1. Introduction
Understanding the dynamics of information spreading in technological, biological, and social networks become one of the most important topics for large-scale networks [
1,
2,
3]. Thus, we studied the dynamics of information spreading by using influential nodes. The information spreading ability of influential nodes is greater than that of other nodes in the network. In this context, computing influential nodes in any network is important to many researchers. We can also study or understand the attributes and characteristics of the network while computing the influential nodes in complex networks [
4,
5]. Several researchers proposed centrality measures to identify the influential nodes in a complex network. The most commonly used centrality measures are the degree centrality [
6], closeness centrality [
7], betweenness centrality [
8], and semi-local centrality [
9]. PageRank centrality [
10] and leader-rank centrality [
11] were proposed based on the importance of the quality and quantity of the node’s neighbors. PageRank is a measure of a page that is measuring the quality or quantity of that page [
10,
12]. Zhang et al. [
13,
14] defined a measure called H-index, which is an indicator of the citation pattern of the paper. Nomura et al. [
15] defined a hyperlink induced topic search (HITS) method which is based on the hyperlink structures of web pages.
Various measures and methods are focused on the network’s structure, and very few measures are based on local information or local attributes of the node in the network [
16,
17]. Some of the commonly used centrality measures are defined based on local information, such as degree centrality, clustering coefficient [
18,
19], semi-local centrality, normalized local centrality [
20], local neighbor contribution [
21], and local centrality with coefficient [
22]. The degree centrality measure has low accuracy due to consideration of first-order neighbors [
18]. Due to the increased time complexity, centrality measures based on global information of nodes have become unsuitable for large-scale networks. In the current scenario, the challenging task is to find the influential nodes with high accuracy and in less running time. The
k-core measure [
23] also concentrates only on network structure. Various local centrality measures are listed in
Table 1. There exist very few centrality measures that are based on the structure of the network and information between nodes [
24,
25,
26].
In social networks, information is spread between two individual people based on similar behavior or other similarities [
17,
30,
31]. Zhao et al. [
16] gave a centrality measure based on structural similarity for finding influential nodes. The K–L divergence [
32] is used to measure the structural similarity of nodes, and enhanced PageRank is used to rank the nodes in large-scale networks. Sheng et al. [
28] defined the trust–PageRank (TPR) measure based on attribute information between nodes and network structure. Trust–PageRank creates a relation between the trust value and the PageRank of a node in the network. The trust value of two adjacent nodes is defined by the similarity ratio and the degrees of those nodes. The similarity ratio of two individual nodes is similar to the characteristics of these nodes. The construction of a measure of trust–PageRank mainly depends on the degree and similarity, which play a key role in spreading the information in the network. During the construction of a measure trust–PageRank, they considered only single a neighborhood level. Thus, we explore this measure not only at one neighborhood level but also the second neighborhood level. This idea can be further extended to other neighborhood levels too.
Our Contribution: In this research work, we propose a nearest neighborhood trust PageRank (NTPR) method which considers not only neighborhood trust values at the one-neighborhood level but also the nearest neighbors of trust values up to the second-neighborhood level. In this work, the degree ratio is also defined, along with next neighbor levels, instead of adjacent nodes. Considering the greater number of neighbors, the degree ratio and trust value capture information spread more accurately. We notice first-level neighbors and second-level neighbors’ information plays a crucial role in the influence of a node. Additionally, our method uses the trust value, which includes a degree ratio with neighbors, the similarity ratio, and the second-level neighbors’ information. We proposed an enhanced version of trust–PageRank, which is a nearest neighborhood trust PageRank measure to compute the influential nodes in complex networks [
29]. By using the proposed centrality, we computed the influential nodes in various real-world networks. We found the maximum influence of influential nodes by using the SIR, independent cascade, and greedy methods. In [
29], we defined the NTPR measure. In this paper, we provide results and comparisons with other basic centralities. We also compare our centrality measure with existing basic centrality measures, and it produces greater influence than the others which are discussed in the coming sections.
The rest of the paper is structured as follows: We list some of the existing basic centralities in
Section 1.1. In
Section 2, we define the nearest neighborhood trust page centrality measure and design an algorithm for computing the measure of each node in the network. We listed some of the network datasets which we used for our experiments and SIR, the independent cascade model, and Kendall’s tau details are given in
Section 3. In
Section 4, we discuss the correlations between NTPR and various basic centrality measures. We observe the difference between infection rate and centrality value with SIR and the independent cascade model. We also explain the performance of NTPR with various basic methods and the maximum influence levels of nodes at different infection rates. Finally, the conclusions are discussed, along with future research work.
1.1. Related Work
In this section, we list a few centrality methods and consider unweighted and undirected networks. Let
be a network, where
V denotes the vertices and
E denotes the edges of network
G. The degree centrality (DC) [
6] denotes the number of nodes adjacent or directly connected to a node. The closeness centrality (CC) [
7] of a node is how closely it is connected to other nodes using distance which is computed within the graph. The closeness centrality (CC) of node
v defined as
where
denotes the distance between vertices
and
v. The betweenness centrality (BC) [
8] of the vertex is a measure of the ratio of the shortest path involving the vertex to all the shortest paths between every pair of vertices. The betweenness centrality (BC) of node
v can be calculated as
where
is the shortest path from the vertex
to
(or
to
), and
is the shortest path between vertices
and
passing through vertex
v. The semi-local centrality (SC) [
9] is defined by the number of neighbors up to two levels, and vertex
v is computed as
where
and
are sets of adjacent nodes to vertices
v and
, respectively; and
represents the second-level neighbors of vertex
. PageRank measures the quality or quantity of a page [
10,
12]. PageRank is used for webpage sorting and for ranking data on various networks’ webpages.
where
n is number of vertices in a network,
represents the neighbors of vertex
v,
is the jump probability,
is the number of vertices to which the vertex
points, and
t represents an iterative parameter. The first term in PageRank is for regularizing the PageRank, and the sum should become one when it is maximized.
The trust–PageRank [
28] method is defined based on involving the trust value in the PageRank method. The intuition behind including the trust value is that if the vertex has more trust value, it receives more information from the other vertices. This is due to information spreading through the neighbor nodes within the network. The trust–PageRank [
28] method is defined as follows:
where
denotes the trust values of nodes
v and
,
n is the number of nodes,
is set of adjacent nodes of
v,
denotes jump probability, and
t represents an iterative parameter. The first term in TPR is for regularizing the TPR, and the sum should be one when it is maximized.
2. A Centrality Measure Using Second-Level Neighborhood Trust Values
We define a nearest neighborhood trust PageRank (NTPR) method which is constructed using the trust values of neighbors up to the second-level. The degree ratio and similarity ratio of neighbors of the node up to the second-level play a crucial role in constructing the centrality measure NTPR. The trust values of neighbors mainly depend on the degree ratio and similarity ratio. In the article [
28], the trust–PageRank (TPR) method was defined. In this research, other levels of adjacent neighborhood attributes were missing. Our intuition is that if we insist on second-level neighborhood trust values, then we could observe the influence maximization by computing the seed nodes or influential nodes in the complex network. We can also apply this logic to getting further level neighborhood information on trust values. However, time complexity may increase if we increase the number of levels.
Similarity Ratio: The similarity ratio of a vertex
and an adjacent neighbor
is the similarity of
and
divided by the addition of the similarity between the adjacent neighboring vertex
and its adjacent neighbor vertices
. The similarity ratio can be measured as follows:
The SimRank [
33] is constructed to measure the similarity of two nodes. In the SimRank method, if any two nodes are similar, then both are related to each other with some common attribute information or characteristics. The similarity between
and
can be calculated as:
where
and
sets of adjacent vertices of
and
, respectively;
is the similarity of
and
. In Equation (
3), computing
is an iterative process. In this iteration, we consider
is 1 if
and
is 0.1 if
.
Degree ratio: The degree ratio of a vertex
and an adjacent vertex
is the ratio of the degree of vertex
to the sum of the degrees of adjacent vertices of
. For normalization of this degree ratio, we use the sum of the degrees of the neighbors of
and the sum of the degrees of the second-level neighbors of
. The degree ratio can be defined as:
Trust value: Trust values of vertices
and
are defined by the similarity ratios and degree ratios of
to
. Trust value is calculated as follows:
where
and
are degree ratios and similarity ratios of vertices
and
, respectively. The parameter
k value is in between 0 and 1 and this value is taken to be
. Now, we propose nearest neighborhood trust–PageRank (NTPR) using trust value of adjacent vertices up to the second-level, as follows:
where
represents the trust values of nodes
v and
;
represents the number of vertices;
indicates jump probability, and we consider this value to be 0.85. The first term in NTPR is a regularizing term, the second term of NTPR contains neighbors’ similarity and degree ratios, and the third term of NTPR contains second-level neighbors’ similarity and degree ratios. Our intuition to define Equation (
6) is if we insist on second-level neighborhood information of trust value, then we can observe the influence maximization by computing the seed nodes or influential nodes in the complex network. We could also extended it up to further levels of neighborhood information of trust value. In Equation (
6), computing
is in iterative relation, and we consider the number of iterations
t from 0 to 1000. We can consider beyond 1000, but we considered up to 1000 to simplify our simulations. We initialized the
at every vertex to
. For more details, see Algorithm 1.
| Algorithm 1: Computing for every vertex of graph G |
Input: Graph with vertices and edges Output: for every vertex of graph G |
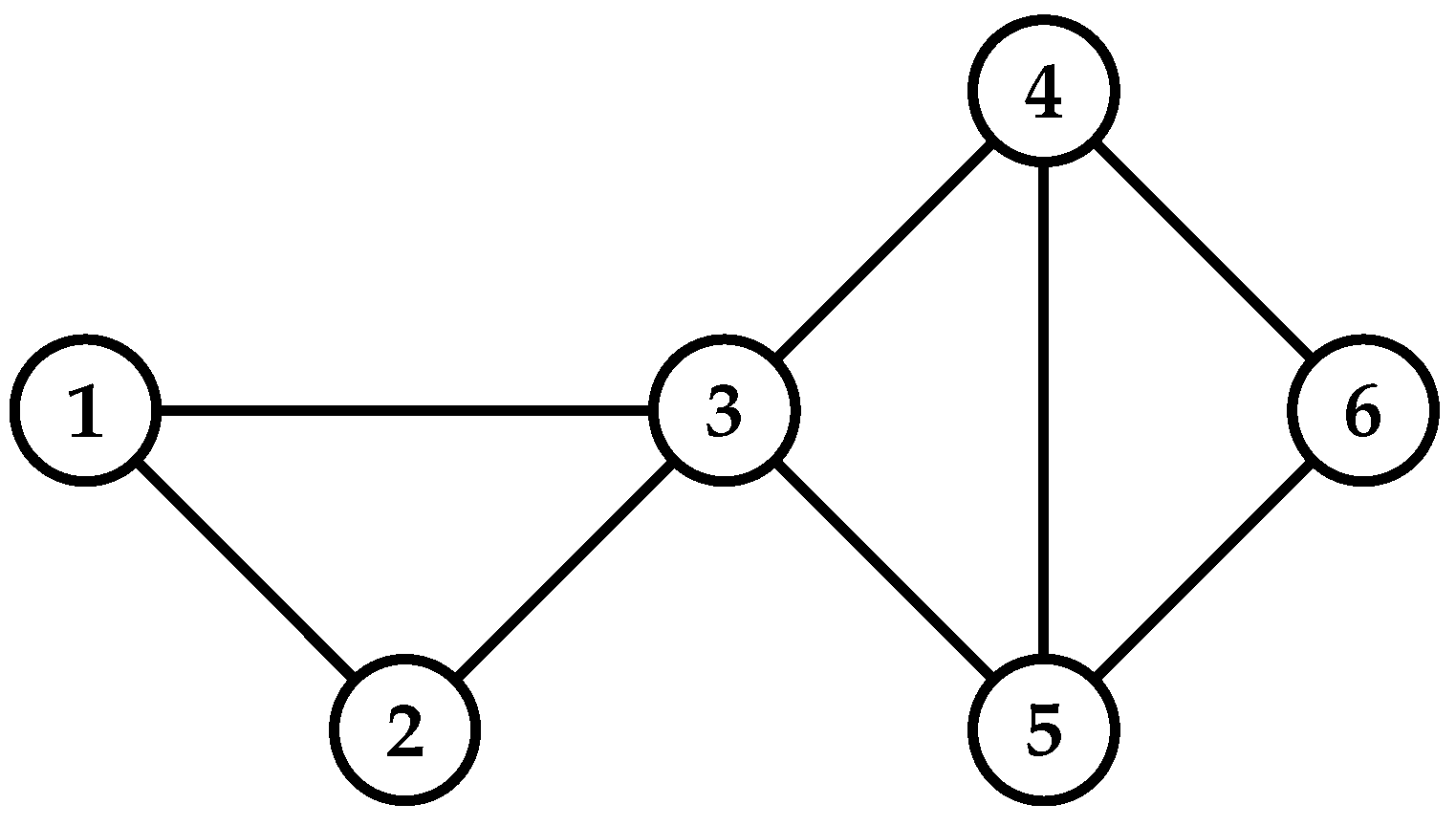
Algorithm 1 is the procedure for computing the NTPR measure for each vertex in the network. We illustrate Algorithm 1 by using an example that is given in
Figure 1. Finding NTPR is depends on trust values. Each trust value is based on similarity and degree ratio. For
Figure 1, we used Equations (
2) and (
4) to calculate the similarity ratio
and degree ratio
for every pair of vertices. We found trust values
by using Equation (
5) with the help of
,
, and
for every pair of vertices in the network, as shown in
Figure 2. We found the NTPR measure for every vertex using Equation (
6). For the network in
Figure 1, NTPR values for all nodes are as follows:
. Thus, vertex 3 has the highest NTPR value, i.e.,
, and the sequence of influenced nodes of the network in
Figure 1 is
. In our simulations, the number of iterations was set to 1000. The combination depends on the value of the damping factor, which is between 0 and 1. The damping factor
[
34] specifies how long a random web surfer spends following the hyperlink structure rather than teleporting. If we consider the damping factor to be
, that means out of total time,
of the time has been taken by a random web surfer to follow the hyperlink structure, and the remaining
of the time they teleport to new web pages randomly. To maximize the influence by computing the influential nodes in the complex network and to avoid the various parameters in our simulations, we fixed the values of
k and
to
[
34]. Complexity will increase if we tune all these parameters.
Time Complexity of NTPR
Consider a graph with and the maximum degree of d. Clearly, we can observe that the time complexities of measures , , and are , , and , respectively. Thus, the time complexity to find the for a vertex is . To find the measure for any vertex in the graph G is . We considered t constant in our algorithm, and the time complexity of Algorithm 1 is , where d is maximum degree and n is the number of vertices of the graph.
3. Details on Implementation
Description of Datasets: To test our suggested centrality NTPR, we used four datasets [
35] in a performance evaluation. The four datasets were email-univ, euroroad, powergrid, and web-polblogs which are provided at
https://networkrepository.com/ on 19 March 2020.
Table 2 summarizes the details of the networks.
Susceptible–Infected–Recovered Model: In this work, we investigated the dynamics of information spreading by using the SIR simulation model [
36,
37]. The SIR model is commonly used for how much information is spread with in the network. This model is used to understand the dynamics of the spreading of diseases and to find a total number of infected nodes at different infection probabilities. The SIR model is divided into 3 components, susceptible, infected, and recovered. The susceptible part tells us that no infection has taken place. The term “infected” refers to infections spread over the network by others. Finally, recovered means the cured individuals, and they do not infect after a certain number of rounds. At the starting stage, seed nodes will be infected, which can help us to find the spreading capability. These infected nodes later in each iteration infect their neighbors with a certain probability in the network. The number of infected nodes grows over time until it reaches a stable state. The SIR model is one of the methods used to estimate centrality measurements in terms of network performance.
Independent Cascade Model (IC): The IC model is a stochastic technique in which data are transferred from one node to another depending on probabilistic criteria [
3]. Li et al. [
38] categorized the diffusion models into two types, predictive and explanatory models. The IC model is a predictive model that uses specific parameters to estimate the forecast information diffusion process and influence maximization in social networks. The IC model’s information diffusion operates as follows: The network’s nodes can be in one of two states: active or inactive. If a node accepts the information being circulated in the network, it is deemed active; if it does not have information, it is considered inactive. Thus, an independent cascade model, which is a form of an epidemic model, proposes that an individual will achieve innovation with a specific probability if at least one of its neighbors has done so. We compared this model with the SIR model.
Greedy Model: The greedy algorithm implements the problem-solving strategy of choosing the locally best option at every stage [
3]. A greedy strategy may not generate an optimal result in many cases, but it can produce locally optimized solutions that resemble globally optimal solutions in acceptable time frames. Greedy algorithms are usually less computationally efficient than other techniques, such as dynamic programming, but they often compromise the quality of the solution to achieve speed. This algorithm was used to find top-ten seed nodes. The greedy model evaluates the incremental spread of each node separately rather than as a whole. It determines the maximum information spread for all remaining candidate nodes before selecting the node with the highest spread. The calculation of the spread for all nodes uses iterations and selects the top 10 nodes in terms fo influence. We compare the maximum influence with the greedy approach with that found by our centrality measure.
Kendall’s tau (): This is used to determine how closely two ranking lists rate the same set of items [
39,
40]. Kendall’s tau (
) measures how many concordant and discordant ranking pairs there are in each of the two lists. Kendall’s tau (
) [
41] is defined as:
where
is a sign function, if
returns 1, if
returns
, and if
returns 0.
and
are the ranks of nodes
i and
j in ranking list one.
and
are the ranks of nodes
i and
j in ranking list two, and
N is the number of nodes. Let us take two variables,
P and
Q.
Case 1: if
, both nodes are concordant pairs in ranking lists one and two.
Case 2: if
, both nodes are discordant pairs in ranking lists one and two.
Case 3: if
, both nodes are in the same rank in ranking lists one and two.
4. Results
In this section, we show the results on the correlations of our method NTPR with other different existing centrality measures. We show that the spread of information increases with the value of the centrality of a node in the network. Based on the SIR simulation and independent cascade models, we compared cumulative infected nodes for NTPR, BC, CC, DC, SC, PR, and TPR centralities, and the greedy approach. We studied the pattern of maximum influence with different infection rates for these centralities.
4.1. Correlations of the NTPR Method with Various Centrality Measures
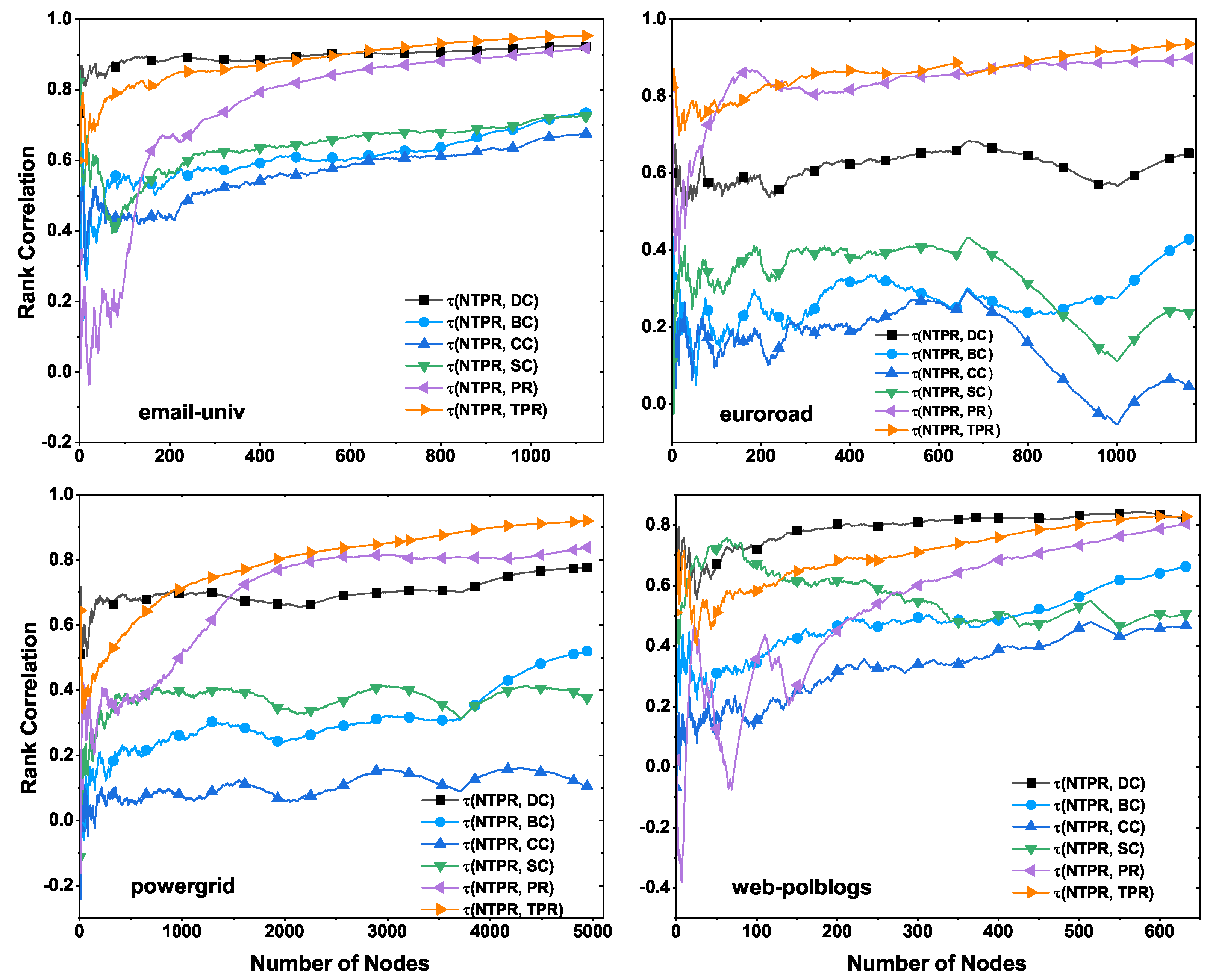
We show the results of correlations between the NTPR method and other basic centrality methods, such as TPR, PR, BC, DC, CC, and SC, on various real-world networks, in
Table 3 and
Figure 3. We computed the ranking of each vertex by using these centralities in the network. In
Figure 3, we show correlation plots of the NTPR method and basic centrality methods for every top-
N vertices, where
and
n is the number of nodes in the network. For every vertex, the correlation value of the NTPR method and each basic centrality method is shown in
Table 3. In
Table 3 and
Figure 3, we can observe the close connection between any basic centrality method and the NTPR method. In
Figure 3 and
Table 3, we see that the NTPR measure is similar to PR for email-univ, euroroad, and powergrid datasets. We can also observe that NTPR is similar to DC for email-univ and web-polblogs datasets. This is because NTPR is an improved version of PageRank with degree centrality. The NTPR method does not have a close correlation with any of the other centralities. Degree centrality is primarily correlated with the NTPR measure at the initial set of vertices in the powergrid network and email-univ. Degree centrality is highly correlated with the NTPR method in the second half of set of vertices in the web-polblogs network. Thus, the NTPR measure does not closely correlate with existing basic centralities except PR and DC.
We show that the information-spreading rate of the NTPR method is higher than those of the BC, DC, SC, CC, PR, and TPR methods with the help of SIR simulations. We computed the centrality value for each node by using each centrality method. The infected node was the single node with the highest centrality value. The cumulative infection was calculated by running SIR simulations 100 times. We took infection probability
to be in between
and
.
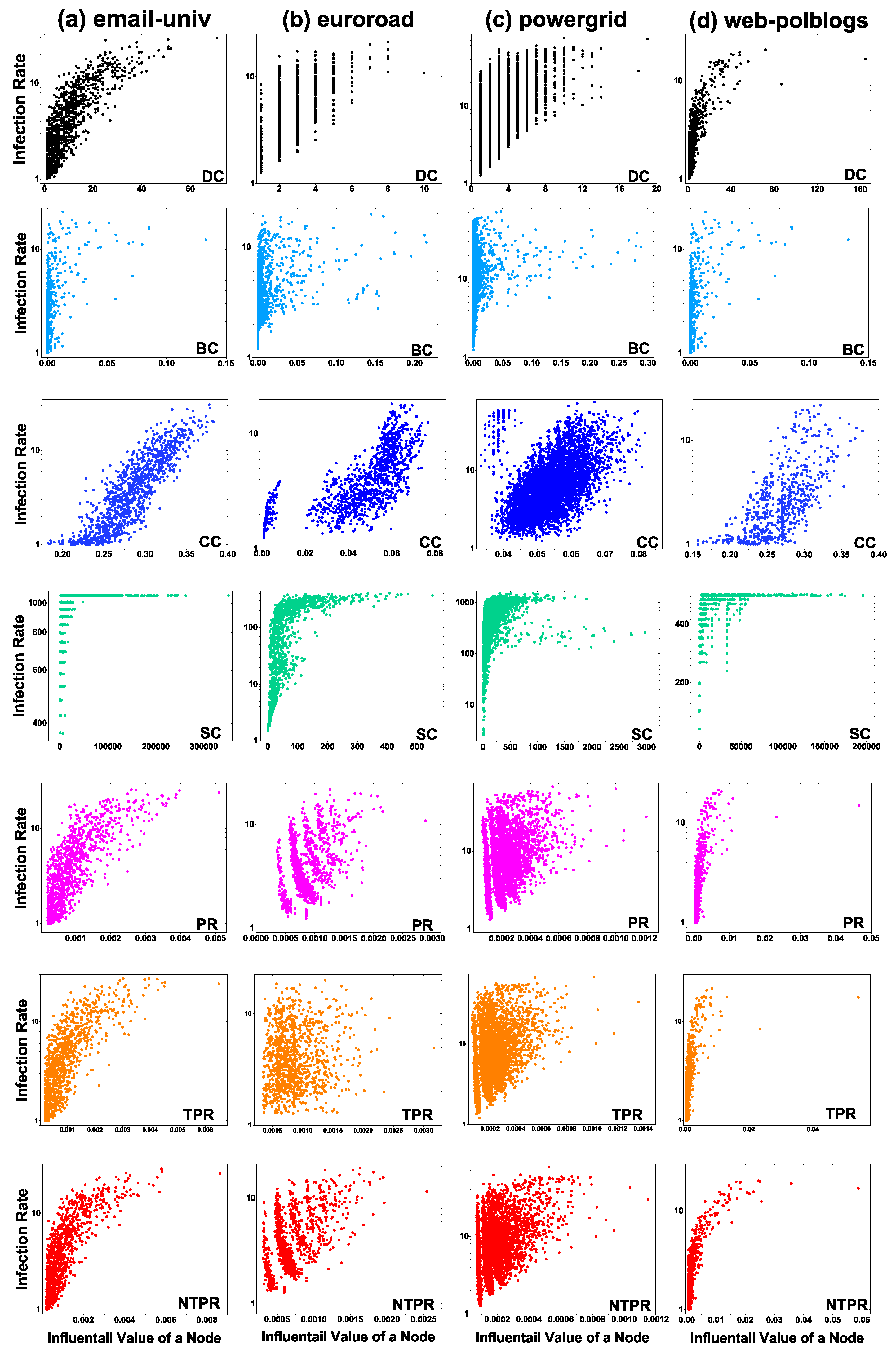
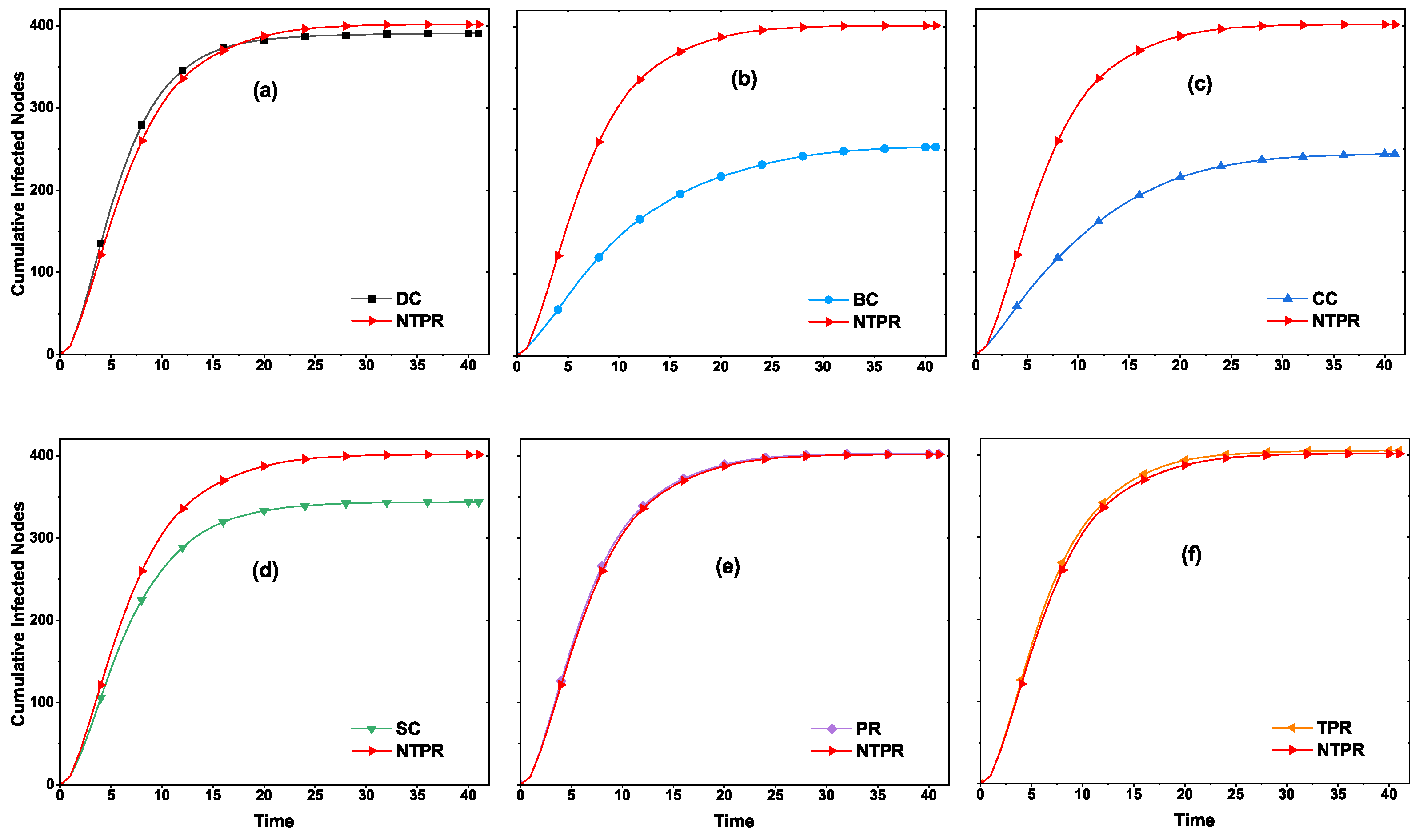
Figure 4 shows a plot of the centrality value of nodes with increasing infection rate. Our method NTPR, TPR, PR, and DC measures had good connections compared with SC, BC, and CC in the email-univ network, as shown in
Figure 4a. The NTPR method shows more information spreading when we compare it with TPR, PR, SC, CC, BC, and DC in the euroroad network (see column b in
Figure 4). We can observe that, if the node has a high NTPR centrality value, then the node has a high information propagation capability (see
Figure 4c). The centralities DC and BC have poor information spreading capabilities when compared with other centralities in the powergrid network, which can be observed in
Figure 4c. The CC, DC, TRP, PR, and NTPR measures show good cumulative infection compared to SC and BC methods in web-polblogs. For the web-polbogs network, SIR simulation plots are given in
Figure 4d. The NTPR centrality method provides more information spreading in the euroroad and powergrid networks. Clearly, we can observe that information spreading increases with the node centrality measure NTPR in four different real-world networks.
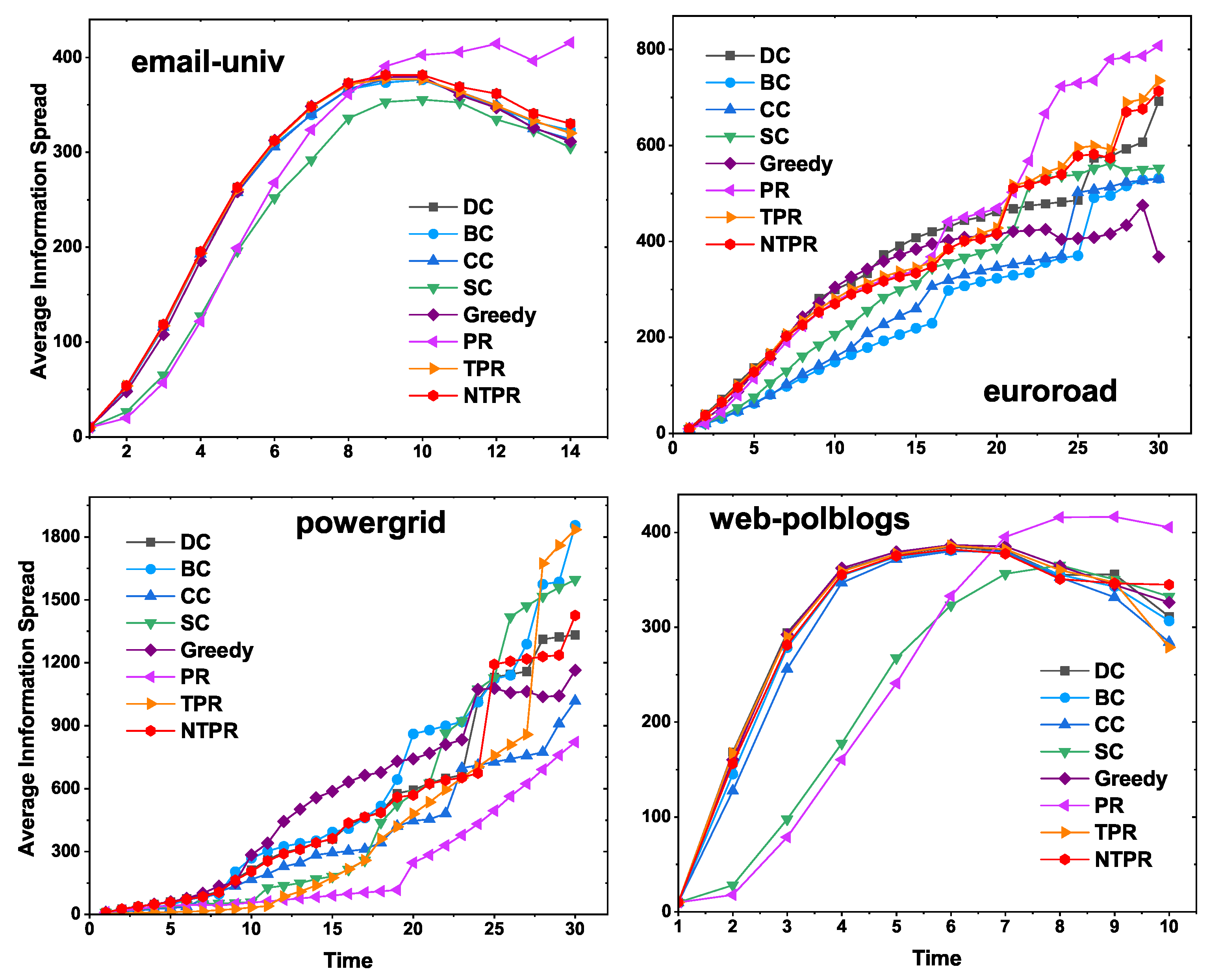
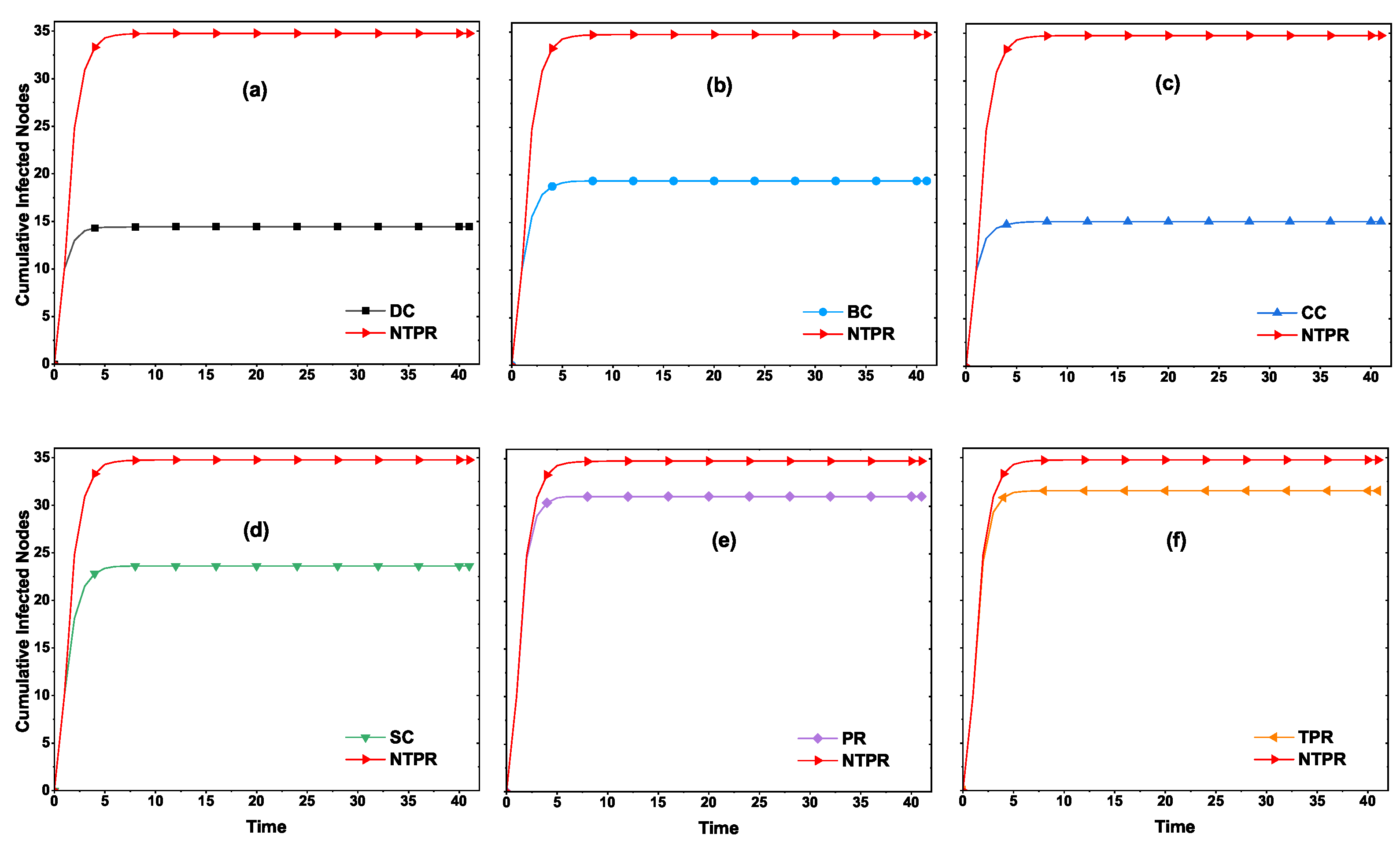
4.2. Cumulative Infected Nodes for the Proposed Centrality and Basic Centralities
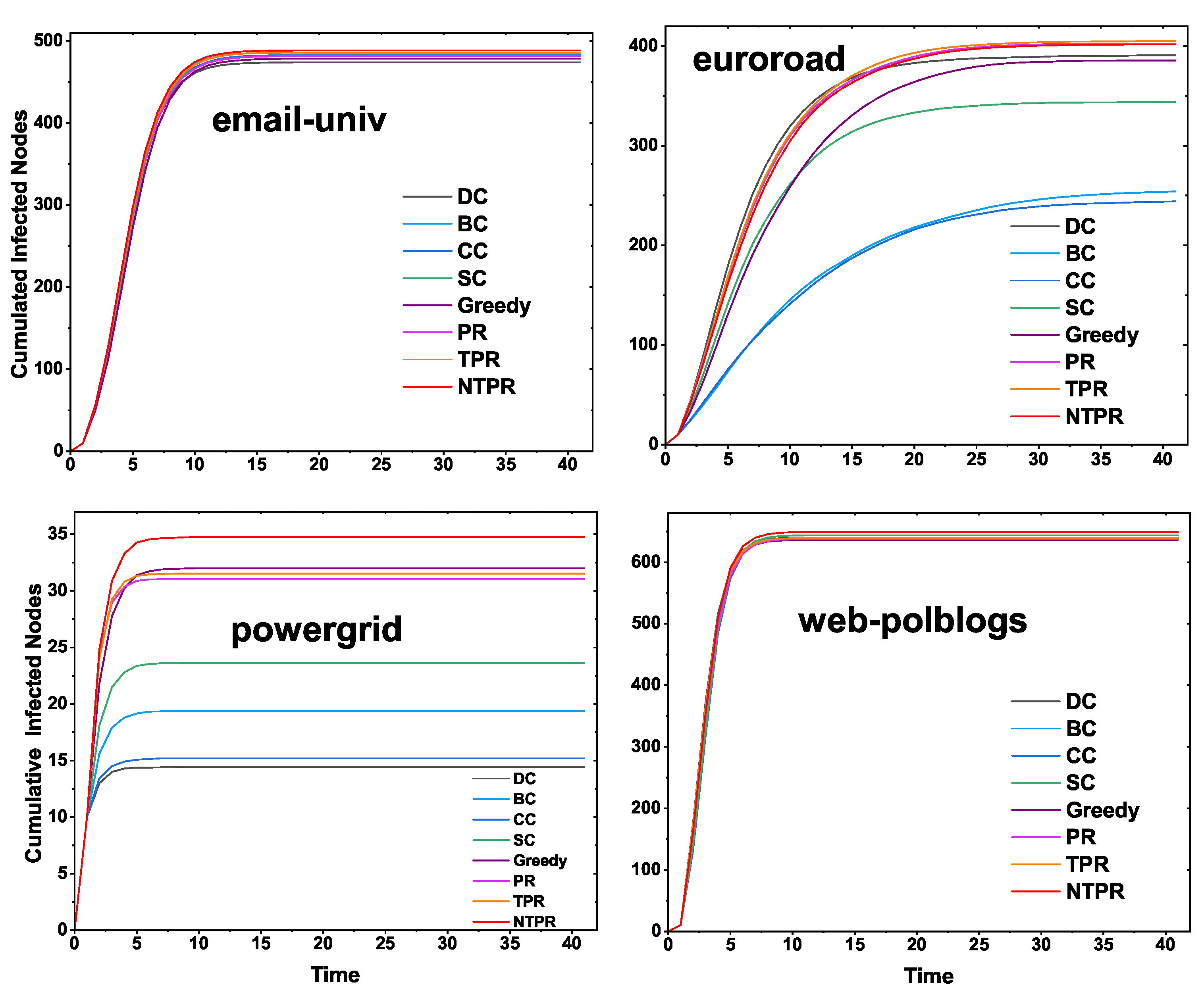
In this sub-section, we show the cumulative infected nodes or the effect of spreading the information while initially infected by the top-ten seed node or influential nodes. We computed the top-ten most influential nodes or seed nodes by using the proposed centrality method (NTPR); basic centrality measures BC, CC, SC, DC, PR, and TPR; and a greedy method. With the help of the SIR model, initially, these top-ten seed nodes were infected. In the next time step, adjacent vertices of these seed nodes get infected with infection probability
. We consider infection probability
to be in between
and
. After some time, whoever gets infected can recover with a certain recovery rate
, which we have considered as one. The time steps were limited to 40, and we ran 100 simulations and found the average cumulative infected nodes. The results for four networks are displayed in
Figure 5. The proposed centrality NTPR gives more cumulative infected nodes than TRP, PR, SC, CC, BC, and DC in euroroad and powergrid networks. The NTPR gives better results than the greedy method in the powergrid and euroroad networks. For email-univ and web-polblogs networks, our method provides similar results to the existing centralities. In email-univ and web-polblogs networks, the NTPR and greedy model give good results. The four networks’ results are displayed in
Figure 5. In
Figure 5, in most cases, information spreading with the proposed NTPR centrality method is dominating compared with the basic centrality measures.
4.3. Results on Spreading Information Rate vs. Centrality Value of a Vertex
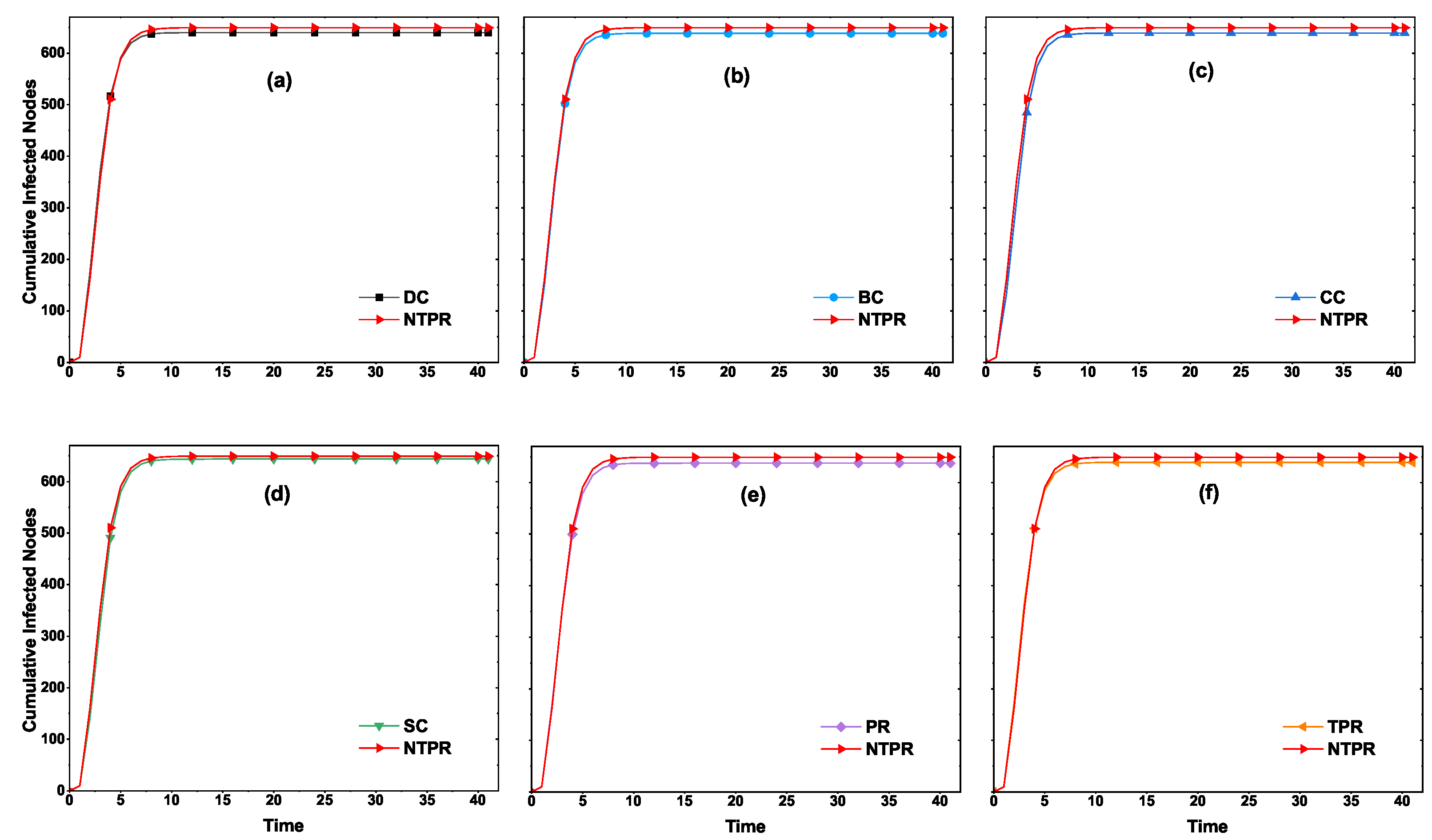
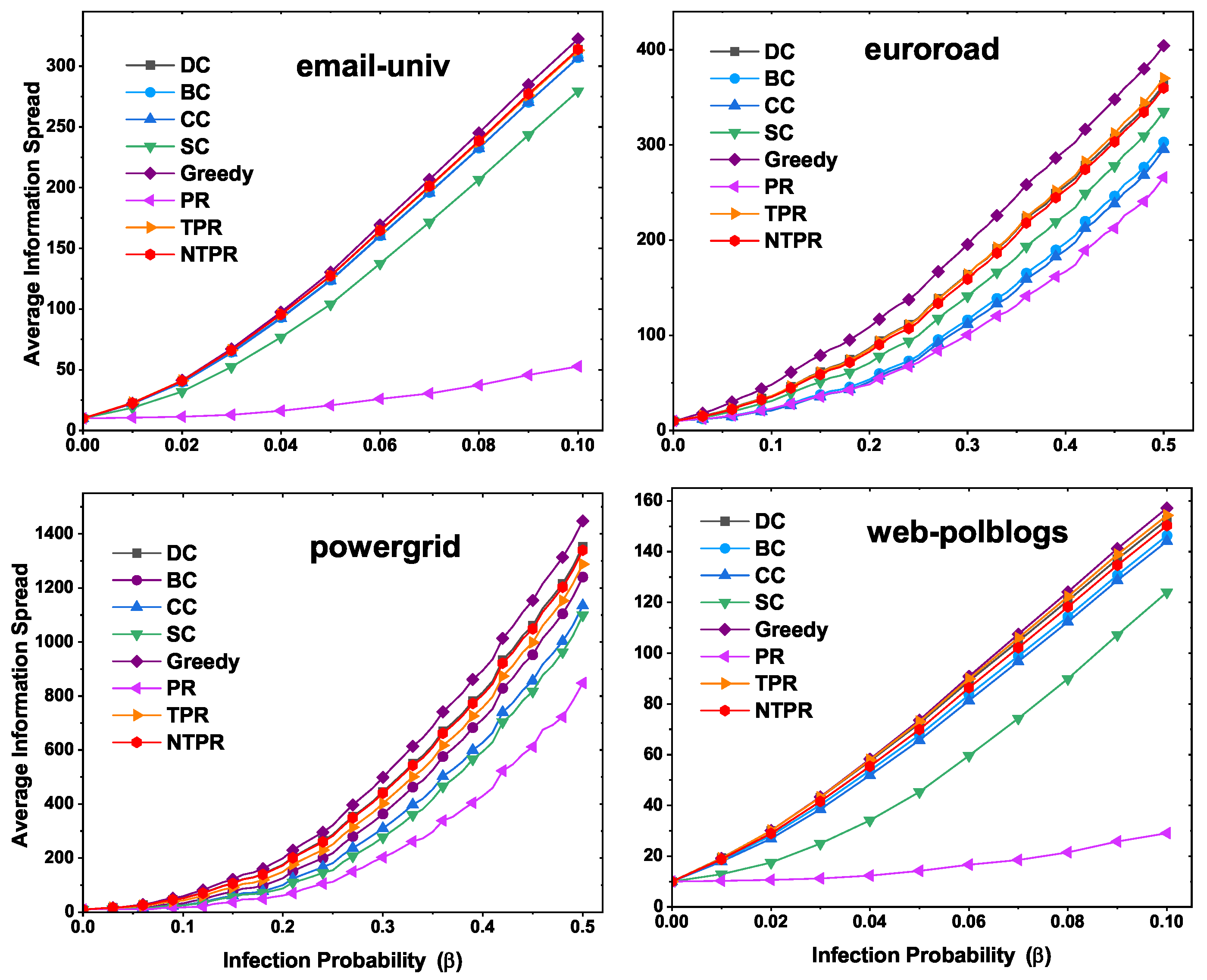
In
Figure 6, we show the average number of nodes at which information is received with different time steps by using the independent cascade model. The seed nodes were computed from different centrality measures which were input to the independent cascade model. In the independent cascade model, the number of iterations used for simulations was 1000. In email-univ and web-polblogs networks, the average information spread was greater at the initial steps for our centrality measure, and in the latter half, PR centrality dominated. However, NTPR and the greedy method both produced good results. The greedy method produced better results than basic centralities (DC, BC, CC, SC). In euroroad and powergrid, early on, our centrality measure produced good information spread, and in the second half of the time, greedy and PR performed well. In some cases, NTPR produced better average information spread than the other basic centrality measures with the independent cascade model. These results are shown in
Figure 6.
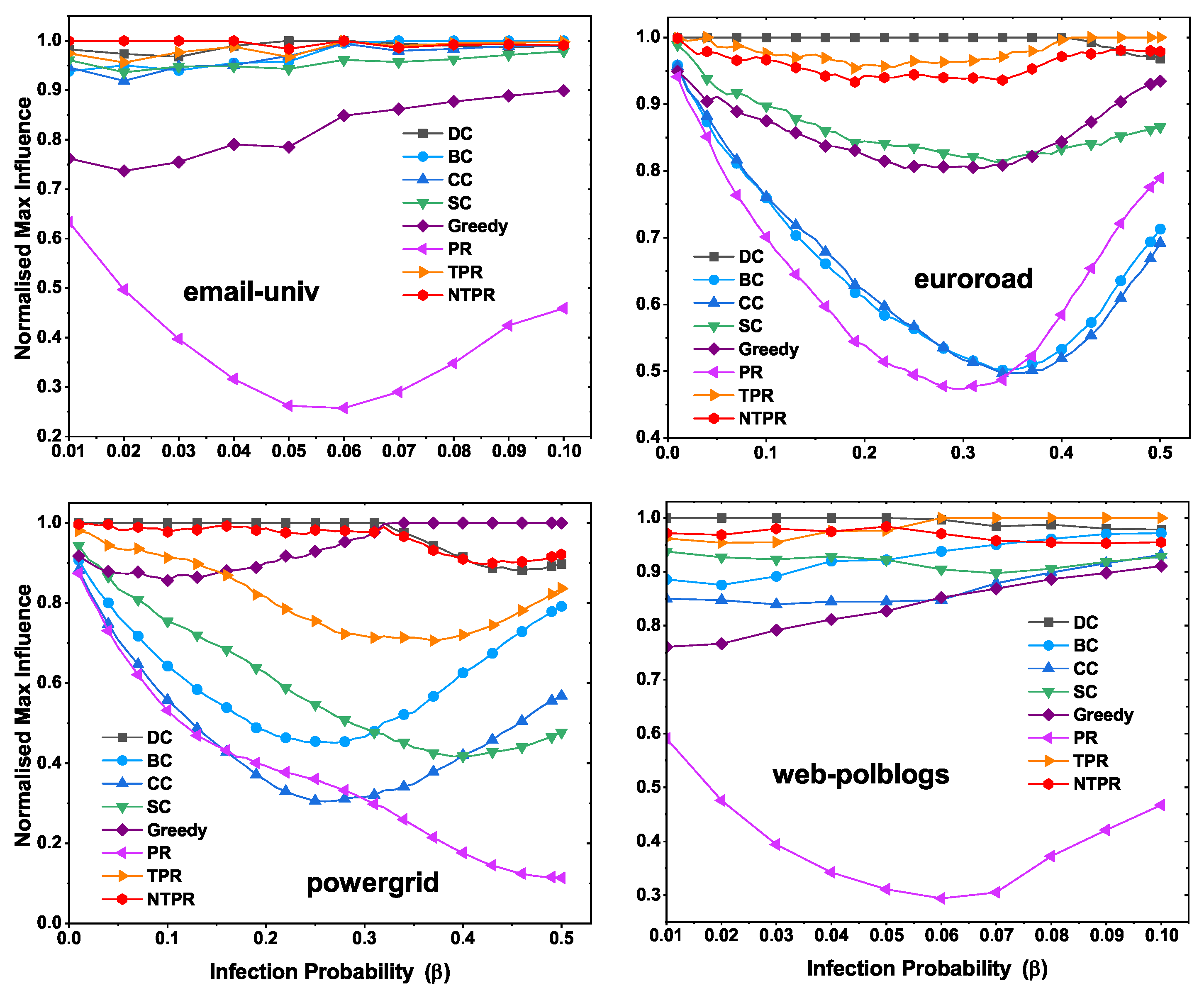
4.4. Maximum Influence at Various Infection Probabilities with Various Centrality Methods
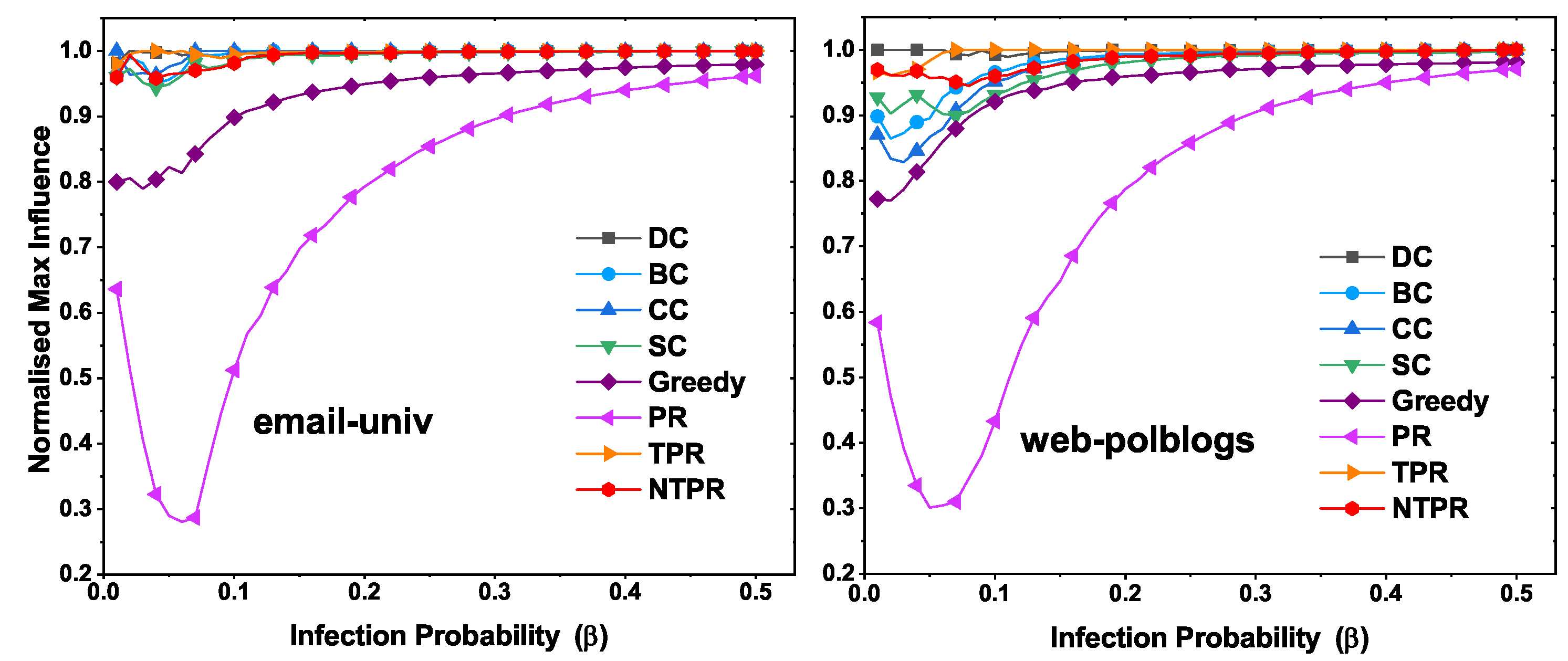
The results of the evaluation of the top-10 most influential nodes of infection spreading ability are displayed in this section. The top-10 most influential nodes were discovered using several centralities, such as TPR, PR, DC, SC, CC, BC, and NTPR. From the information in the networks, we know that most influential nodes have the power to propagate. The SIR model was utilized, and the infection probability was considered to be between and . We ran the SIR simulations with 100 iterations. To observe the effects of basic centralities and our new centrality, we found the maximum infection population at various infection probability levels. In this section, we talk about maximum information spread with different infection probabilities using the IC model. In this model, the infection probability is considered between and . We ran the IC model simulations with 1000 iterations.
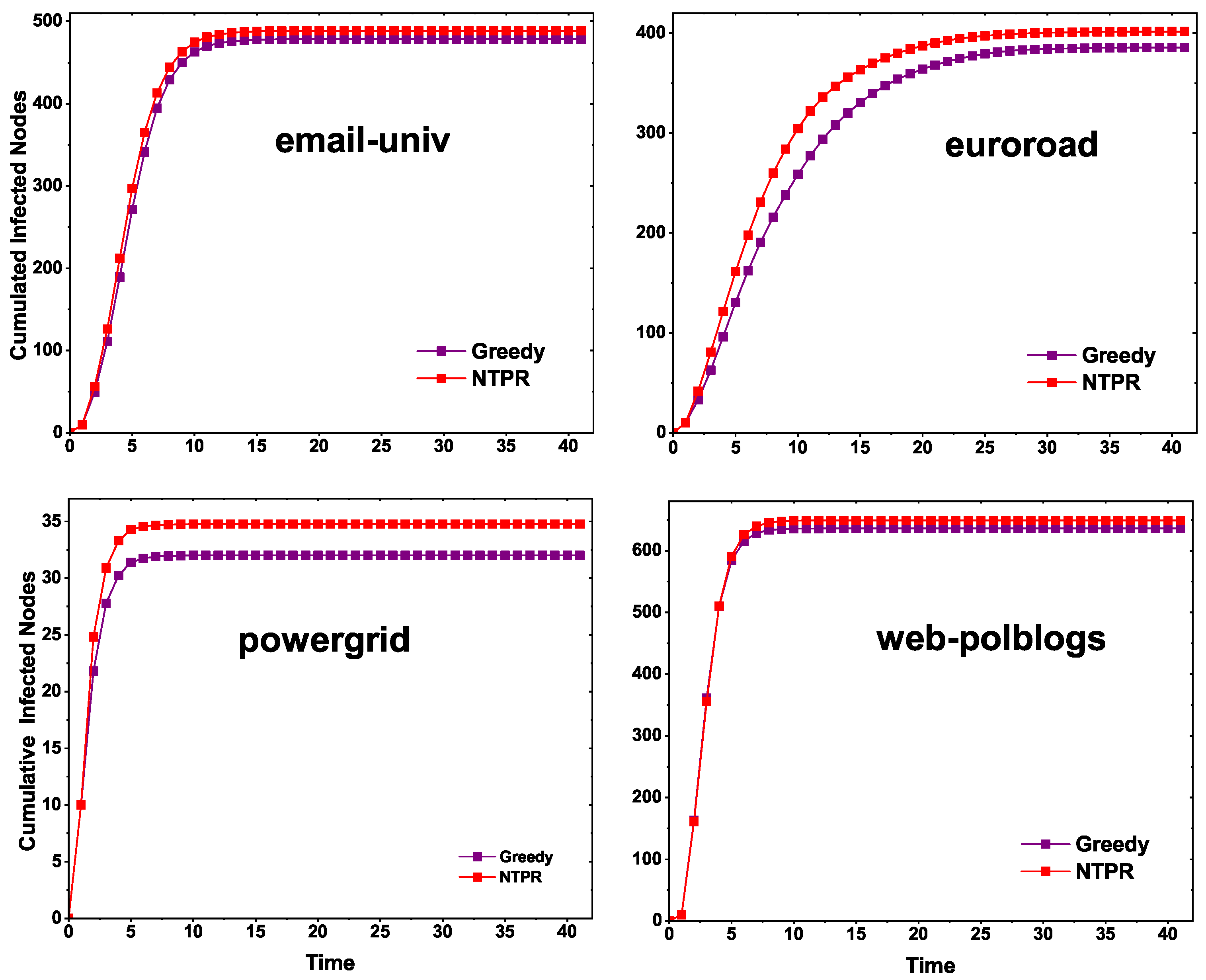
In
Figure 7, we illustrate the normalized maximum infection with various infection probabilities. On the dataset email-univ, our measure NTPR produced good results compared to PR, TPR, SC, CC, BC, and DC, as shown in
Figure 7. For the euroroad and web-polblogs datasets, DC performed well. However, our measure is close to DC centrality. On the powergrid network, NTPR took the top position over other centralities.
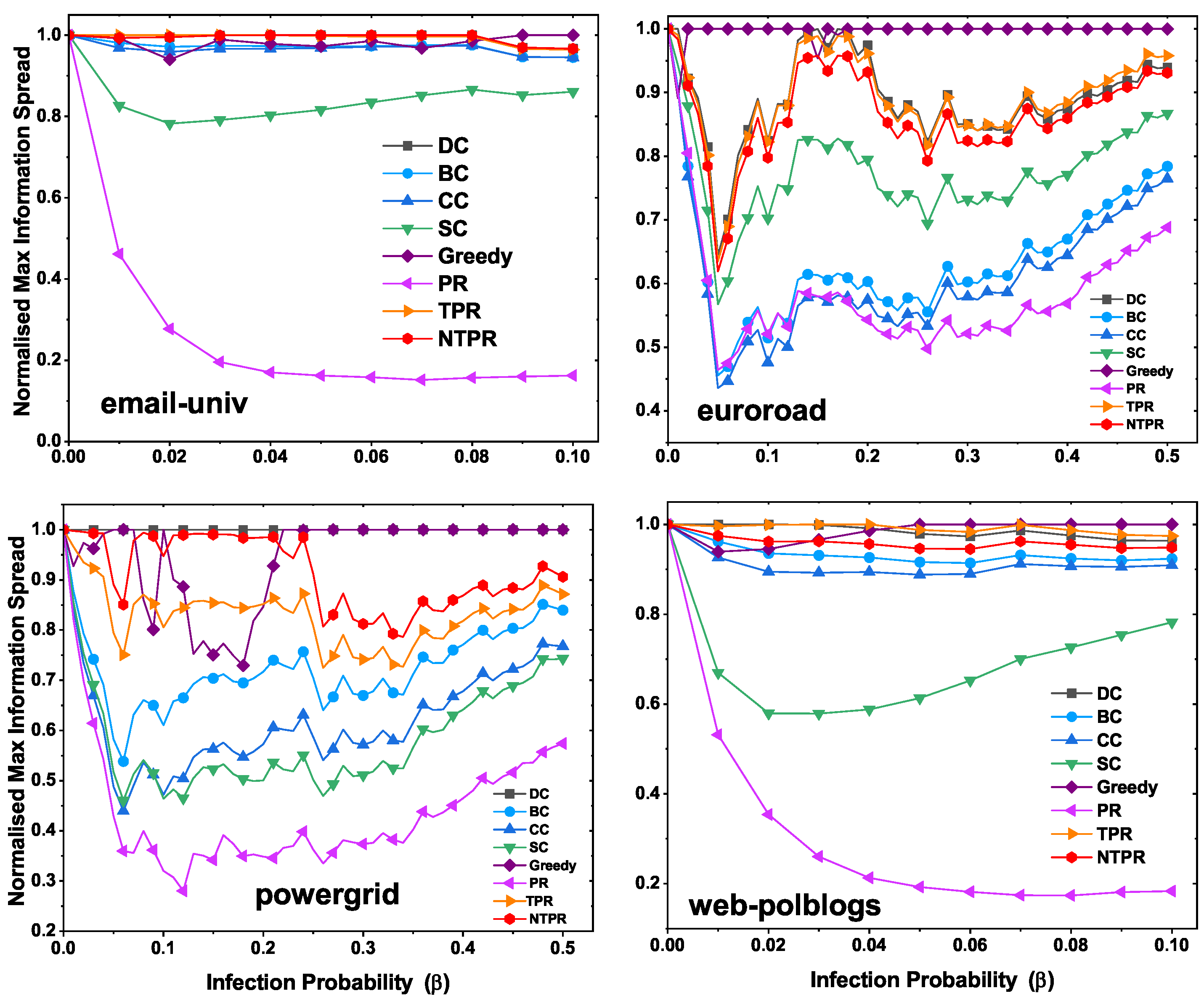
In
Figure 8, we illustrate the maximum information spread with various infection probabilities using the independent cascade model. In the email-univ network, the greedy and NTPR have more influence compared to other centralities. The greedy method has maximum information spread in euroroad and powergrid networks, which is shown in
Figure 8. In webpolblogs networks, the greedy method is at the top position, and NTPR is close to the greedy method.
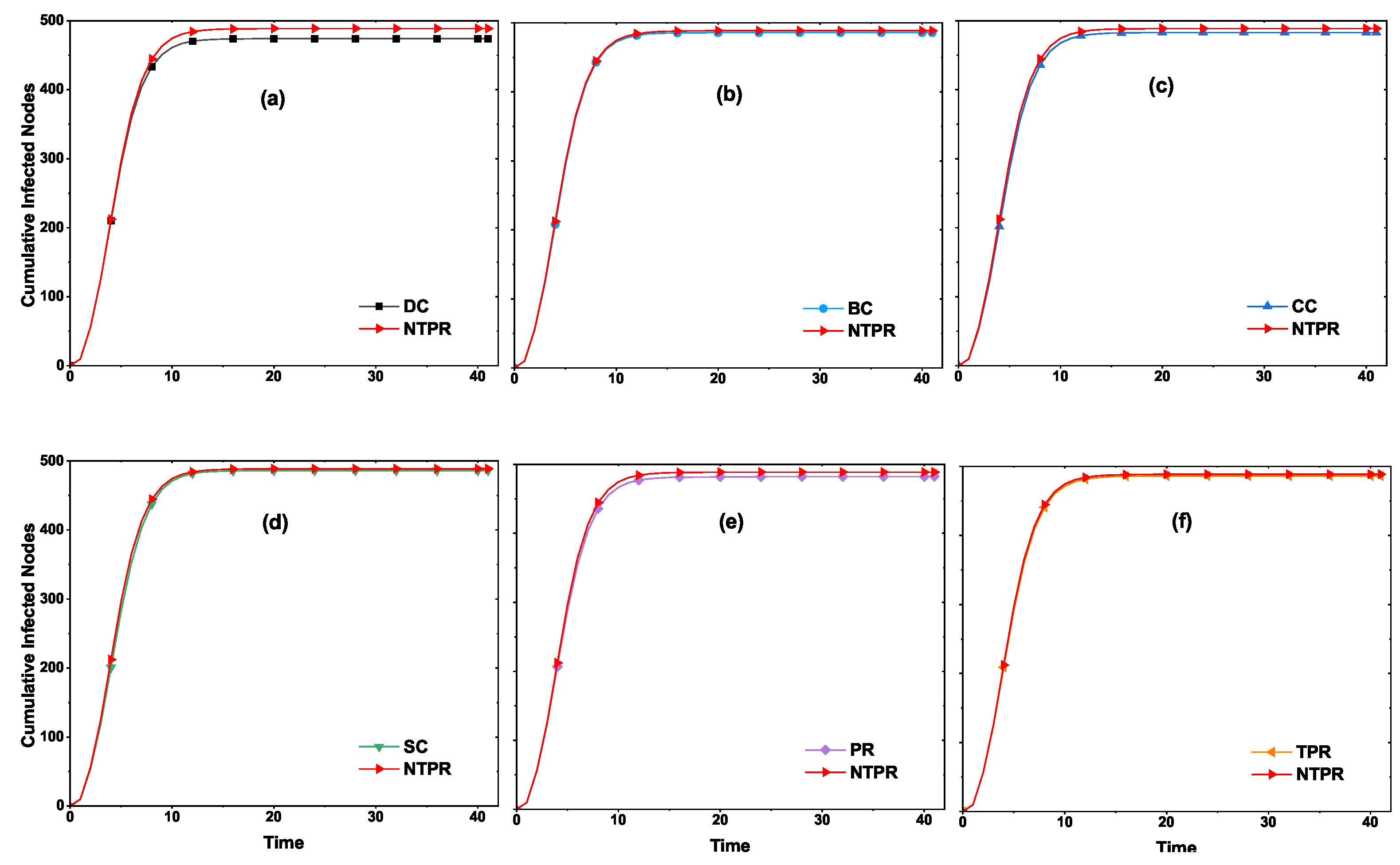
For clearer understanding, we show some of the figures for the two networks, email-univ and web-polblogs, in
Appendix A (
Figure A6); and for maximum information spread with various infection probabilities using the independent cascade model, we display figures for the four networks in
Appendix A (
Figure A7).
5. Conclusions
We focused on creating a centrality metric based on node attribute information and network topology. The degree ratio is utilized for node attribute information, whereas the similarity ratio is used for network structure information. The TPR was combined with trust value and PageRank in the previous work. However, we have focused on the importance of trust value in the nearest neighborhood throughout our work. The major goal of our metric is to evaluate trust value and PageRank, along with the closest neighbors. We use the degree ratio for second-level network neighbors as well. We can analyze the dynamics of spread inside the network by stepping up to the second-level. To assess performance, the SIR model and independent cascade model were used. Kendall’s tau was used to determine whether the NTPR and other existing basic centralities are similar. We obtained the experimental results by employing our nearest neighborhood trust metric, which is intended to identify the network’s most influential nodes.
Instead of using degree ratio, we would like to use closeness, betweenness, or other centrality measures to examine information spread with the proposed measure in the future. The value of the nearest neighborhood trust will also have the ability to expand to more layers of neighbors based on the diameter of the network or the maximum number of vertices of the network.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}