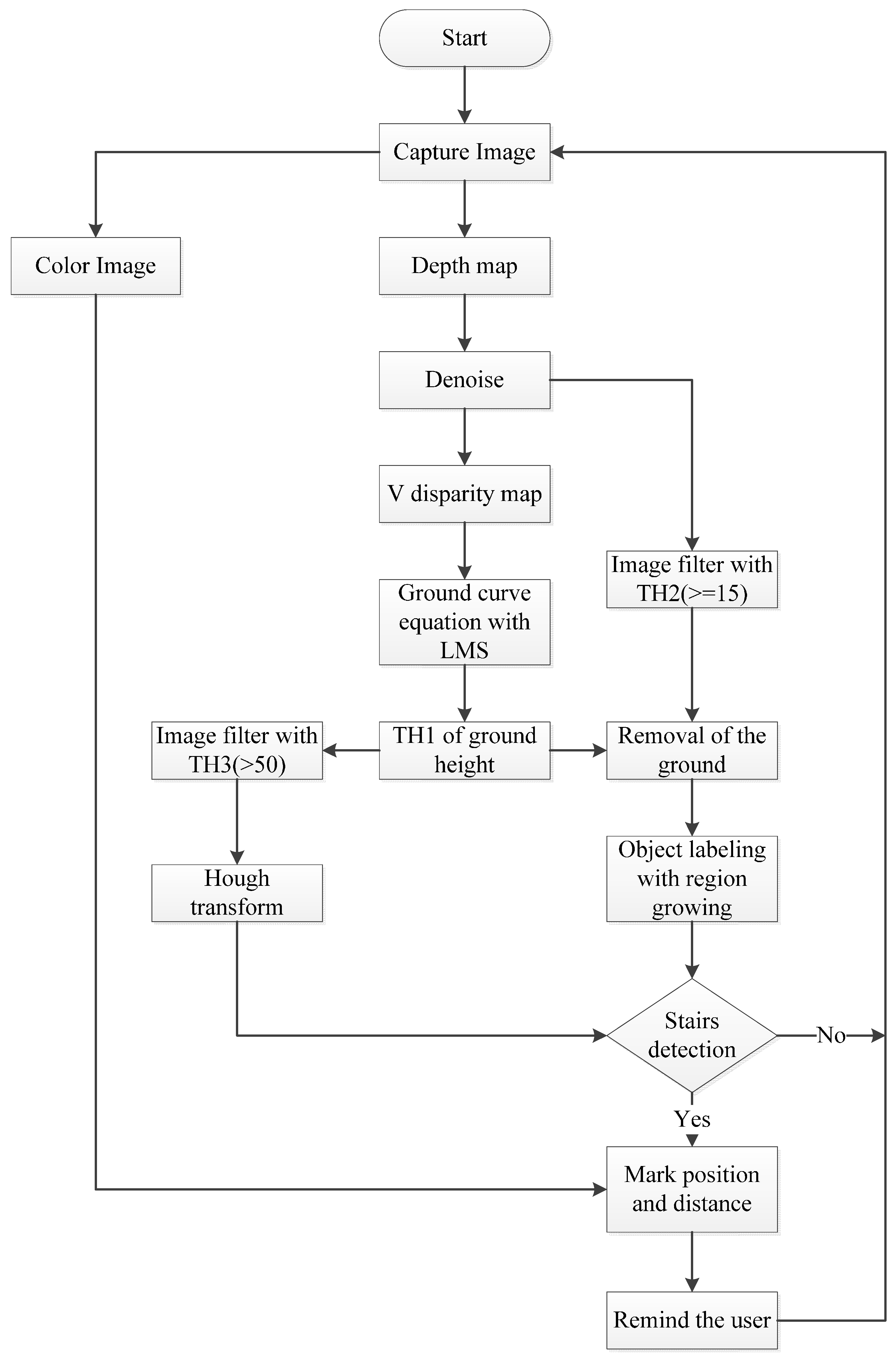
2.3. Ground Height Detection
A UV disparity map is composed of the U disparity map and the V disparity map from the depth map.
Figure 3 shows that the V-disparity [
39] concept simplifies the process of separating obstacles in an image, where “V” corresponds to the vertical coordinate in the (u, v) image coordinate system. Similarly, the U-disparity concept simplifies the process of separating obstacles in an image, where “U” corresponds to the vertical coordinate in the (u, v) image coordinate system.
A UV disparity map [
40] is a statistical method that is similar to a histogram. However, the statistical target is different. The proposed system only uses V-Disparity because the effect is better.
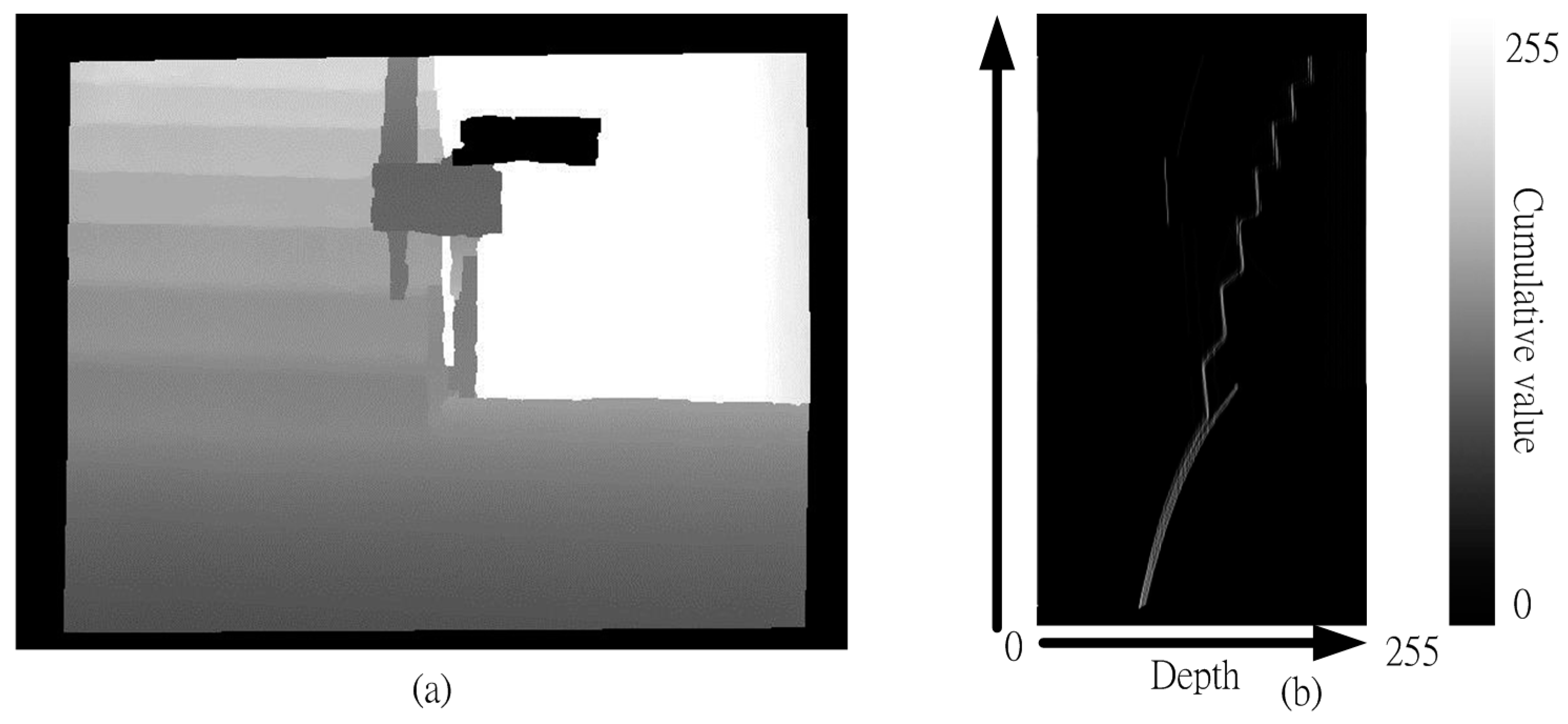
Figure 4a shows that this table is a depth map. The statistics for different depth values are gathered, row-by-row, and the results are shown in
Figure 4b. For example, there are 15 zeros in row one in
Figure 4a, so the position of Row 2 and Column 1 in
Figure 4b records this value (15). This means that the depth value, 0, has an image height of 15.
Figure 3.
The relationship between the depth map and the V-disparity. (a) Depth map; (b) V-disparity.
Figure 3.
The relationship between the depth map and the V-disparity. (a) Depth map; (b) V-disparity.
Figure 4.
A schematic diagram of the V disparity map. (a) Depth map; (b) V disparity map.
Figure 4.
A schematic diagram of the V disparity map. (a) Depth map; (b) V disparity map.
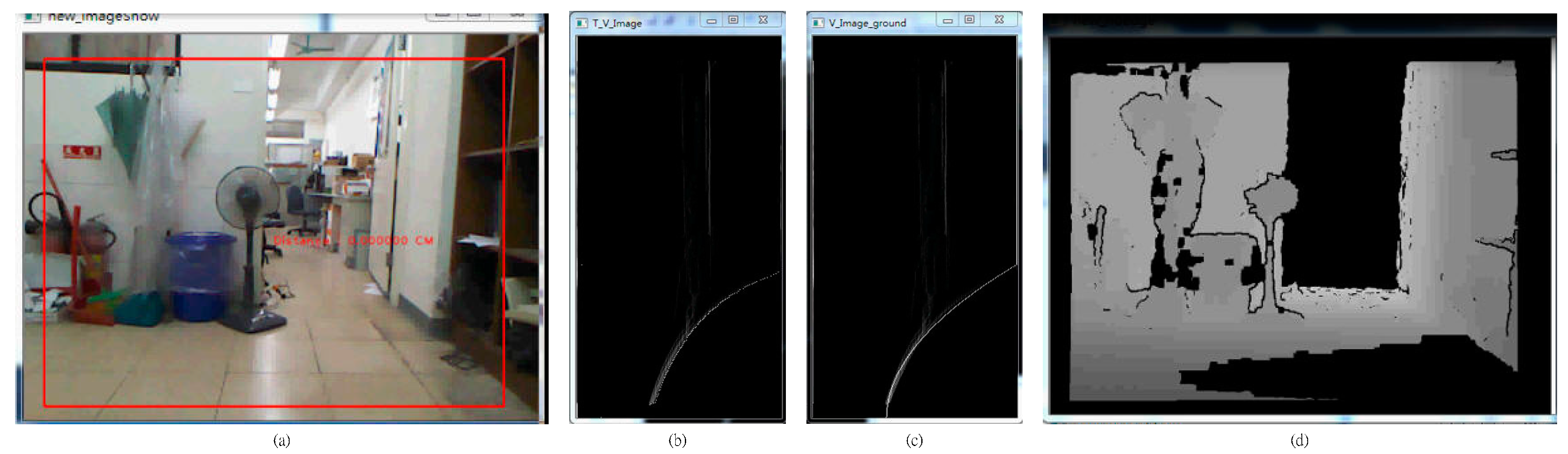
The detection needs for subsequent steps require that noise must be removed from the captured depth map this must be projected into the V disparity map, as shown in
Figure 5. The Y-axis height of the V disparity map corresponds to the Y-axis height of the depth maps, as shown in
Figure 5, so the vertical length of an image represents the height of the actual object in the image. If the object is closer to the right side of the depth map, the distance between the object and the sensor is greater. The greater the pixel value in the V disparity map, the bigger is the object in the image. The normalization equation for the cumulative amount of depth is shown in the following equation. The cumulative value must be between 0 and 255. The cumulative value is statistical value of depth value of the row of the V disparity map image, and the Max cumulative value is image wide value of the depth map:
According to [
11], the ground is a rising curve in a V disparity map. The LSM is used to determine the equation of the curve, as shown in
Figure 6 and Equation (2).
Figure 5.
(a) The depth map with noise removed and (b) the V disparity map image.
Figure 5.
(a) The depth map with noise removed and (b) the V disparity map image.
Figure 6.
The ground curve in V disparity map. (a) Segment consisting of points (red); (b) The line of the equation (red).
Figure 6.
The ground curve in V disparity map. (a) Segment consisting of points (red); (b) The line of the equation (red).
where a, b and c respectively represent the parameters of the equation, y is the image height and d is the horizontal axis value (0 to 255) in the V-disparity map. However, we want to find out a quadratic equation to closer ground curve strip, then use it to remove ground plane. The ground plane is not only a simple line in the V-disparity map. Because pixels that are the same height in a depth map can have a different depth value, the curve becomes a strip, so several approximation targets, such as the minimum, the maximum, the mean and the specific value of every row of V-disparity map are used (the rightmost value of the strip, the leftmost value of the strip, the middle value of the strip on x-axis).When the obstacle is on the ground, these methods do not work. To address this problem, the proposed method uses the quadratic offset equation, which is shown as Equation (3):
where
TH1 is the shifted threshold depending on the ground height. The ground height threshold value indicates a height in the depth map and the minimum value cannot be less than
TH1. The appropriate offset value is 35, which is obtained through experience. The offset value affects the removal of the ground, so several offset values, such as the minimum, the maximum, the mean and the specific value, are tried. The offset value controls the location of the approximation curve for the disparity map. The quadratic offset equation is the fastest and simplest method. Comparing the disparity map in
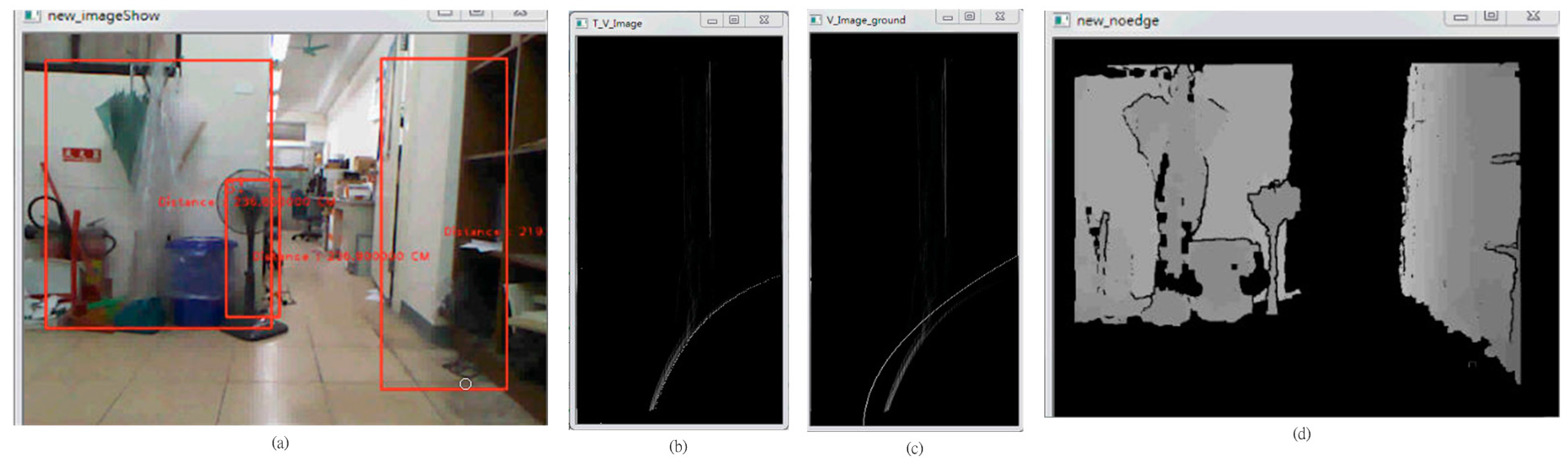
Figure 7 with that in
Figure 8, it is seen that the depth value of the ground plane (background) is greater than the depth value of the obstacle (foreground) for the same height.
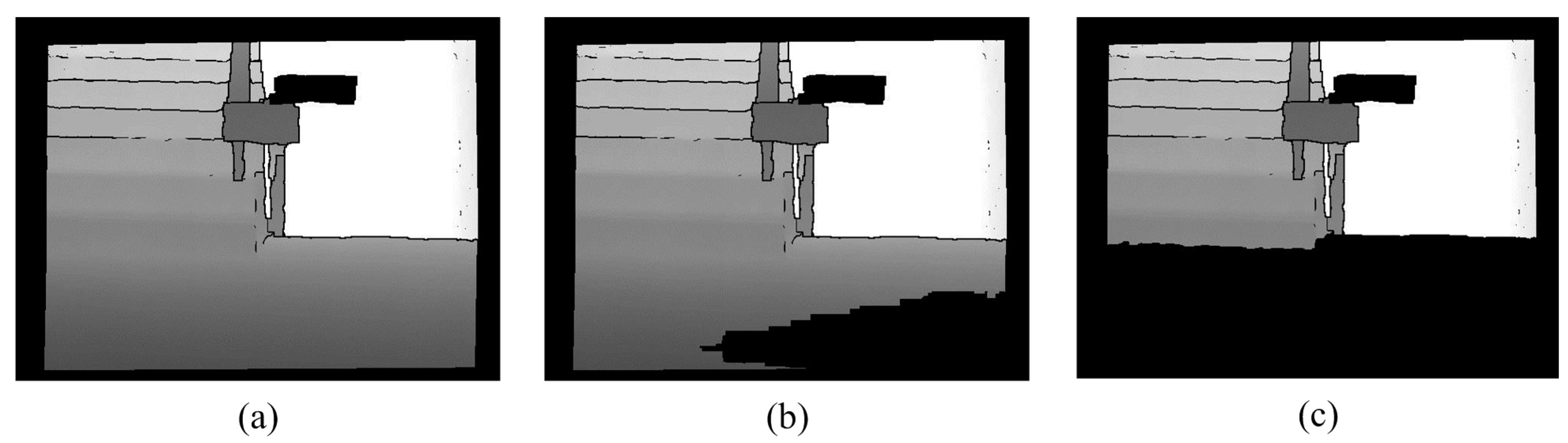
Figure 9 shows that the mean method (no offset) does not completely remove the ground plane. Therefore, the maximum method does not remove the ground plane either. In contrast, the minimum method is perhaps the best, but the depth of the obstacle interferes with this method. Because the depth value for the background is greater than the depth value for the foreground for the same height in the V-disparity, the minimum method cannot be used directly. Using the LSM to subtract the specific value is the best method, as shown in
Figure 10.
Figure 11 shows that Equation (3) improves the robustness of the system.
Figure 7.
The scene without people. (a) Real scene; (b) V-disparity; (c) Depth map.
Figure 7.
The scene without people. (a) Real scene; (b) V-disparity; (c) Depth map.
Figure 8.
The scene with people. (a) Real scene; (b) V-disparity; (c) Depth map.
Figure 8.
The scene with people. (a) Real scene; (b) V-disparity; (c) Depth map.
Figure 9.
No offset. (a) Real scene; (b) No LSM Curve; (c) LSM Curve without offset; (d) Depth map.
Figure 9.
No offset. (a) Real scene; (b) No LSM Curve; (c) LSM Curve without offset; (d) Depth map.
Figure 10.
Offset value = 20. (a) Real scene; (b) No LSM Curve; (c) LSM Curve without offset; (d) Depth map.
Figure 10.
Offset value = 20. (a) Real scene; (b) No LSM Curve; (c) LSM Curve without offset; (d) Depth map.
Figure 11.
The result of the offset. (a) Original depth map; (b) Result image before offset; (c) Result image after offset.
Figure 11.
The result of the offset. (a) Original depth map; (b) Result image before offset; (c) Result image after offset.
2.4. Removal of the Edge
In the depth map, the depth represents the distance between the objects and the sensor. The variation in depth demonstrates whether the obstacles are the same. Variations in depth are usually not too significant for a specific object. If there are different objects, the relationship between the distances causes a significant variation in the depth. In this paper, in order to clarify the characteristics of different objects, the strong edge is removed. There are many edge detection methods, such as Roberts, Prewitt, Sobel, Laplace and Canny. In this paper, a function to detect the edge uses the following Equation (4):
Figure 12.
Removal of the edge. (a) Noiseless image; (b) Processing result; (c) Noiseless image; (d) Processing result.
Figure 12.
Removal of the edge. (a) Noiseless image; (b) Processing result; (c) Noiseless image; (d) Processing result.
The processing result is shown in
Figure 12. Here,
represents the pixel value of the coordinates
and
represents the threshold. If
is
neighboring pixel and
is a set of
neighboring pixels and the image is traversed using Equation (4), then the edges in the image can be detected. When all of the edges in the depth map are found, objects can be isolated, so segmentation is accurate.
2.6. Removal of the Ground
If connected component labeling or other labeling methods are directly used to label tags, it is difficult to separate the obstacles from the ground, because the junctions between the ground and the obstacles have the same depth value. Therefore, the information for the ground must be removed. RANSAC plane fitting [
35,
37] is used to determine the ground plane in the 3D space. Because the sensor cannot be fixed, the calculation of the ground information requires an iterative approach. In order to improve the speed of the system, [
38] and the following information are used to filter out the ground: (1) The ground is usually relatively flat and (2) Using the information on depth, the gray value varies from large to small (from far to near). (3) Only the large areas of the ground are required, so Equation (5) is used. Using these features, the planes of interest meet three conditions. The regions and the sizes of the different planes of interest are determined and then the ground plane is removed using Equation (5), which has a large area. The processing result is shown in
Figure 14. These separated objects are label as different color in
Figure 15. The least squares method (LSM) in a quadratic polynomial is used to approximate the ground curves and to determine the ground height threshold in the V-disparity:
where
and
represent the pixel value of the coordinates
, n determines the range (
n = 10) and
represents the threshold (
). These characteristics of ground plane in depth map must meet the following three points: (1) Depth values of horizontally adjacent points of ground plane are almost the same; (2) Depth values of vertically adjacent points of ground plane are gradient; (3) Depth values must be greater than
TH1.
Figure 14.
Removal of the ground. (a) Edge removed image 1; (b) Processing result of (a); (c) Edge removed image 2; (d) Processing result of (c).
Figure 14.
Removal of the ground. (a) Edge removed image 1; (b) Processing result of (a); (c) Edge removed image 2; (d) Processing result of (c).
Figure 15.
Labeling. (a) Ground removed image; (b) Labeling result; (c) Ground removed image; (d) Labeling result.
Figure 15.
Labeling. (a) Ground removed image; (b) Labeling result; (c) Ground removed image; (d) Labeling result.
2.7. Labeling
The reason of using the labeling is easy to observe the experiment. After observations, we can stop this function, and then the performance is better. The Connected Component Method (CCM) and the region growth method [
13,
41] are the most common methods of labeling. The connected component method is used for a 2-D binary image. It scans an image, pixel-by-pixel (from top to bottom and left to right), in order to identify connected pixel regions,
i.e., regions of adjacent pixels, that share the same set of intensity values. CCM can be either 4-Connected Component or 8-Connected Component for two dimensions. The Connected Component Method can be a 6-connected neighborhood, an 18-connected neighborhood, or a 26-connected neighborhood for three dimensions. The disadvantage of the connected component method is that it is time-consuming.
A Region Growth Algorithm (RGA) is a simple, region-based image segmentation method. RGA is suitable for a gradient image. A Seeded Region Growth Method (SRG) [
42] is a type of RGA. SRG is rapid, robust and allows free tuning of a parameter. SRG is faster than CCM, but it allows over-segmentation there is a problem with the initial positions of seeds. We briefly conclude the advantages and disadvantages of region growing. The advantages of region growing are as follows: (1) Region growing methods can correctly separate the regions that have the same properties we define; (2) Region growing methods can provide the original images, which have clear edges the good segmentation results; (3) The concept is simple. We only need a small numbers of seed point to represent the property we want, then grow the region; (4) We can determine the seed point and the criteria we want to make; (5) We can choose the multiple criteria at the same time; (6) It performs well with respect to noise. The Disadvantage of region growing as following: Noise or variation of intensity may result in holes or over-segmentation. We proposed system could solve this disadvantage of region-growing techniques.
The sensing range of Kinect is 0.8 to 4.0 m. When the range is greater than the maximum distance, it cannot determine the distance, so the distant information must be removed. In order to measure distances accurately, the distance information for less than 3 m is retained.
Different tags are then placed on different objects. The general labeling methods use eight connected component labeling and region growth, but tag harmonization for connected component labeling requires much iteration, because of the complex shape of the connected area:
Equation (6) is 8-connnected of image processing. According to neighbor state of , to determine belongs to which seed (classification). Here, represents the seed coordinate and represents the pixel value at the coordinate .
In order to increase the efficiency of the system, Connected Component Region Growth is used. Traditional region growth initially sprinkles some seeds in the image. If the distribution of the sprinkled seeds is not appropriate, the growth results are imperfect, so the choice of the initial position of the seeds is improved in the proposed system. Information about object edges is used. Because the previous step removes the edge information for an object, each object is isolated by black color. Equation (6) and the mask for the initial seed are used to select the coordinates of initial seeds, as shown in
Figure 16. These coordinates are then used to execute region growth. This ensures that each object has an initial seed and that any growth is not been repeated. Therefore, a system to reduce the amount of computation is proposed. The processing result is shown in
Figure 17.
Figure 16.
The mask for the initial seed.
Figure 16.
The mask for the initial seed.
Figure 17.
The results for obstacle detection. (a) Bright indoor; (b) Bright indoor; (c) Low-light indoor; (d) Low-light indoor.
Figure 17.
The results for obstacle detection. (a) Bright indoor; (b) Bright indoor; (c) Low-light indoor; (d) Low-light indoor.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









