
An Information Quantity in Pure State Models


1
Graduate School of Engineering Science, Osaka University, Osaka 560-8531, Japan
2
Center for Quantum Information and Quantum Biology, Osaka University, Osaka 560-8531, Japan
Entropy 2022, 24(4), 541; https://0-doi-org.brum.beds.ac.uk/10.3390/e24040541
Submission received: 28 March 2022
/
Revised: 8 April 2022
/
Accepted: 10 April 2022
/
Published: 12 April 2022
(This article belongs to the Topic Quantum Information and Quantum Computing)
{kind=link}
{kind=link}
{kind=link}
Abstract
:When we consider an error model in a quantum computing system, we assume a parametric model where a prepared qubit belongs. Keeping this in mind, we focus on the evaluation of the amount of information we obtain when we know the system belongs to the model within the parameter range. Excluding classical fluctuations, uncertainty still remains in the system. We propose an information quantity called purely quantum information to evaluate this and give it an operational meaning. For the qubit case, it is relevant to the facility location problem on the unit sphere, which is well known in operations research. For general cases, we extend this to the facility location problem in complex projective spaces. Purely quantum information reflects the uncertainty of a quantum system and is related to the minimum entropy rather than the von Neumann entropy.
MSC:
81P17; 81P05; 81P45; 90B99; 53A201. Introduction
Building a large-scale quantum computer remains challenging, and there are many problems to be solved. For example, the performance of error correction depends very strongly on how coherent the noise process is [1], and experimenters need to improve the quantum computing system through analysis of the physical noise [2]. When we prepare an imperfect quantum computing system, it is important to specify the noise based on a suitable error model. The process of understanding the physical error model for a prepared system corresponds to that of obtaining a certain amount of information on the system. In the present paper, keeping this in mind, we consider how to evaluate such information without any entropic concept.
An overly simple example is given by a purely rotation error model [2] with a parameter range. Let the ideal qubit state be and the error model be , where and denotes the parameter to be specified. Then the parameter range reflects the information we have on the system. We have more information when we know than when we know .
However, what if we consider a more complicated situation such as = , where , with the parameter range of, say, and ? How do we compare the range with the parameter range and ? To simplify the problem, let us adopt discrete models. We consider two situations: First, the qubit is described by one of the candidate pure states, , where and . Second, it is described by one of the candidate pure states . Then, which state’s information is greater? Or equivalently, which uncertainty is larger? We will give a definite answer in the present article (See Section 8).
Let us describe our problem in a slightly more formal way before going into detail. Let the quantum system be described in a separable Hilbert space and a subset of pure states be given. We call the subset a (pure-state) model. Suppose we know that the quantum system is described by one of the pure states in the model. Then we evaluate the amount of information obtained by knowing the model.
We write the model as a countable set for simplicity, but a model might consist of an uncountable set of pure states, e.g., the above parametric pure state . Another continuous model would be a wavefunction with a certain continuous parameter (see, e.g., Holevo [3]).
Our problem is closely related to so-called quantum estimation, but the above type of problem has still not been investigated. In quantum state estimation [4,5,6,7,8,9] or quantum state discrimination [6,10,11,12,13], for a given model, we find an optimal quantum measurement to extract information on the quantum state and choose the true state in the model from observation. This has been a typical problem and has been investigated by many authors. In quantum information experiments, quantum tomography has been also discussed [14,15,16,17]. As far as the author knows, these studies do not refer to the comparison of several models in terms of information quantity.
In our setting, we focus on the information that we obtain before preparation for a measurement. As we see later, we clearly obtain a certain amount of information other than the dimension of the Hilbert space.
We consider only pure state models so that we can neglect classical fluctuation. As we shall see later, there is no classical counterpart for such information. In other words, we calibrate so that such classical information becomes zero. If a positive amount of information remains under the calibration, then we expect that it reflects the truly quantum information. We do not have a proper name for this information, and we call it model information or information of the model tentatively. It would become an alternative to the usual entropy.
In the next section, we provide a rough idea of how to define model information and present pure state models as examples. Then, we will formulate a pure state model and define the representative quantum state for it in a rigorous manner. In Section 4, we describe the equivalence between the problem of finding the representative quantum state and finding the minimax facility location on the sphere in operations research. In Section 5, we introduce the purely quantum information of the model and calculate it in several examples. We also describe the relationship of entropic concepts to our result and extension to infinite-dimensional Hilbert space in Section 7. Finally, concluding remarks are given in Section 8.
2. Rough Idea on Defining Model Information
2.1. Preliminary Considerations
In this section, we describe a rough idea of how we evaluate model information. First, we recall classical information theory. Suppose that Alice picks a three-letter word , where and we set . If Bob knows , Bob does not feel that he obtains much information. However, if , then Bob feels that he obtains more information on the word Alice picks.
The above situation corresponds to a commutative case in quantum theory. Keeping this in mind, let us consider the model information in the quantum system. We assume that Bob already knows that the quantum system is described in a d-dimensional Hilbert space. Since information quantity is a relative concept, let us compare two models. Let the first model consist of a d-dimensional orthonormal basis, i.e., and the second model consist of (). At least we can say that the second model gives more significant information to Bob than the first model. This is because the quantum state is in a proper subspace.
Now we tackle the case where some quantum states are nonorthogonal. For simplicity, we set and consider the following models:
where , . In explicit calculations, we set .
Suppose that we know that the quantum state is one of the candidate states in (hereinafter, we write for simplicity). Perhaps we agree that the information is more than and . Then, which is more informative, or ? Both models consist of three nonorthogonal state vectors. Likewise, which is more informative, or ? In the present article, we consider how to quantitatively evaluate the information obtained when Bob knows that the quantum state belongs to a model .
2.2. Full Rank Condition
In order to avoid technical difficulties, we give one important assumption here. Let us define the rank of a model as
We assume that the rank of a model is equal to the dimension of the Hilbert space, i.e., . We call it the full rank condition. The full rank condition implies that there exists no complementary subspace that is orthogonal to every state vector in the model .
2.3. Rough Idea on Defining Model Information
Under the full rank condition, we consider the case where a model has considerable information on the quantum system. Suppose that we are given the following model:
(). While this satisfies the full rank condition, clearly all candidate quantum states are approximately in the same direction as .
Then, the quantum system is approximately described by a representative state vector . When but , the model information is expected to increase.
From the above discussion, we find that the information quantity associated with is completely different from the number of elements, . Rather, a certain scale or a size of the model should be included in the definition of the model information.
Along the lines of the above rough idea, we discuss in the next section:
- (a)
- How to determine a representative state vector for a given model ;
- (b)
- One definition of the model information;
- (c)
- The relationship with the concept of entropy.
We emphasize that all of these have no classical counterpart and thus it might be difficult to understand them. Before going into detail, we shall give an overview of each item here.
For (a), we consider maximin overlap between quantum states and define the representative quantum state of a model. Mathematically speaking, it is regarded as a variant of the facility location problem on the unit sphere [18,19], which appears in operations research. In operations research, many authors have developed algorithms on the facility location problem. In particular, finding the minimax solution is our concern. For a finite model (), we present a naive algorithm to find the representative quantum state for a model using this consideration.
In order to consider item (b), we introduce an imaginary two-person game called the quantum detection game. Bob benefits from the information of a given model to obtain a higher score than Alice. The value of the game, which is determined by a least favorable prior [20] in this game, defines one information quantity related to the model .
3. Basic Definitions
3.1. Definition of Pure State Models and Assumptions
In the present paper, let be a d-dimensional Hilbert space. (d could be ∞). We call a finite-dimensional parametric family of quantum pure states
a quantum statistical model of pure states or briefly a (pure state) model. Note that . Basically, the parameter set is a compact subset of finite-dimensional Euclidean space.
We assume the following two conditions:
- (1)
- Identifiability: . Conventionally, we only consider quantum states up to the (global) phase factor below, and we often identify a pure state with a density operator .
- (2)
- Continuity: For every sequence and ,holds. ( denotes the operator norm, i.e., ).
For simplicity, we often consider a finite set of parameters, . Then, is denoted by . We often call it a discrete model, which is written as .
3.2. Preliminary Results
In the present paper, we introduce the information of a model . Although the formal definition is given in Section 5, we need several concepts to understand them analytically and geometrically.
In this section, we introduce the most fundamental concept, the representative quantum state of a model. We shall give a rough idea for when and . Specifically, we set with . When two quantum states are close to each other, , it is natural to consider that a representative quantum state of model should be a “midpoint between two quantum states”. We often identify the state vector with the point on the whole pure states specified by the vector.
Mathematically, we may try to define the point as the point equidistant between and such that
holds.
However, the above equidistance condition does not determine the point generally. Thus, we maximize the above “overlap” under the condition (1). Then we obtain an explicit formula for the representative point of a model,
where satisfies and then the maximum overlap is given by .
Next, we consider the case where . Let us take and introduced in the previous section:
In , the above idea applies, i.e., we find the quantum state to maximize the overlap
Up to the global phase, we set as
Then, we obtain an explicit solution satisfying (3), after lengthy but straightforward algebra. (See also Section 4.1.3).
However, we find no solution satisfying Equation (3) in . We need a more careful treatment. First, we fix an arbitrary quantum state and consider the set of numbers r satisfying , . The condition assures that the overlap between and an arbitrary quantum state in is not less than r. For each , the maximum of r is equal to .
We consider that the larger the overlap gets, the more suitable becomes as a representative quantum state of the model . Thus, we maximize r as a function of .
It is convenient for explicit calculation to use the squared overlap (i.e., Fidelity), , and we regard as a representative quantum state of the model . Based on the above idea, we will give a more formal definition of the representative quantum state in the next subsection.
3.3. Representative Quantum State
Now we are ready to define the representative quantum state of a given model formally. We adopt the distance rather than the overlap.
Definition 1.
Let a model be given. When a quantum state satisfies
is called a representative quantum state of the model with respect to the distance .
When we emphasize the model , we write . While the terms max and min are enough for discrete models, using the terms sup and inf is generally inevitable. (see Section 7). We also use a condition equivalent to (5),
In the above definition, is also interpreted as the minimax estimate in quantum estimation with no observation. Suppose that a parametric family of pure states or countable set of pure states is given. Then we give an estimate, say , as the true quantum state without any observation. The error is evaluated by the Fidelity-based quantity, . The above representative quantum state is a minimax estimate in this setting.
In the context of quantum estimation, this may seem quite strange because we do not perform any measurement. However, it is not unnatural to consider estimation with no observation. For example, in classical information theory, we infer the outcome of an information source with no observation. For a given parametric model of source code distribution , this kind of estimation corresponds to constructing a minimax code [23].
Apart from actual application, quantum estimation with no observation also makes sense theoretically. In a quantum computer, a quantum bit will be processed under a certain quantum gate with an unknown parameter, say, , during the computing process. When is uncontrollable with a range , it might be necessary to estimate the quantum bit. Since there is no reason to estimate , we need a certain formulation to estimate the quantum bit.
We should also mention why we adopt as the distance among several candidates as the closeness measure in our definition. There are two reasons. One is the operational meaning of the quantum detection game, which is explained in Section 5. The other is due to the following property:
Lemma 1.
Let a model be given. Let f be a continuous nondecreasing function on . When we adopt the distance , then the representative quantum state remains the same.
Proof.
It is enough to show that for every ,
holds.
If Equation (6) holds true, then we show the statement in the following way. For every , from the definition of , holds. Since f is an increasing function, applying f to both sides and using Equation (6) yields , which implies that is a representative quantum state with respect to the distance .
Now let us show Equation (6). Let be fixed and set . For every , due to the continuity of f, there exists such that . We take such that . Then
Since is arbitrary, we obtain .
Next, observe that for every since . Taking the supremum of RHS with respect to , we obtain the converse inequality. Thus, Equation (6) is shown, and the proof is complete. □
In Section 5, we shall define the information quantity obtained when we know , which is denoted by . When we find , it is shown to be easy to calculate .
Now let us consider the representative quantum state of a two-state model geometrically. Recall that each pure state in a two-dimensional Hilbert space is written in the form (4). If we switch to the Bloch representation, we obtain one-to-one correspondence between on the unit sphere (Bloch sphere). When one pure state is set to (P), the distance between the pure state and another pure state specified with (Q) is along the shortest path on the Bloch sphere. The shortest path connecting two points P and Q on the Bloch sphere is the arc along the large circle on the Bloch sphere. The arc is called a geodesic connecting P and Q and the equidistant point M on the geodesic from both points is called the geodesic midpoint between P and Q. The representative quantum state corresponds to the geodesic midpoint. The concept of geodesics on the Bloch sphere is often useful and has been investigated in several works [24,25,26,27].
For every pair of independent quantum states and , let us consider a two-dimensional subspace . Then each state in the subspace is regarded as a point on the Bloch sphere. By using the Formula (2), we summarize the above statements.
Lemma 2.
Let a model be given. Then, for every pair of quantum states and with , the geodesic midpoint is given by
where δ satisfies and then arc length α between and is given by and arc length between and is .
Understanding the geometry of the unit sphere is very helpful to find the representative quantum state, which is discussed in Section 4.
3.4. Example of a Representative Quantum State:
As a slightly nontrivial example, let us focus on and find a representative quantum state. First, we focus on the submodel . Then its representative quantum state, is the geodesic midpoint of and . Using the Formula (7),
is obtained.
Next, we use the following lemma.
Lemma 3.
Let a model and its submodel be given. If the representative quantum state of satisfies
then is also the representative quantum state of .
Proof.
Let be an arbitrary quantum state. Since ,
which implies that is also the representative quantum state of . □
It is easily seen that . Due to the above Lemma 3, (8) is also the representative quantum state of .
4. Facility Location Problem
Mathematically, finding the representative quantum state of a given model is equivalent to finding the minimax facility location for a given demand point in operations research [18].
4.1. Facility Location Problem on the Sphere
Decades ago, Drezner and Wesolowsky [18] considered the facility location problem on the sphere. We briefly summarize their formulation. Suppose that there are m demand points with (positive) weights on the unit sphere and our objective is to locate a single facility on the same sphere so as to minimize the weighted sum of distances from the facility to the demand points. Let and denote the locations of the i-th demand point and the facility, respectively, in spherical coordinate (, ). Weights for demand points are denoted as . Without loss of generality, we may take . We obtain the following minimization problem.
where is the distance between the facility and the i-th demand point .
Drezner and Wesolowsky measured distances through the sphere for squared Euclidean distances and they also used the shortest length of arc. Let us denote the shortest length of arc between two points on a sphere with a unit radius by . Then the squared Euclidean distance is given by . Both distances are computed by the equation:
The interpretation of the problem is as follows. The distance is the transportation cost from a facility to the i-th demand point . We regard the relative frequency of each transport as the weight. When we already know the relative frequency, we minimize the objective function with respect to .
Focusing on the correspondence between a point on the unit sphere and a complex unit vector
the problem is completely solved when we adopt the squared Euclidean distance. Let us denote as the location of the facility instead of . Straightforward calculation yields . Thus, the objective function to be minimized is written as
where in the last line, we set . Note that is positive semidefinite and of trace one, and it is regarded as the Bayes mixture (For the definition, see Section 5.1). Then, the minimization problem reduces to finding the maximum of . This is given by the first eigenvector of . This result [28] agrees with that derived by Drezner and Wesolowsky, who obtained the same result by differentiation with respect to variables in the context of operations research.
However, what if we have no information on the relative frequency for each demand point? One idea is to take the minimax point. Through the minimax theorem [20], we obtain the associated weight such that
holds, where is the squared Euclidean distance. (Strictly speaking, the above holds under the condition that the convex hull of all demand points does not include the origin). This is called the least favorable weight.
Now we go back to our problem. Let the Hilbert space be two-dimensional, where each quantum state is specified by in (9). Let a discrete model , be given. Each state corresponds to a demand point on the Bloch sphere. The distance corresponds to the transportation cost measured by a constant multiplied by the squared Euclidean distance. Then, finding the representative quantum state of the model is equivalent to finding the minimax facility location specified by on the Bloch sphere with the distance .
According to this correspondence, we also know the following fact. When we know the least favorable weight in the problem, we obtain the representative quantum state as the first eigenvector of the Bayes mixture with respect to [20].
Following the interpretation of the facility location problem on the sphere, we find the representative quantum state of each model in Section 2.1. Since is a strictly increasing function of , both minimax points for the two distance measures agree due to Lemma 1.
4.1.1. Example 1:
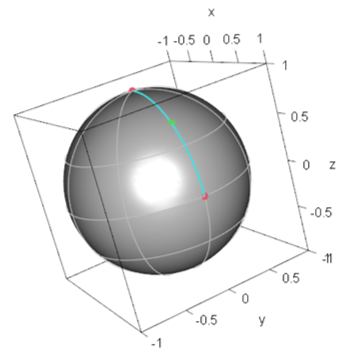
Pure states and correspond to the demand points specified by and (North pole) on the Bloch sphere, respectively. Then, the minimax location on the Bloch sphere is specified by . Thus, of is given by . Figure 1 shows the demand points and the minimax location of the facility on the Bloch sphere.
4.1.2. Example 2:
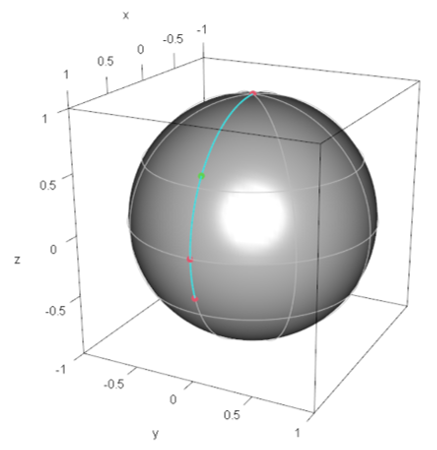
First, the quantum state corresponds to the demand point specified by , where . We follow Algorithm Step (1) described in the next subsection. Then, the most distant pair is (North pole) and . The other point specified by is closer to the center specified by than that pair of points. Thus, the minimax location on the Bloch sphere is specified by and of is given by . Figure 2 shows the demand points and minimax location of the facility on the Bloch sphere.
4.1.3. Example 3:
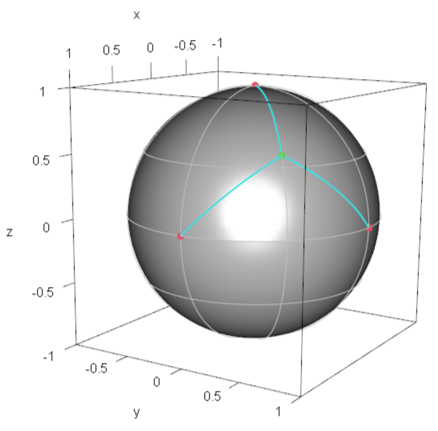
For , we follow Algorithm Step (1) and Step (2) described in the next subsection. After tedious calculation, we find the minimax location, which is specified by ( is defined as above) and of is given by . Figure 3 shows the demand points and the minimax location of the facility on the Bloch sphere.
It may be thought that using the squared Euclidean distance rather than the arc length is unnatural. However, as shown in Lemma 1, The minimax location obtained under the squared Euclidean distance agrees with that obtained under the arc length due to the strict monotonicity of (See the beginning of Section 4.1 for the squared Euclidean distance). In this sense, the representative quantum state of a model is invariant. On the contrary, the least favorable weight for the facility location problem depends on the measure of distance on the sphere; thus, it is not invariant.
4.2. Algorithm to Find Nonrandomized Minimax Location
In operations research, there are several studies on the facility location problem on the unit sphere, where some algorithms to find the minimax facility location are also proposed. Inspired by these studies, we propose a naïve algorithm to find the nonrandomized minimax facility location. Specifically, we consider the facility location problem on a three-dimensional hypersphere in a four-dimensional real Euclidean space. This is easily generalized to a general dimension. Basically, a pure state model in a d-dimensional Hilbert space is regarded as a subset of a complex projective space . A complex projective space is a typical example of a complex manifold but is actually a -dimensional real manifold. This fact is sufficient to understand the following argument. (For complex projective space, e.g., see Section 4 in Bengtsson and Życzkowki [29]).
We exclude the possibility of a randomized strategy, although it is sometimes better than any nonrandomized strategy, at least theoretically. (For example, see Section 1.5 in Ferguson [30]). For example, let us consider six demand points, , , on the unit sphere, where is a small positive constant. Then, a randomized facility location strategy, north pole with probability and south pole with probability , yields the average transportation cost measured by the arc length, for each demand point. Thus, it achieves the minimax location. On the other hand, any nonrandomized strategy yields a higher transportation cost (>) in the worst case. The algorithm presented below fails in this example. When , all demand points are not covered in a hemisphere if and only if there exists a randomized strategy that is better than any nonrandomized strategy. No simple mathematical condition can assure that nonrandomized minimax is not worse than any randomized strategy when . Thus, we implicitly assume this fact and the existence of a nonrandomized minimax strategy in the Algorithm 1.
| Algorithm 1: Find Minimax Facility Location |
|
Due to monotonicity, we may evaluate the squared Euclidean distance or inner product instead of the arc length between two demand points.
When we generalize the algorithm suitably to (as a -dimensional real manifold), we obtain the algorithm to find the representative quantum state of a model in a d-dimensional Hilbert space. In the last subsection, we used the proposed algorithm to find the representative quantum state in some examples. In Section 5, we also demonstrate how to find the representative quantum state following the above algorithm in a specific case.
In the qubit system, the above argument is applied to the mixed states because the Bloch ball is regarded as the hypersphere , a hemisphere of a 3-sphere, in a real four-dimensional Euclidean space (e.g., see Section 9.5 in Bengtsson and Życzkowki [29]).
Though the algorithm itself is not our main concern, we briefly mention the efficiency of the algorithm. The computational complexity of each Step (1), (2), and (3) is, respectively, , , and , and clearly it is not efficient. The above problem is reduced to finding the covering sphere for all demand points with the minimum radius (cf. Shiode [19]). Based on this idea, it could be possible to obtain more efficient algorithms even for a continuous model.
The facility location problem on the sphere and finding the representative quantum state of a model (in a two-dimensional Hilbert space) are completely different. It is a bit surprising that the former problem, which comes from operations research, is helpful for understanding the result in the latter, which comes from quantum physics. What a top manager in a global business really cares about might be essentially the same as a fundamental problem in quantum physics. How does this wonderful connection arise? A mathematician might point out the underlying isomorphism between and [29]. However, this connection arises mainly from a game-theoretic approach. In other words, the unexpected tie implies the universality and effectiveness of game-theoretic concepts, which are different from information-theoretic concepts such as entropy. This is again emphasized when we introduce the definition of model information in the next section.
5. Quantum Detection Game and Model Information
We have explained how to determine a representative quantum state of a given model. Based on the state, in the present section, we define a new information quantity, model information. Geometrically, this is the maximum radius from the representative quantum state as the center.
The basic strategy to define an information quantity is to introduce a certain imaginary two-person game where one player obtains points according to the information available.
For example, in classical information theory, we consider assigning the ideal code length to each alphabet x when we know the code distribution . Bob’ s best score is given by his guessed distribution and obtains the score for each alphabet x. Taking the average with respect to , we obtain the Kullback–Leibler information [23], which is a very fundamental quantity in information theory.
According to Tanaka [20], we consider a quantum detection game as an imaginary two-person game.
5.1. Quantum Detection Game and Definition of Purely Quantum Information
As an example, we introduce a four-dimensional pure state model, and set between . This consists of the following four-dimensional vectors:
while , it is enough to consider each vector in a real four-dimensional vector space.
Let us explain the quantum detection game under the model . First, Alice picks one pure state from the model (i.e., ) and then sends it to Bob. Bob knows only the candidate pure state sets and the model, and prepares a two-outcome measurement in the form , where I is the identity operator and is the unit vector. We call a detector or a detector state. Bob’s purpose is not to guess the number that Alice has chosen but to obtain "detection" with a higher probability.
The detection rate for the chosen state is given by when Alice sends to Bob and Bob prepares as a detector. ( denotes the matrix trace and is regarded as a matrix). As a game, Alice aims at making Bob’s detection rate smaller by choosing with a certain probability. In contrast, Bob aims at making the detection rate larger by preparing his detector based on the knowledge of the model. Later, we will evaluate the information of the model .
Now we go back to the general situation and explain the details. First, we seek the minimum detection rate for Bob among all possible models. Suppose that Alice picks among the whole pure states in a completely random way (i.e., with respect to the Haar measure). This is the worst case for Bob. When Bob is allowed to adopt a randomized strategy, the detection rate is (d is the dimension of the Hilbert space). If the model consists of the orthonormal basis, then again the detection rate is . It is the minimum detection rate.
Next, suppose that Alice has a certain tendency for choosing the pure state, which is also described by the model and Bob knows this for some reason. Although we do not care about the origin of such models, there are various situations where they apply in quantum science and technology. For example, in the bipartite system without interaction, a pure state arises as a product state like . Then an entangled state such as is not expected. In quantum computation, the output qubit state under the unitary gate, which has some rotation error, would be . Then, Bob could obtain a detection rate larger than based on the information of the model. Following this idea, we propose one information quantity for a model below.
A detailed explanation of the quantum detection game and useful results are described in the author’s previous work [20]. Below, we only present some of the results in a formal way, which is necessary to define the information quantity. Those definitions hold in an infinite-dimensional Hilbert space.
First, we define the Bayes mixture in a slightly formal way. Let be a model, (see Section 3) and be a probability distribution on the parameter space . Then, the Bayes mixture is defined as
In the context of Bayesian statistics [31,32,33], we call a prior distribution or briefly a prior. For a discrete model, the above integral is replaced with a finite sum . Then, when Alice sends to Bob with probability , it is equivalent to sending to Bob in the quantum detection game.
Finally, we have come to our main theme: to define the information quantity of a model .
Definition 2.
Let be a model in a d-dimensional Hilbert space. Then, we define the purely quantum information (PQI) of a model as
For calibration, we subtract the lower bound , and thus . When Bob knows that the quantum state Alice prepares is among , we interpret this as Bob obtaining . As shown in Section 5.3, the above infimum is related to the value of the quantum detection game (possible maximum score) through the minimax theorem [20].
Let us rewrite in a slightly simpler form. For a discrete model, there exists a prior distribution that achieves the infimum of . Then, we call the prior a least favorable prior (LFP). LFP is one of the technical terms in statistical decision theory or game theory (see, e.g., Section 1.7, p. 39 in Ferguson [30]). Using the least favorable prior , PQI is defined by
5.2. Basic Properties of PQI
From the form (14), we obtain some properties of PQI easily. First, by definition, is independent of a basis. In other words, both and , where U is a unitary operator, yield the same PQI. Second, clearly the following holds.
Lemma 4.
Let be a model in a d-dimensional Hilbert space. The following conditions are equivalent.
- (i)
- .
- (ii)
- for every LFP.
When , Alice can send the completely mixed state effectively and then Bob obtains no information from the model to achieve a higher detection rate than . Geometrically speaking, such a model fully spreads with no specific direction.
In contrast, when , a certain bias exists and it prevents Alice from preparing the completely mixed state. Thus, Bob benefits after knowing the model. If satisfies the full-rank condition, then there exists a prior such that the Bayes mixture ( denotes the positive definiteness of a Hermitian matrix A). If does not satisfy the full-rank condition, we have a -dimensional subspace where (restricted to the subspace) satisfies the full-rank condition. Since , we have the lower bound of PQI, .
We mention the relation between PQI and the von Neumann entropy . (Recall that the von Neumann entropy is defined by ). It is easily shown that if and only if . The worst case for Bob also corresponds to the maximum entropy state. As we shall see in Section 6, our formulation is instead related to the minimum entropy.
Next, we consider how to calculate the PQI of a given model. If the model has a certain symmetry, then we obtain the LFP analytically and directly calculate . On the other hand, due to the minimax theorem in the author’s previous work [20], the infimum of the operator norm of a Bayes mixture, is easily calculated by finding the representative quantum state of the model, which is defined in Section 3. Thus, we are able to calculate the PQI of a given model by finding the minimax point (the representative quantum state of the model), and to do so, we utilize the algorithm shown in Section 4 in order to find the minimax point in the facility location problem on the unit sphere. We present the above procedure explicitly in Section 5.4 in detail.
The mathematical structure is quite similar to the calculation of channel capacity in classical information theory [34,35]. However, we emphasize that even in a formal analogue, we do not introduce any entropic quantity or any concept from information theory to define the above PQI. What we have used is an imaginary two-person game called the quantum detection game and some basic rules in quantum physics. Taking into account many works in quantum information theory [36], it is a bit surprising to develop purely quantum information without referring to any classical concepts in information theory [37,38,39,40].
We also note that PQI is completely different from other kind of information quantity such as the Fisher information [7,8]. For a parametric model of quantum states, , differentiable with respect to the parameter , Fisher information evaluates the change of quantum states, . It is related to the distinguishability between two close quantum states and from observation after performing some measurements. Let us take a specific example to see the difference. Suppose that we have a continuous one-parameter model . Although quantum Fisher information has been defined in various ways as an extension of classical Fisher information, it is not defined for a discrete model such as . Indeed, for , we only consider distinguishing between two possible states (quantum state discrimination), while for , we have to consider parameter estimation (quantum state estimation), and the estimation error is bounded by SLD Fisher information [4,5,6]. However, PQI yields the same value for both and .
5.3. Basic Formula for PQI Calculation
We provide several examples to show how we calculate the PQI of a model below. We give the following formula, which connects the representative quantum state and PQI. The formula is obtained by the minimax theorem (10).
Or equivalently, we have the formula
Using the above formula and result in Section 4, we obtain the PQI of , , and (For the definition, see Section 2.1).
5.4. Example of PQI Calculation:
Next, as a more nontrivial example, we calculate the PQI of the model introduced in Section 5.1. First, following the algorithm in Section 4, let us find the minimax point (the representative quantum state of the model ).
In Step (1), we find the most distant pair. We mainly focus on the inner product between two vectors instead of the geodesic distance between them. Then, the most distant pair corresponds to those for which the inner product is the closest to zero. Since , , , and , the most distant pair is , , and .
Using the Formula (7) in Lemma 2, we obtain the geodesic midpoint between and , which is denoted by and . Comparing the inner products, it is easily seen that is located at a point more distant from than and . Thus, we go to Step (2) in the algorithm. Note that in the model , all inner products are real and positive.
In Step (2), we find the most distant triplet. In our model, it is enough to consider the circumscribed hypercircle in a real four-dimensional Euclidean space. Due to the symmetry, we only check two triangles, and whose vertices are and , respectively.
First, let Q be the center of the circumscribed hypercircle of the triangle . (Each edge is a geodesic on the sphere). Generally, the point Q is not uniquely determined. However, by imposing the condition that Q is on the three-dimensional real subspace , the point Q is uniquely determined as the point achieving the minimum distance from each vertex (radius of the circumscribed hypercircle). The condition is equivalent to an orthogonality condition, i.e., , where .
Now let , be a vector corresponding to Q. Then it satisfies , , and , where denotes the Euclid norm. We obtain the solution .
Next, we investigate the other circumscribed hypercircle of the triangle . In a similar way, we define the point R for . Then, the state vector corresponding to R is given by .
Let each radius of the circumscribed hypercircle be and . Then , and . Thus, , the most distant triplet is .
Finally, we check whether the circumscribed hypercircle with center and radius includes the other point . (If not, we go to Step (3) in the algorithm) Since we assume that , holds, this implies that is closer to the point than the other three points. Thus, the Algorithm stops and is the minimax location.
Using , we obtain
Due to Equation (16), agrees with the infimum of the detection rate , and we obtain PQI .
5.5. PQI Calculation from LFP
Now let us find the LFP in this model. Since the model has a certain symmetry, we obtain it directly.
First, let the support of be , that is, and , . Then we obtain one of the LFPs, which is given by the uniform distribution, . To see this, we use the following two facts. First, for every permutation (e.g., ),
holds. (To see this, construct the unitary operator , which is the group homomorphism ). Second, the average for every permutation is given by
where is the permutation group acting on the set . Thus, for every ,
holds. Thus, the uniform distribution is the LFP when .
Then, we relax the condition . We set the uniformly mixed state as
Then, the operator norm is given by
From direct but very tedious calculation, we can see that the above achieves the infimum even if we permit . Setting , we obtain
Therefore, we obtain the LFP as
Even when we do not find the representative quantum state directly, we can construct it from the LFP in the following way. Since the Bayes mixture with respect to LFP is given by Equation (17), we find the first eigenvector with the maximum eigenvalue (no degeneracy), which is given by . Actually, this agrees with the representative quantum state, , in Section 5.4.
5.6. Difference from Maximization of von Neumann Entropy
In our formulation, PQI has no direct relation to any entropic concept. Since some readers may expect a certain relationship, let us see what happens if we formally adopt the von Neumann entropy to obtain the LFP in the last example. We consider the maximization of over the prior . The concavity of yields
where denotes LFP (19). For some , we numerically find a positive achieving the maximum of . Thus, a positive weight for could appear under the maximization, which is clearly different from our result.
While the LFP , which is obtained by minimization of , yields the minimax solution in the quantum detection game, the maximizer, say, , is meaningless, at least in this example. Indeed, , which implies that is more informative than , and the prior is not the least favorable to Bob anymore.
We have carefully treated the information or uncertainty of a nonorthogonal pure state model and excluded classical fluctuation. As a consequence, the remaining uncertainty is not evaluated by the usual entropy anymore. For a nonorthogonal pure state model, the von Neumann entropy as a measure of information lacks theoretical justification. At least in the quantum detection game, the method based on the von Neumann entropy is a mere formal extension. It makes sense only for a model that consists of orthogonal pure states (see Section 2).
6. Discussion: Relation to Entropy
In the previous section, we introduced an information quantity for a pure state model called PQI. Under the full-rank condition, any classical model consists of an orthonormal basis. Then PQI of the model necessarily vanishes.
We emphasize that PQI is literally something purely quantum since we have not formally extended something in classical information theory. It is the information quantity completely independent of the concept of entropy, which does make sense in classical information theory. Thus, a natural question arises, i.e., what kind of relationship do the entropy and PQI have? Actually, PQI is related to the minimum entropy instead of the von Neumann entropy, as we will discuss below.
6.1. Jaynes Principle and Distinguishability
Suppose that we are given the set of the alphabet. Then our lack of knowledge on the set is evaluated by Shannon entropy through a probability distribution satisfying . (Recall that classical Shannon entropy is defined as ). The larger the entropy becomes, the larger the uncertainty we have.
We have minimum information as interpreted as the maximum entropy state, that is, and thus
holds. The central idea also provides the theoretical foundation for maximum entropy methods in data processing [44,45].
The underlying concept is distinguishability. In classical information theory, distinguishability holds trivially. In quantum theory, it is represented by the orthogonality of two quantum states. When pure states corresponding to alphabets, say, , are orthogonal to each other, every result in classical information theory is extended in a straightforward manner.
In statistical physics, a physical state of an ensemble is estimated through entropy maximization when we have no knowledge of the system. This way of thinking is called the Jaynes principle [42,43], and it is fundamental to statistical physics. For example, for a given set of eigenstates of a Hamiltonian, say, , with some conditions, we obtain a canonical ensemble by using the principle.
In quantum physics, we are able to consider the maximization of the von Neumann entropy of the density matrix (Bayes mixture) for orthogonal vectors . Since , this maximization completely reduces to the classical case. Then the maximizer is the completely mixed state, i.e., , which corresponds to the uniform distribution. Formally, additional constraints also yield a quantum exponential family [46], which is the quantum analogue of the classical exponential family [47,48].
However, we have no solid criterion such as the Jaynes principle for a nonorthogonal pure states model. For example, a qubit processed under one unitary operation, which is assumed to be among . (, ). In a sense, it is a simplified rotation error model (e.g., Kueng et al. [2]). In our formulation, a model is given. Suppose that we have no information or knowledge on which unitary gate processed the qubit. Then, how do we describe the quantum bit?
Mathematically, it is possible to extend the maximum entropy criterion to the noncommutative case. Then we consider the maximization,
over the prior . Is this kind of formal extension enough in quantum information theory? There are many quantities such as Rényi’s entropy [37,38,39,40,41] in both classical and quantum information theory. Is there another possibility to consider such quantities?
Every quantum state in the model is not orthogonal anymore; thus, they are not distinguishable, which is completely different from the set of the alphabet. In spite of this, do we seek some justification for the maximization of the entropy from classical information theory?
In our formulation, the above formal argument breaks down. First, for the model , we describe the system by the representative quantum state , which is completely independent of the von Neumann entropy. Second, in the quantum detection game between Alice and Bob, we see that the von Neumann entropy is useless in a specific example (Section 5.6). Rather, we consider the least favorable case or the minimization of the detection rate, , which is contrastive to the maximization of entropy (20).
If we seek a purely quantum counterpart of the Jaynes principle, then minimization of would be promising. Luckily, due to monotonicity, the minimization is equivalent to the maximization of , where the function is known as the minimum entropy of . Some of its properties are similar to those of the von Neumann entropy and others are not. In the next subsection, we review basic properties of the minimum entropy.
6.2. Properties of the Minimum Entropy
In the present subsection, we briefly review basic properties of the minimum entropy and then give another definition for purely quantum information. The minimum entropy of the density matrix is defined by , which is a special case of quantum Rényi entropy.
Quantum Rényi entropy has a real parameter and is defined by
for fixed (see, e.g., p. 117 in Ohya and Petz [41]). When , we obtain the minimum entropy.
The minimum entropy inherits some common properties of quantum Rényi entropy. For example, additivity holds. For every pure state, T equals to zero.
However, the concavity does not necessarily hold. Concavity of entropy means that a probability mixture of quantum states increases the uncertainty of the whole system.
This negative property is not due to noncommutativity. To see this, let us take two commutative density matrices,
where . Then, since ,
Thus, convexity rather than concavity holds in the above example.
Since minimum entropy is based on the operator norm, we obtain a sufficient condition for convexity easily.
Lemma 5.
Let two density matrices ρ and σ exist where . Suppose that
holds for every λ, . Then
holds.
Proof.
Since is convex,
holds. □
To see the above lemma, when we introduce as a variant of entropy over the whole density operators, its theoretical significance seems very weak.
However, when we consider PQI in a pure state model, the situation changes drastically. For the pure state family, concavity of the minimum entropy necessarily holds in the following sense.
Lemma 6.
Let a set of pure states be given, say . Then concavity holds, restricted to the model.
Proof.
Choose a finite set of pure states from , say . Then
holds. □
Other properties of minimum entropy are usually shown in the context of quantum Rényi entropy (see, e.g., Hu and Ye [22] (Section III, p. 4), Dam and Hayden [21]).
Observing the above, we provide another possible definition of purely quantum information through . In the quantum detection game, finding the LFP is equivalent to maximizing the minimum entropy rather than the von Neumann entropy . To consider the logarithm of the detection rate, we obtain another definition of purely quantum information such as
By definition, vanishes if the model has orthogonal pure states with the full-rank condition, where the classical case is included.
From Lemmas 5 and 6, we must be careful to treat minimum entropy in the definition of . At least, it should not be considered over the set of the whole density matrices. As a consequence, a comparison of the two definitions, and , also should be performed carefully and would require a deeper understanding of the model information, which will be a topic for future research.
Finally, we make two comments. First, our definition of the model information yields one operational meaning for the minimum entropy. It is apart from the usual extension of entropic concepts in classical information theory. Rather, it comes from an imaginary design of the quantum detector and facility location problem on the unit sphere in a complex projective space. Second, we expect that the purely quantum version of the Jaynes principle is established based on the minimum entropy. (For some related works on maximum entropy methods, see the reference [49]). It might be possible to develop data processing methods and some dynamics based on the new principle.
7. Infinite-Dimensional Hilbert Space
Thus far, we have considered the PQI of a model only in a finite-dimensional Hilbert space. While our definition of PQI applies to infinite-dimensional Hilbert space, technical difficulties seem to arise due to a parametric family of functions. In this section, we only skim them in a specific example.
Let denote the set of square integrable complex functions over and g be a known continuous function in satisfying . Let us consider the quantum statistical model describing a wavefunction with a single parameter.
Parameter estimation of the shift parameter has been theoretically investigated [3]. If we replace the wavefunction g with a probability density function such as the Gaussian density, the estimation problem for the shift parameter is called that for the location parameter and is very common in classical statistics [50].
Before evaluating the PQI of the model , first let us formally consider quantum state estimation with no observation. It is seen that the worst-case error equals one for every estimation.
Lemma 7.
Let and with . Then
holds.
For proof, see the Appendix A.1. The above lemma says that every quantum state in would be a minimax location on “”.
Since the parameter space is noncompact, the minimax theorem [20] does not hold generally. However, we directly show that the Formula (16) holds in this specific example, that is,
The first equality holds due to the following lemma. Because of technical difficulties, we give a proof in the Appendix A.2.
Lemma 8.
Let with and ϵ be an arbitrary positive constant. Then there exists a finite set and the uniform prior over the set such that
Thus, a formal definition of PQI shows that . We can interpret the result as follows. Even if Bob knows that the quantum state is in the model or that the quantum system is described by a wavefunction , he obtains no information, which gives Bob an advantage over Alice in the quantum detection game.
We do not obtain the conditions where PQI is positive with explicit examples. Even if the Formula (16) holds under some conditions, calculation of PQI would become drastically different. A detailed investigation is left for future study.
8. Concluding Remarks
We have defined one information quantity called purely quantum information (PQI) not for a pure state itself, but for a parametric model of pure states. While PQI evaluates the size of a pure state model, it necessarily vanishes in classical cases by definition. We call the center of the model the representative quantum state, and PQI is determined by the maximum length from the center to each quantum state in the model.
Finally, we give the answer to the problem presented in the beginning of the article. Let and calculate PQI for two models:
Model has the same amount of PQI as , . The PQI of the model is , which is smaller than . This implies that spreads more than , and we see that the PQI is independent of the dimension of the parameter space.
Funding
This work was supported by JSPS KAKENHI Grant Numbers JP20H02168, JP19K11860.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Proofs
Appendix A.1. Proof of Lemma 7
For , we show that there exists M such that
First, we take compact sets K and L satisfying and , respectively. Second, there exists a positive constant M such that and K are disjoint. Note that for every . Then, we bound the absolute value of the inner product by two terms:
where denotes the complement of K. Due to the Cauchy–Schwarz inequality, the second term is bounded by
The first term requires more steps. Since ,
Appendix A.2. Proof of Lemma 8
First from (A1), when . Thus, for , there exists M such that .
Using the above, we construct the sequence of a prior distribution with finite support (i.e., discrete probability) and Bayes mixture. First, for fixed n, we take a parameter set satisfying for .
Without loss of generality, we assume that are linearly independent. Then, set (). It is easily shown that the gram matrix is positive definite. Then, we decompose G into the identity and , where diagonal components of A are zero.
For a uniform weight over the parameter set , we define the Bayes mixture
Now we show that
First, we expand an arbitrary normalized vector as . Then , where is a column vector and denotes the conjugate transpose of the vector c. Since G is positive definite, we take another parameter vector d as . Note that there is one-to-one correspondence between and d. Thus,
where .
This implies that
which shows Equation (A2).
Next, we show the inequality (A3). Due to Geršgorin’s Theorem (see, e.g., Section 6.1 in Horn and Johnson [51]), all eigenvalues of A are located in the union of n discs
Thus, we easily show that the absolute value of each eigenvalue is bounded by .
Finally, we obtain from (A2) and (A3), . For fixed , we have . Since is arbitrary, must be zero.
References
- Iyer, P.; Poulin, D. A small quantum computer is needed to optimize fault-tolerant protocols. Quantum Sci. Technol. 2018, 3, 030504. [Google Scholar] [CrossRef] [Green Version]
- Kueng, R.; Long, D.M.; Doherty, A.C.; Flammia, S.T. Comparing experiments to the fault-tolerance threshold. Phys. Rev. Lett. 2016, 117, 170502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holevo, A.S. Asymptotic Estimation of a Shift Parameter of a Quantum State. Theory Probab. Appl. 2005, 49, 207–220. [Google Scholar] [CrossRef] [Green Version]
- Fujiwara, A. Strong consistency and asymptotic efficiency for adaptive quantum estimation problems. J. Phys. A Math. Gen. 2006, 39, 12489–12504. [Google Scholar] [CrossRef] [Green Version]
- Gill, R.D.; Massar, S. State estimation for large ensembles. Phys. Rev. A 2000, 61, 042312. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, M. Asymptotic Theory of Quantum Statistical Inference; World Scientific: Singapore, 2005. [Google Scholar]
- Helstrom, C.W. Quantum Detection Theory; Academic Press: New York, NY, USA, 1976. [Google Scholar]
- Holevo, A.S. Probabilistic and Statistical Aspects of Quantum Theory; North-Holland: Amsterdam, The Netherlands, 1982. [Google Scholar]
- Yamagata, K. Efficiency of quantum state tomography for qubits. Int. J. Quantum Inf. 2011, 9, 1167–1183. [Google Scholar] [CrossRef] [Green Version]
- Eldar, Y.C. A semidefinite programming approach to optimal unambiguous discrimination of quantum states. IEEE Trans. Inf. Theory 2003, 49, 446–456. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Megretski, A.; Verghese, G.C. Designing optimal quantum detectors via semidefinite programming. IEEE Trans. Inf. Theory 2003, 49, 1007–1012. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Stojnic, M.; Hassibi, B. Optimal quantum detectors for unambiguous detection of mixed states. Phys. Rev. A 2004, 69, 062318. [Google Scholar] [CrossRef] [Green Version]
- Yuen, H.; Kennedy, R.; Lax, M. Optimal testing of multiple hypothesis in quantum detection theory. IEEE Trans. Inf. Theory 1975, 2, 125–134. [Google Scholar] [CrossRef]
- Blume-Kohout, R. Optimal, reliable estimation of quantum states. New J. Phys. 2010, 12, 043034. [Google Scholar] [CrossRef]
- Bužek, V.; Derka, R.; Adam, G.; Knight, P.L. Reconstruction of quantum states of spin systems: From quantum Bayesian inference to quantum tomography. Ann. Phys. 1998, 266, 454–496. [Google Scholar] [CrossRef]
- Smithey, D.T.; Beck, M.; Raymer, M.G.; Faridani, A. Measurement of the Wigner distribution and the density matrix of a light mode using optical homodyne tomography: Application to squeezed states and the vacuum. Phys. Rev. Lett. 1993, 70, 1244–1247. [Google Scholar] [CrossRef]
- Vogel, K.; Risken, H. Determination of quasiprobability distributions in terms of probability distributions for the rotated quadrature phase. Phys. Rev. A 1989, 40, 2847–2849. [Google Scholar] [CrossRef]
- Drezner, Z.; Wesolowsky, G.O. Facility location on a sphere. J. Opl. Res. Soc. 1978, 29, 997–1004. [Google Scholar] [CrossRef]
- Shiode, S. Minimax facility location problem on a sphere. Rev. Kobe Univ. Mercantile Mar. 1989, 37, 155–158. [Google Scholar]
- Tanaka, F. Noninformative prior in the quantum statistical model of pure states. Phys. Rev. A 2012, 85, 062305. [Google Scholar] [CrossRef]
- van Dam, W.; Hayden, P. Rényi-entropic bounds on quantum communication. arXiv 2002, arXiv:quant-ph/0204093. [Google Scholar]
- Hu, X.; Ye, Z. Generalized quantum entropy. J. Math. Phys. 2006, 47, 023502. [Google Scholar] [CrossRef]
- Davisson, L.; Leon-Garcia, A. A source matching approach to finding minimax codes. IEEE Trans. Inf. Theory 1980, 26, 166–174. [Google Scholar] [CrossRef]
- Brody, D.C.; Hook, D.W. On optimum Hamiltonians for state transformation. J. Phys. A Math. Theor. 2007, 40, 10949. [Google Scholar] [CrossRef] [Green Version]
- Cafaro, C.; Ray, S.; Alsing, P.M. Geometric aspects of analog quantum search evolutions. Phys. Rev. A 2020, 102, 052607. [Google Scholar] [CrossRef]
- Laba, H.P.; Tkachuk, V.M. Geometric characteristics of quantum evolution: Curvature and torsion. Condensed Matter Phys. 2017, 20, 13003. [Google Scholar] [CrossRef] [Green Version]
- Mostafazadeh, A. Hamiltonians generating optimal-speed evolutions. Phys. Rev. A 2009, 79, 014101. [Google Scholar] [CrossRef] [Green Version]
- Tanaka, F. Bayesian estimation of the wave function. Phys. Lett. A 2012, 376, 2471–2476. [Google Scholar] [CrossRef]
- Bengtsson, I.; Życzkowki, K. Geometry of Quantum States; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Ferguson, T. Mathematical Statistics: A Decision Theoretic Approach; Academic Press: New York, NY, USA, 1967. [Google Scholar]
- Berger, J. Statistical Decision Theory and Bayesian Analysis, 2nd ed.; Springer: New York, NY, USA, 1985. [Google Scholar]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; Wiley: Hoboken, NJ, USA, 1994. [Google Scholar]
- Robert, C.P. The Bayesian Choice: From Decision-Theoretic Foundations to Computational Implementation; Springer: New York, NY, USA, 2001. [Google Scholar]
- Arimoto, S. An algorithm for computing the capacity of arbitrary memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef] [Green Version]
- Blahut, R.E. Computation of channel capacity and rate distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2005. [Google Scholar]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, California, CA, USA, 20 June–30 July 1960; University of California Press: Berkeley, CA, USA, 1961; Volume 1, pp. 547–561. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics; Springer: New York, NY, USA, 2010. [Google Scholar]
- Ohya, M.; Petz, D. Quantum Entropy and Its Use; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. I. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. II. Phys. Rev. 1957, 108, 171–190. [Google Scholar] [CrossRef]
- Kapur, J.N.; Kesavan, H.K. Entropy Optimization Principles with Applications; Academic Press: Boston, MA, USA, 1992. [Google Scholar]
- Rubinstein, R.Y.; Kroese, D.P. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation and Machine Learning; Springer: New York, NY, USA, 2004. [Google Scholar]
- Ruskai, M.B. Extremal properties of relative entropy in quantum statistical mechanics. Rep. Math. Phys. 1988, 26, 143–150. [Google Scholar] [CrossRef]
- Brown, L.D. Fundamentals of Statistical Exponential Families: With Applications in Statistical Decision Theory; Institute of Mathematical Statistics, Hayward: Berkeley Heights, NJ, USA, 1986. [Google Scholar]
- Barndorff-Nielsen, O.E. Information and Exponential Families in Statistical Theory; Wiley: New York, NY, USA, 1978. [Google Scholar]
- Goyal, P.; Giffin, A.; Knuth, K.H.; Vrscay, E. (Eds.) Bayesian Inference and Maximum Entropy Methods in Science and Engineering; AIP Conference Series; AIP Publishing: Melville, NY, USA, 2012; p. 1443. [Google Scholar]
- Lehmann, E.L. Theory of Point Estimation; Wiley: New York, NY, USA, 1983. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: New York, NY, USA, 1985. [Google Scholar]
Figure 1.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points and the green solid point denotes the minimax facility location (the representative quantum state), which is the geodesic midpoint.
Figure 1.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points and the green solid point denotes the minimax facility location (the representative quantum state), which is the geodesic midpoint.

Figure 2.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points and the green solid point denotes the minimax facility location (the representative quantum state), which is the geodesic midpoint between the most distant pair of demand points.
Figure 2.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points and the green solid point denotes the minimax facility location (the representative quantum state), which is the geodesic midpoint between the most distant pair of demand points.

Figure 3.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points, and the green solid point denotes the minimax facility location (the representative quantum state), which is the center of the circumscribed circle of the triangle whose edges are the demand points (See Algorithm Step (2)).
Figure 3.
Configuration of demand points in and the minimax facility location on the Bloch sphere: The red solid points denote demand points, and the green solid point denotes the minimax facility location (the representative quantum state), which is the center of the circumscribed circle of the triangle whose edges are the demand points (See Algorithm Step (2)).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tanaka, F. An Information Quantity in Pure State Models. Entropy 2022, 24, 541. https://0-doi-org.brum.beds.ac.uk/10.3390/e24040541
AMA Style
Tanaka F. An Information Quantity in Pure State Models. Entropy. 2022; 24(4):541. https://0-doi-org.brum.beds.ac.uk/10.3390/e24040541
Chicago/Turabian StyleTanaka, Fuyuhiko. 2022. "An Information Quantity in Pure State Models" Entropy 24, no. 4: 541. https://0-doi-org.brum.beds.ac.uk/10.3390/e24040541
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.