The Need for Multi-Omics Biomarker Signatures in Precision Medicine


1
Center for Precision Medicine, Department of Internal Medicine, Wake Forest Baptist Health Comprehensive Cancer Center, Wake Forest University Health Sciences, Winston-Salem, NC 27157, USA
2
Center for Precision Medicine, Department of Biochemistry, Wake Forest Baptist Health Comprehensive Cancer Center, Wake Forest University Health Sciences, Winston-Salem, NC 27157, USA
3
Center for Precision Medicine, Department of Biochemistry, Wake Forest University Health Sciences, Winston-Salem, NC 27157, USA
*
Author to whom correspondence should be addressed.
Int. J. Mol. Sci. 2019, 20(19), 4781; https://0-doi-org.brum.beds.ac.uk/10.3390/ijms20194781
Submission received: 23 August 2019
/
Revised: 11 September 2019
/
Accepted: 25 September 2019
/
Published: 26 September 2019
(This article belongs to the Special Issue The Promise of Precision Oncology: Molecular Strategies, Methods, Pharmacogenomics and Informatics)
{kind=link}
Abstract
:Recent advances in omics technologies have led to unprecedented efforts characterizing the molecular changes that underlie the development and progression of a wide array of complex human diseases, including cancer. As a result, multi-omics analyses—which take advantage of these technologies in genomics, transcriptomics, epigenomics, proteomics, metabolomics, and other omics areas—have been proposed and heralded as the key to advancing precision medicine in the clinic. In the field of precision oncology, genomics approaches, and, more recently, other omics analyses have helped reveal several key mechanisms in cancer development, treatment resistance, and recurrence risk, and several of these findings have been implemented in clinical oncology to help guide treatment decisions. However, truly integrated multi-omics analyses have not been applied widely, preventing further advances in precision medicine. Additional efforts are needed to develop the analytical infrastructure necessary to generate, analyze, and annotate multi-omics data effectively to inform precision medicine-based decision-making.
1. Introduction
A major goal of biomedical research is to identify accurate, early indicators of disease. Over the past decades, advances in technology have ushered in an unprecedented era in biomedical research. Rather than focusing research efforts on individual molecules, pathways, or cells of interest, new technologies now allow characterization of complex biological systems in great detail and at unparalleled resolution. Sequencing technologies have helped decipher the genetic code of numerous organisms, including humans. Imaging and microscopy technologies have revolutionized our ability to visualize and monitor cellular and molecular processes in cells and tissues, and other advances in analytical methodologies such as NMR, mass spectrometry, and array-based and microfluidics methodologies all have contributed to a rapidly growing knowledgebase about the molecular composition and function of biological systems. This knowledge, in turn, has formed the basis for our continuing research efforts to better understand and characterize the molecular and cellular mechanisms contributing to the development and progression of diseases in humans and model organisms. The general promise and primary goal of precision medicine is to identify more accurate, earlier indicators of health trajectories for individuals, the detection of early stages of disease development, revert disease development, slow disease progression, and alter health trajectories through targeted and more effective pharmacological treatments or lifestyle interventions.
Unfortunately, the implementation of precision medicine approaches, whether in oncology or other fields of clinical medicine, has not kept pace with our ability to generate large-scale molecular data and information. In fact, our ability to analyze and interpret the data for translation into clinically actionable information has been challenging, and the initial promise of genomic and other molecular data as key contributors to clinical decision making has been slow to translate to clinical practice. With rapid technical advances and opportunities for more cost-efficient large-scale data generation in biomedical research, it is likely that our main challenge will continue to be the development of methods for extracting useful information from these complex, multidimensional datasets to guide clinical practice.
The technological advances mentioned above have created various new fields of research, commonly referred to as “omics”. Beginning with the field of genomics, the development of novel sequencing technologies now allows the cost-effective and rapid elucidation of an entire genome and the study of all genes at once, rather than gene by gene analysis. The term “genomics” highlights this comprehensive analysis [1]. A whole range of additional omics technologies has been developed, with ‘omics’ referring to the comprehensive study of the roles, relationships, and actions of various types of molecules in cells of an organism. This includes fields such as transcriptomics (the study of the expression of all genes in a cell or organism [2,3,4], proteomics (the analysis of all proteins, [5,6]), metabolomics (the comprehensive analysis of all small molecules, [7,8]), and epigenomics (the study of the epigenetic regulation of the entire genome, [9,10]), to name a few. It has also yielded a plethora of other ‘omics’ terms, such as lipidomics [11,12], metagenomics [13], glycomics [14], connectomics [15], cellomics [16], and even foodomics [17,18]. While a detailed discussion of these omics technologies exceeds the focus of this review, we will first discuss applications of individual omics technologies to study cancer and other human disorders (summarized in Figure 1), and then provide examples of the initial steps of ‘multi-omics’, the integrative use of multiple omics platforms. Several comprehensive reviews have also discussed the use of multiple omics platforms in cancer research, and provide an in-depth overview about the current state of the field (e.g., [19]). Here, we will focus our discussion on representative examples of integrated omics studies, and then outline the challenges and opportunities for this emerging field of multi-omics for precision medicine and oncology.
2. Genomics Approaches
Most often, a precision medicine approach is equated with a genomics approach. This is likely due to the fact that genomic approaches, technologies, and data were the first widespread omics data available for application in precision medicine. As a result, most early efforts in precision medicine predominantly focused on the use of genomic sequence information to diagnose patients, predict risk of individual patients for developing diseases, and to assess whether specific treatments are suitable and likely successful in individual patients. Over the past decade, genome-wide association studies, and more recently, next generation whole exome and whole genome sequencing data have provided a large set of DNA sequence variants that are associated with a plethora of diseases and traits in humans. Despite these rapidly expanding datasets, progress in identifying the specific disease-causing sequence variants and the pathophysiological mechanisms by which they affect disease development or progression has been slow. The application of polygenic risk score approaches to a range of common diseases has been one strategy to provide potentially clinically useful and actionable information from these genetic data without the need to identify individual causal sequence changes and their modes of action. However, application of these risk scores has been limited to only a few diseases. The extensive genetic variant information has also been used in pharmacogenomics to predict drug responses in individual patients. Similar to risk scores, this strategy has had limited success. Clearly, more progress is needed to effectively use available genomic information and assess benefits and limitations in risk prediction, disease diagnosis, and treatment decision making.
In oncology, genomics approaches have focused on DNA sequencing to identify cancer-specific mutations, both in heritable and spontaneous cancers, and to analyze chromosomal rearrangements to characterize cancer classes or subtypes. DNA isolated from cancer cells carries a wide range of somatic and potentially inherited changes, ranging from single nucleotide polymorphisms, insertions and deletions and larger copy number variations and structural rearrangements. The total number of mutations and/or chromosomal rearrangements varies widely between tumor types, and between the same tumor types from different individuals, making it challenging to identify key functional changes that are essential for tumor formation and growth. The overall mutational pattern in human cancer has been extensively studied over the past decade and several comprehensive reviews have summarized the results [20,21,22].
Initial genetic oncology studies focused on the identification of inherited mutations that significantly elevate cancer risk. Early studies of families with a clustering of particular cancer types led to the identification of a number of genes and mutations that, when inherited, increase the risk for specific types of cancer. Initial examples include Lynch Syndrome, a non-polyposis colorectal cancer often caused by mutations in genes involved in DNA mismatch repair (MLH1, MSH2, MSH6, PMS1, PMS2, [23]), Li-Fraumeni Syndrome, an inherited syndrome most often caused by mutations in the tumor suppressor gene TP53 that can lead to the development of a wide range of cancers, including sarcomas, leukemia, and brain cancers [24], and hereditary breast and ovarian cancer syndrome, often caused by mutations in the genes BRCA1 and BRCA2 [25]. Individuals with mutations in any of these genes have a significantly higher risk of developing cancer compared to non-carriers. These discoveries facilitated the use genetic information for treatment decisions in affected individuals and have led to a wide range of providers that offer genetic testing for any of these conditions—a first application of genetics/genomics in precision oncology. As an extension of these early studies, genome-wide association studies [26] and, more recently, the development of polygenic risk scores [27] have expanded the number of sequence variants and mutations that are associated with increased cancer risk. A significant number of these variants are routinely tested today as companion diagnostics for tumor characterization and staging, and treatment decision-making.
Additional studies have focused on the analysis of chromosomal rearrangements and copy number variation in cancer cells. Numerous technologies, including fluorescence in-situ hybridization (for karyotypic characterization), comparative genomic hybridization (CGH, for small chromosomal rearrangements and copy number variation), and recently next generation whole genome sequencing, allow the detailed characterization of chromosomal abnormalities predisposing to cancer development, and the identification cancer cell-specific alterations that help explain the abnormal cell growth or resistance to treatment, as in the case of the formation of fusion genes such as BCR-ABL (Philadelphia Chromosome) [28]. Lately, next generation whole genome sequencing has also been used to characterize gene conversion by inter-chromosomal recombination by comparing tumor tissues for several cancers with adjacent “paratumor” tissues [29].
Despite this tremendous progress in clinical testing for inherited forms of cancer, progress towards better understanding the underlying genetic mechanisms contributing to the majority of sporadic cancers has been more challenging. Recent advances in sequencing technologies now allow the effective analysis of individual tumors, including sequence analysis at the single cell level. The growing set of data available from these efforts have revealed that the underlying profile of somatic mutations accumulating in tumor cells is highly complex, and it has been challenging to distinguish potential ‘driver’ mutations (that are responsible for tumor formation and growth) from ‘passenger’ mutations that are phenotypically neutral. The understanding of mutational burden in tumors, however, has been used to better define the pathophysiological mechanisms contributing to tumor development and progression. Since 2005, The Cancer Genome Atlas (TCGA), an NIH-funded effort to characterize and profile the genome of 33 different tumor types and 10 rare cancers, sequenced the genomes of over 7500 samples to identify sequence variants [30], other DNA alterations such as fusions [31,32], copy number alterations [33,34], and other complex structural variations [35]. The large dataset has already resulted in more accurate stratification and prognosis of cancer subtypes [36,37,38], and identification of molecular subtypes of cancer that can be treated by available drugs [39,40], highlighting the steady progress made in using genetic information in clinical oncology and practice. Nonetheless, despite these success stories, it has become clear that an exclusive characterization of the genomic state of a tumor cell, or a characterization of the genome of an individual, is often not sufficiently predictive of their risk of developing cancer, nor of their likelihood to respond to treatment or their cancer recurrence risk.
3. Other Omics Approaches
To better characterize tumor cells and their functional abnormalities, other omics technologies have been used across the entire spectrum of human disorders. Virtually all of these approaches were also applied to tumor and cancer samples in the past several years and are beginning to contribute to a better understanding of the molecular mechanisms underlying disease processes. Similar to the chapter above summarizing the genomic approaches and technologies applied in cancer research, we will not attempt to provide a comprehensive review of all omics technologies and approaches that have been applied over the years, and how they individually have impacted and altered clinical practice. Rather, we will highlight a number of applications and discuss the resultant clinical use of the data and information, before we discuss the prevailing challenges in using omics data effectively and comprehensively in the next chapter.
3.1. Transcriptomics
As sequencing and array-based technologies advanced, disease genetics research has extensively used these approaches to profile and quantitatively analyze the transcriptome of cells and tissues, and determine how changes in gene transcription in cells can be used to diagnose disorders and identify molecular mechanisms underlying the disease development and progression. These transcriptome data have also spawned an entire new approach, expression quantitative trait loci (eQTL) analysis, to identify putative functional mechanisms by which genetic sequence variation may lead to a disease by linking DNA sequence variation with changes in gene expression.
To date, almost 800,000 gene expression datasets related to cancer have been deposited in the Gene Expression Omnibus (GEO) database of the National Center for Biotechnology (NCBI) of the NIH. The TCGA initiative has also used transcriptomics to provide detailed gene expression characterization of individual tumors and tissues from over 11,000 patients [41], and together with other initiatives such as the Stand Up To Cancer-Prostate Center Foundation Project [42], has helped in the detailed analysis of gene expression changes associated with tumor formation and growth. Numerous other studies have also revealed characteristic gene expression signatures that can help predict patient outcomes and treatment response for a variety of cancer types, and several clinical tests are now on the market that predict prognosis or recurrence risk for patients with breast cancer, colorectal cancer, glioblastoma multiforme, and non-small lung cancer [43,44,45,46]. Recent studies have extended gene expression analysis to single cells [47], and the resulting data are likely to further expand our understanding of cell heterogeneity in cancer [48], and may influence our clinical decision making.
3.2. Epigenomics
With a growing understanding of gene expression changes in tissues and cells, research has extensively focused on studying the regulation of gene expression. In cancer, this regulation is highly complex, with germline genetic factors, somatic mutations, and epigenetic contributors all affecting gene expression [49]. This interplay has been extensively studied in various cancers, including eQTL analysis to identify inherited genetic factors contributing to gene expression variation (e.g., [50,51]), and single cell gene expression analysis that allows the assessment of the impact of cell-specific somatic mutations on gene expression in individual cells [52,53,54]. In addition to these studies, epigenetic regulatory mechanisms play a key role in cancer cell formation and growth. This includes alterations in DNA methylation [55], histone modifications [56], and expression of miRNAs [57] and lncRNAs [58,59]. Epigenetic differences can be observed between tumor cells and normal cells, and in tumor cells during disease progression or in response to treatment (mostly chemotherapy). Accordingly, DNA methylation has been used to prioritize treatment regimens for some conditions. DNA methylation status at the MGMT promoter is currently used to determine if temozolamide, a DNA alkylating agent, will be effective in glioblastoma treatment [60]. MGMT is a DNA repair enzyme, and when the gene’s promoter is methylated, is expressed at low levels. Treatment with temozolamide is effective in this case because the damage to cancer cells induced by the treatment cannot be repaired, leading to cell death. Conversely, when the MGMT promoter is not methylated, the gene is expressed and the damaging effect of temozolamide is limited by the cell’s ability to rescue the damage [61]. Altered expression of miRNAs has been observed in lung cancers that have become resistant to treatment with doxorubicin [61], and other epigenetic changes have been observed in other cancer types. As a result, DNA methyltransferases or histone deacetylase inhibitors that may interfere with these mechanisms have been tested as putative cancer drugs, and have shown promising preclinical results in pancreatic cancer [62]. Similarly, expression profiles of specific miRNA and lncRNA molecules may help in the identification of drug-resistant tumor cells in patients undergoing standard chemotherapy, identifying them as patients in need of additional treatment. Ultimately, miRNAs and lncRNAs may provide opportunities for novel treatment approaches in cancers that are not effectively targeted by currently available treatment options, such as glioblastoma [63]. However, it is unlikely that epigenomic signatures alone, or treatments aimed at interfering with epigenetic mechanisms in cancer, will be successful for treatment of all types of cancer.
3.3. Proteomics
As gene expression analysis has advanced, investigations have turned to the analysis of cellular proteins, the translational ‘products’ of RNA transcripts, and the predominant mediators of cellular function. While transcriptomics allows the quantification of the immediate product of a cell’s genome at a particular time (thus ‘measuring’ the direct activity of the genome, or any change thereof under different conditions or during disease development), initial large-scale studies of cellular proteomes showed a relatively low correlation between protein expression levels and corresponding mRNA expression levels [64]. Clearly, protein function is mediated and altered by a myriad of mechanisms. Posttranslational modifications of proteins (e.g., phosphorylation) often are required for activity or signaling. Folding and posttranslational processing of pre-proteins, and the formation of multi-protein complexes are necessary to create the machinery that preforms the required cellular functions. Finally, cellular location of a protein often determines whether an expressed protein is active or inactive. As a result, no single methodology is able to appropriately assess the ‘proteome’ in all its facets, and most proteomics methodologies focus on the identification and quantification of individual proteins, usually by mass spectrometry or through affinity-based protein arrays. Additional analytical methodologies, such as NMR and X-ray crystallography, can provide information on the structure of proteins and protein complexes in cells and tissues.
In cancer proteomics, the TCGA Consortium represented the first large-scale effort to profile the tumor proteome. However, the analysis was performed using reverse phase protein arrays, and was therefore limited to the targeted analysis of a few hundred proteins. However, several recent studies have used state-of-the-art mass spectrometry approaches to identify cancer-specific biomarkers in ovarian cancer [65], and used proteomics data to aid in the classification of breast cancer [66]. Additional analyses have also used proteomics data to predict drug sensitivity and identify putative proteins mediating drug resistance [67,68]. These proteome-wide studies complement the traditional immunohistochemical classification of tumor types, such as the characterization of estrogen receptor expression in breast cancer tumors.
3.4. Metabolomics
Metabolomics, the analysis of small molecules present in a cell, tissue, or fluid, has been the focus of biomarker discovery studies for a long time. Metabolites are often viewed as the products of cellular processes, mediated by proteins; therefore, changes in metabolites are presumed to be reflective of changes in function of the mediating enzymes and proteins. The vast majority of metabolomics analyses have focused on the analysis of plasma or serum samples from patients, often as an attempt to identify cancer or tumor-specific biomarkers that can be used in diagnosis without requiring an invasive tumor biopsy sample. However, as in most disease-related studies, determining the specificity of a characteristic change in plasma metabolites for a particular disease, or, in the case of cancer, tumor type, remains difficult, and often metabolites identified as biomarkers in one disease are also altered in other diseases.
The limited studies in cancer biology have identified some putative metabolic biomarkers, such as altered carbohydrates in acute myeloid leukemia [69], and unsaturated free fatty acids in colorectal cancer [70]. In contrast, studies in prostate cancer only revealed changes in citrate [71] and branched-chain amino acids [72], which have been reported for other diseases [73,74], suggesting that the observed biomarkers are likely not specific to prostate cancer and more likely reflective of shared underlying disease pathology mechanisms. Furthermore, it remains to be seen whether changes identified in plasma metabolites are representative of changes in tumor cells.
4. Multi-Omics Approaches: Challenges and Opportunities
As highlighted above, different omics datasets do not overlap extensively, and measures obtained from one omics approach are often not well correlated with data obtained by other methods. Thus, it is likely that different omics methodologies assess different parts of the complex pathophysiology of complex disease development and progression, and the analysis of just one omics subset provides a skewed, biased, and incomplete picture of the underlying biology. However, given the wide range of data that can be generated from tissue samples to characterize differences between normal and diseased cells and tissues, how does one select the most meaningful omic data types to generate (limited primarily by cost and tissue availability), and, more importantly, how does one integrate the resulting multiple omic datasets to obtain a comprehensive picture of the underlying biological processes? Essentially, there are two potential approaches to investigate multi-omics data:
The first approach looks at the various analytes (transcripts, proteins, metabolites, epigenetic factors) in the context of known (reported) pathways and mechanisms. This approach requires prior knowledge that specific molecular pathways are central to the disease process, and a detailed knowledge and annotation of all relevant molecular pathways, with annotations and identifiers that easily link back to transcripts, proteins, metabolites, miRNAs, lncRNAs, genetic sequence variants, and DNA and histone methylation variants, to list just a few. Recent consortium efforts, such as the Encyclopedia of DNA Elements (ENCODE) have begun to link gene expression regulation to DNA sequence variation, epigenetic variation, and chromatin accessibility on a genome-wide scale in various cell types, including cancer cell lines. While this is highly informative, it remains unclear how representative this information is for other cells and tissues, such as specific tumor tissues only distantly related to the cell lines under study. Other omics data can potentially be linked using gene names/protein names, as they have been annotated in databases such as KEGG and other pathway-driven annotations. However, the further data integration becomes complicated since the ENCODE- and other regulatory data do not necessarily directly link to individual genes which in turn can be mapped to KEGG pathways. Likewise, metabolite data are only sparsely linked in the current versions of gene-centric pathway networks. This brief illustration highlights the challenges of true multi-omics data integration, and is likely the reason why most manuscripts referring to multi-omics analyses only analyze data from two or three different platforms (e.g., transcripts and proteins).
The second approach ignores (at least initially) the existing knowledge of pathways and network interactions in cells and tissues, and looks for correlations across multiple data sets to identify molecules/analytes that are changing in a correlated manner. In principle, such an approach would be agnostic to the type of omics data used. The benefit of this approach is ability to discover novel molecules and pathways essential for the disease process. However, such an unbiased analysis very quickly becomes computationally and statistically challenging. The dataset may include RNA-Seq data on 20,000 different transcripts, but proteomics data only on 2,000 proteins. Furthermore, some data are generated using platforms that exhaustively analyze and quantify the molecules of interest (e.g., RNA-Seq), some may be unbiased, but only identify and quantify the most abundant molecules (e.g., proteomics), and yet other methodologies may use targeted approaches to investigate samples (such as targeted metabolomics approaches, array-based DNA methylation platforms). Finally, a complete multi-omics dataset may include over 100,000 analytes, yet they are likely to be measured in only a limited number of tissue samples (100 tumor biopsies), or potentially even in different samples from the same patient (tumor RNA-Seq vs. plasma metabolomics analysis). Analytical tools have been suggested for these types of complex datasets, such as clustering approaches [75], or weighted gene co-expression network analysis (WGCNA, [76]). However, most of these have not been applied extensively to datasets including more than two or three omics datasets. Additional tools will be needed to perform these complex integrated analyses using strict statistical models, and to help in the interpretation and biological annotation of the obtained co-expression networks or clusters of multi-omics analytes [77].
Numerous recent reviews and opinion pieces have suggested that the field of precision oncology will greatly benefit from a multi-omics analytical approach [19,78,79]. Indeed, this suggestion is not specific to the field of cancer research, and other human diseases would likely benefit from similar approaches [80]. Repeatedly, the argument is being made that only the comprehensive integrated analysis will be able to uncover the complex mechanisms underlying cancer development and progression. Despite this push, there are only limited examples of multi-omics studies. In fact, even the TCGA efforts only explored and integrated a limited number of omics approaches, and even though several manuscripts describe so-called multi-omics analyses of various cancer types, most of these analyses integrated only transcriptome and limited epigenome analysis with tumor mutation analysis, and a sparse targeted proteomics dataset. Similarly, virtually all analyses published to date focus primarily on transcriptomics, and add a limited amount of data from additional technologies to complement the RNA expression data, either as a proteogenomics (transcriptomics and proteomics) approach, or by integrating epigenetics (miRNA or lncRNA) with transcriptome data. Often, the analyses beyond transcriptome profiling are targeted analyses, conducted to replicate the initial RNA findings, and/or to propose a potential mechanism by which the transcriptome could have been altered.
Probably one of the most ambitious efforts to assess the opportunities and challenges in using integrated multi-omics data for health assessment and prediction comes from the integrated personal omics profiling (iPOP) project [81]. Initially proposed and started by longitudinally profiling a single individual over time with a broad set of omics approaches and clinical tests [82], the project has expanded and explored both the impact of lifestyle changes on long-term health, such as a brief weight gain followed by a weight loss [83], as well as longitudinal profiling of a diverse cohort to assess parameters that are useful in long-term health management and decision making [84]. The latter study followed 109 individuals at risk for type 2 diabetes on average for about 3 years, and used clinical assessments, wearable devices, and multi-omics profiling to derive predictive models for long-term health outcomes. The analysis highlights how the resulting data allow predictions and treatment decisions across a wide range of clinical specialties, including cardiovascular health, infectious diseases, and oncology. While this study has limitations and does not necessarily provide a clear blueprint for multi-omics studies and clinical applications, it is the first of its kind to assess the potential role of multi-omics data in health outcome predictions in an integrated manner.
Overall, this short summary highlights that the concept of precision medicine is more than the use of genetic variant information to inform clinical practice and the fact that the use multi-omics approaches to achieve precision medicine in the clinic is extremely valuable but still in its infancy. Not only in precision oncology, but in a wide range of human disease-related research, we are just beginning to generate comprehensive, unbiased data that are truly multi-omic. Only with the generation of these different omic datasets from the same biological samples will we be able to develop the necessary analytical (statistical) and annotation tools that will help us interpret these complex datasets, and help extract biological and clinically relevant information. The Trans-Omics for Precision Medicine (TOPMED) Initiative of the NHLBI is one example of a large-scale effort that is beginning to generate more comprehensive omics data for a wide range of study cohorts, based on already existing studies and sample material. Generating multi-omics data is expensive and time-consuming, and the usefulness of the resulting data critically depends on the availability of suitable tissue samples and biopsy material collected in a way that allows the effective analysis of tissue transcriptome, epigenome, proteome, and metabolome. Until recently, biopsy samples were mainly collected for transcriptome analysis or mutation discovery, and accordingly, samples were often collected in buffers that stabilized RNA and DNA, but essentially render the sample material unsuitable for protein or metabolite profiling. Future studies will need to address this so that we can generate the necessary comprehensive multi-omics data and begin to untangle the complex biological mechanisms that control tumor formation and progression, the development of resistance to treatment, and the risk of recurrence. We will need to focus on the characterization of integrated multi-omics signatures and mechanisms rather than small sets of putative diagnostic biomarkers that are currently being marketed to clinicians if we hope to truly advance precision medicine and precision oncology using multi-omics approaches.
Author Contributions
Conceptualization, M.O. and L.A.C.; Discussion, R.A., G.A.H., T.D.H., and L.A.C.; Writing—original draft preparation, M.O.; Writing—review and editing, R.A., G.A.H., T.D.H., and L.A.C.; Project administration, M.O.
Funding
This research was supported in part by NIH grant U19AG057758, and by support to the Center for Precision Medicine provided by Wake Forest University Health Sciences.
Acknowledgments
The ideas and topics discussed in this manuscript evolved from ongoing faculty discussions at the Center for Precision Medicine, Wake Forest University Health Sciences.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yadav, S.P. The wholeness in suffix -omics, -omes, and the word om. J. Biomol. Tech. 2007, 18, 277. [Google Scholar] [PubMed]
- Jiang, Z.; Zhou, X.; Li, R.; Michal, J.J.; Zhang, S.; Dodson, M.V.; Zhang, Z.; Harland, R.M. Whole transcriptome analysis with sequencing: Methods, challenges and potential solutions. Cell Mol. Life Sci. 2015, 72, 3425–3439. [Google Scholar] [CrossRef] [PubMed]
- Mutz, K.O.; Heilkenbrinker, A.; Lonne, M.; Walter, J.G.; Stahl, F. Transcriptome analysis using next-generation sequencing. Curr. Opin. Biotechnol. 2013, 24, 22–30. [Google Scholar] [CrossRef] [PubMed]
- Kalisky, T.; Oriel, S.; Bar-Lev, T.H.; Ben-Haim, N.; Trink, A.; Wineberg, Y.; Kanter, I.; Gilad, S.; Pyne, S. A brief review of single-cell transcriptomic technologies. Brief. Funct. Genom. 2018, 17, 64–76. [Google Scholar] [CrossRef] [PubMed]
- Aebersold, R.; Mann, M. Mass-spectrometric exploration of proteome structure and function. Nature 2016, 537, 347–355. [Google Scholar] [CrossRef] [PubMed]
- Aslam, B.; Basit, M.; Nisar, M.A.; Khurshid, M.; Rasool, M.H. Proteomics: Technologies and Their Applications. J. Chromatogr. Sci. 2017, 55, 182–196. [Google Scholar] [CrossRef] [PubMed]
- Schrimpe-Rutledge, A.C.; Codreanu, S.G.; Sherrod, S.D.; McLean, J.A. Untargeted Metabolomics Strategies-Challenges and Emerging Directions. J. Am. Soc. Mass Spectrom. 2016, 27, 1897–1905. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; He, X.; Jia, W.; Li, H. Novel Applications of Metabolomics in Personalized Medicine: A Mini-Review. Molecules 2017, 22, 1173. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.C.; Chang, H.Y. Epigenomics: Technologies and Applications. Circ. Res. 2018, 122, 1191–1199. [Google Scholar] [CrossRef] [PubMed]
- Stricker, S.H.; Koferle, A.; Beck, S. From profiles to function in epigenomics. Nat. Rev. Genet. 2017, 18, 51–66. [Google Scholar] [CrossRef]
- Han, X.; Gross, R.W. Shotgun lipidomics: Multidimensional MS analysis of cellular lipidomes. Expert Rev. Proteom. 2005, 2, 253–264. [Google Scholar] [CrossRef] [PubMed]
- Wenk, M.R. The emerging field of lipidomics. Nat. Rev. Drug Discov. 2005, 4, 594–610. [Google Scholar] [CrossRef] [PubMed]
- Riesenfeld, C.S.; Schloss, P.D.; Handelsman, J. Metagenomics: Genomic analysis of microbial communities. Annu. Rev. Genet. 2004, 38, 525–552. [Google Scholar] [CrossRef] [PubMed]
- Raman, R.; Raguram, S.; Venkataraman, G.; Paulson, J.C.; Sasisekharan, R. Glycomics: An integrated systems approach to structure-function relationships of glycans. Nat. Methods 2005, 2, 817–824. [Google Scholar] [CrossRef] [PubMed]
- Sporns, O.; Tononi, G.; Kotter, R. The human connectome: A structural description of the human brain. PLoS Comput. Biol. 2005, 1, e42. [Google Scholar] [CrossRef] [PubMed]
- Primiceri, E.; Chiriaco, M.S.; Rinaldi, R.; Maruccio, G. Cell chips as new tools for cell biology-results, perspectives and opportunities. Lab Chip 2013, 13, 3789–3802. [Google Scholar] [CrossRef] [PubMed]
- Braconi, D.; Bernardini, G.; Millucci, L.; Santucci, A. Foodomics for human health: Current status and perspectives. Expert Rev. Proteom. 2018, 15, 153–164. [Google Scholar] [CrossRef]
- Cifuentes, A. Food analysis and foodomics. J. Chromatogr. A 2009, 1216, 7109. [Google Scholar] [CrossRef]
- Gallo Cantafio, M.E.; Grillone, K.; Caracciolo, D.; Scionti, F.; Arbitrio, M.; Barbieri, V.; Pensabene, L.; Guzzi, P.H.; Di Martino, M.T. From Single Level Analysis to Multi-Omics Integrative Approaches: A Powerful Strategy towards the Precision Oncology. High Throughput 2018, 7, 33. [Google Scholar] [CrossRef]
- Alexandrov, L.B.; Nik-Zainal, S.; Wedge, D.C.; Aparicio, S.A.; Behjati, S.; Biankin, A.V.; Bignell, G.R.; Bolli, N.; Borg, A.; Borresen-Dale, A.L.; et al. Signatures of mutational processes in human cancer. Nature 2013, 500, 415–421. [Google Scholar] [CrossRef] [Green Version]
- Burrell, R.A.; McGranahan, N.; Bartek, J.; Swanton, C. The causes and consequences of genetic heterogeneity in cancer evolution. Nature 2013, 501, 338–345. [Google Scholar] [CrossRef] [PubMed]
- Tomczak, K.; Czerwinska, P.; Wiznerowicz, M. The Cancer Genome Atlas (TCGA): An immeasurable source of knowledge. Contemp. Oncol. 2015, 19, A68–A77. [Google Scholar] [CrossRef] [PubMed]
- Silva, F.C.; Valentin, M.D.; Ferreira Fde, O.; Carraro, D.M.; Rossi, B.M. Mismatch repair genes in Lynch syndrome: A review. Sao Paulo Med. J. 2009, 127, 46–51. [Google Scholar] [CrossRef] [PubMed]
- Guha, T.; Malkin, D. Inherited TP53 Mutations and the Li-Fraumeni Syndrome. Cold Spring Harb. Perspect. Med. 2017, 7. [Google Scholar] [CrossRef] [PubMed]
- Kurian, A.W. BRCA1 and BRCA2 mutations across race and ethnicity: Distribution and clinical implications. Curr. Opin. Obstet. Gynecol. 2010, 22, 72–78. [Google Scholar] [CrossRef] [PubMed]
- Sud, A.; Kinnersley, B.; Houlston, R.S. Genome-wide association studies of cancer: Current insights and future perspectives. Nat. Rev. Cancer 2017, 17, 692–704. [Google Scholar] [CrossRef] [PubMed]
- Gibson, G. On the utilization of polygenic risk scores for therapeutic targeting. PLoS Genet. 2019, 15, e1008060. [Google Scholar] [CrossRef] [PubMed]
- Ben-Neriah, Y.; Daley, G.Q.; Mes-Masson, A.M.; Witte, O.N.; Baltimore, D. The chronic myelogenous leukemia-specific P210 protein is the product of the bcr/abl hybrid gene. Science 1986, 233, 212–214. [Google Scholar] [CrossRef] [PubMed]
- Hu, T.; Kumar, Y.; Shazia, I.; Duan, S.J.; Li, Y.; Chen, L.; Chen, J.F.; Yin, R.; Kwong, A.; Leung, G.K.; et al. Forward and reverse mutations in stages of cancer development. Hum. Genom. 2018, 12, 40. [Google Scholar] [CrossRef] [PubMed]
- Bailey, M.H.; Tokheim, C.; Porta-Pardo, E.; Sengupta, S.; Bertrand, D.; Weerasinghe, A.; Colaprico, A.; Wendl, M.C.; Kim, J.; Reardon, B.; et al. Comprehensive Characterization of Cancer Driver Genes and Mutations. Cell 2018, 173, 371–385.e18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bolton, K.L.; Chenevix-Trench, G.; Goh, C.; Sadetzki, S.; Ramus, S.J.; Karlan, B.Y.; Lambrechts, D.; Despierre, E.; Barrowdale, D.; McGuffog, L.; et al. Association between BRCA1 and BRCA2 mutations and survival in women with invasive epithelial ovarian cancer. JAMA 2012, 307, 382–390. [Google Scholar] [CrossRef] [PubMed]
- Gao, Q.; Liang, W.W.; Foltz, S.M.; Mutharasu, G.; Jayasinghe, R.G.; Cao, S.; Liao, W.W.; Reynolds, S.M.; Wyczalkowski, M.A.; Yao, L.; et al. Driver Fusions and Their Implications in the Development and Treatment of Human Cancers. Cell Rep. 2018, 23, 227–238.e3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davoli, T.; Uno, H.; Wooten, E.C.; Elledge, S.J. Tumor aneuploidy correlates with markers of immune evasion and with reduced response to immunotherapy. Science 2017, 355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zack, T.I.; Schumacher, S.E.; Carter, S.L.; Cherniack, A.D.; Saksena, G.; Tabak, B.; Lawrence, M.S.; Zhsng, C.Z.; Wala, J.; Mermel, C.H.; et al. Pan-cancer patterns of somatic copy number alteration. Nat. Genet. 2013, 45, 1134–1140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, E.; Iskow, R.; Yang, L.; Gokcumen, O.; Haseley, P.; Luquette, L.J., III; Lohr, J.G.; Harris, C.C.; Ding, L.; Wilson, R.K.; et al. Landscape of somatic retrotransposition in human cancers. Science 2012, 337, 967–971. [Google Scholar] [CrossRef] [PubMed]
- Killock, D. CNS cancer: Molecular classification of glioma. Nat. Rev. Clin. Oncol. 2015, 12, 502. [Google Scholar] [CrossRef] [PubMed]
- Cancer Genome Atlas Research Network; Brat, D.J.; Verhaak, R.G.; Aldape, K.D.; Yung, W.K.; Salama, S.R.; Cooper, L.A.; Rheinbay, E.; Miller, C.R.; Vitucci, M.; et al. Comprehensive, Integrative Genomic Analysis of Diffuse Lower-Grade Gliomas. N. Engl. J. Med. 2015, 372, 2481–2498. [Google Scholar] [CrossRef] [Green Version]
- Setia, N.; Agoston, A.T.; Han, H.S.; Mullen, J.T.; Duda, D.G.; Clark, J.W.; Deshpande, V.; Mino-Kenudson, M.; Srivastava, A.; Lennerz, J.K.; et al. A protein and mRNA expression-based classification of gastric cancer. Mod. Pathol. 2016, 29, 772–784. [Google Scholar] [CrossRef]
- Wagle, N.; Grabiner, B.C.; Van Allen, E.M.; Hodis, E.; Jacobus, S.; Supko, J.G.; Stewart, M.; Choueiri, T.K.; Gandhi, L.; Cleary, J.M.; et al. Activating mTOR mutations in a patient with an extraordinary response on a phase I trial of everolimus and pazopanib. Cancer Discov. 2014, 4, 546–553. [Google Scholar] [CrossRef]
- Grabiner, B.C.; Nardi, V.; Birsoy, K.; Possemato, R.; Shen, K.; Sinha, S.; Jordan, A.; Beck, A.H.; Sabatini, D.M. A diverse array of cancer-associated MTOR mutations are hyperactivating and can predict rapamycin sensitivity. Cancer Discov. 2014, 4, 554–563. [Google Scholar] [CrossRef]
- Cancer Genome Atlas Research Network; Weinstein, J.N.; Collisson, E.A.; Mills, G.B.; Shaw, K.R.; Ozenberger, B.A.; Ellrott, K.; Shmulevich, I.; Sander, C.; Stuart, J.M. The Cancer Genome Atlas Pan-Cancer analysis project. Nat. Genet. 2013, 45, 1113–1120. [Google Scholar] [CrossRef] [PubMed]
- Robinson, D.; Van Allen, E.M.; Wu, Y.M.; Schultz, N.; Lonigro, R.J.; Mosquera, J.M.; Montgomery, B.; Taplin, M.E.; Pritchard, C.C.; Attard, G.; et al. Integrative clinical genomics of advanced prostate cancer. Cell 2015, 161, 1215–1228. [Google Scholar] [CrossRef] [PubMed]
- Prat, A.; Ellis, M.J.; Perou, C.M. Practical implications of gene-expression-based assays for breast oncologists. Nat. Rev. Clin. Oncol. 2011, 9, 48–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duarte, C.W.; Willey, C.D.; Zhi, D.; Cui, X.; Harris, J.J.; Vaughan, L.K.; Mehta, T.; McCubrey, R.O.; Khodarev, N.N.; Weichselbaum, R.R.; et al. Expression signature of IFN/STAT1 signaling genes predicts poor survival outcome in glioblastoma multiforme in a subtype-specific manner. PLoS ONE 2012, 7, e29653. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Wang, R.; Yan, Z.; Bai, L.; Sun, Z. High accordance in prognosis prediction of colorectal cancer across independent datasets by multi-gene module expression profiles. PLoS ONE 2012, 7, e33653. [Google Scholar] [CrossRef]
- Botling, J.; Edlund, K.; Lohr, M.; Hellwig, B.; Holmberg, L.; Lambe, M.; Berglund, A.; Ekman, S.; Bergqvist, M.; Ponten, F.; et al. Biomarker discovery in non-small cell lung cancer: Integrating gene expression profiling, meta-analysis, and tissue microarray validation. Clin. Cancer Res. 2013, 19, 194–204. [Google Scholar] [CrossRef]
- Song, Q.; Hawkins, G.A.; Wudel, L.; Chou, P.C.; Forbes, E.; Pullikuth, A.K.; Liu, L.; Jin, G.; Craddock, L.; Topaloglu, U.; et al. Dissecting intratumoral myeloid cell plasticity by single cell RNA-seq. Cancer Med. 2019, 8, 3072–3085. [Google Scholar] [CrossRef]
- Suva, M.L.; Tirosh, I. Single-Cell RNA Sequencing in Cancer: Lessons Learned and Emerging Challenges. Mol. Cell 2019, 75, 7–12. [Google Scholar] [CrossRef]
- Li, Q.; Seo, J.H.; Stranger, B.; McKenna, A.; Pe’er, I.; Laframboise, T.; Brown, M.; Tyekucheva, S.; Freedman, M.L. Integrative eQTL-based analyses reveal the biology of breast cancer risk loci. Cell 2013, 152, 633–641. [Google Scholar] [CrossRef]
- Hoffman, J.D.; Graff, R.E.; Emami, N.C.; Tai, C.G.; Passarelli, M.N.; Hu, D.; Huntsman, S.; Hadley, D.; Leong, L.; Majumdar, A.; et al. Cis-eQTL-based trans-ethnic meta-analysis reveals novel genes associated with breast cancer risk. PLoS Genet. 2017, 13, e1006690. [Google Scholar] [CrossRef]
- Fehringer, G.; Kraft, P.; Pharoah, P.D.; Eeles, R.A.; Chatterjee, N.; Schumacher, F.R.; Schildkraut, J.M.; Lindstrom, S.; Brennan, P.; Bickeboller, H.; et al. Cross-Cancer Genome-Wide Analysis of Lung, Ovary, Breast, Prostate, and Colorectal Cancer Reveals Novel Pleiotropic Associations. Cancer Res. 2016, 76, 5103–5114. [Google Scholar] [CrossRef] [PubMed]
- Horning, A.M.; Wang, Y.; Lin, C.K.; Louie, A.D.; Jadhav, R.R.; Hung, C.N.; Wang, C.M.; Lin, C.L.; Kirma, N.B.; Liss, M.A.; et al. Single-Cell RNA-seq Reveals a Subpopulation of Prostate Cancer Cells with Enhanced Cell-Cycle-Related Transcription and Attenuated Androgen Response. Cancer Res. 2018, 78, 853–864. [Google Scholar] [CrossRef] [PubMed]
- Chung, W.; Eum, H.H.; Lee, H.O.; Lee, K.M.; Lee, H.B.; Kim, K.T.; Ryu, H.S.; Kim, S.; Lee, J.E.; Park, Y.H.; et al. Single-cell RNA-seq enables comprehensive tumour and immune cell profiling in primary breast cancer. Nat. Commun. 2017, 8, 15081. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tirosh, I.; Izar, B.; Prakadan, S.M.; Wadsworth, M.H., II; Treacy, D.; Trombetta, J.J.; Rotem, A.; Rodman, C.; Lian, C.; Murphy, G.; et al. Dissecting the multicellular ecosystem of metastatic melanoma by single-cell RNA-seq. Science 2016, 352, 189–196. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kulis, M.; Esteller, M. DNA methylation and cancer. Adv. Genet. 2010, 70, 27–56. [Google Scholar] [CrossRef] [PubMed]
- Audia, J.E.; Campbell, R.M. Histone Modifications and Cancer. Cold Spring Harb. Perspect. Biol. 2016, 8, a019521. [Google Scholar] [CrossRef] [PubMed]
- Kohlhapp, F.J.; Mitra, A.K.; Lengyel, E.; Peter, M.E. MicroRNAs as mediators and communicators between cancer cells and the tumor microenvironment. Oncogene 2015, 34, 5857–5868. [Google Scholar] [CrossRef] [Green Version]
- Bhan, A.; Soleimani, M.; Mandal, S.S. Long Noncoding RNA and Cancer: A New Paradigm. Cancer Res. 2017, 77, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Peng, W.X.; Koirala, P.; Mo, Y.Y. LncRNA-mediated regulation of cell signaling in cancer. Oncogene 2017, 36, 5661–5667. [Google Scholar] [CrossRef]
- Hegi, M.E.; Diserens, A.C.; Gorlia, T.; Hamou, M.F.; de Tribolet, N.; Weller, M.; Kros, J.M.; Hainfellner, J.A.; Mason, W.; Mariani, L.; et al. MGMT gene silencing and benefit from temozolomide in glioblastoma. N. Engl. J. Med. 2005, 352, 997–1003. [Google Scholar] [CrossRef]
- El-Awady, R.A.; Hersi, F.; Al-Tunaiji, H.; Saleh, E.M.; Abdel-Wahab, A.H.; Al Homssi, A.; Suhail, M.; El-Serafi, A.; Al-Tel, T. Epigenetics and miRNA as predictive markers and targets for lung cancer chemotherapy. Cancer Biol. Ther. 2015, 16, 1056–1070. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neureiter, D.; Jager, T.; Ocker, M.; Kiesslich, T. Epigenetics and pancreatic cancer: Pathophysiology and novel treatment aspects. World J. Gastroenterol. 2014, 20, 7830–7848. [Google Scholar] [CrossRef] [PubMed]
- Teplyuk, N.M.; Uhlmann, E.J.; Gabriely, G.; Volfovsky, N.; Wang, Y.; Teng, J.; Karmali, P.; Marcusson, E.; Peter, M.; Mohan, A.; et al. Therapeutic potential of targeting microRNA-10b in established intracranial glioblastoma: First steps toward the clinic. EMBO Mol. Med. 2016, 8, 268–287. [Google Scholar] [CrossRef] [PubMed]
- Washburn, M.P.; Koller, A.; Oshiro, G.; Ulaszek, R.R.; Plouffe, D.; Deciu, C.; Winzeler, E.; Yates, J.R., III. Protein pathway and complex clustering of correlated mRNA and protein expression analyses in Saccharomyces cerevisiae. Proc. Natl. Acad. Sci. USA 2003, 100, 3107–3112. [Google Scholar] [CrossRef] [PubMed]
- Swiatly, A.; Horala, A.; Matysiak, J.; Hajduk, J.; Nowak-Markwitz, E.; Kokot, Z.J. Understanding Ovarian Cancer: iTRAQ-Based Proteomics for Biomarker Discovery. Int. J. Mol. Sci. 2018, 19, 2240. [Google Scholar] [CrossRef]
- Yanovich, G.; Agmon, H.; Harel, M.; Sonnenblick, A.; Peretz, T.; Geiger, T. Clinical Proteomics of Breast Cancer Reveals a Novel Layer of Breast Cancer Classification. Cancer Res. 2018, 78, 6001–6010. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ali, M.; Khan, S.A.; Wennerberg, K.; Aittokallio, T. Global proteomics profiling improves drug sensitivity prediction: Results from a multi-omics, pan-cancer modeling approach. Bioinformatics 2018, 34, 1353–1362. [Google Scholar] [CrossRef]
- Cruz, I.N.; Coley, H.M.; Kramer, H.B.; Madhuri, T.K.; Safuwan, N.A.; Angelino, A.R.; Yang, M. Proteomics Analysis of Ovarian Cancer Cell Lines and Tissues Reveals Drug Resistance-associated Proteins. Cancer Genom. Proteom. 2017, 14, 35–51. [Google Scholar] [CrossRef]
- Chaturvedi, A.; Araujo Cruz, M.M.; Jyotsana, N.; Sharma, A.; Yun, H.; Gorlich, K.; Wichmann, M.; Schwarzer, A.; Preller, M.; Thol, F.; et al. Mutant IDH1 promotes leukemogenesis in vivo and can be specifically targeted in human AML. Blood 2013, 122, 2877–2887. [Google Scholar] [CrossRef]
- Zhang, Y.; He, C.; Qiu, L.; Wang, Y.; Qin, X.; Liu, Y.; Li, Z. Serum Unsaturated Free Fatty Acids: A Potential Biomarker Panel for Early-Stage Detection of Colorectal Cancer. J. Cancer 2016, 7, 477–483. [Google Scholar] [CrossRef] [Green Version]
- Giskeodegard, G.F.; Bertilsson, H.; Selnaes, K.M.; Wright, A.J.; Bathen, T.F.; Viset, T.; Halgunset, J.; Angelsen, A.; Gribbestad, I.S.; Tessem, M.B. Spermine and citrate as metabolic biomarkers for assessing prostate cancer aggressiveness. PLoS ONE 2013, 8, e62375. [Google Scholar] [CrossRef] [PubMed]
- Mayers, J.R.; Wu, C.; Clish, C.B.; Kraft, P.; Torrence, M.E.; Fiske, B.P.; Yuan, C.; Bao, Y.; Townsend, M.K.; Tworoger, S.S.; et al. Elevation of circulating branched-chain amino acids is an early event in human pancreatic adenocarcinoma development. Nat. Med. 2014, 20, 1193–1198. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, J.F.; Wang, T.J. Branched-Chain Amino Acids and Cardiovascular Disease: Does Diet Matter? Clin. Chem. 2016, 62, 545–547. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giesbertz, P.; Daniel, H. Branched-chain amino acids as biomarkers in diabetes. Curr. Opin. Clin. Nutr. Metab. Care 2016, 19, 48–54. [Google Scholar] [CrossRef] [PubMed]
- Rappoport, N.; Shamir, R. Multi-omic and multi-view clustering algorithms: Review and cancer benchmark. Nucleic Acids. Res. 2018, 46, 10546–10562. [Google Scholar] [CrossRef]
- Langfelder, P.; Horvath, S. WGCNA: An R package for weighted correlation network analysis. BMC Bioinform. 2008, 9, 559. [Google Scholar] [CrossRef]
- Misra, B.B.; Langefeld, C.D.; Olivier, M.; Cox, L.A. Integrated Omics: Tools, Advances, and Future Approaches. J. Mol. Endocrinol. 2018. [Google Scholar] [CrossRef]
- Turanli, B.; Karagoz, K.; Gulfidan, G.; Sinha, R.; Mardinoglu, A.; Arga, K.Y. A Network-Based Cancer Drug Discovery: From Integrated Multi-Omics Approaches to Precision Medicine. Curr. Pharm. Des. 2018, 24, 3778–3790. [Google Scholar] [CrossRef]
- Hasin, Y.; Seldin, M.; Lusis, A. Multi-omics approaches to disease. Genome Biol. 2017, 18, 83. [Google Scholar] [CrossRef]
- Sun, Y.V.; Hu, Y.J. Integrative Analysis of Multi-omics Data for Discovery and Functional Studies of Complex Human Diseases. Adv. Genet. 2016, 93, 147–190. [Google Scholar] [CrossRef] [Green Version]
- Kellogg, R.A.; Dunn, J.; Snyder, M.P. Personal Omics for Precision Health. Circ. Res. 2018, 122, 1169–1171. [Google Scholar] [CrossRef] [PubMed]
- Stanberry, L.; Mias, G.I.; Haynes, W.; Higdon, R.; Snyder, M.; Kolker, E. Integrative analysis of longitudinal metabolomics data from a personal multi-omics profile. Metabolites 2013, 3, 741–760. [Google Scholar] [CrossRef] [PubMed]
- Piening, B.D.; Zhou, W.; Contrepois, K.; Rost, H.; Gu Urban, G.J.; Mishra, T.; Hanson, B.M.; Bautista, E.J.; Leopold, S.; Yeh, C.Y.; et al. Integrative Personal Omics Profiles during Periods of Weight Gain and Loss. Cell Syst. 2018, 6, 157–170.e8. [Google Scholar] [CrossRef] [PubMed]
- Schussler-Fiorenza Rose, S.M.; Contrepois, K.; Moneghetti, K.J.; Zhou, W.; Mishra, T.; Mataraso, S.; Dagan-Rosenfeld, O.; Ganz, A.B.; Dunn, J.; Hornburg, D.; et al. A longitudinal big data approach for precision health. Nat. Med. 2019, 25, 792–804. [Google Scholar] [CrossRef] [PubMed]
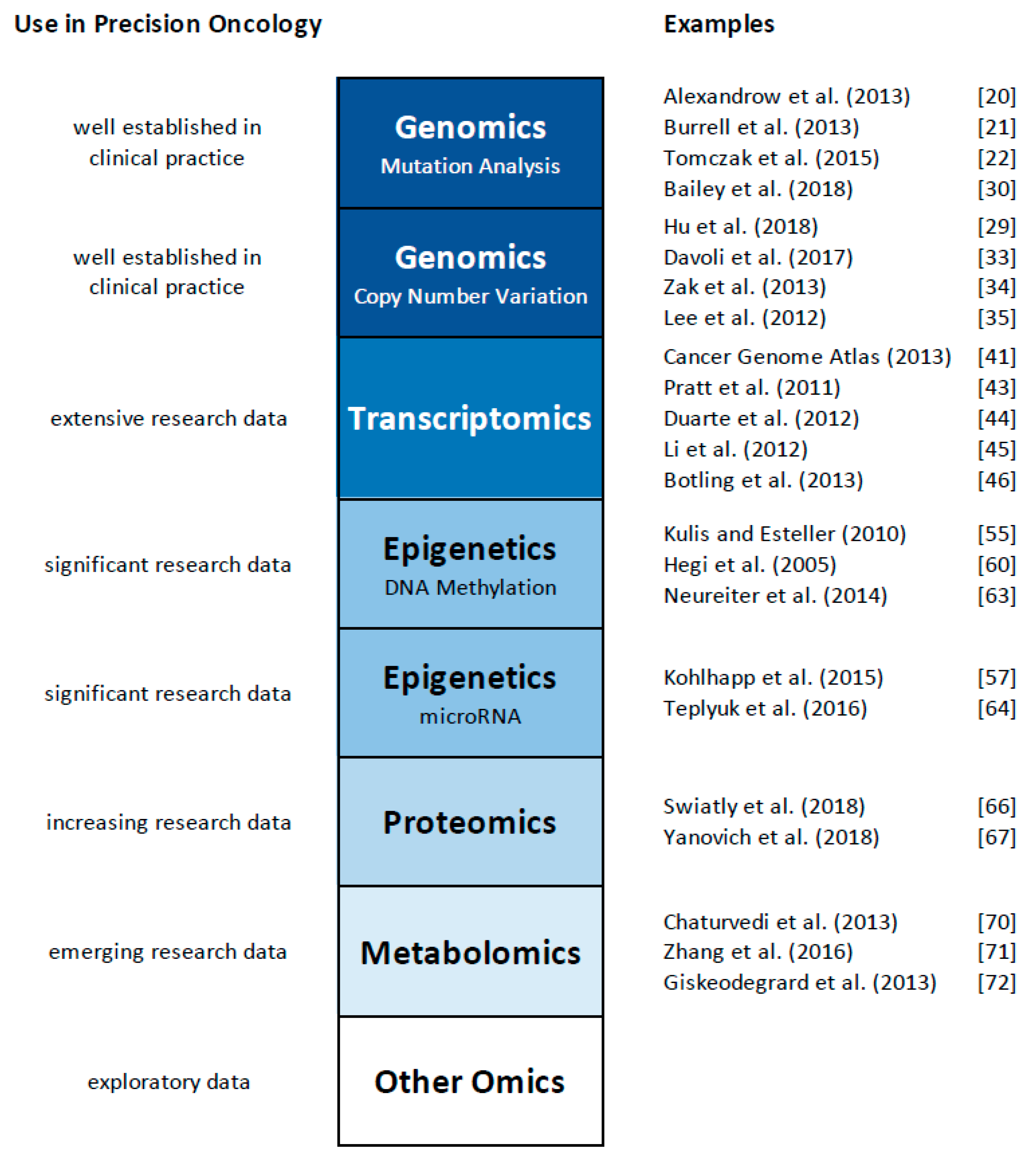
Figure 1.
Summary of the applications of individual omics technologies to study cancer and other human disorders.
Figure 1.
Summary of the applications of individual omics technologies to study cancer and other human disorders.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Olivier, M.; Asmis, R.; Hawkins, G.A.; Howard, T.D.; Cox, L.A. The Need for Multi-Omics Biomarker Signatures in Precision Medicine. Int. J. Mol. Sci. 2019, 20, 4781. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms20194781
AMA Style
Olivier M, Asmis R, Hawkins GA, Howard TD, Cox LA. The Need for Multi-Omics Biomarker Signatures in Precision Medicine. International Journal of Molecular Sciences. 2019; 20(19):4781. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms20194781
Chicago/Turabian StyleOlivier, Michael, Reto Asmis, Gregory A. Hawkins, Timothy D. Howard, and Laura A. Cox. 2019. "The Need for Multi-Omics Biomarker Signatures in Precision Medicine" International Journal of Molecular Sciences 20, no. 19: 4781. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms20194781
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.