Key Aspects of Nucleic Acid Library Design for in Vitro Selection

Abstract
:1. Introduction
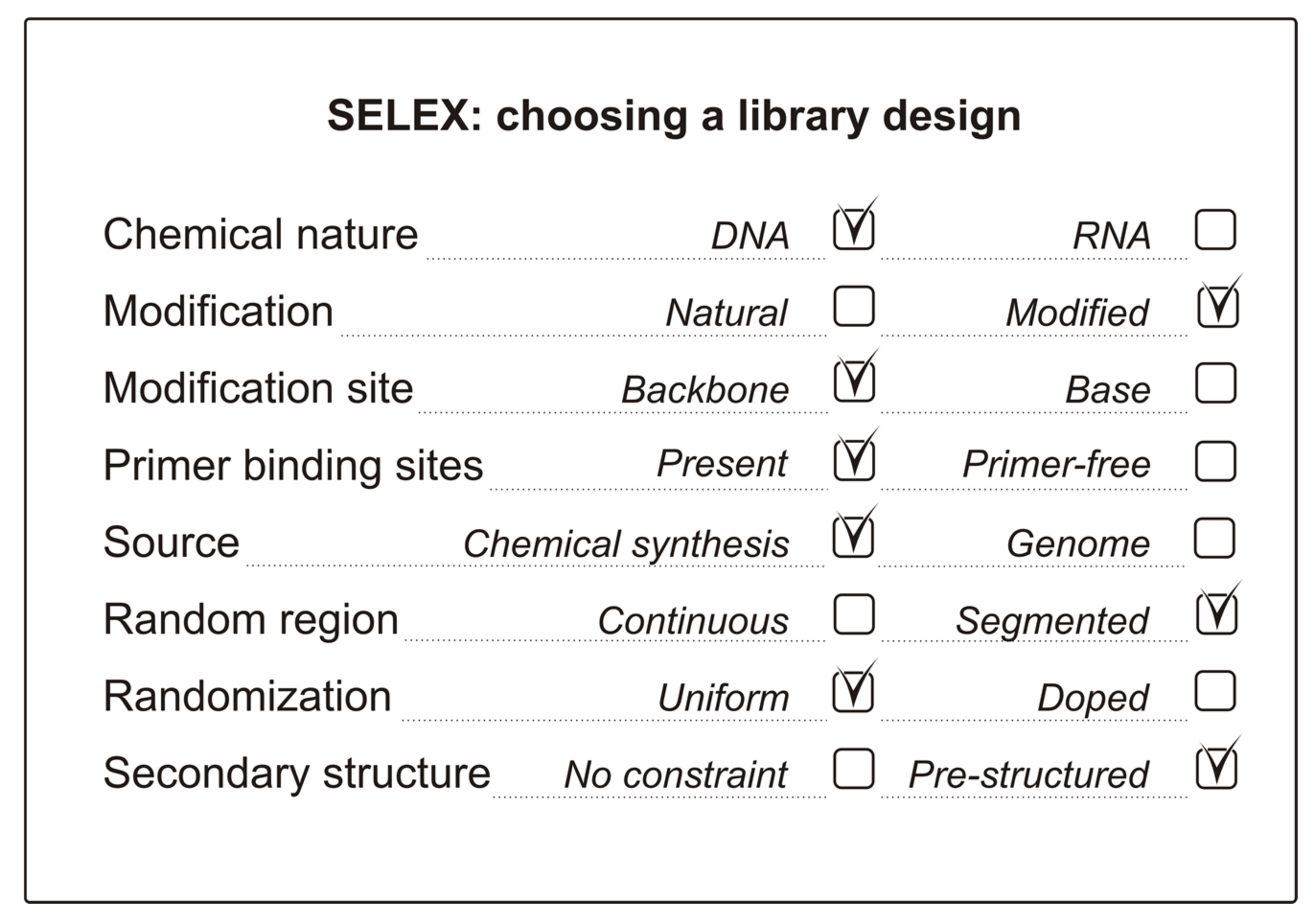
2. General Issues of Initial Library Design
2.1. DNA or RNA?
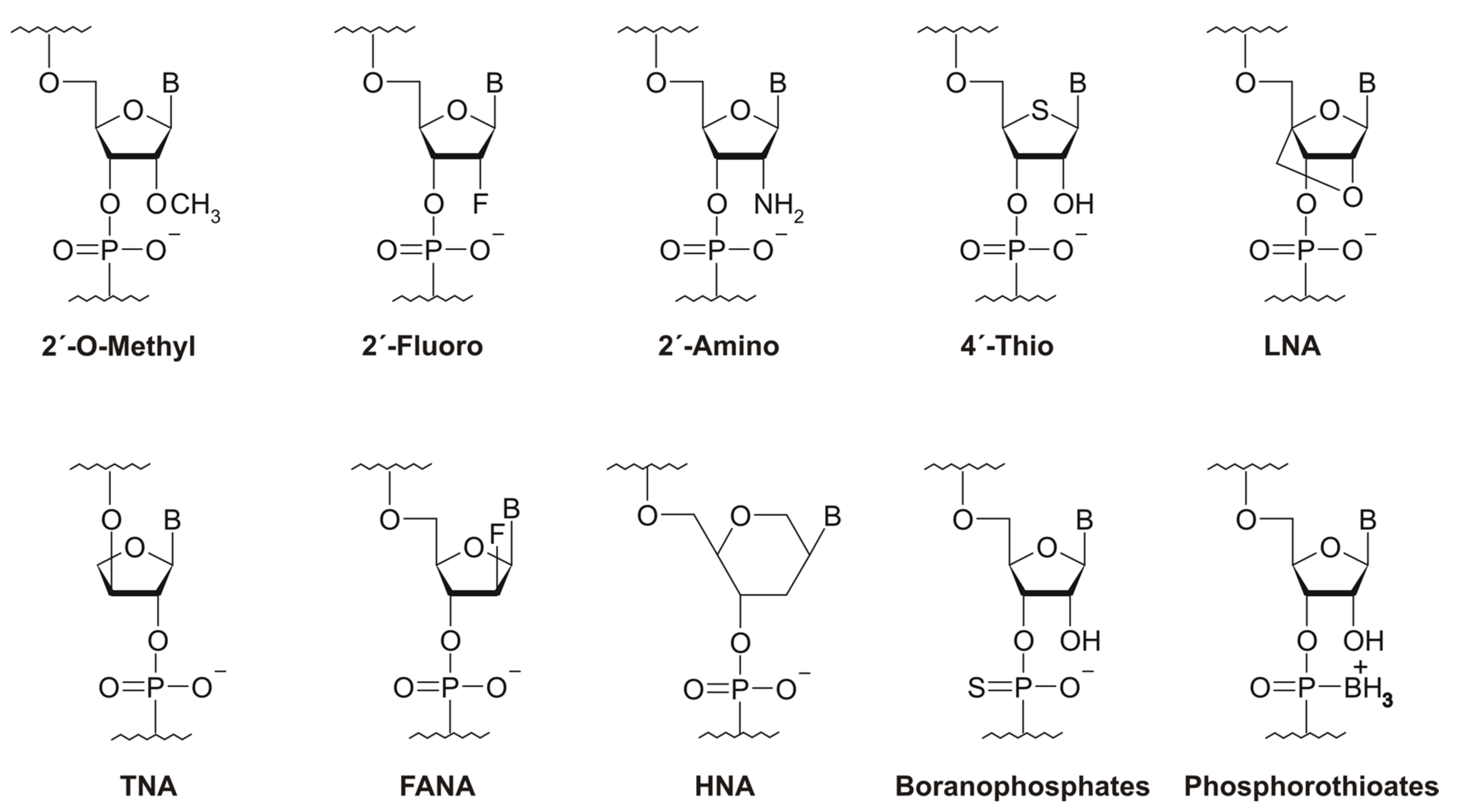
2.2. Backbone Modifications of NA Libraries
2.3. The Length of the Random Region
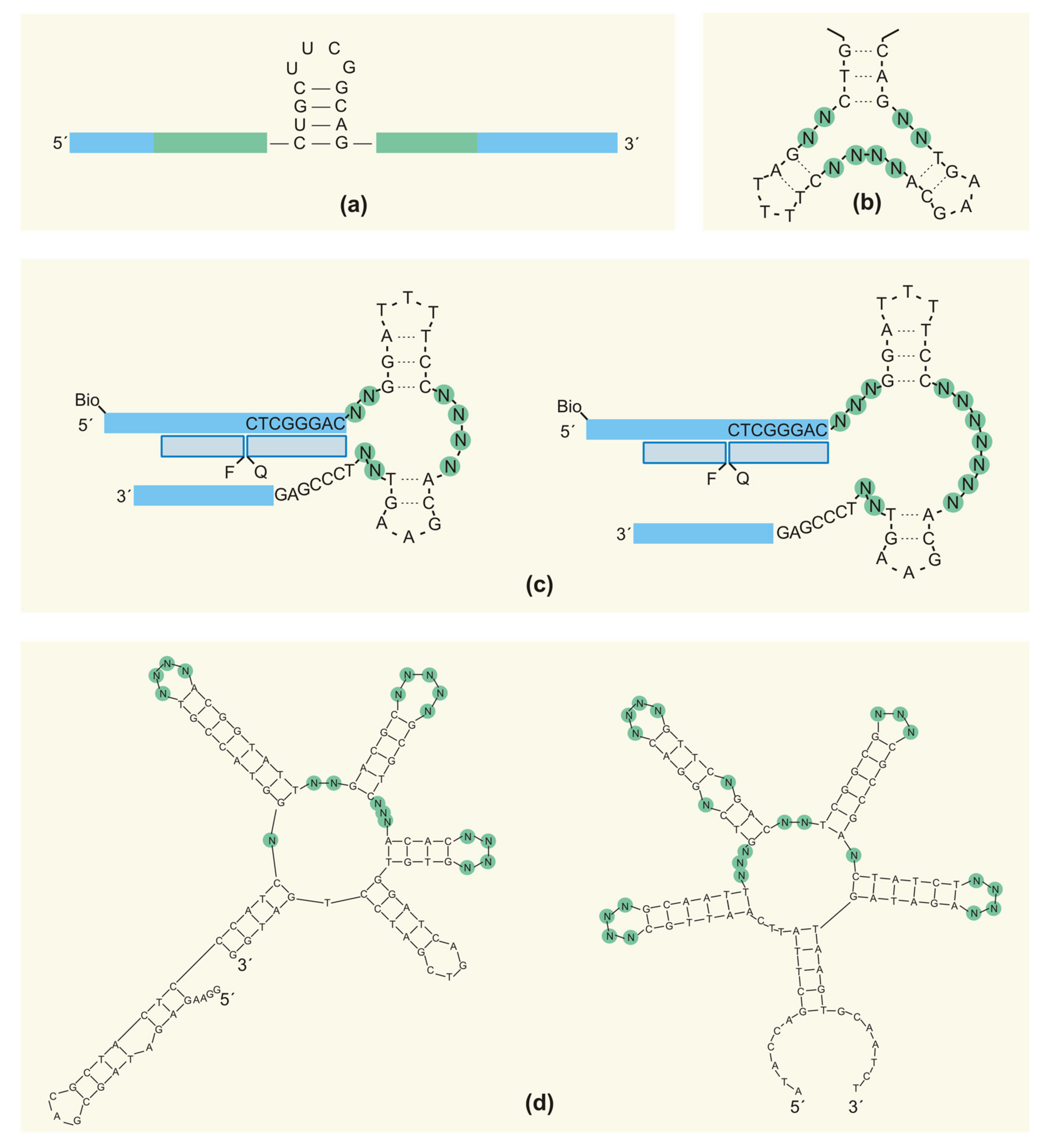
2.4. Primer-Binding Sites and Primer-Free SELEX
2.5. NA Libraries Containing Additional Constant Sequences
2.6. NA Libraries for a Genomic SELEX
3. The Design of Initial NA Libraries for More Affine Aptamers
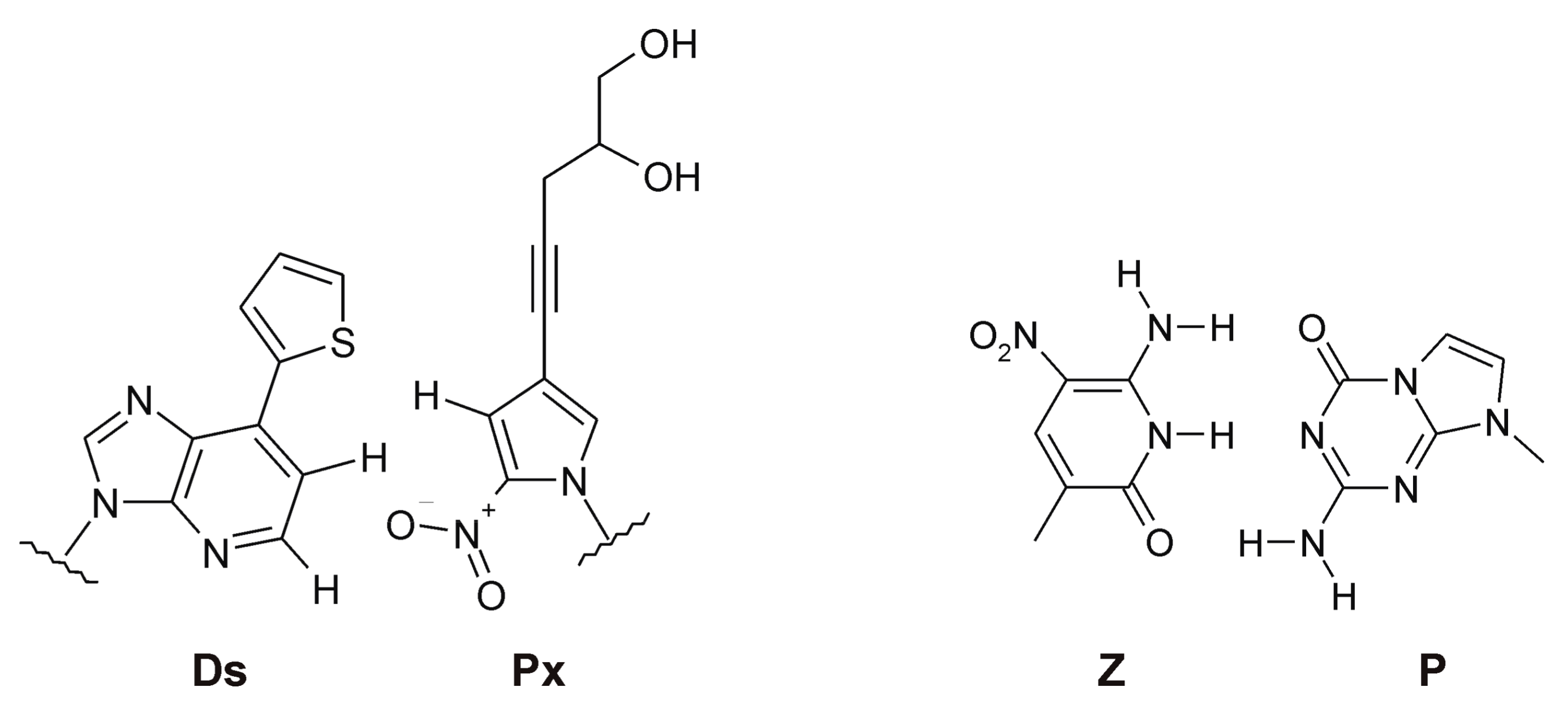
3.1. Expanding the Chemical Repertoire of NA Libraries
3.2. Structural Repertoire of Nucleic Acid Libraries
3.2.1. Uniformly Randomized Libraries
3.2.2. Doped and Segmented NA Libraries
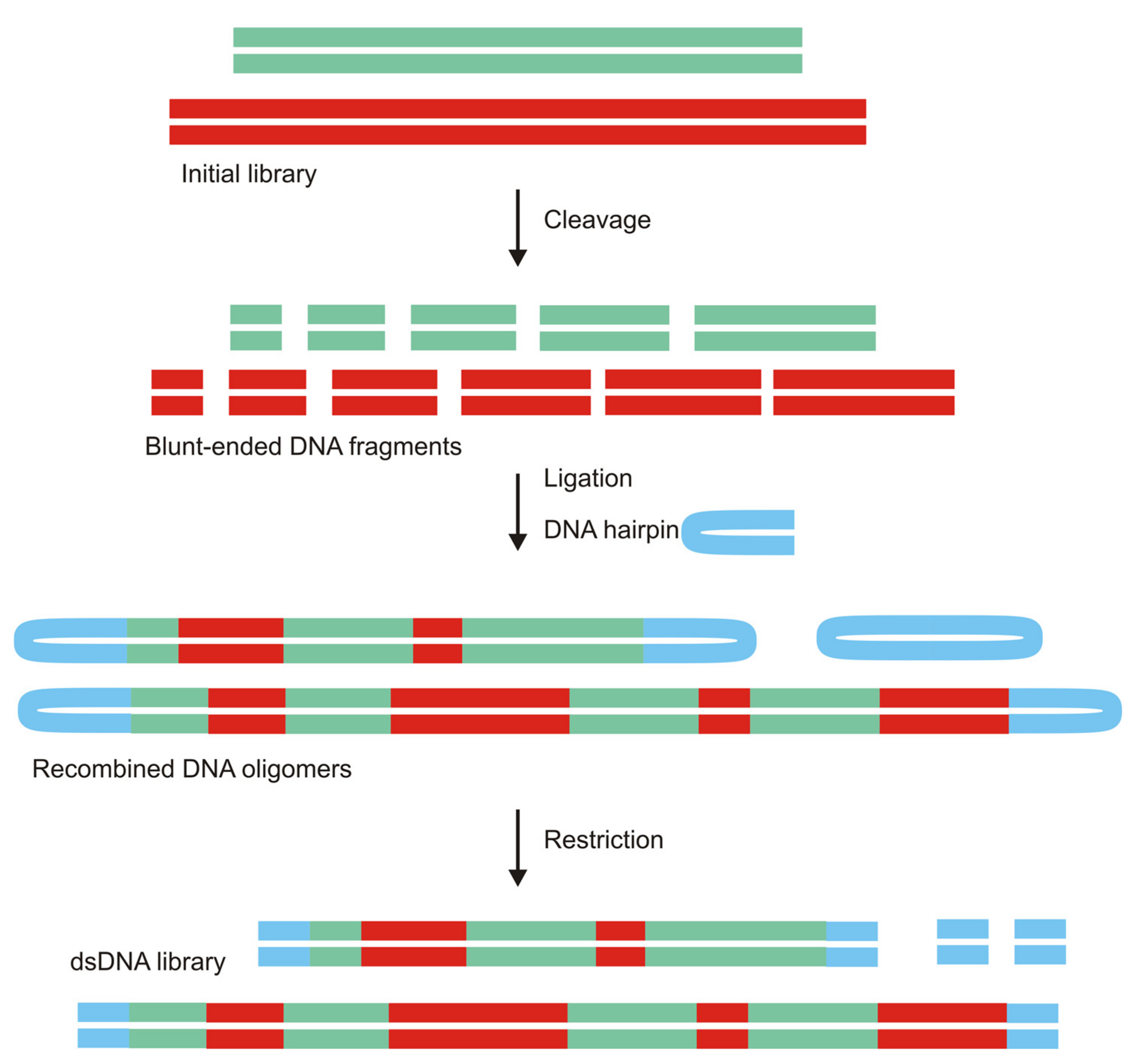
3.2.3. Nonhomologous Recombination as an Alternative to the Doping Strategy
3.2.4. Nucleic Acid Libraries with Pre-Defined Secondary Structures
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| SELEX | Selective Evolution of Ligands by Exponential enrichment |
| NA | Nucleic Acid(s) |
| PBS | Primer-Binding Site(s) |
| PCR | Polymerase Chain Reaction |
| Pu, or R | Purine nucleotide |
| Py, or Y | Pyrimidine nucleotide |
References
- Ellington, A.D.; Szostak, J.W. In vitro selection of RNA molecules that bind specific ligands. Nature 1990, 346, 818–822. [Google Scholar] [CrossRef] [PubMed]
- Ono, A.; Togashi, H. Highly selective oligonucleotide-based sensor for mercury (II) in aqueous solutions. Angew. Chem. Int. Ed. 2004, 43, 4300–4302. [Google Scholar] [CrossRef] [PubMed]
- Ye, B.-F.; Zhao, Y.-J.; Cheng, Y.; Li, T.-T.; Xie, Z.-Y.; Zhao, X.-W.; Gu, Z.-Z. Colorimetric photonic hydrogel aptasensor for the screening of heavy metal ions. Nanoscale 2012, 4, 5998–6003. [Google Scholar] [CrossRef] [PubMed]
- Jenison, R.D.; Gill, S.C.; Pardi, A.; Polisky, B. High-resolution molecular discrimination by RNA. Science 1994, 263, 1425–1429. [Google Scholar] [CrossRef] [PubMed]
- Stojanovic, M.N.; de Prada, P.; Landry, D.W. Aptamer-based folding fluorescent sensor for cocaine. J. Am. Chem. Soc. 2001, 123, 4928–4931. [Google Scholar] [CrossRef] [PubMed]
- Holeman, L.A.; Robinson, S.L.; Szostak, J.W.; Wilson, C. Isolation and characterization of fluorophore-binding RNA aptamers. Fold. Des. 1998, 3, 423–431. [Google Scholar] [CrossRef]
- Grate, D.; Wilson, C. Laser-mediated, site-specific inactivation of RNA transcripts. Proc. Natl. Acad. Sci. USA 1999, 96, 6131–6136. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Geyer, R.; Sen, D. Recognition of anionic porphyrins by DNA aptamers. Biochemistry 1996, 35, 6911–6922. [Google Scholar] [CrossRef] [PubMed]
- Leva, S.; Lichte, A.; Burmeister, J.; Muhn, P.; Jahnke, B.; Fesser, D.; Erfurth, J.; Burgstaller, P.; Klussmann, S. GnRH Binding RNA and DNA spiegelmers: A novel approach toward GnRH antagonism. Chem. Biol. 2002, 9, 351–359. [Google Scholar] [CrossRef]
- Yoshida, W.; Mochizuki, E.; Takase, M.; Hasegawa, H.; Morita, Y.; Yamazaki, H.; Sode, K.; Ikebukuro, K. Selection of DNA aptamers against insulin and construction of an aptameric enzyme subunit for insulin sensing. Biosens. Bioelectron. 2009, 24, 1116–1120. [Google Scholar] [CrossRef] [PubMed]
- Dupont, D.M.; Andersen, L.M.; Botkjaer, K.A.; Andreasen, P.A. Nucleic acid aptamers against proteases. Curr. Med. Chem. 2011, 18, 4139–4151. [Google Scholar] [CrossRef] [PubMed]
- Cerchia, L.; De Franciscis, V. Nucleic acid aptamers against protein kinases. Curr. Med. Chem. 2011, 18, 4152–4158. [Google Scholar] [CrossRef] [PubMed]
- Missailidis, S. Targeting of antibodies using aptamers. Methods Mol. Biol. 2004, 248, 547–555. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Yu, Y.; Jiang, F.; Zhou, J.; Li, Y.; Liang, C.; Dang, L.; Lu, A.; Zhang, G. Development of cell-SELEX technology and its application in cancer diagnosis and therapy. Int. J. Mol. Sci. 2016, 17, 2079. [Google Scholar] [CrossRef] [PubMed]
- Khvorova, A.; Kwak, Y.G.; Tamkun, M.; Majerfeld, I.; Yarus, M. RNAs that bind and change the permeability of phospholipid membranes. Proc. Natl. Acad. Sci. USA 1999, 96, 10649–10654. [Google Scholar] [CrossRef] [PubMed]
- Darmostuk, M.; Rimpelová, S.; Gbelcová, H.; Ruml, T. Current approaches in SELEX: An update to aptamer selection technology. Biotechnol. Adv. 2015, 33, 1141–1161. [Google Scholar] [CrossRef] [PubMed]
- Tuerk, C.; Gold, L. Systematic evolution of ligands by exponential enrichment: RNA ligands to bacteriophage T4 DNA polymerase. Science 1990, 249, 505–510. [Google Scholar] [CrossRef] [PubMed]
- Tremblay, R.; Mulhbacher, J.; Blouin, S.; Penedo, J.C.; Lafontaine, D.A. Natural functional nucleic acids: Ribozymes and riboswitches. In Functional Nucleic Acids for Analytical Applications; Yingfu, L., Yi, L., Eds.; Springer: New York, NY, USA, 2009; pp. 11–46. ISBN 978-0-387-73711-9. [Google Scholar]
- Silverman, S.K. Artificial functional nucleic acids: Aptamers, ribozymes, and deoxyribozymes identified by in vitro selection. In Functional Nucleic Acids for Analytical Applications; Yingfu, L., Yi, L., Eds.; Springer: New York, NY, USA, 2009; pp. 47–108. ISBN 978-0-387-73711-9. [Google Scholar]
- Blackwell, T.K.; Weintraub, H. Differences and similarities in DNA-binding preferences of MyoD and E2A protein complexes revealed by binding site selection. Science 1990, 250, 1104–1110. [Google Scholar] [CrossRef] [PubMed]
- Jacoby, K.; Lambert, A.R.; Scharenberg, A.M. Characterization of homing endonuclease binding and cleavage specificities using yeast surface display SELEX (YSD-SELEX). Nucleic Acids Res. 2017, 45, e11. [Google Scholar] [CrossRef] [PubMed]
- Babendure, J.R.; Adams, S.R.; Tsien, R.Y. Aptamers switch on fluorescence of triphenylmethane dyes. J. Am. Chem. Soc. 2003, 125, 14716–14717. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, Y. Aptamers as therapeutic middle molecules. Biochimie 2017. [Google Scholar] [CrossRef] [PubMed]
- Parashar, A. Aptamers in therapeutics. J. Clin. Diagn. Res. 2016, 10, BE01–BE06. [Google Scholar] [CrossRef] [PubMed]
- Poolsup, S.; Kim, C.Y. Therapeutic applications of synthetic nucleic acid aptamers. Curr. Opin. Biotechnol. 2017, 48, 180–186. [Google Scholar] [CrossRef] [PubMed]
- Catuogno, S.; Esposito, C.L.; de Franciscis, V. Aptamer-mediated targeted delivery of therapeutics: An update. Pharmaceuticals 2016, 9, 69. [Google Scholar] [CrossRef] [PubMed]
- Ni, S.; Yao, H.; Wang, L.; Lu, J.; Jiang, F.; Lu, A.; Zhang, G. Chemical modifications of nucleic acid aptamers for therapeutic purposes. Int. J. Mol. Sci. 2017, 18, 1683. [Google Scholar] [CrossRef] [PubMed]
- Ilgu, M.; Nilsen-Hamilton, M. Aptamers in analytics. Analyst 2016, 141, 1551–1568. [Google Scholar] [CrossRef] [PubMed]
- Seo, H.B.; Gu, M.B. Aptamer-based sandwich-type biosensors. J. Biol. Eng. 2017, 11, 11. [Google Scholar] [CrossRef] [PubMed]
- Vorobyeva, M.; Vorobjev, P.; Venyaminova, A. Multivalent aptamers: Versatile tools for diagnostic and therapeutic applications. Molecules 2016, 21, 1613. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhou, L.; Zhu, Z.; Yang, C. Recent progress in aptamer-based functional probes for bioanalysis and biomedicine. Chem. A Eur. J. 2016, 22, 9886–9900. [Google Scholar] [CrossRef] [PubMed]
- Ruscito, A.; DeRosa, M.C. Small-molecule binding aptamers: Selection strategies, characterization, and applications. Front. Chem. 2016, 4, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Volk, D.E.; Lokesh, G.L.R. Development of Phosphorothioate DNA and DNA thioaptamers. Biomedicines 2017, 5, 41. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Hongdilokkul, N.; Liu, Z.; Thirunavukarasu, D.; Romesberg, F.E. The expanding world of DNA and RNA. Curr. Opin. Chem. Biol. 2016, 34, 80–87. [Google Scholar] [CrossRef] [PubMed]
- Lipi, F.; Chen, S.; Chakravarthy, M.; Rakesh, S.; Veedu, R.N. In vitro evolution of chemically-modified nucleic acid aptamers: Pros and cons, and comprehensive selection strategies. RNA Biol. 2016, 13, 1232–1245. [Google Scholar] [CrossRef] [PubMed]
- McKeague, M.; McConnell, E.M.; Cruz-Toledo, J.; Bernard, E.D.; Pach, A.; Mastronardi, E.; Zhang, X.; Beking, M.; Francis, T.; Giamberardino, A.; et al. Analysis of In Vitro Aptamer Selection Parameters. J. Mol. Evol. 2015, 81, 150–161. [Google Scholar] [CrossRef] [PubMed]
- Dunn, M.R.; Jimenez, R.M.; Chaput, J.C. Analysis of aptamer discovery and technology. Nat. Rev. Chem. 2017, 1, 76. [Google Scholar] [CrossRef]
- Gilbert, W. The RNA world. Nature 1986, 319, 618. [Google Scholar] [CrossRef]
- Ellington, A.; Szostak, J. Selection in vitro of single-stranded DNA molecules that fold into specific ligand-binding structures. Nature 1992, 355, 850–852. [Google Scholar] [CrossRef] [PubMed]
- McKeague, M.; Derosa, M.C. Challenges and opportunities for small molecule aptamer development. J. Nucleic Acids 2012, 2012, 748913. [Google Scholar] [CrossRef] [PubMed]
- Lapa, S.A.; Chudinov, A.V.; Timofeev, E.N. The Toolbox for Modified Aptamers. Mol. Biotechnol. 2016, 58, 79–92. [Google Scholar] [CrossRef] [PubMed]
- Meek, K.N.; Rangel, A.E.; Heemstra, J.M. Enhancing aptamer function and stability via in vitro selection using modified nucleic acids. Methods 2016, 106, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Diafa, S.; Hollenstein, M. Generation of aptamers with an expanded chemical repertoire. Molecules 2015, 20, 16643–16671. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Qiu, Q.; Gill, S.C.; Jayasena, S.D. Modified RNA sequence pools for in vitro selection. Nucleic Acids Res. 1994, 22, 5229–5234. [Google Scholar] [CrossRef] [PubMed]
- Fitzwater, T.; Polisky, B. A SELEX primer. Meth. Enzym. 1996, 267, 275–301. [Google Scholar] [PubMed]
- Lauridsen, L.H.; Rothnagel, J.A.; Veedu, R.N. Enzymatic recognition of 2′-modified ribonucleoside 5′-triphosphates: Towards the evolution of versatile aptamers. ChemBioChem 2012, 13, 19–25. [Google Scholar] [CrossRef] [PubMed]
- Stovall, G.M.; BedenBaugh, R.; Singh, S.; Meyer, A.; Hatala, P.; Ellington, A.D.; Hall, B. In vitro selection using modified or unnatural nucleotides. Curr. Protoc. Nucleic Acid Chem. 2014, 56, 9.6.1–9.6.33. [Google Scholar] [PubMed]
- Pobanz, K.; Luptak, A. Improving the odds: Influence of starting pools on in vitro selection outcomes. Methods 2016, 106, 14–20. [Google Scholar] [CrossRef] [PubMed]
- Cowperthwaite, M.C.; Ellington, A.D. Bioinformatic analysis of the contribution of primer sequences to aptamer structures. J. Mol. Evol. 2008, 67, 95–102. [Google Scholar] [CrossRef] [PubMed]
- Thiel, W.H.; Bair, T.; Wyatt Thiel, K.; Dassie, J.P.; Rockey, W.M.; Howell, C.A.; Liu, X.Y.; Dupuy, A.J.; Huang, L.; Owczarzy, R.; et al. Nucleotide Bias Observed with a Short SELEX RNA Aptamer Library. Nucleic Acid Ther. 2011, 21, 253–263. [Google Scholar] [CrossRef] [PubMed]
- Famulok, M.; Szostak, J.W. Stereospecific Recognition of Tryptophan Agarose by in Vitro Selected RNA. J. Am. Chem. Soc. 1992, 114, 3990–3991. [Google Scholar] [CrossRef]
- Sassanfar, M.; Szostak, J.W. An RNA motif that binds ATP. Nature 1993, 364, 550–553. [Google Scholar] [CrossRef] [PubMed]
- Hall, B.; Micheletti, J.M.; Satya, P.; Ogle, K.; Pollard, J.; Ellington, A.D. Design, synthesis, and amplification of DNA pools for in vitro selection. Curr. Protoc. Mol. Biol. 2009, 88. [Google Scholar] [CrossRef]
- Burmeister, P.E.; Lewis, S.D.; Silva, R.F.; Preiss, J.R.; Horwitz, L.R.; Pendergrast, P.S.; McCauley, T.G.; Kurz, J.C.; Epstein, D.M.; Wilson, C.; et al. Direct In Vitro Selection of a 2’-O-Methyl Aptamer to VEGF. Chem. Biol. 2005, 12, 25–33. [Google Scholar] [CrossRef] [PubMed]
- Burmeister, P.E.; Wang, C.; Killough, J.R.; Lewis, S.D.; Horwitz, L.R.; Ferguson, A.; Thompson, K.M.; Pendergrast, P.S.; McCauley, T.G.; Kurz, M.; et al. 2’-Deoxy purine, 2’-O-methyl pyrimidine (dRmY) aptamers as candidate therapeutics. Oligonucleotides 2006, 16, 337–351. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Hirota, M.; Waugh, S.M.; Murakami, I.; Suzuki, T.; Muraguchi, M.; Shibamori, M.; Ishikawa, Y.; Jarvis, T.C.; Carter, J.D.; et al. Chemically modified DNA aptamers bind interleukin-6 with high affinity and inhibit signaling by blocking its interaction with interleukin-6 receptor. J. Biol. Chem. 2014, 289, 8706–8719. [Google Scholar] [CrossRef] [PubMed]
- Stoltenburg, R.; Nikolaus, N.; Strehlitz, B. Capture-SELEX: Selection of DNA aptamers for aminoglycoside antibiotics. J. Anal. Methods Chem. 2012, 2012, 415697. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.H.; Szostak, J.W. Isolation of high-affinity GTP aptamers from partially structured RNA libraries. Proc. Natl. Acad. Sci. USA 2002, 99, 11616–11621. [Google Scholar] [CrossRef] [PubMed]
- Wiegand, T.W.; Williams, P.B.; Dreskin, S.C.; Jouvin, M.H.; Kinet, J.P.; Tasset, D. High-affinity oligonucleotide ligands to human IgE inhibit binding to Fc epsilon receptor I. J. Immunol. 1996, 157, 221–230. [Google Scholar] [PubMed]
- Shui, B.; Ozer, A.; Zipfel, W.; Sahu, N.; Singh, A.; Lis, J.T.; Shi, H.; Kotlikoff, M.I. RNA aptamers that functionally interact with green fluorescent protein and its derivatives. Nucleic Acids Res. 2012, 40. [Google Scholar] [CrossRef] [PubMed]
- Shtatland, T.; Gill, S.C.; Javornik, B.E.; Johansson, H.E.; Singer, B.S.; Uhlenbeck, O.C.; Zichi, D. A; Gold, L. Interactions of Escherichia coli RNA with bacteriophage MS2 coat protein: Genomic SELEX. Nucleic Acids Res. 2000, 28, E93. [Google Scholar] [CrossRef] [PubMed]
- Ouellet, E.; Foley, J.H.; Conway, E.M.; Haynes, C. Hi-Fi SELEX: A high-fidelity digital-PCR based therapeutic aptamer discovery platform. Biotechnol. Bioeng. 2015, 112, 1506–1522. [Google Scholar] [CrossRef] [PubMed]
- Ouellet, E.; Lagally, E.T.; Cheung, K.C.; Haynes, C.A. A simple method for eliminating fixed-region interference of aptamer binding during SELEX. Biotechnol. Bioeng. 2014, 111, 2265–2279. [Google Scholar] [CrossRef] [PubMed]
- Wen, J.-D.; Gray, D.M. Selection of genomic sequences that bind tightly to Ff gene 5 protein: Primer-free genomic SELEX. Nucleic Acids Res. 2004, 32, e182. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.; Xin, P.; Patrick, S.; Dean, S.; Keating, C.; Clawson, G. Primer-Free Aptamer Selection Using A Random DNA Library. J. Vis. Exp. 2010, 629, 369–385. [Google Scholar] [CrossRef]
- Pan, W.; Xin, P.; Clawson, G.A. Minimal primer and primer-free SELEX protocols for selection of aptamers from random DNA libraries. Biotechniques 2008, 44, 351–360. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.; Clawson, G.A. Primer-free aptamer selection using a random DNA library. Meth. Mol. Biol. 2010, 629, 367–383. [Google Scholar] [CrossRef]
- Vater, A.; Jarosch, F.; Buchner, K.; Klussmann, S. Short bioactive Spiegelmers to migraine-associated calcitonin gene-related peptide rapidly identified by a novel approach: Tailored-SELEX. Nucleic Acids Res. 2003, 31, e130. [Google Scholar] [CrossRef] [PubMed]
- Jarosch, F.; Buchner, K.; Klussmann, S. In vitro selection using a dual RNA library that allows primerless selection. Nucleic Acids Res. 2006, 34, e86. [Google Scholar] [CrossRef] [PubMed]
- Skrypina, N.A.; Savochkina, L.P.; Beabealashvilli, R.S. In vitro selection of single-stranded DNA aptamers that bind human pro-urokinase. Nucleosides Nucleotides Nucleic Acids 2004, 23, 891. [Google Scholar] [CrossRef] [PubMed]
- Legiewicz, M.; Lozupone, C.; Knight, R.; Yarus, M. Size, constant sequences, and optimal selection. RNA 2005, 11, 1701–1709. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.T.; DeStefano, J.J. A primer-free method that selects high-affinity single-stranded DNA aptamers using thermostable RNA ligase. Anal. Biochem. 2011, 414, 246–253. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.-T.; DeStefano, J.J. DNA aptamers to human immunodeficiency virus reverse transcriptase selected by a primer-free SELEX method: Characterization and comparison with other aptamers. Nucleic Acid Ther. 2012, 22, 162–176. [Google Scholar] [CrossRef] [PubMed]
- Tsao, S.-M.; Lai, J.-C.; Horng, H.-E.; Liu, T.-C.; Hong, C.-Y. Generation of aptamers from a primer-free randomized ssDNA library using magnetic-assisted rapid aptamer selection. Sci. Rep. 2017, 7, 45478. [Google Scholar] [CrossRef] [PubMed]
- Nutiu, R.; Li, Y. In vitro selection of structure-switching signaling aptamers. Angew. Chem. Int. Ed. 2005, 44, 1061–1065. [Google Scholar] [CrossRef] [PubMed]
- Nutiu, R.; Li, Y. Structure-switching signaling aptamers. J. Am. Chem. Soc. 2003, 125, 4771–4778. [Google Scholar] [CrossRef] [PubMed]
- Pfeiffer, F.; Mayer, G. Selection and biosensor application of aptamers for small molecules. Front. Chem. 2016, 4, 25. [Google Scholar] [CrossRef] [PubMed]
- Nikolaus, N.; Strehlitz, B. DNA-aptamers binding aminoglycoside antibiotics. Sensors 2014, 14, 3737–3755. [Google Scholar] [CrossRef] [PubMed]
- Paniel, N.; Istambouli, G.; Triki, A.; Lozano, C.; Barthelmebs, L.; Noguer, T. Selection of DNA aptamers against penicillin G using Capture-SELEX for the development of an impedimetric sensor. Talanta 2017, 162, 232–240. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.; Chang, D.; Zhang, Z.; Li, F.; Li, W.; Wang, X.; Li, Y.; Hua, Q. In vitro selection of DNA aptamers that binds geniposide. Molecules 2017, 22, 383. [Google Scholar] [CrossRef] [PubMed]
- Martin, J.A.; Smith, J.E.; Warren, M.; Chávez, J.L.; Hagen, J.A.; Kelley-Loughnane, N. A method for selecting structure-switching aptamers applied to a colorimetric gold nanoparticle assay. J. Vis. Exp. 2015, e52545. [Google Scholar] [CrossRef] [PubMed]
- Spiga, F.M.; Maietta, P.; Guiducci, C. More DNA-aptamers for small drugs: A capture-SELEX coupled with surface plasmon resonance and high-throughput sequencing. ACS Comb. Sci. 2015, 17, 326–333. [Google Scholar] [CrossRef] [PubMed]
- Rajendran, M.; Ellington, A.D. Selection of fluorescent aptamer beacons that light up in the presence of zinc. Anal. Bioanal. Chem. 2008, 390, 1067–1075. [Google Scholar] [CrossRef] [PubMed]
- Morse, D.P. Direct selection of RNA beacon aptamers. Biochem. Biophys. Res. Commun. 2007, 359, 94–101. [Google Scholar] [CrossRef] [PubMed]
- Boots, J.L.; Matylla-Kulinska, K.; Zywicki, M.; Zimmermann, B.; Schroeder, R. Genomic SELEX. In Handbook of RNA Biochemistry: Second, Completely Revised and Enlarged Edition; Hartmann, R. K., Bindereif, A., Schön, A., Westhof, E., Eds.; Wiley-VCH Verlag GmbH & Co: Weinheim, Germany, 2014; pp. 1185–1206. ISBN 9783527327645. [Google Scholar]
- Ogasawara, H.; Hasegawa, A.; Kanda, E.; Miki, T.; Yamamoto, K.; Ishihama, A. Genomic SELEX search for target promoters under the control of the PhoQP-RstBA signal relay cascade. J. Bacteriol. 2007, 189, 4791–4799. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Shi, H.; Lee, D.K.; Lis, J.T. Specific SR protein-dependent splicing substrates identified through genomic SELEX. Nucleic Acids Res. 2003, 31, 1955–1961. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, B.; Bilusic, I.; Lorenz, C.; Schroeder, R. Genomic SELEX: A discovery tool for genomic aptamers. Methods 2010, 52, 125–132. [Google Scholar] [CrossRef] [PubMed]
- Davies, D.R.; Gelinas, A.D.; Zhang, C.; Rohloff, J.C.; Carter, J.D.; O’Connell, D.; Waugh, S.M.; Wolk, S.K.; Mayfield, W.S.; Burgin, A.B.; et al. Unique motifs and hydrophobic interactions shape the binding of modified DNA ligands to protein targets. Proc. Natl. Acad. Sci. USA 2012, 109, 19971–19976. [Google Scholar] [CrossRef] [PubMed]
- Gawande, B.N.; Rohloff, J.C.; Carter, J.D.; von Carlowitz, I.; Zhang, C.; Schneider, D.J.; Janjic, N. Selection of DNA aptamers with two modified bases. Proc. Natl. Acad. Sci. USA 2017, 114, 2898–2903. [Google Scholar] [CrossRef] [PubMed]
- Gold, L.; Ayers, D.; Bertino, J.; Bock, C.; Bock, A.; Brody, E.N.; Carter, J.; Dalby, A.B.; Eaton, B.E.; Fitzwater, T.; Flather, D.; et al. Aptamer-based multiplexed proteomic technology for biomarker discovery. PLoS ONE 2010, 5, e15004. [Google Scholar] [CrossRef] [PubMed]
- Naduvile Veedu, R.; AlShamaileh, H. Next generation nucleic acid aptamers with two base modified nucleotides improve the binding affinity and potency. ChemBioChem 2017, 9, 9–12. [Google Scholar] [CrossRef]
- Ochsner, U.A.; Katilius, E.; Janjic, N. Detection of Clostridium difficile toxins A, B and binary toxin with slow off-rate modified aptamers. Diagn. Microbiol. Infect. Dis. 2013, 76, 278–285. [Google Scholar] [CrossRef] [PubMed]
- Chudinov, A.V.; Kiseleva, Y.Y.; Kuznetsov, V.E.; Shershov, V.E.; Spitsyn, M.A.; Guseinov, T.O.; Lapa, S.A.; Timofeev, E.N.; Archakov, A.I.; Lisitsa, A.V.; et al. Structural and functional analysis of biopolymers and their complexes: Enzymatic synthesis of high-modified DNA. Mol. Biol. 2017, 51, 474–482. [Google Scholar] [CrossRef]
- Kimoto, M.; Yamashige, R.; Matsunaga, K.; Yokoyama, S.; Hirao, I. Generation of high-affinity DNA aptamers using an expanded genetic alphabet. Nat. Biotechnol. 2013, 31, 453–457. [Google Scholar] [CrossRef] [PubMed]
- Sefah, K.; Yang, Z.; Bradley, K.M.; Hoshika, S.; Jimenez, E.; Zhang, L.; Zhu, G.; Shanker, S.; Yu, F.; Turek, D.; et al. In vitro selection with artificial expanded genetic information systems. Proc. Natl. Acad. Sci. USA 2014, 111, 1449–1454. [Google Scholar] [CrossRef] [PubMed]
- Horiya, S.; Macpherson, I.S.; Krauss, I.J. Recent Strategies Targeting HIV Glycans in Vaccine Design Satoru. Nat. Chem. Biol. 2015, 10, 990–999. [Google Scholar] [CrossRef] [PubMed]
- Temme, J.S.; Krauss, I.J. SELMA: Selection with modified aptamers. Curr. Protoc. Chem. Biol. 2015, 7, 73–92. [Google Scholar] [CrossRef] [PubMed]
- Temme, J.S.; MacPherson, I.S.; Decourcey, J.F.; Krauss, I.J. High temperature SELMA: Evolution of DNA-supported oligomannose clusters which are tightly recognized by HIV bnAb 2G12. J. Am. Chem. Soc. 2014, 136, 1726–1729. [Google Scholar] [CrossRef] [PubMed]
- Tolle, F.; Brändle, G.M.; Matzner, D.; Mayer, G. A Versatile Approach Towards Nucleobase-Modified Aptamers. Angew. Chem. Int. Ed. 2015, 54, 10971–10974. [Google Scholar] [CrossRef] [PubMed]
- Warner, W.A.; Sanchez, R.; Dawoodian, A.; Li, E.; Momand, J. Multivalent glycocluster design through directed evolution. Angew. Chem. Int. Ed. 2013, 80, 631–637. [Google Scholar] [CrossRef]
- Warner, W.A.; Sanchez, R.; Dawoodian, A.; Li, E.; Momand, J. Directed Evolution of 2G12-Targeted Nonamannose Glycoclusters by SELMA. Chemistry 2013, 19, 17291–17295. [Google Scholar] [CrossRef]
- Blind, M.; Blank, M. Aptamer Selection Technology and Recent Advances. Mol. Ther. Acids 2015, 4, e223. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, M.; Wu, X.; Ho, M.; Chomchan, P.; Rossi, J.J.; Burnett, J.C.; Zhou, J. High throughput sequencing analysis of RNA libraries reveals the influences of initial library and PCR methods on SELEX efficiency. Sci. Rep. 2016, 6, 33697. [Google Scholar] [CrossRef] [PubMed]
- Blank, M. Next-Generation Analysis of Deep Sequencing Data: Bringing Light into the Black Box of SELEX Experiments. Methods 2016, 1380, 85–95. [Google Scholar] [CrossRef]
- Gevertz, J.; Gan, H.H.; Schlick, T. In vitro RNA random pools are not structurally diverse: A computational analysis. RNA 2005, 11, 853–863. [Google Scholar] [CrossRef] [PubMed]
- Bartel, D.P.; Zapp, M.L.; Green, M.R.; Szostak, J.W. HIV-1 Rev regulation involves recognition of non-Watson-Crick base pairs in viral RNA. Cell 1991, 67, 529–536. [Google Scholar] [CrossRef]
- Hesselberth, J.R.; Miller, D.; Robertus, J.; Ellington, A.D. In vitro selection of RNA molecules that inhibit the activity of ricin A-chain. J. Biol. Chem. 2000, 275, 4937–4942. [Google Scholar] [CrossRef] [PubMed]
- Burke, D.H.; Scates, L.; Andrews, K.; Gold, L. Bent pseudoknots and novel RNA inhibitors of type 1 human immunodeficiency virus (HIV-1) reverse transcriptase. J. Mol. Biol. 1996, 264, 650–666. [Google Scholar] [CrossRef] [PubMed]
- Knight, R.; Yarus, M. Analyzing partially randomized nucleic acid pools: Straight dope on doping. Nucleic Acids Res. 2003, 31, e30. [Google Scholar] [CrossRef] [PubMed]
- Bittker, J.A.; Le, B.V.; Liu, D.R. Nucleic acid evolution and minimization by nonhomologous random recombination. Nat. Biotechnol. 2002, 20, 1024–1029. [Google Scholar] [CrossRef] [PubMed]
- Carothers, J.M.; Oestreich, S.C.; Davis, J.H.; Szostak, J.W. Informational complexity and functional activity of RNA structures. Science 2004, 126, 5130–5137. [Google Scholar] [CrossRef] [PubMed]
- Paige, G.F.; Wu, K.; Jaffrey, S.R. RNA mimics of green fluorescent protein. Science 2011, 333, 642–646. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Carrocci, T.J.; Hoskins, A.A. Evolution and characterization of a benzylguanine-binding RNA aptamer. Chem. Commun. 2016, 549–552. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.A.; Pei, R.; Stefanovic, D.; Stojanovic, M.N. Optimizing cross-reactivity with evolutionary search for sensors. J. Am. Chem. Soc. 2012, 134, 1642–1647. [Google Scholar] [CrossRef] [PubMed]
- Trevino, S.G.; Levy, M. High-throughput bead-based identification of structure-switching aptamer beacons. ChemBioChem 2014, 15, 1877–1881. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Li, C.; Zhu, Z.; Liu, D.; Zou, Y.; Wang, C.; Fu, H.; Yang, C.J. In vitro selection of highly efficient G-quadruplex-based DNAzymes. Anal. Chem. 2012, 84, 8383–8390. [Google Scholar] [CrossRef] [PubMed]
- Ruff, K.M.; Snyder, T.M.; Liu, D.R. Enhanced functional potential of nucleic acid aptamer libraries patterned to increase secondary structure. J. Am. Chem. Soc. 2010, 132, 9453–9464. [Google Scholar] [CrossRef] [PubMed]
- Chushak, Y.; Stone, M.O. In silico selection of RNA aptamers. Nucleic Acids Res. 2009, 37, e87. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.; Gan, H.H.; Schlick, T. A computational proposal for designing structured RNA pools for in vitro selection of RNAs. RNA 2007, 13, 478–492. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.; Shin, J.S.; Elmetwaly, S.; Gan, H.H.; Schlick, T. RagPools: RNA-As-Graph-Pools-a web server for assisting the design of structured RNA pools for in vitro selection. Bioinformatics 2007, 23, 2959–2960. [Google Scholar] [CrossRef] [PubMed]
- RAGPOOLS (RNA-As-Graph-Pools)—A Web Server. Available online: http://rubin2.biomath.nyu.edu/home.html (accessed on 27 October 2017).
- Luo, X.; McKeague, M.; Pitre, S.; Dumontier, M.; Green, J.; Golshani, A.; Derosa, M.C.; Dehne, F. Computational approaches toward the design of pools for the in vitro selection of complex aptamers. RNA 2010, 16, 2252–2262. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Starting Libraries and Primers (5′->3′) | Ref. |
|---|---|---|
| Classical SELEX | ||
| DNA | Library: GGGAGACAAGAATAAACGCTCAA-N40-TTCGACAGGAGGCTCACAACAGGC 5′-primer: GGGAGACAAGAATAAACGCTCAA 3′-primer: GCCTGTTGTGAGCCTCCTGTCGAA | [45] |
| RNA, 2′-F-pyrimidine (Py) modified RNA, 2′-NH2 Py modified RNA | Library: GGGAGACAAGAAUAAACGCUCAA-N40-UUCGACAGGAGGCUCACAACAGGC ssDNA template: GCCTGTTGTGAGCCTCCTTGTCGAA-N40-TTGAGCGTTTATTCTTGTCTCCC 5′-primer: TAATACGACTCACTATAGGGAGACAAGAATAAACGCTCAA 1 3′-primer: GCCTGTTGTGAGCCTCCTGTCGAA | [45] |
| 2′-O-Me RNA | Library: GGGAGAGAGGAACGUUCUCG-N30-GGAUCGUUACGACUAGCAUCGAUG ssDNA template: CATCGATGCTAGTCGTAACGATCC-N30-CGAGAACGTTCTCTCTCCCTATAGTGAGTCGTATTA 5′-primer: TAATACGACTCACTATAGGGAGAGGAGAGAAACGTTCTCG 3′-primer: CATCGATGCTAGTCGTAACGATCC | [54] |
| dRmY (2′-deoxy purine ribonucleotides, 2′-O-CH3 Py ribonucleotides) | Library: GGGAGAGGAGAAGGUUCUAC-N30-GCGUGUCGAUCGAUCGAUCGAUG ssDNA template: CATCGATCGATCGATCGACAGCG-N30-GTAGAACGTTCTCTCCTCTCCCTATAGTGAGTCGTATTA 5′-primer: TAATACGACTCACTATAGGGAGAGGAGAGAACGTTCTAC 3′-primer: CATCGATCGATCGATCGACAGC | [55] |
| SOMAmers | Library: GATGTGAGTGTGTGACGAG-N40-CACAGAGAAGAAACAAGACC, random region containing 5-(N-benzylcarboxamide)-2′-deoxyuridine (Bn-dU) or 5-[N-(1-naphthylmethyl)carboxamide]-2′-deoxyuridine (Nap-dU) in place of dT 5′-primer: GATGTGAGTGTGTGACGAG 3′-primer: GGTCTTGTTTCTTCTCTGTG | [56] |
| Capture SELEX | ||
| DNA | Library: ATACCAGCTTATTCAATT-N10-TGAGGCTCGATC-N40-AGATAGTAAGTGCAATCT Capture oligonucleotide: Bio-GTC-(CH2CH2O)6-GATCGAGCCTCA or GATCGAGCCTCA-(CH2CH2O)6-GTC-Bio 5′-primer: ATACCAGCTTATTCAATT 3′-primer: AGATTGCACTTACTATCT | [57] |
| Pre-structured libraries | ||
| RNA | Library: GGAGGCGCCAACTGAATGAA-N26-CUGCUUCGGCAG-N26-UCCGUAACUAGUUCGCGUCAC ssDNA template: GTGACGCGACTAGTTACGGA-N26-CTGCCGAAGCAG-N26-TTCATTCAGTTGGCGCCTCCTATAGTGAGTCGTATTACAT 5′-primer: ATGTAATACGACTCACTATAGGAGGCGCCAACTGAATGAA 3′-primer: GTGACGCGACTAGTTACGGA | [58] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vorobyeva, M.A.; Davydova, A.S.; Vorobjev, P.E.; Pyshnyi, D.V.; Venyaminova, A.G. Key Aspects of Nucleic Acid Library Design for in Vitro Selection. Int. J. Mol. Sci. 2018, 19, 470. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms19020470
Vorobyeva MA, Davydova AS, Vorobjev PE, Pyshnyi DV, Venyaminova AG. Key Aspects of Nucleic Acid Library Design for in Vitro Selection. International Journal of Molecular Sciences. 2018; 19(2):470. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms19020470
Chicago/Turabian StyleVorobyeva, Maria A., Anna S. Davydova, Pavel E. Vorobjev, Dmitrii V. Pyshnyi, and Alya G. Venyaminova. 2018. "Key Aspects of Nucleic Acid Library Design for in Vitro Selection" International Journal of Molecular Sciences 19, no. 2: 470. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms19020470