 013202. [Google Scholar] [CrossRef] [Green Version]
- Tao, T. Ricci Flow. Available online: https://terrytao.files.wordpress.com/2008/03/ricci.pdf (accessed on 29 June 2021).
- Albert, E.; Perrett, W.; Jeffery, G. The foundation of the general theory of relativity. Ann. Der Phys. 1916, 49, 769–822. [Google Scholar]
- Samal, A.; Sreejith, R.; Gu, J.; Liu, S.; Saucan, E.; Jost, J. Comparative analysis of two discretizations of Ricci curvature for complex networks. Sci. Rep. 2018, 8, 18650. [Google Scholar] [CrossRef]
- Isenberg, J.; Mazzeo, R.; Sesum, N. Ricci flow in two dimensions. arXiv 2011, arXiv:1103.4669. [Google Scholar]
- Topping, P. Lectures on the Ricci Flow; Cambridge University Press: Cambridge, UK, 2006; Volume 325. [Google Scholar]
- Brendle, S. Ricci Flow and the Sphere Theorem; American Mathematical Society: Providence, RI, USA, 2010; Volume 111. [Google Scholar]
- Máximo, D. On the blow-up of four-dimensional Ricci flow singularities. J. Für Die Reine Angew. Math. (Crelles J.) 2014, 2014, 153–171. [Google Scholar] [CrossRef] [Green Version]
- Ollivier, Y. Ricci curvature of metric spaces. Comptes Rendus Math. 2007, 345, 643–646. [Google Scholar] [CrossRef]
- Ollivier, Y. Ricci curvature of Markov chains on metric spaces. J. Funct. Anal. 2009, 256, 810–864. [Google Scholar] [CrossRef] [Green Version]
- Forman, R. Bochner’s method for cell complexes and combinatorial Ricci curvature. Discret. Comput. Geom. 2003, 29, 323–374. [Google Scholar] [CrossRef]
- Sreejith, R.; Mohanraj, K.; Jost, J.; Saucan, E.; Samal, A. Forman curvature for complex networks. J. Stat. Mech. Theory Exp. 2016, 2016, 063206. [Google Scholar] [CrossRef] [Green Version]
- Ni, C.C.; Lin, Y.Y.; Gao, J.; Gu, X.D.; Saucan, E. Ricci curvature of the internet topology. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2758–2766. [Google Scholar]
- Sandhu, R.; Georgiou, T.; Reznik, E.; Zhu, L.; Kolesov, I.; Senbabaoglu, Y.; Tannenbaum, A. Graph curvature for differentiating cancer networks. Sci. Rep. 2015, 5, 12323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farooq, H.; Chen, Y.; Georgiou, T.T.; Tannenbaum, A.; Lenglet, C. Network curvature as a hallmark of brain structural connectivity. Nat. Commun. 2019, 10, 4937. [Google Scholar] [CrossRef] [Green Version]
- Ni, C.C.; Lin, Y.Y.; Luo, F.; Gao, J. Community detection on networks with ricci flow. Sci. Rep. 2019, 9, 9984. [Google Scholar] [CrossRef]
- Sia, J.; Jonckheere, E.; Bogdan, P. Ollivier-ricci curvature-based method to community detection in complex networks. Sci. Rep. 2019, 9, 9800. [Google Scholar] [CrossRef] [PubMed]
- Sandhu, R.S.; Georgiou, T.T.; Tannenbaum, A.R. Ricci curvature: An economic indicator for market fragility and systemic risk. Sci. Adv. 2016, 2, e1501495. [Google Scholar] [CrossRef] [Green Version]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software for exploring and manipulating networks. In Proceedings of the International AAAI Conference on Weblogs and Social Media, San Jose, CA, USA, 17–20 May 2009; pp. 361–362. [Google Scholar]
- Boyer, J.M.; Myrvold, W.J. Simplified O (n) Planarity by Edge Addition. Graph Algorithms Appl. 2006, 5, 241. [Google Scholar]
- Wee, J.; Xia, K. Ollivier Persistent Ricci Curvature-Based Machine Learning for the Protein–Ligand Binding Affinity Prediction. J. Chem. Inf. Model. 2021, 61, 1617–1626. [Google Scholar] [CrossRef] [PubMed]
- Poincaré, M. Cinquième complément à l’analysis situs. Rendiconti del Circolo Matematico di Palermo (1884–1940) 1904, 18, 45–110. [Google Scholar] [CrossRef] [Green Version]
- Smale, S. Generalized Poincare?’s conjecture in dimensions greater than four. Matematika 1962, 6, 139–155. [Google Scholar]
- Freedman, M. The topology of four-differentiable manifolds. J. Diff. Geom 1982, 17, 357–453. [Google Scholar]
- Zeeman, E. The generalised Poincaré conjecture. Bull. Am. Math. Soc. 1961, 67, 270. [Google Scholar] [CrossRef] [Green Version]
- Stallings, J. The piecewise-linear structure of Euclidean space. Math. Proc. Camb. Philos. Soc. 1962, 58, 471–488. [Google Scholar] [CrossRef]
- Thurston, W.P. Three dimensional manifolds, Kleinian groups and hyperbolic geometry. Bull. Am. Math. Soc. 1982, 6, 357–381. [Google Scholar] [CrossRef]
- Hamilton, R.S. Three-manifolds with positive Ricci curvature. J. Differ. Geom 1982, 17, 255–306. [Google Scholar] [CrossRef]
- Perelman, G. The entropy formula for the Ricci flow and its geometric applications. arXiv 2002, arXiv:math/0211159. [Google Scholar]
- Perelman, G. Ricci flow with surgery on three-manifolds. arXiv 2003, arXiv:math/0303109. [Google Scholar]
- Bertsimas, D.; Tsitsiklis, J.N. Introduction to Linear Optimization; Athena Scientific: Belmont, MA, USA, 1997; Volume 6. [Google Scholar]
- Hurlbert, G. Linear Optimization: The Simplex Workbook; Undergraduate Texts in Mathematics; Springer: New York, NY, USA, 2010. [Google Scholar]
- Metei, A.; Jain, V. Optimization Using Linear Programming; Mercury Learning & Information: Dulles, VA, USA, 2019. [Google Scholar]
Figure 1.
A manifold with a “hole” as well as a “void”.

Figure 2.
(a) The cross-correlation matrix for 561 stocks in the SGX from January 2008 to December 2009. In this figure, red correlations are strongly positive, blue correlations are strongly negative, while green correlations are close to zero. No structures can be discerned in this figure, because the stocks are arranged in alphabetical order. (b) After reordering the rows and columns of the cross-correlation matrix, we found strong correlations organized into diagonal blocks, with weaker correlations between them. Material from: Teh et al., Cluster fusion-fission dynamics in the Singapore stock exchange, Euro. Phys. J. B, published 2015 [67], Springer Nature Switzerland AG.
Figure 2.
(a) The cross-correlation matrix for 561 stocks in the SGX from January 2008 to December 2009. In this figure, red correlations are strongly positive, blue correlations are strongly negative, while green correlations are close to zero. No structures can be discerned in this figure, because the stocks are arranged in alphabetical order. (b) After reordering the rows and columns of the cross-correlation matrix, we found strong correlations organized into diagonal blocks, with weaker correlations between them. Material from: Teh et al., Cluster fusion-fission dynamics in the Singapore stock exchange, Euro. Phys. J. B, published 2015 [67], Springer Nature Switzerland AG.

Figure 3.
Pseudo codes for (a) minimal spanning tree and (b) a planar maximally filtered graph.

Figure 4.
In the top row, we show a schematic diagram showing a data cloud and how the filtration process results in various overlapping outcomes for balls of different proximity parameters . In the bottom row, we show the barcodes obtained by scanning through the full range of . In this figure, we partition the barcodes into those for 0-dim simplices, which we indicate using the Betti number , and those for 1-dim simplices, which we indicate using the Betti number . In a barcode diagram, the barcode for a 0-dim simplex (a node) always starts at , since all points are present at the start of the filtration process. The barcode of a 0-dim simplex ends at , when the point is incorporated into a higher-dimensional simplex. In contrast, the barcode of a 1-dim simplex (a link) starts at , when two balls of radius touch. The barcode of this 1-dim simplex then ends at , when a third ball with radius (which may be part of another simplex) touches the first two. At the values of shown in the top row, we can also see going from , and going from , respectively.
Figure 4.
In the top row, we show a schematic diagram showing a data cloud and how the filtration process results in various overlapping outcomes for balls of different proximity parameters . In the bottom row, we show the barcodes obtained by scanning through the full range of . In this figure, we partition the barcodes into those for 0-dim simplices, which we indicate using the Betti number , and those for 1-dim simplices, which we indicate using the Betti number . In a barcode diagram, the barcode for a 0-dim simplex (a node) always starts at , since all points are present at the start of the filtration process. The barcode of a 0-dim simplex ends at , when the point is incorporated into a higher-dimensional simplex. In contrast, the barcode of a 1-dim simplex (a link) starts at , when two balls of radius touch. The barcode of this 1-dim simplex then ends at , when a third ball with radius (which may be part of another simplex) touches the first two. At the values of shown in the top row, we can also see going from , and going from , respectively.

Figure 5.
Topological changes that does not involve fusion or fission: (a) cavitation, in which a void forms within a manifold, (b) annihilation, in which a void within a manifold disappears, (c) rupture, in which a void breaks through the surface of the manifold, (d) healing, in which the surface of the manifold closes over a cavity to form a void, (e) another example of rupture, with the growing cavity proceeding to (f) puncture the manifold, forming a hole. The Betti number signatures of these changes are: (a) , (b) , (c) , (d) , (e) , and (f) .
Figure 5.
Topological changes that does not involve fusion or fission: (a) cavitation, in which a void forms within a manifold, (b) annihilation, in which a void within a manifold disappears, (c) rupture, in which a void breaks through the surface of the manifold, (d) healing, in which the surface of the manifold closes over a cavity to form a void, (e) another example of rupture, with the growing cavity proceeding to (f) puncture the manifold, forming a hole. The Betti number signatures of these changes are: (a) , (b) , (c) , (d) , (e) , and (f) .

Figure 6.
Visualization of the barcodes of TWSE in the seventh period (15 September 2019, 15 March 2020). We restrict our attention to , so that we can inspect the finer details. In this figure, the persistent are highlighted as the pink shaded regions.
Figure 6.
Visualization of the barcodes of TWSE in the seventh period (15 September 2019, 15 March 2020). We restrict our attention to , so that we can inspect the finer details. In this figure, the persistent are highlighted as the pink shaded regions.

Figure 7.
(a) The minimal spanning tree of 671 stocks on the TWSE, computed from their Pearson cross correlations between 1 October 2019 and 31 March 2020. In this figure, the black nodes represent stocks, while the colored links represent the most important cross correlations between stocks discovered using the Kruskal algorithm. If a link is red, it has negative ORC, whereas if a link is blue, it has positive ORC. We also sketched the seven clusters in the minimal spanning tree, using links with the most negative ORCs as a guide. (b) Enlarging the highlighted region in the minimal spanning tree shown in (a), we find that the links between closely spaced nodes have positive ORCs (and thus are shown in blue).
Figure 7.
(a) The minimal spanning tree of 671 stocks on the TWSE, computed from their Pearson cross correlations between 1 October 2019 and 31 March 2020. In this figure, the black nodes represent stocks, while the colored links represent the most important cross correlations between stocks discovered using the Kruskal algorithm. If a link is red, it has negative ORC, whereas if a link is blue, it has positive ORC. We also sketched the seven clusters in the minimal spanning tree, using links with the most negative ORCs as a guide. (b) Enlarging the highlighted region in the minimal spanning tree shown in (a), we find that the links between closely spaced nodes have positive ORCs (and thus are shown in blue).

Figure 8.
Sequence of PMFGs of 671 stocks on the TWSE, computed from their Pearson cross correlations for the time periods (a) 1 August 2019–31 January 2020, (b) 8 August 2019–8 February 2020, (c) 15 August 2019–15 February 2020, (d) 22 August 2019–22 February 2020, (e) 1 September 2019–1 March 2020, (f) 8 September 2019–8 March 2020, (g) 15 September 2019–15 March 2020, (h) 22 September 2019–22 March 2020, (i) 1 October 2019–31 March 2020. In this figure, the black nodes represent stocks, while the colored links represent the most important cross correlations between stocks discovered using the Kruskal algorithm. The links are colored according to their ORCs, with red being negative, green being approximately zero, and blue being positive.
Figure 8.
Sequence of PMFGs of 671 stocks on the TWSE, computed from their Pearson cross correlations for the time periods (a) 1 August 2019–31 January 2020, (b) 8 August 2019–8 February 2020, (c) 15 August 2019–15 February 2020, (d) 22 August 2019–22 February 2020, (e) 1 September 2019–1 March 2020, (f) 8 September 2019–8 March 2020, (g) 15 September 2019–15 March 2020, (h) 22 September 2019–22 March 2020, (i) 1 October 2019–31 March 2020. In this figure, the black nodes represent stocks, while the colored links represent the most important cross correlations between stocks discovered using the Kruskal algorithm. The links are colored according to their ORCs, with red being negative, green being approximately zero, and blue being positive.

Figure 9.
Number of links with over the different time periods (shown in orange): (1) 1 August 2019–31 January 2020, (2) 8 August 2019–8 February 2020, (3) 15 August 2019–15 February 2020, (4) 22 August 2019–22 February 2020, (5) 1 September 2019–1 March 2020, (6) 8 September 2019–8 March 2020, (7) 15 September 2019–15 March 2020, (8) 22 September 2019–22 March 2020, (9) 1 October 2019–31 March 2020. Additionally, the number of links with (blue dashed lines) and the number of links with (green dashed lines) are also shown.
Figure 9.
Number of links with over the different time periods (shown in orange): (1) 1 August 2019–31 January 2020, (2) 8 August 2019–8 February 2020, (3) 15 August 2019–15 February 2020, (4) 22 August 2019–22 February 2020, (5) 1 September 2019–1 March 2020, (6) 8 September 2019–8 March 2020, (7) 15 September 2019–15 March 2020, (8) 22 September 2019–22 March 2020, (9) 1 October 2019–31 March 2020. Additionally, the number of links with (blue dashed lines) and the number of links with (green dashed lines) are also shown.

Figure 10.
Rough sketch of the fission sequence in the TWSE from time window (a) 15 September 2019–15 March 2020 to time window (b) 22 September 2019–22 March 2020 to time window (c) 1 October 2019–31 March 2020. In this figure, we include the nodes 176, 193, and 393 for all three time windows. In each time window, we include all the nearest neighbors of 176, 193, and 393. We show all the links between these nodes with 176, 193, and 393, and color them red if their , green if their , and blue if their . Finally, we show all green and blue links between these nearest-neighbor nodes, and color all simplices bound by green or blue links, to help visualize the clusters in the neighborhoods of 176, 193, and 393. Note that the members of these clusters are dynamic, suggesting strong mixing of cross correlations in the TWSE.
Figure 10.
Rough sketch of the fission sequence in the TWSE from time window (a) 15 September 2019–15 March 2020 to time window (b) 22 September 2019–22 March 2020 to time window (c) 1 October 2019–31 March 2020. In this figure, we include the nodes 176, 193, and 393 for all three time windows. In each time window, we include all the nearest neighbors of 176, 193, and 393. We show all the links between these nodes with 176, 193, and 393, and color them red if their , green if their , and blue if their . Finally, we show all green and blue links between these nearest-neighbor nodes, and color all simplices bound by green or blue links, to help visualize the clusters in the neighborhoods of 176, 193, and 393. Note that the members of these clusters are dynamic, suggesting strong mixing of cross correlations in the TWSE.

Table 1.
The calculated Betti numbers up to , total links, , and total number of simplices for TWSE during 1 August 2019 to 31 March 2021, which covers the COVID-19 crash with a sliding window of seven days.
Table 1.
The calculated Betti numbers up to , total links, , and total number of simplices for TWSE during 1 August 2019 to 31 March 2021, which covers the COVID-19 crash with a sliding window of seven days.
| Date | Links | Simplices | ||||
|---|---|---|---|---|---|---|
| (1 August 2019–31 January 2020) | 1 | 6 | 23 | 27,675 | 1.1 | 3,444,963 |
| (8 August 2019–8 February 2020) | 1 | 9 | 31 | 37,696 | 1.1 | 15,194,973 |
| (15 August 2019–15 February 2020) | 1 | 5 | 33 | 43,708 | 1.1 | 31,321,288 |
| (22 August 2019–22 February 2020) | 1 | 6 | 48 | 46,507 | 1.1 | 41,178,428 |
| (1 September 2019–01 March 2020) | 1 | 2 | 40 | 46,944 | 1.1 | 42,079,525 |
| (7 September 2019–8 March 2020) | 1 | 1 | 40 | 47,482 | 1.1 | 44,068,045 |
| (15 September 2019–15 March 2020) | 2 | 8 | 19 | 58,201 | 1.1 | 39,877,266 |
| (22 September 2019–22 March 2020) | 65 | 17 | 1 | 36,504 | 0.75 | 40,871,885 |
| (1 October 2019–31 March 2020) | 91 | 8 | 1 | 37,640 | 0.65 | 57,119,884 |
Table 2.
In this table on the nine time periods of the TWSE, we show how many stronger cross correlations were rejected in favour of weaker ones, because they would lead to the inclusion of cycles in the MSTs.
Table 2.
In this table on the nine time periods of the TWSE, we show how many stronger cross correlations were rejected in favour of weaker ones, because they would lead to the inclusion of cycles in the MSTs.
| Period | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 0.442 | 0.429 | 0.420 | 0.416 | 0.444 | 0.436 | 0.429 | 0.428 | 0.368 | |
| Links Rejected | 40,519 | 61,601 | 76,327 | 83,437 | 72,813 | 76,895 | 98,935 | 251,601 | 333,363 |
| 0.707 | 0.781 | 0.689 | 0.823 | 0.545 | 0.729 | 0.697 | 0.912 | 0.730 | |
| Links Rejected | 2357 | 977 | 7971 | 661 | 38,811 | 5607 | 11,389 | 977 | 121,433 |
Table 3.
In this table on the nine time periods of the TWSE, we show that many stronger cross correlations were rejected in favour of weaker ones, because they would lead to the loss of planarity in the PMFGs.
Table 3.
In this table on the nine time periods of the TWSE, we show that many stronger cross correlations were rejected in favour of weaker ones, because they would lead to the loss of planarity in the PMFGs.
| Period | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 0.018 | 0.103 | 0.097 | 0.012 | −0.209 | −0.044 | −0.044 | −0.079 | −0.124 | |
| Links Rejected | 245,846 | 224,312 | 237,712 | 286,892 | 380,440 | 313,430 | 340,352 | 415,946 | 429,102 |
| 0.407 | 0.401 | 0.459 | 0.448 | 0.545 | 0.597 | 0.454 | 0.600 | 0.705 | |
| Links Rejected | 49,414 | 70,804 | 59,990 | 69,216 | 37,290 | 24,406 | 86,074 | 149,254 | 103,006 |
Table 4.
Ollivier-Ricci curvatures of the links and in the PMFGs over the nine time periods. If the curvature value is left blank, the two nodes are not connected in the PMFG.
Table 4.
Ollivier-Ricci curvatures of the links and in the PMFGs over the nine time periods. If the curvature value is left blank, the two nodes are not connected in the PMFG.
| Period | ORC (176, 193) | ORC (176, 393) |
|---|---|---|
| 1 August 2019–31 January 2020 | ||
| 8 August 2019–8 February 2020 | ||
| 15 August 2019–15 February 2020 | ||
| 22 August 2019–22 February 2020 | ||
| 1 September 2019–1 March 2020 | ||
| 8 September 2019–8 March 2020 | ||
| 15 September 2019–15 March 2020 | ||
| 22 September 2019–22 March 2020 | ||
| 1 October 2019–31 March 2020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yen, P.T.-W.; Xia, K.; Cheong, S.A. Understanding Changes in the Topology and Geometry of Financial Market Correlations during a Market Crash. Entropy 2021, 23, 1211. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091211
AMA Style
Yen PT-W, Xia K, Cheong SA. Understanding Changes in the Topology and Geometry of Financial Market Correlations during a Market Crash. Entropy. 2021; 23(9):1211. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091211
Chicago/Turabian StyleYen, Peter Tsung-Wen, Kelin Xia, and Siew Ann Cheong. 2021. "Understanding Changes in the Topology and Geometry of Financial Market Correlations during a Market Crash" Entropy 23, no. 9: 1211. https://0-doi-org.brum.beds.ac.uk/10.3390/e23091211
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.