
Characterization of the Human Eccrine Sweat Proteome—A Focus on the Biological Variability of Individual Sweat Protein Profiles

 , , ,
, , ,
Abstract
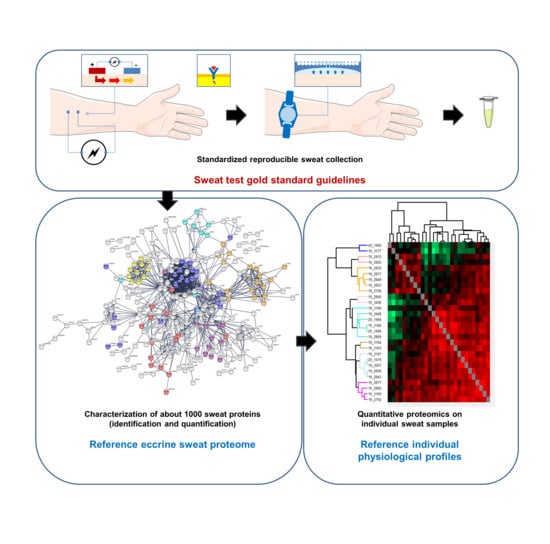
:
1. Introduction
2. Materials and Methods
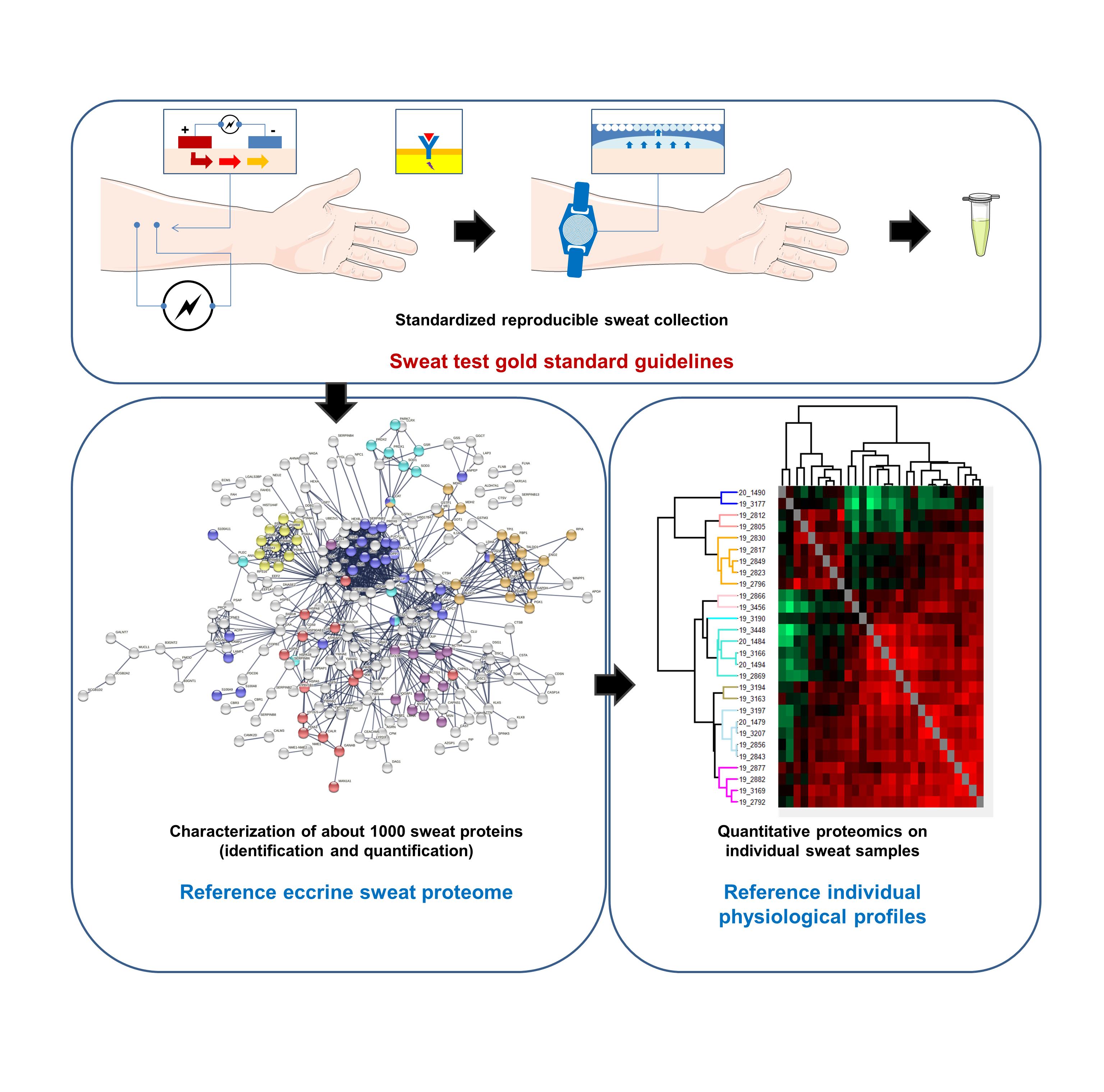
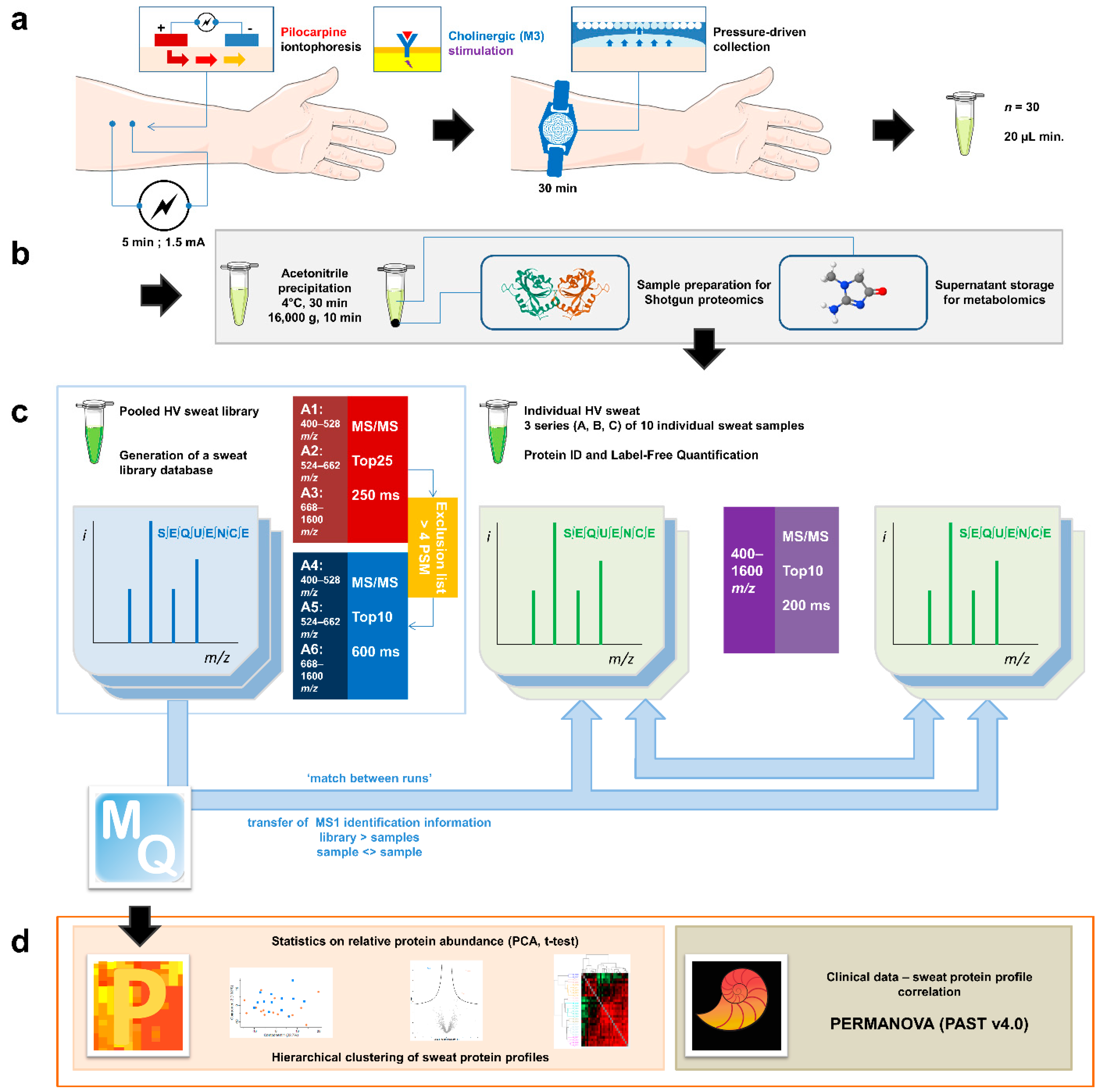
2.1. Sweat Collection
2.2. Sample Preparation for Shotgun Proteomics
2.3. Liquid Chromatography and Mass Spectrometry Data Acquisition
2.4. Bioinformatic Analysis and Statistics
2.5. Subject Inclusion and Study Approval
3. Results
3.1. The Proteome of Human Eccrine Sweat
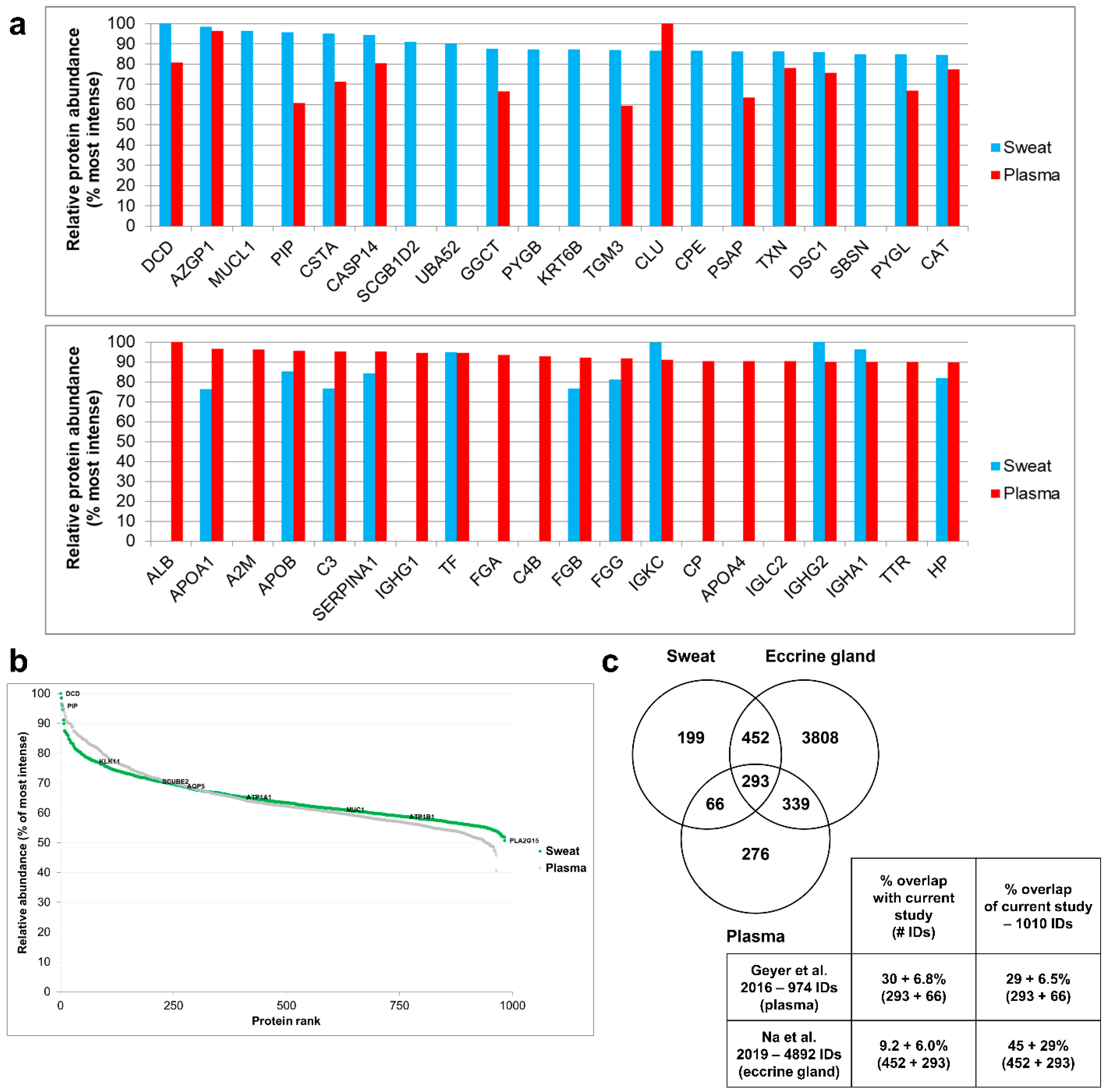
3.2. Protein Identification: Comparison to Previous Studies
3.3. Protein Classification and Over-Representation
3.4. Relative Contributions of Plasma and the Eccrine Gland to Sweat Protein Composition
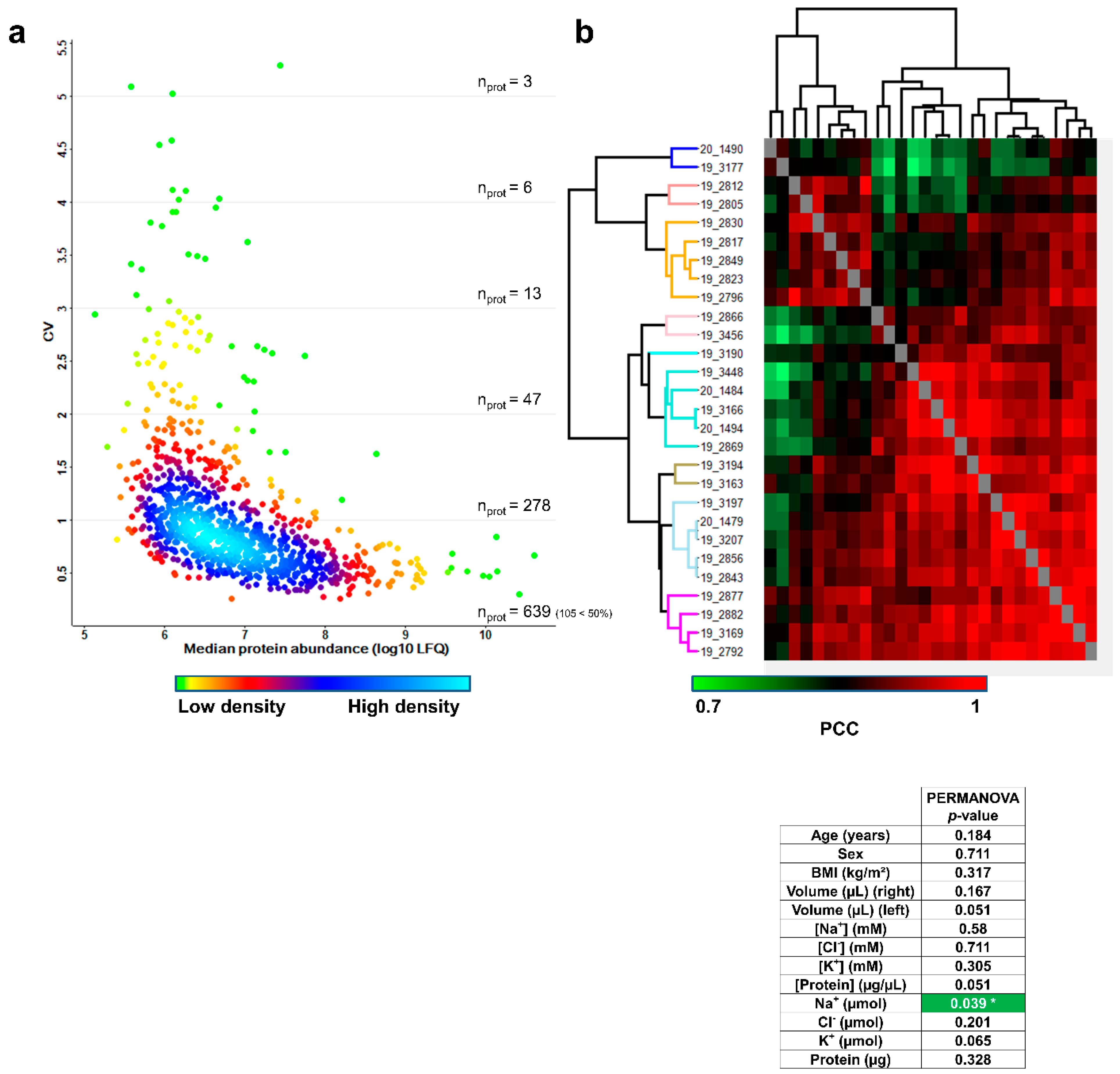
3.5. Inter-Individual Variability of the Sweat Proteome
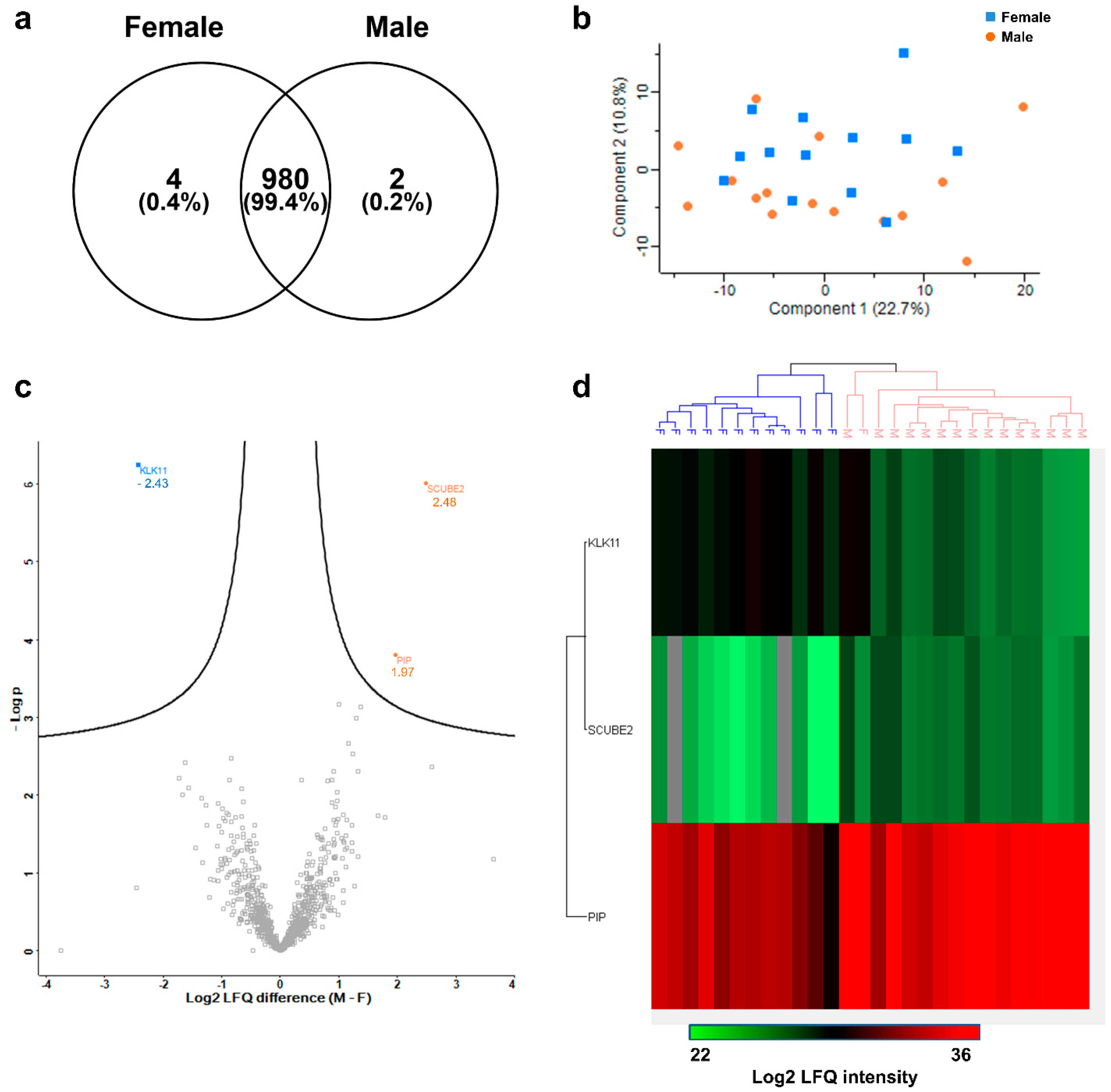
3.6. Inter-Gender Variability of the Sweat Proteome
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ABP | Actin-Binding Proteins |
| AGC | Automated Gain Control |
| BMI | Body Mass Index |
| ER | Endoplasmic Reticulum |
| FDR | False Discovery Rate |
| HV | Healthy Volunteers |
| IT | Injection Time |
| LFQ | Label-Free Quantification |
| MbR | Match between Runs |
| N(CE) | Normalized Collision Energy |
| PCA | Principal Component Analysis |
| PCC | Pearson’s Correlation Coefficients |
| PERMANOVA | PERmutational Multivariate ANalysis Of VAriance |
| UPR | Unfolded Protein Response |
References
- Saga, K. Histochemical and Immunohistochemical Markers for Human Eccrine and Apocrine Sweat Glands: An Aid for Histopathologic Differentiation of Sweat Gland Tumors. J. Investig. Dermatol. Symp. Proc. 2001, 6, 49–53. [Google Scholar] [CrossRef] [Green Version]
- Cui, C.-Y.; Schlessinger, D. Eccrine Sweat Gland Development and Sweat Secretion. Exp. Dermatol. 2015, 24, 644–650. [Google Scholar] [CrossRef] [PubMed]
- Mena-Bravo, A.; Luque de Castro, M.D. Sweat: A Sample with Limited Present Applications and Promising Future in Metabolomics. J. Pharm. Biomed. Anal. 2014, 90, 139–147. [Google Scholar] [CrossRef]
- Calderón-Santiago, M.; Priego-Capote, F.; Jurado-Gámez, B.; Luque de Castro, M.D. Optimization Study for Metabolomics Analysis of Human Sweat by Liquid Chromatography–Tandem Mass Spectrometry in High Resolution Mode. J. Chromatogr. A 2014, 1333, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Delgado-Povedano, M.M.; Calderón-Santiago, M.; Priego-Capote, F.; Luque de Castro, M.D. Study of Sample Preparation for Quantitative Analysis of Amino Acids in Human Sweat by Liquid Chromatography–Tandem Mass Spectrometry. Talanta 2016, 146, 310–317. [Google Scholar] [CrossRef]
- Delgado-Povedano, M.M.; Calderón-Santiago, M.; Priego-Capote, F.; Luque de Castro, M.D. Development of a Method for Enhancing Metabolomics Coverage of Human Sweat by Gas Chromatography–Mass Spectrometry in High Resolution Mode. Anal. Chim. Acta 2016, 905, 115–125. [Google Scholar] [CrossRef] [PubMed]
- Luque de Castro, M.D. Sweat as a Clinical Sample: What Is Done and What Should Be Done. Bioanalysis 2016, 8, 85–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farrell, P.M.; White, T.B.; Ren, C.L.; Hempstead, S.E.; Accurso, F.; Derichs, N.; Howenstine, M.; McColley, S.A.; Rock, M.; Rosenfeld, M.; et al. Diagnosis of Cystic Fibrosis: Consensus Guidelines from the Cystic Fibrosis Foundation. J. Pediatrics 2017, 181, S4–S15.e1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Csősz, É.; Kalló, G.; Márkus, B.; Deák, E.; Csutak, A.; Tőzsér, J. Quantitative Body Fluid Proteomics in Medicine—A Focus on Minimal Invasiveness. J. Proteom. 2017, 153, 30–43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Csősz, É.; Emri, G.; Kalló, G.; Tsaprailis, G.; Tőzsér, J. Highly Abundant Defense Proteins in Human Sweat as Revealed by Targeted Proteomics and Label-Free Quantification Mass Spectrometry. J. Eur. Acad. Dermatol. Venereol. 2015, 29, 2024–2031. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Prassas, I.; Muytjens, C.M.J.; Diamandis, E.P. Proteomic and Peptidomic Analysis of Human Sweat with Emphasis on Proteolysis. J. Proteom. 2017, 155, 40–48. [Google Scholar] [CrossRef] [PubMed]
- Harshman, S.W.; Pitsch, R.L.; Smith, Z.K.; O’Connor, M.L.; Geier, B.A.; Qualley, A.V.; Schaeublin, N.M.; Fischer, M.V.; Eckerle, J.J.; Strang, A.J.; et al. The Proteomic and Metabolomic Characterization of Exercise-Induced Sweat for Human Performance Monitoring: A Pilot Investigation. PLoS ONE 2018, 13, e0203133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katchman, B.A.; Zhu, M.; Blain Christen, J.; Anderson, K.S. Eccrine Sweat as a Biofluid for Profiling Immune Biomarkers. Proteom. Clin. Appl. 2018, 12, 1800010. [Google Scholar] [CrossRef] [Green Version]
- Raiszadeh, M.M.; Ross, M.M.; Russo, P.S.; Schaepper, M.A.; Zhou, W.; Deng, J.; Ng, D.; Dickson, A.; Dickson, C.; Strom, M.; et al. Proteomic Analysis of Eccrine Sweat: Implications for the Discovery of Schizophrenia Biomarker Proteins. J. Proteome Res. 2012, 11, 2127–2139. [Google Scholar] [CrossRef] [Green Version]
- Adewole, O.O.; Erhabor, G.E.; Adewole, T.O.; Ojo, A.O.; Oshokoya, H.; Wolfe, L.M.; Prenni, J.E. Proteomic Profiling of Eccrine Sweat Reveals Its Potential as a Diagnostic Biofluid for Active Tuberculosis. Prot. Clin. Appl. 2016, 10, 547–553. [Google Scholar] [CrossRef] [PubMed]
- Baker, L.B. Physiology of Sweat Gland Function: The Roles of Sweating and Sweat Composition in Human Health. Temperature 2019, 6, 211–259. [Google Scholar] [CrossRef] [Green Version]
- Baker, L.B.; Wolfe, A.S. Physiological Mechanisms Determining Eccrine Sweat Composition. Eur. J. Appl. Physiol. 2020, 120, 719–752. [Google Scholar] [CrossRef] [Green Version]
- CLSI. C34: Sweat Sample Collection & Chloride Analysis. Available online: https://clsi.org/standards/products/clinical-chemistry-and-toxicology/documents/c34/ (accessed on 7 May 2021).
- Geyer, P.E.; Kulak, N.A.; Pichler, G.; Holdt, L.M.; Teupser, D.; Mann, M. Plasma Proteome Profiling to Assess Human Health and Disease. Cell Syst. 2016, 2, 185–195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, C.; Zhao, M.; Chen, X.; Sun, H.; Yang, Y.; Xiao, X.; Guo, Z.; Liu, X.; Lv, Y.; Chen, X.; et al. Comprehensive Analysis of Individual Variation in the Urinary Proteome Revealed Significant Gender Differences. Mol. Cell. Proteom. 2019, 18, 1110–1122. [Google Scholar] [CrossRef] [PubMed]
- Baechle, D.; Flad, T.; Cansier, A.; Steffen, H.; Schittek, B.; Tolson, J.; Herrmann, T.; Dihazi, H.; Beck, A.; Mueller, G.A.; et al. Cathepsin D Is Present in Human Eccrine Sweat and Involved in the Postsecretory Processing of the Antimicrobial Peptide DCD-1L. J. Biol. Chem. 2006, 281, 5406–5415. [Google Scholar] [CrossRef] [Green Version]
- Murakami, M.; Ohtake, T.; Dorschner, R.A.; Gallo, R.L.; Schittek, B.; Garbe, C. Cathelicidin Anti-Microbial Peptide Expression in Sweat, an Innate Defense System for the Skin. J. Investig. Dermatol. 2002, 119, 1090–1095. [Google Scholar] [CrossRef] [Green Version]
- Park, J.-H.; Park, G.-T.; Cho, I.H.; Sim, S.-M.; Yang, J.-M.; Lee, D.-Y. An Antimicrobial Protein, Lactoferrin Exists in the Sweat: Proteomic Analysis of Sweat: Letter to the Editor. Exp. Dermatol. 2011, 20, 369–371. [Google Scholar] [CrossRef] [PubMed]
- Schittek, B.; Hipfel, R.; Sauer, B.; Bauer, J.; Kalbacher, H.; Stevanovic, S.; Schirle, M.; Schroeder, K.; Blin, N.; Meier, F.; et al. Dermcidin: A Novel Human Antibiotic Peptide Secreted by Sweat Glands. Nat. Immunol. 2001, 2, 1133–1137. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.-X.; Liu, Z.-F. Proteomic Profiling of Sweat Exosome Suggests Its Involvement in Skin Immunity. J. Investig. Dermatol. 2018, 138, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Sato, K.; Kang, W.H.; Saga, K.; Sato, K.T. Biology of Sweat Glands and Their Disorders. I. Normal Sweat Gland Function. J. Am. Acad. Dermatol. 1989, 20, 537–563. [Google Scholar] [CrossRef]
- Deutsch, E.W.; Csordas, A.; Sun, Z.; Jarnuczak, A.; Perez-Riverol, Y.; Ternent, T.; Campbell, D.S.; Bernal-Llinares, M.; Okuda, S.; Kawano, S.; et al. The ProteomeXchange Consortium in 2017: Supporting the Cultural Change in Proteomics Public Data Deposition. Nucleic Acids Res. 2017, 45, D1100–D1106. [Google Scholar] [CrossRef] [PubMed]
- Vizcaíno, J.A.; Csordas, A.; del-Toro, N.; Dianes, J.A.; Griss, J.; Lavidas, I.; Mayer, G.; Perez-Riverol, Y.; Reisinger, F.; Ternent, T.; et al. 2016 Update of the PRIDE Database and Its Related Tools. Nucleic Acids Res. 2016, 44, D447–D456. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample IDs | Age (years) | Sex | BMI (kg/m²) | Collected Volume (µL) (Right Arm) | Collected Volume (µL) (Left Arm) | [Na+] (mM) | [Cl−] (mM) | [K+] (mM) | [Protein] (µg/µL) | Na+ (µmol) | Cl− (µmol) | K+ (µmol) | Protein (µg) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 19_2792 | 36 | M | 22.7 | 62.1 | 87.8 | 56 | 26 | 8 | 0.488 | 3.48 | 1.61 | 0.50 | 42.85 | HV (n = 28) |
| 19_2796 | 29 | M | 31.6 | 48.1 | 42.4 | 23 | 4 | 10 | 0.557 | 1.11 | 0.19 | 0.48 | 23.62 | |
| 19_2805 | 28 | M | 30.0 | 98.9 | 97.5 | 59 | 24 | 7 | 0.340 | 5.84 | 2.37 | 0.69 | 33.15 | |
| 19_2812 | 40 | M | 25.5 | 89.6 | 96.5 | 39 | 18 | 8 | 0.432 | 3.49 | 1.61 | 0.72 | 41.69 | |
| 19_2866 | 74 | M | 21.3 | 56.9 | 64.2 | 37 | 12 | 12 | 0.551 | 2.11 | 0.68 | 0.68 | 35.37 | |
| 19_2823 | 31 | F | 19.8 | 71.8 | 89.8 | 32 | 10 | 10 | 0.262 | 2.30 | 0.72 | 0.72 | 23.53 | |
| 19_2830 | 30 | F | 23.1 | 94.0 | 77.9 | 32 | 11 | 8 | 0.462 | 3.01 | 1.03 | 0.75 | 35.99 | |
| 19_2843 | 24 | F | 18.2 | 63.5 | 64.1 | 65 | 36 | 10 | 0.472 | 4.13 | 2.29 | 0.64 | 30.26 | |
| 19_2849 | 27 | F | 20.5 | 97.7 | 84.6 | 22 | 10 | 8 | 0.432 | 2.15 | 0.98 | 0.78 | 36.55 | |
| 19_2856 | 29 | F | 18.7 | 79.7 | 70.4 | 28 | 6 | 8 | 0.422 | 2.23 | 0.48 | 0.64 | 29.71 | |
| 19_3163 | 32 | F | 19.4 | 44.8 | 30.1 | 30 | 12 | 9 | 0.785 | 1.34 | 0.54 | 0.40 | 23.63 | |
| 19_3166 | 26 | F | 18.9 | 57.2 | 64.0 | 44 | 22 | 10 | 0.494 | 2.52 | 1.26 | 0.57 | 31.62 | |
| 20_1490 | 39 | F | 21.3 | 40.1 | 43.5 | 26 | 12 | 8 | 0.371 | 1.04 | 0.48 | 0.32 | 16.14 | |
| 19_3177 | 28 | M | 23.1 | 35.9 | 27.0 | 51 | 30 | 8 | 0.475 | 1.83 | 1.08 | 0.29 | 12.83 | |
| 19_3190 | 29 | M | 24.5 | 98.6 | 80.7 | 55 | 28 | 6 | 0.406 | 5.42 | 2.76 | 0.59 | 32.76 | |
| 19_3194 | 41 | M | 24.1 | 34.4 | 42.7 | 36 | 8 | 9 | 0.736 | 1.24 | 0.28 | 0.31 | 31.43 | |
| 19_3197 | 36 | M | 22.5 | 27.5 | 82.7 | 91 | 44 | 8 | 0.504 | 2.50 | 1.21 | 0.22 | 41.68 | |
| 19_3207 | 28 | M | 23.8 | 84.9 | 93.2 | 45 | 22 | 7 | 0.364 | 3.82 | 1.87 | 0.59 | 33.92 | |
| 20_1494 | 29 | F | 20.9 | 61.3 | 64.4 | 54 | 30 | 12 | 0.441 | 3.31 | 1.84 | 0.74 | 28.40 | |
| 19_2869 | 28 | F | 17.7 | 57.1 | 45.9 | 67 | 10 | 24 | 0.646 | 3.83 | 0.57 | 1.37 | 29.65 | |
| 19_2877 | 33 | F | 22.3 | 102.7 | 83.7 | 35 | 12 | 7 | 0.350 | 3.59 | 1.23 | 0.72 | 29.30 | |
| 19_2882 | 24 | F | 20.6 | 57.2 | 53.6 | 29 | 10 | 6 | 0.377 | 1.66 | 0.57 | 0.34 | 20.21 | |
| 19_3169 | 57 | F | 19.2 | 35.6 | 29.9 | 58 | 24 | 8 | 0.661 | 2.06 | 0.85 | 0.28 | 19.76 | |
| 20_1479 | 25 | M | 24.5 | 56.4 | 72.6 | 69 | 38 | 7 | 0.336 | 3.89 | 2.14 | 0.39 | 24.39 | |
| 20_1484 | 24 | M | 23.6 | 99.0 | 93.4 | 49 | 20 | 8 | 0.622 | 4.85 | 1.98 | 0.79 | 58.09 | |
| 19_2817 | 26 | M | 20.8 | 47.4 | 40.4 | 73 | 44 | 9 | 0.314 | 3.46 | 2.09 | 0.43 | 12.69 | |
| 19_3448 | 30 | M | 20.6 | 91.2 | 74.0 | 50 | 22 | 10 | 0.448 | 4.56 | 2.01 | 0.91 | 33.15 | |
| 19_3456 | 31 | M | 22.6 | 101.5 | 99.5 | 69 | 40 | 5 | 0.198 | 7.00 | 4.06 | 0.51 | 19.70 | |
| Mean | 33 | 13 F 15 M | 22.2 | 67.7 | 67.7 | 47 | 21 | 9 | 0.462 | 3.13 | 1.39 | 0.58 | 29.72 | |
| Median | 29 | 21.8 | 61.7 | 71.5 | 47 | 21 | 8 | 0.445 | 3.16 | 1.22 | 0.59 | 29.98 | ||
| SD | 11 | 3.2 | 24.2 | 22.7 | 18 | 12 | 3 | 0.137 | 1.49 | 0.89 | 0.24 | 9.87 | ||
| SEM | 2 | 0.6 | 4.6 | 4.3 | 3 | 2 | 1 | 0.026 | 0.28 | 0.17 | 0.05 | 1.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burat, B.; Reynaerts, A.; Baiwir, D.; Fléron, M.; Eppe, G.; Leal, T.; Mazzucchelli, G. Characterization of the Human Eccrine Sweat Proteome—A Focus on the Biological Variability of Individual Sweat Protein Profiles. Int. J. Mol. Sci. 2021, 22, 10871. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms221910871
Burat B, Reynaerts A, Baiwir D, Fléron M, Eppe G, Leal T, Mazzucchelli G. Characterization of the Human Eccrine Sweat Proteome—A Focus on the Biological Variability of Individual Sweat Protein Profiles. International Journal of Molecular Sciences. 2021; 22(19):10871. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms221910871
Chicago/Turabian StyleBurat, Bastien, Audrey Reynaerts, Dominique Baiwir, Maximilien Fléron, Gauthier Eppe, Teresinha Leal, and Gabriel Mazzucchelli. 2021. "Characterization of the Human Eccrine Sweat Proteome—A Focus on the Biological Variability of Individual Sweat Protein Profiles" International Journal of Molecular Sciences 22, no. 19: 10871. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms221910871