
TLP-CCC: Temporal Link Prediction Based on Collective Community and Centrality Feature Fusion


Institute of Information Technology, PLA Strategic Support Force Information Engineering University, Zhengzhou 450002, China
*
Author to whom correspondence should be addressed.
Entropy 2022, 24(2), 296; https://0-doi-org.brum.beds.ac.uk/10.3390/e24020296
Submission received: 25 January 2022
/
Revised: 17 February 2022
/
Accepted: 17 February 2022
/
Published: 20 February 2022
(This article belongs to the Special Issue Fractal and Multifractal Analysis of Complex Networks)
Abstract
:In the domain of network science, the future link between nodes is a significant problem in social network analysis. Recently, temporal network link prediction has attracted many researchers due to its valuable real-world applications. However, the methods based on network structure similarity are generally limited to static networks, and the methods based on deep neural networks often have high computational costs. This paper fully mines the network structure information and time-domain attenuation information, and proposes a novel temporal link prediction method. Firstly, the network collective influence (CI) method is used to calculate the weights of nodes and edges. Then, the graph is divided into several community subgraphs by removing the weak link. Moreover, the biased random walk method is proposed, and the embedded representation vector is obtained by the modified Skip-gram model. Finally, this paper proposes a novel temporal link prediction method named TLP-CCC, which integrates collective influence, the community walk features, and the centrality features. Experimental results on nine real dynamic network data sets show that the proposed method performs better for area under curve (AUC) evaluation compared with the classical link prediction methods.
1. Introduction
Link prediction method has been applied to community detection, anomaly detection, influence analysis, and recommendation systems for complex networks. With network topology, attributes, and network time series evolution information, link prediction aims to solve one of the most basic scientific problems, reconstructing and predicting missing information [1,2]. Specifically, link prediction research includes edge missing, edge anomaly, and possible future connections in the network [3,4]. In addition to its application value, the related technology of link prediction has important theoretical research value. It can provide a reasonable explanation for the network evolution mechanism, mine the law of network dynamic changes, and provide reliable theoretical support for understanding the mechanism of network internal changes [5]. Complex networks in the real world are often dynamic and temporal networks, nodes and edges in the network change continuously with time. The method of temporal link prediction can better mine the historical information of network changes, and it can be more effective to achieve the prediction performance.
In recent years, link prediction has many research results in large-scale networks, multidimensional heterogeneous networks, and dynamic temporal networks. Generally, the prediction methods can be divided into three categories: network structure-based methods, likelihood analysis-based methods, and machine learning-based methods [6]. Different categories of prediction methods are based on different network scenarios. The network structure-based methods include structure similarity methods such as Common Neighbors [7], Adamic-Adar [8], Local path [9], Katz [10], etc. They only utilize network connection information and have the widest application scenarios. The method based on likelihood analysis uses the known topology and attribute information to calculate the probability of nonexistent edges. For example, Zhao et al. [11] proposed a Bayesian probability model, which combines the node attributes in various directed and undirected relational networks. Liu Shuxin et al. [12] proposed a similarity model based on the matching degree of bidirectional transmission of resources. Javari et al. [13] establishes link label models for local and global attributes of sparse networks to achieve prediction-related functions. Pan et al. [14] combines clustering mechanisms to propose a conditional probability model of the closed paths. Although these methods can make good use of topological structure information, the computational complexity of the algorithms is high and is not applicable for large-scale networks; machine learning methods have been studied in recent years. The idea is to input the structure and attribute information of the network into various neural networks for training, output the embedded vector representation of nodes, and realize the functions of classification and prediction. Li et al. [15] uses the deep learning method optimized by a limited Boltzmann machine to achieve dynamic network link prediction. With the long short-term memory network embedding time information and graph neural network embedding structure information, Chen et al. [16] shows that the combined vectors greatly improve the accuracy of prediction. Machine learning methods usually perform better than similarity-based methods and have lower time complexity than likelihood probability-based models. However, in real applications, the machine learning methods often need more harsh conditions, and the training process of the optimal parameters needs to consume more resources.
Currently, with the popularity of social media, more and more researchers use classical sociological theory to study link prediction problems in social networks [17,18]. Liu Shuxin et al. [19] regards the motif as the smallest community and defines the three-tuple community consistency index to describe the impact of the three-tuple community attributes on link prediction. Valverde-Rebaza et al. [20] proposed a prediction method based on the combination of user interest behavior and community information. Liu et al. [21] proposed a link prediction method based on weak links, degree, and betweenness of common neighbors. Although simple use of social information improves prediction accuracy, these methods do not distinguish the different effects of different community sizes on prediction results, and can further explore the impact of different community structures on similarity.
Existing community theory and structural similarity methods often solve link prediction problems on static networks, but few on dynamic networks. Aiming at the link prediction problem of dynamic networks, this paper proposes a temporal link prediction approach based on community multi-feature fusion and embedded representation, which combines the methods of influence optimization, community detection, and network embedded representation based on the network topology information. The main contributions include:
- Motivated by the concept of collective influence in percolation optimization theory, the collective influence is considered as the effective attribute of nodes, and construct the weight matrix of edges based on node attribute.
- With CI-based weight matrix and weak link optimization, we use the Louvain algorithm to partition the dynamic network into communities, and design the mechanism of node random walk within the community.
- Different from Deepwalk and node2vec, we design a novel strategy of next hop with priority to the existence of connected edges, and the improved Skip-gram model is used to obtain the node representation vector.
- Concatenate the collective influence, network centrality impact and the representation learning vectors of nodes. By using the joint new vectors to calculate the score matrix of the edges, and the temporal link prediction method TLP-CCC is proposed.
- The experimental results on nine real dynamic network data sets show that the proposed method outperforms the traditional classical temporal link prediction methods under AUC evaluation metric.
2. Preliminary
2.1. Temporal Network
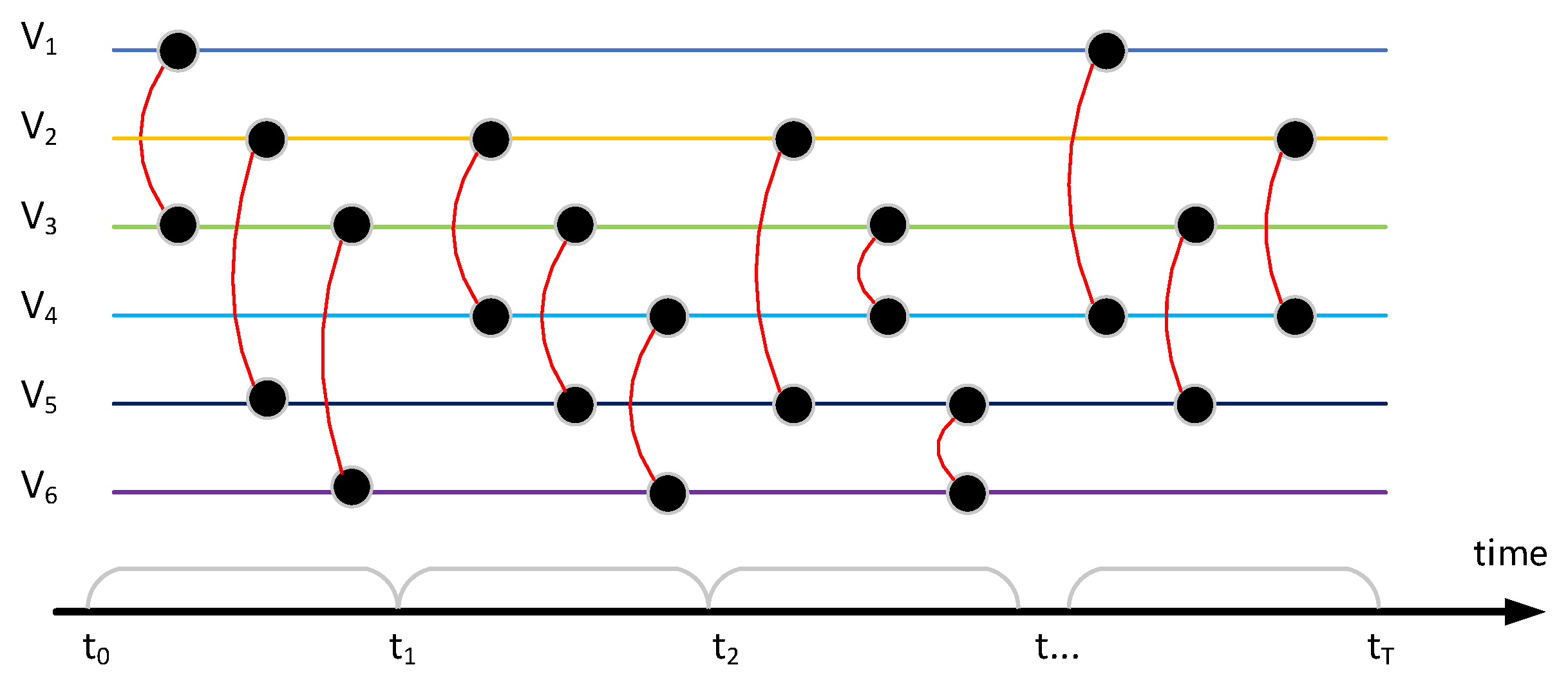
The temporal network includes continuous and discrete temporal network models, and most of them are discrete temporal. As shown in Figure 1, due to the temporal nature of network evolution, a fixed discrete-time window is set to discretize the continuous activities in different time windows. For example, user interacts with user in window . The discrete-temporal model does not consider the situation that the communication continues into the next window; it is considered that the interaction only exists inside the window. In a window unit, repeated multiple contacts are only considered one time, and the node’s own connection is not considered. At the same time, the sampling measurement of the network is set between each time window, so that the network topology in a window period before sampling forms a snapshot diagram.
Given a temporal network G that has N nodes and E edges, each edge in set E can be expressed as , indicating that node i and node j have a connection relationship in the time window t. If the continuous time is discretized according to the fixed time interval w, the window range generated by the edge connection can be expressed as .
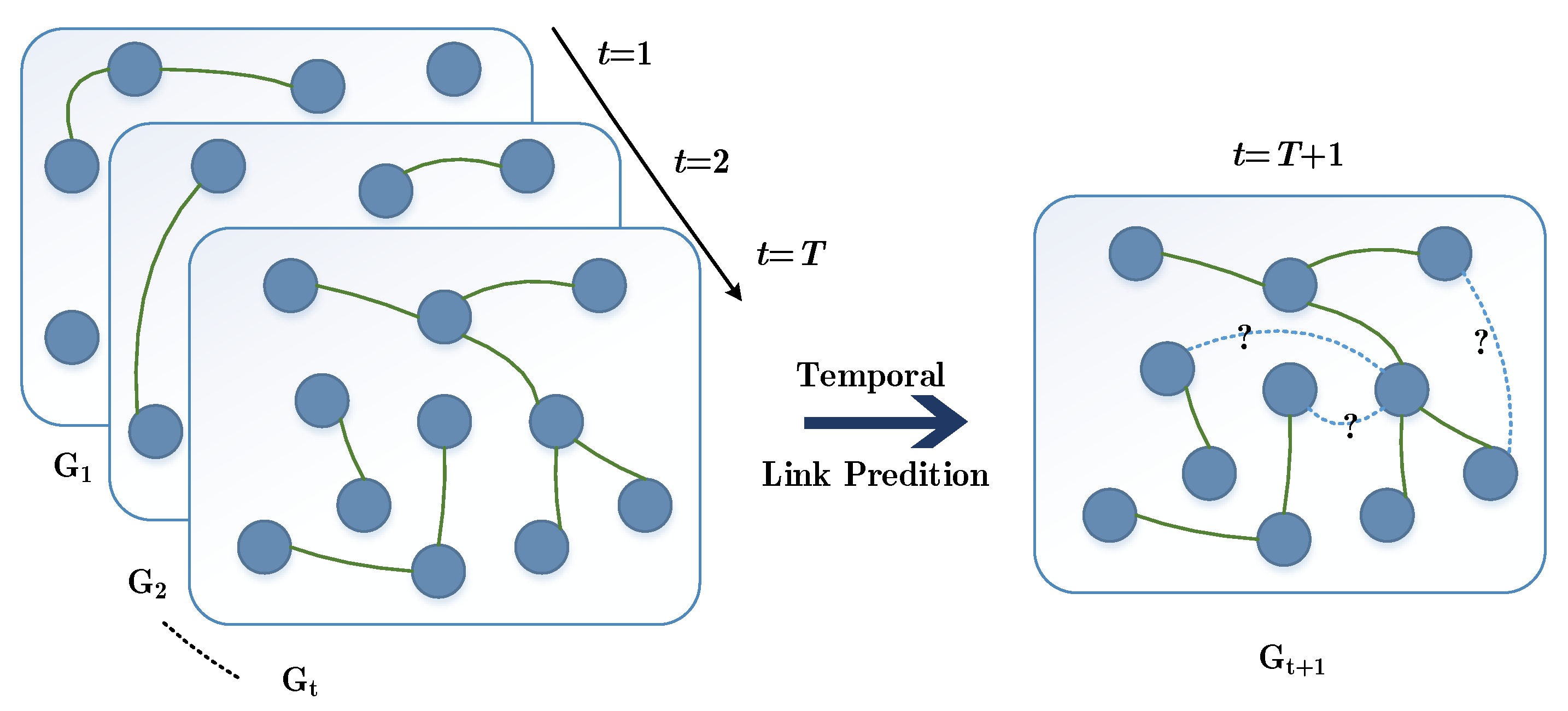
2.2. Problem Definition
Given a dynamic network G, it is divided into T network snapshot sequences by fixed time intervals, where represents the network snapshot at time t, is the node set and is the edge set at time t. Because this paper focuses on the link prediction problem, we only consider the change of edge connection with time, and fix the node set at different times as V. The adjacency matrix of network snapshot at each time t can be expressed as , and is the total number of nodes. In undirected and unweighted network, when edge is connected, otherwise . When a set of network snapshots and their adjacency matrix sequences are given, the dynamic temporal link prediction method aims to study a function to predict the network adjacency matrix at the time t. It generally includes three steps:
- Propose a new similarity index and its corresponding calculation function to calculate the similarity score of each snapshot;
- Propose a new temporal evolution model and its corresponding learning function to predict the expected value in the future;
- Compare and evaluate the expected prediction probability with the real topology.
As shown in Figure 2, network G is the set of all nodes and edges of the dynamic network, represents the network snapshot at time t, V is the node set and E is the edge set at time t. Each node can contain multiple attribute information, and each edge can contain multiple weight information. Nodes and edges can dynamically increase and disappear in the temporal network. The problem of temporal link prediction is to predict the topology connection of the network at time t using the model trained by topology and attribute information of multiple snapshots before time t.
2.3. Metrics
Area under curve (AUC) [22] is a widely used metric for performance evaluation. The AUC measure gives values between 0 and 1, and values above 0.5 show that the proposed algorithm is better than the random prediction for binary classes. In terms of link prediction, AUC means that the probability of a randomly chosen actual edge score is higher than a randomly chosen nonexistent edge score. AUC score is calculated as given in Equation (4):
where n is the times of independent comparisons, indicates how many times actual edge score is higher than nonexistent edge score, and shows how many times scores of actual and nonexistent edges are equal.
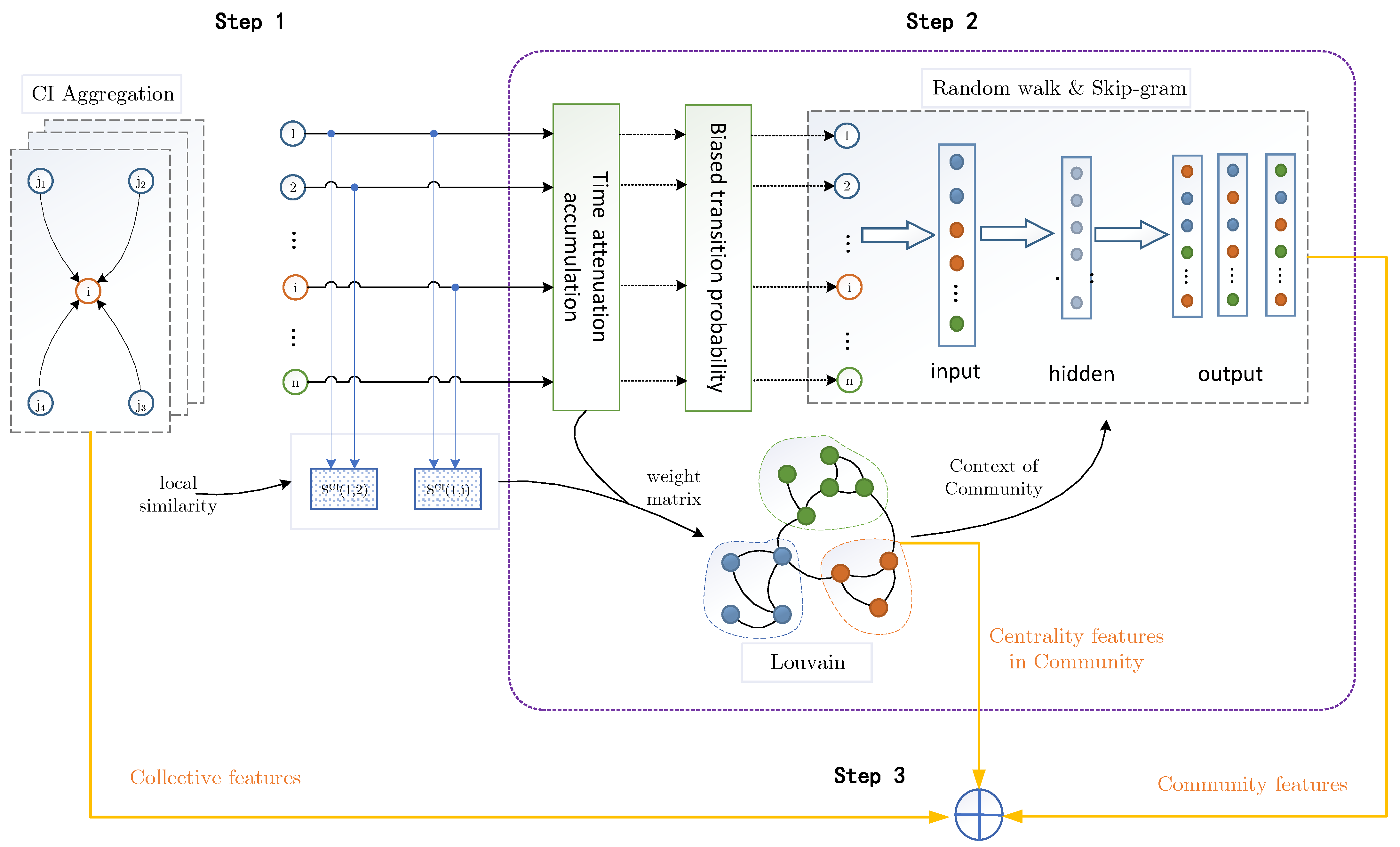
3. TLP-CCC Algorithm
As shown in Figure 3, the proposed algorithm can be divided into three steps. Firstly, quantify node weight and edge weight by using collective influence. Secondly, after processes of time attenuation accumulation and biased transition probability, detect communities by Louvain algorithm according to the principle of modularity optimization, let the nodes perform supervised random walk in the context of the community, and the Skip-gram model is used to obtain the representation vector. Finally, the collective influence, degree centrality, closeness centrality, and betweenness centrality, are combined with the trained node representation vectors, and uses cosine similarity to calculate the similarity index , and the temporal link prediction method TLP-CCC is based on index.
3.1. Similarity Index Based on Collective Influence
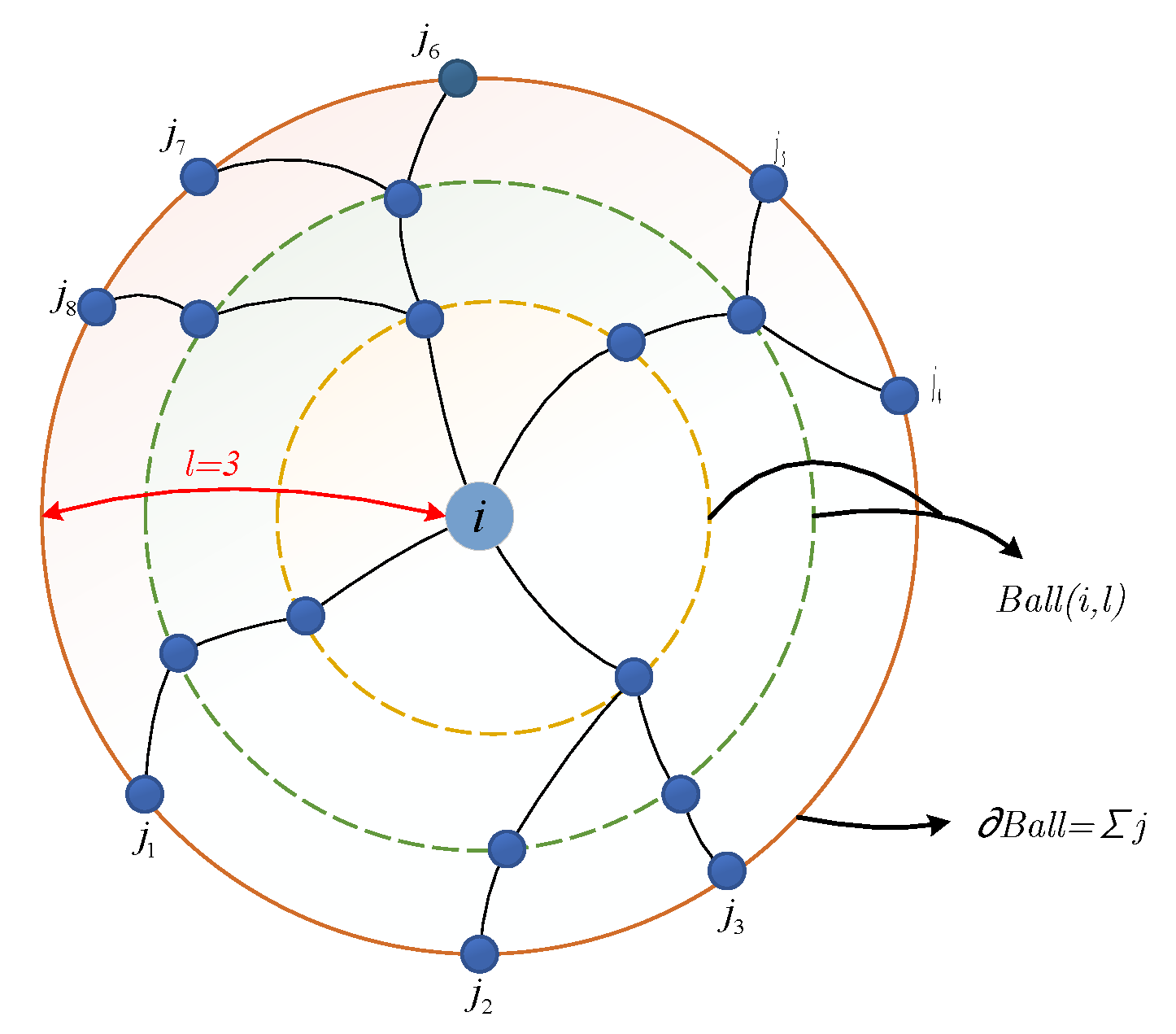
The percolation optimal model is generally used to solve the critical problem of connectivity in complex networks. The optimization of the percolation model is to find the minimum node set that can destroy the maximum connected component of the network, or find a group of nodes that play an important role in the global connection of the network. To solve this problem, Morone et al. [23] proposed a Collective Influence algorithm to quantify the influence of nodes. The collective influence of a node is characterized by nodes on the spherical boundary and has nothing to do with other nodes on the inner path of the ball. The collective influence can more effectively quantify the topology information of nodes in the local range. As shown in Figure 4, the collective influence of nodes in the range of radius 3 can be characterized by boundary nodes to and node i. The collective influence of node i can be defined as:
The collective influence of node i can be defined [23] as:
where represents the degree of node i, ℓ is the radius of the ball, i.e., the path length from ball boundary node to center node, is the node set in the ball with node i as the center and l as the radius, represents the boundary of the ball. The CI algorithm can make more effective use of local topology information. In this paper, the radius ℓ is set to 3.
The dynamic network can be divided into multiple snapshot sets according to a fixed time interval, the train set and the test set can be split as shown in Figure 5. When predicting the network topology at a certain time, p time sliding windows are required as the training set. In order to make full use of the time evolution information, the exponential function is used to fit the temporal evolution of the network to obtain the collective influence weight of each node in the training set.
where represents the time attenuation parameter, and . The greater the value, the smaller the impact of the snapshot relatively far from the prediction time, and represents the collective influence intensity of node i at time t.
After obtaining the collective influence of all nodes, the similarity index based on the common neighbor index and the collective influence on node pair is defined as Equation (7). Because CI is generally a value greater than 1, the numerator is the product of two nodes’ CI, which is used to quantitatively describe the influence of large nodes in social networks. The denominator is the sum of two CI, which indicates the average influence of the node on the surrounding edges. If there is only one edge between two nodes, the collective influence of the node pair is defined as 1.
3.2. Similarity Index Based on Subgraph Walk
The method in this section first divides subgraphs according to community classification, and then performs a random walk within the range of subgraphs.
Firstly, we construct weighted subgraphs using the edge collective influence obtained in the previous section. At the same time, considering that the weak correlation often affects the expression of the association degree between nodes, to filter particularly large and unreasonable communities when dividing large-scale networks, the minimum 5% value in the CI weight matrix with edges is replaced with 0, as shown in Equation (8).
In order to ensure that the edge weight actually exists in the network, the CI weight matrix is correspondingly multiplied by the adjacency matrix to obtain the weight matrix of the collective influence of all edges. At this time, the adjacency matrix is the cumulative weight matrix within the time step p of the training set.
To divide the network into several subgraphs using the Louvain community detection algorithm [24], we input into the module the network topology information and edge weight matrix of the training set. Then, it calculates iteratively according to the mechanism of maximizing modularity. The calculation method of modularity is as follows:
where represents the actual weight of the edge from node i to j, represents the weight sum of all edges connected to node i, represents the weight sum of all edges, represents the probability of the connection between the node j and any node in the whole graph, represents the expected weight of the edges between node i and j, and the difference between and represents the final gain.
The pseudo-code process of calculating the collective influence weight matrix and community division is shown in Algorithm 1.
Secondly, design a supervised random walk strategy, the context scope of node walking is limited to the bounds of the community subgraph. At the same time, the edge with a large weight is preferentially selected in the random walk according to the collective influence of all edges obtained from Equation (7) when selecting the next hop. The Equation (11) represents the probability of walking from node i to the neighbor node j. Different from Deepwalk and node2vec, next hop strategy gives priority to the connected edges. For the random walk path from node i to node j, it is preferred to walk to the neighbor node when the neighbor had a link with the node j, and other cases as same as node2vec method.
| Algorithm 1 |
|
After obtaining the random walk sequence of each node, the node sequence can be input into the classical Skip-gram model to learn the representation vector of the node. Skip-gram is a natural language processing (NLP) model, which is used to maximize the co-occurrence probability between words in the window. It can predict the context node when the current node is known, that is, input the walking information of one node and output the representation vector of multiple nodes. In this section, the Skip-gram model is used to set the following objective functions combined with the divided subgraphs of each community to increase the co-occurrence probability:
where i, , C, represents the input node information, neighbor set of input node, community information, model parameters, respectively. is composed of two matrices u and v, and u is the context matrix and v is the node characteristic matrix. The optimal u and v are finally obtained through iterative training. can be also expressed as:
where represents the probability that neighbor node j exists in the walking sequence. Finally, the output result is optimized by function, so that:
where is the j-th row of u representing the context vector of neighbor node j, and is the i-th row of v to be regarded as the representation vector of seed node i. z represents other community nodes except the current context node. The conditional probability result of Equation (14) can be obtained by on the inner product of the two vectors.
In order to improve the computational efficiency, the negative sampling method is used to optimize the model. The probability that a node is selected as a negative sample can be obtained from the degree distribution of the node, which can be expressed as follow according to Reference [25]:
where K is the number of negative samples, is the collective influence weight of node i. Therefore, based on the improved Skip-gram model and negative sampling method, the objective function of the algorithm can be updated as:
where is the sigmoid function, represents the neighbor node vector information sampled in the community, represents the negative sample information in the community.
The more similar the two node vectors are, the greater the result of point multiplication as well as the probability value obtained after normalization. The normalized probability value of point multiplication can be used to represent the similarity degree of edges. The similarity index based on community-biased embedding representation is defined as Equation (17), in which represents the embedded representation vector of all nodes after community division, biased walk, and Skip-gram learning.
The pseudo-code of computing the embedded representation learning process based on the community-biased random walk is shown in Algorithm 2.
| Algorithm 2 |
|
3.3. Similarity Index Based on Multi Feature Fusion
The node centrality index reflects the node importance in networks. Reference [26] makes effective use of the network structure information and proposes the similarity index fusing community and centrality index. Reference [27] proposes a subgraph similarity feature sequence integrating multiple local similarity indexes and weights. Inspired by these works, the node collective influence weight obtained by Equation (6) and the node subgraph centrality feature are fused with the representation vector in Equation (17) to obtain the new node representation vector, and then the similarity index of multi-feature vector fusion is calculated by cosine similarity.
The degree centrality feature is calculated only within the community to which the node belongs. As shown in Equation (18). represents the exponential attenuation parameter. represents the degree of node i. n represents the number of all nodes in the network. C represents the community to which node i belongs.
The node betweenness centrality is calculated as Equation (19). represents the exponential attenuation parameter. represents the number of shortest paths of . represents the number of shortest paths of passing through node i, and C represents the community to which nodes belong.
The node closeness is calculated as Equation (20). represents the exponential attenuation parameter, n represents the number of all nodes in the network, is the average distance between node i and j, and C represents the community to which nodes belong.
Afterward, the new node representation vector obtained by multi feature fusion is shown in Equation (21), and the features are directly connected with each other to form the new vector.
Cosine similarity measures the similarity of two vectors by calculating the cosine value of the angle between two vectors. For d-dimensional vectors A and B:
The range of cosine similarity is between . The larger the value which represents the high similarity, the smaller the angle between the two vectors. The smaller the value which represents the low similarity, the greater the angle between the two vectors.
The pseudo-code of the temporal link prediction method based on multi-feature fusion embedded representation is shown in Algorithm 3.
In Algorithm 3, the model estimation in step 5 requires time depending on the Louvain method, which is a fast algorithm, and most of the computational time is exploited by step 6, which is determined by the efficiency of step 7 and step 8 of Algorithm 2. For the random walk, the time complexity is , where n is walk num, l is walk length. For the skip-gram, the time complexity is , and it can be optimized to , where d is dimensions and w is the window size. Therefore, the time complexity of the proposed method is , that is finally.
| Algorithm 3 . |
|
4. Experiment
4.1. Datasets
In this paper, nine communication network data sets are used to evaluate the performance of the algorithm. Email [28] is generated from the email data of a large European research institution. Enron [29] is composed of email data sent between Enron employees. Facebook [30] contains the exchange records of Facebook users leaving messages on another user’s wall. DNC [31] is an email exchange network collected by the Democratic National Committee in the event of email leakage. Man [31] is the mail record of employees in a manufacturing factory. UCI [32] is an online social network composed of text messages transmitted between students at the University of California, Irvine. LEM [33] is an interactive network collected by the Kansas event data system based on folders containing WEIS coded events, covering events from April 1979 to June 2004. BIT [32] is a record of reputation scores among members in the Bitcoin OTC trading platform. The SXA2Q [34] is a record of interactions on the stack exchange website Ask Ubuntu. Basic characteristic parameters of data sets are shown in Table 1.
4.2. Baselines
The algorithms compared in this paper include methods based on moving average, topology trend change, and node importance indices. The training and testing set sizes of baseline methods are the same as the proposed method. Details are as follows:
- Moving Average [35]: this kind of method makes quantitative analysis by using the similarity mean of relevant snapshots within the moving range, as shown in Formula (23), which is recorded as Average. If the moving range is only one window before prediction, the model can be used as the nearest time algorithm, as shown in Equation (24), which is recorded as Last. If the whole moments of the moving range are regarded as a weighted static window, the model can be used as the nearest neighbor algorithm of the iteration cycle, as shown in Equation (25), which is recorded as Reduce.
- Node2vec [36]: this method uses the idea of word embedding, inputs the network topology and outputs the representation vector of each node. Equation (26) is the objective function, is the node mapping function, is the characteristic node set of node u sampled by sampling strategy S. In this paper, we set the walking parameters and , and give priority to the breadth walking strategy.
- LINE [37]: this method uses the first-order information directly connected between nodes and the second-order information of common neighbors to jointly design the objective function, such as Equation (27), and are the first-order and second-order objective function, respectively, is the edge weight. This paper uses the second-order similarity method for calculation.
- DySAT [38]: this method combines the structural self-attention layer characteristics and temporal self-attention layer characteristics of the network. The multi-head attention mechanism is adopted to capture the evolution characteristics between network snapshots. The obtained graph embedded representation vectors are used to realize link prediction. Equation (28) is the loss function of the prediction model.
- TSAM [39]: This method uses graph attention network to capture network motif features, and gated recurrent units (GRU) are utilized to learn temporal variations in the snapshot sequence. Both node-level self-attention and time-level self-attention mechanisms are adopted in the model to accelerate the learning process and improve the prediction performance. Equation (29) is the loss function of the prediction model.
- EvolveGCN [40]: this method uses gated recurrent unit (GRU) or long short-term memory network (LSTM) to adjust the parameters of graph convolutional network (GCN) at each time step to capture the dynamic characteristics of graph sequence and then realize the prediction function. This paper uses LSTM to dynamically adjust the network parameters.
4.3. Results
4.3.1. Comparison of Link Prediction Accuracy under AUC Standard
In Experiment 1, set the sphere radius of collective influence , that is, the points on the boundary of the sphere with radius 3 are considered for calculation. Set the training parameters sliding window , time window , that is, using the network data of 7 time steps before the prediction time for training. Set the temporal attenuation coefficient of collective influence , and set the random walk parameters, including the dimensions = 128, the walk-length = 80, the num-walks = 10, the window-size = 10, and concatenate the node collective influence, the three centrality influence, and the walking embedded vector to predict by using the similarity score of Equation (24), which is recorded as TLP-CCC. The AUC performance comparison of the experimental results is shown in Table 2, TLP-CCC method achieves the best prediction accuracy in all data sets.
Firstly, compared to the proposed method with the three CN-based moving average temporal methods, namely Last, Average, and Reduce, it can be seen that the prediction performance of Last is the worst, Average is better than Last and worse than Reduce, which indicates that more topology information can improve the prediction accuracy. These three methods perform well in MAN and LEM datasets, but are a little worse than TLP-CCC. For the other seven datasets, the mean performance of TLP-CCC has been greatly improved, which is about 39% higher than last, 23% higher than Average and 17% higher than Reduce.
Then, we compared the network representation learning methods of node2vec and LINE. These two methods are not end-to-end learning, and the learning process of the node vector is closely related to the random walk path. Useful information in local topology cannot be accurately captured in many cases, and the prediction accuracy will fluctuate by about 1%. TLP-CCC performs a little better in Enron and Facebook, about 2% higher than node2vec and 3% than LINE. For the other seven datasets, the AUC value of TLP-CCC is increased by 11∼49%.
Moreover, compared with the DySAT, TSAM, and EvolveGCN methods based on graph neural network. The results show that the graph neural network methods use richer data dimensions for training and establishes more hidden layer networks to represent the topology, but the improvement in the actual prediction is limited. The accuracy of TLP-CCC has slightly improved in MAN dataset and 7∼26% higher in the other eight datasets.
In a word, methods based on static indices moving average perform better in small scale network, while methods based on graph neural network are relatively more adaptable for large scale complex network applications, and TLP-CCC is outperforming better in nine datasets.
4.3.2. Sensitivity Test of Ball Radius Parameters
The reference [23] recommends setting a three-layer radius in the experiment of connectivity optimization, we set the layer number of the collective influence method from 1 to 6, and observe the influence of the ball radius for the TLP-CCC AUC value. As shown in Figure 6, in the five datasets of Enron, DNC, UCI, LEM, and SXA2Q, the AUC value curve has the largest value when the radius is 1. With the increase of radius, the AUC results show a small fluctuation trend. In BIT and Facebook, it can get the best AUC value when the radius is 6, and in Email and MAN, the best AUC value when the radius is 3 or 4. These results show that using the topology information of the nearest neighbor is the best for the temporal prediction of the structure.
To sum up, the layer number of the spherical radius has a little impact on TLP-CCC, and the fluctuation range of accuracy is about 1%. In general, when the radius of collective influence is large, the node-local topology information has certain limitations. The improvement effect of using only the information of collective influence on link prediction is limited. According to the experimental results, it is recommended to set the ball radius parameter to 1.
4.3.3. Sensitivity Test of Random Walk Parameter
The sensitivity of Skip-gram walk parameters is tested by observing the change of AUC score when changing the size of vector dimension, random walk step, node walk times, and walk window size. Figure 7 shows the score of link prediction using node representation vector when different settings of random walk parameters of TLP-CCC. Figure 7a shows the results of vector dimension parameters. With the increase of dimension parameters, the AUC score fluctuates in a small range, and the optimal value is obtained when the dimension is 32, 64, or 128, respectively. However, the change of dimension parameters has little impact on the AUC score, and the fluctuation range is about 1%. Figure 7b shows the results of the walking step parameter. With the increase of the parameter, the AUC score also gradually increases in a small range. We can see that it has a great impact on the Email and MAN datasets, which increases by about 3% when the step is 80 compared with 20, and the change of the other 4 datasets does not exceed 1%. Figure 7c,d show the test results of the changes of the walk number parameter and the walk window. With the increase of the parameter, the AUC score changes slightly. Considering the computational complexity and the experimental average effect, it is recommended to set the vector dimension greater than 64, the walk step between 40 and 80, the walk times to be 5 and the walk window size to be 10.
4.3.4. Sensitivity Test of Training Window Size
For different data sets, with the training snapshot window size set to 1, 3, 5, 7, 9, and 11, respectively, the experimental results are shown as Figure 8. When the train window size becomes larger, TLP-CCC changes linearly in most datasets except Email, MAN, and UCI, and the optimal value is obtained when the window size is 7 or 9 in the other 3 datasets, which indicates that the topology information of the snapshot will have a certain negative impact on the link prediction result when the initial time is far from the prediction time. Generally speaking, the larger the training window, the better the prediction accuracy in most cases, but there are also fluctuations with the change of the window. Therefore, it is necessary to select the appropriate window size for different real networks.
5. Conclusions
Combining with sociological theory, this paper proposes three novel similarity indices, including based on collective influence, based on community biased walk, and based on multi-feature fusion. The novel method TLP-CCC uses collective influence, degree centrality, betweenness centrality, closeness, and representation learning within the community, which can make more effective use of network subgraph structure information and dynamic network evolution information. By comparing several temporal link prediction methods including moving average, network representation learning, and graph neural network, the experimental results show that our proposed method achieved better prediction accuracy and robustness in nine datasets. This paper does not analyze the impact of the interaction between different subgraphs on the prediction results. The follow-up research problem in the future is how to characterize the different roles of nodes in subgraphs and the influence between subgraphs.
Author Contributions
Funding acquisition, S.L. and Y.L.; investigation, Y.Z. and S.L.; methodology, Y.Z., S.L. and H.L.; software, Y.Z. and Y.L.; supervision, Y.L.; writing—original draft, Y.Z.; writing—review and editing, Y.Z. and S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the National Natural Science Foundation of China under Grant No. 61803384 and Innovative Research Groups of the National Natural Science Foundation of China under Grant No. 61521003.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data, models, or code that support the findings of this study are available from the authors upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gou, F.; Wu, J. Triad link prediction method based on the evolutionary analysis with IoT in opportunistic social networks. Comput. Commun. 2022, 181, 143–155. [Google Scholar] [CrossRef]
- Kim, M.K.; Kim, Y.S.; Srebric, J. Predictions of electricity consumption in a campus building using occupant rates and weather elements with sensitivity analysis: Artificial neural network vs. linear regression. Sustain. Cit. Soc. 2020, 62, 102385. [Google Scholar] [CrossRef]
- Wu, X.; Wu, J.; Li, Y.; Zhang, Q. Link prediction of time-evolving network based on node ranking. Knowl.-Based Syst. 2020, 195, 105740. [Google Scholar] [CrossRef]
- Divakaran, A.; Mohan, A. Temporal link prediction: A survey. New Gener. Comput. 2020, 38, 213–258. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Lorrain, F.; White, H.C. Structural equivalence of individuals in social networks. J. Math. Sociol. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [Green Version]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Zhao, H.; Du, L.; Buntine, W. Leveraging node attributes for incomplete relational data. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 4072–4081. [Google Scholar]
- Shuxin, L.; Xing, L.; Hongchang, C.; Kai, W. Link prediction method based on matching degree of resource transmission for complex network. J. Commun. 2020, 41, 70–79. [Google Scholar]
- Javari, A.; Qiu, H.; Barzegaran, E.; Jalili, M.; Chang, K.C.C. Statistical link label modeling for sign prediction: Smoothing sparsity by joining local and global information. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), Orleans, LA, USA, 18–21 November 2017; IEEE: Orleans, LA, USA, 2017; pp. 1039–1044. [Google Scholar]
- Pan, L.; Zhou, T.; Lü, L.; Hu, C.K. Predicting missing links and identifying spurious links via likelihood analysis. Sci. Rep. 2016, 6, 22955. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Wang, B.; Jiang, Y.; Zhang, Y.; Yan, Y. Restricted Boltzmann machine-based approaches for link prediction in dynamic networks. IEEE Access 2018, 6, 29940–29951. [Google Scholar] [CrossRef]
- Chen, J.; Wang, X.; Xu, X. GC-LSTM: Graph convolution embedded LSTM for dynamic network link prediction. Appl. Intell. 2021, 52, 1–16. [Google Scholar] [CrossRef]
- Daud, N.N.; Ab Hamid, S.H.; Saadoon, M.; Sahran, F.; Anuar, N.B. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Liu, Q.; Du, F. Time series link prediction method based on motif evolution and community consistency. Appl. Res. Comput. 2019, 36, 3674–3678. [Google Scholar]
- Valverde-Rebaza, J.; de Andrade Lopes, A. Exploiting behaviors of communities of twitter users for link prediction. Soc. Netw. Anal. Min. 2013, 3, 1063–1074. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Haddadi, H.; Tian, H. Hidden link prediction based on node centrality and weak ties. Europhys. Lett. 2013, 101, 18004. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Morone, F.; Makse, H.A. Influence maximization in complex networks through optimal percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Ibrahim, N.M.A.; Chen, L. Link prediction in dynamic social networks by integrating different types of information. Appl. Intell. 2015, 42, 738–750. [Google Scholar] [CrossRef]
- Selvarajah, K.; Ragunathan, K.; Kobti, Z.; Kargar, M. Dynamic Network Link Prediction by Learning Effective Subgraphs using CNN-LSTM. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Glasgow, UK, 2020; pp. 1–8. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data 2007, 1, 2-es. [Google Scholar] [CrossRef]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Math. 2009, 6, 29–123. [Google Scholar] [CrossRef] [Green Version]
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, K.P. On the evolution of user interaction in facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks, Barcelona, Spain, 17 August 2009; pp. 37–42. [Google Scholar]
- Kunegis, J. KONECT—The Koblenz Network Collection: Proceedings of the 22nd International Conference on World Wide Web Companion, Rio de Janeiro, Brazil, 13–17 May 2013; Association for Computing Machinery: New York, NY, USA, 2013. [Google Scholar]
- Panzarasa, P.; Opsahl, T.; Carley, K.M. Patterns and dynamics of users’ behavior and interaction: Network analysis of an online community. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 911–932. [Google Scholar] [CrossRef]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: https://snap.stanford.edu/data (accessed on 24 January 2022).
- Paranjape, A.; Benson, A.R.; Leskovec, J. Motifs in temporal networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 601–610. [Google Scholar]
- Güneş, İ.; Gündüz-Öğüdücü, Ş.; Çataltepe, Z. Link prediction using time series of neighborhood-based node similarity scores. Data Min. Knowl. Discov. 2016, 30, 147–180. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Sankar, A.; Wu, Y.; Gou, L.; Zhang, W.; Yang, H. Dysat: Deep neural representation learning on dynamic graphs via self-attention networks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 519–527. [Google Scholar]
- Li, J.; Peng, J.; Liu, S.; Weng, L.; Li, C. TSAM: Temporal Link Prediction in Directed Networks based on Self-Attention Mechanism. arXiv 2020, arXiv:2008.10021. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.; Leiserson, C. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5363–5370. [Google Scholar]
Figure 1.
Schematic diagram of temporal link prediction. Edges exist in a range of , edges exist in a range of , edges exist in a range of , edges exist in a range of . The edges are discretized into a snapshot list .
Figure 1.
Schematic diagram of temporal link prediction. Edges exist in a range of , edges exist in a range of , edges exist in a range of , edges exist in a range of . The edges are discretized into a snapshot list .

Figure 2.
Network slicing instance deployment Diagram of temporal link prediction, which can predict the topology situation at from information of snapshot .
Figure 2.
Network slicing instance deployment Diagram of temporal link prediction, which can predict the topology situation at from information of snapshot .

Figure 3.
Diagram of the multi-features fusion and embedded representation for temporal link prediction. Step 1: Motivated by the concept of collective influence in percolation optimization theory, the collective influence is considered as the effective attribute of nodes, and construct the weight matrix of edges based on node attribute. Step 2: With CI-based weight matrix and weak link optimization, design the mechanism of node random walk within the community, then a novel strategy of next hop with priority to the existence of connected edges within the community, and the improved Skip-gram model is used to obtain the node representation vector. Step 3: Concatenate the collective influence, network centrality impact and the representation learning vectors of nodes. By using the joint new vectors to calculate the score matrix of the edges, and the temporal link prediction method TLP-CCC is proposed.
Figure 3.
Diagram of the multi-features fusion and embedded representation for temporal link prediction. Step 1: Motivated by the concept of collective influence in percolation optimization theory, the collective influence is considered as the effective attribute of nodes, and construct the weight matrix of edges based on node attribute. Step 2: With CI-based weight matrix and weak link optimization, design the mechanism of node random walk within the community, then a novel strategy of next hop with priority to the existence of connected edges within the community, and the improved Skip-gram model is used to obtain the node representation vector. Step 3: Concatenate the collective influence, network centrality impact and the representation learning vectors of nodes. By using the joint new vectors to calculate the score matrix of the edges, and the temporal link prediction method TLP-CCC is proposed.

Figure 4.
Diagram of the collective influence of node. The influence is determined by the joint importance of itself and nodes on the ball boundary.
Figure 4.
Diagram of the collective influence of node. The influence is determined by the joint importance of itself and nodes on the ball boundary.

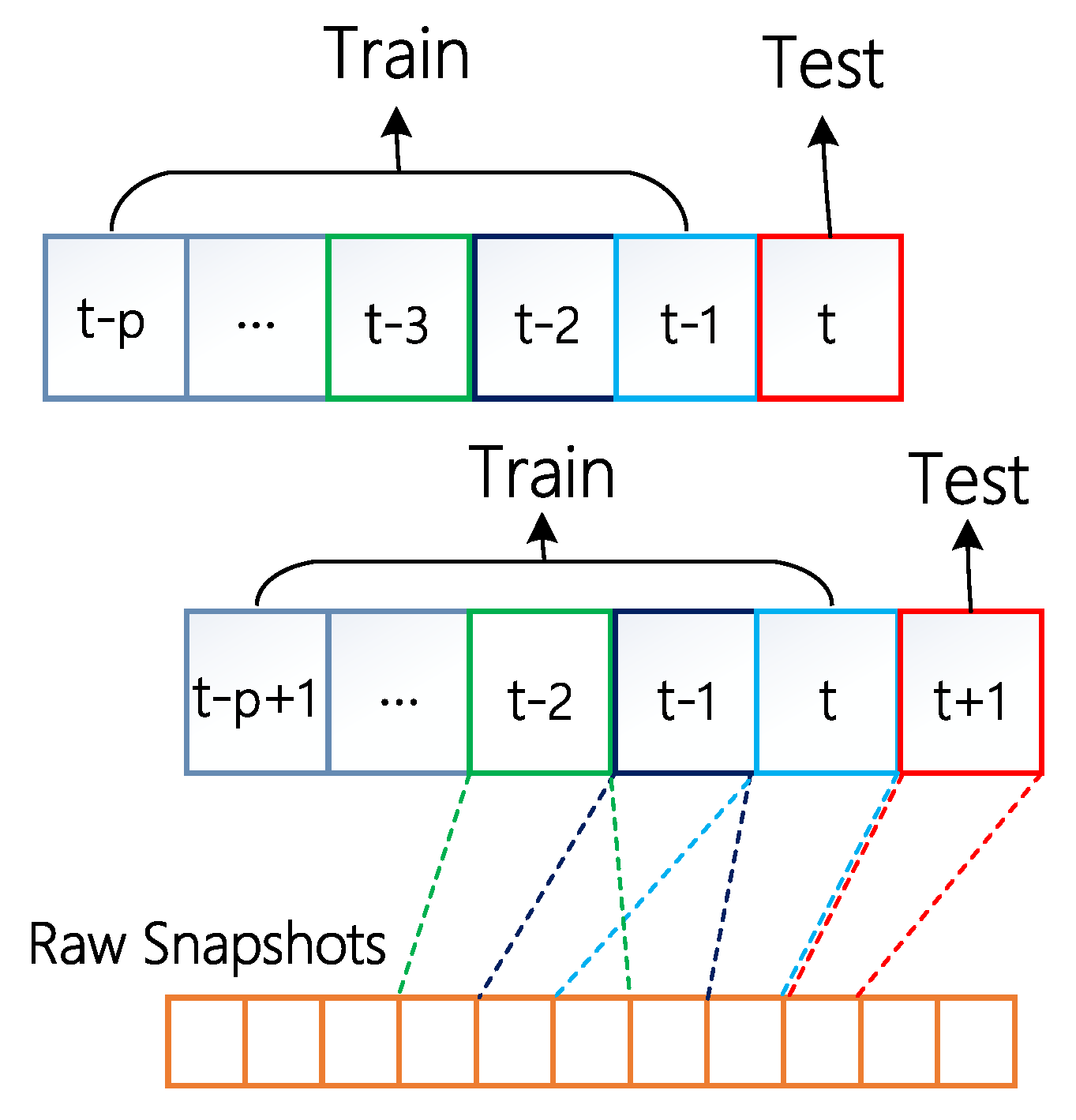
Figure 5.
Schematic diagram of dynamic network data set division. First, construct every time unit from the sliding window. Second, split the data set into the training set and the testing set. Finally, move the train window and the test window step by step, to achieve the mean prediction evaluation.
Figure 5.
Schematic diagram of dynamic network data set division. First, construct every time unit from the sliding window. Second, split the data set into the training set and the testing set. Finally, move the train window and the test window step by step, to achieve the mean prediction evaluation.

Figure 6.
Comparison results of different collective influence radius. (a) The optimal radius of the Email data set is 3. (b) the optimal radius of the Enron data set is 1. (c) the optimal radius of the DNC data set is 1. (d) the optimal radius of the MAN data set is 4. (e) the optimal radius of the UCI data set is 1. (f) the optimal radius of the LEM data set is 1. (g) the optimal radius of the BIT data set is 6. (h) the optimal radius of the SXA2Q data set is 1. (i) the optimal radius of the Facebook data set is 6.
Figure 6.
Comparison results of different collective influence radius. (a) The optimal radius of the Email data set is 3. (b) the optimal radius of the Enron data set is 1. (c) the optimal radius of the DNC data set is 1. (d) the optimal radius of the MAN data set is 4. (e) the optimal radius of the UCI data set is 1. (f) the optimal radius of the LEM data set is 1. (g) the optimal radius of the BIT data set is 6. (h) the optimal radius of the SXA2Q data set is 1. (i) the optimal radius of the Facebook data set is 6.

Figure 7.
Prediction results of different walking parameters. (a) Different dimensions for nine data sets. (b) Different walk-length for nine data sets. (c) Different num-walks for nine data sets. (d) Different window-size for nine data sets.
Figure 7.
Prediction results of different walking parameters. (a) Different dimensions for nine data sets. (b) Different walk-length for nine data sets. (c) Different num-walks for nine data sets. (d) Different window-size for nine data sets.

Figure 8.
AUC performance results of different train window size.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Basic characteristic parameters of dataset.
| Dataset | Enron | DNC | MAN | UCI | LEM | BIT | SXA2Q | ||
|---|---|---|---|---|---|---|---|---|---|
| Node number | 1005 | 87,273 | 60,290 | 2029 | 167 | 1899 | 485 | 5881 | 137,517 |
| Edge number | 332,334 | 1,048,576 | 838,090 | 39,264 | 82,927 | 59,835 | 196,364 | 35,592 | 280,102 |
| Start date | October 2003 | 1 January 2001 | November 2006 | 23 April 2016 | January 2010 | 15 April 2004 | April 1979 | 9 November 2010 | 29 September 2009 |
| End date | May 2005 | 31 March 2002 | January 2009 | 25 May 2016 | October 2010 | 26 October 2004 | June 2004 | 25 January 2016 | 6 March 2016 |
| Total duration | 526 days | 454 days | 103 weeks | 33 days | 268 days | 195 days | 303 months | 1904 days | 2351 days |
| Temporal period | week | week | 2 weeks | day | week | week | half a year | month | month |
| Snapshot number | 76 | 66 | 52 | 33 | 39 | 28 | 51 | 63 | 79 |
Table 2.
Comparison results of prediction accuracy AUC. The proposed method achieves the best prediction accuracy in nine data sets.
Table 2.
Comparison results of prediction accuracy AUC. The proposed method achieves the best prediction accuracy in nine data sets.
| Dataset | Enron | DNC | MAN | UCI | LEM | BIT | SXA2Q | ||
|---|---|---|---|---|---|---|---|---|---|
| Last | 0.7535 | 0.6056 | 0.5158 | 0.7011 | 0.8415 | 0.5152 | 0.9021 | 0.5376 | 0.5340 |
| Average | 0.8793 | 0.7282 | 0.5350 | 0.8156 | 0.8964 | 0.5724 | 0.9520 | 0.5802 | 0.6604 |
| Reduce | 0.8954 | 0.7732 | 0.5522 | 0.8252 | 0.9025 | 0.6157 | 0.9530 | 0.6329 | 0.7593 |
| node2vec | 0.8384 | 0.8877 | 0.8049 | 0.8420 | 0.6028 | 0.5227 | 0.7444 | 0.7019 | 0.7981 |
| LINE | 0.8253 | 0.8784 | 0.7576 | 0.8624 | 0.6068 | 0.6507 | 0.7713 | 0.6266 | 0.7621 |
| DySAT | 0.8603 | 0.7885 | 0.7515 | 0.8376 | 0.9020 | 0.7187 | 0.8352 | 0.7173 | 0.8256 |
| TSAM | 0.8501 | 0.7945 | 0.7702 | 0.8462 | 0.8975 | 0.7230 | 0.8373 | 0.6534 | 0.7266 |
| EvolveGCN | 0.7503 | 0.6347 | 0.6752 | 0.8789 | 0.8016 | 0.6810 | 0.8969 | 0.7565 | 0.8098 |
| TLP-CCC | 0.9518 | 0.9077 | 0.8182 | 0.9120 | 0.9092 | 0.8471 | 0.9563 | 0.7765 | 0.8865 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhu, Y.; Liu, S.; Li, Y.; Li, H. TLP-CCC: Temporal Link Prediction Based on Collective Community and Centrality Feature Fusion. Entropy 2022, 24, 296. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020296
AMA Style
Zhu Y, Liu S, Li Y, Li H. TLP-CCC: Temporal Link Prediction Based on Collective Community and Centrality Feature Fusion. Entropy. 2022; 24(2):296. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020296
Chicago/Turabian StyleZhu, Yuhang, Shuxin Liu, Yingle Li, and Haitao Li. 2022. "TLP-CCC: Temporal Link Prediction Based on Collective Community and Centrality Feature Fusion" Entropy 24, no. 2: 296. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020296
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.