
Information Field Theory and Artificial Intelligence


1
Max Planck Institute for Astrophysics, Karl-Schwarzschild-Strasse 1, 85748 Garching, Germany
2
Physics Department, Ludwig-Maximilians-Universität München, Geschwister-Scholl-Platz 1, 80539 Munich, Germany
Entropy 2022, 24(3), 374; https://0-doi-org.brum.beds.ac.uk/10.3390/e24030374
Submission received: 18 December 2021
/
Revised: 28 February 2022
/
Accepted: 4 March 2022
/
Published: 7 March 2022
(This article belongs to the Special Issue MaxEnt 2020/2021—The 40th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering)
{kind=link}
{kind=link}
{kind=link}
Abstract
:Information field theory (IFT), the information theory for fields, is a mathematical framework for signal reconstruction and non-parametric inverse problems. Artificial intelligence (AI) and machine learning (ML) aim at generating intelligent systems, including such for perception, cognition, and learning. This overlaps with IFT, which is designed to address perception, reasoning, and inference tasks. Here, the relation between concepts and tools in IFT and those in AI and ML research are discussed. In the context of IFT, fields denote physical quantities that change continuously as a function of space (and time) and information theory refers to Bayesian probabilistic logic equipped with the associated entropic information measures. Reconstructing a signal with IFT is a computational problem similar to training a generative neural network (GNN) in ML. In this paper, the process of inference in IFT is reformulated in terms of GNN training. In contrast to classical neural networks, IFT based GNNs can operate without pre-training thanks to incorporating expert knowledge into their architecture. Furthermore, the cross-fertilization of variational inference methods used in IFT and ML are discussed. These discussions suggest that IFT is well suited to address many problems in AI and ML research and application.
1. Motivation
Determining the concrete configuration of a field from measurement data is an ill-posed inverse problem, as physical fields have an infinite number of degrees of freedom (DoF), whereas data sets are always finite in size. Thus, the data provide a finite number of constraints for only a subset of the infinitely many DoF of a field. In order to infer a field, the remaining of its DoF need, therefore, to be constrained via prior information. Fortunately, physics provides such prior information on fields. This information might either be precise, like in electrodynamics, or more phenomenological, in the sense that a field shaped by a certain process can often be characterized by its n-point correlation functions. Having knowledge on such correlations can be sufficient to regularize the otherwise ill-posed field inference problem from finite and noisy data such that meaningful statements about the field can be made.
As a formalism for this, information field theory (IFT) was introduced [1,2] following and extending earlier lines of work [3,4]. IFT is information theory for fields. It investigates the space of possible field configurations and constructs probability densities over those spaces in order to permit Bayesian field inference from data. It has been applied successfully to a number of problems in astrophysics [5,6,7,8,9,10,11,12,13,14,15,16,17,18], particle physics [19,20,21], and elsewhere [22,23,24,25,26]. Here, the relation of IFT with methods and concepts used in artificial intelligence (AI) and machine learning (ML) research are outlined, in particular with generative neural networks (GNNs) and in the usage of variational inference. The presented line of arguments summarizes a number of recent works [27,28,29,30,31,32].
The motivation for this work is twofold. On the one hand, understanding conceptual relations between IFT, ML, and AI techniques allows us to transfer computational methods between these domains and to develop synergistic approaches. This article will discuss such. On the other hand, the current success of deep learning techniques for neural networks has let them appear as a synonym for AI in the public perception. This has consequences for decisions about which kind of technologies get scientific funding. The point this paper is trying to make is that if deep learning qualifies as AI in this respect, then this should also apply to a number of other techniques, including those based on IFT.
The paper is organized as follows. IFT is briefly introduced in Section 2 in its most modern incarnation in terms of standardized, generative models. These are shown to be structurally similar to GNNs in Section 3. The structural similarity of IFT inference and GNN training problems allows for a common set of variational inference methods, as discussed in Section 4. Section 5 concludes on the relation of IFT methods and those used in AI and ML and gives an outlook on future synergies.
2. Information Field Theory
2.1. Basics
IFT allows us to deduce fields from data in a probabilistic way. In order to be able to apply probability theory onto the space of field configurations, a measure in this space is needed. Although no canonical mathematical measure on function spaces exists, for IFT applications, the usage of Gaussian process measures [33], which are mathematically well defined [34,35], is usually fully sufficient. Gaussian processes can also be argued to be a natural starting point for reasoning on fields with known finite first and second order moments, as we will discuss now.
To be specific, let be a scalar field over some domain and our prior knowledge on be the first and second moments of the field, e.g.,
with denoting a field value and a prior expectation value for some function f of the field. If only the first and second field moments are given as prior information, it follows from the maximum entropy principle that the least informative probability distribution function encoding this information is a Gaussian with these moments. Thus, using this Gaussian
as a prior with background information is a conservative choice, as it makes the least additional assumptions about the field except for the moments specified in I.
In many applications, however, the field of interest, the signal s, is not a Gaussian field, but may be related to such via a non-linear transformation. For example, in astronomical applications of IFT, the sky brightness field s is the quantity of interest, which is strictly positive, and therefore cannot be a Gaussian field. However, the logarithm of a brightness can be positive and negative and may therefore be modeled as a Gaussian process. In such a case, one could assign, e.g., as a model for a diffuse (spatially correlated) sky emission component, with a reference brightness, chosen such that for example holds.
Having established a field prior, Bayesian reasoning on the field , and therefore on the signal of interest , based on some data d and its likelihood is possible. The field posterior
is defined as well as the prior and permits us to answer questions about the field, like its most probable configuration (MAP = maximum a posteriori), its posterior mean , or its posterior uncertainty dispersion . IFT exploits the formalism of quantum and statistical field theory to calculate such posterior expectation values [1,28,36,37,38]. These formal calculations, however, should not be the focus here. Instead, it should be the formulation of IFT inference problems in terms of generative models, as these can be interpreted as GNNs.
For this purpose, the likelihood is expressed in terms of a measurement equation
which is always possible if the data can be embedded into a vector space and the data expectation value exists. Here and in the following, we omit the background information I in probabilities. This rewriting of the likelihood in terms of a mean instrument response to the field and a noise process , which summarizes the fluctuations around that mean , allows us to regard the data as the result of a noisy generative process that maps field values and associated noise realizations n onto data d according to Equation (5).
In case the instrument response and noise processes are provided for the signal s instead of the Gaussian field as and , their respective pull backs and provide the necessary response and noise statistics w.r.t. the field .
All this provides a generative model for the signal s and data d via , , , and , which should now be standardized. The standardization introduces a generic latent space that permits better comparison to GNNs used in AI and ML and simplifies the usage of variational inference methods discussed later on.
2.2. Prior Standardization
Standardization of a random variable refers to finding a mapping from a standard normal distributed random variable to that reproduces the statistics of . For a Gaussian field , this is just a mapping of the form
where refers to a square root of , which always exists for a covariance matrix that is positive definite. For the large class of band diagonal and therefore translational invariant covariance matrices , which are very relevant for applications as we argue below, the square root of can be explicitly constructed.
2.3. Power Spectra
In many signal inference problems, no spatial location is singled out a priori, before the measurement. This means that the field covariance between two locations only depends on the distance between these positions, but not on their absolute positions. Thus, . As a consequence of the Wiener–Khinchin theorem, such a translational invariant field covariance becomes diagonal in harmonic space,
Here and in the following, denotes a harmonic transform (a u-dimensional Fourier transform in case of an Euclidean space, as we assume in the following), † the adjoint (complex conjugate and transposed of a matrix or vector), is the so called power spectrum of , the Einstein convention for repeated indices is used, as in , and denotes a diagonal operator in the space of the field with the values of on the diagonal.
Thanks to this diagonal representation of the field covariance in harmonic space, an explicit standardization of the field is given via
where the latter is an amplitude operator that is diagonal in harmonic space and that imprints the right amplitudes onto the Fourier modes of . This can be seen via a direct calculation,
In case no direction of the space is singled out a priori, the two-point correlation function and the power spectrum of become isotropic, and , respectively. In this case, only a one-dimensional power spectrum needs to be known. Such power spectra are often smooth functions on a double logarithmic scale in Fourier space, since any sharp feature in them would correspond to a (quasi-) periodic pattern in position space, which would be very unnatural for most signals. Thus, introducing the logarithmic Fourier space scale variable w.r.t. some reference scale , we expect
to be a field itself, in the sense that it is sufficiently smooth. Here, is a pivot scale for the power spectrum.
2.4. Amplitude Model
Often, the power spectrum as parameterized through is not known a priori for a field , but statistical homogeneity, isotropy, and the absence of long range quasi-periodic signal variations make a Gaussian field prior for plausible, . This log-log-power spectrum may exhibit fluctuations around a non-zero mean . The latter might, e.g., encode a preference for falling spectra and therefore for a spatially smooth field . In this case, just another layer for of a standardized generative model has to be added,
Again, a prior for a field, here the only one dimensional , is needed. A detailed description of how this amplitude model can be provided efficiently is given by [15]. This reference also provides a generative model for the case that the signal domain is a product of sub-spaces, like position space and an energy spectrum coordinate, each requiring a different correlation structure, and the total correlation being a direct product of those. Assuming a direct product for the correlation structures might be possible for many field inference problems [15,39].
2.5. Dynamical Systems
Let us take a brief detour to fields shaped by dynamical systems. Dynamical systems, typically exhibit correlation structures that are not direct products of the spatial and temporal sub-spaces, as was proposed above. Here, the full spatial and temporal Fourier power spectrum , with being the temporal frequency, encodes the full dynamics of a linear, homogeneous, and autonomous system. For example, a stochastic wave field may follow the dynamical equation
where c is the wave velocity and a damping constant. The field dynamics are determined by a response operator (or Green’s function) G that is a convolution of the exciting noise field with a kernel g,
where ∗ denotes convolution. In Fourier-space, this kernel can be applied by a direct point wise multiplication, and is given by
If the excitation of field fluctuations is caused by a white, stochastic noise field , the resulting field has a power spectrum of
In this case, the spectrum is an analytical function in and k. This results from Equation (20) being a linear, homogeneous, and autonomous partial differential equation.
Linear integro-differential equations, however, can still be solved by convolutions, in which case the kernel might not have an analytically closed form any more, if the equation is still homogeneous and autonomous. For example, in neural field theory [40,41,42,43], a macroscopic description of the brain cortex dynamics, the neural activity might be described by
Here, w is a spatial–temporal convolution kernel (that usually contains a delta function in time), an activation function that is applied point wise to the field, , and we added an input term . In case f is linear, the system responds linearly to inputs. Then, the input response is a convolution with a kernel g that has in general a non-analytical spectrum,
where is the slope of f and the Fourier transformed kernel of the dynamics.
An inference of such non-analytical and highly structured response spectra from data is possible with IFT and can be used to learn the system dynamics from noisy system measurements [26,44]. It just requires a more complex spectral prior than discussed here. Let us now return to our main line of argumentation.
2.6. Generative Model
To summarize, the field inference problems of IFT can often be stated in terms of a standardized, generative model for the signal and the data. For the illustrative case outlined above, where the probabilistic model is given by
the corresponding standardized generative model is
This generative model is illustrated in Figure 1. Variants of it are used in a number of real world data applications [5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21]. Its performance in generative and reconstruction mode is illustrated for synthetic data in Figure 2 and Figure 3.
For the noiseless data the generative model reads
This way, the full model complexity as given by Equations (26)–(31) is transferred into an effective response function . For this latent variable vector, the prior is simply , whereas the likelihood has absorbed the full model complexity. This so called reparametrization trick [45] was introduced to IFT by [29] to simplify numerical variational inference.
At this point, it is essential to realize that this generative model consists of a latent space white noise process that generates an input vector and a sequence of non-local linear and local non-linear operations that is applied to it. The Fourier transform and are examples of non-local linear operations within the model. Among the non-linear operations are the exponential functions and the application of the -dependent amplitude operator to the latent space excitations , as there the two components of are multiplied together. Furthermore, the instrument response might also be decomposed into sequences of non-local linear and local non-linear operations, as physical processes in measurement devices can often be cast into the propagation of a quantity (an operation that is linear in the quantity) and the local interactions of the quantity (an operation non-linear in it), respectively.
3. Artificial Intelligence
3.1. Neural Networks
AI and ML are vast fields. AI aims at building artificial cognitive systems that perceive their environment, reason about its state and the systems’ best actions, and learn to improve their performance. ML can be regarded as a sub-field of AI, embracing many different methods like self-organized maps, Gaussian mixture models, deep neural networks, and many others. Here, the focus should be on specific neural networks, GNNs, as those have a close relation to the generative IFT models introduced before.
GNNs transform a latent space variable into a signal or data realization, or . A neural network is a function that can be decomposed in terms of n layer processing functions with
Any of the layer processing functions with consists typically of a non-local, affine linear transformation of the input vector of layer i followed by a local, point wise application of non-linear, so-called activation functions . Thus, the output vector of layer i is
where acts component wise. The set of all coefficients of the s (the matrix elements of the matrices, and the components of the vectors) determines the function the network represents. Putting the input values and network coefficients into a single vector a GNN can be regarded as a function of both, latent variables and network parameters , .
3.2. Comparison with IFT Models
From this abstract perspective, a standardized, generative model in IFT is structurally a GNN, as both consist of sequences of local non-linear and non-local linear operations on their input vector . The concrete architecture of an IFT model and a typical GNN might differ significantly, as GNNs often map a lower dimensional latent space into a higher dimensional data or feature space, whereas the dimension of the IFT model latent space can be very high, as it contains a subset of the virtually infinite many degrees of freedom of a field, see Figure 1.
Additionally, the way IFT-based models and GNNs are usually used differs a bit. Both can be used to generate synthetic samples of outputs by processing random latent space vectors . However, typically an IFT model is applied to infer all latent space variables in from data d. From the latent variables, the signal of interest can always be recovered via .
For this inference the so-called information Hamiltonian, potential, or energy
is investigated with respect to , where . This quantity is introduced to IFT in analogy to statistical mechanics, it summarizes the full knowledge on the problem (as it is just a logarithmic coordinate transformation in the space of probabilities) and has the nice property, that it allows to speak about information as an additive quantity, as .
Investigating the relevant information Hamiltonian for our IFT problem can be done, for example, by minimizing it to obtain a MAP estimator for or—as discussed in the next section—via variational inference (VI). In case of a constant, signal independent Gaussian white noise statistics, the information Hamiltonian becomes
The training of an usual GNN is done with a training data set to which a corresponding latent space vector set and common network parameters need to be found. For this a loss function of the form
might be minimized. Here, a typical GNN data loss function as used for the decoder part of an autoencoder (AE) [49] was assumed. In an generative adversarial network (GAN) [50], however, this data loss function is given in terms of the output of a discriminator network. The network parameter prior term might be chosen to be uninformative () or informative (e.g., in case of a Gaussian prior on the parameters).
Anyhow, by comparison of Equations (45)–(47) with Equations (43) and (44), it should be apparent that the network loss functions can be structurally similar to the IFT information Hamiltonian. Both consist of a standardized quadratic prior-energy and a likelihood-energy and both can have a probabilistic interpretation in terms of being negative log-probabilities, e.g.,
respectively. For this reason, we do not distinguish between an information Hamiltonian and a network loss function by writing for both in the following.
The IFT-GNN can operate with solely a single data vector d due to the domain knowledge coded into their architecture, whereas usual GNNs require sets of data vectors to be trained. Recently, more IFT-like architectures for GNNs were proposed as well, which are also able to process data without training [51].
4. Variational Inference
4.1. Basic Idea
So far, it has been assumed here that MAP estimators are used to determine network parameters for both, IFT-based models as well as traditional GNNs. MAP estimators are known to be prone to over-fitting the data, as they are not probing the adjacent phase-space volumes of their solutions. VI methods perform better in that respect, while still being affordable in terms of computational costs for the high dimensional settings of IFT-based field inference and traditional GNN training. They were used in most recent IFT applications [12,13,14,15,16,17,18,21,52] and are prominently present in the name of variational autoencoders (VAEs) [45] that are built on VI.
In VI, the posterior is approximated by a simpler probability distribution , in many applications by a Gaussian
where . The Gaussian is chosen to minimize the variational Kullback–Leibler (KL) divergence
with respect to the parameters of , and in our case.
Ideally, all degrees of freedom (DoF) of and are optimized. In practice, however, this is often not feasible due to the quadratic scaling of the number of DoF of with that of . Three approximate schemes for handling the high dimensional uncertainty covariance will be discussed in the following, leading to the ADVI, MGVI, and geoVI techniques introduced below, namely
- mean field theory, in which is assumed to be diagonal, as used by ADVI
- the usage of the Fisher information to approximate as a function of and thereby effectively removing the DoF of from the optimization problem as used by MGVI
- a coordinate transformation of the latent space that approximately standardizes the posterior and therefore sets the covariance to the identity matrix in the new coordinates, as performed by geoVI.
Before these are discussed, a note that applies to all of them is in order. Optimizing of the VI KL, Equation (51), is slightly sub-optimal from an information theoretical point of view as this minimizes the amount of information introduced by going from to . The expectation propagation (EP) KL with reversed arguments would be better, as it minimizes the information loss from approximating with [53]. VI is known to underestimate the uncertainties, whereas EP conservatively overestimates them. However, calculating the EP solution for and would require integrating over the posterior. If this would be feasible, any posterior quantity of interest could be calculated as well and there would be no need to approximate in the first place. Estimating and minimizing the VI KL is less demanding, as the integral over the simpler (Gaussian) distribution can very often be performed analytically, or by sample averaging using samples drawn from .
4.2. ADVI and Mean Field Approximation
In all here discussed VI techniques, the posterior mean and the posterior uncertainty covariance become parameters to be determined. The vector has the dimension of the latent space, whereas the posterior uncertainty covariance has independent DoF. For small problems, these might be solved for, however, for large problems with millions of DoF, these cannot even be stored in a computer memory. To circumvent this, the Automatic Differentiation Variational Inference (ADVI) algorithm [54] often invokes the so called mean field approximation (MFA). This assumes a diagonal covariance , with being a latent space vector. Cross-correlations between parameters can not be represented by this, which is problematic in particular in combination with the tendency of VI to underestimate uncertainties.
4.3. MGVI and Fisher Information Metric
In order to overcome this limitation of ADVI that limits its usage in IFT contexts with their large number of DoF, the Metric Gaussian Variational Inference (MGVI) [30] algorithm approximates the posterior uncertainty of with the help of the Fisher information metric
The starting point for obtaining the uncertainty covariance used in MGVI is the Hessian of the log-posterior
as a first guess for the approximate posterior precision matrix . Using this evaluated at the minimum of the information Hamiltonian would correspond to the Laplace approximation, in which the posterior is replaced by a Gaussian obtained from doing a saddle point approximation at its maximum.
However, neither is the MAP solution ideal, as discussed above, nor would this be a good approximation at many locations that differ from . This is because positive definiteness of the Hessian is not guaranteed there, but it is an essential property of any correlation and precision matrix. For this reason, cannot directly be approximated by this Hessian.
It turns out that the likelihood averaged Hessian is strictly positive definite, and is therefore a candidate for an approximate posterior precision matrix for any guessed posterior mean . A short calculation shows that the likelihood averaged Hessian is indeed positive definite:
The last step follows because the Fisher metric is an average over outer products () of likelihood Hamiltonian gradient vectors and thereby positive semi-definite. Adding to the Fisher metric turns the approximate precision matrix into a positive definite matrix , of which the inverse exists for all , and which is positive definite as well.
4.4. Exact Uncertainty Covariance
Being positive definite is of course not the only property an approximation of the posterior uncertainty covariance has to fulfill. It also has to approximate well. Fortunately, this seems to be the case in many situations. The likelihood averaged Laplace approximation actually becomes the exact posterior uncertainty in case of linear Gaussian measurement problems as is shown in the following. If it is exact in such linear situations, it should be a valid approximation in the vicinity of any linear case.
For linear measurement problems, the measurement equation is of the form , the noise statistics , and the standardized prior is . The corresponding posterior is known to be a Gaussian
with mean m and covariance D given by the generalized Wiener filter solution and the Wiener covariance , respectively (e.g., [1]). In this case, the Fisher information metric is independent of . The approximate posterior uncertainty covariance as given by Equation (54) equals the exact posterior covariance, . Thus indeed, the adopted approximation becomes exact in this situation. This should show why this approximation can hold sensible results in sufficiently well behaved cases, in particular when a linearization of the inference problem around a reference solution (e.g., a MAP estimate) is already a good approximation.
Furthermore, for all signal space directions around this reference point that are unconstrained by the data, this covariance approximation returns the prior uncertainty, as it should. Additional discussion of this approximation can be found in Knollmüller and Enßlin [30], where also its performance with respect to ADVI is numerically investigated.
The important point about this approximate uncertainty covariance is that it is a function of the latent space mean estimate i.e., , and therefore does not need to be inferred as well. For many likelihoods, the Fisher metric is available analytically, alleviating the need to store in a computer memory as an explicit matrix. It is only necessary that certain operations can be performed with , like applying it to a vector or drawing samples from a Gaussian with this covariance. Relying solely on those memory inexpensive operations, the MGVI algorithm is able to minimize the relevant VI KL, namely , with respect to the approximate posterior mean . The result of MGVI are then the posterior mean , the uncertainty covariance , and posterior samples drawn according to this mean and covariance. These samples can then be propagated into posterior signal samples , from which any desired posterior signal statistics can be calculated.
4.5. Geometric Variational Inference
ADVI’s and MGVI’s weak point, however, can be the Gaussian approximation of the posterior, which might be strongly non-Gaussian in certain applications. In order to overcome this, the geometrical variational inference (geoVI) algorithm [32] was introduced as an extension of MGVI. geoVI puts another coordinate transformation on top of the one used by MGVI, so that —with to be performed before any of the other IFT-GNN operations — approximately standardizes the posterior, . Astonishingly, this transformation can be constructed without the (prohibitive) usage of any explicit matrix or higher order tensor in the latent space, thus also allowing us to tackle very high dimensional inference problems, like MGVI. The transformation is basically a normalizing flow (network) [55], just with the difference to their usual usage in ML, that the geoVI flow does not need to be trained, but is derived from the problem statement in form of its information Hamiltonian in an automated fashion. Specifically, the coordinate transformation is defined to solve the constraining equation
which fully specifies up to an integration constant . This remaining constant is solved for by minimizing the VI KL with respect to to retrieve the optimal geoVI aproximation.
With geoVI, deeper hierarchical models, which more often exhibit non-Gaussian posteriors due to a larger number of degenerate parameters in them, can be approached via VI. The ability of geoVI to provide uncertainty information is illustrated in Figure 2 (bottom middle and right panels) and in Figure 3. Further details on geoVI and detailed comparisons of ADVI, MGVI, geoVI, and Hamiltonian Monte Carlo methods can be found in [32].
5. Conclusions and Outlook
This paper argues that IFT techniques can well be regarded as ML and AI methods by showing their interrelation with GNNs, normalizing flows, and VI techniques. This insight is not necessarily new, as this paper just summarizes a number of recent works [29,30,31,32] that suggested this before.
First, the generative models build and used in IFT are GNNs that can interpret data without initial training, thanks to the domain knowledge coded into their architecture [29]. Related architectures have very recently been proposed as image priors in the context of neural network architectures as well [51]. As IFT models and the newly proposed image priors do not obtain their intelligence from data driven learning, they are strictly not ML techniques, but might be characterized as (expert) knowledge-driven AI systems. From a technical point of view, however, such a distinction could be seen as splitting hairs.
Second, the VI algorithms used in IFT and AI to approximately infer quantities are a natural interface between these areas. Here, the related ADVI [54], MGVI [30], and geoVI [32] algorithms were briefly discussed, which can be used in classical ML and AI as well as in IFT applications.
And third, the common probabilistic formulation of IFT models and GNNs, as well as the common VI infrastructure of the two areas allows for combining pre-trained GNNs and other networks with IFT-style model components. In that respect, the possibility to perform Bayesian reasoning with trained neural networks as described in [31] might give an outlook on the potential to combine IFT with other ML and AI methods.
Funding
This research received no external funding.
Data Availability Statement
The presented data are synthetically generated via the script getting_started_3.py enclosed in the open source software package NIFTy in its version 8, downloadable at https://gitlab.mpcdf.mpg.de/ift/nifty/-/tree/NIFTy_8 (accessed on 17 December 2021).
Acknowledgments
I am grateful to many colleagues and students that helped me to understand the relation of IFT and AI. The line of thoughts presented here benefited particularly from discussions with Philipp Arras, Philipp Frank, Jakob Knollmüller, and Reimar Leike. I thank Philipp Arras, Vincent Eberle, Gordian Edenhofer, Johannes-Harth-Kitzerow, Philipp Frank, Jakob Roth, and three constructive anonymous reviewers for detailed comments on the manuscript.
Conflicts of Interest
The author declares no conflict of interest.
References
- Enßlin, T.A.; Frommert, M.; Kitaura, F.S. Information field theory for cosmological perturbation reconstruction and nonlinear signal analysis. Phys. Rev. D 2009, 80, 105005. [Google Scholar] [CrossRef] [Green Version]
- Enßlin, T.A. Information Theory for Fields. Ann. Phys. 2019, 531, 1800127. [Google Scholar] [CrossRef] [Green Version]
- Bialek, W.; Zee, A. Statistical mechanics and invariant perception. Phys. Rev. Lett. 1987, 58, 741–744. [Google Scholar] [CrossRef] [PubMed]
- Lemm, J.C. Bayesian Field Theory; JHU Press: Baltimore, MD, USA, 2003. [Google Scholar]
- Oppermann, N.; Junklewitz, H.; Robbers, G.; Bell, M.R.; Enßlin, T.A.; Bonafede, A.; Braun, R.; Brown, J.C.; Clarke, T.E.; Feain, I.J.; et al. An improved map of the Galactic Faraday sky. Astron. Astrophys. 2012, 542, A93. [Google Scholar] [CrossRef] [Green Version]
- Oppermann, N.; Junklewitz, H.; Greiner, M.; Enßlin, T.A.; Akahori, T.; Carretti, E.; Gaensler, B.M.; Goobar, A.; Harvey-Smith, L.; Johnston-Hollitt, M.; et al. Estimating extragalactic Faraday rotation. Astron. Astrophys. 2015, 575, A118. [Google Scholar] [CrossRef] [Green Version]
- Junklewitz, H.; Bell, M.R.; Enßlin, T. A new approach to multifrequency synthesis in radio interferometry. Astron. Astrophys. 2015, 581, A59. [Google Scholar] [CrossRef]
- Imgrund, M.; Champion, D.J.; Kramer, M.; Lesch, H. A Bayesian method for pulsar template generation. Mon. Not. R. Astronmical Soc. 2015, 449, 4162–4183. [Google Scholar] [CrossRef]
- Selig, M.; Vacca, V.; Oppermann, N.; Enßlin, T.A. The denoised, deconvolved, and decomposed Fermi γ-ray sky. An application of the D3PO algorithm. Astron. Astrophys. 2015, 581, A126. [Google Scholar] [CrossRef] [Green Version]
- Dorn, S.; Greiner, M.; Enßlin, T.A. All-sky reconstruction of the primordial scalar potential from WMAP temperature data. J. Cosmol. Astropart. Phys. 2015, 2015, 041. [Google Scholar] [CrossRef] [Green Version]
- Knollmüller, J.; Frank, P.; Enßlin, T.A. Separating diffuse from point-like sources—A Bayesian approach. arXiv 2018, arXiv:1804.05591. [Google Scholar]
- Arras, P.; Frank, P.; Leike, R.; Westermann, R.; Enßlin, T.A. Unified radio interferometric calibration and imaging with joint uncertainty quantification. Astron. Astrophys. 2019, 627, A134. [Google Scholar] [CrossRef]
- Hutschenreuter, S.; Enßlin, T.A. The Galactic Faraday depth sky revisited. Astron. Astrophys. 2020, 633, A150. [Google Scholar] [CrossRef]
- Leike, R.H.; Glatzle, M.; Enßlin, T.A. Resolving nearby dust clouds. Astron. Astrophys. 2020, 639, A138. [Google Scholar] [CrossRef]
- Arras, P.; Frank, P.; Haim, P.; Knollmüller, J.; Leike, R.; Reinecke, M.; Enßlin, T. M87* in space, time, and frequency. arXiv 2020, arXiv:2002.05218. [Google Scholar]
- Arras, P.; Bester, H.L.; Perley, R.A.; Leike, R.; Smirnov, O.; Westermann, R.; Enßlin, T.A. Comparison of classical and Bayesian imaging in radio interferometry. arXiv 2020, arXiv:2008.11435. [Google Scholar] [CrossRef]
- Hutschenreuter, S.; Anderson, C.S.; Betti, S.; Bower, G.C.; Brown, J.A.; Brüggen, M.; Carretti, E.; Clarke, T.; Clegg, A.; Costa, A.; et al. The Galactic Faraday rotation sky 2020. arXiv 2021, arXiv:2102.01709. [Google Scholar] [CrossRef]
- Mertsch, P.; Vittino, A. Bayesian inference of three-dimensional gas maps. I. Galactic CO. Astron. Astrophys. 2021, 655, A64. [Google Scholar] [CrossRef]
- Davis, J.H.; Enßlin, T.; Bœhm, C. New method for analyzing dark matter direct detection data. Phys. Rev. D 2014, 89, 043505. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Enßlin, T.; Selig, M. Galactic dark matter search via phenomenological astrophysics modeling. J. Cosmol. Astropart. Phys. 2016, 2016, 030. [Google Scholar] [CrossRef] [Green Version]
- Welling, C.; Frank, P.; Enßlin, T.; Nelles, A. Reconstructing non-repeating radio pulses with Information Field Theory. J. Cosmol. Astropart. Phys. 2021, 2021, 071. [Google Scholar] [CrossRef]
- Selig, M.; Oppermann, N.; Enßlin, T.A. Improving stochastic estimates with inference methods: Calculating matrix diagonals. Phys. Rev. E 2012, 85, 021134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Enßlin, T.A. Information field dynamics for simulation scheme construction. Phys. Rev. E 2013, 87, 013308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leike, R.H.; Enßlin, T.A. Towards information-optimal simulation of partial differential equations. Phys. Rev. E 2018, 97, 033314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kurthen, M.; Enßlin, T. A Bayesian Model for Bivariate Causal Inference. Entropy 2019, 22, 46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, P.; Leike, R.; Enßlin, T.A. Field Dynamics Inference for Local and Causal Interactions. Ann. Phys. 2021, 533, 2000486. [Google Scholar] [CrossRef]
- Enßlin, T.A.; Knollmüller, J. Correlated signal inference by free energy exploration. arXiv 2016, arXiv:1612.08406. [Google Scholar]
- Leike, R.; Enßlin, T. Optimal Belief Approximation. Entropy 2017, 19, 402. [Google Scholar] [CrossRef] [Green Version]
- Knollmüller, J.; Enßlin, T.A. Encoding prior knowledge in the structure of the likelihood. arXiv 2018, arXiv:1812.04403. [Google Scholar]
- Knollmüller, J.; Enßlin, T.A. Metric Gaussian Variational Inference. arXiv 2019, arXiv:1901.11033. [Google Scholar]
- Knollmüller, J.; Enßlin, T.A. Bayesian Reasoning with Trained Neural Networks. Entropy 2021, 23, 693. [Google Scholar] [CrossRef]
- Frank, P.; Leike, R.; Enßlin, T.A. Geometric Variational Inference. Entropy 2021, 23, 853. [Google Scholar] [CrossRef] [PubMed]
- Edward, C. Rasmussen and Christopher KI Williams. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 211, p. 212. [Google Scholar]
- Lassas, M.; Siltanen, S. Can one use total variation prior for edge-preserving Bayesian inversion? Inverse Probl. 2004, 20, 1537. [Google Scholar] [CrossRef]
- Saksman, M.L.; Siltanen, S. Discretization-invariant Bayesian inversion and Besov space priors. Inverse Probl. Imaging 2009, 3, 87. [Google Scholar]
- Enßlin, T.A.; Frommert, M. Reconstruction of signals with unknown spectra in information field theory with parameter uncertainty. Phys. Rev. D 2011, 83, 105014. [Google Scholar] [CrossRef] [Green Version]
- Enßlin, T.A.; Weig, C. Inference with minimal Gibbs free energy in information field theory. Phys. Rev. E 2010, 82, 051112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Westerkamp, M.; Ovchinnikov, I.; Frank, P.; Enßlin, T. Dynamical Field Inference and Supersymmetry. Entropy 2021, 23, 1652. [Google Scholar] [CrossRef]
- Pumpe, D.; Reinecke, M.; Enßlin, T.A. Denoising, deconvolving, and decomposing multi-domain photon observations. The D4PO algorithm. Astron. Astrophys. 2018, 619, A119. [Google Scholar] [CrossRef] [Green Version]
- Nunez, P.L. The brain wave equation: A model for the EEG. Math. Biosci. 1974, 21, 279–297. [Google Scholar] [CrossRef]
- Amari, S.I. Homogeneous nets of neuron-like elements. Biol. Cybern. 1975, 17, 211–220. [Google Scholar] [CrossRef]
- Amari, S.i. Dynamics of pattern formation in lateral-inhibition type neural fields. Biol. Cybern. 1977, 27, 77–87. [Google Scholar] [CrossRef]
- Coombes, S.; Potthast, R. Tutorial on neural field theory. In Neural Fields; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–43. [Google Scholar]
- Frank, P.; Steininger, T.; Enßlin, T.A. Field dynamics inference via spectral density estimation. Phys. Rev. E 2017, 96, 052104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Selig, M.; Bell, M.R.; Junklewitz, H.; Oppermann, N.; Reinecke, M.; Greiner, M.; Pachajoa, C.; Enßlin, T.A. NIFTY—Numerical Information Field Theory. A versatile PYTHON library for signal inference. Astron. Astrophys. 2013, 554, A26. [Google Scholar] [CrossRef]
- Steininger, T.; Dixit, J.; Frank, P.; Greiner, M.; Hutschenreuter, S.; Knollmüller, J.; Leike, R.; Porqueres, N.; Pumpe, D.; Reinecke, M.; et al. NIFTy 3—Numerical Information Field Theory: A Python Framework for Multicomponent Signal Inference on HPC Clusters. Ann. Phys. 2019, 531, 1800290. [Google Scholar] [CrossRef] [Green Version]
- Arras, P.; Baltac, M.; Ensslin, T.A.; Frank, P.; Hutschenreuter, S.; Knollmueller, J.; Leike, R.; Newrzella, M.N.; Platz, L.; Reinecke, M.; et al. NIFTy5: Numerical Information Field Theory v5. 2019. Available online: https://ascl.net/1903.008 (accessed on 6 March 2022).
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep Image Prior. Int. J. Comput. Vis. 2020, 128, 1867–1888. [Google Scholar] [CrossRef]
- Leike, R.H.; Enßlin, T.A. Charting nearby dust clouds using Gaia data only. Astron. Astrophys. 2019, 631, A32. [Google Scholar] [CrossRef] [Green Version]
- Leike, R.H.; Enßlin, T.A. Operator calculus for information field theory. Phys. Rev. E 2016, 94, 053306. [Google Scholar] [CrossRef] [Green Version]
- Kucukelbir, A.; Tran, D.; Ranganath, R.; Gelman, A.; Blei, D.M. Automatic differentiation variational inference. J. Mach. Learn. Res. 2017, 18, 430–474. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational Inference with Normalizing Flows. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 1530–1538. [Google Scholar]
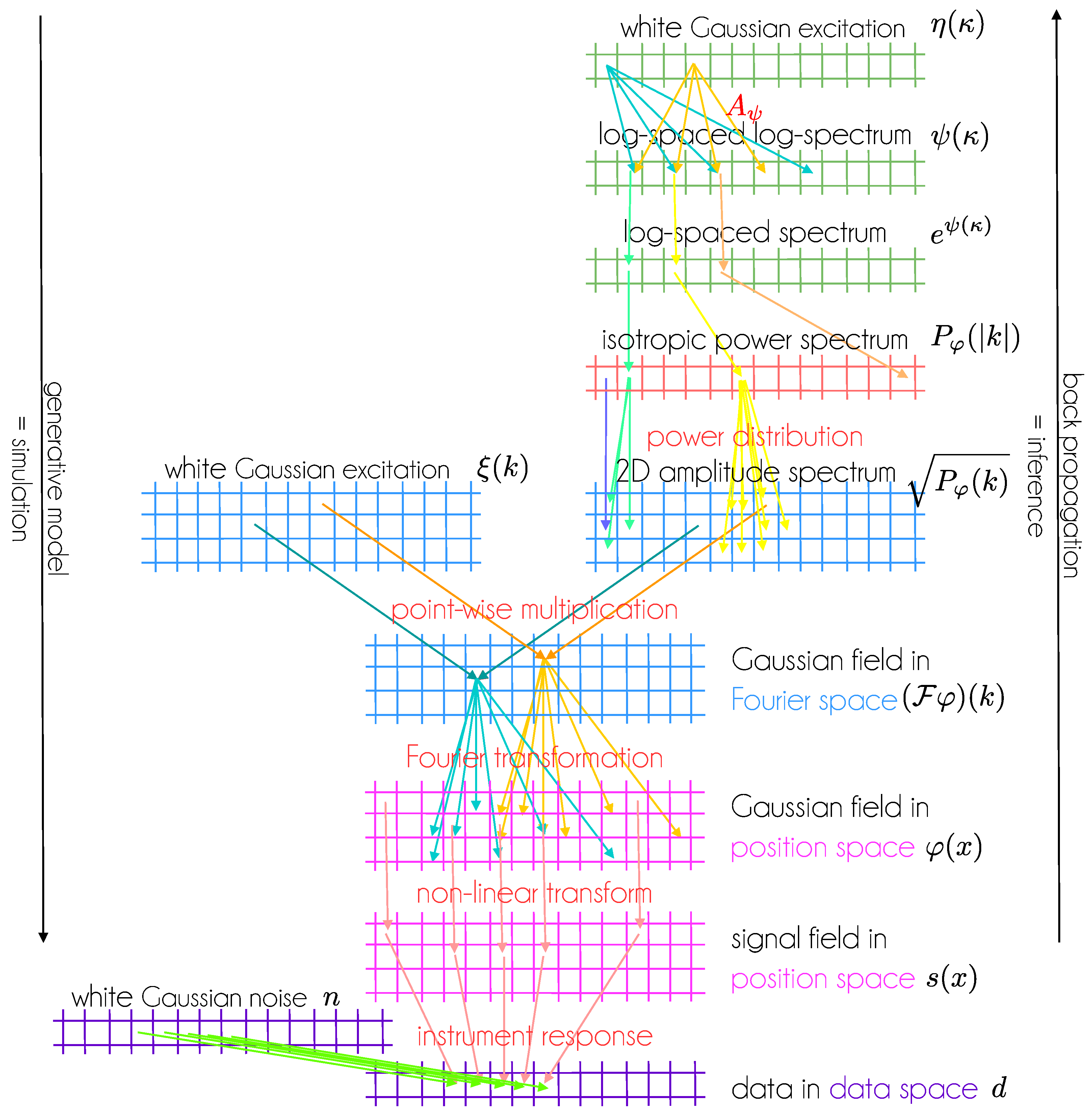
Figure 1.
An IFT model for a 2D Gaussian random field also with generated homogeneous and isotropic correlation structure and its measurement according to Equations (32)–(38) displayed as a GNN. Layers with identical shapes are given identical colors. Note that all layers have a physical interpretation and the architecture of this GNN encodes expert knowledge on the field. Inserting random numbers into the latent spaces and executing the network from top to bottom corresponds to a simulation of signal and data generation. “Learning” the latent space variables from bottom to top via back propagation of data space residuals with respect to observed data corresponds to inference.
Figure 1.
An IFT model for a 2D Gaussian random field also with generated homogeneous and isotropic correlation structure and its measurement according to Equations (32)–(38) displayed as a GNN. Layers with identical shapes are given identical colors. Note that all layers have a physical interpretation and the architecture of this GNN encodes expert knowledge on the field. Inserting random numbers into the latent spaces and executing the network from top to bottom corresponds to a simulation of signal and data generation. “Learning” the latent space variables from bottom to top via back propagation of data space residuals with respect to observed data corresponds to inference.

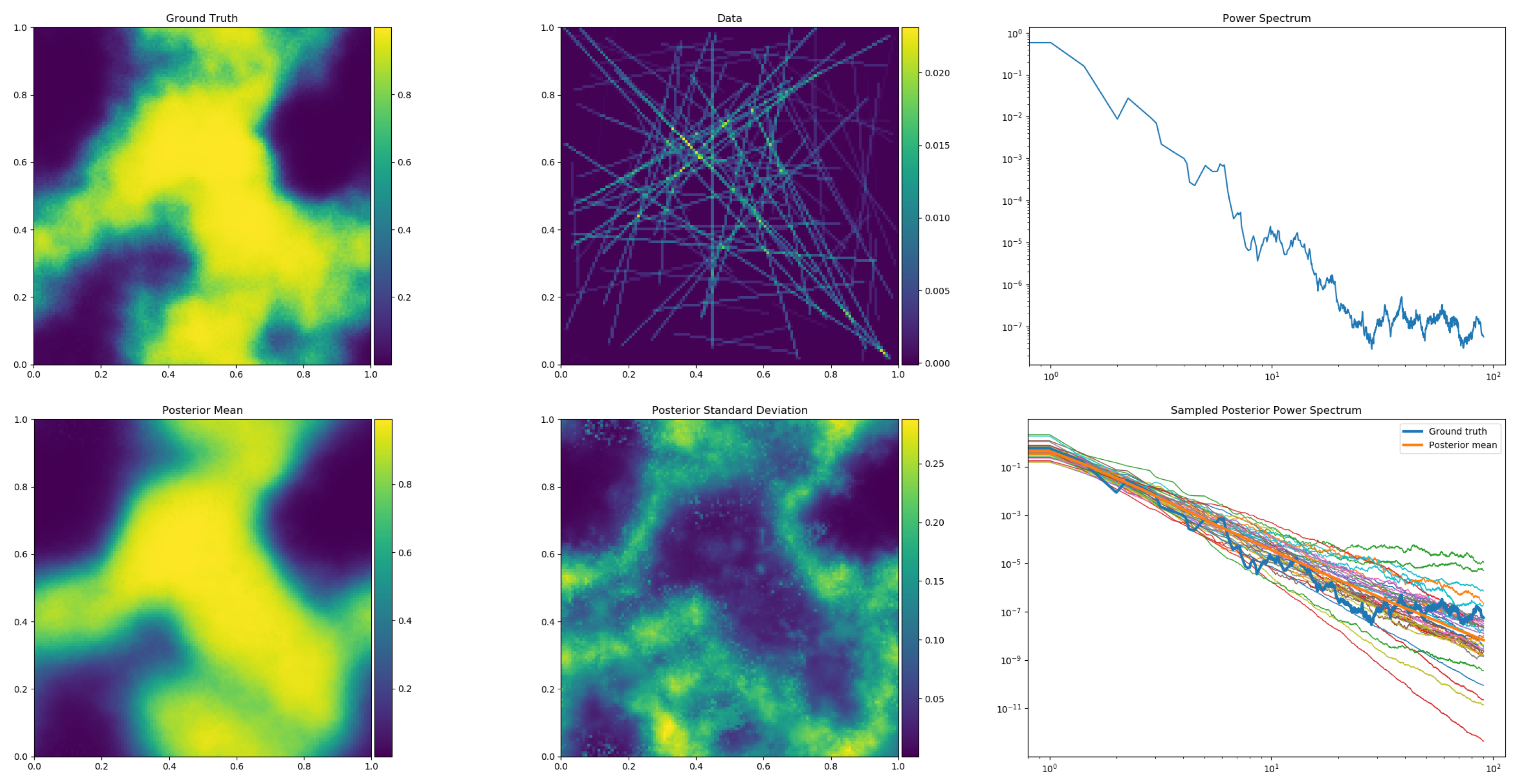
Figure 2.
Output of a generative IFT model for a 2D tomography problem in simulation (top row) and reconstruction (bottom rows) mode. The model is depicted in Figure 1 and described by Equations (32)–(38) with the modification that in Equation (36) the exp-function is replaced by a sigmoid function to obtain more cloud-like structures. Run in simulation mode, the model first generates a non-parametric power spectrum (top right panel) from which a Gaussian realization of a statistical isotropic and homogeneous field is drawn (top left, after procession by the sigmoid function). This is then observed tomographically (top middle), by measurements that integrate over (here randomly chosen) lines of sight. The data values include Gaussian noise and are displayed at the locations of their measurement lines. Fed with this synthetic data set, the model run in inference mode (via geoVI) reconstructs the larger scales of the signal field (bottom left), the initial power spectrum (thick orange line in middle right panel; thick blue line is ground truth), and provides uncertainty information on both quantities (signal uncertainty is given at bottom middle, the power spectrum uncertainty is visualized by the set of thin lines at bottom right). The presented plots are the direct output of the getting_started_3.py script enclosed in the Numerical Information Field Theory (NIFTy) open source software package NIFTy8, downloadable at https://gitlab.mpcdf.mpg.de/ift/nifty (accessed on 17 December 2021) [46,47,48] that supports the implementation and inference of IFT models.
Figure 2.
Output of a generative IFT model for a 2D tomography problem in simulation (top row) and reconstruction (bottom rows) mode. The model is depicted in Figure 1 and described by Equations (32)–(38) with the modification that in Equation (36) the exp-function is replaced by a sigmoid function to obtain more cloud-like structures. Run in simulation mode, the model first generates a non-parametric power spectrum (top right panel) from which a Gaussian realization of a statistical isotropic and homogeneous field is drawn (top left, after procession by the sigmoid function). This is then observed tomographically (top middle), by measurements that integrate over (here randomly chosen) lines of sight. The data values include Gaussian noise and are displayed at the locations of their measurement lines. Fed with this synthetic data set, the model run in inference mode (via geoVI) reconstructs the larger scales of the signal field (bottom left), the initial power spectrum (thick orange line in middle right panel; thick blue line is ground truth), and provides uncertainty information on both quantities (signal uncertainty is given at bottom middle, the power spectrum uncertainty is visualized by the set of thin lines at bottom right). The presented plots are the direct output of the getting_started_3.py script enclosed in the Numerical Information Field Theory (NIFTy) open source software package NIFTy8, downloadable at https://gitlab.mpcdf.mpg.de/ift/nifty (accessed on 17 December 2021) [46,47,48] that supports the implementation and inference of IFT models.

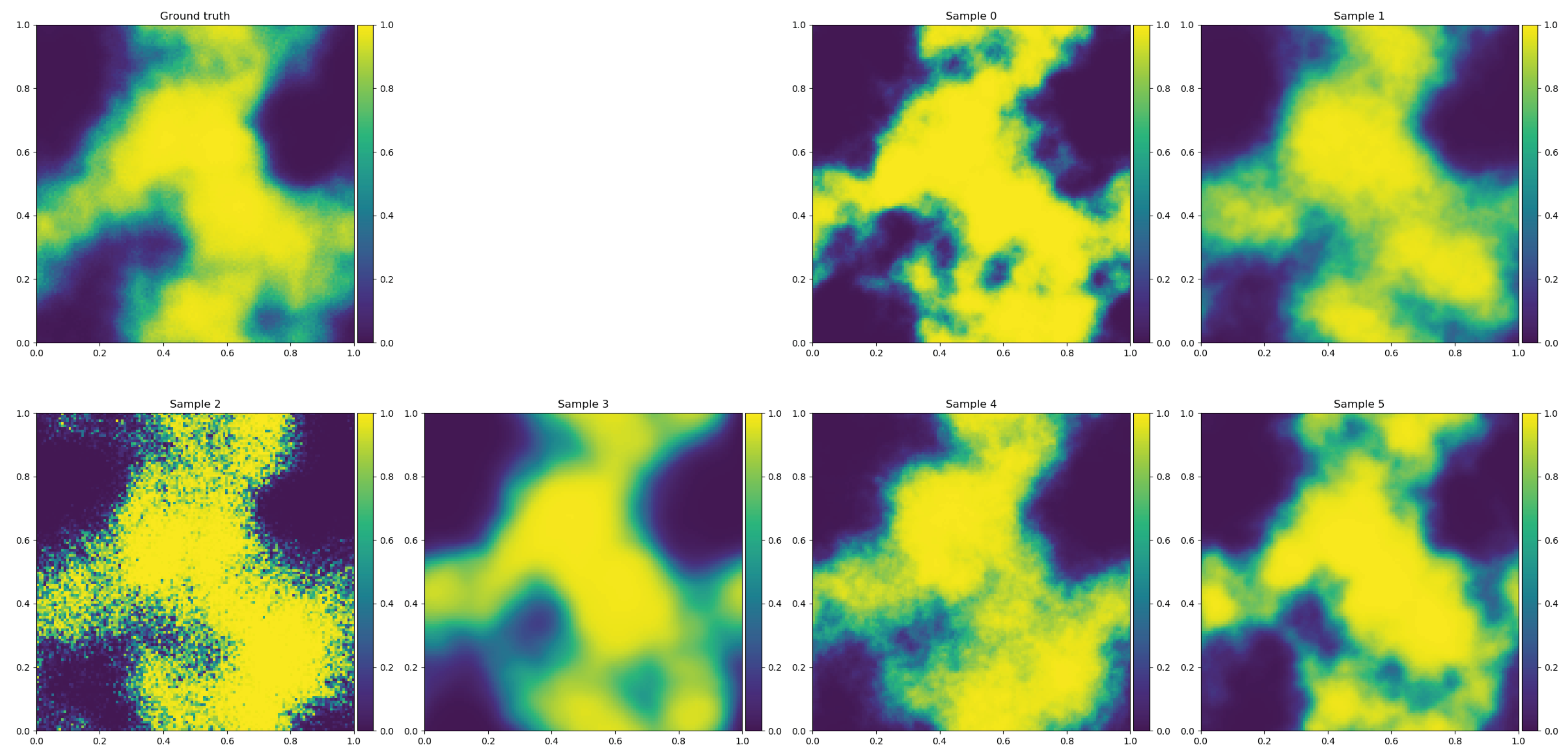
Figure 3.
Signal ground truth (top left panel) and some signal posterior samples (other panels) of the field reconstructed in Figure 2. Note the varying granularity of the field samples due to the remaining posterior uncertainty of the power spectrum on small spatial scales as shown in Figure 2 at bottom right.
Figure 3.
Signal ground truth (top left panel) and some signal posterior samples (other panels) of the field reconstructed in Figure 2. Note the varying granularity of the field samples due to the remaining posterior uncertainty of the power spectrum on small spatial scales as shown in Figure 2 at bottom right.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Enßlin, T. Information Field Theory and Artificial Intelligence. Entropy 2022, 24, 374. https://0-doi-org.brum.beds.ac.uk/10.3390/e24030374
AMA Style
Enßlin T. Information Field Theory and Artificial Intelligence. Entropy. 2022; 24(3):374. https://0-doi-org.brum.beds.ac.uk/10.3390/e24030374
Chicago/Turabian StyleEnßlin, Torsten. 2022. "Information Field Theory and Artificial Intelligence" Entropy 24, no. 3: 374. https://0-doi-org.brum.beds.ac.uk/10.3390/e24030374
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.