PUEGM: A Method of User Revenue Selection Based on a Publisher-User Evolutionary Game Model for Mobile Crowdsensing


College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(13), 2927; https://0-doi-org.brum.beds.ac.uk/10.3390/s19132927
Submission received: 6 May 2019
/
Revised: 24 June 2019
/
Accepted: 28 June 2019
/
Published: 2 July 2019
(This article belongs to the Special Issue Mobile Sensing: Platforms, Technologies and Challenges)
Abstract
:Mobile crowdsensing (MCS) is a way to use social resources to solve high-precision environmental awareness problems in real time. Publishers hope to collect as much sensed data as possible at a relatively low cost, while users want to earn more revenue at a low cost. Low-quality data will reduce the efficiency of MCS and lead to a loss of revenue. However, existing work lacks research on the selection of user revenue under the premise of ensuring data quality. In this paper, we propose a Publisher-User Evolutionary Game Model (PUEGM) and a revenue selection method to solve the evolutionary stable equilibrium problem based on non-cooperative evolutionary game theory. Firstly, the choice of user revenue is modeled as a Publisher-User Evolutionary Game Model. Secondly, based on the error-elimination decision theory, we combine a data quality assessment algorithm in the PUEGM, which aims to remove low-quality data and improve the overall quality of user data. Finally, the optimal user revenue strategy under different conditions is obtained from the evolutionary stability strategy (ESS) solution and stability analysis. In order to verify the efficiency of the proposed solutions, extensive experiments using some real data sets are conducted. The experimental results demonstrate that our proposed method has high accuracy of data quality assessment and a reasonable selection of user revenue.
1. Introduction
With the development of intelligent terminal devices and wireless networks, MCS has become a frontier research issue for cross-space and large-scale data sensing [1]. MCS recruits a group of users to collect sensing data through their handheld devices, and the aggregation of the sensing data enables diverse services ranging from urban environmental monitoring and indoor map building to traffic information statistics and intelligent navigation [2,3]. The popularity of smartphones has accelerated the widespread use of MCS, but the presence of malicious and low-quality users will lead to a reduction in the effectiveness of the MCS platform.
Up to now, the research works on MCS user revenue mainly focused on the following aspects: revenue maximization [4,5,6,7], which aims at encouraging users to participate in the sensing activity, and data quality assessment [8,9,10,11,12,13,14], which determines how to select a suitable set of users to finish a sensing task. However, almost all the above works ignore two important factors: human bounded rationality and learning capacity. Simon pointed out that human bounded rationality refers to rationality between complete rationality and incomplete rationality under certain limits [15]. There are two reasons for people’s bounded rationality: Firstly, people usually face a complex and uncertain world. The more information exchanged, the greater the uncertainty of information, and this ultimately leads to the asymmetry of information. Secondly, people’s ability to calculate and recognize the environment is limited, and people cannot be omniscient. Learning capacity refers to the ability to observe and participate in new experiences, integrate new knowledge into existing knowledge, and thus change existing knowledge structures. That is to say, a user may improve the quality of data if he wants to achieve more revenue, even though the user may have different understanding and cognitive abilities. Meanwhile, existing researches on user revenue are rarely combined with their data quality assessment, which reduce the accuracy of user revenue strategy selection.
Revenue maximization and data quality assessment is not an easy thing in the MCS. For revenue maximization, incentive mechanisms to maximize the revenues of MCS are a hot issue (i.e., profit-based mechanisms [4,5] and reputation-based mechanisms [6,7]). In the research on incentive mechanisms, game theory is an important approach to maximize the revenues of MCS. Nowadays, most of game studies in MCS rely on the assumption of individual complete rationality, which is not consistent with the actual situation. Neglecting the limitations of bounded rationality, modeling and analysis of the behavioral game between the two sides will deviate from the actual situation, thereby reducing the accuracy and practical guiding value of selecting the optimal revenue strategy method. Evolutionary games have a dynamic ability to analyze the game behavior of both sides with bounded rationality, which takes the bounded rationality as the basis of game analysis. It can improve the inherent drive of the behavior strategy through learning mechanism, which can effectively enhance the accuracy and credibility of game model analysis.
Data quality assessment is also a challenging issue in MCS. Current studies on data quality are divided into incentive strategies [9,10,11] and classification strategies [8,12,13]. The research on incentive strategies is aims to encourage users to submit high-quality data by using appropriate incentives. Classification strategies focus on the data analysis stage, using data mining, machine learning and other methods to evaluate the data and filter out abnormal data to improve the data quality. Generally, users’ final revenue is positive proportional to their data quality [11]. If the quality of the user data is not evaluated, honest and high-quality users’ revenue will be affected, which may reduce the effectiveness of MCS. Therefore, the assessment of data quality can not only ensure users’ revenue, but also enhance the effectiveness of MCS.
Based on our previous research in data quality evaluation [16], we propose a user revenue selection for mobile crowdsensing which constructs the publisher-user game model by considering the bounded rationality and data quality, taking advantage of evolutionary game theory. The specific steps are as follows: Firstly, the choice of user revenue is modeled as a Publisher-User Evolutionary Game Model (PUEGM). Secondly, to remove low-quality data and improve overall quality of user data, we propose a data quality assessment algorithm in the PUEGM. Finally, the selected users are solved by the evolutionary strategy solution (ESS) and the stability analysis is carried out to obtain the optimal user revenue strategy under different conditions. Compared with [8], our research has the following advantages. First, we evaluate the quality of user data from view of reducing errors and abnormal data, which aims to detect low-quality and abnormal data with high accuracy. Meanwhile, we can distinguish data with different task requirements by weighting factors. Second, we construct the PUEGM from the perspective of human limited rationality. The game and evolution trends of the behaviors of both publishers and users are comprehensively analyzed and deduced, and the selection of user revenue strategies are analyzed and realized. Different from the existing work in [17], our research considers the effect of data quality on user revenue strategy and maximize the user revenue by improving the data quality. In addition, we derive the ESS of the MCS evolutionary game model and verify it with an example.
Our major contributions may be summarized as follows.
- (1).
- Publisher-User Evolutionary Game Model (PUEGM): We modeled benefits of both publishers and users as evolutionary games, and deduced the evolutionary stability strategy (ESS), which can determine the choice of user revenue strategy.
- (2).
- Analyzing the impact of user data quality on its revenue in MCS, the ultimate user revenue is closely related to the data quality, and it is difficult to guarantee user reasonable revenue in the absence of data quality assessment. We analyzed the impact of user data quality on its revenue. The results can be applied to the user revenue selection under normal circumstances.
- (3).
- User data quality assessment algorithm. We propose an algorithm to remove the quality of low and abnormal data. At the same time, weighting factors are introduced to meet the different data quality concerns. We evaluated and compared the rationality of the proposed algorithm for classifying data quality and recognizing abnormal data.
- (4).
- Finally, as far as we know, this is the first time that the user revenue strategy is selected from the point of view of removing low and abnormal data quality in MCS data quality assessment. We think this is a tentative work for MCS research.
The rest of the paper is organized as follows: Section 2 discusses related work. Section 3 introduces the PUEGM and problem statement. Data quality assessment algorithm and user optimal revenue strategy selection are presented in Section 4. In Section 5, we evaluate our proposed method and present evaluation results. Finally, we conclude this paper in Section 6.
2. Related Work
Revenue maximization and data quality assessment are two important factors in MCS participants’ selection and hence there are several selection methods and models suggested in the literature. In this section, we discuss the state of the art in MCS participants’ selection and the various factors that are considered in those approaches.
2.1. Game Theory on MCS
Although the research on the revenue of MCS based on game theory has become a hotspot in recent years, few models are based on bounded rationality. Researchers have built a variety of MCS revenue models to address optimal revenues of both publishers and users. For example, Nie et al. [4] investigated an optimal incentive mechanism for a crowdsensing service provider, which is based on a Stackelberg game. It can effectively and efficiently recruit a sufficient number of mobile users to increase the revenue of public service providers. Pouryazdan et al. [6] believed that appropriate incentives for users can increase the value of data and propose an intelligent game method, which is to ensure the credibility of users from the perspective of data credibility and authenticity. To solve the interaction problem between the MCS server and multiple smartphone users, Xiao et al. [7] developed a Stackelberg game and used a deep Q-network to derive the best MCS strategy to prevent counterfeit sensor attacks. Similarly, game theory has been widely used in vehicle networks, Xiao et al. [5] deduced the Nash equilibrium between sensing accuracy and overall payment of MCS server in the static vehicle game, showing the trade-off between sensing accuracy and the overall payment of MCS server.
As an important part of game theory, evolutionary gamed have a dynamic ability to analyze the game behavior of both sides with bounded rationality, which take the bounded rationality as the basis of game analysis. Evolutionary game can improve inherent drive of behavior strategy through learning mechanism, which can effectively enhance the accuracy and credibility of game model analysis. Although the existing researches on evolutionary game model most focus on network attack and defense behavior analysis [18], dynamic cloudlet selection and resource allocation [19] and achieve cluster stability in VANETs [20], evolutionary game model is rarely used in the field of MCS. It mainly includes an evolutionary game model proposed by [16] to describe the cooperative game phenomena in MCS networks and Ruan et al. [21] used an evolutionary game model to guarantee the risk of DoS attacks on MCS networks with minimum resource cost.
2.2. Quality-Oriented MCS
The quality issue of MCS has drawn many researchers’ attention in the past several years. In [14], the authors summarize the research on the quality of information in existing MCS, and analyze three important challenges (i.e., How can we trust that the smartphone-human sensors will send useful information? How can we enforce the submission of useful information? How can we estimate the usefulness of the submitted information?). The great differences among the qualities of the users’ data can be caused by both device factors and human factors in general. Device factors refer to different brands of mobile devices with different sensors and perceptions. Human factors refer to the complexity and unpredictability of human behavior. For example, some honest users will strictly obey the task instructions, while some careless or malicious users may use the wrong measurement methods to obtain some low-quality or wrong data.
Current studies on data quality are divided into incentive strategies [9,10,11] and classification strategies [8,12,13]. Incentive strategy refers to the use of appropriate incentives to encourage users to submit high-quality data. Song et al. [9] built an auction-based budget feasible mechanism to maximize the valuation of the performed tasks, which depends on the quality of sensing of users. Yang et al. [10] believe that the incentive value obtained by participants through providing data depends largely on the behavior of their social friends and proposed a social incentive mechanism. Peng et al. [11] improved the incentive mechanism from service quality and service providers’ interests, which not only guarantees the quality of data, but also can improve the overall profit. Classification strategy focuses on data analysis stage, using data mining, machine learning and other methods to evaluate data and filter out abnormal data to improve data quality. Liu et al. [12] proposed a context-aware data quality estimation method. This method confirms the relationship between context information and user data quality through historical data, and realizes the recruitment of users, which improves the overall efficiency of the mobile crowdsensing platform. In [8], the authors combine data quality classification and incentive mechanism methods to design an unsupervised learning method for data quality classification, which uses outlier detection to filter out abnormal data items. The incentive sharing mechanism is used to model the residual sharing process as a cooperative game, and the shapely value method is used to determine the payment for each user. Wang et al. [13] proposed a user selection utilizing data properties in mobile crowdsensing (SPM), where a triple-layer structure considering not only the temporal and spatial probability, but also the data’s property is formulated. This method can finish the largest number of sensing tasks.
While the existing approaches have their merits, they usually rely on specialized game models that only represent some of the aspects impacting the MCS participants’ selection process or are geared toward specific MCS applications. A game model that considers the dynamic and bounded rationality of the user selection strategy is important for MCS user revenue. In addition, the model should identify malicious users to protect the user’s reasonable revenue.
3. Publisher-User Evolutionary Game Model (PUEGM) and Problem Statement
In MCS, publishers and users have different decision-making mechanisms because of their various levels of cognition and skill, which lead to diverse benefits for participants. As time goes by, low-revenue users will constantly improve their strategies to achieve high-revenue, which is driven by the traction and learning mechanism based on the difference of revenue.
3.1. Model Assumptions
We propose a method of user revenue selection based on the PUEGM for mobile crowdsensing. The objectives of the proposed method are to consider the impact of human limited rationality on revenue selection in mobile crowdsensing environments and to define a novel method for evaluation of users’ quality considering malicious and low-quality users, which is more reasonable than the existing models in terms of error rate and wide applicability. We assume the following assumptions about the participants:
- (1).
- The game players are divided into two groups, namely, publishers and users. Publishers can select different incentive mechanisms for the same task to be released according to the actual needs, and users can obtain different benefits according to the incentive mechanism of publishers (multi-selection of player strategies.).
- (2).
- User’s data quality selection strategy and publisher’s incentive strategy change dynamically over time (strategy dynamics)
- (3).
- Publishers’ revenue is directly proportional to the size of incentive mechanism and users’ revenue is directly proportional to the quality of data (revenue relevance).
3.2. Model Construction
In our work, we consider a scenario in which the collection of sounds is used as an example to collect information about the MCS data. Referring to the typical MCS structure, our MCS structure consists of three major components: task publishers (we will refer as “publishers” for simplicity), data providers (we will refer as “users” for simplicity), and a cloud platform. Publishers provide the required tasks and related incentive mechanisms to the cloud platform. Cloud platform will release relevant information to users. At the same time, users use their mobile devices to collect data and upload data to the cloud platform. The cloud platform will gain revenue for users who meet the task requirements through the quality of data. At last, the selected data are transmitted by the cloud platform to publishers, and both publishers and the selected users benefit from the data.
Step 1. Define the Publisher-User evolutionary game model
In our work, we define the Publisher-User evolutionary game model as a four-tuple.
Definition 1.
Define the PUEGM as a four-tuple, i.e., PUEGM = (N, W, R, B).
- (1).
- N = (Nu, Np) is the participants of both evolutionary games, where Nu denotes the user, and Np denotes the publisher.
- (2).
- W = (uw, pw) is the strategy space of both sides, where uw = {uw1, uw2, …, uwn} denotes users’ data quality optional strategy sets, and pw = {pw1, pw2, …, pwn} denotes publishers’ task-motivated optional strategy sets.
- (3).
- R = (d, q) is the game belief set, where di denotes the probability that publishers choose pwi, and qj denotes the probability that users select uwj.
- (4).
- B = (Bu, Bp) is the set of the revenue functions of both sides, where Bu denotes the revenue of the user and Bp denotes the revenue of the publisher.
3.3. Evaluate the Quality of User Data
In [11], the authors prove that the user’s final revenue is positive proportional to user overall data quality. Therefore, we use the error-eliminating decision-making method [22] to improve the quality of user data in the PUEGM, and add assessment of data quality in this model, which ensures that high-quality user data can be better applied and maximizes the value of . When users receive sensed tasks from the platform, they will use the mobile device to collect data. The collected data contains a lot of useful information because of the variety of sensors embedded in the mobile device, such as location, time and etc. In the data quality assessment method, we have data for m users, denoted by . We quantify each user data quality strategy sets into multiple data quality assessment indexes, denoted by , and the decision matrix is denoted by , where represents numerical value of under .
The quality may be directly linked to the timeliness and accuracy of sensor measurements. In addition, high-quality collection environment and reliable collection methods can be given priority in order to guarantee the reliability of data.
Hence, the values of different sensors may be calculated using so-called quality valuation functions which are used to rank sensors from “best” to “worst”. More formally, we consider the overall value of sensors be Ri, expressed as a weighted combination of multiple value dimensions, namely response time (), distance (), error-free data integrity () and data reliability () [23]. Different weights indicate the relative importance of a given value dimension in contributing to overall sensor value, and may be considered to be application specific.
In our case, to quantify each of the value dimensions, there is a need to consider the underlying factors influencing each of these dimensions. In practice, sensor metadata delivered to the platform will provide necessary input parameters (e.g., location, time, technical characteristics) for the valuation function, as discussed in the following:
Response time (): is a metric indicating the time difference between the time of publishing and submitting task.
Distance (): is a metric indicating the distance of users from the geographic location with respect to the specified MCS task. For example, if a given monitoring application requires sensor readings at a certain location, then it will be necessary to consider the distance of the sensor reading with respect to the target location.
Data integrity (): is a quality measure that can be defined as the accuracy of data transmitted by users in different states. For example, in the application of noise monitoring, the noise monitoring results transmitted by users in static state will be much better than the data transmitted in running state.
Data reliability (): is a quality measure that can be defined as the accuracy of data transmitted by users in different environments. For example, in the application of noise monitoring, users are more willing to monitor quiet environments, while in noisy environments they are more likely to provide low-quality data to reduce the pain of noise.
The assessment indexes of data quality are divided into negative correlation and positive correlation [24]. The negative correlation indexes refer to the higher data quality of users, the smaller value of the assessment indexes. The positive correlation indexes refer to the lower data quality of users, the smaller value of the assessment indexes. In this paper, we record the data quality assessment indexes as the cost index and benefit index, denoted by and , which satisfies , , . When the expected range of each data quality assessment indexes are determined, the error elimination rule is used to judge user data and the error value is used to evaluate user data quality. The detailed steps are as follows:
Firstly, we determine the user data quality assessment indexes and calculate the error value of user data by equations (1) and (2):
where , and represents the error value of under . The expected lower and upper limit of data quality assessment indexes are expressed as and . When , we use Equation (1) to calculate the error value of user data. When , we use Equation (2) to calculate the error value of user data. The error value is represented by a constant . In order to distinguish the value of and ensure the same order of magnitude, we specify and is a positive infinite decimal. Through equations (1) and (2), the sequence of error value of the user data under different data quality assessment indexes can be obtained, which is recorded as .
Secondly, we calculate the maximum error value () and judge rationality, which can be expressed as:
When , is the erroroneous data and this data is removed.
Thirdly, we standardize data quality assessment indexes and calculate the limit error value of data quality assessment indexes (), which can be expressed as:
Finally, we calculate and sort the error loss sequence () to achieve the optimal user choice.
Different tasks often need various data. For example, in the fastest route search traffic monitoring of rescue vehicles, the required data pays more attention to the accuracy and effectiveness, which means that the weight of location and time parameters in data quality indexes is larger. In the environmental pollution detection, more attention will be paid to the integrity and accuracy of the data, which means that the weight of integrity and transmission accuracy parameters in data quality indexes is larger. Therefore, weighting is introduced to achieve the change of attention to different task requirements. The error loss sequence of user data is as follows:
where .
The error loss sequence will be seen as the n-dimensional space on the point. Higher data quality means the value of Ri is closer to the origin and the value of Ri is arranged in ascending order. Similarly, we can set the threshold of Ri to remove low quality user data. The equation is:
3.4. Analyze the User Optimal Revenue Strategy
Through the previous section, we can not only remove malicious and low-quality user data, but also achieve a reasonable user data quality strategy set. We combine the publisher’s task to stimulate the optional strategy set, solve the evolution strategy solution and conduct the stability analysis, and finally obtain the user optimal revenue strategy under different conditions.
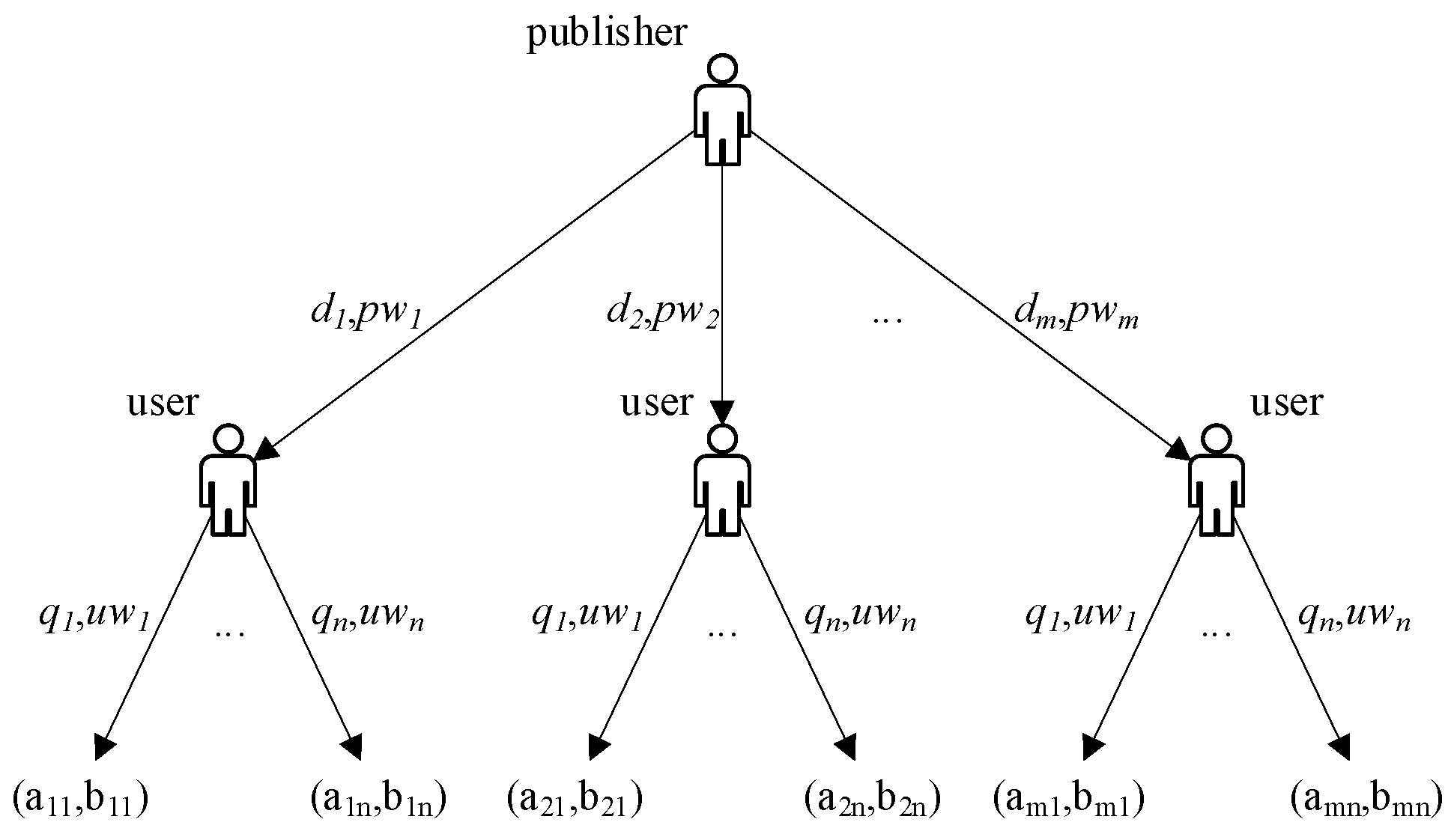
In PUEGM, Nu and Np have multiple choices. The probability that the same strategy adopted by both players may also be different, which in different stages of the game. The decision makers of both sides will constantly adjust their strategies under the influence of revenues, so that the number of decision makers who choose different strategies will change, and the process of the game between the two sides will be characterized by dynamic evolution. The publisher-user game tree is shown in Figure 1.
When different strategies are adopted, both players will generate different revenue values. The payoff matrix is expressed as follows:
where represents the publisher’s revenue when publisher adopts i strategy and user adopts j strategy, represents the user’s revenue when user adopts the j strategy and publisher adopts i strategy, and .
Based on the above conditions, we calculate the expected (i.e., ) and average payoffs (i.e., ) of the user and the publisher:
In PUEGM, to achieve more revenues, low-income users will improve their data quality and change their strategies, which lead to a change in the proportion of user who choose different data quality strategies over time. We use to indicate the proportion of user who choose the strategy , where . For a certain data quality optional strategy , the dynamic rate of change can be denoted by replicator dynamic equation [25], which is written as:
At the same time, to maximize the benefits of publishers, they may change incentive strategies according to the quality of data provided by users, which leads to the proportion of selecting different strategies changes dynamically over time. We use to indicate the proportion of publisher who choose the strategy , where . For any publishers’ strategy, the corresponding replicator dynamic equation is defined as:
Let , we can get duplicate dynamic equations and use the Jacobian matrix local stabilization method to perform stability analysis on all equilibrium points. Finally, the stable equilibrium solution of this model is obtained, and the optimal user data quality strategy selection is analyzed.
3.5. Problem Formulation
User’s goal is to achieve greater benefits with a certain amount of data quality. In PUEGM, those n users can adopt different strategy to get the maximize revenue after the publisher publishes some sensing task. The strategy adopted by the publisher is known, i.e., the expected payoffs of the user in Equation (8) is known. We can achieve the user’s optimal strategy by increasing the average payoffs of the selected users, that is, maximizing . In Equation (9), the value of is related to qi and qi denotes the probability that users select uwi. User’s final revenue is positive proportional to user overall data quality. To maximize the user revenue, we translate the problem of solving into an assessment of user data quality. We formalize it as:
where is the weighting factor, the value of and can be calculated by equations (1), (2) and (4). In our user data quality assessment, the value of this function is related to Ri, for which we define it as:
Therefore, our main purpose is seek an evolution game model which can choose the user’s optimal revenue strategy. In the case of the both strategies are given, the evolution game model can quickly evolve into a robust and stable system in the case of any given strategy probability and obtain the optimized user revenue. What’s more, the proposed data quality assessment method based on the evolution game model can answer the following question. For publishers, it can predict in advance how many are the participant in the game? How about the data quality of each user?
4. Algorithm Introduction and User Revenue Analysis
4.1. Data Quality Assessment Algorithm
A simple and effective algorithm, as shown in Algorithm 1, is used to evaluate the quality of users’ data, which is based on an index that quantifies the quality of existing data.
| Algorithm 1: Implementation of user data quality assessment |
| Input: User data |
| Output: Sorted the user data quality |
| 1: Initialization |
| 2: Determine the user data quality assessment indexes cj |
| 3: for i = 1,2,… ,n, j = 1,2,…,m do |
| 4: Calculate gi,j |
| 5: Judge if cj belongs to the cost index or benefit index |
| 6: if cj ∈ Ccost |
| 7: Calculate the error value of data by Equation (1) |
| 8: else |
| 9: Calculate the error value of data by Equation (2) |
| 10: end if |
| 11: Calculate by Equation (3) |
| 12: if |
| 13: Calculate and by equations (4) and (5) |
| 14: Sort the user data using Equation (6) |
| 15: else |
| 16: Remove errors and low-quality data |
| 17: end for |
When users receive the task, they use smartphone to collect relevant data to generate a user data set, denoted by U = {u1, u2, …, um}. In the assessment of user data quality, we remove low-quality data and sort reasonable user data by descending the loss of errors. At the same time, we also introduce weighting factors to enhance the usability of the algorithm.
The complexity of the algorithm is O(mn). From 1 to 2, the algorithm is used to determine the type of users’ data quality assessment indexes, which aims to quantify each user’s data quality strategy sets. From 3 to 13, it is used to judge whether users’ data will be correct in different quality assessment indexes and obtain errors value of data, which is based on the error elimination decision-making method. From 13 to 17, it is used to sort user data, which can remove low-quality data and select high-quality data.
Algorithm1 realizes the evaluation of user data quality and removes low-quality data. This method provides a guarantee for user revenue by improving the proportion of high-quality data. We believe that the data quality assessment indexes of MCS can be improved continuously according to the need in future research, so that the assessment of data quality of MCS is more accurate. Therefore, the data quality assessment method proposed in this paper has good scalability by the change of assessment indexes.
4.2. User Revenue Optimal Strategy Selection Algorithm
In user revenue optimal strategy selection algorithm, first, a publisher-user evolutionary game tree is constructed to determine the payoff matrix of game, which is denoted by uw and pw. Then, we achieve the ESS solution by computing , , and . Next, we construct the replication dynamic equation and the Jacobian matrix. Finally, we obtain the optimal revenue strategy based on the ESS. ESS is a strategy such that, if most of the members of a population adopt it, there is no “mutant” strategy that would give higher reproductive fitness [26]. An ESS is an equilibrium refinement of the Nash equilibrium. It is a Nash equilibrium that is “evolutionarily” stable: once it is fixed in a population, natural selection alone is sufficient to prevent alternative (mutant) strategies from invading successfully. This means that when the user is in the ESS state, the user’s optimal revenue can be achieved.
In our case, the basic idea of obtaining the optimal user revenue strategy is threefold. Firstly, the publisher-user game tree is constructed to show that publishers and users have their own optional strategy sets and the probability of strategy selection is different; secondly, the corresponding replication dynamic equation is established based on the evolutionary game theory; finally, the optimal user revenue strategy is obtained by calculating the evolutionary stable equilibrium solution. The specific algorithm is as follows.
| Algorithm 2: Implementation of user optimal revenue strategy |
| Input: Publisher-user game tree |
| Output: Users’ optimal revenue strategy |
| 1: Initialization |
| 2: Build users’ type space collection and optional strategy space collection |
| 3: Select reasonable users’ strategy with probability , where |
| 4: Calculate |
| 5: Calculate and by Eqs. 8 and 10 |
| 6: Establish users’ replication dynamic equation u(q) and calculate the evolution equilibrium point |
| 7: Construct a Jacobian matrix to analyze the stability of the equilibrium point and obtain a stable equilibrium solution |
| 8: Output users’ revenue strategy |
| 9: End |
4.2.1. Analysis of Algorithm Time Complexity
From 1 to 5, the time complexity is O(m+n). From 6 to 9, the time complexity is O((m+n)2). Therefore, the time complexity for solving evolutionary stable equilibrium solution is O((m+n)2).
4.2.2. Analysis of Spatial Complexity
The storage space consumption is mainly concentrated on the storage of the intermediate values of strategy benefit and equilibrium solution, so the space complexity is O(mn).
Algorithm 2 obtain the revenue of each strategy, the evolution steady state by analyzing game results, and realize prediction and assessment of strategy selection mechanism. This is a mode of users’ strategy selection from the perspective of maximizing user revenue, which guides user decision-making. Since the number of policies can be extended, the method is versatile and can be applied to general users’ revenue strategy selection. In the next section, we will use a two-category strategy for verification.
4.3. Example Description
We assume that publishers are p, users are u. and is a simple strategy adopted by both sides. Publishers’ incentive strategy and users’ data quality are divided into two categories, namely low and high. The probabilities of selection of different strategies are different and generate different revenues. When publishers adopt high incentive strategy and users adopt high data quality, the revenue of both players can be maximized. The definition of player revenue is as follows.
Definition 2.
The strategic revenue of both players should meet the following requirements, where and .
We calculate the expected and average payoffs of users, which using low and high strategies, denoted as:
For user strategy, the replication dynamic equation is obtained according to Equation (12), denoted as:
When , we can get the equilibrium solution, i.e., , and .
Proposition 1.
Proof.
By Definition 2, we can get , i.e., . Combining and , we have . □
Similarly, we calculate the expected payoffs, average payoffs, and dynamic equations for publishers, which can be expressed as:
When , we can get the equilibrium solution, i.e., , and .
Proposition 2.
.
Proof.
The method of proof is consistent with Proposition 1. ☐
Users and publishers’ dynamic equations are combined to construct publisher-user game evolution equations. When , we can get five sets of equilibrium points, i.e., , , , and .
We use the system dynamics method [27] to analyze the PUEGM. Meanwhile, we use the Jacobian matrix local stability method [28] to analyze the stability of all evolution equilibrium points and solve the stable equilibrium solution. According to the Jacobi matrix local analysis method, if and , the equilibrium point is unstable point. If and , the equilibrium point is stable point. If , the equilibrium point is saddle point. Values of the Jacobi determinant and trace are shown in Table 1.
We obtain that F1 and F5 are stable points and F2 and F3 are unstable points. Since the value of equilibrium F4 is uncertain, we use the replication dynamic evolution graph to analyze it, as shown in Figure 2. According to Equation (18) and Figure 2, F4 has three stable states at most: 0, 1, and , respectively. For any user’s strategy, when the value of d is 0 and 1, the tangent slope is negative and we can define it as a stable evolution strategy. When the value is and the probability q is chosen to satisfy , the state is stable too. When , is the ESS of users. When , is the ESS of users. Similarly, when , is the ESS of publishers. When , is the ESS of publishers. Therefore, this model has an evolutionary stable equilibrium solution.
5. Performance Evaluation
5.1. Basic Simulation Setup
In our experiments, the data we used came from the real Dartmouth College Wi-Fi campus trace data set [29], which was an experiment on the open source middleware NSense. This data takes sound collection as an example, including timestamps, distance between test points and sensing nodes, data collection methods (i.e., STATIONARY, WALKING, and RUNNING), and data collection environments (i.e., QUIET, NORMAL, ALERT, and NOISY). Data quality assessment indexes were divided into response time (), distance (), data integrity () and data reliability (), which is based on the classification method of [23].
To ensure the diversity of data and improve the accuracy of the assessment, we quantify existing data and determine reasonable range as shown in Table 2. Our experiments are all implemented on MATLAB2013b.
5.2. Experiment Results of Data Quality Assessment
We use Algorithm 1 to realize the accurate identification and sorting of user data. Our previous work has proved that this algorithm can solve three problems: removing low quality data, selecting different demand data, and sorting data quality [17]. In this paper, we will supplement the experiment to show that our method can not only solve these three problems, but also has the advantages of abnormal recognition precision and high accuracy of data classification.
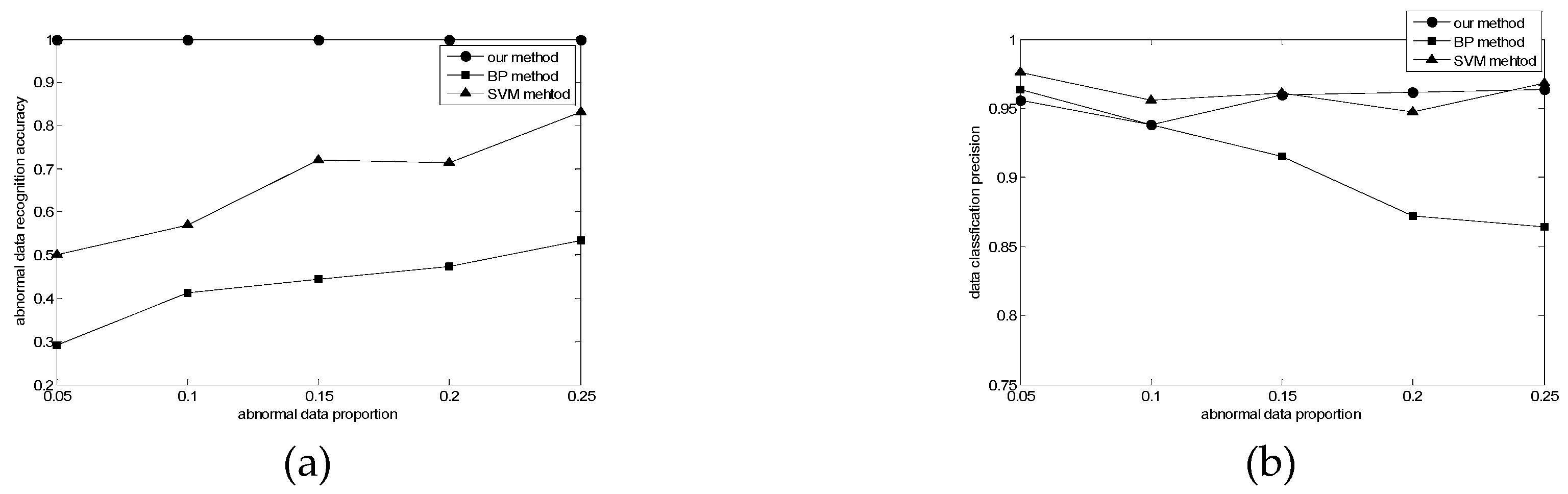
In MCS, high-accuracy data quality assessment means that the overall quality of data can be improved, so that users can achieve greater revenues. Our experiments collected more than 5000 data sets, and some abnormal data were added in the data set, which aims to simulate the error data in the actual application. We will compare the performance with two common anomaly detection methods (i.e., BP method and SVM method [30]), by calculating the abnormal data recognition precision (Xda) and data classification accuracy (Xdp), which can be expressed as:
where sumjad represents the number of true abnormal data that are judged as abnormal data, sumad represents the number of abnormal data, sumjd represents the number of data that are judged correctly, sumd represents the number of data. Comparison of abnormal data recognition precision and data classification accuracy is provided in Figure 3.
In the abnormal data recognition precision experiment, the augmentation of abnormal data increases the precision of BP method and SVM method. The reason is that both methods require a large number of training samples to achieve more accurate recognition. Meanwhile, the precision of our method is better than these two methods, and the accuracy rate is always 1. The purpose of our method is to remove false anomaly data, which can be very sensitive when the values deviate. This shows that our method has the advantage of high precision in recognizing abnormal data, small demand for training samples and only related to the boundaries of each type of data quality.
In the data classification accuracy experiment, with the increase of the proportion of abnormal data, the accuracy of our method and SVM method in recognizing data is basically above 95%, which shows that our method has the advantages of high accuracy and anti-interference in data classification.
5.3. Experiment Results of User Revenue Optimal Strategy
We use system dynamics to simulate and validate the equilibrium solution of the PUEGM, then, we obtain the optimal revenue strategy of users in the PUEGM. Through the analysis of Section 4.3, we know that stable equilibrium solutions of the model are F1, F4, F5. In the following experiments, we change the initial state of d and q to obtain the evolutionary trend and the steady state of the evolutionary game, and finally achieve the optimal revenue strategy of users.
We assume that the benefits of publishers and users using different strategies in MCS are known, so the stable equilibrium solution () of this system can be confirmed (i.e., ). At the same time, the incentive strategies provided by publishers are divided into low incentive strategy (pwl) and high incentive strategy (pwh). The data quality strategies provided by users will be divided into low data quality strategy (uwl) and high data quality strategy (uwh).
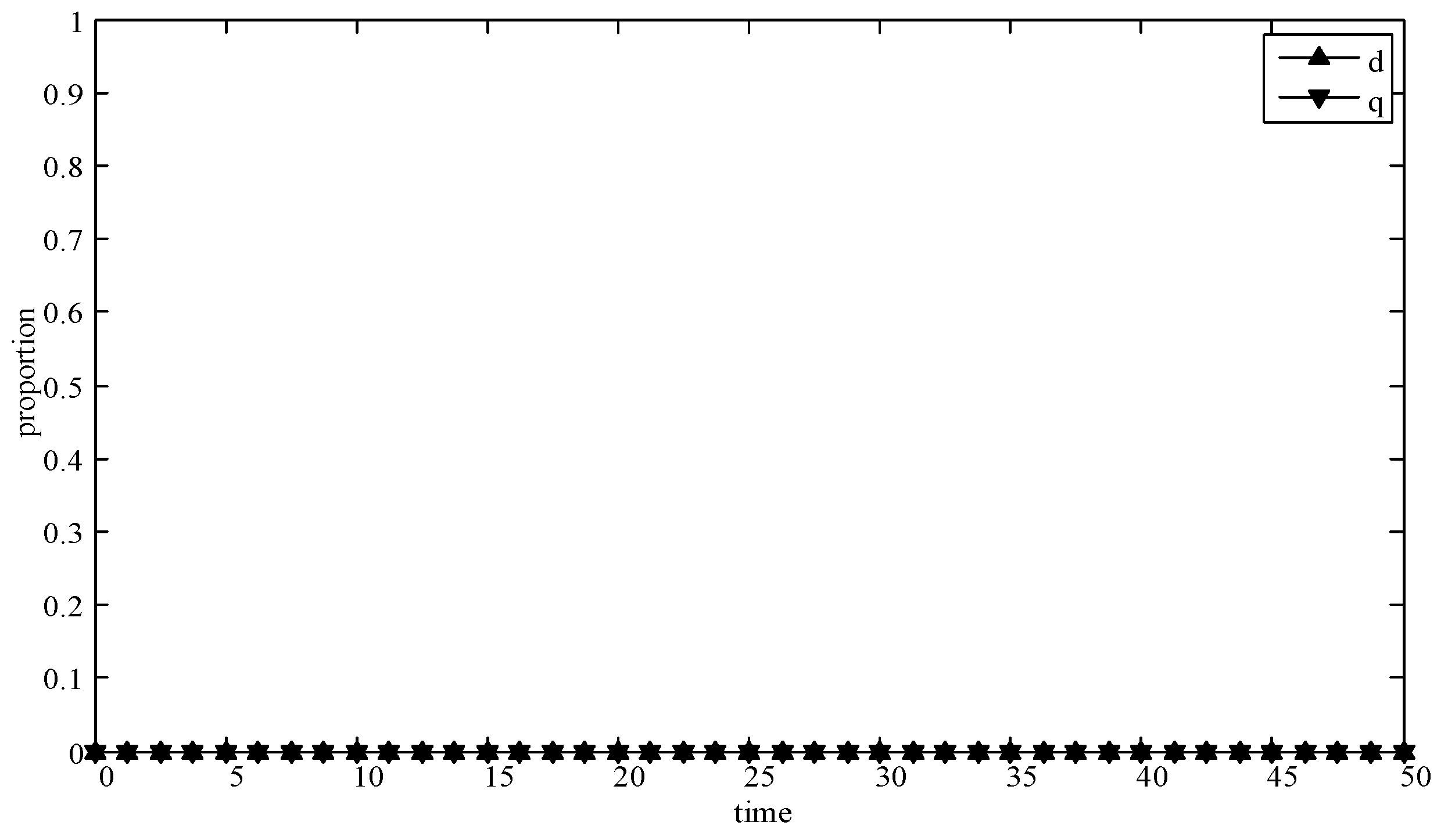
- (1)
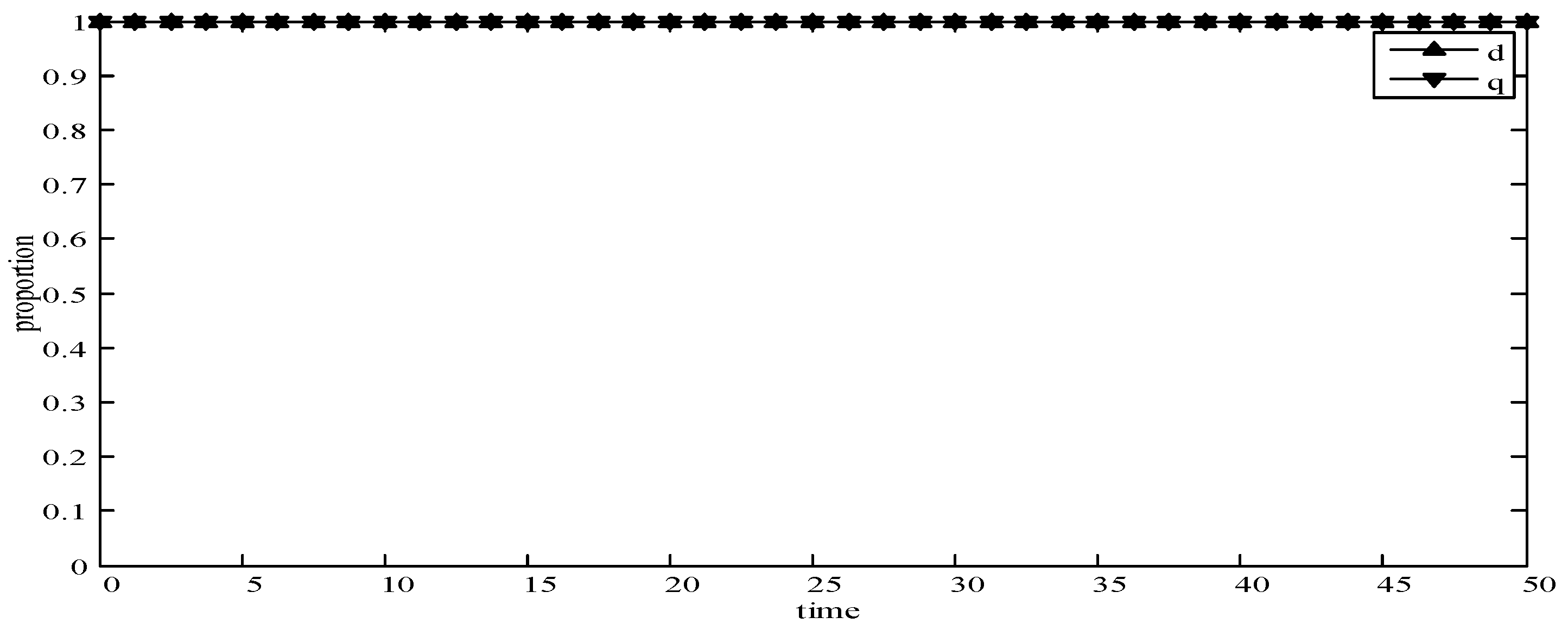
- When d = 0 and q = 0, it means that publishers all provide strategy pwh, and users all provide strategy uwh. According to the simulation, we find that strategies selection has no change with the evolution time, as shown in Figure 4. The evolution result can be one of the stable states of the system, which also verifies that the user revenue can be maximized when publishers adopt a high incentive strategy and users adopt a high data quality strategy.
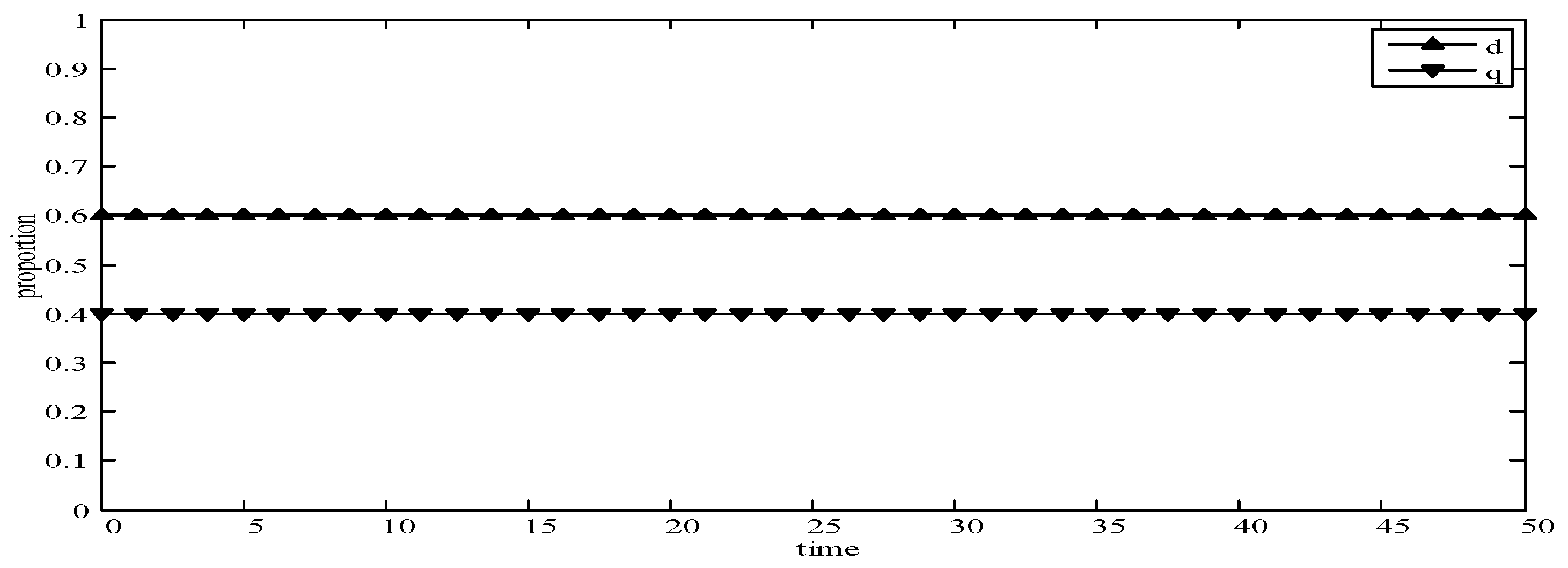
- (2)
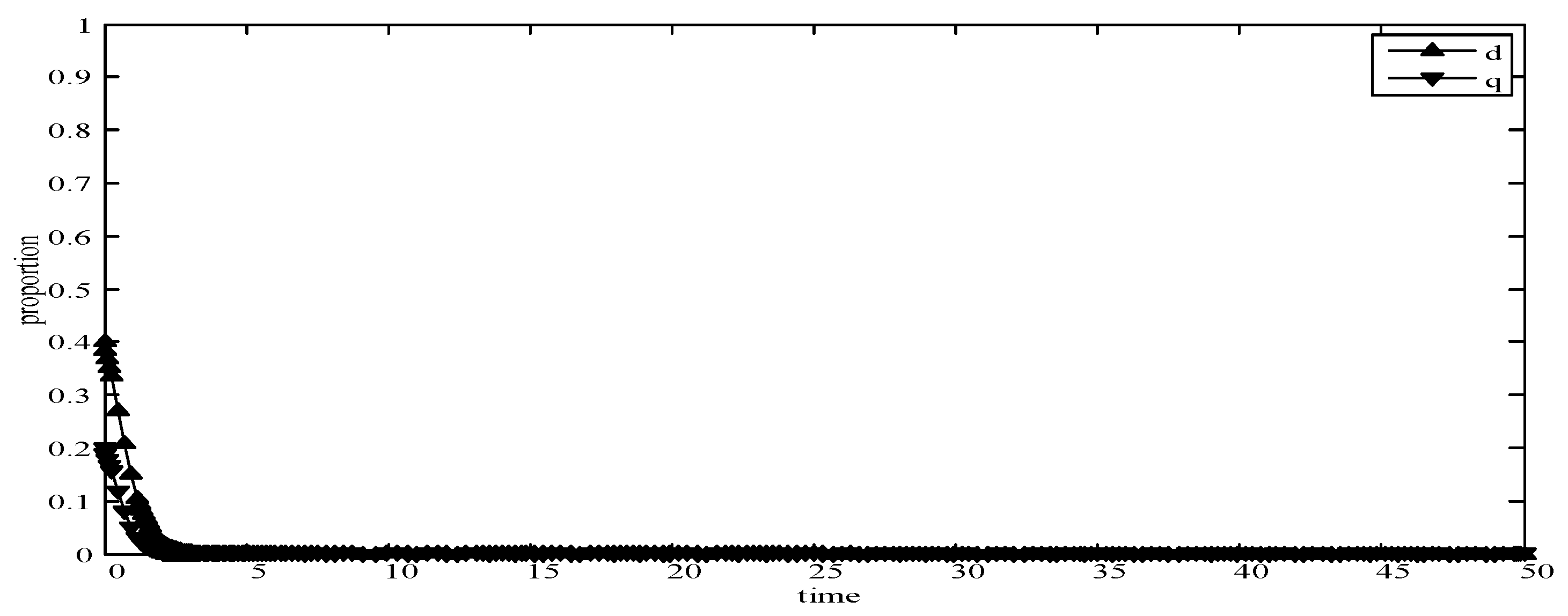
- When d = 0.6 and q = 0.4, it means that publishers choose strategies pwl and pwh with a probability of (0.6,0.4) and users choose strategies uwl and uwh with a probability of (0.4,0.6). According to the simulation, we find that strategies selection has no change with the evolution time, as shown in Figure 5. The evolution result can be one of the stable states of the system, which verifies that this state is the equilibrium point.
- (3)
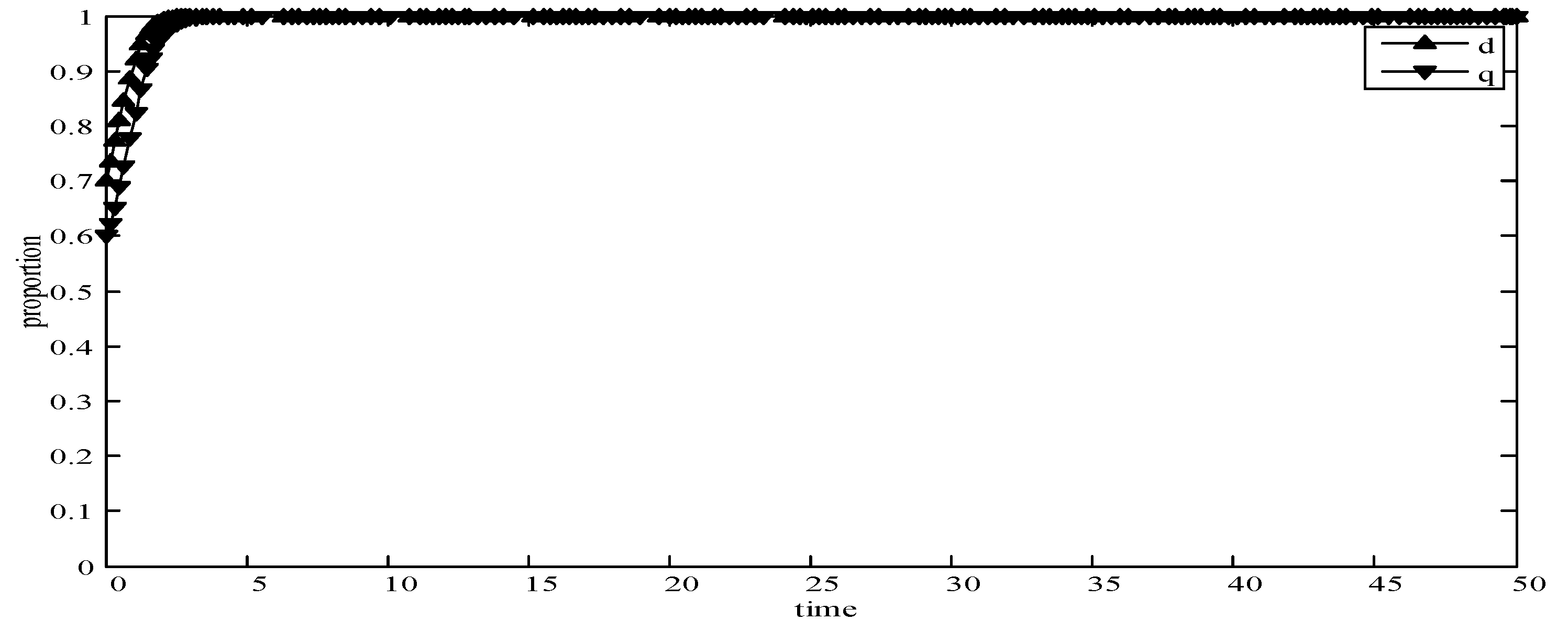
- When d = 1 and q = 1, it means that publishers all provide strategy pwl, and users all provide strategy uwl, as shown in Figure 6. According to the simulation, we find that strategies selection has no change with the evolution time, because publishers only provide a low incentive strategy, and users can’t get higher revenues even if they provide high quality data. Therefore, users only choose strategy uwl to ensure the optimal revenue of users.
- (4)
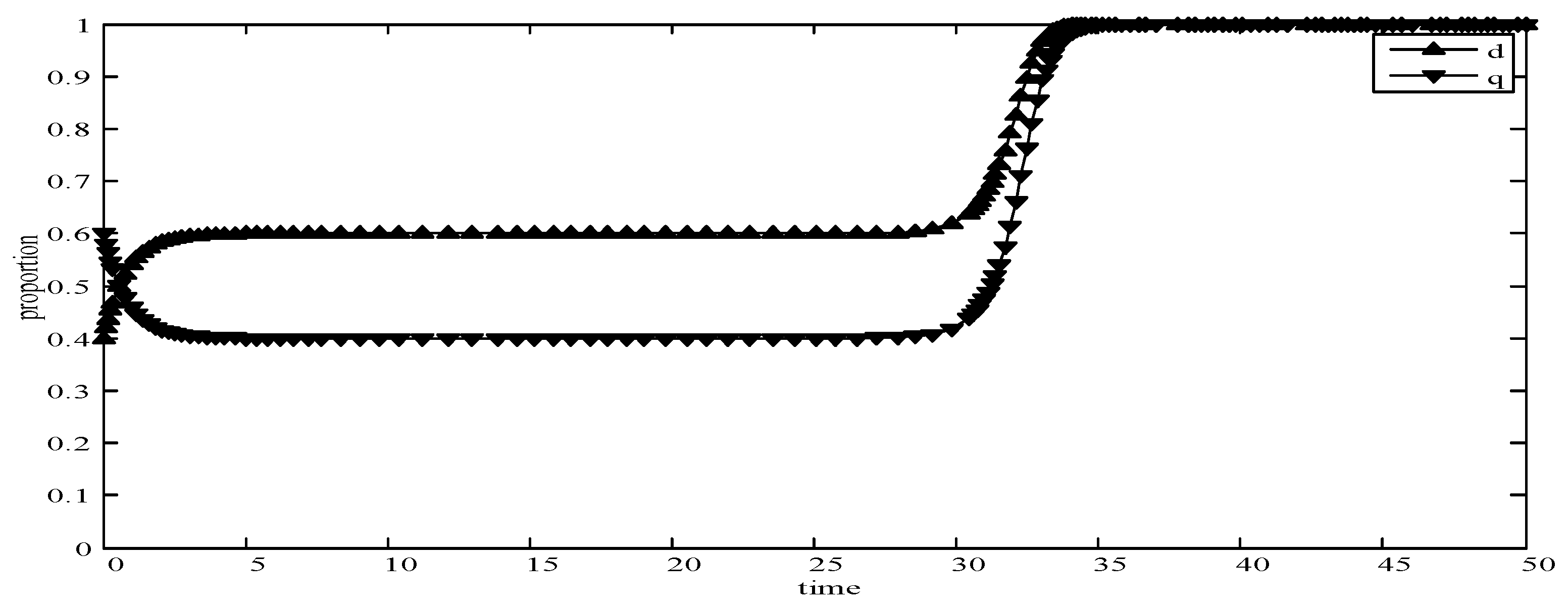
- When d = 0.4 and q = 0.3, it means that publishers choose strategies pwl and pwh with a probability of (0.4,0.6) and users choose strategies uwl and uwh with a probability of (0.3,0.7), as shown in Figure 7. After multiple games between the two players, we find that both sides of the game tend to F1 and users can choose strategy uwh to obtain the optimal revenue, because publishers have a higher probability to adopt a high incentive strategy and user is more likely to provide high quality data to maximize their revenues.
- (5)
- When d = 0.7 and q = 0.6, it means that publishers choose strategies pwl and pwh with a probability of (0.7,0.3) and users choose strategies uwl and uwh with a probability of (0.6,0.4), as shown in Figure 8. After multiple games between the two players, we find that the stable equilibrium solution of both sides of this game tends to F5 and users can choose strategy uwl to obtain the optimal revenue, because publishers have a higher probability to adopt a low incentive strategy and users are more likely to provide low quality data to avoid the loss of their revenues.
- (6)
- When d = 0.4 and q = 0.6, it means that publishers choose strategies pwl and pwh with a probability of (0.4,0.6) and users choose strategies uwl and uwh with a probability of (0.6,0.4), as shown in Figure 9. Although, the stable equilibrium solution of both sides of the game tends to F4 at the beginning, it tends to F5 eventually. The reason for this result is that the values of d and q are very close to F4 at the beginning, which leads to a balance between two players in a short time. However, in F4, the values of d and q can only be the initial equilibrium state, and users are not willing to provide high quality data. Therefore, users will eventually choose strategy uwl to achieve the best revenue.
- (7)
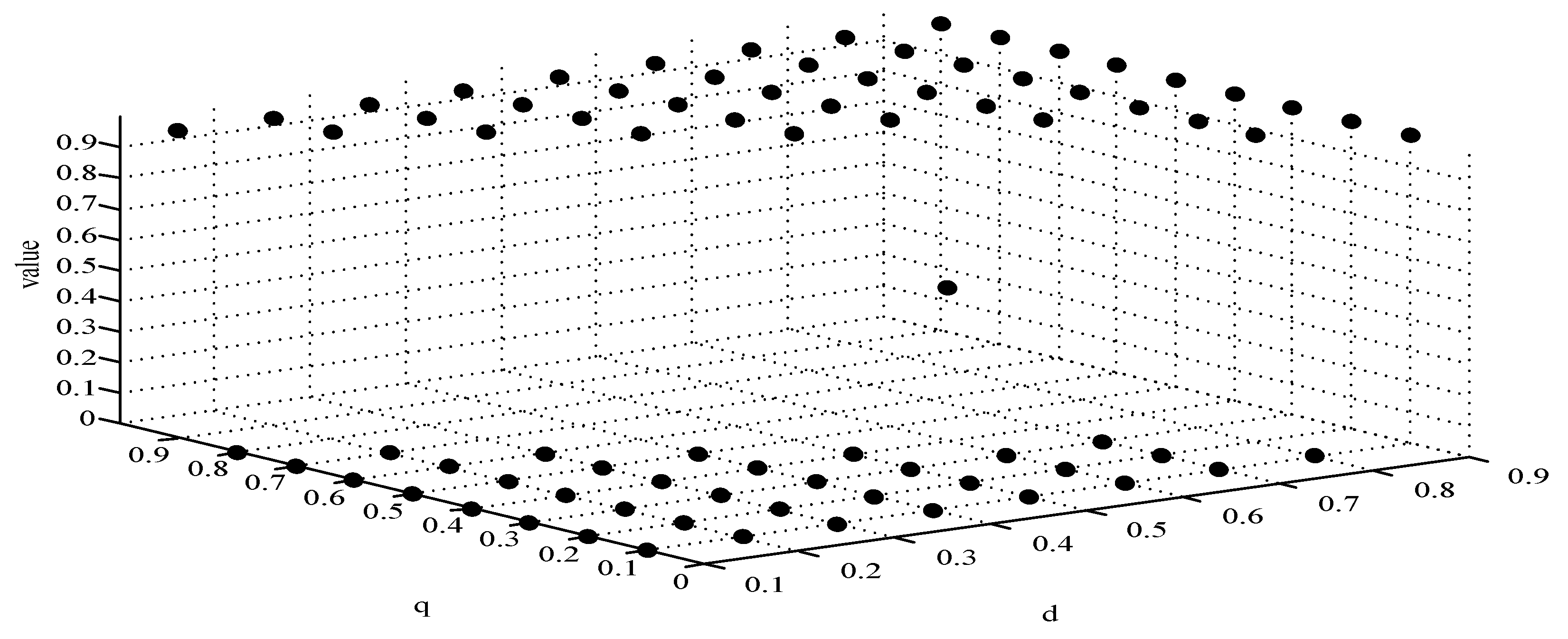
- We find that the stable equilibrium solutions of the two players are different in various initial states, as shown in Figure 10. When the value is 1, it means that both sides of the game will tend to F5 and users can get the best revenue by choosing strategy uwl. When the value is 0, it means that both sides of the game will tend to F1 and users can get the best revenue by choosing strategy uwh. When the value is 0.5, it means that the game will tend to F4 and users select strategies uwl and uwh with a probability of (0.4,0.6) to achieve the best revenue. We find that the higher quality of user data, the more stable equilibrium solution tends to F1, when publishers strategy is unchanged.
It can be seen from the above simulation results that the initial state selected by different strategies will eventually reach a certain stable state through the evolution. Meanwhile, experimental results are consistent with the theoretical analysis in the model, which shows that the evolutionary game model is consistent with the development in reality world. Therefore, in MCS, the PUEGM can be used to analyze the selection of publishers’ incentive strategy and provide a basis for the selection of user optimal revenue strategy.
6. Conclusions
In this paper, the problem of selecting an optimal user revenue selection in mobile crowdsensing and data quality assessment has been investigated. On the one hand, the data quality assessment algorithm can solve three problems, including removing low quality data, selection of data for different needs and sorting data quality. Compared with the BP and SVM methods, this method has high accuracy and a wide application range. On the other hand, to motivate users to provide high quality data and prevent low quality data, we model the user revenue as an evolutionary game and determine the optimal revenue for each user by solving the evolutionary stability strategy solution. According to the needs of different scenarios, different data quality evaluation indexes can be established and the weight of indexes can be modified. Thus, we believe that the proposed model has a good scalability and practical significance. As for future work, reasonable selection of user data quality assessment indexes, user historical credibility and reasonable allocation of different index weights will be our main research content.
Author Contributions
Z.S. wrote the manuscript. H.W. and G.F. gave comments and suggestions for the manuscript. All the authors have read and approved the final manuscript.
Funding
This research was funded by the Nature Science Foundation of China, grant number 61502118, Natural Science Foundation of Heilongjiang Province, grant number F2016009, Fundamental Research Fund for the Central Universities in China, grant number 3072019CFM0603, and National Science and Technology Major Project, grant number 2016ZX03001023-005.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, X.L.; Yang, Z.; Sun, W.; Liu, Y.H.; Tang, S.H.; Xing, K.; Mao, X.F. Incentives for Mobile Crowd Sensing: A Survey. IEEE Commun. Surv. Tut. 2016, 18, 54–67. [Google Scholar] [CrossRef]
- Alvear, O.; Calafate, C.T.; Cano, J.C.; Manzoni, P. Crowdsensing in Smart Cities: Overview, Platforms, and Environment Sensing Issues. Sensors 2018, 18, 460. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, J.B.; Tian, X.H.; Gan, X.Y.; Guan, Y.F.; Wang, X.B. Crowdsensing-Based Consensus Incident Report for Road Traffic Acquisition. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2536–2547. [Google Scholar] [CrossRef]
- Nie, J.; Luo, J.; Xiong, Z.; Niyato, D.; Wang, P. A Stackelberg Game Approach Toward Socially-Aware Incentive Mechanisms for Mobile Crowdsensing. IEEE Trans. Wirel. Commun. 2019, 18, 724–738. [Google Scholar] [CrossRef]
- Xiao, L.; Chen, T.H.; Xie, C.X.; Dai, H.Y.; Poor, H.V. Mobile Crowdsensing Games in Vehicular Networks. IEEE Trans. Veh. Technol. 2018, 67, 1535–1545. [Google Scholar] [CrossRef]
- Pouryazdan, M.; Fiandrino, C.; Kantarci, B.; Soyata, T.; Kliazovich, D.; Bouvry, P. Intelligent Gaming for Mobile Crowd-Sensing Participants to Acquire Trustworthy Big Data in the Internet of Things. IEEE Access 2017, 5, 22209–22223. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.D.; Han, G.A.; Dai, H.Y.; Poor, H.V. A Secure Mobile Crowdsensing Game With Deep Reinforcement Learning. IEEE Trans. Inf. Forensics Secur. 2018, 13, 35–47. [Google Scholar] [CrossRef]
- Yang, S.; Wu, F.; Tang, S.J.; Gao, X.F.; Yang, B.; Chen, G.H. On Designing Data Quality-Aware Truth Estimation and Surplus Sharing Method for Mobile Crowdsensing. IEEE J. Sel. Areas Commun. 2017, 35, 832–847. [Google Scholar] [CrossRef]
- Song, B.Y.; Shah-Mansouri, H.; Wong, V.W.S. Quality of Sensing Aware Budget Feasible Mechanism for Mobile Crowdsensing. IEEE Trans. Wirel. Commun. 2017, 16, 3619–3631. [Google Scholar] [CrossRef]
- Yang, G.; He, S.B.; Shi, Z.G.; Chen, J.M. Promoting Cooperation by the Social Incentive Mechanism in Mobile Crowdsensing. IEEE Commun. Mag. 2017, 55, 86–92. [Google Scholar] [CrossRef]
- Peng, D.; Wu, F.; Chen, G.H. Data Quality Guided Incentive Mechanism Design for Crowdsensing. IEEE Technol. Mobile Comput. 2018, 17, 307–319. [Google Scholar] [CrossRef]
- Liu, S.Z.; Zheng, Z.Z.; Wu, F.; Tang, S.J.; Chen, G.H. Context-Aware Data Quality Estimation in Mobile Crowdsensing. In Proceedings of the INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Wang, E.; Yang, Y.J.; Lou, K.H. User selection utilizing data properties in mobile crowdsensing. Inf. Sci. 2019, 490, 210–226. [Google Scholar] [CrossRef]
- Restuccia, F.; Ghosh, N.; Bhattacharjee, S.; Das, S.K.; Melodia, T. Quality of Information in Mobile Crowdsensing: Survey and Research Challenges. ACM Trans. Sensor Netw. 2017, 13, 34. [Google Scholar] [CrossRef]
- Simon, H.A.J.D. Organization, Theories of Bounded Rationality. 1972, 1, 161–176. Available online: https://www.researchgate.net/publication/242617110_Theories_of_Bounded_Rationality (accessed on 6 May 2019).
- Liu, X.; Ota, K.; Liu, A.F.; Chen, Z.G. An incentive game based evolutionary model for crowd sensing networks. Peer Peer Netw. Appl. 2016, 9, 692–711. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Y.A.; Shao, Z.H. Data quality evaluation method based on the error-eliminating decision-making theory. J. Harbin Eng. Univ. 2018, 39, 172–177. (In Chinese) [Google Scholar]
- Yang, Y.; Che, B.C.; Zeng, Y.; Cheng, Y.; Li, C.Y. MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory. Symmetry 2019, 11, 215. [Google Scholar] [CrossRef]
- Meng, S.; Wang, Y.; Jiao, L.; Miao, Z.Y.; Sun, K. Hierarchical evolutionary game based dynamic cloudlet selection and bandwidth allocation for mobile cloud computing environment. IET Commun. 2019, 13, 16–25. [Google Scholar] [CrossRef]
- Khan, A.A.; Abolhasan, M.; Ni, W. An Evolutionary Game Theoretic Approach for Stable and Optimized Clustering in VANETs. IEEE Trans. Veh. Technol. 2018, 67, 4501–4513. [Google Scholar] [CrossRef]
- Ruan, N.; Gao, L.; Zhu, H.J.; Jia, W.J.; Li, X.; Hu, Q. Toward Optimal DoS-resistant authentication in Crowdsensing Networks via Evolutionary Game. In Proceedings of the 36th IEEE International Conference on Distributed Computing Systems, ICDCS 2016, Nara, Japan, 27–30 June 2016; pp. 364–373. [Google Scholar]
- Huang, H.R.; Cai, K. A method of fuzzy multiple attribute decision making based on the error-eliminating theory. J Intell. Fuzzy Syst. 2016, 31, 2119–2127. [Google Scholar] [CrossRef]
- Marjanovic, M.; Skorin-Kapov, L.; Pripuzic, K.; Antonic, A.; Zarko, I.P. Energy-aware and quality-driven sensor management for green mobile crowd sensing. J. Netw. Comput. Appl. 2016, 59, 95–108. [Google Scholar] [CrossRef]
- Lin, Y.M.; Wang, H.Z.; Zhang, S.; Li, J.Z.; Gao, H. Efficient quality-driven source selection from massive data sources. J. Syst. Softw. 2016, 118, 221–233. [Google Scholar] [CrossRef]
- Cassese, D. Replicator Equation and the Evolution of Cooperation on Regular Communities; Springer International Publishing: Cham, Switzerland, 2018; pp. 869–880. [Google Scholar]
- Smith, J.M.; Price, G.R. The Logic of Animal Conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Ahmad, S.; Tahar, R.M.; Muhammad, S.F.; Munir, A.B.; Rahim, R.A. Application of system dynamics approach in electricity sector modelling: A review. Renew. Sustain. Energy Rev. 2016, 56, 29–37. [Google Scholar] [CrossRef]
- Resendis-Antonio, O. Jacobian Matrix. Encycl. Syst. Biol. 2013, 46, 1061–1062. [Google Scholar]
- Firdose, S.; Lopes, L.; Moreira, W.; Sofia, R.; Mendes, P. CRAWDAD Dataset Copelabs/Usense (v. 2017-01-27). Available online: https://crawdad.org/copelabs/usense/20170127 (accessed on 6 May 2019).
- Zhong, H.M.; Miao, C.Y.; Shen, Z.Q.; Feng, Y.H. Comparing the learning effectiveness of BP, ELM, I-ELM, and SVM for corporate credit ratings. Neurocomputing 2014, 128, 285–295. [Google Scholar] [CrossRef]
Figure 1.
Publisher-user game tree.

Figure 2.
Replication dynamic evolution graph of user strategy.

Figure 3.
(a) Comparison of abnormal data recognition precision; (b) Comparison of data classification accuracy.
Figure 3.
(a) Comparison of abnormal data recognition precision; (b) Comparison of data classification accuracy.

Figure 4.
Evolution curves of d = 0 and q = 0.

Figure 5.
Evolution curves of d = 0.6 and q = 0.4.

Figure 6.
Evolution curves of d = 1 and q = 1.

Figure 7.
Evolution curves of d = 0.4 and q = 0.3.

Figure 8.
Evolution curves of d = 0.7 and q = 0.6.

Figure 9.
Evolution curves of d = 0.4 and q = 0.6.

Figure 10.
Selection of different initial state strategies.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Values of the Jacobi determinant and trace.
| Equilibrium Point | Determinant and Trace | Det | Trace |
|---|---|---|---|
| + | - | ||
| + | + | ||
| + | + | ||
| + | - |
Table 2.
Index quantification.
| Index | Quantification Range | |
|---|---|---|
| 1. Response time ()/ min | [10,90] | |
| 2. Distance ()/ m | [0,5000] | |
| 3. Data integrity () | STATIONARY | [0.7,0.9] |
| WALKING | [0.5,0.7) | |
| RUNNING | [0.3,0.5) | |
| 4. Data reliability () | QUIET | [0.75,0.9] |
| NORMAL | [0.6,0.75) | |
| ALERT | [0.45,0.6) | |
| NOISY | [0.3,0.45) | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shao, Z.; Wang, H.; Feng, G. PUEGM: A Method of User Revenue Selection Based on a Publisher-User Evolutionary Game Model for Mobile Crowdsensing. Sensors 2019, 19, 2927. https://0-doi-org.brum.beds.ac.uk/10.3390/s19132927
AMA Style
Shao Z, Wang H, Feng G. PUEGM: A Method of User Revenue Selection Based on a Publisher-User Evolutionary Game Model for Mobile Crowdsensing. Sensors. 2019; 19(13):2927. https://0-doi-org.brum.beds.ac.uk/10.3390/s19132927
Chicago/Turabian StyleShao, Zihao, Huiqiang Wang, and Guangsheng Feng. 2019. "PUEGM: A Method of User Revenue Selection Based on a Publisher-User Evolutionary Game Model for Mobile Crowdsensing" Sensors 19, no. 13: 2927. https://0-doi-org.brum.beds.ac.uk/10.3390/s19132927
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.