1. Introduction
In recent years, there has been an increasing exploitation of mobile robotic sensors in environmental monitoring [
1,
2]. Gaussian processes defined by mean and covariance functions over a continuum space have been frequently used for mobile sensor networks to statistically model physical phenomena such as harmful algal blooms, pH, and temperature, e.g., [
3,
4,
5]. The significant computational complexity in Gaussian process regression due to the growing number of observations has been tackled in different ways. Xu et al. [
4] analyzed the conditions under which near-optimal prediction can be achieved, using truncated observations when the covariance function is known a priori. Xu and Choi [
6] developed a new efficient and scalable inference algorithm for a class of static Gaussian processes that builds on a Gaussian Markov random field (GMRF) is developed for known hyperparameters. In terms of the computational cost reduction, Ref. [
7,
8] showed that Gaussian processes can be formulated as infinite-dimensional Kalman filtering and such approach can scale down computational complexity. Ref. [
9] combined Gaussian process and Kalman filter for efficient computation. On the other hand, unknown hyperparameters in the covariance function can be estimated by a maximum likelihood (ML) estimator or a maximum a posteriori (MAP) estimator and then can be used for the prediction [
10]. However, the point estimate itself needs to be identified using a certain amount of measurements and it does not fully incorporate the uncertainty in the estimated hyperparameters into the prediction in a Bayesian perspective.
The advantage of a fully Bayesian approach is the capability of incorporating various uncertainties in the model parameters and measurement processes in the prediction [
2]. However, the solution often requires an approximation technique such as Markov Chain Monte Carlo (MCMC), Laplace approximation, or variational Bayes methods, which still requires a high level of computational complexity [
2]. Xu et al. [
11] designed a sequential Bayesian prediction algorithm and its distributed version for Gaussian processes to deal with uncertain bandwidths. Xu et al. [
12] presented sequential fully Bayesian prediction algorithms for a static GMRF with unknown hyperparameters.
Inexpensive wireless/mobile sensor networks [
13] are widespread at the cost of precision in localization. Due to their growing usage, there are many practical opportunities where continuously sampled measurements need to be fused for sensors with localization uncertainty [
14]. Secure indoor localization has been proposed based on extracting trusted fingerprint [
15]. Theoretically-correct yet efficient (or scalable) inference algorithms need to be developed to meet such demands.
Related works involving uncertain localization in our context are as follows. Gaussian process regression has been used in building maps and localization in many practical applications. Brooks et al. [
16] utilized Gaussian process regression to model geo-referenced sensor measurements (obtained from a camera) in a supervised learning manner. Kemppainen et al. [
17] used Gaussian process regression to implement simultaneous localization and mapping (SLAM) using a magnetic field. O’Callaghan et al. [
18] investigated the problem of using laser range-finder data to probabilistically classify a robot’s environment. McHutchon and Rasmussen [
19] presented a Gaussian process for training on input points corrupted by independent and identically distributed (i.i.d.) Gaussian noise. Do et al. [
20] conducted visual feature selection via Gaussian process regression for position estimation using an omnidirectional camera. The works in [
19,
20] assume that all hyperparameters are trained offline a priori. Jadaliha et al. [
21] and Choi et al. [
22] formulated and solved the problem of Gaussian process regression with uncertain localization and known hyperparameters for both centralized and distributed fashions, respectively. A key limitation of such approaches with fixed hyperparameters arises from the fact that, after the initial training phase, learning is discontinued. If the environment changes, it is desirable that the localization algorithm adapts to the changes on the fly. A fully Bayesian approach that treats hyperparameters as random variables can address this issue with increased computational complexity.
The novelty of our work in contrast to ones in [
11,
12] is to fully consider the uncertainty on the sampling positions along with other uncertainties such as hyperparameters, observation noise, etc., in a
fully Bayesian manner. The fully Bayesian field SLAM presented in [
23] is quite similar to our current work in this paper. However, it is limited to a static random field while ours can deal with the time-varying random field. To the best of our knowledge, fully Bayesian prediction algorithms for spatio-temporal random fields that can take into account uncertain localization are scant to date. Hence, this paper aims to develop such inference algorithms for robotic sensor networks in practical situations by building on spatio-temporal models developed by Lynch et al. [
1] and Xu et al. [
2]. With continuous improvement in computation power in embedded systems, it is very important to prepare theoretically-correct, and flexible fully Bayesian approach to cope with such practical problems.
The contributions of the paper are as follows. Firstly, we model a physical spatio-temporal random field as a GMRF with uncertain hyperparameters and formulate the prediction problems with and without localization uncertainty. Next, we derive the exact Bayesian solution to the problem of computing the predictive inference of the random field, taking into account uncertain hyperparameters, measurement noise, and uncertain localization in a fully Bayesian point of view. We show that the exact solution for uncertain localization is not scalable as the number of observations increases. To cope with this increasing complexity, we propose a scalable approximation with a controllable trade-off between approximation error and complexity to the exact solution. The effectiveness of the proposed algorithms is demonstrated by experimental results in both static and dynamical environments.
The paper is organized as follows. In
Section 2, we explain how a GMRF can be viewed as a sparse and discretized version of a Gaussian process. In
Section 3 and
Section 4, we introduce a spatio-temporal field model based on a GMRF and the mobile sensor network. In
Section 5.1, we present a fully Bayesian inference approach to estimate the spatio-temporal field. The Bayesian prediction algorithm is extended for uncertain sampling positions in
Section 5.2. Finally, we evaluate our approach on a real experimental setup in
Section 6.
Standard notation is used. Let and denote, respectively, the sets of real and positive integer numbers. The operator of expectation is denoted by E. A random vector x, which has a multivariate normal distribution of mean vector and covariance matrix , is denoted by . For given and , the multiplication between two sets is defined as . Other notation will be explained in due course.
2. From Gaussian Processes to Gaussian Markov Random Fields
There are efforts to fit a computationally efficient GMRF on a discrete lattice to a Gaussian random field on a continuum space [
12,
24,
25]. It has been demonstrated that GMRFs with small neighborhoods can approximate Gaussian fields surprisingly well [
24]. This approximated GMRF and its regression are efficient and very attractive [
26] as compared to the standard Gaussian process and its regression. Fast kriging of large data sets by using a GMRF as an approximation of a Gaussian random field has been proposed in [
25].
We now briefly review a GMRF as a discretized Gaussian process on a lattice. Consider a zero-mean Gaussian process: where is the covariance function defined in a continuum space . We discretize the compact domain into n spatial sites , where . h will be chosen such that . Note that as The collection of realized values of the random field in is denoted by , where .
The prior distribution of
z is given by
, and so we have
where
is the covariance matrix. The
-th element of
is defined as
. The prior distribution of
z can be written by a precision matrix
, i.e.,
. This can be viewed as a discretized version of the Gaussian process (or a GMRF) with a precision matrix
on
Note that
of this GMRF is not sparse. However, a sparse version of
, i.e.,
with a local neighborhood that can represent the original Gaussian process can be found, for example, making
close to
in some norm [
24,
25]. This approximate GMRF will be computationally efficient due to the sparsity of
. For our main problems, we will use a GMRF with a sparse precision matrix that represents a Gaussian process precisely.
We assume that we take
N noisy measurements
from corresponding sampling locations
. The measurement model is given by
where
is the measurement noise and is assumed to be independent and identically distributed (i.i.d.).
Using Gaussian process regression, the posterior distribution for
is given by
The predictive mean and covariance matrix can by obtained by where the covariance matrices are defined as , , and .
The pose of a robot can be estimated by fusing different sensory information producing its estimate and estimation error statistics [
27,
28]. Throughout the paper, we assume that the positions of mobile robotic sensors and their uncertainties are estimated by a standard technique. Having had the aforementioned assumption, from a localization algorithm, the prior distribution for sampling location
is given as
, possibly with a compact support in
. Then, the predictive distribution of
z given the measured locations
is thus given by
where
can be obtained by Equation (
3). However, the predictive distribution in Equation (
4) does not have a closed-form solution and needs to be computed either by MCMC methods or approximation techniques [
29].
Now we consider a discretized version of the Gaussian process, i.e., (GMRF) with a precision matrix
on
. Since the sampling points of Gaussian process regression are not necessarily on a finite compact domain
, we use the nearest grid point of a given sampling point
in
The sampling positions for the GMRF are then exactly on the lattice, i.e.,
. The posterior distribution of
on
given by measurements in
and sampling positions in
is then obtained by
where
with
and
defined as
The proof of this posterior distribution of
z in Equation (
5) is very similar to that of Proposition 6.1 in Chapter 6 of [
2], which was derived by using the Woodbury matrix identity.
We consider again localization uncertainty for this GMRF. Let the measured noisy location
be the nearest grid point of the measured noisy sampling point
of the Gaussian process. Now we obtain a set of discretized probabilities in
induced by the continuous prior distribution defined in
. The discrete prior distribution for the sampling location
is given by
where
is the continuous prior as in Gaussian process regression and
is the Voronoi cell of the
j-th grid point
given by
The predictive distribution of
z given
y and
is thus given by
where
can be obtained by Equation (
5) and the summation is over all possible locations in
.
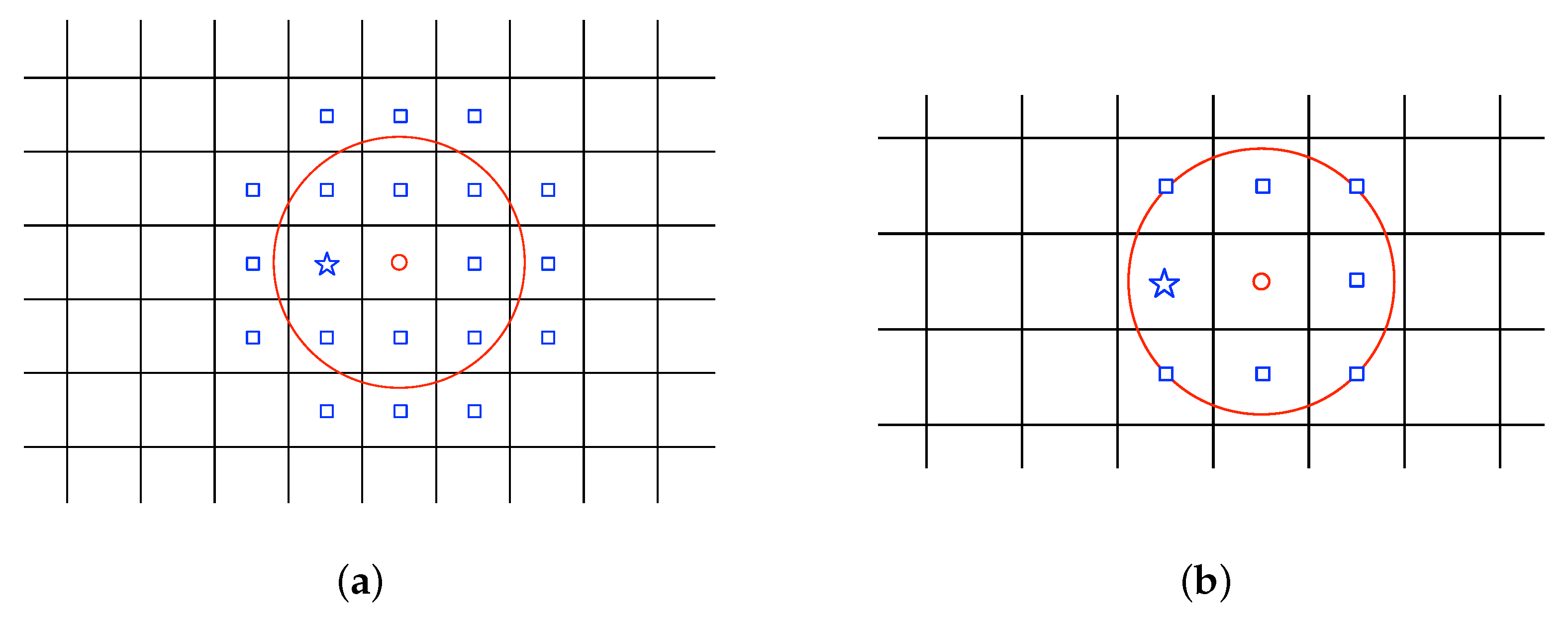
Figure 1 shows two examples of using this approximation approach with
to convert a continuous space to a discrete one. When
,
and the standard Gaussian process regression in a continuum space shall be recovered from the prediction using the GMRF in a discretized space.
4. Spatio-Temporal Field Model
The value of the scalar field at
,
is modeled by a sum of a time-varying mean function and a GMRF
Here the mean function
is defined as
where
is a known regression function and
is an unknown vector of regression coefficients. The time evolution of
is modeled by a linear time-invariant system:
where
,
, and
and
are known system parameters or can be found as discussed in [
30].
In addition, we consider a zero-mean GMRF [
31]
whose covariance matrix is given by
where
t, and
k are time indices, and
is the Kronecker delta defined by
and the inverse covariance matrix (or precision matrix)
is a function of the hyperparameter vector
.
There are different parameterizations of the GMRF (i.e., the precision matrix
) [
31]. Our Bayesian approach does not depend on the choice of the parameterization for the precision matrix. However, for a concrete and useful exposition, we describe a specific parameterization used in this paper. The precision matrix is parameterized with the full conditionals as follows. Let
be a GMRF on a regular two-dimensional lattice. The associated Gaussian full conditional mean is
where
is the
i-th row and
j-th column element of
. Here,
is the collection of
values everywhere except
. The hyperparameter vector is defined as
, where
. The value of
is
as denoted at the center node of the graph. That of
is
if
j is one of the four closest neighbors of
i in the vector 1-norm sense. Thus, the value of
is zero if
j is not one of the twelve closest neighbors of
i (or twelve neighbors whose 1-norm distance to the
i-th location is less than or equal to 2), as shown in [
32]. The equation in Equation (
17) states that the conditional expectation of
given the value of
everywhere else (i.e.,
) can be determined just by knowing the value of
on the twelve closest neighbors (see more details in [
32]). The resulting GMRF accurately represents a Gaussian random field with the Matérn covariance function as shown in [
32]
where
is a modified Bessel function [
33], with order
, a bandwidth
, and vertical scale
. The hyperparameter
guarantees the positive definiteness of the precision matrix
. In the case where
, the resulting GMRF is a second-order polynomial intrinsic GMRF [
31,
34].
From the presented model in Equations (
12), (
14), and (
15), the distribution of
given
and
is
where
.
In other words, is a non-zero mean Gaussian process. Here, the covariance matrix is defined as inverse of the precision matrix (i.e., ). Note that the precision matrix is a positive definite matrix and invertible, and , where is the -th element of the covariance matrix.
For simplicity, let us define
. Using Gaussian process regression, the posterior distribution for
is given by
The basic idea behind the model introduced in Equations (
12), (
14), and (
15) stems from the space-time Kalman filter model proposed in [
35]. The advantage of this spatio-temporal model with known hyperparameters is to make inferences in a recursive manner as the number of observations increases.
In this paper, however, uncertainties in the precision matrix and sampling positions are considered in a fully Bayesian manner. In contrast to [
35,
36], the GMRF with a sparse precision matrix is used to increase the computational efficiency.
5. Fully Bayesian Predictive Inference
5.1. Uncertain Hyperparameters and Exact Localization
In this section, we consider the problem of predicting a spatio-temporal random field, using successive noisy measurements sampled by a mobile sensor network. For a known covariance function, the prediction can be shown to be recursive [
37] based on Gaussian process regression. The uncertainty in
in a GMRF has been considered and its sequential prediction algorithms are derived in [
12]. However, only the static field has been considered, i.e.,
. In this section, we use a Bayesian approach to make predictive inferences of the spatio-temporal random field
for the case with uncertain hyperparameters and the exact localization. To this end, we use the following Assumptions 1–5.
Assumption 1. The spatio-temporal random field is generated by Equations (
12), (
14),
and (
15)
; Assumption 2. The precision matrix is a given function of an uncertain hyperparameter vector θ;
Assumption 3. The noisy measurements , as in Equation (
10)
, are continuously collected by mobile robotic sensors in time t; Assumption 4. The sample positions are measured precisely by mobile robotic sensors in time t;
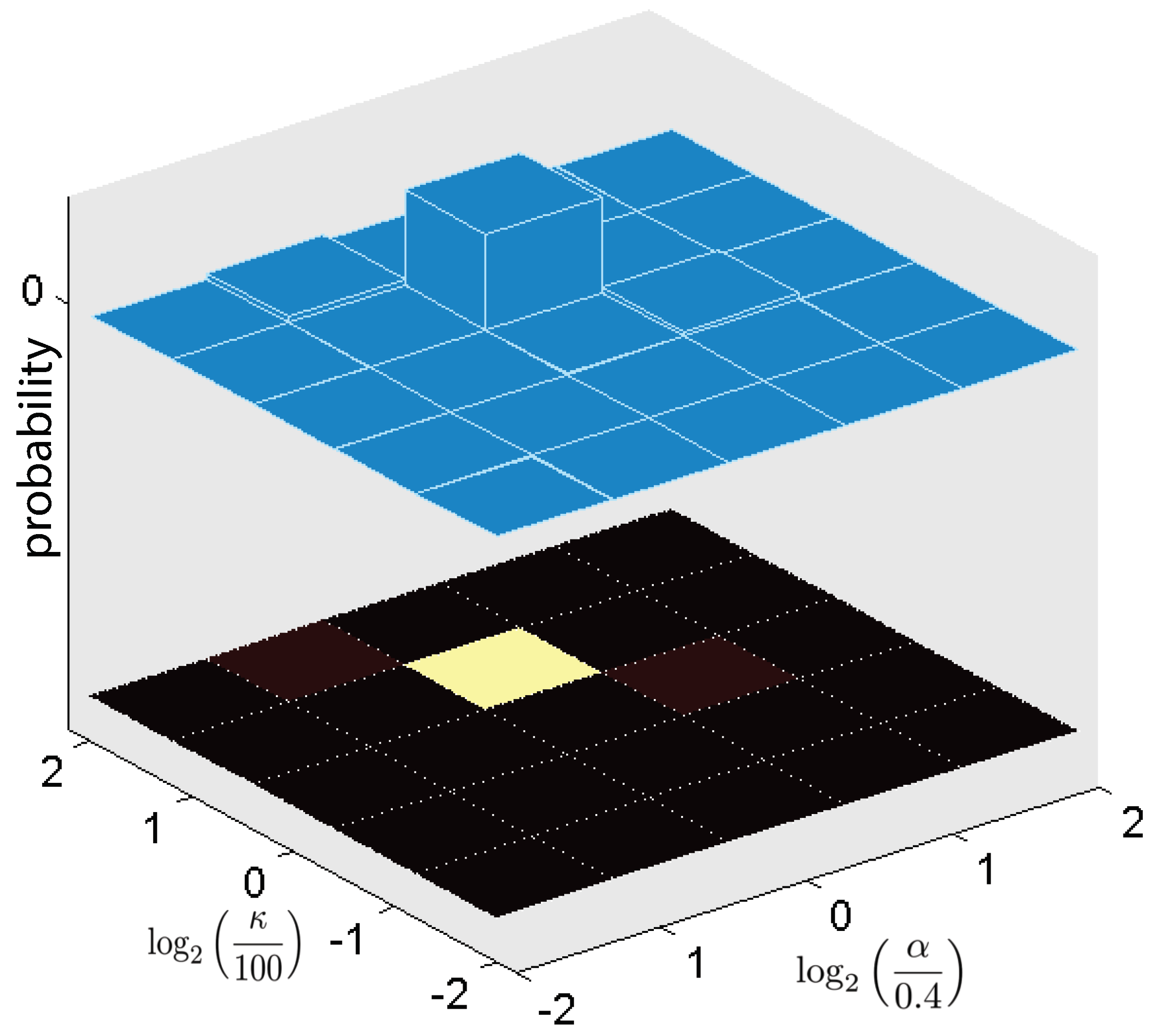
Assumption 5. The prior distribution of the hyperparameter vector θ is discrete with a support .
A.1 and A.2 stem from the discretization of a Gaussian process as we described in
Section 2. From the model in A.1, the zero-mean GMRF represents a spatial structure by assuming that the difference between the parametric mean function and the dynamical environmental process is governed by a relatively large time scale. A.3 is a standard assumption over the measured observations [
36]. A.4 will be relaxed to A.6 in
Section 5.2 to deal with localization uncertainty. A.5 is from the discretization of the hyperparameter vector to replace an integration with a summation over possible hyperparameters.
We denote the full latent field of dimension by . Let’s define , where , and is assumed to be known.
We formulate the first problem as follows.
Problem 1. Consider the Assumptions 1–5. Our problem is to find the predictive distribution, mean, and variance of conditional on .
We then summarize the intermediate steps to obtain the solution to Problem 1. In what follows, our results are presented in terms of lemmas and theorems. We provide proofs when they are not straightforward.
Lemma 1. Under Assumptions 1 and 2, the predictive distribution of conditional on the hyperparameter vector θ and the measurements is Gaussian with the following mean and precision matrix:where denotes the expectation of conditional on θ and and denotes the associated estimation error covariance matrix. Proof of Lemma 1. It can be shown by the update using the prior precision matrix and the previous iteration as in [
12] (see more details in Section 3 of [
12]). ☐
For a given hyperparameter vector
, Equation (
21) provides the optimal prediction of the spatio-temporal field in time
t using data up to time
.
The following lemma is used to compute the posterior distribution of , recursively.
Lemma 2. Under Assumptions 3 and 4, the posterior distribution of the hyperparameter vector θ can be obtained recursively viawhere the distribution of given is Gaussian with the following mean and variance:where . Proof of Lemma 2. The posterior distribution of
given in Equation (
22) is computed by applying Bayes’ rule on
. The predictive statistics of
are straightforward results of using Equation (
10). Note that
is equal to
. ☐
Lemma 3. Under Assumptions 1–4, the full conditional distribution of for a given hyperparameter vector and data up to time t iswhere In order to keep computing the prediction error covariance matrix
alone, the Woodbury lemma could be used to reduce the computational load as follows:
where
can be computed with blockwise inversion using Equation (
21),
The blockwise inversion needs to be updated only with .
The following theorem explicitly illustrates how the results of Lemmas 2 and 3 lead to the predictive statistics of under Assumptions 1–5, which will be the solution to Problem 1.
Theorem 1. Under Assumption 5, the predictive distribution of is given bywhere and are given by Lemmas 2 and 3, respectively. The predictive mean and variance follow as Proof of Theorem 1: The predictive mean and variance is obtained by marginalizing over the conditional distribution of given . The marginal mean and variance are and , where and denote the expectation and the variance with respect to the random variable X. Having and completes the proof of Theorem 1. ☐
The optimal prediction of the spatio-temporal field using predictive statistics of is provided by Lemma 1. Lemma 3 provides the optimal estimator of , using predictive statistics of which is given by Lemma 1. Using Lemmas 1 and 3 sequentially, we can update predictive statistics of for known hyperparameters. Lemma 2 gives us the posterior distribution of based on the measured data. Finally, Theorem 1 provides the optimal Bayesian prediction of the spatio-temporal random field with a time varying mean function and uncertain hyperparameters by marginalizing over the conditional distribution of .
The proposed solution to the formulated problem is summarized by Algorithm 1.
| Algorithm 1 Sequential Bayesian Predictive Inference |
Initialization:
- 1:
initialize - 2:
for , initialize , and compute
At time , do:
- 1:
obtain new observations at current locations - 2:
find the map from to spacial sites , and compute radial basis values in . - 3:
fordo - 4:
predict and using measurements up to time , given by Equation ( 21). - 5:
compute and given by Equation ( 24). - 6:
compute and by Equation ( 23). - 7:
calculate given by Equation ( 22). - 8:
end for - 9:
compute the predictive mean and variance using Equation ( 27).
|
5.2. Uncertain Hyperparameters and Localization
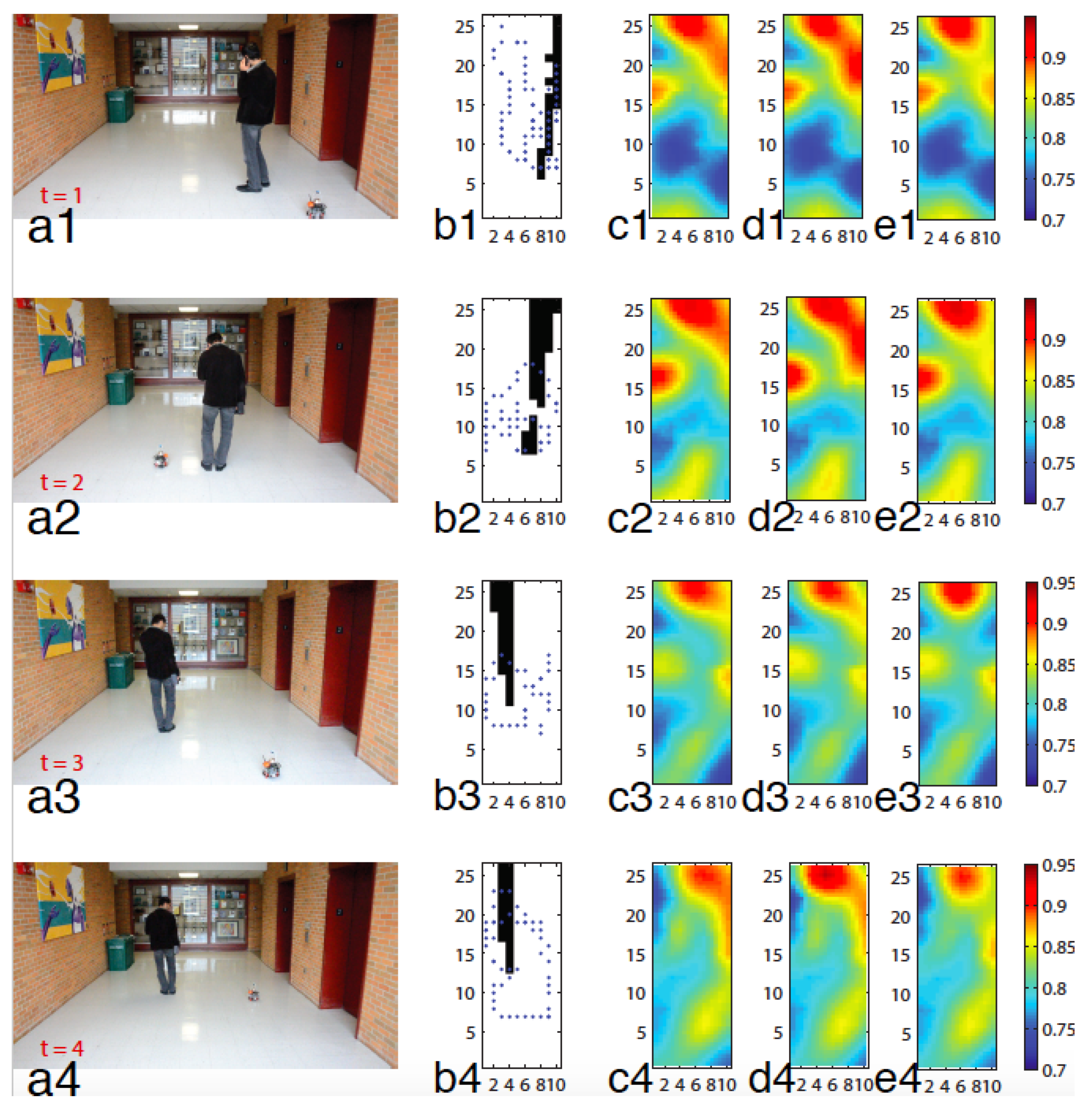
In the previous section, we assumed that the localization data is exactly known. However, in practice, positions of sensor networks cannot be measured without noise. Instead, for example, there could be several probable possibilities inferred from the measured position. In this section, the proposed method in the previous section will be extended for the uncertain localization data.
In order to take into account the uncertainty in the sampling positions, we replace Assumption 4 with the following Assumption 6.
Assumption 6. The prior distribution is discrete with a support , which is given at time t along with the corresponding measurement . Here, denotes the index in the support and is the number of the probable possibilities for .
A straightforward consequence of Assumption 6 is that the prior distribution is discrete with a support . In addition, denotes the index in the support , and is the number of the probable possibilities for . Now we state the problem as follows.
Problem 2. Consider Assumptions 1–3, 5, and 6. Our problem is to find the predictive distribution, mean and variance of conditional on the prior and the measurements .
For the sake of conciseness, let us define . We then have , where we recall that .
To solve Problem 2, we first look for a way to compute the posterior distribution of as summarized in the following lemma.
Lemma 4. Consider given by Equation (
23)
and given by Equation (
22),
where , , and . Under Assumption 5, we have Under Assumption 6, the posterior distribution of can be obtained, recursively, via We now give the exact solution to Problem 2 as follows.
Theorem 2. Consider the predictive distribution given by Theorem 1 and the posterior given by Lemma 4, where and . Under Assumption 6, the predictive distribution of can be obtained as follows: Consequently, the predictive mean and variance are given by the formulas: Proof of Theorem 2: The proof is similar to that of Theorem 1. Hence, the predictive mean and variance are obtained by marginalizing over the conditional distribution of . The marginal mean and variance are and , where and denote the expectation and the variance with respect to the random variable X. Having and proves Theorem 2. ☐
The complexity of the proposed algorithm in Theorem 2 is proportional to the number of possibilities for . The result of Lemma 4 enables us to compute these probable possibilities recursively. However, the number of the non-zero probable combinations grows exponentially by a power of time index t.
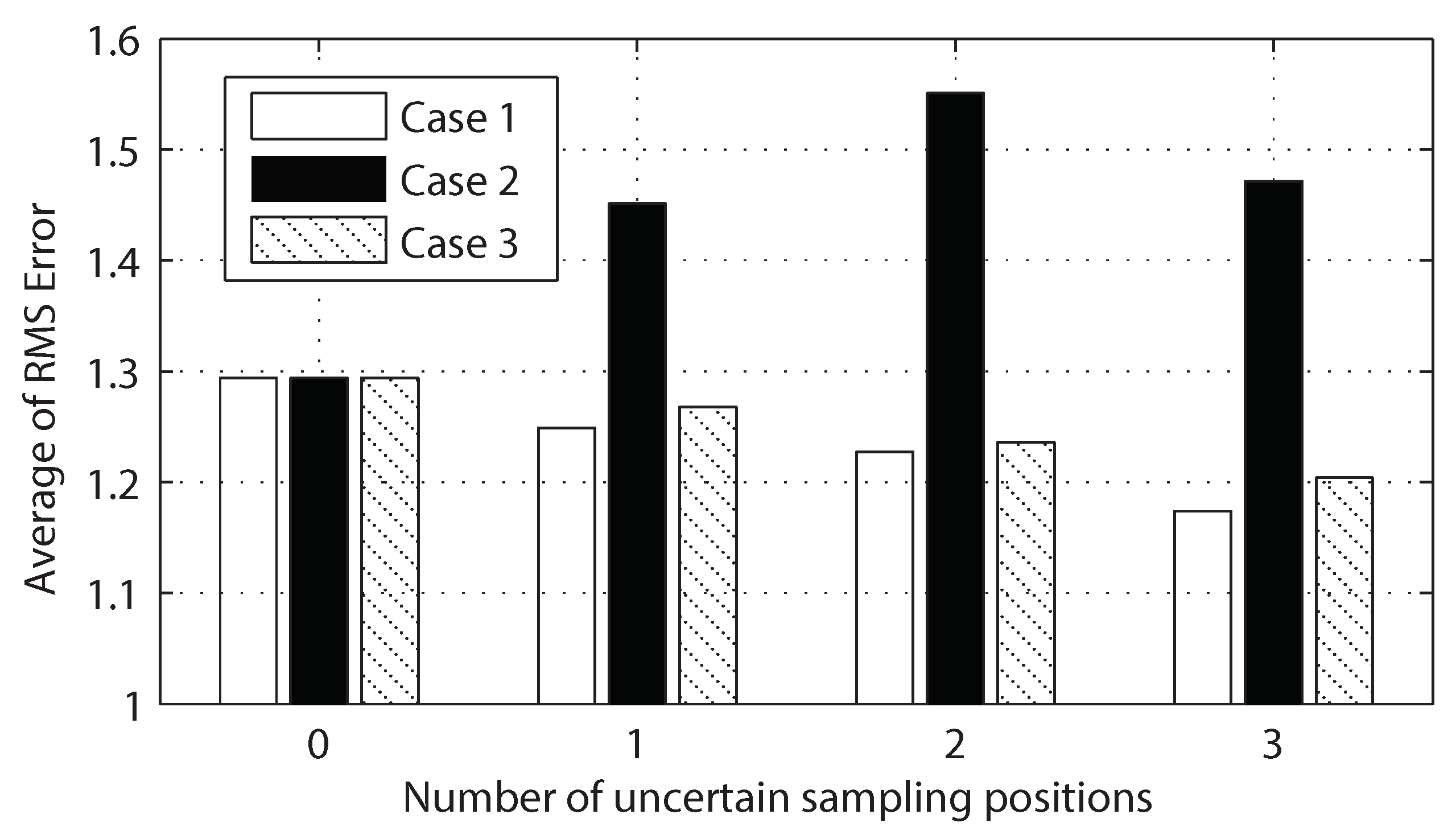
In what follows, we propose an approximation, with a controllable trade-off between approximation error and complexity, to the exact solution given in Theorem 2 by including an option of ignoring uncertainties on past position data. This approximation will include a case of the exact solution with the maximal and original complexity. The idea is based on the fact that the estimation of is more susceptible to the uncertainties in recently sampled positions as compared to old ones. To formulate our idea clearly, we present first the following results.
Lemma 5. Using prior distribution of and measured data , where , the posterior distribution of can be obtained recursively viawhere , and . Theorem 3. Consider and computed by Theorem 1. Under Assumption 6, the predictive statistics of are as follows: To implement approximations to the predictive statistics of which are given by Theorem 2, we consider the following conditions.
- C.1
For
, we have that
- C.2
For
,
can be approximated by
Under conditions C.1 and C.2, it is natural for us to propose the following approximations:
In Theorem 3, the predictive statistics of
are obtained from Algorithm 1, which is given in
Section 5.1. The only difference is that we start from time
instead of time 1 with
instead of
. Note that, without condition C.2, we cannot use Algorithm 1 to calculate the statistics of
. The proposed approximation for the case of uncertain localization in Equation (
35) is quite different from a mere truncation of old data in the sense that past measurements still affect the current estimation through the approximately updated prior information using Equation (
34). Note that we update the prior information from
to
with the cumulative data collected from time
up to time
t, which is different from only using truncated observations. The proposed approximation for the formulated problem is summarized by Algorithm 2.
To further understand the nature of the proposed approximation, consider the following two extreme special cases.
Corollary 1. As a special case of Theorem 3 for , the posterior distribution of can be obtained viawhere . The predictive distribution of can be approximated in a constant time as time t increases in a sequential way.whereand the posterior is given by Equation (
36).
Consequently, the predictive mean and variance can be approximated by and , respectively, i.e., Corollary 2. For another special case with , Theorem 3 becomes Theorem 2.
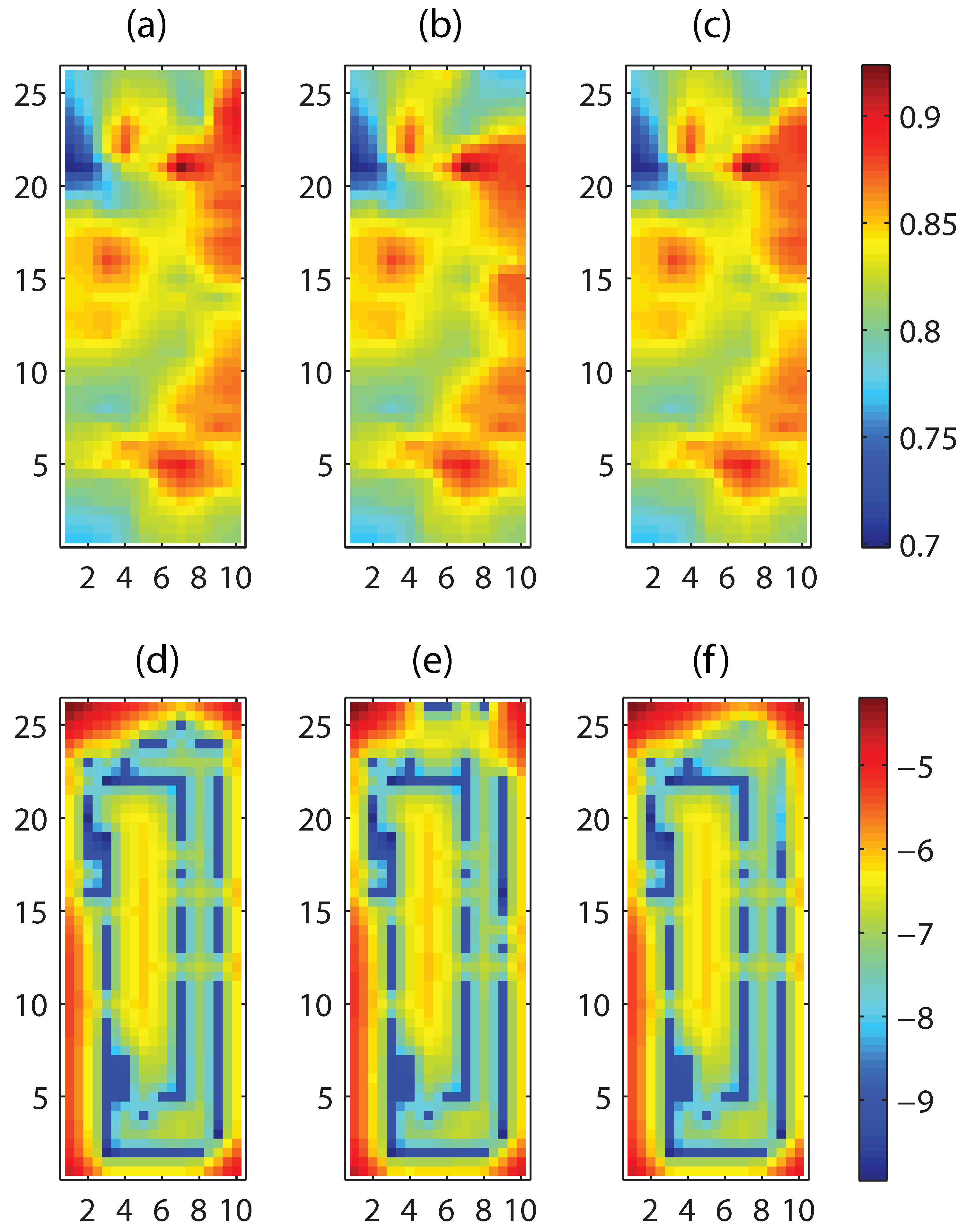
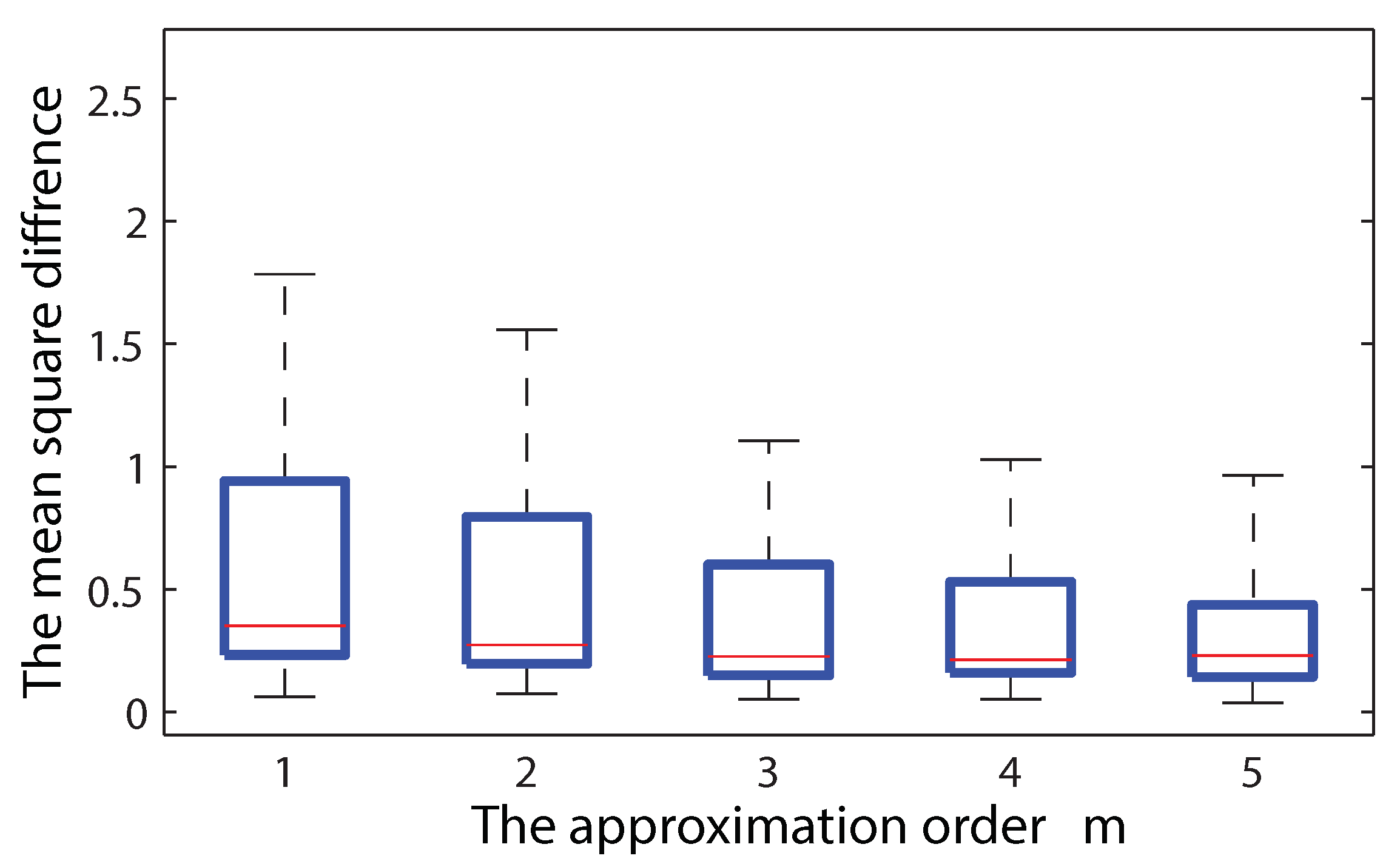
For a fixed , Algorithm 2 is scalable as time t increases. In our approach, the level of the approximation can be controlled by users by selecting a trade-off (or by choosing m) between the approximation error and complexity. Most simplistic and practical approximation can be obtained by choosing as in Corollary 1. The original exact solution with maximal complexity is recovered by selecting as shown in Corollary 2.
| Algorithm 2 Sequential Bayesian Predictive Inference Approximation with Uncertain Localization |
At time , do:
- 1:
obtain new observations along with the probabilities for locations - 2:
fordo - 3:
predict , and using Algorithm 1 - 4:
compute by Lemma 5. - 5:
end for - 6:
compute and , using Theorem 3. - 7:
use following approximation to update estimations
|
5.3. Complexity of Algorithms
In this section, we discuss complexity aspects of the proposed algorithms. For a fixed number of the radial basis functions (i.e.,
p) and a fixed number of the special sites (i.e.,
n), the computational complexity of Algorithm 1 is dominated by Equation (
24). The complexity of Algorithm 1 in each time step is
, where
L is the number of possible hyperparameter vectors and
N is the number of agents. The complexity of Algorithm 2 in time
t is
times the complexity of Algorithm 1 for
m time steps. Hence, the complexity of Algorithm 2 in time
t is
. The numbers of special sites and radial basis functions affect the complexity of Algorithm 1 as well. The complexity of the three cases is
with respect to the number of special sites due to the matrix inversion. Thus, if we use finer grids, we increase the number of special sites, i.e.,
n, and the complexity increase cubical. For a fixed set of
L,
n and
N, the complexity of Algorithm 1 with respect to
p is
.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






