
Enabling UAV Navigation with Sensor and Environmental Uncertainty in Cluttered and GPS-Denied Environments

Abstract
:1. Introduction
2. UAV Navigation as a Sequential Decision Problem
2.1. Markov Decision Processes and Partially-Observable Markov Decision Processes
2.2. POMCP and ABT
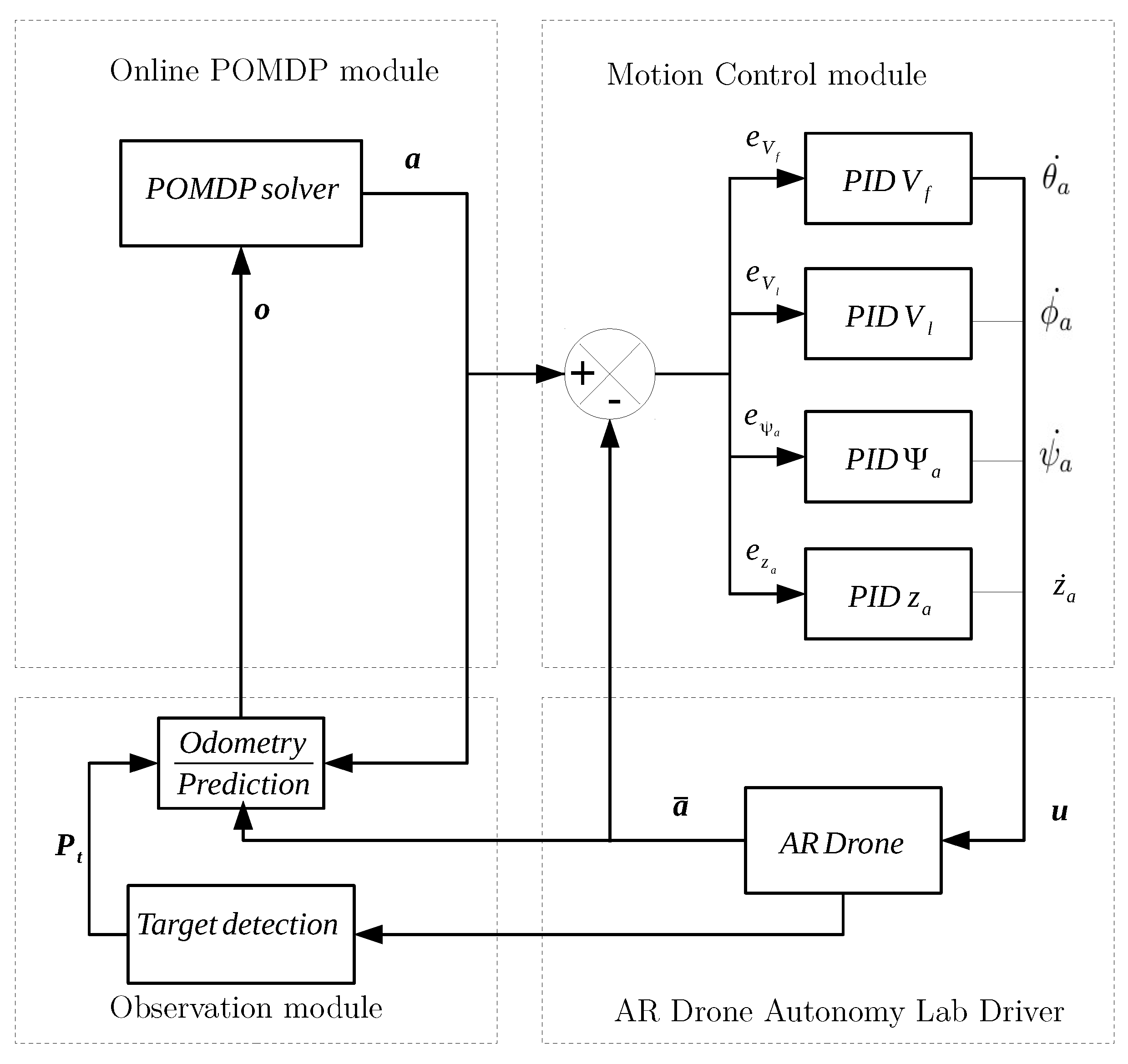
3. System Architecture
3.1. On-Line POMDP Module
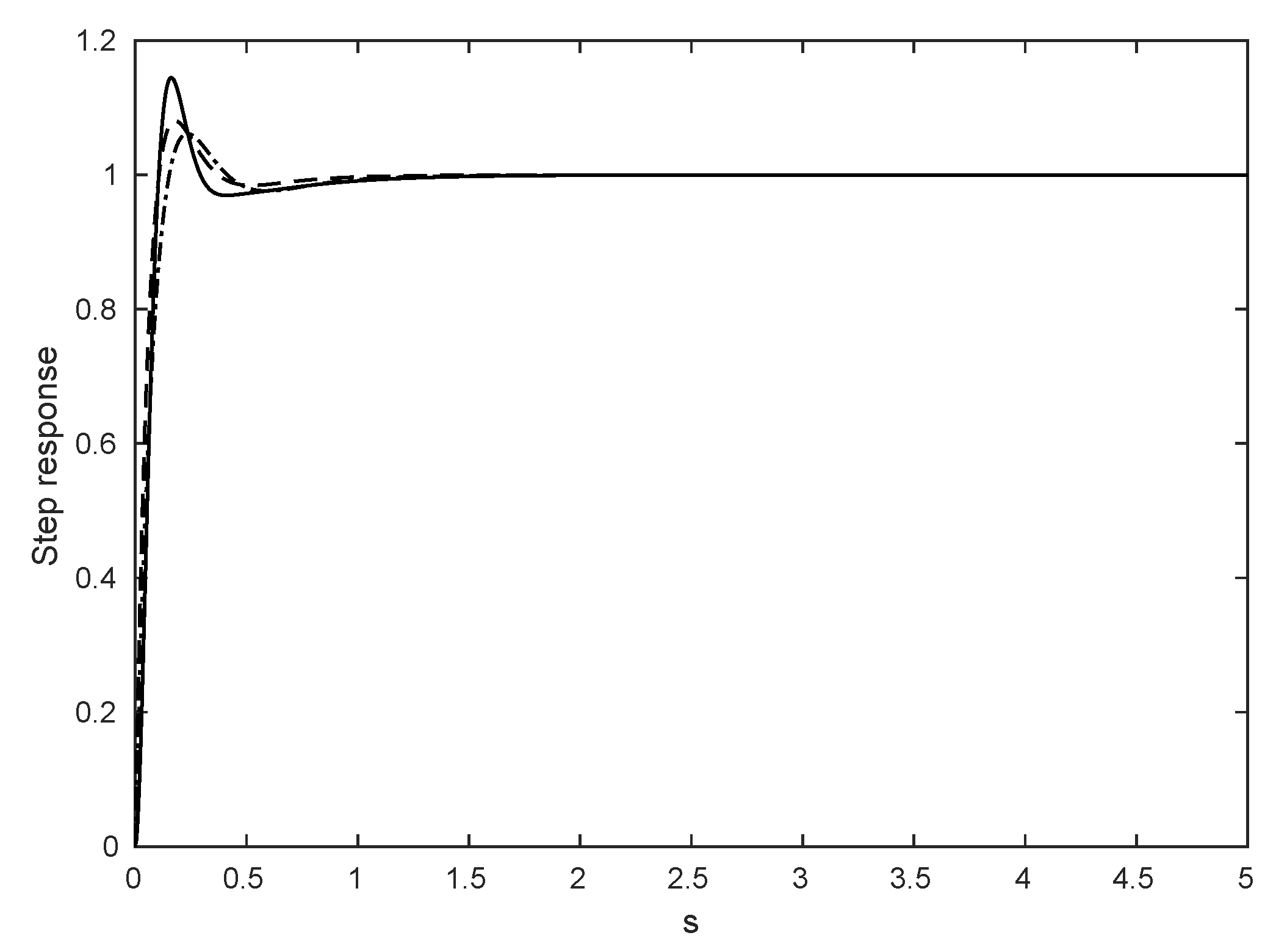
3.2. Motion Control Module
3.3. Observation Module
4. Navigation and Target Detection
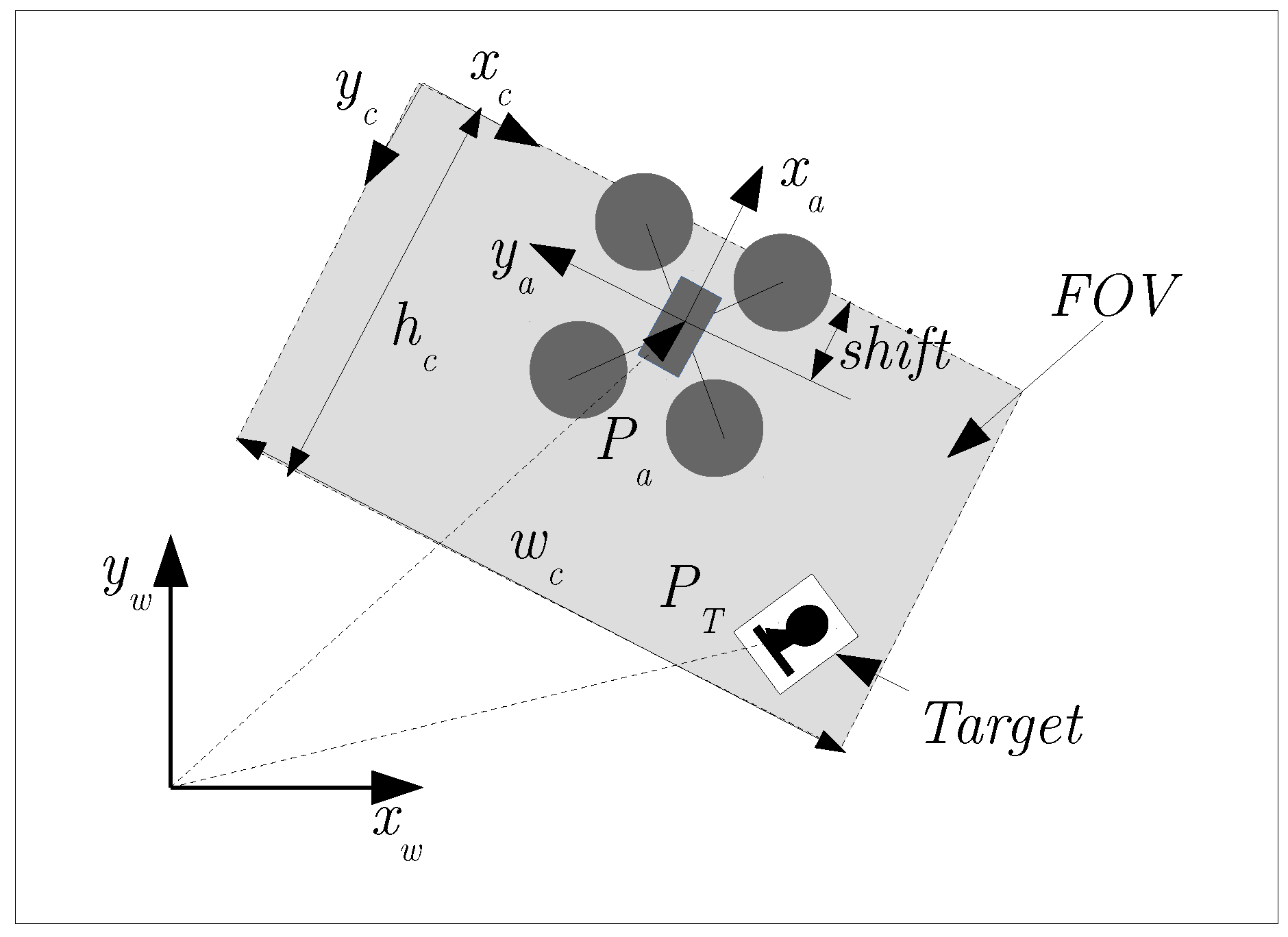
4.1. Problem Description and Formulation
4.2. State Variables (S)
4.3. Actions (A)
4.4. Transition Functions (T)
4.5. Observation Model (O)
4.6. Reward Function (R)
4.7. Discount Factor (γ)
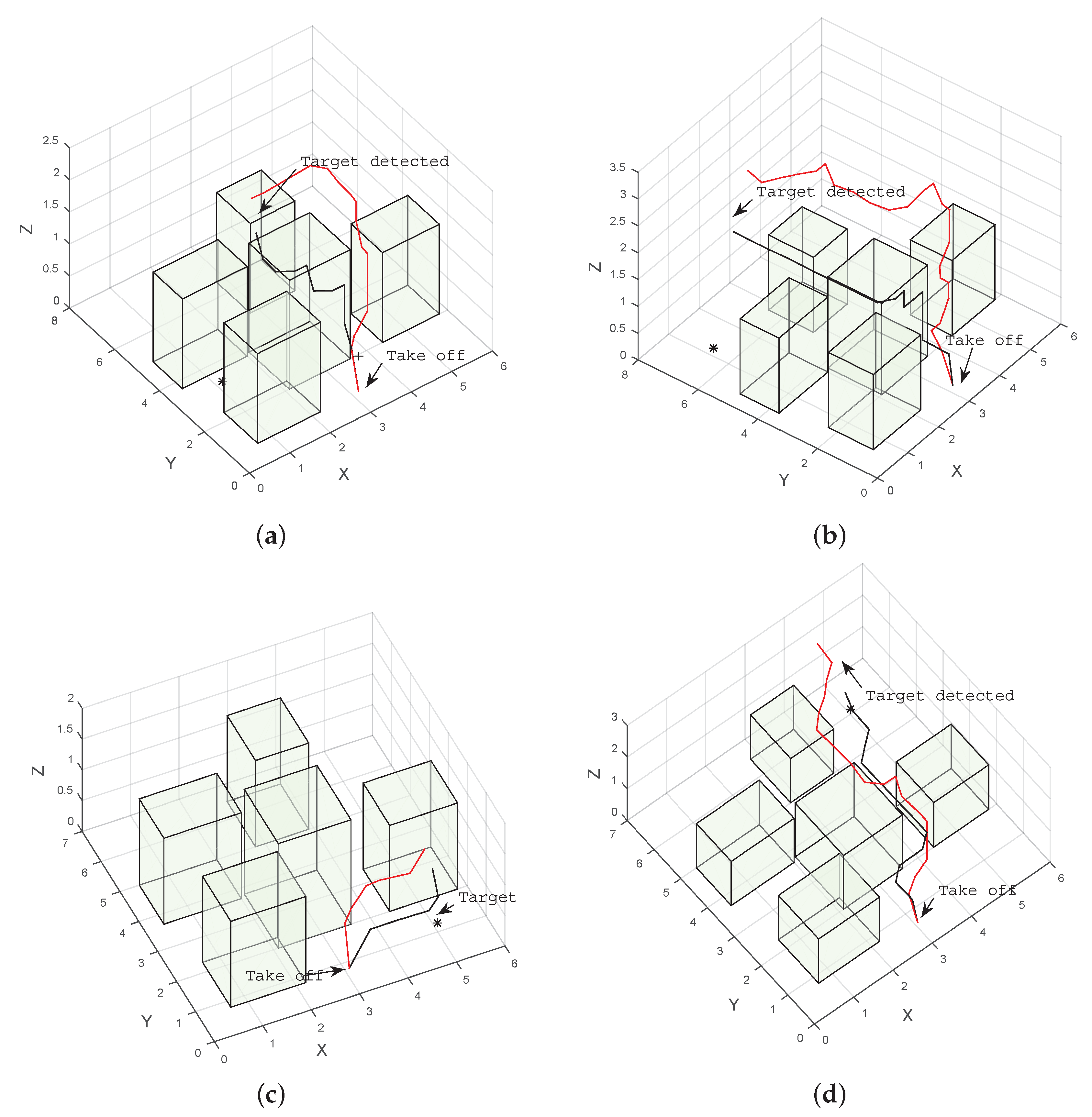
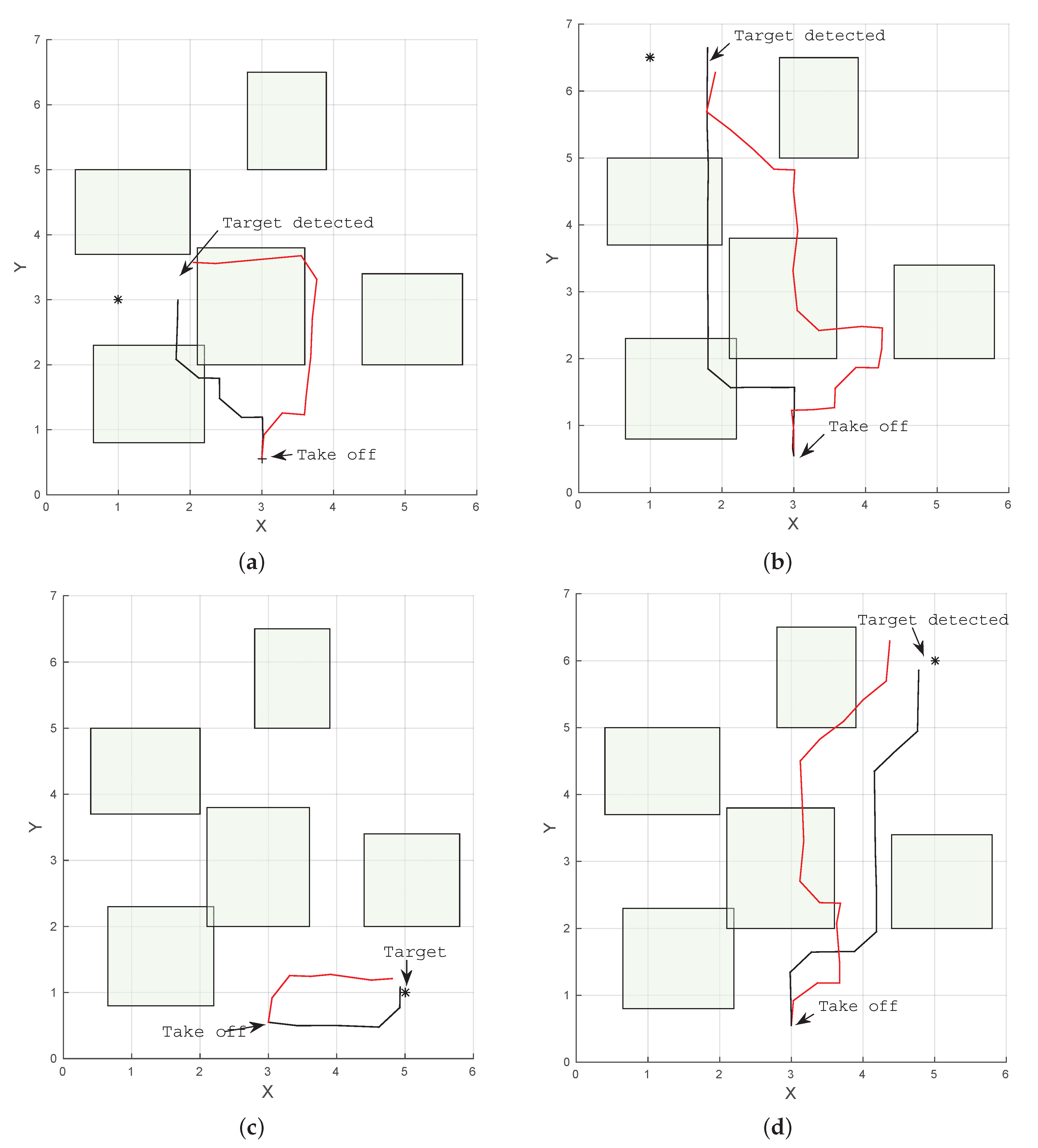
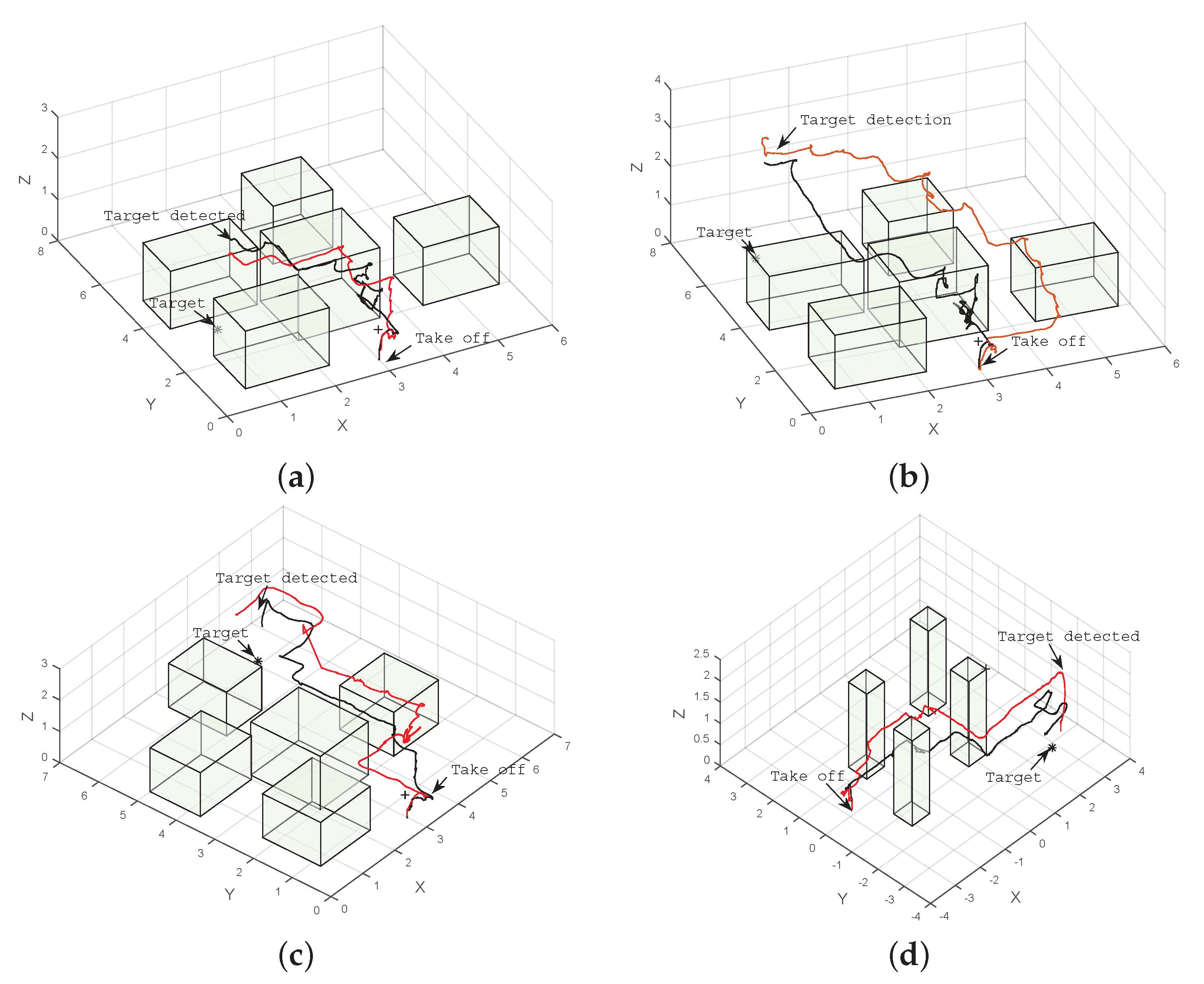
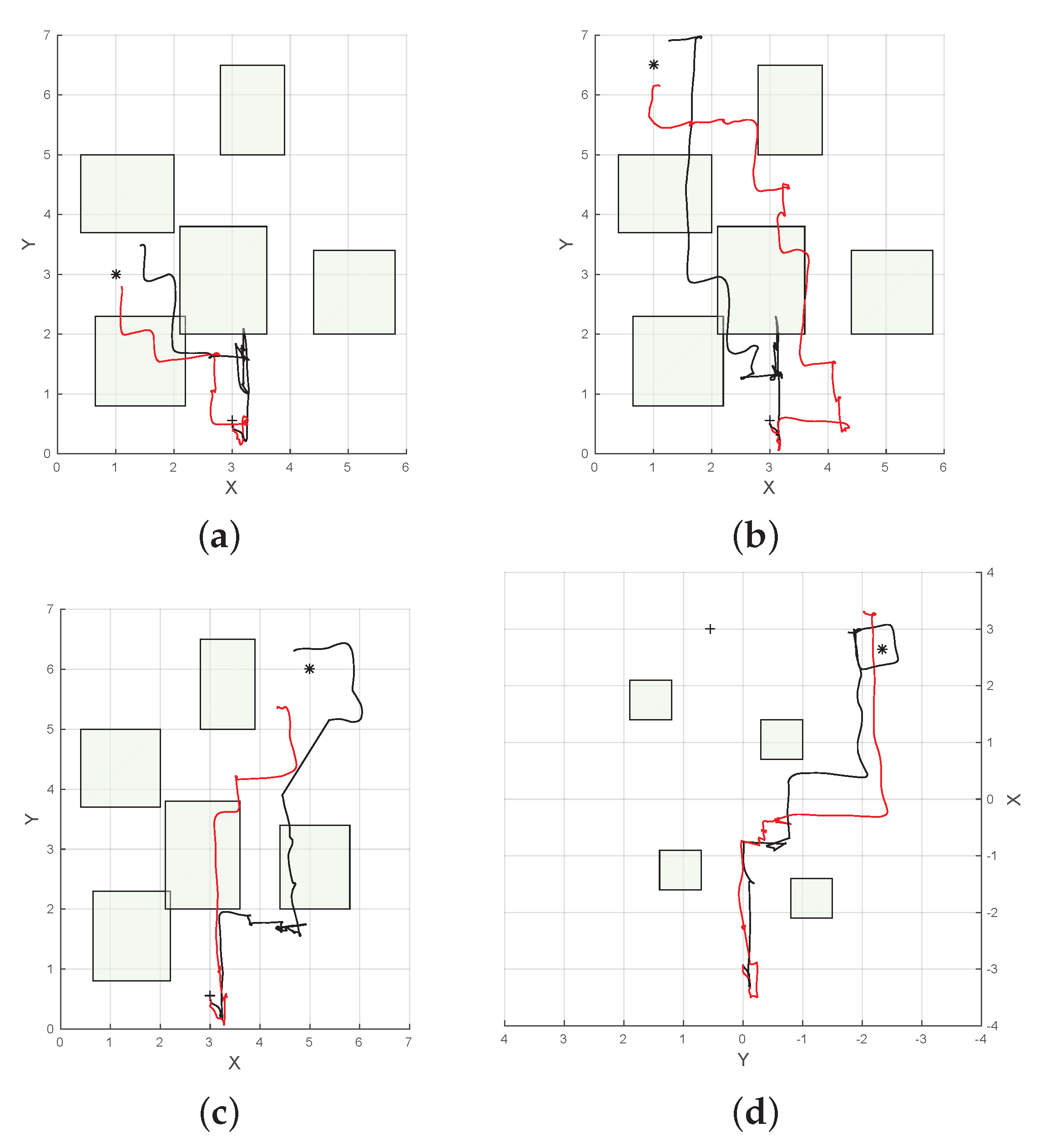
5. Results and Discussion
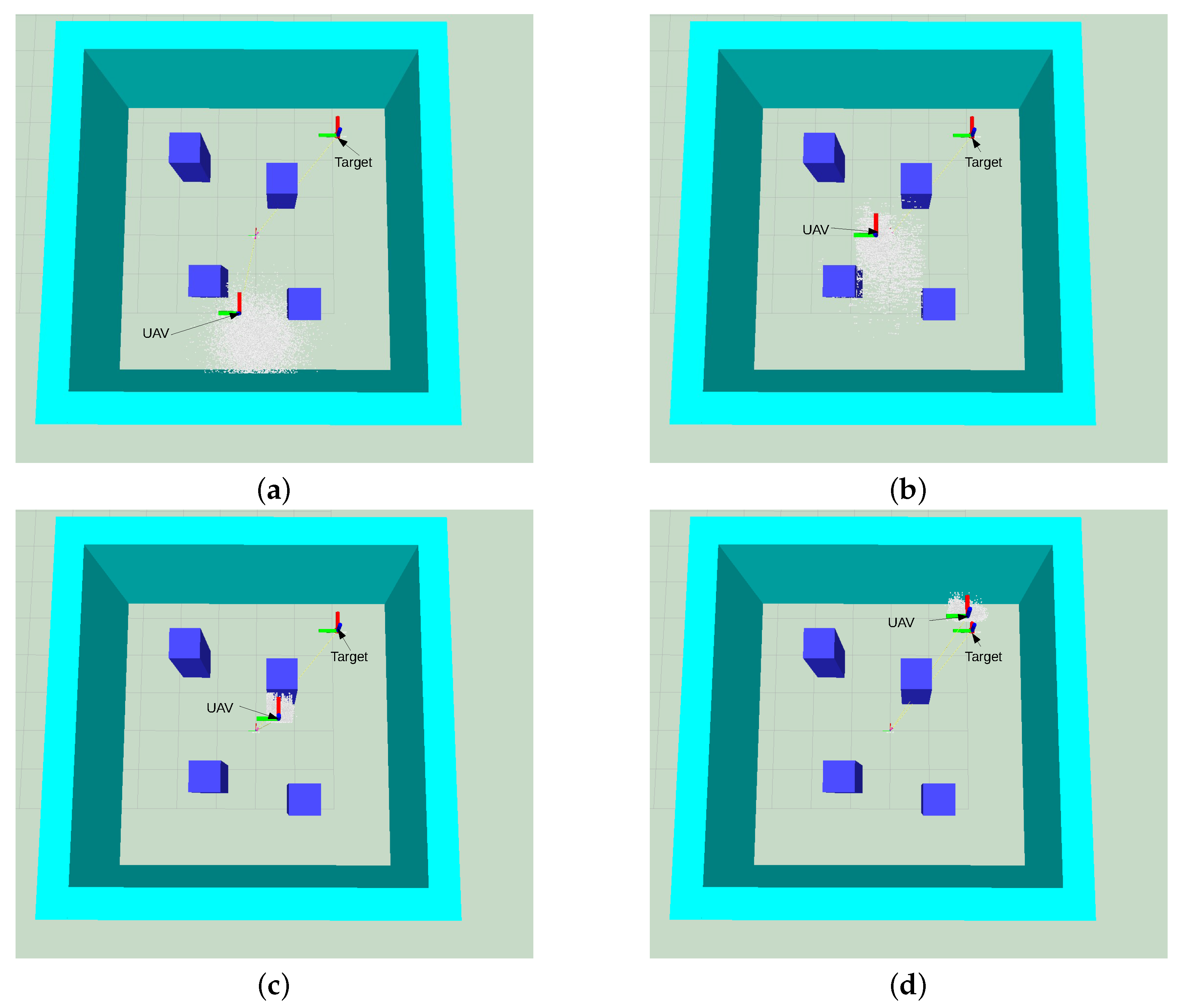
5.1. Simulation
5.2. Real Flight Tests
5.3. Recommendations for Implementation of UAV Navigation Using On-Line POMDP in a Real Flight
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gonzalez, L.F. Robust Evolutionary Methods for Multi-Objective and Multidisciplinary Design Optimisation in Aeronautics; University of Sydney: Sydney, Australia, 2005. [Google Scholar]
- Lee, D.; Gonzalez, L.F.; Periaux, J.; Srinivas, K.; Onate, E. Hybrid-Game Strategies for multi-objective design optimization in engineering. Comput. Fluids 2011, 47, 189–204. [Google Scholar] [CrossRef] [Green Version]
- Roldan, J.; Joossen, G.; Sanz, D.; del Cerro, J.; Barrientos, A. Mini-UAV Based Sensory System for Measuring Environmental Variables in Greenhouses. Sensors 2015, 15, 3334–3350. [Google Scholar] [CrossRef] [PubMed]
- Everaerts, J. The use of unmanned aerial vehicles (UAVs) for remote sensing and mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 1187–1192. [Google Scholar]
- Figueira, N.M.; Freire, I.L.; Trindade, O.; Simoes, E. Mission-Oriented Sensor Arrays And UAVs; A Case Study On Environmental Monitoring. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-1/W4, 305–312. [Google Scholar] [CrossRef]
- Lupashin, S.; Schollig, A.; Sherback, M.; D’Andrea, R. A simple learning strategy for high-speed quadrocopter multi-flips. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 1642–1648.
- Muller, M.; Lupashin, S.; D’Andrea, R. Quadrocopter ball juggling. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 5113–5120.
- Schollig, A.; Augugliaro, F.; Lupashin, S.; D’Andrea, R. Synchronizing the motion of a quadrocopter to music. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 3355–3360.
- Hehn, M.; D’Andrea, R. A flying inverted pendulum. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 763–770.
- Haibin, D.; Yu, Y.; Zhang, X.; Shao, S. Three-Dimension Path Planning for UCAV Using Hybrid Meta-Heuristic ACO-DE Algorithm. Simul. Model. Pract. Theory 2010, 18, 1104–1115. [Google Scholar]
- Smith, T.; Simmons, R. Heuristic search value iteration for POMDP. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, Banff, AB, Canada, 7–11 July 2004; pp. 520–527.
- Pineau, J.; Gordon, G.; Thrun, S. Anytime point-based approximations for large POMDP. J. Artif. Intell. Res. 2006, 27, 335–380. [Google Scholar]
- Hauser, K. Randomized belief-space replanning in partially-observable continuous spaces. In Algorithmic Foundations of Robotics IX; Springer: Berlin, Germany, 2011; pp. 193–209. [Google Scholar]
- Silver, D.; Veness, J. Monte-Carlo Planning in large POMDP. In Proceedings of the 24th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010.
- Kurniawati, H.; Du, Y.; Hsu, D.; Lee, W.S. Motion planning under uncertainty for robotic tasks with long time horizons. Int. J. Robot. Res. 2011, 30, 308–323. [Google Scholar] [CrossRef]
- Kurniawati, H.; Yadav, V. An Online POMDP Solver for Uncertainty Planning in Dynamic Environment. In Proceedings of Results of the 16th International Symposium on Robotics Research, Singapore, 16–19 December 2013.
- Pfeiffer, B.; Batta, R.; Klamroth, K.; Nagi, R. Path planning for UAVs in the presence of threat zones using probabilistic modeling. IEEE Trans. Autom. Control 2005, 43, 278–283. [Google Scholar]
- Ragi, S.; Chong, E. UAV path planning in a dynamic environment via partially observable Markov decision process. IEEE Trans. Aerosp. Electr. Syst. 2013, 49, 2397–2412. [Google Scholar] [CrossRef]
- Dadkhah, N.; Mettler, B. Survey of Motion Planning Literature in the Presence of Uncertainty: Considerations for UAV Guidance. J. Intell. Robot. Syst. 2012, 65, 233–246. [Google Scholar] [CrossRef]
- Al-Sabban, W.H.L.; Gonzalez, F.; Smith, R.N. Wind-Energy based Path Planning For Unmanned Aerial Vehicles Using Markov Decision Processes. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013.
- Al-Sabban, W.H.; Gonzalez, L.F.; Smith, R.N. Extending persistent monitoring by combining ocean models and Markov decision processes. In Proceedings of the 2012 MTS/IEEE Oceans Conference, Hampton Roads, VA, USA, 14–19 October 2012.
- Chanel, C.P.C.; Teichteil-Königsbuch, F.; Lesire, C. Planning for perception and perceiving for decision POMDP-like online target detection and recognition for autonomous UAVs. In Proceedings of the 6th International Scheduling and Planning Applications woRKshop, São Paulo, Brazil, 25–29 June 2012.
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; Volume 1. [Google Scholar]
- Pineau, J.; Gordon, G.; Thrun, S. Point-based value iteration: An anytime algorithm for POMDP. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; Volume 18, pp. 1025–1032.
- Levente, K.; Szepesvari, C. Bandit Based Monte-Carlo Planning. In Machine Learning; Springer: Berlin, Germany, 2006; pp. 282–293. [Google Scholar]
- Klimenko, D.; Song, J.; Kurniawati, H. TAPIR: A Software Toolkit for Approximating and Adapting POMDP Solutions Online. In Proceedings of the Australasian Conference on Robotics and Automation, Melbourne, Australia, 2–4 December 2014.
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3.
- Krajnik, T.; Vonasek, V.; Fiser, D.; Faigl, J. AR-drone as a platform for robotic research and education. In Research and Education in Robotics-EUROBOT; Springer: Berlin, Germany, 2011; pp. 172–186. [Google Scholar]
- Garrido-Jurado, S.; Munoz-Salinas, R.; Madrid-Cuevas, F.J.; Marin-Jimenez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Garzon, M.; Valente, J.; Zapata, D.; Barrientos, A. An Aerial-Ground Robotic System for Navigation and Obstacle Mapping in Large Outdoor Areas. Sensors 2013, 13, 1247–1267. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action a | Forward Velocity (m/s) | Lateral Velocity (m/s) | Altitude Change (m) | Heading Angle (deg) |
|---|---|---|---|---|
| Forward | 0 | 0 | 90 | |
| Backward | 0 | 0 | 90 | |
| Roll left | 0 | 0 | 90 | |
| Roll right | 0 | 0 | 90 | |
| Up | 0 | 0 | 90 | |
| Down | 0 | 0 | 90 | |
| Hover | 0 | 0 | 0 | 90 |
| Reward/Cost | Value |
|---|---|
| Detecting the target | 300 |
| Hitting an obstacle | |
| Out of region | |
| Movement |
| Solver | Number of Obstacles in Scenario | Target Location (x, y, z) | Flight Time to Target (s) (Simulation) | Flight Time to Target (s) (Real Flight) | Success (No Collision) % (Real Flight) |
|---|---|---|---|---|---|
| POMCP | 5 | 14 | 25 | 100 | |
| 4 | 20 | 21 | 100 | ||
| ABT | 5 | 16 | 25 | 90 | |
| 4 | 19 | 27 | 80 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vanegas, F.; Gonzalez, F. Enabling UAV Navigation with Sensor and Environmental Uncertainty in Cluttered and GPS-Denied Environments. Sensors 2016, 16, 666. https://0-doi-org.brum.beds.ac.uk/10.3390/s16050666
Vanegas F, Gonzalez F. Enabling UAV Navigation with Sensor and Environmental Uncertainty in Cluttered and GPS-Denied Environments. Sensors. 2016; 16(5):666. https://0-doi-org.brum.beds.ac.uk/10.3390/s16050666
Chicago/Turabian StyleVanegas, Fernando, and Felipe Gonzalez. 2016. "Enabling UAV Navigation with Sensor and Environmental Uncertainty in Cluttered and GPS-Denied Environments" Sensors 16, no. 5: 666. https://0-doi-org.brum.beds.ac.uk/10.3390/s16050666