1. Introduction
The COVID-19 pandemic has deteriorated the usual dynamics that rule the world [
1]. Its impact on health and the worldwide economy is evident [
2,
3]. The number of people affected by the COVID-19 disease, the significant number of human lives that have been lost, and the consequences of the containment measures are urgent concerns that should be analyzed. This must be done in a technically responsible way to guarantee an effective response from the authorities of each country [
4].
The Coronavirus (COVID-19) disease is caused by the novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) and was first identified in Wuhan City, Hubei Province, China, early in December 2019 [
5]. COVID-19 arrived in South America at the end of February 2020 [
4]. The coronavirus attacks some organs of the human body, but mainly the lungs [
6]. In recent months, experts have detected the presence of some strains, as a result of the mutation of the virus, with higher rates of spread. As mentioned, the world has been greatly affected by the presence of this virus and governments are currently engaged in a mass vaccination process with the aim that people will be able to resume their activities in a normal way [
4].
To confirm suspected cases of COVID-19, the real-time transcription-polymerase chain reaction (RT-PCR) test is applied, based on the detection of a certain amount of genetic fragments other than the virus in an individual [
7]. Nevetheless, other diagnostic tools to detect COVID-19 cases have been proposed [
8].
Proper planning of the response to an emergency is marked by the challenges of economic and political will [
8]. However, the application and adaptation of statistical methods for data analysis that strengthen the interpretation of the information, taken from different points of interest, are actions that undoubtedly improve the quality of the response to the emergency [
4]. These are actions that the citizens expect from their government authorities. As in other regions around the world, in South American countries, the number of infected people and deaths due to COVID-19 are increasing every day.
One popular multivariate statistical method is the principal component analysis (PCA), which allows for classification of variables or individuals [
9,
10]. The PCA has been used in several studies related to COVID-19 [
11,
12,
13]. The objective of the present investigation is to apply the PCA to classify South American countries with respect to the number of infected and deaths due to COVID-19. We want to determine how the pandemic evolves in South American countries by using different multivariate methods, based on both matrix and functional approaches. These methods allow us to identify differences and similarities among the countries under study to understand the damage that the COVID-19 pandemic has caused them. The countries considered for this classification are: Argentina (ARG), Bolivia (BOL), Brazil (BRA), Chile (CHI), Colombia (COL), Ecuador (ECU), Peru (PER), Paraguay (PRY), Uruguay (URY), and Venezuela (VEN). We use modern techniques based on (i) standard PCA; (ii) disjoint principal component analysis (DPCA); and (iii) functional principal component analysis (FPCA). The full data set used in this investigation can be downloaded from
https://ourworldindata.org/coronavirus (accessed on 12 June 2021). The data regarding the numbers (per million inhabitants) of infected cases and deaths are taken from 1 March 2020 to 15 March 2021. We design an algorithm that permits one to summarize the multivariate methods presented in this work to sense changes in the data by using a sensor and having an updated analysis.
The remainder of the paper is organized as follows: In
Section 2, the fundamentals of the PCA, DPCA, and FPCA are provided.
Section 3 and
Section 4 apply the PCA, DPCA, and FPCA described in
Section 2 to analyze the data collected. In
Section 5, we discuss the results of the study and address the conclusions as well as ideas for future research.
5. Conclusions
The behavior of the number of infected cases with COVID-19, and the number of deaths due to this disease, can vary in the countries for different reasons: (i) political and economic decisions; (ii) health infrastructure; (iii) the discipline of the people; (iv) the environment; and (v) the spread rates of the different strains of the virus, among other factors.
Principal component analyses based on recent and modern methods were carried out to study the relationship among the aforementioned variables in ten South American countries. The countries considered were: Argentina, Bolivia, Brazil, Chile, Colombia, Ecuador, Peru, Paraguay, Uruguay, and Venezuela. A k-means analysis was conducted to compare our principal component analyses, which resulted in general consistent.
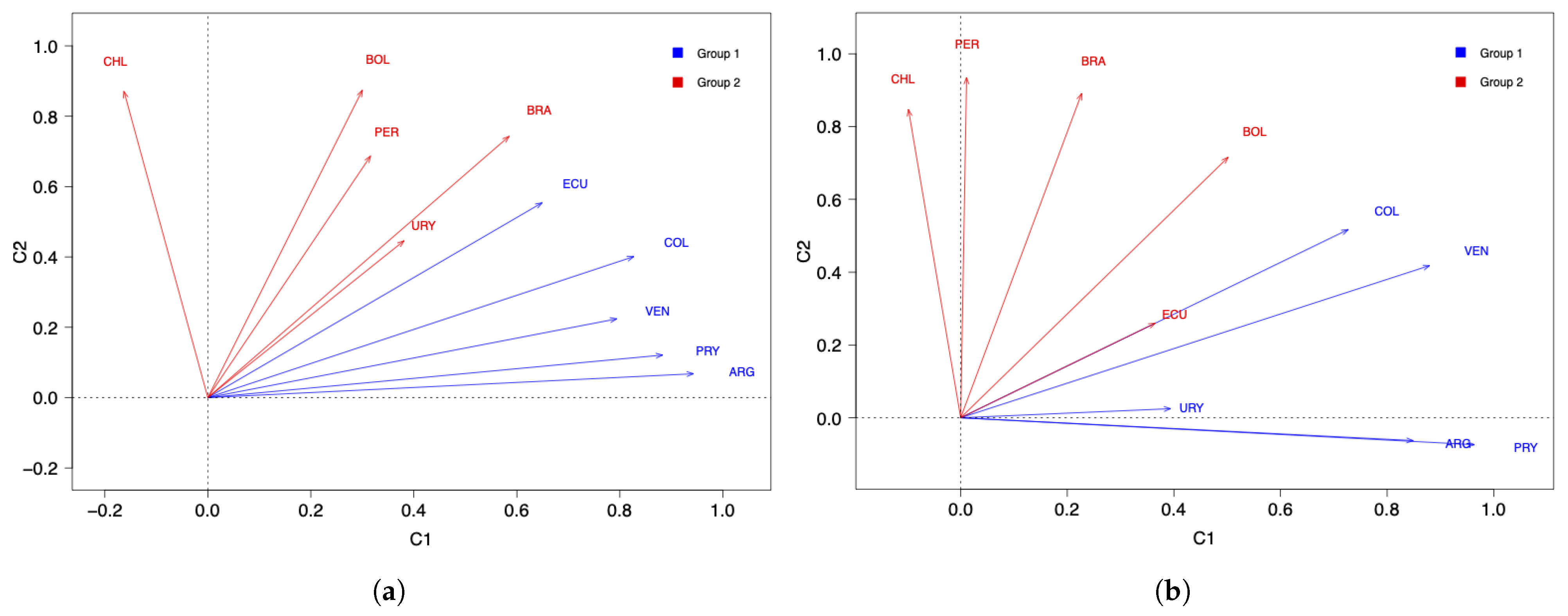
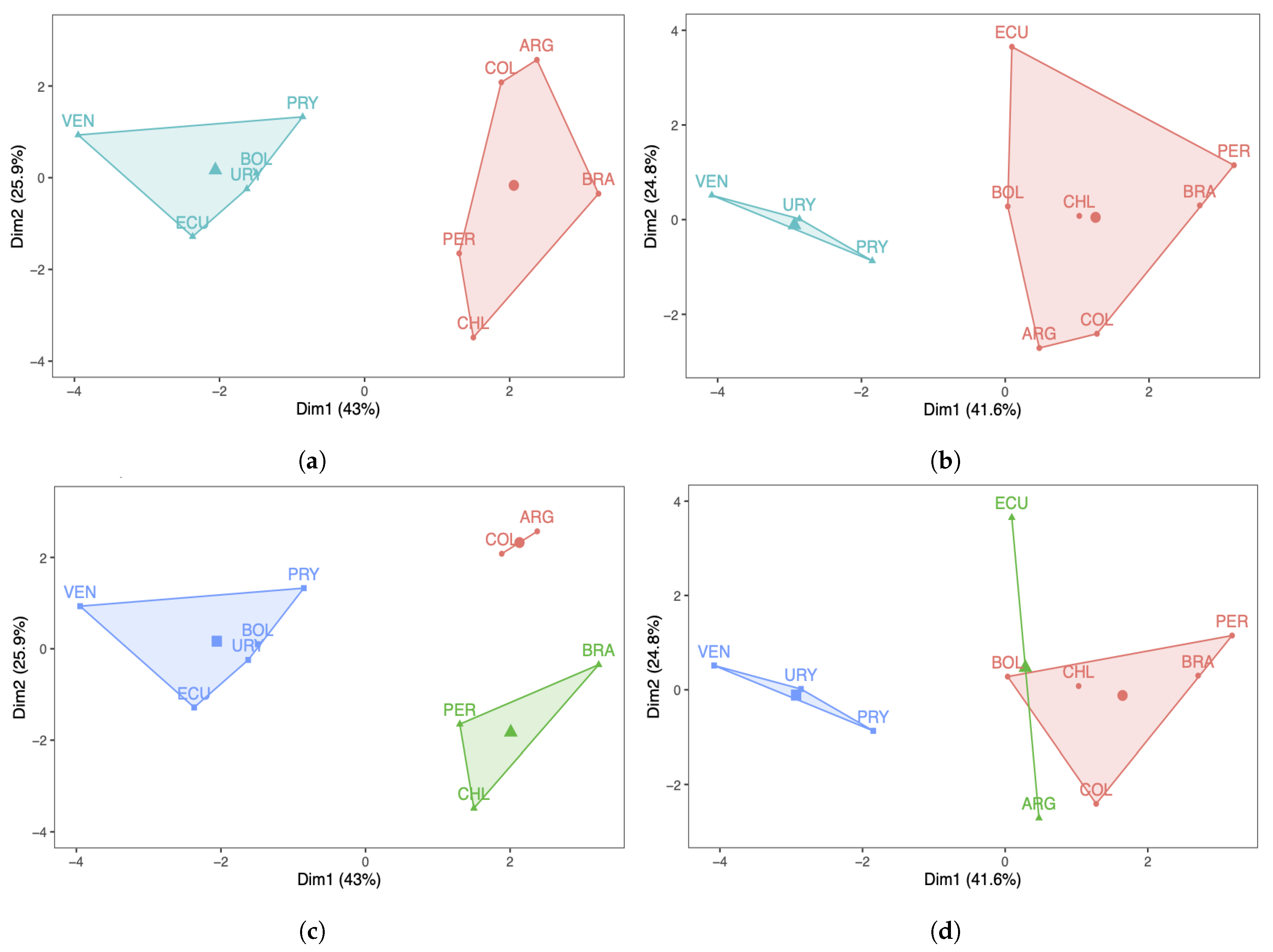
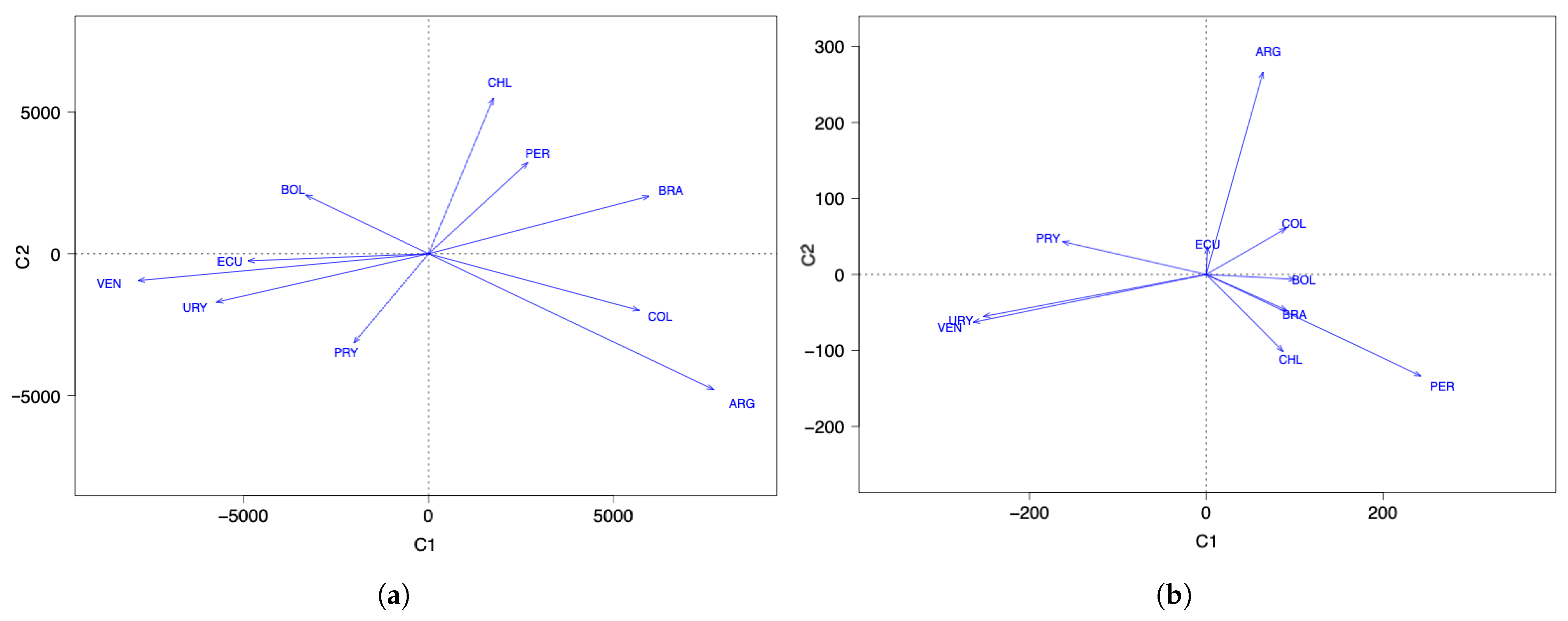
By using a principal component analysis with varimax rotation and a disjoint component analysis, we report the following results: with two components, and considering the number of COVID-19 infected cases, there are two groups of countries, with Argentina, Colombia, Ecuador, and Venezuela in one group, while Bolivia, Brazil, Chile, Peru, and Uruguay are in another group. When increasing the number of components to three, Paraguay and Uruguay moved away from the other countries and formed a third group.
When considering the number of COVID-19 deaths and two components, we established two groups formed by Argentina, Colombia, Paraguay, Uruguay, and Venezuela in one group, while Bolivia, Brazil, Chile, Ecuador, and Peru were in another group. However, with three components, Bolivia and Ecuador moved away from the other countries and formed a third group.
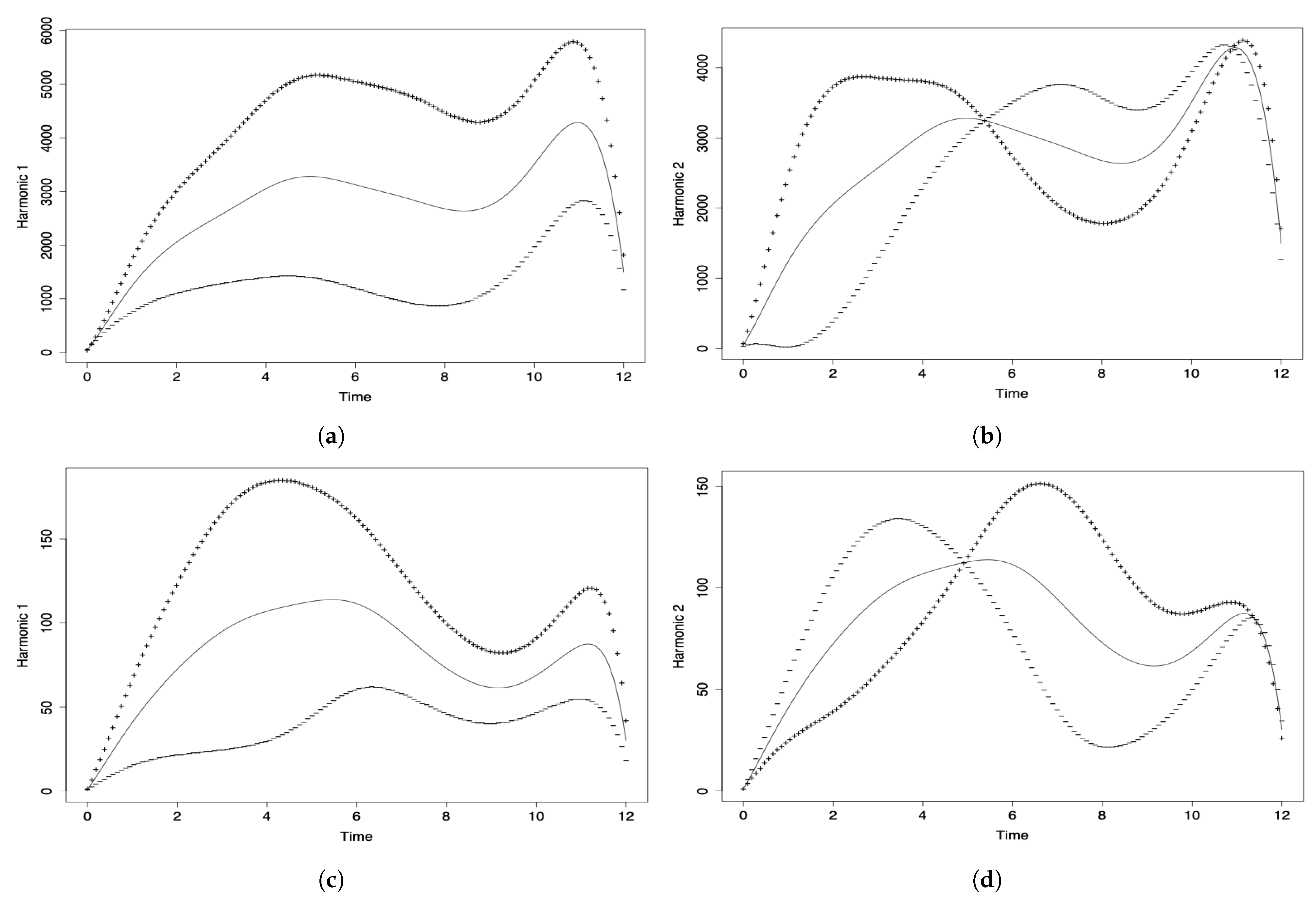
In the case of using functional components, we conclude that both components showed a general evolution of the number of COVID-19 infected cases reported per month throughout the pandemic, in all the countries considered. The largest values were detected in the months of July, August and September 2020 on the one hand, and in the months of January and February 2021 on the other hand. Regarding the relative positions of the countries, Ecuador, Uruguay, and Venezuela had very similar behavior, and Brazil, Chile, and Peru also behaved similarly to each other. Another group was made up of Argentina and Colombia, while Bolivia and Paraguay were far from the rest of the countries and between them.
Considering the number of deaths using functional components, there are peaks in the months of September 2020 on the one hand, and January and February 2021 on the other hand, which is similar to what happened with the number of COVID-19 infected cases. The countries with the smallest number of deaths were Paraguay, Uruguay, and Venezuela, whereas a second group was formed by Bolivia, Brazil, and Chile, with their behavior regarding the number of deaths being similar and greater than the average. In the case of Peru, this country was the most affected by the pandemic, while Ecuador was within the average; Argentina was a little more affected than Ecuador, but less than Chile. It should be borne in mind that the officially reported number of deaths due to COVID-19 may differ significantly from the number of true deaths, as has been observed in several South American countries.
Data related to COVID-19 can change over time. Therefore, the conclusions to be obtained from them, after statistical analyses, are sensitive to these changes. As mentioned, the data were obtained from the repository for the 2019 Novel Coronavirus Visual Dashboard operated by the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE) [
30], which keeps the data updated, particularly the number of COVID-19 infected cases and the number of deaths due to this disease. These data were also used in [
31]. Note that the number of confirmed cases is less than the number of true cases because not all people are tested with PCR. This means that the number of confirmed cases depends on how many PCR tests a country applies.
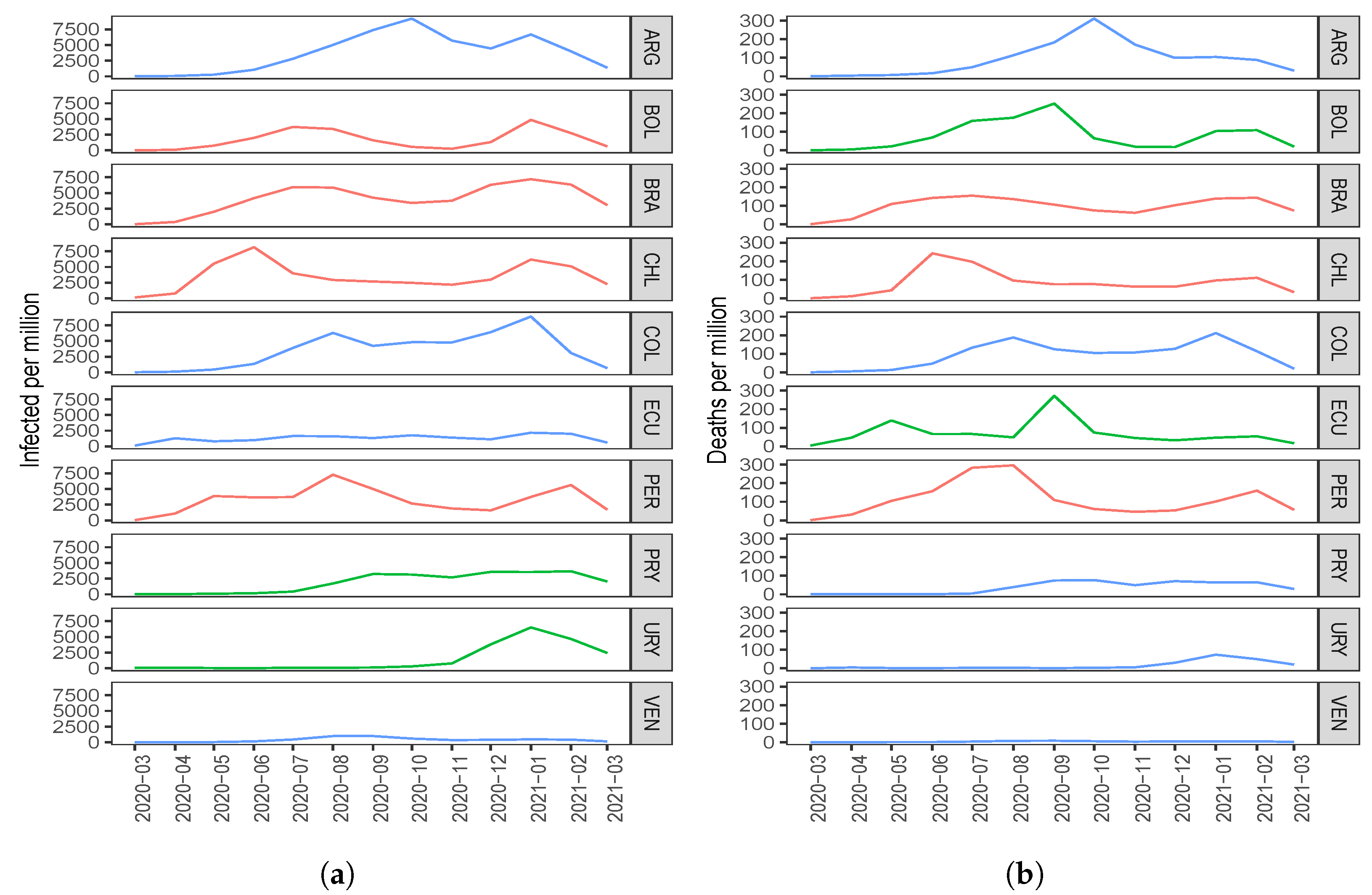
When looking at
Figure 3, we can see that some countries, such as Bolivia, Brazil, Chile, and Peru, reacted late in controlling the pandemic because they were the countries to reach a first peak early with respect to the number of COVID-19 infected cases and deaths.
Figure 3 also shows that countries such as Uruguay, Paraguay, and Venezuela had better control of the pandemic since the peaks of infected cases and deaths due to COVID-19 were reached some time after the aforementioned countries.
Despite the fact that some countries already knew that they had COVID-19 infected cases in their territory since the beginning of February 2020, it was in mid-March 2020 when the governments made the first decisions to control the spread of the virus. With full knowledge of what was happening in Asia and Europe, some South American countries minimized the impact that COVID-19 would have on the economy [
2,
3] and on people’s health. Other countries were a little more cautious and took strong measures from mid-March 2020, such as closing borders and confining citizens. However, it must also be said that, regardless of the policies taken by the governments [
4], the climate, the limitations of the health systems (infrastructure, personnel), the behavior of citizens, among other factors, also affected the variables of this study. By classifying countries into groups, we can comparatively study the damage caused by the COVID-19 pandemic, analyzing peaks and waves.
We consider that a better interpretation and classification of the countries is obtained using three principal components, leading to the following conclusions:
(i) For the number of COVID-19 infected cases, the components C1, C2, and C3 can be interpreted as: C1 grouped those countries that had similar behavior since December 2020; C2 grouped those countries with similar behavior throughout the entire period of analysis; and C3 grouped those countries that had few infected cases at the beginning of the pandemic and reached a peak after the December 2020 holidays.
(ii) For the number of COVID-19 deaths, the components C1, C2, and C3 can be interpreted as: C1 grouped those countries with the smallest number of deaths, at the beginning and at the end of the study period; C2 grouped those countries with similar behavior in both peaks; and C3 grouped the countries that reached their first peak in September 2020 and reached a second peak after the December 2020 holidays.
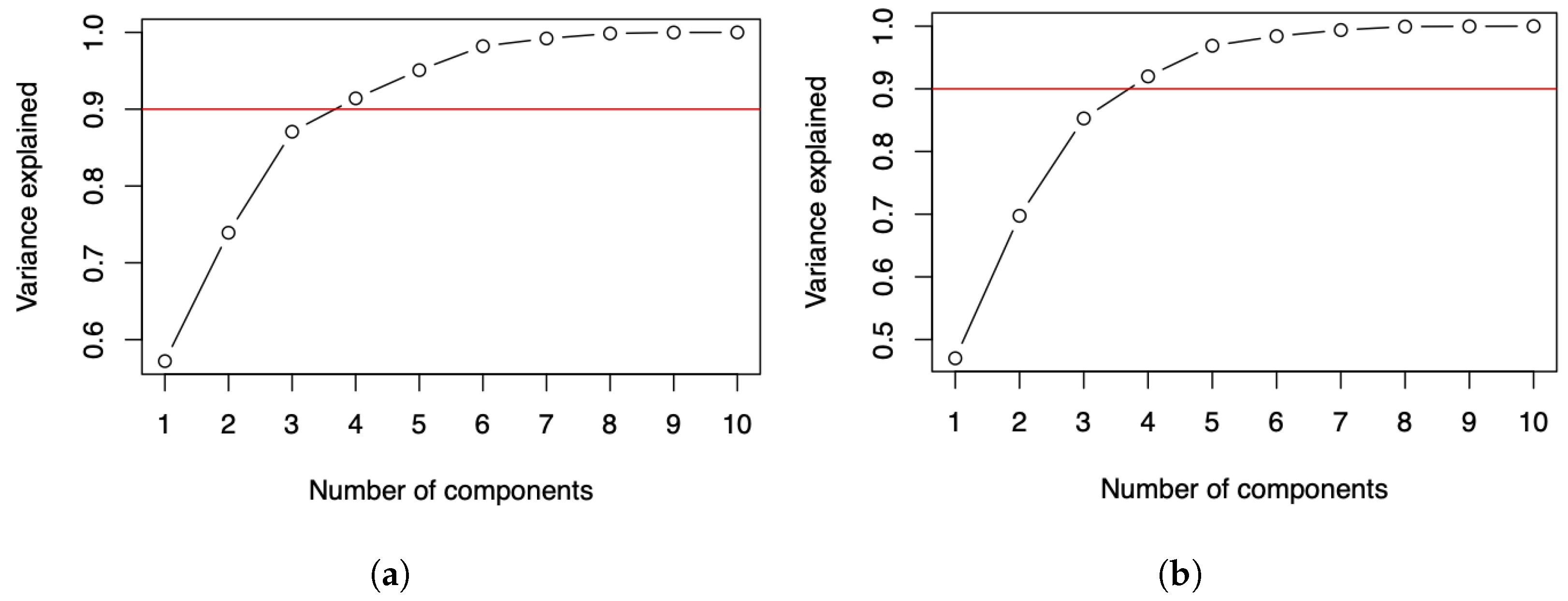
For further research, this study can be replicated for other regions of the planet such as the USA, Europe, and Asia. A study can also be conducted to implement alternative criteria for selecting the correct number of components [
28,
29].


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}