The proposed method can be partitioned into four phases: pre-processing, problem definition, optimization and post-processing. Each phase will be discussed in detail later.
3.1. Pre-Processing
There are three camera coordinates involved in our system (
Figure 1): the Xtion coordinate, the coordinates of the two DSLR cameras before the epipolar rectification and the DSLR camera coordinates after the epipolar rectification. During the pre-processing step, in order to combine the data from the Xtion and DSLR cameras, as shown in
Figure 3, we firstly calibrated two DSLR cameras using the checkerboard-based method [
25] and calibrated the DSLR camera pair with the Xtion sensor using the planar surfaces-based method [
26], respectively. After the calibration, the depth image obtained from the Xtion is first transformed from the Xtion coordinate to the original DSLR cameras’ coordinates, then rotated and up-sampled, so that it registers with the unrectified left image. Furthermore, according to the theory of epipolar geometric constraints, the registered depth image and original left image, as well as the original right image are rectified to be row-aligned, which means there are only horizontal disparities in the row direction. We denote the seed image (Π) as the map with disparities transferred from the rectified depth map. Each pixel
is defined as a seed pixel when it is assigned a non-zero disparity. The initial disparity maps (
and
) of the rectified left and right images (
and
) are computed using a local stereo matching method [
27].
is partitioned into a set of segments using the edge-aware filter-based segmentation algorithm [
28].
Figure 3.
Conceptual flow diagram for the calibration and rectification phase.
Figure 3.
Conceptual flow diagram for the calibration and rectification phase.
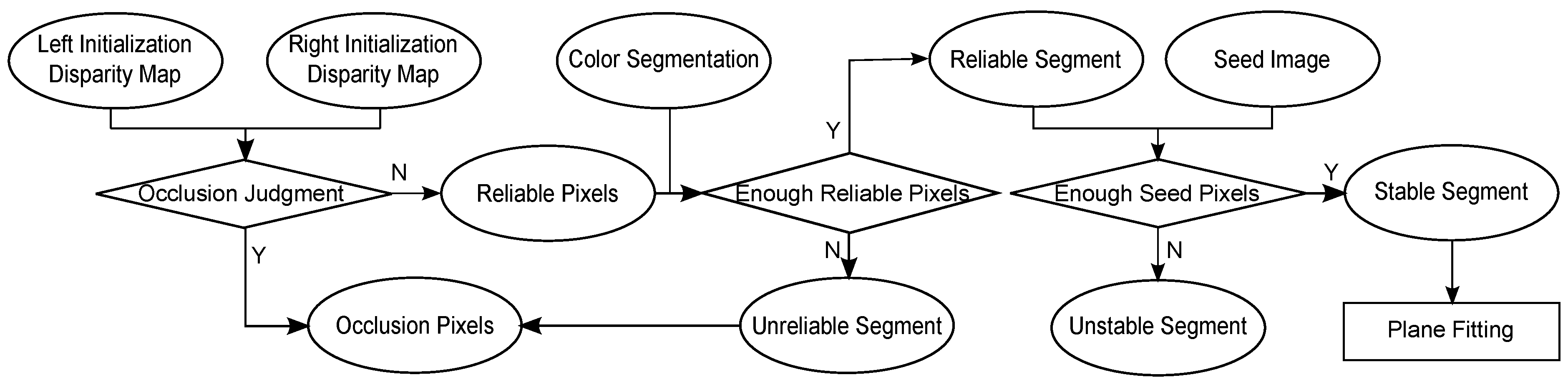
In addition, as shown in
Figure 4, all pixels and segments are divided into different categories. The occlusion judgment is used to find the occluded pixels with initial disparity maps (
and
of
and
, respectively) and to classify pixels into different categories: reliable and occluded. As we known, how to find occluded pixels accurately is always the challenging problem, because it often leads to error results that matching points might not even exist at all, especially in depth discontinuities. Pixels are defined as occluded when they are only visible from the left rectified view (
), but not from the right rectified view (
). Since image pairs have been rectified, we assume that occlusion only occurs in the horizontal direction. In early algorithms, cross-consistency checking is often applied to identify occluded pixels by enforcing a one-to-one correspondence between pixels. It is written as:
and
are the disparity of
p and
q, and
q is the corresponding matching point of
p. If
p does not meet the cross-consistency checking, then it will be regard as an occluded pixel (
); otherwise,
p is a reliable pixel (
). The cross-consistency checking states that a pixel of one image corresponds to at most one pixel of the other image. However, because of different sampling, the projection of a horizontal slant or a curved surface shows various lengths in the image pairs. Therefore, conventional cross-consistency checking that often identifies occluded pixels by enforcing a one-to-one correspondence is only suitable for a frontal parallel surface and cannot be true for a horizontal slant or curved surfaces. Considering the different sampling of image pairs, Bleyer
et al. [
29] proposed a new visibility constraint by extending the asymmetric occlusion model [
30] that allows a one-to-many correspondence between pixels. Let
and
be neighboring pixels in the same horizontal line of
. Then,
will be occluded by
when they meet three conditions:
- -
and have the same matching point in under their current disparity value;
- -
;
- -
and belong to different segments.
In this paper, for each pixel
p of
, if there is only one matching point in
, the conventional cross-checking is applied to obtain the occlusion Equation (
1). Otherwise, if there are more than two matching points in
, pixels in
are marked as either reliable (
) or occluded (
), which satisfy or do not satisfy the Bleyer’s asymmetric occlusion model. As shown in
Figure 4, each segment belongs to the reliable segment (
R) if it contains a sufficient amount of reliable pixels; otherwise, it belongs to the unreliable segment (
). Furthermore, each segment
is denoted as a stable segment (
S) when it contains a sufficient number of seed pixels. Otherwise,
belongs to the unstable segment (
). We apply a RANSAC-based algorithm to approximate each stable segment
as a fitted plane
using the image coordinates and known disparities of all seed pixels belonging to
.
Table 1 lists important notifications used in this paper.
Figure 4.
Conceptual flow diagram for the classification phase.
Figure 4.
Conceptual flow diagram for the classification phase.
Table 1.
Notations.
| D: | Disparity map | : | Disparity value of pixel p | Π: | Seed image |
| : | Initial disparity map of rectified left image | : | Initial disparity map of rectified right image | : | Rectified left DSLR image |
| : | Rectified right DSLR image | R: | Reliable segment | : | Unreliable segment |
| S: | Stable segment | : | Unstable segment | : | i-th segment |
| : | i-th stable segment | : | Fitted plane of stable segment | : | Segment that contains pixel p |
| : | i-th segment | : | Minimum disparity | : | maximum disparity |
| ϖ: | Segment boundary pixels | : | Pixel’s potential minimum disparity | : | Pixel’s potential maximum disparity |
| : | Minimum fitted disparity of the i-th stable segment | : | Minimum fitted disparity of the i-th stable segment | | |
3.2. Problem Formulation
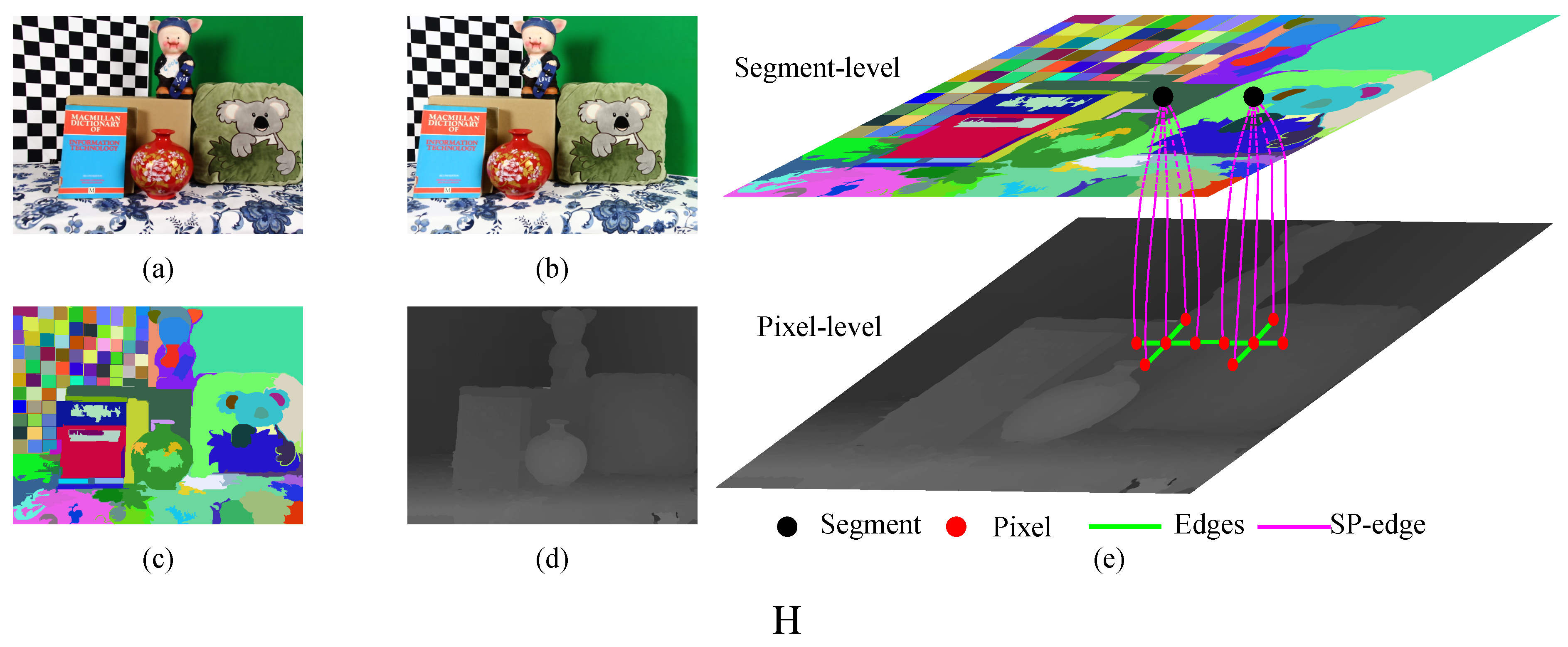
In the problem formulation phase, we propose the MPTL model, which combines the complementary characteristics of stereo matching and the Xtion sensor. As shown in
Figure 2, the MPTL model consists of three components:
- -
The pixel-level component, which improves the robustness against the luminance variance (
Section 3.3) and strengthens the smoothness of disparities between neighboring pixels and segments (
Section 3.4). Nodes at this level represent reliable pixels from stable and unstable segments. The edges between reliable pixels represent different types of smoothness terms.
- -
The edge that connects two level components (the SP-edge), which uses the texture variance and gradient as a guide to restrict the scope of potential disparities (
Section 3.5).
- -
The segment-level component, which incorporates the information from the Xtion as prior knowledge to capture the spatial structure of each stable segment and to maintain the relationship between neighboring stable segments (
Section 3.6). Each node at this level represents a stable segment.
Existing global methods have achieved remarkable results, but the capability of the traditional Markov random field stereo model remains limited. To lessen the matching ambiguities, additional information is required to formulate an accurate model. In this paper, the pixel-level improved luminance consistency term (
), the pixel-level hybrid smoothness term (
) and the SP-edge texture term (
), as well as the segment-level 3D plane bias term (
) are integrated as additional regularization constraints to obtain a precise disparity estimation (
D) for a scene with complex geometric characteristics. According to Bayes’ rule, the posterior probability over
D given
l,
s,
t and
p is:
During each optimization process,
is only dependent on
l,
s,
t and
p. Therefore,
can be rewritten as:
Because maximizing this posterior is equivalent to minimizing its negative log likelihood, our goal is to obtain the disparity map (
D) that minimizes the following energy function:
Each term will be discussed in detail in the following sections.
3.3. Improved Luminance Consistency Term
The conventional luminance consistency hypothesis is used to penalize the appearance dissimilarity between corresponding pixels in
and
, based on the hypothesis that the surface of a 3D object is Lambertian. Because it refers to a perfectly-diffuse appearance in which pixels originating from the same 3D object have similar appearances in different views, its accuracy is heavily dependent on the lighting condition for which colors change substantially depending on the viewpoint. Furthermore, an object may appear to have different colors because different views have different sensor characteristics. In contrast, the Xtion sensor is more robust to the light condition and can be used as prior knowledge to reduce ambiguities caused by the non-Lambertian surface. Thus, the improved luminance consistency term is denoted as:
where
q is the matching pixel of
p in the other image.
is the asymmetric occlusion function described in
Section 3.1, and
is a positive penalty used to avoid maximizing the number of occluded pixels.
is defined as the pixel-wise cost function from stereo matching to measure the color dissimilarity.
where
and
are constant values defined by our experience.
α is the scalar weight from zero to one.
and
are the color dissimilarity and gradient in three color channels as:
is the components from the Xtion sensor, which are defined as:
is the constant threshold, and
is the disparity value assigned to pixel
p in each optimization.
is the disparity of pixel
.
and
are pixel-wise confidence weights that are denoted as
. They are derived from the reliabilities of disparities obtained from stereo matching (
) and the Xtion (
) as:
where
is similar to the attainable maximum likelihood (AML) in [
31], which models the cost for each pixel using a Gaussian distribution centered at the minimum actually achieved cost value for that pixel. The reliability of Xtion data
is the inverse of the normalized standard deviation of the random error [
20]. The confidence of each depth value obtained from the depth sensor decreases with the increasing of the normalized standard deviation.
3.4. Hybrid Smoothness Term
The hybrid smoothness term strengthens the segmentation-based assumption that the disparity variance in each segment is smooth and reduces errors caused by under- and over-segmentation. It consists of four terms: the smoothness term for neighboring reliable pixels belonging to the unstable segment (), the smoothness term for neighboring reliable pixels in the same stable segment (), the smoothness term for neighboring reliable pixels in different stable segments () and the smoothness term for neighboring reliable pixels that belong to stable and unstable segments ().
Because there is no prior knowledge about the spatial structure of unstable segments, we define the smoothness term
as the conventional second-order smoothness prior Equation (
11), which can produce better estimates for a scene with complex geometric characteristics [
11].
where
and
are the geometric proximity and the positive penalty.
is the set of triple-cliques consisting of consecutive reliable pixels belonging to unstable segment.
is the second derivative of the disparity map as:
captures richer features of the local structure and permits planar surfaces without penalty by setting
. However,
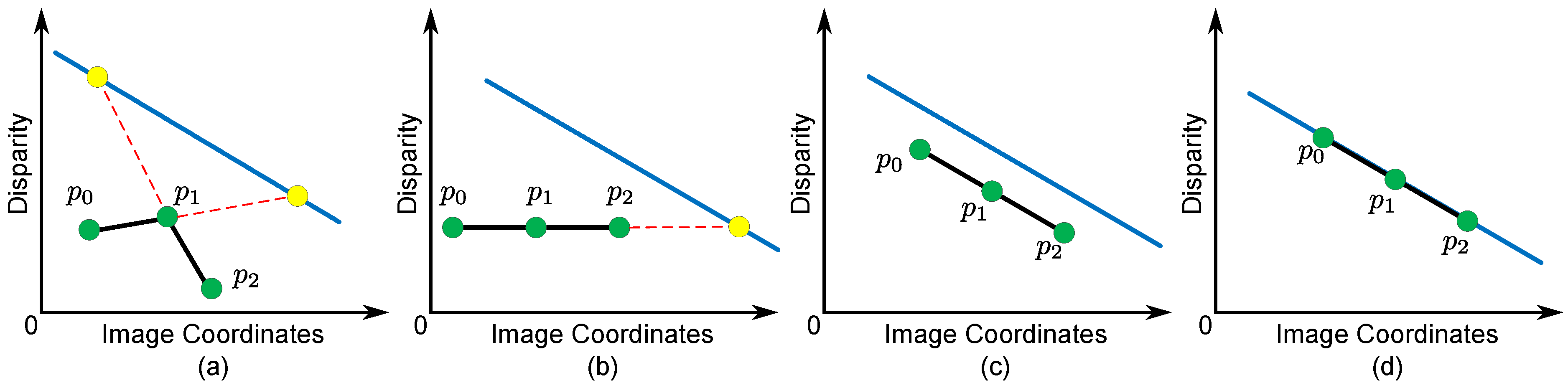
only considers disparity information when representing the smoothness of neighboring pixels. This means that, in several cases, error matching can result in different disparity assignments, which correspond to the same second derivatives in the disparity map (see
Figure 5b–d). Meanwhile, each stable segment can be represented as a fitted plane using the disparity data from the Xtion, which contains prior knowledge about the spatial structure of each stable segment. We can incorporate the spatial similarity weight with the prior knowledge from the Xtion into a conventional second-order smoothness prior. This term encourages constant disparity gradients for pixels in a stable segment and local spatial structures that are similar to the fitted plane of the stable segment. The smoothness term for neighboring reliable pixels in the same stable segment is as follows.
where
is the set of triple-cliques defined by all
and
consecutive reliable pixels along the coordinate direction of the rectified image coordinate in each stable segment.
is a positive value penalty. As for the spatial 3D relationship shown in
Figure 5, let
be the stable segment containing
and
be its corresponding fitted plane. Then, the spatial similarity weight
is denoted as:
- -
Case I: When
, the disparity gradients of pixels in
are not constant (
). This case violates the basic segmentation assumptions that the disparity variance of neighboring pixels is smooth, so a large penalty is added to prevent it from happening in our model (see
Figure 5a).
- -
Cases II, III and IV: When
, the disparity gradients of pixels in
are constant (
). This means that the variance of the disparities is smooth. Furthermore, our model checks the relationship between all pixels in
and
(see
Figure 5b–d).
does not penalize the disparity assignment if all pixels in
belong to
(Case IV in
Figure 5d), because it is reasonable to assume that the local structure of
is the same as the spatial structure of
. Note that we impose a larger penalty to Case II than to Case III to strengthen the similarity between the spatial structure of
and
.
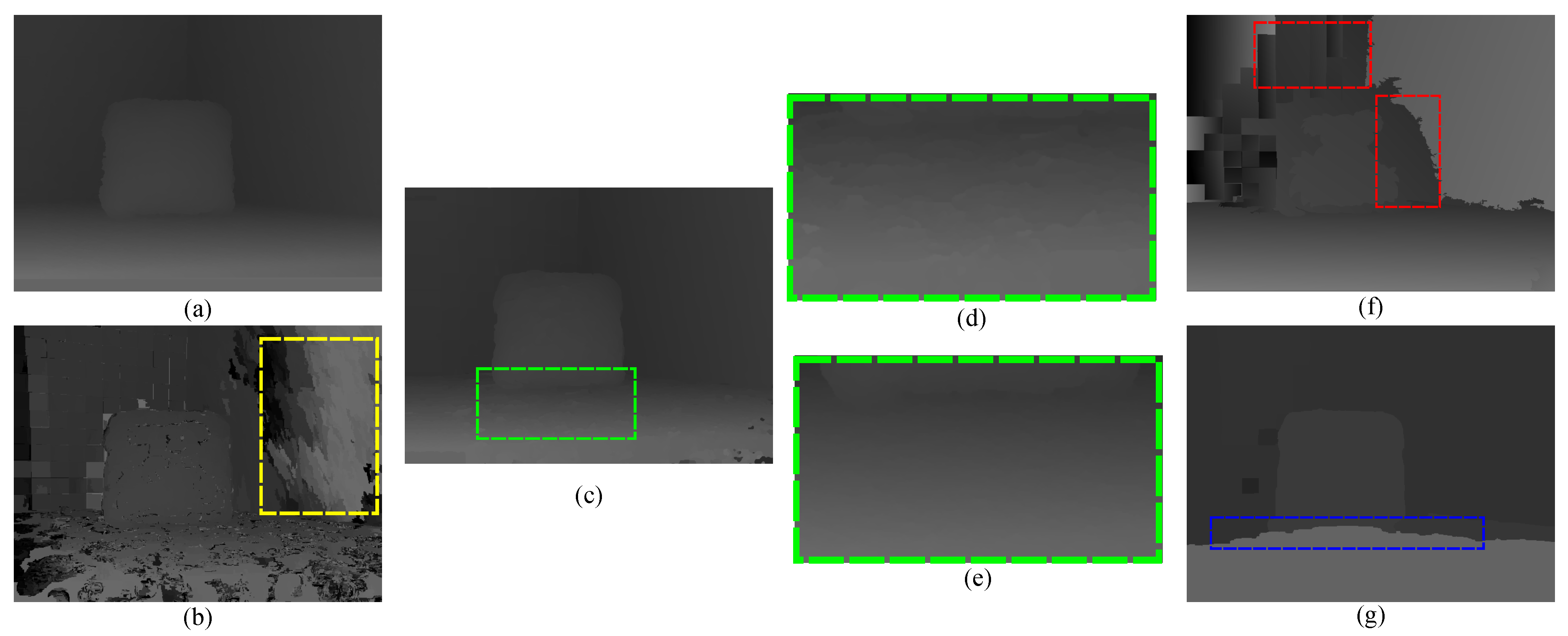
Figure 5.
Smoothness term for pixels in the same stable segment () with the spatial similarity weight as the triple-clique , under different disparity assignments. Given (blue line) as the fitted plane of . Yellow nodes are the intersect points. (a) Case I, with ; (b) Case II, with ; (c) Case III, with ; (d) Case IV, with . As shown in Cases II, III and IV, different disparity assignments correspond to the same second derivative ().
Figure 5.
Smoothness term for pixels in the same stable segment () with the spatial similarity weight as the triple-clique , under different disparity assignments. Given (blue line) as the fitted plane of . Yellow nodes are the intersect points. (a) Case I, with ; (b) Case II, with ; (c) Case III, with ; (d) Case IV, with . As shown in Cases II, III and IV, different disparity assignments correspond to the same second derivative ().
In some segmentation-based algorithms [
32], the segmentation is implemented as a hard constraint by setting
and
to be positive infinity. This does not allow any large disparity variance within a segment. In other words, each segment can only be represented as a single plane model, and the boundaries of a 3D object must be exactly aligned with segment boundaries. Unfortunately, not all segments can be accurately represented as a fitted plane, and not all 3D object boundaries coincide with segment boundaries. The accuracy of the segmentation-based algorithms is easily affected by the initial segmentation. On the one hand, the initial segmentation typically contains some under-segmented regions (where pixels from different objects, but with similar colors are grouped into one segment). As a direct consequence of under-segmentation, foreground and background boundaries are blended if they have similar colors at disparity discontinuities. To avoid this, we use segmentation as a soft constraint by setting
and
to be positive finite, so that each segment can contain arbitrary fitted planes.
On the other hand, pixels with different colors, but on the same object are over-segmented into different segments in the initial segmentation, which causes computationally inefficiency and ambiguities on segment boundaries. In this paper, we considered the spatial structure of neighboring stable segments using disparities from the Xtion. Therefore, we apply the smoothness term for neighboring pixels belonging to different stable segments (
) to avoid errors caused by the over-segmentation. Let
p and
q be neighboring pixels belonging to stable segments
and
, respectively, Then,
can be expressed as:
As shown in Equation (
15), for Cases I and II, if
is not equal to
, this means that
and
have different spatial structures, and the 3D object boundary coincides with the boundary between them. The disparity variance between
p and
q is allowed without any penalty (Case I); otherwise, a constant penalty
is added (Case II). In contrast, for Cases III and IV, if
is equal to
, this means that
and
have different appearances, but have similar spatial structures and belong to the same 3D object. In these two cases, the disparity variance between
p and
q is not allowed by adding a penalty.
reduces the ambiguities caused by over-segmentation and retains only the disparity discontinuities that are aligned with object boundaries from geometrically-smooth, but strong color gradient regions, where pixels with different colors, but from the same object are partitioned into different segments.
Because unstable segments do not have sufficient disparity information from the Xtion to regard their spatial plane models, the smoothness term for neighboring pixels that belong to the stable and unstable segments (
) encourages neighboring pixels to take the same disparity assignment. It takes the form of a standard Potts model,
Thus, let
ϖ be the set of pixels belonging to segment boundaries, the hybrid smoothness term is:
3.5. Texture Term
Stereo matching often fails in textureless and repetitive regions, because there is not enough visual information to obtain a correspondence. However, the Xtion does not suffer from ambiguities in these regions. Therefore, the disparities from the Xtion are more reliable than those obtained from stereo matching on textureless and repetitive regions and should be closer to the range of potential disparities for pixels in these regions. In contrast, the disparities from the Xtion are susceptible to noise and problems caused by rich texture regions and have poor performance in preserving object boundaries. Therefore, the disparities obtained from stereo matching are more reliable than that of the Xtion and should be used to define the scope of potential disparities of pixels in those regions. Considering the complementary characteristics of stereo matching and the Xtion sensor, texture information can be used as a useful guide for disparities.
Figure 6.
Surrounding neighborhood patch, , for: (a) pixel p and (b) its corresponding sub-regions.
Figure 6.
Surrounding neighborhood patch, , for: (a) pixel p and (b) its corresponding sub-regions.
The texture variance and gradient are used as a cue to restrict the scope of potential disparities for pixels. This reduces errors caused by noise or outliers and makes the distribution of the disparity more compact. To do this, we first define a surrounding neighborhood patch
(with a radius of, for example, 20 pixels) centered at each pixel
, as shown in
Figure 6. Considering that the annular spatial histogram is translation and rotation invariant [
33],
is evenly partitioned into four annular sub-regions. For each sub-region
, we compute its normalized intensity 16-bin gray histogram
to represent the annular distribution density of
as a 64-dimensional feature vector.
Finally, let
be a 1D line segment ranging from (
) to (
) in the same row of
p in
. The texture variance and gradient of
p is determined by the texture dissimilarity
Equation (
18), using the Hamming distance Equation (
19) between the annular distribution densities of
p and its neighboring pixel
q in
. That is,
Each pixel’s disparity variance buffer (
) can be denoted as:
and
are the minimum and maximum disparities.
is small in the textureless and repetitive regions and is large in the rich texture regions or object boundaries. The scope of each pixel’s potential disparities [
,
] is denoted as:
where
and
are the minimum and maximum disparities from the Xtion in the region centered at
p in
.
is the segment that contains
p.
and
are the minimum and maximum fitted disparities of
.
is the number of seed pixels in the region centered at
p.
is a positive value. As described in Equation (
23), there are three cases for the definition of
:
- -
When is a stable segment () and contains sufficient seed pixels (), is equal to . In this case, there are enough seed pixels from the Xtion to denote a guide for the variance of disparities of p. If p is in the textureless or repetitive region, is small. This indicates that stereo matching may fail in these regions, and a small search range should be used around disparities from the Xtion. In contrast, if p is in the rich textured region or object boundaries, is large. This indicates that disparities from the Xtion may be susceptible to noise and problems caused by rich texture regions where disparities obtained from stereo matching are more reliable. Then, a broader search range should be used, so that we can extract better results not observed by the Xtion.
- -
When is a stable segment (), but there are not enough seed pixels around p (), is equal to . In this case, although there are some seed pixels from the Xtion, they are not enough to represent the disparity variance around p. On the other hand, because each stable segment is viewed as a 3D fitted plane, the search range for the potential disparities is limited by the fitted disparity of and the disparity variance buffer ().
- -
When is an unstable segment (), is the minimum disparity ().
Similarly,
can be obtained in the same way. Then, the SP-edge term (which defines the scope of pixel’s potential disparities) is:
3.7. Optimization
The energy function defined in Equation (
4) is a function of the real discrete disparity map. In this section, we describe how to optimize Equation (
4) using the fusion move algorithm to obtain the disparity map
:
The fusion move approach [
34] is an extended approach of the
algorithm [
35], which allows arbitrary values for each pixel in the proposed disparity map. It generates a new result by fusing the current and proposed disparity maps with the energy either decreasing or remaining constant. Let
and
be the current and proposed disparity maps of
. Our goal is to optimally “fuse”
and
to generate a new depth map
, so that the energy
is lower than
. This fusion move is achieved by taking each pixel in
from either
or
, according to a binary indicator map
B.
B is the result of the graph cut-based fusion move Markov random field optimization technique. During each optimization, each pixel either keeps its current disparity value (
) or changes it to proposed disparity value (
). That is,
However, the fusion move is limited to optimizing the submodular binary fusion-energy functions that consist of unary and pairwise potentials. Because of the hybrid smoothness term, our binary fusion-energy functions are not submodular and cannot be directly solved using the fusion move [
36]. Using the quadratic pseudo-Boolean optimization (QPBO) algorithm [
37], we can obtain a partial solution for the non-submodular binary fusion-energy function by assigning either zero or one to partial pixels, and leaving the rest unassigned. The partial solution is a part of the global minimum solution, and its energy is not higher than that of the original solution. Because of the given lowest average number of unlabeled pixels, we used Quadratic Pseudo Boolean Optimization with Probing (QPBO-P) [
38] and Quadratic Pseudo Boolean Optimization with Improving (QPBO-I) [
39] as our fusion strategies. During the optimization, the pixel-level improved luminance consistency term (
), the SP-edge texture term (
) and the segment-level 3D plane bias term (
) are expressed as unary terms, respectively. We tackle the transformation problem of the pixel-level hybrid smoothness term (
) that contains triple-cliques using the decomposition method called Excludable Local Configuration (ELC) [
40]. The essence of the ELC method is a QPBO-based transformation of a general higher-order Markov random field with binary labels into a first-order one that has the same minima as the original. It combines a new reduction with the fusion move and QPBO to approximately minimize higher-order multi-label energies. Furthermore, the new reduction technique is along the lines of the Kolmogorov-Zabih reduction that can reduce any higher-order minimization problem of Markov random fields with binary labels into an equivalent first-order problem. Each triple clique in
is decomposed into a set of unary or pairwise terms by ELC without introducing any new variables.
The choice of the proposed disparity maps in the fusion move approach is another crucial factor for the successful use and efficiency of the fusion move. Because there is not an algorithm that can be applied to all situations, our goal is to expect all proposed disparity maps to be correct in some parts and under some parameter setting. Here, we use the following schemes to obtain all proposed disparity maps:
- -
Proposal A: Uniform value-based proposal. All disparities in the proposal are assigned to a discrete disparity, in the range of to .
- -
Proposal B: The hierarchical belief propagation-based algorithm [
41] is applied to generate proposals with different segmentation maps.
- -
Proposal C: The joint disparity map and color consistency estimation method [
42], which combines mutual information, a SIFT descriptor and segment-based plane-fitting techniques.
During each optimization, the result of the current fusion move is used as the initial disparity map of the next iteration.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
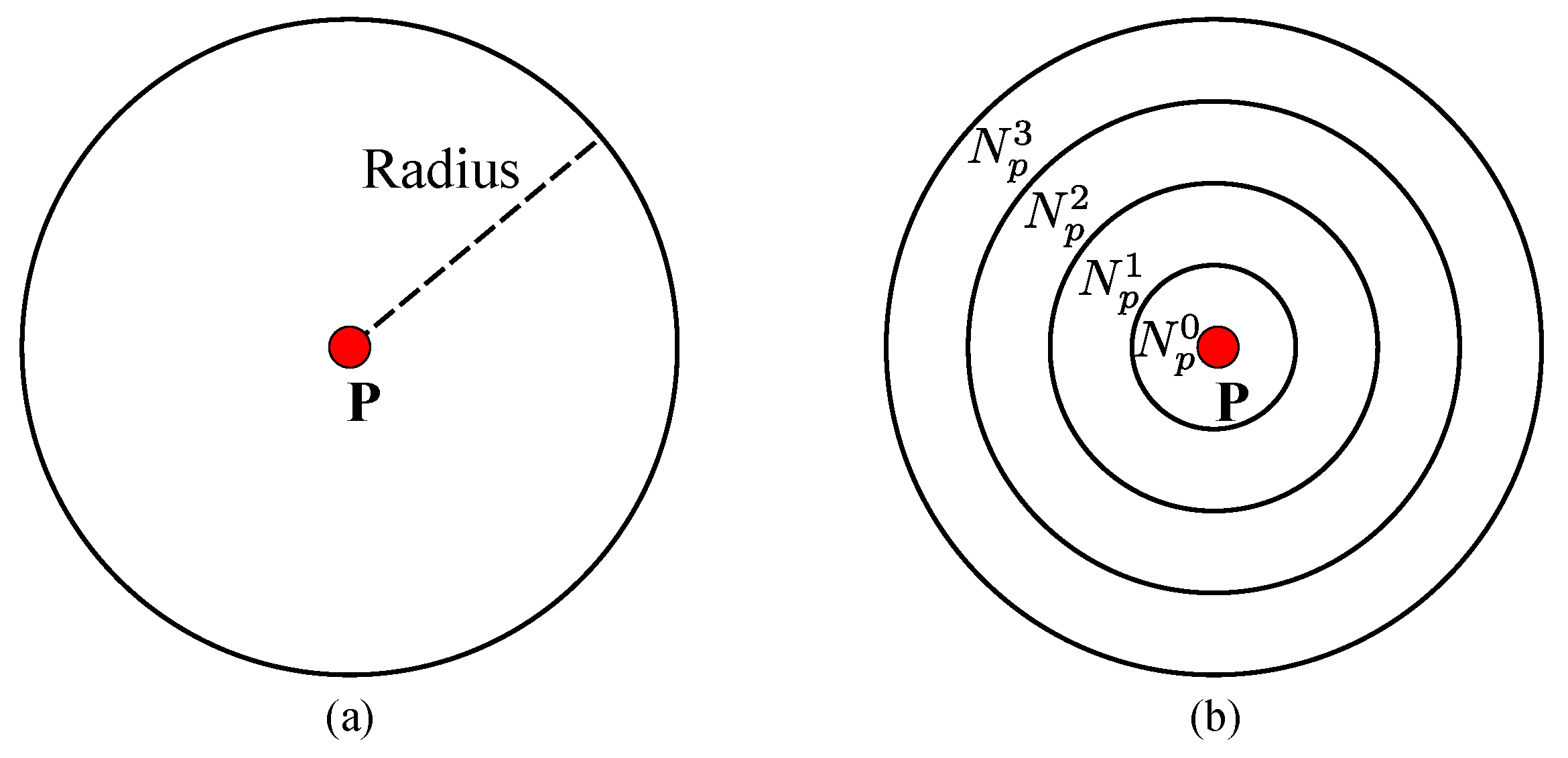{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











