
Data-Driven Multiresolution Camera Using the Foveal Adaptive Pyramid


Abstract
:1. Introduction
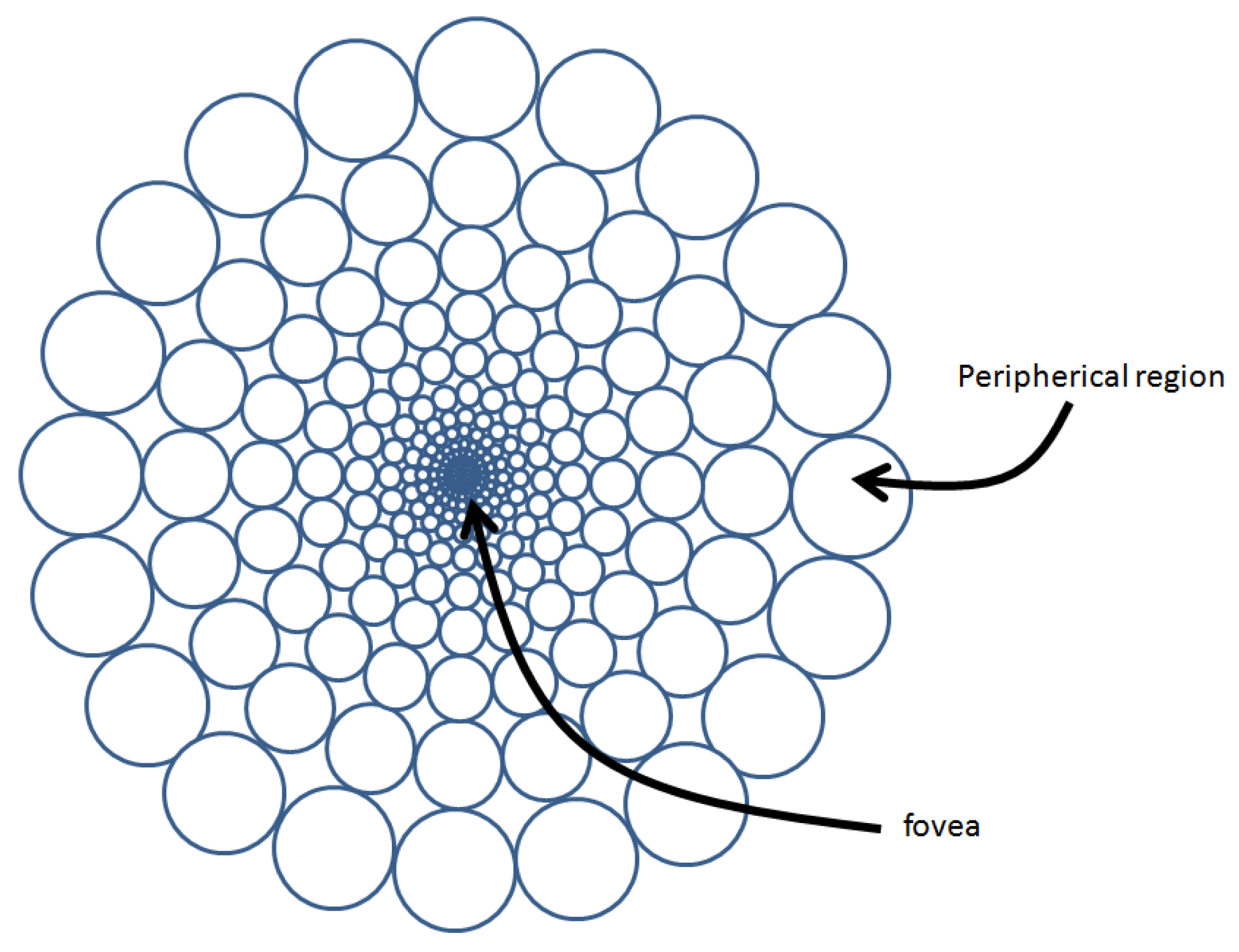
- Maps the sensor data into a foveal lattice. Similar to the proposal from Martinez and Altamirano [16], this work proposes to emulate an artificial retina from a sensor of uniform resolution by a Cartesian space-variant sampling, obtaining a unique space-variant resolution image or foveal image, where the fovea has the highest resolution, and it decreases as we move away from the fovea.
- Processes this foveal image for providing a multiscale segmentation of it in order to obtain the different proto-objects present in the scene. A proto-object can be defined as regions of the image that can be bounded into an object [15].
- Performs a bottom-up attention process for choosing a new fovea.
Contributions and Organization of the Paper
- Within an AP SoC, the hardware-emulated foveal sensor is able to provide a stream of foveal images to the software components in real time, without significant latencies. This foveal sensor is configurable at execution rates, being able to move and adapt the fovea to capture the objects of interest.
- Contrary to previous approaches, this work suggests that the hierarchical segmentation of a captured scene can be achieved by decimating a non-uniform layout. That is, each level of our hierarchy is now a graph whose spatial sampling varies across the FoV. The typical paradigm is that a hierarchical segmentation of an input image provides a stack of successively-reduced graphs (or images) of uniform resolution.
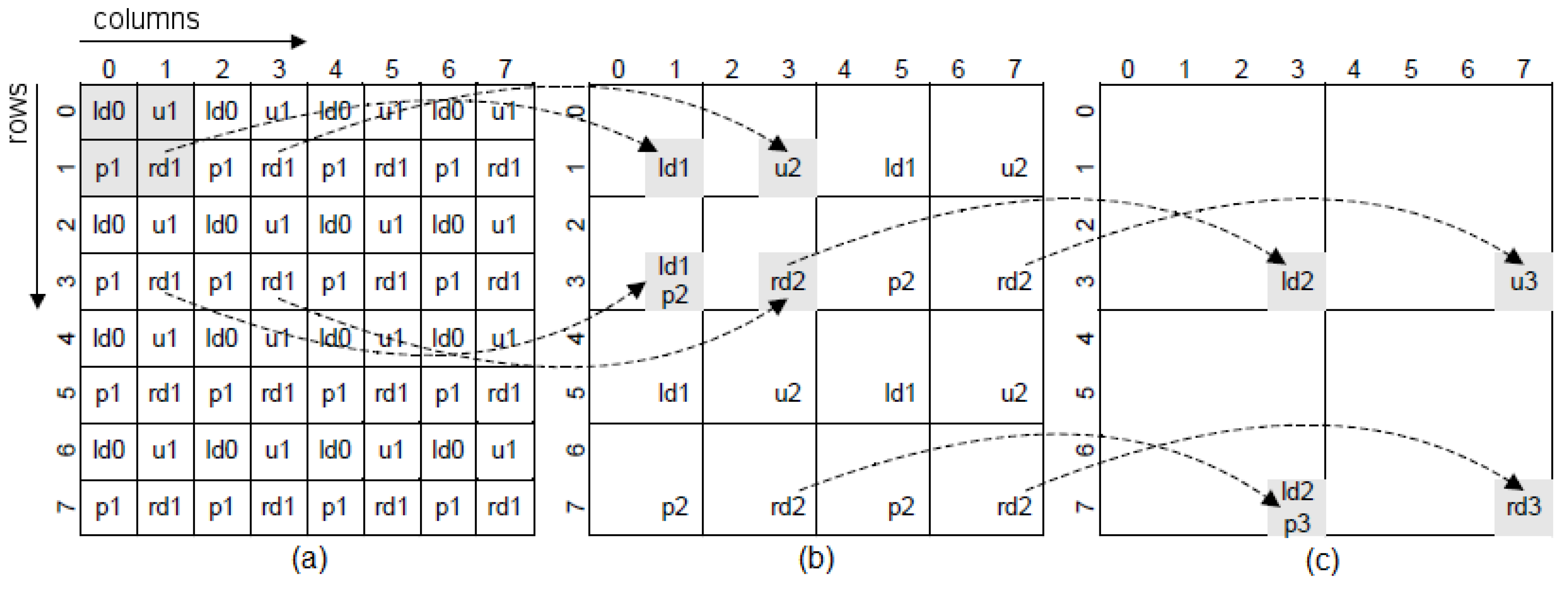
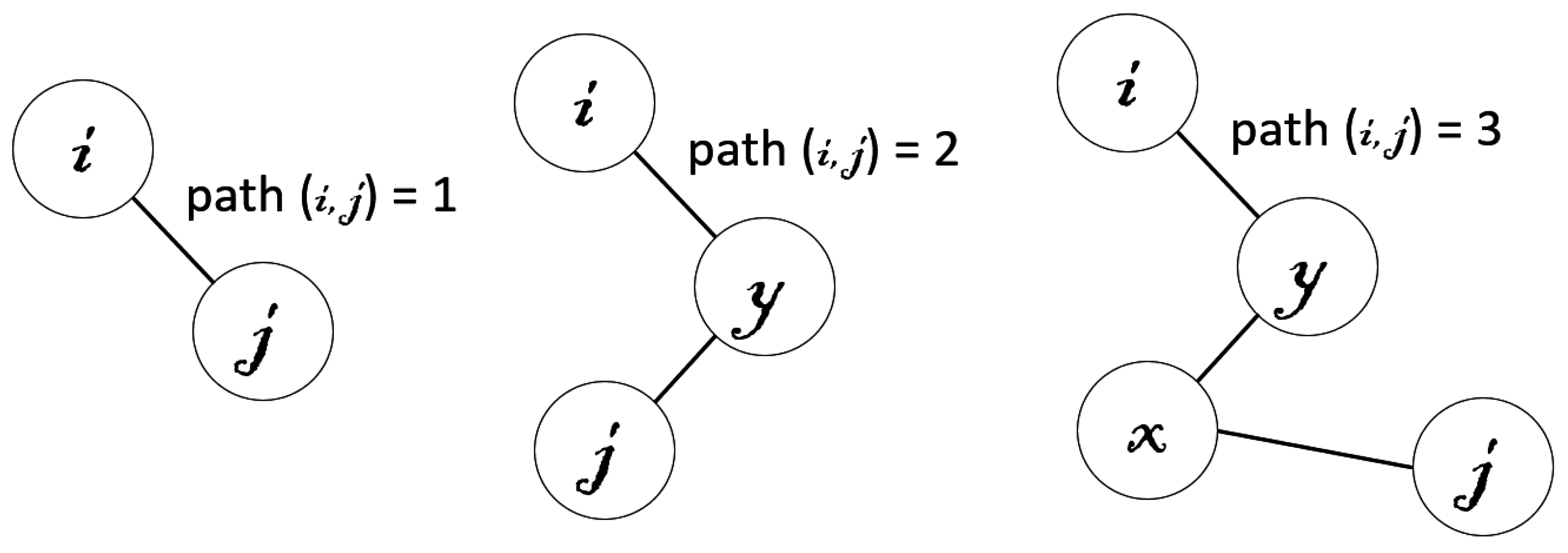
- The image encoding within the hierarchy of an irregular pyramid is typically performed by putting the effort on choosing the set of vertexes that, coming from a given level, will compose the level above. The vertexes at this new level will be subsequently linked among them by considering a connectivity criterion. In this work, we demonstrate that it is also interesting to consider what arcs among vertexes should not be established. Using a very simple strategy, our proposed decimation process runs significantly faster than previous approaches, exhibiting a very similar performance.
- Using the evaluation framework provided by the BSDB500 database, this work demonstrates that it is not really needed to process the full FoV with the same level of detail. In an active scenario and after a few foveations, the proposed system is able to provide segmentation results (i.e., relevant contours) that are very close to the ones provided by human subjects.
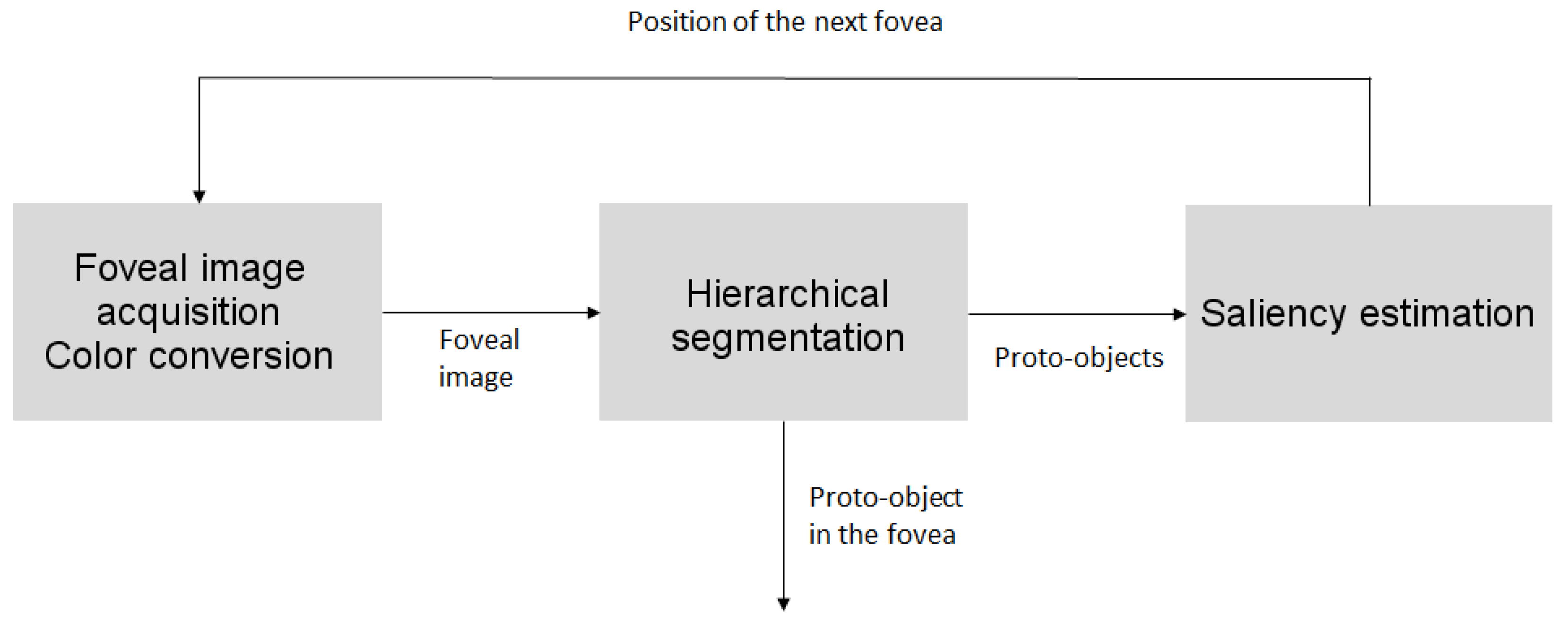
2. Overview of the Framework
3. Foveal Mapping
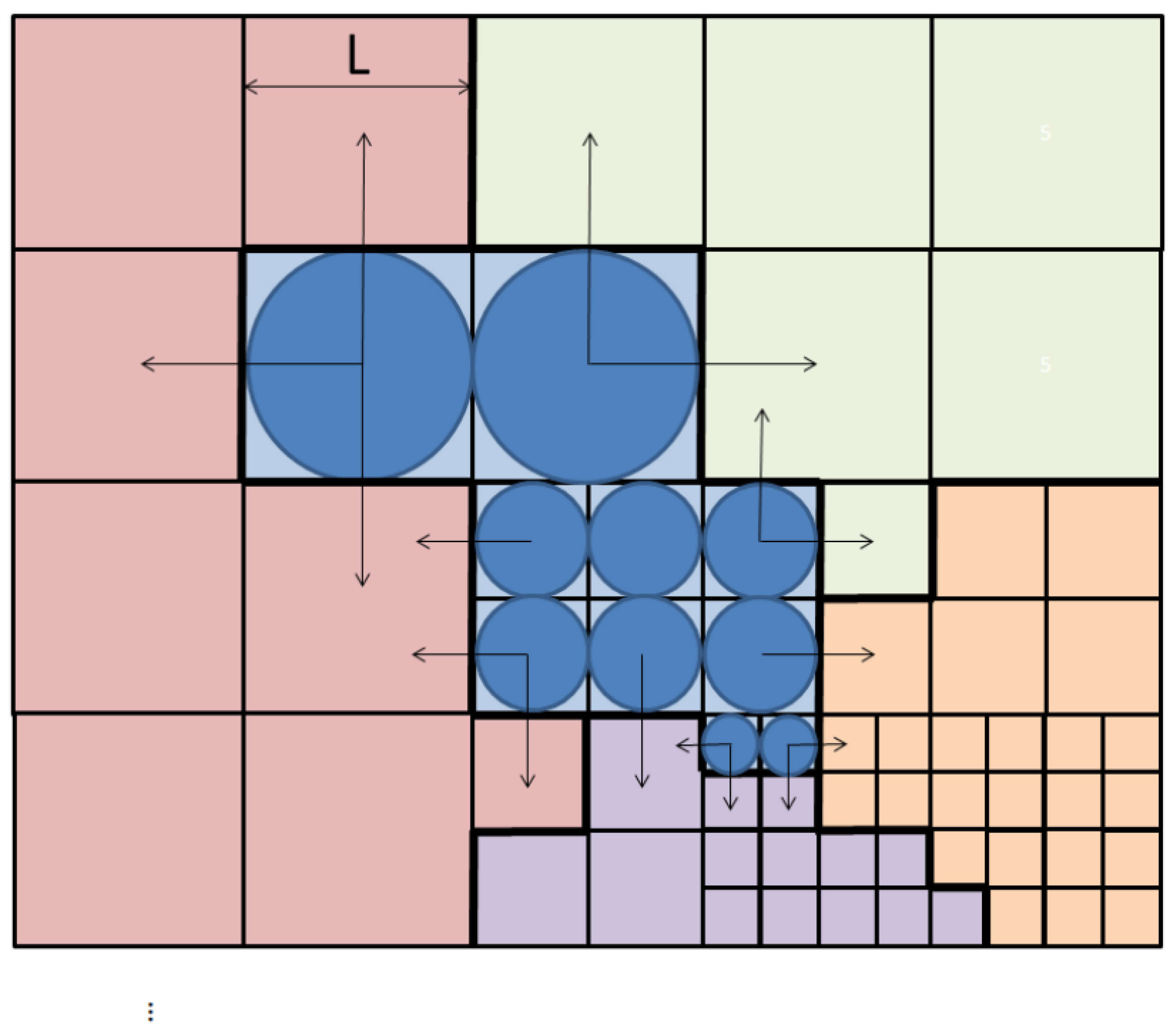
3.1. Cartesian Foveal Geometries
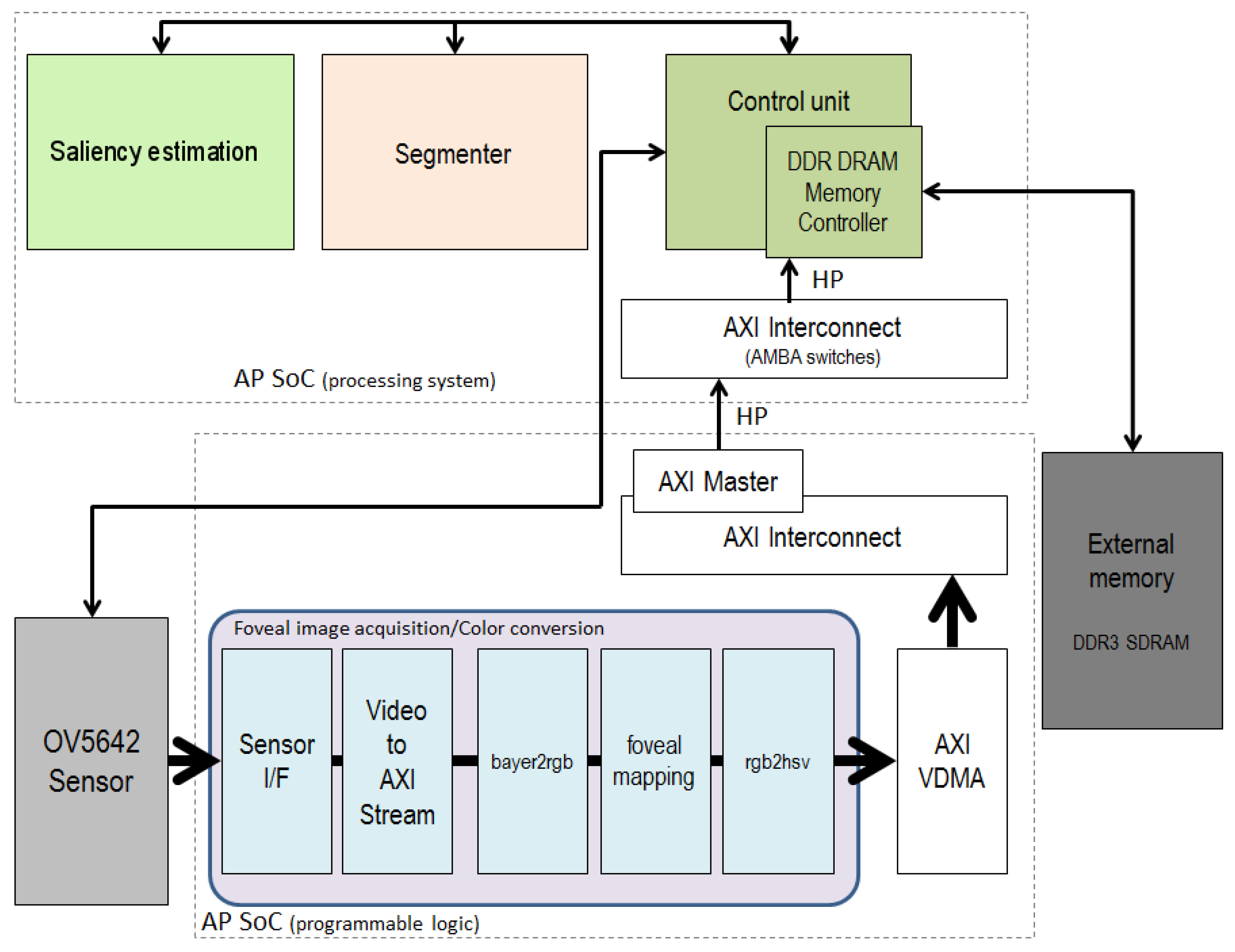
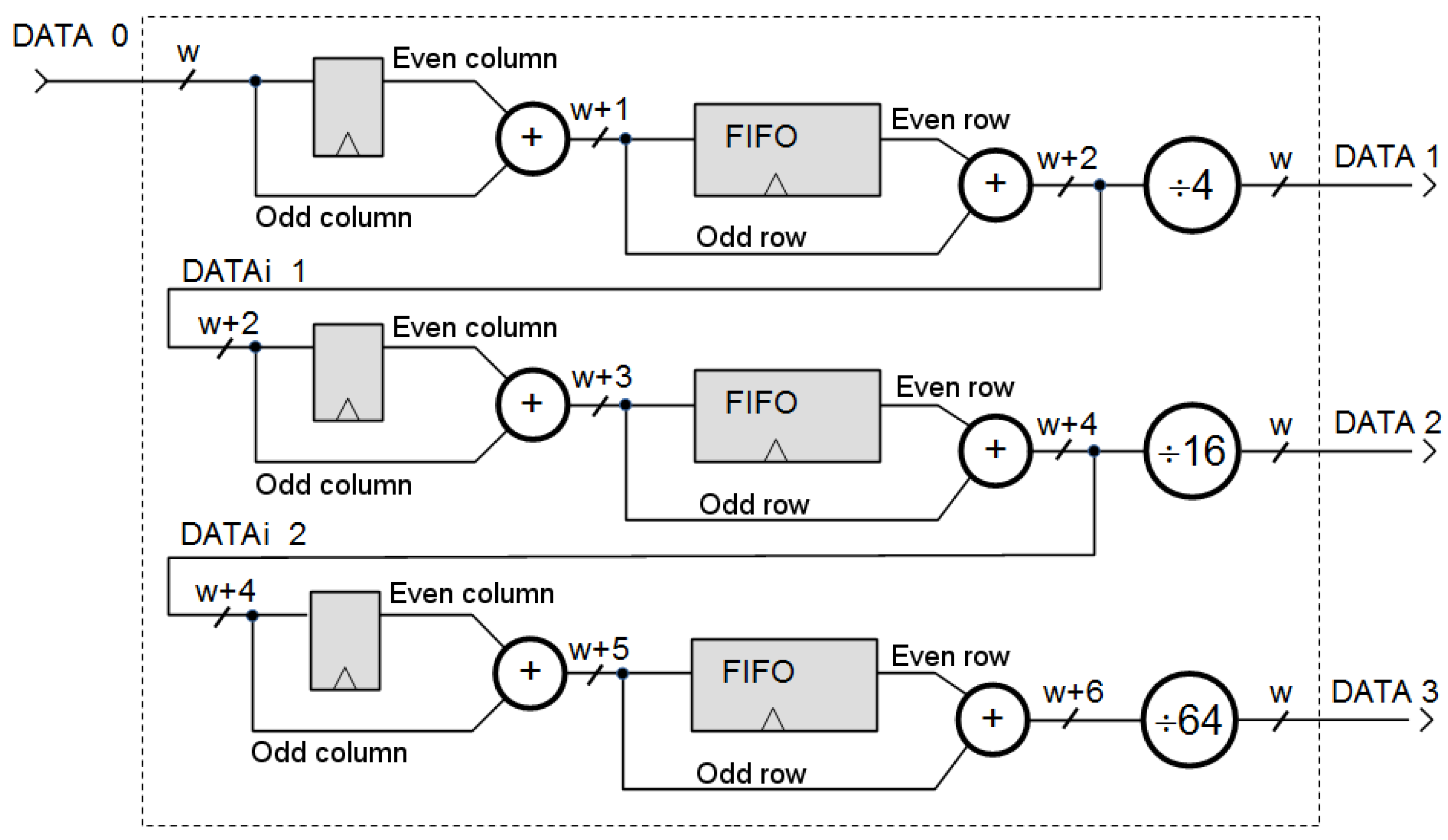
3.2. Hardware Implementation
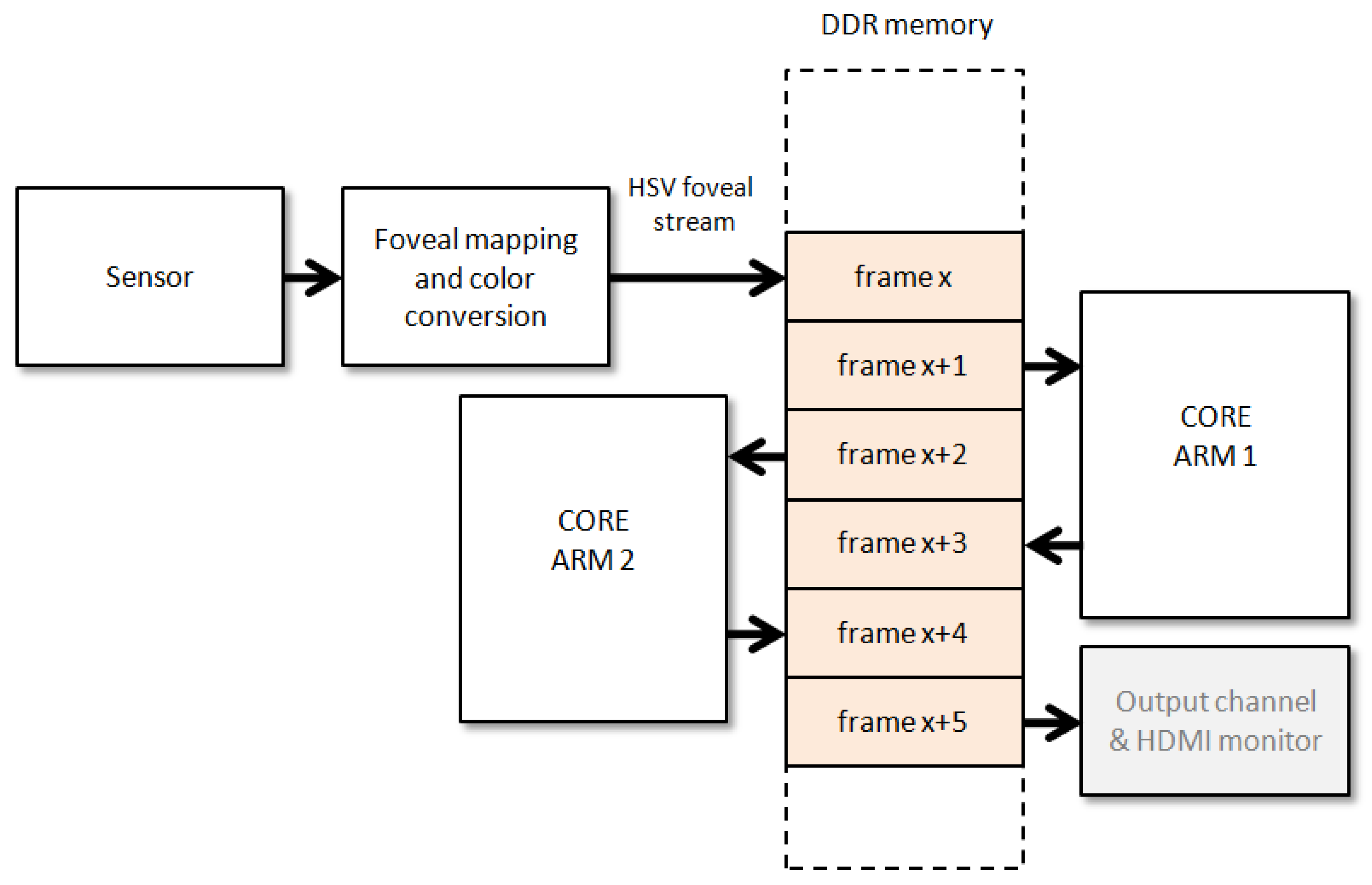
4. Communicating the PL and PS Cores
5. Software Processing: Segmentation and Saliency Estimation
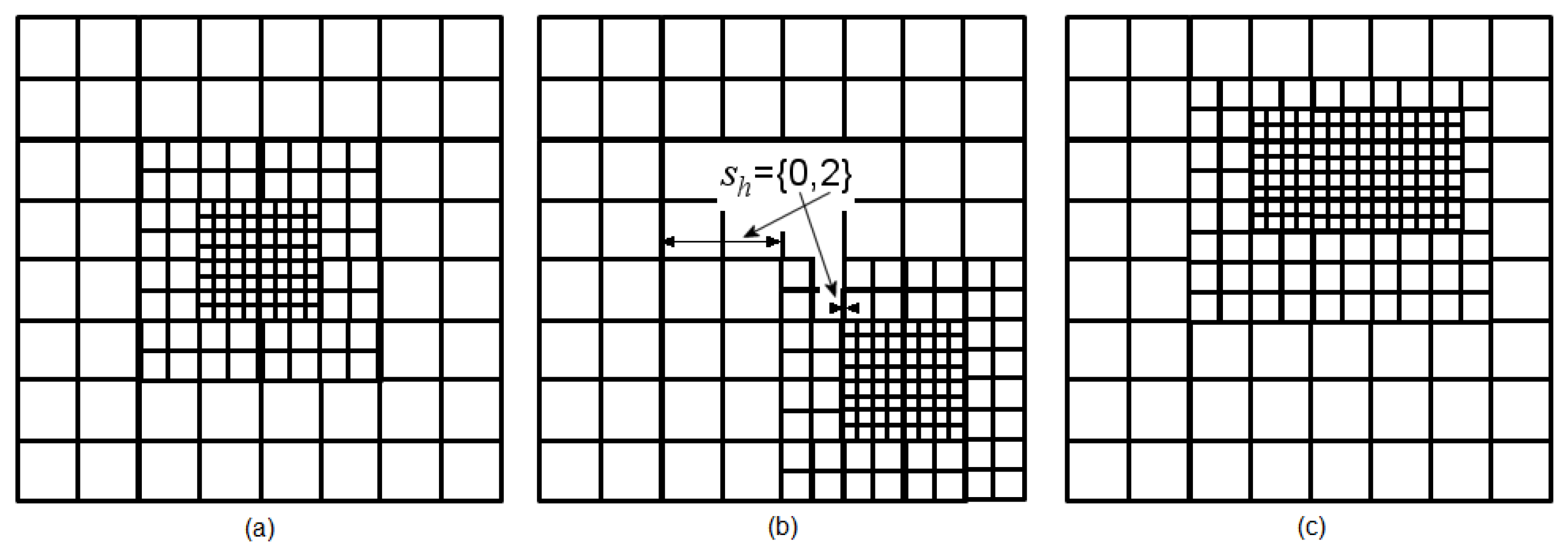
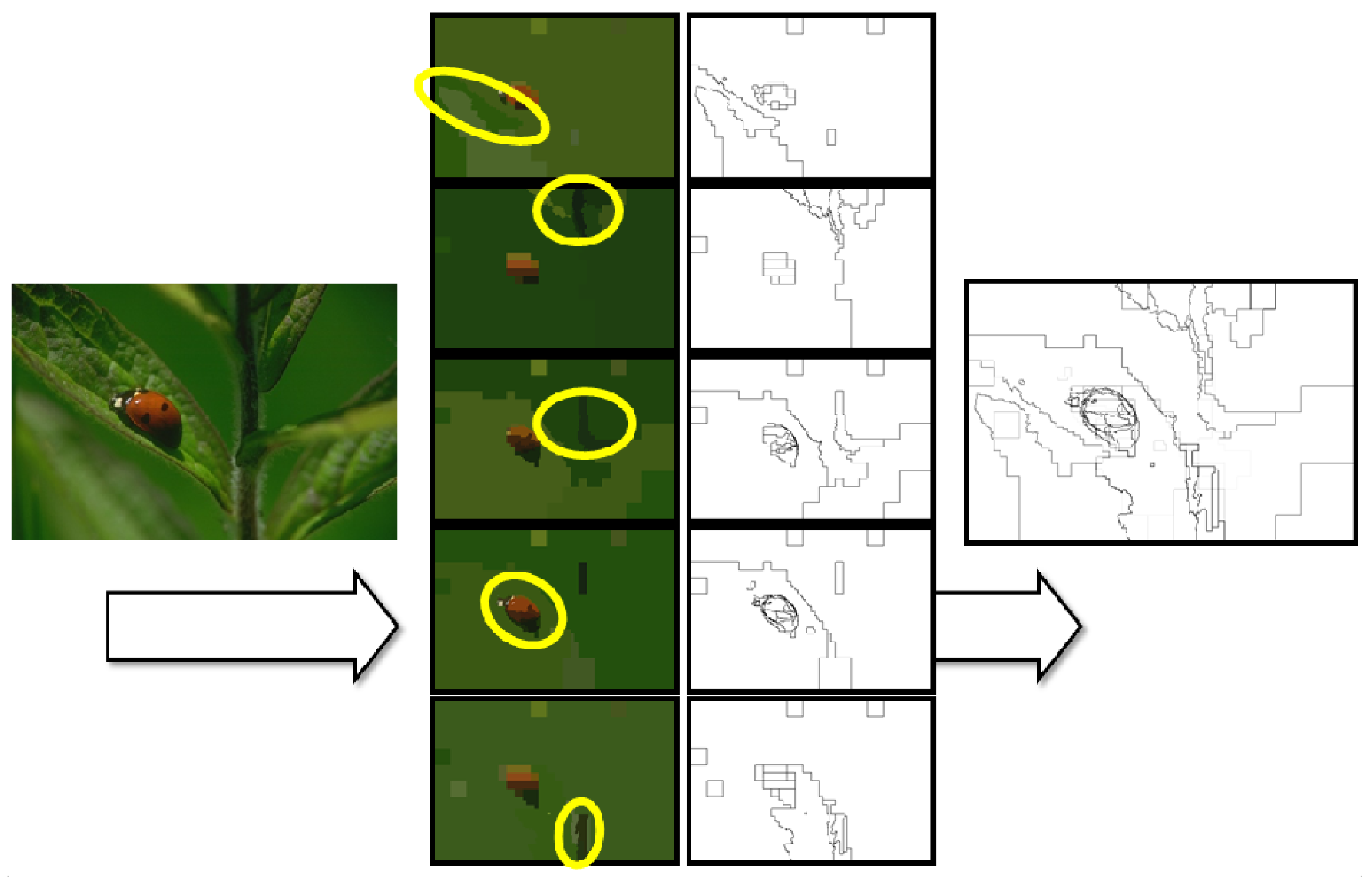
5.1. Hierarchical Segmentation
The Bounded D3P
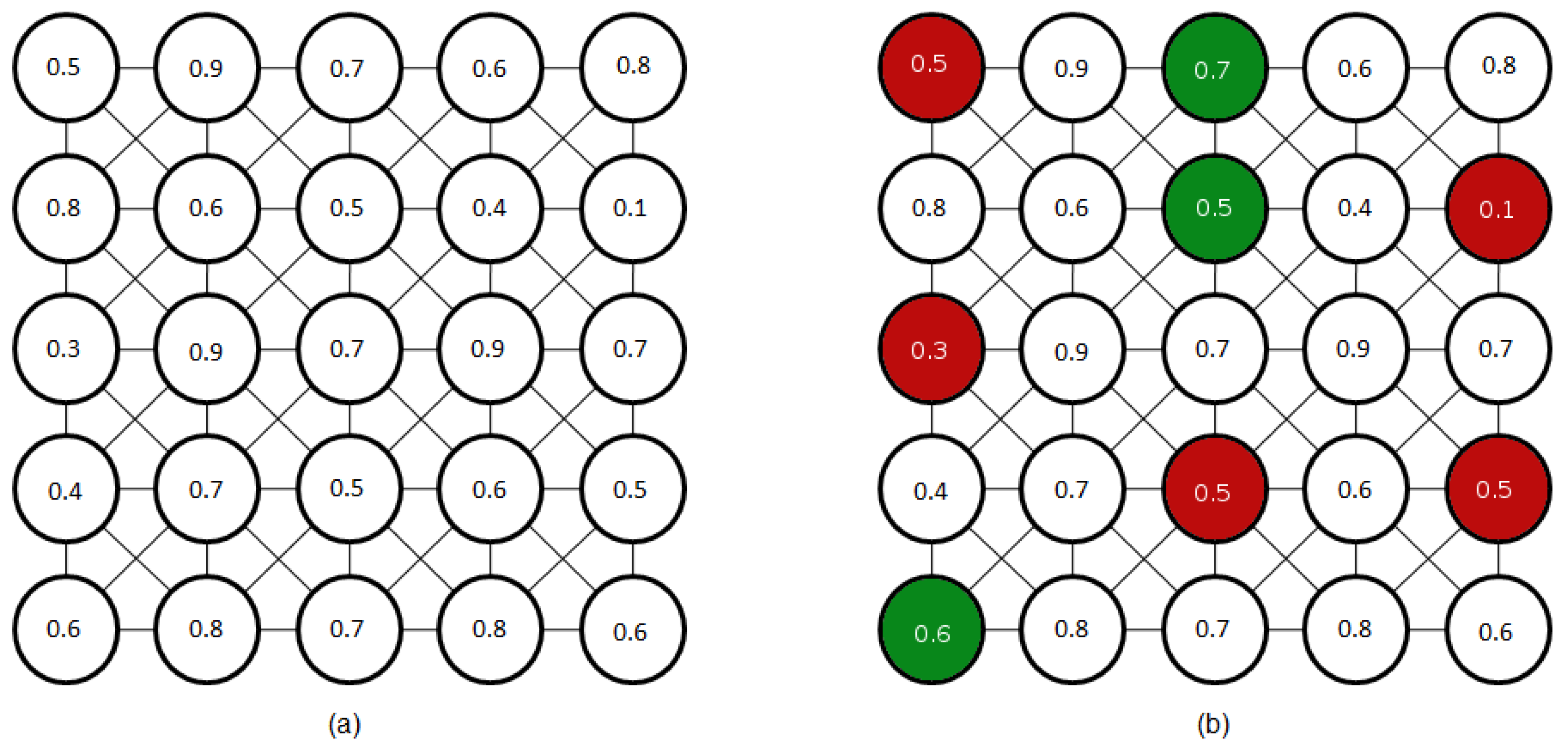
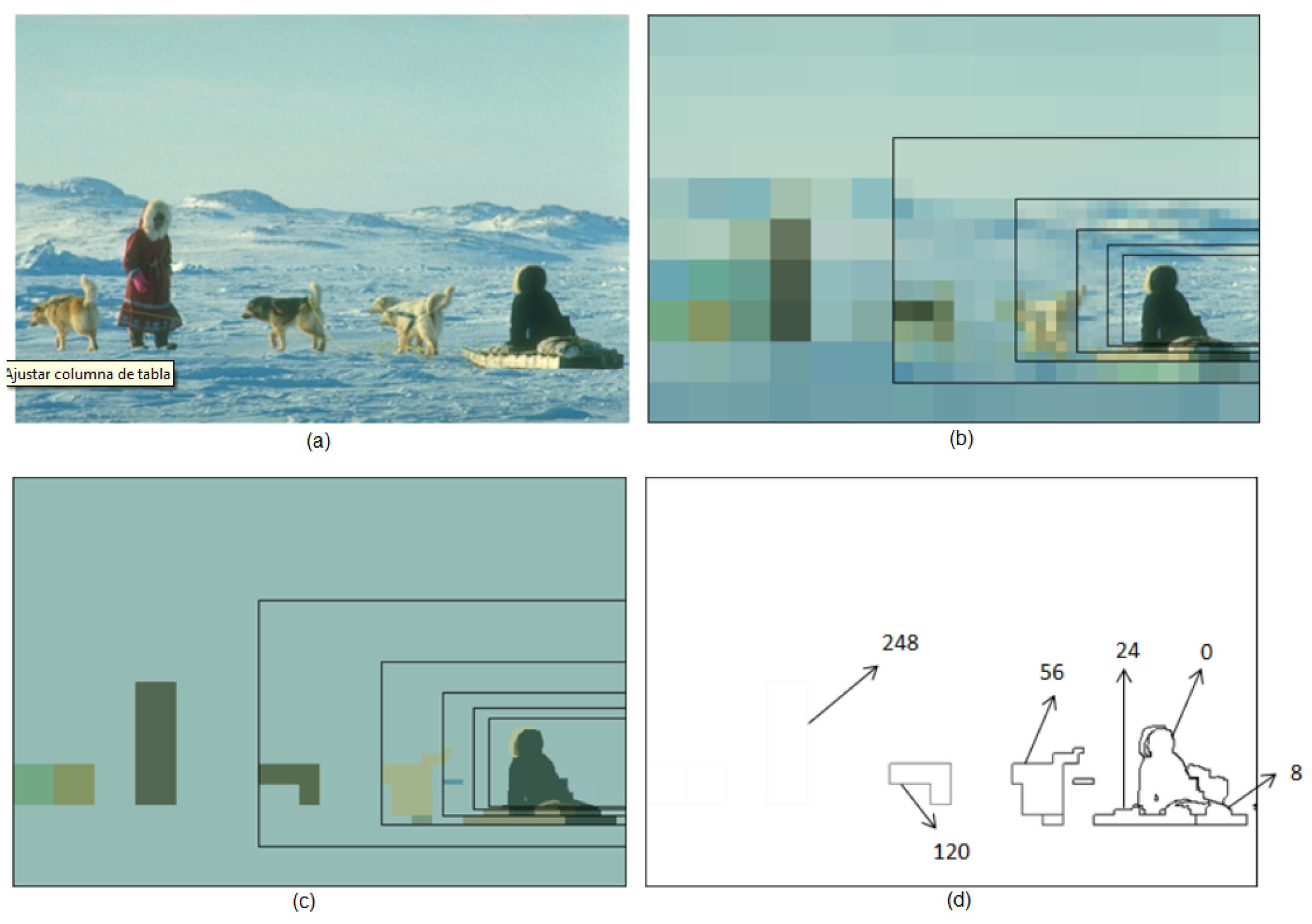
5.2. Estimating the Salience
Influence of the Foveal Lattice on the Salience Estimation
6. Experimental Results
6.1. Performance and Utilization of the PL Cores
6.2. Evaluation of the Segmentation Algorithm
- Obtained regions must be uniform and homogeneous.
- Regions must not have small holes inside.
- Neighbor regions must be significantly different according to the image value used during the segmentation process.
- Regions must not have a small size.
6.2.1. Choosing the Parameters
6.2.2. Evaluation on the BSDB500
6.3. Evaluation of the Attention Model
7. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bailey, D.G.; Bouganis, C.S. Implementation of a foveal vision mapping. In Proceedings of the International Conference on Field-Programmable Technology (FPT), Sydney, Australia, 9–11 December 2009; pp. 22–29.
- Ware, C. Visual Thinking for Design; Morgan Kaufmann: Burlington, MA, USA, 2008. [Google Scholar]
- Sandini, G.; Metta, G. Retina-like sensors: Motivations, technology and applications. In Sensors and Sensing in Biology and Engineering; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Arrebola, F.; Camacho, P.; Sandoval, F. Generalization of shifted fovea multiresolution geometries applied to object detection. ICIAP 1997, 2, 477–484. [Google Scholar]
- Camacho, P.; Arrebola, F.; Sandoval, F. Adaptive fovea structures for space variant sensors. Lect. Notes Comput. Sci. 1997, 1311, 422–429. [Google Scholar]
- Coslado, F.J.; Camacho, P.; González, M.; Arrebola, F.; Sandoval, F. VLSI implementation of a Foveal Polygon segmentation algorithm. In Proceedings of the International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999; pp. 185–190.
- Rybaka, I.A.; Gusakovab, V.I.; Golovanc, A.V.; Podladchikovab, L.N.; Shevtsova, N.A. A model of attention-guided visual perception and recognition. Vis. Res. 1998, 38, 2387–2400. [Google Scholar] [CrossRef]
- Meger, D.; Forssn, P.; Lai, K.; Helmer, S.; McCann, S.; Southey, T.; Baumann, M.; Little, J.J.; Lowe, D.G. Curious george: An attentive semantic robot. Robot. Auton. Syst. 2008, 56, 503–511. [Google Scholar] [CrossRef]
- Rajashekar, U.; van der Linde, I.; Bovik, C.; Cormack, L. Gaffe: A gaze-attentive fixation finding engine. IEEE Trans. Image Proc. 2008, 17, 564–573. [Google Scholar] [CrossRef] [PubMed]
- Geisler, W.; Perry, J. A real-time foveated multiresolution system for low-bandwidth video communication. Proc. SPIE Int. Soc. Opt. Eng. 1998, 3299. [Google Scholar] [CrossRef]
- Gide, M.; Karam, L. Improved foveation- and saliency-based visual attention prediction under a quality assessment task. In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience (QoMEX), Melbourne, Australia, 5–7 July 2012; pp. 200–205.
- Zhang, L.; Tong, M.; Marks, T.; Shan, H.; Cottrell, G. Sun: A bayesian framework for saliency using natural statistics. J. Vis. 2008, 8, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Advani, S.; Sustersic, J.; Irick, K.; Narayanan, V. A multi-resolution saliency framework to drive foveation. Int. Conf. Acoust. Speech Signal Process. 2013, 2596–2600. [Google Scholar] [CrossRef]
- Bruce, N.; Tsotsos, J. Saliency, attention, and visual search: An information theoretic approach. J. Vis. 2009, 9, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Marfil, R.; Palomino, A.J.; Bandera, A. Combining segmentation and attention: A new foveal attention model. Front. Comput. Neurosci. 2014, 8, 96. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Carranza, J.; Altamirano Robles, L. A new foveal Cartesian geometry approach used for object tracking. SPPRA 2006, 6, 133–139. [Google Scholar]
- Sakamoto, T.; Nakanishi, C.; Hase, T. Software pixel interpolation for digital still cameras suitable for a 32-bit MCU. IEEE Trans. Consum. Electron. 1998, 44, 1342–1352. [Google Scholar] [CrossRef]
- Marfil, R.; Molina–Tanco, L.; Bandera, A.; Rodríguez, J.A.; Sandoval, F. Pyramid segmentation algorithms revisited. Pattern Recognit. 2006, 39, 1430–1451. [Google Scholar] [CrossRef]
- Jolion, J.M. Stochastic pyramid revisited. Pattern Recognit. Lett. 2003, 24, 1035–1042. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef] [PubMed]
- Burt, P.; Hong, T.; Rosenfeld, A. Segmentation and estimation of image region properties through cooperative hierarchical computation. IEEE Trans. Syst. Man Cybern. 1981, 11, 802–809. [Google Scholar] [CrossRef]
- Hong, T.; Rosenfeld, A. Compact region extraction using weighted pixel linking in a pyramid. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 222–229. [Google Scholar] [CrossRef] [PubMed]
- Haxhimusa, Y.; Kropatsch, W.G. Segmentation graph hierarchies. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2004; pp. 343–351. [Google Scholar]
- Brun, L.; Kropatsch, W.G. Construction of combinatorial pyramids. Lect. Notes Comput. Sci. 2003, 2726, 1–12. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 416–425.
- Arbeláez, P.; Maire, M.; Fowlkes, C.C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Arbeláez, P. Boundary extraction in natural images using ultrametric contour maps. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), New York, NY, USA, 17–22 June 2006; pp. 182–189.
- Cour, T.; Benezit, F.; Shi, J. Spectral segmentation with multiscale graph decomposition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 1124–1131.
- Felzenszwalb, P.; Huttenlocher, D. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean-shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative analysis of human-model agreement in visual saliency modeling: A comparative study. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Diaz, A.; Fernandez-Vidal, X.R.; Pardo, X.M.; Dosil, R. Saliency from hierarchical adaptation through decorrelation and variance normalization. Image Vis. Comput. 2012, 30, 51–64. [Google Scholar] [CrossRef]
- Dynamic visual attention: Searching for coding length increments. Available online: http://papers.nips.cc/paper/3531-dynamic-visual-attention-searching-for-coding-length-increments (accessed on 23 November 2016).
- Bruce, N.; Tsotsos, J. Saliency based on information maximization. In Advances in Neural Information Processing Systems; Academic Press: New York, NY, USA, 2005. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1–7.
- Liu, H.; Xu, D.; Huang, G.; Li, W. Semantically-based human scan path estimation with HMMs. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3232–3239.
- Walther, D.; Koch, C. Modeling attention to salient proto-objects. Neural Netw. 2006, 19, 1395–1407. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Demosaicing | Foveal Mapping | rgb2hsv | |
|---|---|---|---|
| Digital Signal Processor (DSP) | 3 | 0 | 3 |
| Block Random Access Memory (BRAM_18K) | 6 | 18 | 0 |
| Flip-flop | 500 | 1227 | 3305 |
| LUT | 543 | 1242 | 3006 |
| Clock Period (ns) | 9.40 | 5.42 | 8.91 |
| Loop Latency (clocks) | 5,043,391 | 5,038,862 | 5,038,879 |
| Initiation Interval (clocks) | 1 | 1 | 1 |
| LRP | 1052.1 | 1570.3 | 2210.3 | 9 | 9 | 9 |
| WRP | 1133.7 | 1503.5 | 2080.8 | 9 | 9 | 9 |
| D3P | 355.6 | 818.5 | 1301.1 | 11 | 32.9 | 64 |
| BIP | 343.2 | 1090.9 | 1911.3 | 8 | 8.7 | 15 |
| HIP | 460.5 | 955.1 | 1530.7 | 9 | 11.4 | 19 |
| CIP | 430.7 | 870.2 | 1283.7 | 9 | 74.2 | 202 |
| BD3P | 412.6 | 831.5 | 1497.1 | 9 | 13 | 18 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
González, M.; Sánchez-Pedraza, A.; Marfil, R.; Rodríguez, J.A.; Bandera, A. Data-Driven Multiresolution Camera Using the Foveal Adaptive Pyramid. Sensors 2016, 16, 2003. https://0-doi-org.brum.beds.ac.uk/10.3390/s16122003
González M, Sánchez-Pedraza A, Marfil R, Rodríguez JA, Bandera A. Data-Driven Multiresolution Camera Using the Foveal Adaptive Pyramid. Sensors. 2016; 16(12):2003. https://0-doi-org.brum.beds.ac.uk/10.3390/s16122003
Chicago/Turabian StyleGonzález, Martin, Antonio Sánchez-Pedraza, Rebeca Marfil, Juan A. Rodríguez, and Antonio Bandera. 2016. "Data-Driven Multiresolution Camera Using the Foveal Adaptive Pyramid" Sensors 16, no. 12: 2003. https://0-doi-org.brum.beds.ac.uk/10.3390/s16122003